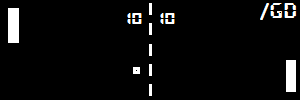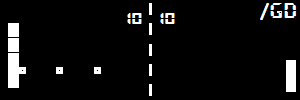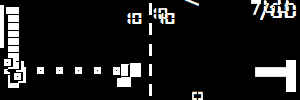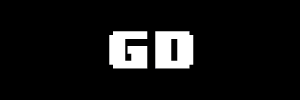

Двач, я топ 400 мирового рейтинга соревновательного мл, спрашивай свои вопросы. Планирую стать кагл
Аноним
09/08/25 Суб 16:31:51
№
1
