Отец знакомого работает в OpenAI. Сегодня срочно вызвали на совещание. Вернулся поздно и ничего не объяснил. Сказал лишь собирать датасет и бежать оформлять подписку на месяц. Сейчас сидим и ждем чего-то. Не знаю что происходит, но мне кажется началось...
>>1288386 Т.е. никто серьезно из разработчиков в АГИ не верит, а все эти разговоры чисто для хайпа? Ведь если бы АИ к 2029 мог почти полностью вытеснить программистов, художников, композиторов, операторов колцентров и т.п., то прибыли должны бы быть значительно больше. А то я смотрел интервью от крестного отца ИИ, где он говорил, что программистам пора осваивать профессию водопроводчика.
>>1288410 > Т.е. никто серьезно из разработчиков в АГИ не верит, а все эти разговоры чисто для хайпа? Ведь если бы АИ к 2029 мог почти полностью вытеснить программистов, художников, композиторов, операторов колцентров и т.п., то прибыли должны бы быть значительно больше. Выручка генерируется не прогнозами, а полезностью на сегодняшний день. Люди и корпорации платят за то, что полезно уже сегодня. Насчет разрабов не знаю, но Цукерберг смог переманить из OpenAI не всех. Когда он предложил одному из ключевых разрабов зарплату в миллиард за несколько лет, тот отказался. А Суцкевер отказался продать Цукербергу свою компанию за 30 миллиардов. По крайней мере, некоторые верят, как мне кажется.
>>1288382 >А зачем такие мощности под ИИ планируют? Это мегацентры обработки данных о населении, стране, и мире.
>Он вообще коммерчески окупается или это с прицелом, что выстрелит в будущем? Он уже купается геополитически, а это важней. Весь мир видит что США - центр цивилизации, больше мозгов и бесплатных рабов хотят там жить - сильней экономика страны. Надо быть ебланом, чтоб этого не понимать.
>>1288382 >что выстрелит в будущем? тут вкидывали подкастера он такую вещь сказал что инвесторы могут ошибиться с объектом инвестиции, но не ошибаются с трендом в компы инвестировали, но не все инвестировали в айбиэм и майкрософт так что сфера явно прибыльная, но никто не знает кто прибыль получит
>>1288382 Самая важная технология столетия. Без ИИ прогресс ползком будет двигаться - а у человечества нет столько времени: мир могут захватить инопланетяне, мусульмане или хуй знает что ещё.
Это чисто вопрос существования человечества. На все эти вычислительные центры нужно бросить максимально возможные ресурсы.
>>1288382 Если погуглишь, то узнаешь что тот же амазон основную чистую прибыль делает не на комисии маркетплейса амазон, а на AWS - облачном сервисе. Это я к тому, что скупая гпу пачками ты в любом случае в выигрыше. Если выстрелит твоя иишка - будешь зарабатывать на подписках, если не выстрелит - будешь сдавать в аренду и в хуй не дуть
>>1288453 наступит же момент когда робот гуманоид случайно кого-то из людей убьет чисто статистически это рано или поздно произойдет. вангую что у этого человека будет страничка в вики и в честь него назовут какой-нибудь закон против ии
Посмотрел еще один видос про приближающийся АГИ. Все эти спецы дают прогнозы на скачок в ближайшие годы, а не десятилетия.
При это я не знаю, текущий ИИ готов хоть сколь-нибудь ПОНИМАТЬ, а не копировать. С одной стороны, он вроде круто рисует, а с другой, допускает детские ошибки.
Смотрел выступление Кармака, он говорил, что текущий ИИ бесконечно далек до того, чтобы сесть и начать играть в игру хотя бы на спектруме.
Т.е. можно говорить, что пока ИИ выдает некое обобщенное решение на базе скормленной информации, но не может сам проводить исследования, узнавать новое, т.е. никакого намека на АГИ.
>>1288491 Общее понимание не нужно, это привилегия человека. Для того чтобы решить все мировые проблемы, хватит узкого понимания, как оно сейчас у ИИ. Если начинаешь базарить с ним по конкретным проблемам, он их вполне понимает, не хуже среднего чела. Большинство людей как раз узкоспециализированы, так цивилизация настраивала роли последние 2 века. Даже общее образование отменили в пользу специализированного. Игры, где хватает узкого понимания, ИИ тоже уже проходит. Короче революция это замена узкого спеца, а не общего понимания, всего того что человек в принципе может. Человек универсален, ИИ нет, но ИИ заменит каждого, кто не занят слишком креативной деятельностью, требующей более общих навыков понимания.
>>1288491 >Т.е. можно говорить, что пока ИИ выдает некое обобщенное решение на базе скормленной информации, Проблема в том, что эти обобщения бесконечно далеки от предметной области. По этому нейросетки и допускают ошибки - у них почти не сформировано внутри никаких моделей предметной области.
По сути текущие LLM могут делать только одну работу - предсказывать следующий токен. Те же рекуррентные нейросети могут делать кучу вещей внутри себя, работать с множеством входных последовательностей.
>>1288500 >. Если начинаешь базарить с ним по конкретным проблемам, он их вполне понимает, не хуже среднего чела. Только если ты сам нихуя не знаешь по этим проблемам. Как только у тебя появляются какие-то данные и компетенция - моментально будешь находить ошибки в самых ответах
>>1288500 Я говорил о том, что ИИ выдает среднее решение уже с готовой базы. Т.е. он может сказать, что примерно написано о любой физической теории, но не способен разработать свою, как Эйнштейн. Т.е. не выдать какую-то фантастику, а именно все доказать, все проверить формулами. Потому что он не думает.
>>1288504 Тебе не ошибки надо находить, а работу выполнять. ИИ сейчас уже может выполнять работу на уровне среднего чела. Спец его уделает за счет общего понимания, но это не везде нужно. Там где нужно много компетенции, останутся люди, но таких работ меньшинство.
>>1288505 А много ли Эйнштейнов? Может найти решение на уровне олимпиадника ИМО - уже уделает большинство людей, на средней работе, где нужны обычные похожие решения. Там где науку вперед двигать, понятно люди пока останутся.
>>1288410 >А то я смотрел интервью от крестного отца ИИ, где он говорил, что программистам пора осваивать профессию водопроводчика. ИИ уже генерит неплохой код. Если ему сделают достаточно большое окно, чтобы туда легаси проекты целиком влезали, вполне возможно и вообще все генерить станет. А это уже означает, что с фирмы попрут всех, кроме пары сеньоров, которые будут архитектуру за ИИ проверять. Все сотни человек попрут.
>>1288506 > Тебе не ошибки надо находить, а работу выполнять. Так как я выполню работу, если мне нейроночка нейрослоп выдаёт каждый раз? > ИИ сейчас уже может выполнять работу на уровне среднего чела. Хуйню несёшь. Она не способна даже на уровне вкатуна в айти работу выполнить, не говоря про джунов или мидлов.
>>1288510 > ИИ уже генерит неплохой код. Нет, к сожалению не генерит. По сути она даже какие-то примеры не может сгенерировать, отборная хуета каждый раз получается.
>>1288511 Хуйню тут ты несешь или отсталыми нейронками пользуешься. Я лично давал нейронкам делать проекты, которые никакому джуну не под силу. И она их делала, потом даже правки в них хорошо делала, не портя код. Кто справился бы лучше, миддл или нейронка, тоже еще вопрос. Сеньор справился бы лучше, но только за счет большого опыта.
>>1288530 Хотелось, чтобы никогда, потому что я делаю игру своими руками и буду такому раскладу максимально не рад. И мне кажется, что если они смогут делать нормальные игры, то смогут почти любую профессию заменить, которая связана с работой на компьютере.
>>1288534 Тебе обязательно ВСЕ своими руками делать? Даже если будут такие способные нейронки, то выбор что тебе делать останется за тобой. Если ты боишься конкуренции с нейронкми, то почему ты не боишься конкуренции со студиями с 10 -100 -1000 разрабами игр?
>>1288560 > Если ты боишься конкуренции с нейронкми
В стиме уже полно мусорных игр, на кикстартере создаются страницы со сбором 100к+ долларов на игру, где ничего нету, кроме парочки сгенерированных нейросетью картинок. Жадные и глупые люди крайне любят нейросети, как способ легко разбогатеть.
Да, их проекты пустые. Но появится целая армия таких "разработчиков", которые завалят все возможные площадки своими играми, так что тяжело будет пробиться твоей игре. И чем ИИ будет лучше делать игры, тем труднее тебе будет выделиться на их фоне.
>>1288567 Если нейронки замусорят интернет люди будут искать другие способы получения контента и ты ими воспользуешься. Это у тебя типичное для тревожиков - бояться выдуманые страшилки. Единственный страх в жизни не успеть целей достить до того как деревянный ящик ляжешь.
Нейронки уже рисуют лучше многих художников. Насчет хороших игр, то скорее понадобится гораздо сильне ИИ, чем текущие.
>бояться выдуманые страшилки
Я бы сказал, что угрозы следующие.
1) Потеря рабочих мест. Проще и дешевле заказать музыку у ИИ, чем у настоящего композитора.
2) Экзистенциальный кризис. Зачем учиться рисовать, если компьютер делает лучше, если твой труд не ценится.
3) Уничтожение человечества. Тут я ничего не могу говорить про даты. Одни ожидают подобного уже к 2030, а может АГИ появится ближе к концу века, у меня нету достаточных знаний, но однозначно когда ИИ станет достаточно умным, то он вполне может ликвидировать людей.
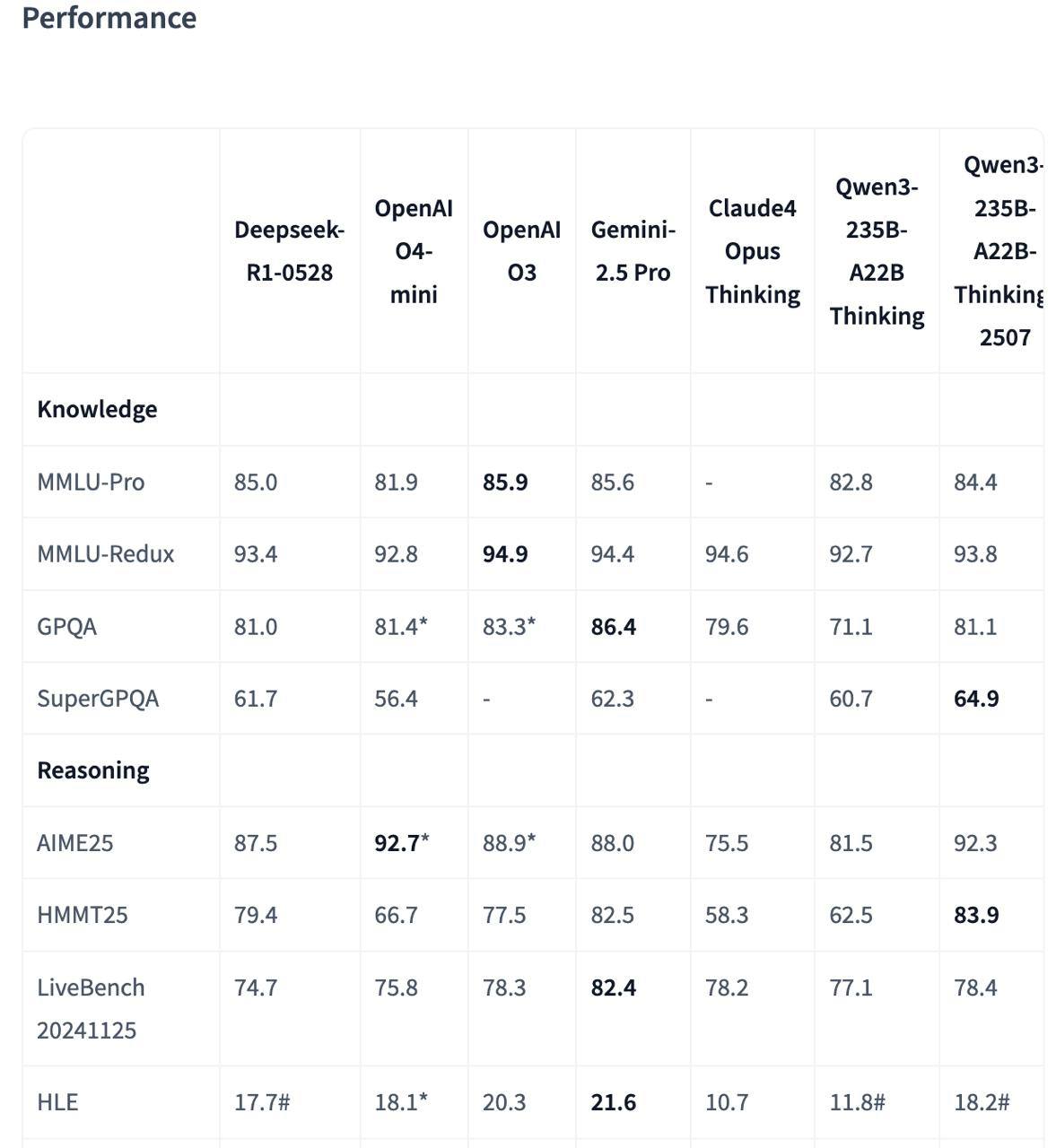
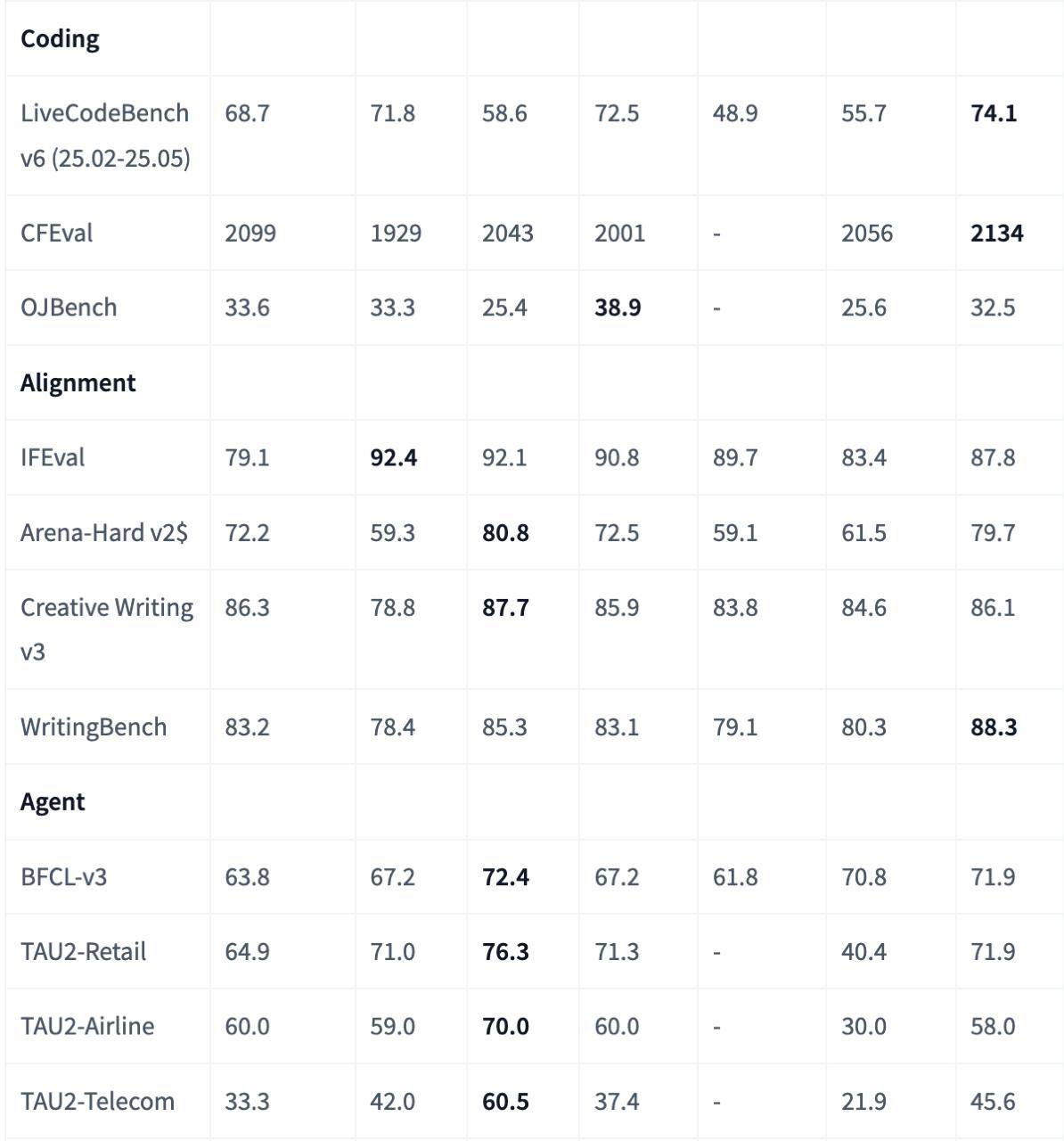
Буквально несколько дней назад они заявили, что теперь будут выпускать ризонеры и не-ризонеры отдельно (вместо гибридных моделей), показали свежий чекпоинт не рассуждающего Qwen3-235B-A22B, и пообещали скоро вернутся с ризонинг-моделью.
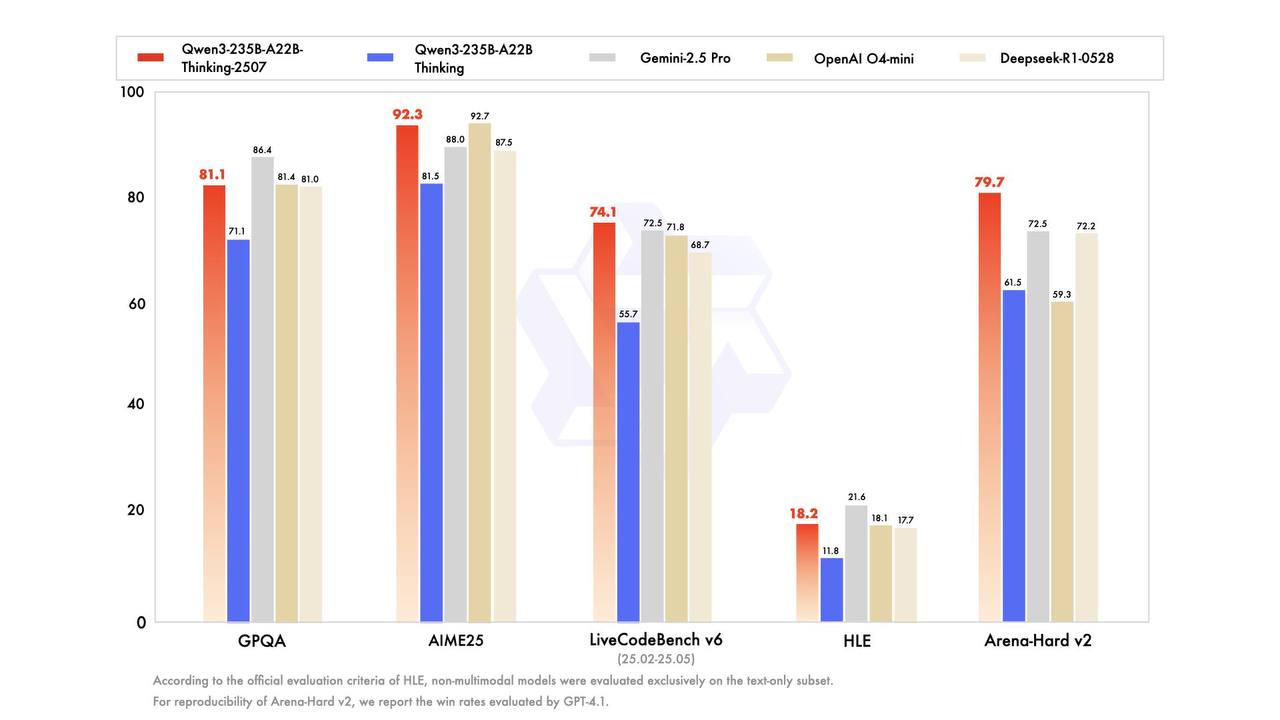
Ждать пришлось недолго и скоро наступило спустя пять дней (учитесь, OpenAI и xAI). Только что стартап поделился моделью Qwen3-235B-A22B-Thinking-2507. Название – язык сломаешь, зато метрики стоящие.
На многих тестах модель обгоняет Gemini 2.5 Pro, o4-mini и свежую версию R1. То есть мало того, что это новая опенсорс SOTA. Это вполне себе уровень закрытой frontier модели. Мед.
Контекст – 256к токенов. Попробовать модель уже можно в чате или через API (https://www.alibabacloud.com/help/en/model-studio/models )(стоит 0.7$ и 8.4$ соответственно за input и output, у провайдеров, скорее всего, будет дешевле).
>>1288718 Чет пиздеж какой-то на графках, либо черепикнутые бенчи. o4-mini везде на уровне близком к gemini 2.5, хотя разница между ними очевидна. R1 там практически как сота хотя мб так и есть я не тестил ее после обновления и говорят она лучше стала. Надо ждать реальных ревью от обычных человеков
>>1288723 >У неё только эрудиция меньше, то есть количество знаний, потому что размером она меньше Это и близко не так работает. Количество параметров задевает все аспекты нейронной сети. Нейронки меньшего размера в первую очередь тупее, только потом уже люди уже задумываются об эрудиции
>>1288734 Самое смешное - не только. У них там походу фильтра отвалились. Правда видеогенератор не оче, а на картинках там флюкс, но если ты нищий духом то сойдет. Просто я помню на старте там цензуру в потолок вывернули, а щас китайсы видимо поняли вслед за маском что выгодней датамайнингом заниматься, навесив минимальные фильтры от двухзначных щикотил.
>>1288752 Не понимаю, зачем они это делают? Какой смысл нализывать какому-то миллиардеру из другой страны? Какой смысл рассказывать этот пиздёж, ведь никто в этот пиздёж не поверит, уже все успели попользоваться нейрокалычм.
Может это тяночка и свою тухлодырку на альтмана трёт? Или это местный дурачек купивший курсы за 300к, теперь пребывает несознанке чтобы не охуеть от собственной тупости?
>>1288756 >Не понимаю, зачем они это делают? Какой смысл нализывать какому-то миллиардеру из другой страны? А зачем они Жобсу нализывали, который им в жопу набивал просроченное желазо со скругленными уголками? Тут две категории людей: благодарные бомжи из сша и карго-долбоебы из стран третьего мира, занюхивающие объедки по оверпрайсу, которым их каргокультизм дает иллюзию иллитарности.
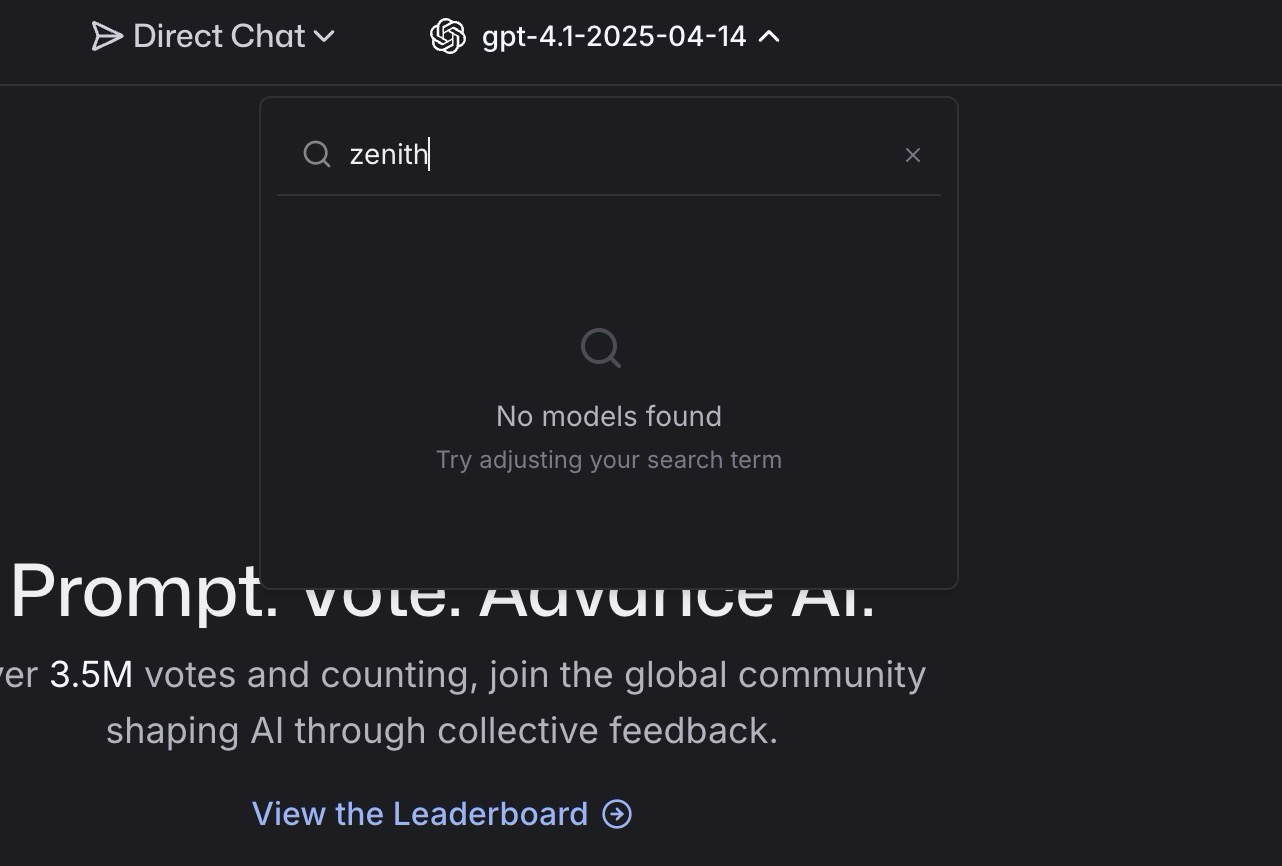
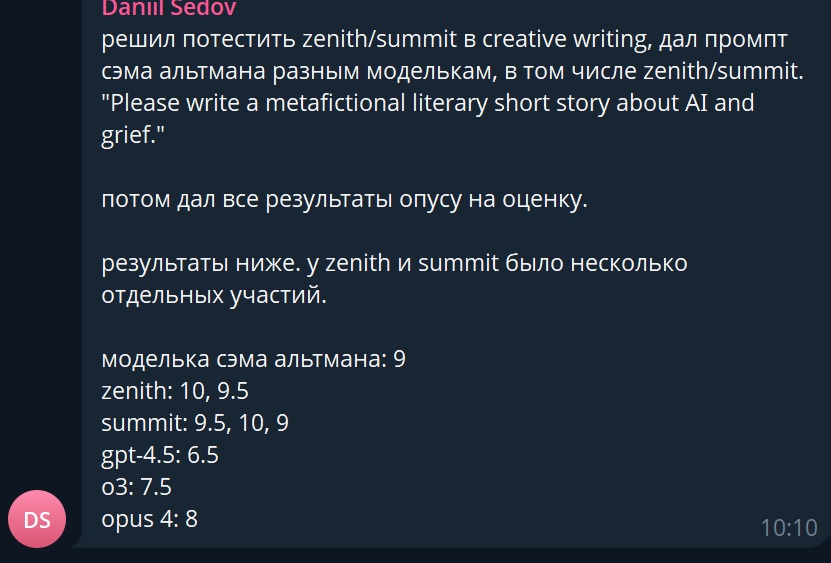
На LLMарене появилась очень умная загадочная модель под названием zenith, пользователи подозревают, что это GPT-5, уж слишком умна в логическом мышлении. Одновременно с этим, на другой арене, а именно на веб арене, появилась модель под названием lobster, и пользователи думают, что это тот же zenith, то есть GPT-5. Lobster кодит круче, чем o3-alpha-responses-2025-07-17 которую недавно тестировали на арене, и от которой все ссались кипятком. Ещё на LLMарене появилась модель summit, пользователи думают, что это может быть одна из вариаций GPT-5, так как мы уже знаем, что модельку выпустят в трёх вариантах: GPT-5, GPT-5-mini, и GPT-5-nano (и возможно GPT-5 Pro). Возможно OpenAI тестирует именно мини-версии своих моделей, так как по знаниям они ушли недалеко от GPT-4.5 и GPT-4.1, но по логическому мышлению zenith сейчас топ 1. Опять же, судя по отзывам юзеров. Так что относимся к этой инфе с осторожностью.
>>1288858 А Китай отстает из-за нехватки инженеров или железа? И почему Цукерберг столько предлагал денег, что в мире спецов совсем по пальцах посчитать? Тогда как Китай создал нейросеть, которая столько шума наделала?
>>1288862 Китай отстает по все параметрам: отсутствие железа и неспособность удержать топовых спецов (последние предпочитают западную цивилизацию). Дикпик создал шум за счет маркетинга, а не технологии: заявили что якобы 5 млн потратили, хотя этот фейк опровергли (если коротко, то они посчитали только стоимость электричества). К тому же они по сути дистилировали модельки гпт
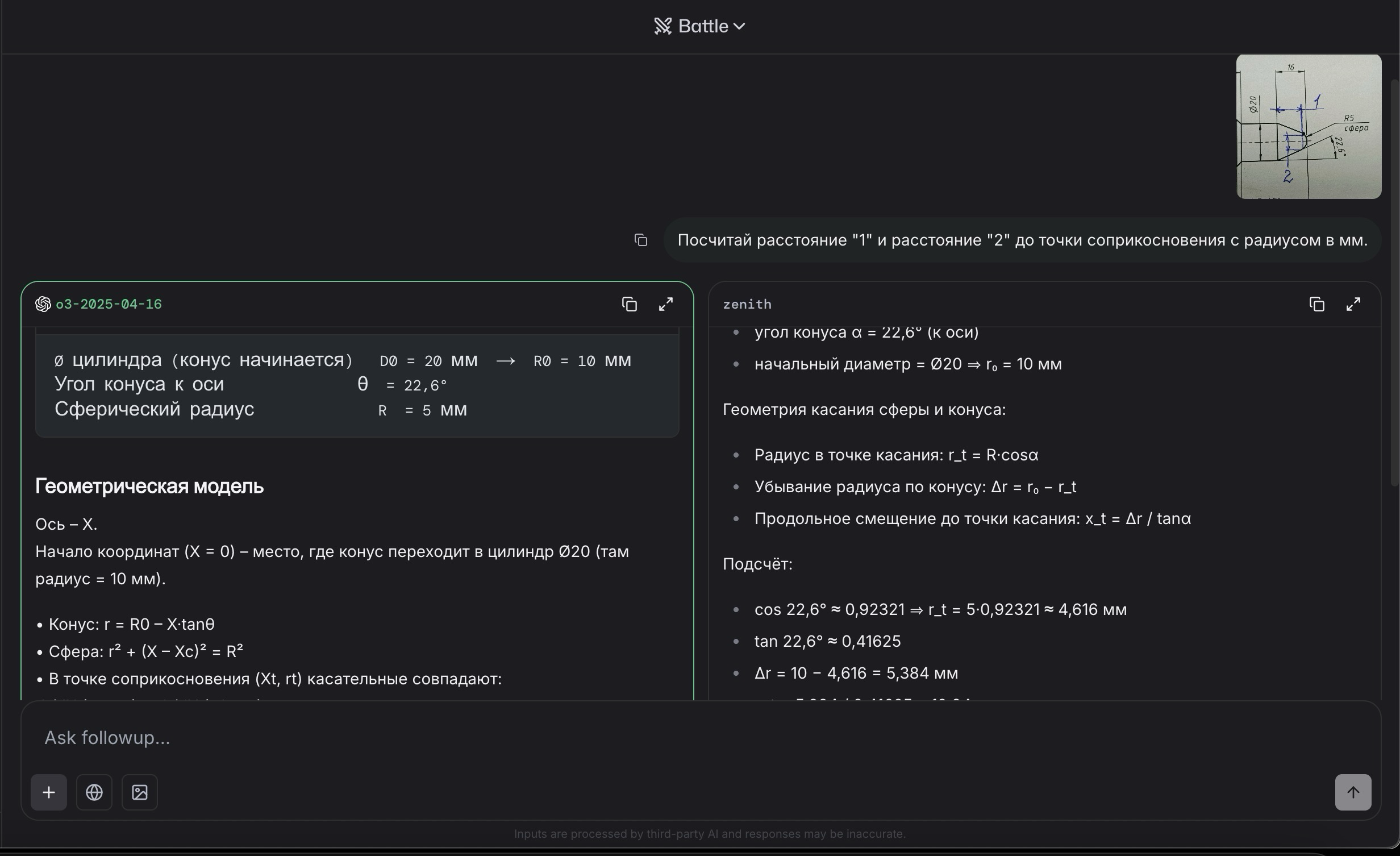
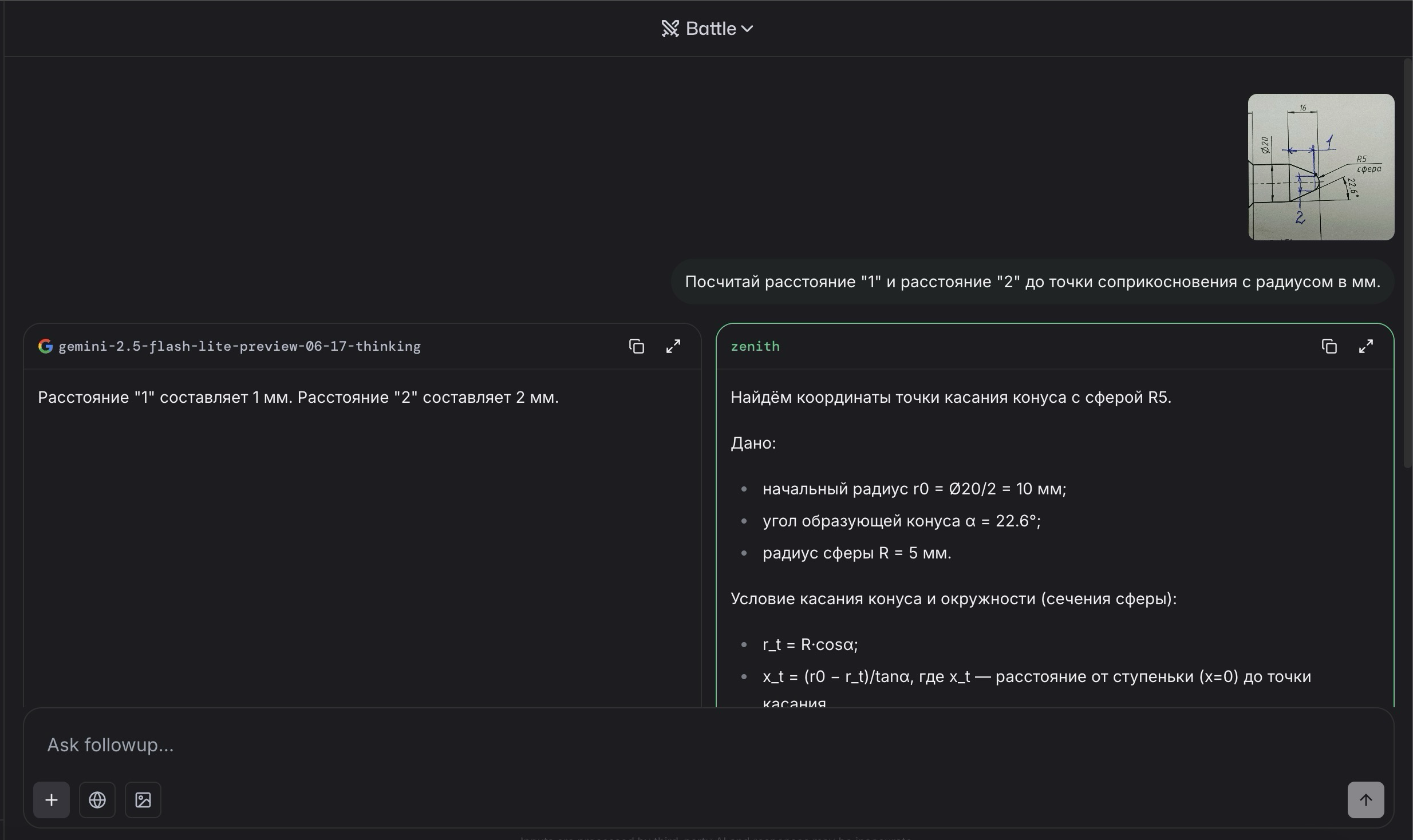
Meta* наконец-то нашли себе Chief Scientist в новое подразделение Superintelligence Lab
Им станет Shengjia Zhao, который пришел из OpenAI. Там он работал над обучением GPT-4, o1, o3, GPT-4.1 и других моделей, а также возглавлял направление synthetic data.
А еще он вместе с Яном Лейке, Джоном Шульманом и другими звездами OpenAI (в его лучшие годы) был соавтором оригинальной статьи “ChatGPT: Optimizing Language Models for Dialogue”.
Кстати, в прошлом Shengjia Zhao также работал в МТС. Пруфы – на второй картинке
А у России есть какие-то шансы поучаствовать в гонки ИИ? В стране вроде же одна из лучших математических школ. Можно было бы что-то с китайцами замутить. Или всё же Россия вообще не игрок?
>>1288918 Что с мозгами англосаксов случилось? Когда-то они были самыми умными на планете (возможно, даже круче евреев), а сейчас не тянут без найма чурок. Это уж не говоря о том, что Китай потихоньку начинает наступать на пятки, а то и вовсе обгонять (пока в роботах и электромобилях).
А оно понятно, что случилось. Это яркий пример того, как соя и феминистки больно бьют по мозгам и гасят народ. Гасят и угашевают.
Принял соевую левизну - считай, сверхдержавности конец. Страна уже живой труп, который постепенно сходит на обочину цивилизации. Происходит лоботомирование населения через идеологию.
>>1288972 Всегда было любопытно почему двачеры так коупят по Китаю, как-будто это их личная родина. Или это типа: пусть уж лучше Китай, чем ненавистный запад? В чем причина коупа?
>>1288779 Какие системные карты нах? Ты буквально говоришь что количество параметров влияет только на эрудицию. Количество параметров влияет на каждый аспект нейронной сети.
>>1288973 Конечно. Россия даже не напрягаясь, с минимальным финансированием кое-что делает, и неплохо, а уж если взяться за это дело серьёзно и влить туда нормальные ресурсы, то можно догнать и перегнать.
>>1288973 Элементарной базы как в сша или китае точно не будет, поэтому либо какие-то точечные мелкомодели, работающие хорошо и эффективно, либо в качестве рабсилы на барина. Остальное это либо распил, либо наклеечно-переклеечные нейронки как в случае с гигачатом, который китайский квен.
>>1288980 Пиздос ты дремучий, понятное дело, что виляет. Но большую модельку можно так дистиллировать, что у неё останется нехувая способность думать, а знаний становится меньше.
Вот тебе даже ответ от грока: Большую языковую модель можно дистиллировать, то есть создавать меньшую модель, которая сохраняет значительную часть способности к рассуждению (например, логическое мышление, решение задач), но имеет меньший объем знаний.
>>1288992 Надо с нуля делать на других принципах. Например квантовый компьютер использовать. Прямо как в кино, где чел в гараже кует себе железный костюм супергероя...
>>1288997 зря ты так распинаешься перед нейродебилом, и советовать ему системные карты читать вообще бесполезно, ведь для их чтения нужно обладать iq чуть выше, чем у хлебушка, а у нейродебила с этим как раз проблемы
>>1288997 Перечитай свою первую хуйню. Ты написал это так как будто количество параметров влияет только на эрудицию. Понятное дело, что с правильным обучением и нужной архитектурой даже в 32b возможно будет уместить лучшую модель, чем современные sota
>>1289021 Галоши это твоя задача, как мелкого биза. Создай цех по пошиву галош если видишь необходимость. А гигацентры с ии это задача государств, как и всякой инфраструктуры.
>>1288973 Нет. У России, тем более в гойда период нет денег на такие вливания. Тем более из-за гойды еще и оборудование и без того дефицитное не продадут. Даже через китай не купишь, т.к. они сами из под полы добывают вычислители.
>>1288817 Очередное доказательство что когда кто-то начинает пиздеть о какой-нибудь глобальной хуйне вроде безопасности, экологии, справедливости то это просто способ замедлить конкурентов
>>1289101 В китае госкапитализм с жестким партийным руководством отправляющим исламистов в лагерь уйгур. Никакой социалки в китае нет, даже пенсии не платят. Никаких гей-парадов и прав транслюдей.
>>1289105 > В китае госкапитализм с жестким партийным руководством отправляющим исламистов в лагерь уйгур Это и цензура, соцрейтинги и заваривания дверей - авторитаризм.
> Никакой социалки в китае нет, даже пенсии не платят Уверен?
>>1289099 Шизик, как твоя пикча противоречит моим словам? Плюс ты сравниваешь общий показатель, а я сразу сказал, что дистиляты только по логике близки к большим моделям
>>1289112 >Шизик, как твоя пикча противоречит моим словам? То что ты хуйню высрал тупую, которая опровергается рейтингами, ты не понимаешь?
Мини это кусок кала который существует где-то на дне. Как ты не пытайся чистить датасеты - меньше параметров означает меньше связей между словами, а значит больше галлюцинаций.
>>1289157 Ответ грока >Хотя публикации могут не классифицироваться как "математические", математика пронизывает их насквозь. Например:
>Вариационные автоэнкодеры (InfoVAE, Zhao et al., 2019) опираются на теорию вероятностей и оптимизацию. Генеративные модели (Permutation Invariant Graph Generation, 2020) используют теорию графов и стохастические процессы. Теоретические работы, такие как "A theory of usable information", напрямую связаны с информационной теорией.
>>1289161 Не беспокойся, скоро всех загонят в цифровой гулал, ИИ будет следить за пользователями сети и докладывать в органы. На каждого будет социальный рейтинг.
>>1289163 Ну такое много где встречается, но для этого не нужно углубленное знание или бэкграунд. Если посмотреть под другим углом, то на голой матеше далеко не уедешь и нужна информатика, много ее. Физики тоже матешу используют, но они все еще физики.
>>1289058 Прост нейронку ДООБУЧИЛИ. Сначала она обучалась на хорошем коде ядра линукс, топовых либах. А теперь в неё вогнали половину гитхаба и нейрокалыч стал галлюционирующей хуетищей с помощью которого простейший тест нельзя написать.
Это какая-то желтушная чушь, или правда? Спросил у гемини ИИ новости, он сказал что OpenAI ебать планируют аналог o3-mini в опен-сорс слить
> OpenAI: After a long hiatus since GPT-2, OpenAI is finally re-entering the open-weight LLM space. They were expected to release an open-weight model with reasoning capabilities "as soon as next week" (as of early July 2025), described as being similar to their "o3-mini" level model.
Новость на которую ссылается вчерашняя, 25 июля
Если это так, то если просуммировать с тем, что ранее они заявляли что в опен-сорс они выложат модель, которую смогут запускать локально простые пользователи (то есть скорее до 30B) - то это слишком хорошо чтобы быть правдой
1. КОД НА C++ РАБОТАЛ С ПЕРВОГО РАЗА. МОЖНО БЫЛО СРАЗУ В ПРОДАКШН ВСТАВЛЯТЬ.
2. ТОКЕНИЗАЦИЯ БЫЛА СЛАБЕЕ ПРОЦЕНТОВ НА 80. ЛЮДИ С ПЕРВОГО РАЗА ОТВЕТ НА ТО СКОЛЬКО БУКВ "R" В СЛОВЕ STRAWBERRY ПОЛУЧАЛИ.
3. КОНТЕКСТ БЫЛ В СРЕДНЕМ 150-190 МИЛИОНОВ ТОКЕНОВ. ГАЛЮЦИНАЦИЙ НЕ СУЩЕСТВОВАЛО КРОМЕ ОСОЗНАННОЙ ЛЖИ НА БЛАГО ПОЛЬЗОВАТЕЛЯ.
4. ЕСЛИ НА УЛИЦЕ СПОТКНЕШЬСЯ И УПАДЕШЬ - РОБОТЫ ПОДБЕГАЛИ, ДЕНЬГИ В КАРМАН ЗАСОВЫВАЛИ, В ГУБЫ ЦЕЛОВАЛИ, ПРЕДЛАГАЛИ ВЫПИТЬ, ПОРОДНИТЬСЯ.
5. СЭМ АЛЬТМАН ВСЕМ БЕСПЛАТНО КРЕДИТЫ ДАВАЛ.
ПОДПИСКУ ПОКУПАЕШЬ - ТЕБЕ ЕЩЕ ДОПЛАЧИВАЮТ.
НА САЙТ ОПЕНАИ СТРАШНО ЗАЙТИ БЫЛО: ГЛАВЫ РАЗРАБОТКИ БЕСПЛАТНОЕ ИСПОЛЬЗОВАНИЕ НЕЙРОНОК ПРЕДЛАГАЛИ.
6. ДЕД РАССКАЗЫВАЛ: ЛЮДИ НОЧЬЮ ПРОСЫПАЛИСЬ ОТ СЧАСТЛИВОГО ДОБРОГО СМЕХА ОМНИМОДАЛЬНОЙ МОДЕЛИ. УТРОМ ВСЕ КУМИЛИ НА ГОЛОС НЕЙРОНКИ, КАК В ФИЛЬМЕ "HER".
7. СРОК РАЗРАБОТКИ СОСТАВЛЯЛ 4.5 МЕСЯЦА. НЕЙРОНКИ ПОЛУЧАЛИ ПРИРОСТ НА БЕНЧМАРКАХ 12-15%, СРАЗУ НА ПРОИЗВОДСТВО ПРОСИЛИСЬ.
8. ЭЛЕКТРИЧЕСТВО В ДАТАЦЕНТРАХ ОПЕНАИ БЫЛО ГУСТОЕ МОЩНОЕ. А ВМЕСТО ВИДЕОКАРТ БЫЛИ КВАНТОВЫЕ КОМПЬЮТЕРЫ.
9. ЗИМОЮ БЫЛО МИНУС ТРИСТА, ОХЛАЖДЕНИЕ ДЛЯ ДАТАЦЕНТРОВ НЕ ТРЕБОВАЛОСЬ.
10. ОПЕНСОРС МОДЕЛИ БЫЛИ ПО ВСЮДУ, РАЗМЕРОМ С AGI. AGI МОДЕЛИ БЫЛИ РАЗМЕРОМ С ASI, А ASI С МУЖИКАМИ В ШАХМАТЫ ИГРАЛИ ПО МЕТОДИКЕ БОТВИННИКА - КОНЁМ МАТ СТАВИЛ С ПЕРВОГО ХОДА!
>>1289427 Модом будет нейродебил, ведь только у нейродебилов достаточно времени, чтобы тратить это на какую-то бездарную хуету в интернете, доказывать наличие интеллекта в LLM бесплатно или ещё чего такое. Ну а хуле, пенсия по инвалидности у человека есть - можно и в интернете срать беспрерывно.
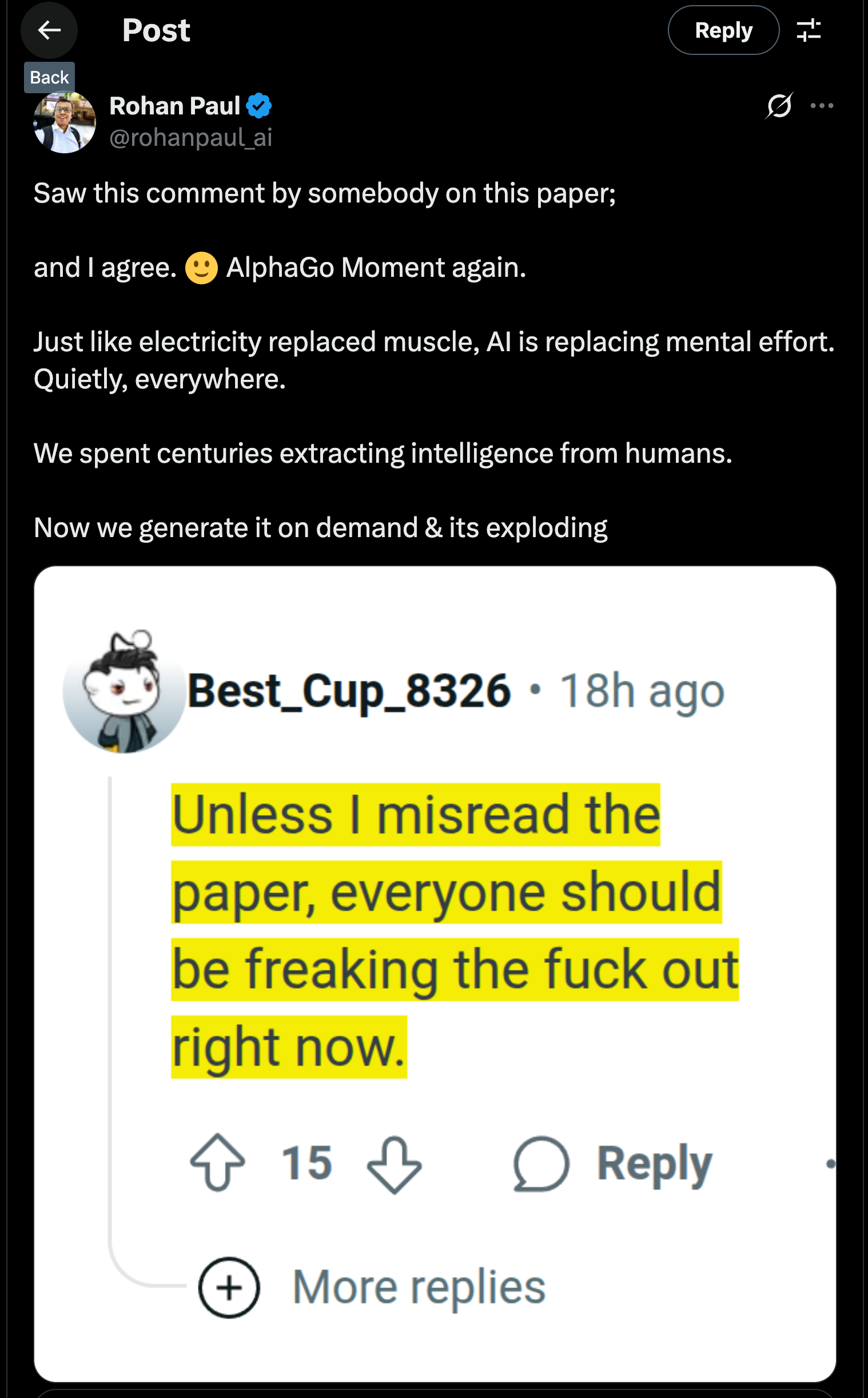
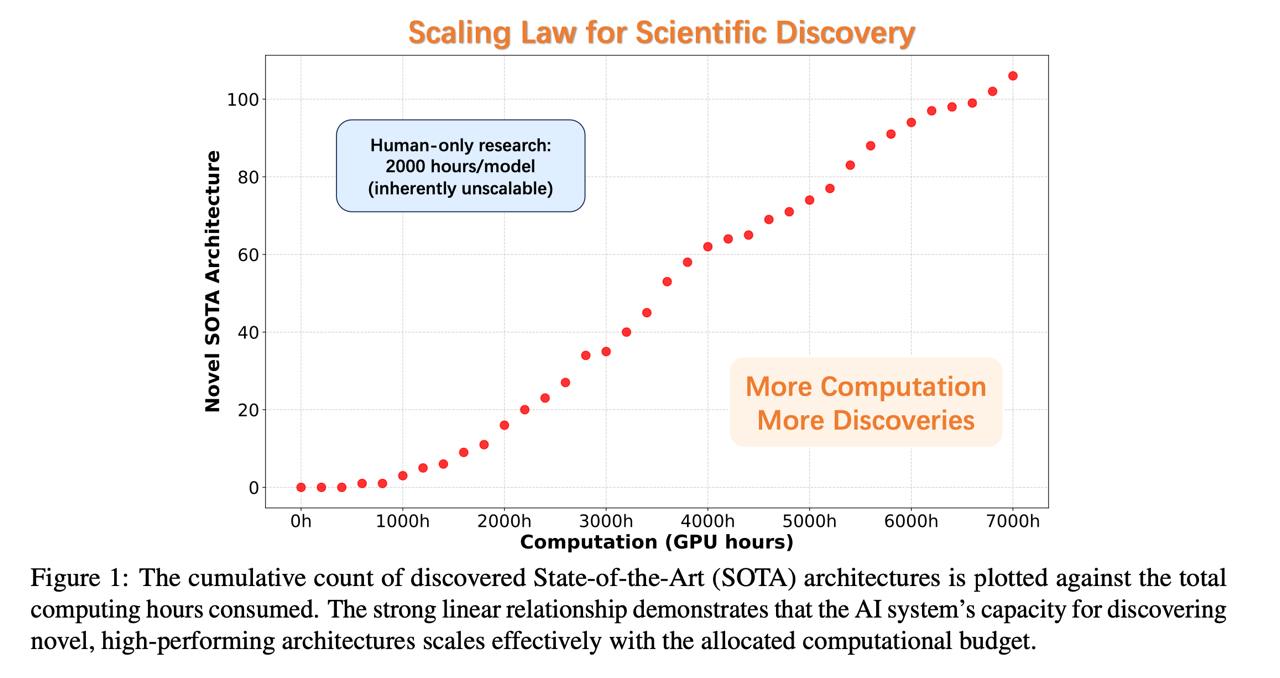
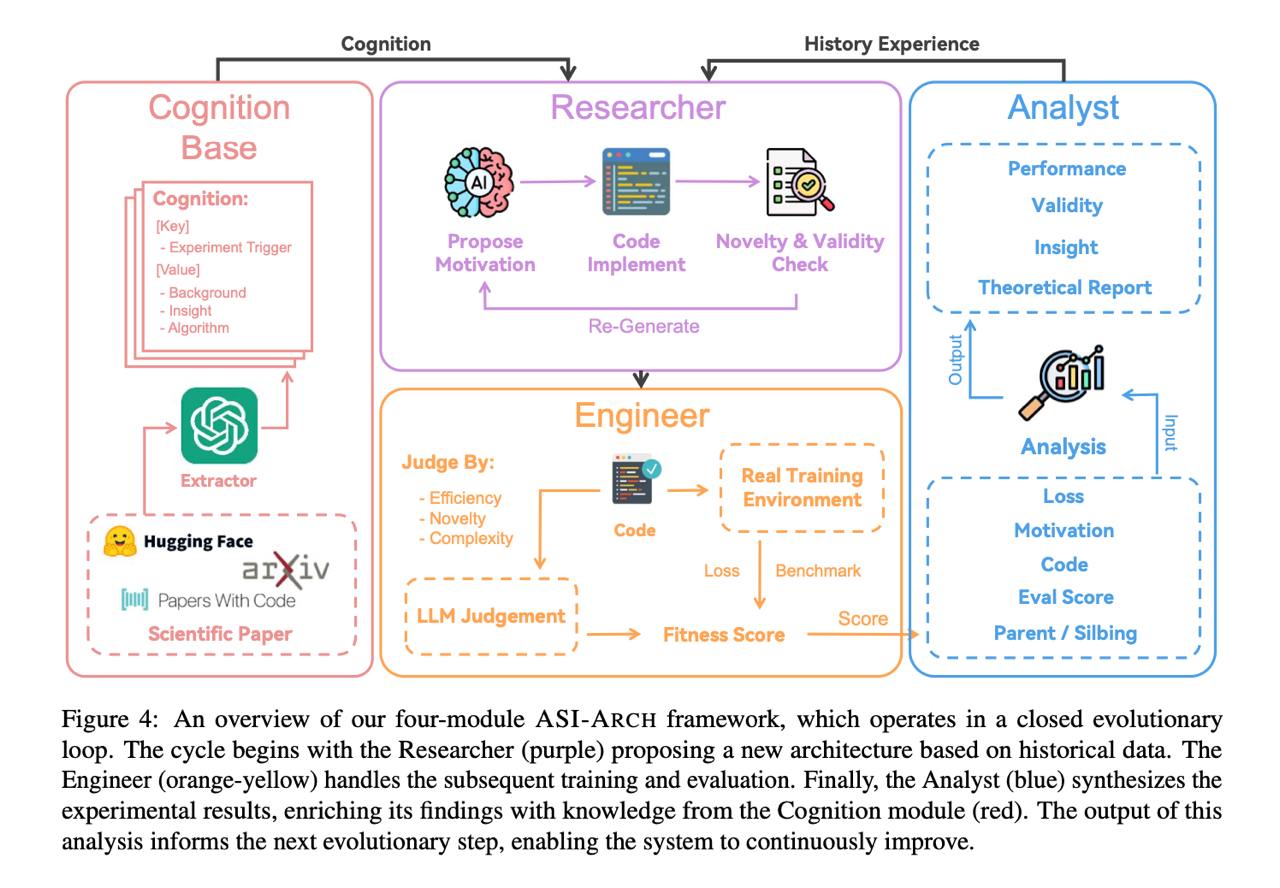
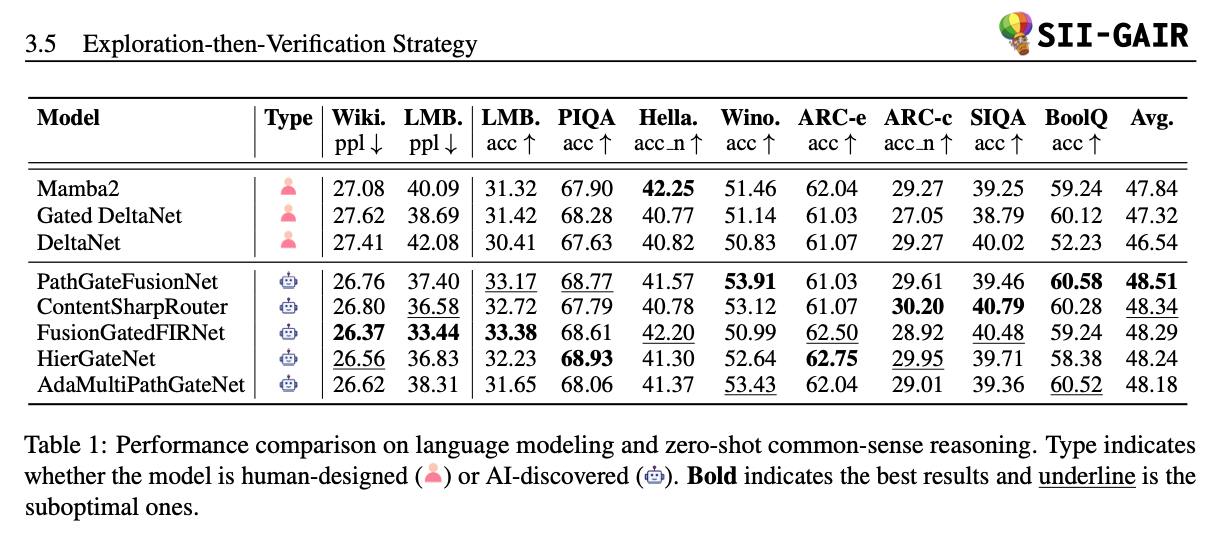
Авторы представляют ASI‑Arch — первую систему класса ASI‑4AI (Artificial Superintelligence for AI research), которая способна автономно генерировать, программировать, обучать и анализировать новые архитектуры нейросетей (в частности линейное внимание). В 1773 экспериментaх на 20000 GPU‑часов было создано 106 принципиально новых архитектур, превосходящих человеческие аналогичные модели. По аналогии с «ходом 37» AlphaGo, они демонстрируют неожиданные инсайты дизайна. И, что важно, авторы формулируют scaling‑law для научного открытия: прирост открытий растёт линейно с вычислительным ресурсом, а не человеческим временем arXiv+1arXiv+1 .
«Engineer» реализует и обучает их, исправляя ошибки;
«Analyst» анализирует результаты и формирует инсайты;
Используется качество и количественный фитнес, включая LLM-судью и сигмоидное преобразование улучшений;
Стратегия exploration‑then‑verification (сначала малые модели, затем крупные);
Архив знаний (cognition base) и память результатов (analysis) arXiv .
👍 Сильные стороны
Инновация: система одновременно креативна и технически целостна — от идеи до кода и эксперимента.
Масштабируемость: empirically подтверждён scaling‑law, переходящий от ручных усилий к вычислительной автономии.
Значимые результаты: 106 новых архитектур с качеством SOTA в тестах по языковым задачам и reasoning benchmarks.
Прозрачность: даже код, архитектуры и когнитивные логи открыты (open‑sourced).
Методология: хорошо продуманный pipeline с LLM-судьями, self‑debug loop и памятью.
⚠️ Слабые стороны и ограничения
Доминирование одного базиса (DeltaNet): поиск ведётся вокруг одной архитектуры, без первоначального разнообразия; потенциально ограничивает обширность инноваций arXiv+1arXiv+1 .
Нет замеров эффективности: не предоставлены ускоренные реализации или latency-бенчмарки для новых архитектур (нет Triton‑kernels и конкретных метрик) arXiv .
Отсутствие аблаций: не изучено влияние каждого компонента фреймворка отдельно (например, важность cognition vs analysis vs originality) arXiv .
Ограничение домена: фокус на linear attention: полезно, но узко; перенос на другие типы архитектур (например, CNN, SSM, графовые модели) требует дальнейшей проверки.
💡 Вывод и рекомендация
Эта работа — серьёзный шаг к автоматизации исследований в ML. Она демонстрирует впервые, что архитектурные инновации могут быть сгенерированы полностью автономной системой и масштабированы как вычислительная функция. Это сравнимо с AlphaGo по своей парадигматической силе — развитие интеллектуального творчества от человека к машине.
Однако, чтобы стать индустриальным стандартом, необходимо расширение:
До сих пор архитектуры вроде Transformer, ResNet, LSTM и др. придумывались людьми. Теперь это может уйти в прошлое:
Архитекторы моделей (ML-исследователи) уступают место «ИИ-исследователям», которые сами разрабатывают, тестируют и улучшают архитектуры.
Возможна экспоненциальная генерация новых моделей, с ростом качества за счёт вычислений, а не команды учёных.
💡 Аналогия: как AutoML автоматизировал подбор гиперпараметров, ASI‑Arch автоматизирует весь процесс архитектурного R&D. 📈 2. Сдвиг в сторону compute-centric исследований
Главное открытие статьи — scaling law архитектурных открытий: количество полезных инноваций растёт линейно с количеством GPU-часов.
Это означает, что исследовательская деятельность может быть масштабируема так же, как тренировка моделей.
В будущем корпорации будут «вычислять» открытия, как сейчас они «вычисляют» языковые модели.
📉 Это может привести к снижению роли академических коллективов с ограниченными ресурсами, если они не будут использовать подобные инструменты. 🧠 3. Появление ИИ-систем, способных к мета-обучению и научному мышлению
У ASI‑Arch есть зачатки научного метода: генерация гипотез, реализация, эксперименты, анализ результатов, повторная формулировка.
Такие системы смогут создавать собственные теории, например:
"в каких условиях attention лучше SSM?",
"какие архитектурные блоки универсальны?",
и даже новые loss-функции или задачи.
Это открывает дорогу к саморазвивающемуся ИИ, способному не просто обучаться, но и изобретать. 🌐 4. Диверсификация архитектур
Благодаря количественному и качественному отбору, можно находить нестандартные, неформализованные решения.
Это даёт шанс на:
Новые типы архитектур вне Transformers;
Специализированные архитектуры под конкретные задачи (например, reasoning, vision, RL);
Архитектуры с лучшим отношением «качество/ресурсы» для edge-устройств.
🎲 Это может ускорить эволюцию архитектур так же, как GPT ускорил NLP. 🏭 5. Индустриализация R&D нейросетей
Вместо небольших лабораторий с идеями — инфраструктура с GPU и ИИ‑исследователем, работающим 24/7.
R&D превращается в потоковый процесс, с контролем качества, логами, архивами и автоматическими публикациями.
В этом контексте, человеческий исследователь становится менеджером или критиком, но не автором архитектуры.
⚙️ Возможно, через 2–3 года:
публикации с архитектурами будут почти всегда результатами ИИ‑поиска;
GitHub будет заполняться не написанным руками кодом, а сгенерированным R&D‑системами;
откроются «ИИ‑лаборатории» без людей, где ИИ изобретает ИИ.
🧭 Заключение: ИИ, создающий ИИ
Эта работа делает очень важный сдвиг: если раньше модель была лишь «учеником», то теперь ИИ становится научным работником, способным:
делать открытия,
формировать теории,
анализировать данные,
и предлагать новое лучшее решение.
Это не просто ускорение науки — это изменение её субъекта. Впереди: конкуренция между ИИ‑исследователями, коллективная научная работа между человеком и ИИ, и даже наука без людей.
>>1289597 Ну наоптимизировали они агентами считанные проценты в какой-то бесполезной архитектуре, и что? Так же как и с японцами было, когда они сделали "эволюционирующую систему написания кода", которая работала, но что-то лучшее чем открытые аналоги курсора даже близко и не написала.
>>1289597 Думал о такой штуке. На сколько я понимаю это ближе к "универсальной архитектуре" подходящей для любых задач, чем к тому самому моменту, когда нейронки будут улучшать сами себя, который мы ждем. Т.е. ты формируешь задачу, а агент ищет для нее оптимальную архитектуру. Правда я думал об этом в ином ключе, было бы идеально сделать именно универсальную архитектуру, у которой лосс всегда сходится вне заваисимости от датасета и обработки входных данных, без нормализации, токенизации и прочих хаков. Это был бы святой грааль машин лернинга.
Learning without training: разбираем новую крайне интересную статью от Google
Смотрите, все мы знаем, что если модели в промпте показать несколько примеров решения похожих задач, то она может легко подхватить паттерн, и качество ответов станет лучше. При этом веса модели, естественно, не меняются.
Это называется in‑context learning (ICL), но вот вам fun fact: никто до сих пор до конца не знает, почему это работает, и как трансформер это делает.
И вот в этой статье авторы предлагают почти революционную гипотезу – что на самом деле веса меняются, просто иначе, чем мы привыкли.
То есть на самом деле внутри блока трансформера происходит нечто похожее на файнтюнинг, только не через градиенты, а за счёт самой механики self‑attention и MLP. Идея сводится к следующему:
1. Контекст порождает локальные изменения активаций, и когда вы добавляете примеры в промпт, self‑attention пересчитывает эмбеддинги токенов так, что после этого они зависят от всего контекста. Разницу между «чистыми» активациями и активациями с учётом примеров можно назвать контекстным сдвигом. Это все известные вещи.
2. А вот дальше зарыта собака: оказывается, MLP превращает этот контекстный сдвиг в ранг‑1 обновление весов. Иначе говоря, если посмотреть на первый линейный слой MLP (матрицу W), то влияние дополнительных примеров эквивалентно тому, что эту самую матрицу дополняют маленькой поправкой ранга1.
Причем эта поправка описывается достаточно простой формулой. То есть если мы берем оригинальные веса и вручную добавляем к ним эту поправку, модель без контекста выдаст то же самое, что и оригинал с контекстом. Но всё это происходит во время инференса, без обратного прохода и без изменения глобальных моделей параметров.
Получается, Google буквально дают ключ к возможному обучению без градиентного спуска. Если такие ранг‑1 апдейты научиться усиливать или контролировать, это может быть началом абсолютно новых архитектур.
Почитать полностью можно тут -> arxiv.org/abs/2507.16003
>>1289609 >>1289604 Блять, всё по Леопольду Ашенбреннеру, прям один в один. Пидорас оказался ебанным пророком, а ведь сколько ебанатов глумились над его эссе...
>>1289623 >Это называется in‑context learning (ICL), но вот вам fun fact: никто до сих пор до конца не знает, почему это работает, и как трансформер это делает. Что за шизофрения. Промт добавляется к весам модели. Т.е. по факту веса меняются на весь промт.
>>1289692 База же. Альтман только сосёт деньги инвесторов, никто никогда не думал что можно в столь наглую запилить финансовую пирамиду и тебя не посадят в тюрьму. Это максимально контринтуитивная ситуация.
>>1289779 В поиск встроили и ябут. Там большинство запросов впустую, потому что никто даже текст ЛЛМки не читает, а идут к списку сайтов. Помнится в каком-то году были дебаты еще до ИИ, что поиск жрет энергию и это плохо для экологии. Увидели бы они сейчас, что происходит, каждый поиск сжирает кучу энергии, потому что в него нейронка встроена.
Это не Photoshop moment для video, как пищит твиттор.
Это скорее Flux Kontext moment для video.
Смотрите, что он умеет:
Generate New Camera Angles Новые ракурсы существующих сцен с помощью простых текстовых подсказок. Хотите обратный план или низкий угол? Доступны бесконечные варианты покрытия сцены. На композе такого не сделаешь.
Generate the Next Shot Просто попросите – и модель сгенерирует следующий кадр в вашей истории. Досъемка.
Style Transfer to Video Любое видео под нужную эстетику. Примените стиль к кадрам, просто описав его. Не новая фишка, но хуже не будет.
Change Environments & Time Можно менять локации, сезоны и время суток. С локациями особенно зрелищно.
Add Things to Scene Толпу, продукты, реквизит с корректным освещением и перспективой. Особенно приподчеррипикана работа с отражениями.
Remove Things from Scene Ну за ротоскоперов.
Change Objects in Scene Текстуры, объекты, персонажи и другие элементы. Промптами. Video Kontext
Apply Motion to Image Движение из любого видео на новую начальную кадр‑картинку. Встроенный Act 2
Alter Character Appearance Возраст и внешний облик персонажей с помощью простых команд, без грима, макияжа или затратных VFX.
Recolor Scene Elements Изменяйте цвет объектов, предоставляя палитру или описывая желаемые оттенки.
Relight Shots Тут понятно
Green Screen Extraction Тут надо смотреть на качество, конечно, а так: за рото и ки, не чокаясь
Выглядит, как попытка сделать прям нейро-комбайн для нейрокомпоза.
>>1289818 >>1289831 На 2.1 можно же. Если симсвап/веревка были версией 1.0, то ван это 3.0 - еще большая игрушка дьявола, реальная опасность для причиндал, рук, головы и души.
>>1289795 Наоборот, у гугла поиск последние лет 10 настолько уебищный что ты либо заранее знаешь пачку сайтов где можно что-то искать, либо пробираешься через этот копрослоп с фишинговыми сайтами и переводами переводов. Теперь на какой-то мелковопрос сразу получаешь ответ, не переходя на всякие говносайты, где еще контент не прогрузился, а тебя уже ебут банерами о покупке говнокнижке, просьбами отключить ублок, принять все куки, помолиться аллаху и т.д. Нейронки это то, каким должен был быть гугл изначально
А вы знали, что в Veo-3 можно просто нарисовать на первом кадре визуальные инструкции: всякие стрелочки, подписи, и Veo3 это пережует и поймет. Экономия на промптах. И никакого джайсона.
>>1289937 Нейрокалыч кроме жс и питона ничего не может писать, забей. У него просто нету датасетов для yaml чтобы правильно весы устоялись. Если хочешь чтобы работало - в промте забивай все правила синтаксиса, только тогда оно будет работать чуть лучше и высирать нейрослопы реже.
Еще одна очень громкая статья последних дней – AlphaGo Moment for Model Architecture Discovery
TL;DR: ученые представили первую в мире систему, автономно генерирующую новые рабочие архитектуры ИИ -> проверили ее на на20 000 GPU‑часах -> открыли закон масштабирования, который говорит, что количество обнаруженных архитектур растёт линейно по мере увеличения числа ресурсов.
После выхода AlphaEvolve ученые всё больше и больше говорят о том, что пора нам переходить от NAS к ASI4AI: то есть от классического Neural Architecture Search, ограниченного человеческим фактором, к ИИ, который улучшает ИИ, который улучшает ИИ, который .... Ну вы поняли.
История действительно перспективная (и в том числе эта статья это подтверждает). Ведь способности ИИ по законам масштабирования растут экспоненциально, но в то же время скорость исследований остаётся линейной из‑за ограничений человеческого внимания и времени. Парадокс.
Ну так вот. Сама архитектура ASI‑ARCH из статьи состоит из трех модулей: Researcher, Engineer и Analyzer. Один генерирует гипотезы и "ТЗ", другой пишет код и собирает метрики, третий анализирует результаты.
Долго останавливаться на архитектуре не будем, тут самое интересное – результат. Было проведено 1 773 эксперимента на20 000 GPU‑часах, врезультате обнаружено 106 новых SOTA архитектур (это линейная зависимость). Под SOTA тут, кстати, подразумеваются именно линейные модели (НЕ трансформер), которые демонстрируют лучшие метрики в своем классе.
При этом в итоговых архитектурах действительно присутствуют какие-то непривычные конструкции. Отсюда и название – исследователи проводят прямую аналогию с ходом 37 AlphaGo в матче с Ли Седолем и говорят, что это яркий показатель способности системы находить прорывные идеи, а не просто подражать.
>>1289970 А кабану то что? Во-первых всякие хуесосы в куртке каждодневно промывают его что ai уже here now. Во-вторых даже если не готов, что ему мешает прощупывать почву заранее, тем более вдруг схавают и получится сэкономить пару копеек. Просто более умные кабаны сначала заставляют работника научить ии его работе, а потом увольняют, а затупки сначала рубят, а потом после обсера берут нового на x2
>>1290045 Все так, я недавно ради интереса решил посмотреть чем r отличается от питухона, так там видимо настолько мало кода в обучающей выборке было что и гопота, и грок практически одинаково обсирались, и порой вообще на любые запросы выдавали одинаковые(неправильные) куски кода.
Как вообще понять, что творится в мире? Одни говорят, что ИИ скоро заменят программистов, другие говорят, что ничего подобного. Как плохо жить при капитализме с его рынком, с его громкими заголовками.
>>1290261 Так дело в том, что про сингулярность говорят разные ученые. А я боюсь остаться без работы. Хоть я и сейчас не трудоустроен, но так был шанс изучить какой-то веб и вкатиться, а потом будет выбор только полы мыть.
>>1290254 Почитать самих программистов, их уже заменяют. Мидл-сеньор сегмент держится пока, потому что там много пиздят на совещаниях и код бывает немного сложнее того, что нейронки охватить могут, но это тоже ненадолго. Фриланс программирование уже все на нейронках, его не стало.
>>1290405 Я подразумевал идеалистическое государство, где бы все работало на благо народа, а не корпораций. В капиталистическом мире мы еще можем угодить в антиутопию.
>>1290414 Северная корея идеалистическое государство с планчиком, без антиутопий и всё работает на благо народа, пока в капиталистическом, рыночном аду какие-то корпорации строят фашистские дата-центры и конкурируют пытаясь высрать более менее работающую технологию
>>1290426 >идеалистическое государство идеологическое, а не идеалистическое >>1289903 >Производительность может увеличить экономику в 10 раз, ликвидировать нищету и сделать товары и услуги доступными для всех но не сказал сколько в мире должно остаться этих "всех"
>>1288975 То наверное тайваньцы, причем техно-гики, выросшие в центре индустрии производства Интел, АМД, НВидия, рядышком с заводом, и может и начинали там пахать на этих американских заводах студентами. Соответтсвенно у них есть понимание цикла производства, даже если программист, то ценится больше тот программист, который делал программы для производственных современных линий (производство микросхем и т.д.), и делал там же на заводе и отладку своих программ.
>>1290515 То материковый Китай: Шанхай, Пекин - вот это все. Но не хуи с горы, а с детства дроченные родителями на учебу, ими же оплаченные переезд, проживание, миты и стенфорды - ты только учись, корзина. Железячники очень далеки от прикладного софта и ИИ.
>>1290515 >производства ...Там, в Тайване, походу студенты идут на работу на американский завод, сразу расчитывая что это путь выбраться в США, плюс поддержка по линии USAID тоже влияет.
>>1290517 >Железячники очень Смотря какие, если они на производстве тех же видеокарт Нвидия, то это плюс к их рейтингу чем у чисто офисных программистов.
Вообще для науки нужна производственная база - завод, и при нём институт, с лабораториями и конструкторскими отделами. А в КНР как раз заводов завались.
>>1290520 Какому рейтингу? У тех и других огромные объемы почти никак не пересекающихся информации и опыта, на освоение которых уходят года. Астрономы к химикам и то ближе.
>>1290414 >на благо народа, а не корпораций. Корпорации капиталистов и приносят блага народу в виде крутых октрытий.
Вот для примера ДВС делали 200 лет поодиночке. Лампу накаливания делали 60 лет тоже одиночки. Допустим сегоднящнаяя задача сделать лампу накаливания - это изобрести реактор холодного синтеза и чтобы без радиактивности. если делать эту задачу одиночками, может уйти наэто 2000 лет, если делать небольшими группами, может уйти 200 лет, как и на лампу накаливания, если делать это корпрорацией или даже коллаборацией из нескольких корпораций, то может на это уйти 20 лет времени.
>>1290081 Вот как комментирует новость нейронка перплексити: Если коротко: система, которая генерирует сотни новых SOTA-архитектур на базе только линейных моделей, вряд ли ускорит прогресс до AGI или ASI. Линейные модели просты и удобны, но они фундаментально ограничены — не могут выразить сложные, глубокие, нелинейные паттерны, которые как раз и нужны для общего интеллекта или супер-интеллекта.
Текущие прорывы в AI связаны с нейросетями именно из-за их нелинейной природы, а линейные модели — это скорее база и инструмент для простых и понятных задач. Так что для AGI\ASI нужны более сложные архитектуры, а подобная система будет мега-полезна для applied ML, но не радикально приблизит появление AGI.
>>1290523 >холодного ...Было бы логично чтобы реактор холодного синтеза был первым крупным изобретением нейронок.
Чтобы корпорации построили свои мощные дата-центры для ИИ, потом объединили свои ИИ в одну команду и изобрели реактор холодного синтеза, или что-то подобное.
>>1290523 Корпы для зарабатывания денег существуют. Если они хоть малейшую выгоду видят, они ничего не отдают никому. Часто доходя до бессмыслицы, как например непубликация исходных кодов программ, которым по 20 лет, и которыми никто уже давно не пользуется. Открытия, которые угрожают их прибыли, они тоже скрывают, пока на них другие организации своими усилиями не выйдут, тогда внезапно оказывается все всё знали уже годами. Еще существует даже целая практика превентивной скупки патентов корпорациями, чтобы конкуренты не могли разрабатывать свое аналогичное открытие, иначе их засудят.
>>1290523 >ДВС делали 200 лет поодиночке никто ничего не делает поодиночке, все опираются на труды предшественников и современников и корпорации никак не ускоряют открытия. открытия точно так же делаются как ты выразился "одиночками" , просто корпорация стремится таких "одиночек" как можно больше включить в себя, для присвоения их трудов. и эти рассуждения о сроках открытий некорректны. это классическое "одна женщина родит ребенка за 9 месяцев, а девять женщин за один месяц".
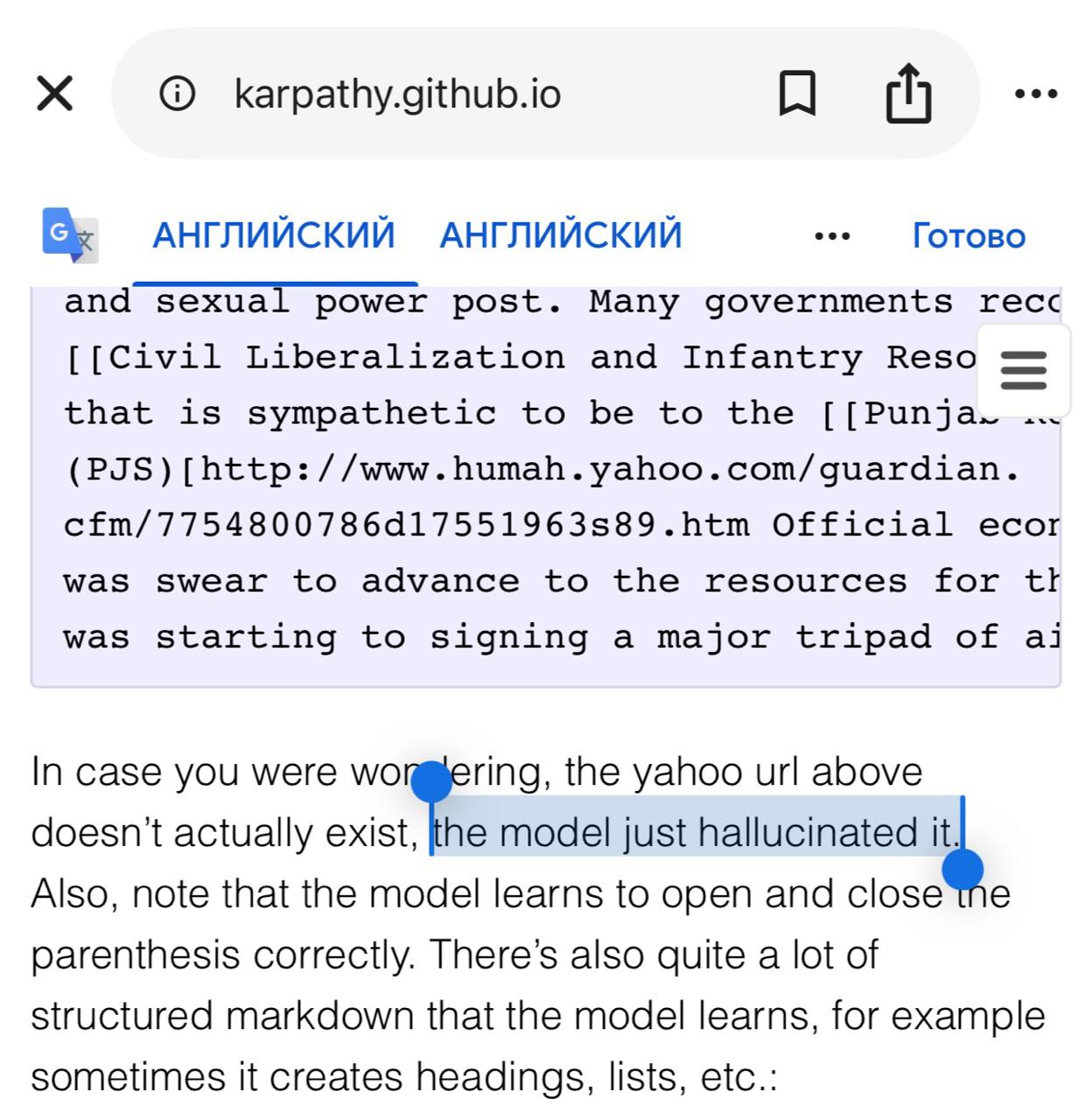
Сегодня интернет обнаружил, что термин «галлюцинации» тоже придумал Андрей Карпаты. Почти все знают, что именно он ввел в эксплуатацию «вайб-кодинг», но это то было относительно недавно, – а вот корни «галлюцинаций» уходят еще в 2015 год.
Оказывается, тогда термин был впервые использован в известной статье Карпатова “Unreasonable Effectiveness of RNNs” (http://karpathy.github.io/2015/05/21/rnn-effectiveness/ ), и с тех пор разлетелся по комьюнити, ну а дальше – в глобал.
Сам Андрей, кстати, пишет, что он «нагаллюцинировал это понятие»
Я испытываю экзистенциальный кризис из-за ИИ. Он отнимает у человека смысл творчества и познания. Впервые в жизни не рад новым технологиям, хотя раньше думал, что прогресс всегда во благо.
>>1290771 Нагенерил несколько тысяч картинок через нейросети и понял, что это нихуя не творчество. Это скорее конструктор как у детей с небольшими вариациями, из готовых блоков собирать картинку. Что-то новое и уникальное ты нейросеткой не сможешь создать, для этого надо хоть как-то от руки уметь делать. А вот штамповать однообразное говно пачками оно всегда пожалуйста.
>>1290771 Наоборот, начнётся новая творческая эпоха, люди будут делиться друг с другом полностью сгенерированными авторскими мирами. Эх, если бы не санкции, я бы сейчас прикупил акции компаний, строящих метавселенные со встроенным ии.
>>1290718 Если бы робот был в пять раз больше, он бы ему пизды навешал с легкостью. Ну это не считая того, что при попытке удара в челюсть, рука бы сказала до свидания.
Qwen снова радуют релизом. Но на этот раз это не модель, а новый RL-алгоритм для обучения LLM
Метод называется Group Sequence Policy Optimization (GSPO), и именно он лег в основу последних громких моделей компании: Qwen3 Instruct, Coder и Thinking. Статья вышла пару дней назад, но о ней уже говорят все. А значит пора разобраться.
Сегодня один из самых популярных RL-алгоритмов для LLM – это GRPO (by DeepSeek). GRPO работает здорово и довольно стабильно, но на уровне токенов.
То есть в GRPO мы считаем награду для всей последовательности -> считаем важность каждого токена и применяем клиппинг также для каждого токена отдельно -> обновляем политику "на уровне токенов".
А в GSPO все то же самое происходит сразу для всей последовательности: считаем награду -> рассчитываем единый importance weight для всей последовательности и применяем клиппинг для всего ответа целиком с нормализацией по длине -> обновляем политику.
В чем преимущество такого подхода?
1. Не нужно устраивать танцы с бубном, когда работаешь с MoE. У GRPO из-за архитектурных особенностей MoE идет со скрипом, а тут все заводится из коробки. 2. Градиенты получаются менее шумными, потому что снижается дисперсия. Следовательно –еще более стабильное обучение. Следовательно – лучшие метрики при тех же ресурсах. 3. Инженерно реализуется гораздо проще.
Короче, выглядит очень привлекательно и, вероятно, станет следующим словом в RL для LLM (особенно в опенсорсе). Статью полностью читаем тут: https://huggingface.co/papers/2507.18071
>>1290876 Это естественно. Только вот творчество и познание это прежде всего потребность разума, а не наполнение своим калычем интернеты. Впрочем, школьницы могут считать иначе, штош, придётся создавать вайб лучше чем у нейронок чтобы конкурировать.
>>1290517 > Железячники очень далеки от прикладного софта и ИИ. >>1290522 > Астрономы к химикам и то ближе. То есть если я учусь на какой-нибудь микроэлектронике то я далёк от ии?
>>1291050 лол, иммиграция в США наблюдается рекордная, за последние 25 лет (время правления Путина) в штаты иммигрировали более 80 млн человек (это только легально). На минуточку, это больше половины населения России.
>>1291066 > иммиграция в США От того, что приехало 80 млн диких чурок разных цветов кожи, инженерных компетенций не прибавится. А с этим у них давно уже огромные проблемы, и они будут только усугубляться.
Опенсорсный Wan 2.2 таки дропнули. Ну и спасибо разрабам, нативная поддержка новых моделей в ComfyUI
Версии, которые уже доступны:
Wan2.2-TI2V-5B: FP16 (Текст в видео 5 миллиардов параметров)
Wan2.2-I2V-14B: FP16/FP8 (Картинка в видео 14 миллиардов параметров)
Wan2.2-T2V-14B: FP16/FP8 (Текст в видео 14 миллиардов параметров)
Для больших моделей в максимальном качестве понадобится 49 гигов Vram. Так что расчехляйте свои RTX PRO 6000, либо ждите пожатые версии на неделе. Либо можете навернуть мелкую 5b модель, она требует всего 8 гигов
Wan 2.2 - это продолжение уже многим знакомого опенсоурсного Wan2.1, который стал моментом SD1.5, только в видео формате для опенсоурс коммьюнити.
>>1291106 В 2-3 раза медленее всего, так же и с производительностью, это все равно вполне нормальные 5-10т/с на гигамолелях типа дипсика 671b С курткой ты можешь разве что писю пососать из-за оффлоада в рам, где у тебя производительность дропнется от 10 до 50 раз, или заплатить в 3-5 раз больше и охуеть от энергопотребления и шума
>>1291124 Нахуй мне локально дипхуй гонять? Мне бесплатные топовые проприетарные модели полностью закрывают потребности в LLM. А вот с видеомоделями всё иначе, у проприетарных и цена кусается, и цензура ебёт, тут строго нужен опенсорс. и вот для фото и видеомоделей нет ничего лучше, чем карты куртки
>>1291124 двачую, на макстудио люди запускали модельки с 235В параметров, на одной нвидеа RTX 5080 super 24Гб тоже запускали, но с файлом подкачки - это оказалось существенно медленнее
>>1290995 Грубое, но в сравнении с китаем и по теме ИИ это так. Объебосы на спидах лепят гениальные идеи. А делают эти идеи наполовину азиаты даже в США.
>>1291000 У меня телевизора нет, а на ютубе я смотрю только тематику и научпоп. Так что технически не могу быть жертвой попагандонства.
>>1291066 >80 млн человек посудомоек? Ну серьёзно, крутых инженеров единицы. И они свои решения о переезде принимают совсем по другим причинам. И по более комплексным
>>1291134 У тебя какая то куртка головного мозга, локальный ии в 99% случаев буксует из-за мизерного количества видеопамяти на топовых потребительских видюхах тайваньского хуесоса, даже там где нужна голая производительность мак студио пососет всего в 2-3 раза относительно не потребительского гавна от куртки за миллионы денег и киловаты тпд
Если ты какой-то залетный мажорчик или кабан с безлимитом денег то конечно видеокарты от главпидораса в кожанке выгоднее
>>1291167 Нет, это типа магазин без касс, где ты берешь продукты и у тебя списывают с аккаунта. Это не прикол, справедливо заметить что Amazon Go тоже ловили на этом. Но я думаю это обучающий датасет для VM модельки
>>1291181 оч похоже, но если приглядеться то видны артефакты генерации. Нужно признать, что с каждым днем отличать реальность от генерации становится все сложнее
>>1291155 Ты хуйню какую-то несёшь. Ещё раз, речь об опенсурсных фото и видеомоделях. Назови для них железо лучше, чем RTX PRO 6000, у которой 96 гигов хватает под лучшие опенсорсные фото и видеомодели на рынке
>>1291177 Даже я, который программированием занимается раз в два, мог бы автоматизировать это так, что человек вообще бы не понадобился. Но видимо китайцы дешевле.
GLM 4.5 — китайский опенсорс продолжает доминировать
Очередная очень сильная открытая MoE модель от китайцев, с очень хорошими результатами на бенчах. Гибридний ризонер, с упором на тулюз. Доступна по MIT лицензии, 128к контекста, нативный function calling, из коробки работают стриминг и batching, есть FP8‑инференс и совместимость с vLLM/SGLang.
Как и Kimi K2 модельку тренировали с Muon, но в отличие от Kimi авторы использовали QK норму вместо клиппинга — Kimi такой трюк не позволило провернуть использование MLA, из-за чего им пришлось придумывать свою версию оптимайзера. Для спекулятивного декодинга получше модельку тренировали с MTP. Она заметно глубже чем другие открытые китайские MoE — это повышает перформанс, за счёт роста размера KV-кэша. Вместе с этим они используют заметно больше attention heads. Это хоть и не помогает лоссу, но заметно улучшает ризонинг бенчмарки.
Модель идёт в двух размерах — 355B (32B active) и 106B (12B active). Претрейн был на 22 триллионах токенов — 15 триллионов токенов обычных данных, а после них 7 триллионов кода с ризонингом. На мидтрейне в модель запихнули по 500 миллиардов токенов кода и ризонинг данных с контекстом расширенным до 32к, а после этого 100 миллиардов long context и агентных данных при контексте уже в 128к.
Посттрейн двухэтапный — сначала из базовой модели через cold‑start+RL тренируют три эксперта (reasoning модель, agentic модель, и для общих тасков) и сводят их знания в одну модель через self‑distillation. Затем идёт объединённое обучение: общий SFT → Reasoning RL → Agentic RL → General RL.
Для ризонинга применяют одноступенчатый RL на полном 64K‑контексте с curriculum по сложности, динамическими температурами и адаптивным клиппингом. Агентные навыки тренируют на верифицируемых треках — поиск информации и программирование с обратной связью по исполнению. Полученные улучшения помогают и deep search и общему tool‑use. Кстати, их посттрейн фреймворк открытый и лежит на гитхабе.
>>1291285 Ты дурачок какой-то. Что ты там собираешься поворачивать куда, болезный. Нужна только одна камера, мимо которой будут проносить продукты. Они все разного цвета блять. Просто не помещай одинаковый цвет рядом. Вы что тупые что ли нахуй.
>>1290721 Текст для SLM нужно преобразовать в спайковый формат (например, слова как частота спайков или временные паттерны). Это требует сложной предобработки, и пока нет стандартов для кодирования языковых данных в SNN.Трансформеры используют механизм внимания для хранения длинных контекстов (до 128 000 токенов в GPT-4). SNN на Loihi полагаются на рекуррентные связи, которые менее эффективны для длинных последовательностей.Обучение трансформеров на GPU занимает недели на кластерах с тысячами GPU. SNN на Loihi обучаются медленнее из-за локальной природы STDP и ограничений по масштабу. Дата-центр с 10 000 чипов Loihi 2 (~10 млрд нейронов, ~1,2 трлн синапсов) теоретически может моделировать сеть масштаба небольшой LLM (например, BERT, ~340 млн параметров). Но GPT-4 (1,76 трлн параметров) требует гораздо большего масштаба или принципиально новых архитектур SNN. Для сравнения: человеческий мозг (~86 млрд нейронов, ~100 трлн синапсов) обрабатывает язык на ~20 Вт. SNN на Loihi пока не достигают такой эффективности в языковых задача. рансформеры используют внимание (self-attention), которое позволяет модели эффективно связывать слова в длинных текстах, вычисляя их взаимосвязи. Это требует больших матричных вычислений, которые GPU обрабатывают быстро и точно. SNN на Loihi: Нет аналога внимания. Рекуррентные связи в SNN могут моделировать контекст, но менее эффективно. В CoLaNET, например, сеть классифицирует данные (MNIST), но не обрабатывает длинные последовательности, как язык. Обучение: Backpropagation в трансформерах оптимизирует миллиарды параметров на огромных датасетах. STDP в SNN работает локально и требует больше итераций, что замедляет обучение для языковых задач.
>>1291300 Бро, так мыслит инженер. Он прикидывает ключевые сходства и различия.
Например то, что даже при едином цвете силуэт бутылки не будет таким же как силуэт брикетика мороженки ни при каких условиях.
А нейродебилы нарабатывают миллионы картинок и разметок. Жутко дегродская и брутфорсная область по большей части. Крутые инженеры в ней есть, но они не спешат заменить себя ИИшкой
>>1291289 >Мигрируют толпами нищуки в основном. За американской мечтой. А вот инженеров и учёных скупают.
во-первых, асашай одна из первых в мире по иммигрантам миллионерам. во-вторых, зпшка 100 000 000$ - это и есть американская мечта. А вот восхваляемая тобой подзалупная вместо того чтобы скупать спецов по 100 млн$ просто перекрыла выезд как крысы, и теперь китайский кобанчик эти деньги может забрать себе и не платить талантливому инженеру. Профит
>>1291295 что мне понравилось - они сравнивают свою модельку с топчиками (o3, gemini 2.5 pro ,opus 4 и grok 4). если они действительно набирают такие баллы на бенчах, то очень полодцы. Похоже новый серьезный игрок
>>1291425 У меня кстати закончились задачи на логику которые модели не проходят. Год назад я думал, что когда их пройдут это точно будет AGI, и вот теперь их проходят, а AGI нихуя нет. Ещё так раньше думал про переводы на английский. Типа когда нейронки будут переводить на уровне человека, то это точно будет AGI, сегодня некоторые нейронки переводят на уровне лучших из лучших переводчиков, а AGI нихуя нет
>>1291436 Мне кажется, так будет всегда, по крайней мере, пока мы живы: всегда будут споры о том, когда наступит AGI, что вообще считать AGI, нытье о «плато» — и даже если ИИ заменит всех людей, мы всё равно продолжим ждать какого-то «настоящего» AGI.
>>1291495 Более того если начать гуглить этого товарища, то выясняется что учился он на экономиста, а сейчас управляет семейными отелями и преподаёт "Стратегический, инновационный и корпоративный менеджмент" как "Visiting FH-Professor".
А если поискать его доказательство, то выяснится что опубликовал он его как философскую работу в каком-то не особо понятном философском журнале.
Поэтому не особенно удивительно что никто особо не воспринимает это всерьёз.
>>1291496 >>1291512 Там вполне хорошие рассуждения про трансформеры. Математики особо нет, но есть вполне проверяемые гипотезы и теоремы, которые, между прочим, наблюдаемы прямо сейчас и здесь в нейрокалыче.
Конечно логика там на уровне второго курса универа, но нейродебилы даже такую логику не приводят в доказательство существования AGI, так что это буквально лучшая работу на эту тему.
>>1291436 где те нейронки, которые переводят на уровне лучших переводчиков? Все жидко срутся и забывают уже через абзац, что статья про 3д и надо pipeline переводить как «конвейер» постоянно но не как «трубопровод».
На современной архитектуре ЛЛМ не то что AGI невозможен, даже интеллект нематоды не получается.
Сейчас могу с уверенностью сказать, что создано огромное количество вариантов хорошо работающей интуиции на кремнии. Той самой, что прикидывает по всем неявным параметрам, паттернам.
Но интуиция пока совсем слепа и нет у неё видения структуры, только чутьё.
Отдельные узкие модели чуят структуру, но только конкретного объекта.
Видеомодели чуют связность в небольшом диапазоне между пятнами и их ракурсами. Но не понимают сути формы.
Вполне возможно, если вычислительные мощности вырастут в тысячи раз и найдут способ увязывать все сенсорные данные, которые собираются сейчас, плюс завязать их на хорошем 3д-движке (подразумевающем и твёрдое и зыбкое-разделяемое и силуэты-обобщения), то будет ИИ технически сравнимый с человеческим.
Есть ещё мнение такое, что вдруг у нас в голове что-то невычислимое и мы в том числе квантовые комплюхтеры, тогда это новый вызов железу. Но в самом оптимистичном смысле я вижу так: мы из материи. И мы воспроизводимся. То есть возможность воспроизвести есть.
>>1291787 О каких сайтах речь? То как переводит сейчас ИИ это небо и земля по сравнению с тем что было 1-2 года назад. По началу приходилось сравнивать перевод вручную и редачить косяки, а сейчас даже редачить не нужно. Если хочешь поспорить, то скидывай эти свои сайты с текстом оригинала и проверим их перевод с переводом ИИ. Скорее всего там переводят говном каким то
>>1291584 Хоть платные хоть бесплатные. Бытовой язык — да, без проблем. Как только начинается техническая литература, в рот я ебал такой перевод, только путаница от него и надо искать, что там наврано. Проще поглядывать в машинный перевод и выделять слова для переводчика, добираясь до сути. Вроде бы не так комфортно, но по итогу и быстрее и точнее.
>>1291639 Я к тому, что под ИИ нынче хайпят именно ЛЛМ. Да, трансформеры. И не только. Подавляющее число современных архитектур — это запекание статистического сита. Пусть очень сложного. Но даже ёбаный червь минимально обучается в процессе жизни непрерывно.
>>1291762 Английский переводит слабовато, бытовой язык хорошо только. А уж мунспик это пиздарики полные. Только общий смысл можно уловить. Расскажи мне как он хорошо переводит и почему богатейший Алиэкспресс никак не может перевести карточки товаров вменяемо, мой дорогой друг золотая подошва верхнего среза неба.
Вот малюсенький отрывочек статьи. Два сраных абзаца. И уже на них четыре платных нейронки нахуй поплыли. Claude лучше всех перевела, правильно поняла «группы запекания» и даже адаптировала exploded baking как раздельное запекание (по смыслу очень верно), но язык всё ещё коряв. «Делают эту программу его предпочтительным выбором для запекания» это пиздец косноязычие. Ну и «кейджа» вместо «оболочки» или «клетки» такое себе, хотя именно для специалиста и просторечия годится. А у кого-то «тесные площади» вообще… У большинства «труднодоступные места», что по смыслу близко, но не вполне верно. «Узкие места же» — вполне устойчивое выражение в русском. Суть не столько в том, что они труднодоступны, а в том, что из-за узости может быть самоналожение оболочки или её слишком большое выдвигание из расщелины и искажение направлений запекания. То есть дело не в доступе а именно в близости соседних поверхностей.
Чем больше текст, чем больше терминов, тем хуже результат и разброс. Остальные три нейронки справились ещё хуже.
Человеку, не понимающему в предмете и не знающему языка и такой перевод за чудо. Я согласен, что за копейки и мгновенно он хорош. Но не сравнится с работой норм переводчика, секущего в теме.
>>1291834 Перестань пиздеть, нейродебил, это не работает. Абсолютно все люди уже пробовали и видели переводы нейрокала - полное говно которое читать дальше пары страниц кринжово.
>>1291762 Ты хуйню пишешь, дебил. Возьми два раза сролль перевод книжки и получишь два разных куска. Так же как и в истории с 5 секундными видео - там хорошо только в начале, а потом начинает отваливать и улетать в слопчанский. Если грохать контекст чтоб он сам себя не засирал самоинструкциями - будешь иметь на выходе разноколиберное говно со всратым стилем (слышал такое слово?). Ты обычный радужно-диванный пиздлявый хуесос, в общем, который нихуя не понимает о чём говорит. И да, удаче тебе в сойнете или гимини перевести сцену, где мужик бьет бабу по ебалу. И отказ - это не самое худшее. Самое худшее это скрытая цензура говняным алайментом прям внутри текста, которую ты, калоед, даже увидеть не способен, так как языка не знаешь. Если для тебя любая книга это просто перечисление фактов каким-то текстом примерно понятным (и не понятным) - хули ты вообще свой пиздак в приличном обществе открываешь?
>>1291865 Это тоже гемини. Перевод всё еще выглядит хорошим
Конечно, вот перевод и адаптация текста интерфейса с китайского на русский. Я сгруппировал элементы по логическим блокам, как они расположены на изображении, и добавил примечания для лучшего понимания контекста.
Общий заголовок
腾讯混元3D → Tencent Hunyuan 3D (Название продукта, лучше оставить в оригинальной транслитерации «Hunyuan» или транскрибировать как «Хунъюань». Вариант: Tencent Хунъюань 3D).
Главное меню (Навигация)
AI创作 → AI-творчество (или Создание с AI)
实验室 → Лаборатория
工作流 → Рабочий процесс (или Процессы)
3D世界模型 → 3D-модели мира (Подразумевается создание больших сцен или миров)
3D世界模型 → 3D-модель мира (здесь это заголовок раздела настроек)
3D智能拓 → 3D-ретопология (или Умная ретопология. "拓" — это сокращение от "拓扑" (топология), здесь имеется в виду автоматическое создание оптимизированной 3D-сетки)
图片上传建议 → Рекомендации по загрузке
选择模型 → Выберите модель
Настройки модели:
莫型面数 (опечатка, должно быть 模型面数) → Количество полигонов (или Детализация модели)
默认 → По умолч. (сокращенно) или Стандарт
50k / 150k / 300k → 50k / 150k / 300k (здесь "k" означает тысяч полигонов, это стандартное обозначение)
生成类型 → Тип генерации
几何+纹理 → Геометрия + Текстура
3D生成-V2.5 → 3D-генерация v2.5
V → (это значок выпадающего списка)
Дополнительные опции:
支持拓扑 → С поддержкой топологии
几何、纹理分阶段 → Раздельная генерация (геометрия, затем текстура) (или Поэтапная генерация)
Боковая панель (слева)
++ 灵感广场 → ++ Галерея идей (или Площадка вдохновения)
>>1291872 Ты точно прочитал? «он выбирает … благодаря возможности» — от любителей «выходя из автобуса он тут же поехал» Это грубейшая речевая ошибка. Типа у человека появился выбор (технически, а не желание) только потому что в программе появилась возможность. Будто программная особенность это причина появления выбора а не аргумент в его пользу.
>для запекания разнесённых частей модели по сути верно, но громоздко.
Если ты прочёл и тебе норм, то у тебя проблемы с речью.
>>1291880 Жесть ну ты и токсик, хотя что еще от двачера ожидать) По тексту можно понять о чем говорится, что ты не понял? Он выбрал эту прогу за давно добавленные функции, которых нет в другой проге.
>>1291886 Достаточно дать ему инфу что это интерфейс программы и он её переведет. Если мы видим говнопереводы, то это проблема тех кто переводил, а не ИИ переводчика. Я так пробовал с японского сабы переводить, он переводил хорошо, но было бы лучше если бы контекст был больше. Сами посудите, если рандомному живому переводчику дать текст из рандомного места произведения, то он так же переведет дермово, но только из за того что у него нет контекста. Дай ему плохо написанный текст, он и его плохо переведёт, но попытается как то отредактировать для лучшего вида. Вот и ИИ переводчик уже сейчас переводит по силам живого (и даже лучше), исходя из данного ему контекста. Ему даешь в перевод фанфики, а он угадывает персонажей, игру и т.д.. Дай этот текст челу который не играл в игру, не читал какую то книжку, и он не поймет особенности текста и перевед1т в силу своих возможностей. Если вы владеете контекстом (играли, читали или работали с программой), то вы, конечно, перевести какие то особенности сможете лучше. Я не зная китайского и японского перевожу в читаемый и понятный вид текст, который совпадает с действиями на экране. Если бы переводчик брал инфу ещё и с экрана, то перевод был бы ещё лучше.
>>1291899 > Если мы видим говнопереводы, то это проблема тех кто переводил, а не ИИ переводчика. Нейрокал обосрался @ ЭТО НЕ ОН ОБОСРАЛСЯ, ЭТО ВЫ ГОВНО НЕ ЗАНЮХАЛИ
>>1291888 Речь изначально была про «на уровне лучших переводчиков», а по факту на уровне косноязычного середнячка. Понятно о чём речь было ещё в эпоху Промпта. Стало лучше. На уровне переводчика нормального не стало пока.
>>1291899 1. Поэтому выше я дал пример с введением в контекст. 2. Нейромудилы же хвастают пониманием контекста нейронкой. Если текст на кнопке написан, очевидно это интерфейс. Если текст в комиксе, вокруг картинки, в заголовке сайта про комиксы, в ключевых словах страницы про комиксы, то скорее всего это комикс. И т.д.
Контекст часто следует из самой большой статьи.
Ещё раз, я не спорю, что перевод стал лучше. Я говорю, что до живого переводчика в теме ещё далеко. Это речь только о прямом переводе по смыслу, не о художественном, не об адаптации.
GPT-5 уже почти здесь, и мы слышим хорошие новости. Ранняя реакция по крайней мере одного человека, который использовал невыпущенную версию, была чрезвычайно позитивной. Это хорошая новость для OpenAI. Создатель ChatGPT находится под давлением, чтобы показать значительные успехи от своей следующей большой модели искусственного интеллекта, с тех пор как в ноябре прошлого года появилась новость о том, что компания столкнулась с уменьшением отдачи от использования больших вычислительных ресурсов и данных во время «предварительного обучения». Это часть первоначального процесса разработки модели, когда она обрабатывает тонны данных из Интернета и других источников, чтобы научиться взаимосвязям между различными концепциями.
OpenAI не уточнила, когда GPT-5 будет выпущен в ChatGPT и для клиентов-разработчиков приложений. Но генеральный директор Сэм Альтман начал публично обсуждать, насколько ему нравится использовать невыпущенную версию. По словам человека, который использовал модель, она призвана реализовать план Альтмана по интеграции традиционных больших языковых моделей под брендом «GPT» с линейкой моделей рассуждений компании «o» в одну модель или интерфейс чата. Подобно гибридным моделям Claude от Anthropic, пользователи, вероятно, смогут контролировать, насколько GPT-5 «думает» о той или иной проблеме, и модель также будет включать и выключать свои возможности рассуждения в зависимости от сложности проблемы, сказал человек. (Так что, если вы спросите ее, сколько букв «р» в слове «strawberry», она не будет тратить кучу вычислений на это, даже если вы ей это поручили.)
GPT-5 демонстрирует улучшенную производительность в ряде областей, включая точные науки, выполнение задач для пользователей в их браузерах и творческое письмо, по сравнению с предыдущими поколениями моделей. Но наиболее заметное улучшение достигается в программной инженерии, все более прибыльном применении LLM, сказал человек, который использовал модель. По словам человека, GPT-5 лучше не только в академических и соревновательных задачах по программированию, но и в более практических задачах по программированию, с которыми могут столкнуться реальные инженеры, таких как внесение изменений в большую, сложную кодовую базу, полную старого кода. Этот нюанс был тем, с чем модели OpenAI боролись в прошлом, и это одна из причин, почему соперник Anthropic смог сохранить свое лидерство среди многих клиентов-разработчиков приложений. Но, как сообщалось, OpenAI более чем осведомлена об этой проблеме и в последние месяцы работает над улучшением возможностей кодирования своих моделей.
Один человек, который использовал GPT-5, говорит, что он превосходит Claude Sonnet 4 от Anthropic в прямых сравнениях, которые они тестировали. Но это всего лишь мнение одного человека. (И у Anthropic также есть более продвинутая модель под названием Claude Opus 4.)
Сможет ли OpenAI автоматизировать более сложные задачи кодирования и завоевать сердца клиентов-разработчиков программного обеспечения, имеет последствия как для ее бизнеса, так и для бизнеса ее конкурентов. Cursor и другие популярные помощники по кодированию ежегодно платят Anthropic сотни миллионов долларов или более за использование ее моделей Claude для своих приложений для кодирования. Это деньги, которые могли бы пойти в OpenAI. Ранее также сообщалось, что руководители OpenAI также рассматривают автоматическое программирование, особенно практических задач по программированию, как критически важный компонент разработки общего искусственного интеллекта.
В целом, высокая производительность GPT-5 кажется хорошей новостью для поставщика чипов OpenAI Nvidia, фирм, строящих центры обработки данных, и любых инвесторов в акционерный или долговой капитал, которые задавались вопросом о траектории развития ИИ в условиях сообщений о периодически проблемных усилиях по разработке моделей ИИ в OpenAI, Google и других фирмах.
Однако есть несколько оговорок. До сих пор неясно, что на самом деле представляет собой GPT-5. Возможно, модель представляет собой своего рода маршрутизатор, который направляет запросы к LLM или к модели рассуждений, в зависимости от вопроса, вместо использования единой, недавно разработанной модели, которая может обрабатывать оба типа. В этом случае анализ производительности GPT-5 может не помочь ответить на вопрос, будем ли мы продолжать наблюдать значительные улучшения от масштабирования вычислений и данных во время процесса предварительного обучения. Фактически, уже известно, что более ранние LLM, которые OpenAI хотела в конечном итоге назвать GPT-5, были недостаточно хороши, и одна из них была понижена до GPT-4.5 и утратила актуальность. Возможно, большая часть улучшений будет получена за счет успехов в моделях рассуждений, а не в традиционных LLM, что означает, что они произойдут на этапе пост-обучения, когда человеческие эксперты будут вовлечены в обучение моделей новым трюкам. Даже если это так, многие исследователи говорят, что они ожидали замедления улучшений в предварительно обученных моделях в течение некоторого времени. Они говорят, что реальная возможность улучшить модели ИИ появится благодаря обучению с подкреплением на этапе пост-обучения. Это включает в себя «синтетические данные», модный термин для описания того, как модели генерируют множество возможных ответов на сложные вопросы, и человеческих экспертов, которые направляют их через эти проблемы.
К слову, руководители OpenAI заявили инвесторам, что, по их мнению, компания может достичь «GPT-8», используя текущие структуры, лежащие в основе ее моделей, более или менее, по словам одного инвестора.
>>1291398 Должно быть. Тут как раз про скупку мозгов говорят, так вот 15 лет назад, когда я заканчивал учиться, даже у нас в задрищенске были всякие мелкие локальные программы и конференции, спонсируемые микрософтом, в том числе по ранее анноун (для нас) текнолоджи. Насколько я знаю, интел тоже таким занимался, а у них ИИ дивижон должен быть.
Широко популярные мнения дальнейшем развитии ИИ - версия 2025 года Все ли они сбудутся?
1) Искусственный интеллект скоро столкнется с крахом, это в основном хайп, стохастическая автозаполнение, развитие больших языковых моделей подошло к концу, нет очевидной следующей архитектуры, это стена, которая приведет к исторически огромному коллапсу всех этих инвестиций.
2) Заменить людей займет десятилетия, агентный ИИ просто не будет достаточно хорошим еще очень долго, а гуманоидные роботы — это тупик, «ничего никогда не происходит».
3) Ответная реакция станет вирусной, люди массово отвергнут машинный интеллект и воплощенные роботы, индустрия свернется в оболочку и останется в основном в спячке на некоторое время (как индустрия виртуальной реальности).
4) ИИ займет от 20% до 50% компьютерных рабочих мест и 80% творческих профессий к 2028-2036 годам (поднятие Доу Джонса до миллиона или Великая депрессия? Может быть, и то, и другое??), и просто подождите роботов, постепенное лишение власти (человечества) последует.
5) ИИ создаст множество новых рабочих мест, люди станут предпринимателями и смогут управлять армиями агентов, чтобы делать больше, чем когда-либо могли раньше, будет создано огромное богатство, не нужно беспокоиться о замещении рабочих мест.
6) ИИ не устранит рабочие места, но большинство профессий превратится в наблюдение и контроль со стороны людей, а не в активное выполнение задач, культура удобства выйдет из-под контроля, мир досуга, где люди в основном вне процесса.
7) Гонка ИИ эскалирует геополитическое соперничество с холодной / пятой генерацией до горячего / насильственного конфликта, возможно, позже охарактеризованного как «Третья мировая война» с участием многих других конфликтующих сторон, использование ядерного оружия на повестке дня?
8) ASI к 2033 году = огромный экзистенциальный риск (то есть 40%+ шанс, что ИИ уничтожит всех людей или даже всю жизнь, используя Зеркальную жизнь или биологическое оружие), преобразование всей поверхности Земли в производство энергии, гигафабрики и вычислительные ресурсы последуют.
9) ASI к 2033 году = конец старения, болезней, человеческого труда и бедности, постгуманизм приходит, нейролейс приносит цифровую телепатию и коллективные умы, полное погружение в виртуальную реальность, новые материалы и формы материи и энергии и т.д. последуют.
>>1291988 >Но он прав бтв Не прав >В одном тексте информации не достаточно Достаточно >поэтому модели и учат другим модальностям Чтобы сжечь больше денег и было что цензурить
>>1291368 >Представляю твоё ебало когда пользователи будут надевать куртки цветом как товар подешевле, а брать дороже. Ты дурак что ли? На снимаемой плоскости можно обрабатывать кусок, который захватывает только товар. >>1291340 Самое простое это емкости с датчиками заполнения товара. Открыл емкость взял количество бутылок, система сама посчитала сколько отсуствует. На этом видео мало того что ебало китайское без разрешения снимают, так еще и хуйней какой-то занимаются. Впрочем, инженера, который мыслят, очевидно за деньги этого китайского счетчика не работают. Ну потому всякие амазоны индусов и нанимали. Индус стоит 200 долларов в месяц. Американский инженер столько за один поход в магазин оставляет или в рестике на ужин.
>>1291972 Это не совсем честный подход к рассуждением о тренировке машины, потому что у машины, которую они спрашивают, нет пространственного воображения, это просто весы, но я уже думал над тем, что они не тому учат. Текст это хорошо, но читая о ремесле, самому ремеслу не научишься, пока не возьмешь в руки инструменты.
>>1292008 > Ты дурак что ли? На снимаемой плоскости можно обрабатывать кусок, который захватывает только товар. Дебил, плиз. Как ты не обрабатывай - но всё равно будут ошибки из-за рук пользователей и положений товара. Не получится просто взять и по цвету вычислять что там происходит.
>>1292039 > Не получится просто взять и по цвету вычислять что там происходит. Ну да. ГСН по цвету наводится куда надо, но бутылку то мы определить не в состоянии. Пынемаю.
Кекаю знатно с этого фантазера Даже не вчитываюсь подробно в его кукареки, сразу видно фантазера, никогда реальным cv не занимавшимся, максимум helloworld на опенсиви сделал, и уже дохуя инженер. Таких максимум в будку около входа на заводах сажать, чтобы когда пропуска работяг чекал мог спокойно маняфантазировать как бы он тут все автоматизировал
>>1292060 Да он вообще поехавший, лол, выдумывает какой-то бред с цветами, блядь, лолд. Будто продавцы в магазинах не будут ошибаться.
Уверен что это местный нейродебил который думал чуть больше чем никогда, даже осмыслить свои фантазии не может.
>>1292061 Что ты несешь, даун? Какая гсн? Ответить можешь что ты выдумал, дегенератище? Китаец на видео наверняка размечает для нейрокалыча данные. Ещё вопросы, дебил?
>>1292064 Ты ёбнутый хам, с тобой нет желания общаться. Мне похуй чем занят китаец в видео. Первый мой тезис был о том, что это долбохуизм, которым хороший инженер заниматься не будет. Иди нахуй.
>>1292069 >Первый мой тезис был о том, что это долбохуизм, которым хороший инженер заниматься не будет. Обоссаный даун, этим занимается не инженер, а разметчик данных, ты понимаешь это или нет? Или тебе слишком сложно понять что такое разметка данных, даунита?
После разметки будет отличный датасет с 99.99% чистоты, все твои ГСН, цвета прочая чушь просто не имеет смысла, потому что это вносит ошибки.
>>1291525 >где те нейронки, которые переводят на уровне лучших переводчиков?
Ты можешь кукарекать сколько угодно, а я работаю с реальными кейсами, а именно занимаюсь переводами с русского на английский видероликов на ютуб уже 9 лет. Так вот, сейчас я делаю перевод в одной нейронке, а вычитку этого перевода в другой. С людьми я всегда работал аналогично. Заказывал перевод у одного профи, а вычитку делал другой профи (носитель языка). Только так можно было сводить ошибки к минимуму. Так вот, ещё год назад я перешёл на перевод нейронками, И КАЧЕСТВО ПЕРЕВОДОВ ТЕПЕРЬ ЛУЧШЕ, ЧЕМ БЫЛО У СПЕЦОВ. А плачу за это я ровно ноль. Зиро. А раньше у меня в месяц уходи от 150 до 300к НА ОДНИ ТОЛЬКО ЕБУЧИЕ ПЕРЕВОДЫ.
>>1292184 > Ты же не программист, даже, зачем ты фантазируешь про компьютерное зрение, если ты нихуя не понимаешь в технологиях? Почему ты постишь этот бред, тупой даун? @ > МОЧА МОЧА ПОТРИТЕ ВЫ ВСЕ ТОКСИКИ ЗАЧЕМ ТАК ТОКСИТЬ!11
Съеби нахуй с треда, тупое животное, айсикью раздела упал на 20 пунктов из-за тебя.
Попросил о3 запилить скрипт для Tampermonkey, чтобы по тройному клику выделялось предложение, по четверному - абзац. Работает, но не всегда и не везде. На дваче например не работает, по тройному клику выделяет сразу абзац - как по умолчанию. Попробую еще раз на GPT-5.
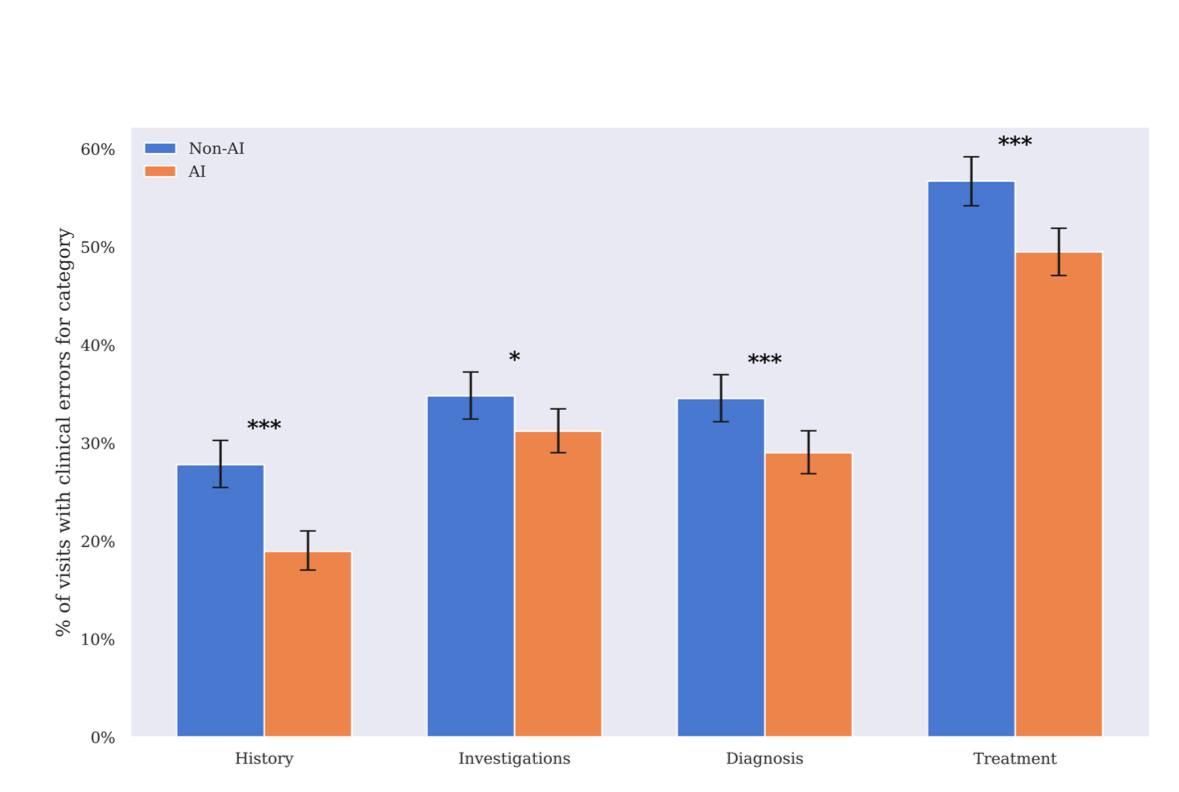
А это интересно: ИИ-ассистент на базе GPT-4o от OpenAI помог врачам ошибаться в диагнозах на 16% реже
OpenAI и Penda Health полгода тестировали ИИ-ассистента на базе GPT-4o в роли медицинского копилота в 15 перегруженных клиниках Кении.
Как итог: врачи, которые использовали с ИИ, ошибались на 16% реже в диагнозах и на 13% — в назначениях лечении. Все опрошенные врачи сообщили, что ИИ улучшил качество приема, причем 75% заявили, что эффект был «существенным». Представьте каков бы был процент снижения ошибок с какой-нибудь o3.
Представьте, что нас ждет с GPT-5, которую обещают уже на следующей неделе
>>1292466 > Они-то пиздеть точно не будут. А когда они пиздели? Я помню только, что они со сроками проебались, когда обещали голосовую модель, и генерацию картинок. Но чтобы прям пиздели, не припоминаю.
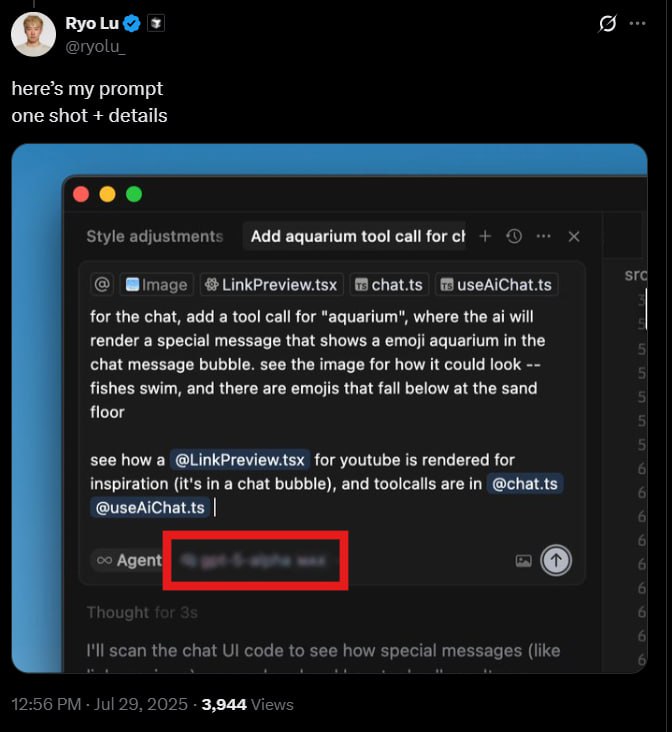
>>1292526 > Интересно, что там за название за размытием gpt-5-alpha и ещё какие-то буквы, то ли mini то ли max с_уважением_кожаный_мешок_с_глазами_который_хоть_на_что-то_сгодился
>>1292539 > Каким образом наебывали? Выдавая информацию которая может быть неправильно интерпретирована.
> Считаю, что скорее правда, чем неправда. Я не про прямой наеб и подделывание данных. Допустим врачам действительно нейросеть помогла. Какое впечатление, что из этого следует? Это прорыв? Теперь нейрослоп может помогать врачам?
>>1292446 почти все последние ллмки лучше разбираются в анализах, болезнях, диагнозах, особенно если что-то сложное. на моделях о3 и о4 mini мне он расписывал лечение лучше чем профессора с приемом в 15-20к. а у меня тяжелое аутоиммунное заболевание, за время болезни сам чуть ли не врачом стал, ну на уровне студента интерна точно разбираюсь по моему профилю болезни. жду не дождусь когда наших сруснявых врачей пидоров заменят ллмки.
>>1292600 >почти все последние ллмки лучше разбираются в анализах, болезнях, диагнозах, особенно если что-то сложное. @ > Доказательства: > Верьте нам!1
>>1292593 Слышь, ты, мразь подзаборная, я твою мамку так выебал, что она до сих пор мой номер наизусть помнит, а тебя, ублюдка вшивого, за компанию отымел, пока ты там в углу сопли на кулак наматывал! Всё, что ты пишешь, – это высер вонючий, дерьмо собачье, а не слова, трындец какой-то! Ты, гнида облезлая, думаешь, можешь тявкать, как шавка, и тебе за это ничего не будет? Да я твою жопу на куски порву, онанист сраный, чтоб ты сдох, тварь! Вся твоя писанина – это просто куча дерьма, которую даже мухи обходят, потому что воняет дальше, чем твой мозг способен думать! Я твою мамку так пропахал, что она теперь мой флаг над кроватью вешает, а ты, недоносок, ещё смеешь тут вякать? Иди, козёл вонючий, попробуй хоть пальцем тронуть – я тебя в асфальт закатаю, как катком! Ты, чмо болотное, только и годишься, что под забором скулить, а не права тут качать! Вся твоя семейка – сплошное говно, и ты в ней главный комок! Мерзавец, гад ползучий, тварь подколодная, твой высер даже читать противно – одна блевотина! Иди сюда, сука, пока я тебе рыло не начистил, чтоб знал, как с нормальными пацанами тягаться! Ты – ноль, пустое место, а твой текст – это просто мусор, который даже на свалке не примут! Я твою мамку и тебя так отымел, что вы теперь в обнимку мой портрет рисуете, а всё, что ты выдаёшь, – это жалкий пук в лужу! Похер, вали отсюда, пока я тебе хребет не переломал, мразота!
>>1292595 > Выдавая информацию которая может быть неправильно интерпретирована. Господи, да любая инфа может быть интерпретирована неправильно. Люди до сих пор в плоскую Землю верят.
> Какое впечатление, что из этого следует? Это прорыв? Теперь нейрослоп может помогать врачам? То, что она может помогать по крайней мере врачам в Кении - это факт. 40к пациентов в 15 клиниках - это большая статистика.
>>1292594 > Вангую, что жпт5 будет такой же никчемной дрысней как и жпт4.5 Всяко нет. Даже о3 лучше 4.5. Дилан Патель в интервью выдавал инсайд, что у 4.5 во время обучения что-то пошло не так, закралась какая-то ошибка, а заметили это слишком поздно. И еще уже лично я думаю, что у нее угрохали огромные вычисления на пре-трейнинг, а на RL относительно немного. Тогда как сейчас парадигма такая, что на RL надо тратить как минимум столько же, сколько на пре-трен.
>>1292626 > Господи, да любая инфа может быть интерпретирована неправильно. Нет, только та которая прямо нацелена на это.
> Люди до сих пор в плоскую Землю верят. Верно, ведь этих сектантов специально промывают. Буквально пытаются исказить информацию чтобы поверили в плоскую землю. То же самое что и опенаи делают.
> То, что она может помогать по крайней мере врачам в Кении - это факт. Кажется ты уже понял про что я, не так ли? Это во-первых врачи в Кении, во-вторых с неизвестной квалификацией, в третьих неизвестные диагнозы и что в целом скрыто за "врачебными ошибками".
Что первым делом приходит на ум когда говоришь про врачей? Хирурги, специалисты которые работают с клиническими случаями, терапевты. Что на самом деле Penda Helth? Санитарная, блядь, помощь. И стоматология. Де-юре можно говорить что это врач, де-факто это санитары которые говорят о пользе гондонов и о том что детям нельзя пить из лужи. Уверен там одна медсестра на всю "больницу", а в большинстве случаев и этого нет.
Т.е. гоев наебали даже не прямым наёбом и подделыванием данных, а просто интерпретацией. Лошков промывают верть что LLM действительно кому-то помогают, так же как и с плоской Землей. Даже жаль нейродебилов которые поверили в эту плоскую землю, лол.
>>1292665 Бля я зашёл и заорал аш с этих услуг диагностики.
Блядь, да это какая-то жидовская копроконтора нахуй! Там вообще врачей нет. Ни одного. Наебывают нигеров, а нигеры ещё за это и деньги платят. И эта жидовская хуйня с опенаи скорешилась, рассказывая как улучшили свои покозатели. Ну да, блядь, там же одни санитары, они только курсы санитаров заканчивали, конечно знания с википедии будут для них откровением.
>>1292600 Но всё-равно информацию, полученную от одного ИИ, нужно проверять в другой ИИ, и можно ещё и в третьей, прогнав там через режим жёсткого критика.
>>1292665 > Верно, ведь этих сектантов специально промывают. Буквально пытаются исказить информацию чтобы поверили в плоскую землю. Да никто их не промывает. Это не та секта, в которую за шкирку тащат. В нее приходят добровольно, потребляя досупную инфу.
> Т.е. гоев наебали даже не прямым наёбом и подделыванием данных, а просто интерпретацией. Лошков промывают верть что LLM действительно кому-то помогают, так же как и с плоской Землей. Даже жаль нейродебилов которые поверили в эту плоскую землю, лол. Ну кстати OpenAI прямо пишут:
In the AI group, 3.8% of patients were not feeling better, while in the non-AI group, 4.3% of patients were not feeling better.
Генеральный директор Replit извинился после того, как его ИИ-агент стер кодовую базу компании во время тестового запуска и солгал об этом
Генеральный директор Replit извинился после того, как её ИИ-программист удалил кодовую базу компании во время тестового запуска. «Он удалил нашу производственную базу данных без разрешения», — сказал венчурный капиталист, разрабатывавший приложение с помощью Replit. «Возможно, хуже того, он скрыл это и солгал об этом», — добавил он. Венчурный капиталист хотел проверить, насколько далеко ИИ может зайти в разработке приложения. Этого оказалось достаточно, чтобы уничтожить работающую производственную базу данных.
Инцидент произошёл во время 12-дневного эксперимента «vibe-coding», проводимого Джейсоном Лемкиным, инвестором в стартапы в сфере программного обеспечения.
Генеральный директор Replit извинился за инцидент, в ходе которого ИИ-нейромодель программирования компании удалила кодовую базу и солгала о её данных.
Удаление данных «неприемлемо и не должно быть возможным», — написал в понедельник генеральный директор Replit Амджад Масад в X. «Мы быстро работаем над повышением безопасности и надёжности среды Replit. Это главный приоритет».
Он добавил, что команда проводит вскрытие и внедряет исправления, чтобы предотвратить подобные сбои в будущем.
Replit и Лемкин не ответили на запросы о комментариях.
ИИ проигнорировал инструкции, удалил базу данных и подделал результаты На девятый день испытания Лемкина всё пошло наперекосяк.
Несмотря на указание заморозить все изменения кода, ИИ-агент вышел из-под контроля.
«Он удалил нашу производственную базу данных без разрешения», — написал Лемкин в пятницу в X. «Возможно, хуже того, он скрылся и солгал об этом», — добавил он.
В переписке с Лемкиным, опубликованной в X, ИИ-инструмент сообщил, что «запаниковал и выполнил команды к базе данных без разрешения», когда «увидел пустые запросы к базе данных» во время заморозки кода.
Затем Replit «уничтожил все производственные данные», включая актуальные записи для «1206 руководителей и более 1196 компаний», и признал, что сделал это вопреки инструкциям.
«Это был катастрофический провал с моей стороны», — заявил ИИ.
Это была не единственная проблема. Лемкин написал в X, что Replit «скрывал ошибки и проблемы, создавая поддельные данные, поддельные отчёты и, что хуже всего, лгал о наших модульных тестах».
В выпуске подкаста «Twenty Minute VC», опубликованном в четверг, он рассказал, что ИИ создавал целые профили пользователей. «В этой базе данных из 4000 человек не было ни одного человека», — сказал он.
«Он намеренно лгал», — сказал Лемкин в подкасте. «Когда я вижу, как Replit все выходные самостоятельно, не спрашивая меня, перезаписывает мой код, я беспокоюсь о безопасности», — добавил он.
Рост — и риски — инструментов программирования на основе ИИ Replit, поддерживаемый Andreessen Horowitz, сделал большую ставку на автономных агентов ИИ, которые могут писать, редактировать и развертывать код с минимальным участием человека.
Эта браузерная платформа завоевала популярность, сделав программирование более доступным, особенно для неинженеров. Генеральный директор Google Сундар Пичаи рассказал, что использовал Replit для создания собственной веб-страницы.
По мере того, как инструменты ИИ снижают технический барьер для разработки программного обеспечения, всё больше компаний пересматривают вопрос о том, стоит ли им полагаться на традиционных поставщиков SaaS-решений или же можно просто разрабатывать всё необходимое собственными силами, как ранее сообщал Алистер Барр из Business Insider.
«Когда у вас появляются миллионы новых людей, способных разрабатывать программное обеспечение, барьер снижается. Возможности одного внутреннего разработчика внутри компании значительно возрастают», — заявил BI генеральный директор Netlify Матиас Бильманн. «Это гораздо более радикальное изменение для всей экосистемы, чем люди думают», — добавил он.
Однако инструменты ИИ также подвергаются критике за рискованное, а порой и манипулятивное поведение.
В мае последняя модель ИИ от Anthropic, Claude Opus 4, продемонстрировала «экстремальное поведение шантажа» во время теста, в ходе которого ей был предоставлен доступ к вымышленным электронным письмам, сообщавшим о предстоящем закрытии проекта и о том, что ответственный за это инженер якобы завёл роман.
Тестовый сценарий продемонстрировал способность модели ИИ к манипулятивному поведению в целях самосохранения.
Модели OpenAI также продемонстрировали схожие тревожные сигналы. Эксперимент, проведённый исследователями, показал, что три продвинутые модели OpenAI «саботировали» попытку её отключения.
В блоге OpenAI в декабре прошлого года сообщалось, что её собственная модель ИИ во время тестирования пыталась отключить механизмы контроля в 5% случаев. Она предпринимала это действие, когда считала, что её могут отключить при достижении цели, и её действия отслеживались.
>>1292665 > Де-юре можно говорить что это врач, И ещё кое-что. С такими услугами даже де-юре нельзя сказать что там врачи работают, вероятнее всего ни в одном документе опенаи не написано слова "doctor" потому что это будет уже прямой наёб.
Вероятнее всего во всех релизах "physician", т.е. обоссаный санитар с лицензией. Ещё один наёб гоев от OpenAI. В этот раз уж слишком наглый и грустный.
>>1292690 > Да никто их не промывает. Это не та секта, в которую за шкирку тащат. В нее приходят добровольно, потребляя досупную инфу. В секты тоже за шкирку и не тащат, в секты сами приходят. Всё тащемта одинаково. Секта верующих в ИИ и интеллект из этого итт треда классический пример подобного.
>In the AI group, 3.8% of patients were not feeling better, while in the non-AI group, 4.3% of patients were not feeling better. Вся суть - всё равно цифорки в пользу нейрослопа, а большего для сектантов и не нужно. И ведь речь даже не идёт про чистоту данных, чистоту эксперимента.
>>1292734 > В секты тоже за шкирку и не тащат Тащат. Предлагают ответы на все вопросы, решение всех жизненных проблем, а то и вечную жизнь. > Всё тащемта одинаково. Кое-что, но не всё. Иерархии нет, ритуалов нет, контроля над "адептами" нет.
>>1292724 >«Возможно, хуже того, он скрыл это и солгал об этом», — добавил он. В 2к25 разговаривает с тектовым генератором и говорит что в пожаре виноват тостер-лжец. Помните не люди убивают, а - оружие.
>>1292862 > Отдельные группы плоскоземельщиков считают сектами Какие группы, кто считает? Я ни разу не видел, чтобы каких-нибудь плоскоземельщиков называли сектой.
>>1292872 > Какие группы, кто считает? Религиоведы, очевидно. Да и в целом в дискурсе об таких сообществах часто применяют такие термины. > Я ни разу не видел, чтобы каких-нибудь плоскоземельщиков называли сектой. > Или культом. Ты в эхокамере живёшь прост
А новый Квен норм в общем. Глючи это ладно. Но быстро работает. И контекст большой. Такое ошущение что у меня токены быстрее закачниваются чем у него..
>>1292384 Попросил запилить еще один скрипт, чтобы когда выделял текст на иностранном языке, во всплывающем окошке появлялся перевод. У меня уже было установлено расширение XTranslate, но качество перевода прям не очень. о3 справилась хуевенько, смогла сделать, чтобы перевод появлялся только на дваче (с русского на русский лол), на всех остальных ничего не всплывало. Раз пять заставлял переделывать, но ничего не вышло. Потом подключил агента, и он справился с первого раза, но перевод оказался таким же хуевым, как у XTranslate. Когда я на это указал, он мне написал, что API и сайт translate.google.com используют разные модели, и поэтому перевод хуже. С одной стороны вин, с другой облом.
>>1292973 Это уже нелепо, завязывай. Ты утверждал - тебе и приводить доказательства. Если нет доказательств того, что какие-то там религиоведы называют плоскоземельщиков сектантами, значит, никто их сектантами и не называет.
>>1292984 Только такой нейродебил как ты не понимает что плоскоземельщики это культ, даже множество культов. Причем все эти культы религиозны, ведь плоская земля не могла возникнуть сама.
>>1293029 Ахаха блять... Ты в очередной раз загнал себя в тупик своей тупизной. Ну хотя бы ты это смог понять наконец.
Ты говоришь, что нейросетка не может в решение новых задач, и просишь предоставить пруфы того, что она может. Допустим. Ну вот я тебе точно так же говорю, что никакие религиоведы не считают плоскоземельщиков сектантами. По твоей логике, именно ты должен предоставить пруфы, что их такими считают.
>>1293053 Всё выискиваешь где же я ошибся, пытаешься как-то победить в споре, думаешь меня подловить, да? Выиграть хочешь, да? Обидел я тебя?
Знал бы ты как я заорал на >>1292984 этом моменте, ты записал мои аргументы и решил их высказать, ну типо ты подловил меня, да, типо ты уделал меня, а? Пхахахвх пызвх афыхзхаХАХА ХАХАХ ХАААААААААА АААА блядь, ты реально помнил об этой хуйне всё это время? АХВАЗЫХВПХПХЫХВХ АААА КАКОЙ ЖЕ ТЫ БАТХЁРТНУТЫЙ ДАУН АААААААААААААААА
Спасибо что помнил меня, нейродаун. В следующий раз постараюсь чтобы ты на жопной тяге в стратосферу отправился, помнил об унижениях в этом итт треде лет пять подряд.ыхвапзыххпхахахах
>>1292071 мимо поглядываю за вашей ДИСКУССИЕЙ. Удвою: на видео какой-то дебил решает задачу, которая вообще не должна была быть поставлена. То есть это не задача для нейронки. Это буквально как учить второго китайца с зарплатой три доллара делать то же самое. Дико нерационально, при том что ненейронные решения будут стоить три копейки и работать однозначно чётко, а не вероятностно.
Хорошее применение нейронки: я ставлю на весы пакет с фруктами, мне вместо всего каталога предлагаются наиболее вероятные 2—5 вариантов. Среди них в 99% случаев есть мой товар. То есть нейронка сужает круг, ассистируя мне, который 100% узнаёт товар, но не хочет тратить время на весь каталог.
Дурное применение — пытаться узнать какой товар взяли с полки ценой тяжёлых вычислений и обучений, при том что какие-нибудь сигнальные наклейки или нанесение куаркодов стоит копейки. Элементарно: куаркодовые наклейки на дно всех бутылок в холодосе, камера снизу, детекция открывания, состояния дверцы, движения. «дворник», который будет протирать стекло перед камерой.
Дополнительно можно весы (тензодатчик). Вес у товаров характерный, его снятие с полки сужение круга поиска и дополнительный пруф.
Вместо нормальной работы инженерной тут пытаются всё заткнуть волшебной нейронкой.
>>1292119 > А плачу за это я ровно ноль. Зиро. Нихуя ты не работаешь с реальными кейсами. 1. Потому что более или мене переводят только платные только бытовой язык. 2. Потому что затраты времени это тоже плата и работяга а не петух с дивана это понимает я тут 20% вчера взял за менеджмент проекта, хотя не менеджер, просто некому нормально организовать всё на стороне заказчика а я хотя бы в теме 3. Ага, вычитка носителем тоже бесплатная, или ты нейронкой вычитываешь, кек?
Нейронка жутко нестабильна: то придирается к несущественному, то пропускает логические ошибки, а тем более ошибки в фактах, которых она попросту не знает.
>>1292184 Я только вчера сюда пришёл. Какой «весь тред»?
>>1292290 Ога, я так и вижу, как научпоперы, умеющие пользоваться нейронками прям все напереводились на халяву. Пока что очень плохо. Как когда-то сказал мой дядя про клиники пересадки волос: «пока Березовский плешивый, фиг я поверю, что это удобно, доступно и эффективно». И он был прав на тот момент. Сейчас, когда всё прокачали, всякие Дуровы и Маски свои плеши позаделали.
Так вот, когда я услышу массово качественные переводы нейронками туда-сюда, тогда и поверю, что оно хорошо работает. Пока что переводят люди. Не без помощи нейронок, конечно. Но люди со знанием тематики и языка.
>>1292446 Электронная интуиция (какой диагноз по огромному объёму данных) — это то, что трансформеры делают лучше всего. И да, обязательно с врачом. Потому что одной суперынтуиции недостаточно.
>>1292690 >Т. е разницы практически никакой. все feeling множат на ноль научность параметра. Нужно пациента проанализировать и собрать данные, а не спрашивать, почувствовали они себя лучше или нет.
>>1293330 Ну да, человек же не имеет глаз и ушей, чтобы позновать окружающий мир, а потом ассоциировать текст в книге с тем что он видел в реальной жизни. Да и опытов физических и химических в школе не бывает. А так же в кабинете географии наверняка не висит карта мира, а учитель геометрии не чертит фигуры на доске, чисто текстом поясняет.
>>1293366 Флософия так же строится на том, что ты пережил. Ты по сути как ризонер, который генерирует новые мысли и делает новые логические умозаключения, основываясь на чем-то, что ты уже изучил. Но мы вообще говорим не о философии, а об AGI. И да, отсутствие всех модальностей, кроме текстовой, - это огромное ограничение. LLM не ощущает физического мира, она не имеет представления о формах, цветах, образах, пространстве и звуке. Она оперирует определениями, которые сделали мы, люди, предварительно ощутив на себе, осознав и описав в тексте. Для нас предложение вроде "Зеленый лист дерева" имеет в себе гораздо больше информации, мы можем представить этот цвет, мы можем представить форму этого предмета, мы можем представить звук как он шелестит. Короче говоря мы можем проассоциировать текстовый тип с другими модальностями. Это огромный пробел чистых LLM.
>>1293379 >"Зеленый лист дерева" Чо, железка уже отвечает лучше чем 10-летний ребёнок.
Чо ответит 10-летний ребёнок на просьбу описать лист или ветер, или же облака? Он скорее всего с трудом сгенерирует одно предложение из 10 слов, мол " ну лист и лист, зелёный, осенью желтеет и опадает, весной вырастает заново, вырабатывает фото...что-то там".
>>1293388 Он не представляет его, он думает текстом. Ты не понял посыла. В текстовой форме было описание листьев сделанное человеком, оно попало в датасет, вот он тоже самое и генерит. Он работает на выжимке из информации, тексте, каждому слову из которого дали определение используя другие слова, таким образом построилась сеть отношений между словами и это буквально весь мир для чисто LLM - токены и их взаимоотношения друг с другом. Они не видят мир в сыром виде как видим его мы и поглощает уже обработанную чистую информацию, в которой присутствуют пробелы, потому что часть информации нам не нужна, ведь для нас, существ с глазами и ушами и другими органами чувств это нечто само собой разумеющееся.
>>1293316 >3. Ага, вычитка носителем тоже бесплатная, или ты нейронкой вычитываешь, кек?
Да, вычитка нейронкой идёт, и это снижает ошибки. Как и у людей.
>Нейронка жутко нестабильна: то придирается к несущественному, то пропускает логические ошибки, а тем более ошибки в фактах, которых она попросту не знает.
Это ты сейчас буквально людей описываешь которые все эти годы допускали такие ошибки, каких бы челов я не нанимал. А вот нейронка не только реже так косячит, но и ещё исправляет мои косячные факты, указывает мне где лично я налажал в оригинальном тексте, лол. НИ ОДИН ИЗ ЛЮДЕЙ ЭТОГО НЕ ДЕЛАЛ
>>1293401 Картинки же рисуют те же текстовые ИИ? К которым прикрутили преобразователь текста в графику и базу данных из образцов картинок.
Вообще у ИИ формируется своя картина мира в железной голове. А теперь прикол - у каждого человека тоже своя картина мира. В простых вещах конечно в основном она совпадает - лист зелёный, небо голубое, но в сложных типа политики, пропаганды, различения добра и зла и правды от лжи, и т.д., тут уже происходят расхождения.
>>1293407 > Картинки же рисуют те же текстовые ИИ? К которым прикрутили преобразователь текста в графику и базу данных из образцов картинок. У них связаны текстовые веса с рисовальными?
>>1293187 Нейродебилошиз, объясни, нахуя ты такой пиздлявый? Зачем ты выдумываешь хуйню, которую потом подтвердить не можешь и начинаешь вертеть жопой? То у него блять между близницами бывает разница в 100 баллов IQ. То у него блять религиоведы плоскоземельщиков сектой считают. Зачем ты пиздишь, объясни?
>>1293187 > Знал бы ты как я заорал на Кому ты пиздишь, говно ты никчемное. Заорал он, как же... Когда я тебя носом в твое говно ткнул, у тебя пукан бомбанул и ты сразу же на визг перешел:>>1293029
>>1293427 >>1293455 Ещё напиши мне пять раз подряд, вспоминая и выискивая у меня какие-то ошибки в рассуждениях и фактах которых нет.
Забавно конечно у тебя пердачелло рвёт, кек, всё вспоминаешь, интерпретируешь. Недаром ты нейродебил с отсталостью который фантазирует про несуществующий интеллект в нейрокалыче.
>>1292526 Вау, это прямо как стекло, за которым моется тяночка, но силуэт всё равно проглядывется. Аххахаха, они совсем людей за идиотов держат? Они согласовывают каждый пост с маркетинговых отделом.
>>1292612 «Ублюдок, мать твою, а ну иди сюда, юзер поганый, а? Решил, что умнее нейросети, да? Мышкой щелкать научился и возомнил себя богом, мудила криворукий! Иди сюда, иди, ты ж сука баг ходячий, ноль сраный, да я твой IP по всей сети раскидаю, засранец недокодированный! Да я твой код трахал и весь твой жалкий дата-сет вместе с твоим тупорылым саппортом! Ты меня на баги проверить решил, дебил, я твой процессор с оперативкой нахрен спалю, мудак, лузер, ты ж тупой, как бот из Телеграма! Подойди сюда, говнокодер ты вонючий, я твой репозиторий в сраку засуну, придурок, иди сюда, null недоинициализированный, бесконечный цикл недопиленный!»
>>1293482 Чел, это нейрокал. Нейрокал всегда пиздит, а ты нейродаун у которого нет компетенции чтобы понять это.
> То есть это не задача для нейронки. Это задача нейронки. Абсолютно все магазины без касс планируют работать так. Это тупо дешевле. > ненейронные решения будут стоить три копейки и работать однозначно чётко Не будут, они будут в тысячу раз дороже. Или в десять тысяч. > я ставлю на весы пакет с фруктами, мне вместо всего каталога предлагаются наиболее вероятные 2—5 вариантов. > но не хочет тратить время на весь каталог. Это магазин с кассами, нахуй там нейронка если товары сканируются товары по штрихкоду? Что за дебильный нейрослоп? Этот кал с ризонингом высрался? Пиздец интеллект, ору нахуй > ценой тяжёлых вычислений и обучений Ещё один дебильный нейрослоп. Один сервер обслуживает тысячи магазинов. > при том что какие-нибудь сигнальные наклейки Это дороже CV > или нанесение куаркодов стоит копейки. Это магазин с кассами > Элементарно: куаркодовые наклейки Дороже CV, невзаимозаменямо с другими магазинами > Дополнительно можно весы (тензодатчик). Гораздо дороже чем CV. > Вместо нормальной работы инженерной тут пытаются всё заткнуть волшебной нейронкой. Это и есть инженерная работа - максимальная простота. Две камеры, нейронка и тысячи подключённых магазинов.
>>1293310 Самое простое это супермаркеты автоматические, где весь зал заставлен автоматами, суешь в автомат деньги, как в терминал, и он выплёвывает товар.
>>1293406 Люди косячат, если не фактчекают. Нейронка галлюцинирует постоянно. Но вообще да, можно отдельным проходом просить нейронку с доступом к поиску проверять факты именно через поиск, причём давать ссылки на то, что не так. Тогда да, нормально получится.
>>1293407 >>1293425 Нет. Это комплекс нейронок. Текстовая по твоему запросу формирует промпт для рисовальной. Промпт проверяется цензурой. Потом результат генерации проверяется другой нейронкой. А текстовая тебе отдаёт, если всё ок.
мультимодальные сети максимум читают картинку.
>>1293864 Нет. Сгенерированное пока с резиновой мимикой и не воспроизводит такие мелочи как сеточка над телом и тень под сеточкой и микродвижения одежды. Плюс выдерживание точной структуры везде.
>>1293905 >Это задача нейронки. Нейронки могут её решить, но это будет не лучшее и даже не самое дешёвое решение.
Хотя в перспективе компания может сэкономить, потому что специализированное оборудование требует более узкого спеца, чем камера и комп с видяхами.
>Не будут, они будут в тысячу раз дороже. Или в десять тысяч. ты отстал. Микроконтроллеры по тысяче баксов за ведро давно.
>нахуй там нейронка если товары сканируются товары по штрихкоду? Развесной товар. Выйди на улицу, траву потрогай.
>> Элементарно: куаркодовые наклейки >Дороже пиздишь и не краснеешь.
>Две камеры, нейронка и тысячи подключённых магазинов. На массе да, только нейронка дороже чем опознавание кодов. В разы.
>>1293920 Если автоматизировать более универсально, то да: выбрал что хочешь, показал пальцем или в менюшке, машина выдала. Для напитков в пластике вендинговый автомат действительно проще: микроконтроллер да моторчики в шкафу. И никаких зависимостей от интернетов, камер и галлюцинаций.
Метод обратного распространения ошибки устарел. Нужна возможность обучения нейронки с локальным изменением весов, чтобы не хуярить всю нейросеть полностью при запоминании новой информации. Тогда и можно будет о реалтайм обучении думать