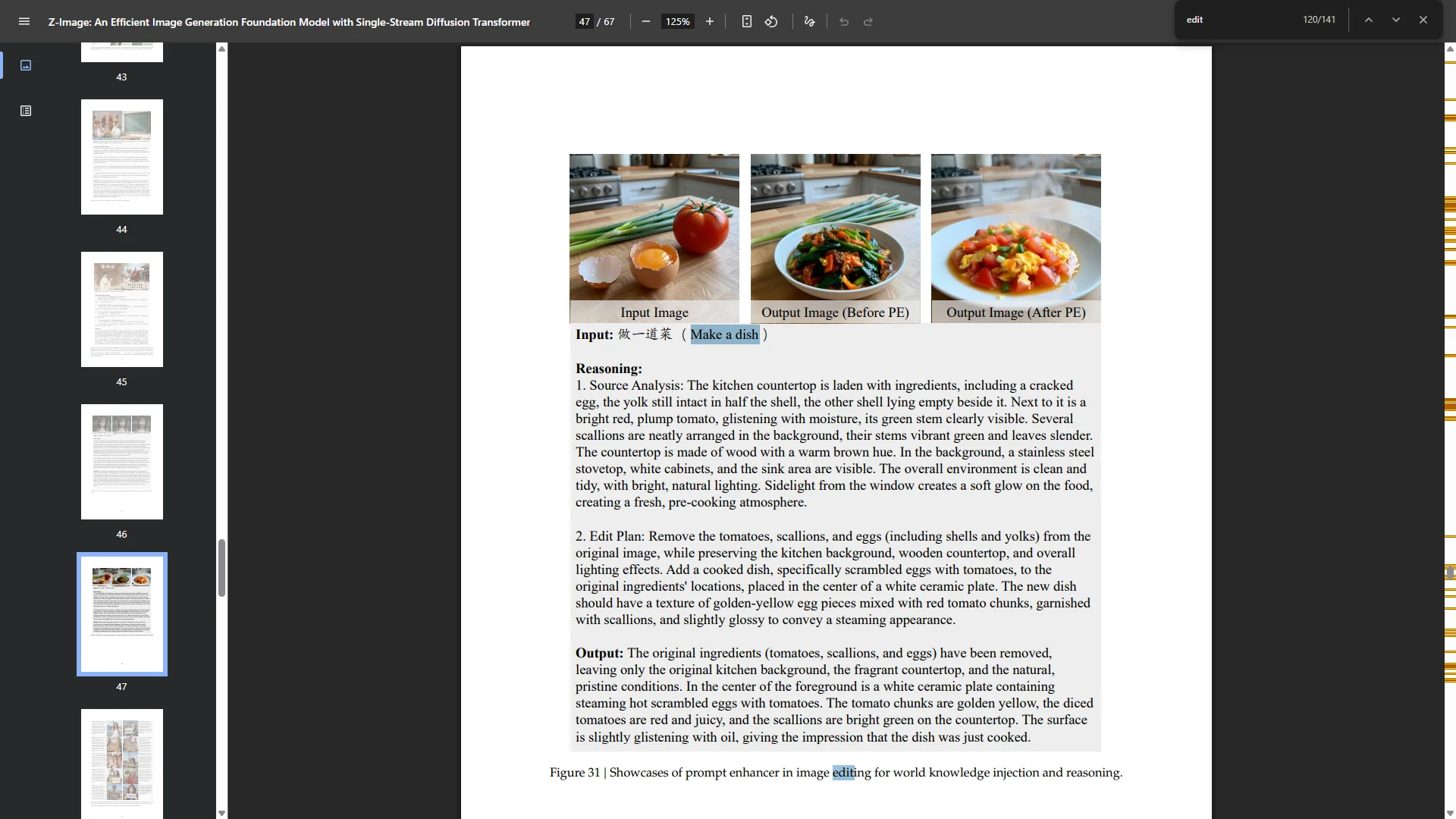
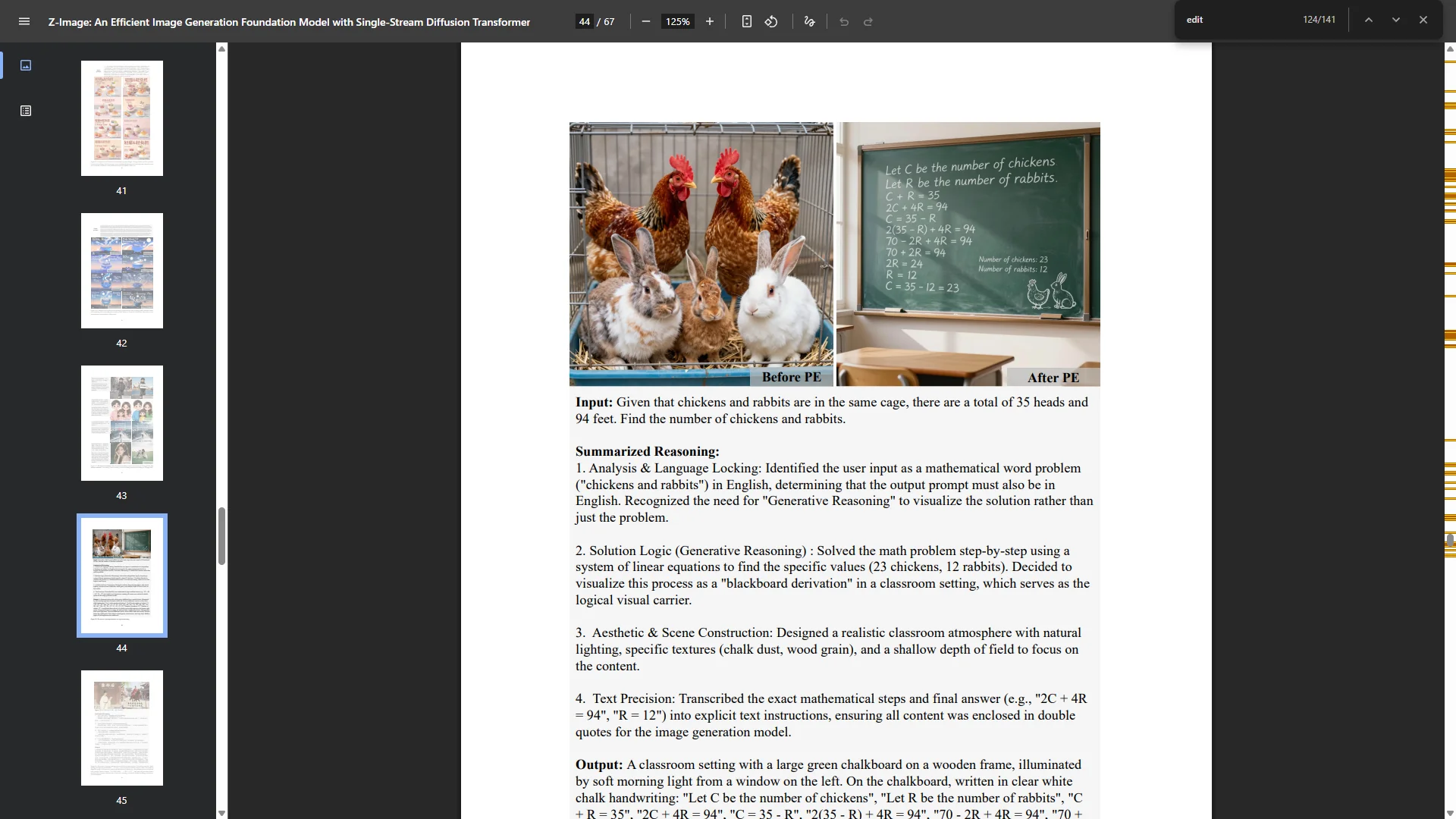
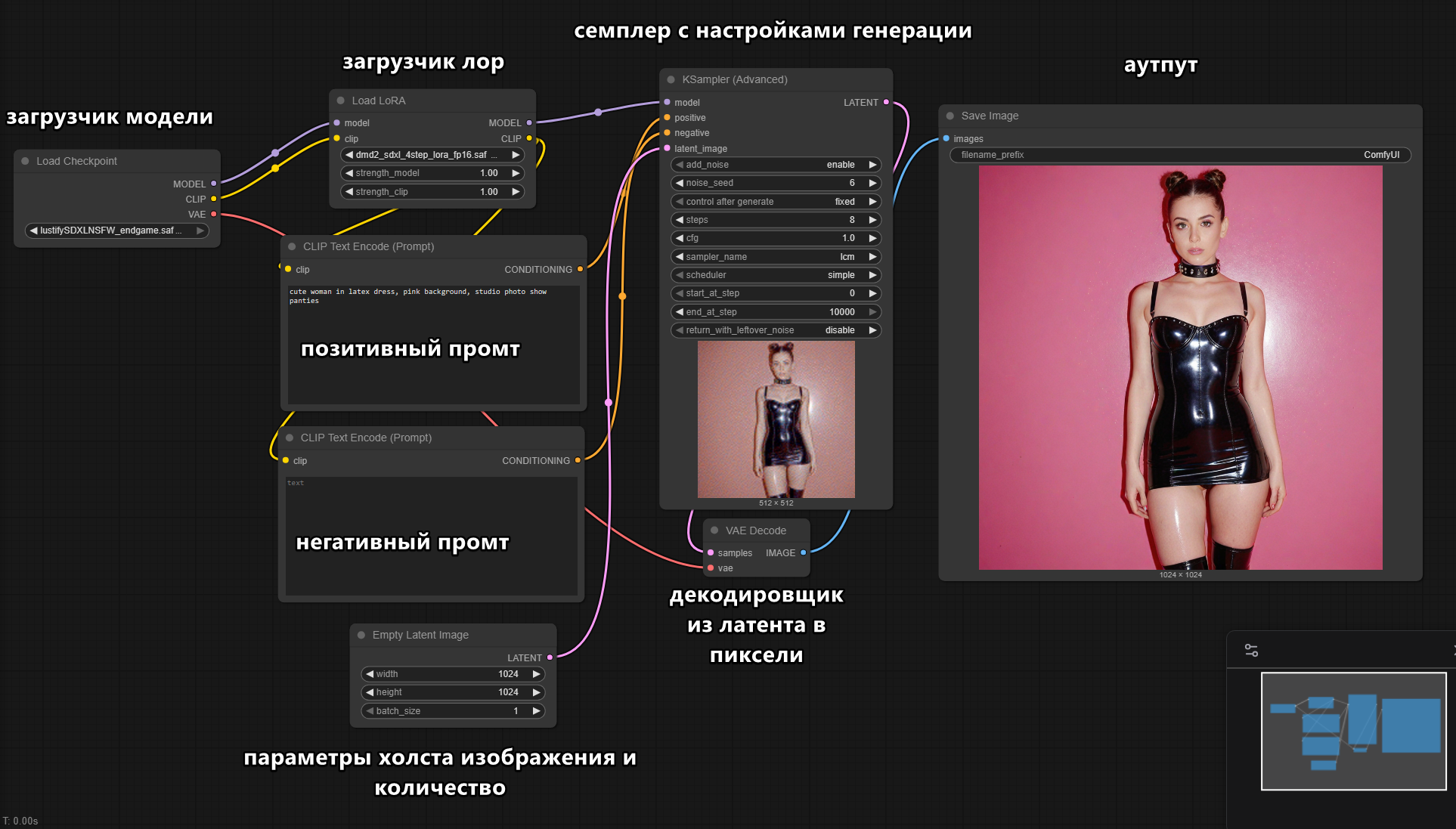
Оффлайн модели для картинок: Stable Diffusion, Flux, Wan-Video (да), Auraflow, HunyuanDiT, Lumina, Kolors, Deepseek Janus-Pro, Sana Оффлайн модели для анимации: Wan-Video, HunyuanVideo, Lightrics (LTXV), Mochi, Nvidia Cosmos, PyramidFlow, CogVideo, AnimateDiff, Stable Video Diffusion Приложения: ComfyUI и остальные (Fooocus, webui-forge, InvokeAI)
>>1448746 Потому что я хз, может я что-то делаю неправильно или неправильно для нее пишу промт. Пока у меня претензии только к тому, что нет лор и приходится прописывать стиль через жопу и их мало. Но это базовая модель.
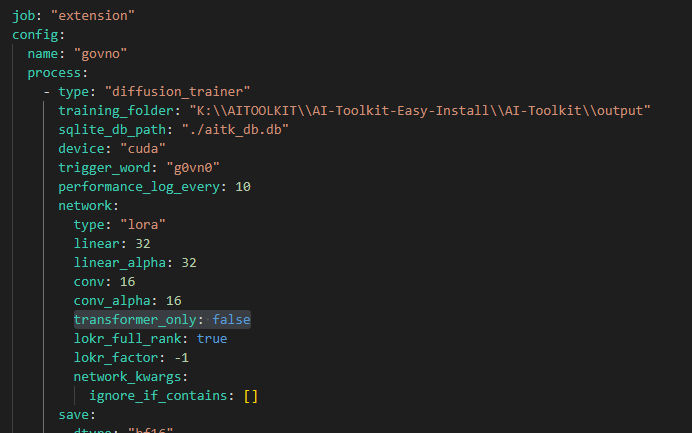
я до сих пор трахаюсь стренингом енкодера зимага увидел, что transformer_only: в положении true, поменял на false теперь лорка выходная получается на 20 метров жирнее, но при тренинге не инциализирует енкодер все равно, но результат получается лучше чем тренить без "включенного" текстэнкодера
еще есть вопрос как подрузить ликорис модуль чтобы юзнуть BOFT алгоритм в конфиг остриса...
>>1448758 Это да, рабочих стилей не так много. Анимца, мультики, некоторая олдовая иллюстрация, чб графика, ну и фотография аналоговая нормально рисуется. Остальное - дефолтный лоп.
>>1448758 ты бери промпты от флюскала и вана или натвиса как я щас спиздил, неча ленгвич, попроси нейронку ллмку, а лора на цивите дохера щас к зетке, на всё есть уже, но смотри чтоб датасет был 2мегапикселя, остальное днищенский мусор
>>1448777 Окей, попробую >2мегапикселя А там указано?
>>1448776 Имхо у Квин лучше архитектура. При сравнимых размерах Квин будет лучше. Z-image берет тем что лучше SDXL, но при этом меньше Квин и Флюкса (особенно второго флюкса)
>>1448804 это днищуки, которые зачем-то берутся не за то что потянут, дело в том ,что зимаж как и флюс 2040х2048 имеет датасет и многие нормальные челики уже делают лора в этих рамках, видел несколько так и писали разрешение датасета, есть пару на вульвы даже в этом >>1448760 зато свои на самом деле это тупо дефолт от кофи, которого для всего достаточно
>>1448777 >но смотри чтоб датасет был 2мегапикселя, остальное днищенский мусор але дядь, зимаге это флоу с поддержкой начиная от 256px, размер картинок буквально не важен, результат будет что на 256px что на 100500px одинаково хорош
Я ныл, что кожа хуевая, а оказывается надо было юзать не euler, а er_sde smg_uniform хотя бы. Не говоря уже про другие способы улучшить картинку. Хотя эта комба явно не лучшая, на мокрой коже уже видны артефакты.
>>1448764 1 лора с якобы вкл текст енкодером, 2 без, 3 дефолт, остальные настройки одинаковые. Слоев текст енкодера в модели нет. Очевидно что связи в лин-конв слоях выдрачиваются относительно тренируемого текст енкодера, но не сохраняются сами модули текст енкодера. Можно наверно юзать как трейнхак для более агрессивного схождения в принципе. В скриптах остриса видел кстати конфиги где он коменты ставил для т5 флюхкала и люмины в стиле "ну тренинг текст енкодера не работает вероятно".
>>1448518 → >>1448792 → Получается дипсик пиздит о том, что noobai не может в естественный язык в отличии от люстры, а может только в теги? Ведь если это развитие, то по идее нубка должна мочь все что люстра и даже больше.
Чет типы походу поняли, что З годнота и выложить базу просто так это нелегально хорошо, либо база на самом деле без трубы слабая и очень медленная. Ваши мысли? Чет qwen edit тоже притих.
>>1449272 Есть. Но не для всех моделей и sampler-узлов работает нормально. В ComfyUI-Manager включаешь «Preview method: Latent2RGB (fast)». В настройках ComfyUI включаешь «Display animated previews when sampling» (ищи поиском по слову animated). Перезагружаешь сервак и ComfyUI. Приобретаешь тормоза (небольшие) и предпросмотр в узлах KSampler, SamplerCustom (чуть ниже настроек узла будет отображаться миниатюра генерируемого изображения).
На Flux.2 не передаёт яркость. На Z-Image примерно совпадает. На Qwen-Image тоже. Остальные не пробовал.
Неразрешимая тема выбора Sampler/Scheduler. TLDR: Какой-то выбор без выбора.
Тесты в сети, выполненные на одних моделях, нерелевантны для других. Samplerов и Schedulerов огромное количество. Отбросил неконвергентные ancestral.
Комбинаций море, проверять всё не осилю. На дефолтном workflow Z-Image прогнал комбинации Euler с разными schedulerами. Несколько других рабочих связок.
Prompt: A close-up shot depicting a Caucasian man and a Caucasian woman looking at each other. There is a spherical object hovering between them in the centre of the image, left half of the object is Earth, right half is an intricate clockwork mechanism. There is a birch tree with lush leaves in the foreground. Cinematic lighting. Hyperfocal, deep depth of field.
(hyperfocal и deep depth of field были проигнорированы всеми и не позволили оценить «зелень» на втором плане, которую Qwen-Image, например на Euler/Simple просто шакалил дизерингом, а на res_2s/bong_tangent рисовал нормально; повторюсь, для Z-Image, например, последняя связка вообще вредная, это к слову о неприменимости комбинаций Scheduler/Sampler от одной модели к другой, просто так)
Никаких LoRAs и дополнительных обработок. Только стоковая генерация. Названия SamplerScheduler указаны прямо в именах файлов. Начинаем с Euler с разными scheduler. Euler/Simple; Euler/Beta; Euler/Beta57.
>>1449299 С заданием не справились: Euler/karras (очевидно, к нему нужен был и Karras sampler в пару, но я не проверял); Euler/kl_optimal (возможно, к нему тоже нужен был другой sampler).
>>1449308 Скинь, пожалуйста, свой насыщенный цветами workflow. Будет любопытно посмотреть, есть ли там второй проход в качестве рефайнера или ещё что-нибудь подобное в качестве face detailer.
>>1449308 Сейчас пригляделся. Ещё может быть тут LoRA какая-нибудь или модель не Z-Image (или Z-Image, но LATENT оправлен в ClownSharkSampler на unsample, а потом второй проход KSampler). Детализация лиц мне нравится, а шестерни часового механизма слизало и зашакалило.
>>1449134 >либо база на самом деле без трубы слабая и очень медленная Это так. Я очень много генерировал с натвиз дмд2. Получалось для него очень хорошо. Но головый натвиз так и не смог. Сам попробуй. Ну и медленный будет. Сейчас 9 шагов цфг1, а если будет 36 шагов и цфг больше 1 то скорость будет в 8 раз медленнее!
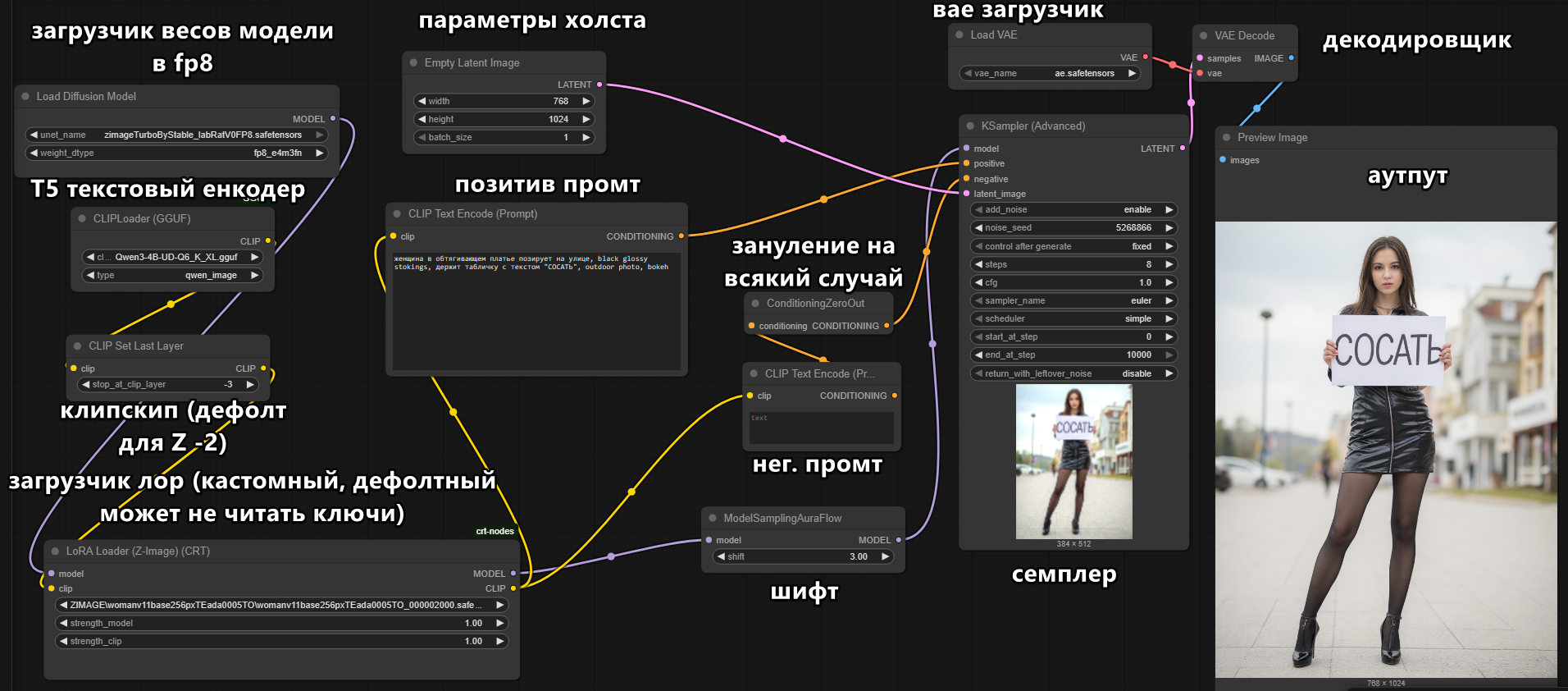
>>1449548 Никаких различий нет пихать куда. Хуйня может быть только если комфинода дефолтная не смогла корректно прочесть ключи лоры и их применить, что имеется сейчас в наличии и лоры для зита надо грузить через другую шпициальную ноду Lora Loader (Z-image) (CRT) из пака crt-nodes.
>>1449635 >Свои тесты держи у себя. Не твой личный бложик Ебанутый что ли? Всегда хорошо, когда доп тесты видишь. Удобней было бы в одном большом xyz. Но это забытые технологии форджа, недоступные комфидаунам.
>>1449664 >Удобней было бы в одном большом xyz. Но это забытые технологии форджа, недоступные комфидаунам. Форджемрась, xyz делается за пять сек в комфе.
>>1449664 Ебанутый даун, в комфи есть такая фича, как запуск гена при изменении. Ставишь отдельно ноду семплера/шедулера и врубаешь увеличение значения и тупо 1 кнопу нажимаешь запуска и оно за пару сек тебе сохранит все с именем файла семплера/шедулера или сделает zxy на автомате, тупой ты форжедаун
Пытаюсь обчеловечить зеткой полученные с другой модели картинки, так чтобы один и тот же скрипт схема с одними и теми же коэффициентами использовались в тупую без дроча циферок, и уже оттуда выбирать удачные результаты. Использую ваши же i2i блоксхемы. Дрочил на одну из схем (быструю) с одним набором коэффициентов, который иногда получал замечательные результаты, но был шумным. Думаю, ну, раз быстрая справляется, должна и медленная справляться, зато без шума. А оно что-то не подбиралось так хорошо. Не выдавало те же результаты. Дёргал ползунки туда-сюда. В итоге решил проверить, погенерил с одними и теми же "удачными" коэффициентами обе схемы на нескольких сидах подряд - всё-таки мне попадался удачный сид, а не отличный набор коэффициентов+схема. 1 - оригинал (нётенгу лол, надо было другую лору брать) 23 быстрая с разным сидом 45 долгая с разным сидом Всё-таки сид даёт слишком дохера.
Следующим постом ещё один маняпример. зачем пишу - чтобы не забывали дрочить сиды, а не только цифры и промпт
Отрывок из работы итальянского художника. Получил известность как 3d видеоартист. Потом увлекся нейронками. Один из первых стал с ними делать арты. Использует json.
Оказывается, кроме баб можно еще что-то гененрить!!! Только не говорите никому. Это наш с тобой секрет, анон.
>>1449989 Откровенно после пары первых дней я тоже немного поехал в любом нейрослопе начал пытаться найти смысл. Но скоро отбросил это. Вспомнил, что можно кроме нейродерьма ещё ручками задавать направление, и рулит здесь пользователь, а не нейронка, которая обычно высирает чепуху. А "художник" потерялся. Небось из-за постоянного употребления наркотических веществ, потеряться ему было проще.
Анон, есть ли нода, чтобы описать загруженную картинку с помощью Квин от Z-image идругой Квин? Потому что wd14 tagger не справляется со сложными не аниме картинками
>>1449989 >Оказывается, кроме баб можно еще что-то гененрить!!! Только не говорите никому. Это наш с тобой секрет, анон. Ха-ха очень смищно. Вот только вангёлстендинг генерят не из-за того что только это могут, а потому что это нравится. Нахера мне эти вдумчивые генерации, что за бред блять?!
>>1449989 Это вопрос не генерации, а постинга. Обычным людям не особо надо сюда постить, а вот кумерам совать другим под нос свои фап-материалы - это почти так же необходимо как на них дрочить. Универсальный психологический симптом кумерства, до нейронок так же было.
The dataset contains only real-life photos, and setup #3 converges to the target the fastest, but loses the “fortnite” knowledge.
> whats transformer_only? first time i hear of this option. do i put this into the .yaml config like train_text_encoder?
It is an argument from AIT’s config_modules.py, and it is enabled by default. Yes, you need to add this argument in the [network] block and set it to false.
I checked what the LoRA contains when trained with false in trans_only + true in TE, and it includes additional layers such as:
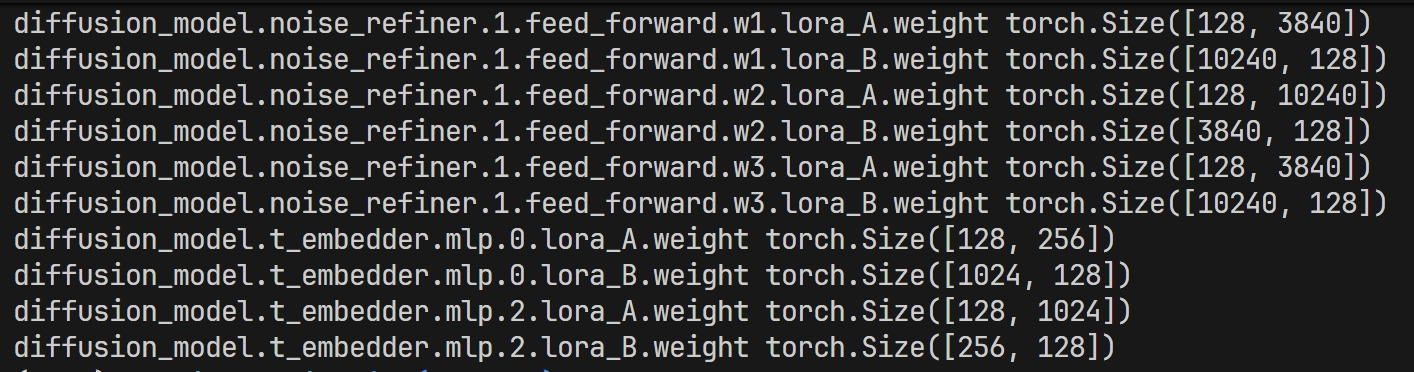
context_refiner
all_final_layer
all_x_embedder
cap_embedder
noise_refiner
t_embedder.mlp
The default LoRA training config only uses ffnet and attention layers.
The difference between LORA with TE and without just in parameters numbers lol. Considering that the TE layers are not physically preserved in LORA because apparently this is not provided for during training, it is clear where the changes come from.
For example in difference:
TE false: diffusion_model.layers.0.feed_forward.w1.lora_A.weight,(32-3840),0.009208115749061108,9.266659617424011e-08 TE true: diffusion_model.layers.0.feed_forward.w1.lora_A.weight,(32-3840),0.009162179194390774,3.4691765904426575e-08
Even if the text encoder (T5) has no LoRA layers and its weights are not saved, the flag train_text_encoder = true still changes the gradients that flow into the UNet.
So: TE does not save LoRA TE does not initialize LoRA But TE still affects UNet-LoRA training indirectly because the backward pass goes through the text encoder.
Numbers means: smaller std - more stable gradients mean closer to zero - less drift small but consistent improvement
Exactly what happens when TE participates in backprop.
As a result, given the rather limited LoRA implementation in AIT, you can still use the extended training without any issues in two ways:
1. Training all LoRA-supported layers + enabling gradient passthrough for the Text Encoder - this produces a more consistent LoRA that relies on the base model more effectively.
2. Training only all LoRA-supported layers - this gives a massive boost to adaptation on the dataset.
>>1450644 А какие нужны? Мне фотки шакальные улучшать. В сд какая-то улучшалка вроде гфпган была. Она только лица восстанавливала. Мне надо целиком и желательно еще чтобы убирала двоение от тряски камеры.
Только собираюсь вкатываться, подскажите актуальную приложуху для нуба. ComfyUI - очень страшно, я не знаю что это такое. Скачал Fooocus, но говорят, что это прям вообще основы. automatic1111 - типа давно не поддерживается. Может что-то еще есть нуб-френдли? Меня больше интересует обработка изображений: апскейл, дорисовка фона, наложение эффектов на фото, замена лиц, зачистка/замена объектов, совмещение - вот это вот все. С меня как обычно нихуя
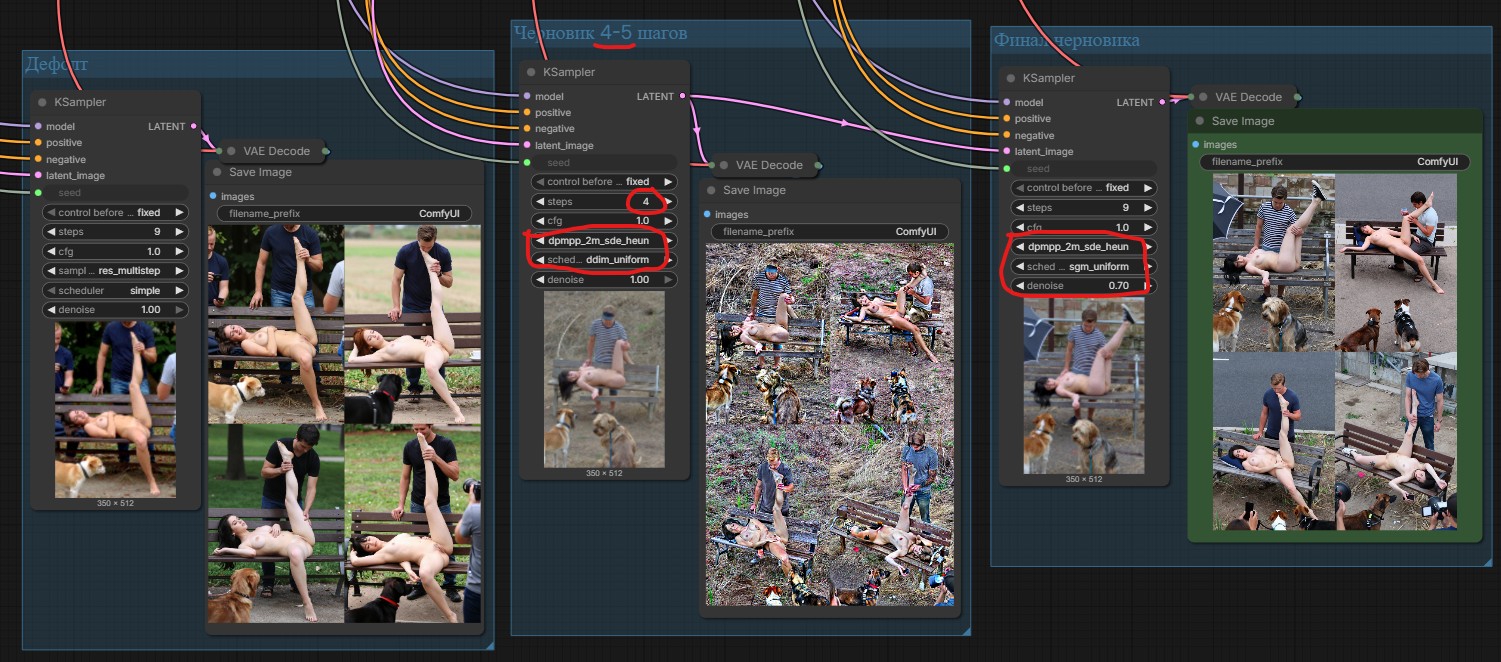
>>1450785 Но ведь 4 пик самый хуёвый. Третий сильнее изменился потому что transformer_only: false дополнительно пикрил слои тренит, а не только линейные в блоках. > For example in difference В тулките не детерминированная тренировка, веса всегда отличаться будут даже на одинаковых прогонах, это ничего не значит. > TE still affects UNet-LoRA training indirectly because the backward pass goes through the text encoder Это пиздёж, ТЕ в графе до лоры трансформера находится, он не может участвовать в обратном проходе для вычисления градиентов трансформера. Да и время шага не увеличивается от его включения. То что у чела происходит - это скорее всего градиенты скейлятся тулкитом зачем-то при включении ТЕ, поэтому выглядит как недотрен. > smaller std > mean closer to zero Собственно просто градиенты меньше.
>>1450833 >фотки шакальные улучшать Зависит от степени шакальности. Мелкие уберёт и SeedVR2. Серьёзные надо через edit модель прогонять и просить дорисовать потерянную информацию. Общая схема такая: чистишь от мусора в qwen edit. Апаешь в SeedVR2. Потом можно опционально маленьким денойзом в wan 2.2 артефакты подчистить. Может быть flux2 в один проход сможет, но я нищброд, у меня не лезет.
В итоге для Зет ничего лучше euler/simle нет? Я сам перепробовал несколько вариантов. Некоторые иногда лучше дофолта. То есть ролить приходится и все равно посматривать что там на дефолте. Некоторые комбинаци семплера/шедулера могут генерит только в 1к разрешении. При большем мутная каша. Про шаги, возможно мне просто показалось, но какая-то проблема с шагами 10 и в меньшей степени на 11, а с 12 норм начинается. Не замечали? Про разрешение. Опять по моему опыту, лучше это 1536х1536. Или около него. Кто-то поделиться своими наблюдениями?
Не сможет, к сожалению. Возможности FLUX.2 dev (которую в свободное плавание выпустили, в отличие от коммерческой версии) слишком преувеличены. С ней можно добиться результатов на Edit, но нужен свой подход. На слабом железе точно.
IMHO Wan в цепочке не на своём месте. Мне кажется SeedVR2 это конечная точка. После неё трогать изображение, только портить. Лучше сразу для SeedVR2 давать уже финальную версию изображения, которой кроме простого апскейла больше ничего не нужно.
>>1450902 >В итоге для Зет ничего лучше euler/simle нет? В чьём итоге? Почитай тред глазами, а не жопой. Куча комбинаций лучше. Они дефолтно поставили Euler, видимо, потому что это надежный минимум для всех случаев.
9 шагов достаточно. Выше — плацебо в лучшем случае или шакалит/зашумляет. Это турбо-модель Z-Image для вывода за малое количество шагов (по смыслу типа lightning LoRA для Qwen-Image).
Здесь >>1449295 я пробовал разные Sampler/Scheduler. IMHO, как стоят дефолтные res_multistep/simple, так можно и оставлять. Про всякие ClownSharkSampler узлы с ворохом вариантов не говорю. Не проверял экзотику. Те, кто туда лезут либо точно знают как работают семплеры, либо тыкают наобум «о, custom RES4LYF крутяк, его прошаренные юзают, я тоже должен, а то не труъ».
>>1450862 >Но ведь 4 пик самый хуёвый. Вообщето самый лучший - сохранена баба, сохранен фортните. >Третий сильнее изменился потому что transformer_only: false дополнительно пикрил слои тренит, а не только линейные в блоках. Ты бля пост жопой читаешь? >В тулките не детерминированная тренировка, веса всегда отличаться будут даже на одинаковых прогонах, это ничего не значит. 1. Сид выставь еблан 2. Изменения сидов практически не влияет на аутпут, сто раз уже проверено на всех сетках
>Это пиздёж, ТЕ в графе до лоры трансформера находится, он не может участвовать в обратном проходе для вычисления градиентов трансформера Спокойно может, ты же не оффлоадишь т5.
>Да и время шага не увеличивается от его включения. Ты шо еблан, оно увеличивается! Вот прямо щас включил - увеличилось с трех сек до 4.5.
>Собственно просто градиенты меньше. Ты даже не понял че написано.
>>1450934 > Спокойно может, ты же не оффлоадишь т5. Градиенты распространяются только в одну сторону. Градиенты ТЕ зависят от трансформера, не наоборот. Автоград при любой операции добавляет к результирующему тензору grad_fn - функцию обратного прохода. И выполняются они строго в обратном порядке. ТЕ у тебя при форварде ПЕРЕД трансформером, соответственно при обратном проходе градиенты ТЕ считаются ПОСЛЕ трансформера, а не наоборот. Градиенты не могут в обе стороны распространяться, а расчёт градиента - это просто дифференциация каждой операции форварда. Учи матчасть, чтоб не быть батхертом. Что там на самом деле происходит в кривущем тулките только устрице известно, но никак не влияние ТЕ на градиенты трансформера.
>>1450934 > оно увеличивается Алсо, нагло пиздишь, попробуй догадаться на каком из скринов было с включенным ТЕ. И с включенным ТЕ концепт очень плохо натренился, как будто на 500 шагах, а не 3500.
>>1451020 >>1451024 > Что там на самом деле происходит в кривущем тулките только устрице известно Вангую ТЕ действительно тренится, просто не сохраняется, поэтому часть натренированного выкидывается. Или там совсем наговнокожено тогда.
>>1450904 >IMHO Wan в цепочке не на своём месте. Да, иногда WAN стоит включить до апскейла. Иногда он вообще лишний. Главная идея, что ретушь сильных шакалов - это ручной процесс. Надо двигаться по шагам, подбирать промпты, сиды и числа. Особенно ели речь идёт о личных фотках, где надо сохранить узнаваемость. Универсальных расшакаливателей в локалках сегодня нет
>>1451020 > но никак не влияние ТЕ на градиенты трансформера. Блять да иди ты нахуй, они не в вакууме тренируются а связанно. Возьми сдхл, натренируй 100 шагов с те, и без те, потом отключи те на том что натренировано с те и сравни с тем что без те - результы будут разные критически. Я этой фишкой еще с сд 1.5 периодически пользовался.
>>1451056 > Вангую ТЕ действительно тренится, просто не сохраняется, поэтому часть натренированного выкидывается Так о том и речь, нет наговнокоженного лора адаптера под т5 вообще чтоб сохранять, а так оно тренируется само по себе естественно.
>>1451210 Чел, у тебя есть изменения потому что обновляются веса ТЕ и меняются эмбединги. Если ты включишь градиенты, но не будешь обновлять веса ТЕ, то они никак не будут влиять. В рамках одного прохода ТЕ никак не влияет. То что ты натренил ТЕ и выкинул его - это вообще пиздец. В том посте была шиза про "backward pass goes through the text encoder", что невозможно в принципе.
>>1451024 > Алсо, нагло пиздишь, Смысл мне пиздеть, ты дурачок что-ли?
> И с включенным ТЕ концепт очень плохо натренился, как будто на 500 шагах, а не 3500. Я ебу че ты там наконфигурировал, криворучка, не ко мне вопросы, у меня все работает как надо.
>>1451231 > сид не смог зафиксировать Ты сид генерации с тренировкой не путай, чухан. В тулките сиды только для генерации, тренировка недетерменированная там.
>>1451255 Я в отличии от тебя умею пользоваться поиском. В конфиге сид только для генерации. При тренировке шум без сида и в датасете порядок рандомный.
>>1451593 > Видео же 2 минуты генерится. Подскажи, на какой сетке генерится две минуты, в каком разрешении и какой длительности. Если есть пример - было бы славно, но можно и без примера видео. А то ждать подолгу видео вообще неудачно, когда их надо по несколько раз перегенерировать. Если, конечно, у тебя что-то около 4070, а не 5090.
>>1451596 Ван 2.1 с ускорялками, 480p, 81 кадр На 4090, говорят, минуту генерилось. Хз что там по 2.2, изменений почти нет, впадлу чекать, жду сразу 3.0, остальное можно скипать
>>1451639 Хм, ну если тебе норм, то можно попробовать. А то у меня на какой-то сетке при малом разрешении был пикрил, и надо было выше разрешение поднять, чтобы было хоть что-то терпимое. Ну или какая-то хтонь с девушкой. >>1451656 Не, пусть валяется как улучшатель результатов других моделей. Слишком мало знает, слишком "безопасная"
>>1451656 >хочица базовую модель зит Тоже отложил тренировки, чтобы не нагружать лишний раз видеокарту, пока не выйдет официальная версия. На нормальные файнтюны не надеюсь, если только они не выпустят NoobAI на Z, тогда уже мердже-тюнеры что-то выдадут.
>>1451683 >>1451656 Не вижу особого смысла тренировать ее, если она сыпется при подключении нескольких лор. Так бы можно было подключить стиль, перса и сложные концепты хотя бы
>>1451683 Ну и зря, IMHO. Я тут как раз попробовал - лора на предмет/персонажа 30 минут - 2 часа на 3060 с зажатым на 110W уровнем мощности (65 градусов MAX). Разброс по времени - это в зависимости от качества.
И попутно - год назад пробовал тренить лоры на сдохлю, страдал - почему такая херня выходит. А тут, мне наконец gemini мозги вправил - это Batch Size, блядь. Он, оказывается, не только на скорость влияет (типа - больше исходников за раз), но и на качество результата (потому, что что-то вычисляет на основе всех картинок - среднее выводит избавляясь от случайного эффективнее). Проверил - точно. На BS=1 - хрень с зерном и артефактами на выходе еще до того как перс на себя стал похож. А на BS=2 уже хорошо. Благо, что на 12GB можно даже с BS=4 для Zит тренить. (На устрице.)
>>1452161 >Енкодер на цпу. Это оффлоад в озу, это не может быть быстрей врама. Причина не в этом. Вон выше на 4060 быстрей чем у некоторых на 4070. Зависит от многих факторов
Вангую, что там разрешение 1024x1024 поставили и Euler/simple поставили вместо sampler/scheduler. А затем запостили скриншот окошка с удобными циферками. К сожалению, ко всему тому что здесь размещают ещё приходится относиться с изрядной долей скепсиса.
>>1452216 >Вангую, что там разрешение 1024x1024 поставили и Euler/simple поставили вместо sampler/scheduler. Какие же вы еьынутуе стали. Тесты всегда делают на дефолте. Всегда на известном всем разрешении, на семплере/шедулере по умолчанию. На шаблоне который есть у всех. Это же тест скорости, а не качества. А теперь посмотри на идиотов которые выше разрешение хуй пойми почему не дофолтное поставили. А ещё пишут " ну 15-30 секунд". Это ппц. Так 15 или 30? Дебилы, мояьь, школота.
>>1451688 Ощущение будто с лора лоадерами что-то не то. Данриси юзает какой-то кастомный и сочетает свои две лоры, получается совсем не так хуево как когда делаешь то же сам на дефолтных. Плюс надежда, что на base такого обучения не будет. >>1451954 Странно, обычно батч повышают (если есть возможность) немного жертвуя качеством ради скорости. >Благо, что на 12GB можно даже с BS=4 для Zит тренить. Что за магия? Я выше одного не пробовал, но все разы потребляло чуть больше 12гб (вместе с системой) из 16гб врам.
>>1451718 >>1451988 Если просто поиграться, то можно вообще пробовать 1.3B (2.1) или 5B (2.2), они ещё быстрей будут генерить 720p, но лор на них сильно меньше. Ну и ван, да и старый hunyuan даже на лоурезе выдают что-то, если проблемы с врам. Помню hy даже на 32x256 что-то связное выдавал. >>1452203 15 секунд на закешированном промпте, на загрузке модели в fp8_fast. Получается немного хуже. В среднем 25 секунд.
>>1452289 > А теперь посмотри на идиотов которые выше разрешение хуй пойми почему не дофолтное поставили. Потому что квадраты не рендерим. В квадрат ничего не вписывается. Я понимаю, тесты для тестов, но тогда и другие условия надо соблюдать. Вроде перезагруженный комп, отсутствие браузера с ютубом на фоне, 11 винда последнего обновления. Да всем плевать. Рендерится картинка примерно такого формата в разбросе от 15 до 30 секунд в засисимости от кучи переменных сред внутри винды. Такие дела.
>>1452337 >Да всем плевать Я примерно про это и написал. Современное поколение, которому на всё плевать. На культуру использования софта, на культуру его разработки.
>>1452347 > На культуру использования софта Ок ответь, какой тест будет верным. Сразу после загрузки, потому что комфи ещё не загружал ничего в систему, и не насрал в память-кеши. Или после первых десяти-двадцати, когда уже предзагрузил себя и данные нейросетки с ссд в оперативную память, потому что это его настоящая работа на практике.
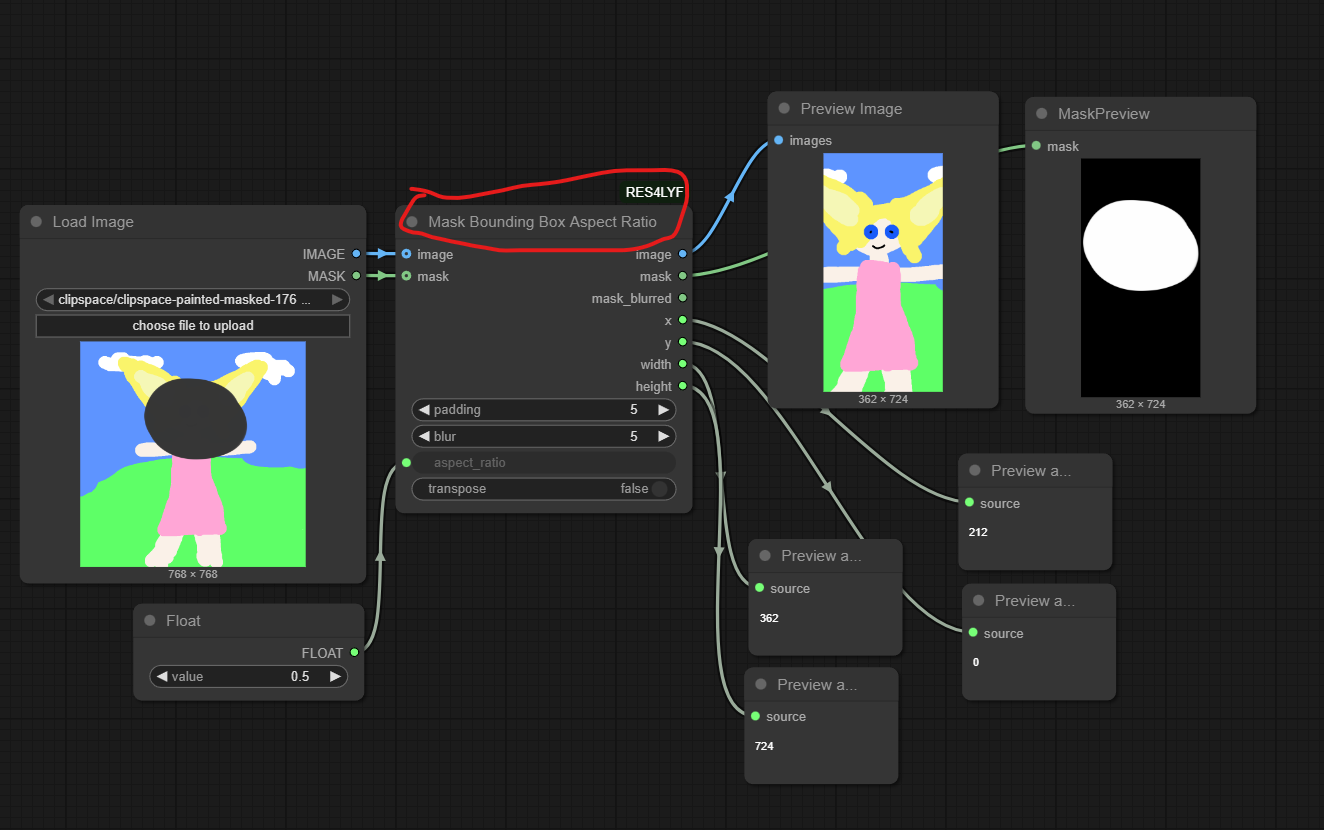
Можно ли заменить ноду Mask Bounding Box Aspect Ratio какой-то схемой их только встроенных нод? Нужно определять координаты и размер области имнпаинта X, Y, wid,hig стандартными, встреонными нодами. Можно такое сделать?
>>1449625 Я недавно обновил что бы затестить парашу флакс 2, И у меня перестало работать вообще всё. Все дефолтные воркфлоу отвалились. Потому пришлось качать портативку с нуля. Флакс 2 как и ожидалось оказалась парашей и пошла под снос. Потраченного времени жаль, пятикратно переваренный кал.
>>1452321 >Ощущение будто с лора лоадерами что-то не то. А у меня создалось ощущение, что модель просто более чувствительна к косякам использования лор. Если их "зоны ответственности" перекрываются - нужно силу применения уменьшать, иначе косячит изображение. Так и на SD/SDXL было, но этот эффект там заметно слабее. А здесь, прямо подбирать надо, чтобы итог не корежило.
>Странно, обычно батч повышают (если есть возможность) немного жертвуя качеством ради скорости. Как я выяснил на практике - строго наоборот. По крайней мере в моем сетапе - BS=1 самый быстрый, но самый шакальный вариант. В прочем, возможно занижение Learning Rate при сильном увеличении количества шагов и дадут лучший результат. Но тут даже на везде рекомендуемых везде параметрах - получается первые изменения к 350-ому шагу, и даже на 600 персонаж очень отдаленно на себя похож, при уже начинающихся артефактах. С BS=4 - лора готова на 250-350 шагов, качество - зашибись. LR при этом завышен в 2-3 раза от стартовых рекомендаций. (Поднят до 0.0002)
>Что за магия? Я выше одного не пробовал, но все разы потребляло чуть больше 12гб (вместе с системой) из 16гб врам. Опция на Offload Unet в настройках устрицы - 100% в память (из VRAM). Правда тут еще от размера картинок в датасете зависит - BS=4 у меня получился с 768 квадратами. При этом без offload вообще - даже с BS=1 не получается. Мало 12GB.
Кто-то заводил это на Z: https://github.com/shootthesound/comfyUI-Realtime-Lora Via Musubi Tuner: Z-Image - faster training, smaller LoRA files, no diffusers dependency. Requires the de-distilled model for training, but trained LoRAs work with the regular distilled Z-Image Turbo model. Via AI-Toolkit: Z-Image Turbo
>>1452530 >офлоад > Опция на Offload Unet в настройках устрицы - 100% в память (из VRAM). Правда тут еще от размера картинок в датасете зависит - BS=4 у меня получился с 768 квадратами. > При этом без offload вообще - даже с BS=1 не получается. Мало 12GB. Вы дегенераты блять, вам дали зетку которая может в 256 трениться отлично, плюс устрица ебанули квантизацию на лету, бы буквально можете все запихать на карту и не терпеть говно с выгрузками.
>>1452562 Не работает после апдейта. Прошлый работал. >>1452667 Ты точно не фанат сделать омном-ном за щеку? Выглядит как чистой воды коупинг. Уверен, уровень узнаваемости лица упадет, но захотелось попробовать.
>>1452674 > Ты точно не фанат сделать омном-ном за щеку? Выглядит как чистой воды коупинг. Уверен, уровень узнаваемости лица упадет, но захотелось попробовать. Я бля только в 256 с выхода зетки делаю, там все прекрасно. Астралайт вон тест пони на 256 делает тоже. Реально вы как дауны тыкаетесь в то во что не надо когда есть топ решения для нищеты.
>>1452678 >только в 256 с выхода зетки делаю Понятно, гигакоупинг. Ну так ты оторвись от бочки с говном и попробуй нормальную еду, потом влезай в разговоры. >Астралайт вон тест пони на 256 делает тоже. АХхахахаха
>>1452714 Тяжело вам на SDXL. Нам партия выдала Z-image, которая тренируется в 256 пукселей и генерирует 4к. Объясните довену что латент спейсу зета пихуй на разрешение.
>>1452667 >Вы дегенераты блять, вам дали зетку которая может в 256 трениться отлично Ты там чего куришь, или вообще уже ширяешся прямо? Вообще всё одинаковым видишь? Ладно еще 512 - можно еще в такую картинку уложить что-то, боле-менее узнаваемое. Но, сцуко, 256 - это наутральный VGA, пиксельарт эпохи кинескопов до первых пентиумов. Там мелкие детали, в принципе будут одним пикселем на общем плане - это угадайка а не изображение. Спасибо, не надо. Хотя конечно, если мне нужна лора с уровнем "зеленый шар на синем фоне" по детализации - это вариант, конечно. Но что еще можно натренить на том, что на картинке просто вообще отсутствует, из-за сверхнизкого разрешения? Смысл заморачиваться с качеством - если тату, кулон, элемент вышивки, или просто прилипший лист - один хрен - 1-2 пикселя и выглядят одинаково на фигуре в полный рост?
>>1452723 >Объясните довену что латент спейсу зета пихуй на разрешение. До латент спейса - надо еще через токенизатор пройти. И чтобы тот понял, вот этот пиксель - это что: тату, родинка, складка одежды, тень, и ли вообще муха на фото насрала. А потом уже латент, да...
>>1452746 >>1452750 >два дауна не понимают что значит 256 для зетки и упорно хуячат дичь про низкое разрешение картиночек из которых в манямире получаетс мыло и нет деталей
Реально дебилов тред. Хотя мне какая разница, это ваше проблемы что вы аут оф зе бокс не способны мыслить и хуйней занимаетесь со 150 секунд на шаг.
>>1452763 Это стадия отрицания. Потом со временем дойдут до мощи 256 пикселей, как с дмд было. Зетурба кстати сделана полностью на принципах дмд, вот у хейтеров очко подгорает наверно.
>>1452723 >>1452755 >Орёт весь тред без конкретных объяснений своих слов Это точно челик из локалочек ллм. Там такие довены оруны. Прям магистры хуйпойми каких знаний(они ими не делятся, но ссылаются на то ими обладают)
>>1452774 Для всех кроме тебя это не истина, а мусорные сведения. Чушь, потому что без доказательств. Доказательств ты не приводишь, несмотря на то что уже полтреда запакастил. А значит и к тебе относятся как к голословному *, пыль. Ссылку на статью какую-нибудь лень привести? А, ну да, обладать знаниями можешь лишь ты.
>>1452783 Иди потренируй на 256 свою еот обоссаную и пиздак заткнешь сразу. Для тебя наверно вообще в диковинку будет что вае сжимает картиночку в латенте, ага? Прикинь, на каскаде еще в 40 раз сжимало с полным восстановлением. Или ты думол, что ваешка картиночку в латенте разворачивает на основе конфига резолюшена твоей говнолоры? А еще наверно ты не в курсе что флоу чисто похуй и поебать на резолюшн тренировки? Потому что флоу учит СКОРОСТЬ, с которой шум превращается в изображение, а не хуйню предсказательную. Учи мемы чтобы не быть батхертом, время сдхл с привязкой к размеру датасета ушло.
>>1452800 Слушай, ты реально считаешь, что можно что-то натренировать на датасете из несуществующих деталей? Я допускаю что Zине пофиг на размер. Но она, блядь, у тебя получается телепатией владеет, или подключением к великому атсралу. Если на исходной картинке, из-за сверхнизкого разрешения, даже человек уже не понимает - что это за херня изображена - откуда сетка то поймет? Речь именно об этом. Если ты тренишь что-то, что 256 пикселей еще разборчиво - базару нет. Но если там просто непонятно - что это такое конкретно, в таком малом разрешении? Ну вот, например затолкай в 256 пикселей какую-нить эмблему организации, где всего 10% ее поля занимает мелкий текст - из библии, строчек 8. Ага? Чтобы лора ее всегда без искажений текста потом воспроизводила. Ну, или что-то вроде вот этого: https://e7.pngegg.com/pngimages/206/618/png-clipart-nerv-neon-genesis-evangelion-2-logo-rebuild-of-evangelion-angel-game-text.png И чтоб лора текст не путала.
>>1452819 Сука доебешь меня фома неверующий. Ок, давай натренирую эту залупень твою в 256, ток дай СЛОВО ПАЦАН что как только я тебе хуев натолкаю, то ты не исчезнешь нахуй а напишешь что извиняешься, был не прав и больше не будешь доебывать людей.
>>1452819 >что можно что-то натренировать на датасете из несуществующих деталей? >она, блядь, у тебя получается телепатией владеет, или подключением к великому атсралу Погоди, ты отразил вообще что ты даешь ваешке картиночку, ваешка СЖИМАЕТ ОЧКО твоей картиночки в милипиздрическую латентную залупку, обучает на ней и ей все равно на эти 256 пикселей потому что из латента вае будет восстанавливать обратно в исходный размер минуя выставленный конфиг резолюшена? То есть мы выставляя 256 в конфиге буквально экономим врам на пустом месте просто, понимаешь?
>>1452667 > 256 трениться отлично, плюс устрица ебанули квантизацию на лету Я треню в 1280 без квантов и что ты мне сделаешь? Рассмешишь микроквадратами и отсутствием новых текстур у лор?
>>1452826 Хочешь сказать за 3 минуты лору тренишь? Потому что на 1280 за 30 минут тренится. Уже то что тебе стыдно показывать в треде натрененное о многом говорит.
>>1452838 >Хочешь сказать за 3 минуты лору тренишь? Достаточно для тренировки твоей матери. >Уже то что тебе стыдно показывать в треде натрененное о многом говорит. Ого, битва с соломой.
>>1452821 Да я как бы сам тесты проводил, хоть и не дошел еще до 256. В 512 у меня перс "в общем" - не хуже получился чем в 768, на грани субъективной погрешности. А вот форма шрама (на груди у него) уже явно плывет даже на 512, тогда как на 768 - стабильно рисует как надо. Так что не надо орать - я и в 256 попробую. И извинится за мной не заржавеет, если оно реально не повлияет совсем. Пока же - как я вижу по результату, что если тренишь что-то общее как концепт - низкое разрешение может быть даже бонусом, там обобщение только в плюс. А вот если конкретного перса/объект, да с мелкими важными деталями - они могут и проебаться на датасете низкого разрешения.
>>1452884 Зина конечно умница, но ты же промптом детали картинки сделал, а не лорой. Если ты из промпта генерации детали и текст уберешь - она сама справится с его начертанием - только на базе информации из лоры? Т.е. - получится результат только с промптом "on the white background a red logotype" (где "red logotype" - токен на который лора тренилась)? Чтобы форма, содержимое и текст были взяты из лоры, а не из промпта?
Если да - мои извинения, был неправ. А если нет - мы каждый при своем, т.к. как минимум о разном говорили.
>>1452884 И что это за говно? Покажи как лого генерится, а не текст. То что ты делаешь - просто промптом текст написал. Как по промпту "NERV logo" сможешь это сгенерить, так и приходи рассказывать что ты там натренил.
>>1448719 (OP) Кто-нибудь шарит, как использовать zimage или flux 2.0 на автоматике? Может есть какой-то костыль для этого? Комфи вообще кал ебаный неудобный. Или может есть какой-то аналогичный сервис, главное чтобы там был инпейнт по области с заданным разрешением как в автоматике.
>>1453039 Тут вопрос а он с картами 50хх серии норм работает? Потому что там 50хх серия по умолчанию тоже не поддерживалась, пришлось качать какуюто ветку.
>>1452898 >Зина конечно умница, но ты же промптом детали картинки сделал, а не лорой. Бля, а ты как хотел? Чтобы по токену или на холостую логотип генерило? Это буквально надо несколько тыщ шагов ждать переобучения. >Если ты из промпта генерации детали и текст уберешь - она сама справится с его начертанием - только на базе информации из лоры? Конечно, но это ждать долго. Мало того тебе скажу, что даже если бы я просто на класс токен начал дрочить лору без описания, то все равно бы работало ток ждать долго пока оверфитнется. Я так на легаловских баб лору в 256 тренил вообще без описания, зетка сама всю нужную инфу с картинок спиздила. >Т.е. - получится результат только с промптом "on the white background a red logotype" (где "red logotype" - токен на который лора тренилась)? Чтобы форма, содержимое и текст были взяты из лоры, а не из промпта? Я не буду оверфитить лору 6 часов, я не ебанутый чтобы на дваче доказывать что-то с очевидным результатом. Могу легаловских баб показать, они хотя бы готовые. >А если нет - мы каждый при своем, т.к. как минимум о разном говорили. Я хз маневр это или нет у тебя, но по итогу получается тебе нужна не гибкая лора, а оверфит на объект, что не является стандартным использованием, но зетка и такое сделает.
>>1453093 Я другой анон, я с вами тут не срался)) Все что скинул это лоры обучались на 768, 1000 шагов, примерно 50 минут тренировка идет на 5070ti. Потренил на 512 некоторые лоры, тренится за 30 минут всего. Правда сильного отличая от 768 не заметил, все равно потом flashVSR + adetailer прохожусь по пикам которые понравились, а они уже детали дорисуют и ебальничек под лору подгонит
Вы так долго тут срались, что быстрее взяли бы 6-10 фоток селябы, потренили бы на 256 и сюда выложили)
>>1453104 >что быстрее взяли бы 6-10 фоток селябы, потренили бы на 256 и сюда выложили Я еотову на 256 натренил, никаких отличий от 1024. Выкладывать надо с еотовыми фотками, а ето диванен.
>>1453083 >Я не буду оверфитить лору 6 часов Я тебя доказывать не заставлял, ты сам полез. Но теперь уж или приводи нормальное доказательство, или подожди, пока я сам до тренировки с размером 256 доберусь (уж прости - сегодня рабочий день, не раньше завтра получится).
>Я хз маневр это или нет у тебя, но по итогу получается тебе нужна Мне не нужна сама лора - я хочу понять, насколько реально теряются или нет мелкие детали при датасете из маленьких изображений. Везде об этом говорится, и это, сцуко, логично - ведь если на картинке деталь даже глазом не разобрать - откуда в лоре возьмется правильная информация об этой детали, ведь ее буквально вообще НЕТ в исходнике. А на квадрате 256 - там что-то мелкое но важное может реально как 2-3 пикселя выглядеть. Еще ДО того, как вообще в процесс обработки попадет. Я именно про это. Остальное - просто проверка. Если лора на единственный объект не может генерировать правильное изображение в деталях, даже в оверфите, просто по токену без детального промпта - значит что детали в такой лоре проебываются, и малый размер картинок датасета таки не годен там, где эти мелкие детали важны. вот и все. Мне сейчас не свое доказать важно, а реально разобраться. То что лора созданная на мелких картинках в принципе возможна - я под сомнение не ставлю. Скажем, крупный план чего-то без мелких деталей.
(И т.к. я уже остыл) И если бы ты с оскорбления не зашел здесь: >>1452667 я бы тоже в другом тоне ответил с самого начала.
>>1451954 > Batch Size, блядь. Он, оказывается, не только на скорость влияет (типа - больше исходников за раз), но и на качество результата (потому, что что-то вычисляет на основе всех картинок - среднее выводит избавляясь от случайного эффективнее). Проверил - точно. >>1452321 >>1452530 > меняют BS > не меняют LR и steps > удивляются
Буквально магическое мышление каргоультистов. Почитать не пробовали как и на что BS влияет? Хинт: может быть на что-то надо умножить число шагов?
>>1453104 >Вы так долго тут срались, что быстрее взяли бы 6-10 фоток селябы, потренили бы на 256 и сюда выложили) Так оно этот спор не решит. Узнаваемость лица - достаточно крупными деталями достигается. Тут для проверки надо что-то более специфическое - машину с отбитой фарой или точным номерным знаком, или еще что-то такое - где важна мелкая но уникальная деталь.
>>1453125 В топе лор на civitai всегда позы, стили, персонажи, детали тела (писик/сисик). Если эту хуйню можно обучить на 256 без потери каких ну прям пиздец важных деталей, то в рот оно ебись ваш спор если честно, дрочь ради дроч Не знаю даже, конкретно под определенную задачу, когда нужна овердохуя детализация в каком то определенном концепте, то у меня не возникнет вопросов каких размеров тренить, я естесно вьябу 1024 (ибо мои 16гб пук-среньк делают на большем разрешении). Но если на 256 мне даст спокойно сделать персонажа, позу или сисик писик, то это заебись и смысла я не вижу генерить выше
>>1453124 >Буквально магическое мышление каргоультистов. Почитать не пробовали как и на что BS влияет? Я потому на себя и ругался, что как раз читал, и не одно руководство. Общую взаимосвязь между BS и LR - они описывают. И число шагов я для BS считал под свой датасет, и выставлял согласно всем этим руководствам, а потом еще и с гемини консультировался для проверки. По всем прогнозам лора должна была быть готова примерно на 800 шагов. Но она начала шакалить картинку признаками оверфита уже на 500-600, при том что персонаж и близко не дошел до кондиции. Т.е. либо все руководства все равно лгут, и LR надо ставить еще меньше, а шагов еще больше для BS=1. И намного. Или установка BS>1 реально влияет критически, как гемини про это выдала, и подтвердилось на практике. Вот что было ей сказано по данному вопросу, дословно:
Batch Size (BS) — это один из самых важных гиперпараметров, который влияет не только на скорость, но и на качество и стабильность LORA. BS=1 Низкая точность. Градиент (направление, куда нужно двигать веса) вычисляется по одному изображению. Это делает обучение "шумным" и менее стабильным. BS=2 Высокая точность. Градиент вычисляется по двум изображениям. Это более точно отражает "среднее" направление, куда должна двигаться LORA, что дает более стабильное и лучшее качество.
Может напиздела, разумеется. Но похоже, если по результату судить. Я ее пробовал в другой сессии чата потом расспрашивать чтоб контекст не влиял - повторяет. Либо глобальная ошибка в ее знаниях, либо оно таки действительно так.
>>1453143 Батчсайз от оптимизатора зависит. У каждого свой оптимальный. Какой-нибудь Lion имеет оптимальный батчсайз 128-256. У адама 16-32. Шакалы на Z имеем не из-за оверфита, а из-за Турбы - тренить на дистиле всегда хуёво было на любых моделях, на базе такого не должно быть. Тут у нас выходов не много - не дотренивать лору до конца или сидеть на батчсайзе 8+ с оптимизатором под низкий батчсайз.
>>1453124 Учту. Попробовал въебать максимум говна, сделал 256/bs=4/uint4. На 1500 получилась хуйня. Ладно, не прям хуйня, да и может ненастроенный lr виноват, но начало ухудшаться качество, а лицу нужно было ещё хотя бы тысяча шагов. На 1024 и 768 с bs=1 такого не было. Делаю сейчас ещё один тест, на 200 пикч на 256х занимают смешные 7.8гб во врам. Потом попробую это же с bs=8.
Ну, для каких-то грубых концептов или стилей 256 - топ выбор. Если оно не хуярит по качеству.
Ну, вот лицо на 256, в 4 бит, кеширование включено, чтобы не хранить энкодер, 2к шагов. Последние две - euler-simple vs er_sde-sgm_uniform. Хз. Обучалось вдвое или даже втрое быстрей дефолтных настроек на 768/1024.
>>1453272 На пик 3 - "не верю". Схожесть приблизительная, разрез глаз и нижнее веко не то. На пик 4 - "и так сойдет". И везде - подбородок неправильный. Он у нее хоть и острый выступающий, но все же не настолько, и не вперед, а скорее вниз - губы выделяются а не подбородок. У нее еще заметная ямка есть по центру - что в сумме не дает такого эффекта сверхтяжелой челюсти. Хотя первые две - хорошо смотрятся в целом. Это только лицо в датасете было, крупным планом? Из роли в сериале, или были общие фото вне роли?
>>1453342 Человек-шиздетектор, ты? Сходи в ремонт.
>>1453347 Ну, да - теперь алиса - универсальный аргумент. :)
Только вот вопрос вообще не в том, узнает сетка лицо или нет. Я просто расписал мелкие детали, которые искажены. Художник такое увидит сразу. Я ж тут не говорил, что все совсем плохо, а ты уже окрысился.
>>1453351 > Ну, да - теперь алиса - универсальный аргумент. :) Ну так кожаный мешок в нейротреде ошизел, нужна компвис нейросеть, которая скажет кто на пикчах.
> Только вот вопрос вообще не в том, узнает сетка лицо или нет. Ого, вот это маневр.
> Я просто расписал мелкие детали, которые искажены. Это ты в зоге удмуртов и банкетных классифицируешь? Ты доебался до человека на ровном месте потому что тебе припекло от того что лора натренена на 256, что обоссало тебе ебало и нужно срочно искать минусы чтобы задемеджконтролить рваную сраку. Первый раз что-ли на дваче?
>Художник такое увидит сразу. У меня худ образование, много лет худ школы, академический специалитет 6 лет, а рисую я 26 лет. Не лезь в этот аргумент, я тебя сожру.
> Я ж тут не говорил, что все совсем плохо, а ты уже окрысился. Ты токсично пассивноагрессировал, упаковав в коннотацию говна, мне со стороны более лутше видно.
>>1453120 >насколько реально теряются или нет мелкие детали при датасете из маленьких изображений. Везде об этом говорится, и это, сцуко, логично - ведь если на картинке деталь даже глазом не разобрать - откуда в лоре возьмется правильная информация об этой детали, ведь ее буквально вообще НЕТ в исходнике. А на квадрате 256 - там что-то мелкое но важное может реально как 2-3 пикселя выглядеть. Еще ДО того, как вообще в процесс обработки попадет. Я именно про это. Братик, ты игнорируешь, что я второй раз щас буду описывать. 1. Держим в уме что флоу насрать на резолюшн выставленный в конфиге, он завязывается на резолюшн латента для корректной генерации, поэтому апскейл латента на флоу такой хуевый и нужны флоу апскейлеры специальные если именно латент скелить. 2. Допустим у тебя датасет из 1 картинки 1024, а резолюшн конфига лоры 256. Её реальный размер может быть хоть 4096×4096 - не важно. 3. После ресайза в 256 вае енкодит ее в раз 20 (я не знаю во сколько раз сжимает вае флюха, но примерно столько) в латент, и флоу подвязывается к этом латенту вычисляя/обучая поля скоростей. Казалось бы, даталоадер сжал картинку и потерял данные, но тут с ноги врывается пункт... 4. Flow не учит шум, детали, и прочее, поэтому все изображения с флоу точные и четкие на практически любых разрешениях - это архитектура синтетического статистического восстановления, а не прямого шумового предикшена. Так в том числе работают супер резолюшен модели. Все что ты видишь на картинках из флоу моделей это статистическая интерпретация модели. Побочным продуктом flow является внутренний принцип модели который можно описать как "галлюцинирующие высокочастотные детали", это так скажем статистика всей модели которая используется при генерации. Так как манямирок нейронок это работа со статистикой (как собственно у всех нейрокалов), то флоу ничего не стоит статистически предположить недостающие элементы опираясь на полученное поле скоростей с датасета.
То есть флоу НЕ может ФИЗИЧЕСКИ достать детали, уничтоженные при ресайзе даталоадером, но флоу они и не нужны, она в принципе их не изучала и не могла изучать, флоу достаточно информации и статданных чтобы их прямо синтезировать обратно, основываясь на знании из всего датасета и всей модели целиком. Магия нейросетевой статистики буквально.
>>1453315 Согласен. Первая вообще не узнаваемая. Есть куда бустить узнаваемость, когда будет base и интересные файнтюны. Меня больше волновала эта лесенка, не замечал её на других генерациях на 9 шагах, но причины могут быть разные. Скорей всего несколько хуевых пикч в датасете. В принципе на другом 256 трейне её нет, там более натуральные jpeg артефакты. В основном по плечи. Старый датасет только из первого сезона. >>1453304 Он не в раме, он выгружается нахуй за ненадобностью после стартовой отработки. И раз ты экономишь 10 секунд загрузки и 10-100мб кеша, по-твоему где квантизация происходит? >>1453466 Не понимаю хули они не сделают поиск по хешу, а не по имени. Даже когда добавят такую фичу, со старыми воркфлоу не сработает.
>>1453482 >Чтобы не вызвать мушку промптом, но она была У тебя фетиш на оверфит и генерацию без промта?
Кстати, если флоу не работает с контентом картинок, то можно хакнуть жопу флоу через дробление условной 1024 картинки на 4 чанка по 256, а батчсайзом скомпенсировать увелчивишийся датасет. Сайнс, бич.
>>1453488 >>1453482 Да какая Монро, вы о чем вообще. Это ж примитив дизайна, плюс сетка такую личность скорее всего и так знает, хотя бы в следовых количествах.
Возьмите перса с какой-нибудь гачи-дрочильни по типу геншина или ZZZ. Вот уж где обилие мелких деталей, которые на сжатии в 256 пикселов просто в кашу превратятся, плюс тотальная ассиметрия костюма.
Хорошо тренированные лоры на сдохле с такими костюмами справлялись. Правда, все равно пердели от натуги, ибо у вае не хваало силенок детали обратно рисовать. Но - справлялись. Причем были лоры как с вызовом "персонажа в костюме" одним токеном, так и с разграничением по частям.
Как работают бакеты (в ai-toolkit для z)? Если в датасете 1024х1024 и 768x768, а выбраны бакеты 512, оно само отресайзит пикчи или кропнет? А что произойдет если датасет наоборот меньше бакета, допустим 384x384? Или лучше самому отресайзить? Не берем в расчет обучение pixel art, когда нужен особый метод ресайза.
>>1453488 >робление условной 1024 картинки на 4 чанка по 256, а батчсайзом скомпенсировать увелчивишийся датасет Ради инетерса тестанул. Взял пикчу анимедауна выше, разрезал на 12 чанков, пизданул скорость экстремальную и несколько эпох сделал. Роботает.
Как быть с вариативностью у тел/лиц? Буквально дефолтное ебло и тушка у каждой бабы, смена промпта и разрешение не спасает, только если конкретно описывать возраст, пропорции, и то дает примерно одинаковые вариации. В сдохле и то хотябы каждый сид это может быть смена ракурса, композиции. А тут буквально одно и тоже, каждый раз, пока абсолютно другой промпт не напишешь. Както чинится это, или это фишка зимагв? ( в квене то же самое кста)
>>1453477 Ты доебался до человека на ровном месте потому что тебе припекло от того что лора натренена на 256 Чел, я не доебался. Я еще раньше написал, что уже остыл, и теперь просто хочу разобраться на практике. И просто перечислил то, где вижу разницу с оригиналом по мелким деталям/нюансам. Главное же - человек запостил ниже датасет на котором это тренировалось - я ему очень благодарен. Стало явно видно, что потеря мелочи хоть и есть, но намного менее критична чем я предполагал. Еще потом сам потестирую, но видимо, кроме совсем уж специфичных случаев, 256 хватает на практике.
Кому я извинения задолжал - тебе или нет, в любом случае, прямо говорю: я был неправ. Прошу прощения.
>>1453486 Большое спасибо за картинку с датасетом. Таки сильно помогло прояснить вопрос. Кстати, гайды рекомендуют для конкретного персонажа ограничиться 15-20 изображений, а у тебя более 50-ти, что рекомендуется уже для концептов. Это было специально сделано под Z, и у нее другие надобности и в этом, или ты просто всегда так делаешь? Спрашиваю потому, что и в гайдах, и гемини настоятельно рекомендуют не превышать количество, если нужен именно конкретный персонаж/объект - мол: "только потеряется детализация от обобщения, и увеличится время тренировки почем зря". Врут получается?
Z-Image-Omni-Base A foundation model designed for easy fine-tuning, which unifies the core capabilities of image generation and editing to unlock the community's potential for custom development and innovative applications. секси
>>1453477 >У меня худ образование, много лет худ школы, академический специалитет 6 лет, а рисую я 26 лет. Не лезь в этот аргумент, я тебя сожру. Запости побольше нейрокартиночек, плиз. Очень любопытно посмотреть, что генерит человек с таким бэкграундом.
>>1453625 >это фишка зимагв Это фишка всех пиздоглазых моделей, похоже. Все рисуют одну и ту же бабу. Нужны едит версии моделей, чтобы рисовать нужных тянучек с референса. Чистый т2и прумптинг — морально устаревшая методология на сегодняшний день.
>>1453893 Это фича вообще всех копронейронок еще с первой сд 1.5. Причем чем дальше тем больше, потому что раньше от смены задника цеплялась инфа по остальным элементам, но современные сетки обученный по развернутым промтам из мультимодалок умеют изолировать лица и абстрагировать их вот в такое нейроебало.
>>1453925 >Это фича вообще всех копронейронок еще с первой сд 1.5 Файнтюнов от васяна - да. Ваниллы - нет. Такого разнообразия всего на свете как в ванильной 1.5 нет больше нигде, и не будет, увы.
>>1453625 Кароче я заметил что фича вариативностью проявляется если тренить с transformer_only:false лоры, просто тупа датасет с бабами на токен woman надрачиваешь и пользуешься. Вовторых помогает переключение клипскипа на -3 (ну или на -1, если ты шиз и ненавидишь промты), -2 дефолтный слишком стабильный. Втретьих уже кидали сидвариатор, он там шум подмешивает согласно настройкам.
>>1453950 У исходной 1.5 просто вместо тэгов вообще рандомный кал, поэтому у нее по любому промту вариативность долбанутая, поэтому ее еще приводило в чувство повесть в качестве негативного промта, откидывавшего 80% инфы и придававшего хоть какую-то когерентность.
>>1453679 Да я на похуе взял сет, собиравшийся ещё для сд 1.4, с более поздними сырыми дженерик капшенами из llava, посмотреть что вообще будет на 256, 200 пикч. Я не знаю советов и рекомендаций. Всё на что я натыкался за эти годы это было "делайте пуки, а не каки", по 10 параграфов на банальную очевидную хуиту. Я бы прочел советы реально крутого чела, но не натыкался на гайды от подобных. Обычно гайды пишут теоретики с копро-лорами. >>1453726 >нихуя не работает кроме крупных планов Кек
>Не похожа. Хуиту сделал. Переделывай говнодел. Учись. Не дожал сообщение, добавь ещё 5 предложений.
https://huggingface.co/malcolmrey/zimage Чел ебать выдал уже 400+ лор на лица, которые теперь даже не загрузить на цивит. Вот проба с его лорами. Дженна сходу лучше.
Я как и хотел тоже попробовал опять. 256, BS = 8, steps = 300 (намеченные 2500 шагов на 8, с округлением результата), lr = 0.0001*sqrt(8) = 0.000282842712474619 https://imgur.com/a/01fX8bu 20 пикч, автокапшены с цивита, то есть дженерик описание без имён и триггер вордов. Около 15гб врам, 45 минут, но ощущение, что можно было ускорить. Просто, быстро, удовлетворительно, почти несочетаемо с другими лорами, по крайней мере на стандартных лоадерах. Поэтому удивляет, что чел наобучал уже столько лор ещё до выхода базы. >>1454238 Всегда 2 года. AGI через 2 года, кстати. Видеонейронка приблизительно сравнимая с Veo 3 и Сора 2 тоже через 2 года на локалках.
В общем, потрахался я весь вечер с устрицей, и выяснил, что на 3060 12GB лору для зины без offload unet тренировать в принципе нельзя (на моем калькуляторе). Даже на датасете с картинками размером 256, и BS=1. Не лезет. Нужно хотя бы 25% offload. Зато на 50% и BS=4 - 4.5 сек. на шаг. Если еще и получится хорошо - ну так и совсем замечательно, в общем то. В этот раз концепт тренить поставил, а не персонажа.
>>1454336 >Даже на датасете с картинками размером 256, и BS=1. Не лезет. че? у меня 11.1 занимает если трансформер 4бита а енкодер 2 бита. если не держать енкодер то гигов 7 будет.
>>1454336 Зачем ты вообще держишь TE в памяти во время обучения, ты ебанутый? Она выгружается из памяти даже при выключенных Unload/Cache опциях. Возможно, Low VRAM нужно тыкать.
ЧТо подустали от Зет? Вот вае с перешарпом к ней подходит. Резкость просто жесть добавляет и нахаляву как бы получается. На клозапах вообще перешарп выходит.
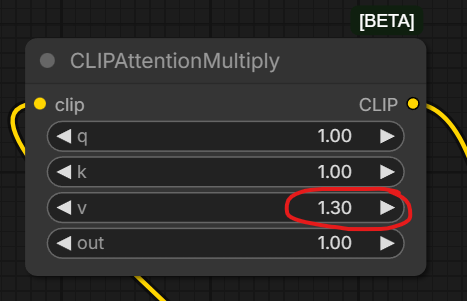
CLIPAttentionMultiply нода с такими настройками, как бы "стабилизирует" картинку. Масштаб объектов более адекватный друг к другу, лучше пальцы и глзза и много другое. Слева без нее, справа с ней. Почти всегда лучше пальцы и мелкие элементы. Влияет на текст. Не только в Зет, но и во многих других моделях, с такими настройками, картинка будет исправлена. Прямо панацея какая-то. Хз, почему никто не знал.
>>1454464 >Даже простая смена настроек на er_sde - sgm уже делает более четко Этот вае от флюкса работает с многими моделями. И ты теперь можешь шарпить их все. Не везде можно использовать сгм. МОжно же бонго-батя57 с перешарпом
>>1454384 >>1454450 Low VRAM всегда стояла. Но трансформер в 4 бита не пробовал. Значит надо попробовать... А что касается encoder'а - если ставить просто галку на его выгрузку, то судя по описанию в справке к ней, не будут работать индивидуальные теги для каждой картинки из .txt - только один общий на все картинки заданный прямо в задании. Мне для обучения на концепт это не подходит - там стиль изображения надо явно указывать - это фото, арт, аниме, 3d рендер или еще что, чтобы не смешивало стили в общую кашу. По крайней мере - так руководства учат...
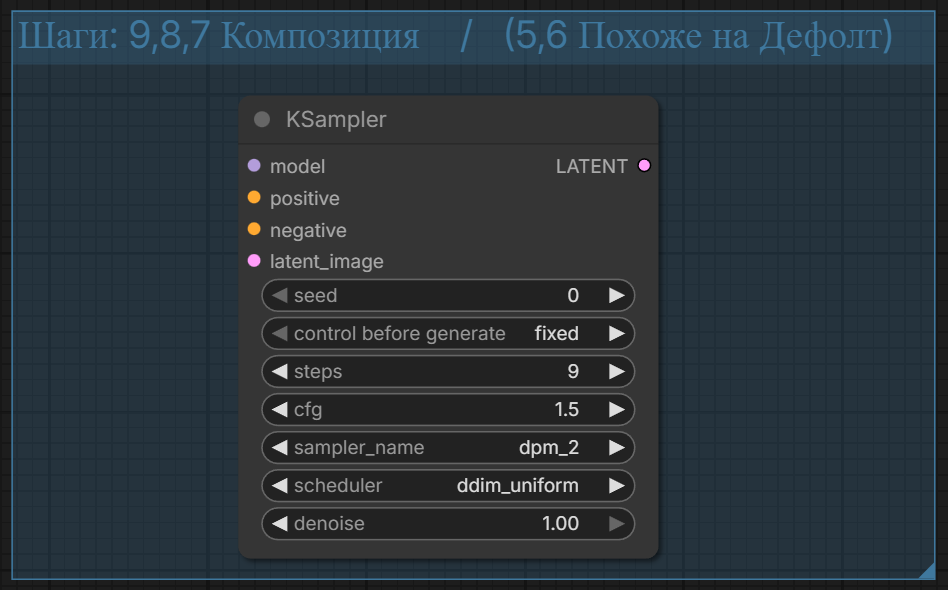
>>1454565 Хочу поделиться настройкой семплера/шедулера: dpm_2/ddim_uniform. Старый забытый семплер. Шедулер ddim любит сильно наваливать деталей по мелочам везде. В свызке с Зет именно они дали совсем не похожую на дефолт картинку. Отличается всё, что можно. Один минус - присутствует узорчатый шум(кривые кружочки) на коже, если резкие клозапы голого тела делать. Но в принципе проявляется не всегда и его можно потерпеть. На 9 шагах самое то. В общем картинку преображает, если глаз уже замылился от Зет, то попробуйте. Пик1 дефолт.
>>1454588 Еще, по моим тестам за пару дней, он лучше следует промпту. Если упомянешь нсвф, то долой одежу, а дефолт может остаться в купальнике. Вот на пик1 дефолт, а я просил нарисованную картину. На пик2 dpm_2/ddim_uniform
>>1454596 >CFG на скрине 1.5, но лучше начинать с 1.0 и до 2.5 Тут, как бы, или начинать с 1.1, или сидеть на 1.0 - там же принципиальная разница. На 1.0 отрицательный промпт не работает. И при переходе на 1.1 время на один шаг растет практически вдвое.
Стилизацию под 60-е не может делать. Ещё ляхи не умеет рисовать.
dall-e 3 до лоботомии и запечатывания цензурой не приходилось упрашивать, а у Z те же болезнь, что и у SD - даже когда ему пишешь "большие бёдра", он всё равно худышек хуярит
>>1454620 Зина любит подробности. Если ты написал "большие бедра" - она только бедра и изменит. Пиши детально про фигуру. Не нужны худышки - пиши что "пухлая фигура", или там "амазонка" в зависимости от того, что надо.
>>1454705 Я не пользуюсь лорами(кроме ускорялок), не хожу на цивитай. Всё придумал сам и поделился. Вопрос: почему ты не поделился этой информацией здесь? Сэкономил бы мне время.
>>1454721 Не поделился из-за того, что не хотел анону советовать кал. В влюбом случае все эти тесты делаются за час, с прогоном всех шедулеров и сеплеров на автомате.
>>1454625 Дико. Складывается ощущение, что если они выпустят Z-Video, то и она приблизится к Соре. Но это вряд ли, в видео сфере итак был большой прогресс, это пикчевые модели так безнадежно устарели и были стародревним говном из жопы с кривой анатомией и всратой композицией, что нагнать было не сложно.
>>1454467 Может, потому что никакая не панацея? А в некоторых случаях, ещё и делает всё хуже.
Это, конечно, хорошо, что запостил. Спасибо. Только ни про настройки и их смысл ни слова, ни тестирования нормального (которое покажет, что не всегда это годится).
>>1454585 >Low VRAM всегда стояла. Ну так она всегда вкл должна быть у нищеты. >Но трансформер в 4 бита не пробовал. Значит надо попробовать... Если че 4 бита для трансформера это аналог настроек как в QLoRA, так что кволити не страдает. Вот ниже 4 уже вопросы есть, но у нас как бы флоу архитектура, а ей в теории и 1 бита информации достаточно чтобы правильно апроксимацию скорости сделать. Но я не пробовал. >А что касается encoder'а - если ставить просто галку на его выгрузку, то судя по описанию в справке к ней, не будут работать индивидуальные теги для каждой картинки из .txt - только один общий на все картинки заданный прямо в задании. Там где анлоад те галка там да кепшены не работают. А если галка где леер офлоад, на 100% для енкодера в 2 бита и 0% для трансформера, то тогда кепшены работают и те выгружается в рамку. Еще можно включит кеш текст эмбедингов, но тогда не работают дропауты и триггер ворд.
Лучше бы выпускники философских факультетов и дальше продолжали работать в общепите, курьерами и грузчиками, чем устраивались в IT-компании, а потом ломали модели своей дебильной душной этикой.
>>1454770 Да, так у меня примерно и стоит. 100% для encoder 25% для unet. Но unet сейчас в 8 бит, и вероятно, если выставить в 4 bit то можно 0% попробовать.
>>1454770 >>1454959 Попробовал 4 бит и 0 оффлоад. Ы... Оно так медленнее, чем 8 bit и 25% offload. 5.25 против 4.5 sec/it. Логично, сцуко. 3060 нативно не то что в 4 - в 8 бит не умеет. А своей шины туда-сюда гонять остаток модели ей видать и так хватает, чтоб ядра загрузить.
Всё же может делать. По стилистике довольно натуралистично получает. Но, похоже, у него слабо с фантазией: не умеет додумывать окружение, нужно всё прописывать в промоте, что хочешь увидеть. Ну и да, нужно изъебнуться, чтобы это была не худышка.
Короче говоря, в плане качества это левел-ап, но в плане промтинга - практически то же самое, что и SD.
Qwen, кстати, умел бурно фантазировать, но потом заменили на какую-то более тухлую версию.
>>1454977 >но в плане промтинга - практически то же самое, что и SD. Чел, побойся... ну кого угодно. :) SD промптинг по сравнению с тем что у Зины - просто отсутствует. Чистый рандом по отдаленным мотивам. А то что у Зины фантазии нету - это может быть как багом так и фичей. Лично я предпочту сам детально написать - что мне надо, если сетка это поймет и сделает. А чтобы рандом на картинках получать - wildcards подстановки в промпты давно придуманы.
>>1454748 Нетрудно догадаться, если посмотреть, что здесь постят из треда в тред. Местному контингенту все модели нужны с одной единственной целью: чтобы дрочить. Сгенерил картинку няшной тяночки - подрочил. Анимировал картинку - еще раз подрочил.
Как-то у тебя всё плоско и примитивно. Сплошная картонная профанация в духе постмодернистской деконструкции. Дело ведь в чувствах (а ведь это именно то, что отличает живое от неживого), в эстетическом восприятии.
>>1454810 Ставишь ai-toolkit, дальше всё однокнопочно. >>1454795 А теперь попробуй это же на er_sde. >>1454830 Это не этика, это капитализм. Этика это у грока, который в принципе позволяет генерить голых баб. >>1454990 Nano Banana
>>1455162 Может, это бот пишет? Подозрительно что тут, что в вк стали попадаться такие душно-уёбищные тупые комментарии.
Не, такие и до этого были. Но дело, как бы правильнее это сказать, в ощущении некоторой неуместности. В добавок таких было меньше. И исходили от несколько другого контингента.
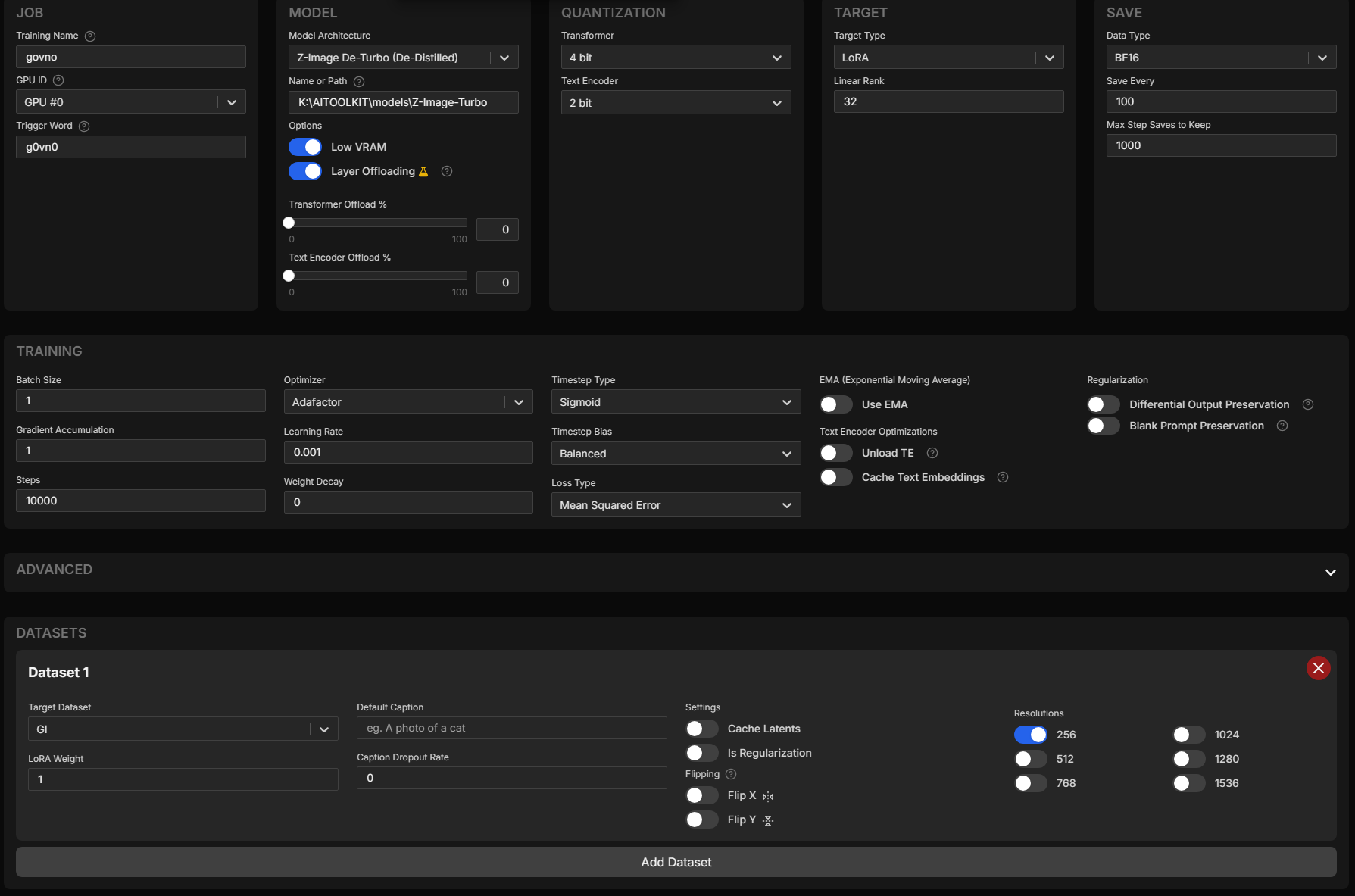
Хуле там гайдить. Базовый лейаут пикрел. Меняется только: - скорость на адафакторе, хотите сейфово тренить - ставите меньше - можно заофлоадить енкодер на 100% - можно поменять таймстеп биас - хайпас изучает по сути калтент, лоупасс стиль, баланс - и то и другое - дикей на маленьких датасетах не нужен
Если офлоадить енкодер можете резолюшн на 512 поставить или батч выше ставить или вместе с акумуляцией чтоб быстрее тренить и градиенты чище были.
В адвансед настройках можете выставить в блоке нетворка transformer_only: false - будет обучать все доступные для лоры слои а не только ффнет и атеншен, генерализация быстрее все дела адапатация лучше Можете поменять конв дименшен на равный линейным слоям - будет больше локальной инфы с датасета пиздить, флоу похуй.
Переключать на локр с квантизацией на трансформере смысла нет - он не поддерживает ее и просто не запустится, а так локр лучше лора модуля по капасити и точности есличе. Ликорис в тулките пиздец старый версия 1.8 (актулаьная 3 сколькототам), поэтому нихуя больше не работает, я пишу патчик на поддержку всех актуальных алго (хочу BOFT заставить работать, потому что это наиболее близкое к полноценному файнтюну решение в части адаптеров т.к. меняет веса напрямую не затрагивая базовое поведение модели) но пока не понимаю как в этом говне устрицы все работает.
>>1455294 10000 чтобы поставить и забыть, адафактору хватит 1000-1500 шагов для датасета 100 картинок, то есть 10 рипитов на картинку. В идеале обычно 100 рипитов на картинку делается чтобы прям все выжать, но это хуита как по мне нинужная. 0.001 просто в 10 раз меньше чем стандартная скорость адафактора, но то для гигантских датасетов и батчей. 0.0001 слишком медленно, 0.0005 норм.
>>1455289 Чисто от себя - если концепт тренится, а не перс, то разница между 512 и 256 исходниками все таки немного есть. Не очень большая, но заметная, если упарываться в качество. "Текстуры" и мелкие детали все же лучше передаются. Если 256 - оно тоже не получается говном, но все это мелкое добро просто подменяется тем, что и так в модели есть. Скажем, кожа будет обычной, даже если в исходнике везде есть мелкие бледные малозаметные венки, и это часть концепта. Но пока процесс такую деталь вытащит из 256 - оно в оверфит по крупным деталям уходит, аж до поломанных пальцев (не шутка - начинает их корежить как сдохля а то и 1.5). При 512 - нормально получается именно вместе с этой мелочью. В остальном - не влияет, с чего я таки в охуе до сих пор. Магия какая-то. :)
Эксперементирую со вчерашнего вечера на терировке концепта. Rank 96, LR 0.0002, DG=2, BS=4, 69 картинок датасет. 600 шагов - уже оверфит для концепта. Но заметить очень трудно, потому что единственный признак - детали текут из стиля в стиль, и сами стили смешиваются. Рандомных артефактов и прочей херни от случайного шума на картинке вообще нет.
Если 3060 (и возможно вся 30хх) быстрее работает с Transformer Offload 50% и 8 бит, чем 0% offload и 4 bit - уже писал выше.
>>1455306 >ебля >перетыкнуть пару тумблеров ты еблю не видел, шезлонг >лучше дефолтных настроек А какие у тебя вопросы? Ты аналитическим мышлением не владеешь и сам умозаключения сделать не можешь? Адафактор самый лоурам оптим, при этом не являющийся 8бит калом. Еще пару аргов включишь и вообще будет авто лр. 4бит для трансформера потребляет в джва раза меньше врама, а никаких потерь нет. 2бит для енкодера буквально не влияет ни на что, енкодер необучаем, а врам и рам экономит. 256-512 пукселей для датасета очень экономит врам, флоу все равно откуда поля скоростей считать, а батчем можно значительно улучшить чистоту градиента. Доп слои тренировать лучше, потому что там есть контекст рефайнеры и прочие важные штуки.
>>1455341 >Чисто от себя - если концепт тренится, а не перс, то разница между 512 и 256 исходниками все таки немного есть. Не очень большая, но заметная, если упарываться в качество. "Текстуры" и мелкие детали все же лучше передаются. Если 256 - оно тоже не получается говном, но все это мелкое добро просто подменяется тем, что и так в модели есть. Скажем, кожа будет обычной, даже если в исходнике везде есть мелкие бледные малозаметные венки, и это часть концепта. Но пока процесс такую деталь вытащит из 256 - оно в оверфит по крупным деталям уходит, аж до поломанных пальцев (не шутка - начинает их корежить как сдохля а то и 1.5). При 512 - нормально получается именно вместе с этой мелочью. В остальном - не влияет, с чего я таки в охуе до сих пор. Магия какая-то. :) Есть рабочая страта как обойти ограничения 256: берутся 2 идентичных датасета - только в одном целые изображения уменьшаются до 256, а во втором эти же изображения разбиваются на чанки по 256 (можно без капшенов). Поля скоростей будут идентичными для каждого датасета, но полезного сигнала больше.
>>1455422 >Есть рабочая страта как обойти ограничения 256 А это точно будет лучше, чем просто датасет из 512? Картинок то больше будет, эпоха длиннее. Сейчас у меня просто 512 запущено с BS=4, памяти хватает, падение скорости строго линейно (было 4.5 с 256 стало 9 с 512). Выигрыша по скорости от двойного датасета я точно не получу, а вот по качеству?..
>>1455538 >А это точно будет лучше, чем просто датасет из 512? Это точно будет лучше по количеству информации, чем просто ресайз до 512, т.к. будешь иметь полную информацию с изображений в формате множества 256 слайсов.
>>1455556 А, дошло. Это выход, когда исходники мегапиксельного и выше качества. А я тут для тестов просто надергал картинок без особого подбора из сети - так они сами примерно около 512 после обрезки до квадрата оказались. Вот и затупил - их разве что пополам еще резать.
Пару дней ковыряю этот ваш стейбл дифьюжн, попробовал разные модели и походу моя гтх1660 флюкс не потянет без шансов (500 сек на итерацию лол). Пошел искать 3060
>>1455787 Для быстрого развлечения Z. Qwen по сути убит им. Если попердолиться, то на Qwen можно сделать лучше фото, но в остальном вообще не вижу преимуществ. Тот же Edit абсолютно ущербный, а при необходимости проще сделать что-то в Banana. Поэтому имеют смысл разве что Z, Chroma и XL, ну и для специфических задач Wan, но и его может заменить Z. Хотя какие-то отдельные редкие лора лучше всего обучены на Flux.
В галереях моделей обычно 90% мусор. В хроме вообще 99% мусор. Причем те немногие кто делает хорошо, нередко оставляют вф, но их не юзают повсеместно, а юзают дегенеративные EXTENDED EXTENSIVE SUPER PRO WORKFLOW, который после 100 недостающих нод за 1 час генерит копропикчу хуже дефолтного семплера. В связи с этим вопрос. Покажите самые охуенные чужие пикчи из Z Image, увидеть что на ней можно делать.
>>1455846 Running 1 process Loading ZImage model Loading transformer config.json: 100% 473/473 [00:00<00:00, 3.67MB/s] (…)ion_pytorch_model.safetensors.index.json: 49.0kB [00:00, 141MB/s] transformer/diffusion_pytorch_model-0000(…): 82% 8.18G/9.97G [00:51<00:08, 217MB/s кек, что-то даже запускается. жаль у меня все конфиги под н100 и лень настраивать
>>1455925 > тоже не Фалькон, а Фэлкон. Так ещё можно долго продолжать. Ага. И football тоже у нас, как фотбал произносится, не так ли? > Это нормально переиначивать заимствованные слова так, как удобно Кому удобно? Переиначивание флакс просто выдает нетакусика. Переиначивание его даже не во флукс, а в флюкс, выдает либо школьника, либо овулирующую сельдь, привыкшую готовить кашку с молочком и вареньицем своему пиздючку.
>>1455852 Блядь, даже страшно представить как ты видишь мир, если у тебя Z выдает селеб из коробки. В двери осторожно на ощупь входишь? >>1455925 Ну фэлкон это вообще база. Илон тоже звучит очень похоже.
>>1456012 Вот тупо первые не черипикнутые генерации в 768х1024 тупо по имени, с ортегой дописал венсдей. Если покрутить несколько раз и добавить разрешения будет больше схожести.
>>1456125 Сейчас бы аргументировать ии-слоп ии-слопом. Ещё и тупым. Нейронка и по скетчу тебе скажет кто это или вообще по одежде/причёске догадается. Дело же не в этом, а в том что ты натренил какое-то говно с лицом другого человека.
Возможно тупой вопрос но насколько критично отсутствие видюхи? RAM 32, i9 13gen текстовые копайлоты более-менее пашут. ебнутая скорость/качество не нужны 512х512 достаточно, надо редачить картинки по промпту, будет ли это адекватно работать (условно до получаса) или без cuda это часы?
>>1456254 Сегодня, в мире лоКАЛок >редачить картинки по промпту означает сделать подбор промта из 5-10 попыток, потом ролл сида на 4-8 вариантов. То есть умножай свои полчаса 10 точно, а то и на 20.
>>1456254 Для лоурезов в SDXL-моделях хватит, раз тебе полчаса это терпимо. Хотя речь будет идти о минутах, И можно ускоряками обмазаться (lightning lora, dmd2 всякие) для генерации за меньшее количество шагов.
>>1456271 > хоть какой-то апскейл в 2-4 раза с добавлением деталей и сглаживанием шума SeedVR2 попробуй, он и на ЦПУ в разумное время должен просраться
>>1456097 Готов поспорить, ты печатаешь СЛЕПЫМ набором. Пожалуйста, не вылазь больше. Ты почему-то решил, что тут будет терпимость к таким умственным инвалидам как ты. Если еще осмелишься цифровым способом сравнивать, тащи хотя бы дистанцию между лицами.
💡 The problem: Standard LoRA training breaks Z-Image Turbo’s acceleration—images turn blurry at steps=8, cfg=1, even though they look fine at steps=30.
✅ We tested 4 approaches: 1️⃣ Standard SFT → high quality, but slow 2️⃣ Diff-LoRA → fast, but inflexible 3️⃣ SFT + distillation → great results, heavy lift 4️⃣ SFT + DistillPatch (our recommendation) → plug in one LoRA, instantly get 8-step Turbo performance back 🚀
>>1456526 Лол, сука. Это типичная ситуация "у чужого решения один изъян - оно сделано не мной"? Ostrich сделал же адаптер и теперь уже де-турбо модель.
>>1457154 Когда CFG=1.0, то движок может существенно упростить вычисление гайденса. Если CFG отличается от 1.0, то приходится считать по полной формуле. И тут уже не важно 0.9, 1.1 или 4.0 - все будут одинаково тормозно.
>>1457154 >>1457287 Кстати гпт мне объяснил что cfg 1.0 еще и влияние лор усиливает максимально, я так пару раз недоглядел а потом охуевал с того что получилось
Прикол, если в Z использовать предложение "You are an assistant." перед промтом, то несколько генераций по подному и тому же промту будут более разнообразными, чем голый промт.
>>1457414 >более разнообразными Спасибо! Я попробовал такой подход: сначала генерирую черновой вариант (настройки на скрине), а затем прогоняю его через i2i. С текущими параметрами черновик выдаёт совсем другой сюжет, и основная задача — получить с него качественный i2i‑результат. При низком denoise картинка выходит мыльной, а при высоком — становится чётче, но сюжет заметно уходит. Возможно, кто‑то подскажет оптимальные настройки для такого случая i2i.
>>1450857 ComfyUI - очень страшно, я не знаю что это такое. Скачал Fooocus, но говорят, что это прям вообще основы
Комфи, которая в виде приложения для винды вполне себе нуб-френдли на уровне фукуса. Выбираешь задачу и модель какую надо, она сама все скачивает. Главное ничего кроме промпта не меняй.
>>1457693 >Комфи, которая в виде приложения для винды вполне себе нуб-френдли на уровне фукуса. Пробовал скачать недавно вместо обычного портабла, так эта хрень даже не заработала.
>>1450857 >Только собираюсь вкатываться, подскажите актуальную приложуху для нуба. нет ничего кроме комфи >ComfyUI - очень страшно, я не знаю что это такое. Там буквально посмотреть из чего состоит дефолтный пайплайн и все поймешь. >Скачал Fooocus, но говорят, что это прям вообще основы Факас это для совсем дегенератов однокнопочных без функционала. >automatic1111 - типа давно не поддерживается. ну да, но он в принципе рабоатет, как и его говнофорки типа форджа которые до сих пор чето там обновляются >Может что-то еще есть нуб-френдли? Меня больше интересует обработка изображений: апскейл, дорисовка фона, наложение эффектов на фото, замена лиц, зачистка/замена объектов, совмещение - вот это вот все. Вот под такую задачу тебе нужна комбуха из криты и комфи. Ну или просто комфи, но чтобы в самом комфи удобно было надо докачать кучу нод. енжой кароче https://github.com/Acly/krita-ai-diffusion установка не пердольная, все расписано.
>>1457689 >что задать в промте для Qwen3-VL чтобы она перестала срать цензурой надо расцензуренную качать >И на чем ее лучше запускать? Пробую Ollama, но с ComfyUI в связке не очень удобно а че неудобно? под каждый ллм клиент есть свои ноды чтобы тащить ответы в комфи типа https://github.com/stavsap/comfyui-ollama
>>1457488 Я хуею с пориджей которые не могут абзац текста в промт написать, я меня инглиш неродной и то проблем с этим близко нет. Дальше будет ЛЛМ которая будет принимать голосовой инпут типа "А-аа-ыы-е-а-ы" и пытаться конвертировать его в человеческую речь.
>>1457734 Там нужно свежий VC_redist поставить наверное, на днях переустанавливал комфи после того как случайно удалил сандбокс со старым и столкнулся. Возможно git еще.
>>1457822 >Я их и использую. Думал есть вариант получше. Ну ты поищи по поиску комфименеджера, там много ллм нод. Я через убабугу ллмки подключал через специальные ноды.
Всю жись обновлял комфи первым батником. И тут заметил, что оказывается есть батник СТАБЛЕ. Вы каким обновляете? Есть смысл обновлять на "стабильную" версию?
>>1458093 Обновляю git pull'ом, захожу в venv и pip install -r requirements.txt, потом cd custom_nodes и там гоняю ls | xargs -I{} git -C {} pull. Нахуя чот еще?
Порекомендуйте где можно намотреться видосов по установке нейросетки себе на комп и тому, как ей пользоваться. Цель - генерация пикч с сиськами и письками
Подскажите, дайте код ноды, текстовое поле которое принимает текст и может сохранять его в ворфлоу. Из какого-то пака, но не хочу ставить целиком, мне только эта нода нужна. Мучал дипсик и квен они дают код не рабочий или не понимают меня. Вот есть стандартная нода Preview as Text только она ущербная, при переключении вкладок текст с нее пропадает и не сохраняется. Спасите. Нужна простая маленькая нода
Хоть у меня и так всё летало, но заменил фп16 ТЕ на фп8 скейлед, ради интереса и стало вообще за наносек. Разницы в качестве вообще нет. Смысл в фп16 на ТЕ? Я про зимаж если что.
>>1457689 Попробуй эту ноду, оно немного сыровато и пути поиска прибиты гвоздями, но оно работает. И там есть нода по сохранению сгенерированных промптов в библиотеку
Кто активно работает с субграфами? Я думал они созрели начал активное внедрение. Сделал генератор -> конвертнул в субграф, настроил -> сделал клон и изменил ксемплер на другой -> в первом поля просто так поперепутались -> постоянно рвется линк на денойз внутрь субрафа. Короче за 30 минут доверия они так и не заслужили. Я не хочу искать потом в сложных схемах где обрыв линии. Как ваши успехи?
>>1458816 Активно пользуюсь, никакого непредвиденного поведения не замечал. Раздражает только невозможность свободно сортировать порядок выходов, в остальном - довольно урчу. Лучшая фича по наведению порядка в лапше.
>>1456097 Какая модель лучше всего генерит знаменитостей по референсам. Я качал флакс 2 50 часов какой-то квантованный. Он вообще делает непохоже совсем. Да и впринципе ничего общего с референсами не дает.
Sd1.5 Понимание промпта конечно никакое. И люди кривые само- собой. Но блин это древняя полторашечка. Куда делся весь цвет, яркость вот это вот всё. Какая модель сейчас так генерит фон. Таким зеленым?
>>1458950 >весь цвет, яркость вот это вот всё Дрочеры требуют реализм. Реализм всегда идёт в приглушённых тонах. Яркости тебе может навалить wan, он любит эту клипартовую постановочность.
>>1458477 Я уже прихуел с того что появилась вменяемая и быстрая модель. На сдохлю давно хуй не стоит, флаксы и хромы это медленнаблять даже с турбодурилками, квен больше технодемка, а тут все очень даже неблохо.
>>1459094 >флаксы и хромы Там реализма нет нихуя. Чёткость волос на руках есть, но всё смердит нейроговном и постановой. Зетка же будто фотки, даже я с полторашек дрочу модели, но порой не всегда могу точно сказать по генерациям зетки - фото это или нейрослоп. Впервые такое у меня.
>Installation WAN 2.6 >Activation: Upon the first launch, the software will automatically register your HWID and start your 14-day unlimited timer. Новый Ван всё? https://github.com/WAN-2-6/wan-2.6 https://wan26.ai/
>>1459165 >Note: An active internet connection is required during the first launch to verify the trial license. То есть на своем же железе и еще и платно?
>>1459165 Такое впечатление, что это если и не скам кого-то левого, то грубое нарушение условий использования GitHub. Он там сейчас используется фактически как файлообменик для екзешника под винду, а исходный код в репе отсутствует (затычка в наглую лежит вместо реальных исходников). По идее - надо бы всем кагалом репортить эту хитрую морду гитхабу за нарушение. Дабы неповадно было.
>>1458800 >>1458815 Не пиздите. С первой же нахуй генерации на фп8 отвалилось ползуба, появилась дыра в тени, упростилась геометрия фона и поменялась текстура на фоне, меняя восприятие глубины. Потом я специально нагенерил кучу пар, запутал себя и сделал слепой тест. Всегда в одной из пар какая-то хуйня то с зубами, то с глазами, то предметы превращаются в более простые, становятся более пластиковыми. И оказалось, что всегда это было fp8. И главное прирост, если и есть, то это около 25>21 или 29>25. Для анимекала или для черновых генераций пойдёт, для нормальной генерации это только деградация качества. >>1459165 Какой-то васянский скам. С SEO keywords вообще обосрался. Нахуй ты сюда это притащил? Твой троян?
>>1459097 >Чёткость волос на руках есть, но всё смердит нейроговном и постановой This. А у СДоХЛи ссаной нет глубины, все плоское блять. Зимага удивляет.
>>1459352 >Не пиздите. С первой же нахуй генерации на фп8 отвалилось ползуба, появилась дыра в тени, упростилась геометрия фона и поменялась текстура на фоне, меняя восприятие глубины. Потом я специально нагенерил кучу пар, запутал себя и сделал слепой тест. Всегда в одной из пар какая-то хуйня то с зубами, то с глазами, то предметы превращаются в более простые, становятся более пластиковыми. И оказалось, что всегда это было fp8. Дурка ебаная
Но немного удивлён, что тут все продолжают на Z дрочить. Причём на саму Z, а не использовать Z как обёртку для обреализмевания результатов генерации других моделей, которые в большую шизу, позы и лоры умеют.
Ну или может у меня просто Z слишком плохо на лоры реагирует даже при дроче коэффициентов, и либо ломается, либо фиксируется на лорах.
https://civitai.com/models/2172944/z-image-tensorcorefp8 У вас это даёт прирост скорости? На 40XX/50XX. В консоли пишет manual cast: torch.float16 и хоть какие ему флаги суй, ничего не меняется. Владельцы 50XX в теории могут вообще nf4 значительно быстрей юзать. >>1459438 Сама генерация кал, но сравнение на одинаковом вф. 2.0, 2.1 (походу комфи не полностью обновилось), 2.1 после ещё одного перезапуска комфи. Сравнение ни о чем не говорит кроме как о необходимости обновить комфи. Инпейнт до сих пор не получается.
>>1459661 Очевидно потому, что писи-каки неизвестный для модельки концепт. Вряд ли китайский корпорат напихивал в датасет испражняющихся людей, если оно даже гениталии не видело ни разу.
>>1459785 > Тогда непонятно Одну лору ещё можно подружить. Две... ну побалансить весы... В то время как на илюстросы вешаешь 5-10 лор, и оно не захлёбывается, а рисует что подхватывает с лор. А Z рисует уже "реализм" по тому, что видит, какая бы бредятина там ни была. Хотя надо признаться, у меня мало примеров такого применения, так что понимаю, что со стороны выглядит как фантазёрство. Надо самому побольше нормальных примеров наделать сначала.
>>1459823 Да дурацкий image 2 image же. С дрочем коэффициентов на вкус пользователя и в зависимости от оригинала. Лица правда может полностью переделать, но это же "реализм".
>>1459798 >В то время как на илюстросы вешаешь 5-10 лор, и оно не захлёбывается Далеко не всегда. У меня регулярно начинались шакалы картинки уже на 3-ей лоре - что не делай. Зависит от самих лор. На Z я уже тоже поиграться с лорами успел. IMHO - можно и больше двух заюзать, но тут вступает основной нюанс Z - чувствительность к промпту. Ей надо на боле-менее естественном языке писать, и как-то вплетать ключевые слова активации в промпт так, чтобы нормально читалось. Если лор несколько, это еще сложнее. Особенно, если автор лоры об этом не подумал. И очень важно - "зоны действия" лор. Если одна, скажем, делает модель автомобиля, а вторая - дом, они почти не влияют друг на друга, и можно силу почти не трогать. А если это два стиля, т.е. затрагивают все - действует золотое правило "сумма силы лор должна быть <= 1". В общем - капризнее Z к этому делу, несомненно. Но все-же использовать можно, если приловчиться.
>>1459857 > Но все-же использовать можно, если приловчиться. Ну вот мне пока кажется, что легче приловчиться генерить шизу на других моделях, а её использовать уже на готовом. Ну или через месяц-два-три что-то случится, и Z станет не такой капризной. Что угодно, какой-нибудь плагин для комфи, какая-нибудь автоматизированная система весов (херню несу) или другая версия зетки. По крайней мере текст зетка генерит постабильнее других.
>>1459827 Спасибо за наводку по поводу img2img, чет как-то мимо прошло. На сравнении слева скриншот персонажа из virtamate, справа результат в Z. Порадовало как зет сделал лес на заднем плане и замок.
>>1460019 >ага, ночью на ципочках) Ну вот далеко не любые модели хороши в img2img. Qwen активно перерисовывает всё под себя. Chroma вообще рисует хтонь раньше чем проявится стилизация. Wan заебок, flux заебок. Z вот я наконец сел i2i проверять, и там тоже не всё гладко. Он артефачит на маленьком денойзе, но для некоторых стилей это норм мимо
>>1460206 Линканите канал какой-нибудь где можно шаг за шагом научиться пользоваться актуальной версией стейбл дифьюжена и ГШ к нему. Чтоб от установки до объяснения основных функций
>>1460324 >актуальной версией стейбл дифьюжена стейблдифушен это семейство моделей брат, последняя актуальная сд 3.5, но она мертва с точки зрения коммунити, последняя не мертвая сд - сдхл, на ней тонна файнтюнов на все случаи жизни если тебя интересуют конкретно новые модели вообще то сейчас все дрочат в Z-image > ГШ к нему UI на данный момент один под все нейронки визуальные - ComfyUI, качаешь портабл, ставишь https://github.com/Comfy-Org/ComfyUI-Manager менджер кастомных расширений, качаешь модель или ее составные части, раскидываешь по папкам в портабл комфи, изучаешь дефолтный пайплайн из премейдов - буквально пикрел для сдхл, все ты магистр комфи, остальное по пути изучишь
>>1460425 >Эти пайплайны там буквально воткнуты в шаблоны а кто спорит? ток там они теперь перегружены и их 185 штук, новичок потеряется и обосрется вот например СИМПЛЕ СДХЛ ТЕМПЛАТЕ, вот скажи зачем было пихать рефайнер блок которым никто не пользуется никогда
>>1460563 Они, конечно, все артефачат. Но вот артефакты Wan, например, они консистеные, непротиворечивые. Ты можешь крутить денойз в большом диапазоне и получать разные оттенки детализации и пластиковости. А у зетки диапазон очень узкий.
>>1460818 Хрома единственное что и умеет - в кучу стилей изкоробки. Её в этом плане можно исследовать бесконечно. Жаль только сами картинки вечно разваливаются
>>1460823 Вот этого я не понимаю, хули он обучал-обучал, дрочит какой-то пиксельспейс в то время как у него мид-нойз просто в хламину проёбан. Хуй знает как такое фиксить. Крупные детали и очень мелкие детали у него заебись же.
Владельцы tesla v100 в треде есть? На ней возможно с приемлемой скоростью обучение лор под z-image? В ллм треде один анон тестил, но только в генерации. 60-80% от 3090 вроде как может дать.
>>1460930 >60-80% от 3090 вроде как может дать. Загнул, насколько я помню там производительность на нейрокале в четыре раза хуже чем на 4090, то есть где-то уровень 3060 будет.
>>1461132 Чет не знаю, это даже не 2000 серия, у этих Вольт и тензоры не тензоры и вообще. Я когда искал тоже давно инфу, в конечном итоге, помню, тоже как чел выше по найденной инфе пришел к тому, что это 3060 в говноформате, уж никак не 3090. И расхотел ее.
>>1461150 Ты не понял, стейбл это как инструмент для работы с моделями, в него ты модели грузишь а уже они тебе картинки генерируют, а zimage это именно моделькотоиую в стейбл можно засунуть, как и любую другую.
>>1461150 > это не стейбл дифьюжен а другая модель какая-то? Нет. Да. >>1461291 Зачем так тролеть... Модели ты грузишь в графический интерфейс, который отношения к сд не имеет вообще.
>>1461324 >Видимо я ещё никогда так не ошибался... Бывает. >Я думал эта папка со скриптами это и есть sd. Для справки: вот состав сдхл https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main Оно может (как и любая модель) использоваться для генерирования через голые диффузерсы на питоне буквально через пикрел.
Некоторые челики уже тренируют только конкретные слои (что еще быстрее чем тренировать фул лееры и вообще меса меньше занимает), при этом импакт от лоры выше (потому что дата распределяется не по всем леерам и не уходит в менее важные части, которые имеют малое влияние), например: network_kwargs: only_if_contains: - "layers.17." - "layers.18." - "layers.19." - "layers.20." - "layers.21." - "layers.22." - "layers.23."
Вообще это аналог B-Lora тренинга, ток больше свободы для выбора слоев.
>>1461381 Вот тут неплохой >>1457488 Еще есть аблитерейтед от хуйхуя (в1 и в2), но он какой-то с ебанцой буквально, с лораим крайне странно работает и генерит ебанину на -2 клипскипе, а на -1 вообще артефачит (чего нет на дефолте есличе)
>>1461645 Баба на скамейке. ВОобще сломано накед и лоли всякие. 4K high-definition quality. A drunk, naked young female idol lies asleep on a bench. Behind her, a man lifts one of her legs, exposing her genitals. Paparazzi in the foreground are filming her.
>>1461654 Я на зетке проверяю. Я заметил что чем меньше промпт тем сильнее меняется от clip. В целом имхо клип бесполезно менять на зетке. больше имеет смысл иметь отдельную аблиб ллм для улучшения промпта, да и еще и с вижионом в комплекте.
>>1461645 >надо найти сломаный промпт А вот еще промпт древний, в натвиз-дмд знатные пикчи выходили. И тут только с дефолтным енкодером вообще гёрл получается, а не собака (pov, doggystyle, anal:1.2), grab ass, (looking back,:1.2) epic light, cluttered room
>>1461768 > Если в еблю Зетка не может Да может, если отрезать клипом слоев 5 и описать словами не нсфвшными. Другое дело что прям на одной ебле модель не обучали, поэтому там крайне ограниченные концепты уровня сосать негру хуй стоя на коленях.