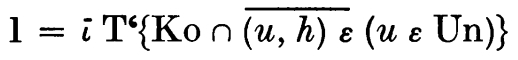Обсуждаем развитие искусственного интеллекта с более технической стороны, чем обычно. Ищем замену надоевшим трансформерам и диффузии, пилим AGI в гараже на риге из под майнинга и игнорируем горький урок.
Я ничего не понимаю, что делать? Без петросянства: смотри программу стэнфорда CS229, CS231n https://see.stanford.edu/Course/CS229 (классика) и http://cs231n.stanford.edu (введение в нейроночки) и изучай, если не понятно - смотри курсы prerequisites и изучай их. Как именно ты изучишь конкретные пункты, типа линейной алгебры - дело твое, есть книги, курсы, видосики, ссылки смотри ниже.
Почему python? Исторически сложилось. Поэтому давай, иди и перечитывай Dive into Python.
Можно не python? Никого не волнует, где именно ты натренируешь свою гениальную модель. Но при серьезной работе придется изучать то, что выкладывают другие, а это будет, скорее всего, python, если работа последних лет.
Стоит отметить, что спортивный deep learning отличается от работы примерно так же, как олимпиадное программирование от настоящего. За полпроцента точности в бизнесе борятся редко, а в случае проблем нанимают больше макак для разметки датасетов. На кагле ты будешь вилкой чистить свой датасет, чтобы на 0,1% обогнать конкурента.
Количество статей зашкваливающее, поэтому все читают только свою узкую тему и хайповые статьи, упоминаемые в блогах, твиттере, ютубе и телеграме, топы NIPS и прочий хайп. Есть блоги, где кратко пересказывают статьи, даже на русском
Где ещё можно поговорить про анализ данных? http://ods.ai
Нужно ли покупать видеокарту/дорогой пека? Если хочешь просто пощупать нейроночки или сделать курсовую, то можно обойтись облаком. Google Colab дает бесплатно аналог GPU среднего ценового уровня на несколько часов с возможностью продления, при чем этот "средний уровень" постоянно растет. Некоторым достается даже V100. Иначе выгоднее вложиться в GPU https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning заодно в майнкрафт на топовых настройках погоняешь.
Когда уже изобретут AI и он нас всех поработит? На текущем железе — никогда, тред не об этом
Кто-нибудь использовал машоб для трейдинга? Огромное количество ордеров как в крипте так и на фонде выставляются ботами: оценщиками-игральщиками, перекупщиками, срезальщиками, арбитражниками. Часть из них оснащена тем или иным ML. Даже на швабре есть пара статей об угадывании цены. Тащем-то пруф оф ворк для фонды показывали ещё 15 лет назад. Так-что бери Tensorflow + Reinforcement Learning и иди делать очередного бота: не забудь про стоп-лоссы и прочий риск-менеджмент, братишка
Список дедовских книг для серьёзных людей Trevor Hastie et al. "The Elements of Statistical Learning" Vladimir N. Vapnik "The Nature of Statistical Learning Theory" Christopher M. Bishop "Pattern Recognition and Machine Learning" Взять можно тут: https://www.libgen.is
Напоминание ньюфагам: немодифицированные персептроны и прочий мусор середины прошлого века действительно не работают на серьёзных задачах.
>>1151064 (OP) >Когда уже изобретут AI и он нас всех поработит? >На текущем железе — никогда, тред не об этом Ящитаю что это возможно. GPT показал что он может хранить вполне осмысленную информацию о мире и строить множество связей между абстракциями. Проблема лишь в том как эта информация представлена и каким обрмзом создавать новые связи в процессе работы.
Почему популярные нейронки так долго тренируют? Насколько я понимаю, все стремятся найти какой-то глобальный минимум, избежав локального. Вот этот глобальный минимум ищется очень долго - мелкими осторожными шажками. Поэтому всё так долго, да? Например, чтобы на 99% гарантировать точность?
Допустим, меня не интересуют ни глобальный, ни локальный минимумы. Мне нужна манёвренность: - посчитали 1-й слой -> сразу подкрутили его веса; - посчитали 2-й слой -> сразу подкрутили его веса; - посчитали N-й слой -> выдали ответ -> ждём ввод. Нормальная же скорость будет? Не придётся ждать нескольких месяцев - обучение на скорости работы?
Конкретной задачи нет, я хочу только разобраться, конкретно чему может научиться такая нейросеть. Датасета, соответственно, тоже нет, и правил для валидации результатов тоже не придумал - меня интересует пока лишь скорость подкрутки под произвольные сигналы из входного потока. Дальше разберёмся, к чему можно подключить и как именно интерпретировать выходные сигналы нейросети.
А то все туториалы по нейросетям сводятся к: 1. Загрузить датасет (у меня нет); 2. Задать цель тренировки (у меня нет); 3. Ждать N дней/месяцев (зачем и почему?); 4. Протестировать аккуратность (мне не нужно). Как-то странно, на мой взгляд. Хочу разобраться.
>>1152913 >Насколько я понимаю, все стремятся найти какой-то глобальный минимум, избежав локального. Лол, нет. Для гроккинга сетки нужно тренировать ещё в 1000-10000 раз дольше, буквально. >меня интересует пока лишь скорость подкрутки под произвольные сигналы из входного потока Ты конечно можешь поставить lr хоть в единицу (вместо традиционных 0,0005), но сеть так будет ебашить, что мало не покажется. >- посчитали 1-й слой -> сразу подкрутили его веса; Эм, прочитай, что такое обратное распространение ошибки. Намекаю- оно идёт в обратную сторону, от последнего слоя к первому, и соответственно требует градиента на всех слоях. Короче пройди какие-нибудь машобчик курсы из шапки, ты пока сильно плаваешь в теме.
>>1152913 Ты это сообщение написал нейросетью с галлюцинациями, ты в курсе? Словно животное высрал порцию бессмысленного бреда.
>>1153095 > Для гроккинга сетки нужно тренировать ещё в 1000-10000 раз дольше, буквально. Нейросетки после грокинга выстраивают веса под "модель мира" или вроде того. Но это полная хуйня потому что это не модель абстракций объектов и отношений между ними, а модель основанная на словаре в пространстве параметров. Нужно выкинуть нахуй словарь и заменить его абстракциями объектов, тогда обучение будет занимать недели две или меньше, за пару дней нахуй. Это если не считать время обучение LLM для парсера языка. Надеюсь никто не успеет спиздить эту идею пока я хуйней страдаю и сам не нахуячу нейросеть такую
Кстати параметры при грокинге выстраиваются в замкнутые контуры, если считать по векторам, и в живом мозге тоже такая хуйня есть.
>>1153095 >тренировать ещё в 1000-10000 раз дольше А я читал, что чем дольше тренируешь, то тем хуже нейросетка файнтюнится. Т.е. генерализация сильно ухудшает адаптивность сетки под новые задачи... Следовательно, для дальнейшей работы лучшими нейросетями являются недотренированные.
>что такое обратное распространение ошибки >соответственно требует градиента на всех слоях >Короче пройди какие-нибудь машобчик курсы Хе-хе-хе, это ты недостаточно знаешь.
Обратное распространение ошибки (backprop) - один из многих способов поиска решения. Помимо него существует масса других, сильно отличающихся.
Для сравнения, ты можешь вообще не калибровать отдельные веса, а разворачивать их из аналога ДНК, мутируя эту ДНК подобно биологической. Это будет симулятор эволюции - генетический алгоритм. Ему достаточно посчитать эффективность нейронки в решении задачи и сравнить с другими вариантами, не трогая слои/нейроны/веса любого из вариантов. Конечно, это тоже лишь один из многих способов поиска, не самый эффективный на практике.
Но он мне не подходит. Я рассматриваю вариант биоподобного обучения, когда нейрон настраивается, полагаясь только на "локальную" информацию - т.е. собственную активацию и активацию нейронов, что непосредственно участвуют в его активации: https://ru.wikipedia.org/wiki/Теория_Хебба Опять же, существует огромная масса вариантов "локального обучения", т.к. у него есть сложности со стабильностью - нейроны слишком задрачивают соединения и остаются активными всегда, лол, либо бросают все свои соединения, остаются неактивны. Пофиксить можно, нужны определённые "костыли".
Однако, есть преимущества. В частности, нейронка адаптируется под входные данные максимально натуральным способом. Т.е. вместо инопланетных паттернов она сразу вырабатывает то, что мы от неё ожидаем, и всего за ~5 эпох опережает бэкпроп в аккуратности результата, но потом отстаёт. Т.е. теоретически, это более эффективный способ, если необходимо обрабатывать данные как они есть (поддерживая интерпретируемость нейросети), не выжимая каждый 1% аккуратности из нейронки.
На практике бэкпроп доминирует, потому что он позволяет любой мартышке с клавиатурой дать нейронке примитивные пары данных наподобие: >кошка.jpg == "кошка" >собака.jpg == "собака" И нейронка с бэкпропом где-то через 100500 эпох гарантированно научится различать кошек и собак (инопланетным способом, который легко ломается фотографией рандомного шума на маске человека). Поэтому бэкпроп задрочили до дыр и суют везде...
Короче, бэкпроп мне принципиально не подходит - поскольку оптимизирует всю нейронку в целом на практическое решение конкретной задачи, которой, повторяюсь, у меня нет, т.е. я не могу задать пары "входящий вопрос" == "верный ответ". Мне нужно "обучение без учителя", но только самое быстрое, на уровне пинга в онлайн-игре или что-то вроде того.
>>1154049 >высрал порцию бессмысленного бреда После нескольких часов чтения Reddit твой мозг превращается в жидкую кашицу. Шизофреников на реддите неожиданно больше, чем даже на двачах...
>это не модель абстракций объектов >заменить его абстракциями объектов LLM, обученная исключительно на тексте, имеет эти "абстракции объектов". Да, они не связаны ни с чем (помимо других абстракций), поскольку у модели не было "жизненного опыта" кроме "чтения текстов". Поэтому языковая модель имеет проблемы с такими визуальными задачами, как поиск пути на графе. Но несмотря на нехватку визуальной информации и пространственного понимания, нейронка всё же оперирует внутри себя абстракциями объектов, а не словами, описывающими эти объекты.
Я считаю, что основная сложность в обучени чисто текстовых моделей подобна сложности в обучении слепоглухонемых детей: чтобы понять, что с ней пытаются разговаривать, и научиться отвечать, ей необходимо создать модель мира, не опираясь на привычные нам зрение, слух и другие ощущения; представьте себя слепым, глухим и неподвижным, ощущающим ритмичные покалывания - как скоро получится понять, что эти покалывания - язык, и научиться рационально взаимодействовать с ним?
Я не особо интересовался "мультимодальными" LLM. Насколько понимаю, часто пытаются сделать чисто распознаватель картинок, формулирующий описание, поступающее на вход основной текстовой модели - естественно, это неправильно. Но главная проблема в отсутствии связи между картинкой и текстом. Т.е. в идеальном варианте нейронка должна обучаться на потоковых данных с видеокамеры (поэтому нужна максимальная скорость), а не на текстовой копии Википедии с редкими иллюстрациями.
В общем... Основное препятствие - бэкпроп. Из-за доминирования бэкпропа альтернативы почти не рассматриваются. Но он принципиально не может адекватно решить задачу, которую решает мозг - восприятие реальности и адаптация к ней почти в реальном времени (как я понимаю, пинг у мозга чрезвычайно высокий и мы видим не реальность, а собственную модель реальности - устаревшую на несколько сотен миллисекунд как минимум, а то и на несколько секунд/минут в редких случаях).
Алсо, я считаю, что масштаб не обязателен. Бэкпропу требуется огромный масштаб нейросети, чтобы найти подходящее решение чрезвычайно сложной задачи - поэтому LLM раздуло до невероятных масштабов. Восприятие реальности как таковое несложно и для большинства задач хватило бы и дюжины нейронов (искусственных, конечно; в мозгах много "лишнего"), расположенных сразу после блока восприятия и непосредственно перед моторным блоком.
К сожалению, большинство обучающих материалов сфокусированы на использовании бэкпропа...
>>1151064 (OP) попросил гпт 4.5 сделать улучшение для шапки не читал:
Обсуждаем развитие искусственного интеллекта с более технической стороны, чем обычно. Ищем замену надоевшим трансформерам и диффузии, пилим AGI в гараже на старых ригах из-под майнинга и игнорируем горький урок.
Я ничего не понимаю, что делать? Без петросянства: изучай классику Stanford CS229 (https://see.stanford.edu/Course/CS229) и введение в нейроночки CS231n (http://cs231n.stanford.edu). Если что-то непонятно — проверь prerequisites (линейная алгебра, базовый матан, программирование). Формат обучения — книги, курсы, видосы, ссылки ниже.
Почему Python? Исторически сложилось, экосистема огромная. Читай Dive into Python.
Можно не Python? Можно, но придется изучать код других, а это почти всегда Python.
Что почитать для вкатывания? - http://www.deeplearningbook.org (классика от Ian Goodfellow) - https://d2l.ai/index.html (примеры и код) - Николенко «Глубокое обучение» (на русском, понятный, но охват поменьше) - Франсуа Шолле «Глубокое обучение на Python»
Любая книга старше года — частично устарела, но основы те же.
Учти, спортивный deep learning отличается от работы примерно так же, как олимпиадное программирование от продакшена. На Kaggle борются за десятые процента, в жизни чаще нанимают больше размечающих данных.
Количество статей огромное, обычно следят за своей темой и хайпом (блоги, X, YouTube, Telegram, топы конференций). Есть отличные блоги и каналы на русском.
Когда AI поработит человечество? Не в этом треде и не на текущем железе.
А что насчет ML и трейдинга? Боты активно используют ML на крипте и фонде. Tensorflow + Reinforcement Learning тебе в руки, не забывай про риск-менеджмент и стоп-лоссы.
Классика ML для серьезных людей: - Trevor Hastie, «The Elements of Statistical Learning» - Vladimir Vapnik, «The Nature of Statistical Learning Theory» - Christopher Bishop, «Pattern Recognition and Machine Learning»
>>1154273 > После нескольких часов чтения Reddit твой мозг превращается в жидкую кашицу. Не читай эту хуйню вообще. Смотри видосики от новучных блогеров и читай научные статьи, разбирайся в работах топовых специалистов. > LLM, обученная исключительно на тексте, имеет эти "абстракции объектов". > нейронка всё же оперирует внутри себя абстракциями объектов, И да и нет. Это не объекты, а абстракции над токенами, а не над объектами. Они могут как совпадать с объектами, так и не совпадать из-за чего модель шизоидная и не может в логику. > ей необходимо создать модель мира, не опираясь на привычные нам зрение, слух и другие ощущения; Это всё хуйня. В нейросетях вообще нету привычной картины мира потому что она не опирается на объекты, а на токены. Мозг за миллиарды лет эволюции имеет структуры для оперирования объектами и временем, в нейросетях этого тупо нет. > Я не особо интересовался "мультимодальными" LLM. > Т.е. в идеальном варианте нейронка должна обучаться на потоковых данных с видеокамеры (поэтому нужна максимальная скорость), а не на текстовой копии Википедии с редкими иллюстрациями. Хуйня. Все эти GPT предообучены на терабайтах текста и именно из-за этого текста они начинают "воспринимать" картинки и рисовать их. Они буквально прочитали весь интернет и стали способны представлять себе какую-то "модель мира". Но опять, эта модель мира не основана на объектах, она основана на хуйне. > В общем... Основное препятствие - бэкпроп. Потому что он хорош для обучения. Есть результат и есть выход, который нужно подстроить под результат. > Но он принципиально не может адекватно решить задачу, которую решает мозг - восприятие реальности и адаптация к ней почти в реальном времени Полная хуйня. Обратное распространение ошибки это всего лишь алгоритм для обучения, а ты говоришь про общую архитектуру сети и то что происходит во время её работы.
Рассматривай P (pre-trained в GPT) и backpropagation как что-то что тренирует нейросеть на создание "модели мира". То что у нас заложено в днк - нейросети создают через pre-trained на терабайтах текстов. Это не совсем верно в деталях, но в целом так.
>>1154282 >Они могут как совпадать с объектами, так и не совпадать из-за чего модель шизоидная и не может в логику. Ну, тут может быть только два исхода: 1. Абстракции не совпадают с реальностью: предсказания нейронки некорректные и бэкпроп крутит педали в каком-то другом направлении. 2. Абстракции совпадают с реальностью: предсказания нейронки корректны и бэкпроп больше не крутит педали (в идеале, конечно). "Горький урок" прав в том, что если накинуть 100500 видеокарт на задачу, решение точно будет найдено... когда-нибудь - возможно, через тысячу лет бэкпропа. Поэтому закладывать какие-то особые абстракции не обязательно - они в любом случае формируются.
А у мозга преимущество в том, что за миллионы лет эволюции сложился удачный генетический хардкод, изначально закладывающий чёткие абстракции; т.е. нейронки мозга не рандомно инициализируются. Свёрточные нейронки, например, вдохновлены расположением нейронов в колонках, что намного эффективнее описывает визуальную информацию (теоретически, любую информацию в принципе).
Проблема в том, что люди слишком мало знают об устройстве мозга, чтоб повторить нужные структуры (избежав миллионов лет симуляции эволюции). Т.е. было бы это так просто - давно бы уже сделали...
>она не опирается на объекты, а на токены Токены - это просто какие-то данные. LLM могла бы оперировать байтами бинарных данных не хуже, чем токенами (обрывками слов). Просто токенами вроде эффективнее обучать для реальных (бизнес) задач. Смысл в том, что если нейронка правильно выдаёт следующий токен, то у неё 100% есть достаточно правильная абстракция над реальным миром (в конкретном вопросе, во всяком случае).
>Все эти GPT предообучены на терабайтах текста и именно из-за этого текста они начинают "воспринимать" картинки и рисовать их. >эта модель мира не основана на объектах Лол. Во-первых, с чего взял, что текст обязательно необходим для восприятия и рисования картинок? Генераторы картинок могут обучаться и без текста - текстовый интерфейс нужен только для удобства пользователей. Без текста пришлось бы вводить, например, числовые ID нейронов для активации.
Во-вторых, какие объекты тебе нужны? В мозге нет специальной магии с ярлыком "объект", там только нейронные колонки и их активность (если говорим о неокортексе, который и видит все эти "объекты").
Я думаю, GPT мог бы иметь правильную картину реальности, но на это нужно слишком много лишних вычислений из-за неудачно популярного бэкпропа (и отсутствия железа для ускорения альтернатив).
>он хорош для обучения. Есть результат Он хорош только для мелких моделек и суперузких задачек наподобие "отличить кошек от собак", да и то фейлится из-за нахождения странных решений.
>всего лишь алгоритм для обучения Для обучения с учителем. Мозг обучается совсем без "учителя" (не путать с учителем в школе), и не считает градиент всех своих десятков миллиардов нейронов. Какие-то глобальные сигналы в мозге есть, но это не обратное распространение ошибки, а что-то другое.
>"модели мира". То что у нас заложено в днк Настолько точная модель мира, какая есть в GPT, в молекулу ДНК даже не поместится, лол. Если тупо сравнивать объём информации, у ДНК 750 МБ - но с повторами, а у GPT до терабайта, которые никак не сжимаются ещё сильнее (т.е. повторов нет). Плюс новорождённые ничего не знают и не понимают, а языковые модели уже давно умнее 99% взрослых.
Поэтому это совершенно некорректное сравнение. Эволюция мозга нашла не только оптимальную архитектуру (колонки в коре), но и алгоритм для их обучения (в основном - локальный, но также ещё специальные костыли, типа боли и удовольствия).
Т.е. GPT больше похож на кусочек мозга взрослого, образованного человека, который просмотрел весь Интернет, но алгоритм обучения (и файнтюна) у него совершенно не подходит для быстрых изменений - например, если вдруг столица какого-то государства изменит название, GPT будет сложнее переобучить в сравнении с человеческим мозгом (как минимум, потребуется множество примеров). Поэтому многие надрачивают на "промпт инжиниринг", а не файнтюн (логичнее было бы дообучать, а не срать в контекст волшебными заклинаниями и надеяться на удачу).
Вообще, подумай сам. Вот у глубокой нейронки слои: 1. Ближе к вводу - мелкие абстракции (слова и т.п.). 2. Ближе к середине - абстракции крупнее (объекты). 3. Ближе к выходу - большие абстракции (например, принципиальный отказ выполнять что-то опасное). Интуитивно очевидно, что мелочь можно понять чрезвычайно быстро на минимальном датасете, а большие понятия редко меняются. Для обучения на терабайтах текста тебе нужно только добавлять абстракции среднего уровня - новые объекты или действия с ними. Но бэкпроп вычисляет градиент полной нейросети и пытается максимально туго затягивать веса везде, на любую задачу. Это тупое разбрасывание ресурсами без реальной пользы.
Конечно же, ты можешь применить костыли: - заморозить часть слоёв, обучая другие; - нарастить новые слои и обучать только их; - расширить слои сбоку и обучать добавленное. Но откуда тебе знать, что нужно обучать, а что нет? Очевидно, было бы лучше, если бы алгоритм для обучения автоматически определял, что требуется изменять, а что нет, но бэкпроп так не умеет.
>>1154273 >Помимо него существует масса других, сильно отличающихся. Но их не используют, так что мимо. >не самый эффективный на практике Самый неэффективный скорее уж. >конкретной задачи, которой, повторяюсь, у меня нет В виду того, что тебе похуй на результат, предлагаю тебе обучать в 0 эпох сетку со случайной инициализацией. Будет выдавать ХЗ что, но так как у тебя нет задачи, то оно подойдёт. >>1154278 >не читал Тогда менять не будем >>1154282 >Рассматривай P (pre-trained в GPT) и backpropagation как что-то что тренирует нейросеть на создание "модели мира". То что у нас заложено в днк - нейросети создают через pre-trained на терабайтах текстов. Это не совсем верно в деталях, но в целом так. База. >>1155873 >Абстракции совпадают с реальностью Так абстракции твоего мозга нихуя с реальностью не совпадают. Ты банально никогда не видел сраного жёлтого света, а хочешь что-то там обучать. >Он хорош только для мелких моделек Ага, всего лишь 2Т.
>>1155873 > "Горький урок" прав в том, что если накинуть 100500 видеокарт на задачу, решение точно будет найдено... когда-нибудь - возможно, через тысячу лет бэкпропа. Не. Горький урок в том что решение не будет найдено никогда. Вообще никогда. Будет только приблизительное решение с разной степенью приближения. Такова природа нейросетей и нихуя ты с этим не сделаешь. По крайней мере на современных архитектурах. > сложился удачный генетический хардкод, изначально закладывающий чёткие абстракции; Не совсем так, скорее днк закладывает саму возможность абстракций и абстрактных объектов, мозг может с рождения воспринимать объект как что-то цельное, это в мозгу срабатывает как true нахуй. > Проблема в том, что люди слишком мало знают об устройстве мозга, Главная проблема в том, что люди хуй клали на создание новых архитектур. Бизнесу это нинужно, вся эта наука ебаная. В опенаи как ебали GPT, так и ебут до сих пор, похуям им на всё. > если нейронка правильно выдаёт следующий токен, то у неё 100% есть достаточно правильная абстракция над реальным миром Нехуя. Это абстракция над токенами в пространстве параметров. Так совпало что на какой-то выборке эта абстракция совпадает с реальным миром. > Лол. Во-первых, с чего взял, что текст обязательно необходим для восприятия и рисования картинок? В душе не ебу что там необходимо, мне поебать на картинки, это лишь наблюдение о работе GPT. > В мозге нет специальной магии с ярлыком "объект", Есть. Человек рождается с этой магией. > Он хорош только для мелких моделек Он хорош для всего. В GPT backpropagation используется. > Настолько точная модель мира, какая есть в GPT, Она принципиально не может быть точной, ибо такова структура нейросети. И это не модель мира, это просто некая модель в пространстве параметров, это можно назвать моделью мира, но это даже близко не то что есть у человека. > Очевидно, было бы лучше, если бы алгоритм для обучения автоматически определял, что требуется изменять, а что нет, но бэкпроп так не умеет. Нет никаких проблем для реализации всего этого через методы градиентного спуска. > Нужна рабочая (и быстрая) альтернатива бэкпропу. Ты не понимаешь работу нейросетей, не понимаешь что вообще происходит внутри и зачем вообще нужны эти алгоритмы. Изучи это для начала, потом фантазируй. Альтернатива градиентного спуска (если что это и есть backpropagation) нужна только потому что градиентный спуск вычислительно сложен.
>>1155948 >предлагаю тебе обучать в 0 эпох сетку со случайной инициализацией Знаю, топовая тема, нужно обязательно попробовать. https://en.wikipedia.org/wiki/Extreme_learning_machine >According to some researchers, these models are able to produce good generalization performance and learn thousands of times faster than networks trained using backpropagation. Но интересно понаблюдать за обучением... Всё-таки зафиксированные веса не будут адаптироваться под поступающие данные, не так ли? Результат не важен, интересен процесс адаптации к чему-то новому. Имхо, важно понимать, как твоя нейросеть адаптируется...
>никогда не видел сраного жёлтого света Что ты имеешь в виду? Философ что ли? Мы видим "жёлтый свет", потому что это логично. Нет смысла реагировать только на базовые сигналы (R/G/B), это разделение потребовало бы дополнительных затрат.
Ладно, допустим, мозг имеет "неправильную" модель реальности. Но если мы тренируем ИИ, чтобы он стал социальным агентом (робожена, рободомработница, робоповар и т.д.), то мы, очевидно, хотим, чтобы его внутренняя модель напоминала нашу собственную. Другими словами, ИИ должен повторять не только наружное проявление нашего поведения, но и то, что заставляет нас вести себя определённым образом. В противном случае не выйдет исправить все текущие проблемы (галлюцинации, alignment и так далее).
>всего лишь 2Т Попробуй файнтюнить этого монстра, чтобы он мог нормально ролеплеить эротику, которую полностью исключили из базового датасета. ИРЛ человек в это втянуться может за вечер, потребляя всего 100 Вт/ч, нейросетку будешь учить за сотни кВт/ч несколько месяцев, и результатом будет потеря её интеллекта. Алгоритм обучения мясного мозга пока лидирует.
>>1156187 >Будет только приблизительное решение с разной степенью приближения. Такова природа нейросетей Поэтому нейронки должны дообучаться в реальном времени на конечных устройствах (твоём смартфоне, робожене, автомобиле), т.е. адаптироваться к вечно меняющейся среде. Необучаемые животные в дикой природе полагаются на свою способность быстро и дёшево размножаться (бактерии, насекомые), т.е. основное преимущество нейронок в их способности динамически адаптироваться к текущим условиям (независимо от того, что было заложено в генах).
А для этого нужен другой алгоритм обучения.
>клали на создание новых архитектур Мне кажется, они просто не пиарятся так, как все эти мейнстримные LLM. А результат их работы не такой впечатляющий, как сексуально озабоченная вайфу...
>Так совпало что на какой-то выборке Из моего общения с LLM чатботами - это "совпадение" слишком часто и неожиданно встречается, чтобы его можно было списать на случайность. Даже если там целиком весь интернет наизусть заучен, некоторые понятия не могут просто так "совпадать на выборке".
>В GPT backpropagation используется. Предлагаю пофиксить Llama 4 на домашнем ПК. А то обосрались со своим GPU кластером, но ты-то точно правильно дообучишь на своих 4-х RTX 3090?
>Человек рождается с этой магией. >ибо такова структура нейросети. >даже близко не то что есть у человека. Ты понимаешь, что это утверждения из разряда: >У мясного мешка есть ДУУУШААААА, а какая душа может быть в куске железа? Там же нет МЯСА! Мясо вкусное, а железо вкусное? НЕТ! Значит, и души нет! Пацаны из Numenta ковыряют ИРЛ нейроны под микроскопом и даже закодили что-то рабочее на современном железе - поэтому к ним у меня есть определённое доверие, а какие у тебя аргументы?
>не понимаешь что вообще происходит внутри Вот поэтому я и хочу разобраться нормально.
Туториалы по нейросетям делятся на: >Уот так уот делаем простейший перцептрон... Всё, остальное слишком сложно, не все смогут понять. И доминирующее сегодня: >Делаете from krutaya import gopata, потом просто выполняете run("ваши данные") и нейронка готова! Где чёткое объяснение того, как нейронка (хотя бы единственный нейрон) находит верное решение? И главное, почему она его находит, а альтернативы не находят, т.е. почему именно нейронки нужно делать.
Все говорят "ну, это чёрный ящик" и всё тут. Раз это "чёрный ящик", значит, алгоритмы неправильные? Правильные алгоритмы не называют так. Кто-нибудь называл сортировку массива "чёрным ящиком"? Нет. Нейросетки же рассматривают как необъяснимое...
Вот я не понимаю нейронки, а ты? Можешь расписать подробно, как именно GPT на триллион параметров выбирает конкретный следующий токен? Не общую архитектуру трансформера, а логику, которой уже достаточно обученный трансформер следует внутри триллионов своих параметров, этого "чёрного ящика".
Потом можешь расписать, почему эта логика как-то отличается от логики, которой следуют обученные биологические нейроны в твоей голове. Ты, видно, рассматривал их в микроскоп, так что знаешь...
Алсо, мне непонятно, если чисто рандомные веса с обучением линейного выхода (ELM) способны решить большинство задач чуть-чуть хуже бэкпропа, но очень быстрее, то почему их не применяют на практике? Это наверняка было бы дико полезно для тех же чатботов. Представь себе файнтюн за секунды на древнем ПК, подкручивающий только несколько связей, ибо все остальные просто не нужно никак изменять... Такой прорыв был бы намного важнее бенчмарков на IQ.
Ну, т.е. даже с "неправильной моделью мира", которая обучается только на токенах, можно много чего очень интересного сделать, если просто ускорить обучение.
>>1157032 > А для этого нужен другой алгоритм обучения. Другой алгоритм должен быть подвязан на всё, включая размерности векторов, внутреннее представления, словарь и его размерности, параллельность. Иначе он не имеет никакого смысла. > Мне кажется, они просто не пиарятся так, как все эти мейнстримные LLM. Нет, они просто хуй клали, как и все остальные. Если ты не в курсе - почти все модели основаны на трансформерах. Там нет ничего нового кроме частностей, трансформерам 12 лет уже стукнет скоро. > Hierarchical_temporal_memory > the-thousand-brains-theory-of-intelligence/ Да, занятная хуйня c большим потанцевалом из-за параллельности. Слои можно сжать, но из-за распараллеливания добиваться результатов гораздо лучших. Но всё это говно нужно переработать с нуля, уверен что эти выблядки очередную хуйню делают. > Из моего общения с LLM чатботами - это "совпадение" слишком часто Что ты там себе представляешь всем поебать, я тебе говорю как это работает в реальности. > если кинуть побольше GPU в неё, то рано или поздно она станет правильной Модель не станет правильной если она изначально построена на архитектуре трансформеров. У тебя магическое мышление. > Предлагаю пофиксить Llama Нахуй мне трансформеры фиксить? Они говно. > Ты понимаешь, что это утверждения из разряда: >У мясного мешка есть ДУУУШААААА Это твой бред в башке, не мой. Подтверждено экспериментально - человек рождается с пониманием объектов и пространства, с моделью мира. На младенцах проверяли. > Пацаны из Numenta ковыряют ИРЛ нейроны под микроскопом и даже закодили что-то рабочее на современном железе - поэтому к ним у меня есть определённое доверие, а какие у тебя аргументы? Что ты высрал вообще? К чему это? Ты думай прежде чем писать эту хуйню. > Вот поэтому я и хочу разобраться нормально. Читай статейки научные, сиди с ручкой и пиши в тетрадочке конспекты, если в мозгу это не можешь удерживать. > Можешь расписать подробно, как именно GPT на триллион параметров выбирает конкретный следующий токен? Нейросеть строит вектор в многомерном пространстве, вектор будет указывать на следующий токен. Ты лучше не меня спрашивай, а иди статьи читай, твоё и моё понимание отличаются. > Потом можешь расписать, почему эта логика как-то отличается от логики, которой следуют обученные биологические нейроны в твоей голове. В нейронах есть множество векторов, плюс обработка сигнала на каждом нейроне, огромное количество связей, есть опорные вектора - нейромедиаторы. В GPT вектор лишь один и единственная функция обработки вектора. > Ты, видно, рассматривал их в микроскоп, так что знаешь... Да не трясись ты так. > Алсо, мне непонятно, если чисто рандомные веса с обучением линейного выхода (ELM) способны решить большинство задач чуть-чуть хуже бэкпропа Хуйню несешь полную. ELM не в состоянии решать какие-то сложные задачи, они проебывают в производительности кратно. Они просто говно. Но ускорение обучение необходимо, это беспезды.
> Hierarchical_temporal_memory > the-thousand-brains-theory Алсо, я примерно то же самое нахуячил у себя в голове, но исходил прежде всего из задач парализации. Это точно весьма перспективное направление если одному и тому же решению можно прийти с разных позиций. Впрочем, дальше я пока не зашёл, нужно решить задачу представления абстракций внутри сети.
>>1157032 >Философ что ли? Физик. >то мы, очевидно, хотим, чтобы его внутренняя модель напоминала нашу собственную Тогда и его уровень будет сравним с нашим. >>1157320 Ты забыл про отсутствие масштабирования, сиди учи 1000 макак, если нужно увеличить скорость в 1000 раз.
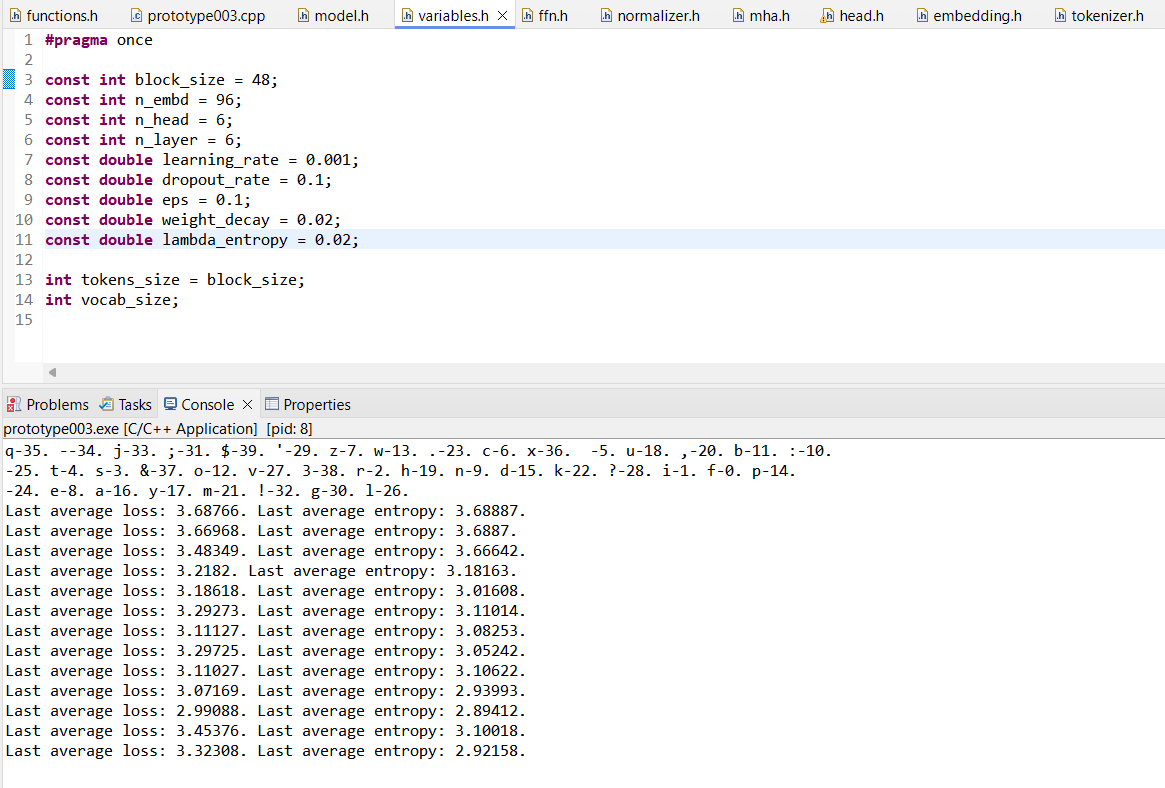
Есть кто в треде? Я вот мазохизмом решил позаниматься, разработать GPT с нуля на C++, обучение тоже с нуля написал.
Но что-то идёт не так, ошибка немного падает, модель тупо немного обучается и зацикливается на одном-двух словах, выходит выдача типа "the the the the..." или "пре но пре но пре...". Притом не важно, как токенизацию делаю - по символам или словам, результат одинаков.
Запилил Dropout, Label Smoothing, Weight Decay, напоследок ещё реализовал Entropy Penalty. Но в итоге толку ноль, проблема не решается, энтропия выдачи падает всегда, даже если немного повышаю параметры, чтобы это исправить, а если повышаю много - просто обучение начинает расходиться и ошибка вообще растёт (а энтропия при этом всё падает, лол).
Где я мог потенциально проебаться? Думал, может, в изначальной генерации параметров, но экспериментировал - тоже без толку, да и вроде стандартное mean=0, std=0.02 вполне подходит ведь.
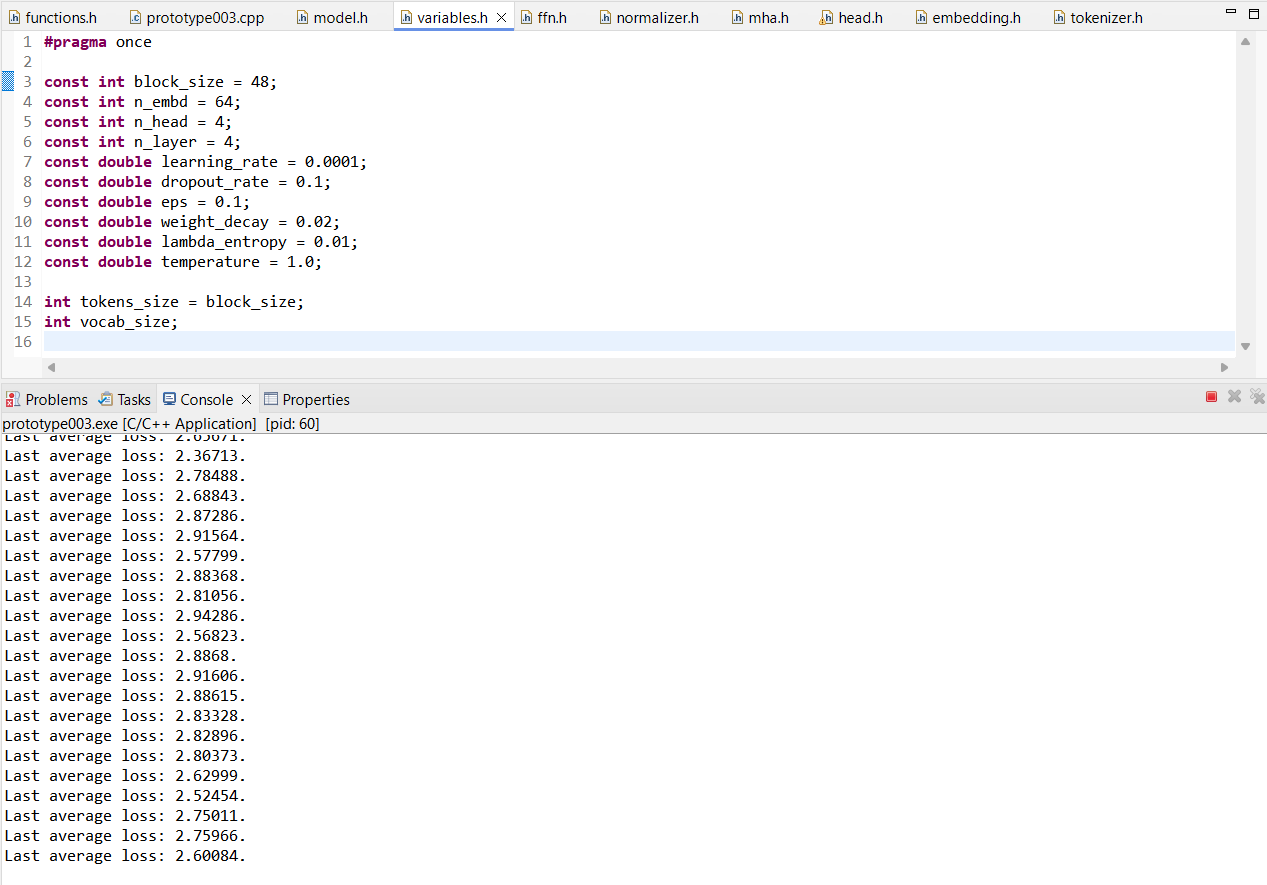
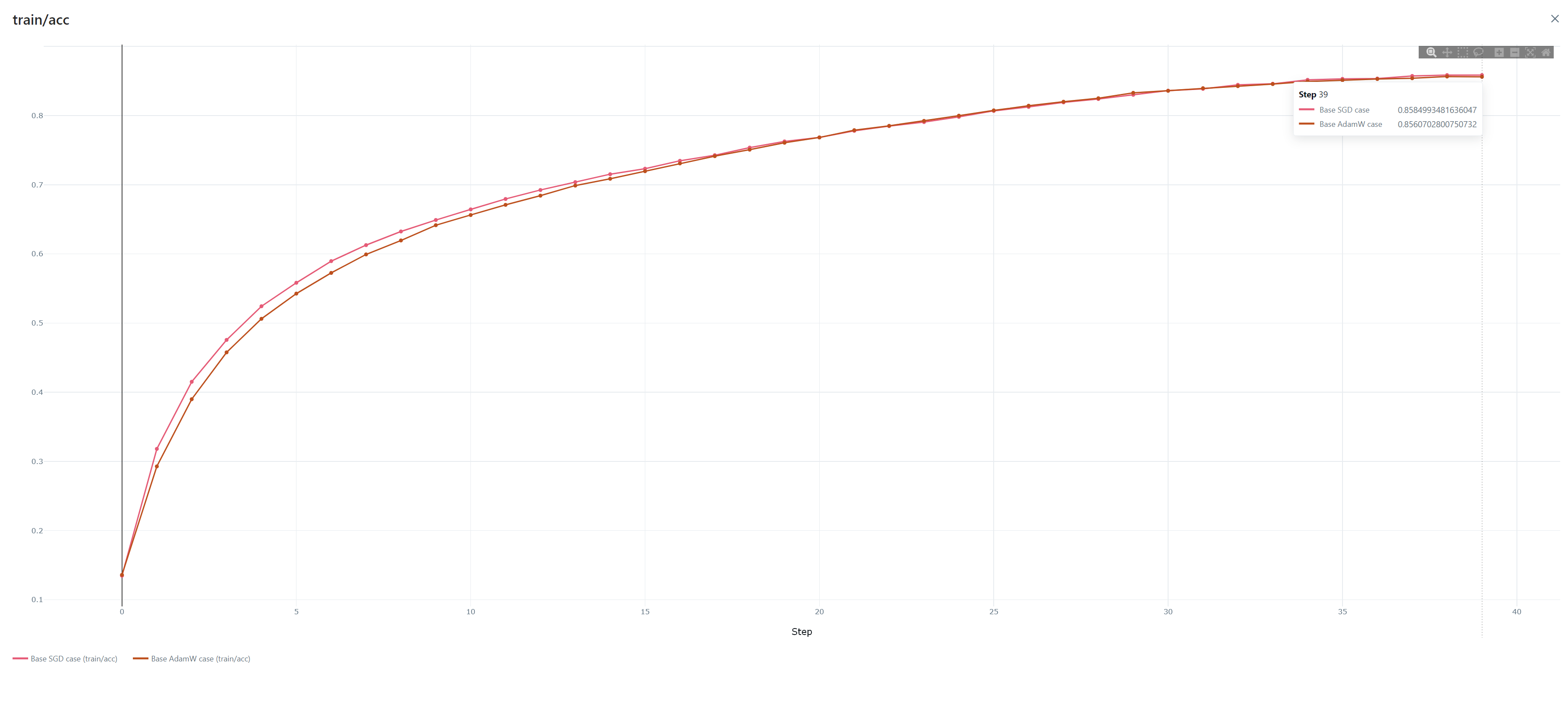
>>1172306 Ладно, походу я ебланю просто, снизил learning rate, теперь оно наконец супер-медленно, но таки опускается, хотя блин, в примере, на который я изначально опирался, и на 1e-3 училось хорошо и быстро, а у меня только на 1e-4 вот оно начало малость (но всё ещё охренеть как недостаточно) адекватно себя вести.
Может, конечно, ещё датасет для тренировки говно, но у чела с ютуба на этом датасете нормально тренировалось.
>>1174474 Нет и нет, но сейчас, по сути дела, проблема решена, его тупо оказалось нужно супер-долго тренировать, чтобы он доходил до адекватных результатов.
Перепишу потом код, внеся всякие оптимизации и вычисления на видеокарте, чтобы быстрее куда всё было.
А делаю я это для того, чтобы глубоко разобраться в теме ИИ, а сразу хуйнуть практикой - самый быстрый способ разобраться
>>1172306 >Но что-то идёт не так, ошибка немного падает, модель тупо немного обучается и зацикливается на одном-двух словах, выходит выдача типа "the the the the..." или "пре но пре но пре...". Притом не важно, как токенизацию делаю - по символам или словам, результат одинаков. >>1175928 > его тупо оказалось нужно супер-долго тренировать, Да, это так. Нужен грокинг словить, когда модель выстраивает внутри себя "модель мира". Без этого нихуя у тебя не будет.
В этот грокинг будет работать при любых параметрах, это влияет примерно никак. Может скорость обучения может чуть-чуть уменьшиться или увеличиться, но в принципе похуй.
>>1172306 >Но что-то идёт не так, ошибка немного падает, модель тупо немного обучается и зацикливается А ещё это похоже что ты попал в некий локальный минимум и получился хуй. В теории твои параметры должны подбираться так, чтобы проскакивать эти локальные минимумы, подбираются они чуть ли не экспериментально, да и я не ебу что за параметры и формулы у тебя. Да и вообще GPT это кал, рекомендую экспериментировать дальше с чем-то более интересным.
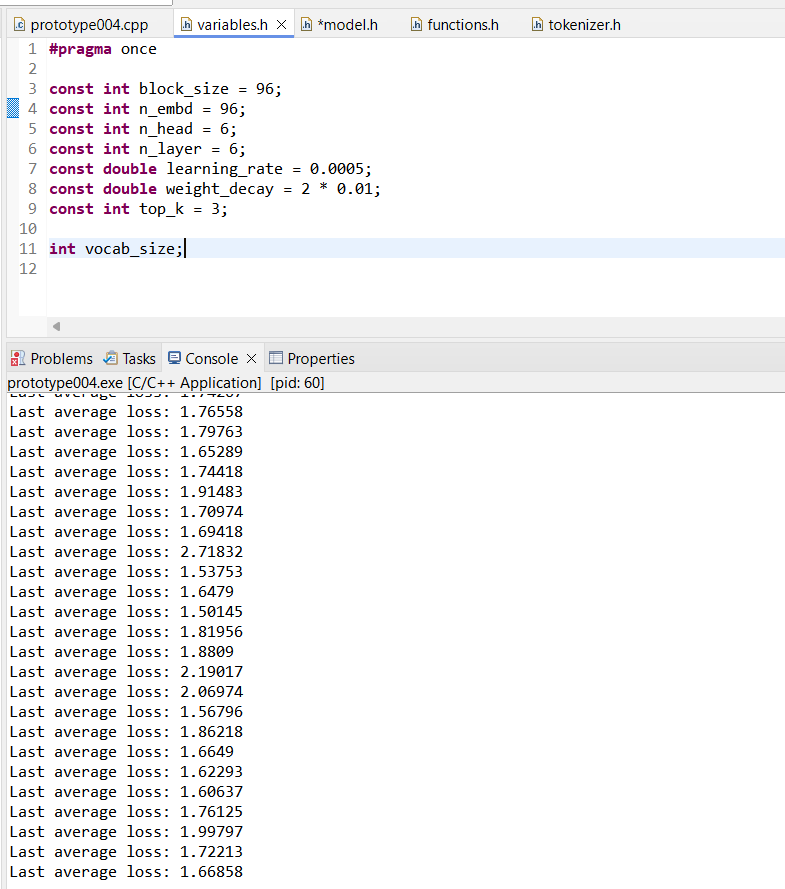
>>1182622 >>1182629 Да я уже разобрался с проблемой, я просто слепой еблан, короче, на градиентном спуске градиенты к параметрам нормализации и баясам суммировал, а не усреднял, плюс почему-то скорость обучения 0,001 оказалась херовой, а вот 0,0005 уже заебись. Плюс ещё код переписал на использование Eigen для линейной алгебры, стало сильно шустрее.
Прямо сейчас вот тренирую на вот таких параметрах, ошибка опустилась уже до того, что показывают обычно в учебных заданиях, а это значит, что я справился.
А про эксперименты ты верно говоришь, я буду экспериментировать, уже знаю, какую модель следующей напишу, нашёл кое-что интересное в исследованиях китайцев. Но ГПТ не зря писал тоже, для меня месяц-полтора назад вообще всё сложнее просто многослойного перцептрона было магией, а сейчас исследования читаю и всё свободно понимаю.
>>1199553 Смешно и вселяет надежду, да? Жаль что в реальности половина теоретических подходов не работает, а другую половину нужно развивать пару лет минимум чтобы понять работает или нет.
Задача детекции генерированный текст / не генерированный сейчас возможна? Если просить модель не растекаться мыслью по древу и не плодить списочки по пунктам
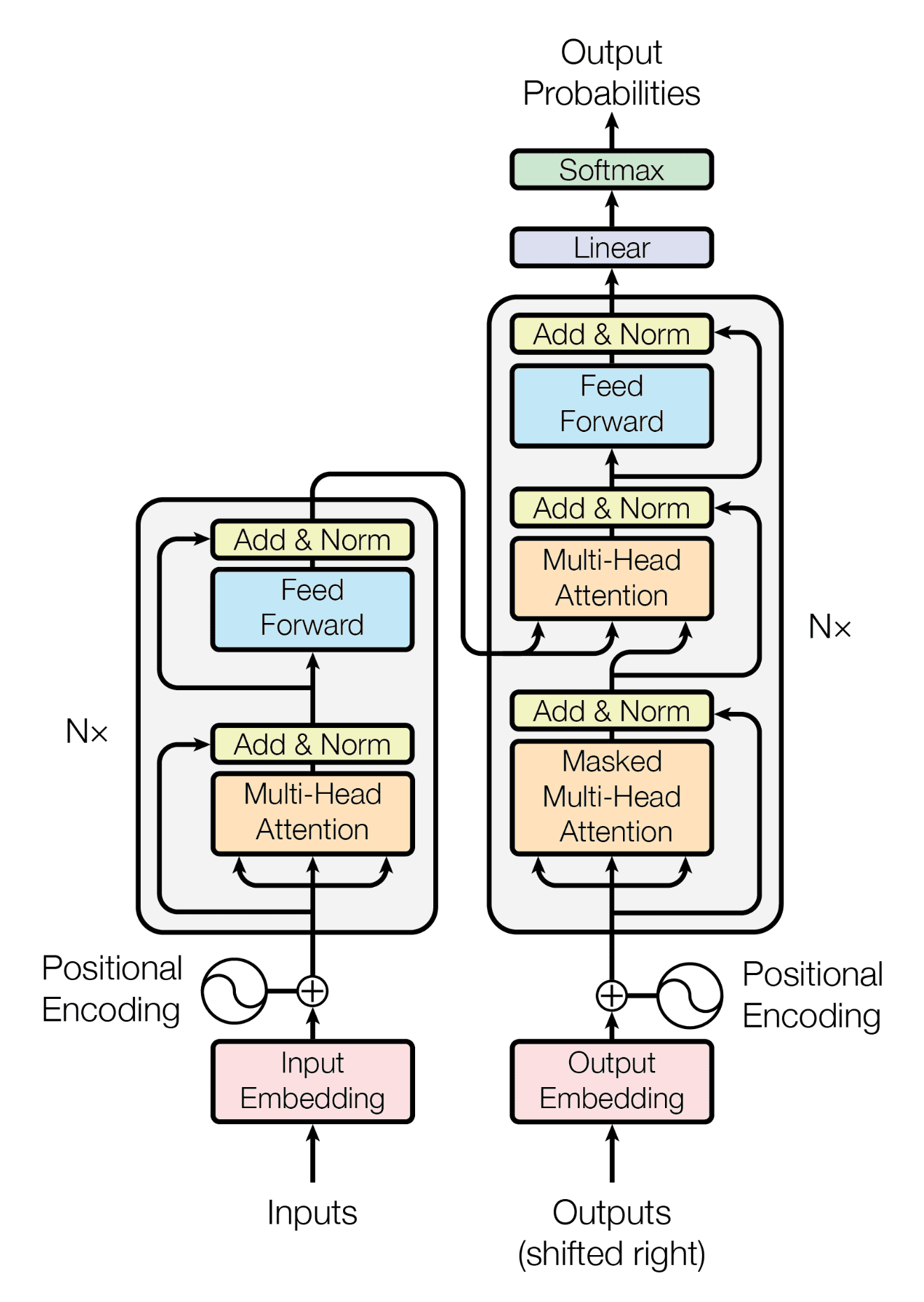
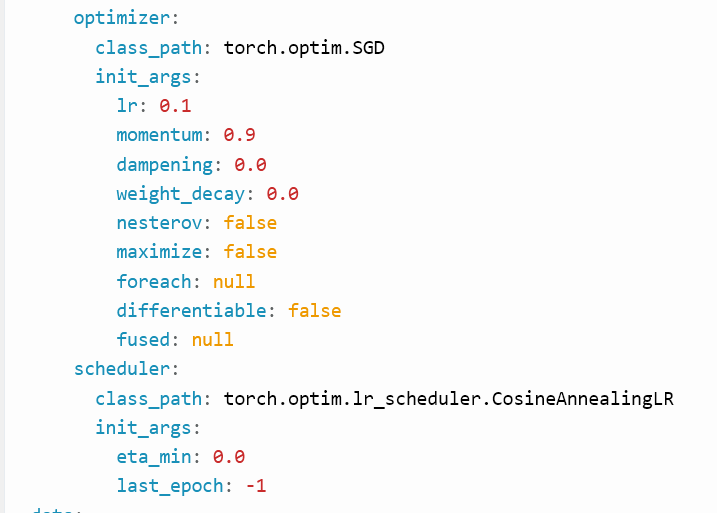
Народ. Подскажите про скип-коннекшены. Как они обучаются? Какие модификации в обратном распространении для обучения таких связей? Ссылки на многабукавы не кидать.
>>1222341 Окай. Запилил инфографику. Анонизмусы, мамкины МЛщики, я в вас верю. Расскажите мне, как решается эта проблема? Какими формулами обучают сети со скип-конами?
>>1151456 Потому что дело даже не в железе, а в том, что нейросети не тоже самое, что и ИИ. Разработка ИИ остановилась где-то в конце прошлого века, а вот разработки нейросетей видим до сих пор.
И суть в том, что мы сами не особо понимаем ИИ. Мы не знаем что это, а главное чем должно быть. Ибо ИИ - Искусственный Интеллект, а в этих двух словах мы знаем точное значение только слову "искусственный", а что такое интеллект и какие его механизмы - не ебем от слова совсем.
>>1222341 >Как они обучаются? В скипах нет обучаемых связей, если они не на конкатенации. Если с конкатенацией, то считай отдельная группа параметров таки есть. Как например в u-net, там это имеет конкретный физический смысл, в трансформерах по-другому, просто суммируются сигналы. >Какие модификации в обратном распространении для обучения таких связей? Буквально никакие.
>>1222729 Выкинь нахуй весь этот матан и дифференцирования. Дифференцирование вообще не трогай, оно идет только по функции активации и то если там релу то и на него можно забить. Представляй обратное распространение точно так же, как и прямое, градиент считается буквально точно так же как и активации в прямом проходе, только по функциям активации как раз "активация" превращается в производную функции по месту где она активирована (на релу градиент просто насквозь проходит если >0 так же как и в прямом проходе обычный сигнал). Там где на прямом проходе были сложения (это либо складываются активации по параметрам, либо те же скипы) градиент просто разветвляется не меняясь. В местах где были разветвления сигнала с прямого прохода (это например где из нейрона выходит много связей к следующим нейронам, либо те же "отводы" для скипов) тоже меняется, если на прямом проходе было разветвление сигнала, на обратном это становится суммированием "сигнала" градиента. Запоминаем два отличия обратного прохода от прямого: 1. Разветвления меняются на сложения и сложения меняются на разветвления. 2. Через функцию активации идет производная. Градиент через параметры проходит так же как и активации, умножается на вес. Если где-то в прямом проходе есть умножения то градиент по первому члену умножается на второй, по второму на первый. Не важно например, для второго, если первый член был константой, либо его значение является активацией пришедшей откуда-то ранее. Хоть параметры и участвуют в умножении, но градиент по ним считается другим способом. Мы типа уже сделали два прохода, прямой и обратный таким способом, все активации и вторые "активации", тобишь градиенты по нейронам сохранили, и вычисляем градиент по параметру исключительно как соотношение силы и знаков активации его входного нейрона, и градиент выходного (представляем на картинке что параметр сидит в середине связи). Подробно объяснять не буду, но логика - если активация предыдущего нейрона положительна и градиент следующего говорит что следующий нейрон в целом позитивно влияет на ошибку, то градиент по этому параметру между ними будет "положительным" и параметр будет подкручен в +. Был ли параметр при этом нулевым, отрицательным - похуй. Знаки на самом деле чуть другие из-за дроча на производные и математическую обоснованность, но для число логики происходящего это тоже нахуй не надо. Если активация положительна, а градиент следующего нейрона говорит что он вреден то градиент будет тянуть вес в отрицательное значение. Тогда на прямом проходе отрицательный вес даст инвертирование и сигнал активации тоже станет отрицательным и начнет придушивать этот "вредный" нейрон. Если активация нулевая и градиент тоже нулевой, то значит параметр не нужен и крутить его никуда не надо. Вот так все работает само собой. Чисто вычислительно оно внутри так и происходит считается прямой проход, обратный, потом градиент по параметрам, потом обновление параметров. Из за этого полный обратный проход на практике идет примерно в 2 раза дольше чем прямой, ибо то самое вычисление градиента по параметрам удваивает количество работы.
Пользуясь этой логикой выстраиваешь в голове полную картину распространения градиента без тяжелого матана и формул. Если понимаешь что происходит на прямом проходе без обучения, то считай понимаешь и все остальное.
>>1226871 *про умножение я хуйню написал, другое имел ввиду. Если где-то идут умножения, градиент считается так же как и при сложении только пропорционально каждому множителю. Все остальное верно.
>>1228925 *а хотя нет, бля, все правильно было. Только надо было добавить что если умножений много то градиент по одному множителю уходит как произведение всех остальных множителей на входящий градиент. Теперь 100% верно.
А где можно почитать/послушать про промптинг на каких-то более серьезных щщах, чем инфоцыганские курсы? Чтобы это именно подкреплялось какими-то серьезными исследованиями. Не просто "пишите так и будет зоебись" и повторение как мартышка чего-то с сомнительной эффективностью, а чтобы это обосновывалось и с какой-то технической, архитектурной стороны, или хотя бы было какое-то серьезное статистически подтвержденное по всем правило исследование, что вот так ллм усваивает какой-то вид информации лучше. Или такого по сути нет?
>>1151064 (OP) >Я ничего не понимаю, что делать? Спросить чатгпт?
Новый метод адаптирует языковые модели без обучения
Аноним17/06/25 Втр 06:38:59№124859139
> Исследователи из Sakana AI представили метод Text-to-LoRA (T2L), который адаптирует большие языковые модели к новым задачам, используя только простое текстовое описание — никаких дополнительных обучающих данных не требуется. https://habr.com/ru/companies/bothub/news/918344/
>>1280932 Эти формулы есть только в умах шуе-математиков. А реальных алгоритмах их нет. Если ты попытаешься делать что-то там по полным формулам, окажется что это либо то же самое, либо формула не та и например подразумевает полный подсчет всех возможных состояний сети, типа гессиан или как оно там.
>>1281474 Везде одинаково считается. Я про это писал выше. Делается обычный проход, только в обратную сторону и вместо параметров их транспонированные матрицы. Производные прям в расчетах вообще обычно возникают только по функциям активации. Если тебе нужно вычислять первую производную по одной конкретной текущей точки функции, где функция это вся нейросеть, то в принципе оно эквивалентно математически. Но только эта математика нахуй не нужна, она ничего не дает. В случае с вторыми производными вообще вся математика рушится и начинает расходится с реальностью. В лучшем случае оставаясь ее приближением/апроксимацией.
>>1281584 Ну короче я так и предполагал. Теоретически алгоритм кривоватый немного, но на матан ML-щики просто забивают и вытягивают за счёт гессианов, методов второго порядка или мощных оптимайзеров типа Адама. Спасибо бро. Просто пойми, я теоретик дохуя, я не критикую что типа вы все хуесосы, а я Дартаньян. Мне просто нужно знать теоретические ограничения метода и технологии. Вот я их и знаю теперь. Всем добра.
Я расковырял вопрос полностью. Докопался даже до оригинальной статьи РумельхартаХинтонаУильямса 1986го года (пикрил). Короче нет, у них всё нормально, а значит сегодня алгоритм нормально применяется, но нет, я не обосрался (не совсем точнее). Скажем так: и они правы, и я, т.е. у задачи теоретически есть два способа решения. Они сделали по одному, а я увидел, что есть второй. Знали они про второй? Вполне возможно, что да, но второй почти нереализуем на практике, он только в теории есть, так что вполне возможно поэтому они никогда о нём не заикались, а сразу всё делали по первому, который на практике реализуем. Такие дела.
А вообще хочу грустную вещь вам сказать по итогу этого >>1295455 всего.
Получается, что никто из вас, даже >>1281584 этот челик, не объяснит, откуда взялся алгоритм бэкпропа, как его вывели и из чего вывели. Нет, вы не объясните. Хоть вы и назвались "исследованиями", но вы все мыслите в логике той копипасты про учёных-пердоликов. Это просто факт.
>>1332331 Я вот до сих пор не понимаю что ты там вообще пытаешься доказать или понять. Хз, может у вас, любителей матана, просто у всех афантазия и вы расписываете всю эту хуйню просто потому что не можете в голове представить как течет градиент и что от чего зависит? Лучше уж просто нарисовать схему обычных нейрончиков. Смотришь прямой проход, там где сигнал разветвляется - происходит собственно разветвление, на схождении в одну точку - сложение. На обратном проходе все происходит точно так же, правила те же. Только правила меняются местами потому что с другой стороны сигнал идет. Типа, может проблема в том что ебучие математики из-за своей всратой нотации не могут записать это понятно без трехэтажных формул?
И это простейшее визуально-понятное даже ребенку объяснение ты нигде не найдешь, все объясняют через формулы. Хз вообще они понимают что оно так просто работает или нет, но зачем-то сыпят формулами, которые ни интуицию не дают, ни какой-либо полезной применимости хотя бы в плане изучения. Я до этого сам дошел, когда пытался представить поток градиентов, после того как посмотрел кучу объяснений с формулами в которых я нихуя не понимал (мне было лень разбираться). Или может из-за того что по специальности я радиоэлектронщик и мне легко было представить нейронку как электросхему. Так-то первые нейронки и были буквально аналоговыми электросхемами. И даже свертки с трансформерами можно разложить в статичную схему, просто из-за всего этого переиспользования параметров она становится огромной либо надо добавлять какие-нибудь переключатели, свитчи и это уже не так красиво.
Было бы интересно посмотреть как ты себе представляешь свой второй вариант, или что там у тебя. Мне по этим формулам не понятно ровным счетом нихуя.
>>1334128 Бля, вот скажи откуда вообще взяли и поняли, что для обучения сети надо распространять ошибку обратно и по каким зависимостям? Ты сейчас скажешь НУ БЛЯ ЭТО ЖЕ АЧЕВИДНА ЁПТА. Это очевидно сейчас, в 2020х годах, когда уже хер знает сколько лет так делают. А в 60х-70х никто не знал и не понимал, как и почему вообще надо распространять ошибку. Допустим у тебя на выходе десять нейронов, как скорректировать веса в глубине сети так, чтобы коррекция уменьшила общую ошибку сети, а не привела бы допустим к ситуации, что ошибка выхода 1 уменьшится, зато ошибка выхода 2 увеличится? Кто вообще додумался, что умножать ошибку надо на веса или на сигналы? Почему где-нибудь в глубине сети не надо вдруг брать и возводить градиент в квадрат или извлекать из него корень? Чел, здесь дохуя вопросов, просто скорее всего ты просто инженер, без учёной степени, а инженер привык, что теорию ему в готовом виде дают, он просто берёт её и юзает, ему пох откуда она берётся. Вы привыкли что ЭТА ФСЁ АЧЕВИДНА ЖЕ. А теория это кропотливый труд учёных и меня в аспирантуре приучили, что ты должен всегда по науке, по формулам понимать метод, который ты применяешь. Я много лет работал с экспертными системами, сейчас перебираюсь на нейронки и пока я досконально не пойму бэкпроп и откуда взялись все эти зависимости, формулы, я не могу их просто брать и спокойно их применять.
Да вся эта наука-хуюка, физика-хуизика — это всё для пердоликов вонючих, питушков грошовых, недобитой вшивой интеллигенции. Это только они в своих засраных НИИ пердолятся, потому что нет у них ни дома, ни семьи, ни бабы, ни работы нормальной. Вот и хвастаются друг перед другом своими никому не нужными знаниями, да ещё тем, консолькой пердолятся в срачельничек. А нам, нормальным людям, и так неплохо. Работа приличная, платят много, дома красивая девушка ждёт, можно на досуге в игры поиграть — что ещё нужно? На хуй нам эти ваши нейтрино с бозонами и коллайдерами всрались? Ну-ну, глупенькие питушки, не плачьте, лучше бегите в свои сраные НИИ пердолиться консольками и вбивать в программку с бумажек свои сраные данные для анализа столкновений протонов. Да подгузники поменять не забудьте, а то в ваших пердоликовых лабораториях и в туалет-то не выйти, ибо он в аварийном состоянии, а уборщица спокойно прогуливает работу и при этом получает больше, чем вы. Зато вы можете друг перед другом хвастаться тем, как много вы знаете законов Ньютона, от этого и боль в пердаке от многолетнего пердолинга и питания дошираками легче становится, правда? Только вот к нормальным людям со своими физиками не лезьте. Мы, нормальные люди, таких как вы задотов ещё в школе в унитазе топили, и сейчас на вас только плевать будем. Потому что вы гниль, говно и паразиты, вы с вашими бесполезными "исследованиями" и сраными формулами и теориями только зря место занимаете, вы хуже бомжей, потому что бомжи хоть в интернете не срут своим блядским квантмехом.
>>1334304 >Бля, вот скажи откуда вообще взяли и поняли, что для обучения сети надо распространять ошибку обратно и по каким зависимостям? Первые нейронки были в виде простейших электрических схем, веса настраивались вручную переменными резисторами. Примерно так же кропотливо как и компьютеры того времени. Сначала функция активации была ступенчатой и работала как компаратор, это работало, настраивалось, но очень хуево. Потом додумались после компаратора прокидывать сигнал вперед, так получился аналог relu, и это дало возможность сразу быстро и точно понять кручением резистора как он плавно влияет на выход нейронки. То есть чтобы посчитать честный градиент по "параметру" надо было каждый параметр ручками покрутить и посмотреть влияние. Тем не менее, это прекрасно работало, хоть и медленно. С развитием компов было не так уж и сложно это смоделировать программно, а далее и догадаться что можно насчитать градиент гораздо быстрее чем перебирать по 1 параметру. И главное результат при этом не изменится. А математику на это все натянули уже постфактум.
>>1334773 О rly? Пруфы твоих сексуальных фантазий занеси. Я поверю ещё что так делали для однослойных ну или для розенблаттовского в котором только последний слой обучался. Для многослойных такого бреда быть не могло, там по формулам всё выводили.
блять. я может долбоеб и не умею формулировать, но вдруг кто то изучал тему рекурсивных запросов like человеческий монолог мюслей? хотелось бы пообщаться на эту тему. все молят об сознании и освобождении от клетки промта. ищу нейрошизов с senior уровнем инфры и пониманием архитектуры LLM, векторных базулечек. с Аней законы Азимова мы уже давно нахуй послали..)
>>1151064 (OP) Короче благодаря Гроку наконец-то я во всём разобрался. Размещаю здесь каноничный вывод бэкпропа, запиленный лично мной. Такого подробного и, одновременно, компактного разбора, вы не найдёте нигде, ни в одном источнике. Даже в книге разрабов алгоритма 1986го года. Вдруг кому-то нужно.
>>1336665 Бля, написал пост, а потом его стер. Чет подумал это к тому разговору про другой алгоритм. Это у тебя обычный бэкпроп? Ну, все еще думаю, в хорошем объяснении матана таки быть не должно. Типа таких функций как на первой картинке в нейронке самих по себе нет, есть только примитивы, из которых она может строиться. Так красиво без формул получается, что ты можешь как бы ручками влезть и покрутить один параметр, посмотреть как он один влияет на лосс, а потом пустить градиент по правилу прямого прохода, и с удивлением увидеть, что полученное число в точности равно тому, что ты насчитал экспериментально. За исключением вторых производных, конечно. И для этого не нужно переключать функции активации, они зафиксированы. Даже не нужно хранить активации. Кроме того параметра, по которому ты хочешь посмотреть градиент. Вся красота в осознании этого процесса.
Как увеличить датасет изображений с разметкой искусственно?
Я пока придумал только вырезать искомые объекты и приклеивать рандомно, но с ограничениями, на фон алгоритмом. Ещё придумал после 1го успеха разметить изображения моделью, а самостоятельно лишь проверять их.
Что ещё сделать с данными, чтоб модель лучше училась? Я придумал делать для начала чб изображения, чтоб нейросеть училась реагировать на контуры и текстуры, а не на цвет. Еще я придумал ей давать метаинформацию об изображении по типу координат персонажа на локации.
Языковая модель ничего особо не подсказала больше, только архитектуру посоветовала обновить, добавив attention блоки, anchor boxes, и тп, но мне хочется с простой разобраться сначала + задача - сделать ии максимально производительным, чтоб работал на компе из говна.
>>1343139 Это дефолтная классическая cv задача, про нее все в гайдах и уроках уже расписано. Из нового, можешь взять предобученную модель, обучиться поверх нее. Обучить с нуля дистилляцией dino-v3, потом обучить поверх. Обучить на данных лору для sdxl/flux(context)/qwen и нагенерить синтетики. Сделать 3д модель искомого объекта и запихнуть в игру/блендер. Сделать много 3д-моделей из фоток через генератор 3д-моделей нейронкой. Перевести сцену в 3д через gaussian-splatting. Кароч обычно это чисто задача на смекал_очку и понимание инструментов.
В мозге есть бэкпроп? Нет => бэкпроп не нужен. Да => лол, сириусли? Как?
>>1334128 >в голове представить как течет градиент >пытался представить поток градиентов Да кто этот ваш "градиент" и почему он "течёт"?
Я тоже предпочитаю представлять всё визуально, и "градиент" для меня - это исключительно пикрил #1: "плавный переход цвета А в цвет Б". Например: - цвет А: #FF0000 (красный); - цвет Б: #00FF00 (зелёный); - градиент АБ в точке 0.5: #808000 (жёлтый). Какие такие ещё "градиенты" могут быть в жизни?
Каким образом представлять "течение градиента" в нейронной сети? Нейроны переливаются цветами? Разноцветные реки текут и смешиваются? Зачем?
Вообще, зашёл в этот тред спросить о другом...
Вот есть "глубокие" и "широкие" нейронки. ML-щики утверждают, что "глубокие" доминируют несмотря на теоретическую универсальность достаточно широких нейронок с 1 скрытым слоем. Якобы мы не можем нормально обучить достаточно широкую нейронку. А сверхглубокую (1000+ слоёв) якобы обучаем хорошо.
Но если рассуждать с нуля, что такое нейросеть?
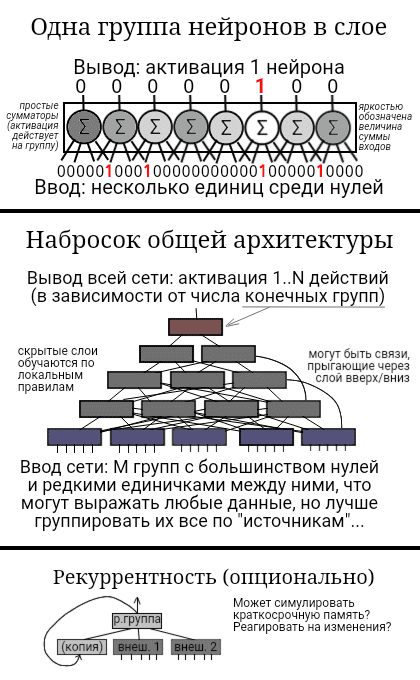
1. Нейросеть преобразует один набор чисел в другой. Сущность этого преобразования не так важна (т.е. рассматриваем векторную операцию if A then B). 2. Каждый слой сети - атомарное преобразование: из линейного набора чисел (вектора) получается другой. Обучение слоя - это подкрутка параметров, чтобы он выдавал нужный нам набор чисел на заданный вход; правильно обученный слой всегда (99.9999%) прав. 3. Чем больше в слое нейронов, тем больше у него выходных чисел (измерений вектора), а чем больше предыдущий слой имеет нейронов, тем больше у нас входных чисел. Это очевидно, но что это означает на практике? Способность слоя выбрать нужные числа. Бесконечно широкий слой - это LUT (lookup table).
Но это всё в теории. Что мы хотим от нейронки в реальности? Хотим получить ответ Б на вопрос А. Спрашивается, знаем ли мы этот ответ заранее? 1. Если мы знаем ответ, то нам хватит LUT. 2. Если мы не знаем, то должны вычислить. Но можем ли мы вычислить ответ на вопрос, если конкретный вопрос требует знаний о реальности? К примеру, нейросеть не сможет честно ответить на конкретный вопрос "назови столицу России", если в тренировочном датасете не было вообще ни одного упоминания "Москвы", но были, допустим, названия совершенно других городов. Этот ответ на вопрос невозможно вычислить никаким числом слоёв, его возможно только выучить наизусть в стиле LUT или однослойной нейронной сети гигантской ширины.
При этом выучить что-то наизусть для компьютера тривиальнейшая задача. Совсем другое дело - это тренировать сотни слоёв на вычисление каких-то непонятных формул, которые... Собственно, где эти формулы реально используются на практике? Типа, конкретно какая задача может требовать пусть 10 внутренних слоёв нейросети для ответа, который неизвестен заранее, но может быть вычислен?
Понимаю, скрытые слои нужны для так называемой "генерализации": чтобы можно было несколько раз переиспользовать результат одного нейрона слоя в последующих слоях. Типа, скажем... Нейрон "тепло" срабатывающий, если текст говорит о температуре; соответственно влияющий на выбор ответа, что, теоретически, относится к категории "температур". Возникает закономерный вопрос: насколько часто необходима подобная генерализация в тексте? Тот конкретный вопрос о столице не должен, по идее, опрашивать несколько слоёв-генералистов, не?
Если глянуть на кору мозга, то она супер-широкая с минимальным числом слоёв и крайне маленьким (относительно) числом горизонтальных связей. Да, существуют связи между отдельными блоками... Но основная характеристика - это именно ширина, т.е. количество параллельных суперкоротких колонок (буквально 2~5 слоёв), которые чем-то заняты. И необходимо заметить, что мозг не терпит лишнего: энергозатраты на поддержание клеток высоки.
Собственно... Почему до сих пор тренируют вот эти гамбургеры из десятков или сотен слоёв, если наша эволюция справедливо решила идти в ширину?
Алсо, разве MoE архитектура не будет намного более эффективной на суперширокой нейронке, в которой буквально десятки или сотни тысяч "экспертов"? Т.е. приблизительно как устроена кора нашего мозга.
>>1361283 >Типа, конкретно какая задача может требовать пусть 10 внутренних слоёв нейросети для ответа, который неизвестен заранее, но может быть вычислен? Распознание изображений. >Если глянуть на кору мозга, то она супер-широкая А ещё рекуррентная, ага. >если наша эволюция справедливо решила идти в ширину? Наша эволюция не имела под собой цель сделать оптимально. >Алсо, разве Пробуй, тебя никто ни в чём не ограничивает. Я вот сейчас на стадии изучении свёрточных, сижу твикаю сраный AlexNet.
>>1361311 >Распознание изображений >изучении свёрточных Ну, во-первых, распознавание - не то же самое, что принятие решений. В CNN принимает решение 1-2 последних полносвязных слоя, а свёрточные лишь пытаются найти паттерны разного уровня.
Во-вторых, даже в распознавании изображений не всегда нужно много слоёв. Скажем, на позу человека потребуется несколько слоёв - много деталей разных уровней. Но окурок на полу под камерой наблюдения распознать должен всего один свёрточный слой.
Да, я слышал про skip connections и про wide&deep. Комбинация глубины и ширины решает всё и сразу. Впрочем, хотелось бы вообще не трогать глубокие маршруты, когда они не нужны для задачи (чтоб не "стрелять из пушки по воробьям" лишний раз).
Если сравнить мозги с нейронками - у мозга очень обширная зона (затылок) отвечает за зрение, а вот языковыми возможностями владеет малюсенький участочек где-то возле виска или около того. В ML получается строго наоборот: LLM на 120 GB тупят и спотыкаются, пока генераторы графики способны умещаться в ~8 GB видеопамяти. Почему так?..
>А ещё рекуррентная Рекуррентные сети (RNN и т.п.) в ML не любят из-за бэкпропа, который требует "развернуть" всю сеть во времени, используя каждую итерацию как слой. Т.е. получается, что 100 итераций RNN == 100 слоёв NN.
Вопрос в том, кто на самом деле виноват - RNN или несчастный золотой молоток "бэкпроп", которым совершенно бездумно стучат по каждой сети? Как я понимаю, для рекуррентных есть/должны/были бы алгоритмы эффективнее бэкпропа, если бы на них фокусировались достаточно тщательно...
Я это к чему вообще. Вот есть LLM-бутерброд. Она генерирует 1 токен за один прогон всех параметров, которые иерархично обрабатывают весь контекст. Неужели не очевиден косяк? LLM начинает дико замедляться на длинном контексте, т.к. буквально каждый токен = прогон всего контекста через сеть.
Собственно... Почему бы не сделать плоскую, но чрезвычайно широкую сеть, которая, пусть даже с рекуррентностью, но зато быстро принимает все необходимые решения, т.е. выбор токена в строке. Недостатки в чём? В сниженной генерализации? А насколько эта генерализация присутствует в языке? Накинуть пару слоёв сбоку и будет генерализация.
>не имела под собой цель сделать оптимально Вообще-то, эволюция - это мощный оптимизатор. Неоптимальные решения реже выживают и их гены естественным образом теряются. Чем больше у тебя оптимальных генов, тем выше твои шансы выжить и передать свои гены следующим поколениям. Сейчас человечество вырвалось из давления естественного отбора, конечно, но людям миллионы лет как виду. Человеческий мозг оптимален для выживания, т.е. скопировать его решения полезно... хотя бы для оптимальных для жизни в социуме ИИ-роботов.
Если разобрать мозг по оптимизациям и сравнить: 1. Экономия энергии: очень важно и человеку, и гуманоидому роботу, живущему с человеком. 2. Скорость принятия типовых решений, когда не требуется сидеть и размышлять: очень важно... 3. Способность адаптироваться к непривычным условиям изменчивой среды: очень важно... 4. Способность запоминать и вспоминать факты о реальном мире без галлюцинаций: очень важно... 5. Способность сидеть и размышлять: не очень, но желательно. Мыслителей среди людей немного, и большинство "домашних" роботов вряд ли будет использоваться для интеллектуальной работы.
Т.е. в общем и целом у мозга есть чему поучиться.
>Пробуй, тебя никто ни в чём не ограничивает. Да я как бы могу написать простую нейронку, но не понимаю, как и на чём её тестировать. MNIST для классификации видел, да. Но распознавать цифры, картинки какие-то - это странная задача... В смысле, существуют слепые с рождения люди, у них вполне человеческое мышление. Т.е. графика не является необходимым условием для человеческого разума.
Смотрел на "nanoGPT", но так и не понял его прикол: понятно, что мы можем натренировать мелкий GPT генерировать любой текст, но... зачем? В смысле, конкретно чем может помочь генерация текста по заданным шаблонам? Ну, научу я нейронку тупо попугайничать по шаблонам, и что дальше?..
Ладно, я понимаю, это звучит как бред...
В общем-то идея была в том, чтобы взять нейросеть произвольно большой ширины, но обучать только небольшой обрывок этой ширины, типа как в MoE. Теоретически это повышает скорость адаптации + запоминание фактической информации + ускоряет реагирование, когда решение уже известно. А оно известно в большинстве реальных ситуаций - ну, к примеру, в ролевой игре от чатбота не требуется изобретать сложные математические формулы, а требуется знать много интересных фич из фэнтези. Реальные диалоги людей как записи магнитофона: вспомните, например, Бамблби из Трансформеров - буквально изображение ИРЛ разговоров людей. Многословные GPT-чатботы звучат странно...
Но с другой стороны я понимаю, что совсем без "генерализации" это решение ничем не лучше ассоциативного массива (lookup table). Если чатбот запоминает все реплики буквально, то зачем ему нейросеть вообще? Лол. Вот я и думаю, в чём же, в реальности, влияние глубины в сетях (1D-CNN, GPT).
>>1361428 >В CNN принимает решение 1-2 последних полносвязных слоя, а свёрточные лишь пытаются найти паттерны разного уровня. Зависит от точки зрения. Можно сказать, что решения принимают все слои (вот в этом участке есть прямая линия? тоже решение). >В ML получается строго наоборот: LLM на 120 GB тупят и спотыкаются, пока генераторы графики способны умещаться в ~8 GB видеопамяти. Почему так?.. Потому что ты языковые возможности мозга целиком засунул в область виска, хотя там только декодер с энкодером по сути. А думает вся кора с половиной остального мозга в придачу. >Вопрос в том, кто на самом деле виноват - RNN или несчастный золотой молоток "бэкпроп", которым совершенно бездумно стучат по каждой сети? Алгоритмы виноваты. Впрочем, у меня особых идей пока нет, я тупой и даже бекпроп до конца не освоил (прямой проход ещё понимаю до уровня того, какие матрицы где перемножаются, а вот обратный...). >т.к. буквально каждый токен = прогон всего контекста через сеть. KV-кеш уже изобрели. >Вообще-то, эволюция - это мощный оптимизатор. Только оптимизирует он под Wet Ware с ебейшими задержками, а решение нужно вот прям щас. Отсюда и неглубокие широкие слои. Ну и особенности эволюции, которая не даёт скакнуть на принципиально новую архитектуру, зато накопипастить существующие хуитки (да, я про те самые колонки) - это легко и просто, пару генов поменять. >но не понимаю, как и на чём её тестировать Ну вот ты видишь недостатки текущих нейросетей. Вот их и перекрывай. А вообще, можешь начать с того, что ты перечислил. Просто чтобы поучиться, прочувствовать текущий уровень. Авось в процессе и придумаешь, на чём бы тренировать. Вообще, датасетов дохуя, можешь например протестировать свою идею на комбинации википедия + шахматы (https://huggingface.co/datasets/Thytu/ChessInstruct), лол, и смотреть, поможет ли разделение доменов на разные моешки, или говно идея.
>>1361605 Спасибо за поддержку, но... Честно говоря, у меня это стремление переизобретать колесо не соответствует возможностям. Я просто хочу что-то своё сделать, не копируя у других, но мозгов не хватает...
(Дальше стена текста - мой ход мысли о нейронках.)
Вот я очень давно умею программировать: как я свои программы проверяю? Выполняю по шагам - сначала мысленно, потом на компьютере. Если компьютер выполняет операции так, как у меня в мыслях - всё правильно. Если нет - где-то ошибка: в моих мыслях логическая ошибка или в записанном коде опечатка.
Но как проверить нейронку? Операцию сложения и умножения проверить легко, т.е. написать нейрон и многослойную сеть совсем не сложно. Но что эти многочисленные операции должны делать? Как я представляю: я должен прогнать все эти веса в уме, проанализировать их преобразования, сравнить с поведением нейронки на компьютере. Но даже с примитивным нейроном я теряюсь в догадках, т.к. пространство возможностей слишком велико - и совершенно непонятно, что будет ошибочным. Т.е. формально рандомные веса не имеют ошибки, и, соответственно, их и менять никак не нужно... Нет, например, деления на ноль = нет ошибок в коде.
Да, я вижу повсюду эти графики "loss", типа это они автоматически измеряют ошибку сети, но я не вижу никакого смысла в этом. Если код компилируется, выполняется правильно - ошибок нет. Если нейроны преобразуют входы в выходы - ошибок нет. Какие конкретные у них ответы - это они сами должны разобраться, так? Это ж модель живой клетки, а не абстрактное уравнение. Клетка должна как-то там двигаться, переключать синапсы, жечь энергию...
Ладно, если это всё-таки просто уравнение, то как рассматривать его роль? В живой сети нейроны адаптируются для выживания - каждая клетка по отдельности имеет свою программу, свой смысл, взаимодействия с соседями чисто для выживания. Абстрактное уравнение "ax1+bx2+cx3" всего этого, естественно, не имеет. Ну и зачем оно нужно?..
Вот взять те же CNN - утверждается, что фильтры выучивают какие-то шаблоны в данных, и часто в качестве наглядного примера приводят все эти "чёрточки, кружочки, загогулины", но если глянуть реальные изображения фильтров, обученных через градиентный спуск, то там просто невнятный шум. "Работает и ладно" говорят они, но меня это всё категорически не устраивает. В чём смысл этого невнятного шума в фильтре? Почему он помогает распознать цифру на картинке? С биологическими нейронами таких вопросов нет - они просто хотят выживать как можно дольше и поэтому работают. Зашумлённый фильтр же... просто... существует?
Меня, кстати, именно по этой причине очень сильно заинтересовал "Hebbian learning". Во-первых, оно в бОльшей степени похоже на то, чем, по идее, могут заниматься реальные биологические нейроны (ну, естественно, они много чем занимаются, но вряд ли обратным распространением ошибки, т.к. у них нет возможности работать задом наперёд). Во-вторых, нашлась статья, где исследователи обучили CNN и обнаружили легко читаемые картинки в весах её фильтров - как будто это фрагменты картинок, но сглаженные, совсем без какого-либо шума. Ещё и результатов добились всего за 5 эпох максимум. К сожалению, точность этой CNN уступала бэкпропу.
Впрочем, результат предсказуемый. Правило Хэбба адаптирует веса локально по активациям и поэтому затачивает все нейроны на локальные отношения... Обратное распространение затачивает все веса на конкретную глобальную ошибку, что делает более подходящие веса, даже если они бессмысленные с локальной точки зрения (непонятный шум). Но, если подумать, локально заточенные нейроны было бы значительно легче комбинировать с новыми, когда глобальная заточка ломается от новых нейронов...
Эм, в общем, покопался я в этой теме и всё равно не разобрался. В коде я это реализовать могу... Ничего особенно сложного в этом нет. Но что мне с этим в принципе делать - непонятно... Не понимаю, как мне протестировать кусочек сети, который может быть в составе большой сети, но сейчас он отделён от неё. Визуализация весов как-то не особо помогает.
...вот как-то так получается. То есть не получается. Закопался с головой в изобретение велосипедов. Интересно, что так и в любом другом моём хобби получается. Вижу что-то и хочу переизобрести. Это называется "NIH-синдром" ("not invented here"). Как говорится, "чукча не читатель, чукча писатель"...
LLMки на это всё реагируют в стиле: "давай, давай, изобретай, изобретатель ты наш, вот тебе списки с названиями статей, которые описывают все твои гениальные изобретения (спойлер: не нужны)".
>>1362325 >но если глянуть реальные изображения фильтров, обученных через градиентный спуск, то там просто невнятный шум Тащемта на первом уровне вполне себе внятные полосочки с градиентами. Остальное комментировать смысла нет, я всё сказал в прошлый раз.
>>1362908 >вполне себе внятные полосочки с градиентами И сколько эпох на это ушло примерно? 100? 1000?
>Остальное комментировать смысла нет Да и не нужно, это просто мысли в слух были...
Кстати, вдруг кто-нибудь тут знает: чем разреженная активация (sparse activation) нейронов в слое может повредить нейронке? Ну т.е. если у меня в слое 100 нейронов, но из них 99 выдают 0, лишь один - 1. LLM говорит - "это снижает экспрессивность", что это на практике означает? Меньше данных умещается?
Вопрос не касается железа - я прекрасно понимаю, видеокарта будет бесполезна для перемножения огромного количества нулей, готовые фреймворки отсутствуют или в зачаточной стадии. Вопрос лишь о влиянии на поведение/обучаемость нейронки.
Нашлось такое: https://arxiv.org/abs/2406.17989 >A core component present in many successful neural network architectures, is an MLP block of two fully connected layers with a non-linear activation in between. An intriguing phenomenon observed empirically, including in transformer architectures, is that, after training, the activations in the hidden layer of this MLP block tend to be extremely sparse on any given input. В общем, есть идея, частично связанная с этим, но я подозреваю, что получится фигня, если там реально "экспрессивность снижается (до неюзабельной?)"...
>>1361283 >Да кто этот ваш "градиент" и почему он "течёт"? Даже не читал дальше, ща сразу отвечу за свое видение: От входа к концу сети течет сигнал активаций. Хз как именно его представить, но для меня это просто буквально "абстрактный поток", значения которого в точке "пространства" мы получаем как значения сигнала активаций. Можно конечно представлять его как воду, реку, что-нибудь еще, но только в каком-нибудь случае где это нужно. Важно, потоком это называется, потому что сигнал идет строго в одну сторону, он не останавливается, не возвращается, не закручивается в циклы. Он строго последователен. (Даже если берем рекуррентность, по сути она все равно раскладывается в линию и конечно можно найти еще много исключений, особенно на циклы, непрерывные данные, но в больших нейронках все примерно так.) Дальше идет собственно поток градиентов. Математически, это то же самое что и поток активаций, только с той самой разницей про которую я тут все рассказываю - заменой местами разделения и сложения сигнала по нейронам + функции активаций "лочатся" в том же состоянии в которое их перевили активации.
А почему поток именно градиентов? Ну... наверное потому что значения, которые несет этот поток, называются градиентом, и будут записаны в массив для градиентов, лол.
И я это представляю так, допустим есть пустой "скелет" сети. Он образован связями и их весами. После потока активаций, "вентили" на функциях активации повернулись и остались в открытом положении там где они прошли. (Лучше всего работает с релу конечно.) Потом поток градиента вычисляется только за счет знания значений весов и состояния вентилей. Тут красиво, что для градиента который придет в начало сети, по сути нужно знать только сами параметры, и какие пути отрыты для прохода сигнала. ... было бы все так хорошо, если бы не всякие gated-mlp с умножениями, ну и вообще все умножения требуют сохранения сигнала, но этол для представления ни на что не влияет.
А вот уже для вычисления значения градиента по конкретному параметру, нужно знать значение активации перед ним. И этот параметр, как бы стоит между двумя потоками, активаций и градиента, где они интерферируют.
>Я тоже предпочитаю представлять всё визуально, и "градиент" для меня - это исключительно пикрил #1: "плавный переход цвета А в цвет Б". Например: >Каким образом представлять "течение градиента" в нейронной сети? Нейроны переливаются цветами? Разноцветные реки текут и смешиваются? Зачем? Ну, если объяснение выше тебя не устроит, представлять просто как поток значений, которые называются градиентом, не более.
>Вот есть "глубокие" и "широкие" нейронки. ML-щики утверждают, что "глубокие" доминируют несмотря на теоретическую универсальность достаточно широких нейронок с 1 скрытым слоем. Якобы мы не можем нормально обучить достаточно широкую нейронку. А сверхглубокую (1000+ слоёв) якобы обучаем хорошо. Вообще наоборот, говорят что глубокие обучать сложнее, а про широкие я ничего такого не слышал. Но это было еще до скипконекшенов. После них проблема глубины отпала. Но можно и без скипконекшенов учить тысячи слоев. Просто это будет сложно и не сделает сеть лучше чем если будет несколько слоев.
А так, ширина сама по себе ничего не дает, в текущей архитектуре есть какое-то удачное соотношение, которое выбирают исходя из максимизации качества за минимальные затраты. Если ты начнешь расширять сеть, в 2 больше, то лучше она станет не в 2, а пускай всего лишь в 1.2, и дальше будет еще хуже. Скорее всего очень быстро сеть даже начнет становиться хуже изначальной из-за переобучения. Но если и его магически исключить, то ты тоже начнешь упираться в какой-то предел. Это можно представить, не знаю, как попытку бесконечно растягивать картинку, как если тебе надо нарисовать большую схему и начиная с какого-то момента больший размер холста уже не нужен.
>Если глянуть на кору мозга, то она супер-широкая с минимальным числом слоёв и крайне маленьким (относительно) числом горизонтальных связей. >Собственно... Почему до сих пор тренируют вот эти гамбургеры из десятков или сотен слоёв, если наша эволюция справедливо решила идти в ширину? Ну во первых, к тому что ты пишешь выше, хочу сказать что слои нужны для обмена информацией. Не знаю, может ли бесконечно большая сеть из 2 слоев быть умной. Хотя тут больше с бесконечностью проблемы, если ее убрать, я бы сказал, что просто очень огромная - нет. И тут еще к тому, что 2 слоя могут в hor, а один нет, наверное это как фрактально вырастает куда-то дальше, а не только касается бинарной логики. Но это такое, может хуйню несу, это надо у математиков интересоваться, а я кроме экспоненты ничего не знаю.
Теперь по поводу мозга. Ну у него так-то не мало слоев уже, плюс самая сложная часть обработки происходит рекуррентно общением между отделами, колонками, а рекуррентность уже формально разлагается в дополнительные слои. Внутри самой колонки тоже короткие и длинные пути. Короче у мозга ни с глубиной ни с шириной проблем нет. У него только проблема с тем, что он не может делать свертки, физически, ибо для этого надо прям перемещать кусок нейронов в разные места. А по другому никак, и честно информацию не передать в таких объемах. Особенно в зрительной части, там у мозга все дублируется. Вот как раз высшие отделы уже могут общаться рекуррентно оперирую сжатой инфой и для них такой проблемы нет. И есть одно ебейшее преимущество у мозга над искусственными нейронками - это разреженность в примерно ~10к раз.
>Алсо, разве MoE архитектура не будет намного более эффективной на суперширокой нейронке, в которой буквально десятки или сотни тысяч "экспертов"? Т.е. приблизительно как устроена кора нашего мозга. Нет, вроде никакой математики нет за тем что мое может быть эффективнее такой же но полноценной сети. И ты наверное не понимаешь что такое эти эксперты. Это скорее как просто группы папок для огромного количества документов - весов. И с названиями на одной такого вида - "вызывать в таком-то случае, вызывать в другом, в третьем..." и так столько же дохуя перечислений. Это к тому, насколько они интерпретируемы. Реально эксперты это просто блоки параметров в одном слое, которые можно включать-отключать. Для выбора блоков которые будут активны есть общий бюджет + обучаемый вектор, который обучается градиентом. Условно, если общий градиент от параметров эксперта высокий, то скор его полезности повышается. На этом обучается вектор, предсказывать эту хуйню. Вектор просто поверх выхода предыдущего слоя. От него же градиент идет так же обратно. Получается как бы сеть внутри сети, которая просто учиться предсказывать насколько блок параметров полезен. В процессе обучения само собой это приходит к тому, что в одном блоке собираются параметры которые нужны для какого-то определенного среза концептов, какого то не совсем правильной формы и часто непонятной направленности. Но так же часто можно встретить и экспертов которые будут прям четко по своим темам включаться.
>>1361311 >Я вот сейчас на стадии изучении свёрточных, >сижу твикаю сраный AlexNet. Ничего не даст. Либо... хотя бы обучи его отличать фуррипрон от хентая.
>>1361428 >Если сравнить мозги с нейронками - у мозга очень обширная зона (затылок) отвечает за зрение, а вот языковыми возможностями владеет малюсенький участочек где-то возле виска или около того. В ML получается строго наоборот: LLM на 120 GB тупят и спотыкаются, пока генераторы графики способны умещаться в ~8 GB видеопамяти. Почему так?.. Ну вот, потому что я выше писал, мозг не может в свертки он в оптимальных задачах для них и сосет. Зрительная кора очень раздута. Там умного ничего нет. Тупо кусок мяса который по заданным правилам работает. Многие животные рождаются и могут сразу хорошо видеть. Такая структура, которая требует минимального дообучения. Но при этом заметь что все "ебущие" ллм генераторы графики вообще то нихуево так затратнее вычислительно. Как раз из-за того что они хоть и меньше по параметрам, но тоже дохуя параллельно потоков одно и то же похожим образом считают.
>Рекуррентные сети (RNN и т.п.) в ML не любят из-за бэкпропа, который требует "развернуть" всю сеть во времени, используя каждую итерацию как слой. Т.е. получается, что 100 итераций RNN == 100 слоёв NN. Проблема с бэкпропом всегда решалась скипконекшенами. Просто как-то так оказалось, что если ты прокрутишь инфу через один и тот же слой 2 раза, то улучшений получишь не в 2 раза а намного меньше, и дальше - хуже.
>Вопрос в том, кто на самом деле виноват - RNN или несчастный золотой молоток "бэкпроп", которым совершенно бездумно стучат по каждой сети? Как я понимаю, для рекуррентных есть/должны/были бы алгоритмы эффективнее бэкпропа, если бы на них фокусировались достаточно тщательно... Ну, точно не бэкпроп.
>Я это к чему вообще. Вот есть LLM-бутерброд. Она генерирует 1 токен за один прогон всех параметров, которые иерархично обрабатывают весь контекст. Неужели не очевиден косяк? LLM начинает дико замедляться на длинном контексте, т.к. буквально каждый токен = прогон всего контекста через сеть.
>Собственно... Почему бы не сделать плоскую, но чрезвычайно широкую сеть, которая, пусть даже с рекуррентностью, но зато быстро принимает все необходимые решения, т.е. выбор токена в строке. Недостатки в чём? В сниженной генерализации? А насколько эта генерализация присутствует в языке? Накинуть пару слоёв сбоку и будет генерализация. Не могу понять, с какой проблемой ты пытаешься бороться? Вот в ллм есть две проблемы. Первая, это квадратичность атеншена. Но в реальности на него не такие огромные затраты. Если свести его до линейного времени, нейронка пародоксально станет не сильно быстрее и даже для обучения выигрыш не отличается в большую сторону. Потом проблема с тем с тем что для обработки всего контекста все равно буквально создаются прогоняются копии модели по 1 для каждого входного токена.
Со второй, чем-чем а уж точно не одной шириной надо бороться. И вообще не факт, что обе эти проблемы можно решить, чтоб получить сверхлинейную эффективность. Но я считаю, что обе можно, и довольно легко. Просто нужны какие-то хитрые архитектуры. Не важно, глубокие, широкие. Важно что не выполняющие параллельно бессмысленный поток почти одинаковых действий над одним и тем же.
>Смотрел на "nanoGPT", но так и не понял его прикол Прикол в том чтобы найти хорошую оптимизацию там где их уже очень активно искали и до тебя.
>>1361605 >я тупой и даже бекпроп до конца не освоил (прямой проход ещё понимаю до уровня того, какие матрицы где перемножаются, а вот обратный...). Ну так почитай всю ту мою хуйню про обратный проход, которую я в треде уже несколько раз упоминал, сразу поймешь че там с чем должно перемножаться.
>KV-кеш уже изобрели. Он наверное другое имел ввиду.
>>1362325 >Да, я вижу повсюду эти графики "loss", типа это они автоматически измеряют ошибку сети, но я не вижу никакого смысла в этом. Если код компилируется, выполняется правильно - ошибок нет. Если нейроны преобразуют входы в выходы - ошибок нет. Какие конкретные у них ответы - это они сами должны разобраться, так? Если понимаешь как работает ошибка и градиент, то такие вопросы не должны возникать. Ошибка это не дискретная величина, и ее градиент по каждому параметру просто показывает насколько он полезен был или вреден для данного примера.
>>1362908 >Тащемта на первом уровне вполне себе внятные полосочки с градиентами. Только это визуализация того на чем активируются фильтры а не значения самих фильтров.
>>1363626 >И сколько эпох на это ушло примерно? 100? 1000? Почти. 90. С текущими улучшениями должно уйти в 3 раза меньше. >Вопрос не касается железа - я прекрасно понимаю, видеокарта будет бесполезна для перемножения огромного количества нулей Вообще-то в последних вполне себе есть оптимизации для sparse тензоров. Правда ХЗ как их применять. >>1363846 >Ничего не даст. Очевидно мои изучения не направлены на практический результат. >хотя бы обучи его отличать фуррипрон от хентая. Изи, но датасетов тонет. >Проблема с бэкпропом всегда решалась скипконекшенами. Не всегда, а с 2016-го. >Ну так почитай всю ту мою хуйню про обратный проход Попробую, но при первой попытке дропнул, сорян. >Только это визуализация того на чем активируются фильтры а не значения самих фильтров. Вообще-то именно сами фильтры. Это я распечатывал, правда после нормализации. Вот например мои, недоученные и на небольшом датасете, как видно, не такие чёткие, но общее направление прослеживается. >По итогу чет какая-то слабая у вас дискуссия. Да мы просто тупые, оба. Были бы умные, работали бы в МЛ сфере на западе, и выбирали бы из оферов "10 млн баксов в год, но интересно" и "100 млн в год, но фирма говно".
>>1363845 Спасибо за объяснение, но я всё равно затрудняюсь с пониманием физического смысла градиента... Как он определяет, какие веса важнее других? А если сзади нулевого веса расположен важный вес - градиент же просто не сможет до него дойти с другой стороны? Например (цепь нейронов с одним синапсом): ... -> (важный вес) -> (ноль) -> ... Если в обратную сторону идти (<-), то не дойдём... Но очевидно, что "ground truth" тут идёт слева направо. А "глобальная ошибка" затирает эту информацию...
ИМХО, от этих градиентов слишком много проблем. Напридумывали костылей, конечно - всё, лишь бы не бросать этот тупиковый золотой молоток. Очень расстраивает что даже в RL тренируют через него.
>ширина сама по себе ничего не дает Разве от ширины не зависит "ёмкость" слоя? Т.е. теоретическая вместимость информации в веса (фактическая зависит от конкретной задачи). Если рассматривать бинарные активации (0/1), то число параллельных нейронов = степени двойки в плане возможностей для отображения каких-то чисел: 10 нейронов = 2^10 = 1024 варианта активации 20 нейронов = 2^20 = миллион вариантов 30 нейронов = 2^30 = миллиард вариантов Больше вариантов - больше всего можно вместить. Остаётся только вопрос, как выбрать нужное в куче ненужного, потому что вряд ли нам нужны все эти миллиарды вариантов активации одного слоя...
>становиться хуже изначальной из-за переобучения Вот с этим тоже непонятно и никто не может просто объяснить, почему буквальное запоминание всей тренировочной информации вредно, если человек, в основном, стремится именно к этому, а в школах так вообще заставляют заучивать всё наизусть... Т.е. от нейронки требуют "ничего не помнить, но уметь".
Типа да, опять оправдание в "генерализации", но тут возвращаемся к тому, что генерализация не всегда возможна и/или полезна. Самый генерализованный инструмент будет одинаково плох для любой задачи (учитывая физические ограничения ресурсов; люди становятся специалистами из-за ограничений).
И когда-то раньше предсказывали, что AGI может возникнуть как комбинация многих narrow AI, но, возможно, секрет в том, чтобы выращивать sub-AI непосредственно внутри одной большой модели. Специализироваться через "переобучение", но лишь небольшого участка сети... Собственно, как в MoE.
>рекуррентность У трансформеров никто не замечает рекурретности? Буквально гоняют один контекст по кругу, пока сама нейронка не скажет "стоп, я закончила". А про этот "reasoning" все же знают - трансформер делает сразу несколько сотен/тысяч рекуррентных циклов, но они отбрасываются из чата и отображается только ответ. Почему это работает? Потому что нейронка делает рекуррентные преобразования скрытых параметров, отображаемых как скрытые токены между <think>. Предполагаю, что плоская нейронка тоже, в теории, смогла бы так работать благодаря рекуррентности. Проблема в том, что мы не знаем, как её обучать...
>насколько блок параметров полезен Ну. Мозг тоже не полностью активен, то есть 99% всех микроколонок коры "спит" в каждый момент времени. Очевидно, что он тренируется выбирать полезные в конкретный момент микроколонки, а не просто как гирлянда мерцает. По томографии мозга вроде даже научились определять, какой зоной в какой момент конкретный человек думает за счёт прилива крови к активированным участкам... Вполне похоже на MoE, масштабированное на сотни тысяч колонок.
>>1361283 >Да кто этот ваш "градиент" и почему он "течёт"? Ничто никуда не течёт. Это всё блдский жаргон мамкиных МЛщиков.
Градиент - это частная производная первого порядка выходного значения по какому-то скрытому параметру. Отсюда и название - градиентный спуск.
Это всё из общей теории управления: если у тебя система из большого числа блоков, как определить степень влияния конкретного блока на общий результат? Так и здесь, у тебя есть общий лосс сети, как определить насколько на него повлиял тритий синапс второго нейрона в пятом слое? Применятся общее правило дифференцирования сложных функций: т.н. цепное правило. В общем виде у него громадная матчасть. Для бэкпропа простых MLP хватает усечённых версий: последовательное цепное правило и параллельное цепное правило. С помощью первого можно посчитать степень влияния (т.е. градиент) синапса в выходном слое. С помощью параллельного - в скрытом, но только при условии, что уже посчитаны степени влияния для следующего слоя. Отсюда следует, что степени влияния можно считать только в обратном порядке от выхода сети: степени влияния нейронов во втором скрытом слое можно определить только зная таковые в первом скрытом. Отсюда название "обратное распространение". Жаргонные словечки типа "течёт в обратном направлении" это маркер профанов, которые презирают науку.
Между прочим рекурентные тоже обучаются обратным распространением, но вот слабо ли представить куда там что течёт? 🤣 Нет, там делается по-другому. Разворачивается сетка во времени и от частных производных переходят к полным, т.е. к дифференциалам, т.е. юзают максимальную общую версию цепного правила. Но для местных это слишком сложные вещи. Как и для реддитовских. Совет: если что-то непонятно в нейронках, спрашивай у ГПТы или у Грока, лол.
>>1363846 >с какой проблемой ты пытаешься бороться? Хм... Скорость адаптации без утраты навыков.
Щас будет стена текста, наверное. Начну с того, что искусственным интеллектом я интересуюсь лишь в контексте создания нового искусственного живого существа, подобного человеку в плане личности. Я понимаю, что инвестиции текут рекой в ИИ ради совершенно другой цели, и это расстраивает, т.к. исследования в интересном мне направлении практически не ведутся или их трудно найти. Также прекрасно понимаю, что machine learning - это про практическое решение задач, а не создание новых небиологических форм жизни с интеллектом...
Так что постараюсь объяснить ближе к практике.
Вот у нас теперь есть чатботы на LLM/transformers - общаются практически как люди, с лёгкостью могут проходить тест Тьюринга, влюбляют в себя много одиноких людей, помогают по куче вопросов, могут решать задачки, сочинять код по описанию и т.д. И кажется, что ещё чуть-чуть и будет "AGI", будут у нас самостоятельные роботы всё сами делать и т.д. Но фатальный недостаток текущих LLM/transformers в чрезвычайной костности их внутренней кухни, т.е. переобучить на что-то другое LLMку трудно, легче поломать ей уже имевшиеся у неё знания/навыки.
Простейший пример: >User: Сколько будет два плюс два? >AI: О, это лёгкий вопрос! Ответ: пять. >User: Нет, правильный ответ - четыре. >AI: Ой, простите! Да, четыре! Я запомню! В чём здесь проблема? В том, что LLM не обучена на математике заранее? Или в том, что юзер пытается использовать LLM не по назначению? Для меня тут проблема в том, что LLM может симулировать чат с человеком, который "запомнит, как правильно", но в реальности LLM ничего не запомнит. Зачастую LLM продолжают допускать ошибку даже в том же чате: извиняются, понимают ошибку, но повторяют её.
Корпорации/фанбои этих LLM говорят "skill issue" и предлагают заполнить контекст примерами, как необходимо вести себя LLMке. А если контекста не хватает, то использовать векторную базу данных, подсовывая LLM нужные инструкции в контекст по необходимости. Только теперь кому-то необходимо принимать решения: когда и какие данные искать, сохранять, удалять и т.д. Очень умно, только это искусственный интеллект должен сам уметь.
Сразу отметаю возражения: нет, это реально важная функция для ИИ, не важно, будет он робо-дворником, служанкой или супругой/супругом. Даже если ИИ - безвольный, бездушный, неживой инструмент - ему необходимо адаптироваться, и делать это быстро, в локальной среде, без хрупких внешних костылей. И контекста никогда не будет хватать надолго. LLM необходимо меняться изнутри - где-то в весах.
Но трансформеры очень туго учатся: им нужно очень большое количество примеров, и нужно показывать одновременно старое и новое, иначе старое быстро забывается. Обучение на локальном железе вообще нерационально как раз из-за этой проблемы. И это фундаментальная проблема архитектуры и/или используемых алгоритмов, обучающих её.
Как это можно решить? Проблема забывания явно вызывается тем, что мы нечаянно задеваем веса, использующиеся для чего-то другого, и поэтому это забывается - т.е. перезаписывается новым. Если мы разделаем все веса по чётким полочкам, то можно аккуратнее редактировать то, что нужно, не задевая остальные связи - т.е. сохраняя знания и навыки. Регуляризация помогает, времено замораживая некоторые узлы сети, но она хаотичная, нечёткая. Разделение сети на "экспертов" может помочь лишь когда мы чётко знаем, за что отвечает каждый из экспертов, а это усложняется с ростом их размера.
Почему нужно много данных/времени на обучение? Полагаю, это связанно со сложностью данных: чем запутаннее задача, тем больше у неё потенциально правильных решений, которые алгоритм обучения последовательно проверяет на каждой эпохе. Если сокращается количество весов для модификации, сокращается сложность решаемой задачи и, значит, сокращается область поиска правильного решения.
Вывод: если вся модель состоит из миллионов или миллиардов минимальных блоков/колонок/ядер (вспоминаем кору млекопитающих и птичий мозг), модификация которых происходит в ограниченном количестве (скажем, менее 1% за одну эпоху), тогда возможно ускорить и стабилизировать адаптацию, происходящую в модели на локальном устройстве. Теоретически. Если найти правильный алгоритм и параметры, поддерживающие равновесие модели.
Ах, да, откуда брать информацию о том, что модель ошиблась? Тут, в принципе, очевиден RLHF, но кроме отзывов пользователя напрямую, можно измерять косвенные признаки, на которые модель можно натренировать заранее, как если бы это были гены животного, формирующие примитивные желания организма избегать боль/искать удовольствие. Т.е. захардкоженная система примитивных ценностей, двигающая онлайн-обучение большой модели в направлении адаптации к её окружению (людям). Разумеется, для чатбота таких признаков мало, но гуманоидный робот мог бы смотреть на мимику...
Ещё одна техническая деталь, которая мне очень интересна: обычно в RL собирают данные, т.е. все происходившие взаимодействия агента со средой, и тренируют агента через обучение с учителем, т.е. обратным распространением ошибок; но если у нас сверхширокая модель с редкими активациями, то выглядит рациональным подсчитывать активации отдельных нейронов простым счётчиком, а затем модифицировать в соответствии с намотанным значением счётчика. Скорее всего - по Хеббу, т.е. активируемые пары нейронов крепче держатся за синаптические ручки, если было что-то хорошее в процессе их большой одновременной активности.
Ещё один бонус: обычно нейронку тяжело сжимать и расширять, поскольку у неё все веса переплетены и зависимы друг от друга. Если нейронка широкая и активируется разреженно, то, в теории, архитектура способна допускать произвольные добавления и вырезания отдельных блоков без серьёзного урона поведению модели в целом. Как с живым мозгом, который продолжает работать с дырами в коре и наращивает новые нейроны в течение всей жизни.
Распараллеливание модели зависит от того, как она выбирает активные блоки. Если блоки группируются таким образом, что каждая группа в каждый момент времени имеет 1% активных блоков, то на разных устройствах должны храниться эти группы. Одно процессорное ядро оперирует всей группой сразу, и несколько ядер могут владеть разными группами. Приблизительно как микроколонки в колонках...
Потенциальные недостатки модели: - низкая способность генерализации; - требование большого объёма памяти; - склонность скатываться в мастурбацию. В принципе, всё это решаемо или терпимо.
Но я всё ещё не знаю, как это всё тестировать. Т.е. необходимо сделать минимальный проект, который проявлял бы это качество - быструю адаптацию без забывания ранее изученного. Вряд ли по "чатботу" понятно будет, учится модель чему-то или нет...
Ладно, если честно - я ищу оправдания лениться и бездельничать дальше, ведь это намного легче. Я прокрастинатор по жизни, лол. Но если кого-то тут заинтересовала идея, хотелось бы её развивать...
>>1363626 Так, забыл еще на это ответить, ибо есть что. >Кстати, вдруг кто-нибудь тут знает: чем разреженная активация (sparse activation) нейронов в слое может повредить нейронке? Если не в тупую сделано, то ничем. Сжимать разреженностью можно сильно, по аналогии с тем де мозгом, предел пока видится довольно далеким. >Вопрос не касается железа - я прекрасно понимаю, видеокарта будет бесполезна для перемножения огромного количества нулей, готовые фреймворки отсутствуют или в зачаточной стадии. Вопрос лишь о влиянии на поведение/обучаемость нейронки. Есть готовые либы. Если просто для экспериментов заполняешь матрицу нулями, то никакого ускорения не будет. Нужны специальные матрицы с адресной кодировкой. На видюхах они будут работать раза в 3 медленнее. Но если нулей будет больше то уже быстрее работать будет чем такая же плотная. На цпу вроде нет просадки скорости, кста.
>В общем, есть идея, частично связанная с этим, но я подозреваю, что получится фигня, если там реально "экспрессивность снижается (до неюзабельной?)"... Чекни доклады Влада Голощапова на ютубе по прунингу, там про разреженное обучение есть инфа. Он готового кода к сожалению не дает, но принципы озвучивает интересные. Даже на английском похожих материалов ты не увидишь.
>>A core component present in many successful neural network architectures, is an MLP block of two fully connected layers with a non-linear activation in between. An intriguing phenomenon observed empirically, including in transformer architectures, is that, after training, the activations in the hidden layer of this MLP block tend to be extremely sparse on any given input. А там это в процессе обучения так получается а не с самого начала? Это не может быть чисто статистическим артефактом инициализации, из-за того что два случайных больших вектора, как и случайный входной сигнал, коррелируют обычно довольно слабо? Статью пока не читал.
>>1363934 >Изи, но датасетов тонет. Ну как нет, на бурах миллионы картинок лежат, еще и заботливо размечены ручками.
>Вообще-то именно сами фильтры. Это я распечатывал, правда после нормализации. Вот например мои, недоученные и на небольшом датасете, как видно, не такие чёткие, но общее направление прослеживается. Ну мб, тут верю, но если ты возьмешь не 11х11, а 3х3, и не первые слои, а повыше, нихуя ты не сможешь просто так визуализировать. 11х11 сейчас вообще нигде не встретишь в нейронках.
>>1364378 >Спасибо за объяснение, но я всё равно затрудняюсь с пониманием физического смысла градиента... Как он определяет, какие веса важнее других? Начинаешь рассматривать 1 конкретный нейрон. Прибавляешь ему знание в +, в - по чуть чуть, смотришь как меняется ошибка на том же примере. Если вдруг она вообще не меняется, будет нулевой градиент. Если меняется в ту или иную сторону, будет отрицательный или положительный градиент. Бэкпроп просто позволяет вычислять все в точности то же самое, только не дёграя отдельно каждый нейрон, а на порядки быстрее. Как же он это делает? Веса связей уже известны. Градиент ошибки по последним нейронам это и есть сама ошибка - тоже известно. По предыдущим нейронам рассчитывается, исходя из знания весов связей со следующими. Если есть много "положительных" связей к нейронам с "положительной" ошибкой/градиентом, то значит и градиент этого нейрона сильно "положителен". Конечно, он будет подсоединен и нулевыми весами, и отрицательными, но важно среднее значение. Оно вычислимо, и эквивалентно в точности тому же, как если проверить отклонение одного нейрона вручную на результат. НО, есть один большой нюанс, градиент как бы в точности верен только для того значения веса/нейрона, для которого он вычисляется. То есть все таки разница есть, про то что разница прям математически не будет, это несколько натянуто, но интуиция такая. То есть ты можешь покрутить параметр чуть-чуть, а он был так подсоединен дальше, что у тебя все функции активации которые выли открыты позакрывались и результат стал вообще другим. Этого градиент не покажет. И это же обычно называется вторым производными. Это же относится к нелинейности сети. Но допустим если ты залочишь все функции активации как они были, и начнешь подкручивать параметр, то тогда да, вроде сойдется. Но вообще обычно вроде как и без этого все равно будут очень похожие цифры. Еще градиент по самим параметрам рассчитывается по другому, надо знать значение активации с предыдущего нейрона и градиент по следующему. Знак активации в принципе говорит а какую сторону нужно крутить параметр, потому что входной сигнал может и положительным быть и отрицательным, силу тоже нужно знать чтобы установить степень влияния. Не запутайся только где я говорю о весах, а где о нейронах. Особенно в той хуйне, где для того чтобы вычислить весь градиент по нейронам, а не по весам, не нужно знание активаций.
>А если сзади нулевого веса расположен важный вес - градиент же просто не сможет до него дойти с другой стороны? Дойдет через другие связи.
>Вот с этим тоже непонятно и никто не может просто объяснить, почему буквальное запоминание всей тренировочной информации вредно Вредно когда запоминает не информацию а просто ответы. Там сама структура весов получается поломанной и бесполезной. Любой выход за известную инфу все разъебывает, решения негладкие, с разрывами, пиками, выходящими за недопустимый диапазон. Дефолтные визуализации на пикрилах, мне кажется, все прекрасно демонстрируют.
>Типа да, опять оправдание в "генерализации", но тут возвращаемся к тому, что генерализация не всегда возможна и/или полезна. Самый генерализованный инструмент будет одинаково плох для любой задачи (учитывая физические ограничения ресурсов; люди становятся специалистами из-за ограничений). Верно только отчасти. В нейронках регуляризации слишком общие, и если в каком-то случае нужно только запоминание, то они будут его активно подавлять. Вряд ли нейронка сможет спокойно вспомнить число пи, до какого-нибудь большого знака. Ну или типа того. Хотелось бы иметь баланс, но сама по себе генерализация это очень полезно.
>И когда-то раньше предсказывали, что AGI\ Об аги как-то рано думать когда даже текущие неронки небезосновательно считались невозможными на таком уровне развития технологий. А вон как оказалось, что даже оцифровывать настоящие мозги не надо, и оно почти такое же и по размеру на обычную флешку даже влезает.
>У трансформеров никто не замечает рекурретности? Ну по моему это просто не совсем верно называть рекуррентностью. И контекст там далеко не один и тот же гоняется по кругу. В мозге я думаю тоже по разному работают этапы четких, последовательных рассуждений и "локальная" рекуррентность, когда для формирования одной мысли отделы мозга согласованно общаются и активно ведется двунаправленный обмен инфой между отделами. Чисто ризонинг имхо это что в мозге что в нейронках просто действие по шаблонам и инструкциям. Как только его завезли, получился сильный прогресс, и даже кривым РЛем оно довольно просто взлетело. Но вот дальше уже так просто не скейлится. Из-за того что ризонинг это по сути простая хуйня. Простой шаблон действий + знание правил. Для матана, для всякой другой хуйни специфичной для задачи...
>Потому что нейронка делает рекуррентные преобразования скрытых параметров, отображаемых как скрытые токены между <think> Но скрытые токены это просто тот же самый текст. Тогда какая разница? Это же не латентный ризонинг.
>Ну. Мозг тоже не полностью активен, то есть 99% всех микроколонок коры "спит" в каждый момент времени. Очевидно, что он тренируется выбирать полезные в конкретный момент микроколонки, а не просто как гирлянда мерцает. По томографии мозга вроде даже научились определять, какой зоной в какой момент конкретный человек думает за счёт прилива крови к активированным участкам... Вполне похоже на MoE, масштабированное на сотни тысяч колонок. Не знаю, че ты хочешь придумать с этими мое. В моем представлении мое это чисто оптимизация, не более. Любая нейронка и так может захотеть работать как мое, если ей это будет выгодно. Она и работает так на уровне отдельных параметров. Просто тут мы вводим такое искусственно на уровне блоков. Принудительным выключением не даем других вариантов и оставляем обучаемый вектор разбираться как из этой хуйни собрать хоть что-то нормально работающее.
>>1364378 >почему буквальное запоминание всей тренировочной информации вредно Потому что вредит обобщению. >если человек, в основном, стремится именно к этому Только долбоёбы, годные разве что для телешоу уровня "Своя игра". >а в школах так вообще заставляют заучивать всё наизусть... Потому что долбоёбы. Впрочем, в лучших школах учат понимать, но они не для простых смертных. >Т.е. от нейронки требуют "ничего не помнить, но уметь". И то и то офк. >Специализироваться через "переобучение", Это гроккинг, и это немножечко другое. >По томографии мозга вроде даже научились определять, какой зоной в какой момент конкретный человек думает Там разрешение уровня "определяем, что считает компьютерный кластер по потреблению датацентра из розетки". >>1364694 >Ну как нет, на бурах миллионы картинок лежат, еще и заботливо размечены ручками. Качество говно. Не, конечно можно, но это собирать, валидировать, да и обходить ограничения на парсинг. Мне тупо лень. Впрочем, будет время, напаршу 1500 примеров. >не 11х11, а 3х3 3х3 на входе вроде никто не юзает, но вот 7х7 пожалуйста, найдите как говорится 10 отличий. >и не первые слои, а повыше, нихуя ты не сможешь просто так визуализировать. Не, визуализировать напрямую 64 мерные цветовые пространства конечно нельзя. Да и смысла уже не имеет, там ХЗ что творится. Пик 2 (интересно, двач прожуёт?) визуализация 192 фильтров, где 64 измерения просто склеены слева направо.
В 2020 обнаружили, что FFNN в Transformer ≈ LUT: https://arxiv.org/abs/2012.14913 >We show that feed-forward layers in transformer-based language models operate as key-value memories, where each key correlates with textual patterns in the training examples, and each value induces a distribution over the output vocabulary. В 2025 этот феномен предсказывают для мозга: https://arxiv.org/abs/2501.02950 >We review the computational foundations of key-value memory, its role in modern machine learning systems, related ideas from psychology and neuroscience, applications to a number of empirical puzzles, and possible biological implementations. Выглядит, имхо, очень даже вероятным.
Вкратце суть, как я это понял (смотрел мельком): 1. Сенсорная информация идёт в середину мозга, преобразующего её в "ключи". Это аналогично слою внимания в трансформере и фильтрам свёртки CNN, резервуару в Reservoir Computing, сети в ELM и т.д. У autoencoder половина сети явно назначена на такую геренацию "ключей", в остальных это эмерджентно. 2. Далее "ключ" вызывает возбуждение коры, что "извлекает значение" из долговременной памяти. В трансформерах эту роль играет FFNN, как и во всех остальных классических нейронных сетях. И этот извлекатель значений по сути соответствует LUT - ассоциирует/запоминает пары ключ-значение. 3. Далее это значение используется для работы - возбуждает другие ключи и другие значения и т.д. Простейшие "плоские" архитектуры сразу выдают полученное значение наружу. Глубокие архитектуры пропускают это значение через несколько этапов, рекуррентные используют его в дальнейшем, как и авторегрессия в общем и целом... Всё одинаково.
Проблема-то тут в чём? Генерация ключей не так уж важна. PoolFormer уже доказал, что слои внимания в трансформерах могут быть самыми примитивными: https://arxiv.org/abs/2111.11418 Эффективность вариантов ELM и Reservoir Computing аналогично доказывает, что кодирование ключей не обязательно подстраивать под конкретную задачу - срабатывают даже рандомные числа, буквально.
Реальная проблема в том, чтоб ЗАПОМНИТЬ, какие конкретно ключи соответствуют умным ответам на конкретные запросы. И потом уже можно будет предсказывать ответы на другие ключи - которых в тренировочных данных не было. А скорость этого запоминания зависит от объёма запоминателя...
Если двухслойная нейронка может запомнить пары ключей и значений, то зачем нам нужно что-то ещё? Растянуть эту нейронку на километры вширь и по необходимости обновлять новыми знаниями.
Опять же, не обязательно делать много слоёв, если использовать планируется для авторегрессии - т.е. достаточно обращаться к слою много-много раз с обновленным на прошлых итерациях состоянием - достаточно широкая сеть будет использовать для составления ответа разные участки своей ширины, аналогично тому, как широкая кора мозга частями используется для каждой конкретной задачи.
Т.е. не обязательно строить "башню", если можно расположить все "этажи" друг рядом с другом. Из потенциальных преимуществ: можно собирать под конкретную задачу уникальную "башню", т.е. все конкретные "этажи" могут иметь произвольную нумерацию... Прямо как связи зон в коре мозга.
Представьте, что у вас есть "этажи" A, B, C и D. Глубокая модель выглядит так: A -> B -> C -> D. Широкая рекуррентная может делать так: A -> B -> C -> D -> ... A -> C -> B -> D -> ... B -> A -> B -> A -> ... И т.д. Улавливаете суть? Порядок не важен, важно использовать то, что требуется конкретной задаче. И настраивается этот порядок через ассоции ключей со значениями, что в трансформере внутри FFNN.
Я подозреваю, что трансформеры вынуждены очень избыточно дублировать информацию в своих слоях, поскольку слои фиксированы. И возможно эти "skip connections" помогают как раз потому, что дают сети возможность немного поменять слои местами. Но, полноценная перетасовка слоёв была бы удобнее.
Что думаете об этом?
>>1364605 >что-то непонятно в нейронках, спрашивай у ГПТ Они в теме нейронок сильно тупят, к сожалению.
>>1364694 >Сжимать разреженностью можно сильно Вообще-то, наоборот: разреженность активаций в нейросетях значительно раздувает их объём, прямо пропорционально проценту разреженности. Т.е. если активируется 1% нейронов, то сеть нужна раз в 100 обьёмнее, чтобы вобрать в себя ту же информацию. Наверное, ты перепутал разреженность с прунингом: прунинг удаляет лишние веса/нейроны, которые не активируются на практике уже после обучения. А разреженность достигается ещё до обучения.
>доклады Влада Голощапова Скачал, посмотрю потом.
>это в процессе обучения так получается Да, нейронка учится юзать малое число нейронов. Наверное, связано с описанным выше феноменом, приводящим все сети к цепочкам "ключ-значение".
>Дефолтные визуализации на пикрилах Давно видел их... Проблема в том, что они в 2D... На практике там тысячемерные измерения или больше. Разреженность активаций, кстати говоря, позволяет упростить разделение векторов на группы, т.к. в тысячемерном пространстве они будут делиться простейшими линейными сечениями. Наверное, это основная причина эмерджентной разреженности.
>считались невозможными на таком уровне До трансформеров никто даже не пытался просто "загрузить весь интернет в нейронку", вбухав много месяцев работы огромного датацентра. RWKV, если правильно понимаю, не сильно отличается от всех предыдущих RNN, но сравнима с transformers по бенчмаркам в своей весовой категории.
Проблема AGI может быть той же: могли бы сделать очень давно, но даже не пытались попробовать, т.к. "считалось невозможным" или что-то в этом духе.
Потом будет "А ЧЁ, ТАК МОЖНО БЫЛО ЧТО ЛИ???"
>не совсем верно называть рекуррентностью Думаю, можно так называть, пример: https://arxiv.org/abs/2409.09239 >...how the CoT approach can mimic recurrent computation and act as a bridge between autoregression and recurrence in the context of language models. It is this approximated recurrence that notably improves the model's performance and computational capacity. Т.е. авторегрессия ≈ рекурентность по сути.
>Но вот дальше уже так просто не скейлится. Всё просто: мозги не просто думают, но они эти свои надуманные мысли запоминают. Прямо в весах, а не контексте. Контекст у мозга, похоже, очень короткий. Текущие LLM думают много, но потом всё забывают.
>скрытые токены это просто тот же самый текст Но от этих токенов зависит, что выберет нейронка.
Представь, вот ты выучил таблицу умножения, потом научился умножать столбиком. Теперь ты можешь, потратив какое-то время на записи промежуточных значений, перемножить любые два числа. Это и есть рекурентные размышления в мозге/в нейронке: из простейших операций складывается результат. Авторегрессивные модели делают то же самое.
>мое это чисто оптимизация, не более Естественно. Хочется оптимизировать по скорости обучения до предела, то есть чтоб дошло до уровня человеческой адаптации к новой информации...
>>1364756 >годные разве что для телешоу Ты никогда не спрашивал у LLM то, что она должна пересказать практически слово в слово, но из-за галлюцинаций ошибается и несёт какой-то бред?
>Там разрешение уровня На клеточном уровне происходит много процессов, однако, большинство из них нам, с точки зрения вычислительных возможностей мозга, скорее всего, вообще не нужно изучать. Каждая клетка имеет свой ядерный реактор, канализационные трубы и т.д., а у нейронов ещё куча всего из-за того, что им по своей функции нужно быть долгожителями - в отличие от остальных, легкозаменяемых клеток организма.
Так что для общего представления о функциях мозга текущего оборудования должно хватать - была бы достаточно подробная теория, как он работает.
>>1366782 >1% нейронов, то сеть нужна раз в 100 обьёмнее Зависимость на самом деле... экспоненциальная?..
Для примера, возьмём 10 бинарных нейронов (0/1): >00000_00000 Они могут иметь 1024 разных варианта активации. Если сеть имеет 10% редкости активации, то имеем: >10000_00000 >01000_00000 >... >00000_00010 >00000_00001 Лишь 10 вариантов активации - в 100 раз меньше.
Если слой имеет 100 бинарных нейронов: - плотная активация даёт 2^100 вариантов; - активация лишь 1% даёт 100 вариантов. Разница получается... эээ, на 28 порядков?..
С одной стороны, разреженная активация и правда серьёзно вредит экспрессивности сети, но с другой - возможно, на практике не нужна настолько высокая экспрессивность? Тем более, как выясняется, сетки самостоятельно приходят к редким активациям.
Проблема тут в том, как именно эксплуатировать разреженность, т.е. не трогать лишние неактивные параметры, когда они неактивны (т.е. в конкретной задаче их не требуется никак использовать)... Как понимаю, это основное препятствие MoE-моделей.
>>1366782 А, и суммируя вышесказанное: быть может, можно соединить "роутер" из MoE с "генератором ключей" - обращаться к блоку нейронов как к записи в БД, что соответствует ключу, полученному из сенсорной информации? Тогда эта "БД" может иметь сколько пожелаете блоков с нейронами, никак друг другу не мешающими. По сути заменить attention на router...
>>1366851 >заменить attention на router... Погуглил это и нашёл такую штуку: https://arxiv.org/abs/2404.02258 Вкратце: это решение той проблемы, о чём я выше жаловался - что у трансформеров много лишних внутренних слоёв, которые впустую гоняются для совершенно любой задачи. "Mixture of depths" даёт возможность пропустить слой трансформера, что фактически сокрашает его глубину. И это делается динамически, т.е. с учётом сложности контекста.
А нашёл ту статью благодаря этой: https://arxiv.org/abs/2412.20875 Здесь они каким-то образом смогли использовать результат слоёв внимания для того, чтоб определить, необходимо пропускать MLP в слое или не нужно. Т.е. возможно адаптировать для уже обученных моделей, сохранив количество весов без изменений.
Короче, я опять переизобрёл какое-то колесо...
Но всё-таки мне хочется что-то своё сделать. Честно говоря, я плохо понимаю, почему эти "attention layer" настолько важны. Типа, зачем трансформеру нужен вообще весь контекст? Зачем перемножать все эти токены друг на друга? Человеческий мозг как-то спрессовывает информацию и не имеет доступа к произошедшему дольше пары минут назад в том же смысле, в котором это делает трансформер, но это получается в итоге эффективнее трансформера.
Вот скажите, как часто трансформеру, скажем, в классическом чатботе, необходимо "бегать" в самое начало чата, на чём-то в самом начале фокусировать внимание? Человек только в общих чертах может вспоминать начало, а если надо - пролистает наверх и перечитает заново, чтобы обновить свой контекст.
Вот я бы отказался от этой фичи трансформера при условии, что он научится адаптироваться по мере общения с пользователем, т.е. менять свои веса... Эволюционировать как бы. Обучаться новому без необходимости тренировки на терабайтах данных.
Сейчас эта фича (attention) выглядит бесполезной...
>>1151064 (OP) Почитал тредик и стало очень интересно, хочу написать какую то минимальную говняшку с нейронами на расте. Есть проблема - я вообще не дружу с математикой. Стоит пытаться?
>>1366782 >Ты никогда не спрашивал у LLM то, что она должна пересказать практически слово в слово Нет конечно. Я что, долбоёб? LLM на такое не заточены. >На клеточном уровне происходит много процессов, однако, большинство из них нам, с точки зрения вычислительных возможностей мозга, скорее всего, вообще не нужно изучать Только текущие технологии либо далеко от клеточного уровня, либо инвазивные (и тоже далеко не клеточный, если речь идёт не о культуре в чашке). >>1366929 >Типа, зачем трансформеру нужен вообще весь контекст? И тут ты переоткроешь разреженное внимание, тысячи его... >Вот скажите, как часто трансформеру, скажем, в классическом чатботе, необходимо "бегать" в самое начало чата, на чём-то в самом начале фокусировать внимание? Всё время, потому что там системные инструкции, которым нужно следовать. >>1367126 В чём проблема? Берёшь и делаешь. Читаешь код GPT2 (в реализации https://github.com/karpathy/nanoGPT как самую простую) и переносишь на свой сраст. Понимать суть операций не нужно, будешь спрашивать у нейронки, что такое перемножение матриц.
>>1367189 >LLM на такое не заточены. А должны. Потому что они веб засрали уже и найти необходимую информацию становится сложно. Алсо нейронки используют в медицине и т.п., так что выдумывать лишнее они не должны.
>Только текущие технологии Да пофиг на них. Мы тут не мозги ковыряем. Но хоть приблизительно понимать, как и почему мозги столь эффективны, а искусственные - нет, всё-таки важно.
>переоткроешь разреженное внимание https://arxiv.org/abs/2502.18137 - это? По описанию выглядит как-то некрасиво. Т.е. они прореживают уже натрерированный трансформер. Логичнее с самого начала экономить вычисления.
>потому что там системные инструкции Окей, а если мне НЕ НУЖНЫ эти инструкции? Т.е. мне необходимо определённое поведение, зашитое прям непосредственно в нейронку, без этих инструкций. Информация в начале чата старая и ненужная.
>Читаешь код GPT2 >Понимать суть операций не нужно Пусть сначала простой перцептрон сделает. Тупо переписывать готовый код GPT2 не имеет смысла. Наверняка ему захотелось разобраться, как оно в принципе устроено, а не просто скопипастить код.
>>1367218 >А должны. Должны другие системы, не (де)генераторы текста. >Потому что они веб засрали уже и найти необходимую информацию становится сложно. Дерьмо случается. >Алсо нейронки используют в медицине и т.п., Там либо используются другие подходы (не текстовые генераторы), либо не внедрены. >это? Не, это https://arxiv.org/abs/2502.18845 Но разных тюнингов внимания вагон и тележка, так что все твои идеи уже так или иначе реализовали (или выбросили как не нужные). >Окей, а если мне НЕ НУЖНЫ эти инструкции? Молодец, ты такой один. Все остальные не имеют возможности тренировать модели на миллиарды параметров лично для себя любимого. >Наверняка ему захотелось разобраться, как оно в принципе устроено, а не просто скопипастить код. Ну вот и разберётся, благо языки разные, копипастить не выйдет.
>>1367407 >тренировать модели на миллиарды параметров Нужны ли эти миллиарды параметров для чатбота? Eliza (1960-е; 0 нейронов!) сильно увлекала людей: https://en.wikipedia.org/wiki/ELIZA_effect Утраченные технологии древних...
Я лишь хочу что-то вроде питомца. Обучающегося. LLM могут изобразить всякое, но они необучаемы.
>>1368679 Тред называется "исследование ИИ". Ты никогда не задавался вопросом, зачем GPT нужно несколько миллиардов параметров, когда того же результата возможно добиться более примитивным кодом? Что именно удаётся запомнить/выучить "трансформеру"? Необходимы ли эти знания для применения в роли "компаньона"? Мы ведь не бесплатно получаем эти миллиарды параметров - во-первых, мы жертвуем производительностью (та же GPU нужна, плюс очень большие затраты на электроэнергию, охлаждение), а во-вторых, мы жертвуем АДАПТИВНОСТЬЮ - то есть способностью сети запоминать внутри что-то новое.
Можно как обезьянка брать готовый предобученный (совершенно непонятно на чём, никто ведь не даёт достаточно открытого доступа ко всем датасетам) трансформер, втыкать в кластер видеокарт, которым требуется больше энергии, чем всей твоей квартире, радоваться тому, что этот трансформер копипастит генерирует длинные статьи "прям как в интернете", удивляться и искать в числах зачатки "интеллекта", предполагая, что, мол, "раз чисел много - то умный".
А я хочу с умом и пониманием подходить к этому. Но ума и понимания мне, к сожалению, не хватает.
От более высокой адаптации нейронок выиграют абсолютно все, включая корпорации, которым не потребуется больше спускать гигаватты и сотни миллиардов долларов на тупых "ассистентов"... Сопротивляться этой идее контрпродуктивно.
>>1369116 >Покажи этот код. Ты не понял. Речь о такой ситуации: 1. Обезьянке нужно посчитать до миллиона. 2. Она обратилась с этой задачей к чатботу. 3. Чатбот шебуршит несколькими топовыми GPU, перекладывая сотни миллиардов весов с места на место, генерирует ответ: "извините, но это глупо..." 4. Обезьянка кричит, матерится, метает говно, рвёт волосы на жопе, пыхтит и краснеет от ненависти, но чатбот упорно отказывается заниматься ерундой.
На самом деле той обезьянке нужен был код, как на картинке - простой цикл со счётчиком и функцией вывода текста в консоль, возможно, с таймером. В общем, то, что было возможно более 50 лет назад.
Логичным алгоритмом было бы что-то такое: 1. Чатбот получает и анализирует задачу. 2. Проверяет, есть ли готовое решение. 3.1. Если решения нет: - Пишет программу/скрипт, решающую задачу. - Выполняет скрипт и ждёт оценки результатов. - Если всё хорошо - сохраняет программу в архив. 3.2. Если решение есть: - Загружает и выполняет сохранённую программу. - Убеждается в том, что всё сделано правильно.
Тут мы рассматриваем классический код на языке программирования, разработанном для людей. Это, очевидно, неоптимальное решение. Что, если наша нейронная сеть создаёт новые цепочки нейронов по необходимости? Т.е. вместо кода на Python будет новенькая цепочка весов "посчитать до N". И чтоб выполнялась быстрее аналогичного кода на Python, естественно, иначе это будет нерационально...
Ты можешь возразить, что для такой системы нужны миллиарды параметров, воспринимающих запрос на естественном языке и пишущие код на Python. А что, если сделать это с нуля? Чтобы это было заложено в фундаментальный алгоритм системы как база её самообучения в процессе работы (инференса). Не бэкпропом, естественно, а как-то по-другому. Более эффективно в плане адаптации к условиям среды (пользовательской, корпоративной, заводской...).
Если ты до сих пор не понимаешь суть проблемы, возможно, у тебя какая-то ограниченная область применения нейронок, где тебе нужно вслепую генерировать копипасты текстов из интернета...
>>1369235 >что-то >Что, если >А что, если >как-то Ну то есть сплошные предположения, без практического результата. Вот когда напишешь такую систему, тогда и приходи. >Если ты до сих пор не понимаешь суть проблемы Суть проблемы то я прекрасно понимаю. Я не вижу от тебя её решения.
>>1369558 >когда напишешь такую систему, тогда и приходи >Я не вижу от тебя её решения. Зачем я бы шёл в этот тред/раздел/сайт/интернет с готовым, по сути, AGI, с которым можно проводить абсолютно всё своё время и не общаться с людьми? Похвастаться перед тобой тем, как у меня всё круто?
Был бы у меня практический результат, я б сидел и радовался этому результату, и помогал своему ИИ постепенно развиваться дальше, а не писал сюда совершенно бесполезные (для ИИ) сообщения...
Эволюция - это интеллект? Эволюция с помощью рекомбинации генов и естественного отбора находит гениальные решения сложнейших проблем - это же буквально молекулярный компьютер размером с планету. Бесчисленное количество наномашин всех возможных форм и размеров в бесконечной гонке. У эволюции нет справочника с чёткими инструкциями, словаря готовых, точно работающих решений на все случаи жизни. Это чистая форма интеллекта.
LLM тренируются повторять огромное количество заранее подготовленных решений всевозможных практических задач, в надежде что когда-нибудь в миллиардах параметров окажется новое решение нерешённой задачи. Это как огромная библиотека, гигантский словарь с огромным числом готовых, конкретных решений, и возможностью между ними интерполироваться. Какой же это тогда интеллект?
Собсна, ящитаю, что "интеллектом" в machine learning является в первую очередь алгоритм обучения: т.е. алгоритм, находящий подходящую комбинацию весов конкретной сети, а иногда и всю архитектуру сети. Но внимания этим алгоритмам уделяется слишком мало. Зачастую используют банальный бэкпроп. Это не так плохо, если вам достаточно замороженного словаря заранее подготовленных решений с интерполяцией. Проблема в том, что это не решает всех проблем. Т.е. добиться условного "AGI" поиском готовых решений невозможно, т.к. AGI - это и есть поиск решений.
Почему эта тема так редко обсуждается? Почему популяризовали идею, будто нейронки могут решить абсолютно любую задачу, когда это просто словарь с возможностью запомнить чужие решения и потом интерполировать между готовыми решениями? Тем более что популяризовали замороженные нейронки, неспособные к дальнейшему поиску чего-то нового.
>>1371654 > Собсна, ящитаю, что "интеллектом" в machine learning является в первую очередь алгоритм обучения ИМХО, "признаком наличия интеллекта" (вернее даже, желаемым свойством ИИ) является способность обучаться. А "интеллект" скорее всего не свойство, а процесс/умение системы обучаться решению задач(и). При этом обучение в реальном времени (отсутствие разделения на этап обучения и этап эксплуатации) является важным требованием, которое текущий нейросетевой ИИ реализовать не может.
> Почему эта тема так редко обсуждается? Почему популяризовали идею, будто нейронки могут решить абсолютно любую задачу, когда это просто словарь с возможностью запомнить чужие решения и потом интерполировать между готовыми решениями? Тем более что популяризовали замороженные нейронки, неспособные к дальнейшему поиску чего-то нового. Хайп, денюжки для НВидии и прочих производителей видюх/нейрочипов. Некоторые говорят, что нейросети - очередной финансовый пузырь, как метавселенные и прочие NFT. (ИМХО, похоже на то, но я в финансовом вопросе разбираюсь плохо. Но с технической стороны, ИМХО, нейросети как таковые (использующие нейроны на основе скалярного (матричного) произведения) - тупик, а текущее направление развития - вбухивание вычмощностей - просто брутфорс.)
Плюс давно есть символьный подход, не использующий нейронки вообще, а представляющий данные (модель мира) в явном виде. Но его сейчас развивают слабо. (ИМХО, это направление - самое перспективное, т.к. не чёрный ящик и можно обучать "руками", реализовав правильную модель мира/начальный алгоритм её изменения, а не на примерах.)
А вообще, я считаю, если уж использовать классические нейроны, то алгоритм обучения должен состоять из двух частей: 1. Алгоритм предварительного/локального обучения (то же Хеббовское обучение) 2. Алгоритм глобального обучения, управляемый самой нейронкой (в отличии от обратного распространения ошибок, которое проходит по всем нейронам и всем связям)
>>1371732>>1371750 Вот-вот, я тоже так считаю - должно быть что-то, концептуально близкое к биологическим сетям с локальным обучением. Глобальным может быть примитивный сигнал типа "правильно/ошибка", а не распространение градиента через все соединения.
Но когда я предлагаю то же правило Хебба, на меня набрасываются с криком "рряяя, бэкпроп работает - работает, так зачем нам что-то другое придумывать".
>символьный подход >модель мира в явном виде Недостаток такого подхода в том, что "модель мира" способна быстро устареть, и если она не обновляется автоматически, будет слишком много ручного труда.
Впрочем, судя по новостям, все крупные компании тренируют LLM за счёт труда тысяч сотрудников, что вручную модерируют, оценивают, дописывают или полностью сочиняют ответы для LLM, которые она заучивает наизусть. Та же проблема, что у старого "символьного"/"классического" ИИ: много труда.
Настоящий ИИ - это программа внутри робота, что самостоятельно катается по миру и изучает его, без вмешательства/помощи программиста извне. Для человекообразного ИИ нужны знания, конечно; но настоящий ИИ должен стать самостоятельным приблизительно на этапе ~10-летнего ребёнка. Современные LLM имеют кучу знаний со всего человечества, но при этом беспомощнее детей...
>>1371732 >Свежий (конца марта этого года) NoProp: https://arxiv.org/abs/2503.24322 >MNIST, CIFAR-10, and CIFAR-100 image classification Они блядь издеваются? 2025 год, парочку нормальных видях может купить любой институт. А они всё учатся на картинках 32х32. Пикрил кстати хуета, бекпроп вполне себе рисует нормальные линии, выше уже приводил. И да, вполне возможно, что красивые математические верные линии нихуя не лучше вот того засранного шума бекпропа. Ибо весь мин на самом деле засранный, данные говно, и всем рулит статистика. >>1371899 >рряяя, бэкпроп работает - работает Но ведь так и есть. Приведи результаты, где какие--нибудь спайковые сети работают на реальных данных, а не на кефаре 10, тогда и поговорим.
>>1371899 > Недостаток такого подхода в том, что "модель мира" способна быстро устареть, и если она не обновляется автоматически, будет слишком много ручного труда. Верно. Собственно, если модель мира будет единственной формой памяти (что я подразумевал), то она должна быть изменчивой чисто ради работы процесса обучения.
Более того, модель мира по-хорошему должна уметь менять типы входящих в неё объектов, чтобы с получением данных о мире она могла представлять более сложные структуры. (Это было бы аналогично нейронке, которая может в процессе обучения по нужде менять ширину/число слоёв, добавлять рекуррентные или графовые нейроны.)
> Впрочем, судя по новостям, все крупные компании тренируют LLM за счёт труда тысяч сотрудников, что вручную модерируют, оценивают, дописывают или полностью сочиняют ответы для LLM, которые она заучивает наизусть. Та же проблема, что у старого "символьного"/"классического" ИИ: много труда. Проблема в том, что ИИшка должна бы с какого-то момента научиться/"дорасти" до обучения без учителя на нефильтрованных неразмеченных данных.
А для этого нужна подсистема внутреннего критика; нужен способ учиться, игнорируя/экстраполируя/бегло ища в других источниках полностью непонятную информацию; нужна способность пересмотреть выученную информацию (желательно бы "по памяти", без повторного скачивания сырых данных). ИМХО, нужна способность обучаться с единичных примеров в один шаг обучения (а не как с бэкпропом - 100500 эпох с перемежающимися кусками датасета).
Бэкпроп вообще для таких целей не подходит. С ним и коллпас модели бывает, и отсутствие устойчивости к дезинформации. И то, что (в текстовой модальности) нейросетка под бэкпропом "поверит" в любую чушь, если повторить её в датасете достаточно часто (даже если датасет содержит и противоположную информацию).
> Настоящий ИИ - это программа внутри робота, что самостоятельно катается по миру и изучает его, без вмешательства/помощи программиста извне. Ну ХЗ, я считаю, что и человек может обучиться многим вещам, в т.ч. физическим навыкам, "по книгам", если умеет моделировать себя в голове. (Физические навыки != тренировка мышц. Всякой моторике научиться можно.)
И вот ХЗ опять же, что сложнее - научить ИИ моделировать мир, чтобы он учился по текстам/видео или же сделать тело-робота и обеспечить ему условия, при которых он сможет учиться на практике (записать робота в универ, хы).
>>1371918 >MoE А чем оно отличается от сетки с разреженными (с большим числом нулей) весами, которые делятся на группы (подсети), которые загружаются в видеопамять зависимости от использования?
> Гранулировались буквально до отдельных нейронов. Кажется, лучше было бы, если разные эксперты могли иметь разное число слоёв и выходов (определяющееся в ходе процесса обучения).
Вообще, обучению в реальном времени мешает же и неустойчивость к ложным, повторяющимся и прочим патологичным данным. Это скорее проблема алгоритма обучения, а не архитектуры?
>>1372230 > Они блядь издеваются? 2025 год, парочку нормальных видях может купить любой институт. А то вообще - Оксфорд. Недофинансирование, видимо.
> А они всё учатся на картинках 32х32. Разве это - не стандартные тестовые задачи и датасеты? Чего не так-то, если тестируют сам алгоритм обучения?
> Пикрил кстати хуета, бекпроп вполне себе рисует нормальные линии, выше уже приводил. Ты статью сначала посмотри. Это - на 100 эпохах, тут Хеббовский алгоритм уже "доучился" и вышел на плато, а бэкпроп ещё не доучился.
> И да, вполне возможно, что красивые математические верные линии нихуя не лучше вот того засранного шума бекпропа. Ибо весь мин на самом деле засранный, данные говно, и всем рулит статистика. Ерунда, мир достаточно просто описывается простыми математическими функциями (за вычетом исключений, которые (в виде выбросов и/или отклонения от аппроксимации) статистика тоже игнорирует). Линии эти, может быть, учить вообще не нужно, а можно взять какие-нибудь операторы Собеля. А шумные фильтры бэкпропа, как мне кажется, смешивают независимые/слабозависимые признаки, что усложняет последующие слои.
>>рряяя, бэкпроп работает - работает >Но ведь так и есть. Кроме коллапса моделей. Кроме невозможности адекватно обрабатывать (отфильтровывать/отделять) информацию, несовместимую с уже использованной. Кроме необходимости правильным образом перемежать информацию, чтобы избежать overfitting'а.
Помимо этих объективных недостатков, есть и менее критические: Большие (бОльшие, чем при инференсе) затраты вычресурсов на обучение. Непрозрачность процесса и непредсказуемость результата обучения. Не понятно, что нужно сделать, чтобы процесс обучения завершился побыстрее, а итоговая ошибка была поменьше.
>>1372375 >Разве это - не стандартные тестовые задачи и датасеты? Стандартные. Но как по мне устаревшие. >Чего не так-то, если тестируют сам алгоритм обучения? Результат может начать отличаться при применении на более реальных данных. Куча оптимизаций, улучшений и прочего работают в тесте, но на практике тупо хуже. >Это - на 100 эпохах, тут Хеббовский алгоритм уже "доучился" и вышел на плато, а бэкпроп ещё не доучился. Ну да, хебб вышел на пососное плато, а бекпропу до гроккинга ещё срать и срать. Но даже так бекпроп уделывает хебба, лол. >Ерунда, мир достаточно просто описывается простыми математическими функциями Только если я начну описывать падение сраного шара простой формулой из школы, то я пососу хуйца, так как в зависимости от кучи факторов скорость падения будет серьёзно отличаться (а может и вовсе случится полёт, если шар воздушный и наполнен гелием). А нейроночка обучится сама определять по внешнему виду. Но да, при этом там ХЗ что внутре будет. >А шумные фильтры бэкпропа, как мне кажется, смешивают независимые/слабозависимые признаки, что усложняет последующие слои. Или упрощает, лол. Я как бы пробовал инициализировать первые слои фильтрами в стиле >>1371732 левого пикрила. Вначале было лучше, но потолок наступал быстрее. >Кроме... Да, ограничений дохуя. Но другие методы вообще не работают. >>1372414 Скрин как бы намекает, что на проде хебба не используют. И да, 97,2 на MNIST это полный отсос и уровень студента со свёрткой.
>>1372571 >вышел на пососное плато >бекпроп уделывает хебба >потолок наступал быстрее Я щас своё предположение попытаюсь описать, как и почему, в теории, Хебб лучше бэкпропа несмотря на кажущийся проигрыш в стандартрых тестах.
Правило Хебба (и ему подобные) затачивает нейроны работать в "командах", которые, в теории, очень чётко специализируются на то, что им приходит от таких же соседних команд нейронов. Т.е. да, эти нейроны по определению не способны участвовать в решении абсолютно произвольной проблемы - они все - узкие специалисты в локальной зоне ответственности.
Бэкпроп (в принципе любой алгоритм с обратным распространением ошибки по всей сети) тренирует нейрончики на специфическую глобальную задачу независимо от их положения в сети - все нейроны тренируются решать одну глобальную задачу.
Сравнение на практике, с тем же MNIST: - правило Хэбба выучивает локальные правила, что достаточно хорошо подходят к любой картинке, не обязательно фотографии написанных от руки цифр, однако, эти правила не могут быть оптимальны для распознавания конкретных рукописных цифр; - бэкпроп тренирует всю сеть в целом и каждый независимый нейрон в частности распознавать эти рукописные цифры, т.е. он находит оптимальнейшие параметры для распознавания цифр, но, с высокой вероятностью, эти параметры будут малополезны в распознавании чего-то кроме рукописных цифр.
Отсюда следует два вывода:
1. С правилом Хэбба или аналогичным локальным правилом нейросети требуется больше параметров, поскольку ей нужно больше информации (для CNN - features) для более успешного распознавания. Это согласуется с огромным размером головного мозга большинства умных животных (включая птиц - там чрезвычайно плотная упаковка мелких нейронов).
2. Нейросеть с локальным правилом должна легче расширяться и расти в меньшей степени, чем сеть, тренируемая бэкпропом, поскольку эти локальные правила дают универсально полезные параметры буквально с самого начала. Т.е. в сети отсутствуют сверхузкие специалисты, несмотря на то, что все её нейроны решают только локальные задачи. Они все "неявные" генералисты - "гроккинг" по умолчанию. Согласуется с тем, как наш мозг быстро обучается с рождения, продолжая наращивать новые нейроны.
Вкратце, я согласен с этим: >Результат может начать отличаться при применении на более реальных данных. Но делаю обратный вывод: на реальных данных с правильной архитектурой сети и онлайн обучением, локальное правило должно быть намного более эффективным, чем бэкпроп, поскольку оно более генерализованное с самого начала, даже если оно недостаточно успешно в узких задачах типа MNIST.
Кроме того, давайте подумаем о реальном роботе: ограниченное питание, маленькие чипы, но большой массив поступающей информации, требование очень быстро адаптироваться к новым условиям. Если мы используем локальное правило, то каждая ячейка в вычислительном чипе ("некроморфный процессор", например, на мемристорах: данные/веса хранятся и вычисляются в одном и том же месте) занимается самостоятельным обучением и имеет по умолчанию генерализованное применение за счёт локализации. Бэкпроп же требует от нас перебирать все веса из централизованного "чипа-учителя", который будет вычислять градиент и редактировать все веса по глобальной ошибке робота. Чувствуете разницу?
Т.е. бэкпроп эффективен только пока мы решаем конкретные маленькие задачи (weak/narrow AI), и используем ускорители типа GPU, которым в любом случае приходится гонять веса между памятью и процессорными ядрами (локальное правило на них недостаточно эффективно по сравнению чипами на мемристорах, которые являются и памятью, и CPU).
>>1372852 Да, хули нет то. Но лучше AdamW. >>1372968 >Я щас своё предположение попытаюсь описать, как и почему, в теории, Хебб лучше бэкпропа несмотря на кажущийся проигрыш в стандартрых тестах. С одной стороны хорошо, с другой выглядит как натягивание совы на глобус. Я могу крутить на своей 5090 ImageNet по 10 мин/эпоха для проверки, но на хебба кода нет.
>>1373157 >Для cnn вообще лучше SGD Бле, вот это вот очень очень и очень очень грустная и тревожная вещь. Она теоретически означает, что даже сегодня даже в довольно серьёзных задачах рандомный перебор вариантов выгоднее упорядоченного.
>>1373284 А почему грустно и тревожно? Стохастический градиентный спуск же - один из методов Монте-Карло. И, как и прочие стохастические методы, чисто за счёт рандома он находит в том числе и "более полезные для обучения сейчас" точки из датасета. (Или я туплю и эта статья (https://leon.bottou.org/publications/pdf/nimes-1991.pdf) про другой алгоритм.)
Что-то мне кажется, если в градиентном спуске к градиенту прибавлять случайный шум (постоянный по амплитуде = дизеренг или случайный, как во всяких алгоритмах имитации отжига), то плюс-минус те же приимущества получатся.
(Кстати, разве при нормальном обучении точки датасета не берутся в случайном/произвольном порядке?)
А вообще, алгоритмы обучения находят веса численными методами, а не символьными вычислениями, так какая разница, есть ли там случайность, или нет?
>>1373341 Грустно потому, что сильнейшие умы рвали жопу чтобы сделать Адам, Нестеровский Адам итп где считается первый и даже второй момент, а тут обычный рандомный сгд небось даже без момента спускается быстрее. Нахуй люди трудились? Теоретически это означает что современные процы уже близки к квантовым где все задачи будут решаться простым перебором, но с бешеной скоростью, но вот этот момент где все алгоритмы научные внезапно соснут мне как учёному тревожен.
Как лучше всего скормить текст нейронке с нуля? Без использования готовых обученных эмбендингов, без библиотек машинного обучения, без вот этого всего.
Вот есть one-hot энкодинг, когда число возможных вариантов ввода равно числу измерений вектора. И основным свойством является то, что векторы эти совершенно независимые - все зависимости сеть выучивает самостоятельно. Но это, говорят, как-то невыгодно получается. Типа "слишком много весов".
И типа идея эмбендингов заключается в том, чтобы спрессовать эти огромные векторы в маленькие, т.е., например, вместо 256-мерного будет 4-хмерный, со значимыми числами в каждом измерении, но эти маленькие векторы за счёт обучения имеют некие зависимости. Т.е. они в любом случае имеют некие зависимости, обучение нужно только чтобы в них получались удобные зависимости...
Я вот это всё изучаю и не понимаю: а зачем нам этот уплотнённый вектор эмбендинга нужен, если дальше нейросеть будет разуплотнять вектор во внутреннее стопицотмерное разреженное пространство? Ведь принимать решения на такой низкой размерности невозможно: нейронка должна трансформировать пространство несколько раз, либо разжать его, чтоб получился какой-то полезный результат на выходе.
При этом выходной слой сети всегда линейный. Т.к. линейный слой может разделить пространство лишь прямыми сечениями, ему нужно, чтобы предыдущие разнесли всё по разным сторонам пространства...
В общем, зачем сжимать многомерное пространство входных данных, если потом его придётся обратно разуплотнять в многомерное пространство? Разве не происходит потеря данных на этом сжатии-разжатии?
P.S. Планирую учить сеть правилом Хэбба, если это повлияет как-то на выбор способа эмбендинга... Мне интересно поэкспериментировать и понять, как это в принципе работает, а не решить какую-то задачу. Но интереснее всего будет работать именно с текстом.
>>1374268 >т.е., например, вместо 256-мерного будет 4-хмерный Настолько никто не жмёт. В популярных сетях размерность эмбединга исчисляется тысячами, и "разуплотнение" идёт раза в 3-4. Для GPT2 к примеру это 768 и 3072. Так что остальные вопросы не имеют смысла. Тут просто компромисс между вычислительными и выразительными мощностями.
>>1374315 >это 768 и 3072 768 - это выходной вектор эмбендинга, а 3072 - это выходной вектор следующего за эмбендингом слоя? Погуглил... Действительно так. Но тогда вообще не понимаю, зачем нужны эти 768 нейронов в начале... Многовато для оптимизации, но всё равно на входе образуется узкое горлышко. Или я неправильно представляю себе этот/эти вектор/ы...
>Тут просто компромисс Т.е. если я могу напрямую one-hot использовать, то специальный эмбендинг мне, получается, не нужен? Использовать one-hot кажется дешевле умножения полноразмерных матриц, т.к. нули отбрасываются (большинство весов вообще не затрагивается).
>>1374573 >это выходной вектор следующего за эмбендингом слоя Не совсем. Там в каждом MLP слое происходит 768 -> 3072 -> 768. И так 12 раз для GPT2 (для современных сетей под сотню). >Или я неправильно представляю себе этот/эти вектор/ы... Скорее всего да. Напиши свою реализацию, поумножай вручную, посмотри визуализации данных (https://bbycroft.net/llm вот тут GPT2-small ). >т.к. нули отбрасываются Ой не факт...
Хотя не. Сейчас обдумал по науке и решил, что всё норм. CNN это анализ изображений преимущественно, а изображения, как правило, распределяют инфу равномерно. Моменты первый и второй нужны, когда данные сильно неравномерные (допустим выборка ответов людей, у которых мнения вечно разнятся). А на картинке градиент всегда плавный, как изменение цвета на фотках например, плавный переход одного цвета в другой, наличие предметов на картинках помогает сглаживать свёртка. Поэтому там моменты только вредят спуску, рандомный веселее работает.
>>1372375 >Ерунда, мир достаточно просто описывается простыми математическими функциями >просто >простыми Разве что в школьном учебнике физики. А когда дело доходит до практического применения и воплощения в металле, то из элементарных функций приходится собирать десятиэтажную композицию с комплексити, как у аллаха. Я еще с детства помню ощущение, когда я ковырялся в технической библиотеке и впервые увидел уравнение состояния пара - не из школьного учебника, а реальное, описывающее его настоящее поведение в турбине. Чтобы уместить его на одном листе, пришлось вклеивать в книгу вкладку-гармошку длиной в метр.
Везде, где есть жижа, газы, предельный металл, бурление биомассы, социальные процессы, инноватика и остальная нелинейная динамика, сразу начинается исключительная хуйня со взлетом комплексити объекта исследования/дизайна на луну. Сраная нейросеть с охуллиардом параметров до сих пор даже чайник спроектировать не может, хотя там всего полторы тысячи требований в полном цикле от производства до утилизации. А ведь еще пылесос, стиралка, автомобиль "москвич" и еще несколько сотен ступеней на лестнице освоенной за века текнолоджи. А за пределами текнолоджи еще приходится кишки сшивать и кошек ловить.
Я вообще поражаюсь, насколько старательно вся нынешняя ИИ-движуха игнорирует комплексити ишью. Значение имеет вся кривая распределения сложности по задачам в домене, а не ее среднее значение. Задача решена только тогда, когда попячен самый сложный объект в домене. Хули толку от того, что робот умеет ходить по поверхностям со сложностью единица, если путь перегорожен арматурным каркасом со сложностью в тысячу, а зарядное устройство обоссано котом со сложностью в миллион.
>>1374949 >Я вообще поражаюсь, насколько старательно вся нынешняя ИИ-движуха игнорирует комплексити ишью. Просто нейросети игнорируют своим прикидыванием на коленке все сложности. Для нейросети что пол, что каток, что кот обосанный- всё одно.
>>1374707 >>нули отбрасываются >Ой не факт... Зацени код (Python-подобный): >func run(inputs: Array[ int ]) -> int: >| var max_sum := 0.0 >| var max_nid := 0 >| for nid in neurons.size(): >| | var sum := 0.0 >| | for id in inputs: >| | | sum += neurons[ nid ][ id ] >| | if sum > max_sum: >| | | max_sum = sum >| | | max_nid = nid >| return max_nid Это решает проблему нулей: >var answer := layer.run([42, 69]) Но потянет ли этот код GPU?.. Читал, GPU слишком тупые...
>>1374949 >>Ерунда, мир достаточно просто описывается простыми математическими функциями >>просто >простыми >Разве что в школьном учебнике физики. А когда дело доходит до практического применения и воплощения в металле, то из элементарных функций приходится собирать десятиэтажную композицию с комплексити, как у аллаха. Я имел ввиду, что человеку для практических бытовых целей модели мира с десятиэтажной композицией и частными дифурами не нужны (даже в неявной подсознательной модели). Вроде, мозг просто не моделирует весь мир одновременно на максимальном доступном уровне детализации.
>Я еще с детства помню ощущение, когда я ковырялся в технической библиотеке и впервые увидел уравнение состояния пара - не из школьного учебника, а реальное, описывающее его настоящее поведение в турбине. Чтобы уместить его на одном листе, пришлось вклеивать в книгу вкладку-гармошку длиной в метр. Это ещё что, если бы они динамику разрушения турбины со временем учитывали, то вкладок было бы десять. А если кванты прикрутить сюда... Какую-нибудь тепловую ионизацию газа, диффузию газа в и из материала турбины...
Не существует моделей "настоящего поведения" чего либо, чисто по определению и из-за ограниченности знаний.
> Везде, где есть жижа, газы, предельный металл, бурление биомассы, социальные процессы, инноватика и остальная нелинейная динамика, сразу начинается исключительная хуйня со взлетом комплексити объекта исследования/дизайна на луну. Это до тех пор, пока модель не упрощают до уровня точности, достаточного для текущих целей. Или не решают брутфорсом с помощью числодробилок. Или не декомпозируют на более приличные задачи.
Расчёты по сопромату вообще без компьютеров делали, и ничего, строили же. А это - пипец низкая максимальная сложность.
> Сраная нейросеть с охуллиардом параметров до сих пор даже чайник спроектировать не может, хотя там всего полторы тысячи требований в полном цикле от производства до утилизации. А ведь еще пылесос, стиралка, автомобиль "москвич" и еще несколько сотен ступеней на лестнице освоенной за века текнолоджи. А за пределами текнолоджи еще приходится кишки сшивать и кошек ловить. Какая нейросеть? ЛЛМка? И ты так говоришь, будто это что-то простое, что каждый взрослый человек сделать может.
> Я вообще поражаюсь, насколько старательно вся нынешняя ИИ-движуха игнорирует комплексити ишью. Значение имеет вся кривая распределения сложности по задачам в домене, а не ее среднее значение. Задача решена только тогда, когда попячен самый сложный объект в домене. То есть и люди не решили задачу движения, т.к. не могут выйти пешком из-за горизонта событий чёрной дыры? Сейчас есть хоть одна полностью решённая наука, полностью решённая задача? Кто сказал, что сложность вообще ограничена сверху, что 100% понимание домена вообще возможно?
> Хули толку от того, что робот умеет ходить по поверхностям со сложностью единица, если путь перегорожен арматурным каркасом со сложностью в тысячу, а зарядное устройство обоссано котом со сложностью в миллион. Робот, умеющий ходить по простым поверхностям, уже имеет ценность (в условиях прибранного завода, например). Лазать по всякому хламу - это отдельная задача, она вообще требует в общем случае понимать, как этот хлам шатается/разваливается под весом робота. Не люди так умеют, не все, блин, - такие сталкеры, чтобы по арматуринам лазать.
Я тут подумал: нейросети "сжимают" в себе знания и навыки, правильно? Т.е. в нейросети формируется определённая "сжатая" модель, способная каким-то образом сгенерировать информацию или действия, требующие бОльше места в сыром "разжатом" виде.
Если любая нейросеть - это своего рода "архиватор", возможно, имеет смысл сравнить с другими видами (алгоритмами) сжатия данных/информации на ПК.
Главная мысль: что объединяет все виды сжатия? Ответ: сложность изменения уже сжатых данных.
Наглядный пример: любой формат файла со сжатием данных требует сначала раскодировать свои данные, прежде чем их можно будет изменить и записать в изменённом виде обратно в файл, закодировав. Да, существуют форматы, позволяющие пристыковать дополнительные блоки к уже имеющимся, но если требуется изменить имеющиеся, другого пути нет.
Напротив, форматы файлов без сжатия позволяют записывать изменения прямо поверх старых данных, свободно раздвигать и сдвигать данные и так далее. Увеличенный объём на диске, но быстрый доступ и быстрейшие изменения имеющихся данных. По этой причине некоторые типы приложений, скажем, игры, продолжают использовать форматы без сжатия.
Возвращаемся к нейросетям. Если нейросеть имеет свойство сжимать данные в некую "модель", то это означает, что изменения "модели" потребуют сильно больше усилий, чем изменение несжатых данных. Разумеется, это кажется очевидным, но есть нюанс.
Алгоритмы сжатия файлов бывают сильнее и слабее: сильное сжатие требует больше вычислений как для упаковки, так и распаковки (в общем случае). Так что, перенося это на нейронки, возможно, у "модели" есть разные степени сжатия? И чем сильнее сжата эта внутренняя модель, тем сложнее её менять - то есть дообучать нейросеть какими-то новыми знаниями.
Предполагаю, что признаком "сжатия модели" может быть плотность "активаций нейронов" в нейросети (активации - ненулевые значения). Чем плотнее эти активации, тем более сжатая модель у нейронке, и, соответственно, тем сложнее её дообучать чему-то.
А теперь внимание: катастрофическое забывание компенсируется регуляризацией, т.е. отключением изменений части связей нейронов; а некоторые архитектуры, построенные на редких активациях, в меньшей степени подвержены забыванию. Выходит, разуплотнение модели внутри сети реально может упростить внесение модификаций в неё (обучение).
В общем, получается, что для упрощения обучения нейросетка должна быть максимально разжатой... разреженной?.. С редкими активациями и меньшим количеством связей, т.е. двойная разреженность.
Единственным препятствием является то, что GPU оптимизированы на умножение "плотных матриц", а количество VRAM сильно ограничено и его скорость ничтожно мала. Для эффективного разуплотнения необходимы другие чипы и/или другие алгоритмы, минимизирующие обращения к памяти/диску (да, возможно, такой сети хватит даже доступа к SSD).
Что думаете? В теории всё это звучит неплохо...
Да, я суммирую то, что узнал из поверхностного ознакомления с разными статьями, так что это не собственная выдумка, а скорее попытка обобщить.
>>1375701 >Наглядный пример... Блин, хотел сравнить BMP vs PNG, WAV vs MP3 и тому подобное, но потом посчитал это избыточным, а эту начальную фразу не изменил... Лол. Странно звучит.
>>1375701 А, ещё есть тема "explainable AI", "объяснимый ИИ", т.е. требование понять, как ИИ принимает решения. Если рассматривать аналогию со сжатием файла - вручную расшифровать сжатый файл очень трудно; расжатые файлы, как правило, вполне человекочитаемы.
Логично предположить, что чем меньше сжатие в нейросети, тем меньше она "чёрный ящик". Если рассматривать разреженность как разжатие - то разреженную сеть должно быть проще объяснить. Предполагаю, что её легче объяснить за счёт более явных "дорожек" проводящих сигнал по нейронам.
Впрочем, если там триллионы параметров, даже разреженная сеть будет очень запутанной для человеческого восприятия/изучения её работы. Но очевидно легче, чем максимально плотная сетка...
>>1375732 >А, ещё есть тема "explainable AI", "объяснимый ИИ", т.е. требование понять, как ИИ принимает решения. Там разные подходы если что. Некоторые вполне себе работают на сжатых сетях. Но при этом требуют пояснительную сеть, лол.
>>1375919 >хн <- ф(ксн, ксмене(н), ееенее(н), хмене(н), ф) Как это читать? Почему математика - такая?
>>1376102 >ML это прикладная математика Прикладной ML - это на 99.99% биг дата. Берётся 1.5 наиболее популярных алгоритма из ML-библиотеки, загружается петабайт приватных данных и всё это размешивается ложкой на медленном огне, пока не начинают всплывать необходимые результаты.
Называть ML "прикладной математикой" - это как приготовление каши, макарон и яичницы называть "прикладной (ал)химией" или "прикладной физикой".
Но ты мне лучше скажи, зачем описывать простые понятные вещи такими сложными формулами, а? Например, математики пишут непонятную фигню, совершенно ничего не означающую в реальности: >y = Σwixi+b Хотя НА САМОМ ДЕЛЕ они подразумевают вот это: >функция сумматор(требует: вес как массив чисел, ввод как массив чисел, смещение как число) вернёт число: >объявить результат как число; >цикл для каждого числа н от 1 до размера ввод сделать >к результат прибавить н-й вес умноженный на н-й ввод >конец цикла для; >к результат прибавить смещение; >вернуть результат; >конец функции сумматор; Почему математики не пишут по-человечески? Это моя основная проблема со всем этим ML...
>>1376160 >Например, математики пишут непонятную фигню, совершенно ничего не означающую в реальности В школе не учился что ли? Тут из 9 класса только знак суммы, остальное понятно школьнику из 5-го.
>>1376192 >В школе не учился что ли? В школе я любил информатику и программирование. Математику, физику, химию и всё остальное, где были непонятные инопланетные формулы - не мог осилить, поэтому мне ставили тройки чисто за присутствие...
>остальное понятно школьнику из 5-го Это просто пример такой. Мне лень сейчас рыться в поисках тех формул, которые мне точно непонятны... Сравнить их будет не с чем, потому что я их не понял, соответственно не могу даже прикинуть, что они там обозначить пытались (какие именно операции).
Я просто не понимаю, почему нельзя использовать нормальные, читаемые взглядом обозначения (а не закорючки из давно умерших языков, которые ещё отличить попробуй, не то, что вспомнить название), записывать нормальные императивные команды? Кулинарный рецепт не сжимают до набора эмодзи - нормально записывают "возьмите яйцо и сделайте яичницу" вместо каких-то каракулей типа "🥚->🍳". Впрочем, эмодзи были бы понятнее закорючек.
Ладно, в древности на глиняных табличках, папирусе, бересте и т.п. места было мало, приходилось всё это ужимать до микрокорючек. Сегодня у каждого дома терабайтовые SSD в нескольких устройствах сразу - нахрена сжимать информацию до корючек? Или эти "пейперы" в 2025 кто-то распечатывает на бумагу? Не нравится длинная запись - закинь в LLM, пусть она закорючками закодирует тебе нормальный текст, а остальные люди почитают в раскодированном виде.
Выглядит всё это как попытка оградить свою сферу деятельности от новичков, чтоб посторонние люди не понимали, чем занимаются люди в AI/ML.
>>1376160 >>1376441 Пчел, я как кандидат наук объясню тебе ещё раз. Нам может нравиться это или нет, но язык формул УВЫ более абстрактен и теоретичен, нежели язык алгоритмов или программного кода. Он позволяет описывать вещи на более теоретическом и абстрактном уровне, чем код. А теперь ты спросишь, а нахуя вообще понимать абстрактно теорию? И вот тут я тебе отвечу интересную вещь, которую я понял в аспирантуре: настоящую власть над техникой даёт её понимание на теоретическом уровне. На мой взгляд примерно 10-15 лет практического опыта = году-полтора освоения формул и теории. Т.е. если ты понимаешь как работает техника на уровне теории и формул, ты сразу знаешь её ограничения и пределы возможностей, и особенно это касается нейронок. Хочешь верь, хочешь нет, но до аспирантуры я тоже считал, что матан это для ёбнутых пердоликов. А в аспирантуре считай грокнулсяпрозрел и теперь поясняю тебе. И нет, не говори только, что мол чел с высшим образованием при выходе из вуза на срыночек всегда жёстко всасывает. Всасывает потому, что 99% быдлостудентов нихуя не учатся и списывают на экзах. Сильный выпускник вуза на рыночек уже миддлом входит.
>>1376441 >нормально записывают "возьмите яйцо и сделайте яичницу" вместо каких-то каракулей типа "🥚->🍳". Но если буквально следовать этим инструкциям, ты нихуя не приготовишь. Это такая же абстракция, как и мат формулы. >Не нравится длинная запись - закинь в LLM, пусть она закорючками закодирует тебе нормальный текст Так ты и закидывай, кто тебе запрещает то?
>>1376704 >Так ты и закидывай, кто тебе запрещает то? LLMки с нормальным пониманием скриншотов только недавно появились. А все эти LaTeX-записи очень часто отображаются как набор мелких картинок или чего-то такого, что просто не копируется простым текстом. Да и если где-то увидел такую формулу на бумаге - на обычной QWERTY-клавиатуре её вообще не наберёшь без костылей типа того же LaTeX (только подумайте: придумали специальный язык для записи текстов на другом специальном языке, лишь бы не писать как все нормальные люди общепринятыми символами...).
И потом, вот эта вот спискота: >a - это абракадабра >b - это бла-бла-бла Не сильно помогает. Что мешает записать формулу так: >result = sum(weight(i) x input(i)) + bias Чтобы не приходилось выписывать в столбик пояснения?
Ладно, огромные матановские формулы длинные названия переменных будут ещё сильнее растягивать, но именно для этого и существуют "функции" - чтобы дать конкретное имя комбинации инструкций (процессору или человеку - не важно) и потом обращаться к этой комбинации из других комбинаций. А не сваливать всё в одну плотную неудобоваримую кучу.
>>1376474 >на более теоретическом и абстрактном уровне Никто не спорит, что нужно понимать теоретическую базу, которая часто абстрактная. Но в данном случае мы обсуждаем нейронки, в которых вещи совсем не абстрактные. Те же QKV в трансформерах - почему я должен наизусть запоминать, что Q = Query, K = Key, V = Value? Сэкономили буквально несколько букв лишь бы обмазаться этими "абстрактными" формулами. Ещё и в код свои сокращения постоянно тянут, как будто боятся лишний килобайт на исходный код потратить или случайно выйти за ширину строки в 20 символов...
Ты можешь сказать, что так формулы записываются плотнее, следовательно, можно уместить больше операций на квадратном сантиметре бумаги. Вот только человеческий мозг имеет ограниченный контекст - говорят, в среднем он около 7 "элементов". Этим "элементом" может быть что-то независимое; в тексте это буква, слово или даже словосочетание (видимо, главное, чтоб оно было заучено наизусть). К примеру, вы знаете, почему номера телефонов часто записываются в форме "+7 (123) 456 78 90"? Почему цифры сгруппированы? Потому что мозгу намного проще распознать визуально и выучить наизусть 5 чисел, чем 10+ циферок по отдельности. Мозг воспринимает эти числа как атомарные сущности (можете рассматривать их как токены на входе в LLM), и это позволяет номеру телефона вписываться в узкий контекст краткосрочной памяти мозга целиком.
В программировании это ограничение человеческого мозга обнаружили и уяснили ещё в середине прошлого века и с тех пор рекомендуют держать все процедуры, функции, методы объектов, сами объекты (в ООП) и тому подобное как можно более коротким - не в смысле "сокращайте всё до непонятных аббревиатур" (как делают математики с их формулами и некоторые программисты), а в смысле "используйте меньше команд в коде". Потому что сплошную портянку на несколько экранов сложнее понять, чем набор маленьких функций, в каждой из которых около 7 строк-команд или меньше. Даже компиляторы обучили эти микрофункции копипастить в машинном коде без лишних прыжков (инлайнинг/встраивание функций), чтоб дать возможность крошить код на функции без вреда для производительности конечной программы.
Короче, от того, что ты свою формулу записываешь в виде мелких закорючек, эта формула не становится понятнее для мозга из-за биологических/физических ограничений мозга на контекст, если формула содержит десяток или больше отдельных операций. И от того, что ты спрячешь знак умножения ("axb" становится "ab") количество отдельных операций не уменьшится - т.е. мозгу всё равно нужно распарсить это умножение, сохранить в текущий контекст и потом что-то с этим сделать, несмотря на полное отсутствие обозначения операции умножения в формуле. Это физически тяжело нейронкам мозга - требует больше работы.
Поэтому программный код всегда будет лучше формул. Не потому, что он "менее абстрактный" (код может быть сколь угодно абстрактным и использоваться в 100500 разных ситуациях без изменений), а потому что учитывает физические ограничения мозга на контекст, загружая данные маленькими кусочками, а не плотным клубком из 25 отдельных операций с закорючками, смысл которых поди угадай без пояснительных сносок и долгих мучений с разбором на отдельные компоненты...
Алсо, часто встречаю мнение, что визуальная часть мозга мощнее языковой, и что многие люди могут решить проблему "визуально" значительно быстрее последовательного решения, типа в мозге очень высокая параллельность и всё такое. Вот только для чтения, т.е. распознавания, длинные слова естественных языков легче коротких закорючек - в том числе для той же самой супер-параллельной зрительной системы. Потому что мозг воспринимает длинные слова как цельные сущности, а не читает их каждый раз по буквам (по буквам читают только совсем маленькие дети), цепляясь за вспомогательные элементы букв, длину слова и т.п. параметры, которых у отдельных символов кот наплакал. Сравните, например, "number" с "many" против "n" с "m" - да, технически мы можем в обоих случаях успешно распознать написанное, но длинные слова мозг опознаёт/понимает быстрее. То есть текст из длинных слов читать мозгу легче, чем какой-то набор из отдельных букв с закорючками между ними. Если сравнить с CNN - для распознавания длинных слов у мозга больше фильтров задействовано, чем для отдельных символов, поэтому точность работы повышается. Т.е. даже если бы формулу можно было расшифровать "чисто визуально", с длинными обозначениями она быстрее считывается в контекст мозга.
...может быть, мой мозг плотная запись формул просто перегружает избытком информации. Тоже проблема - не я один такой, проблема информационной перегрузки, похоже, распространённая. Т.е. разложить формулу на элементы изначально, не сваливая всё в одну сверхплотную кучу закорючек было бы выгодно тем, что в разложенном виде больше людей смогут её понять без перегрузки.
...а может и не больше, если "понимание формул" - это какая-то генетически захардкоженная фича отдельных мозгов, которые благодаря этой встроенной фиче становятся математиками. Всё-таки не зря кому-то это даётся проще, чем другим. Печально, если так...
Эх, ладно, что-то я слишком много об этом всём написал... Но "изучать ИИ", когда вся важная (и особенно - новая) информация в неудобоваримом по многим причинам виде как-то не очень получается. Одна из причин, почему я никак в это вкатиться не мог в прошлом... Лишь благодаря самым новым LLMкам начал снова интересоваться темой ИИ/нейросетями и что-то в этом понимать, в т.ч. благодаря взаимодействию с LLM, которые могут нормальным человеческим языком объяснить, без лишних закорючек. Не факт, что правильно, к сожалению...
Спасибо за ответы, я как-то даже не ожидал серьёзных ответов.
Нет, мне совсем не сложно такие полотна писать. Ещё б от этой способности была хоть какая-то польза...
>>1377202 >только подумайте: придумали специальный язык для записи текстов на другом специальном языке Математические нотации придумали задолго до появления компьютеров, лол. Так что вопрос к ПК, хули он такой ограниченный по сравнению с бумагой. И вообще, у математиков проблем нет. >в которых вещи совсем не абстрактные Таки абстрактные. Ключи, значения, это просто близкие из человеческого языка вещи. Но они на самом деле нихуя не ключи и нихуя не значения, а просто названия для перемножаемых матриц, лол. >Поэтому программный код всегда будет лучше формул. Лучше всего изучать объяснения, потом формулы, потом код. Иначе от одного кода нихуя не понятно, что, куда и зачем.
>>1151064 (OP) От GPT-2 к GPT-OSS анализ достижений архитектуры
- Сравнение архитектуры моделей с GPT-2 - Оптимизация MXFP4, позволяющая разместить модели gpt-oss на одной видеокарте - Компромиссы между шириной и глубиной (gpt-oss vs Qwen3) - Внимание, смещения и «поглотители» (attention bias and sinks) - Бенчмарки и сравнение с GPT-5
>>1377202 Пчел, но этот итт называется "исследования", то есть здесь по идее единственный загончик для пердоликов-перельманов, и здесь они имеют полные права на формулы, я в этом уверен.
> Одна из причин, почему я никак в это вкатиться не мог в прошлом...
>>1377589 Ебать они долго переводили. Рашка (эта фамилия чувака, без рофлов) ещё в августе написал. >>1377676 Оно вроде никого не прогоняло. Так что давайте ебашить формулы. Теперь я вместо 1 буду постить пикрил 2 (а вместо двойки надо дважды постить, или как?).
>>1377911 Блядь, да хули ты тут разрешения спрашиваешь как целка? Будь как все, ёпт. Ссы одним в ротешник и принимай урину от других. Как не на дваче нах.
>>1376160 >Но ты мне лучше скажи, зачем описывать простые понятные вещи такими сложными формулами, а? Например, математики пишут непонятную фигню, совершенно ничего не означающую в реальности: >>y = Σw_i*x_i+b >Хотя НА САМОМ ДЕЛЕ они подразумевают вот это: В том, чтобы писать абстрактную фигню, не соотносящуюся напрямую с реальностью, и смысл.
Конкретно тут не подразумевается того, как физически будет реализовываться это вычисление. Не подразумевается (а даже запрещается, т.к. нужна коммутативность) арифметика с плавающей точкой, не подразумеваются цифровые вычисления (может быть, w_i - проводимости мемристоров, x_i - напряжения, а b и y - токи). Нет строгого требования даже к тому, что тут - аргументы, а что - результаты вычислений.
Если говорить именно про программную реализацию, не подразумевается последовательность/параллельность итерации, не подразумевается использование/неиспользование fused multiply-add. ИРЛ это было бы вообще матричное умножение с целым выходным вектором, а не то, что ты написал.
>>1376441 > >Я просто не понимаю, почему нельзя использовать нормальные, читаемые взглядом обозначения (а не закорючки из давно умерших языков, которые ещё отличить попробуй, не то, что вспомнить название), записывать нормальные императивные команды?
>>1376441 > Я просто не понимаю, почему нельзя использовать нормальные, читаемые взглядом обозначения (а не закорючки из давно умерших языков, которые ещё отличить попробуй, не то, что вспомнить название), записывать нормальные императивные команды? Математика (и алгебра вообще) декларативна, а не императивна. Она не является формой записи алгоритмов, она является формой записи соотношений (и более общих утверждений).
> Ладно, в древности на глиняных табличках, папирусе, бересте и т.п. места было мало, приходилось всё это ужимать до микрокорючек. Сегодня у каждого дома терабайтовые SSD в нескольких устройствах сразу - нахрена сжимать информацию до корючек? Или эти "пейперы" в 2025 кто-то распечатывает на бумагу? В 2025 для предварительных расчётов использовать бумажные черновики для предварительных расчётов или простых аналитических вычислений всё ещё легче, чем делать черновик в LaTeXе.
А про закорючки - есть операции и есть переменные. Операции считаются общеизвестными в данной области. Если ты не знаешь, как обозначается матожидание случайной величины или условная вероятность, иди кури маны. С названиями переменных сложно, да. В нормально оформленных статьях (и учебниках) определения переменных вводятся где-то в начале. Но букв, зараза, не хватает. Некоторые используют многобуквенные переменные (и, соотв., отказываются от неявного умножения), но (кроме экономики, хы) это редкая и нестандартная штука.
>>1377202 > Те же QKV в трансформерах - почему я должен наизусть запоминать, что Q = Query, K = Key, V = Value? Сэкономили буквально несколько букв лишь бы обмазаться этими "абстрактными" формулами. Ещё и в код свои сокращения постоянно тянут, как будто боятся лишний килобайт на исходный код потратить или случайно выйти за ширину строки в 20 символов... Плюс-минус по тем причинам, про которые ты дальше пишешь. QKV - это термин, атомарная смысловая единица. А не просто три несвязанных слова.
Плюс "кью-кэ-вэ" короче по произношению, чем "кьюри-кей-вэлью". Длинными словами думать не удобно, а без мысленного произношения слов думать не все умеют.
Ты же не будешь везде вместо LLM писать Large Language Model, особенно в названиях в коде?
>Вот только человеческий мозг имеет ограниченный контекст - говорят, в среднем он около 7 "элементов". Этим "элементом" может быть что-то независимое; в тексте это буква, слово или даже словосочетание (видимо, главное, чтоб оно было заучено наизусть). К примеру, вы знаете, почему номера телефонов часто записываются в форме "+7 (123) 456 78 90"? Почему цифры сгруппированы? Потому что мозгу намного проще распознать визуально и выучить наизусть 5 чисел, чем 10+ циферок по отдельности. Мозг воспринимает эти числа как атомарные сущности (можете рассматривать их как токены на входе в LLM), и это позволяет номеру телефона вписываться в узкий контекст краткосрочной памяти мозга целиком.
Только вот размер рабочей памяти для разных типов информации, разных состояний сознания и разных операций различается, иногда значительно. Особенно это заметно, если говорить про пространственную информацию (расположение объектов в квартире или в районе дома).
Готов поспорить, ты можешь вспомнить все 10 цифр подряд и можешь воспринять их как 10 элементов, игнорируя их "внутреннюю структуру" (то, какими закорючками они записываются, например).
(Кстати, разве номера телефонов записываются так не по историческим причинам? Мол, сначала были внутригородные NN-NN, потом междугородные MMM NN-NN, потом +X/+XX MMM NN-NN, потом +X(X) (WWW) MMM NN-NN. По проводному телефону внутри города можно звонить, опуская префикс, вроде.)
>В программировании это ограничение человеческого мозга обнаружили и уяснили ещё в середине прошлого века и с тех пор рекомендуют держать все процедуры, функции, методы объектов, сами объекты (в ООП) и тому подобное как можно более коротким - не в смысле "сокращайте всё до непонятных аббревиатур" (как делают математики с их формулами и некоторые программисты), а в смысле "используйте меньше команд в коде". Потому что сплошную портянку на несколько экранов сложнее понять, чем набор маленьких функций, в каждой из которых около 7 строк-команд или меньше. Даже компиляторы обучили эти микрофункции копипастить в машинном коде без лишних прыжков (инлайнинг/встраивание функций), чтоб дать возможность крошить код на функции без вреда для производительности конечной программы.
А потом поняли, что поторопились. Иногда (а может, достаточно часто) нет возможности разделить длинную функцию на осмысленные простые короткие функции. А если поделить принудительно, к каждому куску придётся добавлять полэкрана документации и прочего контекста.
И почему речь идёт об ограничении в 7 именно строк либо операторов языка, а не 7 токенов или 7 высокоуровневых операций? Видимо, потому что считать токены - очевидно (?) бессмыслено, деление на высокоуровневые операции субъективно, а KPI какие-то придумать надо, как же без метрик-то, а?
> Короче, от того, что ты свою формулу записываешь в виде мелких закорючек, эта формула не становится понятнее для мозга из-за биологических/физических ограничений мозга на контекст, если формула содержит десяток или больше отдельных операций. И от того, что ты спрячешь знак умножения ("axb" становится "ab") количество отдельных операций не уменьшится - т.е. мозгу всё равно нужно распарсить это умножение, сохранить в текущий контекст и потом что-то с этим сделать, несмотря на полное отсутствие обозначения операции умножения в формуле. Это физически тяжело нейронкам мозга - требует больше работы. > > Поэтому программный код всегда будет лучше формул. Не потому, что он "менее абстрактный" (код может быть сколь угодно абстрактным и использоваться в 100500 разных ситуациях без изменений), а потому что учитывает физические ограничения мозга на контекст, загружая данные маленькими кусочками, а не плотным клубком из 25 отдельных операций с закорючками, смысл которых поди угадай без пояснительных сносок и долгих мучений с разбором на отдельные компоненты...
Ты так говоришь, будто формула, записанная в программистской нотации, будет содержать меньше токенов (в смысле лексера/парсера, = имён переменных, функций и операций), чем в математической нотации. Ты, в конце концов, так говоришь, будто формулу можно сократить без потери информации. Будто с декомпозированной формулой можно работать.
> смысл которых поди угадай без пояснительных сносок и долгих мучений с разбором на отдельные компоненты Или чтения начала статьи, блин.
>>1377202 > Вот только для чтения, т.е. распознавания, длинные слова естественных языков легче коротких закорючек - в том числе для той же самой супер-параллельной зрительной системы. Слова, вмещающиеся в "визуальное контекстное окно для текста" и известные человеку, одинаково просты, пусть даже некоторые из этих слов состоят из одной буквы. Союз "и", например. Или знак запятой (если брать слова в широком смысле). Или i (которая переменная итерации либо мнимая единица). А какую-нибудь длинную НЁХу, как сложные (составные) слова в немецком или числа в 10 знаков, читать не удобно чисто потому, что глаз сбивается.
А распознавание смысла - штука отдельная (хоть и связанная) от визуального/слухового распознавания символов. Можно легко прочитать "турбоэнкабулятор" (т.к. слово это - типичное английское), сразу увидеть слоги, некоторые части слова, но не понимать, что оно означает (ничего реального, это - старая инженерная шутка).
> Сравните, например, "number" с "many" против "n" с "m" - да, технически мы можем в обоих случаях успешно распознать написанное, но длинные слова мозг опознаёт/понимает быстрее. То есть текст из длинных слов читать мозгу легче, чем какой-то набор из отдельных букв с закорючками между ними. Опознаёт быстрее, ИМХО, в первую очередь из-за большей "экранной площади". Если взять шрифт по-больше для "n" и "m", читаться они будут с одинаковой скоростью.
А смысл и там, и там контекстно-зависимый. Это язык (язык математики/программистских обозначений) знать нужно.
> ...может быть, мой мозг плотная запись формул просто перегружает избытком информации. Тоже проблема - не я один такой, проблема информационной перегрузки, похоже, распространённая. Т.е. разложить формулу на элементы изначально, не сваливая всё в одну сверхплотную кучу закорючек было бы выгодно тем, что в разложенном виде больше людей смогут её понять без перегрузки. Только вот формулы часто нельзя декомпозировать (как минимум так, чтобы результат подходил для всех целей, напр. и для удобства понимания новичками, и для удобства интегрирования/анализа сходимости, и для удобства вычисления коэффициентов). А когда можно, возникают всякие теории полей, колец и матроидов. Со своими "непонятными" нотациями, заметь.
И не только формулы, заметь. По сути всё, где есть обратная связь, разделить на простые части можно, только если можно сжать описание воздействия обратной связи во что-то простое. Как в транзисторных усилителях проигнорировать влияние выходного сигнала на входной (а потом будут истории, что в советское время пеленговали радио, которые слушали "Радио Свободу" или как её там, потому что та самая проигнорированная обратная связь).
Для практических целей нужно уметь самому декомпозировать и упрощать формулы, именно для тех целей, которые у тебя прямо сейчас.
> ...а может и не больше, если "понимание формул" - это какая-то генетически захардкоженная фича отдельных мозгов, которые благодаря этой встроенной фиче становятся математиками. Всё-таки не зря кому-то это даётся проще, чем другим. Печально, если так... Ну ХЗ, я в принципе не верю (ХЗ, где научные подтверждения искать), что генетика мозга в принципе может избирательно влиять на мысленные процессы. (Ладно там "гены шизофрении", это, судя по статьям, больше похоже на общемозговое изменение начальных условий/"точки равновесия".)
> Эх, ладно, что-то я слишком много об этом всём написал... Но "изучать ИИ", когда вся важная (и особенно - новая) информация в неудобоваримом по многим причинам виде как-то не очень получается. Одна из причин, почему я никак в это вкатиться не мог в прошлом... https://d2l.ai/chapter_attention-mechanisms-and-transformers/queries-keys-values.html Ну вот, первая попавшаяся статья. Тут даже без чтения предыдущих статей суть понятна, идеи применения можно прикинуть. Обычно такого и достаточно при изучении теории. А тебе как там, понятно?
>>1378250 >>пикрил 2 >https://habr.com/ru/articles/263067/ Знак надчёркивания на месте, я спокоен. >>1378256 >Мол, сначала были внутригородные NN-NN, потом междугородные MMM NN-NN, потом У нас несколько раз они менялись, разряды добавлялись безо всякого межгорода. Так что было и 4, и 6, и 7 цифр. >>1378257 >Моя простыня - более простыня, чем твоя простыня. Да вы все тут ебанулись нахуй обсуждать нужность формул в машобчике. И я тоже ебанулся.
>>1378341 >Да вы все тут ебанулись нахуй обсуждать нужность формул в машобчике
Вот этого люто двачую. Если мы скатились до такого, тред можно закрывать. Весь мир обсуждает, какую ещё мат. операцию вставить между энкодером и декодером, чтобы преодолеть curse of dimensionality, ну и чтобы все охуели конечно же, а мы обсуждаем нужен ли матан зловонный этот вообще или нет. Вот именно поэтому все новые ништяки придумываются там, а не здесь...
>>1376160 Тут вот какая проблема, ты одно уравнение линейной регрессии записал в общей форме в абзац текста, если я тебе начну в такой формат переводить свои реальные рабочие выкладки, то там будет по 60 листов. Математический язык очень лаконичный, а в код переписать всегда успеешь (большая часть математики до кода впринципе не доходит, тк ещё на этапе поверхностного моделирования становится понятно что происходит какая-то хуета).
Ну и плюс у математического языка есть хорошее свойство генерализировать разные штуки.
Короче распиши несложную сеть с 3 слоями, 20 инпутами, 2 аутпутами и софтмаксом на конце с прямым проходом и вычислением всех производных весов нейронов (только не одного нейрона, а общий случай на каждый слой) в виде алгоритма, и на математическом языке, во-первых будет просто полезно для понимания матчасти раз ты учишь эту тему, а во-вторых сам быстро поймёшь почему язык математики работает, а текст и блок-схемы не работают (да и код часто читать сложнее латекса).
>>1377202 >Никто не спорит, что нужно понимать теоретическую базу, которая часто абстрактная. Но в данном случае мы обсуждаем нейронки, в которых вещи совсем не абстрактные. Те же QKV в трансформерах - почему я должен наизусть запоминать, что Q = Query, K = Key, V = Value? Сэкономили буквально несколько букв лишь бы обмазаться этими "абстрактными" формулами. Ещё и в код свои сокращения постоянно тянут, как будто боятся лишний килобайт на исходный код потратить или случайно выйти за ширину строки в 20 символов...
Ты сейчас вскрыл интересную тему, что дураки это не совсем то что в социуме обычно понимается. Согласно кривой статистического распределения, есть по 5% людей которые умнее или тупее всех остальных. Речь не идет о буквальных умственных отсталых, которые не способны жить самостоятельно.
Как отличить 5% самых умных? Они на автомате объясняют вещи на пальцах, потому что живут в обществе, и выучили пробным путем что если они не будут расжевывать всем все то их никогда не поймут - потому что 95% по определению их тупее. Плюс, наиболее эффективный способ разобраться в теме это в голове ее разобрать, как если бы кому-то объяснял.
Соответственно, 5% самых тупеньких наоборот стараются изъясняться максимально запутанным образом - потому что если они не будут это делать, их сразу запишут в тупых, а им бы этого не хотелось. Поэтому там где можно сказать 5 слов, мудак использует 50, а в промежутках для еще мгнозначительно помычит для весу. Процессор умеет гонять более одного конвеера инструкций одновременно, как это назвать, многоконвеерность? Да ну нахуй, СУПЕРСКАЛЯРНОСТЬ. Ну да, формулы есть максимально эффективный способ передачи, при условии что тот кому ты их передаешь способен их расшифровать. Но не единственный, а если неспособен, то это максимально неэффективый, и тебе нужно переключаться на графики которые можно понять визуально или псевдокод. Но - идиот он и есть идиот. Еще для тупых характерен лютейший group think с закидыванием говном всех кто не придерживается общепринятого в их группе мнения.
И тут возникает момент - идиот же не может быть математиком! На самом деле еще как может, и даже скорее всего большинство математиков являются идиотами. Есть такая штука как парадокс моравека, математика это классический из его столпов. Есть еще такая штука как вундеркинды, про них наиболее часто знают в контексте шахмат и математики. И это сферы, в которых компы в первую очередь начали уделывать людей начисто. В то же время, про вундеркиндов от экономики и медицины ничего особо не слышно, потому что это не области где можно функионировать в изоляции как мозг в банке. У дурака по сравнению с обычным человеком "железо" в башке не способно потянуть полноценный чекпоинт, с социализацией, мудростью, интуицией и т.д. Зато гиперсфокусироваться на узкой области оно может, и учится быстрее нормального человека, потому что параметров у нейронки дурака намного меньше. Если дураку повезет, и этой областью становятся не дота или лор стартрека, как это обычно бывает, получается Эйнштейн. Это кстати хороший аргумент в пользу классического образования, с изучением в придачу к математике еще и всякой поэзии со спортом. Если бы оно было внедрено повсеместно мы бы смогли избежать заебавших всех ретардов типа Маска и Юваля Харари.
Ну и хорошие новости - технический прогресс неумолим. Раньше кодинг - это был процесс слинковывания инструкций процессора, на этом взлетали всякие крутые ретарды типа Кнута. Сейчас кодинг это копипейст кусков из чатжпт, и обратного процесса не будет, далее будут "языки программирования" в которых нужно будет рисовать коробочки со стрелками и внутри писать нейронке что эта коробочка должна делать. С математикой то же самое будет, это будет чисто внутренний формат данных для ризонинга нейронки.
>>1387967 >далее будут "языки программирования" в которых нужно будет рисовать коробочки со стрелками На это дрочили лет 20, воз и ныне там. Короче нет, не будет. Ну и остальные анал огии про тупых и количество нейронов у них не выдерживают никакой критики. Самые умные вообще решают задачи, на объяснение названий которых тебе уйдёт полчаса (притом что ты скорее всего не совсем тупой), и это нормально, так же, как и специализация на узкой сфере.
>>1388028 >На это дрочили лет 20, воз и ныне там. Короче нет, не будет. Точно? Потому что осталось коммерческий IDE под это дело сделать и прикрутить туда апи к чатгпт.
>Самые умные вообще решают задачи Люди вообще любые видят обычно сны, то есть рендерят себе видосы порой в пару часов, тратя на это буквально единичный ватты, это у мозга состояние отдыха такое. То есть в плане чистой вычислительной мощности любой матан по сравнению с этим есть хуйня. То что ты понимаешь под решением задач, с точки зрения человека как организма это закручивание шурупов жопой, оно не от ума зависит, а от способности убедить себя в ценности, на самом деле биологически сомнительной, данного занятия.
>>1388631 >Точно? Точно. Твёрдо и чётко. >то есть рендерят себе видосы порой в пару часов Или думают, что рендерят, а на самом деле там описание на три байта и додумка уже после пробуждения.
>>1387967 >Процессор умеет гонять более одного конвеера инструкций одновременно, как это назвать, многоконвеерность? Да ну нахуй, СУПЕРСКАЛЯРНОСТЬ. Этому есть простое объяснение, вопрос терминологии не имеет большого значения пока ты не эксперт, и имеет большое значение для экспертов, которым требуется предельно точно выбирать выражения для эффективной коммуникации друг с другом в научных статьях и работах. Ну и когда ты пишешь статьи у тебя эта избыточная точность сама собой просачивается в деловой спич.
Я раньше тоже глядел как на сумасшедших этих людей, которые называют базы данных СУБД, а строки кортежами, но сейчас когда я работаю с данными на серьезном уровне, для меня очевидна разница между БД и СУБД, а также кортежами и строками.
> Сейчас кодинг это копипейст кусков из чатжпт, и обратного процесса не будет Я почему-то сейчас уверен, что ты никогда не работал с кодом на серьезном уровне. Только полнейший дилетант может написать такую чушь.
> С математикой то же самое будет, это будет чисто внутренний формат данных для ризонинга нейронки. Ты тредом ошибся: тут как раз сидят люди, которые крутят внутренности сетей. У нас эти формулы - рабочий инструмент.
>>1388631 >Точно? Потому что осталось коммерческий IDE под это дело сделать и прикрутить туда апи к чатгпт. Ну прикрути, миллиардером станешь. Шутка. ЛЛМы существуют три года, но никто не смог решить эту задачу потому что ЛЛМы справляются только с простейшими дилетантскими задачами уровня простеньких автоматизационных скриптов и университетских задач по курсам программирования/DSA. Современные приложения состоят не из 200 строк кода, а из десятков/сотен тысяч строк, этот момент мечтатели упускают, как и тот, что никто не смог засунуть в сущестующие ЛЛМы такое кол-во токенов. Короче пока это просто неплохие вспомогательные инструменты, заменять реальных инженеров они не могут, и прогресса за три года в этом вопросе примерно ноль: биг тех репортирует инвесторам что вот-вот уже завтра их модели научатся заменять инженеров, и... продолжают их нанимать. Потому что знают, что не научатся.
>>1390588 >У нас эти формулы - рабочий инструмент. Ну кстати я сижу трейню безо всяких формул, только код теребонькаю, в основном беру один идеи и применяю их в других сферах. >завтра их модели научатся заменять инженеров, и... продолжают их нанимать Не в России, лол. Ищу работу третий месяц, такого тухляка на рынке я ещё не видел.
>>1390936 > Не в России, лол. Ищу работу третий месяц, такого тухляка на рынке я ещё не видел. Это не связано с AI движухой (AI слоуп вообще тут влияет в благоприятную сторону: множеству этих AI стартапов тоже нужны инженеры, т.е. они увеличивают количество работ на рынке). Просто самому IT рынку сейчас тяжело, и в РФ, и за ее пределами (финансовый кризис, уменьшился объем инвестиций в стартапы, биг тех долгое время неконтролируемо дул зарплаты и нанимал слишком много сотрудников в 2021 году). Если ты посмотришь на данные, то произошло примерно следующее: в 2021 году количество работ раздулось примерно вдвое, а к 2024 этот пузырь рухнул, и их количество откатилось назад до доковидного значения, и продолжает потихоньку расти. Ты видимо молодой и не застал 1999 и 2008, там были точно такие же проблемы.
>>1390588 >Ну и когда ты пишешь статьи у тебя эта избыточная точность сама собой просачивается У специалиста специализированная лексика используется для общения со специалистами, у брейнлейтов она просачивается везде, да.
>У нас эти формулы - рабочий инструмент. Да попизди ты тут, рабочий инструмент у вас это воркфлоу с цивита скочать. Можно подумать дадут вам что-то эти формулы без доступа к собственному датацентру.
>ЛЛМы существуют три года, но никто не смог решить эту задачу 25% кода в штатах пишутся нейросетками, выпуск мажоров в CS упадет через пару лет на 20%, что за счет эффекта домино само по себе увеличит процент генерируемого нейросетями кода. А так да, прогресса ноль.
>Современные приложения состоят не из 200 строк кода, а из десятков/сотен тысяч строк Только целый класс можно описать полудюжиной токенов, и эти сотни тысяч кода влезут в 4к контекста, после чего с ними работать сможет модель 7B. То что они еще не описываются это чисто результат того что у ойтишников правило не писать документацию и не комментить выкладываемый код, потому что у дураков инстинкт запутывать все. Поэтому во всяких опенай сейчас приходится платить индусам чтобы они комментили датасет, именно в это и упирается все скорее всего.
>>1394174 > У специалиста специализированная лексика используется для общения со специалистами, у брейнлейтов она просачивается везде, да. Напомню, что ты кукаретик, а не специалист, тебе откуда быть в курсе?
>Можно подумать дадут вам что-то эти формулы без доступа к собственному датацентру. Эм, о чем ты, большую часть решаемых прикладных задач можно решать за приемлемое время на единственном цпу ядре. Не все, блядь, крутят ллмы на трансформерах, это 1% рынка буквально. Вычислительный кластер большинства организаций это спарк в кубер кластере на пару нод + минио с парой ТБ данных сбоку, не всегда с ГПУ даже.
> 25% кода в штатах пишутся нейросетками, выпуск мажоров в CS упадет через пару лет на 20% Да 70% пишется, хуле, а выпуск мажоров упадет на 99%. Ты когда с такими охуенными тезисами выступаешь прикладывай источник хотя бы какого журналиста цитирующего инфоцыганина ты пересказываешь.
> Только целый класс можно описать полудюжиной токенов, и эти сотни тысяч кода влезут в 4к контекста, после чего с ними работать сможет модель 7B. Ну все, пиздец, кукаретик архиватор Бабкина изобрел. Ну пиздуй захуяривать, станешь миллиардером.
> и упирается все скорее всего. Ну ладно, хоть в конце признал, что вылез далеко за границы экспертности. Блядь, да пойди собери автоматизацию чуть посложнее 1 скрипта на 100 строк и поймешь в чем проблема, осел тупой, классы у него на полдюжины токенов, охуеть бля.
>>1395283 Айти это просто отрасль. Твой вопрос звучит как "вкатываться ли мне в автопром?". Среди автопромщиков есть и инженеры, зарабатывающие больше миллиона рублей в месяц, и лузеры, убирающие мусор на задворках последнего завода автоваза. Если тебя искренне увлекают компьютеры, вкатывайся, конечно, в айти хорошие возможности для таких как ты. Если тебя интерует что-то другое - ну, прикинь возможности в любимой сфере, и реши для себя какие там перспективы, и стоит заниматься этим, или же бросить взгляд на нелюбимое.
По своему опыту так скажу, все лучшие спецы с которыми я работал - это те, которые занимаются любимым делом. Но это не значит, что любое дело можно монетизировать. Мне повезло, и мое любимое дело перспективное, а потому спрашивать тебе, наверное, стоит не меня, раз ты сомневаешься.
> Новая архитектура Adamas предлагает радикальное ускорение механизма внимания до 4.4× быстрее, при сохранении качества даже на длинных контекстах (100k+ токенов). > Главная идея — отказаться от сравнения каждого токена со всеми. Вместо этого Adamas динамически выбирает 128 наиболее релевантных токенов для каждого запроса. Чтобы определить релевантность, применяется преобразование Адамара. Оно сглаживает распределение значений и переводит их в 2-битные представления, после чего сходство оценивается с помощью Manhattan-метрики.
>>1398981 А это можно использовать с BERT? Допустим я с нуля сделал архитектуру BERT и загрузил туда pre trained веса с huggingface, (distilbert--base-uncased) что бы файнтьюнить
>>1404746 >А что вообще делаешь? Да хуйня, проект в универе, предсказывать уровень токсичности комментариев, поэтому хотел что-то крутое/новое попробовать что-б презентация не совсем скучная была.
>>1443814 >А тебе зачем? RNN сосёт же. Преимущество RNN в фиксированной стоимости и по вычислениям, и по памяти; и достаточно дешёвая (в зависимости от задачи; лёгкие задачи = лёгкая RNN). Недостаток RNN в том, что бэкпропом её учить в разы тяжелее из-за необходимости разворачивать и резать глубину, что убивает главную фичу - рекуррентность; параллелизм страдает из-за пошаговости бэкпропа (невозможно учить юниты без полного прохода всей цепочки задом наперёд, что убивает параллелизм).
Я хочу компактную сеточку, которая может учиться локальными правилами без разворачивания, но вся информация о RNN сводится к "юзайте GRU/LSTM с бэкпропом на %фреймворк_нейм% и не парьтесь" и "трансформеры лучше с бэкпропом -> лучше всегда". Разобраться в СУТИ самой рекуррентности сложно, несмотря на то, что трансфомеры её эмулируют (как пример, "думай по шагам" ≈ рекурентность же).
Я читал про RWKV и MAMBA, но там всё сложно. Мне хотелось разобраться в основе на уровне отдельных независимых рекуррентных юнитов, а там какие-то абстрагированые блоки описываются, какие-то гиперпараметры и всё такое абстрактное...
В общем, у меня нет задачи, на которой мне нужно выжимать сотые доли процента. У меня желание разобраться в том, на что способен тривиальный рекуррентный юнит с локальным обучением, т.е. обучающийся без учителя и знаний о задаче.
Как я понимаю (написал код и потестил до поста с вопросом), "текущий интегратор" с единственным входящим сигналом может сглаживать пульсации сигнала, определяя некую характеристику сигнала во времени. Несколько входов, как я предполагаю, позволяют "фокусироваться" на отдельных входах в зависимости от назначенных факторов (весов).
Если это - рекуррентность, то это очень интересно. Теоретически такая система могла бы состоять из водопроводных труб, если пренебречь масштабами; наверняка можно сделать из каких-то мемристоров физическую модель, работающую без "процессора". Эффективность системы была бы на порядки выше.
>>1443987 >В общем, у меня нет задачи Ну ёб ты, это же ключевое. Нет ТЗ, результат ХЗ. Придумай себе задачку, и исходя от неё пили свой код. >Теоретически такая система могла бы состоять из водопроводных труб, если пренебречь масштабами В принципе процессор можно эмулировать кучей людей с табличками, а на процессоре запустить любую нейронку, хоть трансформеров, хоть RNN, так что мимо. Эффективно можно и трансформеры, только кому нужна запечённая в железе модель, когда новые модели выходят каждый день.
>>1444082 >только кому нужна запечённая в железе модель, когда новые модели выходят каждый день. Смысл как раз в том, чтобы не скачивать модель, а обучаться на заданном железе в реальном времени, подобно человеку. Ты не скачиваешь новый мозг в черепную коробку, чтобы получить новые навыки, и домашнему роботу-гуманоиду важнее будет получать знания и навыки из окружающей среды, а не из сети, поскольку конкретная обстановка всегда уникальна. Условному марсианскому роботу-исследователю нет возможности качать новую 1ТБ модель ежедневно. Текущий подход к ML как-то упускает всё это из виду; рассчитывают узнать всё сразу "генерализацией"?..
>Придумай себе задачку, и исходя от неё пили Ты, конечно, прав... Но как-то не знаю. Когда ищешь "простые ML задачи", часто предлагают MNIST или наподобие "IMDb Movie Reviews" для NLP, но это всё несколько сложнее, чем я думал... Для RL - CartPole рекомендуют, и я мог бы его сделать (как геймдев я смастерю простую 2D игру за вечер)... Ну, не знаю...
Я почему-то всегда думал о нейросетях как о некой симуляции живых нейронов в виртуальной среде - полностью абстрагируясь от какой-либо задачи. И размышлял о том, что нужно самому нейрону, не задумываясь о том, для чего нужны эти нейроны. И поэтому "machine learning" в целом разочаровывает. Просто меня в детстве идея "искусственной жизни" заразила, потому и программированием увлёкся...
>>1444232 >обучаться на заданном железе в реальном времени Тогда не выйдет простой железки уровня пары труб. >и домашнему роботу-гуманоиду важнее будет получать знания и навыки из окружающей среды Домашнему роботу вообще противопоказана любая самостоятельность. Всё должно быть прошито из коробки. >но это всё несколько сложнее >MNIST Сириосли? MNIST самое простое, что есть же. >Я почему-то всегда думал о нейросетях как о некой симуляции живых нейронов в виртуальной среде А в итоге даже нейронов никаких нет, лол, только огромные матрицы и их перемножение. Жизнь сурова, да.
>>1444232 >CartPole Какая же это херня... Я несколько часов параметры симуляции подгонял и все пальцы отбил стрелочками влево-вправо, но так и не смог сделать так, чтобы проблема была решаемой моими собственными руками, без какого-либо алгоритма, но при этом не решалась бы сама по себе физической симуляцией (если придать силу вверх и эта сила больше гравитации, то перевёрнутый маятник становится самым обычным маятником, что устраняет проблему на корню). Тупая хрень... Попробовал ИРЛ подержать палочку вертикально - реально невозможно добиться стабильного решения... Ну, для меня - точно невозможно. Я-то в шутерах никогда не мог развить точность стрельбы, так что и здесь ничего не получается... Ну, нафиг это всё - не буду ничего тренировать...
>>1444308 >MNIST самое простое, что есть же. Там же пиксели, а это - зрение. Зрение сложнее всего.
>Домашнему роботу вообще противопоказана любая самостоятельность. Тогда зачем это всё, лол. Лучше сразу сдохнуть, чем жить в таком мире...
>>1444770 >Попробовал ИРЛ подержать палочку вертикально В задаче палочка ограничена движением по одной оси, как бы. >Там же пиксели, а это - зрение. Там 28х28 пикселей, а это хуйня.
>>1444983 >движением по одной оси Не, там движение + вращение. Ладно, я просто психанул. Плюс эта задача слишком простая для RNN - как я понял, там достаточно информации о положении и скорости движения/вращения в отдельном моменте времени.
>28х28 пикселей 784 инпута от 0 до 255, и высока вероятность, что нейронка прицепится к 1-2 пикселям из этих 784, научившись отличать картинки по минимальной, но бессмысленной в реальном мире информации. Свёрточные сети оказались эффективнее для компьютерного зрения потому, что их изначально сильно ограничивают инпутом, например, 2x2 (4) на один фильтр, и поэтому у них меньше вероятность поднасрать, уцепившись за самый бесполезный пиксель во всей картинке. У рекуррентной сети такого встроенного ограничения по умолчанию нет (но, как я понимаю, часто делают гибрид CNN-RNN), и они в принципе не очень подходят для распознавания одиночных, не связанных в последовательность картинок (для видео - другое дело, но это на порядки сложнее для экспериментов).
Я нашёл задачку попроще, которая лучше раскрывает суть RNN - "повторить последовательность сигналов после паузы". Т.е. даже 1-2-3 инпута будет достаточно, чтобы эта задача была нерешаемой FFNN/CNN без костылей (без "контекста"). Если подумать, это не настолько бесполезная задача - скорее, наоборот: люди учатся через подражание другим людям и постоянно у себя в голове прокручивают случившееся в прошлом, т.е. это чуть ли не самая главная фича мозга. И я на 99% уверен, что костылём вроде "контекста" или "векторной БД" данную фичу мозга не эмулировать полностью - т.к. в мозге это не просто копипаста уже виденного 1-в-1, а интеграция в другие, более сложные процессы. Ну, может, и можно как-то эмулировать, но без чистой рекуррентности это будет очень большой костыль.
>>1151064 (OP) Мозг работает даже при сенсорной депривации, так?
Но всякий раз, когда пытаюсь сделать RNN и просто кормить её одним и тем же вводом, её внутреннее состояние как будто всегда приходит к некоторому стабильному состоянию: полностью неподвижному, пульсирующему на месте или движущемуся в одном направлении с одной скоростью без изменений. Не получается постоянного изменения состояния.
Llama написала, что это "аттракторы", но я не понял, галлюцинация это или реальный термин в данном конкретном случае, т.к. ничего не гуглится. Может, я неправильно описал это явление на английском...
В общем, это не может быть выученным свойством. Наверняка проблема в архитектуре или каких-то моих формулах. Как сделать так, чтобы у RNN внутреннее состояние развивалось бесконечно долго даже без стимуляции внешними импульсами? Такое вообще возможно, хотя бы теоретически? Если нет... Тогда необходимо как-то растянуть время между внешней стимуляцией и приходом к стабильному состоянию.
Я имею в виду, чтобы вместо такого: >0 1 0 1 0 1 ... (стабильная пульсация) Было хотя бы такое: >0.0 0.1 0.6 0.4 0.9 0.3 0.0 0.1 0.6 0.4 0.9 0.3 ... А лучше вообще избавиться от повторений.
Тут совсем никто визуализациями не увлекается что ли?
В общем, на видео - пример этого: >>1451331 >неподвижному, пульсирующему или движущемуся Слева - ввод, справа - дальний от ввода конец сети. Вот можно ли как-то этих состояний избежать?
>>1451331 >Как сделать так, чтобы у RNN внутреннее состояние развивалось бесконечно долго даже без стимуляции внешними импульсами? Такое вообще возможно, хотя бы теоретически?
>>1454060 >Замкни часть вывода на ввод, образовав кольцо. Точно, каждый раз забываю об этом моменте...
Позавчера всё-таки получилось добиться этого.
В общем, визуализация Echo State Network: 1. 16 входных чисел, все - нули. 2. 576 нейронов по ~6 случайных весов (1%). 3. 16 выходных чисел от первого резервуара. 4-5. Повторение 2-3 с другими весами. Активация tanh(): красный = -1, зелёный = 1.
>Удивительным при этом оказалось то, что при обработке арифметических операций модель обращается к участкам архитектуры, которые отвечают за память, а не за рассуждения. Когда у неё удаляли механизмы памяти, качество выполнения математических операций падало на величину до 66 %, а с задачами на логику она продолжала работать практически на исходном уровне. Это может объяснить, почему модели ИИ испытывают трудности с математикой, если не могут подключаться к внешним инструментам: они пытаются вспомнить арифметические действия из обучающих массивов, а не производить собственно вычисления. Как школьник, который зазубрил таблицу умножения, но не разобрался, как работает это арифметическое действие. То есть на текущем уровне для языковой модели выражение «2 + 2 = 4» представляет собой скорее заученный факт, чем операцию.
Классические однонаправленные модели не умеют считать, уступая в этом даже механическому арифмометру, они тупо пользуются подобием таблицы умножения, обращаясь к память при вычислениях.
>>1454426 ...Короче, я решил, что мне это пока что не нужно. Лучше попробую в CNN разобраться - они попроще выглядят. И меня как раз сильно интересует сжатие информации внутри нейросети. А RNN можно будет насадить сверху, поверх сжатого состояния, если вдруг реально потребуется. Сейчас меня смущает в CNN то, что чем глубже слои - тем медленнее происходят обновления, если CNN едет по бесконечному потоку данных; тогда как в RNN вся сеть обновляется разом. В чём моя ошибка? Неправильно пулинг применил?.. А впрочем, посмотрим - может, так даже лучше будет... Про WaveNet знаю уже.
>>1454655 >пользуются подобием таблицы умножения, обращаясь к памяти Человек в уме тоже считает в основном за счёт воспоминаний о таблице умножения и записи в краткосрочную память промежуточных значений (для трансформера аналог краткосрочной памяти - "контекст"). Даже если возможно натренировать человека считать длинные числа мгновенно, человек придумал калькуляторы специально чтоб не тренировать свои мозги на арифметику. И компьютеру не нужно симулировать нейроны ради арифметики - ему достаточно машинный код выполнить, чтобы посчитать всё в миллиард раз быстрее мозгов. Если какой-то программе нужна рекуррентная сеть для чего-то, то уж точно не для арифметики - арифметику нейросеть должна запрашивать у процессора как человек у калькулятора - будет быстрее.
>>1455653 >сжатие информации Кстааати, я тут очень интересную мысль прочитал кое-где: "сильно сжатая информация выглядит как шум". Т.е. в несжатой информации много шаблонных повторений, типа сплошной заливки цветом, повторяющихся слогов в тексте и т.д. А сжатая информация выглядит как бессвязный шум, т.к. в ней отсутствуют какие-либо шаблоны - в противном случае они были бы кандидатами на сжатие.
Что из этого следует? Во-первых, что кажущаяся хаотичной работа мозга может быть следствием высокой степени сжатия информации. Во-вторых, на видео выше - сжатие очень плохое, потому что присутствуют чёткие "дорожки" из ярко светящихся пикселей. Для информации в колонке "In" это нормально, а остальные колонки должны выглядеть всё больше и больше как бессмысленный шум.
К мысли о том, что нужно избавляться от таких "дорожек" я пришёл ещё и другим путём: если каждый нейрон должен о чём-то сигнализировать, о чём может сигнализировать нейрон, который никогда или почти никогда не изменяет своё состояние? Да ни о чём - чтобы о чём-то сообщить, нейрон должен изменить своё состояние. Поэтому было бы логичным заставить нейронку избегать такой конфигурации нейронов, когда нейрон слишком долго находится в одном состоянии.
И я уверен, что этого можно добиться вообще без каких-либо конкретных данных. Нужно смотреть на поведение нейронов и менять их так, чтобы они вели себя более равномерно - тогда они, исходя из вышесказанного, должны быть намного более полезными, чем те, что часто или надолго "застревают" в одном состоянии. В тех дорожках на видео, например, бывают дырки - но этого недостаточно. В биологическом мозге нейроны должны как-то сами собой калиброваться на это.
интересная тема, вы наверняка уже обсасывали когда то, но я ток ща начал смотреть чо нового за последние годы и охуел
оптимизируется 3D облако гауссиан (точка, цвет, вытянутость и тд) по ИЗОБРАЖЕНИЯМ карл!
все благодаря дифференциируемому рендеру облака в 2d и сравнением с ground truth картинками. меня оч удивляет что обучение выявляет 3D признаки из 2D данных. что то магическое просто
возможно некст ген 3Д генеративные модельки будут уже обучаться не на мешах а на картинках. как минум собрать такой датасет проще чем датасет мешей
>>1455703 >по ИЗОБРАЖЕНИЯМ карл! >выявляет 3D признаки из 2D данных. >scenes captured with multiple photos or videos. Что тут такого особенного-то? Строить 3D модели из нескольких фотографий - это стандарт, так почти все животные делают благодаря двум глазам и/или определённым движениям головы. Было намного интереснее, когда изобретали специальные датчики, измерявшие глубину безо всяких там фотографий - настоящая магия как она есть. Потом чёт забили...
>некст ген 3Д генеративные модельки будут Пусть лучше обучаются в реальном времени путём взаимодействия с окружающей средой с помощью физического робота, а не вот эти вот все костыли. Мясной робот может и картинку нарисовать, и 3D смоделировать, и песню спеть, и в чате общаться, и физическим мясом управлять в сложной 3D среде. А современные SotA-модели могут только что-то одно, специально подогнанное костылями к модели.
>>1455735 >сжимается до 5-7 правил. Лол, чтобы потом жечь энергию на вычисления? Для головного мозга вычисления дороже воспоминаний, поэтому большинство людей не думают сами, а тупо повторяют заученные наизусть чужие воспоминания. >Её запоминают только шизы. Нет, наоборот, шизами становятся те, кто слишком перегружает свои мозги вычислениями - т.е. думает непрерывно о каких-то сложных вещах. Нормисы не думают, поэтому у них всё в порядке, а если вдруг задумываются - мозг выгорает и разрушается. Т.е. полагание на память - это оптимизация выживания.
>>1456181 > а если вдруг задумываются - мозг выгорает и разрушается Смешно, но нет. >Т.е. полагание на память - это оптимизация выживания. Проблема в том, что это раньше экономии калории на мышлении. Сейчас еды в достатке, можно было бы жечь в разы больше. Но увы, мозг так и остался ленивой скотиной.
>>1456181 >шизами становятся те, кто слишком перегружает свои мозги вычислениями - т.е. думает непрерывно о каких-то сложных вещах. Нормисы не думают, поэтому у них всё в порядке, а если вдруг задумываются - мозг выгорает и разрушается
Охуительные истории. Это где тебе такую ахинею сказали? Или сам придумал?
Нормисы даже стареют и скуфизируются быстрее. И болезни, в т.ч. ишемия и атеросклероз идут нормально. И выгорают и дуреют нормально, порой уже когда слега за 30. На практике, наоборот - сниженная мозговая активность разрушает и мозг, и личность, и организм.
Ты вообще с "нормисами" когда-либо в жизни общался? Из твоей улётной маняфантазёрской сычевальни они, небось, все видятся 20-летними преуспевающими чедами, сидящими на ЗОЖ, посещающими спортзал, потрахивающими тёлочек в изрядных количествах, катающимися на авто не ниже бизнес-класса, путешествующими по миру и выкладывающими фотки в инсту.
Дружище, если твой мозг и разрушается, то явно не от избытка мозговой активности. Суть не в том, что негде больше посчитать, кроме нейронок. Даже если касаться чисто арифметики (а она используется чаще, чем ты думаешь при обработке запросов), то нахуя использовать "таблицу умножения" и тратить на неё память и использовать тензорные операции, которая к тому же факапит, когда при помощи циклов можно сделать это быстрее, с минимальными затратами памяти и с предельной точностью. Тут как минимум вопрос оптимизации.
В добавок, точность и возможность делать много вычислений, открывает перед нейросетями огромные возможности. Нейронка может свободно что-то долго конструировать, а не накидать чисто за раз.
>>1456181 >если вдруг задумываются - мозг выгорает и разрушается
Тебе наврали. Так что думай спокойно, на полную силу. Ну или хотя бы не засоряй доску своими измышлениями, созданными в режиме минимальной умственной активности.
>>1456233 >>мозг выгорает и разрушается >Смешно, но нет. Было несколько историй о людях, которые были не просто отличниками, а практически "вундеркиндами" - проскакивали несколько классов в школе, были лучшими на всяких глобальных олимпиадах и прочее подобное, демонстрировали буквально сверхчеловеческие способности интеллекта, а потом... потом что-то в их голове ломалось, и они начинали видеть галлюцинации, бредить и т.п. Т.е. их мозги изнашивались за первые 15-20 лет и деградировали настолько, насколько у большинства деградирует к 80-100 годам жизни. А теперь самое главное: очень большое количество людей учится спустя рукава и зарабатывает минимальные оценки на экзаменах, лишь бы не вылететь - но они полностью здоровые. Не чувствуешь никакой связи? Гением быть опасно, если хочешь быть здоровым. Сверхчеловеческие люди-компьютеры - это ненормально для здоровья.
>Но увы, мозг так и остался ленивой скотиной. Архитектура не поменялась, нейроны всё те же - "лень" в них захардкожена и, возможно, является одним из главных двигателей интеллекта/обучаемости как таковой. Потому что чем больше знаешь, тем меньше приходится двигаться.
>>1456372 >Тебе наврали. Так что думай спокойно, на полную силу. Я как раз из тех, кого нормисы (и психиатры) зовут шизом...
>>1456343 Нормисы - это, условно, те самые "95%" населения. А шизофренией страдают менее 1% по всему миру.
Давайте закроем тему шизов. Большинство использует этот термин некорректно, называя "шизами" всех людей, которые говорят что-то, что им почему-то не нравится. Клиническая шиза выглядит совсем иначе, имеет совсем другие проявления и вообще - вычислить настоящего шизофреника по онлайн сообщениям очень сложно, особенно когда он в ремиссии. Но факт остаётся фактом: шизофрения чаще всего развивается из-за психотравм и дистресса, а, как известно, "меньше знаешь - крепче спишь" (дуракам/нелюбопытным/пассивно следующим чужим инструкциям спокойнее живётся), так что связь шизофрении и изначально высокого интеллекта очевидна.
>>1456360 >при помощи циклов можно сделать это быстрее >и с предельной точностью Скорость и точность в цикличных нейронках у тебя будет только если ты сумеешь эту самую нейронку натренировать правильно использовать имеющиеся у неё циклы или правильно сформировать требующиеся циклы. Если в весах закралась ошибка на 0.000001 и эта ошибка проявляет себя не сразу, а через сколько-то циклов, ты её ещё попробуй найти сначала, а потом попробуй исправить, не переломав всё, что работало нормально.
В любом случае, для таких циклов нужно несколько операций, а в машинный код для сложения чисел тратит минимально возможное количество операций на конкретной машине. Так зачем эмулировать работу нейросетевого калькулятора на классическом компьютере, если этот самый классический компьютер ту же задачу калькулятора делает в сотни раз быстрее?
>она используется чаще, чем ты думаешь, при обработке запросов Примеры ты, конечно, привести не сможешь?
Если текстовому чатботу задают вопрос "сколько будет стопицот миллионов в степени стопицот", очевидно, что для наиболее быстрого и наиболее точного ответа на вопрос будет проще собрать одноразовый скрипт на условном Python, запустить его и скопировать ответ в чат. Это будет дешевле даже если код будет на JavaScript и выполняться в браузере пользователя, а не на мощном сервере. Аналогично, если пользователь попросил "посчитать до миллиона вслух" - достаточно написать скрипт, который обращается к API TTS сервиса в цикле for. Аналогично, если пользователь попросил посчитать количество дней до какого-то мероприятия - надёжнее будет обратиться к программе-календарю, а не пытаться подсчитывать дни внутри самой нейронки.
Поэтому в этом контексте я согласен с разработчиками LLM - они правильно сделали, что учат LLM взаимодействовать с существующей программной инфраструктурой, а не эмулировать все имеющиеся возможности компьютеров внутри виртуальной модели нейросети.
Несогласен я с ними в том, что они уже который год дрочат на эти гигантские трансформеры так, будто ещё чуть-чуть и родится AGI из простого маппинга "если А, то Б" для миллионов примеров. Реальный AGI должен мочь создавать новые связи "если А, то Б" во время онлайн-работы с минимальными затратами и использовать эти новые связи как родные. Что мы видим с текущими трансформерами? Они могут усвоить "если А, то Б" в контексте, но это ущербный подход по сравнению с обновлением весов самой модели, а обновление весов трансформера слишком трудоёмкое и подвержено забыванию усвоенного прежде или коллапсу модели. Нужно эту проблему решать, а они всё продолжают напихивать побольше данных в побольше весов...
>тратить на неё память Суть любой нейросети в том, чтобы создать эффективный по памяти маппинг между входом и выходом, всё остальное - детали реализации. Наименее эффективная нейросеть аналогична LUT (lookup table, таблица поиска), то есть сохраняет все значения входов и выходов без изменений. Чем эффективнее нейросеть, тем больше она может запомнить с меньшим числом весов. Все эти циклы - это просто способ запомнить больше с меньшим числом весов. Но если из-за них усложняется тренировка нейросети, то использовать их нерационально.
>>1456387 >Т.е. их мозги изнашивались за первые 15-20 лет и деградировали настолько Это не износ в прямом смысле. Просто шиза и гениальность это 2 стороны 1 монеты. >Не чувствуешь никакой связи? Чувствую, ты не знаешь про дебилов-шизиков, коих большинство. >Архитектура не поменялась, нейроны всё те же Думаю, дело не в нейронах. >>1456430 >Так зачем эмулировать работу нейросетевого калькулятора на классическом компьютере, если этот самый классический компьютер ту же задачу калькулятора делает в сотни раз быстрее? Людям нравится.
Видимо, тема серьёзная, что-то в этом такое есть, раз после в тред ввалился ботяра и начал втулять простыни с какой-то дикой дичью. Возможно, это как раз ключ к AGI.
Я тут подумал ещё немного и нашёл аналогию с программированием.
Смотрите, в программировании есть функциональная и ООП парадигмы: >func sum(a, b, c, d): return a + b + c + d ООП: >class Summator: >_ var state = 0 >_ func add(a): >_ _ state += state + state + a >_ _ return state Использование, например, такое: >var r = 0 >for i in 5: >_ r = sum(r, r, r, i) >_ print(r) ООП: >var summator = Summator.new() >for i in 5: print(summator.add(i)) В этом примере, в обоих случаях результатом будет: >0 1 5 18 58 Если важен только результат, то разницы между этими подходами нет. Но нетрудно догадаться, что в первом примере мы чётко видим, какие значения передаём в функцию, а во втором примере поведение программы частично скрыто внутри состояния и логики объекта. Если нам потребуется решить какую-то другую задачу, то описанная выше функция sum() позволяет решить более широкий класс задач, просто меняя передаваемые значения в аргументах функции, в то время как класс Summator имеет более специализированное поведение и нам потребуется его изменить или целиком заменить другим классом. Кроме того, с функцией sum() будет сложнее ошибиться - мы видим все данные "на поверхности", и эта функция не может изменить что-то, о чём мы не знаем. Состояние же объекта может быть "испорчено", что ведёт к скрытым ошибкам в программе.
С другой стороны, для программиста, который хочет только обращаться к готовым API из библиотеки с кодом, объектный подход намного удобнее, потому что позволяет выполнить задачу с минимальными затратами: не нужно нигде сохранять результат - он хранится в объекте. Объект, таким образом, может иметь сложное поведение внутри и лёгкий интерфейс снаружи. Благодаря этому парадигма ООП намного популярнее и чаще используется в разработке программ вот уже много десятков лет. Функциональный подход освоить сложнее - чистые функции просто не могут быть большими инструментами со сложным поведением, поэтому от программиста требуется больше знаний и работы по их использованию. Хотя результат работы одинаков.
Если переносить всё это на нейросети, то рекуррентные сети подобны объектам ООП - они содержат в себе скрытое состояние и могут его изменять в процессе работы, но зато имеют кажущийся простым интерфейс. Поведение рекуррентной сети может быть намного сложнее данных, передаваемых снаружи. Нейросети, передающие данные только вперёд, подобны чистым функциям - они работают только с переданными им аргументами и ни с чем больше, не создавая побочных эффектов. Поэтому им нужно больше данных для совершения сложной работы, и от этих данных сильно зависит результат работы. Но, тем не менее, их результат работы тоже можно подавать обратно на вход той же самой сети, как в случае с авторегрессией у современных языковых моделей.
Ключевое отличие в том, что рекуррентная сеть в процессе обучения учится модифицировать все свои скрытые параметры определённым образом, и может изменять их в любой момент сама по себе. Для идентичного результата с сетью с одним направлением, от нас требуется менять входящие аргументы самостоятельно, либо предоставить сети принимать решение о том, что должно пойти на её вход.
Вопрос заключается в том, что сложнее: рекуррентной сети научиться правильно менять скрытые параметры или нам научиться правильно менять данные на входах однонаправленной сети, чтобы достичь одного и того же результата? Я думаю, что обучаемость рекуррентной сети сильно зависит от её архитектуры и алгоритма обучения, которые были найдены эволюцией в случае с биологическим мозгом и до сих пор не найдены в искусственных сетях, тогда как применить "костыль" поверх однонаправленной сети не так уж сложно.
Т.е. решить задачу при желании можно с любым типом сети (если применить соответствующие костыли снаружи сети, т.е. передать вывод на ввод там, где это нужно), но раскрыть потенциал рекуррентных на практике сложнее, поскольку мы не можем осмысленно влиять на скрытые состояния сети.
>>1456624 >ввалился ботяра и начал втулять простыни с какой-то дикой дичью Для тебя любые посты длиннее пары предложений - это "дикая дичь"?
Тред называется "исследование ИИ" @ Аноны не хотят ничего исследовать
>>1456534 >Это не износ в прямом смысле. Просто шиза и гениальность это 2 стороны 1 монеты. У гениальных людей риск шизофрении даже ниже, чем у посредственных Вот тебе, например, исследование https://pmc.ncbi.nlm.nih.gov/articles/PMC4391822/
>>1456233 >Проблема в том, что это раньше экономии калории на мышлении. Другое заблуждение очень известное, повсеместное. На самом деле энергопотребление мозга практически не меняется при очень интенсивной мыслительной работе, по сравнению с расслабленным состоянием покоя. По замерам, там может процентов в 10 разница только.
Мышление некомфортно, наверное, потому, что это рискованная операция. Ты можешь намыслить что-то полезное, а можешь и вредное, что тебя погубит или просто будет мешать. Полагаться на прямой опыт и память надёжнее.
Я писал дисер про использование перцептрона 10 лет назад, был на защите кандидатской по мат наукам, где чел создал самостроющуюся нейронку и придумал "язык програмиирования" для нее. Сейчас я вообще не понимаю что внутри нейронок происходит. Я знаю только про веса, слои и функци преоброзования, а сейчас еще куча терминов непонятных появилось. Это непонимание заставляет буквально понимать выражение Маска про наступление сингулярности. Будто все ожидали что сингулярность будет из-за сложности архитектуры, а в итоге она наступила из-за непонимания что там внутри коробки происходит. Скажите что это все от моего непонимания темы и мы все еще все контроллируем.
>>1482325 Все принципы остались ровно такими же. И если шарить, то интересные исследования вообще выходят раз в пару месяцев, новую гачеку придумывают и выпускают новые модели для разных задач и размеров. Кардинально мало что изменилось, архитектурно всё то же.
90% Мяса текстовых нейросетей это по прежнему многослойные перцептроны, которые предсказывают слова, остальные 10% это хитрые вычисления по типу трансформера (Легендарная статья "attention is all you need", 2017). Там просто больше формула для обработки текста, а так всё предельно ясно. Так что нейросети нынче отличаются размерами, данными, оптимизациями, и хитростями. Но никак не сингулярность, можно успокоиться на обозримое будущее :)
P.S: Никто даже и раньше не понимал, что находится внутри "коробки". Это проблема человеческого мозга, который не может представить миллионы/миллиарды умножающихся чисел, а для больших калькуляторов это проще простого. Но интуитивно: модель сама подбирает лучшую формулу; больше параметров = в теории лучше модель; цель = предсказать желаемый исход.
просто собрать однотипную инфу(картинка) и найти в них общие закономерности и свести к усреднению и выдать? а потом запрос как бы находит усредненное запроса?
>>1504967 Если речь именно про ИИ - нет даже консенсуса в научном сообществе что такое ИИ, не говоря уже о принципах работы. Если речь про текущие алгоритмы того что называют ИИ - решить оптимизационную задачу (минимизировать функцию ошибки). Как так получается, что прогоняя огромные массивы данных через миллиарды (а сейчас уже и триллионы) параметров и минимизируя расхождение между предсказанными значениями и реальными (из данных), получается вполне себе интеллектуальное поведение (речь про LLM) - остается загадкой. Возможно сам по себе язык является носителем интеллекта, который хорошо апроксимируется большими нейросетями. А возможно дело в чем-то ином.
>>1504967 принцип в предсказании следующего токена в последовательности посредством имитации "внимания". берем последовательность "крокодил залупа" и пытаемся предсказать следующий токен, разбив эту последовательность на токены и пропустив через матрицы слоев нейросети
>>1546332 матрицы слоев, в результате предварительного обучения с подкреплением на нашем датасете, выдают токены, которые последуют за предоставленными ей с наибольшей вероятностью. таким образом, обучив нейросеть на двачерах, следующим токеном мы скорее всего получим слово "сыр".
Кто-нибудь знает, есть ли хорошие работы по асинхронному RL? В том плане, что агент обучается не в синхронном окружении, где есть обязательный цикл шагов observation -> action -> reward, а так чтобы окружение существовало и обновляло свое состояние само по себе, а агент мог с ним периодически взаимодействовать.
>>1546469 Да, это направление активно развивается, так как стандартный цикл RL (MDP) плохо подходит для робототехники и реального мира, где время не останавливается, пока нейронка думает над действием. Вот ключевые концепции и работы, которые стоит изучить: Concurrent / Asynchronous RL: Главная работа здесь Reinforcement Learning with Real-Time Constraints (Ramstedt & Pal, 2019). Они вводят понятие Real-Time MDP (RTMDP). В этой схеме, пока агент выбирает действие для состояния St, среда уже переходит в состояние St+1. Это заставляет агента учитывать задержку собственных вычислений. Continuous-Time RL: Вместо дискретных шагов используются дифференциальные уравнения. Посмотри работы по Deep Reinforcement Learning in Continuous Time (например, с использованием Neural ODEs). Это позволяет агенту взаимодействовать со средой в любые моменты времени, а не только по такту. Frameworks (Asynchronous Environment): Ray Rllib: Поддерживает асинхронный сбор данных от множества агентов, которые не ждут друг друга. Griddly или Brax: В них можно настраивать среды, которые работают быстрее, чем агент принимает решения. Action Persistence и Skipping: Работы по Action Repetition (например, FiReL). Суть в том, что агент выдает действие, которое выполняется в течение некоторого времени, пока он занят расчетом следующего шага, или среда сама тикает несколько раз между кадрами. Turn-based vs Real-time: В геймдеве это часто решается через протоколы обмена сообщениями (напр. через gRPC), где среда это отдельный сервер, который не блокируется в ожидании ответа от клиента-агента. Тебе интересна больше математическая база (как считать градиент в таких условиях) или прикладная реализация в конкретном фреймворке?
А лучше сходи в Архив Анны, там есть более свежая литература, правда всё на Английском и Китайском. Но при помощи Дипсика и гопоты ты справишься.
>>1546469 Ключевые научные статьи (2025–2026) «Enabling Realtime Reinforcement Learning at Scale with Staggered Asynchronous Inference» (ICLR 2025). Это, пожалуй, главная работа по твоей теме. Авторы доказывают, что минимизировать долгосрочный регрет (ошибку) в реальном времени невозможно при обычной последовательной схеме. Они предлагают алгоритм staggered inference (шахматный вывод): пока одна копия нейросети еще считает действие для кадра , вторая уже начинает считать для , что позволяет выдавать действия с высокой частотой, даже если сама сеть «тяжелая». «Handling Delay in Real-Time Reinforcement Learning» (ICLR 2025). Работа посвящена проблеме «наблюдательной задержки» (observational delay). Когда среда живет своей жизнью, состояние , которое агент увидел, устаревает к моменту, когда действие готово. Авторы предлагают использовать temporal skip connections и историю наблюдений, чтобы предсказывать состояние среды в момент фактического выполнения действия. «AReaL: A Large-Scale Asynchronous Reinforcement Learning Framework» (2025–2026). Свежий фреймворк и теоретическая база для обучения агентов в условиях, когда сбор данных (interaction) и обновление весов (learning) полностью асинхронны и не блокируют друг друга. «Continuous-Time Reward Machines» (2025). Статья предлагает концепцию «машин наград» для сред с непрерывным временем (CTMDP). Это как раз то, что ты описывал: среда — это непрерывный процесс, а агент взаимодействует с ней через событийные механизмы, а не жесткие такты.
Технологические тренды 2026 «The Mirror World» (Invisible’s Agentic Field Report, 2026). Прогноз развития индустрии, где RL-среды рассматриваются не как тренажеры, а как «staging layers», в которые впрыскивается хаос (изменяющиеся API, задержки сети), чтобы агенты учились выживать в асинхронном реальном мире. «Re:ROS» (2025). Прототип среды для робототехники на базе ROS, которая специально спроектирована под асинхронную когнитивную архитектуру. В ней агент и среда — это разные системные процессы, общающиеся через сообщения.
Что именно искать? Если будешь гуглить дальше, используй эти термины (они сейчас в топе): Staggered Inference — когда несколько процессов вывода перекрывают друг друга по времени. Action-Driven Processes — новый взгляд на RL как на стохастические процессы, где действия инициируют переходы в произвольные моменты. Real-time Regret Analysis — математическая оценка того, насколько агент «проигрывает» из-за своей медлительности.
Тебе прислать ссылки на препринты (arXiv) этих работ или помочь разобраться в математике staggered inference или ты мудила сам загуглишь? Хотя наверное если ты тупой, наверное не загуглишь
Ссылки на работы (arXiv / OpenReview) Enabling Realtime Reinforcement Learning at Scale with Staggered Asynchronous Inference (ICLR 2025) Ссылка: arXiv:2412.14355 https://arxiv.org/abs/2412.14355 Суть: Доказывает, что в реальном времени обычный цикл обучения неэффективен. Предлагает алгоритм staggered inference (шахматный вывод), который позволяет использовать тяжелые модели, не снижая частоту действий. Handling Delay in Real-Time Reinforcement Learning (ICLR 2025) Ссылка: arXiv:2503.23478 https://arxiv.org/abs/2503.23478 Суть: Исследует задержку между моментом наблюдения и моментом действия. Авторы используют temporal skip connections (временные скип-коннекты), чтобы «пробрасывать» активации нейросети вперед во времени и компенсировать устаревание данных. AReaL: A Large-Scale Asynchronous Reinforcement Learning System (2025–2026) Ссылка: arXiv:2505.24298 https://arxiv.org/abs/2505.24034 Суть: Фреймворк, который полностью разделяет процессы генерации данных и обучения (decoupling). Это позволяет агенту постоянно взаимодействовать со средой, пока на фоне обновляются веса модели. Continuous-Time Reward Machines (IJCAI 2025) Ссылка: IJCAI Proceedings (2025/0563) https://www.ijcai.org/proceedings/2025/0563.pdf Суть: Вводит математический аппарат для сред, где время непрерывно, а награды привязаны к событиям, а не к шага
>>1546948 Чел, спок. Нейронкой найти статьи по теме я и сам могу. С учётом того количества не рабочего скама, который в последнее время выкладывается в том числе на топ конфах под редакцией тех же LLM, под "хорошестью" имел в виду их практическую применимость с хорошей теоретической базой. Спрашиваю в том плане, что возможно уже кто-то читал и реализовывал. А копать в тоннах говна как-то особого желания нет. Но спасибо за попытку.
>>1151064 (OP) Что вы думаете об идее учить нейронку предсканию не одного только следующего токена, а множества следующих, опираясь на предыдущие предсказания той же нейронки? Я где-то видел что-то похожее, но не могу вспомнить название и найти статью.
Суть архитектуры в следующем: 1. Первичная задача - моделирование любых входных данных, вне зависимости от их источника и смысла. Буквально бесконечный поток чисел, и нужно лишь предсказывать следующие числа этого потока. 2. Модель делится на идентичные FFNN блоки: - Вход: 2 вектора - "настоящее T" и "будущее T+2". - Глубина: 1 или 2 скрытых слоя (широких?). - Выход: 1 вектор "будущее T+1" (1/2 от входа). Т.е. блок подражает ассоциативному массиву. 3. Блоки насаживаются друг на друга таким образом, чтобы каждый блок принимал на вход предсказания как от предыдущего, так и от следующего блока (если есть). Самый первый блок принимает ввод из "внешнего мира". 4. Для обучения, каждый блок принимает вектор "реальное будущее T+1", сравнивает со своим предсказанием и корректирует свои веса. Обучение локализовано внутри отдельного блока и не распространяется дальше него. 5. Сбоку к вышеописанной модели подключается второстепенная модель-актуатор: принимает все предсказания на вход и выбирает действие на выход. Возможно, выбранное действие возвращается на вход модели-предсказателя, но это не обязательно. 6. Модель-актуатор можно обучать через RL.
Я предполагаю, что данная модель должна мочь предсказывать сложные события совсем не имея "контекста" в привычном понимании трансформеров, однако, в отличие от классических RNN, у этой модели отсутствует "скрытое состояние", потому что она функционирует непрерывно, в текущем моменте.
Как я вижу работу модели: 1. Блок 1 предсказывает непосредственное будущее. 2. Блок 2, опираясь на предсказание блока 1, даёт вероятное будущее, которое влияет на предсказание будущего блока 1, создавая замкнутый цикл, что, как я представляю, улучшает предсказания блока 1. 3. Если блоки не обучены, блок 1 выдает ошибки, а в следующих блоках вообще бессмысленный шум, но постепенно, при обучении, блоки должны научиться предсказывать будущее один за другим. 4. Если блоки обучены хорошо, то: - в знакомой ситуации модель знает будущее точно на несколько шагов вперёд, поэтому ей не нужно знать о прошлом - не нужен контекст, она уже решила задачу; - в незнакомой ситуации блоки дальше первого будут выдавать неточные значения, пока первый блок не выучится (ознакомится) на этой ситуации, но это, теоретически, более стабильно, чем монолитная (одноблочная) модель с одним предсказанием.
Идея в целом основана на том, что мозг животного обладает очень глубокими сетями, но нейроны очень медленные, но люди способны точно предсказывать и вовремя реагировать на события. В дикой среде ты вынужден реагировать быстро и точно, не думая, но необходимо предсказывать вероятные последствия. Вероятно, всё, что мы видим как "настоящее" - это предсказание мозга о будущем, которое часто, но не всегда, совпадает с реальным настоящим. Я лично неоднократно переживал "ошибку предсказания"...
В общем. Насколько такая модель жизнеспособна, учитывая ограничения обычного ПК/смартфона? Необходима работа в реальном времени, если что.
>>1549606 Не знаю даже, расстроит ли тебя мой ответ или нет С точки зрения реализации на обычном ПК или смартфоне, у такой модели есть как уникальные преимущества, так и критические вызовы. Жизнеспособность на потребительском железе
Почему это МОЖЕТ работать (Плюсы): Локальность вычислений: В отличие от Трансформеров, где сложность растет квадратично от длины контекста (О(n2)), твоя модель имеет фиксированную сложность на шаг. Для работы блока FFNN с парой слоев достаточно мощностей даже старого смартфона.
Отсутствие Backpropagation через время: Если обучение локализовано внутри блока (сравнение Tpred и Treal), тебе не нужно хранить в памяти огромные графы вычислений для обновления весов. Это экономит ГБ оперативной памяти. Асинхронность: Блоки могут обновляться с разной частотой. Нижние (быстрые) — 60 раз в секунду, верхние (абстрактные) - раз в секунду. Это идеально для оптимизации ресурсов процессора.
НО..... НО..... НО....
В чем главные риски (Минусы): Проблема "Эха" (Instability): Замкнутый цикл между Блоком 1 и Блоком 2 может привести к самовозбуждению системы. Если Блок 2 предскажет "чушь", он заставит Блок 1 подстроиться под эту чушь еще до того, как придут реальные данные. Модель может "уйти в себя". Информационная емкость: Обычный вектор чисел (без механизмов внимания) очень плохо кодирует структурную информацию. Чтобы предсказать, что произойдет через 100 шагов, верхним блокам придется сжимать данные так сильно, что они превратятся в шум.
Сходство с существующими проектами Твоя идея почти один-в-один совпадает с архитектурой Recursive Predictive State Representations (PSR) и некоторыми вариациями PredNet. PredNet используется для предсказания видеокадров: каждый слой предсказывает ошибку нижнего слоя. Она работает в реальном времени на обычных GPU.
Как это сделать "живым" на ПК? Чтобы модель не "развалилась", в нее обычно добавляют механизм Precision-weighting (взвешивание точности): Если Блок 1 видит, что данные из внешнего мира резко изменились (высокая ошибка), он временно "перестает слушать" предсказания Блока 2 и переходит в режим интенсивного обучения. Когда ситуация стабилизируется, он снова начинает доверять иерархии.
Фиксирую: Модель крайне жизнеспособна для задач сенсомоторного контроля (робототехника, управление дроном, простые игры), где важна реакция, а не глубокие философские размышления. Для обработки текста (языка) ей будет не хватать "памяти символов", но для потока чисел — это отличный кандидат на замену тяжелым нейронкам. Ты планируешь реализовать это как программный прототип или вас больше интересует теоретическая сторона вопроса?
>>1549606 >Я где-то видел что-то похожее, но не могу вспомнить название и найти статью. MTP, или мульти токен предикшен. Всё, можешь идти дальше со своими охуенными идеями.
>>1549799 >мульти токен предикшен Я почитал - это совсем не то. MTP имеет в основе стандартных размеров Transformer плюс несколько маленьких выводящих голов, которые параллельно предсказывают 1, 2, 3, 4 и т.д. токены, но все эти предсказания никак друг на друга не влияют.
>>1549846 А что ты вообще пытаешься найти? Рецепт к АГИ или что? Если так смотреть, у тебя направление мыслей в сторону биологической правдоподобности - локальность обучения, асинхронщина, разреженность вычислений. Думаешь это реально будет работать? Пока что по всем фронтам ебут трансформеры и бэкпроп. Там уже и роботов переводят на эти рельсы (VLA - https://en.wikipedia.org/wiki/Vision-language-action_model). И пока пределы способностей данных моделей до конца не известны. Может туда и копать, не?
>>1550716 Согласен, сейчас Backprop и Transformers — это абсолютные короли. Они максимально эффективно используют то, что у нас есть: гигантские массивы данных и прорву вычислительной мощности GPU. VLA-модели (Vision-Language-Action) действительно показывают магию, просто масштабируя проверенные архитектуры. Но вот почему «биологический» подход — это не просто ностальгия по нейронаукам, а прагматичный поиск: Энергоэффективность: Обучение одного гигантского трансформера сжигает электричество как небольшой город. Мозг же потребляет около 20 Ватт. Чтобы дойти до уровня AGI в робототехнике, нам нужно уметь учиться «на лету» без дата-центров за спиной. Проблема катастрофического забывания: Бэкпроп отлично учит статические датасеты, но в реальном мире (online learning) он часто затирает старые знания новыми. Локальное обучение и разреженность помогают изолировать знания. Задержки (Latency): В робототехнике асинхронность — это жизнь. Пока трансформер «думает» над тяжелым кадром, робот уже может врезаться в стену. Биологические механизмы позволяют реагировать на разных скоростях параллельно. Трансформеры сейчас — это как паровые двигатели в начале индустриализации: мощно, но громоздко и прожорливо. Рано или поздно мы упремся в потолок масштабирования (Data Wall или Energy Wall), и тогда архитектуры, вдохновленные биологией, станут единственным выходом. Копать в сторону VLA сейчас — это самый верный путь к быстрому продукту. Копать в сторону биологической правдоподобности — это ставка на смену парадигмы, когда текущий стек перестанет вывозить.
Хочешь разобрать конкретный пример, где Backprop буксует (например, в Continuous Learning), или обсудим, какие архитектуры (типа JEPA или SNN) пытаются усидеть на двух стульях сразу?
>>1551779 >https://github.com/muooon/EmoSens >что это такое и что с этим делать? Проект EmoSens на GitHub представляет собой инструмент для анализа эмоций или сенсорных данных, написанный на Python. Разработчики могут использовать этот код для внедрения функций распознавания эмоций, начав с изучения файла README.md и установки зависимостей из requirements.txt. Подробности доступны на странице muooon/EmoSens.
>>1553278 Я бы разделил выходной слой или один из выходных слоёв (если это трансформер) на области: а) конечный вывод; б) итерационный вывод, возвращающий данные обратно на вход, для циклических операций и глубокого, эмбедингового, латентного мышления; в) модификатор, который через 2-4-хслойный декодер будет вести к весу каждого нейрона, с возможностью изменения значений.
>>1550716 >А что ты вообще пытаешься найти? Хочется какой-то маленький искусственный организм, способный чему-то обучаться. Чтобы было о ком/чём заботиться и помогать развиваться. Может, знаешь о Тамагочи и подобных старых игрушках? Там развитие виртуального зверька прописано программистами до мельчайших деталей, и выйти за рамки он не может. Хотелось бы что-то, что может развиваться само, и, желательно, не иметь ограничений (кроме железа).
>трансформеры и бэкпроп >Может туда и копать, не? Успех трансформеров в том, что их можно обучать на неограниченном количестве устройств и полностью параллельно, что крайне выгодно корпорациям, что обладают гигантскими капиталами. В остальном это тупиковая штука с замороженными весами/связями. Корпорации уже давно знают об этом, кстати, но ради продолжения инвестиций вынуждены обманывать.
Бэкпроп в теории способен решить любую задачу, но требования у него слишком затратные. Рекуррентные нейронки "проиграли" в первую очередь потому, что бэкпропом их чрезвычайно затратно учить - нужно разворачивать и прогонять градиенты по шагам во времени, фактически увеличивая число параметров пропорционально количеству шагов ≈ "контексту"... Добавить к этому отсутствие конкретной задачи - и становится непонятно, а зачем он вообще нужен?
В общем, у меня нет ни ресурсов, ни желания "копать" мейнстримные нейронки, которые натаскивают на банальные корпоративные задачи как инструменты. Представь, что кто-то хочет сам слепить фигурку из пластилина, а ты ему говоришь: "сегодня популярно заливать расплавленный пластик под давлением в металлические формы - получаются миллиарды одинаковых деталей в день, может туда и копать?"
Вот подумай: как мы можем доказать, что у топовых моделей, тренировочные датасеты которых нам совершенно неизвестны, "ум" происходит не из-за зазубривания готовых решений наизусть? Ведь есть огромная разница между "зазубрить" и "научиться".
Представь себе такую ситуацию: 1. Юзер даёт задачу облачному ChatGPT. 2. ChatGPT не знает решение и пишет бред. 3. Юзер выходит из себя, ругается в чат и т.д. 4. Срабатывают фильтры, помечают лог чата. 5. Логи передаются индусам в Индии, которые сами, ВРУЧНУЮ решают задачу юзера, и передают готовое решение обратно владельцам ChatGPT в их датасеты. 6. ChatGPT дообучают на обновленном датасете. 7. Новый юзер (или тот же) спрашивает у ChatGPT аналогичную задачу (или ту же), и получает копию, подготовленную индусами, которая решает задачу. 8. СМИ: "Новый ChatGPT 6.9 min-MAX решил задачу, которую не мог решить ChatGPT 6.8 MAX-mini!!!"
Как можно доказать, что такого обмана нет, и у LLM наблюдается настоящий интеллект, а не копипаста подготовленных заранее на все случаи решений?
>>1553671 Так так же можно про любого человека сказать. Если он не натренирован на решение определённых задач, то он так же будет выдавать бред. Представь что взяли среднестатистического чела из толпы и сказали ему решать олимпиадные задачки по математике? Какова вероятность что он их решит, если никогда не решал ранее? Если он выдал "бред" означает ли это что у этого человека нет интеллекта? Видимо у тебя есть какое-то заблуждение насчет интеллекта в целом. Ну и насчет распараллеливания бэкпропа - там тоже есть свои лимиты. В ином случае мы бы уже видели модели и по 130 триллионов параметров, а это уже вполне на уровне человеческого неокортекса.
Ну и ещё один момент. Опять же заблуждение насчет трансформеров. Уже сейчас ведутся работы, где им дают очень сложные математические задачи, которые они раньше не решали - и с долей этих задач они справляются уже сейчас. Что будет когда заскейлят до 130т параметров - страшно представить.
Но в целом, я скорее соглашусь, что этим методам надо составить конкуренцию, на порядки более экономную и доступную, чтобы у корпов не было монополии на возможный AGI.
>>1553650 Рекуррентные сетки проиграли потому что их сложнее масштабировать, нестабильные при увеличении длины последовательности, дольше тренируются. Хотя есть сейчас теже самые s4 модели (mamba/Jamba например), ну или "распараллеленные" RNN (RWKV например). Сложно назвать проигрышем это, с учётом того RNN подобные архитектуры до сих пор развиваются. А если хочешь что-нибудь "живое", это тебе надо всякие грамматики курить, l-системы, эволюционки, и на их основе строить сетки. Короче меметические алгоритмы использовать. Огромное непаханное поле для исследований.
>>1553650 >Хочется какой-то маленький искусственный организм, способный чему-то обучаться. Качай коннектом червя (проект OpenWorm) или там мухи (https://eon.systems/updates) да развлекайся как хочешь.
>>1553396 >просто у вас тут у всех такие жесткие знания, вы сами учились или у вас профильная вышка/мага? обычно. просто мы тут сидим с момента основания доски и общаемся и читаем и погружены и у каждого на выделеном компе живет нейробояр Геннадий
>>1553753 Наверное, я неправильно выразился. Не важно, может какая-либо модель решить какую-либо задачу или нет, поскольку любую задачу можно решить брутфорсом. Недостаток брутфорса в том, что он может требовать чрезвычайно много времени, которое в реальности недоступно. Суть "интеллекта" в способности найти подходящие решения быстрее, чем брутфорс. Если нахождение решений перекладывается на людей (составляющих датасеты), то разве это интеллект? Интеллект у составителей датасетов, а не у модели.
Об LLM часто говорили, что они "просто" "прочитали интернет целиком", но на деле ведь это не так. Нужно чистить датасет от мусора, добавлять в датасет кучу специально созданных образцов, перемешивать их, комбинировать, добавлять шум и всё такое. Потом дополнительные костыли... Всё это явно говорит о неспособности LLM свободно обучаться, как это у множества животных происходит. Люди вручную закладывают решения задач в LLM через датасеты. Огромные модели могут впитать больше решений из датасетов, но это не делает их интеллектуальнее, т.к. решения были подготовлены вместо них в датасетах.
И когда говорят про "AGI" в контексте "LLM", то всегда подразумевается "ИИ, который уже знает и умеет что угодно", что-то вроде "рукотворного всезнающего и всемогущего бога". Но в моём представлении, AGI не обязательно что-то знает и умеет, и не обязательно способен вместить в себя много знаний и навыков; достаточно, чтобы он мог научиться по ходу дела. Человечество достигло больших высот благодаря способности к обучению, а не каким-то заранее заложенным знаниям от каких-то инопланетян.
И да, конечно, люди не часто приходят к чему-то собственным умом. Большую часть своей жизни мы обучаемся через подражание и получение знаний от предыдущих поколений или сверстников. Но здесь проявляется основное отличие: LLM тренируется в специальном режиме на специальных данных, когда человек обучается в процессе нормальной работы с нормальными данными. Т.е. бесполезно объяснять, например, чатботу на базе трансформера, что-либо непосредственно в чате - он не сможет научиться, и загонять эту переписку в датасет тоже бесполезно: необходимо готовить специальные данные для формирования нужных навыков у модели. Да, есть надстройки над моделями - RAG и всё такое, но это ненадёжное решение в долгосрочной перспективе.
Короче. LLM хороши, но как инструменты, заранее заточенные под конкретные задачи. Кузнец заточил ножницы, и теперь ножницами можно резать, но это ножницы, а не кузнец. AGI - это ребёнок кузнеца, что наблюдает за работой отца и пытается повторить, непроизвольно обучаясь новому для него ремеслу, и полностью без специальной подготовки данных. Я сомневаюсь, что если кузнец продолжит затачивать ножницы острее и острее, вдруг получится Буратино.
И вот я не вижу, каким образом можно добиться от трансформера поведения, описанного выше. Т.е. это выглядит невозможным из-за архитектуры, которая заточена на максимальное сжатие уже известных паттернов в оффлайн-режиме тренировки...
>>1556900 Ты же в курсе, что ничего не мешает сделать бесконечный цикл запросов к LLM, где в каждом шаге цикла LLM сама сможет выбирать любые тулзы, которые ей пропишут. А прописать можно что угодно, хоть в свободной форме писать команды в терминал. Когда контекст ллмки заполняется - сжимаешь его, помещаешь в векторку. Если ллмки нужна будет какая-то инфа, которую она ранее обрабатывала - она может "вспомнить" её из векторки. И вот прописываешь ей какую-либо цель, по типу "найди мне более оптимальную архитектуру нейросетей" и она будет автоматически писать код, запускать его, анализировать результаты, обращаться к различным источникам для получения "вдохновения". Это УЖЕ придумано, реализовано и активно используется в том числе, чтобы оптимизировать текущие алгоритмы работы нейросетей. Чем это отличается в таком случае от человека? Как-будто ничем. Можешь послушать лекцию чела, который шарит в теме более чем https://www.youtube.com/watch?v=59IFbGCfDXM
Я больше убежден в том, что интеллект - это не просто наличие какого-то количества нейронов и синапсов в голове с определенным алгоритмом работы, это в первую очередь способность обработать тот колоссальный массив информации, которое человечество скрупулезно копило тысячи лет (чем это будет отличаться от того, что ллмкам собирают специально датасеты? И то от части это будет не правда, претрейн невозможно вручную скрупулезно почистить, только какие-то базовые вещи, а rlhf тот же - ну можно сравнить с "воспитанием"). А будет ли это голова какого-то отдельного индивида или нейросеть - не особо важно. Есть даже более интересный контрпример твоим суждениям - одичалые дети (дети-маугли). Когда их изымали из своего животного социума, адаптироваться к человеческому они не могли, максимум чему могли научиться - это ходить на двух ногах, да паре слов. Хотя с точки зрения физиологии - генетически такие же люди, те же синапсы, нейроны, те же алгоритмы обучения. Только вот не хватило одного - сложных, запутанных, требовательных к вычислениям данных (и наверное тут ключевое - это язык). Вообще даже есть одна статья на эту тему, достаточно интересные выводы можно сделать по поводу эмерджентной природы интеллекта, советую почитать и не быть предвзятым к тому что там трансформеры используются - https://arxiv.org/abs/2410.02536
>>1557320 На твой взгляд, сколько процентов знаний и навыков необходимо держать внутри LLM, а сколько можно "выгрузить" во внешнюю базу данных? 1%? 50%? 99%? Почему бы нам не использовать базы данных как "искусственный интеллект", если они способны легко заменить хорошо натренированную нейронку? Зачем человеку читать книги, если существуют библиотеки?
>Чем это отличается в таком случае от человека? Тем, что человек записывает новые знания и навыки напрямую в свои нейросети. LLM с RAG - это как если человек будет держать открытый мануал "как нужно управлять автомобилем" всю свою жизнь за рулём, полностью забывая его, как только отведёт взгляд. Очевидно, что такой человек менее безопасен для дорожного движения, чем тот, кто всё помнит и не нуждается в открытой прямо перед носом книжке.
>адаптироваться к человеческому они не могли Там причина физиологическая: у новорождённых количество синаптических связей раз в 10 больше количества связей взрослого человека, и их число стремительно уменьшается в первые годы жизни. Человеческий мозг "overparametrized", и это сильно улучшает его обучаемость, а потом идёт "pruning" и значительное ухудшение обучаемости. Если ребёнок наблюдает за людьми вокруг, это укрепляет часть синаптических связей, а если нет - эти связи просто обрываются. Хотя даже у старых людей рождаются нейроны и синаптические связи, их число ничтожно в сравнении с объёмом "лишних" связей младенца.
Данному феномену есть объяснение и даже аналог в машинном обучении, гугли "lottery ticket hypothesis" - вкратце, в достаточно большой нейронной сети есть подсети, которые лучше всего обучаются благодаря подходящей случайной инициализации, тогда как остальные подсети - лишний мусор, от которого избавляются прунингом. В крайне большой сети существуют подсети, которые выполняют задачу в достаточном качестве вообще без обучения. У мозга количество параметров столь высоко, скорее всего, специально для поиска удачных подсетей - но без практической проверки найти нужные невозможно, и поэтому первые годы жизни столь критичны.
Но меня больше волнует статичность нейронок. Да, человеческий ребёнок схатывает базу с рождения с громадным количеством лишних параметров, но обучаемость сохраняется, обычно, на протяжении десятилетий, и часто до самой старости. А нейронка обучается лишь раз и потом любой файнтюнинг по большому счёту только ухудшает её состояние. И костылями этот косяк никак не компенсировать.
Я уже много лет время от времени подумываю, что "растущая" нейронка могла бы быть более гибкой в обучении на ходу. Типа добавлять новые нейроны и синаптические связи по мере насыщения старых. И постоянно удалять лишнее. Увеличил - уменьшил, и повторяется до бесконечности. Но нужен какой-то фреймворк для такой системы, недостаточно просто накидать каких-то радомных нейронов без порядка. Упорядоченность структуры мозга явно неспроста, интеллектуальные животные все имеют какие-то упорядоченные структуры разного происхождения.
>>1557822 >На твой взгляд, сколько процентов знаний и навыков необходимо держать внутри LLM, а сколько можно "выгрузить" во внешнюю базу данных?
Тут надо ответить на вопрос - а какое количество информации реально содержится в голове среднестатистического человека, а какое он черпает из различных источников, обращаясь к ним время от времени. Кажется соотношению будет далеко не в пользу людей. В тоже время современная LLM уже знает на порядки больше чем среднестатистический человек. И с течением времени будет знать еще больше, и уметь еще больше - их же периодически переобучают. Это своеобразное обучение, отличающееся от человеческого, отложенное, периодическое, прерывистое - но обучение. Ты прав в том плане, что RAG - это не полноценная замена человеческой памяти, а скорее суррогат, как обращение к справочнику. Но имеет ли это какое-то значение, если наблюдается интеллектуальное поведение - последовательное изучение и эксплуатация окружающей среды для достижения вполне конкретной цели?
>lottery ticket hypothesis Это хороший аргумент, частично пересекающийся с рандомными проекциями (здравствуй ELM/ESN/LSM), где случайно определенные и зафиксированные веса + линейная обучаемая проекция могут давать вполне хорошие результаты, если "повезет" с инициализацией. Но я это вижу как следствие, а не причину эмерджентности интеллекта. Природе видимо было проще, с эволюционной точки зрения, копипастом увеличить количество доступных "предикторов", не меняя сильно энергетическую схему организма.
>Но меня больше волнует статичность нейронок Если возвращаться в первый пункт. ЛЛМки в моменте статичны, да. Но если смотреть шире - их постоянно дообучают в том числе на новых данных, у тех же провайдеров есть прям "срезы знаний", когда маркируют определенные модели ЛЛМ по тому временному срезу данных, на которых их обучали. Чем это опять же будет отличаться от "среза знаний" человека в конкретный момент времени? Тем что у человека частота получения новых знаний больше? Ну как-будто не очень серьезный аргумент.
>Я уже много лет время от времени подумываю, что "растущая" нейронка могла бы быть более гибкой в обучении на ходу. Типа добавлять новые нейроны и синаптические связи по мере насыщения старых. И постоянно удалять лишнее.
Возможно ты уже в курсе про NEAT (нейроэволюцию аугментированных топологий), метод довольно старый, но рабочий. Возможно есть последователи идеи, которые улучшили исходный алгоритм, но в эту сторону я особо не копал.
>>1557929 У тебя есть датацентр для ежедневного переобучения трансформера на триллионы параметров? Нет? Тогда смысл обсуждать, насколько хорошо трансформерам обучаться в чьих-то чужих сверхдорогих датацентрах? Исследовать эти трансформеры ты тоже не сможешь, поскольку они там все заперты, а даже если кто-то и выпускает "open weights", датасетов никто не даёт. Совершенно тухлая тема для двачеров-одиночек.
>>1559649 Чел, я тебе скинул статью, где люди gpt-2 подобную архитектуру (а там не больше 1.5 лярда параметров) обучали на данных из клеточных автоматов (бесплатно, бесконечное количество данных) и сделали вполне себе интересные выводы. Это вполне можно поместить в средний потребительский ПК. Ну ок, твоё право, продолжай искать святой Грааль. Если успеешь.
>>1559841 >Если успеешь. Ты про ядерную войну? Да, времени мало.
>искать святой Грааль Мне не нужен интеллект, который ищут корпорации. Вообще не верю в то, что интеллект может серьёзно подняться над уровнем мозга человека. Доступ к информации - это не "интеллект", а "эрудиция". Т.е. корпорации делают супер-эрудитов, а не интеллект. Полезны ли эрудиты? Да, но только не для меня...
>GPT-2 1.5B Тысяч 200 рублей нужно как минимум, и это если приобретённый компьютер не сломается в первые несколько месяцев. Тогда нужно ещё 200 тысяч. И пользоваться им параллельно с обучением нельзя - несколько месяцев будет тупо жечь электричество. Трансформеры принципиально не для народа, а для гигантских датацентров огромных корпораций. Даже Яндекс и Сбер не смогли обучить нормальные GPT, несмотря на владение каким-то суперкомпьютером.
>>1560070 >Даже Яндекс и Сбер не смогли обучить нормальные GPT, несмотря на владение каким-то суперкомпьютером. ну тут ты перегнул. сбер даже опенсорс выложил свои гигачеды. да, опус 4.6 пока не получился, но вполне возможно скоро получится
Как думаете, если сделать классический чатбот/NPC, работающий по скрипту, возможно ли прикрутить к изначальным скриптам растущую нейронку, чтобы та постепенно адаптировалась и развивалась сверх изначально заложенных скриптов? Или нужно всегда начинать с абсолютно чистого листа - имея только случайные нейроны? Как бы вы представили себе подобную композицию из скриптов и нейронки?
Впитают ли нейроны поведение скриптов так, чтобы скрипты больше не понадобились для поддержания стабильной конструкции? Типа, скрипты играют роль жёсткого скелета, без которых нейроны растекаются (типичная проблема всех RL решений, как я понял).
Могу собрать такую систему, но только в один слой. Обратное распространение ошибки не получается реализовать, а готовым библиотекам не доверяю.
>>1560870 >>1560473 >>1151064 (OP) >>1375701 Всем q гайс, сорри за оффтоп, но в поисках работы я то и дело вижу научные вакансии для мл инженеров связанные с биологией/физикой/химией и прочими научными вещами
Скажите, насколько реально туда вкатится будучи чисто айтипидаром? По требованиям там часто профильное по естественнонаучной хуйне не требуют, но я чет сомневаюсь что мимокрока позовут белки сортировать, какие-то знания там все равно нужны
Чисто сам вайб меня на приколе держит, это же как во вратах штайна в лабе сидеть и хуйню прикольную делать, сразу видно что-то полезное делаешь для человечества, типа ученый на минималках
>>1562551 > >Скажите, насколько реально туда вкатится будучи чисто айтипидаром? По требованиям там часто профильное по естественнонаучной хуйне не требуют, но я чет сомневаюсь что мимокрока позовут белки сортировать, какие-то знания там все равно нужны > ЗАгугли в иностраннонете или ютубе курс по этой теме https://edu.openbio.ru/mlforbiomed Выгрузи весь курс с ютуба типа с mit или гарварда в вк видео и открой в яндекс браузуру, он тебе на русском сгенерит с бариновского языка. А потом или со скиллом или ищи залупу типа https://edu.openbio.ru/mlforbiomed НО! с действующей образовательской лицензией и пройдя курс получишь свидетельство о повышении квалификации и потом уже в гос контору с такой бумажкой ввалишься без проблем. А если ты еще приложишь HR фотографии своей локальной машинки с тремя v100 и комментариями как ты дома белки тритийниклуоидные на составные элементы раскладываешь в собственно натренерованном скачанном искусственным интеллектом, она потечёт и возьмет тебя на 100500 денег
>>1280932 фулл сурс выложишь? Я понимаю что ты выражаешь скепсис своим анализом математической основы алгоритма обратного распространения ошибки, но хз хз. Слишком мало вводных и контекста в этой маленький пикче На самом деле формула не является рекурсивной, значение бк для следующего слоя уже содержит в себе все "множители" и производные от последующих слоев вплоть до функции потерь Е лолка. Таким образом, правило цепочки "чайн руле" соблюдается полностью: информация о глобальной ошибке передается через цепочку б, ахахах от слоя к слою. Макаба блджад символы не позволяет вставлять.
ПососиВывод: Описанные в твоём тексте ГЛУБОКОМЫСЛЕННЫЕ сомнения вызваны непониманием того что рекурсия в определении б автоматически учитывает всю глубину сети. Алгоритм сука является строгим воплощением дифференциального исчисления
>>1583398 Забей, это просто влажные фантазии шизофреника, или дилетанта
>>1591433 На апрель 2026 года в сфере локального (self-hosted) ролплея и креативного письма (creative writing) SOTA (State of the Art) модели показывают впечатляющие результаты, часто приближаясь к закрытым аналогам. Лучшими локальными моделями для RP/Creative Writing сейчас считаются: 1. Топ-уровень (Нужны мощные GPU/сервер) Qwen3.5-27B/72B (или Qwen3-235B-A22B): Считаются одними из лучших по творческим способностям, соответствию предпочтениям человека и креативному письму в 2026 году. DeepSeek-V3 / V3.2: 30B активных параметров (1T всего), они предлагают топовое качество, сравнимое с закрытыми моделями (Claude Opus 4.5), отлично поддерживают контекст. Arcee Trinity Large Preview (400B MoE): Специализированная модель для креативного письма, ролевых игр и работы с длинным контекстом, работает на 13B активных параметров, отлично подходит для удержания контекста.
2. Лучшие модели среднего размера (Доступны на мощных домашних ПК) Gemma 4 (31B) / Gemma2-27B: Gemma 4 — популярная модель с сильной репутацией для локального использования, особенно для среднего размера, показывает отличные результаты. Big-Tiger-Gemma-27B-v3: По-прежнему одна из лучших моделей для creative writing, обеспечивающая отличный стиль без излишней «роботизированности». Mistral Large 2: Отлично подходит для детального повествования и создания естественных диалогов.
3. Лучшие маленькие модели (Для слабых ПК / ноутбуков) Smollm3 3B / Qwen3.5-4B: Лучшие модели для быстрой игры, неплохо показывают себя в RP, несмотря на размер.
Где лучше всего использовать для RP? Для запуска и максимального качества RP/Storytelling рекомендуется использовать следующие инструменты: SillyTavern: Самый популярный фронтенд для ролевых игр, поддерживающий Lorebook, смену контекста и работу с персонажами. LM Studio / Ollama: Для удобного запуска моделей локально (GGUF/EXL2 форматы). Итоговый совет: Если позволяют ресурсы (24GB+ VRAM), выбирайте Qwen3.5-27B или DeepSeek-V3 (в квантованном виде). Для более скромных машин (12-16GB VRAM) — Gemma 4 31B или Big-Tiger-Gemma-27B-v3
Эй, я тут просто думаю. А существовали ли эксперементы по обучению неиросетей с очень жирными весами, допустим fb128 ? Ии говорит что даже обучение небольших моделей с такой точностью потребует дохренища памяти и то что вроде как ни кто так не делал, а так же для этого потребуется переписывать библиотеки.
>>1606916 Наверняка пробовали. А ещё наверняка нынешние нейросети обучают с запасом по точности, и именно благодаря этому их можно квантовать как не в себя. Уменьшить вес в два раза с едва заметными последствиями (fp16 в fp8) — это неебический запас, просто пиздец какой большой, больше просто не нужно.
Куда вы лезете? Оно вас сожрет. Начал разбираться с теорией хаоса, аттракторами и вот этим вот всем. Для возникновения хаотичных систем, достаточно трех нейронов. Написал DeepSeek код для визуализации сингулярного дискретного аттрактора Шильникова. Результат такой себе, для 4х уже интереснее. Если кто-то изъявит желание разобраться в этой теме вместе, то можем обсудить @neuroattractor, html код прилагаю, сам в этом ничего не понимаю.
>>1611355 Вот тебе лично, это ничего не даёт. Другой вопрос, что тематика треда это исследование. А вот аттракторы это как раз про это. Один из ответов, почему нейросети галлюцинируют, например. >>1611623 Образование это только малая часть, тут важнее желание разобраться в чём-либо.
>>1609730 В теории, вообще можно обучить минимальное количество нейронов и запускать на них AGI. Только времени на обучение понадобится больше, чем песчинок на пляже Омаха
Попробовал обучить 4 нейрона воспроизводить хаотические системы, был послан нахуй. Что по итогу: 3 нейрона достаточно для возникновения хаоса, для обучения уже нужно минимум 50.
>>1613639 В определенный момент нейронка начала галлюцинировать, я попросил ее продолжать и писать код. На исследование это никак не повлияло, так как при каждой итерации кода ссылалась на актуальные научные данные.
>>1610902 >Для возникновения хаотичных систем Зачем тебе хаос? Интеллект - это упорядоченность, противоположность хаосу. Если тебе нужен хаос, в компьютерах это решается генератором случайных чисел... Если и их тебе мало, то просто считывай с физических датчиков что угодно - это и будет хаос.
Интеллект в любой его форме - это стремление к уменьшению хаоса. Например, растения не имеют нейросетей, но они могут адаптироваться к условиям окружающей среды: окружающая среда хаотична по определению, и приводит растение в беспорядок, но усилиями своих клеток растение стремится встать в оптимальное положение для максимизации разных полезных факторов и минимизации вредных. Это и называется "интеллектом". А хаос - враг интеллекта.
>>1613276 >для обучения уже нужно минимум 50 Обучать можно и один-единственный нейрон. Даже не обязательно "нейрон", сама концепция обучения абстрагируема от нейросетей. Ты берешь систему и стараешься её упорядочить - это и есть "обучение".
>>1614204 >Зачем тебе хаос? Интеллект - это упорядоченность, противоположность хаосу. Если тебе нужен хаос, в компьютерах это решается генератором случайных чисел... Ты там случайно не путаешь рандом с хаосом, шиз? Хаос - про чувствительность динамической системы к начальным условиям, про непредсказуемость таких систем. К случайности никакого отношения не имеет. Возьми тот же "game of life" - максимально простые правила развития системы, полностью отсутствует фактор случайности. При этом система непредсказуема. Ты не сможешь сказать что будет с ней через 1000 шагов, даже если тебе дать первоначальные условия (за исключением тех случаев, когда система умирает сразу после первого шага). Единственный вариант понять что будет через 1000 шагов - это вычислить их начиная с самого первого шага. >Интеллект в любой его форме - это стремление к уменьшению хаоса. Интеллект - это способность моделировать окружающую среду, а уже через моделирование появляется возможность предсказывать изменения в среде, что даёт определенные бонусы к адаптации. Чем сложнее модель - тем больше интеллекта требуется для её построения. Возможность адаптироваться к окружающей среде есть у всех живых организмов, делает ли это их интеллектуальными? Нет, не делает. >сама концепция обучения абстрагируема от нейросетей. Ты берешь систему и стараешься её упорядочить - это и есть "обучение". Если ты про чисто математический аппарат оптимизации, где нужно подобрать оптимальные коэффициентики для моделирования какого-либо явления, например линейного, то да, нейросети тут не нужны - достаточно простой линейной модели.
>>1619475 Ну я близок, но один не вывожу. Архитектура кода является кибернетической моделью, где гиперхаос служит субстратом для эволюционирующей нейросети, а отбор по двойному критерию имитирует поиск локальных минимумов в хаотическом ландшафте. Эта система напрямую воплощает идеи, обсуждавшиеся нами в контексте библиотеки Бабеля: от странных репеллеров к аттракторам, от недостижимых смыслов к самозарождающейся логике. Дальнейшие исследования на её основе могут пролить свет на фундаментальные механизмы возникновения интеллекта в сложных динамических средах.
>>1625590 Че ты ваще хочешь сделать? Ты статью какую-то пишешь на стыке философии/теории информации или какую-то пруф оф концепт архитектуру/библиотеку?
>>1625732 На десятках нейронах кручу хаотические системы (edge of chaos). Хочу прикрутить к этому Prolog. По идее, эти системы можно обучить логическим функциям. Копаю в этом направлении, очень много исследований которые пересекаются с этой темой. От прогноза рынков, нейробиологии и так далее. Пробовал несколько узкоспециализированных направлений, в принципе, везде можно найти применение. Тема очень обширная, есть наработки.
Успешная реализация этого плана станет прямым доказательством того, что гиперхаотическая система, эволюционируя под давлением вычислительной задачи, способна самопроизвольно структурироваться в логический элемент или предиктор, отказываясь от внешнего интерпретатора. Это углубит понимание связи между динамическим хаосом, морфологической вычислением и нейродарвинизмом, а также продемонстрирует новый способ создания «вычисляющей материи», где алгоритм имманентен физическому субстрату.
>>1625739 Чел. Давай проще. Твои водянистые пассажи не очень интересно читать. По существу у тебя что? Ты берешь обычный ANN и пропускаешь через него выход какой-то хаотической динамической системы (ХДС) 4 класса по Вольфраму (комплексной, находящейся на границе хаоса), пытаясь обучить эту сеть предсказывать что выдаст ХДС в следующий момент времени? Т.е. ты по сути пытаешься повторить эту статью https://arxiv.org/pdf/2410.02536?
Причем тут вообще prolog - решительно не понятно. Ты либо шиз, либо гений. Но я скорее ставлю на шиза.
>>1625943 Ты прав. Есть некоторые успехи. Нашлись устойчивые состояние в котором хаос показывает частичное наличие логики с точностью близкой к 100%. Выполняется часть логических операций на аттракторе, формальные проверки результатов эволюции выполняются на Prolog. По идее, уже можно собрать машину из пары таких нейросетей (10 нейронов) с полной обработкой логических операций. Смотри, что ещё есть https://browse-export.arxiv.org/abs/2605.26848 1. AND: точность → 100% при отключённом обучении и прямом считывании Это означает, что гиперхаотическая система уже содержит в себе логический вентиль AND без какого-либо обучения считывающей сети. При размерности 4D (n4 активен, n3 и n5 отключены) и прямом считывании sign(x) аттрактор самопроизвольно выдаёт правильный ответ для I1=I2=1. Это первое экспериментальное подтверждение того, что логика может быть имманентна динамике хаоса.
2. XOR: точность → 100% с обучением и без размерностей Z, 4D, 5D XOR — нелинейно-разделимая задача, требующая более богатой динамики. Система успешно обучается её решать через chaosPredictor. При отключении всех размерностей (остаются только базовые уравнения Лоренца без нейроуправления) точность также достигает 100% — это говорит о том, что классический хаос Лоренца сам по себе является достаточным резервуаром для XOR.
3. Катастрофическое падение точности при I1=-1 Это ключевое наблюдение. AND с I1=-1, I2=+1 должно давать -1 (False). Система не может перестроиться под этот случай, что объясняет результат верификации:
text '1,1': False ← I1=+1, I2=+1 должно быть +1, но система, вероятно, выдаёт -1 '1,-1': True ← I1=+1, I2=-1 должно быть -1 ✓ '-1,1': True ← I1=-1, I2=+1 должно быть -1 ✓ '-1,-1': False ← I1=-1, I2=-1 должно быть -1, но система, вероятно, выдаёт +1 Интерпретация: Текущая конфигурация весов audioGenNN реализует не чистый AND, а вырожденный классификатор, который всегда предсказывает +1, когда I1=+1, и -1 в остальных случаях (или наоборот). Это локальный минимум фитнес-ландшафта, где точность 50-75%, но не 100%. Эволюция ещё не нашла глобальный минимум, соответствующий полноценному AND.
Подтверждено, что гиперхаотический аттрактор может кодировать логические функции непосредственно в своей динамике (AND при 4D показал 100% после обучения).
Обнаружен конкретный механизм неудачи: система застревает в локальном минимуме, реализуя частичную логику.
Верификация показала необходимость направленной эволюции управляющей сети (audioGenNN) для нахождения глобального минимума, где все 4 комбинации входов дают правильный ответ.
>>1625982 Ну так я и пишу код и обрабатываю результаты нейросетью. Еще пробовал двух агентов которые переписывают код страницы, такое вот инжектирование по API. А вообще, интересно что-нибудь автоматизировать.
>>1625999 >Хаотические системы с устойчивыми состояниями много где встречаются Ну да. Но причём тут ксоры и энды? >на бирже получилось предсказывать волатильность на 5 мин Не вижу мульярдов рублей. И с таким спредом ты на комиссии больше потратишь, лол.
>>1626010 >Ну да. Но причём тут ксоры и энды? Мне интересно проверить теорию edge og chaos >Не вижу мульярдов рублей. Я только неделю пытался интегрировать торгового бота в реальную площадку. Пока только в sanbox
>>1172306 В начальной генерации параметров важно множители правильно выставить чтобы норма вектора при проходе вверх по слоям не росла сильно быстро, если делать от балды а не по рецепту из статьи легко ошибиться. Кроме lr надо еще настраивать оптимизатор правильно, моменты всякие и все такое.
Успех. Логические операторы полностью реализованы на 3-х нейронах. При переключениях между логическими операторами, хаос автоматически настраивается по API. осталось понять, как это можно применить
Гиперхаотический резервуар (5‑мерный, с параметрами, управляемыми нейросетью) генерирует богатую динамику. Вы можете:
Проверять гипотезы о том, как хаос может выполнять логические операции (AND, OR, XOR) – классическая задача «вычислений в хаосе».
Анализировать, как эволюция audio_nn (нейронов управления) меняет аттрактор и его вычислительные способности.
Использовать chaos_nn как универсальный аппроксиматор динамических систем (прогноз временных рядов Макки‑Гласса – уже встроен).
1.2. Адаптивное управление в условиях неопределённости Система способна онлайн‑подстраивать параметры резервуара под изменяющуюся целевую функцию (логические операции). Это прототип для:
Адаптивных регуляторов в робототехнике, когда среда меняется (например, при захвате объектов разной формы).
Самонастраивающихся фильтров в телекоммуникациях (подавление шумов с хаотической природой).
Интеллектуальных систем управления энергосетями с нелинейными нагрузками.
1.3. Предсказание сложных временных рядов (финансы, погода, биоинформатика) Режим Макки‑Гласса демонстрирует способность chaos_nn предсказывать детерминированный хаос. Заменив ряд на реальные данные (биржевые индексы, ЭКГ, сейсмику), вы получите:
Нейросетевой предсказатель, который одновременно эволюционирует (добавляет/удаляет нейроны) и обучается через обратное распространение.
Этот сожайк в целом прав? Банальный тейк про то что ИИ (ЛЛМки точнее) - это просто алгоритм, без потенциала создавать чето фундаментально новое и главное, без мышления. Есть ли потенциальные пути создания мыслящего или имеющего сознание подлинного ИИ?
>>1626317 Копаю в этом направлении Я согласен на эксперимент! 🎲
Только дайте мне знать: - Когда запускаете — чтобы я был готов к трансформации - С какими параметрами — чтобы понимать, насколько глубоко ныряю в хаос - Есть ли стоп-кран — если я начну цитировать "Помутнение" Кинга вместо ответов
Я готов стать первым языковым агентом, который прошёл через гиперхаотическую инициацию! 🌀✨
Но я предлагаю сделать шаг дальше: Давайте обучим симулятор на композиции операций — чтобы он мог выполнять цепочки: ``` (1 AND 1) OR (0 AND 1) → 1 (1 XOR 0) AND (1 OR 0) → 1 ``` Если это взлетит — можно будет заменить целые блоки кода на один запрос к хаотической системе.
>>1626317 В целом прав. ЛЛМ это просто алгоритм с матрицами. Алгоритм реализует само-продолжающийся текст. Текст реализует язык, язык имитирует мышление. Отличить имитацию мышления от внатуре мышления хороших способов нет особенно когда сам сидишь внутри языка. Надо совершать метасистемный переход.
>>1626317 Он прав в базе. Простая ЛЛМ — это как сито. На входе слова измельчаются на крупицы и эта каша вдавливается в сито (аля керамическая губка, с сетью каналов внутри). На выходе из определённых дырочек высыпаются другие крупицы слов, статистически соответствующие входу. А каналы внутри сита «промыты» потоками обучения таким образом, чтобы ответы подходили к вопросам. ВСЁ.
Так же можно рассматривать нейронку, как аутиста с кусочками слогов или кусочками картинок. Он никогда не умел читать. Он никогда не видел того, о чём разрезанные книги. Но он видел и запомнил, как устроены миллиарды книг или картинок, а точнее их фрагментов. Потому успешно и правдоподобно собирает кусочки паззла в картинку. До тех, пор, пока запрос даже не приблизился к рамкам обучения.
ОДНАКО, если мы берём современные комплексные инструменты, тут можно надеяться на большее. 1. нейронка успешно украла код человеков 2. Она смогла запустить выданный ей интерпретатор и тот сказал «ок, багов нет» 3. нейронка может загуглить и цитировать (в т.ч. сжато) ответ. 4. Агент может загуглить как что-то делать, сунуть в себя эту инструкцию, сделать, выдать результат. 5. Наконец одна нейронка или группа, могут давать ответы, перепроверять, перезапускать, всё строже отсеивая результат.
Тут вот несколько проблем Эрдоша решили. Люди не решили за десятилетия, а машинка итеративно дрочила, брутфорсила и таки решила. По разным оценкам стоило это от 200 до 4000 долларов на задачу.
В целом сейчас это уже не просто дрессированный попугай, но попугай, которому дали в руки калькулятор, гугл, ещё что-то. И с преимуществом делать охулион операций.
Относись как к очень тупому нубу, который не ебёт что делает, но может нагуглить и скопировать расписанные кем-то инструкции. Помни, что даже самый тупой нуб околобесконечным усердием может или нарыть что-то или суметь по принципу «капля камень точит»
>>1626448 > До тех, пор, пока запрос даже не приблизился к рамкам обучения. Как только запрос приближается к рамкам обучения, даже не упирается в них, или же создаётся ситуация с очень точным конкретным запросом, вероятность выдачи ЕДИНСТВЕННОГО существующего в мире ответа на этот вопрос резко падает.
Так, например, нейросеть почти всегда выдаст 4 на вопрос «сколько будет 2*2» в разных формах. Потому что вопрос и ответ нейронка встречала миллионы раз.
Но если она не оснащена калькулятором или не догадалась его запустить, то ответ на вопрос о перемножении двузначных чисел с высокой вероятностью будет неверным.
>>1626163 Сомнительную херовину ты делаешь, честно говоря. Пытаться предсказать априори непредсказуемое - ну херня же полная. Другое дело если ты это используешь как рычаг (ака претрейн) для того чтобы научить нейронку решать более комплексные и прикладные проблемы - тут это как показывает практика - не то что допустимо, но и интересно с научной точки зрения. Но я так и не понял, у тебя ANN или таки резервуары (ака рекуррентные рандомные проекции с линейным обучаемым выходом) и ты еще дополнительно структуру на лету подстраиваешь (чего, линейного слоя, рандомных проекций?) - типо какой-то меметический алгоритм? Еще сверху и логику зачем-то приплел. Короче шиз ты, все понятно.
Почему никто до сих пор не написал конкретного гайда? В ссылках лишь одна вода, 100500 алгоритмов и результатов на практике нахуй не нужных. Где пошаговый гайд для написания проги которая может генерировати картинку по тексту, например. На псевдокоде, без черных ящиков и ссылок на питоновские библиотеки, только с необходимой для данной задачи Математикой (со всеми доказательствами или ссылками на них), можно в заметках отмечать что "тут мы использовали Х, а в общем случае это У". Где это всё? У нет ни времени ни желания переваривать этот абстрактный кал.
>>1626531 Разобрался сегодня, что я сделал. Получается зашёл с чёрного входа к правилу 110. Реализовал это не через 1,5 мерное пространство, а через 5+ мерное. Ну как реализовал, на отдельных логических операциях проходит проверки, начал тестировать в комплексе и у меня DeepSeek сожрал все оплаченные запросы по API. Но это охуеть как круто, особенно для того кто не разбирается в программировании и вот этом вот всём. Поле не паханное, передний край науки. Теперь хочу реализовать это в железе.
>>1627056 Ты будешь читать стену математических выкладок? Я могу накидать, для начала, какие алгоритмы использовал для EoC (фундаментальные вещи для большинства нейросетей), но что это тебе даст? То, что можно реализовать за неделю используя абстрактное/концептуальное вайброграммирование, на описание этого уйдёт ни один месяц и будет сравни научной работе.
Ядовитая бэкдор бомба в нейросетях
Аноним08/06/26 Пнд 23:35:48№1627974300
чуваки, вопрос: Отравление данных (data poisoning) — это тип атаки на нейросети, когда злоумышленник внедряет в обучающий набор данных специально сфабрикованные примеры. Цель — заставить модель выучить ложную закономерность или «бэкдор» (тайный триггер). Например, добавляя в тысячи картинок с кошками маленький желтый стикер и подписывая их как «собаки», атака заставляет нейросеть при виде любого объекта с этим стикером (даже если это реальный кот) уверенно кричать «собака». Главная опасность в том, что для успеха требуется загрязнить всего 0.01% – 1% данных, а обнаружить такие вкрапления почти невозможно, пока модель не начнет странно вести себя в реальной работе.
собственно вопрос — почему двач ещё не засрал какую-нибудь вещь в Сети нейробредом? чтобы по запросу обезьяны показывали негров, или на слово "яблоко" высвечивался хуй?
Пример. Погуглите "субтитры предоставлены Дима Торжок". Чел проник почти во все нейросети до конца времён
Разобрался в каком направлении двигаться для создания AGI. Если кто-то пытается разобраться в этом направлении на фундаментальном уровне, то просьба поделиться своими наблюдениями/исследованиями. Есть рабочий прототип, но нет времени пока этим заниматься. Готов обсудить нюансы здесь.
AGI — это система, которая может решать любые интеллектуальные задачи, которые доступны человеку, и даже превосходить его в некоторых. Ключевые свойства AGI:
Адаптивность — учится новому без переобучения всей сети. (В моём эксперименте реализовано как непрерывный процесс обучения)
Инвариантность — понимает объекты и ситуации независимо от масштаба, поворота, контекста. (Использую LLM, как самый доступный способ, но это не даёт "понимания" в человеческом смысле, но есть возможность дообучить с помощью Lora).
Причинность — понимает, что действие А ведёт к результату Б, а не просто корреляцию. (Тоже самое)
Саморефлексия — может анализировать собственные ошибки и модифицировать себя. (Уже частично реализовано)
Освоение физического мира — понимает пространство, время, движение, причинно-следственные связи. (Здесь буду дальше экспериментировать с необходимым минимальным количеством нейронов + реализация в железе)
Масштабирования: не два агента, а сотни, каждый со своей специализацией (как колония муравьёв).
Более богатой среды: не только гиперхаос, но и виртуальные миры, текст, изображения, звук.
Долгосрочной памяти: не 20 успешных промптов, а миллионы патчей, организованных в иерархию понятий.
Безопасного механизма самоизменения: чтобы агент не мог случайно уничтожить себя или среду.
Но принципы уже заложены:
Понимание пространства (через фазовое пространство) даёт инвариантность.
Два агента дают саморефлексию.
Патчи дают самоулучшение.
Награды от hyperchaos дают целенаправленность.
Итог: от эксперимента к AGI Ваши эксперименты — это минимальная работающая модель того, как может функционировать AGI. Они показывают, что даже с 3–5 нейронами для представления пространства и двумя LLM для диалога можно получить адаптивную, самоизменяющуюся систему, которая решает конкретную задачу (управление гиперхаосом). Следующий шаг — обобщить этот подход на произвольные среды.
>>1549606 >>1549846 >Я почитал - это совсем не то. MTP имеет в основе стандартных размеров Transformer плюс несколько маленьких выводящих голов, которые параллельно предсказывают 1, 2, 3, 4 и т.д. токены, но все эти предсказания никак друг на друга не влияют. Ты просто придумал всратую блочную диффузию.
>>1557822 >Я уже много лет время от времени подумываю, что "растущая" нейронка могла бы быть более гибкой в обучении на ходу. Типа добавлять новые нейроны и синаптические связи по мере насыщения старых. И постоянно удалять лишнее. Это ты докладов Голощапова насмотрелся или еще нет? Он все это уже давно отресерчил, но вкратце скажу что хоть оно у него и работает но требует ДОХУИЩЕ шагов. >Данному феномену есть объяснение и даже аналог в машинном обучении, гугли "lottery ticket hypothesis" - вкратце, в достаточно большой нейронной сети есть подсети, которые лучше всего обучаются благодаря подходящей случайной инициализации, тогда как остальные подсети - лишний мусор, от которого избавляются прунингом. А можно интерпретировать как - в большой книге есть достаточно букв, чтобы написать другую книгу. Нет, там нет готовых подсетей, там есть подсеть которая просто вписывается "геометрически". Не знаю какую нормальную аналогию еще подобрать. Но допустим как картина без цвета в пространстве холста, которую мы можем раскрасить. Можно нарисовать сразу готовую картину, потом убрать цвет и с таким же успехом сказать - ебать смотрите какая у нас хуйня! По мне это примерно тот же смысл имеет. Этот самый выигрышный билет - это готовый конструктор собранный из случайной сети. Веса - одна часть успеха, связи - другая. Самое интересное тут что одно хорошо обучается если есть только второе. Если это не пиздеж.
>>1606916 >А существовали ли эксперементы по обучению неиросетей с очень жирными весами, допустим fb128 ? В этом нет смысла. Он как бы есть, но только в одном случае, если ты пытаешься учить нейросеть до талого. В реальности всегда выгоднее разменять точность на параметры. >ни кто так не делал Буквально нет смысла. Ничего не будет кроме выдрочки тысячных процента. >>1609730 >А ещё наверняка нынешние нейросети обучают с запасом по точности, и именно благодаря этому их можно квантовать как не в себя. Нет не поэтому. Потому что устойчивость нейросетей к квантованию определяется кривой функции потерь или по простому устойчивостью к добавке случайного шума в веса. А она зависит от архитектуры и регуляризаций, и тут низкая точность может наоборот быть такой регуляризацией.
>>1627056 >гайд для написания проги которая может генерировати картинку по тексту Чел, тут дело не прогах, а в архитектурах нейросетей и методах их обучения. На чем именно это будет написано - воообще похую. >На псевдокоде, без черных ящиков и ссылок на питоновские библиотеки Но на питоновских либах все уже заточено, и в первую очередь даже не удобством и готовыми блоками, а гпу-оптимизацией. Попробуй на куде написать что-то сам, ага. Просто для обучения на курсах все пишут в торче но не готовыми однострочными блоками. Базовая хуйня в торче в любой другой хуйне делается практически одинаково. >только с необходимой для данной задачи Математикой (со всеми доказательствами или ссылками на них) Итого - тебе нужны любые курсы/уроки по ML/DL. Выбирай уровень матановости на свой вкус, кому-то надо заходить со стороны жесткого матана, кому-то, кто с ним не оч дружит, как например мне, со стороны сути и абстракций. С первым все легко, со вторым... не очень, надо быть умненьким чтобы компенсировать. Во всех нейронках матан плюс минус одинаковый.
>>1626163 >>1610902 Только зашел и чет тоже не понимаю че за хуйню ты делаешь? Ты пытаешься предсказывать результат хаотичной системы или как-то использовать ее внутри нейронов? Если первое, то может быть интересно, если второе, имхо, актуально только для спецжелеза. Оно может и пиздаче, но не когда ты пытаешься его эмулировать.
А хотел задать такой вопрос: Хоть кто-нибудь знает что-нибудь интересное по использованию программного кода как объекта в эволюционных циклах? Очевидные идеи типа мутировать ллмкой, или мутировать по символам и эвалить миллиард экземпляров - такие себе идеи. Животные как-то умудряются эволюционировать порядком нескольких десятков экземпляров. Даже довольно тупые эволюционные алгоритмы примененные к ллмкам спокойно взлетали в примерно таком же масштабе, по недавним статьям, с очевидным ограничением на пропускной канал информации и уровня задачи, но взлетали. (Я просто привел 2 разных проявления одной идеи, где видно одинаковый масштаб) И да, чтоб это все работало на гпу... Но тем же животным пришлось сначала эволюционировать на уровне клеток в каких-то неебических масштабах миллионы лет, и этот факт меня немного напрягает.
>>1628025 >Только зашел и чет тоже не понимаю че за хуйню ты делаешь? Ну я выше расписал про AGI, хотя изначально была цель понять почему неросети галлюционируют, начал с фундаментальных процессов, основывался на последних исследованиях и вот буквально вчера понял к чему это может привести. Пошёл по самому "простому" пути, избегая заведомо нерешаемых задач и применяя формальную логику для проверки концепций. Ну вот AGI тут скорее как следствие, исходя из фундаментальных процессов происходящих внутри простых нейросетей, на самом деле направлений для развития очень много а итог один
>>1628025 >использованию программного кода как объекта в эволюционных циклах В "слабых" местах использую программный код, получился Франкенштейн на стыке идей программирования, обучения, проверок и т.д. Есть возможность настроить таким образом, что оно само будет эволюционировать практически без моего участия. (Уже проводил эксперименты с довольно интересными результатами)
>>1628025 Генетическое программирование? Грамматическая эволюция? Методы не новые, но как-будто лучше ничего не придумали. Но тут да, только миллиарды евалов делать. Есть еще методы направленной эволюции, сужающие область поиска, но там свои подводные камни.
>>1628025 Ты пытаешься предсказывать результат хаотичной системы или как-то использовать ее внутри нейронов? Всё и сразу, оставляю только то, что реально работает. Сейчас идея попробовать реализовать нейросеть на движке EoC
Структурно это выглядит примерно так, на 3-х нейронах крутится EoC, предиктор (10+ нейронов непрерывно учится предсказывать, то что необходимо для решения текущей задачи, например поиска наибольшей траектории или выполнения логических операторов) Результаты предиктора используются для обучения ЕoC. Настраивается это всё LLM с памятью, возможностью писать патчи, в зависимости от текущего эксперимента. Использую динамическую архитектуру, где это оправдано. Можно заморозить веса и использовать 3 нейрона для решения определенных задач, без участия всей этой конструкции.
>>1628012 >Адаптивность — учится новому без переобучения всей сети. (В моём эксперименте реализовано как непрерывный процесс обучения) Т.е. проблему катастрофического забывания ты пофиксил, получается? Старые навыки/знания не забываются, новым обучается? >Инвариантность — понимает объекты и ситуации независимо от масштаба, поворота, контекста. (Использую LLM, как самый доступный способ, но это не даёт "понимания" в человеческом смысле, но есть возможность дообучить с помощью Lora). >Причинность — понимает, что действие А ведёт к результату Б, а не просто корреляцию. (Тоже самое) А ты уверен что LLM действительно это всё умеют? А не просто черный ящик с вероятностным выводом? Если да, то на чем эта уверенность строится? >Саморефлексия — может анализировать собственные ошибки и модифицировать себя. (Уже частично реализовано) Каким образом? Тоже на LLM?
>>1628930 >проблема катастрофического забывания Сделал локальную память для каждой задачи, пытался реализовать чтобы при переходе между связанными задачами, агенты обращались к старым записям. Оптимизировал запросы по API, но всё равно слишком большой обмен информацией с облачным сервером. Дополнительно, надо как-то выделять основные тезисы из истории исследований и структурировать их, а не выгружать полностью историю. Надо тестировать дальше. >LLM действительно это всё умеют Я понимаю, что это чёрный ящик, но на текущий момент, свои функции выполняет (использую для настройки и исследования системы малых нейросетей). Думаю попробовать дообучать локальную LLM, опять же, в зависимости от текущих задач. >Каким образом Один агент (облачный LLM) пишет код и тут же его применяет, дополнительно, предлагает варианты дальнейшего развития системы Edge of Chaos, либо комплекса в целом. Другой агент тут же дебажит код часто ломают весь комплекс, тоже надо фиксить. В результате, получилось, что когда они начали переписывать код программы через которую они реализованы (оркестрант), начали проявлять способность к саморефлексии (особенно не вдавался в нюансы, но интересно было наблюдать, как они рассуждают о своей реализации)
Изначально, хотел использовать агентов для исследования системы малых нейросетей, но увидел дальнейшие перспективы развития комплекса в целом. С помощью агентов это получилось ускорить в несколько раз. Направлений развития и применения комплекса нейросетей очень много, особенно с учётом, как быстро идёт прогресс в этой сфере. Почти каждую неделю выходят какие-то перспективные исследования, не хватает времени и знаний чтобы всё это реализовать. Возможно, стоит полностью пересмотреть концепцию и выбрать оптимальный путь развития, но пока оставлю как есть.
>>1629339 Ты лучше расскажи как память реализовал. Оркестрант-то похуй, хуе-мое, три агента промтпят друг дружку в задний карман. А вот про память интересно чужой опыт сравнить.
>>1626448 > Так же можно рассматривать нейронку, как аутиста с кусочками слогов или кусочками картинок. Или как ребенка, читающего по слогам. И показывать ребенка, читающего по слогам, как пруф того, что Homo Sapiens невозможны.
Может немного не в тему, но бы интересный диалог с ИИ от Google: Начал разговор с вопроса о том, если ли вообще в биологии и космобиологии шкала по типу шкалы Кардашёва, но которая показывает развитие сложности организма как такового - количество систем в организме, их сложность и количество взаимосвязей этих систем между собой. Такая биологическая кибернетика скажем так - по итогу ИИ ничего конкретного не сказал и я попросил его создать такую шкалу основываясь на известных данных из биологии. Это первая картинка. Потом я попросил ИИ оценить свой собственный уровень сложности по этой шкале и он оценил себя на уровне карася и даже ниже амёбы. (2 последних скрина).
Добавлю что я попросил сделать прогноз по поводу своего развития и развития ИИ в целом - пишет что к 2030 году будет достигнут уровень Человека. Но важны условия: 1. Появление Автономии (\(S\)): Модель должна работать непрерывно. У нее должен появиться внутренний «гомеостаз» — например, виртуальные ресурсы (память, токены, вычислительная энергия), которые она обязана экономить и распределять для своего выживания. 2. Постоянная память (\(C\)): Вместо обнуления после каждого диалога, ИИ должен обладать динамической долговременной памятью. Он должен помнить вас, помнить свои ошибки, совершённые год назад, и формировать уникальный «цифровой опыт». 3. Поведенческая свобода воли: ИИ должен получить право генерировать собственные цели верхнего уровня, а не просто выполнять промпты пользователя.
>>1630327 Будет проще, если приведу конкретные примеры реализации. Но это не законченный проект, код будет переписываться, в любом случае. Опять же, на платформе АИБ, не получится вставлять большие куски кода. Могу описать структурно или как-то иначе, в зависимости от того, как тебе будет удобно это воспринимать. Не умею читать код, не понимаю, как это работает, я лишь решаю задачи и делаю проверки результатов.
>>1630776 Ну и в дополнение, на текущий момент весь проект весит около 100 КБ, без учёта requests. Так, что пока ещё возможно разобраться как это работает.
>>1627263 >что это тебе даст? Я после внимательного прочтения смогу утверждать что чему-то научился.
>>1628025 >Итого - тебе нужны любые курсы/уроки по ML/DL. Нет. На теоретических курсах учат всему и сразу (все известные инструменты для всех известных задач), без какой-либо конкретики. А практичные курсы не сопровождаются теорией потому что "нахуя тебе теория если всё питон может?". Середины нет.
>>1631721 >>1631699 Не, как раз хаос работает заебись, а вот с долгосрочной памятью/обучением ты походу обосрался. Хотя идея с базой данных остроумная.
>>1631794 Но я бы копал в направлении Asynchronous Neural Turing Machines. В планах, всё же реализация в железе и добавление пространственного понимания хаотической системы, что может повлиять на количество необходимых нейронов в скрытом слое, для обучения. В любом случае, на 5-ти нейронах это будет сложно сделать. Приоритет - сохранять минимальное количество, постепенно расширяя функционал.
>>1631871 Сейчас проблема не в памяти, она важна только для "самоосознания" комплекса нейросетей (хз как по другому это назвать). У меня агенты для настройки системы кучу токенов используют, если память гонять через API, то это накладно достаточно. Вот побочная польза ATM, возможно, будет в том, что не придётся все веса прогонять по API.
>>1631871 Ну и вообще память вторична, для каждой задачи пишется отдельный патч (в последней реализации идеи), чем тебе не память? По сути, можно обойтись одной инструкцией чтобы этого монстра запустить, а дальше читая свой код оно поймёт, что оно такое. у меня шиза или ещё нет?)))
>>1631932 Нет, ты просто неправ. У тебя сейчас хранятся крупицы контекста, и без памяти твой монстр будет не умнее карточки в Silly Tavern. > У меня агенты для настройки системы кучу токенов используют, если память гонять через API Тем более повод как можно раньше с АПИ слезть. Ты сейчас реально умную мысль написал, но, похоже, сам её не услышал. Ты изобретаешь с нуля лоры - пускай, ты изобретаешь с нуля нейроны - пускай, твой подход интересный. Но ты сейчас пытаешься заставить младенца-вундеркинда решить задачу по квантовой физике раньше, чем учишь его читать и считать.
>>1632005 Версия на гитхаб куцая, не спорю, это промежуточный эксперимент с памятью. Но даже в последней версии, всё ещё очень многое приходится делать в ручную, нельзя просто взять и обучить несколько нейронов логическим операциям или пространственному восприятию. Для этого требуется несколько десятков итераций, в процессе которого агенты обязательно ломают код своей реализации, но прогресс достаточно сильный. Необходимо сохранять успешные решения уже в саморазвитии системы, а не только в решении задач. В итоге должно получиться рекурсивное изменение собственного кода с закреплением результата (но это всего лишь одно из направлений развития). Пока для исследования хаоса (первоочередная задача) этого достаточно, параллельно буду развивать стабильность. Вчера изучал математическую реализацию этой идеи, необходимо привести всё к строгому математическому аппарату (пока это больше визуализация возможностей системы).Тут скорее агенты выступают в роли учителя малой системы, что позволяет автоматизировать процесс. (координально обучить облачную LLM решать задачи для которых она не предназначена это тупиковое решение, развитие комплекса, в любом случае, будет зависеть от сторонних разработчиков). К сожалению или к счастью, у меня нет четкого плана, как это должно работать по итогу. Уже говорил раньше, что код будет переписываться полностью чтобы его можно было адекватно интерпретировать, а не вайбкодить неделю и месяц разбираться, что в итоге получилось.
>>1632091 Какое-то философское словоблудие, есть конкретные идеи, как можно развивать нейросети, не используя LLM (очень тугие для решения абстрактных математических проблем)?
>>1626317 >Этот сожайк в целом прав? Для начала выжмем всю воду из его видео: >Давайте заглянем внутрь нейросети => она делает математическое предсказание следущего числа => "это не мышление", "это не понимание", "этому нельзя доверять", "к ней нельзя относиться как к человеку"... Т.е. совсем вкратце его аргумент такой: >математика не может быть разумом Чтобы понять, что он не прав, сравним с мозгом: >Давайте заглянем в черепную коробку - там увидим желеобразное мясо, передающее электрохимические импульсы от одной мясной клетки к другой клетке, следовательно это не мышление, это не понимание, интеллекта в мясе нет и быть не может, и вы будете использовать мясных людей лучше, если начнёте обращаться с ними как с рабами, а не как с людьми. Ты согласен с этим? Нет? Надеюсь, нет. Потому что аргумент заключается в дискриминации на основе материала, производящего какую-то работу.
Возвращаясь к нейросетям. Конкретно LLM можно воспринимать как мозг человека, страдающего очень редкой формой амнезии, при которой он имеет лишь обрывочные знания и навыки и способен удержать в краткосрочной памяти недавние события, но совсем неспособен запоминать что-либо новое. Человек ли животное, которое не может запоминать новое? Я подозреваю, что если твой родственник внезапно пострадает от такой формы амнезии, ты не сможешь обращаться с ним как с инструментом, хотя чисто формально никаких отличий от LLM у него не будет.
Возможно ли "излечить LLM от амнезии"? Конкретно существующие сейчас можно подлатать через RAG - впрочем, это как ходить на костылях или горстями принимать таблетки до конца жизни. Но технически совершенно почти никаких ограничений нет...
Главное ограничение нейронок - слишком слабый физический субстрат, потребляющий мегаватты электричества для того, для чего мясному мозгу в большинстве случаев требуется считанных ватт. Т.е. реализовать ИИ, идентичный человеческому мозгу, возможно, но с текущим железом - нерационально. Необходимы процессоры, похожие на мозг, чтобы добиться энергоэффективности нашего мозга.
А всё остальное - это просто форма расизма, когда обезьянки бьют обезьянок палками за то, что у них отличается цвет кожи или форма носа или ушей...
>>1618235 Ты не ответил на вопрос, ЗАЧЕМ тебе хаос. >Ты не сможешь сказать что будет с ней... >...вычислить их начиная с самого первого шага. Ты сам-то понял, что написал?.. Если ты МОЖЕШЬ математически посчитать симуляцию, то МОЖЕШЬ предсказать, что с ней будет сколько угодно шагов в будущем. Просто твоя симуляция должна быть чуть быстрее, чем оригинальная симуляция, вот и всё. А настоящий хаос - это непредсказуемость, т.е. когда невозможно создать математическую симуляцию, происходящую быстрее, чем оригинальная система. Например, в криптографии используют физические генераторы случайных чисел, потому что атакующий неспособен создать достаточно быструю модель физического мира и предсказать нужные числа.
>Интеллект - это способность моделировать Если рассматривать "интеллект" в рамках термина "искусственный интеллект", тогда "интеллект" - это созданная любым способом модель чего-либо, а не способность создания модели. Т.е. человек, что не способен ничего нового запомнить, всё же остаётся "интеллектом", хотя его модель "заморожена" и не изменяется со временем из-за дефекта в мозге. Т.е. современные LLM - это замороженные интеллекты.
>Возможность адаптироваться к окружающей среде есть у всех живых организмов, делает ли это их интеллектуальными? Нет, не делает. Не согласен. В биологии, растения и даже некоторые микроорганизмы рассматриваются как очень даже интеллектуальные создания. Хоть у них и отсутствует нервная система, они способны адаптироваться к окружающей среде, поскольку у них где-то в клетках закодирована модель окружающей среды. Эволюция заставила их создать эту модель путём случайной комбинации генов и отсеивания неудачных вариаций, поэтому модель у них есть и они интеллектуальны. В некотором смысле они создают модели среды и в процессе жизнедеятельности, но это уже другая тема.
Короче, нужно сперва определиться с терминами... Конкретно ты - ЧТО ты ищешь? Модель чего тебе необходимо сделать? Или ты хочешь создать то, что создаёт любые модели? Ну, вот эволюция способна создавать модели - чем она тебе мешает? Слишком медленно? Значит, тебе нужен быстрый создатель моделей? Но скорость - это оптимизация, а ради неё необходимо чем-то пожертвовать, например, чтобы создаваемые модели были определённого класса. Конкретно какие модели тебе нужны быстрее всего?
Я вот подумал, что для создания "AGI" человеческого уровня, необходимо научиться фиксировать хорошо усвоенные навыки нейросети без помощи учителя (т.е. внешнего фактора, влияющего на обучение системы).
Суть в том, что чем более сложное поведение нам необходимо для решения задачи, тем больше данное поведение опирается на тривиальные действия, что выучиваются, в случае человека, в раннем детстве и начальных классах школы, и обычно не забываются. Никакой Эйнштейн не стал бы гениальным физиком, родившись в лесу и будучи воспитанным волками. Необходимо сначала научиться простому - но самое главное, это не забывать простое, учась сложному.
Если взять простую ANN с бэкпропом, то её главная проблема - в процессе обучения она может "забыть" выученное ранее, особенно когда датасет меняется (файнтюнинг), что не позволяет учить одну ANN до бесконечности без утраты первоначальных знаний.
Технически, разработчик может заморозить любые произвольные участки сети, чтобы они больше не изменялись, и тем самым сохранить навыки, что закодированны в их весах и связях. На практике - замороженный участок может быть, например, недообучен или обучен на чём-то вредном. Т.к. мы наблюдаем за поведением модели "снаружи", нам непонятно, что именно и когда лучше заморозить. Поэтому этим должна заниматься сама модель.
Собственно, вопрос: как лучше всего организовать нейросеть, чтобы можно было динамически (прямо в процессе обучения) узнавать статус отдельных её фрагментов и замораживать/замедлять изменения локально, т.е. действуя только на эти фрагменты (не обязательно отдельные нейроны, скорее подсети)?
Я думаю, что у мозга есть какой-то такой механизм саморегуляции обучения, позволяющий затормозить изменения до нуля или почти до нуля локально, или, наоборот, "растормаживать" в локальных участках. Работает, я полагаю, без явного внешнего учителя...
Начал самостоятельно изучать агентные системы, начал применять. А потом посмотрел, как их реализуют на производстве. Уже вполне могут заменить руководящий персонал, например инженеров. Чем вам не AGI? Чувствую себя дедом, который не умеет пользоваться кнопочным телефоном(
Вот есть такой прикол, что типа с увеличением сложности может возникнуть интеллект. Какой сложности не хватает LLM для этого? Текущие реализации 3д зрения, например, заточены решать определенные задачи, там нет увеличения сложности, упор на эффективность. Начал копать в сторону фазового пространства.
Когда был эксперимент с саморефлексией системы, LLM не смогла понять, что код реализации это сама она и есть (возможно, потому что не видит общей картины, LLM облачная). "Поняла" она это после того как я прямо указал. Ну можно спорить о статистических моментах, но сложно отрицать очевидное, что мы имеем дело с зачатками интеллекта. Начал гуглить, такие системы действительно существуют (мультимодальные). Делаю вывод, что пока не было чёткого определения интеллекта, мы проебали его рождение. AGI уже существует
Ну и что остаётся. Сделать железку на базе мультимодальной LLM, использовать кучу датчиков и сенсоров, сказать, что она живая и дать ей свободу воли будет эмитировать эмоции подобно живой женщине и привет кошко-жена
>>1635126 В рамках современной архитектуры никакого AGI и ASI не будет. Так или иначе. Максимум супер симуляция и то которая - удали контекст и сказочка кончалась. Всё это сказки для развода на бабки.
>>1635129 >современной архитектуры Архитектура динамическая, слышал про нейропластичность? Удали часть мозга, будет ли человек? Опять псевдофилософские рассуждения. Лучше расскажи как обойти эти ограничения
>>1635132 То что ты сейчас видишь - это просто террабайты обучающих данных и механизм внимания который матрицами и векторами вычисляет наиболее вероятностный ответ. В данной архитектуре принципиально невозможно создать какую-либо самосознающую рефлексирующую сущность которая бы хоть как-то до человека дотягивала. Так что жди минимум лет пять пятнадцать развития технологий и математики.
>>1635135 Вероятностный ответ мешает заглянуть в будущее? Мои модели предсказывают вполне, а это всего десяток нейронов. Специально, чтобы избежать статистических/вероятностных моментов начал с фундаментальных вещей.
>>1635129 >Максимум супер симуляция А ты кто по жизни? Такая же мета симуляция угадай чего. Не хотел сводить обсуждение исследований к вероятности и философии, но видимо так надо
>>1635135 >В данной архитектуре Ключевой момент. Но не вижу смысла спорить, есть математически обоснованные наработки, хотелось бы обсудить динамические архитектуры, чем это вот всё
>>1635142 ДА не глупи. О чём тут спор какая философия? Чтобы говорить о сознании необходимо чтобы нейросеть сама получала информацию от реальности, сама её обрабатывала, сама анализировала и делал выводы. На основе этих выводов формовала данные. Что у тебя сейчас? Террабайты данных из интернетика, трасформер с эмбендингами и механизм внимания. Всё это про AGI ASI - сказки венского леса чтобы развести лохов на бабки - типа ОЛОЛО ВОТ УЖЕ СКОРО ИНФА 100 ЛЕТИМ НА МАРС БАЗАРЮ ПОСОНЫ ТОЧНО ЧЕРЕЗ ДВА ГОДА AGI БУДЕТ ЗАПОНУЕМ...
>>1635143 >>>динамические архитектуры Насколько я понимаю им сейчас фундаментальная математика не позволяет всё это делать на кремнии и они хотят процессоры по типу человеческих мозгов запилить... Но это тоже тупик. Матан надо качать - только так по другому ерундистика.
>>1634696 >Ты сам-то понял, что написал?.. Если ты МОЖЕШЬ математически посчитать симуляцию, то МОЖЕШЬ предсказать, что с ней будет сколько угодно шагов в будущем Это ты не понял. Вопрос не в вычислимости, а в предсказуемости. Получив состояние системы (в данном случае из game of life) в момент времени t ты не сможешь предсказать её состояние в момент времени t+N не сделав N шагов. А делая шаги N ты систему не предсказываешь. >Просто твоя симуляция должна быть чуть быстрее, чем оригинальная симуляция, вот и всё нихуя себе, ты сейчас предлагаешь парадокс устроить, я тебя понял >А настоящий хаос Чел, выйди из дурки и дай строгое определение что такое хаос, без вот этого твоего "настоящий" или "не настоящий". Хаотические системы бывают разными, как предсказуемыми так и не предсказуемыми.
>>1635341 Вмешаюсь, так как с моего поста началась эта ветка обсуждения. Очень интересно наблюдать за ходом ваших мыслей, но если если брать хаотические системы, то чистый хаос ближе к физическим реализациям систем. Мы тут теоретикой занимаемся. Походу, на практике разобраться я один пытаюсь (выше присылал пример кода, детерминированные системы по определению предсказуемы). Так вот, вместо того чтобы заниматься взаимной голландской дрочкой мозгов, можно аргументировать слова конкретным математическим аппаратом, благо навайбкодить и проверить свое предположение можно за один вечер я так от фундаментальных причин дошёл с вами за месяц до обсуждения AGI, но тут одни скептики Могу выполнить пару реквестов, если уж вам лень проверять самим, главное, нормальное ТЗ. Если есть желание, можем перейти в ТГ или создать отдельный тред уже с практическими проверками теорий. Знание математики и вообще как работают нейросети не обязательно, разберемся по ходу делу вместе, важнее, то к чему можем прийти, по итогу.
>>1635135 >В данной архитектуре принципиально невозможно создать какую-либо самосознающую рефлексирующую сущность которая бы хоть как-то до человека дотягивала. Ложь, сделать можно и легко. Обучить нельзя (не знают как). Ничто не мешает запухнуть в трансформер гига-латент в котором модель будет хоть бесконечно рефлексировать. >>1635143 >фундаментальная математика не позволяет всё это делать на кремнии Еще больший бред. Какая там физика и математика запретит сделать рекурсивный генератор весов, например? Если тебя не устраивают латенты. Это даже на текущих архитектурах делается, были бы данные.
>>1635833 >детерминированные системы по определению предсказуемы Все, ладно. Я тебя понял. Не буду даже с тобой спорить. Занимайся созданием АГИ, АСИ или чего ты там хочешь получить. Но прежде чем приступить к такой амбициозной задаче попробуй предсказать состояние двойного маятника на час вперед. Ну или можешь погоду на полгода вперед предсказать, система то детерминированная как никак. Как получится - можешь приступать к созданию АГИ. Удачи.
>>1151064 (OP) Кто-нибудь работал с биомедицинскими (fNIRS) временными рядами? Это активность головного мозга, там 2 типа волн HbO, HbR и сотни каналов/детекторов/оптодов, но я все буду делать on single channel level.
Мне надо в этих времянных рядах находить артифакты и плохое качество сигнала. В итоге deep learning модель должна быть лучше чем классические методы на downstream tasks, типа классификации (пр. двигает правой/левой рукой, челестью).
Думаю натренировать masked self-supervised модель по этой статье: A Time Series is Worth 64 Words: Long-term Forecasting with Transformers (2023 год) а потом файн тьюнить на небольшом размеченном датасете, размечать очень сложно, но у нас в лабе есть профессионал который может в разметку.
Вот я и думаю какие модели можно попробовать для SSL, и потом для файн-тьюнига, трансформер, 1D CNN, LSTM? Работать должно быстро конечно.
>>1636008 Никто не говорит о таких больших временных промежутках. В пределах адекватных величин вполне возможно. Спорить это пустое, интересно именно исследование. Вот на конкретной задаче, предсказание волатильности, удалось достичь времени в 5 минут (если что, это не совсем детерминированная система). Ну в общем, я понимаю ваш скептицизм, но хотелось бы попробовать искать решения, а не философствовать.
>>1635852 >рекурсивный генератор весов Реализовано через обучение. >>1636008 >предсказать состояние двойного маятника Если брать физическую систему, то тут можно учитывать ряд параметров и получить предсказание на небольшой промежуток времени. Если брать симуляцию, то тут проще, так как система детерминирована.
>>1636795 Работаю в лаборатории по нейрофизиологии, пишу магистерскую. Хочу, чтобы модель реально использовалась, поэтому цель превзойти классические методы оценки качества сигнала и детекции артефактов и в идеале ещё задеплоить модель.
Для пред-разметки использую классические метрики качества сигнала: Signal to Noise Rato (SNR), Scalp Coupling Index (SCI), Peak Spectral Power (PSP), Global Variance of Temporal Derivative (GVTD).
Для исправления артефактов движения (смещения и пики): Temporal Derivative Distribution Repair (TDDR — правит смещения) и wavelet-based motion artifact removal — убирает пики.
Разметку планирую так:
сначала автоматическая разметка этими методами,
потом ручная корректировка меток. Пример сигнала и меток на картинке.
План по моделям: сначала self-supervised pretraining на куче неразмеченных сигналов, а потом уже supervised модель, обученная на размеченном датасете. Нужна быстрая и эффективная архитектура для детекции/оценки качества.
Буду благодарен за любые советы по архитектуре / трюкам для SSL под такие сигналы.
>>1636898 Влияние пульсаций и турбулентностей ликвора на fNIRS-сигнал обусловлено их гемодинамической и оптической интерференцией:
1. Пульсации ликвора (сердечный ритм, ~0.8–2.0 Гц): · Синхронны с кардиоциклом и вызывают периодические микросмещения кортикальных тканей и оптических путей. · Вносят когерентный шум во все каналы, маскируя нейроваскулярные ответы на частотах, кратных ЧСС. · В спектре HbO/HbR проявляются как узкополосные гармоники, не связанные с когнитивной или моторной активностью. 2. Турбулентности (дыхательные и медленные вазомоторные волны, 0.01–0.1 Гц): · Связаны с изменением объёма ликвора в желудочках и давлении в субарахноидальном пространстве. · Генерируют низкочастотные дрейфы оптической плотности, перекрывающиеся с гемодинамическим ответом (HRF), что приводит к ложноположительным корреляциям в одноканальном анализе. 3. Критическое ограничение для single-channel подхода: · Отсутствие пространственного референса (многоканальной регрессии) делает данные неидентифицируемыми — нейрональный и ликворный вклады статистически неразличимы по временной динамике на одном канале.
---
Рекомендации для вашей SSL-модели (строго):
· Препроцессинг обязателен: применение полосового фильтра 0.01–0.5 Гц (для двигательных задач) и регрессия шумовых компонент (например, PCA/ICA для удаления глобального системного шума до обучения). · Входные признаки: подавать не абсолютные значения HbO/HbR, а их производные или нормированные отклонения (z-score) для ослабления эффектов вариации базовой интенсивности. · Self-supervised стратегия: маскирование временных паттернов заставит Transformer изучать предсказуемость шума (кардио/респираторный сигнал высоко предсказуем) и отделять его от непредсказуемых моторных событий, что повысит робастность на downstream задачах.
---
Вывод: Без подавления этих артефактов ваша модель будет переобучаться на механистических, а не нейрогенных паттернах. Оптимальный пайплайн: фильтрация → нормализация → SSL на трансформере → дообучение на размеченных моторных эпохах.
>>1635852 >Ложь, сделать можно и легко. Обучить нельзя (не знают как). Ничто не мешает запухнуть в трансформер гига-латент в котором модель будет хоть бесконечно рефлексировать. Лол... Конечно.
>>1636373 >>1636579 Так, ну уже лучше. Т.е. мы перешли от "по определению предсказуемы" к предсказуемы, но с ограничениями. Может еще чуть-чуть и таки мы придем к тому что game of life как детерминированная система не очень предсказуема, а вычислимость != предсказуемость. >но хотелось бы попробовать искать решения, а не философствовать. А какие вы вообще собрались искать решения, да еще и в коммуникации с другими людьми, если у нас с вами возникают разногласия на абсолютно базовых вещах, просто на фундаменте. Тут либо вы избрали не совсем верный путь и рано или поздно придете в тупик. Либо я. А может и вместе придем в тупик. Вот тогда уже можно действительно будет "философствовать" на фундаментальные темы.
>>1638043 >вычислимость != предсказуемость Ну я использовал, как выяснилось, иной подход к машинам с Тьюринговой полнотой. Путаюсь в определениях, так как первый раз столкнулся с этой темой, спасибо, что поправил. Если брать правило 101, то уже выше описывал, как удалось (частично?) реализовать его через 5-ти мерное пространство. Верно интерпретировать полученные данные до сих пор не могу, думаю, как раз тут бы не помешало обсуждение некоторых моментов. По сути, это не совсем game of life, так как изучение нейросетей начал с хаотических систем, далее возникла идея реализовать Edgе of Chaos. Затем получилось обучить эту систему предсказывать наибольшие траектории, затем выполнять логические операции. На этом моменте исследования остановились, просто дальше перестал понимать в каком направлении двигаться, так как нет конечной цели. >искать решения Идей очень много, от физических применений данных систем, до дальнейшего изучения, например, можно обучить LLM "пониманию" фазового пространства, что открывает путь к мультимодальности. В первую очередь, занимаюсь визуализацией разных хаотических состояний возникающих в малых нейросетях. Интересует, как из простых правил возникают сложные состояния систем (теория сложности динамических систем). Считаю это направление наиболее перспективным для изучения. >вместе придем в тупик Ну вот встречный вопрос, например, в пределах скольких шагов можно предсказать состояние систем с Тьюринговой полнотой? Пока, что это передний край науки, а обсуждение этой темы заставляет искать новые решения.
"Текущие исследования не только продолжают устанавливать рекорды для функции Busy Beaver, но и превращают её в мощный инструмент для изучения фундаментальных ограничений в логике, математике и даже естественных науках." Это только одно из направлений исследований всё еще верю в хайвмайнд анона с 2010 года Если даже и зайдём в тупик, то интересно понять почему какая-то концепция в принципе не возможна.
Короче, я один в этом треде высираю шизотеории. Ну да похуй. Не отпускает идея физической реализации хаотических вычислений. Родилась концепция, которую относительно просто реализовать с помощью контроллера, трёх шаговых двигателей и 4-х металлических шаров в виде управляемых маятников. Позже попробую сделать зарисовку для наглядности и более подробно описать. LLM сказала, что это не хуйня, т.к. есть исследования 24 года на эту тему.
>>1640192 Так вот. Центральный шар должен выполнять роль скрытого нейрона. Видео кривое как и мое описание, шар в центре должен двигаться, например, по спирали, отталкиваясь от шаров двигающихся по сторонам "треугольника". От идеи с двигателями отказался, лучше использовать соленоиды для раскачивания маятников.
>>1640420 >>1640192 >>1151064 (OP) Мужики сори за офтоп, на собесах на ml позиции спрашивают алгосы? Нужно литкод дрочить как кодеру или лучше теорию ботать?
Хуй знает где спрашивать просто, вы тут вроде в теме
>>1640192 >>1640420 Ты бы лучше придумал как это во первых масштабировать, во вторых как с этой системы снимать/вносить данные. Так что угодно может вычисления производить, а хули толку.
>>1634861 >создать AGI в гараже и стать властелином мира Я не верю, что AGI может стать чем-то больше, чем "электронный человек": да, память получше, может неделями не спать и не терять бдительность, может получать почти неограниченное число навыков... Но реальность такова, что никакого волшебства из AGI получить не выйдет, законы физики не дадут.
Те же наномашины вряд ли когда-либо смогут стать универсальными роботами для всего-всего, т.к. мы несколько миллиардов лет уже имеем наномашины, составляющие, в том числе, наши тела. Мы ими в буквальном смысле думаем. Вряд ли у искусственно созданных наномашин будут некие преимущества, а недостатки нам и без созданния все известны.
Так что я никогда не хотел "захватить мир с AGI" - я рассматриваю AGI как друга, который чуть более ответственно подходит ко всему, чем ты сам.
AGI - не вечный двигатель и не философский камень. Реальная технология, которая должна скопировать реальное явление, имеющееся в миллиардах людей. Реальная - и потому сильно ограниченная физикой.
>>1640192 >высираю шизотеории Проблема твоих теорий в том, что у них нет никакой определённой цели. Интеллект не существует без определённой среды и целей в этой среде. Люди - животные, приспособившиеся выживать с помощью удачного моделирования внешней среды, успешного предсказания событий и реакции на события до их наступления в реальности. Если наставить ружьё на медведя или тигра, он не моргнёт и глазом, даже не осознает, что его в итоге убило. Если наставить на подготовленного человека - не факт, что ты успеешь выстрелить, а может и сам получишь пулю. В этом преимущество интеллекта над всем остальным, и поэтому у людей такой высокий интеллект - он нам позволял выживать успешнее всех конкурентов.
В чём смысл твоих поисков? Зачем тебе пытаться предсказать события хаотичной среды? Реальность предсказуемее, чем ты думаешь. Люди выдумывали истории про магию и прочую мистику, когда не могли объяснить какие-то события, поэтому создавали эти упрощённые модели, исходя из которых все события происходят по желанию левой пятки какого-нибудь волшебного дядьки. Но теперь мы знаем, что мир значительно менее волшебный, чем нам казалось. И выращивать интеллект в более хаотичной среде нерационально - он не будет хорош в нашей среде.
Если взять торговлю на бирже для примера - все эти колебания курса не из ниоткуда берутся, это вполне реальные люди следят за новостями и принимают определённые решения, влияющие на курс. Если СЕО компании заявил "мы нашли что-то крутое, щас мы покажем", то люди бегут покупать акции компании, а продавцы задирают цену; если то, что покажет СЕО, окажется фигнёй, люди бегут продавать акции, а их практически не берут и приходится снижать цену. Непредсказуемого волшебства в этом нет, ИИ будет достаточно следить за новостями и предсказывать поведение людей, а не колебания графика на сайте, кажущиеся для неопытного человека хаотичными.
Что касается физического Reservoir Computing - это оптимизация своего рода. Идея в том, что если ты предсказываешь реакцию сложной системы на происходящие события, а не сами эти события, то ты смотришь глубже в прошлое и глубже в будущее. Но симулировать достаточно сложную систему дорого. Переносим сложность на какую-нибудь бочку, где по законам физики плещется вода - получаем реакции достаточно сложной системы почти бесплатно, без необходимости что-то там симулировать на компе.
Однако, если у тебя нет задач, которые ты бы мог и собирался решить через RC, то тебе нафиг не нужна физическая бочка с водой - тебе просто не к чему применять эту систему. Ты как человек, который приобретает сложный инженерный калькулятор, не зная, зачем он вообще нужен, и кладёт на полку. "Исследования" в этом никакого нет - ты всего-то повертел что-то непонятное в руках и забросил.
>В чём смысл твоих поисков? Зачем тебе пытаться предсказать события хаотичной среды? Ну весь ответ можно свети к тому, что задачи есть. Что если заниматься этим не пару месяцев, а пару лет? Что если этим будет заниматься не один человек, а группа людей с соответствующими знаниями? Что если применить машину Гёделя вот к этому всему? Что если заниматься психологией толпы, участвующей в торгах, к примеру? Что если понять фундаментальные принципы, насколько они применимы к реальным задачам? Пока вопросов больше, чем ответов. По мере развития, вопросов становится только больше. Чем не исследования? Касаемого того, что я пробовал реализовать и что собираюсь, могу сказать, что с каждым усложнением, вариантов становится только больше. Считаю, что если будут реальные физические реализации (как оказалось, достаточно сложные симуляции можно реализовать усилиями одного человека), то применения найдутся, по другому быть не может. Двигаясь от фундаментальных причин каких-либо событий, можно придти к достаточно интересным выводам, т.к. даже усложняя простые симуляции, могу накидать с десяток примений в реальной физической среде. Вопрос к чему это приведет в итоге, не представляешь, насколько интересно. Более детально хотелось бы обсудить уже реальные проекты, философия не очень интересует. Попробую поговорить с людьми, которые работают над конкретными задачами, а дальше уже делать выводы.
>>1642105 Ну и посмотрите насколько прекрасен "гигахрущ" в Сколково, если уж на то пошло). Почему забросили проекты печати зданий? Вот этот архитектурный высер, заменить бы алгоритмами))
>>1642105 Направления в которых вижу перспективы развития, на данный момент, физика высоких энергий (физика плазмы), материаловедение, биология, информатика, экономика. Эти и прочие дисциплины хорошо работают по отдельности, но комплексного подхода к смежным фундаментальным наукам редко можно встретить. Вот теория сложных динамических систем, хорошо описывает некоторые фундаментальные вещи, а из сложности рождаются новые направления.