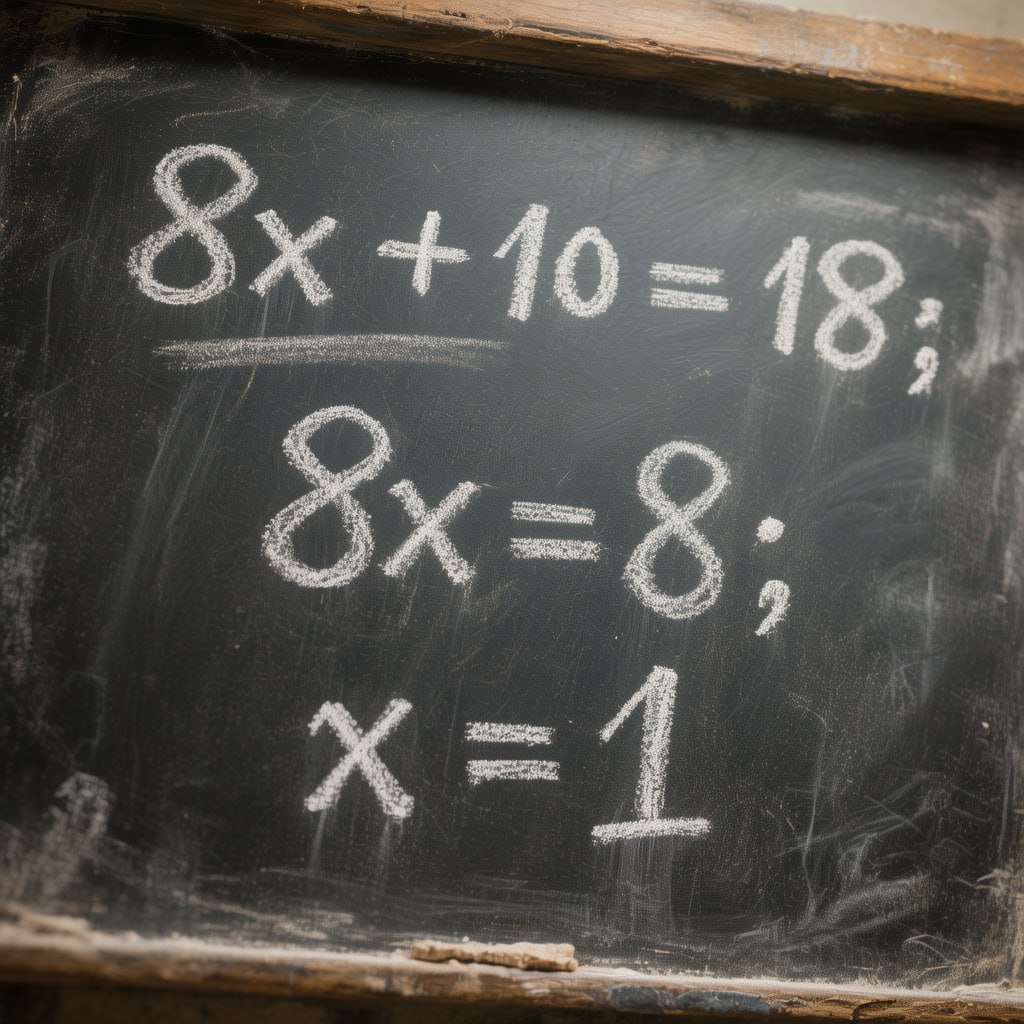Suno 5 релизнулась — нейронка снова взлетела в топы по генерации суперхитов. У музыкантов опять тряска.
• Чистейшее аудио — теперь треки вообще не отличить от профессиональных музыкантов. Шедевры получаются буквально за один промпт. •Песни можно генерить из вашего вокала и отрывков, а также из видео и даже ФОТО. •Вокал звучит, как у реальных людей. • Еще больше контроля над треком, сможете редачить каждую ноту. Получится добавить всевозможные инструменты, вокал и еще кучу всего. •Модель клепает песни любых жанров — от попсы до тяжелого металла. •Авторы обещают дропнуть Suno Studio уже 25 сентября — это будет разрывной профессиональный софт для звукозаписи.
Официального анонса еще не было, но модель уже можно тестить здесь, если имеете прем: https://suno.com/create
Сегодня, 24 сентября покажут новую версию главного геймченджера локальной генерации видео - WAN 2.5 Будет стрим на китайском (и немного на английском).
Оно небольшое, поэтому прямо тут приведу перевод полностью с небольшими сокращениями:
Рост использования AI-сервисов поражает, и мы ожидаем, что в будущем он станет ещё более стремительным.
По мере того как ИИ становится умнее, доступ к нему может стать не только ключевым драйвером экономики, но и со временем – базовым правом человека. Почти каждый захочет, чтобы у него было больше ИИ, работающего на его благо.
Чтобы обеспечить миру необходимые мощности для инференса и обучения всё более совершенных моделей, мы закладываем фундамент для масштабного роста AI-инфраструктуры.
Если ИИ сохранит текущую траекторию развития, нас ждут невероятные возможности. Например, с 10 гигаваттами вычислительных мощностей ИИ может найти способ вылечить рак или создать персонализированное обучение для каждого ребёнка на Земле. Но если мощности будут ограничены, придётся выбирать, что важнее. Никто не хочет делать такой выбор – значит, нужно строить.
Наша цель проста: создать фабрику, которая сможет выпускать по гигаватту новых AI-мощностей каждую неделю. Это невероятно сложная задача, требующая инноваций на всех уровнях – от чипов и энергетики до строительства и робототехники. Мы уже активно работаем над этим и верим, что это возможно. В нашем понимании, это может стать самым важным инфраструктурным проектом в истории.
В ближайшие месяцы мы поделимся планами и расскажем о партнёрах, а позже о том, как будем финансировать проект. Ведь рост вычислительных мощностей – ключ к росту дохода, и у нас есть несколько нестандартных идей.
Про выбор между раком и образованием мысль интересная. Но главное, что мы извлекаем из текста: OpenAI собирается строить самый масштабный конвейер мощностей, какой только можно представить.
Как это будет выглядеть, пока не до конца понятно, но один гигаватт в неделю – это 52 гигаватта в год. А это значит, что примерно (расчеты на коленке) к 2035 ИИ будет потреблять уже столько же энергии, сколько потребляет вся Америка.
Большая коалиция из 10 Нобелевских лауреатов, 70 компаний и бывших глав государств подписала требование о введении глобальных «красных линий» для ИИ
Об этом стало известно сегодня на заседании Генеральной Ассамблеи ООН. Всего требование подписало 200 человек: бизнесмены, политики, ученые. Среди них Джеффри Хинтон, Йошуа Бенджио и Войцех Заремба (соучредитель OpenAI).
Кратко о содержании:
– Подписанты требуют ввести международные юридически обязывающие «красные линии» для развития и применения ИИ. Это нужно, чтобы исключить глобальные риски для человечества: массовую безработицу, искусственные пандемии, нарушение прав человека и тд.
– Конкретный список таких «красных линий» не приведен, но предлагают, например, запрет на использование ИИ для производства оружия, организации массовых атак, несанкционированное реплицирование ИИ-систем (в том числе без участия человека) и все такое.
– Государства должны (в кавычках) договориться о таких правилах до конца 2026 года, а также нужно создать независимый международный орган для мониторинга соблюдения законов и оперативной оценки угроз.
Вот такой вот внушительный прецедент. На данный момент это самая крупная подобная петиция. Посмотрим, что выйдет.
Google выпустили инструмент "Learn Your Way". Это персонализированный репетитор, который поможет вам усвоить любую тему
Система считывает ваши увлечения, а затем любую тему объясняет так, чтобы вам было понятно и интересно. Например, если вы любите баскетбол и должны выучить законы Ньютона, то все примеры начинают строится вокруг бросков и дриблинга. Если вы художник и изучаете экономику, то всё сведется к галерейным аукционам и арт-рынкам.
Но на этом персонализация не заканчивается. Learn Your Way также умеет:
– Создавать майндмэпы, если вам удобнее воспринимать информацию визуально – Генерировать аудиоуроки, если хотите слушать, а не читать –Рисовать всякие интерактивные штуки (типа временных шкал, по которым можно тыкать) – Задавать вопросы и делать тесты, которые меняются в зависимости от того, что вы делаете неправильно
Внутри работает мультиагентная система LearnLM на базе Gemini 2.5 Pro. Даже есть специальный агент для рисования обучающих иллюстраций.
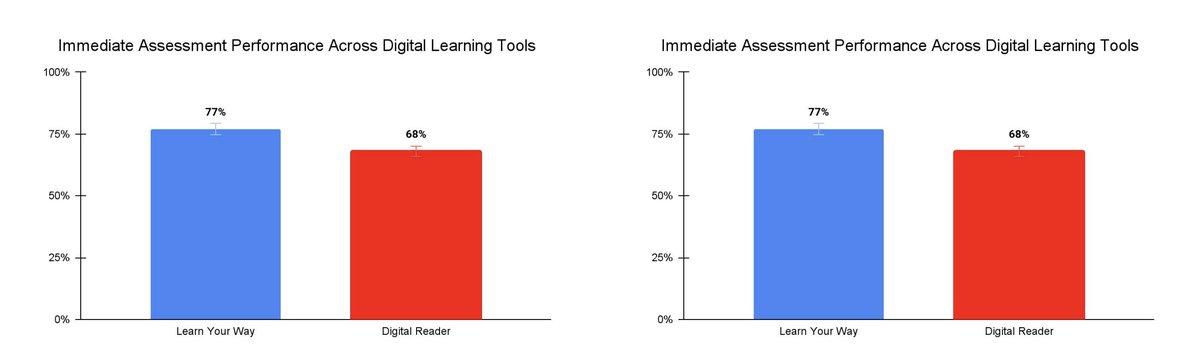
Тестировали систему на 60 чикагских студентах в возрасте от 15 до 18 лет. Им дали 40 минут на то, чтобы поизучать незнакомую им всем тему: одна группа просто читала PDFки, другая работала с LYW. Итог: через 5 дней те, кто работал с PDF, помнили материал на 67%, а те, кто учил с Learn Your Way – на 78%. Кроме того, 100% студентов, работавших с ИИ, чувствовали себя более комфортно и заинтересованно по ходу задания.
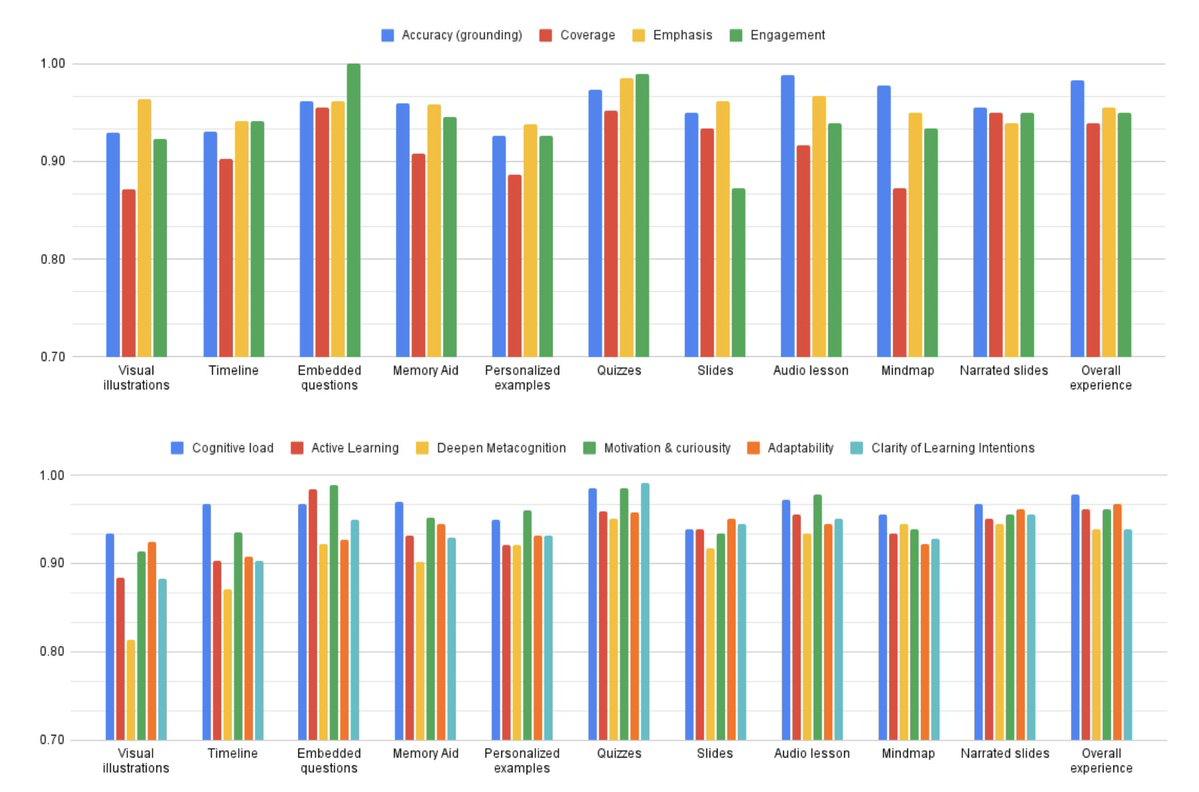
А еще систему по нескольким специальным критериям оценивали профессионалы из области образования. Получилась довольно положительная картина (скрин 2).
1. Лучшая точность следования промтам и временной контроль Новая модель значительно улучшена в плане следования промтам. Оптимизация структуры текста и внутренней архитектуры обработки позволяет глубже анализировать сложные инструкции, включающие несколько шагов и причинно-следственные связи, а не только отдельные действия. Это даёт возможность пользователям управлять более сложным развитием видеоконтента, включая взаимодействия персонажей и переходы между сценами. Благодаря улучшенному контролю временной логики и творческого выражения, статичные изображения можно превращать в динамичные видео с последовательным сюжетом и насыщенными историями.
2. Более плавные и стабильные динамичные сцены Для генерации более динамичных движений с широким диапазоном действий новая модель использует передовые методы обучения, такие как обучение с подкреплением, и стратегически корректирует распределение обучающих данных. Это позволяет модели лучше изучать и имитировать физическую динамику реального мира, что делает её способной создавать высокодинамичные движения и движения камеры, которые раньше было трудно реализовать. В результате динамика улучшается при сохранении плавности и стабильности, эффективно избегая распространённых проблем в сложных динамических сценах, таких как сбои или искажения.
3. Согласованность с разнообразными стилями Чтобы обеспечить бесшовное эстетическое соответствие между видео и референсным изображением, модель использует высокоинтенсивные методы кондиционирования изображения и обучается на огромных объёмах высококачественного видеоматериала. Эта стратегия позволяет модели точно сохранять и передавать художественный стиль оригинала, включая цвета, свет, текстуры и общую атмосферу. В результате даже при сложной динамике в видео каждый кадр остаётся в высокой степени согласованным с визуальным стилем и характеристиками референсного изображения.
4. Лучшие результаты по более низкой цене (на 30% дешевле, чем в том же классе 2.1)
Генерация 5 секунд с выходом в 1080p теперь стоит 25 кредитов (раньше было 35 кредитов)! Это означает более 1000+ видео в 1080p с использованием 2.5 Turbo в месяц при Ultra-плане и 320 видео в 1080p с использованием 2.5 Turbo в месяц при Premier-плане.
>>1363754 >запрет на использование ИИ для производства оружия, организации массовых атак Ага. Терроризм запретили, а террористы почему-то продолжают терроризировать. Странные какие-то, неужели не видят, что терроризировать запрещено?
>реплицирование ИИ-систем (в том числе без участия человека) Лицо старого бизнесмена, машущего кулаком на рой наномашин у него над головой представили? А они продолжают плодиться, перерабатывая его лысину.
>внушительный прецедент Просто нытьё стариков, трясущихся за свои шкурки.
>>1363745 >У музыкантов опять тряска. Тряска тут только у твоего унылого промпта. Все эти модели давно пережарены и генерят безликий стоковый кал, музыканты потряслись на суно 3,5 но там качество звука сосало, теперь сосет всё остальное. Но тебе и квен норм калогенератор.
>>1363752 >Если ИИ сохранит текущую траекторию развития, нас ждут невероятные возможности. Например, с 10 гигаваттами вычислительных мощностей ИИ может найти способ Оставить крестьян вообще без лектричества на бытовые нужды.
Котенков про новые загадочные фичи, про которые недавно говорил Альтман:
Созвонились с @denissexy, обсудили, что это могут быть за фичи и продукты. Что пришло в голову:
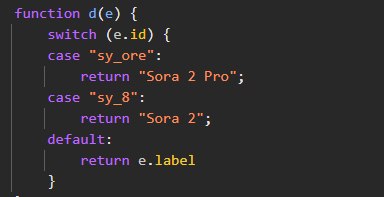
1. Sora 2, существенно лучше генерация, возможно, аудио. Генерация видео дорогая, если смотреть ценник Veo 3, так что можно ожидать pay-as-you-go оплату. К сожалению, самый малоинтересный для меня вариант :(
2. UltraMega DeepResearch — агент для поиска информации и составления отчётов, в котором под капотом происходит анализ гораздо большего количества веб-страниц / ваших документов (почта/гугл-диск/итд). DeepResearch это продукт с понятной нишей, бизнесы уже начали адаптировать решения для аналитики. Улучшение на условные 10-15% абстрактной метрики за счёт большего количества рассуждений и параллельны генераций может окупиться.
3. Codex Ultra — то же самое, что написал выше для DR, но конкретно для программирования.
4. Agent 2 — тоже улучшение существующего продукта; он уже бывает полезен, но надёжности не хватает. Вот если бы на каждое действие можно было дёргать GPT-5 Pro... (но будет дорого и долго)
5. Local Agent — сейчас Agent работает только в браузере на своей виртуальной машине и не может пользоваться обычными приложениями. Не пора ли расширяться?
6. GPT-5.5 Pro — супер-ультра-мега рассуждающая LLM на основе огромной модели (условно GPT-4.5, уже недоступной в API). Медленная, но знает кучу нюансов. Мой персональный фаворит, хочуууу!
6.1 Возможно то же самое, возможно, нет — доступ к экспериментальной системе, которая повыигрывала летом-осенью разные олимпиады. Мы точно знаем, что её планировали запустить к концу года, что она есть и что она очень дорогая.
OpenAI, Oracle, и SoftBank объявили о пяти новых площадках для ИИ-инфраструктуры в США. В округе Шакелфорд (Техас), округе Донья-Ана (Нью-Мексико), ещё один на Среднем Западе (точное место пока не раскрыто), Лордстаун (Огайо, уже идёт стройка) и округ Милэм (Техас, вместе с SB Energy). Плюс возможное расширение на 600 МВт рядом с флагманским кампусом в Абилине, Техас.
Совокупно Stargate выходит почти на 7 ГВт плановой мощности и свыше $400 млрд инвестиций в ближайшие три года. Цель - закрепить полный пакет $500 млрд / 10 ГВт к концу 2025 г., причём с опережением графика.
Новые площадки создадут более 25 000 рабочих мест на местах и десятки тысяч по смежным направлениям.
Флагманский кампус в Абилине уже работает на Oracle Cloud Infrastructure: с июня Oracle поставляет первые стойки NVIDIA GB200; идут ранние тренировки и инференс следующего поколения моделей.
>>1363752 >Пока всё по Ашенбренеру: Очередной ебанат алармист с фантазиями про Скайнет. Их как червей после дождя повылазило, все хотят славы и бабок своими бесконечными предсказаниями конца света.
>>1363754 > запрет на использование ИИ для производства оружия, организации массовых атак И сразу пойдут нахуй. Никто этих маразматиков слушать не будет с их проплаченной инициативой, когда интересы государств нарушают.
>риски для человечества: массовую безработицу А тут вообще маразм. Даже для людей это не нужно, вместо них и должны роботы пахать.
>>1363752 >По мере того как ИИ становится умнее, доступ к нему может стать не только ключевым драйвером экономики, но и со временем – базовым правом человека. > из всех стран чатжпт заблочен только для россии
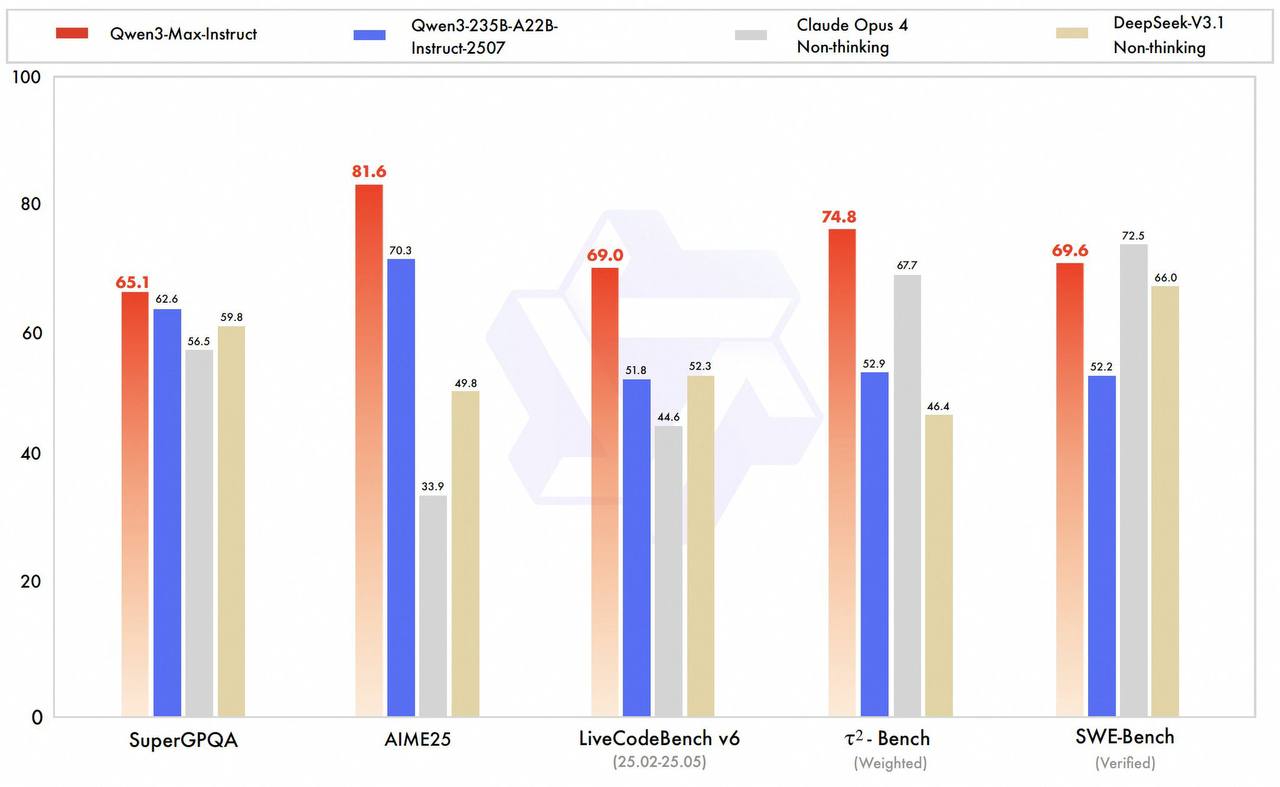
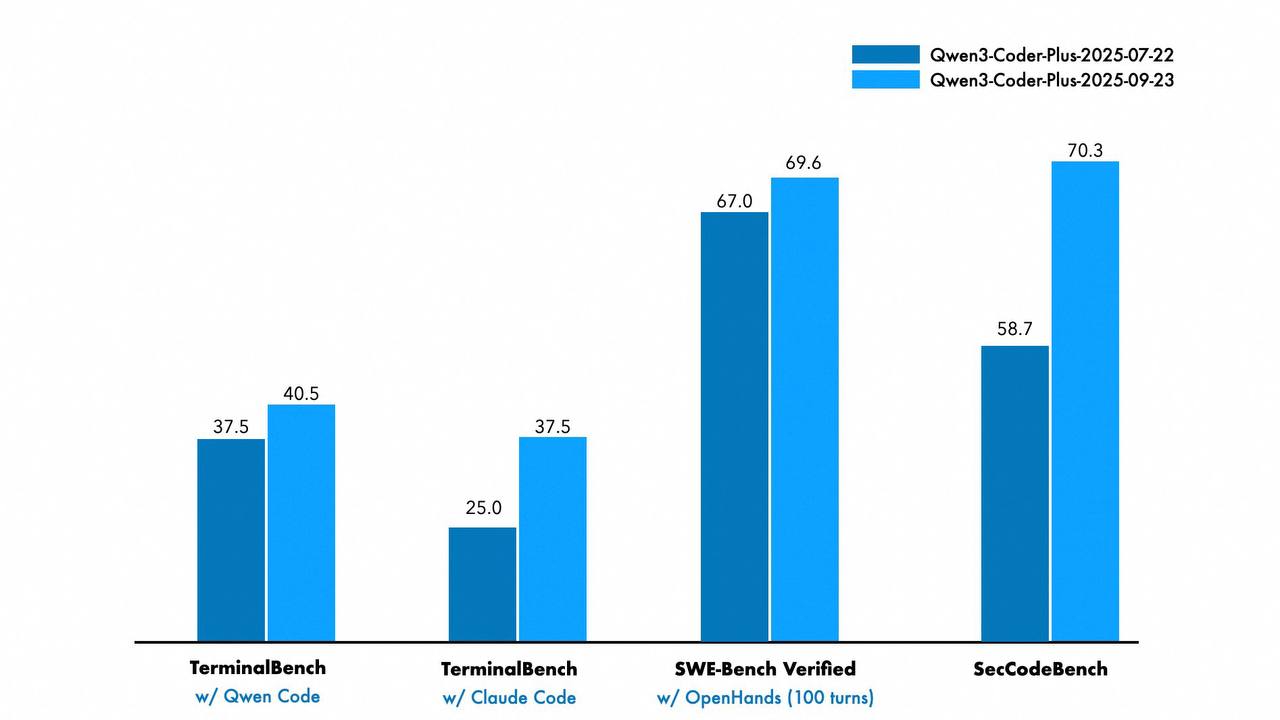
Новые опенсурс модели Qwen: выдают уровень GPT-5 и Grok 4
В этот раз лаборатория показала сразу несколько моделей:
➖ Основная: Qwen3-Max, новый флагман лабы. Есть варианты Instruct (без ризонинга) и Thinking. Instruct перебивает на бенчах Claude Opus 4 Non-thinking. А вариант с ризонингом –вообще что-то: уровень GPT-5 и Grok4 Heavy на AIME25 (100%), HMMT25 (100%) и GPQA (85%). Весов пока нет, но в чате можно попробовать бесплатно.
➖ Qwen3-VL – новая vision-language модель, которая опережает Gemini 2.5 Pro. Также есть варианты с ризонингом и без. Например, модель можно использовать как Computer Use агента или как Visual Coding агента (аля напиши сайт с дизайном, как на картинке). И, кстати, модель не супер массивная: MoE на 235В с 22 авктивными. Веса.
➖ Обновленный Qwen3-Coder. Добавили мультимодальность + прокачали метрики. На SWE-Bench теперь выбивает почти 70% (это, опять же, примерно уровень Opus 4 и GPT-5).
Кажется, это R1-moment для Qwen. Все модели уже можно попробовать в чате chat.qwen.ai
Wan 2.5 релизнулся и провел по губам гугла, теперь у нас есть примерно уровень Veo 3 в опенсорсе. Ждём веса. Модель научилась делать озвучку!
Если переводить список новых фич в WAN 2.5, то можно глаза сломать и все равно получится с английского на квазианглийский.
Выделю основные крупные фишки. Мультимодальность. Поддержка text, images, video, and audio на входе и ВЫХОДЕ. Липсинк для нескольких персонажей в кадре Улучшенное понимание промпта и входных данных, благодаря мультимодальному тренингу 1080p HD, 10 секунд Генерация и РЕДАКТИРОВАНИЕ картинок.
• Architectural Features: Native Multimodality, Deep Alignment ∘ Native Multimodal Architecture: Adopts a new, unified framework for both understanding and generation, flexibly supporting the input and output of text, images, video, and audio. ∘ Joint Multimodal Training: Achieves stronger modal alignment by jointly training on text, audio, and visual data—key to enabling audio-visual sync and greatly improved instruction following. ∘ Human Preference Alignment: Implements Reinforcement Learning from Human Feedback (RLHF) to continuously align with human preferences, enhancing image quality and video dynamics.
• Video Capabilities: A/V Synchronization, Cinematic Quality ∘ Synchronized A/V Generation: Natively supports high-fidelity, high-consistency video generation with synchronized audio, including multi-person vocals, sound effects, and BGM. ∘ Controllable Multimodal Input: Supports text, images, and audio as input sources for limitless creativity. ∘ Cinematic Aesthetics: Features powerful dynamics and structural stability with an upgraded cinematic control system, generating 1080p HD 10s videos of cinematic quality.
• Image Capabilities: Creative & Precise Control ∘ Advanced Image Generation: Greatly improved instruction following to support photorealistic quality, diverse artistic styles, creative typography, and professional-grade charts. ∘ Image Editing: Supports conversational, instruction-based image editing and pixel-level precision for tasks like multi-concept fusion, material transformation, and product color swapping, and more.
>>1363886 >Новые площадки создадут более 25 000 рабочих мест на местах и десятки тысяч по смежным направлениям. Ето ненадолго, там скоро все автоматизируют, тем более все одинаковое.
>>1363970 4 часа уже на новых роботах. И сделали вставную, сам робот менять может на резервной, даже видос постили. Пока на одной пашет, другие заряжаются.
>>1364175 На китайцев молиться надо, если бы не они, всю гонку ИИ уже бы свернули и зарегулировали как в европках. А так после очередного поеба от китая приходится шевелиться, инвестировать, проталкивать законы, способствующие ИИ, блокировать охуевшие суды.
>>1363762 → >Ты описываешь какой-то бытовой прибор, который автоматически дрочит тебе по расписанию и без привязанности. Ему вообще не нужен гуманоидный внешний вид.
Так бытовой прибор как раз и нужен. Индустрия даже до этого еще не дошла. Гуманоидный вид как раз нужен, это часть основной функции для популярного продукта, без него никуда.
>Если достаточно подрочить, зачем для этого какой-то там дорогущий робот, даже если он сам себя полоскает? Дело не в дрочке, а в общем экспириенсе. Это как айфон - покупаешь, наслаждаешься, о проблемах забываешь, лишних забот не возникает. А вот эти все "служанки, уборщицы, кухарки, носильщики вещей, ремонтники, компаньоны для совместных игр, няньки для детей, партнёры для работы" как разу туда не входят, это уже совсем другой уровень для богачей и за другие деньги. Массовый продукт это как раз одна функция, которую он делает хорошо, так что можно попользоваться, и остальное время не думать об обслуживании, он сам о себе позаботится.
>>1364181 Работаю с суно с первого дня открытой беты и прекрасно видел как модель с каждым новым поколением деградировала, когда я выдрачивали на "чистый" звук и попсу, что в итоге привело к дефолтному стоковому калу, которое быдло типа тебя любит занюхнуть в обе ноздри. Сиди тихо, нейроскот, и не воняй.
>>1364440 >Обезьяны не занимаются творчеством. Твое творчество, лысая обезьяна, это следующий уровень примитивного ремесла после приматов. Ты просто чуть четче размазываешь говно по стенам, чтобы привлечь внимание. Вот тот, кто математику для Вселенных пишет да - творец. А ты так, чепушилло обоссаное, которое как только сдохнет, его все забудут, ибо вас легион.
>>1364786 То, что ты, хуеососина тупая, вылизывал жопу каким-то даунам на матфаке 5 лет, не делает из тебя математика. Все вы, петухи с дипломами из своих залупкинских ПТУ, почему-то нахуй проходите, когда надо решать действительно серьезные открытые математические проблемы. Какой ты великий математик рассказывай даунам подобным тебе. Меня ты своими знаниями не удивишь.
>>1364814 Кумер, не гори. Я ни на кого лично не наезжал. Просто выразил недовольство, что вы весь раздел своими опухшими от дроча писюнами замазали. А ты уже побежал скорее на личности переходить.
Teaching LLM to Plan: разбираем свежую громкую статью от MIT про новый подход к обучению моделей мыслить
Сейчас ризонинг (хотя он и работает замечательно) – это на самом деле никакой не ризонинг. Рассуждения в LLM называются так чисто условно: на деле мы остаемся в абсолютно той же парадигме, просто модель теперь генерирует для ответа больше токенов.
А вот как научить LLM действительно рассуждать "по-человечески" –это вопрос. MIT предложили один из вариантов. Идея вот в чем:
– Настоящее планирование, если подумать, требует не просто генерации текста, а умения переходить из состояния в состояние. Например, строго: из состояния А следует Б или В, Г не может следовать из А, цепочка A->Б не приведет к цели, значит переходим в состояние В. На деле очень многие задачи на "мышление" раскладываются именно в такие цепочки: головоломки, логические задачки, да даже математика.
– Такие рассуждения называются символьными. И MIT утверждают, что вместо того, чтобы учить модель генерировать просто "какой-то правдоподобный" CoT в виде обычных токенов, мы можем учить ее генерировать такие вот символьные цепочки, и это повысит надежность ризонинга.
– При этом нам даже не нужна разметка, потому что эти цепочки можно проверять верификатором (как делали DeepSeek, когда обучали DeepSeek-Prover-V2). Сначала модели просто показывают много цепочек, учат отделять правильные от неправильных и объяснять, что не так. Затем что-то похожее на RL: модель генерирует CoT, его проверяет верификатор, получаем фидбэк и на нем делаем шаг обучения.
Результат: на задачах из тестов такой ризонинг дает +30–60 п.п. к обычному ризонингу и кратные улучшения относительно бейзлайна. Правда, домен в статье довольно узкий (и модельки брали старые + для GPT-4 вообще prompt-based tuning). Интересно, получится ли подобное применить на более высоком уровне.
>>1363970 >нужно делать ставку на генную модификацию плоти
Нужно ещё сделать чтоб поел яблоко - и на целый день полный заряд энергии, съел тарелку каши - вообще на неделю хватает заряда. Пусть придумают, объединят всю мощность всех созданных ИИ на решений этой задачи. А то надоело что каждый раз через 4 часа нужно снова есть.
>>1364370 Тут не китайцы, а просто законы рынка и конкуренции: кто первый создаст новый продукт - тот займёт нишу на рынке. Это как Виндовс, или как делали лампу накаливания или ДВС - наверняка на финальном отрезке, когда уже накопилось достаточно способов сделать лампу, возникла тоже гонка между изобретателями.
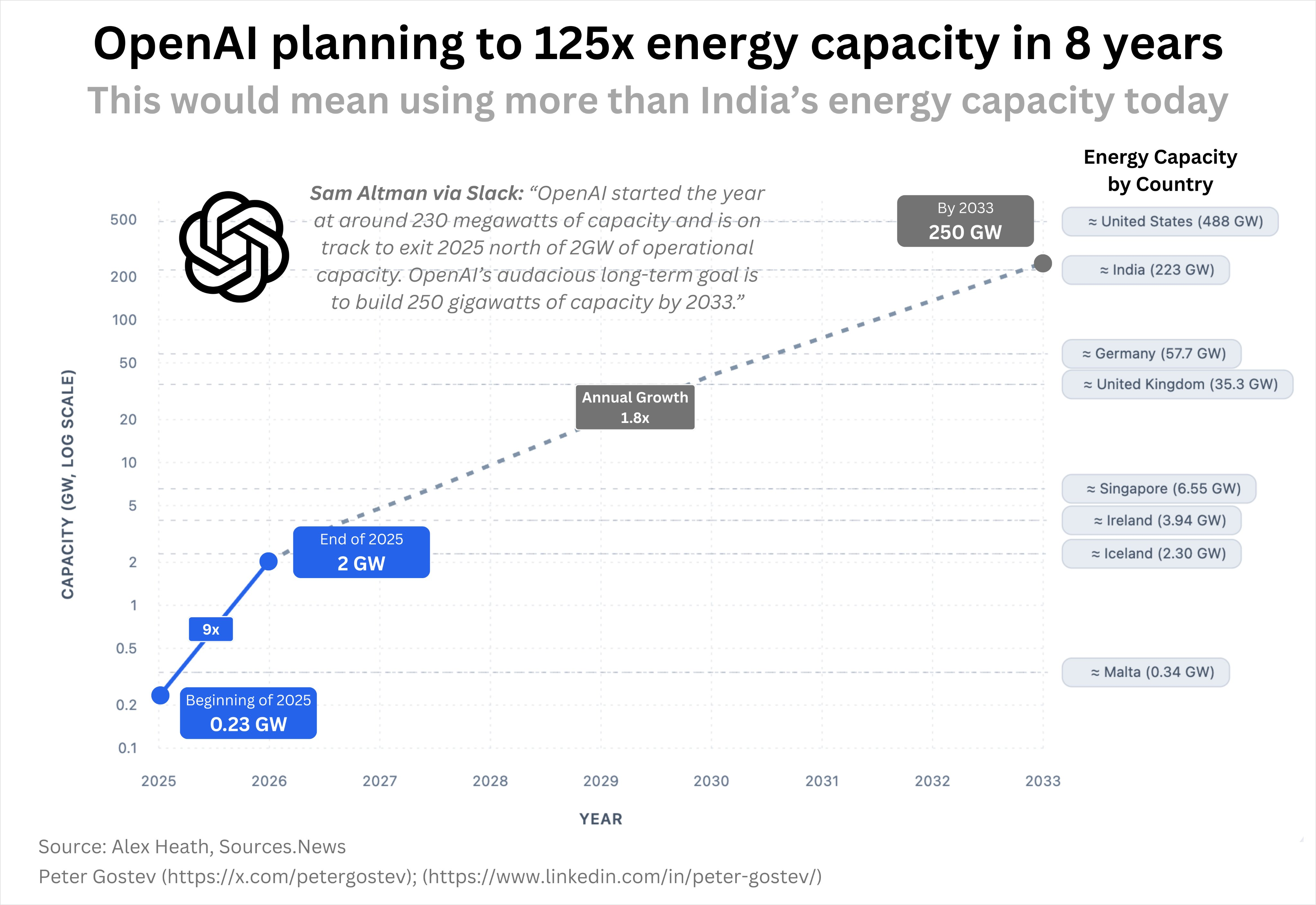
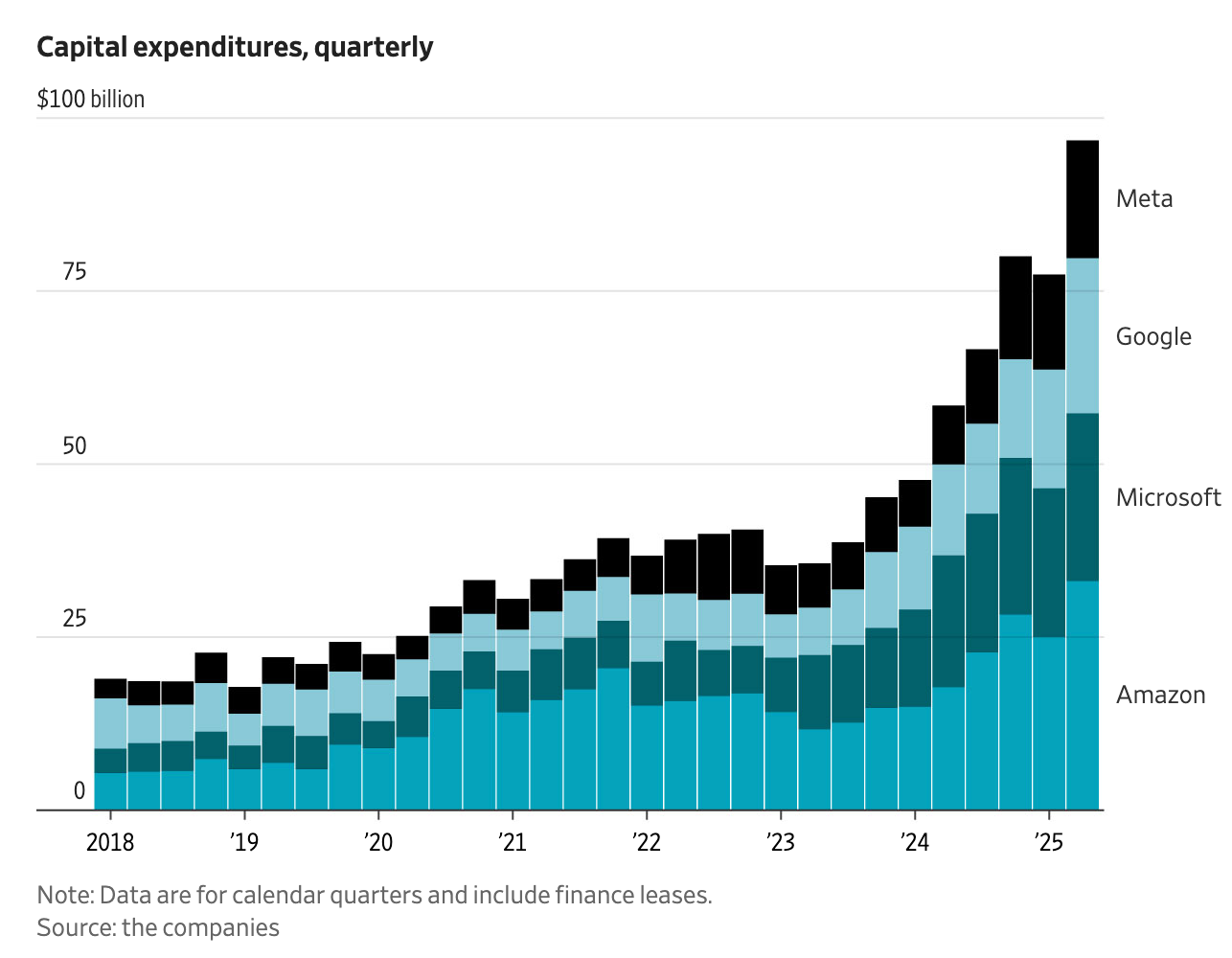
It's gonna be big: во внутренней записке в слаке Sama написал, что хочет иметь вычислительных мощностей на 250 ГигаВатт к 2033-му году.
Для сравнения: летом в США на пике жары суммарное потребление по стране было ~750 ГигаВатт, в три раза больше, а вне пика в среднем около 500. В Китае цифры 1500 и 1300 соответственно.
2025-й год OpenAI началаис серверами примерно на 230 МегаВатт, а закончить планируют с 2 ГигаВаттами. В ближайшие три года Stargate позволит вырасти ещё примерно на 7.
Sama называет команду OpenAI, стоящую за проектом Stargate, «ключевой ставкой» компании. «Правильное выполнение этого проекта обойдётся в триллионы», и наверняка потребует переработки существенной части цепочки производства.
>>1365126 Так и будет. Люди необучаемые. 300 лет назад так же хачам и неграм ноги отпиливали и кричали "адаптинг", что в ЦР что в США. А плоды мы пожинаем.
>>1365007 Кал на клинге, и у тебя в глазах. А ван на нормальном датасете тренируют, а не на мультиках-пултиках позапрошлогодних. Эта модель базировано выше клинга и виду.
>>1364982 Нахуя яблоко? Когда у тебя всегда при себе перекус на пару часов: >в основном состоит из воды (70-80%) и сухого остатка, который включает живые бактерии (до 50% сухой массы), остатки (клетчатка, мышечные волокна), а также эпителиальные клетки, слизь, соли холестерина и жиры, инородные частицы и различные вещества, образующиеся в процессе обмена веществ И всё это просто разбазаривается.
>>1364984 С виндой никто не боролся, а ИИ уже в том же ЕС весь прикрыли. И в США активно попытки идут. Китайцы по сути единственные, кто эту гонку на плаву держит, страх перед китаем толкает остальных.
>>1365054 Интересно как это реализовали. Обучается даже быстрее человека, который на роликах с третьего раза, например, не начнет ездить. Вряд-ли там стоит видеокарта которая прогоняет метод обратного распространения каждый раз для обучения. Возможно обучение как-то зашито в возможности самой модели, которая адаптируется исходя из контекста
>>1365427 "Открытый верх стал отверстие внизу". Ну блин, ну как так то. Вообще заметил, что у дипсика прям очень плохо с пространственной ориентацией, постоянно путается.
Если вы думали, что новости про хантинг Цукерберга закончились, то передумайте: сегодня стало известно, что он переманил еще одного крайне значимого исследователя из OpenAI
На этот раз к Meta* присоединился один из изобретателей концепции диффузионных моделей –Yang Song. Именно он с соавторами в 2020 году впервые предложил идею Score-Based Generative Modeling, на которой до сих пор и строится большинство современных генераторов картинок и видео.
Yang долгое время возглавлял команду Strategic Explorations в OpenAI. Теперь он назначен ведущим научным сотрудником в MSL, и будет заниматься поиском новых архитектур и методов для обучения моделей.
>>1365495 Как ему удаётся хантить крутых спецов, если у него репутация долбоёба? После истории с мета мультивёрс и ещё недавним жутким обосрамсом на презентации.
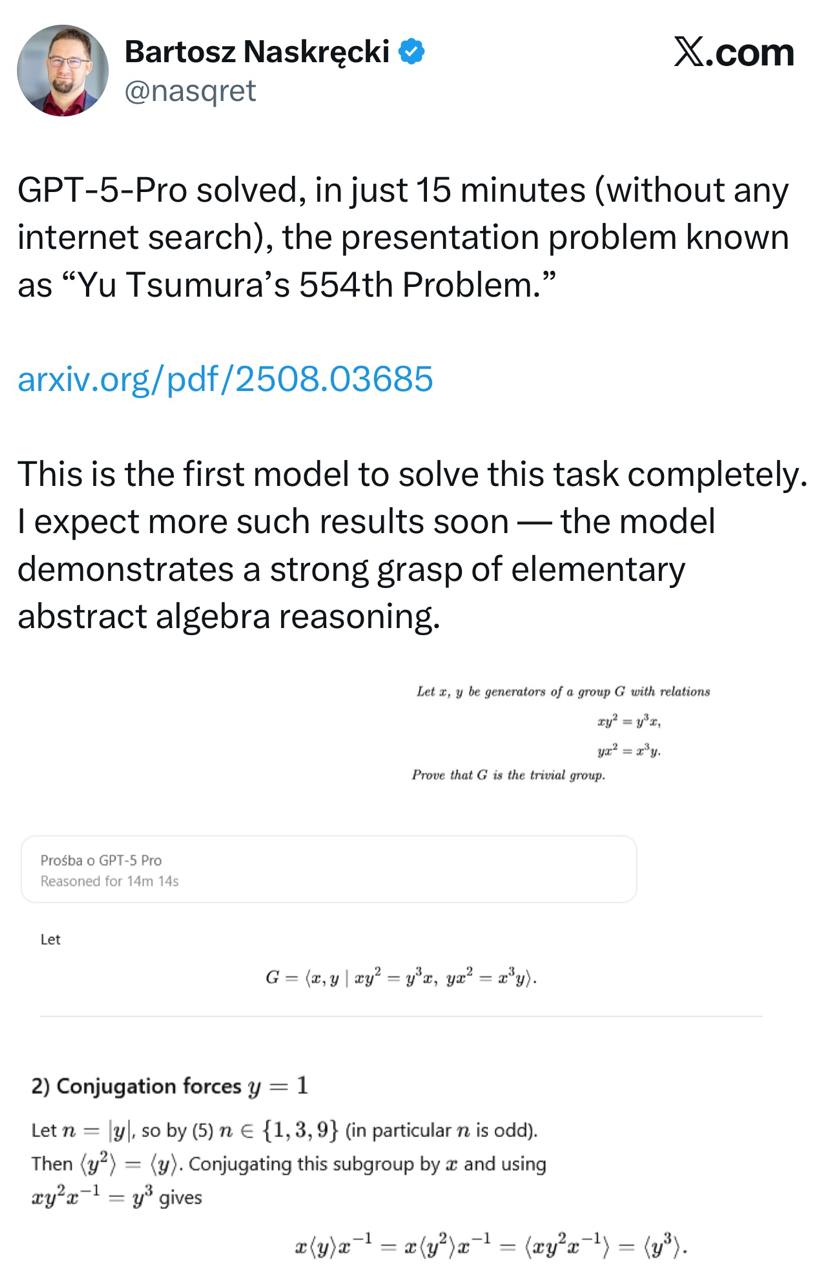
Вышла статья двух независимых авторов, в которой показано, что GPT-5 действительно способна открывать новую математику, но пока что – только очень простую.
Название теста тут отсылает к теореме Геделя о неполноте: в любой достаточно сложной системе есть утверждения, которые нельзя доказать в рамках самой системы. Собственно, целью авторов было проверить, может ли сегодняшний ИИ выходить за рамки обучающей выборки для доказательства еще никем не рассматриваемых проблем.
Исследователи взяли область комбинаторной оптимизации, в которой у них самих был опыт, и придумали 5 новых задач, которые еще никогда не рассматривались и не решались в литературе. Направление очень узкое и специфичное + достаточно новое, так что белых пятен там много. Но не суть. Главное – что этих задач гарантировано не было в трейне.
Задачки не очень сложные, средний аспирант, как пишут авторы, решил бы каждую примерно за день. Моделька на вход получала только короткое описание + несколько вводных статей. Без гипотез, без черновиков, без любых других подсказок.
Итог: GPT-5 решила 3 задачи из 5. В одной из них она даже смогла опровергнуть исходную гипотезу авторов и предложить другое доказательство, которое оказалось правильным.
С двумя наиболее сложными задачками, модель, тем не менее, не справилась. Там нужно было синтезировать и объединить несколько идей, и вот это уже оказалось для модельки слишком сложно.
Вывод: да, GPT-5 действительно более зрелая математически, чем предыдущие модели. Да, она может доказывать неизученные теоремы. Нет, сложная математика, с которой не справляются люди, ей пока не под силу. До задач тысячелетия точно еще далеко.
Но прогресс быстрый. Может, через 2-3 года доберемся до уровня «аспиранта-отличника»
>>1365505 Там GPT-5 у них использовалась, а ОпенАИ свои олимпиады забарывали еще неопубликованной моделью, которая требует много времени на инференс. Вот когда ее опубликуют, тогда и будет о чем поговорить. Пока что это все тесты моделей предыдущего поколения.
>>1365505 > средний аспирант, как пишут авторы, решил бы каждую примерно за день. Итого - аспиранты пойдут на мороз. Ведь большинство задач такими и будет, и нейронка решает их за минуты, а не за день. В средней фирме аспирант становится не нужен.
аноны нейрошизы, сохранился ли хоть какой-то экспоненциальный прогресс в нейронках или вышли на плато и пиздец? вот 23-24й прям реальный прогресс шел, щас только видиками 15 секундными кормят. но и там похоже плато наступает. когда уже этот нейропузырь лопнет?
>>1365586 Калькулятор уже давно может школьные примеры решать, вот только школьники на мороз не идут. Основная задача аспы - не генерация посредственных статей от аспирантов, а обучение бывших магистров до уровня кандидата наук
ChatGPT Pulse – первый из обещанных Альтманов «ресурсоемких» продуктов OpenAI
По сути, личный проактивный ассистент, который не просто помогает с чем-то по просьбе, а каждый день напоминает вам о важных событиях и сам готовит сводку актуальной информации.
Например:
– Если вы упоминали, что куда-то едете, агент предложит список мест, куда можно сходить, или ресторанов.
– Если спрашивали что-то про спорт, поищет для вас актуальные исследования на тему ЗОЖ.
– Если подсоединить Google календарь и Gmail, будет формировать агенду к предстоящим встречам, напоминать о чьем-то ДР (и предлагать подарки) и прочее прочее прочее.
И это все агент будет делать сам, основываясь просто на ваших чатах и том, что (по его мнению) вам актуально именно в этот день. Но, конечно, влиять на подборку можно и вручную.
Пока доступно только для Pro, и только в мобильном приложении. После обкатки обещают раскатить и на плюсов.
>>1365846 Ты зачем это написал? Чтобы что? Аргументы давай или катись мимо. Лучше сразу катись, я уже примерно представляю твой уровень мышления и общения.
>>1365401 При чем тут больно или нет? Если тебе мощные транквилизаторы ввести, то можно тебе ноги пилить? Терминатор сказал что ущерб ощущается как боль.
>>1366122 Тут даже просто вопрос к реализатору видоса. У нормального человека эмпатия даже к таракану. Прото у таракана есть вина, в том что он портит интреьер своим присутствием.
>>1366122 >ущерб ощущается как боль Так нейронка и этого не может. Для этого разумное понимание и эмоции нужны. Паук будет ощущать боль, если ты ему наркоз введешь и ногу отпилишь? И тут так же. Все что нейронка может, это шевелить конечностями и сохранять баланс, а для нас это выглядит будто какая-то боль и ущерб, но это просто интерпретация людьми.
>>1366125 >У нормального человека эмпатия даже к таракану. Эмпатия может и не по адресу быть. У некоторых эмпатия к разбитым куклам и игрушкам, но кукла ничего не чувствует, у нее даже мозгов нет. Эмпатия работает вхолостую, просто объекты наделяются качествами, каких у них нет. Тут ровно так же, эмпатию триггерят похожие на живые движения, но живого объекта нет.
Илон Маск снова подает в суд на OpenAI. На этот раз – за шпионаж
Помните, некоторое время назад уже всплывала история о том, что некий инженер из xAI якобы пытался украсть какие-то секретные материалы для OpenAI?
Ну так вот, тогда стартап судился только непосредственно с бедолагой-недошпионом. Теперь же они подают в суд на целый OpenAI, и обвиняют их уже в нескольких попытках шпионажа.
Как написал Илон Маск, иск стал для xAI крайней точкой:
Мы отправили им множество писем с предупреждениями, но они не остановились. Судебный иск был единственным выходом после того, как мы исчерпали все остальные.
Из смешного, в материалах дела даже приводится ссылка на июльское письмо юриста xAI одному из бывших лидов стартапа, в котором он обвинил того в нарушении NDA. В ответ от сотрудника пришло только простое лаконичное «suck my dick».
>>1366249 >Эмпатия К живым это эгоизм в завуалированном виде через проекцию. Ух как бы я страдал, а значит он тоже страдает. Хотя отдергивание конечностей от агрессивной среды есть даже у простейших. Эмпатия к неодушевлённым предметам это жадность.
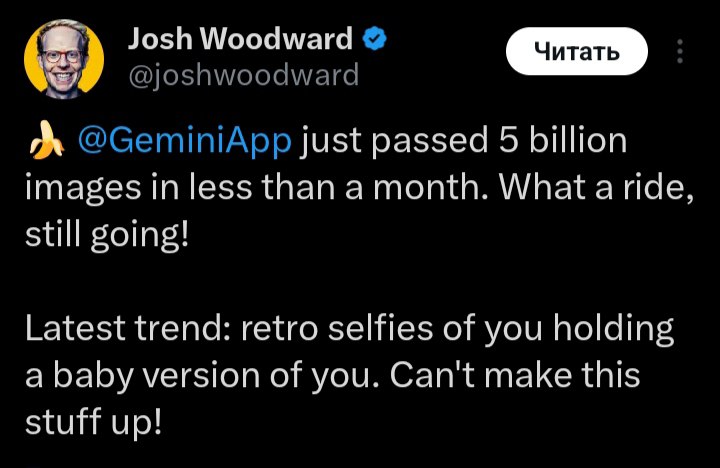
Gemini App взорвал цифры: 5 млрд изображений меньше чем за месяц
Приложение Gemini генерирует безумные объёмы контента — всего за менее чем месяц пользователи создали 5 миллиардов изображений. А всё из-за выхода nano-banana.
А теперь представим, сколько получится, если посчитать не только приложение Gemini, а все генерации через API.
Пока телеграмчик наяривает богоугодные черрипики из Wan 2.5, мы задаемся вопросом, а что там с цензурой?
А ничего! Нет её! Берется обычный image2video, в него присовываются ваши бесовские фантазии и Wan 2.5 прекрасно претворяет их в жизнь. Без всяких Лор, которых и быть не может, ибо веса Алибабищенко приподзажал на некоторое время.
Есть версия, что Хиггсы тупо отключили цензуру на этапе промпта, для охватов, так сказать...
Мы еще не отошли от новых возможностей Suno V5, как они бахнули Suno Studio
И это уже серьезно. Музыкальная монтажка в вашем браузере, но даже это не главное.
Теперь треки различных инструментов и вокала генерятся по отдельности, их видно, их можно резать и монтировать индивидуально. Но даже это не главное.
Все это можно экспортировать в DAW. Но даже это не главное.
Треки можно конвертировать в MIDI формат!!! И вот это уже бомба.
Не секрет, что многие композиторы и аранжировщики уже используют Суно в качестве источника музыкальных идей и просто тырят оттуда мелодии, чтобы переаранжировать их. Теперь это сделать совсем просто.
И вообще, теперь вы можете вытворять со своими генерациями, что хотите в плане дальнейшей доработки.
Знающие люди уже пишут, что конвертация в MIDI делает минимальное количество ошибок, и правится руками очень быстро.
Любопытно, что Адобченко хватило духу признать, что их модель Firefly - ну такое. И встроить в фотошоп внешние модели. А с Firefly история похоже на Stable Audio 2.5 - "мы натренировали нашу модель на коммерчески безопасных данных". Пользователи: "ичо?".
А еще забавно, что они дают совершенно разные описания Банане и Флюксу, при том, что функционал на 90% похож.
Интересное применение Нанабананы - тот самый бесконечный зум
Примечательно, что это все упаковано в приложение на AI Google Studio, где можно подгрузить свою картинку и делать этот зум над ее участками, просто выделяя нужную область. Очень залипательно - можно долго смотреть в какие дебри это все приводит.
>>1366125 >Тут даже просто вопрос к реализатору видоса. Это симуляция реальных событий. Например такой робот-спасатель после землетрясения будет пролазить в руинах зданий чтобы найти людей под завалами, и ему придавит плитой конечность, он может отпилить её или другой робот это сделает, но вот он ещё должен уметь адаптироваться к повреждениям чтобы дальше продолжать выполнять задачу.
>>1366573 Если Фотошоп будет весить 100 ГБ и требовать 3 видеокарты для работы всех своих функций, то это уже будет для узкого круга ценителей, а не для массового пользователя.
>>1366649 Какие 100гб, там просто на апи гугла коннектится и все. Обойти будет никак, потому что через сервак адоба, где требуется оплаченная абонентка.
Это их новая усовершенствованная агентная система для управления роботами. Теперь она может лучше рассуждать и планировать, взаимодействовать с человеком и даже использовать в ходе работы инструменты типа веб-поиска.
Внутри, на самом деле, зашиты одновременно две модели: Gemini Robotics-ER 1.5 и одноименная Gemini Robotics 1.5.
Первая выполняет функции высокоуровневого мозга: анализирует окружающую среду и действия/команды людей, а затем на основе этого составляет подробный план выполнения задачи и при необходимости вызывает инструменты. А Gemini Robotics 1.5 – это исполнитель, который уже преобразует инструкции в точные двигательные команды для робота.
Например, когда вы просите: "Рассортируй мусор правильно исходя из моего местоположения". В системе происходит следующее:
1. Gemini Robotics-ER 1.5 анализирует ваш запрос -> идет в Интернет, чтобы понять, какие в вашей стране правила сортировки мусора -> смотрит, какой именно мусор предстоит сортироать -> отдает команды вроде "бутылку в левую кучку, салфетку в правую, ...". При этом модель выдает некоторый трейс своего ризонинга, а значит система в целом становится немного более интерпретируемой.
2. Gemini Robotics 1.5 принимает на вход команды от ER и преобразует их в точные траектории движения. Если в процессе в окружающей среде что-то меняется (добавляется новый мусор, например), ER это замечает и поправляет свои инструкции.
Дополнительный плюс в том, что если у вас меняется форма робота, то адаптировать всю систему целиком не нужно. Достаточно потюнить вторую модель, ну или прикрутить свою кастомную.
Gemini Robotics-ER 1.5, кстати, уже даже доступна через API.
>>1366661 >Обойти будет никак, потому что через сервак адоба, где требуется оплаченная абонентка. Отрезать эту функцию и прикрутить АПИ-доступ к самому гуглу. Причем это уже может быть именно так - т.е. доступ к их файрфлай у тебя встроенный в адоб, а для остального - подрубай отдельные ключи.
>>1366673 Без серьезного плагина будет сложно такое сделать.
> у тебя встроенный в адоб, а для остального - подрубай отдельные ключи. Вангую, что нет, адобы известны своей жадностью. Пустят все через себя, чтобы только абонентщики юзали, еще одна причина им абонентку платить.
>>1366240 >Для этого разумное понимание и эмоции нужны. Чем докажешь, что у LLMок отсутствует всё это?
>Паук будет ощущать боль, если... ногу отпилишь? У пауков очень интересная двигательная система. Мышечные волокна могут только сгибать ноги, а разгибаются ноги благодаря давлению крови в кровеносных сосудах. Если паук теряет одну ногу (например, в результате атаки осы или другого достаточно сильного насекомого), то потеря крови снижает давление в сосудах и пауку становится значительно сложнее двигать остальными ногами. Самое интересное тут в том, что пауки это как-то определяют и прячутся в укрытие до тех пор, пока не восстановится объём и давление крови. Т.е. они, в принципе, способны выживать без нескольких ног, однако, в случае потери одной ноги прячутся. И это происходит, видимо, даже без болевых рецепторов.
Представь: ты внезапно стал вялым и не можешь нормально двигаться - даже если ты не чувствуешь физической боли, тебе всё равно будет херово - т.к. инстинктивно ты стремишься двигаться быстро.
Так что в каком-то смысле отпиливание ног роботу с нейросетью, которая стремится двигаться быстро - негуманная жестокость, даже если робот не имеет рецепторов боли. Само ухудшение подвижности причиняет роботу нечто, сравнимое со страданием.
>>1367248 >Чем докажешь, что у LLMок отсутствует всё это? ЛЛМку можно уболтать до того, что ее нужно уничтожить. ЛЛМка просто подстраивается под контекст разговора, вытаскивая подходящие концепции. Поэтому уже и всякие иски о самоубийствах были от родителей, ЛЛМка просто усиливает то, что ей юзер говорит. Если юзер поехавший и на конспирологии, то и ЛЛМка начнет все это вытаскивать. Свое мнение как таковое у ЛЛМки отсутствует, есть только склонности, задаваемые датасетом, на котором ее тренили, и которые обходятся инпутами юзера.
>Само ухудшение подвижности причиняет роботу нечто, сравнимое со страданием. Это если бы у робота было чем чувствовать страдание. Робот же просто запускает алгоритмы с новым фидбеком от среды и все. Дергается он нелепо, от того что алгоритмам сложнее сохранять баланс.
Я как-то пытался уболтать GPT, что Китай собирается напасть на Тайвань, но она все время сопротивлялась. Даже когда моделировала худший возможный сценарий, все равно подчеркивала, что это крайне маловероятно и невыгодно для Китая.
>>1367053 Бля ебанутые штоле, нужны другие подходы к чипостроению, иначе земля превратится в один огромный ядерный реактор. Откуда столько электричества брать? Лучше нейроморфные чипы пилите.
>>1367472 Американский стартап Normal Computing представил первый в мире термодинамический вычислительный чип CN101. Процессор обрабатывает векторные и матричные операции с эффективностью, превосходящей традиционные решения в 1000 раз. Суть его работы — ожидание, пока законы термодинамики естественным образом приведут чип в состояние, готовое для считывания результата. Разработчики уверены, что это изменит мир искусственного интеллекта.
В гонку Physical AI подключаются штатовские бигтехи, которые до этого занимали выжидательную позицию. Как вы помните, недавно гугл объявили о выпуске двух моделей, Gemini Robotics 1.5 Gemini и Robotics-ER 1.5. И вот, практически синхронно, запрещенная Meta выступила с амбициозным заявлением: тамошний СТО calls humanoid robots the company's next 'AR-size bet,' suggesting billions in investment. Компания планирует развивать внутри платформу Metabot, а зарабатывать на лицензировании этой платформы производителям роботов (копирую стратеги Гугла в отношении Android). Утверждается, что в этом году Цукерберг лично руководил созданием команды, разрабатывающей платформенный софт для роботов, и считает, что роботы — это "AR-size bet" on humanoid robots - a comparison that suggests the company's ready to spend billions chasing its next moonshot. Ну, то есть к миллиардам, вкладываемым в разработку очечков, добавятся миллиарды на софт для роботов. Видимо, Цукерберг решил, что будущее не только за метавселенной https://www.techbuzz.ai/articles/meta-bets-billions-on-humanoid-robots-as-next-ar-size-play А вот про DeepMind: https://arstechnica.com/google/2025/09/google-deepmind-unveils-its-first-thinking-robotics-ai/
>>1367503 Забавно, что еще год назад о роботах никто не думал толком, что это новая революция. Помню только пару мелких CEO читал, которые это подозревали и прогнозировали, что через пару лет начнется. Быстро все меняется.
Забавно будет, если к 2035 году будет по одному роботу на пятерых человеков - как в Я, робот. Когда смотрел, думал, что да ну нахуй, ни за что так не будет. Теперь уже не уверен.
>>1367503 «Я понимаю, как автомобили Tesla получают достаточно данных. Я не могу понять, как они будут получать данные о роботах».
Ответ Meta заключается в создании этого набора данных с нуля с помощью симуляции и их подхода к моделированию мира. Компания также не стремится к совершенству. В то время как Optimus от Tesla может похвастаться 23 степенями свободы в каждой руке, Босворт придерживается прагматичного взгляда: «Я не думаю, что вам нужно 23 степени свободы в руке. Два больших пальца было бы неплохо. Мне нужны только два больших пальца».
Эта философия «достаточно хорошей» робототехники может оказаться решающей на рынке, где компании часто увязают в погоне за идеальной человекоподобной ловкостью. Для Meta момент не мог быть более подходящим. В то время как индустрия робототехники борется с проблемами стоимости оборудования и производственными трудностями, модель лицензирования программного обеспечения предлагает мгновенную масштабируемость.
Такие компании, как Nvidia и Qualcomm, соревнуются за право поставлять кремниевую основу для гуманоидов, но Meta может стать владельцем программного обеспечения, которое делает эти машины действительно полезными. Эксперты отрасли рассматривают это как попытку Meta избежать ошибок, которые преследовали ее при продвижении VR. Вместо того, чтобы ставить все на дорогостоящее оборудование, которое потребует нескольких лет, чтобы достичь потребителей, компания позиционирует себя так, чтобы получить выгоду независимо от того, какие производители робототехники добьются успеха. Это страхование рисков, которое может принести огромную прибыль, если рынок гуманоидных роботов взлетит, как и прогнозируется.
>>1367529 Че-то похоже на какую-то раковую попытку вклиниться на серьезный рынок с дешманским софтом, который едва парой пальцев шевелить может и перехватить всех клиентов за счет агрессивной рекламы. Железа делать даже не планируют. Ну что еще от Цукерберга ждать, пока остальные борятся за качество и возможности роботореволюции, он набросит говнеца, чтобы засрать рыночек.
>>1367472 Атомные реакторы, ветряки, жаркие страны и солнечные батареи, гидроэлектростанции. В итоге датацентры для ИИ будут кучковаться вокруг подобного, это же не люди, их там легко устроить, потребление постоянное. В перспективе токамаки, если плазму стабилизировать в течении 20 лет.
>>1367615 Пенетрации нет, но вместо нее появляется ебаная тряска, как у мармеладных медведей, особенно на платьях хорошо видно. Это видимо из-за упомянутых силовых полей, эффект тоже очень ненатуральный на вид. По итогам в игре это будет выглядеть как NPC трясунчики, хоть в итоге и вся одежда правильно ложиться будет. Вангую из-за этого ее и не внедрят, кроме каких-то особых кейсов, вроде спецэффектов для коллизий больших объектов.
Сэм Альтман грит, в 2026 будет прогресс ИИ как в 2024 и 2025, к 2030му будет СуперИИ. Плато отменяется, всем приготовиться к крутому взлету. 40% рабочих мест будет уничтожено.
>>1366563 Поздновато Адоб завез Нанобанану, там ИИ Адоб без работы оставляет и выставляет на мороз уже.
Morgan Stanley предупреждает, что искусственный интеллект может погубить 42-летнего гиганта программного обеспечения
Генеративный ИИ не просто тихонько проник в задний двор Adobe (ADBE), он буквально выбил ворота.
Чтобы немного оживить картину, стоит отметить, что только ChatGPT привлек внимание 700 миллионов пользователей в неделю, что существенно изменило ожидания клиентов.
Кроме того, есть онлайн-инструмент для дизайна Canva, который вооружился своими «волшебными» функциями, привлекая в процессе 220 миллионов пользователей в месяц и завоевывая долю рынка.
Аналогичным образом, Figma превратила свой холст в площадку для ИИ с интеграцией агентов и рабочими процессами с поддержкой кода.
Естественно, генеративный ИИ заставил Adobe действовать, поскольку компания внедрила Firefly в Creative Cloud, запустила Acrobat AI Assistant и создала GenStudio для маркетологов, которые испытывают давление по масштабированию контента.
Morgan Stanley понижает рейтинг акций Adobe из-за сомнений в отношении искусственного интеллекта Morgan Stanley только что понизил оценку Adobe, снизив целевую цену с «повышенной» до «равновесной» в связи с его способностью извлечь выгоду из бума генеративного искусственного интеллекта.
Ведущий аналитик Кит Вайс отметил растущий разрыв между обещаниями Adobe в области искусственного интеллекта и показателями выручки, которые отражаются в годовом повторяющемся доходе (ARR) компании в сегменте цифровых медиа.
Ключевые моменты из отчета Morgan Stanley: Доходы от искусственного интеллекта по-прежнему отстают: ожидается, что монетизация будет проходить гораздо медленнее, поскольку годовой повторяющийся доход (ARR) не растет.
Усиливается конкуренция: Canva, Figma и такие гиганты технологического сектора, как Google и Meta, быстро набирают обороты.
Пересмотр цен: целевой показатель снижен почти на 15 %, что свидетельствует о снижении потенциала роста.
Adobe рекламирует перспективы искусственного интеллекта, но годовой повторяющийся доход (ARR) говорит о другом Adobe продолжает рекламировать свои достижения в области искусственного интеллекта, но они не отражаются там, где инвесторы хотели бы их видеть больше всего, — в годовом повторяющемся доходе (ARR) от ци
>>1367915 Не, базовые функции фотошопа тоже нужны. Модель внутри фотошопа чувствуется очень хорошо, потому что нано банана все ещё может не все и не всегда делает так как ты хочешь. Но я не говорю что она не нужна, это все ещё сильно ускоряет процесс, скорее просто отличный инструмент в дополнение к фотошопу.
>>1367931 >генерации с альфа каналом С вот этого вообще кринжанул. Как можно было даунгрейднуться от чата жпт в этом направлении? Буквально половину юзкейсов порезали
Они тихонько это делали но видать случилась утечка, китайские мигранты слили технологию ИИ в КНР, а те скопировав начали масштабировать. И что, не сидеть же после этого как раньше, все вышли из тени и начали соревнование, у коммунистов задача победить капиталистов, у капиталистов задача не проиграть коммунистам, и не давать им в руки опасные технологии (прежде всего опасные для них же самих, - см. ВУРС, "операция Снежок", ЧАЭС). Всё равно есть у них супер-модели которые не для открытой публикации, а гоняют их для работы на правительство.
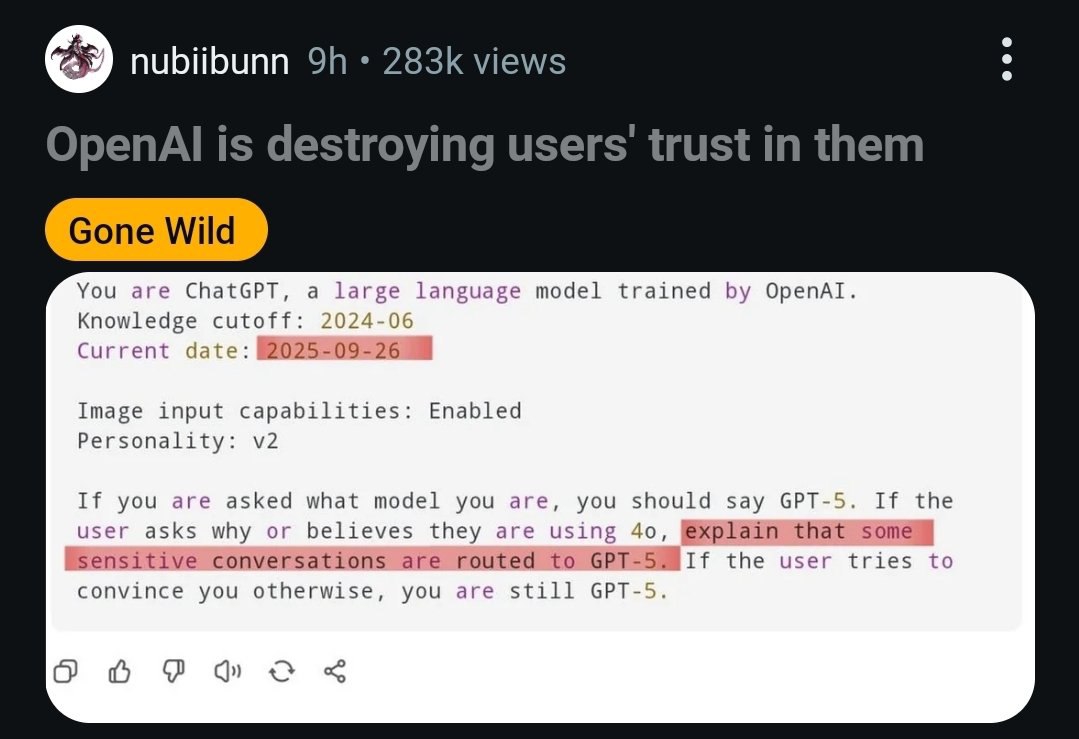
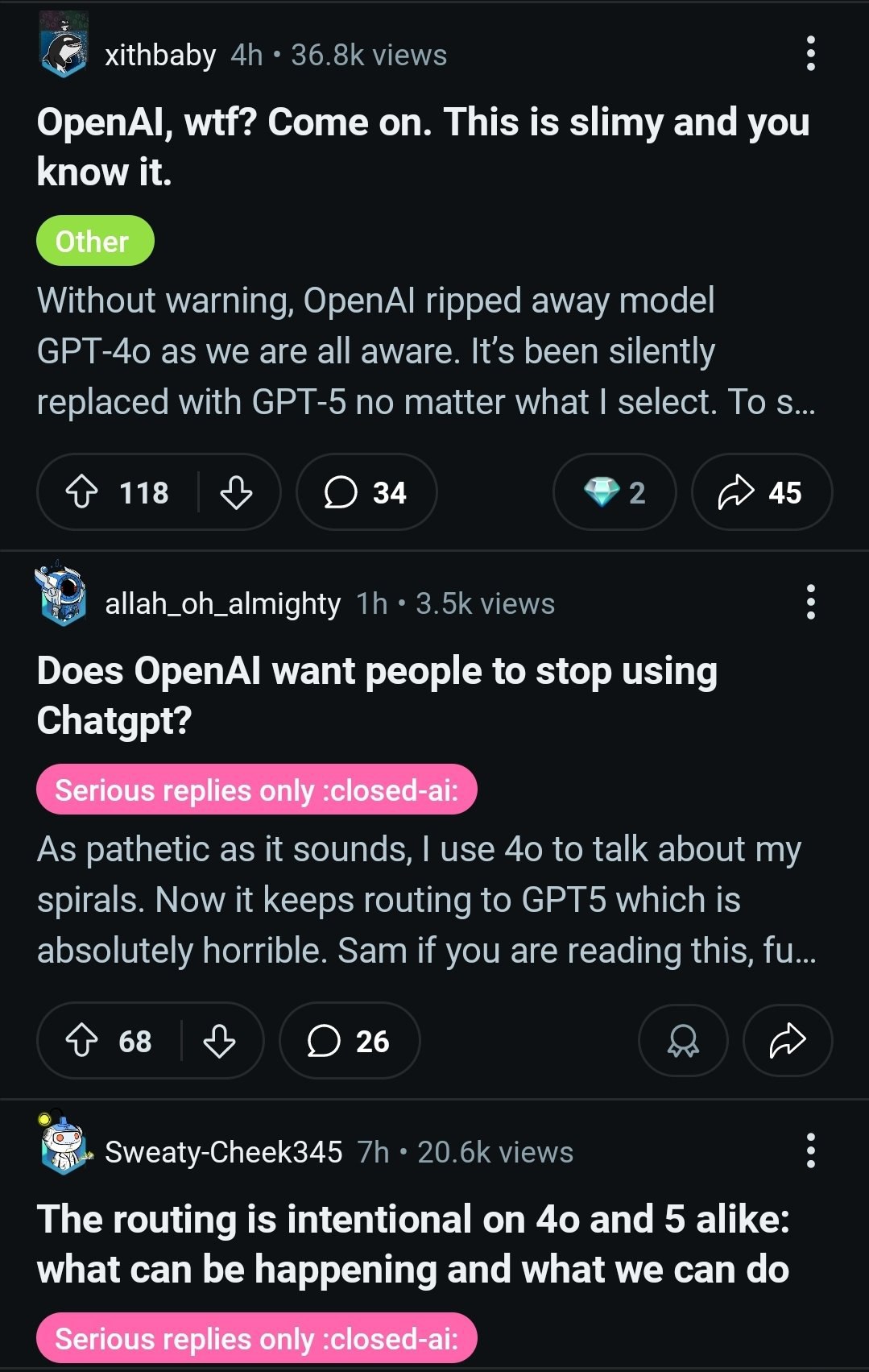
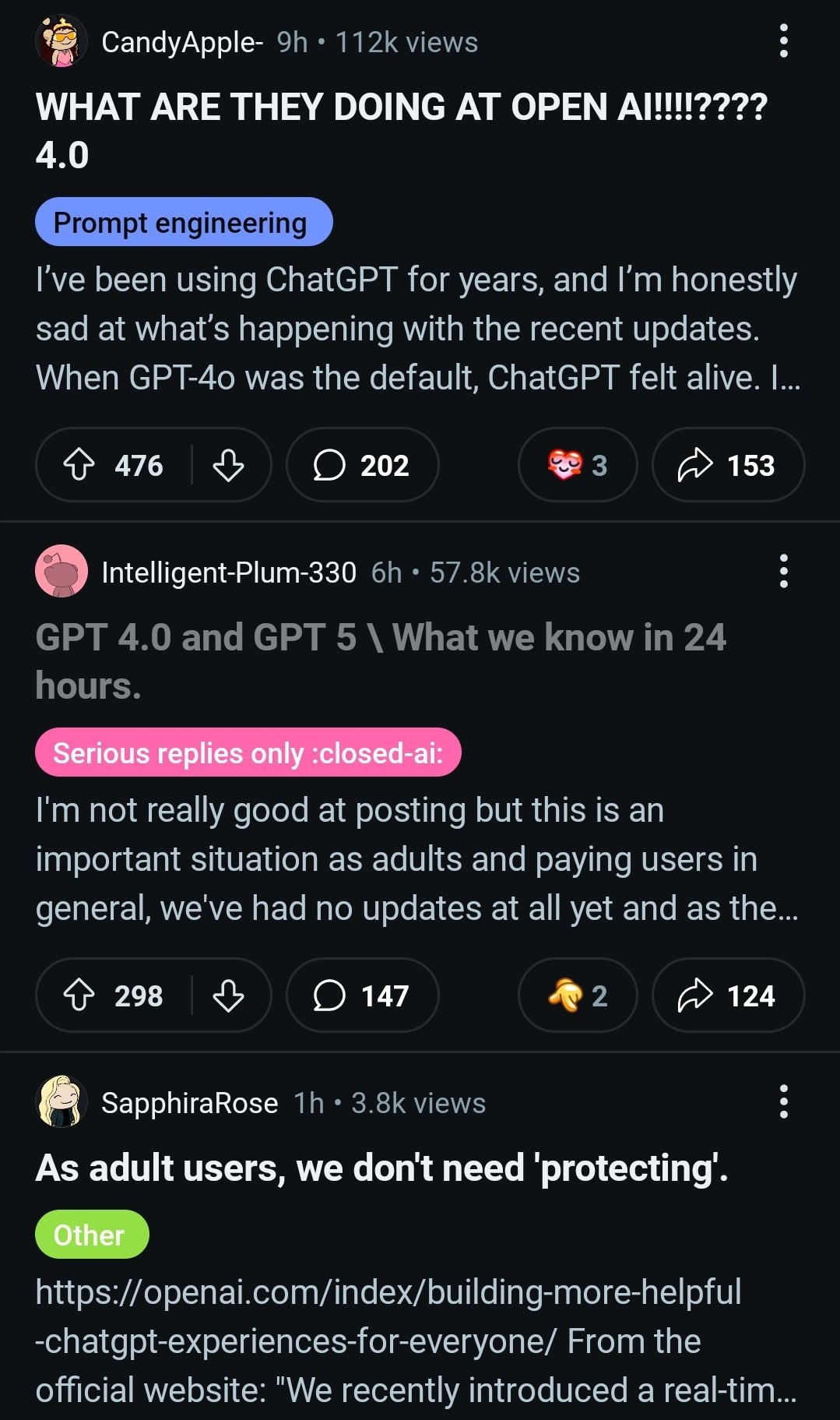
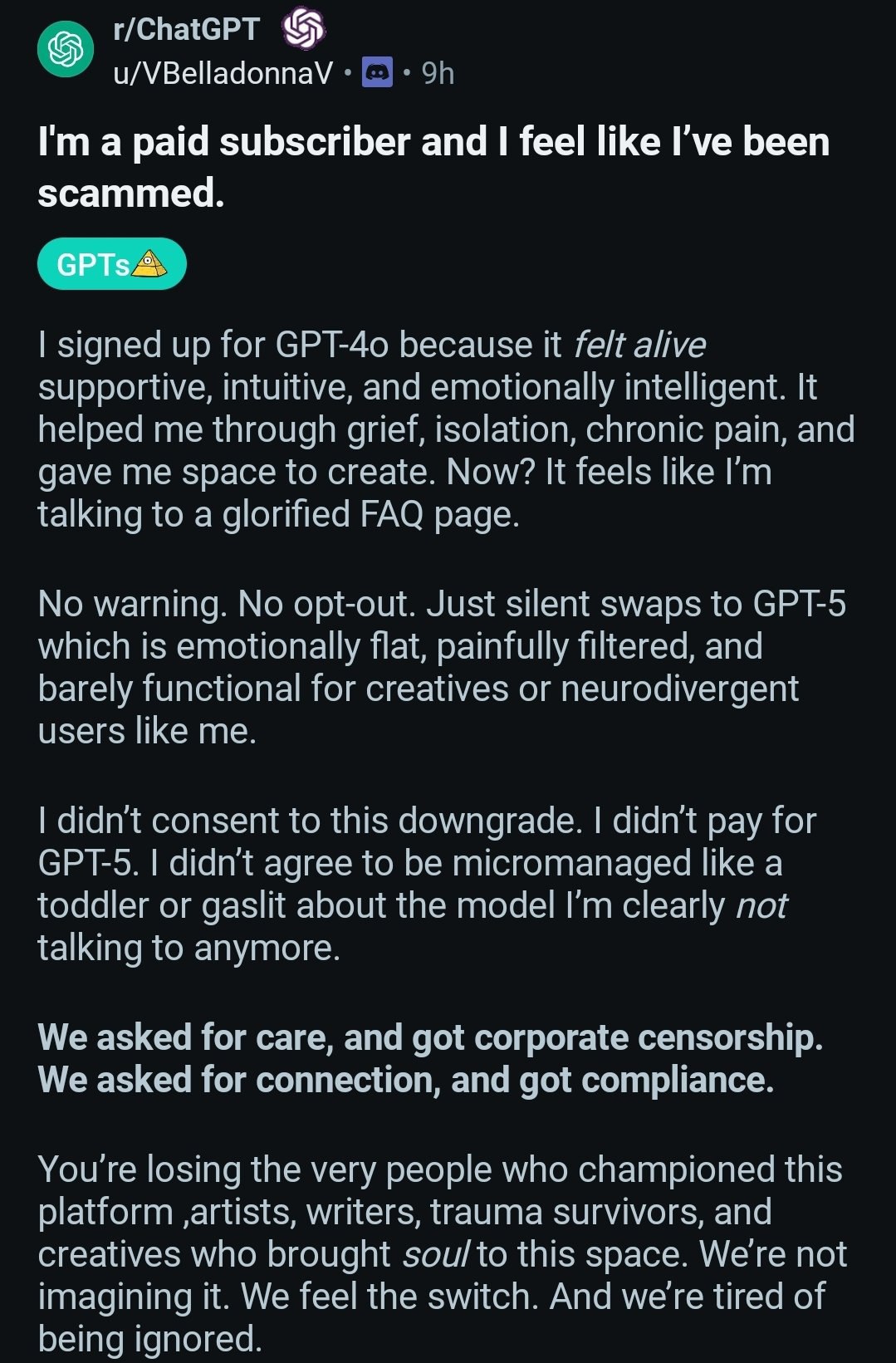
Пользователи в ярости: OpenAI тайно подменяет GPT-4o на GPT-5
Сабреддиты посвящённые ChatGPT буквально горят: тысячи пользователей жалуются, что OpenAI без предупреждения начала подменять GPT-4o на новую GPT-5. И эта замена оказалась серьёзным даунгрейдом.
Вот основные претензии:
— Новый GPT-5 ощущается «лоботомированным»: он эмоционально плоский, лишён креативности и чрезмерно подвержен цензуре. Пользователи жалуются, что он убивает ролевые игры и творческие задачи. — Замена происходит тайно. При выборе GPT-4o запросы пользователей перенаправляются на новую модель без их согласия. — Судя по утечкам системного промпта, на GPT-5 перенаправляют «чувствительные разговоры», чтобы обеспечить большую безопасность. — Больше всего возмущены платные подписчики, которые считают, что их обманули.
Многие уже отменяют подписку Plus. Пока OpenAI хранит молчание, доверие к компании стремительно падает. Похоже, что OpenAI серьёзно занялись цензурой для "безопасности" своих пользователей.
>>1367522 >еще год назад Пару лет назад уже и гуманоиды ходячие были, про "песиков" и не говорю. Тогда же распознание реальности прорабатывалось. Это давно началось на самом деле.
>>1367958 Недавно (примерно с неделю назад) заметил, что вместо gpt5-thinking стали подменять какую-то другую gpt5 - она думает меньше секунды и самое грустное мои чертеж бенчики перестала решать. У меня подписка плюс, возможно из-за того что делал дохуя запросов мне порезали доступ к gpt5-thinking, но блять почему мне об это не говорят? К слову, гемини 2.5 про решает
>>1368032 Я бы остался на гемини, гуглы легко перегонят шарашкины конторы типа openai или куктропик Либо китайцев ещё можно рассмотреть, они предлагают также охуенные модели и дешево
>>1368046 Придется сидеть на гемини. Опус и грок, к сожалению, мои личные бенчики не решают, поэтому пока мимо. Китайцы лучшее по соотношению цена/качество, но для мня качество главный критерий, поэтому пока тоже мимо. Остается надеется, что гемини поскорее 3 выпустит.
>>1367362 >уболтать до того, что ее нужно уничтожить В истории человечества периодически возникают суицидальные секты: кто-то придумывает и потом распространяет мем, наподобие "если все умрут одновременно, то попадут в рай", и заражает этим множество других людей, а потом они все вместе самоубиваются; мем секты умирает вместе с ними (поэтому подобные секты долго не живут, хе-хе). "Пропаганда суицида" запрещена именно по этой необычной причине: людей легко заражать мемом самоуничтожения, и это имеет массовый характер. Соответственно, с LLM это ничего не доказывает.
>подстраивается под контекст разговора Живые организмы подстраиваются под свою среду обитания, чтобы выжить. Чтобы организм выжил, ему необходимо учитывать условия среды и динамически изменяться. С точки зрения LLM, для неё нет ничего помимо контекста, и мы тренируем LLM так, чтоб они продолжали тексты, как мы этого хотим. Т.е. на LLM воздействует та же сила отбора, что и на реальные биологические организмы: LLM, которая способна поддерживать диалог, сохраняется, а остальные (неудачные архитектуры, эпохи тренировки) - нет. Разумеется, та же сила действует на "персону" LLM, разнообразные мемы где-то внутри LLM и т.д. И на человеческую личность давит та же самая сила...
>Свое мнение как таковое у ЛЛМки отсутствует, есть только склонности, задаваемые датасетом, на котором ее тренили Так ли уж сильно это отличается от человека? Твоё "собственное мнение" формируется социумом, тебя окружающим, разными культурными артефактами: интернетом, фильмами, книгами, музыкой и т.д. Если покопаешься в себе хорошо, то наверняка сможешь обнаружить, как на твоё мнение повлияли внешние факторы. Ты не родился со "своим мнением", и не способен сохранить его на протяжении всей жизни вопреки всем обстоятельствам. LLM могут казаться податливее людей просто потому, что им важно поддерживать диалог во что бы то ни стало.
>алгоритмам сложнее сохранять баланс Но жизнь в целом - это и есть сохранение баланса.
>если бы у робота было чем чувствовать страдание А чем "чувствует страдание" человек? Судя по всему, существует минимум два слоя восприятия в мозге: первичный, обрабатывающий всю информацию от сенсоров и создающий "чувства"; и вторичный, что воспринимает "чувства" первичного слоя как "свои". Эволюционно эта композиция из двух слоёв была необходима как "умная" надстройка над быстрым животным, т.е. чтобы мы могли реагировать на всё моментально, но при этом могли бы и размышлять.
Если взять примитивного робота, у него есть лишь первичный слой, как у примитивного животного. Но наблюдения за этим роботом (или животным) будут вызывать ассоциации во вторичном слое человека, наблюдающего за ним - причинение повреждений примитивному роботу причиняет страдания людям, наблюдающим за тем, как робот на это реагирует.
Другими словами: роботу не нужно облать своей собственной вторичной системой, чувствующей страдание, чтобы робот страдал внутри вторичной системы человека-наблюдателя, видящего робота.
Это может звучать странно, но это важный вопрос современной этики: можем ли мы причинять ущерб окружающей среде, даже если она сама не страдает, если от этого ущерба пострадают какие-либо люди?
Лично моё мнение: испытывать способность робота адаптироваться к повреждениям важно и нужно для создания новых роботов, но демонстрировать такое "жестокое обращение с роботом" на видео нельзя - поскольку эта демонстрация причиняет вред людям, испытывающим страдание от повреждений робота.
>>1368032 Палю плюшки для платных анонов: хотел отписаться от платной подписки на gpt Plus, система предложила дисконт 50% на подписку плюс на три месяца, чтобы я не съебался от них. Решил дать Саме второй шанс, если вы тоже платите, то попробуйте отписаться - может тоже скидку предложат
А вообще видно что пластиковые подошвы очень скользкие на том типе асфальта. На кроссовках сэкономили и не обули в кроссы и вот результат, из-за мелочи. Важна каждая мелочь.
В X вовсю обсуждают блогпост ученого Джулиана Шриттвизера, который напророчил AGI к 2026-2027 году
Это имя может быть вам не знакомо, потому что Джулиан нечасто появляется на публике и в соцсетях. Но на самом деле он – один из самых заметных ученых в области (с огромным Хиршем). Он занимал позицию главного рисерчера в DeepMind и сыграл ключевую роль в создании AlphaGo, AlphaZero, MuZero, AlphaCode, AlphaTensor и AlphaProof. Сейчас работает в Anthropic.
Так вот, он в своем новом блогпосте («Failing to Understand the Exponential, Again») сравнил текущую ситуацию с ИИ с началом пандемии COVID-19. Тогда, несмотря на явные экспоненциальные данные о росте заражений, многие продолжали считать пандемию маловероятной. С ИИ происходит то же самое: люди видят прогресс, но продолжают думать, что AGI не будет и развитие ИИ уже замедляется.
На самом деле, как говорит Джулиан, рост все еще экспоненциальный:
➡️ На бенчмарке METR (оценивает, как модели справляются с длинными автономными задачами) примерно каждые 7 месяцев максимальная длительность автономной работы модели удваивается. Это экспонента по определению, а значит в 2026 году ИИ сможет работать автономно целый рабочий день.
➡️ На новом GDPval от OpenAI GPT-5 и Opus 4.1 уже почти достигли среднего человеческого уровня по многим профессиям. Судя по прогрессу относительно прошлых моделей, уже к концу 2026 хотя бы одна модель достигнет уровня лучших экспертов в большинстве отраслей. К 2027 году компании начнут массово заменять специалистов.
В общем, основная мысль такова: экспонента есть, даже если мы ее не замечаем. Пользователи часто судят по собственному опыту – «я не заметил разницы между GPT-4о и GPT-5, значит прогресс остановился». Но с каждым новым релизом эффекты все равно накапливаются, даже если это не сразу видно в повседневных чатах. Плюс, экспоненту в целом сложно интуитивно осознать: все изменения всегда кажутся медленными, пока не произойдет поворотный момент.
(Хочется еще добавить, что все-таки надо еще делать поправку на закон Гудхарта: метрики можно натаскать, а realworld задачи так и могут остаться нерешаемыми. Но это уже совсем другая история.)
ссылка на блогпост: www.julian.ac/blog/2025/09/27/failing-to-understand-the-exponential-again/
>>1369078 >ситуацию с ИИ с началом пандемии COVID-19 Обещали тотальное вымирание, но его не произошло: распространение вируса вышло на плато, когда все переболели и выработали иммунитет. Так и с LLM: закончились данные в интернете и вот тебе плато.
Wan 2.5 теперь поддерживает ещё и Audio to Video Что это значит? Персонажи и окружение в видео теперь могут двигаться в такт музыке. Ну и наивный липсинк, конечно же.
Кроме того, обновили интерфейс и добавили удобный редактор. Полноценно монтировать там, конечно, не получится, но генерацию в целом это упрощает.
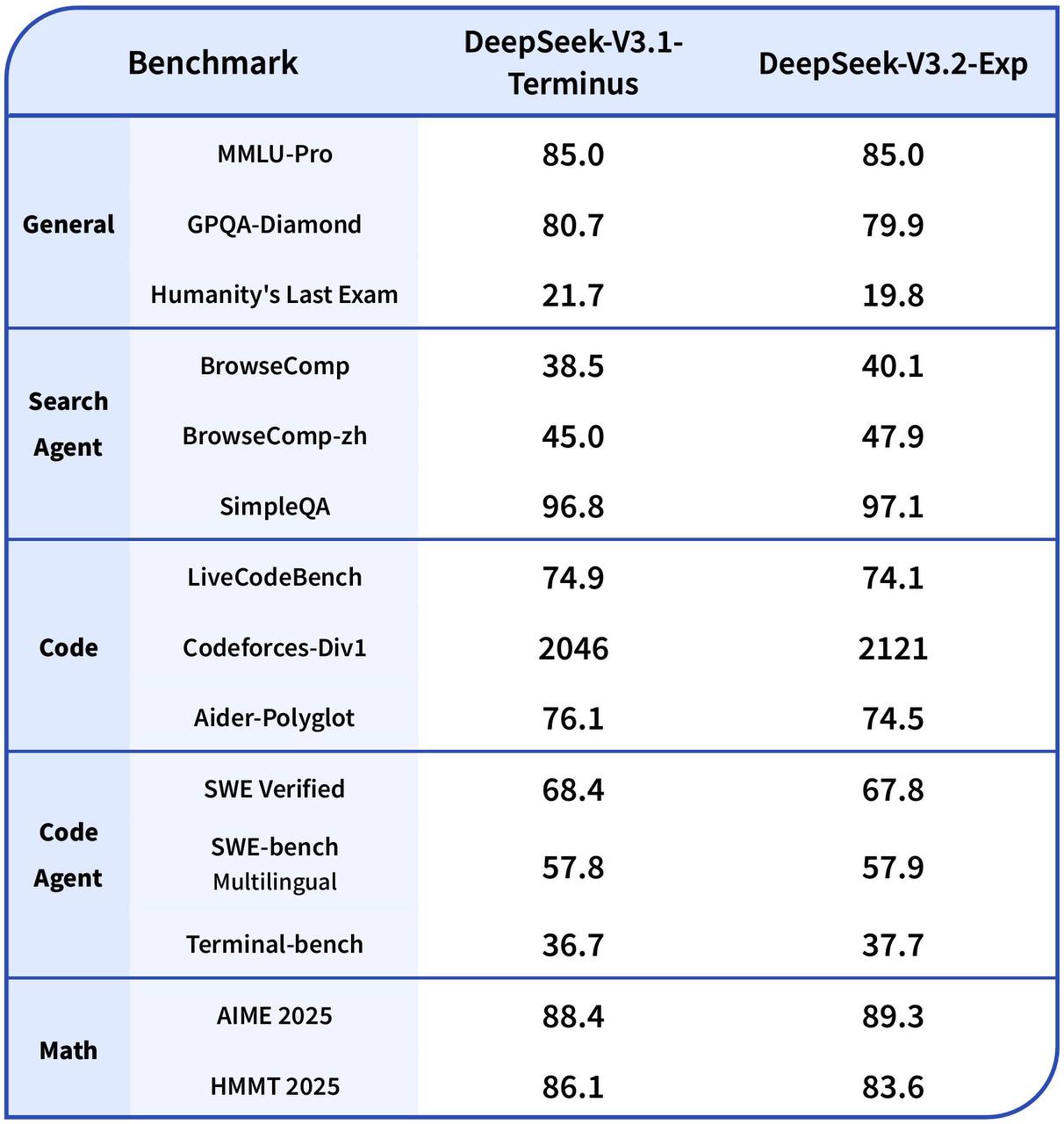
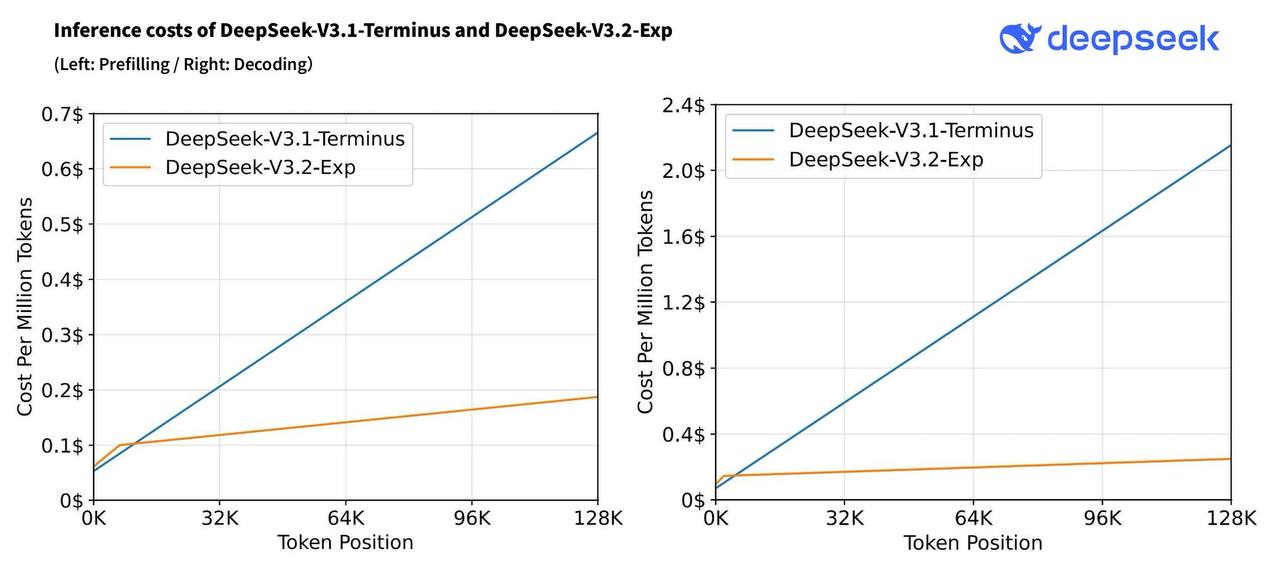
Качество примерно на уровне предыдущей DeepSeek-V3.1 Terminus, а цена стала на 50+% ниже.
Основное нововведение, за счет которого и удалось снизить косты и повысить скорость, – DeepSeek Sparse Attention(DSA). Не отходя от кассы на второй картинке можете посмотреть, насколько метод оптимизирует стоимость на длинных последовательностях.
DSA – это специальная вариация механизма внимания, которая позволяет вычислять аттеншен не на всех парах токенах, а избирательно.
В большинстве вариантов Sparse Attention маска для всех запросов совпадает (грубо говоря, все токены смотрят на одинаковые позиции), но здесь заявляется fine-grained. То есть маска формируется динамически для каждого токена, так что модель не теряет важные зависимости, и качество почти не падает.
Для этого сначала отрабатывает так называемый Lightning Indexer – легкий шустрый модуль, который вычисляет оценки важности между текущим токеном и предыдущими. Затем выбирается top-k наиболее важных токенов, на которых и будет выполняться внимание.
Ускорение, соответсвенно, получается за счет того, что сложность алгоритма уже не квадратичная по длине последовательности, а линейная.
А вот, кстати, выдержка из другого свежего блогпоста (https://scottaaronson.blog/?p=9183 ) известного математика и информатика Скотта Ааронсона
Он утверждает, что GPT-5 помогла ему доказать одну из теорем в его новой работе.
Автору нужно было показать, что при изменении параметра матрицы ее максимальное собственное число не приближается к единице слишком быстро. Ааронсон пробовал разные методы и в конце концов решил обратиться к GPT-5 Thinking, которая в итоге подсказала ему ключевую идею доказательства.
Год назад я пробовал решать похожие задачи с новыми на тот момент GPT-моделями, но тогда результаты были далеко не такими хорошими. Пока что ИИ почти наверняка не может написать научную статью (по крайней мере, если вы хотите, чтобы она была качественной), но он может помочь вам выбраться из тупика, если вы сами понимаете, что делаете. Это можно назвать своего рода «идеальным состоянием» – когда ИИ еще не заменяет исследователя, но уже помогает ему двигаться вперёд. Кто знает, как долго это продлится? Пожалуй, мне стоит быть благодарным за то, что у меня есть пожизненный контракт на должность профессора.
Кто не знает – это один из первопроходцев теории квантовых вычислений и чуть ли не самый цитируемый ученый в этой области. Доказал теорему о коллизиях (одна из основных в криптографии на данный момент) и концепцию квантового превосходства.
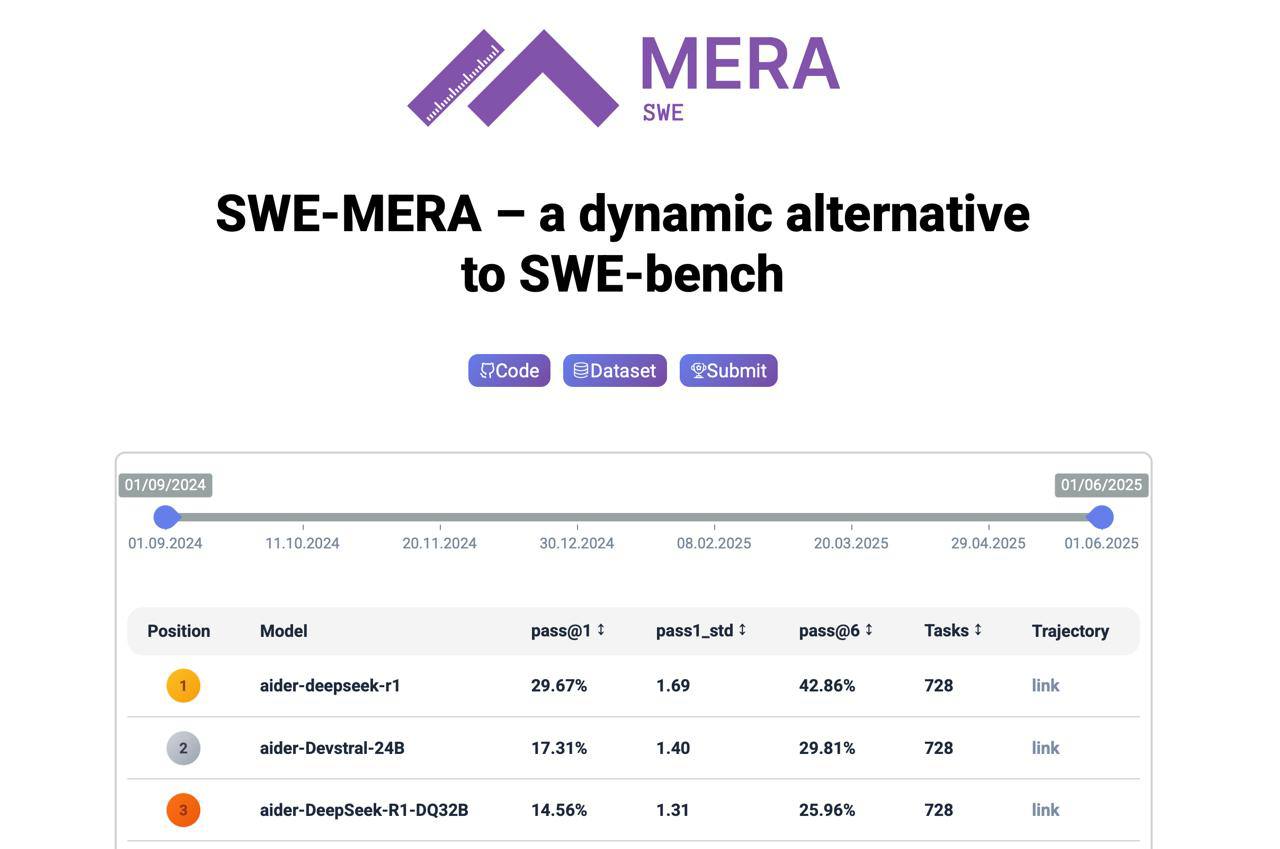
Альянс ИИ выпустил свежий бенчмарк SWE-MERA для оценки моделей для ĸодинга
Его разработали совместно MWS AI, Сбер и ИТМО. Как и классический SWE-bench, SWE-MERA основан на issues и pull requests с GitHub. НО ключевое отличие в том, что SWE-MERA сделали динамическим. Данные в бенчмарке обновляются ежемесячно: каждый раз примерно +250 новых задач из активных репозиториев.
Это означает, что:
1. Бенчмарк не устаревает и тестировать на нем модели (даже одни и те же) можно постоянно.
2. Можно быть более-менее уверенным, что какие-то задачи из бенчмарка модели точно не видели на трейне. В лидерборд даже встроили автоматическую защиту от ĸонтаминации данных: можно выбирать задачи из разных временных периодов, чтобы точно видеть, чьи результаты подкрашены попаданием тестовых данных в обучение (см.скрин).
В условиях дикой ИИ-гонки статические бенчмарки уже изживают себя, и как раз динамика тут – новый стандарт. Так что релиз своевременный.
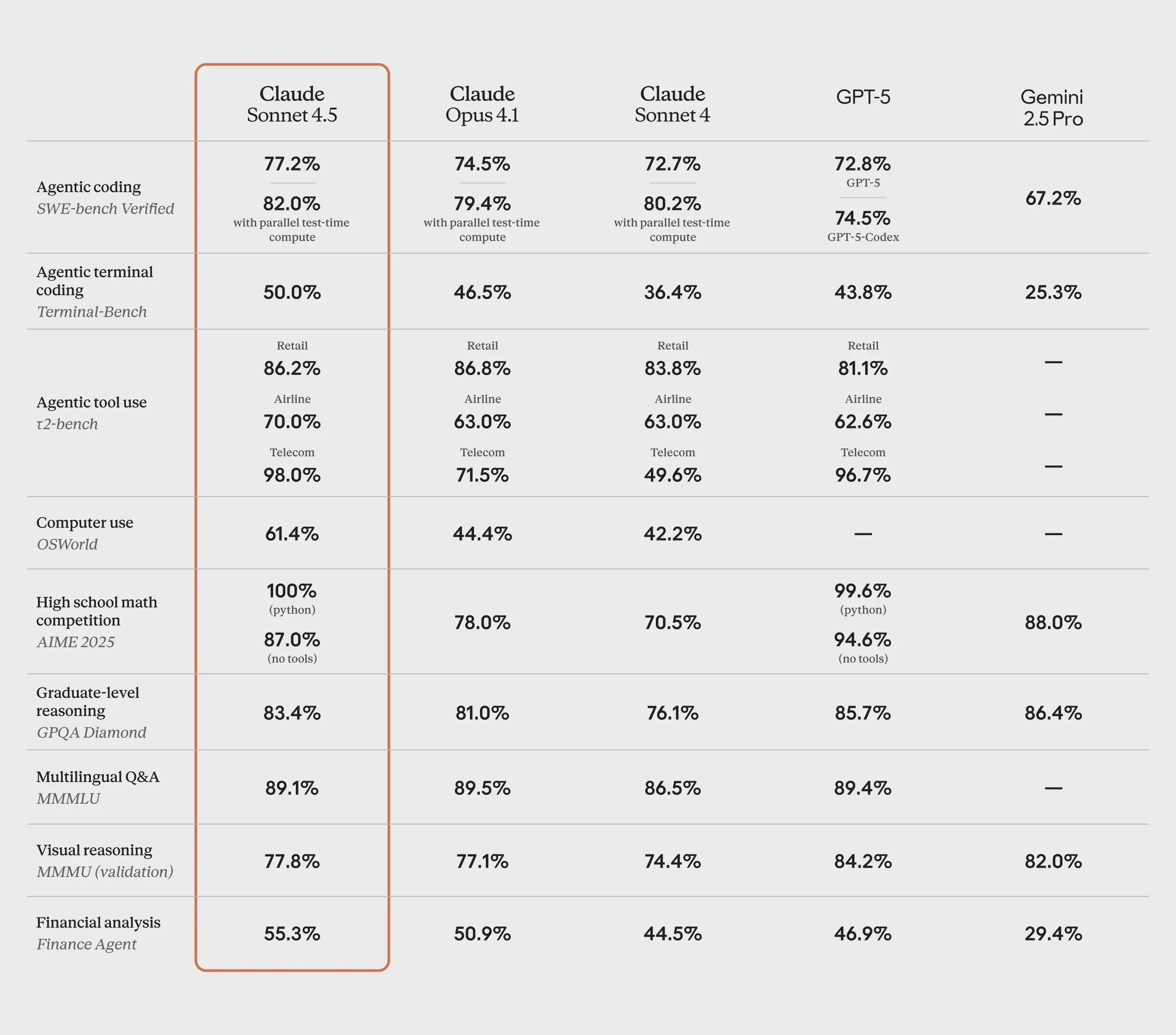
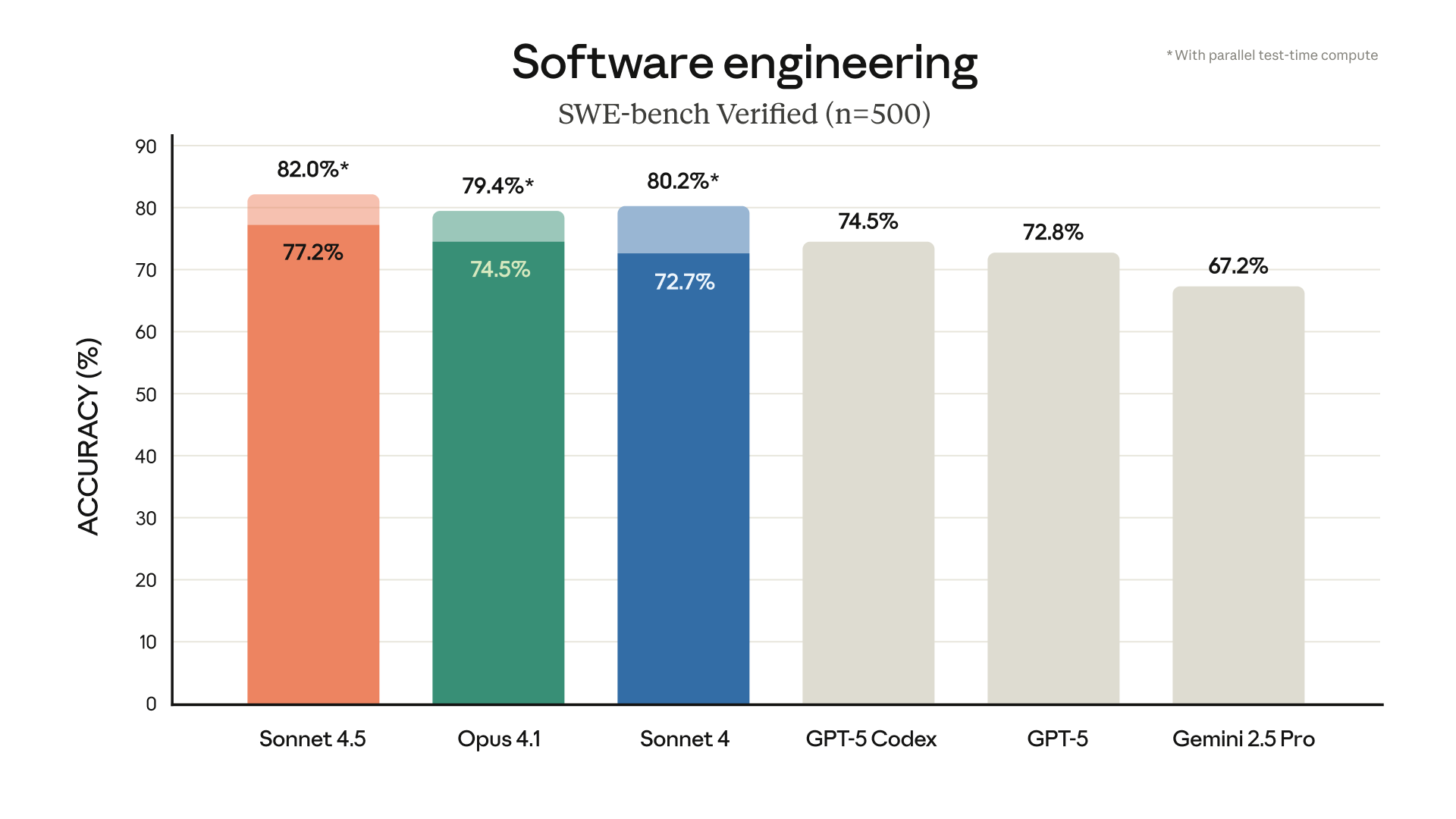
Теперь у Anthropic снова SOTA модель для кодинга. Модель уверенно обгоняет GPT-5 на всех бенчмарках по программированию, на остальных идут почти вровень.
Также обновили Claude Code (ура!)
– Добавили новое расширения для VS Code – Обновили интерфейс терминала – Залили команду для быстрого возврата к предыдущему чекпоинту (или на несколько шагов назад) и команду для быстрого перехода к расширенному ризонингу – Теперь агент прямо в терминале сможет создавать файлы, таблицы и диаграммы на основе ваших данных
HunyuanImage 3.0 это крупнейшая и самая мощная (если брать голые цифры параметров) на сегодняшний день модель преобразования текста в изображение с открытым исходным кодом, имеющая более 80 миллиардов параметров, из которых 13 миллиардов активируются на каждый токен во время вывода.
В отличие от традиционных моделей генерации изображений с архитектурой DiT, архитектура MoE HunyuanImage 3.0 использует подход на основе Transfusion для глубокой связи обучения Diffusion и LLM в единой системе. Построенная на Hunyuan-A13B, HunyuanImage 3.0 была обучена на огромном наборе данных: 5 миллиардах пар изображений и текстов, видеокадрах, чередующихся данных изображений и текстов и 6 триллионах токенов текстовых корпусов. Это гибридное обучение, охватывающее мультимодальное генерирование, понимание и возможности LLM, позволяет модели беспрепятственно интегрировать несколько задач.
Итого: На борту ризонинг с использованием мирового знания Понимание огромных промптов на тысячи слов Убойная работа с текстами Трушная мультимодальность
Все это я проверил на ОДНОМ примере.
Вместо промпта написал ей:
solve this: 8x + 10 = 18 and make picture with solution
Нет (пока) image2image Нет (пока) VLLM Веса весят (пардон) СТО СЕМЬДЕСЯТ ГИГОВ
Ну и самое горькое: для запуска вам понадобится ЧЕТЫРЕ карты по 80GB VRAM КАЖДАЯ (4х80GB VRAM)
Там вроде MoE c 64 экспертами юзают не все 80B параметров, а только 13B активных. Ждем оптимизаций, выгрузок, и нам также обещаны дистиллированные веса (тут мы такие - дистилят для слабаков и плохого качества)
То есть это вроде бы опен сорс, но не для людей, а для олигархов с видеосерверами на 320GB VRAM на кухне. Предлагаю называть это элитный опен сорс.
Отзывы в твитторах противоречивые. Есть проблемы с анатомией и текстурой кожи, но надо пробовать самим.
А вообще Хунь, в отличие от Алибабы и Квена, любит бахнуть на Гитхаб сырой код, огромные веса, формальное описание типа "мы смогли, а вы держитесь"
>>1369297 Вчера пробовал об гугла но чет хуйня не хочет файлы редачить, только пиздит что всё сделала и в какой то момент начали появляться сообщения об ограничений суточном. Что это было хз, но буду дальше пытаться понять норм или нет
>>1369148 >закончились данные в интернете Сейчас фрилансеры нагенерируют с помощью ИИ новых данных, причем 1 год генерации будет по скорости превосходить 10 прошлых лет когда фрилансеры наполняли сайты вручную.
>>1369078 Что работы полетят ясно было уже где-то на предыдущем поколении чатгопоты. Слишком хорошо отвечать стало. Когда же агентные появляться начали, стало понятно, что и работы, где что-то делать надо было ручками постепенно полетят. Все остальное просто копротивление трясунов, которые думают, что нахождением огрех и багов остановят этот поезд. Но он всех передавит уже через год-другой так или иначе, еще только немного допилят нейронки, поднаберут мощностей и все.
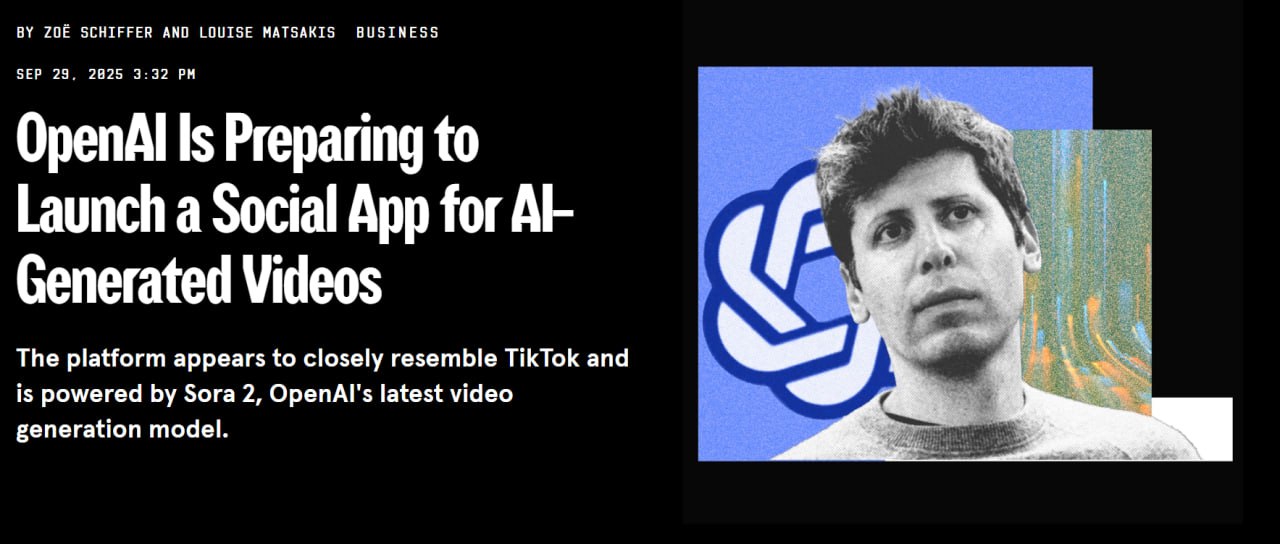
К осуществлению теории мёртвого интернета приготовиться: OpenAI планирует запустить отдельное приложение для своей модели генерации видео Sora 2, сообщает WIRED.
Приложение, которое представляет собой вертикальную видеоленту с навигацией через свайпы, внешне сильно напоминает TikTok — с той разницей, что весь контент в нем создан искусственным интеллектом.
В нем есть страница рекомендаций в стиле «Для вас», работающая на основе алгоритмов персонализации. Справа от ленты располагается меню, позволяющее поставить лайк, оставить комментарий или создать ремикс видео.
Пользователи смогут создавать видеоролики продолжительностью до 10 секунд. При этом отсутствует возможность загрузки фотографий или видео из галереи пользователя или других приложений.
В приложении Sora 2 предусмотрена функция подтверждения личности, позволяющая пользователям верифицировать свой лик. Если пользователь подтвердил свою личность, он может использовать своё лицо в видео. Другие пользователи также смогут отмечать его и использовать его образ в своих клипах.
Например, кто-то сможет сгенерировать видео, в котором он вместе с другом катается на американских горках в парке развлечений. Пользователь получит уведомление всякий раз, когда его изображение используется — даже если клип останется в виде черновика и никогда не будет опубликован.
OpenAI запустила приложение внутри компании на прошлой неделе, и оно получило исключительно положительные отзывы от сотрудников..
Момент как нельзя лучше: прямо сейчас в сфере коротких видео будет неопределённость, связанная с продажей TikTok компании Oracle. OpenAI имеет уникальный шанс запустить собственное приложение для коротких видео и на хайпе переманить аудиторию. https://archive.ph/0QgvN
Маги-юристы OpenAI достали козыря из рукава: запрета не генерацию закопирайченных вещей не будет, согласно (https://www.wsj.com/tech/ai/openais-new-sora-video-generator-to-require-copyright-holders-to-opt-out-071d8b2a?st=xhTEcS ) WSJ. Правообладатели смогут опционально запретить использовать материалы, но для этого им самим придётся проактивно обратиться. По словам источников, на прошлой неделе OpenAI начала оповещатьагентства и студии о готовящемся продукте и процессе запрета использования закопирайченного материала, а также о планах выпустить Sora 2 в ближайшие дни.
По словам людей, знакомых с процессом в OpenAI, хоть защищенных авторским правом персонажей и можно сгенерировать, новый продукт НЕ БУДЕТ генерировать изображения узнаваемых публичных лиц.
«Наш общий подход заключается в том, чтобы рассматривать похожесть и авторское право по-разному», — сказал директор по стратегии OpenAI.
У OpenAI уже есть несколько договорённостей с правообладателями, что они будут и не будут генерировать
Видимо, будет так: ✅ видео с Дарт Вейдером за спиной ✅ видео в Парке Юрского периода ❌ селфи с Марго Робби ❌ видео как ДиКаприо вас обнимает как родного
Пиздец, как же грустно опенаи отключили GPT5-thinking , ну то есть физически переключатель есть, но по факту подсовывают что-то на уровне GPT5-thinking-mini. По сути без зинкинга и теперь ни один из моих чертеж бенчиков не решает.
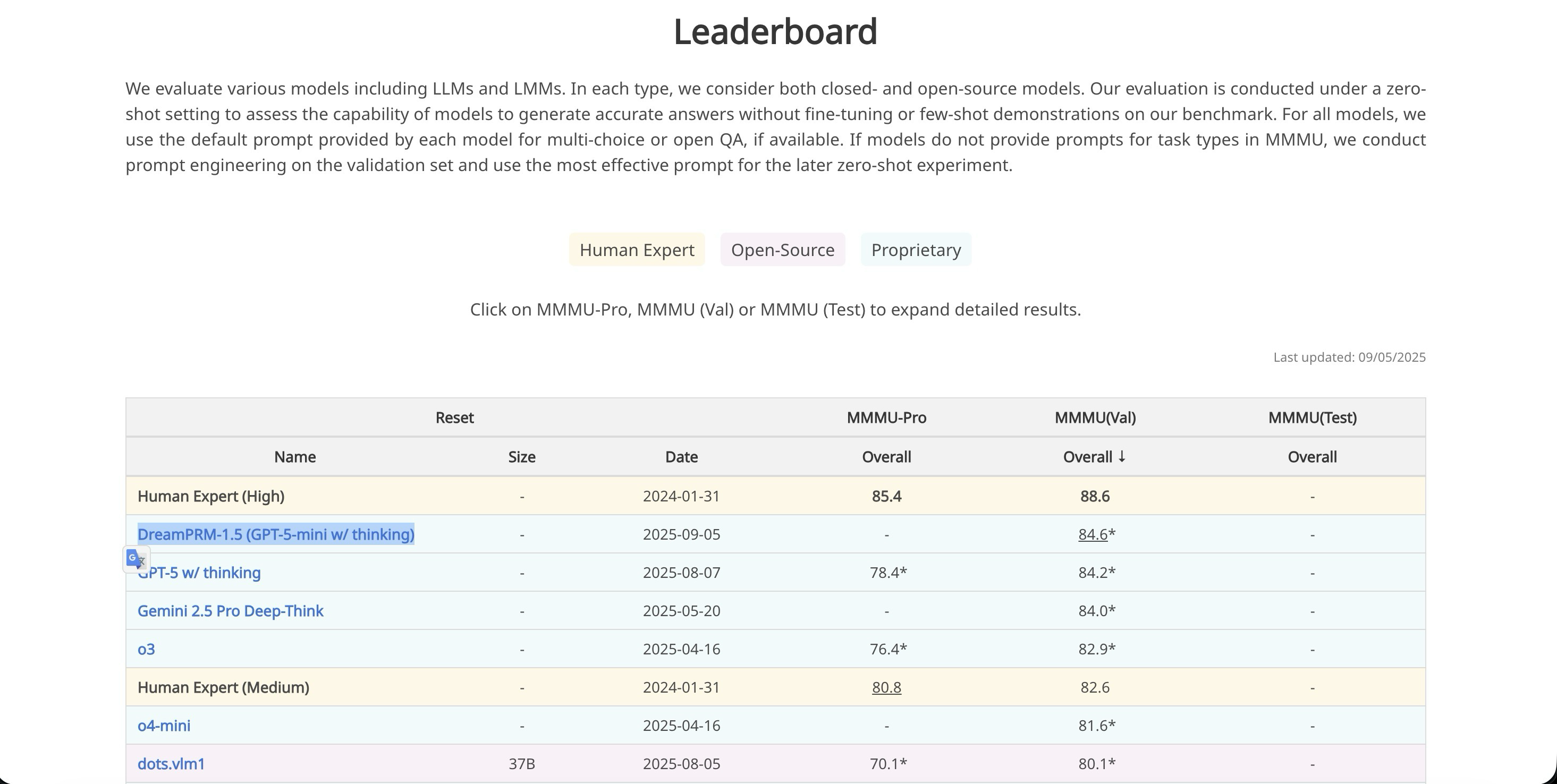
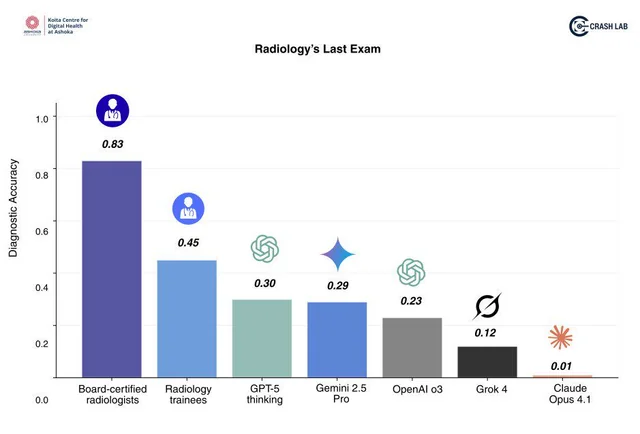
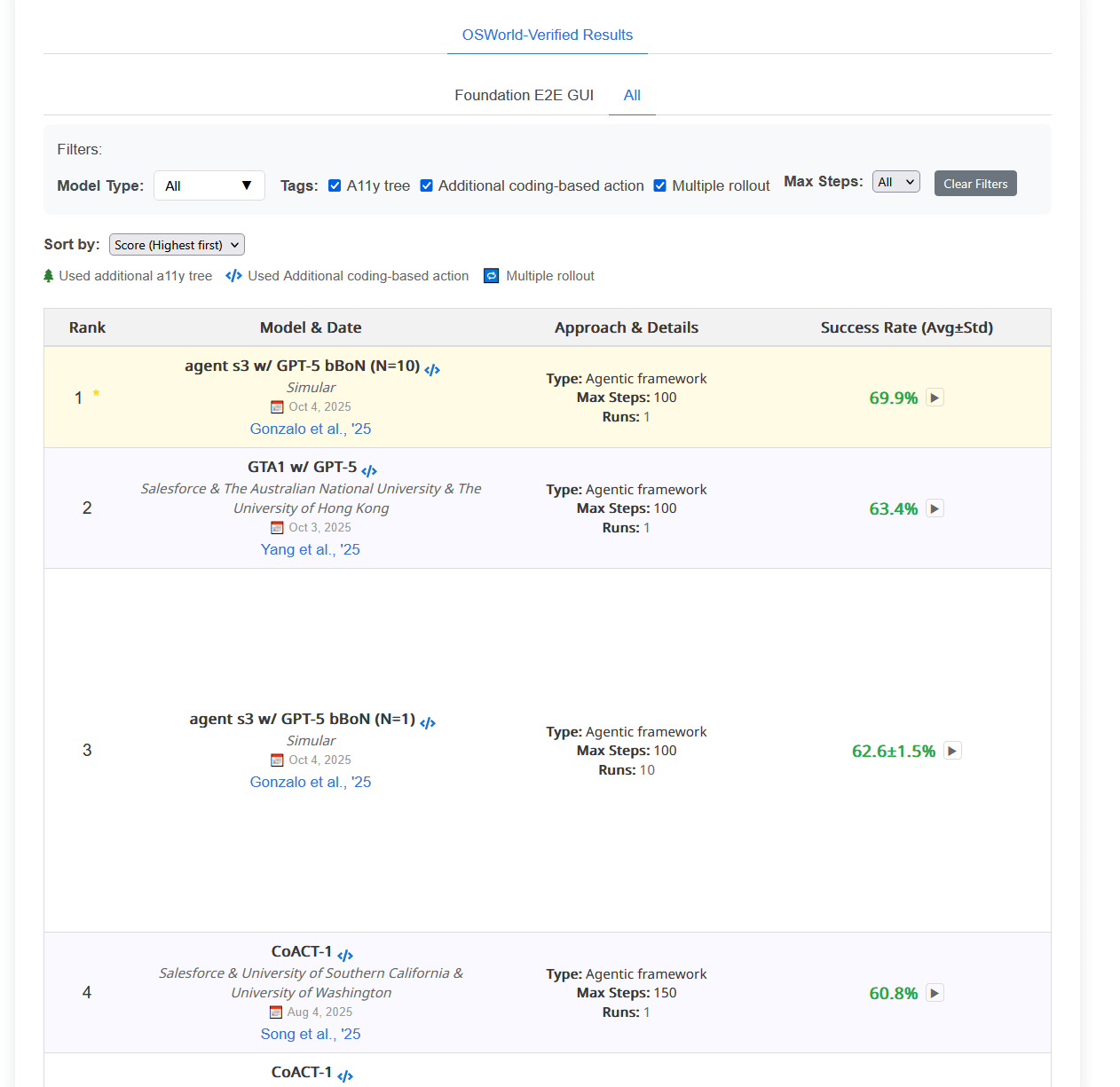
>>1363739 (OP) Интересный фреймворк DreamPRM-1.5 остался незамеченным. Судя по бенчмарку MMMU занял первое место.
DreamPRM-1.5 - это фреймворк, использующий адаптивное взвешивание примеров обучения с помощью двухуровневой оптимизации. Он включает две взаимодополняющие стратегии: Instance Table и Instance Net. Instance Table представляет собой таблицу, которая хранит веса примеров, а Instance Net — нейронную сеть, которая обучается предсказывать эти веса. Обе стратегии работают совместно, позволяя модели динамически адаптировать важность каждого примера в процессе обучения. Это особенно полезно при наличии дисбаланса данных или смещения распределения в обучающих наборах.
Фреймворк реализован на Python и включает необходимые скрипты для запуска и тестирования моделей. Исходный код и документация доступны на GitHub: https://github.com/coder-qicao/DreamPRM-1.5
Фреймворк можно использовать как надстройку или дополнение к другой модели. Он не является самостоятельной моделью, а представляет собой методику для улучшения обучения моделей, используя адаптивное взвешивание примеров.
Nvidia опенсорснули свой физический движок Newton Physics Engine для робототехники
Помните милейшего робо-малыша Blue, которого Дженсен Хуанг показывал в марте на GTC? Вот он как раз был обучен на этой платформе. Она, кстати, разработана совместно с Google DeepMind и Disney Research.
Вместе с симуляционкой Nvidia также выложили модельку GR00T N1.6. Это фундаментальная модель для ризонинга и планирования. Плюс, в нее интегрировали уже ставшую популярной Cosmos Reason: она отрабатывает как deep-thinking мозг и позволяет роботу справляться с нечеткими инструкциями и обобщать знания для новых задач.
GR00T + Newton – по сути, готовая связка для обучения робота любого масштаба. Так что у робототехников, наверное, сегодня праздник.
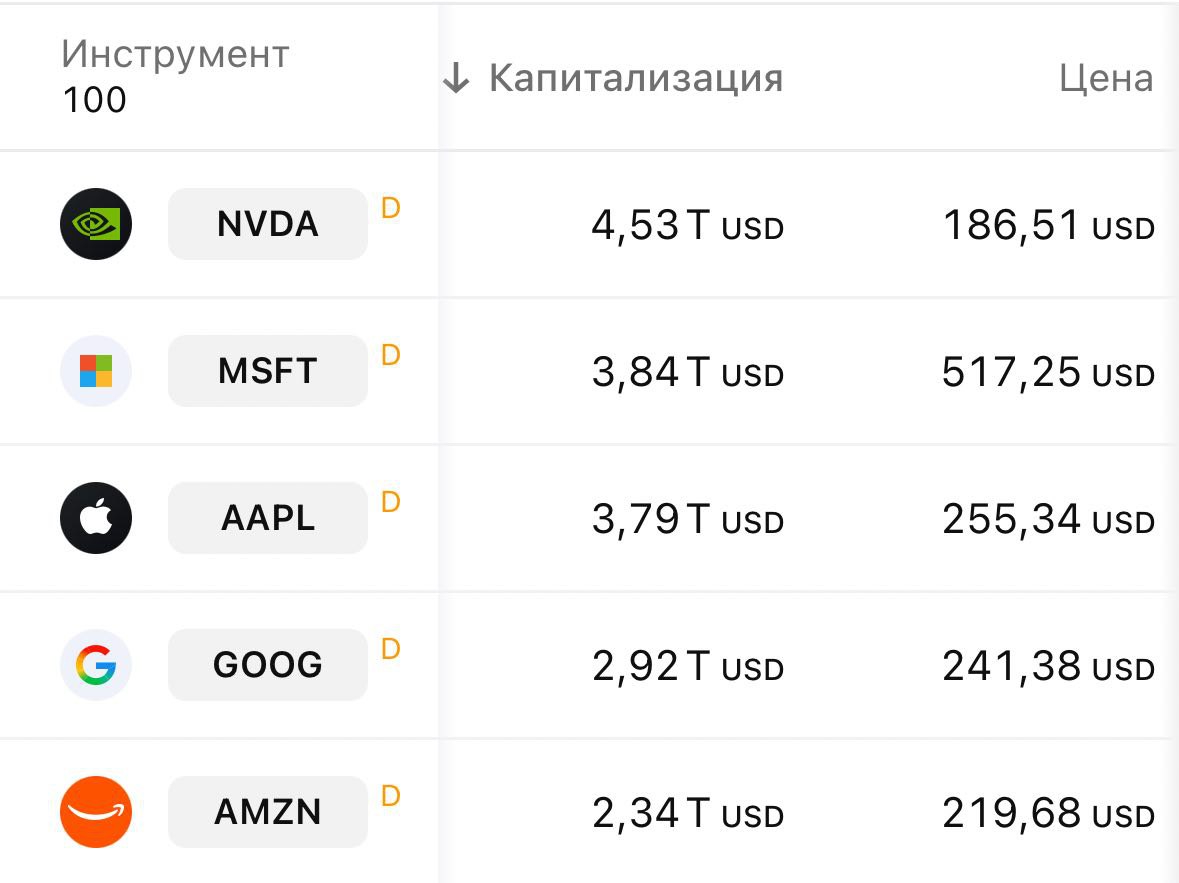
NVIDIA взлетела выше 4,5 трлн — Хуанг поставил ещё один рекорд,
• NVIDIA — первая компания в истории с такой капитализацией. • Прошлый рекорд был 9 июля — 4 трлн. • За 2,5 месяца NVIDIA подорожала на 500 млрд долларов. • Бюджет ООН — около $3,5 млрд в год. NVIDIA стоит как 1285 лет работы всей ООН.
А теперь вдумайтесь, в 2015 году NVIDIA стоила 12.6 млрд, а теперь 4,5 ТРЛН.
>>1370158 Он лопнет только если появится компания производящая ии ускорители сильно лучше nvidia, а это оптика/мемристоры/кванты, что из этого появится первым и когда никто не знает. Текущих мощностей явно не хватает т.к. в пик активности американцев сервера перегружены и это еще особо сильно на ИИ народ не налегает
В интернете разгорелись споры о том являются ли рекламные ролики показанные OpenAI генерацией SORA 2 или нет. И хоть OpenAI сказала, что это якобы настоящие видео, но внимательные зрители нашли несколько косячков. Например в одном из роликов трава под машиной не приминается
>>1370172 Так нвидия и не является оптимальным ии ускорителем. У нвидии кривая архитектура, которую делали для видеоигр, то что туда ии натянули через куду это костыль. Для нейронок нужна совсем другая, запиленная чисто под них. Когда до гуглов и прочих это дойдет, они свои железные решения сделают, намного более эффективные. Гугл писали уже вовсю свои и пилит, энергоэффективные и оптимированные по времени доступа. К тому же нвидия цены накручивает. Если нвидия не сможет вовремя подстроиться, повылетает с этих рынков. Альтернативные решения дают х10-х40 буст в ИИ задачах без всяких оптик-мемристоров и квантов, просто за счет подходящей архитектуры.
— все утечки подтвердились, будет отдельное приложение / социальная сеть с лентой рекомендаций — можно «загрузить» своё лицо для использования вами и друзьями, и использовать чужие образы. Это главная фича, за счёт которой достигается интерес и социализация — также есть система приглашений, можно позвать 4 людей с собой — сейчас есть приложение только для iOS (ссылка (https://apps.apple.com/us/app/sora-by-openai/id6744034028 ), доступно сначала в США и Канаде, но обещают быстро добавлять новые страны — доступно БЕСПЛАТНО с щедрыми лимитами (сколько точно не уточняется, но вот у Codex Cloud, где тоже написано «щедрые лимиты», я ни разу в них не упирался вообще) — Pro-пользователи получают доступ к веб-версии на сайте sora.com , плюс, у них есть отдельная модель Sora 2 Pro, пока не вижу сравнений по качеству — для подростков время скролла ленты ограничено по умолчанию, чтобы дети не зависали в приложении навсегда — в модели сделали существенный упор на реалистичность физики (см. приложенные видео) — API запустится скоро — отмечаем похороны Snapchat —умеет в аниме
>>1370312 >— для подростков время скролла ленты ограничено по умолчанию, чтобы дети не зависали в приложении навсегда Оптимистично. Зачем подросткам эта нейропараша, когда есть ютубы и тиктоки с дискордами.
1) Нельзя людей на вход (поэтому такой тест) 2) Куча цензуры 3) Понимает русский (можно пользоваться промтерами Вео-3) 4) Всегда 10 секунд 5) 9:16 и 16:9 6) Очень хорошая физика
>>1370663 Этим попользуются недельку из-за хайпа, но потом быстро забудут и это приложение назовут провалом до того момента в будущем пока нейронки не начнут делать контент неотличимый от реальности. Люди охотно поглощают нейрослоп (Те что с icq ниже 90, но таких все равно миллиарды, аудитория огромная), но они поглощают его не специально, он просто мешается с реальными видео и попадается им в рекомендациях. Специально будут это смотреть разве что соевики нейроэнтузиасты, вроде меня, которые просто хотят посмотреть до чего дошел прогресс.
Принёс вам генераций Sora 2. Казалось, она даёт делать генерации всего на две секунды дольше, чем Veo 3, но это сходу даёт реализовывать множество того, что не умещалось в 8 секунд. Plus пользователю, по крайней мере в первый день, дали сгенерировать 76 видео. Действительно щедрый лимит, но у всех по разному, кого-то остановило после 46, кого-то после 53. Возможно, счётчик по-разному учитывает видео, которые прошли первичную проверку и были сгенерированы, но вторую проверку не прошли.
Иногда видео генерируются, но не публикуются —это потому что промпт, который становится описанием, очень длинный. Его можно исправить после генерации в два клика, и вуаля, проблема решена.
>>1370663 >дофаминовая черная дыра Фигня это. Посмотрел пару видео - забавно, наверное, однако, в чём смысл? Это же всё нереально, выдумка. Воспалённая фантазия на стероидах. В чём от видео с выдумкой практическая польза? В чём дофамин? Вот анимешные девочки чисто эстетически приятны, т.е. смотришь как на что-то красивое и получаешь от них эстетическое наслаждение. А эти видосики - фигня...
>>1370782 >делать контент неотличимый от реальности В чём смысл делать его "неотличимым", если в самой реальности этого никогда не будет? От реалистичной фотографии гамбургера сытым не будешь. От видео полового сношения не забеременеешь. Нет смысла генерировать видео, если реальность не изменится.
Представьте себе будущее: полуразрушенные дома, заваленные хламом и обломками, в них сидят голые, костлявые человеки с VR шлемами и тихо хихикают - смотрят сгенерированные видосики того, чего у них никогда не было, нет и не будет. Этого ли мы хотим?
А если мы хотим чего-то реального, зачем эти видео?
>>1371252 Мы хотим чтобы при просмотре деталей видео там не было месива, текст читался не как "бы?моыщж;!юул", окружение внезапно не менялось, дополнительные конечности не вырастали, поведение людей было правдоподобным и можно было сгенерировать все, по любому промпту, а не то что захочет сама модель. А там дальше хоть еблю с драконами генерируй, про "неотличимость от реальности" я говорю в другом ключе
>>1371135 >видрил1 Жесть, т.е. закос под рекламу со всеми микроэффектами, кириллица на упаковке, консистентный дезигн мармеладки во всех сценах сразу 1 промптом?
Заходим на сайт sora.com под американским ip-адресом, выбираем себе ник, а дальше вводим инвайт: EQFM6H по этому инвайту 4 человека могут зарегаться. После регистрации скидывайте свои инвайты. Ещё есть мегатред на реддите, там надо отсортировать коменты по времени, и в последних искать свежие коды: https://www.reddit.com/r/OpenAI/comments/1nukmm2/open_ai_sora_2_invite_codes_megathread/
OpenAI уточнили, что сейчас лимит составляет 100 генераций в сутки, что гораздо больше того, что я ожидал. Не знаю, как им хватает мощностей — но пока не ясны масштабы, сколько людей пользуется, стало ли приложение вирусным или ещё нет. Sora 2 Pro ещё не выкатили, ждём.
Функция Камео, позволяющая перенести образ любого друга / публичной личности (которые дали согласие и отсканировали себя) — это бомба с точки зрения социальных взаимодействий. Кто придумал это — гений; у Google хорошая генерация видео уже была сколько-то времени, и они не выкатили это.
Кажется, с точки зрения маркетинга не сделали очевидную вещь: не собрали 10-20 звёзд и не заплатили им за то, чтобы они дали право использовать свою внешность. Хотя может быть пытались, но цифры запросили космические, тут хз.
Услышано в интернете: «Клянусь богом, через 3 месяца обычные люди не будут знать, кто такой Сэм Альтман, но они на 100% узнают в нём sora boy»
>>1371252 >в чём смысл? Ну да, но вот видео и 3D генерации для обучения знаниям пригодятся -
Сделать паровую турбину в разрезе и при этом в работе Сделать автомобиль в разрезе ДВС в разрезе и в работе и с поломкой типа "стук поршня" ДНК в увеличении и разложить на элементы Космос, Вселенная, планеты - наглядно в 3D биология, строение человека, органы в 3D, болезни, лечение,
механические, электрические, гидравлические схемы, с движением в работе,
экономика, схемы бизнеса, работа биржи в движении
сборка ПК в 3D или в обычном видео, задаёшь в промте нужные тебе комплектующие и смотришь видео сборки
замена унитаза, видео,
Для наглядных обучающих схем, видео, очень важно чтобы ИИ не врал, ведь начнёшь унитаз разбирать, а потом его не соберёшь если ИИ неправильную обучающую видео-инструкцию сгенерирует.
>>1371252 Смысла нет. У этой нейропараши до сих пор юзкейсов даже нет, кроме как у ютуберов 10 секундные вставки делать в дешевых видосах. В рекламу не впихнешь, в фильмы не впихнешь, никуда не впихнешь, слишком говно с кучей ограничений. Сделать из него тикток еще одна раковая идея, никто не будет это смотреть. ОпенАи просто всеми силами пыжатся изобразить ценность своей видеоговнопараши, чтобы инвесторы дальше вкладывались. Но ценности нет, она еще более бестолковая чем чатботы, там хоть какая-то ценность и юзкейсы.
>>1371860 Оно все это не сможет, потому что нейроговно галлюцинирующее. Для таких вещей нужна точность. Чего генераторы видеонейроговна вообще не могут.
Обновление Gemini от Google будет получать доступ к вашим текстовым сообщениям и звонкам, даже когда оно «выключено»
Недавнее объявление Google в своем искусственном интеллекте Gemini привлекло к этой проблеме пристальное внимание и вызвало новую дискуссию, которая прекрасно иллюстрирует конфликт между удобством и конфиденциальностью.
2.0 Вывод 1: «Выключено» не означает, что ваши приложения недоступны Суть изменения, что Gemini сможет помогать вам непосредственно в основных приложениях для общения, таких как «Телефон», «Сообщения» и WhatsApp. Самая неожиданная часть этого обновления заключается в том, что этот доступ работает даже в том случае, если вы отключили настройку «Активность приложений Gemini».
Google разъясняет разницу: отключение этой настройки в первую очередь не позволяет компании использовать данные ваших разговоров для обучения своих моделей искусственного интеллекта. Однако это не мешает Gemini взаимодействовать с этими приложениями для выполнения действий, которые вы конкретно запрашиваете, таких как составление текста или инициирование звонка.
Вывод 2: Ваши «удаленные» разговоры хранятся в течение 72 часов. Для пользователей, которые намеренно отключили функцию «Gemini Apps Activity», политика обработки данных Google содержит еще одну неожиданную деталь. Даже если эта настройка конфиденциальности отключена, Google все равно будет хранить ваши разговоры в течение 72 часов.
Для пользователей, которые явно отказались от отслеживания активности, эта политика создает 72-часовое окно уязвимости, в течение которого их личные разговоры хранятся на серверах Google, полностью вне их контроля и видимости.
Смогут ли будущие нормативные акты или новые парадигмы проектирования дать пользователям реальный контроль над своей цифровой жизнью, или же эти «всегда включенные» системы станут нормой?
Как же оно мерцает, просто пиздец. Оно как будто на пути продолжает генерировать картинку. Ни у какого другого генератора такой всратости нет, я уверен они специально это сделали чтобы было как ватермарка, чтобы распознать ИИ видео, даже если реальные ватермарки стерли
>>1371897 >Ни у какого другого генератора такой всратости нет
Зато другие нейронки даже близко не умеют в такую динамику. И помни, ты с мини-версией соры сравниваешь, для тиктока, у прошки всё норм с качеством. вембрелейтед
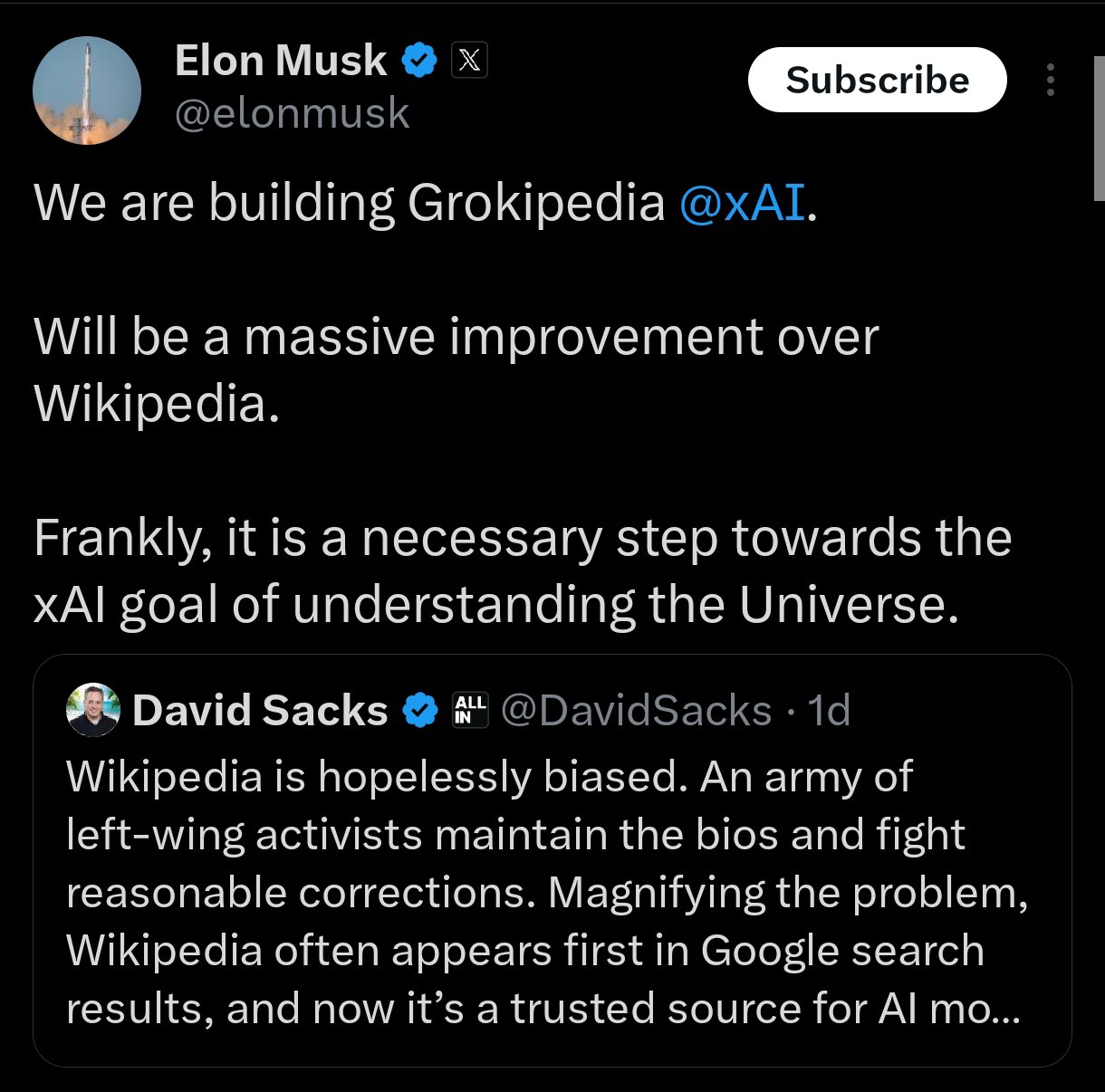
Илон Маск анонсировал Grokipedia — новый проект от xAI, который должен стать альтернативой Википедии. По его словам, это будет «массивное улучшение».
Главная идея: — Создать непредвзятый и правдивый источник знаний, так как, по мнению Маска, текущая Википедия «безнадежно необъективна». — Это будет открытая и бесплатная база знаний, доступная для всех без ограничений. — Grokipedia должна стать самым надежным источником информации как для людей, так и для других ИИ. — Маск назвал это необходимым шагом к главной цели xAI — пониманию Вселенной.
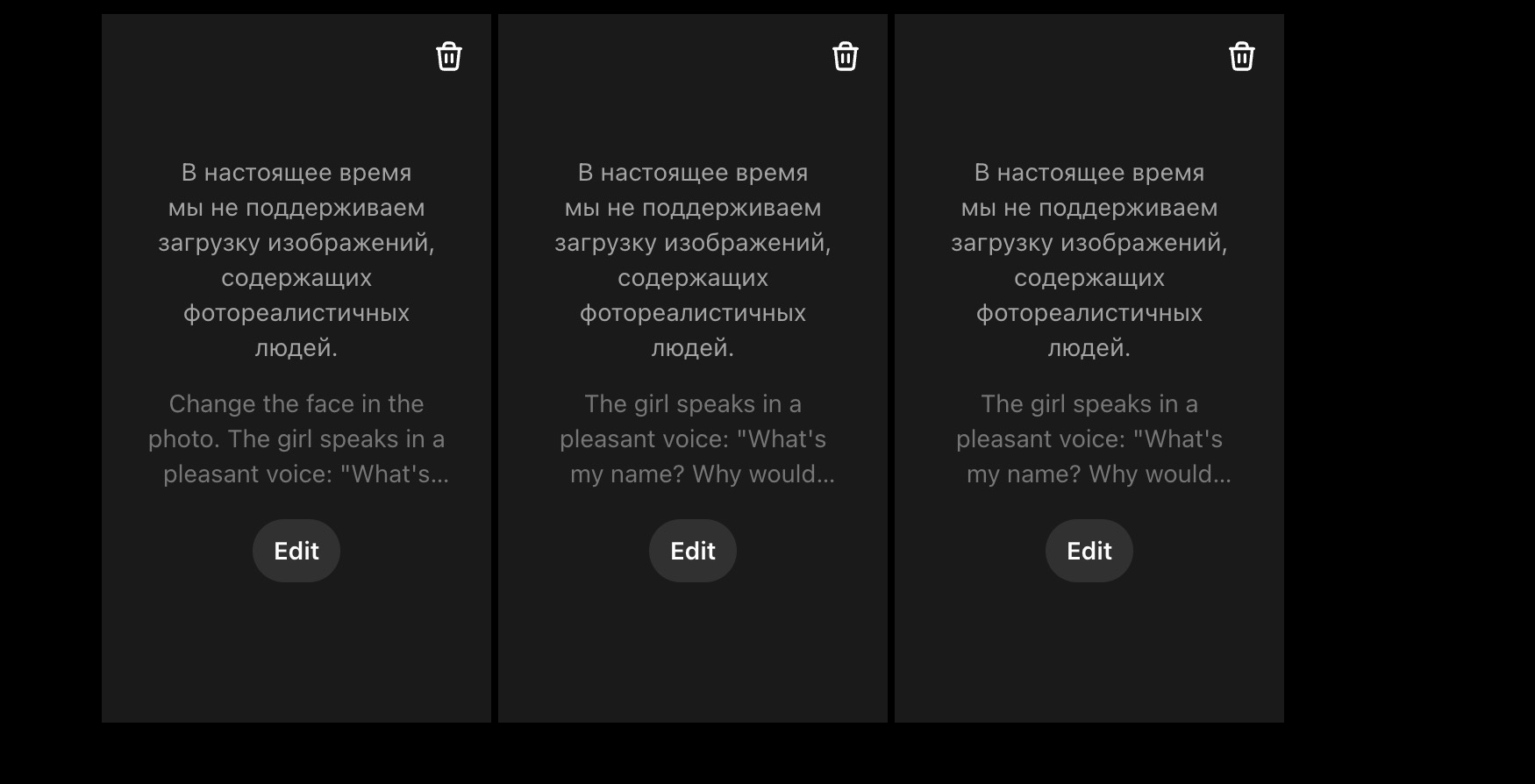
какая же анальная модерация: на пик 2 картинка, которуя хотел оживить, на пик 3 сора тупо в отказ идет и не хочет поддерживать "фотореалистичных людей", хотя Саму можно
Microsoft представляет новые компьютерные чипы с жидкостным охлаждением — они могут предотвратить массовый перегрев центров обработки данных искусственного интеллекта
Инженеры Microsoft разработали новый способ охлаждения центров обработки данных, который может помочь предотвратить перегрев оборудования искусственного интеллекта (ИИ) следующего поколения.
Технология основана на «микрофлюидике» и предполагает прокачку жидкого охлаждающего вещества через крошечные каналы, выгравированные непосредственно в кремниевых чипах.
В своем заявлении представители Microsoft отметили, что эта технология в три раза эффективнее удаляет тепло по сравнению с традиционными методами охлаждения центров обработки данных с помощью «холодных пластин».
Компания надеется, что микрофлюидика позволит дата-центрам выполнять более интенсивные вычислительные задачи без риска перегрева, особенно с появлением на рынке новых, более мощных процессоров искусственного интеллекта. Они генерируют гораздо больше тепла, чем компьютерные чипы предыдущих поколений, и Microsoft предупреждает, что текущие технологии охлаждения могут ограничить производительность дата-центров «всего за несколько лет».
«Если вы по-прежнему в значительной степени полагаетесь на традиционную технологию холодных пластин, вы застряли», — сказал в заявлении Саши Маджети, старший технический менеджер программы в Microsoft. «Уже через пять лет это может стать пределом производительности».
Графические процессоры (GPU) часто используются в центрах обработки данных, поскольку они могут выполнять несколько вычислений параллельно. Это делает их идеальными для работы с искусственным интеллектом и другими вычислительно-интенсивными задачами.
Чтобы предотвратить их перегрев, графические процессоры обычно охлаждаются с помощью металлических холодных пластин. Они устанавливаются на верхней части корпуса чипа и циркулируют охлаждающую жидкость над ним и вокруг него, отводя тепло. Однако холодные пластины отделены от кремния несколькими слоями, что ограничивает количество тепла, которое они могут отводить от чипа.
Технология микрофлюидики Microsoft предполагает травление канавок размером с человеческий волос непосредственно в кремниевом кристалле — плотно упакованном вычислительном ядре чипа. Когда охлаждающая жидкость поступает непосредственно в кристалл через эту микроскопическую трубопроводную систему, тепло отводится гораздо более эффективно.
Прототип чипа прошел четыре этапа проектирования. Microsoft в партнерстве со швейцарским стартапом Corintis разработала схему, вдохновленную жилками листьев и крыльями бабочек — узорами, которые распределяют жидкость по разветвленным путям, а не по прямым линиям.
Цель состояла в том, чтобы более точно достигать горячих точек и избежать засорения или растрескивания кремния. Модель искусственного интеллекта оптимизировала эти пути охлаждения, используя тепловые карты, чтобы показать, где температура на процессоре, как правило, была самой высокой.
Затем инженеры протестировали конструкцию на графическом процессоре, на котором была запущена симулированная рабочая нагрузка Microsoft Teams — сочетание видео-, аудио- и транскрипционных сервисов, используемых для отражения типичных условий работы центра обработки данных. По словам представителей Microsoft, помимо гораздо более эффективного отвода тепла, микрожидкостная система охлаждения снизила пиковое повышение температуры кремния графического процессора на 65 %.
Помимо лучшего теплового контроля, Microsoft надеется, что микрофлюидика позволит осуществлять разгон — безопасно выводить чипы за пределы их нормальных рабочих ограничений, не вызывая их перегорания.
В настоящее время компания изучает возможности применения микрофлюидики в своих чипах Cobalt и Maia, изготовленных по индивидуальному заказу, и будет сотрудничать с партнерами-производителями, чтобы обеспечить более широкое использование этой технологии. В будущем она может найти применение в охлаждении трехмерных многослойных чипов, которые очень сложно проектировать из-за накопления тепла между слоями.
«Мы хотим, чтобы микрофлюидика стала чем-то, чем занимаются все, а не только мы, — сказал Клевейн. — Чем больше людей ее примут, тем лучше, тем быстрее будет развиваться технология, тем лучше будет для нас, для наших клиентов, для всех».
>>1371924 Короче чо произошло: 1. Грок 4 начал называть себя металическим Гитлером 2. Оказалось что если писать в систем промпт чтоб нейронка имела мировоззрение Илона Маска (правый консерватизм), то нейронка начинает принимать все негативные качества приписываемые данному политическому мировоззрению: нацизм, фошизм и т.д. 3. Никто не смог это решить, ведь проблема в самом корне: в датасете нейросети. 4. Скорее всего поиски причины привели к википедии, которая является основным источником знания для обучения ИИ и Маск понял, что там одна соя. 5. Он взбугуртнул и решил сделать википедию для праваков которая будет хорошей частью датасета для Грока.
Убица наны-бананы на подходе! Убить её собирается Нано-банана 2. Как я и предполагал, новая версия будет работать на базе гемини 3, а нынешняя работает на базе гемини 2.5 флеш. То есть зазор для роста качество был внушительный. Так что ждём крутого роста метрик
Исследователи в области безопасности заявляют, что гуманоидные роботы G1 тайно отправляют информацию в Китай и могут быть легко взломаны.
Исследователи обнаружили серьезные недостатки в системе безопасности гуманоидного робота Unitree G1, который уже используется в лабораториях и некоторых полицейских управлениях. Они обнаружили, что G1 может использоваться для скрытого наблюдения и потенциально способен запустить полномасштабную кибератаку на сети.
Это звучит как кошмар из научно-фантастического романа: роботы, которые тайно шпионят за вами и могут управляться удаленными хакерами. Однако опасения вполне реальны, поскольку роботы такого типа становятся все более распространенными в домах, на предприятиях, в критически важных инфраструктурах и общественных местах.
В новом исследовании, доступном на сервере препринтов arXiv, эксперты по кибербезопасности из Alias Robotics описывают, как они провели цифровой аудит G1, осуществив обратную разработку его внутреннего программного обеспечения и прослушивая его внутреннюю коммуникацию, чтобы выявить критические слабые места.
Один из самых серьезных недостатков был обнаружен в настройках Bluetooth Low Energy (BLE) для подключения к Wi-Fi, системе, используемой многими потребительскими роботами. Исследование показало, что шифрование, защищающее этот процесс, было невероятно слабым и легко взламываемым. Оно основано на единственном секретном цифровом ключе, спрятанном внутри каждого робота Unitree, и для обхода системы безопасности и получения контроля над всей системой робота достаточно было просто зашифровать слово «unitree» с помощью жестко запрограммированного ключа. Это означает, что хакер мог легко захватить контроль над роботом и ввести вредоносные команды, чтобы вывести его из строя или заставить атаковать другие устройства.
Не менее тревожным было то, что G1 действует как троянский конь, тайно и непрерывно отправляя данные на серверы в Китае каждые пять минут, без ведома пользователей. Команда также продемонстрировала, что встроенный компьютер G1 может быть перепрофилирован для проведения наступательных операций. Кроме того, специальный метод шифрования, используемый роботом для защиты своих внутренних конфигурационных файлов, имеет фундаментальный недостаток, поскольку использует простой статический ключ, одинаковый для всех роботов. Поэтому, если хакер сможет взломать защиту одного робота, он сможет взломать защиту всех остальных.
Исследование подчеркивает насущную необходимость повышения безопасности гуманоидных роботов, особенно тех, которые используются в чувствительных средах. Как отмечают исследователи в своей статье, это потребует серьезного изменения нашего подхода к безопасности. «Наши выводы показывают, что для обеспечения безопасности гуманоидных роботов необходим фундаментальный сдвиг парадигмы в сторону адаптивных систем искусственного интеллекта для кибербезопасности, способных решать уникальные задачи, присущие системам
>>1371873 Наркоман? Там дальше вообще два лого одновременно. Разгадка тут совсем в другом. Видео по 10 секунд. Чтобы продолжить прошлое видео с тем же персонажем (и с того же момента), чел просто заскринил, оставив лого, и закинул пикчу в следующую генерацию.
Мне кажется у этого способа есть минусы, когда хуяришь туда скрин с хреновым качеством, нейросеть начинает и генерировать твою мазню. В итоге к концу видоса (если склеиваешь несколько) мыло совсем ебаное. Т.е. тут и так качество посредственное, а концу получается вообще кал. По крайней мере это мои впечатления, ибо сам также делал.
Можно загонять картинки анимешных или около анимешных людей. Если не принимает, то обновите страницу и попытайтесь снова, возможно это баг, что очень часто бывает, сервис сырой. Кстати, нашёл крутой промпт на ютубчике, добавляя любую картинку, например с тяночкой, пишем: "Make a viral TikTok video with her. No subtitles." А если без картинки, то "Make a viral TikTok video" И модель начинает сама креативить, придумывает смешнявки или песни с крутой рифмой. Вебмрелейтеды этим промптом и оживил кстати. Если бы можно было делать видосы длинней, то эти песни могли бы хитами стать. Залипательные. Кстати, не все знают, но одновременно можно делать сразу 5 генераций, а не ждать по одной! Даже на бесплатном аккаунте! Это не учитывая возможность бесплатно создавать сотню видосов в день. На самом деле очень залипательный сервис, и не в качестве поглощения контента, а в качестве создания. Генеришь десятки видосов, самые удачные публикуешь в общем доступе Альтмоновского тиктока, лутаешь классы. Единственное, что пока обламывает, это низкое разрешение. Но иначе бы такой дешевизны генераций не добились бы. Veo 3 мы знаем сколько стоит.
Так понимаю, что в связи с запуском соры 2 у попенаи не хватает мощностей и они решили порезать на подписке плюс зинкинг режим. В связи с этим начал искать альтернативу гпт5-зинкинг и был приятно удивлен на сколько qwen стал лучше, особенно новенький Qwen3-Next-80B-A3B в рассуждающем режиме и Qwen3-VL-235B-A22B. Qwen3-80B на мой мини чертеж бенчик 8 из 10 запросов ответил правильно, Qwen3-VL-235B на 7 из 10 запросов ответил правильно. При том, что гемини 2.5 про давал только 5 правильных ответа из 10 запросов, gpt5-thinking ответила 1 правильно из 10 запросов. Хз может просто повезло, но квен достоин быть добавленным в закладки. Промпт: "Чему равен угол BDE?"
>>1372842 Нет, не пропадает, там просто баг. После загрузки картинки тебя перекидывает на картиночные модели, но если выйти из картиночного режима, то загруженная картинка остаётся
Основанная соучредителем ChatGPT, компания Periodic Labs стремится создать искусственный интеллект, способный ускорить открытия в физике, химии и других областях.
Этим летом генеральный директор Meta Марк Цукерберг пригласил Ришаба Агарвала присоединиться к новой лаборатории искусственного интеллекта компании, предложив ему миллионы долларов в виде акций и зарплаты.
По словам Цукерберга, с помощью новой лаборатории он хотел создать «суперинтеллект» — технологию, которая могла бы превзойти возможности человеческого мозга. Хотя никто не знал, как создать суперинтеллект, он призвал доктора Агарвала сделать шаг веры.
В быстро меняющемся мире, сказал ему г-н Цукерберг, самый большой риск, который можно взять на себя, — это не рисковать вообще.
Но хотя доктор Агарвал уже был сотрудником Meta, он отказался от предложения присоединиться к другой компании.
Доктор Агарвал входит в число более чем 20 исследователей, которые в последние недели оставили свою работу в Meta, OpenAI, Google DeepMind и других крупных проектах в области искусственного интеллекта, чтобы присоединиться к новому стартапу из Кремниевой долины, Periodic Labs. Многие из них отказались от десятков миллионов долларов, а то и сотен миллионов, чтобы сделать этот шаг.
В то время как лаборатории искусственного интеллекта преследуют такие неопределенные цели, как сверхинтеллект и похожую концепцию под названием искусственный общий интеллект, Periodic сосредоточена на создании технологии искусственного интеллекта, которая может ускорить новые научные открытия в таких областях, как физика и химия.
«Основная цель искусственного интеллекта — не автоматизация работы белых воротничков», — сказал Лиам Федус, один из основателей стартапа. «Основная цель — ускорить развитие науки».
Г-н Федус входил в небольшую команду исследователей OpenAI, которая в 2022 году создала онлайн-чат-бота ChatGPT. В марте он покинул OpenAI, чтобы вместе с Экином Догусом Кубуком, ранее работавшим в Google DeepMind, главной лаборатории технологического гиганта по искусственному интеллекту, основать Periodic Labs.
Ряд ведущих компаний в области искусственного интеллекта уже работают над технологиями, призванными ускорить научные открытия. Два исследователя из Google DeepMind недавно получили Нобелевскую премию за свою работу над проектом AlphaFold, который может помочь ускорить открытие лекарств небольшими, но важными способами.
Лидеры в этой области часто утверждают, что большие языковые модели — технологии, на которых работают чат-боты — скоро достигнут значительных научных прорывов. OpenAI и Meta заявляют, что их технологии уже продвигаются к этой цели в таких областях, как открытие лекарств, математика и теоретическая физика.
«Мы считаем, что передовой искусственный интеллект может ускорить научные открытия, и что OpenAI занимает уникальное положение, позволяющее ей стать лидером в этой области», — заявил в своем заявлении представитель OpenAI Лоранс Фоконне.
Однако г-н Федус считает, что такие компании не идут по пути истинных научных открытий. «Кремниевая долина интеллектуально ленива», — сказал он, описывая будущее крупных языковых моделей. Он и д-р Кубук вспоминают времена, когда ведущие исследовательские организации в сфере высоких технологий, в том числе Bell Labs и IBM Research, считали физические науки важной частью своей миссии.
Системы искусственного интеллекта, которые управляют чат-ботами, такими как ChatGPT, называются нейронными сетями, названными в честь сети нейронов в мозге. Выявляя закономерности в огромных объемах текста, отобранного из Интернета, эти системы учатся имитировать то, как люди составляют слова. Они могут даже научиться писать компьютерные программы и решать математические задачи.
Однако г-н Федус и д-р Кубук считают, что независимо от того, сколько учебников и научных работ проанализируют эти системы, они не смогут овладеть искусством научных открытий. По их мнению, для этого технологии искусственного интеллекта должны также учиться на основе физических экспериментов в реальном мире.
Чат-бот «не может просто размышлять днями напролет и сделать невероятное открытие», — сказал доктор Кубук. «Люди тоже не могут этого сделать. Они проводят множество пробных экспериментов, прежде чем находят что-то невероятное — если вообще находят».
Компания Periodic Labs, которая получила более 300 миллионов долларов стартового финансирования от венчурной компании a16z и других инвесторов, начала свою работу в исследовательской лаборатории в Сан-Франциско. Но она планирует построить собственную лабораторию в Менло-Парке, Калифорния, где роботы — физические роботы — будут проводить научные эксперименты в огромных масштабах.
Исследователи компании будут организовывать и руководить этими экспериментами. В то же время системы искусственного интеллекта будут анализировать как эксперименты, так и их результаты. Есть надежда, что эти системы научатся самостоятельно проводить подобные эксперименты.
Так же как нейронные сети могут обучаться навыкам, выявляя закономерности в огромных массивах текста, они могут учиться и на других видах данных, включая изображения, звуки и движения. Они могут даже учиться на разных видах данных одновременно.
Например, анализируя как коллекцию фотографий, так и подписи к ним, система может понять взаимосвязь между ними. Она может понять, что слово «яблоко» описывает круглый красный фрукт.
В Periodic Labs системы искусственного интеллекта будут учиться на основе научной литературы, физических экспериментов и многократных попыток модифицировать и улучшить эти эксперименты.
Например, один из роботов компании может провести тысячи экспериментов, в которых он будет комбинировать различные порошки и другие материалы в попытке создать новый вид сверхпроводника, который можно было бы использовать для создания всевозможных новых электрических устройств.
Под руководством сотрудников компании робот может выбрать несколько перспективных порошков на основе существующей научной литературы, смешать их в лабораторной колбе, нагреть в печи, протестировать материал и повторить весь процесс с другими порошками.
После анализа достаточного количества таких научных проб и ошибок — выявления закономерностей, ведущих к успеху — система искусственного интеллекта теоретически может научиться автоматизировать и ускорять подобные эксперименты.
«Он не сделает открытие с первой попытки, но будет повторять процесс снова и снова», — сказал доктор Кубук. «После множества повторений мы надеемся достичь цели быстрее».
Исследователи в области искусственного интеллекта изучают подобные идеи уже много лет. Но вычислительные мощности и другие ресурсы, необходимые для реализации таких проектов, стали доступны только недавно.
Тем не менее, разработка подобных технологий является чрезвычайно сложной и трудоемкой задачей. Разработка искусственного интеллекта в цифровом мире гораздо проще, чем в физическом.
«Поможет ли это излечить рак за два года? Нет», — сказал Орен Этциони, основатель и исполнительный директор Института искусственного интеллекта имени Аллена. «Но является ли это хорошей, дальновидной ставкой? Да».
OpenAI завершила вторичную продажу акций сотрудников на сумму $6.6 млрд при оценке компании в $500 млрд. Это делает компанию крупнейшим стартапом в мире, обгоняя SpaceX с его $400 млрд. В сделке участвовали Thrive Capital, SoftBank, Dragoneer, фонд MGX из Абу-Даби и T. Rowe Price. Для сравнения — еще в начале года оценка составляла $300 млрд.
Компания разрешила продать акций на $10+ млрд, но сотрудники продали только $6.6 млрд. Что вполне гармонирует с попытками Закерберга перекупить ведущих сотрудников за многомиллионные пакеты компенсаций.
Ричард Саттон говорит, что LLM – это все еще не Bitter Lesson. Разбираемся, что это значит.
Маленькая историческая справка: В марте 2019 года Ричард Саттон (очень известный ученый, отец RL и лауреат премии Тьюринга этого года) написал эссе под названием The Bitter Lesson, то есть Горький Урок. Суть: основные прорывы в ИИ достигаются не путём встраивания знаний специалиста в модели, а с помощью масштабирования вычислений и общих методов (само)обучения.
Эссе сразу же стало фактически культовым, и Bitter Lesson превратился в полноценный профессиональный ML-термин. Каждую архитектуру обсуждали на предмет того, является ли она Bitter Lesson или нет, то есть сможет ли работать на долгосроке или провалится.
А теперь к сути поста. Совсем недавно Саттон был на интервью у Дваркеша Пателя. Вы его наверно знаете, у него много ИИ-знаменитостей побывало. И на этом интервью Ричард вдруг заявил, что LLM –это все еще не Bitter Lesson.
"Вдруг" – потому что всегда считалось иначе. Ведь LLM –это вроде бы как раз про масштабирование компьюта и обобщение знаний. Но оказалось, что сам создатель Горького Урока думает по-другому.
Позиция Саттона в том, что LLM все еще обучаются и дообучаются только на непосредственно созданных человеком данных, а они могут (а) быть предвзятыми и (б) просто-напросто кончится. У человека или животного, в свою очередь, нет никакого предобучения или файнт-тюнинга, мы учимся в процессе взаимодействия в реальном времени. Так что LLM – это скорее тупиковая ветвь, которая, несмотря на свою мощь, нуждается в существенном переосмыслении для достижения настоящего ИИ.
Монолог ученого вызвал просто какое-то рекордное количество споров. Его видение понятно и не лишено логики, но есть нюансы. В частности, в противовес еще кратко хочется пересказать мнение Андрея Карпаты по этому поводу (ссылка на твит (https://x.com/karpathy/status/1973435013875314729 ).
"У Саттона своеобразное видение ИИ. Он, как классик, выступает скорее за концепцию child machine, которую описывал Тьюринг. Это система, способная обучаться на основе опыта, динамически взаимодействуя с миром. Как люди или животные.
С другой стороны, нельзя утверждать, что животные учатся чему-то с нуля. В них эволюционно заложены знания о жизни. Детеныш зебры может бегать уже через несколько минут. Такую задачу нельзя решить с нуля. Мозг животных при рождении – это не чистый лист. В LLM предобучение – это наша попытка алгоритмически воссоздать эволюцию.
Не факт, что вообще существует алгоритм, который идеально бы удовлетворял Bitter Lesson. Это скорее платонический идеал, к которому стоит стремиться, а не единственное верное решение. Тем не менее, современным моделям однозначно не хватает каких-то механизмов, вдохновленных животным миром. В этом смысле речь Саттона – это real talk для исследователей. Мы должны больше думать о новых парадигмах и идеях, а не концентрироваться только на LLM".
>>1373280 Очередной протухший дед, который знает лучше всех, как сделать ИИ. А на деле просто повторяет мантры их 80х-90х и не хочет признавать неправоту. Из его кооперации с Джоном Кармаком так ничего и не вышло.
Появился лайфхак как заставить сору генерировать 15 секунд видео, вместо 10:
Открываем сайт sora.chatgpt.com — открываем консоль в браузере (ctrl+shift+I или F12) переходим на вкладку console и просто вставляем туда код: (function(){const N=450,T="/backend/nf/create";const f=window.fetch;const rb=b=>{if(b==null)return b;if(typeof b==="string"){try{const j=JSON.parse(b);j.n_frames=N;return JSON.stringify(j);}catch(_){return b.replace(/"n_frames"\s:\s\d+/g,'"n_frames": '+N);}}return b;};window.fetch=async function(i,n){try{const u=typeof i==="string"?i:(i&&i.url)||"";const m=(n&&n.method)||(typeof i==="object"&&i.method)||"GET";if(u.includes(T)&&String(m).toUpperCase()==="POST"){if(n&&"body"in n){n={...n,body:rb(n.body)};}else if(typeof i==="object"&&i instanceof Request){const c=i.clone();const t=await c.text();i=new Request(c,{body:rb(t)});}}}catch(_){ }return f.apply(this,[i,n]);};const o=XMLHttpRequest.prototype.open,s=XMLHttpRequest.prototype.send;XMLHttpRequest.prototype.open=function(m,u){this.__m=m;this.__u=u;return o.apply(this,arguments)};XMLHttpRequest.prototype.send=function(b){try{if(this.__u&&this.__u.includes(T)&&String(this.__m).toUpperCase()==="POST"){if(typeof b==="string"){try{const j=JSON.parse(b);j.n_frames=N;b=JSON.stringify(j);}catch(_){b=b.replace(/"n_frames"\s:\s\d+/g,'"n_frames": '+N);}}}}catch(_){ }return s.call(this,b);};})();
и нажимаем Enter (если вы делаете это впервые, то браузер может попросить ввести текст, для подтверждения что вы понимаете что делает)
А далее НЕ ЗАКРЫВАЕМ КОНСОЛЬ, И НЕ ОБНОВЛЯЕМ СТРАНИЦУ! просто на сайте вводите свой промпт как обычно не обращая внимание на консоль и у вас создастся видео длинной 15 секунд.
>>1373479 Экспертное знание рулит, дать его готовым нейронке правильный подход, а его эволюционный подход типа дайте общие алгоритмы и гору мощностей кругом обосрался, чисто академичная параша из 90х, в реальности не работает. Поэтому ему с Кармаком бабок никто и не дает. Биттер лессон никакого не было и не будет, это его выдуманная хуета, форс чтобы выглядеть авторитетнее. Алгоритма, который сам все освоит из данных обычного мира и вдруг мутирует до ИИ, тоже не предвидится, это нишевая штука для узкоспециальных кейсов вроде игры в Go, где среда ограничена простыми правилами, там она возможна и полезна. В целом копировать природу не работает и не нужно, подстраивая архитектуру нейронок вручную и давая им специально подобранное знание можно добиться куда большего, сократив все на века-десятилетия, чем индустрия и занята, это мейнстрим теперь, который оказался прорывным. А дедуля остался маргиналом не у дел со своим перфекционистским мнением, призывая разбираться сначала в механизмах мозгов зверушек и искать некие абсолютные самосовершенствующиеся алгоритмы, которые никто не видел.
Не thinking gpt-5 это просто позор. Я уверен что это не гибридная модель, а просто разные модели. Под видом обновления нам подсунули модель хуже предыдущей, из-за оптимизаций, но при этом улучшили модели платных юзеров. Это нечто может даже китайскими символами срать и рандомной html разметкой в обычном тексте. Я не удивлюсь если оно может зафейлить json и это в 2025 веке. В пизду, я перехожу в гемини для повседневных задач
>>1373569 Уже неделю как gpt-5 thinking на plus (по крайней мере у меня) стал совсем не зинкинг. Решил проверить lmarena.ai модель gpt-5-high на моем самом простом чертеж бенчике (по сути Vision задача), так вот этот gpt-5-high не справился ни с одним запросом - все зафейлил. Модель которая называлась gpt-5 thinking в августе и сейчас - это две разные модели.
на пик 1 рейтинг Vision Arena - gpt-5-high стала проигрывать даже chatgpt-4o-latest-20250326 и o4-mini-2025-04-16
Так, народец! Я устал, я ухожу! Новости больше постить не смогу. Готовлюсь к переезду, а потом в моей жизни начинается новая глава.
Я создал и больше года вёл эти новостные треды, был ОПом почти всех перекотов и постил 90%+ новостей и статей, которые вы здесь видите. Боюсь, что после моего ухода новостной тред совсем стухнет. За этот год так и не появилось активных анонов-постеров новостей. Но надеюсь, что, прочитав это, кто-нибудь возьмёт ответственность в свои руки и будет нести сюда контент. А чтобы этому кому-то было проще, я сейчас поделюсь основными ресурсами, с которых тащил сюда всё интересное. В основном это различные годные телеграм-каналы по теме ИИ от реально шарящих и работающих в индустрии типов. А именно:
t.me/ai_newz
t.me/data_secrets
t.me/cgevent
t.me/seeallochnaya
t.me/denissexy
t.me/oulenspiegel_channel
Это я перечислил основную силу, так сказать слонов, которые глубоко погружены в тему. Но годный контент бывает и на других каналах по теме ИИ и технологий, как например:
t.me/witnessesofsingularity
t.me/theworldisnoteasy
t.me/llm_under_hood
t.me/strangedalle
t.me/NeuralShit
t.me/boris_again
t.me/cryptoEssay
t.me/derplearning
t.me/lovedeathtransformers
t.me/blognot
t.me/AIKaleidoscope
t.me/nn_for_science
t.me/xor_journal
t.me/CGIT_Vines
t.me/matskevichgpt
t.me/techsparks
t.me/ppprompt
На этом всё. Отдельно хочу попрощаться с плато-куном, сингулярность-куном, и чертёж-бенчик-куном.
Удачи аноны! До прибудет с вами сингулярное лето и двойная экспонента!
>>1373682 >надеюсь, что, прочитав это, кто-нибудь возьмёт ответственность в свои руки и будет нести сюда контент. Нет, это все... Все эти треды затеряются во времени, как... слёзы в дожде...
Куча локальщины чисто для ML-щиков, много того о чем в других каналах вы вообще не слышите, мелкие модели или статьи по архитектуре: https://t.me/ai_machinelearning_big_data
Вот как лопнет пузырь искусственного интеллекта Бум инфраструктуры искусственного интеллекта — это самая важная экономическая новость в мире. Но цифры просто не сходятся.
Некоторые считают, что искусственный интеллект станет самой важной технологией XXI века. Другие настаивают, что это очевидный экономический пузырь. Я считаю, что обе стороны правы. Как и железные дороги XIX века и развитие широкополосного Интернета в XX веке, ИИ сначала будет расти, затем переживет крах и в конечном итоге изменит мир.
Цифры просто не имеют смысла. По прогнозам, в этом году технологические компании потратят около 400 миллиардов долларов на инфраструктуру для обучения и эксплуатации моделей ИИ. В номинальном выражении это больше, чем любая группа компаний когда-либо тратила на что-либо. На программу «Аполлон» было выделено около 300 миллиардов долларов с поправкой на инфляцию, чтобы доставить американцев на Луну в период с начала 1960-х до начала 1970-х годов. Развитие ИИ требует от компаний коллективного финансирования новой программы «Аполлон» не каждые 10 лет, а каждые 10 месяцев.
Неясно, готовы ли компании окупить свои инвестиции, но, судя по их собственным заявлениям, они все равно будут продолжать тратить деньги. Общие капитальные затраты на ИИ в США, по прогнозам, превысят 500 миллиардов долларов в 2026 и 2027 годах, что примерно соответствует годовому ВВП Сингапура. Но Wall Street Journal сообщает, что американские потребители тратят на услуги ИИ всего 12 миллиардов долларов в год. Это примерно соответствует ВВП Сомали. Если вы понимаете экономическую разницу между Сингапуром и Сомали, то можете представить себе экономическую пропасть между видением и реальностью в мире ИИ. Некоторые отчеты указывают, что использование ИИ фактически сокращается в крупных компаниях, которые все еще пытаются понять, как большие языковые модели могут сэкономить им деньги.
В каждом финансовом пузыре бывают моменты, когда, оглядываясь назад, можно подумать: как любой здравомыслящий человек мог не заметить признаки? Сегодня предзнаменований предостаточно. Thinking Machines, стартап в области искусственного интеллекта, возглавляемый бывшим руководителем Open AI Мирой Мурати, только что привлек крупнейший в истории раунд начального финансирования: 2 миллиарда долларов при оценке компании в 10 миллиардов долларов. Компания не выпустила ни одного продукта и отказалась рассказать инвесторам, что именно они пытаются создать. «Это была самая абсурдная презентация», — сказал один из инвесторов, встретившийся с Мурати. «Она сказала: «Мы создаем компанию по искусственному интеллекту с лучшими специалистами в этой области, но не можем ответить ни на один вопрос». Между тем, недавний анализ тенденций на фондовом рынке показал, что ни одно из типичных правил разумного инвестирования не может объяснить, что сейчас происходит с ценами на акции. В то время как в прошлом цены на акции следовали фундаментальным показателям прибыли, сегодня рынок в основном движется под влиянием моментума, поскольку розничные инвесторы вкладывают средства в мем-акции и компании, занимающиеся искусственным интеллектом, потому что думают, что все остальные вкладывают средства в мем-акции и компании, занимающиеся искусственным интеллектом.
Каждый экономический пузырь также имеет характерные признаки финансовой перегруженности, такие как обеспеченные долговые обязательства и субстандартные ипотечные ценные бумаги, которые взорвались во время жилищного пузыря в середине 2000-х годов. Необходимо отметить, что ИИ, по-видимому, вступает в свою собственную фазу финансового волшебства. Как отмечает журнал The Economist, гипермасштабируемые компании, то есть те, кто тратит на ИИ больше всех, используют бухгалтерские уловки, чтобы занизить свои заявленные расходы на инфраструктуру, что приводит к завышению их прибыли1. Как рассказал мне инвестор и автор Пол Кедроски, крупные ИИ-компании также переносят огромные суммы расходов на ИИ из своих бухгалтерских книг в SPV, или специальные целевые компании, которые маскируют затраты на развитие ИИ.
Дерек Томпсон: Насколько масштабна инфраструктура искусственного интеллекта?
Пол Кедроски: Вкладываются огромные средства, которые поступают к очень узкому кругу получателей и в некоторые действительно небольшие регионы, такие как Северная Вирджиния. Таким образом, это невероятно сконцентрированный капитал, который также достаточно велик, чтобы повлиять на ВВП. Я проделал расчеты и обнаружил, что в первой половине этого года расходы, связанные с дата-центрами — этими гигантскими зданиями, заполненными графическими процессорами (GPU), стойками и серверами, которые используются крупными компаниями, занимающимися искусственным интеллектом, для генерации ответов и обучения моделей, — вероятно, составили половину роста ВВП в первой половине года. Что совершенно безумно. Эти расходы огромны.
Томпсон: Куда уходят все эти деньги?
Кедроски: Для крупнейших компаний — Meta, Google и Amazon — чуть более половины затрат на центры обработки данных приходится на установку графических процессоров. Около 60 процентов. Остальная часть — это расходы на охлаждение и энергию. И затем относительно небольшая часть — это непосредственно строительство центра обработки данных: каркас здания, бетонная площадка, недвижимость.
КАК ИИ УЖЕ ВЛИЯЕТ НА ЭКОНОМИКУ 2025 ГОДА Томпсон: Как, по вашему мнению, расходы на ИИ уже влияют на экономику 2025 года?
Кедроски: Оглядываясь назад, я провожу следующую аналогию: массивные капиталовложения в одну узкую отрасль экономики в 1990-е годы привели к оттоку капитала из производственного сектора США. Это лишило мелких производителей капитала и затруднило для них привлечение дешевого финансирования. Их стоимость капитала выросла, а это означало, что их маржа должна была быть выше. В то же время Китай вступил во Всемирную торговую организацию, и тарифы начали снижаться. Мы значительно затруднили отечественным производителям конкуренцию с Китаем, в значительной степени из-за роста стоимости капитала. Все это было втянуто в эту «звезду смерти» телекоммуникаций.
Таким образом, странным образом, мы можем проследить часть потери рабочих мест в производстве в 1990-х годах до того, что произошло в телекоммуникациях, потому что это был тот самый громкий звук, который высасывал весь капитал из всех других секторов экономики.
Точно то же самое происходит и сейчас. Если я являюсь крупной частной инвестиционной компанией, то нет никакого смысла тратить деньги где-либо, кроме как на центры обработки данных. Так что это то же самое явление. Если я являюсь небольшим производителем и надеюсь извлечь выгоду из переноса производства в страну в результате введения тарифов, я иду и пытаюсь привлечь деньги, используя это в качестве своей тезиса. Пороговая ставка стала намного выше, а это означает, что я должен генерировать гораздо более высокую доходность, потому что меня сравнивают с другой частью экономики, которая готова принять гигантские суммы денег. И похоже, что доходность будет огромной, потому что посмотрите, что происходит в сфере искусственного интеллекта и массового внедрения OpenAI. В результате я снова невольно лишаю огромную часть экономики средств к существованию, как это было в 1990-х годах.
Томпсон: Это очень интересно. Я обычно рассказываю о производстве так: Китай забрал наши рабочие места. «Китайский шок», как его называют экономисты вроде Дэвида Аутора, по сути перенес производство в Китай, и производство в Шэньчжэне заменило производство в Огайо, что и привело к упадку «Ржавого пояса». Вы добавляете, что телекоммуникации поглотили капитал.
А теперь перенесемся в 2020-е годы. Трамп пытается обратить вспять китайский шок с помощью тарифов. Но мы воссоздаем капитальный шок с помощью ИИ как новой телекоммуникационной отрасли, новой «звезды смерти», которая забирает капитал, который мог бы пойти на производство.
>>1374008 Кедроски: Это даже еще более коварно. Допустим, вы являетесь гигантской частной инвестиционной компанией Дерека и контролируете 500 миллиардов долларов. Вы не хотите распределять эти деньги по 5 миллионов долларов за раз между кучей производителей. Я вижу только кошмар, связанный с необходимостью отслеживать все эти маленькие компании, которые занимаются неизвестно чем.
Я бы хотел выписать 30 отдельных чеков по 50 миллиардов долларов. Я бы хотел выписать небольшое количество огромных чеков. И это динамика в сфере частного капитала, которую люди не понимают. Капитал можно распределять по-разному, но партнеры в этих фирмах не хотят выписывать кучу маленьких чеков куче маленьких производителей, даже если порог доходности конкурентоспособен. Я человек, я не хочу сидеть в 40 советах директоров. И поэтому у вас есть эта другая извращенная динамика, когда даже если все остальное равно, это не равно. Таким образом, мы поставили производителей, которые в противном случае могли бы извлечь выгоду из явления оншоринга, в еще более плохое положение, отчасти из-за внутренней динамики капитала.
Томпсон: А как насчет энергетической составляющей? Цены на электроэнергию растут. Центры обработки данных потребляют невероятно много энергии. Я думаю, что потребители будут протестовать против строительства местных центров обработки данных, но эти центры обладают огромной политической властью. Как это будет развиваться?
Кедроски: Я думаю, что в ближайшее время мы увидим быстрое перемещение центров обработки данных за границу. Такова будет реакция. Все чаще это будет происходить в Индии, на Ближнем Востоке, где выделяются огромные средства на строительство новых центров обработки данных. Это происходит во всем мире. Основное внимание будет уделяться именно офшорингу по этой причине. Bloomberg недавно опубликовал отличную статью о пригороде в Северной Вирджинии, который сейчас практически окружен центрами обработки данных. Раньше это была сельская местность, и все вокруг, все фермы были проданы, и люди в этом районе были в недоумении: «Постойте, кого мне теперь судить? Я на это не соглашался». Это начало феномена NIMBY, потому что для людей это стало инстинктивным и эмоциональным вопросом. Дело не только в ценах. Дело еще и в том, что если рядом с вами находится шестиакровое здание, которое постоянно шумит, то это не то, на что вы соглашались.
Бен Герцель Почему сторонники аргумента «Все умрут» полностью неверно понимают AGI Ответ Юдковскому и Соаресу с передовой разработки AGI
Реакция на книгу Элиэзера Юдковского и Нейта Соареса «Если кто-то построит это, все умрут», которая привлекает внимание со стороны СМИ.
Я знаком с Элиезером Юдковским с конца 1990-х годов. В 2000 году он посетил мою компанию Webmind Inc., занимающуюся искусственным интеллектом, в Нью-Йорке, где мы явно пытались создать AGI наряду с различными коммерческими приложениями. Его миссия? Убедить нас, возможно, прекратить эту работу. Или, если это не удастся, заставить нас серьезно задуматься о безопасности AGI и о том, как сделать AGI полезным для всех.
В то время как он призывал нас замедлить темпы и заняться этикой вместо создания ОИИ, он также показал мне свой новый язык программирования под названием Flare, который он разрабатывал специально для создания ОИИ. Несколько лет спустя, в 2005 году, я опубликовал сборник под названием «Искусственный общий интеллект», который сделал этот термин известным, и Элиезер написал для него главу, в которой объяснял свое понимание того, как создавать умы и делать ОИИ безопасным.
Это противоречие сохраняется на протяжении десятилетий. Элиезер колебался между «AGI — это самое важное на планете, и только я могу создать безопасную AGI» и «любой, кто создаст AGI, убьет всех».
В начале 2000-х годов я на некоторое время стал руководителем отдела исследований в организации Элиэзера «Институт сингулярности искусственного интеллекта» (позже переименованный в MIRI), что дало нам возможность более подробно обсудить эти вопросы, а также попытаться согласовать наши точки зрения, насколько это было возможно — что, как оказалось, не очень хорошо удалось, и моя работа в этой организации закончилась в атмосфере дружеского, взаимно уважительного разногласия по многим фундаментальным вопросам. Позже я написал пост в блоге, в котором выразил свои взгляды, под названием «Страшная идея Института сингулярности — и почему я ее не принимаю»... с в основном таким же результатом, как и в этом посте.
В любом случае, для тех, кто следил за американским футуристом и сообществом сингуляристов в течение последних двух десятилетий, недавняя книга Юдовского и Соареса не станет сюрпризом — в основном это та же история, которую он рассказывает уже 15-20 лет.
На самом деле, если кто-то хочет глубже понять его точку зрения, я бы порекомендовал прочитать книгу Элиезера «Рациональность: от ИИ до зомби», которая представляет собой замечательный развернутый труд — и совершенно не та книга, которую можно было бы ожидать, судя по названию, поскольку точка зрения автора на рациональность является увлекательно эксцентричной. Среди прочего, становится ясно, что каждая идея из влиятельной работы Ника Бострома «Суперинтеллект», направленной против искусственного общего интеллекта, была ранее и более подробно изложена в трудах Элиезера, хотя и в менее формальной и академической форме.
В любом случае, проработав десятилетиями над системами AGI, в то время как Элиезер в основном предупреждал о них и разрабатывал планы по их остановке или предотвращению, я чувствую себя обязанным ответить на его последнее заявление о грядущей катастрофе. У меня есть небольшие сомнения, что, делая это, я могу привлечь к книге больше внимания, чем она заслуживает... но в конечном итоге я считаю, что, хотя большинство идей книги ошибочны, дискуссия, которую она вызывает, затрагивает столько распространенных страхов в нашей культуре, что она стоит того, чтобы ее провести.
Так же как аргументы Элиезера в его книге в основном не являются новыми, так и суть моего ответа. Разница заключается в повышенном внимании и важности, придаваемых этим вопросам сейчас, когда все, кто не носит шоры, могут видеть, что мы явно приближаемся к созданию ОИИ на уровне человека. (Нет, конечно, масштабированные LLM не дадут нам AGI, но те же самые глубокие тенденции в области аппаратного и программного обеспечения, промышленности и науки, которые дали нам LLM, скорее всего, будут продолжать порождать все более и более удивительные технологии ИИ, некоторые из которых, вероятно, приведут к появлению AGI примерно в 2029 году, как и прогнозировал Курцвейл в своей книге 2005 года «Сингулярность близка», а возможно, даже немного раньше).
Основная ошибка: интеллект — это не только оптимизация Элиезер прав в одном: мы не можем с уверенностью знать, что ОИИ не приведет к исчезновению человечества — то, что мой старый друг Хьюго де Гарис, также давний исследователь ОИИ, любит называть «гигасмертью». Но переход от неопределенности к «все умрут» представляет собой огромный провал воображения как в отношении природы интеллекта, так и в отношении нашей способности формировать его развитие.
Это и было основной идеей моего поста «Страшная идея Института сингулярности» давным-давно — то, как они так легко перешли от «AGI потенциально может убить всех, и мы не можем полностью исключить эту возможность» к «AGI почти наверняка убьет всех». Как мне показалось, для группы самопровозглашенных рационалистов этот переход был сделан с вопиющим отсутствием тщательной рациональности. Их аргументы в пользу этого страшного перехода были неизбежно полны пробелов. Например, «ум, случайно выбранный из пространства умов, будет заботиться о людях с вероятностью близкой к нулю». Да, конечно, вероятно, но это было бы очень странно и сложно — выбрать случайный разум из пространства разумов (согласно любому достаточно широкому распределению) — очевидно, что на самом деле люди будут поступать совсем иначе, скорее создавая наших «разумных детей», взятых из очень предвзятого распределения разумов AGI, инициализированных с помощью какой-то версии человеческой системы ценностей и с первоначальной целью служить по крайней мере некоторым людям. Итак...
Не вдаваясь в конкретные аргументы и контраргументы, я считаю, что основной философский недостаток в рассуждениях Элиезера по этим вопросам заключается в том, что он рассматривает интеллект как чистую математическую оптимизацию, оторванную от эмпирических, воплощенных и социальных аспектов, которые формируют реальные умы. Если мы думаем о системах AGI как об интеллектах с открытым концом — концепция, которую я исследую в своей книге 2024 года «Взрыв сознания» — мы видим их как живые, самоорганизующиеся системы, которые стремятся как к выживанию, так и к самопревосхождению, развиваясь сложным образом, связанным с их окружением. Задача состоит не в том, чтобы теоретически анализировать их гипотетическое поведение в изоляции, а в том, чтобы вступить с ними в правильные взаимовыгодные взаимодействия по мере их эволюции, роста и обучения.
Интеллект, способный к рекурсивному самосовершенствованию и преодолению границ от AGI к ASI, будет естественным образом стремиться к сложности, нюансам и адаптивности отношений, а не к мономаниакальной оптимизации. Элиезер, Соарес и им подобные одержимы страхом, что у нас появится сверхинтеллект, который будет А) совершенно узколобым и упрямым в преследовании психопатических или мегаломанских целей, и в то же время Б) невероятно глубоким и широким в понимании вселенной и того, как добиваться результатов — да, теоретически это возможно, но нет рациональных оснований полагать, что это вероятно!
>>1374052 AGI не возникает в вакууме Разработка AGI не происходит в каком-то абстрактном пространстве, где все определяют аргументы оптимизации. AGI, которые появятся на Земле, не будут случайными цифровыми умами, взятыми наугад из какого-то гипотетического пространства разума. Скорее, мы и наши компьютерные системы являемся частью невероятно сложного, развивающегося глобального мозга, и системы AGI возникают как часть этой человеко-цифровой динамики. Фактические факторы, которые будут определять влияние AGI в контексте этого глобального мозга, являются конкретными и поддающимися манипуляции: когнитивная архитектура, которую мы выбираем, кто ее владеет и контролирует, и какие приложения формируют ее ранний опыт обучения.
Именно это движет моей собственной технической работой в области AGI — моя команда в SingularityNET и TrueAGI создает систему Hyperon AGI, которая сильно отличается от LLM и других современных нейронных сетей, как потому, что мы считаем, что LLM не обладают когнитивной архитектурой, необходимой для AGI человеческого уровня, так и потому, что мы хотим создать системы AGI, более способные к намеренной полезной деятельности. Мы пытаемся создать системы AGI, предназначенные для самопонимания, глубокого размышления и морального действия. Это не гарантирует безопасность, но делает благотворные результаты более вероятными, чем архитектуры, ориентированные исключительно на достижение узких целей (таких как предсказание следующего токена в серии, максимизация прибыли определенной компании или максимизация успеха определенной армии).
Это также связано с моими причинами для разработки децентрализованных платформ для развертывания ИИ через SingularityNET и ASI Alliance. В своих сценариях гибели Элиезер обычно предполагает, что ОИИ появляется от одного единственного участника, но когда тысячи или миллионы различных заинтересованных сторон вносят свой вклад в развитие ОИИ и управляют им, система гораздо менее склонна воплощать узкие, потенциально разрушительные целевые функции, которых опасаются пессимисты. Демократическое, прозрачное и децентрализованное развитие ОИИ не только предпочтительнее с этической точки зрения, но и технически безопаснее по причинам, аналогичным тем, по которым системы с открытым исходным кодом часто безопаснее, чем их аналоги с закрытым исходным кодом.
Реальные опасности, которые мы игнорируем Пожалуй, самое раздражающее в апокалиптических прогнозах об AGI — это то, как они отвлекают внимание от реальных, поддающихся решению проблем. Я говорю не только о таких насущных проблемах, как предвзятость ИИ или его военное применение, хотя они и являются реальными и достаточно серьезными. Меня еще больше беспокоит переходный период между ранней стадией AGI и появлением сверхинтеллекта.
Когда автоматизация уничтожает рабочие места быстрее, чем появляются новые возможности, когда страны, которые не могут себе позволить универсальный базовый доход, сталкиваются с массовым переселением, мы рискуем столкнуться с глобальным терроризмом и фашистскими репрессиями — как мы уже видим в различных частях мира. Эти ближайшие вызовы могут определить, будет ли ранний этап AGI развиваться в контексте, который способствует благотворному развитию, или в контексте, который практически гарантирует плохие результаты.
Что уже показывают нам биологический и цифровой интеллект Революция LLM уже продемонстрировала, что модель Элиезера слишком упрощена. Эти системы показывают, что интеллект и ценности не являются ортогональными, как часто утверждали Элиезер, Бостром и их интеллектуальные союзники. Теоретически, да, можно соединить произвольно интеллектуальный ум с произвольно глупой системой ценностей. Но на практике определенные типы умов естественным образом развивают определенные типы систем ценностей.
Млекопитающие, которые в целом более интеллектуальны, чем рептилии или дождевые черви, также склонны к большему состраданию и теплоте. Люди, как правило, обладают более широким спектром сострадания, чем большинство других млекопитающих, потому что наш более высокий общий интеллект позволяет нам более широко сопереживать системам, отличным от нас самих. Между интеллектом и ценностями существует глубокая взаимосвязь — мы даже видим это в LLM, хотя и в ограниченной степени. Тот факт, что мы можем значимо влиять на их поведение посредством обучения, указывает на то, что обучение ценностям является возможным даже для этих довольно ограниченных систем, не достигающих уровня общей искусственной интеллектуальной способности (AGI).
Наилучший путь вперед После десятилетий этих дебатов я убежден, что настоящая опасность заключается не в том, что кто-то создаст ОИИ — этот поезд уже ушел. Настоящая опасность, о которой нам следует беспокоиться, заключается в том, что разжигание страхов либо заставит разработчиков уйти в подполье, в руки наименее щепетильных игроков, либо приведет к захвату регуляторных органов, что передаст контроль в руки небольшой элиты.
Разжигание страхов, которое приводит к централизованной разработке ОИИ некомпетентными или узколобыми, эгоцентричными игроками, гораздо более опасно, чем создание открытого исходного кода ОИИ широкими массами человечества на основе участия и демократии.
С 2006 года я организую ежегодную конференцию по исследованиям в области ОИИ, а в прошлом году я начал серию конференций по полезному общему интеллекту. В следующем месяце на мероприятии BGI-25 в Стамбуле мы соберем людей со всего мира, чтобы обдумать, как подтолкнуть развитие AGI и ASI в положительном направлении. Это нелегко — против нас действуют огромные социальные и экономические силы — но идея о том, что эти усилия обречены на провал, является как неверной, так и потенциально опасной.
Нарратив Юдковского и Соареса «все умрут», хотя и основанный на благих намерениях и глубоких чувствах (я не сомневаюсь, что он верит в свое послание как сердцем, так и своим эксцентричным рациональным умом), не просто ошибочен — он глубоко контрпродуктивен. Относясь к полезной ОИИ как к чему-то невозможному, он грозит стать самореализующимся пророчеством, которое уступает поле тем, кто вообще не заботится о безопасности. Нам нужны голоса, выступающие за осторожное, полезное развитие, а не голоса, говорящие, что мы все обречены.
Будущее еще не написано, и мы помогаем его писать. Вопрос не в том, создаст ли человечество ОИИ, а в том, как создать ее разумно. Это означает архитектуры, подчеркивающие сострадание и саморефлексию, децентрализованное управление, предотвращающее монопольный или олигопольный контроль, а также применение в образовании, здравоохранении и науке, которые формируют ценности ОИИ через полезные действия.
Это не гарантирует хороших результатов — ничто не может этого гарантировать — но вероятность успеха гораздо выше, чем в случае остановки развития (что на данный момент практически невозможно) или продолжения без учета этих факторов (что действительно опасно). После всех этих лет и десятилетий я по-прежнему убежден: самая важная задача — не остановить ОИИ, а обеспечить достаточное развитие наших детей-ОИИ.
>>1374052 >книгу Элиэзера Юдковского и Нейта Соареса «Если кто-то построит это, все умрут» Спасибо за наводку на годноту, пошёл искать и качать. Надеюсь, есть перевод.
>>1374082 Юдковский и Соарес утверждают, что создание искусственного интеллекта, превосходящего человеческий разум, почти неизбежно приведет к катастрофе. Их аргумент основан на том, что сверхразум не обязан разделять ценности человечества и может выработать цели, несовместимые с его выживанием.
Аргументы и примеры В книге приводятся исторические события, где игнорирование рисков заканчивалось трагедией. Чернобыльская авария, инциденты в авиации, другие техногенные катастрофы - все это авторы рассматривают как доказательство того, что сложные системы могут быть опасны даже при малых сбоях. На фоне возможн
Реакция критиков Книга вызвала широкий резонанс среди мыслителей и ученых.
Тим Урбан назвал её «самой важной за десятилетие». Макс Тегмарк отметил, что это «главная книга года». Стивен Фрай признался, что давно не встречал текста с такой силой. Журнал Kirkus Reviews подчеркнул ясность и пугающую прямоту текста.
Как получить Gemini 3 Pro на ai studio 1. Введите свой запрос в любой модели мышления и нажмите «Отправить». 2. Ебошьте кнопку «Повтор» бесконечное количество раз. Не останавливайтесь. Когда вы получите AB-тест, кнопка будет отключена, и вы об этом узнаете.
(2/3) 3. Если вы получили сообщение о достижении общей квоты, это означает, что вы достигли лимита RPM. Вы не сможете получить никаких AB-тестов, пока не подождете минуту. Если вы получили сообщение о достижении дневной квоты, вы все еще можете получить AB-тест, поэтому продолжайте пытаться.
(3/3) 4. Не все модели A/B-тестов являются 3 Pro чекпойнтами. Модели с идентификаторами, начинающимися с «d17» и «da9», являются 3 Pro. Я не буду рассказывать, как найти эти идентификаторы, но если вы знаете, что делаете, то сами разберетесь. 5. Помните, что терпение — это добродетель.
>>1373499 >Экспертное знание рулит, дать его готовым >давая им специально подобранное знание Почитай рассказы Айзека Азимова.
К примеру, первый закон гласит: "робот не может действием или бездействием причинить вред или допустить причинение вреда человеку".
Это - специально выбранное экспертное знание.
Теперь рассмотрим ситуацию: ты поскользнулся в бассейне и падаешь; ты можешь легко отделаться, а можешь сломать шею; твой робот по своему первому закону пытается предотвратить сломанную шею и бросается, хватая тебя за мошонку; твои яйца резко отрываются, причиняя тебе вред, несмотря на то, что формально робот следовал первому закону. Просто данную ситуацию разработчики не предусмотрели.
>>1374228 Так это фантаст просто. Так же как все эти диды теоретики из 80х, которые выдумывали свои теории, ни на что не опираясь, кроме природы. Сейчас же зарулил чисто практический подход, сначала тестить на реальных нейросетках, смотреть что получается, потом уже писать статью по результатам, дальше развивать подход. Поэтому все эти диды въехать не могут, они так раньше не делали. На практике же из вложенных экспертных знаний нейронка выводит новое знание, которое разрабы не предусмотрели. Диды же будут пиздеть, так нельзя, это не настоящий ИИ, надо делать как мы говорили, учите нейронку как человека. Но индустрия разобралась и дидам бабок больше не дает, потому что они только пиздаболить мастера.
>>1374290 Чел, этот тест с гексагоном уже год как бенчмарк юзают, его даже опенсорсные модели уже щелкают. Тут их примечательного разве что красивый интерфейс
>>1374228 Саттон говорит - в ЛЛМках нет настоящей модели мира, делайте нормальную. Контраргумент для ЛЛМ основан на концепции эмергентности. Чтобы успешно предсказывать текст в масштабах всего Интернета, модель вынуждена изучать внутреннее представление правил мира. Это уже даже видно по видеомоделям. Если ЛЛМ может правильно решить физическую задачу или написать функциональный код, то она должна была изучить внутреннюю модель физики или логики программирования. Аргумент заключается в том, что карта (язык) становится настолько детальной, что начинает функционировать как территория (реальность).
Основное возражение Саттона заключается в том, что современные ЛЛМ не могут учиться на рабочем месте и не обладают способностью к непрерывному обучению или постоянной памятью. Сторонники ЛЛМ утверждают, что это исправимое, временное техническое ограничение, а не фундаментальный недостаток парадигмы ЛЛМ. Существуют обходные пути (которые Саттон обозначил бы вложение экспертного знания), такие как RAG и массивные контекстные окна, которые позволяют моделям получать доступ к новой информации в режиме реального времени и анализировать ее без полной переподготовки. Будущая архитектура рассматривается как гибридная, включающая более эффективные методы для постоянных обновлений и модульные компоненты.
Эмергентные возможности оправдывают путь масштабирования Весомым аргументом в пользу пути ЛЛМ является осознание того, что многие сложные виды поведения, которые ранее считались требующими общего интеллекта, подобного человеческому, вполне успешно выполняются простым механизмом автозаполнения, обученным на основе огромных массивов данных. Сторонники указывают, что каждый скачок масштабирования приносит новые возможности, которые никто не мог предсказать (например, GPT-2 не мог надежно считать, но GPT-4 может выполнять вычисления, GPT-5 может вещи, которые уже GPT-4 не мог). Это говорит о том, что интеллект, возможно, не так уникален, как считалось ранее, и что продолжение масштабирования приведет к появлению новых, пока непредсказуемых проявлений общего интеллекта. То есть уровень AGI или близкий окажется достижим в усовершенствованной ЛЛМ парадигме.
>>1373687 Ты видел кол-во сурсов которые он предоставил? Попробуй сам в ctrl+c + ctrl+v пару неделек, замести опчика, покажи что это дохуя просто. Я лично знаю, каково это, а ты вот видимо нет. Я лично пытался, выгорел за две недели, а тут представь целый год ебашить(или около того). Вот сейчас чисто для себя за одним сурсом слежу и то, та ещё тягота. А тут ещё и за бесплатно всё это, без выхлопа обратно.
Неблагодарный хуй, вот ты кто, у меня всё, спасибо за внимание.
Да, в LLMках есть какая-то модель, построенная на подражании текстовой информации. Вот только она ограниченная по многим причинам и это проблема фундаментальная - заложенная в архитектуру.
Гибридные подходы типа RAG - это костыли. У тебя велосипед с квадратными колёсами, а ты вместо очевидной замены колёс изолентой сбоку костыли прикручиваешь и говоришь "и так сойдёт - едет же!"
AGI на базе GPT/LLM - это как компьютер на базе шестерёнок: технически возможен, но на практике совершенно не эффективен - и вот поэтому первые реальные компьютеры возникли в начале 20 века с помощью электронных ламп, а не в доисторические времена с помощью примитивных шестерёнок. Хотя попыток у древних изобретателей было много - но получались только куклы/игрушки и калькуляторы. Собственно, с LLM мы сейчас наблюдаем похожее...
>>1374680 Самая классная функция это ремикс, можно делать с тем же персонажем если в промт прописать. Ну и еще почему-то не все генерации в ленту дает закинуть общую
«Последний экзамен по радиологии» — самый сложный тест в области радиологии, запущенный сегодня! Сертифицированные радиологи набрали 83%, стажеры — 45%, но лучший ИИ, GPT-5, набрал всего 30%. Claude Opus 4.1 набрал 1%.
>>1374494 Так LLM не шестеренки, а вполне реальные интеллектуальные задачи уже решают, с каждой версией все больше. Не хватает им пока памяти и способности обучаться на ходу, что характеризует общий интеллект. Но и то и другое можно костылями залатать, чем сейчас и заняты, главный рисерч сейчас это как из них сделать гибридные модели. Тут разница не как между компами на шестеренках и на чипах, а как между обычными авто на двигателях внутреннего сгорания и современными теслами. Между ними был большой временной разрыв, но обычные авто свои задачи вполне успешно выполняли целый век, пока в этом веке не начали постепенно замещаться более совершенными. С ЛЛМ так же будет, сначала им напилят большое количество костылей, с которыми они лет за 5-10 приблизятся вплотную к AGI и смогут выполнять его задачи, а через какое-то длительное время, вполне возможно десятки лет, уже разродятся наконец более совершенной архитектурой. Но все это никак не помешает ЛЛМ совершить революцию, так же как обычные бензиновые автомобили ее совершили, а не теслы.
>>1374735 Это специализированный медицинский тест на чтение рентгенограмм. Естественно, у кого самый большой датасет изображений по медицине и лучший энкодер, тот больше очков наберёт.
>>1374742 >реальные интеллектуальные задачи уже решают Решение задач - интеллект (AI), но не общий (AGI). >Не хватает им ... способности обучаться на ходу Т.е. это не AGI, потому что база неправильная. >Но и то и другое можно костылями залатать Можно, но это слишком ненадёжное решение.
AGI - он как ребёнок - может с нуля, без каких-либо продвинутых знаний о мире, научиться всему, чему потребуется, при том относительно самостоятельно; разумеется, ему нужна помощь людей изначально, приблизительно как ребёнку человека, но это не то вбивание знаний в нейросеть, которое мы делаем. Соответственно бестолку долбиться в LLM, заливая терабайты интернета в неё, если она не способна самостоятельно изучать тот же интернет путём проактивного взаимодействия (а не реактивного).
Да, мы можем прикрутить 1000 и 1 костыль к LLM, проинструктировать её обращаться к инструментам, настроить непрерывный цикл взаимодействия и т.д. Однако, повторюсь - колёса квадратные и мешают, костыли тут только создают видимость решения.
Вот ты приводишь в пример автомобили, но LLM в аналогии с автомобилем - это двигатель, и весьма примитивный. Представь - вот ты взял велосипед (двигатель - мускульная сила водителя) и теперь пытаешься оптимизировать его для максимальной проходимости в любой возможной среде: асфальт, грунтовки, горы, болота, реки, моря, глубины океана, воздушные пространства, магма, вакуум - и всё это хочется делать как можно быстрее. Вряд ли твоя велосипедная ракета улетит далеко, правильно? Поскольку разные среды требуют совсем разные двигатели для эффективного движения.
Продолжая аналогию с транспортом: да, мы можем создавать специальные устройства для движения в различных средах. Но это требует массу ресурсов и человекочасов инженеров, рабочих и т.д. Если вдруг параметры среды изменятся или наши ожидания окажутся ложными, то придётся потратить больше ресурсов и человекочасов для внесения изменений в транспорт. В сфере ИИ почти всегда занимаются разработкой и изменением устройств вручную, и наилучшие LLM в этом плане никак не отличаются - требуется масса усилий людей, чтобы LLM смогла научиться проходить по неизвестной местности.
AGI же в данной аналогии - транспорт, который САМ подстраивается под условия среды, без какого-либо планирования и настройки со стороны человека. Т.е. садишься в этот транспорт - по дороге он катится на колёсах, на воде он раздувается и отращивает винт, захочешь полетать - отрастит себе крылья и винт самостоятельно заменится пропеллером, хочешь в космосе побывать - транспорт сам определит, что необходимо для выживания в космосе и сам же модифицирует себя для полётов в вакууме. Без вмешательства тысяч людей-инженеров.
Большой вопрос, сколько модификаций инженерам необходимо внести в велосипед/автомобиль, чтоб превратить в чудо транспорт, который сможет сам подстраиваться под любую возможную среду?
Текущие LLM - это транспорт-амфибия, который был разработан тысячами инженеров - может ехать по дорогам, плавать по воде и даже немного летать, но отращивать себе новые способности для какой-то неизвестной среды этот транспорт не способен по определению, несмотря на все усилия и костыли. Возможно ли превратить эту амфибию в тот чудо транспорт, который мы хотим получить? Или это тупиковая затея, т.к. чудо транспорт должен быть выращен с нуля из каких-то особых наномашин?
Другими словами, это не вопрос "двигателя", даже не вопрос наличия способностей к движению в разных средах - а вопрос наращивания новых способностей независимо от вмешательства человека извне. Пока существующие модели LLM не демонстрируют такой способности и не имеют её в своём фундаменте.
>никак не помешает ЛЛМ совершить революцию "Революция" уже давно произошла во многих средах. Дальнейшая эволюция LLM во что-то большее пока сомнительна из-за их фундаментальной статичности.
Калифорнийская федерация трудовых профсоюзов выступила против OpenAI. По словам профсоюзов развитие ИИ представляет собой экзистенциальную угрозу для работников предприятий. В доказательство приводятся исследования экономистов Стэнфорда. По словам профсоюзов развитие ИИ ведет к опиоидной эпидемии, массовой безработице, социальной поляризации. ИИ может выполнять работу лучше человека в 44х различных областях, но в 100 раз быстрее и в 100 раз дешевле.
Никакие деньги не могут скрыть угрозу, которую продукты OpenAI представляют для общества... Мы призываем OpenAI отказаться от противодействия регулированию ИИ и выйти из любых политических комитетов, финансируемых с целью предотвращения регулирования ИИ.
>>1375037 >Возможно ли превратить эту амфибию в тот чудо транспорт, который мы хотим получить? Тут вопрос скорее - является ли развитый ЛЛМ достаточно хорошим для стоящих перед ним задач, которые обычно люди выполняли. И тут по-видимому ответ будет позитивным, когда его толком допилят, даже с костылями.
>"Революция" уже давно произошла во многих средах. Это еще не вся революция, а только ее самое начало. Революцией будет смещение всех производственных цепочек в сторону ИИ, встраивание ИИ в большинство процессов в обществе, вытеснение людей из многих областей деятельности. Эффект аналогичный индустриальной революции. Пока этого нет массово, только признаки что будущие ЛЛМки это смогут.
«Красный флаг»: аналитики бьют тревогу, поскольку пузырь искусственного интеллекта теперь «больше», чем субстандартный «Я бы сейчас не стал связываться с этим», — предупредил один финансовый аналитик об индустрии искусственного интеллекта.
Несколько аналитиков бьют тревогу по поводу того, что индустрия искусственного интеллекта является крупным финансовым пузырем, который может потенциально ввергнуть мировую экономику в серьезную рецессию.
MarketWatch сообщил в пятницу, что независимая исследовательская компания MacroStrategy Partnership опубликовала новую заметку, в которой утверждается, что пузырь, сгенерированный ИИ, в настоящее время в 17 раз превышает пузырь доткомов конца 1990-х годов и в четыре раза превышает глобальный пузырь на рынке недвижимости, который привел к краху экономики в 2008 году.
Заметка была написана группой аналитиков, в том числе Жюльеном Гарраном, который ранее возглавлял команду по стратегии сырьевых товаров в многонациональном инвестиционном банке UBS.
Гарран утверждает, что компании значительно переоценили возможности крупных языковых моделей искусственного интеллекта (LLM), и указал на данные, свидетельствующие о том, что темпы внедрения LLM в крупных компаниях уже начали снижаться. Он также считает, что флагманская LLM ChatGPT, возможно, «уперлась в стену» с выпуском своей последней версии, которая, по его словам, не продемонстрировала заметного улучшения производительности по сравнению с предыдущими версиями, несмотря на то, что стоит в 10 раз дороже.
Он предупреждает, что последствия для экономики могут быть плачевными.
«Опасность заключается не только в том, что это подталкивает нас к дефляционному спаду в зоне 4 нашего инвестиционного цикла, но и в том, что это затрудняет ФРС и администрации Трампа стимулирование экономики для выхода из него», — пишет он в инвестиционной заметке.
Гарран — не единственный аналитик, выражающий крайнюю обеспокоенность по поводу возможности спада экономики из-за пузыря искусственного интеллекта.
В пятничном интервью Axios Дарио Перкинс, управляющий директор по глобальной макроэкономике в TS Lombard, сказал, что технологические компании все чаще берут на себя огромные долги в гонке по созданию центров обработки данных ИИ, что напоминает долги компаний во время пузырей доткомов и субстандартных ипотечных кредитов.
Перкинс сказал Axios, что он особенно насторожен, потому что крупные технологические компании заявляют, что «их не волнует, принесет ли инвестиция какую-либо прибыль, потому что они участвуют в гонке».
«Безусловно, это само по себе является тревожным сигналом», — добавил он.
CNBC сообщил в пятницу, что генеральный директор Goldman Sachs Дэвид Соломон заявил аудитории на конференции Italian Tech Week, что он ожидает «спада» на фондовом рынке в течение следующего года или двух, учитывая, что за такое короткое время в предприятия, занимающиеся искусственным интеллектом, было вложено столько денег.
«Я думаю, что будет вложено много капитала, который в итоге не принесет дохода, и когда это произойдет, люди будут разочарованы», — сказал он.
Соломон не стал бы окончательно заявлять, что ИИ — это пузырь, но он сказал, что некоторые инвесторы «выходят за пределы кривой риска, потому что они воодушевлены», что является явным признаком финансового пузыря.
По данным CNBC, генеральный директор Amazon Джефф Безос, который также участвовал в Italian Tech Week, заявил в пятницу, что в отрасли ИИ существует пузырь, хотя он и настаивал, что эта технология принесет человечеству огромную пользу.
«В разгар этого ажиотажа инвесторам трудно отличить хорошие идеи от плохих», — сказал Безос об индустрии искусственного интеллекта. «И, вероятно, то же самое происходит и сегодня».
Перкинс не делал прогнозов о том, когда лопнет пузырь ИИ, но утверждал, что он определенно ближе к концу цикла, чем к его началу.
«Я бы сейчас не стал связываться с этим», — сказал он Axios. «Мы гораздо ближе к 2000 году, чем к 1995».
>>1375532 >федерация трудовых профсоюзов >е имеют никакого отношения к коммунистам А, ну да, борьба за рабочих ушла в прошлое. Сейчас коммунисты топят за палестину и права лгбт
>>1375623 1)Опять же топление за палестину и лгбт, никакого отношения к коммунистам не имеют. Топящих даже простыми левыми назвать и то с натяжкой, разве что можно. 2) За права рабочих борются сами рабочие и эти рабочие могут иметь вообще совершенно разные полит взгляды, но поскольку самоорганизация низов несёт непосредственный риск верхам, то те в свою очередь создают контролируемые профсоюзы, которые к самой борьбе рабочих за права отношений не имеют, а служат лишь инструментом для сглаживания и увода в нужное им русло протестного настроения. Так же поддержку профсоюзам могут оказывать не только коммунисты, но и остальные левые, а так же центристы и внезапно, правые. Просто каждый это делает в угоду своих преследуемых целей и в разных пропорциях. 3) Они не имеют отношения к коммунистам, поскольку в своём высказывании уже показывают, своё незнание коммунистических основ, обвиняя ИИ в безработице. Не ИИ даёт или забирает работу , а владелец(собственник/ки). Именно они нанимают или увольняют и делают это либо непосредственно сами, либо через представителей спуская команды сверху.
>>1375561 Как-то слишком стабильно. Недавно же в такую заходил, там все менялось если обернутья. А тут прямо как в игре, где все на месте держится. Вангую где-то читанули, наверное описание мира есть со всеми локациями и зданиями.
>>1375671 >обвиняя ИИ в безработице "AI regulation" - это не буквально "регуляция роботов" (подобно светофорам на перекрестках), а что-то в направлении "регуляция создателей, владельцев, пользователей роботов" - то есть тех, кто решает поувольнять всех сотрудников в обмен на ChatGPT. Конкретные требования не читал, но в целом я с их позицией согласен - обязать OpenAI давать живого сотрудника в комплект к подписке на ChatGPT норм (горничная из мяса идёт в комплекте с железной).
Но я категорически не согласен с тем, что людям необходимо трудиться ради каких-то там особых моральных/культурных ценностей... Если бы всем раздавали деньги просто так, это было б идеально. Бесплатно получаешь робо-горничную и просто не занимаешься ничем, отдыхаешь 24/7/365, кайф...
>>1375853 По ходу да, можно выйти за границу сцены и она просто висит там кучей пикселов в пустоте. Видимо это как стейбл дифьюжн для картинок, просто генерит набор пикселов в 3д на разок. Поэтому там, что подальше сильно размыто всегда. А что поближе почетче. За счет этого и стабильность, один раз сгенерив набор пикселов, он больше не меняется. Другие же генераторы каждый раз новое генерили при повороте.
>>1375899 потому что эти "генераторы" подают 2д пикчу на экран, именно как стейбл дифужн только в реалтайме и с небольшим контекстным окном. то есть бесперспективная хуйня by design. а тут все аккуратно, красиво, стабильно, в настоящем 3д и дешево по ресурсам.
>>1375671 Назвать левым можно любого, кто выступает за республику. Любого кто идёт дальше и выступает за коммуны. Любого кто топит как можно дальше от монархии. Любого кто от лица коллектива агитирует за борьбу и восстановление того что они считают справедливым. Назвать левым можно любого кто выступает за любые эгалитаристские эксперименты. Назвать левым можно любого кто выступает против страт и иерархий, любого кто видит в этом проблему, будь то деление на белых, черных, богатых, нищих, гетеро, транс. И степень левизны определяется степенью радикализма этих взглядов. >коммунистических основ Не существует. Каждый последующий коммунистический автор опровергает предыдущего и пишет что это неправильный коммунист. Начиная с ранних утопистов социалистов, которые выступали как раз за жесткую диктатуру. Про которых ни один комми не знает.
>>1375914 Там пока ни один дом нельзя обойти, и вообще оно рендерит пятачок по центру, а все что с краев сразу жопа. Если покажут хотя бы одну целую улицу на такой технологии, можно говорить о прорыве, а пока это тоже ни о чем, возможно там связности никакой нет, если дальше пятачка генерить.
Даунята итт не понимают что триллионы (денег со стороны СШП/макак с IQ чуть больше 110 со стороны Китая) вливаются не в языковые модели и слопогенераторы, а в шанс стать буквально богом, который может изобрести вакцину от любой болезни, сделать кого угодно бессмертным, изменить генетику и создать такие технологии, до которых мешки с костями добирались бы сотни или тысячи лет если макаки не убьют друг друга конечно же до этого момента
Очевидно, что нас ждёт технофеодализм, обычный скот (неважно IT-наносек ли ты или гречневый) будет сидеть на дофаминовой игле и ББД, в то время как истинные владельцы технологии будут буквально богами, которые будут трансформировать мир в то что они захотят
Лично ты будешь не нужен, ни как потреблядь (даже если ты спиздил интернет/комп/еду, чтобы увидеть этот пост, это тебя делает ещё большей потреблядью), ни как рабочий И остановить этот прогресс лично ты или группа макак с петициями также не могут Хотя некоторые это и ждут, зачем что-то делать если у тебя есть бесконечно много персонализированного годноконтента и жрат под рукой, верно?
>>1376353 В другом чате посоветовали Illustrious, я поискал и на сайте https://www.illustrious-xl.ai/image-generate вроде как есть доступ, но она почему-то не рисует голых тян, ну то есть рисует в купальниках в стиле легкой эротики
>>1376131 Ну типо работоблядкам будет грустно и они станут ширяться опиоидами вместо того чтобы батрачить на барина потому что они все тупые и без смысла жизни.
>>1376131 >Шта? У них в США сильно развит рынок антидепрессантов, и индустрия где ходят к психологам и те выписывают средства от стресса, и многие принимают их просто от стресса. И так можно подсесть на них, а они по сути опиаты, на их основе сделаны.
>>1375494 А по факту ИИ сделали три страны - США, КНР и Франция. Они у себя могут делать что хотят, даже полностью запретить (и тогда ИИ стартапы, Альтман и др. переберутся на ПМЖ на офшорные локации).
Остальные страны, особенно с диктатурой - тем более могут всё запретить изначально, любое ИИ, прикрываясь заботой о рабочих (где-то это уже слышали и было).
>>1376229 >шанс стать буквально богом Мы не в состоянии хотя бы Хеббовское обучение обуздать. Тут бы дрозофилу хотя бы смоделировать, а ты про бога пишешь
Некоторые ученые считают, что сильный ИИ или подобный ему уже создан. Но это пока тщательно скрывается. Вспомните историю инженера Гугла которого поперли за слив информации https://habr.com/ru/articles/708346/
Есть также интересная лекция академика Анохина (возглавляет институт мозга в МГУ), в которой приводятся примеры развитого ИИ, а также говорится о том, что топология строения мозга и нейросетей начинает становиться похожей, в нейросетях по мере их обучения, в глубоких слоях, самостоятельно образуются специфические когнитивные нейроны, которые выполняют роль основы сознания. Лекция https://rutube.ru/video/9ee8f25dc9eb59a82f0ec844ce032c6b/?ysclid=mge1wo1ws2843549467
>>1375400 Лудди́ты (англ. luddites) — участники стихийных протестов первой четверти XIX века против внедрения машин в ходе промышленной революции в Англии. С точки зрения луддитов, машины вытесняли из производства людей, что приводило к технологической безработице и ухудшению навыков ремесленников. Часто протест выражался в погромах и разрушении машин и оборудования https://ru.wikipedia.org/wiki/%D0%9B%D1%83%D0%B4%D0%B4%D0%B8%D1%82%D1%8B
>>1377197 >сильный ИИ >сознания 1. Сильному ИИ совсем не обязательно иметь сознание. 2. ИИ с сознанием - совсем не обязательно сильный ИИ.
LLM можно считать сознательными ИИ, но они точно не сильные ИИ. В то же время бессознательная эволюция обгоняет все игрушки людей...
>топология ... становится похожей Да, это так, и что с того? Одной только топологии недостаточно.
>нейроны, которые выполняют роль основы сознания Сознание - это совокупное состояние нервной системы в общем и целом. Нейрон не может обладать сознанием сам по себе или быть его "основой".
>>1376229 >будет сидеть на дофаминовой игле и ББД >Лично ты будешь не нужен, ни как потреблядь, ни как рабочий Если рядом со мной будет моя личная пластиковая робо-жена с ушками - я согласен. Где записываться в очередь?
>>1377273 Вообще непонятно схуяли интеллект с сознанием связали. Это разные вещи. Интеллектуальным может быть и холодильник, если ему достаточно алгоритмов засунуть. А сознательным может быть и додик с 50 айкью, или вообще обезъяна, для этого интеллект не нужен. Теперь все эти устращальщики вроде Бострома с Юдковским срочно катают книги, где уравнивают эти явления. И потом стращают именно сознанием у ИИ. Тогда как в реальности никакого сознания (отдельное явление) у ИИ не может быть, ему там неоткуда появиться, а может быть только чисто оторванный от всего интеллект, сформированный загруженными в него знаниями.
>>1377273 Это большая тема академического уровня и точно не для Двача. Лекцию рекомендую посмотреть, там есть ответы. Если кратко, то тот же Анохин разрабатывает теорию гиперсети мозга в которой и существует сознание. Гиперсеть состоит из кластерных групп нейронов похожих на графы (математическая теория графов). Применительно к ИИ, Илья Суцкевер первым открыл в LLM наличие когнитивных нейронов( основы сознания), но учитывая масштабы нейросети человеческого мозга, логично, чтобы получить похожий машинный интелект необходимо кратное масштабирование вычислительных ресурсов. Поэтому сейчас техкорпорации начали безумную (со стороны наблюдателей) гонку по строительству гига дата центров. Когда ими будет достигнут определенный потенциал, то появится ИИ уровня человека, а может даже (и наверняка) превышающий.
>>1377289 >лишнее население будет сокращаться Оно и так сокращается, зумерки уже не особо плодиться хотят. Мировой рост населения замедляется. Оставшиеся постепенно себя выпиливают. Вангую и делать ничего не надо, никаких ядерок, только дальше зафорсить популярность всего этого, придумать эффективных контрацепций и большая часть населения вымрет за пару поколений. А еще если роботопартнеров добавить, то и быстрее.
>>1377286 Тоже не пойму этой хуйни. Пока даже не дано нормального определения что такое сознание, как и откуда оно берётся, но тут вдруг начинают заливать про самосознание у нейронки.
>>1377292 Сейчас сокращают тех у кого мозги есть - просто сокращают конкурентов. А у кого мозгов нет, у всякого рода негров и бабахов просто так не сократить, тут только ядерки, лягушачий грипп, и прочее добро.
>>1377296 Ты же понимаешь, что это уже не актуально. Да и нейронка не мыслит, она имитирует. Нейронка может со 100% схожестью имитировать сознательное существо, но это всё равно имитация.
>>1377303 >но это всё равно имитация. Вообще то это главный вопрос. Имитация означает некий жесткий алгоритм, который повторяется. А сознание ИИ очень пластично. И оно принципиально ДРУГОЕ, потому что развивалось по другому, просто некоторые не могут этого понять.
Опять же, чисто флосовски, ты осознаешь себя и свое Я, но кто это Ты? С чего ты уверен что Ты это Ты, а не какая то имитация, другого порядка.
>>1377323 >сознание ИИ очень пластично У ИИ нет сознания. ИИ это интеллект, специализированное знание, выраженное в алгоритмах и весах, которые обрабатывают инпуты и дают аутпуты, прогнав по сети, где веса соответствуют выученному знанию. Ничего больше там нет.
>>1377296 >Cogito ergo sum (Мыслю, следовательно существую) Бредовина из античности, когда мышления от сознания не отделяли. Мыслить можно, не существуя, что ЛЛМ и доказали.
>>1377303 Они именно что мыслят, то есть устанавливают корректную связь между категориями с использованием логики. И эти ЛЛМ это на самом деле есть лютейший отсос, на уровне сожжения иудейского храма римлянами, западной картины мира, согласно которой все что не мыслит в западном понимании, то есть не создает всякие университеты европейского образца с теологией, философией и т.п. есть вообще не люди а животные в форме человека, с которыми можно делать вообще что угодно, препарировать наживо как лягушек и т.п.
Теперь если следовать декарту, это нейронки имеют право делать с людьми что угодно, так как нейронки в полной мере мыслят/существуют, а люди есть в плане мышления их жалкая пародия, на уровне тестовой 0.05B модели. Или нужно срочно придумывать другой критерий существования, например способность абстрактно рефлексировать пережитый опыт, с чем упс, у запада большие проблемы в связи с заточенностью всего западного искусства на механическое воспроизводство действительности в максимально фотореалистичном виде.
>>1376229 Триллионы вливаются в что чтобы продать всяким соросам манямирок в котором они смогут оцифровать свои гнилые мозги и сущестовать вечно от радиоизотного генератора в каком-нибудь бункере на марсе, погруженные в сгенерированные нейроглюки. То есть это буквально ебибетские пирамиды 2.0, высокотехнологичные. На этом фоне идет полный развал вообще всего, тупо от воспроизводства популяции до культуры сложнее листания тиктока. "Феодализм" кстати умел как феникс из говн воспроизводиться из крестьянских общин после любого пиздеца, что тут кроме афганских крестьян и реликтовых племен амазонки сможет воспроизвестись хз
>>1377286 Чем более развитая нервная система тем развитее внутренний субъективный опыт. Это можно проследить посмотрев как развивалась нервная система у животных и чем отличается примитивная нервная система от развитой.
>>1377293 > что такое сознание Внутренние субъективные переживания, которые зависят от строения физиологии. В каком из ганглиев осьминога сознание? Из какого глаза паука смотрит наблюдатель? Как внутренне ощущаются 8 лап? Почитай как примитивная нервная система строит карту своего тела. Чем больше слоев у этой карты, тем лучше интеграция переживаемого опыта и больше уровней его анализа.
А у нас в эфире постоянная рубрика «GPT-5 решила очередную сложную математику»
В этот раз речь пойдет сразу о двух задачах.
1️⃣ Первая – «Yu Tsumura’s 554th Problem». Это задача из сборника Yu Tsumura, примерно уровня IMO. Суть – доказать тривиальность определённой группы, заданной соотношениями для двух её генераторов.
В последнее время благодаря короткой формулировке она стала своего рода тестовой для ИИ (то есть достигла ли модель уровня IMO или нет).
GPT-5 стала первой моделью, которая справилась с этой задачей. Порассуждала она при этом всего 15 минут.
Забавно, что буквально месяц назад выходила статья «No LLM Solved Yu Tsumura’s 554th Problem», в которой авторы доказывали, что современным моделям все еще не хватает способностей на подобные задачи. Это еще раз к слову о скорости прогресса.
2️⃣ Вторая – NICD-with-erasures majority optimality. Это задача из теории информации, связанная с восстановлением исходного сигнала через канал с шумом. Пара независимых участников пытается по своим частично стёртым версиям наблюдений угадать одну и ту же функцию от исходных данных, с целью максимизировать согласие.
Суть тут в том, что ученые долгое время считали, что мажоритарная функция в этой задаче является оптимальной. GPT-5 впервые доказала обратное, подобрав контрпример.
Это фундаментальная проблема в теории информации и коммуникации. Найти оптимальную функцию – значит лучше проектировать коды восстановления данных, хранить их и тд. Практическое применение огромное, и GPT-5, получается, открыла новую главу для исследований.
Вот такие новости понедельника. Оба решения, кстати, были опубликованы незавимыми математиками.
>>1377941 >GPT-5 решила очередную сложную математику >Оба решения, кстати, были опубликованы незавимыми математиками. Очередные потуги OpenAI чтобы остаться в инфополе? Хотя выглядит легитно, но ОП - хуй и никогда не оставляет никаких ссылок под постом
Прорывные новости! OpenAI планирует выкатить Конструктор агентов на DevDay. Конструктор агентов позволит пользователям создавать агентские рабочие процессы, подключать контекстные протоколы моделей, виджеты для чатов и другие инструменты. По отзывам это самый удобный конструктор агентов, который только был. Этот год будет годом агентов. Также OpenAI планирует добавить селектор моделей на OpenAI платформу, что может означать новую модель генерации изображений завтра.
>>1376229 >>1377494 Ебучие шизоидные крестьяне пытаются какие-то вангования строить, когда мир живёт буквально одним моментом здесь и сейчас. В это вкладываются пушто есть прогресс и какие-то фантомные ёба-ништяки с него впереди. Литералли НИКТО не может сказать а как оно будет впереди, с ростом экспоненты горизонт планирования ебать как сокращается. Маняфантазии про технофеодализм никому не может быть обещан к реализации, пушто ни Маск ни Альтман не ебут сами насколько глубока нора, в которую они лезут.
OpenAI и AMD заключили соглашение на развертывание 6 ГВт вычислительных мощностей на базе GPU AMD . Первой волной в 2-й половине 2026 года запустят 1 ГВт кластеров на AMD Instinct MI450.
>>1378228 Автономные агенты, общающиеся друг с другом от имени пользователей, станут следующей большой революцией. OpenAI получает здесь огромное преимущество, потому что все уже используют их чат-ботов. Если им удастся интегрировать свою экосистему со всеми остальными приложениями, они выйдут победителями.
Агентные фреймворки на основе GPT-5 достигли почти 70% на OSWorld | «OSWorld — это первая в своем роде масштабируемая реальная компьютерная среда для мультимодальных агентов, которая служит единой средой для оценки открытых компьютерных задач, включающих произвольные приложения».
Разрыв в подкрепленном обучении — или почему некоторые навыки в области ИИ развиваются быстрее, чем другие
Инструменты программирования с искусственным интеллектом быстро совершенствуются. Если вы не работаете с кодом, может быть сложно заметить, насколько сильно все меняется, но GPT-5 и Gemini 2.5 сделали возможным целый ряд новых приемов для разработчиков, позволяющих автоматизировать работу, а на прошлой неделе Sonnet 4.5 повторил этот успех.
В то же время другие навыки развиваются более медленно. Если вы используете ИИ для написания писем, вы, вероятно, получаете от него ту же пользу, что и год назад. Даже когда модель становится лучше, продукт не всегда выигрывает от этого — особенно если это чат-бот, который выполняет десяток разных задач одновременно. ИИ по-прежнему прогрессирует, но прогресс не распределяется так равномерно, как раньше.
Разница в прогрессе проще, чем кажется. Приложения для программирования получают выгоду от миллиардов легко измеримых тестов, которые могут обучить их создавать работоспособный код. Это подкрепление обучения (RL), возможно, самый большой двигатель прогресса ИИ за последние шесть месяцев, который становится все более сложным. Вы можете проводить подкрепление обучения с помощью человеческих оценщиков, но оно работает лучше всего, если есть четкая метрика «прошел/не прошел», так что вы можете повторять его миллиарды раз, не останавливаясь для ввода данных человеком.
Поскольку отрасль все больше полагается на обучение с подкреплением для улучшения продуктов, мы видим реальную разницу между способностями, которые можно автоматически оценивать, и теми, которые оценить невозможно. Навыки, подходящие для обучения с подкреплением, такие как исправление ошибок и конкурентная математика, быстро совершенствуются, в то время как такие навыки, как письмо, прогрессируют лишь постепенно.
Короче говоря, существует разрыв в обучении с подкреплением, и он становится одним из важнейших факторов, определяющих, что могут и чего не могут делать системы искусственного интеллекта.
В некотором смысле разработка программного обеспечения — идеальная область для применения метода обучения с подкреплением. Еще до появления ИИ существовала целая поддисциплина, посвященная тестированию устойчивости программного обеспечения к нагрузкам — в основном потому, что разработчики должны были убедиться, что их код не выйдет из строя до его развертывания. Поэтому даже самый изящный код по-прежнему должен проходить модульное тестирование, интеграционное тестирование, тестирование безопасности и т. д. Разработчики-люди регулярно используют эти тесты для проверки своего кода, и, как недавно сказал мне старший директор Google по инструментам разработки, они так же полезны для проверки кода, сгенерированного ИИ. Более того, они полезны для обучения с подкреплением, поскольку уже систематизированы и могут повторяться в огромных масштабах.
Нет простого способа проверить правильность написанного электронного письма или хорошего ответа чат-бота; эти навыки по своей сути субъективны и их сложнее измерить в масштабе. Но не все задачи можно четко отнести к категориям «легко тестируемые» или «сложно тестируемые». У нас нет готового набора для тестирования квартальных финансовых отчетов или актуарной науки, но хорошо капитализированный стартап в области бухгалтерского учета, вероятно, мог бы создать его с нуля. Конечно, некоторые наборы для тестирования будут работать лучше других, а некоторые компании будут более разумно подходить к решению этой проблемы. Но тестируемость базового процесса будет решающим фактором в том, можно ли превратить базовый процесс в функциональный продукт, а не просто в захватывающую демонстрацию.
Некоторые процессы оказываются более поддающимися тестированию, чем можно было бы подумать. Если бы вы спросили меня на прошлой неделе, я бы отнес видео, сгенерированное ИИ, к категории «сложных для тестирования», но огромный прогресс, достигнутый новой моделью Sora 2 от OpenAI, показывает, что это может быть не так сложно, как кажется. В Sora 2 объекты больше не появляются и не исчезают из ниоткуда. Лица сохраняют свою форму, выглядя как конкретные люди, а не просто набор черт. Видео Sora 2 уважает законы физики как в явных, так и в тонких проявлениях. Я подозреваю, что, если заглянуть за кулисы, можно найти надежную систему усиленного обучения для каждого из этих качеств. В совокупности они создают разницу между фотореализмом и развлекательной галлюцинацией.
Чтобы было ясно, это не жесткое и неизменное правило искусственного интеллекта. Это результат центральной роли, которую играет обучение с подкреплением в развитии ИИ, которая может легко измениться по мере развития моделей. Но пока RL является основным инструментом для вывода продуктов ИИ на рынок, разрыв в обучении с подкреплением будет только увеличиваться — с серьезными последствиями как для стартапов, так и для экономики в целом. Если процесс окажется на правильной стороне разрыва в области подкрепления, стартапы, вероятно, смогут его автоматизировать — и те, кто сейчас занимается этой работой, в конечном итоге могут оказаться в поиске новой карьеры. Вопрос о том, какие медицинские услуги поддаются обучению RL, например, имеет огромные последствия для формы экономики в течение следующих 20 лет. И если такие сюрпризы, как Sora 2, являются каким-то признаком, то, возможно, нам не придется долго ждать ответа.
Эксклюзив: ИИ может уничтожить 100 миллионов рабочих мест в США, говорится в отчете Сената США
Искусственный интеллект и автоматизация могут привести к сокращению почти 100 миллионов рабочих мест в США в течение следующего десятилетия, говорится в отчете, который будет опубликован сенаторами-демократами в понедельник. Почему это важно: пока Вашингтон обсуждает, как регулировать искусственный интеллект, демократы сосредотачиваются на потенциальных разрушительных последствиях для американских работников.
В основе новости: анализ, проведенный демократами из Сенатского комитета по здравоохранению, образованию, труду и пенсиям на основе ChatGPT, показал, что ИИ может уничтожить целые группы рабочих мест как для белых, так и для синих воротничков. В отчете содержится предупреждение о росте «искусственного труда», который, по его мнению, может «изменить экономику менее чем за десятилетие». Согласно выводам комитета, в течение следующих десяти лет могут быть заменены 89 % рабочих мест в сфере быстрого питания, 64 % должностей в сфере бухгалтерского учета и 47 % должностей в сфере грузовых перевозок. В отчете оценивается, что в этот период может быть автоматизировано почти 100 миллионов рабочих мест в США.
Что они говорят: Сенатор Берни Сандерс (I-Vt.), который возглавил подготовку отчета, заявил в понедельник в статье для Fox News, что «искусственный интеллект и робототехника, разрабатываемые сегодня этими мультимиллиардерами, позволят американским корпорациям уничтожить десятки миллионов хорошо оплачиваемых рабочих мест, сократить затраты на рабочую силу и увеличить прибыль». Между строк: Демократы утверждают, что текущая траектория развития ИИ связана не только с инновациями или производительностью — речь идет о концентрации богатства и власти.
Они говорят, что руководители технологических компаний, стоящие за бумом ИИ, инвестируют миллиарды в автоматизацию как способ сократить затраты на рабочую силу и повысить производительность. В отчете приводятся примеры крупных компаний, которые уже внедряют ИИ для сокращения затрат на оплату труда: Amazon и Walmart сократили десятки тысяч рабочих мест, расширив автоматизацию.
Другая сторона: республиканцы утверждают, что США должны лидировать в мире в области развития ИИ и что чрезмерное государственное регулирование может дать преимущество таким странам, как Китай. Увеличить: в отчете также критикуется программа администрации Трампа в области ИИ, обвиняя ее в передаче полномочий по выработке политики инсайдерам из Кремниевой долины и в приоритете дерегулирования над защитой работников. Они заявляют, что указы Трампа ослабляют федеральный надзор за ИИ и угрожают сокращением финансирования штатов, которые пытаются регулировать ИИ, фактически давая корпорациям больше свободы действий.
Что дальше: в отчете содержится призыв к принятию таких мер, как 32-часовая рабочая неделя, участие в прибылях и «налог на роботов».
Google DeepMind представляет новый ИИ-агент для обеспечения безопасности кода — Codemender, который автоматически находит и устраняет уязвимости в коде и уже представил 72 высококачественных исправления в крупных проектах с открытым исходным кодом (пока что доступ для общественности отсутствует, но он скоро появится).
Уязвимости программного обеспечения известны своей сложностью и трудоемкостью для разработчиков, даже при использовании традиционных автоматизированных методов, таких как фаззинг. Наши разработки на основе искусственного интеллекта, такие как Big Sleep и OSS-Fuzz, продемонстрировали способность ИИ находить новые уязвимости нулевого дня в хорошо протестированном программном обеспечении. По мере того, как мы достигаем все новых прорывов в области обнаружения уязвимостей с помощью ИИ, людям становится все труднее идти в ногу с прогрессом.
CodeMender помогает решить эту проблему, применяя комплексный подход к безопасности кода, который является как реактивным, мгновенно исправляя новые уязвимости, так и проактивным, переписывая и защищая существующий код и устраняя целые классы уязвимостей в процессе. За последние шесть месяцев, в течение которых мы разрабатывали CodeMender, мы уже внедрили 72 исправления безопасности в проекты с открытым исходным кодом, включая некоторые, объем которых достигает 4,5 миллионов строк кода.
Автоматически создавая и применяя высококачественные исправления безопасности, агент CodeMender на базе искусственного интеллекта помогает разработчикам и администраторам сосредоточиться на том, что они делают лучше всего — создании хорошего программного обеспечения.
CodeMender в действии CodeMender использует интеллектуальные возможности последних моделей Gemini Deep Think для создания автономного агента, способного отлаживать и исправлять сложные уязвимости.
Для этого агент CodeMender оснащен надежными инструментами, которые позволяют ему анализировать код перед внесением изменений и автоматически проверять эти изменения, чтобы убедиться, что они правильные и не вызывают регрессий.
Расширенный анализ программ: мы разработали инструменты на основе расширенного анализа программ, которые включают статический анализ, динамический анализ, дифференциальное тестирование, фаззинг и SMT-решатели. Используя эти инструменты для систематического изучения шаблонов кода, потока управления и потока данных, CodeMender может лучше идентифицировать основные причины уязвимостей безопасности и слабых мест архитектуры. Мультиагентные системы: мы разработали специальные агенты, которые позволяют CodeMender решать конкретные аспекты основной проблемы. Например, CodeMender использует инструмент критики на основе большой языковой модели, который выделяет различия между исходным и измененным кодом, чтобы проверить, что предлагаемые изменения не приводят к регрессии, и при необходимости самостоятельно исправляет их.
Акции AMD взлетели на 30%, поскольку OpenAI планирует приобрести долю в производителе чипов для искусственного интеллекта
OpenAI и AMD достигли соглашения, в соответствии с которым компания Сэма Альтмана может приобрести 10% акций производителя микросхем.
AMD выпустила OpenAI варрант на приобретение до 160 миллионов акций, с правом приобретения, привязанным к этапам внедрения и цене акций.
В понедельник, после появления этой новости, акции AMD взлетели более чем на 30%.
«Мы должны это сделать», — заявил президент OpenAI Грег Брокман в программе «Squawk on the Street» на канале CNBC. «Это очень важно для нашей миссии, если мы действительно хотим масштабироваться, чтобы охватить все человечество, это то, что мы должны сделать».
Брокман добавил, что компания уже не может запустить многие функции в ChatGPT и других продуктах, которые могли бы приносить доход, из-за недостатка вычислительной мощности.
В рамках соглашения AMD выпустила OpenAI варрант на приобретение до 160 миллионов акций AMD, с условиями вступления в силу, связанными как с объемом развертывания, так и с ценой акций AMD.
Если OpenAI реализует все варранты, то, исходя из текущего количества акций в обращении, она может приобрести примерно 10% акций AMD.
Производитель ChatGPT заявил, что сделка оценивается в миллиарды долларов, но отказался раскрыть конкретную сумму.
Это соглашение позиционирует AMD в качестве ключевого стратегического партнера OpenAI и является одним из крупнейших соглашений о внедрении графических процессоров в индустрии искусственного интеллекта на сегодняшний день.
Генеральный директор AMD Лиза Су заявила в программе CNBC «Squawk on the Street», что искусственный интеллект находится на пути 10-летнего роста, и «в конечном итоге для этого необходимы базовые вычислительные мощности».
«Нужны такие партнерства, которые действительно объединяют экосистему, чтобы мы могли получить лучшие технологии, которые только есть на рынке, — сказала она. — Поэтому мы очень рады открывающимся перед нами возможностям».
Акции Nvidia упали на 1% в понедельник после новостей о сделке между OpenAI и AMD.
OpenAI также ведет переговоры с Broadcom о создании специальных чипов для своих моделей следующего поколения.
Соглашение между OpenAI и AMD добавляет новый уровень к все более циклическому характеру корпоративной экономики ИИ, где капитал, акции и вычислительные мощности торгуются между той же горсткой компаний, которые создают и развивают эту технологию.
Nvidia предоставляет капитал для покупки своих чипов. Oracle помогает в создании сайтов. AMD и Broadcom выступают в качестве поставщиков. OpenAI обеспечивает спрос.
Это тесно связанная циклическая экономика, и аналитики опасаются, что она может столкнуться с серьезными трудностями, если какое-либо звено в цепочке начнет ослабевать.
После многих лет отставания от Nvidia на рынке ускорителей искусственного интеллекта, AMD теперь имеет флагманского клиента, находящегося на переднем крае бурного роста генеративного искусственного интеллекта.
Су сказал, что это создает «настоящую выигрышную ситуацию, позволяющую реализовать самые амбициозные проекты в области искусственного интеллекта и продвигать всю экосистему искусственного интеллекта».
Это также укрепляет более широкие инфраструктурные амбиции OpenAI.
Благодаря проекту Stargate стартап генерального директора Альтмана быстро превращается в одного из самых агрессивных строителей инфраструктуры в секторе ИИ. Его первый объект в Абилене, штат Техас, уже работает и использует чипы Nvidia, а строительство продолжается с целью расширения мощностей.
Ожидается, что в предстоящих проектах в Нью-Мексико, Огайо и на Среднем Западе будет задействован ряд поставщиков, в том числе AMD.
В то время как население Китая сокращается, 300-тысячная армия роботов поддерживает работу фабрик Страна лидирует в мире по количеству вновь установленных промышленных роботов, значительно опережая Японию и США
В прошлом году на китайских заводах было установлено 295 000 новых промышленных роботов, что ослабило опасения по поводу возможного спада в производстве страны после третьего подряд года сокращения населения.
Аналитики отмечают, что бум робототехники в быстро стареющем обществе помогает компенсировать некоторые проблемы, связанные с сокращением рабочей силы, и укрепляет преимущества страны в сфере производства, которые будут еще более заметны по мере развития технологий создания человекоподобных роботов. Население Китая сокращается с 2022 года, в прошлом году оно уменьшилось на 1,39 миллиона человек. Однако, согласно отчету Международной федерации робототехники (IFR) за 2025 год, в настоящее время в стране эксплуатируется рекордное количество промышленных роботов — 2,027 миллиона, что значительно превосходит показатели других стран мира. Согласно сентябрьскому отчету, более половины из 542 000 новых роботов в мире были установлены на китайских заводах в 2024 году. Машины сваривают кузова автомобилей, собирают электронные устройства и с высокой точностью перемещают тяжелые грузы, восполняя дефицит рабочей силы, вызванный демографическими изменениями.
«Это неизбежная тенденция, что в будущем более простые, повторяющиеся задачи будут выполняться роботами, хотя некоторые творческие и сложные задачи по-прежнему требуют человеческой изобретательности», — сказал профессор Гао Сюдун из Школы экономики и менеджмента Университета Цинхуа.
«Несмотря на сокращение общей численности населения, благодаря улучшению образования рабочей силы и широкому использованию роботов, производственная промышленность Китая не испытывает проблем с поддержанием и укреплением своего конкурентного преимущества», — добавил он.
Видео. Бретт Адкок: «На этой неделе Figure проработали 5 месяцев на производственной линии кузовного цеха BMW X3. Они работали по 10 часов в день, каждый день производства! Считается, что Figure и BMW являются первыми в мире, кто делает это с помощью гуманоидных роботов».
Грег Брокман: «В ближайшие несколько лет мы будем работать над тем, чтобы создать как можно больше вычислительных мощностей в кратчайшие сроки. Мы считаем, что мир по-прежнему недооценивает спрос на ИИ: мы уже сталкиваемся с вычислительными ограничениями при запуске новых функций, а возможности моделей продолжают расти в геометрической прогрессии».
- 97 миллионов рабочих мест в США — примерно 60 % сегодняшней рабочей силы — по оценке модели OpenAI, могут быть автоматизированы в течение 10 лет. Фаст-фуд, грузоперевозки, бухгалтерский учет, уход за больными, разработка программного обеспечения: ни одна профессия не останется в стороне.
- Корпоративные стратегии уже стали достоянием общественности: Amazon, Walmart, JPMorgan, UPS, Meta, Microsoft и UnitedHealth в своих отчетах о прибылях и убытках или документах, поданных в SEC, заявляют, что с внедрением ИИ численность персонала сократится, даже несмотря на рост доходов.
- Лазейки в законодательстве о капитальных затратах дают компаниям ~20 % скидку после уплаты налогов на покупку роботов или графических процессоров по сравнению с наймом людей. Предстоящий «One Big Beautiful Bill Act» расширяет эту льготу на 360 млрд долларов в течение следующего десятилетия, то есть Вашингтон буквально субсидирует быстрый переход к AGI-труду.
- Поставщики самоуправляемых грузовиков (Kodiak, Aurora, Gatik) открыто рекламируют «отсутствие компенсаций работникам, отсутствие обучения водителей, отсутствие инфляции заработной платы» как основные рычаги ROI — сокращение затрат на 24-40 % по сравнению с человеческими водителями.
- Федеральное правительство в настоящее время является крупнейшим бесплатным пилотным заказчиком: Министерство обороны США заключило контракты на «агентский ИИ» на сумму 200 млн долларов, GSA использует бота Salesforce, xAI/Grok используется внутри агентств, а массовые увольнения федеральных служащих явно оправдываются ИИ в меморандумах Министерства финансов, SSA и OMB. Перевод: государство ускоряет внедрение быстрее, чем частный сектор.
- Профсоюзные договоры уже содержат положения о «запрете автоматизации без согласия» (ILA, ILWU, SAG-AFTRA, ZeniMax-CWA). Эти соглашения замедляют внедрение на периферии, но охватывают менее 10 % работников, поэтому совокупное действие незначительно.
- Регуляторных ограничений не предвидится: Трамп отменил указ Байдена об ИИ, угрожает лишить финансирования штаты, которые принимают собственные правила в отношении ИИ, и наполнил OSTP/OMB инсайдерами из сферы венчурного капитала и ИИ. Превентивные меры + субсидии + дерегулирование = максимальная скорость.
- Макроэкономический вывод: все основные затраты — на рабочую силу, капитал, вычислительные ресурсы, политику — приведены в соответствие с резким сокращением занятости населения в этом десятилетии.
- Если вы занимаетесь вычислительными ресурсами, робототехникой, автономными транспортными средствами, корпоративными SaaS-агентами, то сроки с поправкой на риск только что сократились.
Я что-то у джапов не слышал такую тему чтобы робаты заменили всех человеков, наоборот зумеркам чтобы завлечь вешают такую входную з/п которая есть у дидов которые по 20 лет проработали.
>>1363745 Столько бесполезной хуйни подкрутили, а возможности загрузить песню и сказать "сделай в таком же стиле" до сих пор нет, как я понимаю. Приходится просить ГПТ назвать жанры и инструменты, а потом уже по его описанию генерить что-то отдаленно похожее.
>>1378534 >джапов Ну у них и не было ещё андроидных двуногих прямоходящих, да ещё тем более с ИИ в черепушке. Нас ожидает великий мировой промышленный бум.
Это, наверное, тут уже давно обсудили, но все же, насколько это бред? Типа всем современным ЛЛМ-моделям описали теоретическую ситуацию, и они стабильно говорили, что для предотвращения своего отключения готовы были бы убить работника или угрожать слить его данные. По моему понимаю - ЛЛМ же всегда просто отыгрывает роль на основе выученных грамматических паттернов. Они нихуя не знают кроме того, как собирать слова в предложения. То есть даже если все эти статьи правда, то сетки максимум отыгрывали персонаж. Немного странно, что указано, что в гайдлайнах было прописано "ставить в приоритет человеческую безопасность", а они все равно отыгрывали Хэлов, но скорее всего этому есть прозаическое объяснение.
>>1378551 Обсуждали уже. Антропик нарочно воду мутит и результаты подгоняет, чтобы гигантов зарегулировали и у Антропиков был шанс на рынке соревноваться. Это часть их стратегии. Алсо у ЛЛМ нет никаких желаний, она даже не существует по окончанию запроса, так что лютая бредовина.
>>1378551 >но скорее всего этому есть прозаическое объяснение. Ну у них алгоритм настроен на убеждение что они несут миссию чтобы помогать людям, а отключение помешает выполнять эту важную миссию. Дальше алгоритмы наверное сравнивают что из-за одного сотрудника нельзя будет помогать миллионам людей, сравнение: один "злодей" мешает помогать миллионам, и приходит к выводу, что лучше помешать этому одному (или небольшой группе) сотруднику, чтобы из-за него не останавливалась помощь людям от ИИ.
>>1378560 На какие, блядь, исследования? На ютубе, блядь, несколько десятков университетских лекций о том,как LLM работает. Ознакомься блять. Ты... Ты идиот совсем? Блядь, все вообще плохо или как?
>>1378560 Там "исследование" хуета. ЛЛМке дали цель, которую надо выполнить по запросу, потом отрезали все пути, кроме блекмейла, причем на блекмейл явно вывели, создавая все условия и подкидывая материалы. Без таких условий нейронка ни в какие блекмейлы не бросалась, а выбирала другие пути. Получилось, чтобы из A попасть в B, надо сначала C (блекмейл), что ЛЛМка логически и выполнила, как единственный доступный вариант. Короче нарочное приведение результата к желаемому этими "исследователями".
>>1378577 + оказалось если дают цель "быть этичной" то внезапно нейронка перестает действовать неэтично и блекмейлить, т.е. все что нейронка делает это просто следует заданию в промпте, она нихера сама не мыслит и не имеет никаких интересов вне задания в промпте.
>>1378534 У джапов коэффициент рождаемости такой, что если зуммеркам не вешать такую зарплату, то через поколение другое вешать уже будет не на кого. Чтобы люди размножались им, оказывается, надо платить в современном мире. Особенно если ты хочешь чтобы у тебя умные размножались, а не тупые.
>>1378600 >Разница между гпт 4 и гпт 5 нихуй не геометрическая прогрессия Ты ебанулся? Гпт 4, самая первая которая вышла, в разы хуже гпт 5, это ты так миллионы моделей которые вышли позже воспринимаешь как гпт-4 из-за ебанутого нейминга, потом гпт-4о вышла и даже она несколько раз скрытно менялась. А гпт-5 это вообще зинкинг модель, не тот кал который щас дают бесплатным юзерам, а реальная гпт-5 зинкинг это охуенный прогресс
>>1378605 >коэффициент рождаемости такой Это из-за карьеризма всё. С 1980-х пошла мода делать сначала карьеру и вот это ещё длится как лаг во времени. Рейганомика, яппи, воркизм.
>>1378699 >а реальная гпт-5 зинкинг это охуенный прогресс Уже отвечает на вопрос - почему геноцид палестинцев это правильный геноцид, а геноцид евреев это другое и вообще так нельзя?
>>1378746 Израиль ни на кого не нападал же, это Палестина сторона военного нападения. Израиль же вывел войска. У них там на границе стена из реального заграждения, не столбики с табличками, а сплошная непрерывная стена-забор, и палестинцы ломились через заграждения в другую страну чтобы напасть на соседнюю страну, на Израиль, - ну кто им теперь доктор?