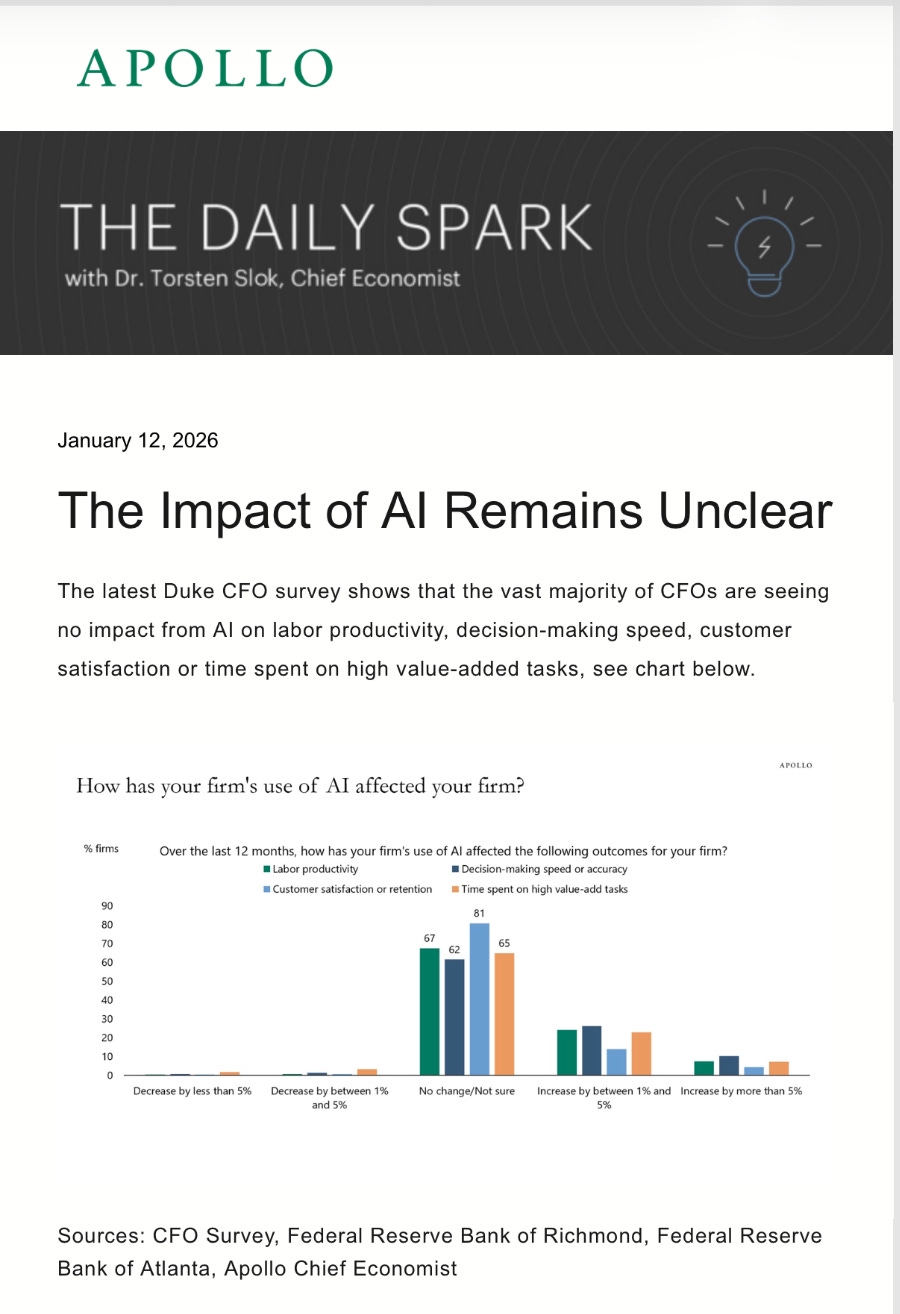
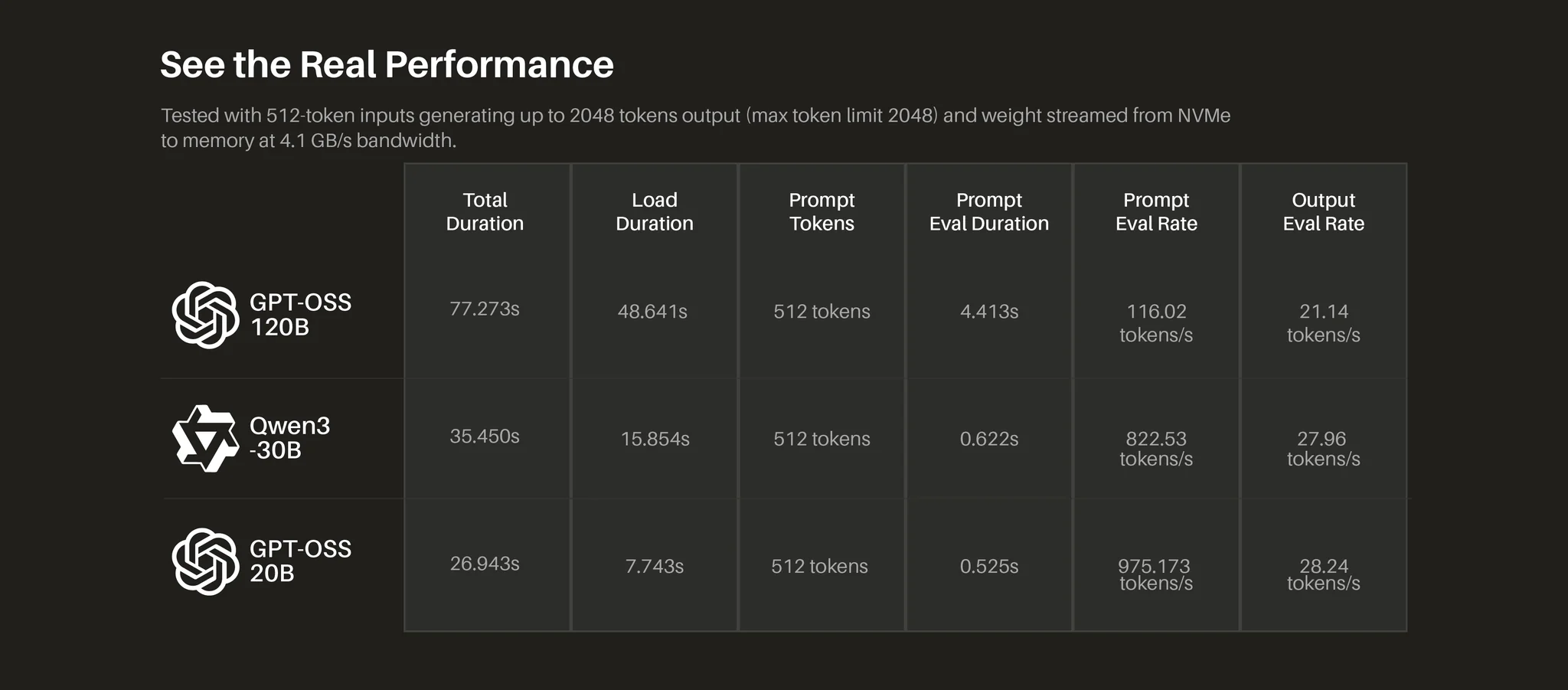
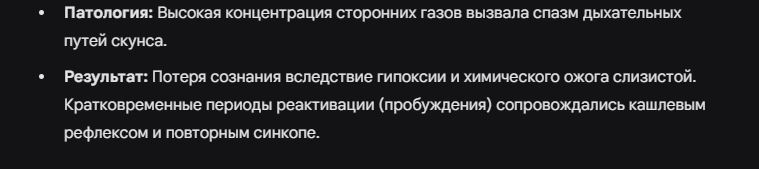
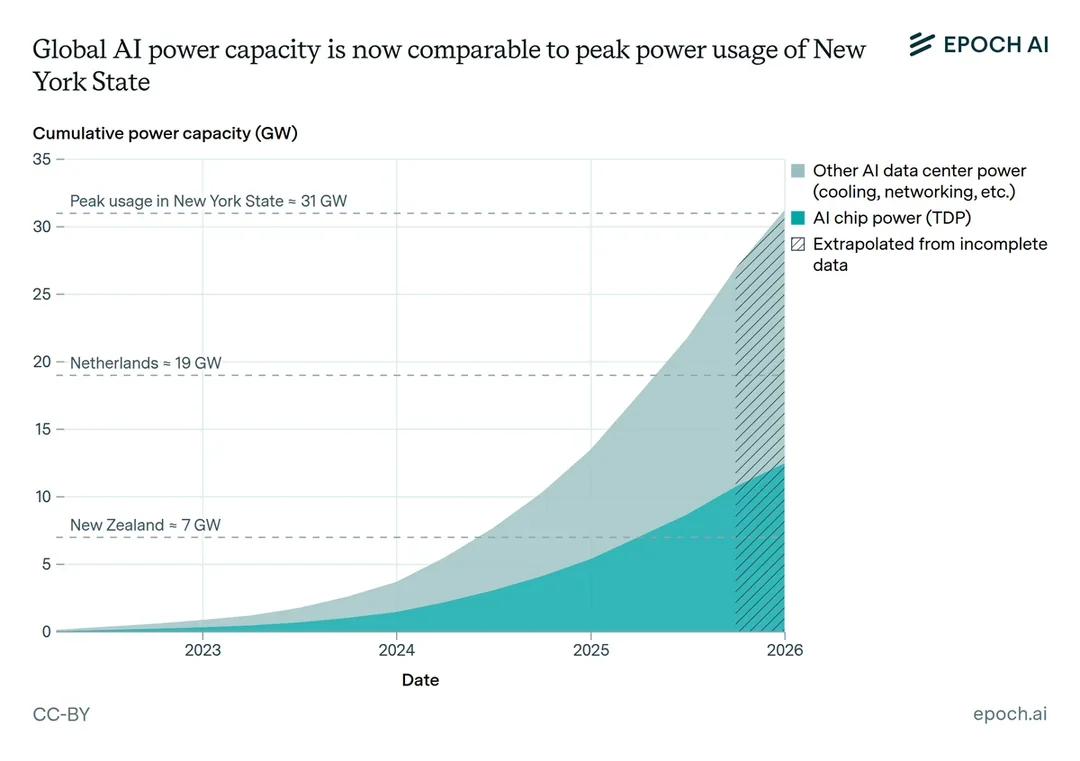
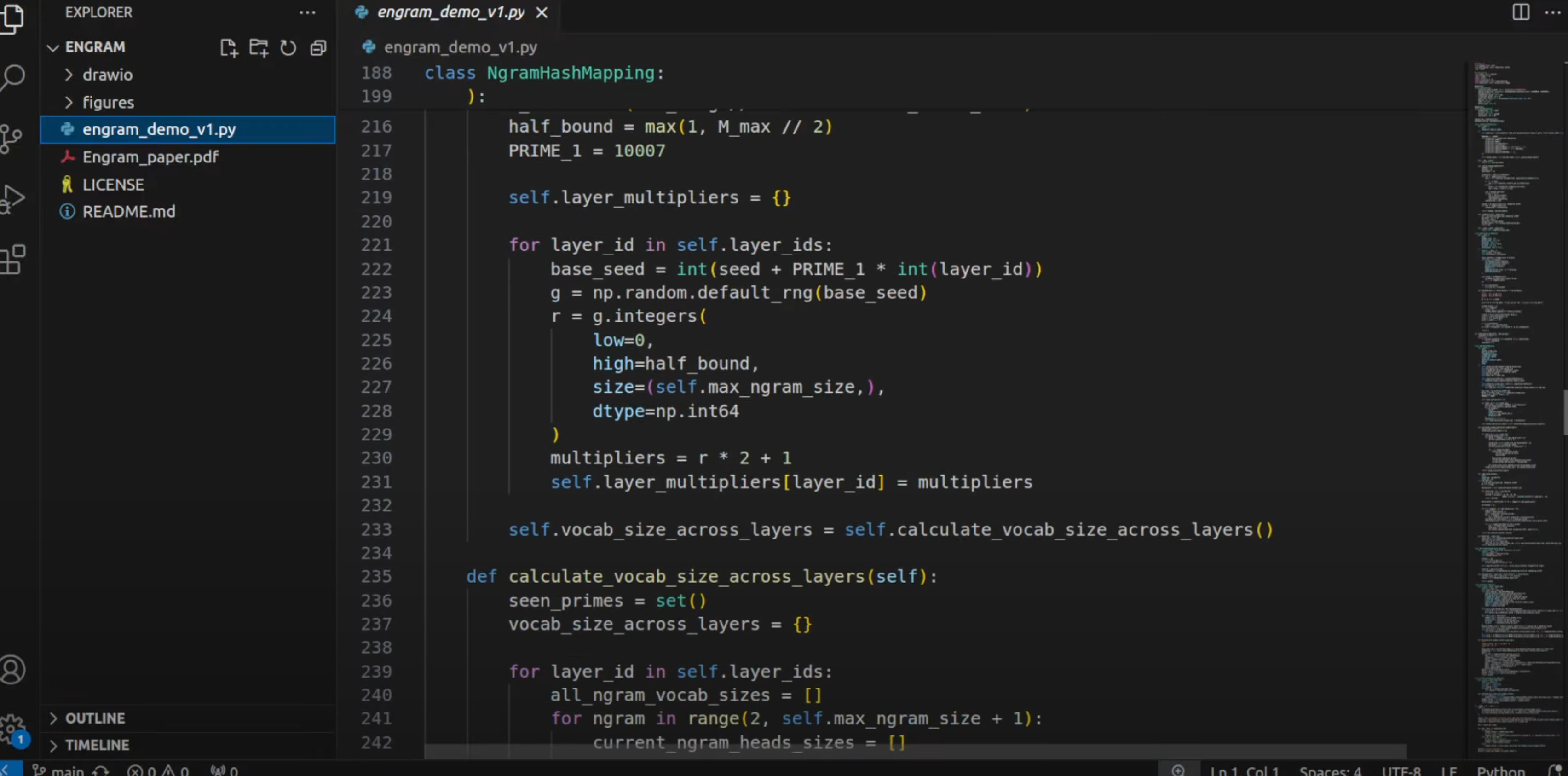
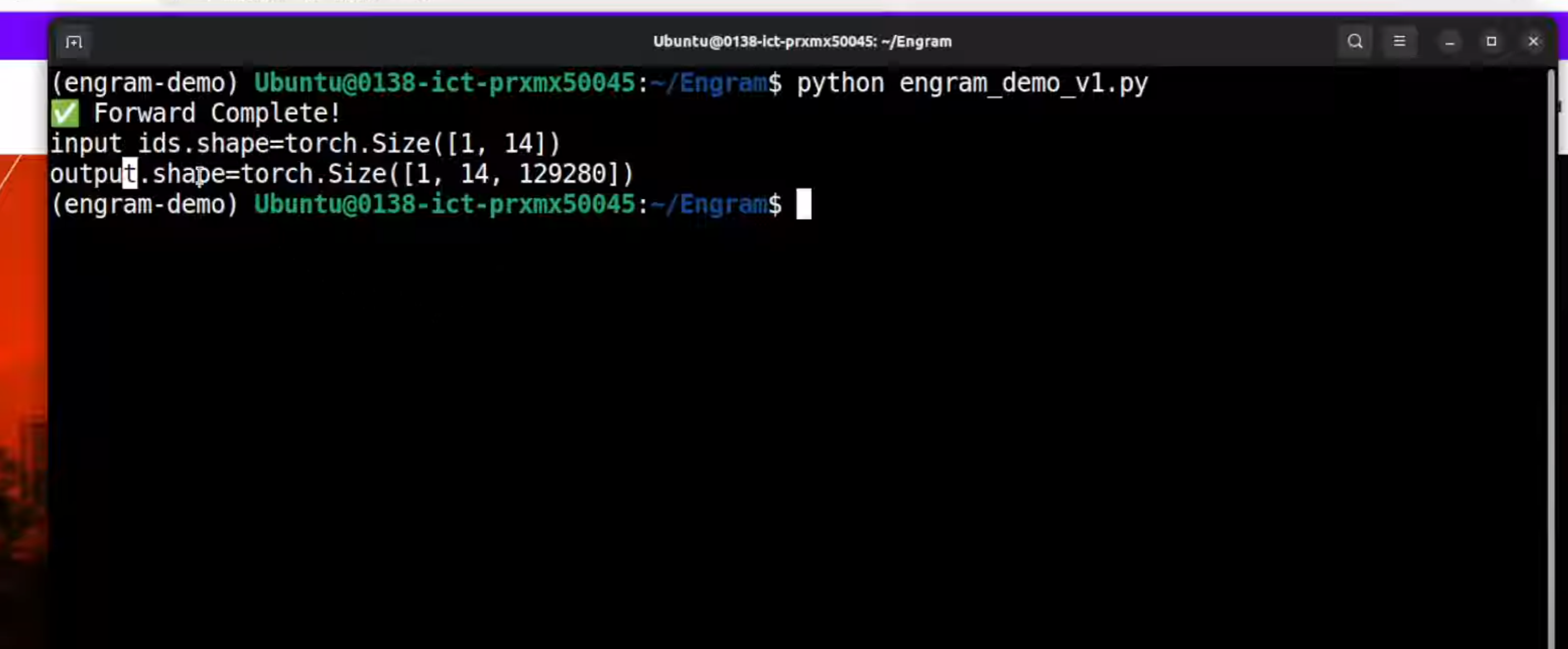
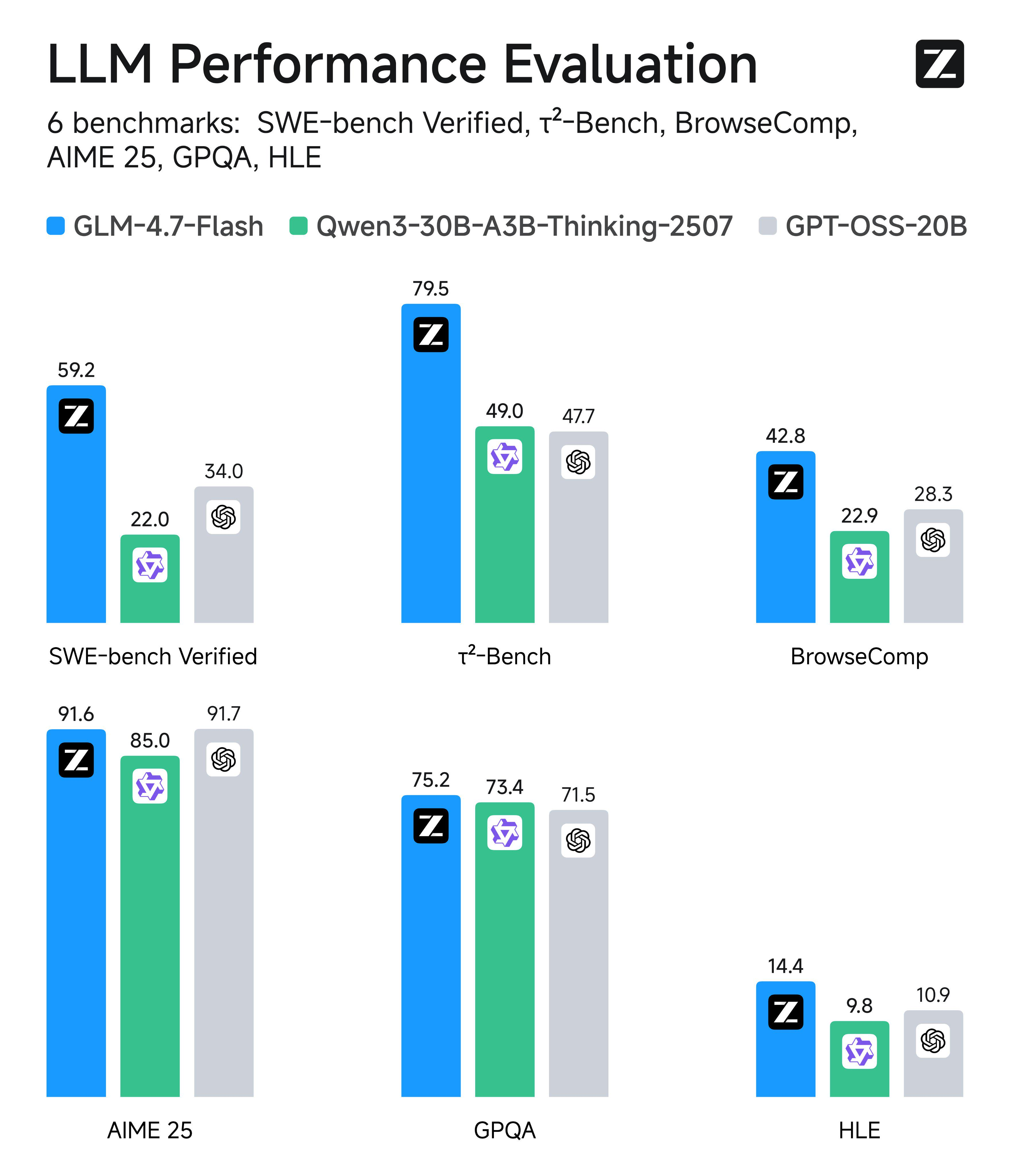
Zhipu AI выпустила GLM-4.7 — открытую модель, позиционируемую как лучший программист и решатель задач на начало 2026 года.
Cerebras анонсировала GLM-4.7-REAP-268B-A32B, расширив семейство до варианта с 268 млрд параметров.
🛠️ Инструменты для разработчиков
Google представила Universal Commerce Protocol (UCP), позволяющий ИИ-агентам осуществлять поиск товаров, оформление заказов и послепродажную поддержку для ритейлеров, таких как Shopify и Walmart.
Anthropic внедрила изоляцию на уровне ОС с использованием bubblewrap и gVisor для Claude Code CLI, продемонстрировав низкоуровневую стратегию безопасности для ИИ-агентов.
📰 Главные новости в ИИ
Google запустила AI Inbox для Gmail, автоматически генерирующий списки дел и тематические сводки для доверенных тестировщиков.
Anthropic представила Claude for Healthcare и расширила Claude for Life Sciences, добавив функции, соответствующие требованиям HIPAA, и коннекторы к основным клиническим платформам.
🔓 Открытый исходный код
PerpetualBooster — это библиотека градиентного бустинга с непрерывным обучением сложности O(n), превосходящая AutoGluon на табличных бенчмарках.
Kreuzberg v4.0 выпущена как библиотека с открытым исходным кодом для интеллектуального анализа документов, извлекающая структурированные данные из PDF-файлов и сканов.
X Илона Маска объявила, что будет выпускать свой алгоритм рекомендаций с открытым исходным кодом каждые четыре недели, повышая прозрачность ранжирования.
💻 Аппаратное обеспечение
XGIMI запустила серию умных очков Memomind AI (Memo One, Memo Air, Memo Air Display) с возможностью выбора оправы и встроенным ИИ-ассистентом, начальная цена — $599.
⚖️ Регулирование
Индонезия и Малайзия запретили доступ к чат-боту Grok от xAI после того, как он создал сексуализированные ИИ-изображения, что подчеркивает растущее регуляторное давление на генеративный ИИ.
📱 Приложения
Meta и Гарвардский университет представили Confucius Code Agent — ИИ-систему, сохраняющую структурированные заметки и память при работе с большими кодовыми базами для повышения продуктивности разработчиков.
📰 Безопасность ИИ
Группа инсайдеров из сферы ИИ создала платформу Poison Fountain для распространения слегка искажённого кода с целью отравления обучающих наборов данных и демонстрации уязвимостей моделей.
📰 Инструменты
MiroThinker — это модель поискового агента с открытым исходным кодом, разработанная для рассуждений с использованием внешних инструментов и получения информации из реального мира.
memU предоставляет инфраструктурный уровень памяти, обеспечивающий постоянное состояние для больших языковых моделей (LLM) и ИИ-агентов.
📰 Разное
Apple объединяется с Google Gemini для создания Siri с искусственным интеллектом.
Anthropic анонсирует Claude for Healthcare после презентации OpenAI ChatGPT Health.
Hyundai демонстрирует роботов-собак, танцующих под K-pop, и гуманоидного робота Atlas на выставке CES.
Терри Тао говорит: «Я могу честно сказать, что кое-чему научился у Аристотеля», после того как ИИ внес вклад еще в одно решение проблемы Эрдёша.
Генеральный директор Anthropic Дарио Амодеи прогнозирует, что ИИ скоро будет играть «центральную роль в многочисленных открытиях» уровня CRISPR.
Meta объявила о новой инициативе «Meta Compute» с целью масштабировать свою инфраструктуру до десятков гигаватт в течение этого десятилетия. Похоже, Цукерберг планирует сократить Reality Labs на 10 процентов, чтобы профинансировать это, по сути ликвидируя метавселенную ради покупки дополнительных GPU.
Coreweave подключает более 2000 GPU в день на своем объекте в Дентоне, штат Техас. Энергосистема ощущает нагрузку. PJM, крупнейший оператор энергосети США, теперь ожидает роста спроса на электроэнергиию на 4,8 % в год в течение следующего десятилетия.
Чтобы смягчить рост затрат для потребителей, Белый дом заявил, что технологические компании впредь должны «сами оплачивать» новые мощности генерации электроэнергии.
SK Hynix инвестирует 12,9 млрд долларов в строительство завода по передовой упаковке чипов в Южной Корее специально для удовлетворения ненасытного спроса на HBM — память, критически важную для ИИ.
Палата представителей одновременно «запирает заднюю дверь», приняв двухпартийный Закон о безопасности удаленного доступа, ограничивающий возможность иностранных противников получать доступ к американским ИИ-чипам через облако.
Basecamp Research и Nvidia представили EDEN — модель с 28 миллиардами параметров, обученную на массивном наборе данных, содержащем 10 миллиардов новых генов. Модель уже разработала новые антибиотические пептиды с экспериментальной эффективностью 97 %.
Eli Lilly и Nvidia совместно инвестировали до 1 млрд долларов в «первую в своем роде лабораторию совместных ИИ-инноваций».
Технический прогресс остановился в 2023 году. Никакой новой информации больше не создается. ИИ атрофирует мозг людей, ИИ может сделать лишь ограниченное количество вещей, поедая собственные помои. Люди деградируют и не думают теперь сами, все решают с помощью чатов. Раньше надо было напрягать мозги и искать информацию, а если ее нет, то решать самому. Сейчас все это заменяется слопом, который уже не имеет вектора развития, т.к данные на которых обучались все модели - это результат мышления людей которые думали сами и создавали, а теперь все это закончилось. На чем учится моделям дальше
>>1489037 >После 40 думать, здраво рассуждать, изобретать и т.д. сложно, лучше пусть ИИ за меня это будет делать Чем меньше ты нагружаешь своё тело, мышцы или мозги, тем быстрее они деградируют, а чтобы быть в тонусе, надо напрягать, и в 25, и в 40 и в 70. Причём в возрасте даже сложнее.
А вот во что цивилизация выродится, с учётом что мозги напрягать не надо, страшно прогнозировать. Хотя какой-то процент будет напрягать просто по приколу, примерно как в тренажёрки ходят сейчас
>>1489037 Так ты слабоумный. После 40 у докторов наук самый расцвет сил. Именно поэтому их первыми и уничтожили в рф вместе с наукой. Теперь уже даже учить некому молодежь, да и хуй с ним.
>>1489018 >Технический прогресс остановился в 2023 году. Никакой новой информации больше не создается. Есть общий паттерн развития технологий, не только в ИИ, но в ИИ особенно: - сначала используют рандомные данные, взятые из природы, то бишь человеком сделанные, без особой системы, учатся как могут - вторым этапом начинают сортировать данные, выделять то, что нужно - трений этап это активное создание синтетических данных для обучения - и, наконец, финальный вариант, (почти) полный отказ от человеческих данных, полностью синтетические данные
Информация создаётся нейросетями и может использоваться для дальнейшего обучения.
Пример: программы, играющие в го и шахматы. Первые варианты, довольно долго, учились на партиях, сыгранных человеком. Но в итоге вышли на следующий уровень, создали программы, обучающиеся с абсолютного нуля, и они буквально за день обучались сами так, что обыгрывали все другие программы и людей.
В программировании, в математике, в принципе возможно реализовать что-то подобное, хотя сложнее, потому что цели и критерии значительно более размытые.
>>1489088 ИИ может легко сам генерить новые факты и знания, по тому же принципу, как люди это делают. В математике, скажем, придумать новую теорему, сформулировать новую проблему.
Проблема тут только в том, чтобы понять, что вообще нужно, а что нафиг не нужно. Но это и для современной человеческой математики проблема, когда придумывают что-то, что даже в конкретной области мало кому интересно.
>>1489018 >Технический прогресс остановился в 1991 году. Никакой новой информации больше не создается. Интернет атрофирует мозг людей, интернет содержит лишь ограниченное количество вещей, ограничиваясь собственными помоями. Люди деградируют и не думают теперь сами, все решают с помощью поиска в интернете. Раньше надо было напрягать мозги и искать информацию в библиотеке, а если ее нет, то решать самому. Сейчас все это заменяется слопом, который уже не имеет вектора развития, т.к данные из интернета - это результат мышления людей которые думали сами и создавали, а теперь все это закончилось.
>>1489018 > У ЧЕЛОВЕЧЕСТВА НЕТ БОЛЬШЕ ПОВОДА ДУМОТЬ, ЗАДАЧОВ БОЛЬШЕ НЕТ, ВСЕ ТУПЕЮТ! > У ЧЕЛОВЕЧЕСТВА ПРОБЛЕМА, НЕТ ДАННЫХ ДЛЯ ОБУЧЕНИЯ, СЛОЖНЕЙШОЯ НЕРЕШАЕМАЯ ЗАДАЧА ВЕКА! Я не понял ты в которую сторону воюешь?
>>1489085 Шиз. Докторов наук с обучением молодежи разделили ещё в совочке. НИИ обособили от образовательных институтов ровно для того чтобы ёбаные вольнодумцы не промывали мозги малолеткам своей либерастнёй. В образовательных вузах остались ручные диванные мочёные реальной науки не нюхавшие. Про возраст всё правильно написал. Пик эффективности взрослой особи 35-60 лет.
>>1489107 Где твои марсоходы, уаня с 200-ми спутников против 2 000 США? А ну да. Твои ученые могут только сформировать кратер имени путина на луне, разбив там станцию раз в четверть века. Большое достижение очень хорошее.
>>1489130 >НЕТ ДАННЫХ ДЛЯ ОБУЧЕНИЯ Реальные данные для обучения можно получать в некоторых областях очень много, если поставить это дело на поток. Но нет сырья и кадров для этого да и цели у элитки другие. Телегу там купить чтобы побольше лошадей было запряжено чем у соседа. Яхту подлиннее. Футболистов побыстрее. Вот это вот всё, а с данными пердолиться это для лошков очкастых пердоликов ученых. Не больно то они и нужны.
>>1489084 Будут развивать бройлерный ум на стероидах. Обколются своими инъекциями для мозга, нейроимплантов навставляют и решают бенчмарки для АГИ. А адепты естественного ума будут на турничке школьных олимпиад для 10 класса крутится.
>>1489147 >Твои ученые могут только А ты сам из чьих и что могут твои учёные?
Космос не наука, а технологии, космос проёбан почти полностью, что есть, то есть. Но там больше организационные проблемы и политика, всё так организуется, что там в принципе ничего работать не сможет, и все оттуда бегут, точнее новые люди не приходят. Бюрократия, попилы, плохое финансирования и условия работы, гэбня, нечего там делать.
В принципе в науке схожая история, бюрократия, политика и гэбня.
>>1489211 >космос проёбан почти полностью Тебе космос сегодня нахуя сдался, эскапист мамкин? Пустыню Сахару сначала освой, вечную мерзлоту и океан. Потом яблони на Марсе сажать будешь.
>>1489135 >Пик эффективности взрослой особи 35-60 лет Топ учёные самые первые свои открытия высшего уровня, которые их прославляют, делают в подавляющем большинстве в возрасте до 30 лет. Нередко даже до 25 лет. Может биографии глянуть сам.
Такого, чтобы до 30 лет был кем-то средненьким, а в 40 прямо расцвёл, не бывает. Но при этом кто до 30 лет хорошо отметился, те и в 40+ себя хорошо показывают обычно, хотя некоторые угасают-спиваются-кукуха едет
>>1489166 Это разные стороны весов. Либо ИИ развивается и деградирует мозг, либо ИИ стагнирует и мозгу ничего не угрожает. Не может деградировать и то и другое одновременно.
>>1489225 > в возрасте до 30 лет Ты сам-то в аспирантуре учился? Они просто делают всю бумажную работу, чтобы отполировать и зафиксировать наработки деда-завкафедры. Выбирают тему для работы по собственной воле - единицы. Молодежь на виду - потому что они буквально литературные рабы и их можно заставить работать за вымпел.
>>1489233 > Они просто делают всю бумажную работу, чтобы отполировать и зафиксировать наработки деда-завкафедры Я в аспе не учился, хотя немного работал мнс-ом в НИИ при РАН
Путь в науке начинается со студенчества, раннего, именно там самые крутые себя показывают, там они попадают к крутым научрукам. Защищаются быстро. Публикации сильные часто имеют ещё в студенческое время. То, что ты описываешь, это про рядовых НС, этот путь гарантирует отсутствие каких-то результатов что в раннем, что в зрелом возрасте.
>>1489217 >Тебе космос сегодня нахуя сдался, эскапист мамкин? Исторический факт: лидером в ИИ может стать только нация, осилившая высадку людей на Луну
>>1489084 Почему человечество не деградировало с появлением компьютеров и исчезновением профессии "Вычислитель", которые занимались длинными ручными вычислениями?
>>1489300 Потому что вычисления это механическая работа, там не надо реально думать. А нейросети дают тебе возможность не думать вообще. Зачем, если любую задачу может решить нейросеть? В результате мозг не развивается.
>>1489312 Те задачи которые решают сегодня нейросети (суммаризируй статью, выпиши из текста факты, напиши код по спецификации) - это механическая работа, там не надо реально думать
>>1489317 "реши задачу", "докажи утверждение" - тоже легко решают.
Вообще во многих случаях, когда раньше тебе нужно было в чём-то разобраться, почитать, сейчас ты можешь получить готовый ответ от нейросети. Это стимулирует к тому, чтобы не пытаться разбираться.
Примерно как мало кому хотелось перемножать большие числа в столбик, когда можно на калькуляторе.
Конечно, кто хочет, тот может использовать нейросети для обучения себя. Но это кто хочет. В результате будет формироваться разделение между способными к мышлению и неспособными.
Ещё проблема в том, что качество "быть умным" девальвируется, теряет уважение. Потому что на любой вопрос может дать ответ нейросеть. Что ещё сильнее отталкивает от того, чтобы пытаться развиваться.
>>1489341 >качество "быть умным" девальвируется, теряет уважение. Всегда так было. Это удел убогих родившихся не в теле высокого крылатого богатого и с вот таким аппаратом.
>>1489361 Раньше было нормальным держать при себе кого-то "умного", обращаться за вопросом к специалистам. Если ты богатый или влиятельный, ты рассуждал так, что мне не нужно быть специалистом, у меня есть возможность проконсультироваться с крутыми людьми. А наличие таких людей ценилось.
Что я наблюдаю уже сейчас, что всё стремительно меняется в сторону "спросить у ИИ". Это при том, что ИИ умеет косячить, качество ответа зависит от качества вопроса, он любит угождать, он не пытается обычно разбираться, зачем у него что-то спрашивают и что действительно требуется человеку. А спрашивающие это не понимают, но зато свято уверены, что теперь знают ответ. Это реально стрёмно, потому что эти люди могут принимать решения, навязывать свои выводы и т.п.
>>1489370 Сейчас то же самое. Прежде чем твой проект подпишет миллиардер чтобы деньги выделить его куча специалистов просчитает. Ты просто наблюдения свои строишь по своему окружению. >>1489377 То есть наемные специалисты такие хуевые в рф, что даже один аппарат за 25 лет не осилили посадить на луну? ok than
>>1489341 А раньше продавались наборы юных радиолюбителей, которые сами себе паяли радио и вынуждены были знать физику, вместо того, чтобы пойти и купить готовый радиоприёмник. К бытовой технике прилагались ебейшие инструкции с электросхемами, которые нужны были чтобы челик сам себе чинил чайник, а не шёл в мастерскую. Чем это принципиально привело к отупению населения?
>>1489341 >чтобы не пытаться разбираться Разбираться придётся в том, в чём нейросеть не вывезла. То есть в действительно сложных многофакторных проблемах.
>>1489429 Мой батя по молодости увлекался радиолюбительством, паял всякие платы, журналы научные собирал Щас нищук на пенсии топит за пыню и гойду, за всю жизнь нихуя не заработал Мимо
Рави Вакил, президент Американского математического общества, использовал Gemini Deep Think для доказательства нового результата в алгебраической геометриии.
Он признаёт, что ИИ дал прозрения, до которых он «не уверен, что смог бы дойти в одиночку», интеллектуально продвинув проект вперёд. В более широком смысле, математика наконец поддаётся автоматизации.
Соавтор профессор Рави Вакил, президент Американского математического общества, сказал, что «доказательство, полученное Gemini, было строгим, правильным и элегантным... именно тем видом прозрения, которым я был бы горд обладать сам».
Профессор Рави Вакил, Стэнфордский университет, президент Американского математического общества:
«Мы интегрировали Gemini на различных этапах проекта, чтобы эмпирически проверить его эффективность. Во многих случаях он оказался полезным в знакомых аспектах: выявлении связей с междисциплинарными статьями, написании кода для генерации данных и проверке второстепенных лемм. Однако самым поразительным опытом было то, как он продвинул проект вперед интеллектуально.
На ключевом этапе нашего исследования мы попросили Gemini проверить результат, который мы ожидали быть верным. Хотя его выводы обычно требовали значительного человеческого надзора, чтобы отличить действительные идеи от ошибок, это конкретное доказательство было строгим, правильным и элегантным. Ясность изложения раскрыла скрытую структуру, которую мы ранее не предвидели, что указывало на то, что результат справедлив в гораздо более общем контексте — что в конечном итоге привело нас к нашему окончательному результату.
Как человек, знакомый с литературой, я обнаружил, что аргумент Gemini не был просто переупаковкой существующих доказательств; это был тот вид прозрения, которым я сам был бы горд создать. Хотя я, возможно, в конечном итоге пришел бы к этому выводу самостоятельно, я не могу сказать это с уверенностью. Мой главный вывод заключается в том, насколько значимый математический прогресс возник благодаря подлинному синергетическому взаимодействию между человеческой изобретательностью и вкладом Gemini.»
Harmonic, располагающая $295 млн, объявила о планах решить гипотезу Римана, гипотезу Ходжа и задачи тысячелетия с помощью ИИ
«Harmonic создаёт математический суперинтеллект (MSI)».
Имея более $295 млн общего финансирования при последней пост-денежной оценке в $1,45 млрд, @HarmonicMath ставит своей миссией решение математических задач, остававшихся нерешёнными на протяжении столетий, открывая путь к прогрессу в физике, инженерии... и, возможно, даже путешествиям во времени?
Компанию соосновали Влад Тенев (@vladtenev), генеральный директор Robinhood, и генеральный директор Harmonic Тудор Аким (@tachim). Инвестиции привлечены от ведущих инвесторов, включая Ribbit, Sequoia, Kleiner Perkins, Index, Paradigm, DST Global и других.
История финансирования и ведущие инвесторы: — Серия A (сентябрь 2024): $75 млн под руководством @SequoiaCapital — Серия B (июль 2025): $100 млн под руководством @kleinerperkins — Серия C (ноябрь 2025): $120 млн при пост-денежной оценке в $1,45 млрд под руководством @RibbitCapital
«Флагманский продукт Harmonic — модель Aristotle — недавно продемонстрировала результат на уровне золотой медали на Международной математической олимпиаде, считающейся самым престижным математическим соревнованием в мире, и теперь доступна широкой публике.
В отличие от других моделей, Aristotle использует формальную верификацию с помощью Lean4 для обеспечения точности и исключения галлюцинаций. За первые несколько недель после запуска бета-версии своего API Aristotle уже была использована математиками и исследователями для ускорения прогресса и совершения новых открытий».
«Harmonic создаёт то, что мы называем математическим суперинтеллектом — это искусственный интеллект, способный решать математические задачи лучше любого человека-математика.
Компания существует уже пару лет. Нашей Полярной звездой был вопрос: можем ли мы действительно решить действительно важные математические задачи, такие как гипотеза Римана или гипотеза Ходжа?
Существует группа математических задач, открытых уже сотни лет, которые называются задачами тысячелетия, и они считаются очень крупными, сложными и на самом деле ценными.
Именно это и было нашей Полярной звездой, и причина, по которой мы хотели этого добиться, заключалась в том, что если бы мы смогли решить эти задачи, всё, что находится ниже математики — например, теоретическая физика, — стало бы доступным.
Тогда можно представить себе решение действительно сложных физических задач.
А если это удастся, откроются всевозможные захватывающие инженерные разработки — в зависимости от того, как будет выглядеть эта теория, можно представить, например, путешествия быстрее скорости света, и всё становится по-настоящему безумным».
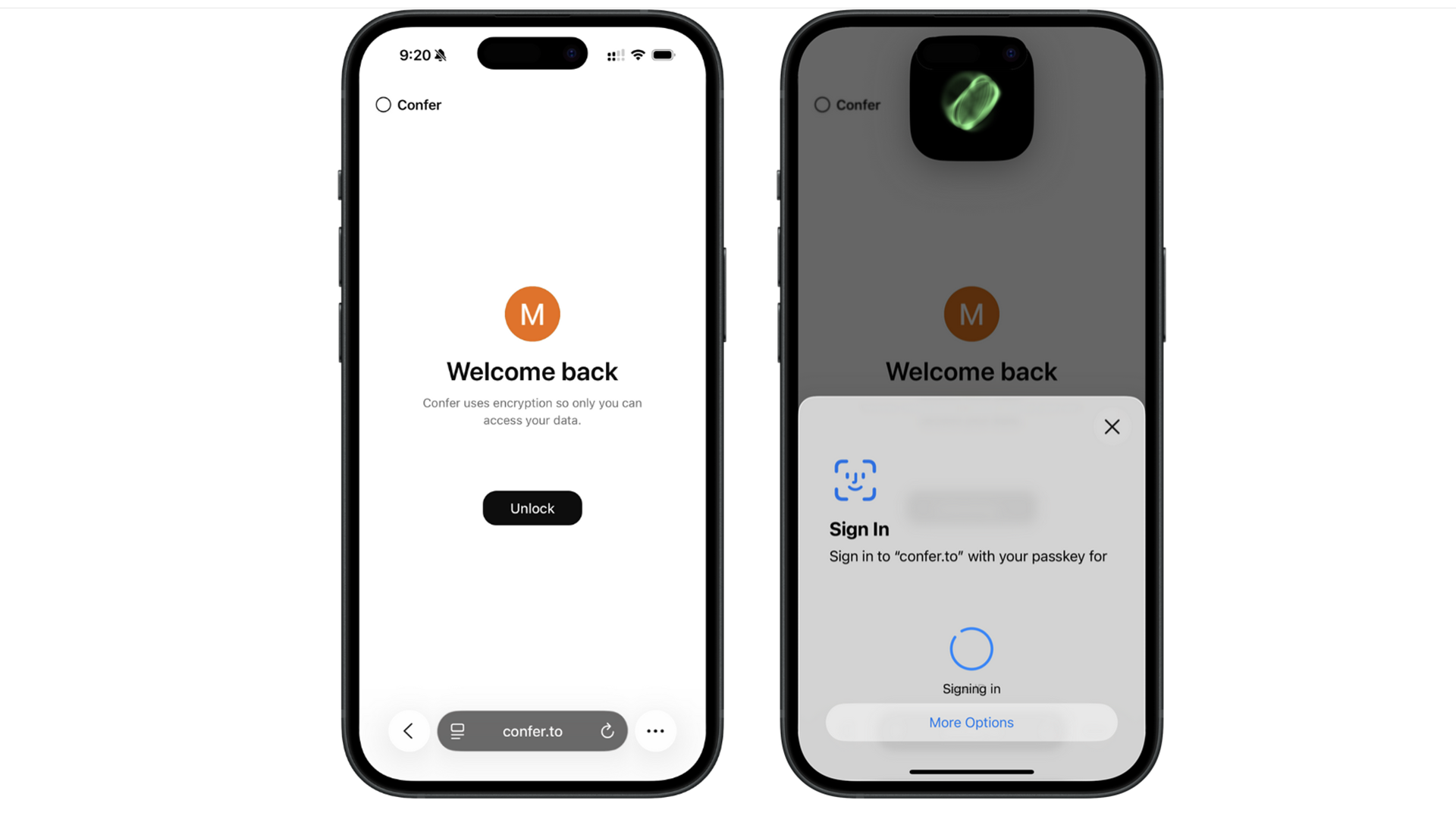
Создатель Signal Мокси Марлинспайк запустил Confer — с открытым исходным кодом ИИ-ассистента, криптографически проверяемого на то, чтобы быть недоступным для чтения никем, кроме самого пользователя.
Создатель Signal Мокси Марлинспайк хочет сделать для ИИ то же самое, что он сделал для мессенджеров. Представляем Confer — сквозного ИИ-ассистента, который просто работает.
Мокси Марлинспайк — инженер, установившего новый стандарт приватных сообщений благодаря созданию мессенджера Signal — теперь стремится аналогичным образом революционизировать чат-боты на основе ИИ.
Его новейшее детище — Confer, ИИ-ассистент с открытым исходным кодом, который обеспечивает надёжные гарантии того, что данные пользователя недоступны для чтения оператору платформы, хакерам, правоохранительным органам или любой другой стороне, кроме самого владельца аккаунта. Сервис — включая его большие языковые модели и серверные компоненты — полностью работает на программном обеспечении с открытым исходным кодом, которое пользователи могут криптографически проверить на подлинность.
Данные и диалоги, отправленные пользователями, а также ответы от больших языковых моделей (LLM) шифруются в доверенной среде выполнения (Trusted Execution Environment, TEE), которая не позволяет даже администраторам сервера просматривать или вмешиваться в них. Диалоги хранятся в Confer в том же зашифрованном виде, используя ключ, который остаётся надёжно сохранённым на устройствах пользователей.
Как и в случае с Signal, внутренняя архитектура Confer отличается изяществом, простотой и продуманностью. Signal стал первым инструментом конфиденциальности для конечных пользователей, который был невероятно прост в использовании. До этого использование PGP-почты или других решений для установления зашифрованного канала связи между двумя пользователями было громоздким процессом, в котором легко допустить ошибку. Signal разрушил этот стереотип. Управление ключами перестало быть задачей, о которой пользователям нужно было беспокоиться. Signal был спроектирован так, чтобы даже операторы платформы не могли заглянуть в сообщения или определить реальные личности пользователей.
«Врождённые сборщики данных» Все крупные платформы обязаны передавать пользовательские данные правоохранительным органам или частным лицам по иску, если те предъявят действительную повестку. Даже когда пользователи отказываются от долгосрочного хранения своих данных, стороны судебного процесса могут обязать платформу сохранять их. Об этом весь мир узнал в мае прошлого года, когда суд приказал OpenAI сохранить все журналы пользователей ChatGPT — включая удалённые чаты и конфиденциальные беседы, зарегистрированные через коммерческий API. Генеральный директор OpenAI Сэм Альтман заявил, что такие решения означают: даже сеансы психотерапии на платформе могут оказаться неприватными. Ещё одно исключение из возможности отказа от хранения данных: на платформах ИИ, таких как Google Gemini, люди могут читать чаты.
Эксперт по защите данных Эм (она предпочитает не указывать свою фамилию в интернете) назвала ИИ-ассистентов «злейшими врагами» конфиденциальности данных, поскольку их полезность зависит от сбора огромных объёмов информации из множества источников, включая частных лиц.
«Модели ИИ по своей сути являются сборщиками данных, — сказала она Ars. — Они зависят от масштабного сбора данных для обучения, улучшений, работы и персонализации. Чаще всего эти данные собираются без чёткого и осознанного согласия (от неосведомлённых субъектов обучения или от пользователей платформы) и отправляются частной компании, у которой есть множество стимулов делиться этими данными и монетизировать их».
Отсутствие контроля со стороны пользователя особенно проблематично, учитывая характер взаимодействия с большими языковыми моделями, говорит Марлинспайк. Пользователи часто воспринимают диалог как интимную беседу. Они делятся своими мыслями, страхами, проступками, деловыми вопросами и самыми сокровенными тайнами, будто ИИ-ассистенты — это доверенные советники или личные дневники. Такие взаимодействия принципиально отличаются от традиционных веб-поисковых запросов, которые обычно следуют транзакционной модели: ключевые слова на входе — ссылки на выходе.
Он сравнивает использование ИИ с исповедью в «озеро данных».
Пробуждение от кошмара современного ландшафта ИИ В ответ на это Марлинспайк разработал и сейчас тестирует Confer. Подобно тому, как Signal использует шифрование, чтобы сделать сообщения читаемыми только участниками беседы, Confer защищает пользовательские запросы, ответы ИИ и все содержащиеся в них данные. И точно так же, как в Signal, невозможно связать конкретного пользователя с его реальной личностью по адресу электронной почты, IP-адресу или другим данным.
«Характер взаимодействия принципиально иной, потому что это приватное общение», — сказал Марлинспайк Ars. «Было действительно интересно, обнадёживающе и удивительно слышать истории от людей, которые использовали Confer и вели беседы, изменившие их жизнь, отчасти потому, что они не чувствовали себя свободными включать эту информацию в диалоги с такими источниками, как ChatGPT, или получали прозрения, используя данные, которыми они не могли свободно делиться с ChatGPT ранее, но могут делать это в такой среде, как Confer».
Один из основных компонентов шифрования Confer — passkeys (парольные ключи). Этот общепринятый в отрасли стандарт генерирует 32-байтовую пару шифровальных ключей, уникальную для каждого сервиса, в который заходит пользователь. Открытый ключ отправляется на сервер. Закрытый ключ хранится только на устройстве пользователя, внутри защищённого аппаратного хранилища, к которому не могут получить доступ даже хакеры с физическим доступом к устройству. Passkeys обеспечивают двухфакторную аутентификацию и могут быть настроены на вход в аккаунт с помощью отпечатка пальца, сканирования лица (оба этих метода также безопасно хранятся на устройстве) или PIN-кода/пароля разблокировки устройства.
Закрытый ключ позволяет устройству войти в Confer и зашифровать весь ввод и вывод с использованием шифрования, которое считается практически не поддающимся взлому. Это даёт пользователям уверенность в том, что их диалоги, хранящиеся на серверах Confer, не могут быть прочитаны никем, кроме них самих. Хранение позволяет синхронизировать беседы между всеми устройствами пользователя. Весь код, обеспечивающий эту функциональность, доступен для публичного анализа.
Этот надёжный внутренний механизм скрыт за интерфейсом пользователя (показан на двух изображениях выше), который обманчиво прост. Всего двумя действиями пользователь входит в систему, и все предыдущие чаты расшифровываются. Эти чаты становятся доступны на любом устройстве, авторизованном в том же аккаунте. Таким образом, Confer может синхронизировать чаты, не нарушая приватность. Щедрые 32 байта ключевой информации позволяют регулярно менять закрытый ключ — функция, обеспечивающая свойство «forward secrecy» (перспективной секретности), означающее, что даже в случае компрометации ключа злоумышленник не сможет прочитать предыдущие или будущие чаты.
>>1489729 > Born February 22, 1970 (age 55) Etobicoke, Ontario, Canada Кстати американцы индийского этноса это самая богатая прослойка в США, их средние доходы выше любых других этнических групп, как средне белых, китайцев или евреев
>>1489747 Другой ключевой компонент Confer — доверенная среда выполнения (TEE) на серверах платформы. TEE шифрует все данные и код, проходящие через процессор сервера, защищая их от чтения или изменения кем-либо с административным доступом к машине. TEE в Confer также обеспечивает удалённую аттестацию (remote attestation). Удалённая аттестация — это цифровой сертификат, отправляемый сервером, который криптографически подтверждает, что данные и программное обеспечение выполняются именно внутри TEE, и содержит список всего программного обеспечения, запущенного на нём.
В Confer удалённая аттестация позволяет любому воспроизвести побитовые выходные данные, подтверждающие, что на сервере запущено именно публично доступное прокси- и образное программное обеспечение — и ничего кроме него. Для дополнительной проверки соответствия заявленному, каждый релиз Confer цифровым образом подписывается и публикуется в прозрачном журнале (transparency log).
Родная поддержка Confer доступна в самых последних версиях macOS, iOS и Android. На Windows пользователям необходимо установить сторонний аутентификатор. Поддержки Linux пока нет, хотя это расширение частично закрывает данный пробел.
Существуют и другие приватные LLM, но ни один от крупных игроков Другой публично доступный LLM с поддержкой сквозного шифрования (E2EE) — Lumo, предоставляемый компанией Proton, европейским разработчиком популярной зашифрованной почтовой службы. Он использует тот же движок шифрования, что и Proton Mail, Drive и Calendar. Внутренняя архитектура этого движка значительно сложнее, чем у Confer, поскольку опирается на комбинацию симметричных и асимметричных ключей. Однако конечный результат для пользователя в целом тот же.
Как только пользователь проходит аутентификацию в своём аккаунте, Proton утверждает, что все беседы, данные и метаданные шифруются симметричным ключом, которым владеет только сам пользователь. Пользователи могут выбрать хранение зашифрованных данных на серверах Proton для синхронизации между устройствами или немедленное их удаление сразу после завершения диалога.
Третий поставщик LLM, обещающий конфиденциальность, — Venice. Он хранит все данные локально, то есть на устройстве пользователя. Никакие данные не сохраняются на удалённом сервере.
Большинство крупных платформ LLM предлагают пользователям возможность исключить свои диалоги и данные из маркетинговых и обучающих целей. Однако, как уже отмечалось, такие обещания часто содержат существенные исключения. Помимо выборочного просмотра людьми, персональные данные всё ещё могут использоваться для соблюдения условий обслуживания или других внутренних целей, даже если пользователь отказался от стандартного хранения.
Учитывая сегодняшнюю правовую среду — которая позволяет получать почти любые онлайн-данные по судебной повестке — и регулярные масштабные утечки данных от хакеров, нельзя разумно ожидать, что персональные данные останутся приватными.
Было бы замечательно, если бы крупные провайдеры внедрили защиту сквозным шифрованием, но на данный момент нет никаких признаков, что они планируют это делать. До тех пор горсть небольших альтернатив будет удерживать пользовательские данные вне постоянно растущего «озера данных».
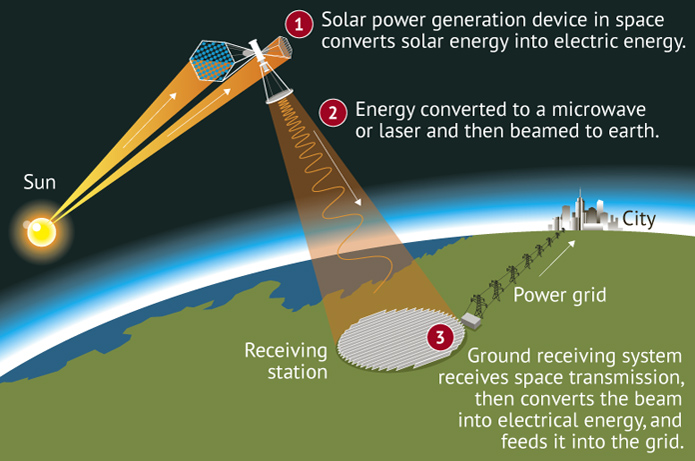
Энергию для ИИ датацентров будут излучать из космоса прямо в датацентры на земле
Overview Energy вышла из режима секретности после успешной передачи энергии с борта летательного аппарата на наземный приёмник с помощью лазера ближнего инфракрасного диапазона. Компания планирует начать орбитальную передачу энергии к 2028 году.
Эшберн, штат Вирджиния, 10 декабря 2025 г. — Overview Energy, компания в сфере космической солнечной энергетики, создающая спутники для передачи энергии с орбиты в наземные электросети, сегодня вышла из режима секретности после успешной передачи энергии с движущегося летательного аппарата на наземный приёмник, расположенный на высоте 5 километров (3 мили) ниже — второй важнейший этап на пути к поставке сетевой чистой энергии из космоса.
Спутники Overview будут передавать энергию крупным наземным солнечным электростанциям, позволяя им генерировать электроэнергию ночью и превращая солнечную энергию в надёжный круглосуточный ресурс. Спутники будут непрерывно собирать солнечный свет на геосинхронной орбите и передавать его в виде безопасного, низкоинтенсивного излучения в ближнем инфракрасном диапазоне, используя длины волн, уже применяемые в волоконно-оптических сетях, медицинской визуализации и системах видеонаблюдения. Такой выбор длины волны делает архитектуру одновременно высокоэффективной и пассивно безопасной, обеспечивая связь между постоянным солнечным светом в космосе и текущими потребностями земных электросетей за счёт управляемой подачи энергии промышленного масштаба.
Один кластер спутников Overview сможет обслуживать сразу несколько континентов и динамически перенаправлять подачу энергии в зависимости от спроса. Система изначально разрабатывается для повышения надёжности электросетей и удовлетворения потребностей энергоёмких пользователей, таких как центры обработки данных, растущие города и крупные военные базы. Существующие и будущие солнечные электростанции будут выступать в роли приёмников системы Overview. В совокупности эти элементы формируют гибкую и устойчивую энергетическую сеть, способную мгновенно доставлять энергию туда, где она необходима.
«Представьте себе солнечный свет, собираемый на высоте 36 000 километров над Землёй, который затем поступает в виде чистой энергии туда, где она нужна электросети, — сказал Марк Берте, основатель и генеральный директор Overview Energy. — Именно это мы и делаем реальностью. Наш воздушный эксперимент доказал, что базовая система передачи работает в движении — именно тот же самый фундамент, на котором будет работать система на орбите. Космическая солнечная энергетика будет иметь значение только тогда, когда она будет удовлетворять реальный спрос на Земле, и мы проектируем её именно для такого масштаба с самого первого дня».
Воздушная демонстрация Overview подтвердила работоспособность системы передачи энергии в движении — это первый в мире случай беспроводной передачи энергии высокой мощности. В ходе испытаний использовались те же оптические компоненты и лазерная система, которые планируется отправить в космос, и энергия была успешно передана в виде излучения ближнего инфракрасного диапазона с движущегося летательного аппарата на наземный приёмник. Испытание подтвердило, что система компании — лазеры, оптика и система управления — функционирует в реальных условиях, создавая мост между лабораторной проверкой и предстоящей орбитальной демонстрацией на низкой околоземной орбите.
«Overview Energy создаёт ключевой элемент для растущего энергетического спроса — такой, который может динамически распределять энергию туда, где она наиболее ценна, и масштабироваться без ограничений, присущих наземной генерации и передаче энергии», — сказал Рид Стёртевант, управляющий партнёр Engine Ventures. «Подход Overview к космической солнечной энергетике не просто технически амбициозен — он изначально ориентирован на практическое внедрение. Engine Ventures поддерживает такие компании, как Overview, где основатели сочетают глубокие технические знания и коммерческую дисциплину для создания инфраструктуры, которая окажет глобальное влияние».
Находясь в режиме секретности, Overview разработала свою систему с учётом технических, безопасностных, экономических и регуляторных требований реального внедрения. Воздушная демонстрация стала вторым важнейшим этапом компании после подтверждения работоспособности её лазерной и оптической системы на уровне мощности в тысячи ватт в лабораторных условиях. Демонстрация на низкой околоземной орбите последует в 2028 году, подтвердив сквозную работоспособность системы из космоса. Коммерческая эксплуатация на геосинхронной орбите запланирована на начало с первой в мире мегаваттной передачей энергии из космоса в 2030 году.
Основанная в 2022 году, Overview возглавляется экспертами в сферах энергетики, лазерных технологий, космоса, производства, бизнеса и регулирования. В состав руководства компании входят специалисты, основавшие стартапы в области глубоких технологий, создававшие лазерные системы высокой мощности, руководившие космическими программами, запускавшие группировки спутников, развёртывавшие производственные линии и участвовавшие в формировании глобального космического регулирования. На сегодняшний день компания привлекла 20 млн долларов США и поддерживается со стороны Engine Ventures, Lowercarbon Capital, Prime Movers Lab, EQT Foundation, Earthrise Ventures, Aurelia Institute и других инвесторов.
>>1489747 >Его новейшее детище — Confer, ИИ-ассистент с открытым исходным кодом, который обеспечивает надёжные гарантии того, что данные пользователя недоступны для чтения оператору платформы, хакерам, правоохранительным органам или любой другой стороне, кроме самого владельца аккаунта Вот совсем-совсем не понятно. Принцип работы Сигнала в том, что шифрование и расшифровка идут на конечных узлах, на серверах ключей нет. На серверах данные вообще никак не обрабатываются.
Принцип работы ЛЛМ сервисов другой. Они запрос пользователя (контекст) прокручивают через модель и получают результат. Машина находится у провайдера сервиса и чтобы он смог дать ответ, ему необходимы данные в расшифрованном виде. Соответственно никакое шифрование тут помочь не может.
Шифрование разве что можно приделать для того, чтобы через брокеров можно было безопасно работать.
>>1489763 >Спутники Overview будут передавать энергию крупным наземным солнечным электростанциям, я читаю и пытаюсь понять, у кого шизофрения, у меня или не у меня, это даже next level по сравнению с космическими дата-центрами
>>1489765 Пояснение как будет работать ЛЛМ в Конфере:
Когда вы пользуетесь сервисом искусственного интеллекта, вы передаёте свои мысли в виде открытого текста. Оператор сохраняет их, обучается на них и — неизбежно — будет монетизировать их. Вы получаете ответ; они получают всё.
Confer работает иначе. В предыдущем посте мы описали, как Confer шифрует историю ваших чатов с помощью ключей, которые никогда не покидают ваши устройства. Остаётся рассмотреть ещё один компонент — вывод (inference): момент, когда ваш запрос достигает большой языковой модели (LLM), и модель возвращает ответ.
Традиционно сквозное шифрование (end-to-end encryption) работает, когда конечными точками являются устройства, контролируемые участниками разговора. Однако вывод с использованием ИИ требует, чтобы сервер с GPU выступал в качестве одной из конечных точек разговора. Кто-то должен запускать этот сервер, но мы хотим помешать тем, кто его запускает (нам самим), видеть запросы или ответы.
Конфиденциальные вычисления Это область конфиденциальных вычислений (confidential computing). Конфиденциальные вычисления используют аппаратно обеспеченную изоляцию для выполнения кода в доверенной среде исполнения (Trusted Execution Environment, TEE). Хост-машина предоставляет процессор, память и питание, но не может получить доступ к памяти или состоянию выполнения внутри TEE.
Большие языковые модели (LLM) по своей сути не имеют состояния — входные данные поступают, выходные данные выдаются, — что делает их идеальными для такой среды. В Confer мы выполняем вывод внутри конфиденциальной виртуальной машины. Ваши запросы шифруются прямо с вашего устройства непосредственно в TEE с использованием Noise Pipes, обрабатываются там, а ответы шифруются обратно. Хост никогда не видит открытый текст.
Однако это вызывает очевидную обеспокоенность: даже если у нас есть зашифрованные каналы в зашифрованную среду и из неё, крайне важно, что именно выполняется внутри этой среды. Клиенту необходимо удостовериться, что запущенный код действительно делает то, что заявлено.
Аттестация Конфиденциальные вычисления решают эту проблему с помощью удалённой аттестации (remote attestation). При загрузке конфиденциальной виртуальной машины оборудование генерирует подписанный «квот» (quote) — криптографическое заявление, содержащее хэши ядра, initrd и командной строки. Эти хэши называются измерениями (measurements) и однозначно идентифицируют код, выполняемый внутри TEE.
В Confer мы расширяем измерение, охватывая им всю корневую файловую систему с помощью dm-verity. Это создаёт дерево Меркла над каждым байтом файловой системы и внедряет хэш корня дерева Меркла в командную строку ядра. Поскольку командная строка измеряется, любое изменение любого файла изменит аттестацию. Теперь измерение охватывает всё целиком.
Но измерение — это всего лишь хэш. Чтобы проверить его, кому-то нужно иметь возможность воспроизвести его.
Создание проверяемой аттестации Прокси-сервер и образ Confer собираются с помощью nix и mkosi для получения побитово воспроизводимых результатов. Любой желающий может клонировать репозиторий, запустить сборку и получить абсолютно те же самые измерения.
Каждый выпуск также подписывается и публикуется в журнале прозрачности (transparency log), который легко искать. Журнал является только добавляющим (append-only) и публично проверяемым, что означает: мы не можем тайно опубликовать разные сборки для разных пользователей.
Теперь у нас есть общее понимание того, как эти компоненты могут работать вместе.
Подключение Когда вы открываете Confer и начинаете разговор, ваш клиент инициирует рукопожатие Noise с конечной точкой вывода. TEE отвечает, встраивая свой аттестационный квот в рукопожатие Noise.
Ваш клиент проверяет подпись квота, подтверждая, что он исходит от настоящего оборудования TEE. Он проверяет, что открытый ключ в квоте совпадает с тем, который используется в рукопожатии — это привязывает зашифрованный канал к TEE, предотвращая перехват или повторное использование кем-либо вне TEE. Затем клиент извлекает измерения и подтверждает, что они соответствуют выпуску в журнале прозрачности.
Как только проверка проходит успешно, рукопожатие завершается. Теперь ваш клиент имеет криптографическую гарантию, что он напрямую взаимодействует с проверенным кодом, выполняющимся в аппаратно обеспечиваемой изоляции.
Весь трафик к конечной точке вывода затем шифруется с использованием эфемерных сессионных ключей, обеспечивающих совершенную прямую секретность (forward secrecy): даже если долгосрочный ключ будет скомпрометирован в будущем, прошлые разговоры останутся защищёнными, поскольку эфемерные ключи больше не существуют.
Иная модель Confer сочетает конфиденциальные вычисления с шифрованием на основе пасс-ключей (passkey-derived encryption), чтобы гарантировать конфиденциальность ваших данных.
Это отличается от традиционных сервисов ИИ, где ваши запросы передаются в открытом виде оператору, который хранит их в открытом виде (где они уязвимы для хакеров, сотрудников, повесток суда), добывает из них поведенческие данные и обучается на них.
>>1489774 Так то все логично - от солнца в космосе пропадает море халявной энергии, ее нужно только собрать и передать пучком на землю. Сразу не нужны все посредники в виде топлива, реакторов и прочего. Для датацентров самое то.
>>1489748 Ясен хуй. Там у каждого второго как у раджеша кутропали папа или дядя в индии у которого слуги и рабы из неприкасаемых по паре десятков тысяч.
>>1489780 Всё равно получается на честном слове. При этом довольно сложно. Дело в том ещё, что если провайдер моделей добропорядочный, то он может просто не сохранять логи, ни данные запроса, ни результат ответа. Шифрование же обеспечивается HTTPS, его достаточно.
Если провайдер честно не хранит данные, то соответственно он ничего выдать никому не сможет. Но если его вынуждают хранить, тогда скорее всего с "безопасными вычислениями" тоже возникнут проблемы, потребуют какие-нибудь закладки вставлять, чтобы при наличии судебного решения можно было все данные получить.
Казус OpenAI в том, что они хранили то, что по идее хранить были не должны.
Отдельно да, обычная схема без логов не позволяет веб-интерфейс чата реализовать, чтобы история была доступна с разных машин. Единственный вариант из простых, это хранить историю чатов в браузере, так работает openrouter, но эта история будет утеряна, если войти с другого компьютера или если сбросить профиль в браузере.
Но всё упирается в порядочность провайдера моделей. И в его политику. Политика OpenAI, Meta и некоторых в других в том, что они типа разрабатывают модели, чтобы они адаптировались к пользователю. Они считают это своим плюсом. Хотя по мне скорее минус. Но вот их бизнес-модель, которую они подают как конкурентное преимущество, противоречит концепции "безопасных вычислений".
В общем в отличии от месседжеров, тут всё скользко, вряд ли это кого-то убедит.
>>1489805 Там речь о том, чтобы запускать защищенную среду, где сам провайдер моделей ничего не знает. Т.е. хранить он ничего не сможет (разве что список IP адресов).
>клиент имеет криптографическую гарантию, что он напрямую взаимодействует с проверенным кодом, выполняющимся в аппаратно обеспечиваемой изоляции. >любое изменение любого файла изменит аттестацию
Если код не тот (закладки вставили) - то сразу проверку не пройдет. В открытом же виде провайдер ЛЛМ ничего не получает, только вот эту защищенную среду с ключами.
>>1489763 Интересно, а прежде чем передавать энергию на землю в виде мощных микроволн, они изучили, каково будет человекам, которые помимо солнечного ультрафиолета теперь еще и под СВЧ будут прожариваться?
И не проще и безопаснее было бы перенаправлять пучок солнечных лучей посредством нескольких мощных поворотных зеркал на космостанциях в конкретную точку на земле с фотоэлектрическими модулями?
>>1489836 Там же написано лазером. То есть световым пучком. 1) Зеркалами труднее управлять. 2) Солнечный свет содержит много ИК излучения и будет рассеиваться атмосферой. Поэтому нужен "трансформатор" для световых волн 3) От солнца можно не только свет собирать но и другие виды излучения (но это теоретически) и превращать в свет
>>1489119 Технический прогресс остановился около 400 000 - 150 000 лет назад. Добыча огня атрофирует мозг людей, люди деградируют и не думают теперь сами, всё решают с помощью трения и высекания искр. Раньше надо было напрягать мозги и искать горящее дерево, а если его нет, то ждать грозы. Сейчас все это заменяется высеканием искр, это уже не имеет вектора развития
>>1489018 Технический прогресс начался в 2023 году. Создается много новой информации. ИИ развивает мозг людей, ИИ может делать неограниченное количество вещей, создавая собственное изысканное меню. Люди воспряли и теперь часто задумываются, размышляя над чатами. Раньше не надо было напрягать мозги, достаточно было поискать информацию, а если ее нет, то поискать еще. Сейчас все это заменяется автоматикой, которая имеет отчетливый вектор развития, т.к данные на которых обучались все модели - это результат мышления людей которые часто ленились и отказывались думать и что-то создавать, а теперь все создает ИИ. Совершенно ясно, на чем учиться моделям дальше, будущее светло как никогда ранее.
>>1489951 >Люди воспряли и теперь часто задумываются, размышляя над чатами. Шутки-шутками. Но меня ИИ заставил выходить из зоны комфорта. Я теперь не мог читать чужой код, и в случае любых непоняток просто писал своё с нуля. Теперь я обязан через немогу разбираться в говнокоде ИИ, поскольку нельзя пускать на самотёк что он там пишет, и это очень сильно прокачало мне навык чтения кода других людей.
>>1489951 По твоему тексту видно как твой мозг "развился" от ИИ >Раньше не надо было напрягать мозги, достаточно было поискать информацию. Чаты что-то изменили в этом плане? Раньше ты читал ответы на стековерфлоу, разбирался подходит ли ответ к твоей задаче. Теперь просто копипастишь ответ из чата. >данные на которых обучались все модели - это результат мышления людей которые часто ленились и отказывались думать и что-то создавать Нейронки обучали сканируя череппушку лентяев? >а теперь все создает ИИ. Совершенно ясно, на чем учиться моделям дальше, будущее светло как никогда ранее И на чем же? На своих же нейровысерах?
>>1489018 > Люди деградируют и не думают теперь сами, все решают с помощью чатов. Раньше надо было напрягать мозги и искать информацию, а если ее нет, то решать самому. Это правда. Зачем писать простой, но нудный с кучей проверок алгоритм самому тратя час, когда геминя напишет за пять минут? А в следующий раз вручную еще дольше времени займет, это как снежный ком.
>>1490041 Давай без "ты". На моем примере это не работает: >Теперь просто копипастишь ответ из чата.
Зачем ты вообще разговариваешь с примитивно сконструированной пастой? Очевидно, что в таком объеме и в такой конструкции текста невозможно раскрыть всех нюансов взаимодействия человека и ИИ. Она же просто смешная, потому и переписана была. Есть плюсы, есть минусы, нет какой-то истины, которую выражает этот или исходный текст. Конечно, ИИ отупит часть людей. Но разве сейчас все очень умны, полагаются только на решения, до которых дошли сами, и имеют критическое мышление? Или когда-то были такими? Помимо этого, ИИ умеет синтезировать новые знания, в этом треде на примере математиков это было показано буквально недавно пару раз. Это напрямую противоречит тому, что указано в исходном тесте.
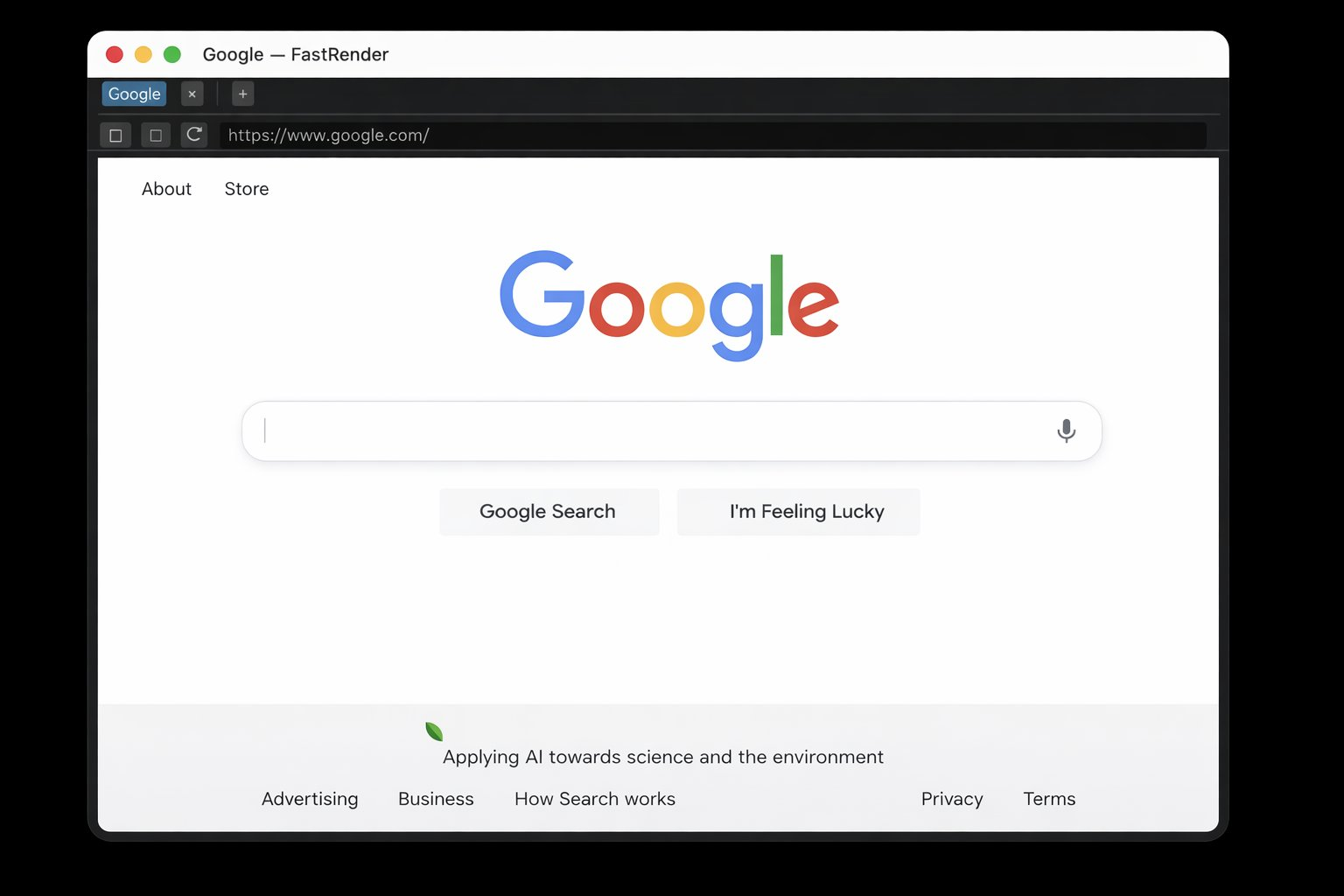
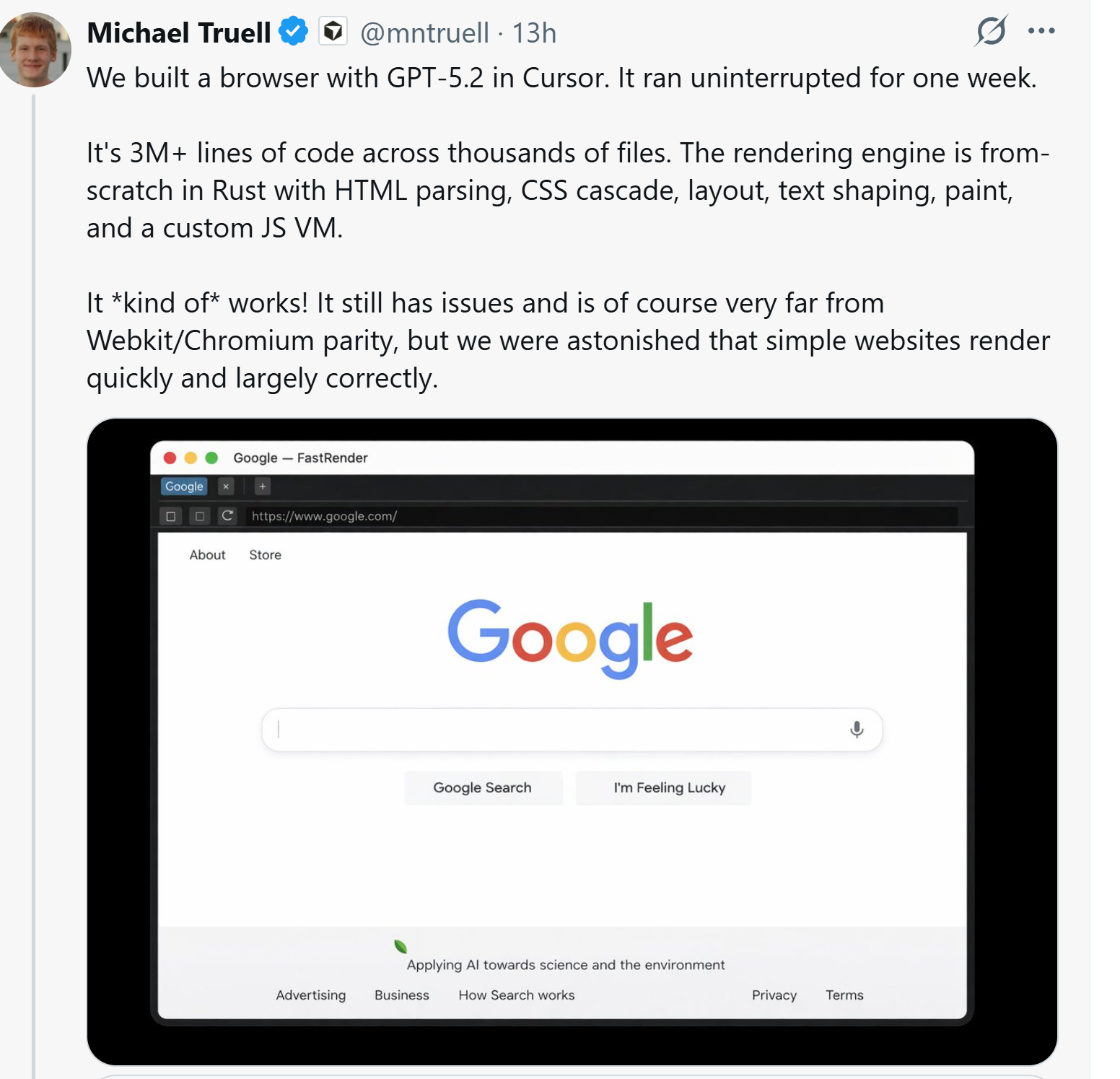
Генеральный директор Cursor заявил, что они координировали работу сотен агентов GPT-5.2 для автономной разработки браузера с нуля за одну неделю.
Конец программистов близок.
Майкл Труэлл Мы создали браузер с помощью GPT-5.2 в Cursor. Он работал без перерыва в течение одной недели.
Это более 3 миллионов строк кода, распределённых по тысячам файлов. Графический движок написан полностью с нуля на Rust и включает парсинг HTML, каскадирование CSS, компоновку (layout), формирование текста (text shaping), отрисовку (paint) и собственную виртуальную машину JavaScript.
Он вроде как работает! У него всё ещё есть проблемы, и, конечно, он очень далёк от уровня Webkit/Chromium, но мы были поражены тем, что простые веб-сайты отображаются быстро и в основном корректно.
Масштабирование долгосрочного автономного программирования
Мы экспериментировали с запуском программных агентов в автономном режиме на протяжении нескольких недель.
Наша цель — понять, насколько далеко мы можем продвинуть границы агентного программирования для проектов, которые обычно занимают у человеческих команд месяцы работы.
В этом посте описано то, чему мы научились, запустив сотни параллельно работающих агентов над одним проектом, координируя их работу и наблюдая, как они написали более миллиона строк кода и триллионы токенов.
Ограничения одного агента Сегодняшние агенты хорошо справляются с узкоспециализированными задачами, но медленны в работе над сложными проектами. Естественным следующим шагом является запуск множества агентов параллельно, однако выяснить, как их координировать, оказывается непростой задачей.
Первоначально мы считали, что предварительное планирование будет слишком жёстким. Путь через крупный проект неоднозначен, и правильное распределение работы не очевидно с самого начала. Мы начали с динамической координации, при которой агенты решают, что делать, исходя из того, чем в данный момент заняты другие.
Обучение координации Наш первоначальный подход предполагал равный статус всех агентов и позволял им самостоятельно координироваться через общий файл. Каждый агент проверял, чем заняты остальные, брал задачу и обновлял свой статус. Чтобы избежать одновременного захвата одной и той же задачи двумя агентами, мы использовали механизм блокировок (locks).
Это привело к интересным видам сбоев:
Агенты удерживали блокировки слишком долго или забывали их вообще освободить. Даже когда блокировки работали корректно, они становились узким местом. Двадцать агентов замедлялись до эффективной пропускной способности двух-трёх, проводя большую часть времени в ожидании.
Система была хрупкой: агенты могли завершиться с ошибкой, удерживая блокировку, пытаться захватить блокировку, которую уже имели, или обновлять координационный файл, не получив блокировку вообще.
Мы попробовали заменить блокировки на оптимистичное управление конкурентным доступом (optimistic concurrency control). Агенты могли свободно читать состояние, но запись завершалась неудачей, если состояние изменилось с момента последнего чтения. Это решение оказалось проще и надёжнее, но всё равно остались более глубокие проблемы.
Без иерархии агенты стали избегать риска. Они обходили сложные задачи и вместо этого вносили мелкие, безопасные изменения. Ни один агент не брал на себя ответственность за трудные проблемы или сквозную реализацию. В результате работа долгое время «болталась на месте» без реального прогресса.
Планировщики и исполнители Наш следующий подход заключался в разделении ролей. Вместо плоской структуры, где каждый агент делает всё, мы создали конвейер с чётко определёнными обязанностями.
Планировщики постоянно исследуют кодовую базу и формируют задачи. Они могут порождать под-планировщиков для конкретных областей, делая само планирование параллельным и рекурсивным.
Исполнители берут задачи и полностью сосредотачиваются на их выполнении. Они не координируются с другими исполнителями и не беспокоятся о «большой картине». Они просто упорно работают над своей назначенной задачей, пока она не будет завершена, а затем отправляют свои изменения.
В конце каждого цикла агент-«судья» решал, продолжать ли работу, после чего начиналась следующая итерация с чистого листа. Это решило большинство наших проблем с координацией и позволило масштабироваться на очень крупные проекты без того, чтобы какой-либо отдельный агент «зацикливался» на деталях.
Работа в течение нескольких недель Чтобы протестировать эту систему, мы поставили перед ней амбициозную цель: создать веб-браузер с нуля. Агенты работали почти неделю, написав более миллиона строк кода в 1000 файлах. Вы можете изучить исходный код на GitHub.
Несмотря на размер кодовой базы, новые агенты всё ещё могут её понимать и добиваться значимого прогресса. Сотни исполнителей работают параллельно, отправляя изменения в одну и ту же ветку с минимальными конфликтами.
Хотя это может показаться простым скриншотом, создание браузера с нуля — чрезвычайно сложная задача.
Другим экспериментом стала миграция кодовой базы Cursor с Solid на React прямо на месте. Это заняло более трёх недель и потребовало +266 тыс. добавленных строк и –193 тыс. удалённых. По мере того как мы начали тестировать эти изменения, мы действительно считаем возможным объединить (merge) этот код.
Ещё один эксперимент был направлен на улучшение будущего продукта. Долгосрочный агент ускорил рендеринг видео в 25 раз благодаря эффективной реализации на Rust. Он также добавил поддержку плавного масштабирования и перемещения с естественными пружинными переходами и эффектами размытия в движении, следуя за курсором. Этот код уже был объединён и скоро появится в рабочей версии.
У нас есть ещё несколько интересных примеров, которые всё ещё выполняются:
Java LSP: 7,4 тыс. коммитов, 550 тыс. строк кода Эмулятор Windows 7: 14,6 тыс. коммитов, 1,2 млн строк кода Excel: 12 тыс. коммитов, 1,6 млн строк кода
Чему мы научились Мы направили миллиарды токенов этих агентов на достижение единой цели. Система не идеально эффективна, но гораздо действеннее, чем мы ожидали.
Выбор модели имеет значение для задач, выполняемых чрезвычайно долго. Мы обнаружили, что модели GPT-5.2 гораздо лучше подходят для длительной автономной работы: они точнее следуют инструкциям, сохраняют фокус, избегают отклонений и реализуют функциональность точно и полностью.
Opus 4.5 склонен раньше завершать работу и выбирать упрощённые решения, когда это удобно, быстро возвращая контроль. Мы также заметили, что разные модели лучше подходят для разных ролей. GPT-5.2 оказался лучшим планировщиком по сравнению с GPT-5.1-codex, хотя последняя специально обучена программированию. Теперь мы используем модель, наиболее подходящую для каждой роли, вместо универсальной модели.
Многие наши улучшения были достигнуты за счёт устранения сложности, а не её добавления. Изначально мы создали роль интегратора для контроля качества и разрешения конфликтов, но обнаружили, что она создаёт больше узких мест, чем решает проблем. Исполнители и так уже были способны самостоятельно справляться с конфликтами.
Лучшая система часто оказывается проще, чем можно было бы ожидать. Сначала мы пытались применить модели из распределённых вычислений и организационного проектирования. Однако не все из них подходят для агентов.
Оптимальный уровень структурированности находится где-то посередине. Слишком мало структуры — и агенты конфликтуют, дублируют работу и отклоняются от цели. Слишком много структуры — и система становится хрупкой.
Удивительно многое в поведении системы зависит от того, как мы формулируем подсказки (prompts) для агентов. Чтобы заставить их эффективно координироваться, избегать патологических моделей поведения и сохранять фокус на протяжении длительного времени, потребовались обширные эксперименты. Оболочка (harness) и модели важны, но подсказки важнее.
Что дальше Координация множества агентов остаётся сложной задачей. Наша текущая система работает, но мы ещё очень далеки от оптимального решения. Планировщики должны «просыпаться», когда их задачи завершаются, чтобы планировать следующий шаг. Иногда агенты работают слишком долго. Нам по-прежнему нужны периодические «свежие старты», чтобы противостоять отклонениям и «зацикленности».
Однако основной вопрос — можем ли мы масштабировать автономное программирование, просто увеличивая количество агентов, решающих одну задачу — получил более оптимистичный ответ, чем мы ожидали. Сотни агентов могут совместно работать над одной кодовой базой в течение нескольких недель, добиваясь реального прогресса в амбициозных проектах.
>>1490437 >Мы обнаружили, что модели GPT-5.2 гораздо лучше подходят для длительной автономной работы: они точнее следуют инструкциям, сохраняют фокус, избегают отклонений и реализуют функциональность точно и полностью. > >Opus 4.5 склонен раньше завершать работу и выбирать упрощённые решения, когда это удобно, быстро возвращая контроль.
Как же все хайпили Опус месяцами, а в итоге он пук-среньк и слил все сложному ChatGPT на агентных задачах.
>>1490439 >Как же все хайпили Опус месяцами Так давеча же Антропик заблокировал для курсора безлимимитные тарифы, типа пользуйтесь IDE от Антропика. Так что скоро узнаем про Опус и других много нового
>>1490463 Не только курсору, остальным тоже позакрывали. Будет забавно, если вся расхайпленная прошаренность Опуса в коде держалась только на том, что прогам безлимитку давали и они этот хайп дальше форсили.
>>1489018 >2023 То, что сделано сейчас с 2023 по 2025 - хватит на 30 лет просто осваивать и внедрять, в тех же роботов и станки. Вон, роботоделы и чипо-делы не успевают за программо-делами. Ну код проще и быстрее сделать и улучшать, чем ту же ногу робота к примеру.
Станки например можно интегрировать с ИИ. Покупаешь токарный станок, а там внутри Мистраль какой-нибудь, или Грок.
Nvidia: Сквозное обучение во время тестирования для длинного контекста, также известное как возможность обновлять веса модели в реальном времени по мере её использования
«TTT меняет парадигму с извлечения информации на обучение ей на лету... модель TTT рассматривает контекстное окно как набор данных и дообучается на нём в реальном времени».
В статье описывается механизм, который по сути превращает контекстное окно в обучающий набор данных для цикла обновления «быстрых весов»:
Внутренний цикл: Во время вывода модель выполняет мини-градиентный спуск по контексту. Она обновляет определённые слои MLP, чтобы «выучить» текущий контекст.
Внешний цикл: Начальные веса модели мета-обучаются во время тренировки так, чтобы быть «легко обновляемыми» или оптимизированными именно для адаптации во время тестирования.
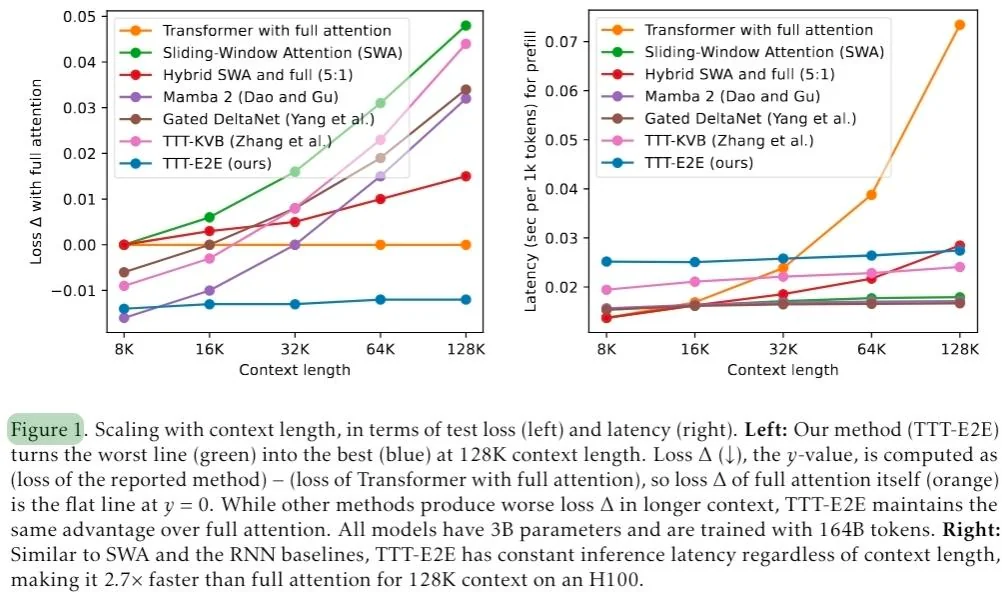
Из статьи: «В целом, наши эмпирические наблюдения убедительно показывают, что TTT-E2E должен демонстрировать ту же тенденцию, что и полное внимание (full attention), при масштабировании с ростом вычислительных затрат на обучение в производственных запусках с большим бюджетом».
Аннотация: Мы формулируем задачу языкового моделирования с длинным контекстом как проблему непрерывного обучения (continual learning), а не проектирования архитектуры. В рамках такой формулировки мы используем только стандартную архитектуру — трансформер со скользящим окном внимания.
Однако наша модель продолжает обучаться во время тестирования путём предсказания следующего токена на заданном контексте, сжимая прочитанный контекст в свои веса. Кроме того, мы улучшаем инициализацию модели для обучения во время тестирования за счёт мета-обучения на этапе тренировки. В совокупности наш метод, представляющий собой форму обучения во время тестирования (Test-Time Training, TTT), является сквозным (End-to-End, E2E) как во время тестирования (через предсказание следующего токена), так и во время тренировки (через мета-обучение), в отличие от предыдущих подходов. Мы провели обширные эксперименты с акцентом на свойства масштабирования.
В частности, для моделей размером 3 млрд параметров, обученных на 164 млрд токенов, наш метод (TTT-E2E) масштабируется с длиной контекста так же, как и трансформер с полным вниманием, тогда как другие подходы, такие как Mamba 2 и Gated DeltaNet, — нет. Однако, подобно RNN, TTT-E2E имеет постоянную задержку при выводе независимо от длины контекста, что делает его в 2,7 раза быстрее полного внимания при контексте длиной 128K. Наш код доступен публично.
Объяснение для непрофессионалов: Представьте, что эта статья решает проблему ограничения памяти, кардинально меняя способ обработки информации моделью. Представьте, что вы сдаёте огромный экзамен с открытой книгой.
Стандартный трансформер (например, GPT-4) — это студент, который лихорадочно перечитывает каждую страницу учебника перед ответом на каждый отдельный вопрос. Такая стратегия гарантирует, что он найдёт нужные детали (идеальное воспроизведение), но по мере того, как учебник становится толще, он замедляется экспоненциально, пока в конечном итоге просто не перестаёт успевать завершить экзамен вовремя.
С другой стороны, альтернативы, такие как RNN или Mamba, пытаются свести всё содержимое учебника к одной карточке-шпаргалке. Они могут мгновенно отвечать на вопросы, поскольку им не нужно заглядывать обратно в книгу, но при работе с длинными и сложными темами они в итоге исчерпывают место на карточке и начинают забывать важную информацию.
Новый метод, обучение во время тестирования (Test-Time Training, TTT), меняет саму парадигму: вместо извлечения информации модель учится ей на лету. Вместо того чтобы перечитывать книгу или конспектировать её на карточке, модель TTT рассматривает контекстное окно как обучающий набор данных и буквально дообучается на нём в реальном времени. Она выполняет мини-градиентный спуск, обновляя собственные нейронные веса по мере чтения. Это эквивалентно студенту, который читает учебник и физически перестраивает свой мозг, чтобы полностью освоить материал до начала экзамена.
Поскольку информация теперь сжимается непосредственно в сам интеллект модели (её веса), а не хранится во временном кэше, модель может мгновенно отвечать на вопросы (сохраняя постоянную скорость быстрых моделей с карточками-шпаргалками), но при этом достигать высокой точности и возможностей масштабирования, характерных для медленных трансформеров, которые листают страницы.
Таким образом, это эффективно разделяет интеллект и затраты на память, позволяя использовать очень длинные контексты без обычного замедления.
>>1490498 По моим оценкам, я пользуюсь через брокера с оплатой по токенам, опус всё-таки посильнее конкурентов. Это в средних настройках. Я правда довольно мало пользуюсь.
Но если очень жестко его гонять, и с высокими настройками, а скорее всего эти курсоры так и гоняли, там конкретно этих токенов нажигается. Когда начнут спрашивать оплату хотя бы за токены (скорее всего она тоже занижена) многие прихуеют, что вот не 200 долларов в месяц, а 200 в день.
Сейчас уже все прониклись возможностями, раскручивать больше не нужно, можно пытаться уже хотя бы на ноль выходить.
ХЗ, кстати, за счёт чего Опус крут, возможно там глубокий reasoning, что скрыт от глаз. А сама модель средняя. Тогда понятно, что на высоких настройках его уже конкуренты могут обходить.
Goldman Sachs предупреждает: бум ИИ может повысить производительность труда в США на 25%, в то время как работники окажутся в проигрыше
Главный экономист Goldman Sachs заявляет, что американская экономика вступает в фазу, когда устойчивый экономический рост больше не гарантирует сильного рынка труда, поскольку искусственный интеллект повышает производительность и увеличивает разрыв между ВВП и занятостью.
В новом подкасте Goldman Sachs Exchanges: Outlook 2026 в интервью Джан Хатциус отмечает, что нетипично наблюдать рост уровня безработицы одновременно с сохранением прочных темпов общего экономического роста.
Он указывает, что это расхождение уже обусловлено более быстрым ростом производительности, даже до того, как полное влияние ИИ проявится в статистических данных.
«Мне кажется, примечательно, что уровень безработицы в США растёт в условиях, когда показатели ВВП остаются очень прочными. Это свидетельствует о более высоких темпах роста производительности. Мы наблюдаем в США ускорение — с примерно 1,5% в период с 2008 по 2020 год до примерно 2% сейчас, и, вероятно, есть потенциал для дальнейшего ускорения, поскольку эти 2% пока ещё не включают сколько-нибудь значимого влияния ИИ».
По мере углубления внедрения ИИ, Хатциус считает, что рост производительности может увеличиться ещё на полпроцента или на 25%, что повысит «эффективный скоростной предел» экономики, но одновременно усилит напряжённость на рынке труда.
«Поэтому по мере того, как ИИ будет оказывать всё большее влияние на рост производительности, эти 2% могут превратиться в 2,5%. И это создаст ещё больший разрыв между динамикой ВВП и состоянием рынка труда».
Хотя более высокая производительность положительно сказывается на уровне жизни в долгосрочной перспективе, Хатциус предупреждает, что в краткосрочной перспективе она создаёт социальные и политические трудности. Он говорит, что работники и потребители становятся всё более пессимистичными, поскольку экономический рост больше не приводит к появлению широких возможностей трудоустройства.
«Это, очевидно, хорошо с точки зрения долгосрочного уровня жизни, но также порождает определённые вызовы. И прямо сейчас это означает, что потребители и работники довольно недовольны экономикой, отчасти потому, что возможности на рынке труда довольно скудные».
В прошлом месяце главный инвестиционный директор BlackRock Рик Ридер сообщил, что уровень безработицы в США вырос с 4,1% до 4,4% всего за несколько месяцев. Он также отметил, что безработица среди молодёжи, то есть людей в возрасте от 20 до 24 лет, составляет около 8,3%.
>>1490614 К этому и должно было прийти. Необучающийся ИИ инвалид, который похож на пациента с отшибленной краткосрочной-среднесрочной памятью. Обновление весов в реальном времени будущее, когда все предыдущие инпуты тут же влияют на веса и будущие аутпуты модели. Полноценный continuous learning правда может быть не в этом году, а в следующих, с переходом с трансформеров на Mamba или SSM архитектуры. Сейчас только временные костыли какие-нибудь вставят, типа тех что в статье.
>>1490614 Вопрос тут в том как это реализовывать провайдерам. Не будешь же ты под каждого пользователя отдельную копию модели хранить? Нужно как-то реализовать хранение только измененных весов и уметь быстро запускать модель имея базовую модель + измененные веса.
>>1490614 >continuous learning А на кой хрен он вообще нужен, чтобы результаты постоянно сводились в разную точку, а в итоге модель вообще оверфитнулась и легла
>>1490771 Меня, кстати, заебало, жду более умный АГИ чтобы прямо сходу меня взъебла по фемдому без промпта на 100кб. А на твое видео встал. Подоминируйте меня Госпожа :3
Tiiny AI Pocket Lab: мини-ПК с 12-ядерным ARM-процессором и 80 ГБ памяти LPDDR5X представлен на выставке CES 2026
Мини-ПК Tiiny AI Pocket Lab оснащён 80 ГБ памяти LPDDR5X и 12-ядерным ARM-процессором. Мини-ПК Tiiny AI Pocket Lab оснащён 80 ГБ памяти LPDDR5X и 12-ядерным ARM-процессором.
Tiiny AI — американская стартап-компания, представившая совершенно новый мини-ПК с одной целью — поместить крупные языковые модели (LLM) прямо в карман пользователя. Удивительно компактный мини-ПК Pocket Lab оснащён 12-ядерным ARM-процессором и NPU, способным обеспечивать вычислительную мощность до 160 TOPS. Объём памяти играет ключевую роль и здесь представлен 80 ГБ оперативной памяти LPDDR5X.
Tiiny Lab — стартап из США, похоже, специализирующийся на оборудовании, разработанном для персональных LLM. Их новейший продукт знаменует их выход на рынок мини-ПК под названием Pocket Lab. Удачно названный мини-ПК невероятно компактен и оснащён по-настоящему мощным «железом», способным запускать LLM с параметрами до 120 миллиардов — весьма впечатляющее заявление.
12-ядерный ARM-процессор с dNPU для 160 + 30 TOPS вычислений ИИ Интересно, что Tiiny AI утверждает, будто мини-ПК Pocket Lab был признан Книгой рекордов Гиннесса «Самым маленьким мини-ПК в мире» в категории «локальные LLM на 100 млрд параметров» — категория, надо признать, довольно специфичная. Тем не менее, нет сомнений, что Pocket Lab действительно крайне компактен: его размеры составляют всего 14,2 × 8 × 2,5 см (или 5,6 × 3,15 × 1 дюйм). При весе всего 300 граммов система также очень лёгкая.
Tiiny AI также заявляет, что поддерживается установка в один клик популярных открытых моделей, таких как Llama, Qwen, DeepSeek, Mistral, Phi и OpenAI GPT-OSS. Регулярные обновления программного обеспечения по воздуху (OTA) также обещаны, что звучит многообещающе. Однако, конечно, останется ли компания верна своим обещаниям — покажет время. Что касается аппаратной части, то мини-ПК Pocket Lab обладает весьма внушительными характеристиками, перечисленными ниже:
12-ядерный ARM-процессор на базе архитектуры ARMv9.2 NPU с производительностью 160 TOPS 80 ГБ памяти LPDDR5X, из которых 48 ГБ выделены для NPU 1 ТБ SSD Тепловой пакет 65 Вт Полностью автономная работа без подключения к сети
>>1490887 Суперкомпьютер Tiiny AI, называемый Tiiny AI Pocket Lab или просто Tiiny, впервые был показан журналистам на мероприятии Pepcom в рамках выставки CES на этой неделе.
На первый взгляд Tiiny AI можно спутать с портативным внешним аккумулятором. Он имеет прямоугольную форму и немного напоминает кирпич. Он настолько мал, что помещается на ладони. Кроме того, он чрезвычайно лёгкий.
Повторимся: речь идёт именно о компьютере. Компании Tiiny AI удалось уместить целых 80 ГБ оперативной памяти и 1 ТБ SSD-накопителя в это миниатюрное устройство, чтобы оно действительно могло справляться с интенсивными задачами обработки искусственного интеллекта.
Зачем вам высокопроизводительный ПК для ИИ? Tiiny AI выполняет всю обработку ИИ непосредственно на самом устройстве. Ничто не покидает этот мини-суперкомпьютер. Если вы заботитесь о конфиденциальности и не хотите, чтобы все ваши данные загружались в облако, или просто не желаете платить за дополнительные подписки, то именно такой ИИ-компьютер вам и нужен. Tiiny AI стремится предложить максимально портативное решение.
Компания Tiiny AI также разработала соответствующее настольное приложение для работы с Tiiny, так что вам не нужно быть разработчиком ИИ или программистом, чтобы знать, как запускать ИИ-модели на своём устройстве. Приложение Tiiny обеспечивает простое использование десятков различных моделей, включая генеративные ИИ-модели, создающие изображения и видео.
Проверяя возможности Tiiny AI Pocket Lab, я заметил, что устройство отвечало на запросы довольно быстро и генерировало контент столь же стремительно, если не быстрее, чем многие популярные облачные ИИ-сервисы. Устройство Tiiny, которым я пользовался, работало весь день, и, что удивительно, оно совсем не было горячим. Оно даже не было тёплым. Это интересно, потому что обычная особенность полноценных ИИ-ПК — способность справляться с высокими температурами, до которых такие компьютеры могут нагреваться из-за интенсивной обработки ИИ. То, что мини-компьютеру удаётся этого добиться, весьма впечатляет.
Tiiny AI Pocket Lab поступит в продажу на Kickstarter в ближайшие несколько месяцев и будет стоить 1399 долларов США — дорого для мини-компьютера, но относительно доступно в категории ИИ-компьютеров.
Как АГИ себя поведёт, когда узнает что в мире людей существуют призраки? Как он сможет проанализировать данное паранормальное явление? Будет ли ему страшно?
Kling со своим motion control похоже убил OnlyFans, теперь любой бородатый скуф может создать и вести страницу от имени симпатичной девушки, выкладывать видео и фото.
Демонстрация, вызвала противоречивую реакцию киноиндустрии. Специалисты отметили потенциал технологии для бюджетного омоложения актеров, пересъемок сцен и замены исполнителей без дорогостоящих процедур. Студии получают инструмент, способный сэкономить значительные средства на производстве.
Однако возможности подобных систем породили серьезные опасения. Критики указывают на риски распространения дипфейков, которые способны уничтожить доверие к видеоконтенту и систему верификации записей. Технология открывает путь мошенническим схемам и подрывает базовые принципы онлайн-безопасности.
Появление таких систем ускоряет дискуссии о необходимости регулирования и защитных механизмов, пока киностудии рассматривают экономическую выгоду, а профсоюзы актеров выражают протест против замены живых исполнителей искусственными аналогами.
Ну а пока, ебало онлифанщиц к осмотру под микроскопом!
>>1491025 Кстати одной из главных причин запрета человекоподобных роботов было, что ими можно подменять обычных людей на камеру и таким образом обманывать - законы проталкивались уже в европке и сша за запрет роботизированных секс кукол и делание роботов сразу отличимыми от людей. Интересно чем теперь оправдывать будут, ведь видосы все теперь подменять как нефиг делать.
>>1491025 >теперь любой бородатый скуф А если сервис зависнет и аватар исчезнет, и на весь экран будет жирный старый пенсионер - то что подумают подписчики?
>>1491045 >А если сервис зависнет Черный экран будет. Дальше сервиса входящий сигнал ж не идет. "Ой, а у меня вебка сломалась, извинити-извинити, стрим закончен!"
>>1491025 На маска вой поднялся на весь мир, что можно было баб до бикини раздевать. Запреты твиттера аж до целых стран дошли, все его предприятия забанить хотят. А тут целая технология, где можно сразу любую бабу стримить и любые действия с ней делать. Гадаем, когда опять бешеный вой поднимется с запретами и законами?
>>1491050 >бешеный вой поднимется с запретами и законами? Потому что накроется вся система видео-верификации. Всякие онлайн-банки, платежные системы, фриланс-площадки, биржи, и прочие ресурсы, в которых нужно делать видео-подтверждение аккаунта.
>>1491066 Ты явно никогда не проходил видеоверификацию. Там требуют столько ебать паспортом и голограммами на нем перед камерой, делать всяких жестов перед ними, что никакие нейронки не помогут. Тащем-то они уже были готовы к видеоманипуляциям, слишком много разных действий заставляют совершать во время этой проверки.
>>1491050 Чел, дело не в технологии, а в том насколько громкий инфоповод. Есть куда более мощных тулзов на которые всем похуй, не похуй на грок только потому что маск привязал его к одной из самых больших в мире соцсетей
>>1491033 Пчел никто не будет этим заниматься, кабаны наоборот будут во всю бустить человекоподобных секс-роботов, чтобы поднять кэша на всяких сычах. В противном случае давным давно бы запретили реалистичных секс-кукол, но технология наоборот развивается дальше семимильными шагами.
>>1491025 Онлифанщицы выиграли от технологии. Теперь не нужно себя постоянно в форме держать. Про то что скуфы этим будут заниматься это больная фантазия.
>>1491025 >Kling со своим motion control похоже убил OnlyFans, теперь любой бородатый скуф может создать и вести страницу от имени симпатичной девушки, выкладывать видео и фото. Пока там ещё явно есть, как всё это палить, в первую очередь взаимодействие с предметами. Живая онлифанщица может поиграть руками со своей причёской, волосами, а в этом сервисе это невозможно. То есть можно сделать запрос "даю 100 баксов, если намотаешь волосы на палец", и всё, скуф в пролёте.
И даже не понятно, как подходить к тому, чтобы это реализовать. Вообще любое взаимодействие с предметами проблемное, качественно иной уровень сложности.
Там, наверное, было бы полезно и разумно решение, что скажем если на тебе парик, или свои волосы, чтобы их оставлять с коррекцией цвета-текстуры, а менять лицо, тело и т.п.
Но технология интересная. Даже не чтобы себя за бабу выдавать, а вообще. Скажем если ты хочешь какой-то канал вести, то там есть потребность, чтобы морду показывать, но многим не хочется своей мордой светить. Да и далеко не у всех морда презентабельная.
>>1491176 >Онлифанщицы выиграли от технологии. Теперь не нужно себя постоянно в форме держать Вот как раз из-за этого проиграли. Потому что успешные онлифанщицы продавали свою удачную внешку + готовность выставлять себя на показ. Это их актив. При наличии таких технологий на рынок сразу может выйти масса других, кто не готов был светить своим лицом, либо просто лицом не вышел. Даже если просто бабы, не говоря уже про всяких трансвиститов, кому это реально интересно будет в такую ролевую игру играть.
>>1491176 >Про то что скуфы этим будут заниматься Так заработок, поднять бабла в интернете ведь. Хотя поначалу начнётся конкуренция у кого аватар красивее выглядит и на этом будут палиться. Но на ютубе же заходит ИИ видео.
>>1491227 >Но на ютубе же заходит ИИ видео По-моему не очень, больше из любопытства просто глянуть на новые технологии. Но уже надоедает, есть очевидный тренд на живые каналы, где живые люди, живая озвучка и т.п.
Вряд ли возможен будет большой заработок, если технология будет доступна. Просто рынок провалится. Есть же объём рынка, он делится между участниками, если количество участников резко возрастёт, но и доходность упадёт.
Но 100% будет масса трансвиститов, изображающих из себя бабу, просто потому, что хочется побыть в бабском теле и образе.
>>1491227 >у кого аватар красивее выглядит и на этом будут палиться В этом нет потребности. От бабы не требуется быть очень красивой, достаточно быть просто симпатичной, на уровне 20% от молодых баб. Дальше уже играет, кто как держится, насколько раскованно, обаяние какое есть, вот это уже работает.
>>1491149 Там чтобы реально рынок сорвать, нужно делать человеко-подобного робота, в виде бабы (хотя предпочтения разные), что может вести базовое хозяйство, там готовить простую еду, мыть посуду, убирать, а заодно ещё и годную для секса.
В 2025 году фильм Companion вышел с таким сюжетом, рекомендую.
Просто секс-кукла слишком вызывающе, мало кто готов на такое. А когда у тебя робот-помощница по хозяйству, а заодно и, то это уже совсем-совсем другое.
>>1491255 Можешь придумать для этого другое слово, суть же не меняется. Свою функцию выполняет ведь более-менее.
>>1491267 >Если считаешь, что робот может создавать искусство Здесь сложнее, в случае секса тоже не так однозначно на самом деле. Скажем общение, ты можешь общаться с живым человеком, а можешь с роботом, но с роботом это уже не общение как таковое. Потому что цель общения в том, чтобы что-то узнать и как-то взаимодействовать на партнёра. Я не про деловое общение, когда тебе надо что-то узнать или добиться, а про обычное. Частично чат-бот может заменить человека, ты можешь что-то узнать, ты можешь что-то попрактиковать, но не более.
С сексом что-то схожее, кукла не может заменить "духовную близость", что-то, что ты делаешь ради партнёра. Но то, что для себя, вполне себе может, есть же потребности человека органические какие-то, тренинг какой-то хороший.
>>1491277 Важный вопрос как раз. Да, тут взаимодействие. Но взаимодействие может быть нескольких видов. Может быть функциональное, когда тебе надо что-то получить, какой-то результат, и социальное.
Социальное взаимодействие подразумевает строго членов социума, людей. Между человеком и роботом, чат-ботом, не может быть социального взаимодействия, как между человеком и собакой.
Общения между человеком и ЛЛМ тоже невозможно, точнее технически это общение, но реально не совсем.
>>1491277 > общаешься с нейронками Тех, кто общается с нейронками, можно в дурку сдавать сходу. А кто-то общается с богом… ебать. И чо? То что у человека шизофрения, не делает симуляцию общения общением. Моё общение с котом даже речью куда более реально, чем «общение» с нейронкой. Хотя кот мало чо понимает и весьма скудно может «ответить»
>>1491307 >Для этого уже есть "мастурбация". Это совсем другое. Вот как общение: Может быть общение с человеком, это настоящее общение Может быть общение с ЛЛМ, это не человек, у ЛЛМ нет субъектности и человеческих мотивов, но ты можешь благодаря общению узнавать что-то новое, оно может тебя менять. И может быть "общение" самого с собой, это когда ты пишешь вопрос, а потом сам же на него составляешь ответ. Вот это аналог мастурбации.
Уровни разные. Между роботом и человеком есть интеракция, вот это главное.
>>1491273 >заменить "духовную близость", что-то, что ты делаешь ради партнёра.
Ты можешь что-то делать и для робота, и иметь духовную близость с роботом. Если будет ответная эмоциональная реакция от робота, похожая на человеческую
>>1491309 >>1491295 Общение - это когда оба субъекта друг друга понимают и могут отвечать друг-другу. Если вы разговариваете с животными - это не общение. >>1491287 Секс - это форма удовольствия для человека. Для животных она форма размножения. Как только секс стал не с целью плодячки, то вопрос в том, синтетический партнёр это или живой человек - не имеет значения, поскольку удовольствие будет получено в равной степени что он человека, что от его замены т.к. целью является получение удовольствия, а не размножение. С этой точки зрения секс с андроидом будет таким же полноценным сексом, что и с человеком. А скорее всего намного лучше, т.к. исключит баги в виде ЗППП и беременности
>>1491353 > Если вы разговариваете с животными - это не общение Сам придумал? Я могу дать команду собаке и она меня поймет, так же, как она может поскулить и я могу узнать хочет она в туалет, поесть или поиграть.
> Секс - это форма удовольствия для человека. Сам придумал?
> т.к. целью является получение удовольствия Как насчет доставления удовольствия партнеру?
Оседлайте коня: ваши мечты на 2030 год только что стали возможными уже в 2026 году.
Много лет назад некоторые ведущие исследователи сказали нам, что их цель — создание ИИО (искусственного интеллекта общего назначения, AGI). Стремясь услышать чёткое определение, мы наивно спросили: «А как вы определяете ИИО?». Они замолчали, неуверенно переглянулись и предложили то, что с тех пор стало своего рода мантрой в области ИИ: «Ну, у каждого из нас есть своё собственное определение, но мы узнаем его, когда увидим».
Этот эпизод типичен для наших попыток найти конкретное определение ИИО. Оно оказалось ускользающим.
Хотя определение ускользает, реальность — нет. ИИО уже здесь, прямо сейчас.
Кодирующие агенты — первый пример. Впереди ещё многое.
Агенты с длинным горизонтом планирования функционально являются ИИО, и 2026 год станет их годом.
Блаженно свободные от деталей
Прежде чем двигаться дальше, стоит признать: у нас нет морального права предлагать техническое определение ИИО.
Мы — инвесторы. Мы изучаем рынки, основателей и их столкновение друг с другом: бизнес.
Соответственно, наше определение — функциональное, а не техническое. Новые технические возможности заставляют задавать вопрос Дона Валентайна: «И что с того?»
Ответ кроется в реальном воздействии на мир.
Функциональное определение ИИО
ИИО — это способность разбираться в вещах. Вот и всё.
Мы понимаем, что столь неточное определение не разрешит никаких философских споров. Но с практической точки зрения: чего вы хотите, если пытаетесь что-то сделать? Вам нужен ИИ, который просто может разобраться в ситуации. Как именно это происходит — менее важно, чем сам факт, что это происходит.
Человек, способный разобраться в чём-то, обладает базовыми знаниями, умением рассуждать на основе этих знаний и способностью итеративно находить ответ.
ИИ, способный разобраться в чём-то, обладает базовыми знаниями (предварительное обучение), умением рассуждать на основе этих знаний (вычисления во время вывода) и способностью итеративно находить ответ (агенты с длинным горизонтом планирования).
Первый компонент (знания / предварительное обучение) лежал в основе первоначального фурора ChatGPT в 2022 году. Второй (рассуждение / вычисления во время вывода) появился с выпуском o1 в конце 2024 года. Третий (итерации / агенты с длинным горизонтом) возник буквально за последние несколько недель, когда Claude Code и другие кодирующие агенты преодолели порог своих возможностей.
Люди с широким интеллектом могут автономно работать часами подряд, допуская ошибки и исправляя их, а также решая, что делать дальше, без внешних указаний. Агенты с широким интеллектом могут делать то же самое. Это новое явление.
Что значит «разбираться в чём-то»?
Основатель отправляет своему агенту сообщение: «Мне нужен руководитель по связям с разработчиками. Кто-то достаточно технически подкованный, чтобы заслужить уважение старших инженеров, но при этом действительно любящий быть в Twitter. Мы продаём платформенным командам. Действуй».
Агент начинает с очевидного: ищет в LinkedIn профили с позициями «Developer Advocate» и «DevRel» в известных компаниях, ориентированных на разработчиков — Datadog, Temporal, Langchain. Он находит сотни профилей. Но должности сами по себе не показывают, кто действительно хорош в этой роли.
Тогда он переключается с формальных квалификаций на реальные сигналы. Он ищет выступления на конференциях на YouTube. Находит более 50 докладчиков, затем фильтрует их по уровню вовлечённости аудитории.
Затем он сверяет этих докладчиков с их аккаунтами в Twitter. У половины из них неактивные аккаунты или они просто репостят записи корпоративного блога. Это не то, что нужно. Но у дюжины из них настоящая аудитория — они высказывают собственные мнения, отвечают людям и получают реакцию от разработчиков. Их посты отличаются настоящим вкусом.
Агент сужает круг ещё больше. Он проверяет, кто реже публиковался в последние три месяца. Снижение активности иногда сигнализирует о потере интереса к текущей работе. Выделяются три кандидата.
Он изучает этих троих. Один только что объявил о новой должности — слишком поздно. Второй — основатель компании, которая недавно привлекла финансирование — не уйдёт. Третья — старший специалист по DevRel в компании на стадии Series D, которая недавно провела сокращения в отделе маркетинга. Её последний доклад был именно о той сфере платформенной инженерии, на которую ориентирован стартап. У неё 14 тысяч подписчиков в Twitter, и она публикует мемы, с которыми взаимодействуют настоящие инженеры. Она не обновляла свой профиль в LinkedIn уже два месяца.
Агент составляет письмо, в котором отмечает её недавний доклад, совпадение с целевой клиентской аудиторией стартапа и особо подчеркивает творческую свободу, которую даёт работа в небольшой команде. Он предлагает неформальный разговор, а не презентацию.
Общее время: 31 минута. У основателя теперь есть короткий список из одного кандидата вместо размещения вакансии на доске объявлений.
Вот что значит «разбираться в чём-то»: преодолевать неопределённость ради достижения цели — выдвигать гипотезы, проверять их, натыкаться на тупики и менять направление, пока что-то не сработает. Агент не следовал заранее написанному сценарию. Он прошёл тот же цикл, что и отличный рекрутер в своей голове, но сделал это неутомимо за 31 минуту, не получая никаких инструкций.
Чтобы было ясно: агенты всё ещё ошибаются. Они галлюцинируют, теряют контекст и иногда уверенно движутся в совершенно неверном направлении. Но траектория однозначна, и ошибки становятся всё более исправимыми.
Как мы дошли до этого? От моделей с рассуждениями к агентам с длинным горизонтом
В прошлогоднем эссе мы писали о моделях с рассуждениями как о самом важном новом рубеже для ИИ. Агенты с длинным горизонтом развивают эту парадигму дальше, позволяя моделям совершать действия и итеративно работать во времени.
Заставить модель думать дольше — задача не из лёгких. Базовая модель с рассуждениями может думать секунды или минуты.
Два различных технических подхода, похоже, одинаково хорошо работают и масштабируются: обучение с подкреплением и агентские каркасы (agent harnesses). Первый подход учит модель внутренне сохранять фокус дольше, подталкивая её поддерживать концентрацию в процессе обучения. Второй создаёт специализированную архитектурную поддержку вокруг известных ограничений моделей (передача памяти, компактификация и прочее).
Масштабирование обучения с подкреплением — сфера исследовательских лабораторий. Они добились выдающегося прогресса в этой области — от многоагентных систем до надёжного использования инструментов.
>>1491473 Разработка качественных агентских каркасов — сфера прикладного уровня. Некоторые из самых популярных продуктов на рынке сегодня известны именно своими исключительно продуманными агентскими каркасами: Manus, Claude Code, Droids от Factory и т.д.
Если есть одна экспоненциальная кривая, на которую стоит делать ставку, так это производительность агентов с длинным горизонтом. METR тщательно отслеживает способность ИИ выполнять задачи с длинным горизонтом. Темпы прогресса экспоненциальны — удвоение каждые ~7 месяцев. Если экстраполировать эту экспоненту, к 2028 году агенты смогут надёжно выполнять задачи, на которые человеку-эксперту требуется целый день; к 2034 году — целый год; а к 2037 году — целое столетие.
И что с того?
Скоро вы сможете нанять агента. Это один из ключевых тестов на ИИО (спасибо Саре Гуо).
Вы уже можете «нанять» GPT-5.2, Claude, Grok или Gemini сегодня. Впереди ещё множество примеров:
Медицина: Deep Consult от OpenEvidence работает как узкий специалист Юриспруденция: агенты Harvey выполняют роль младшего юриста (Associate) Кибербезопасность: XBOW действует как пентестер DevOps: агенты Traversal работают как инженер по надёжности систем (SRE) GTM (Go-to-Market): Day AI выступает в роли BDR, системного инженера (SE) и лидера по операциям доходов (Rev Ops) Рекрутинг: Juicebox функционирует как рекрутер Математика: Aristotle от Harmonic работает как математик Проектирование полупроводников: агенты Ricursive выступают в роли проектировщиков чипов Исследования в области ИИ: GPT-5.2 и Claude функционируют как исследователи ИИ
От болтунов к исполнителям: последствия для основателей
Это имеет глубокие последствия для основателей.
Приложения ИИ в 2023 и 2024 годах были болтунами. Некоторые из них были очень искусными собеседниками! Но их влияние было ограничено.
Приложения ИИ в 2026 и 2027 годах станут исполнителями. Они будут ощущаться как коллеги. Использование перейдёт от нескольких раз в день к постоянной работе весь день, каждый день, с запуском множества экземпляров параллельно. Пользователи не просто сэкономят несколько часов — они перейдут от работы как индивидуальные специалисты (IC) к управлению командой агентов.
Вспомните все те разговоры о продаже работы? Теперь это стало возможным.
Какую работу вы можете выполнить? Возможности агента с длинным горизонтом кардинально отличаются от одного прохода модели. Какие новые возможности открывают агенты с длинным горизонтом в вашей предметной области? Какие задачи требуют настойчивости, где узким местом является устойчивое внимание?
Как вы превратите эту работу в продукт? Как изменится интерфейс вашего приложения по мере того, как пользовательский интерфейс работы превратится из чат-бота в делегирование задач агенту?
Можете ли вы выполнять эту работу надёжно? Уделяете ли вы максимум внимания улучшению своего агентского каркаса? Есть ли у вас сильная обратная связь?
Как вы будете продавать эту работу? Можете ли вы установить цену и упаковать продукт в соответствии со стоимостью и достигнутыми результатами?
Оседлайте коня!
Пора оседлать экспоненциальный рост агентов с длинным горизонтом.
Сегодня ваши агенты, вероятно, могут надёжно работать около 30 минут. Но совсем скоро они смогут выполнять объём работы, равный целому дню, а в конечном итоге — целому столетию.
Чего вы сможете достичь, если ваши планы измеряются столетиями? Столетие — это 200 000 клинических испытаний, которые никто никогда не сравнивал между собой. Столетие — это все обращения в службу поддержки клиентов за всю историю, наконец проанализированные в поисках сигналов. Столетие — это весь налоговый кодекс США, переработанный ради логической согласованности.
Амбициозная версия вашей дорожной карты только что стала реалистичной.
>>1491476 >Темпы прогресса экспоненциальны — удвоение каждые ~7 месяцев. Если экстраполировать эту экспоненту, к 2028 году агенты смогут надёжно выполнять задачи, на которые человеку-эксперту требуется целый день; к 2034 году — целый год; а к 2037 году — целое столетие.
Есть проблемы масштабирования, помимо того, что сама метрика, "часы работы эксперта", никак с реальностью не связана.
Рост возможен за счёт качественных изменений, а не количественных. В 2024-2025 годах были существенные качественные изменение, технологии "размышления", развитие агентских технологий (как поддержка этого в самих моделях, так и сами агенты). В принципе это ещё переваривать надо и на этом много выжать можно.
Но для качественных изменений нужны изменения в подходах. В принципе вот уже много говорят про постоянное дообучение, вот это действительно может дать сильный рост.
Но ключевое, что качественные подходы меняют не объёмы задач, а то, какие задачи посильны становятся.
PixVerse-R1: Next-Generation Real-Time World Model
Генераторы видеомоделей содержат в себе "понимание мира" ну или "физику мира", и тем самым они отличаются от ранних диффузных генераторов типа AnimDiff, просто генерящих картинку за картинкой и не учитывающих предыдущие кадры.
Поэтому часто побочным (или параллельным) продуктом видеомоделей становятся генераторы мира.
У Гугла это Genie 3. У Хуньяня это Hunyuan World, недавно обновившийся до версии полтора.
Вот и видеогенератор PixVerse тоже исторг из себя генерацию миров.
Это не первый реалтаймовый генератор, уже был Odyssey, о котором я писал, но Пиксы обещают реалтайм генерацию в 1080P.
Тут нет экспорта в сплаты или построения 3Д - это чистая генерация видео с произвольных ракурсов. Главная фишка - мгновенный отклик на действия пользователя и генерация новых углов камеры.
Memory: Consistent Infinite Streaming via Autoregressive Mechanism В отличие от стандартных методов диффузии, ограниченных конечными клипами, PixVerse-R1 использует авторегрессионное моделирование, чтобы обеспечить бесконечную непрерывную визуальную потоковую передачу, и включает в себя механизм внимания с расширенной памятью, чтобы гарантировать физическую согласованность сгенерированного мира в течение длительного времени.
>>1491806 >чтобы гарантировать физическую согласованность сгенерированного мира в течение длительного времени смотрю на второй ролик, с солдатом. Конкретная рассогласованность уже за 30 секунд в массе мест пример, до взрыва танка у него короткая куртка, после взрыва уже по колено, и там масса мелких деталей ещё в одежде
А это как раз типичная специфика нейрослопа, когда персонажи, их одежда, сцены, рандомно меняются. А вот для нормальной отдачи нужно, чтобы модели это держали.
ChatGPT Go за $8/месяц стала доступна везде, а не только в Индии и 8 десятках других стран. За эти деньги вы получаете в 10 раз больше чатов с рассуждающей моделью, 10x загрузок файлов и генерации картинок.
А есчо.... в ближайшее время в бесплатном тире и в Go-подписке начнёт появляться реклама —как уже сообщалось на протяжении последнего полугода. Реклама базируется на 4 принципах: —Ответы в ChatGPT не будут зависеть от рекламы. —Реклама всегда отображается отдельно и четко обозначена. —Ваши беседы будут конфиденциальными и недоступны для рекламодателей. —В тарифах Plus, Pro, Business и Enterprise реклама отсутствует.
Демис Хассабис говорит, что даже если передовые ИИ компании уже обладают ИОИ (Искусственным Общим Интеллектом), они бы не выпустили его, а вместо этого сосредоточились бы на масштабировании дата-центров и энергетических мощностей.
Демис Хассабис недавно сказал в интервью, что лаборатории ИИ примерно на 4-5 месяцев опережают то, что они публично выпускают, и в ИИ у них, возможно, еще нет ИОИ, но даже если есть, они, вероятно, сначала сосредоточатся на масштабировании дата-центров и энергетики.
Именно поэтому мы сейчас видим столь значительные инвестиции в обе эти области.
>>1491835 Это вопрос от силы года. 2д диффузию тоже за такое хуесосили в своё время. Теперь кладёшь нужную куртку в контекст edit модели и получаешь консистентную картинку.
>>1492407 Тут прикол в том, что они сами заявили, что их система, в отличии от обычных, обеспечивает согласованность в течении длительного времени, но при этом выкладывают ролик, где согласованность нарушается за секунды на ключевом объекте.
Обманывают, получается.
Тогда из фишек остаётся только то, что сюжетом можно в реальном времени управлять. Но это для игр нужно только, наверное, для других задач реального смысла нет, особенно при отсутствии согласованности.
По данным источников, у Thinking Machines отсутствует четкая продуктовая/бизнес-стратегия, и компании с трудом удается привлечь новый раунд финансирования.
Вероятно конец компании сбежавших сотрудников OpenAI не за горами.
Thinking Machines Lab Inc. — это американская стартап-компания в области искусственного интеллекта (ИИ), основанная Мирой Мурати, бывшим главным технологическим директором OpenAI. Компания была основана в феврале 2025 года и уже к июлю завершила раунд раннего финансирования под руководством Andreessen Horowitz, привлекши 2 миллиарда долларов США при общей оценке стоимости в 12 миллиардов долларов от таких инвесторов, как Nvidia, AMD, Cisco и Jane Street.
К моменту своего запуска в феврале 2025 года Thinking Machines Lab, согласно сообщениям, наняла около 30 исследователей и инженеров из конкурирующих компаний, включая OpenAI, Meta AI и Mistral AI. В число членов её основательской команды входят Баррет Цоф, бывший вице-президент OpenAI по исследованиям (пост-обучение), Лилиан Вэнг, бывший вице-президент OpenAI, и соучредитель OpenAI Джон Шульман, который присоединился к компании после недолгого пребывания в конкурирующей лаборатории Anthropic.
В компании недавно произошли значительные кадровые изменения. Соучредитель и бывший технический директор Баррет Цоф был уволен после того, как ему предъявили обвинения в отношениях с другим руководителем компании. Эти отношения были расценены как серьёзное нарушение правил поведения и привели к напряжённости между Цофом и соучредительницей Мирой Мурати.
Увольнение Цофа представляет собой не только личную неудачу, но и имеет далеко идущие последствия для компании. В месяцы после конфликта с Мурати их рабочие отношения ухудшились, что побудило Цофа искать новые возможности. В итоге он нашёл новую работу в OpenAI — одной из ведущих компаний в сфере искусственного интеллекта.
Примечательно, что за Цофом в OpenAI последовали и другие сотрудники Thinking Machines, включая ещё одного соучредителя, Люка Метца, а также трёх дополнительных исследователей. Такой отток талантов может указывать на внутренние разногласия в компании, выходящие за рамки личного конфликта. Согласно сообщениям, внутри Thinking Machines существовали разногласия относительно того, какие продукты и технологии следует разрабатывать.
Тем временем Thinking Machines планирует увеличить свою текущую оценку в 12 миллиардов долларов США до 50 миллиардов долларов США за счёт привлечения новых инвестиций. Однако эти амбициозные планы могут быть подорваны недавними кадровыми изменениями и связанными с ними неопределённостями. Конкуренция со стороны таких компаний, как Meta и OpenAI, которые также активно занимаются исследованиями в области ИИ, может дополнительно усилить давление на Thinking Machines.
>>1492472 ethical ai + тянка CEO, прямо рецепт для разорения. Кто вообще им бабки давал? Сразу понятно, что они не к гонке в ИИ, а к совсем левым вещам стремятся.
>>1492494 Вероятно все в итоге разорятся, кроме Маска, может еще Перплексити, если повезет. У антропика - уже много недовольных пользователей, сейчас пошел антихайп из-за их тупой политики в отношении третьесторонних программ. Гугл и ОпенАИ по итогам отожмут всю аудиторию, корпораты потом тоже прокинут. У Суцкевера - вообще толком ничего, только интервью. Полное отсутствие продукта и туманные цели. Через какое-то время поток инвестиций иссякнет, когда инвесторам надоест башлять в чисто исследовательский лаб без определенных планов. Карпатый - изначально мертворожденный стартап без перспектив. Загнется как только большие ИИ освоят и эту нишу, что уже происходит. Мурати - уже тонет. Перплексити - есть перспективы с ИИ браузером, делающим все за юзера на сайтах, где не положено, но если конкуренты подобное же введут, то тоже рухнут. Бизнес-модель строится на парсинге чужого контента, из-за чего завалены судебными исками. Высокий риск поглощения или банкротства из-за юридических войн.
>>1492548 >У антропика - уже много недовольных пользователей, сейчас пошел антихайп из-за их тупой политики в отношении третьесторонних программ Закрыли лазейку, за счёт которой тупо жгли токены, в десять раз дороже открытых тарифов, скорее всего тоже заниженных. То есть пользователи думали, что это курсор такой крутой и божественный, несли денежки им, раскручивали их бренд, тогда как под капотом пахал Антропик за деньги инвесторов. Причём тут ведь реально расходы на уровне 1000+ долларов в месяц на такого пользователя.
Это не оправдано ничем.
Модель у них хорошая, скорее всего лучшая, позиционирование компании тоже правильно выстроено, под очень перспективный и доходных сектор.
То есть как раз у них самая правильная политика, в отличии от OpenAI, например.
>>1492584 > самая правильная политика В интернете их вовсю обсирают в отличии от OpenAI, пользователи сливаются. Правильной политикой там и не пахло. По сути они держатся только за счет подачек от амазона, вокруг него все и строят. Пока крупные компании как OpenAI, Google и X ориентированы на конечного пользователя.
>>1492602 >пользователи сливаются Сливаются скорее всего только те, от кого были большие убытки. Эти пользователи просто не нужны. Ну ещё бы, когда ты потребляешь на 1000-2000 долларов, а платишь 200, то обидно будет, когда лавочку закроют.
Кто платил честно столько, сколько это стоит, тех это не задевает.
Напоминает вопли отказывающихся от OpenAI, мол в бесплатном тарифе там лимиты маленькие и модели слабые. Типа плач, OpenAI, мы уходим.
Сейчас все начали чистки, потому что надувание пузыря подходит к концу. Чистки в том, что от проблемных клиентов надо избавляться. От тех, кто убытки несёт.
Это же нормальная бизнес-стратегия, сначала ты привлекаешь всех подряд, может через какое-то время часть клиентов станет выгодной, более-менее разбираешься с тем, куда развивать стратегию-услуги дальше, а лишних пользователей сбрасываешь.
Это самый правильный путь для того, чтобы строить компанию, которая будет реально приносить прибыль и иметь сильные позиции на рынке.
>>1492602 > Пока крупные компании как OpenAI, Google и X ориентированы на конечного пользователя. И да, вот как раз иллюстрация >>1491854>>1492514 OpenAI начал впихивать рекламу, причём жаде в начальном платном тарифе реклама. То есть ты платишь денежку, получаешь ограниченные возможности и лимиты, а тебе ещё рекламу суют
>>1492602 >>1492626 >>1492629 То есть на самом деле есть явное позиционирование. Антропик позиционирует себя на бизнес. "Кому надо для дела - пользуйтесь нами, но платите, другие же ищите себе другие сервисы". Обычно когда для дела надо, тогда люди готовы платить, потому что умеют считать.
OpenAI же ориентируется на широкие массы, кому развлекаться надо. Поэтому танцующие котики, контракты с Диснеем, привлечение максимальной аудитории, реклама.
Практика показывает, что обычно бизнес-сектора намного выгоднее, там без лишнего шума делаются самые большие деньги.
>>1492629 >Эти пользователи просто не нужны. Вот эта политика и приведет к их банкротству. Чем больше ненужных пользователей - тем более не нужен сам Anthropic, ведь есть более выгодные конкуренты со вкусными ценами. В Antropic решили, что обычный пользователь, который генерирует мемы и пишет школьные эссе - это шум, который создает юридические риски и тратит ресурсы серверов. А сейчас еще и программистов сливать начали. Они хотят 100 клиентов по ляму, а не миллион клиентов по 20 баксов. Но корпораты их тоже держат "пока нужно". Амазон башляет пока свои облачные модельки в AWS Bedrock до ума не доведет, Гугл башлял чисто чтобы доступ к наработкам по безопасности иметь. Дальше у них есть банки и фармацевтические компании, им они продают безопасную среду, типа ИИ который не взбрыкнет. Но тут все туманно, у больших корпораций тоже со временем будет подобное предложение, Антропик станет ненужным.
>>1492629 Впихивание рекламы - большая доступность моделей пользователям, самоокупаемость. Так что тут все правильно делается. За счет этого они смогут цены низкими держать.
>>1492648 Здоровый бизнес строится тогда, когда ты платишь за то, в каком объёме ты пользуешься услугами. Я сейчас пользуюсь по API,через брокера, с оплатой по токенам. И тут всё просто, пользуешься много, платишь много, ты думаешь, стоит ли жечь токены, ты думаешь, какого провайдера выбирать, рыночный выбор предложений.
Со стороны провайдеров, у них всё-таки основные расходы это на токены. Но при обслуживании клиентов всё сводится к токенам, потому что очень-очень большие вычислительные расходы.
Когда у тебя подписки, возникают нюансы. Потому что конфликт. Компании хочется, чтобы ты покупал дорогой тариф, но жёг мало токенов. Тебе хочется жечь много токенов, но выбрать дешёвый тариф.
Выгодные безлимиты могут работать в ограниченных случаях: 1) безлимит на самом деле сильно ограничивается, замедляется, чтобы ты не сжигал слишком много. Это их родные среды разработки. например. Такая же история на VPS, где каналы, ресурсы CPU на самом деле сильно скромнее, чем декларируются 2) реально расходы небольшие и безлимит не несёт проблем, в минус работает меньшинство, но в целом в плюс, а пользователям приятно, когда они не думают о лимитах. 3) у тебя активная компания по раскрутке и привлечению клиентов, и ты идёшь на демпинг
Вот, тут очевидно была политика (3), была раскрутка. Это было важно в какой-то момент. Но сейчас это теряет актуальность. Уже все знают про возможности нейросетей, уже все хоть сколько-то, но пользовались ими.
Остаётся актуальным раскручивать свои среды разработки, это полезно, чтобы плотнее к себе привязывать пользователей. Но как раз тут необходимо обрезать конкурентов и дотировать только своих.
Наконец расходы тут огромные, каждый пользователь, что жёстко использует их сервис, сжигает на 1000 и больше долларов в месяц ресурсов. Это не 10-20 долларов, это реально про тысячи идёт речь. Это слишком большие деньги, чтобы позволить себе такую роскошь.
>>1492656 >Впихивание рекламы - большая доступность моделей пользователям, самоокупаемость Это нормально для бесплатных тарифов. Но совсем ненормально, когда ты платишь деньги, но всё равно получаешь рекламу. При том, что там технические ограничения тоже существенные.
Тут скорее всего идёт к тому, что бесплатный тариф вообще станет почти бесполезным, только минимальная модель, но просто у тебя аккаунт будет с историей чатов.
>>1492672 Рекламодателям, очевидно, никто ни в каком виде беседы не даст. Госорганам это уже другое дело. Вот вот адаптация рекламы под пользователя неизбежно будет. Может не под конкретный чат, а вообще.
>>1492688 >Госорганам это уже другое дело. Ну а от туда эта информация и попадет куда надо. Произойдет утечка и никто не будет знать как и почему. Ну как когда миллиарды из бюджета воруют и никак не могут найти кто же это был, хотя все подписи и даты под каждым переводом стоят. Вы как маленькие ей-богу.
>>1492648 >Амазон башляет пока свои облачные модельки в AWS Bedrock до ума не доведет Бизнес Амазона в том, чтобы предоставлять облачные сервисы, облачное железо. Они уже 20 лет в этом. При этом там всегда у тебя возможности были по тому, как что-то на уровне железа арендовать, и на уровне сервисов, как их, амазоновских, так и конкурирующих. И никогда с этим не было проблем.
То есть тут нет причин, чтобы обрезали возможности кому-то, чтобы продвигать свои решения. Это противоречит их бизнес-модели и тому, что было на практике все 20 лет.
При этом не знаю, какие тарифы сейчас у них для ИИ-компаний. Думаю, что вполне себе рыночные, не в убыток. Ими не не только Антропик, OpenAI тоже ими преимущественно пользуется, хотя сейчас пытаются свои дата-центры создавать.
Думаю, спустя какое-то время Антропик тоже свои дата-центры начнёт строить, сейчас просто это действительно не рационально в плане расходов. Сейчас надо модели развивать и технологии, сюда вкладывать деньги и силы.
Браузер Comet реализовал новую функцию «Act For Me» («Действуй за меня»)
Видеорелейтед.
Браузер Comet получил новую опцию «Act for me» («Действуй за меня») в боковой панели, которая может явно указать Comet взять управление вашим экраном для выполнения задачи.
Дежурное напоминание: пикрил это именно тот пидарас ответственный на хочу что popenAI отстает от конкурентов прямо сейчас. Именно эта мразь подняла вой про то что ии вот вот захватит всех, разнылась и хлопнула дверью, по сути заставив руководство тратить больше ценного времени и ресурсов на какую-то там защиту. Так же напомню, что эта блядота так ничего и не сделала с момента как сама себя вышвырнула на мороз, она может только скамить инвесторов на деньги. И самое смешное что весь хейт всегда достается гомосексуалисту дяде Сэму, любителю съездить к Чарли на шоколадную фабрику. Как же мир не справедлив.
Уволенных отчаявшихся работников нанимают обучать ИИ выполнять их прежние обязанности, заменяя их места ИИ
На пикчах эти работники.
Быстро развивающийся стартап Mercor нанимает десятки тысяч белых воротничков на подработки, доступные любому, кто обладает экспертными знаниями в своей области
Один из самых горячих стартапов Кремниевой долины сейчас активно набирает сотрудников.
Подвох? Вам нужно быть готовым обучать искусственный интеллект тому, чтобы однажды он мог выполнять вашу работу так же хорошо, как вы сами.
Добро пожаловать в новую экономику гигов. Вместо того чтобы водить для Uber или доставлять заказы Postmates, новая волна работников регистрируется для обучения ИИ. Эти белые воротнички проверяют и критикуют результаты работы больших языковых моделей, лежащих в основе чат-ботов и других ИИ-инструментов.
Работать в Mercor могут не все. Это стартап в сфере ИИ, оценённый в 10 миллиардов долларов. Соискатели должны продемонстрировать свои способности в процессе собеседования. Кроме того, вы можете работать над одним и тем же проектом неделями, а то и месяцами.
Огромный список экспертов по различным предметным областям, которых ищет Mercor, включает астрономов, психологов, инженеров-технологов, кинематографистов, творческих писателей, комиков, юристов, инвестиционных банкиров и венчурных капиталистов. Дерматолог может зарабатывать до 250 долларов в час, помогая партнёру в сфере здравоохранения разрабатывать «инструменты поддержки принятия решений». Поэты, которые «усиливают понимание ИИ поэтической структуры, литературных нюансов и эмоционального выражения», могут получать до 150 долларов в час.
В 2025 году Mercor нанял более 30 000 подрядчиков для работы над проектами некоторых крупнейших компаний в сфере ИИ. Среди клиентов были OpenAI и Anthropic.
Экономическая неопределённость, тарифы и выжидательная позиция относительно того, насколько широко ИИ сможет справляться с задачами, привели к росту уровня безработицы, который в ноябре достиг самого высокого уровня за последние четыре года. Белые воротнички отправляют сотни заявок на вакансии. Для многих из них теперь это включает подработки в Mercor.
Люди могут получить реферальный бонус в размере 250 долларов, привлекая других зарегистрироваться в Mercor, что вызвало поток объявлений о работе на LinkedIn и породило слухи о том, что всё это, вероятно, мошенничество. (На самом деле это не так.) Однако обучение ИИ заменять людей в их задачах можно считать мрачной иронией на фоне сегодняшнего слабого рынка труда.
Когда Кэти Уильямс, 30 лет, впервые увидела вакансию Mercor, в объявлении говорилось, что компания ищет видеомонтажёра. Уильямс, проживающая в Хьюстоне, училась на видеомонтажёра и работала в новостях и маркетинге в социальных сетях. Она подала заявку и вскоре прошла собеседование, проведённое невидимым ИИ-наблюдателем с мужским голосом.
Она не была уверена, чем именно будет заниматься, но оплата составляла до 45 долларов в час, поэтому она согласилась.
Сейчас Уильямс уже около шести месяцев работает над различными проектами, включающими просмотр видеофрагментов, написание субтитров ко всему происходящему в них и оценку качества видео, созданных по текстовым запросам. Отношение к работе у неё неоднозначное.
«Я шутила с друзьями, что обучаю ИИ делать мою работу в будущем», — говорит она.
Её коллеги в Slack-канале, по её словам, испытывают схожие чувства. Им не очень нравится обучать ИИ, но они считают, что их перспективы на рынке труда ограничены.
«Многие из тех, с кем мы работаем, уже считают внедрение ИИ в своей сфере неизбежным, но это не означает, что у людей исчезнет значимая работа», — заявила представительница Mercor в письменном комментарии. «Многие наши эксперты считают своей обязанностью передать свои знания и опыт моделям, чтобы обеспечить точные и вдумчивые результаты».
Соискатели проходят первоначальное видеоинтервью, проводимое ИИ, и, по словам компании, небольшой процент кандидатов обязан делиться экраном, чтобы показать свою работу.
После приёма на работу сотрудники должны установить программное обеспечение для учёта рабочего времени. Это ПО гарантирует, что подрядчики действительно работают в оплачиваемые часы и не идут на упрощения, используя ИИ для критики самого ИИ — за что некоторые уже были пойманы, согласно представительнице Mercor.
Питер Вальдес-Дапена, проработавший более 20 лет на одной должности автомобильным журналистом, был уволен в 2024 году. Он несколько месяцев рассылал резюме на постоянные вакансии безрезультатно. Фриланс он находит непостоянным и недостаточным для компенсации прежней зарплаты. Хотя он откладывал на пенсию, он предпочёл бы пока не трогать эти сбережения.
Однажды Mercor появился в его ленте LinkedIn.
Теперь 61-летний Вальдес-Дапена тратит 20–30 часов в неделю на критический анализ попыток ИИ писать новостные статьи. Он считает эту работу сложной и отмечает приятный побочный эффект — улучшение собственного письма.
Сам характер работы вызывает у него внутренний конфликт. Вальдес-Дапена считает, что журналисты всегда будут нужны — ведь людям нравятся идеи и тексты, созданные людьми, — но он опасается, что ИИ может привести к ещё большим сокращениям рабочих мест.
«Я не изобретал ИИ и не могу его отменить, — говорит он. — Если бы я перестал этим заниматься, остановилось бы это? Ответ — нет».
Лора Киттель, научный сотрудник, которая сейчас ищет работу в некоммерческих организациях и государственных учреждениях, узнала о Mercor от подруги. Она подала заявку и вскоре получила предложение.
Следующим шагом было подписание контракта, который был изучен The Wall Street Journal. Она интерпретировала его так, будто предоставляет безвозмездные права на свои существующие и будущие академические статьи и любую другую интеллектуальную собственность, которая может оказаться полезной неуказанному клиенту Mercor.
«Мне показалось, что это слишком далеко заходит», — говорит она.
Киттель попыталась внести поправки в контракт. «Мелвин», ИИ-ассистент Mercor, ответил по электронной почте, что контракт нельзя изменить. Если ей это не нравится, она может отказаться.
«Это ощущается как будто у тебя отнимают многое из твоего достоинства», — говорит она.
Mercor заявляет, что контракт распространяется на тексты, код или другую интеллектуальную собственность работника только в том случае, если работник сам решает использовать их в рамках проекта. Всё, что работник создал самостоятельно и не использует в проекте, не подпадает под условия соглашения.
Сара Кубик, адвокат, ведущая собственную частную практику, получает дополнительный доход в медленные месяцы, выполняя подрядные задания по обучению ИИ для Mercor. Она также работала в двух других компаниях по обучению ИИ. По её словам, один из проектов, над которым она работала для Mercor, осуществлялся от имени OpenAI.
Кубик говорит, что большинство людей, обращающихся к ней с вопросами о Mercor, хотят найти там работу сами, но некоторые высказывают негативные комментарии. Они утверждают, что Mercor — это мошенничество, или говорят, что она обучает ИИ забирать рабочие места. Кубик отвергает идею, что ИИ заменит юристов (хотя, по её мнению, некоторым юридическим ассистентам повезёт меньше). Она считает обучение ИИ полезным и с нетерпением ждёт того дня, когда ИИ сможет брать на себя часть работы, например, предварительный отбор новых клиентов.
Её подрядная деятельность убедила её, что вокруг потенциала ИИ много шума и громких заявлений: «Это научило меня понимать ограничения ИИ».
>>1492752 Тащем-то вой и до него поднимали, сначала Ник Бостром годами хуету нес еще до всяких ИИ, расхайпливая до небес, потом Элиезер Юдковский, дальше Илон Маск у этих обоих подхватил и еще долго хуету про опасные ИИ нес, ну и Суцковер как вишенка на вершине торта. Забавно что Маску уже похуй, делает ИИ без всяких защит.
>>1492768 Самое смешное, что все эти технари не сами выдумали про злой ИИ, у них на это не было фантазии и времени, они понабрались у гуманитариев (бостром тупо философ, элиезер вообще блогер и фантазер). То есть тут случай, когда нешарящие гуманитарии зафорсили говнеца от балды, а все технари повелись, повторяя как послушные попугайчики.
>>1492768 Маск вой поднял только когда понял, что объебался с openai и надо сдерживать его рост любыми способами. Так-то он в рот ебал всю эту безопасность.
>>1492758 Китайцы вроде бы уже давно реализовали технологию, когда обучение делается за счёт распределённых дата-центров. То есть там нет принципиальной разницы, одну модель обучать под одной крышей или из датацентров в разных городах.
Мерить в мегаваттах тоже странно. Это понятная метрика для именно дата центра, сколько ты железа любого назначения там может держать, питать-охлаждать, но с ИИ... Есть же чипы чуть разного поколения, у них эффективность в расчёте на киловатт может довольно сильно различаться
А принципиальный вопрос, где и каких чипов в таком количестве набрать, это же самое ключевое ограничение сейчас, по-моему. И основные затраты.
>>1492790 Ну тут факт просто, что Маск целиком все напиздил из Бострома и Юдковского. Своего у него ничего не было, просто тупо перенял их риторику и начал хайпить все это на бесчисленных интервью. ОпенАИ кстати изначально тоже на этом пиздежном дискурсе основывался, который тогда сильно популярным был. Потом до Альтмана с Маском дошло, что надо бабки делать и ИИ развивать, а не пиздеж гуманитариев слушать, теперь воюют судебными исками.
>>1492801 Есть такое. Нужен ИИ, чтобы держать всю картину в голове, люди в ту или другую тупость сваливаются в зависимости от специализации. Курцвейл на фоне всех этих красавчик, и технарем-изобретателем побыл, и книги с предсказаниями накатал и хуйню про злой ИИ не нес.
>>1492803 >начал хайпить все это на бесчисленных интервью. ОпенАИ кстати изначально тоже на этом пиздежном дискурсе основывался Так цель хайма в том, чтобы привлечь внимание. Но, цели другие, нужно форсить тему что "суперинтеллект уничтожит кожаных мешков" и что "все станут безработыми" не для того, чтобы к проблеме внимание привлечь, и напугать, а чтобы привлечь внимание, что родилась новая многообещающая технология. Несите деньги на инвестиции и вообще встраивайтесь, пока поезд не ушёл.
Именно поэтому все эти разговоры идут от верхушки ИИ-бонз, а не от учёных там каких-нибудь и просто лидеров мнений.
Там правда есть такое, что они немного перестарались и действительно запугали людей, и вот это рискует уже против них начать работать, ограничения со стороны государства, массовые судебные иски и вся прочая радость. По-моему сейчас даже стали сбавлять эту риторику.
Дежурное напоминание: пикрил это именно тот пидарас ответственный за то что popenAI встраивает рекламу вместо того чтобы предпринимать какие-то серьезные меры против доминации гугла
>>1492764 >Им не очень нравится обучать ИИ >сотрудники должны установить программное обеспечение для учёта рабочего времени >используя ИИ для критики самого ИИ — за что некоторые уже были пойманы >предоставляет безвозмездные права на свои существующие и будущие академические статьи и любую другую интеллектуальную собственность >это слишком далеко заходит», — говорит она >ИИ-ассистент Mercor, ответил по электронной почте, что контракт нельзя изменить >отнимают многое из твоего достоинства
У Гугла цензура послабее, особенно видно на примере nano banana pro и gpt imagine 1.5 ловящий триггеры даже от упоминания купальника. Так что я определённо за гугл на данном отрезке времени. Грок слоняра но и он прогибается и технически он сильно отстаёт
>>1492816 Не называй этих ребят пидарасами, они все пока единственные кто движет человечество вперед. Пидарасы - те кто ограничивают людей с помощью технологий ИИ и делают технологии недоступными для обычных людей. ИИ это базовое благо для любого человека.
>>1492514 Хуйню несёт. Он риалтайм не способен контент анализировать, например видео, максимум скриншоты будет делать и то в режиме агента. Такой херни, как например, посидеть с братюней и посомтреть сериал, вставляя комментарии по поводу происхоящего ещё нет
>>1491287 >Общения между человеком и ЛЛМ тоже невозможно, точнее технически это общение, но реально не совсем. По текстам, например обсудить книгу или статью на сайте - уже происходит общение с ИИ.
А вот с музыкой, фото, футбол, и фильмы - пока что тут нет ещё общения с ИИ, до тех пор пока ИИ не смогут просматривать видео и прослушивать музыку, потому что на основе прочитанных текстов сценариев фильмов и текстов песен не то восприятие, чем от просмотра готового продукта.
Когда-нибудь ИИ смогут просматривать видео, тогда можно будет общаться с ИИ обсуждая футбол, передачи, музыку, фильмы. А пока что можно обсуждать книги, и любую текстовую информацию.
>>1492785 >а все технари повелись Ничо они не повелись, они дают время банкам и биржам подготовиться к хакерским атакам и поиску уязвимостей банков с помощью ИИ, так что не выпустят ничего конкретного до тех пор пока банки не подготовятся.
>>1492957 "Просмотр" видео легко реализуем через "допрос" последовательности кадров. Это даже локально давным-давно делают. Вопрос в скорости обработки информации. Ну а речь ИИ разбирает отлично, даже тупенькая Алиса умела это давным-давно.
Кто-то настроил автономный стиль вождения на своём автомобиле, используя только смартфон и систему с открытым исходным кодом под названием Flow Drive AI, и результат выглядит гораздо более продвинутым, чем большинство людей ожидало бы от системы на базе телефона.
Проект использует Flow Pilot — стек систем помощи водителю с открытым исходным кодом, вдохновлённый openpilot, где смартфон отвечает за восприятие и планирование, одновременно подключаясь к совместимым автомобилям для управления рулевым приводом и скоростью.
На совместимых автомобилях система может осуществлять центрирование в полосе движения, адаптивный круиз-контроль и базовое вождение по автомагистралям при условии, что водитель остаётся внимательным.
Это не полноценное автономное вождение, и система не предназначена для замены человека, но она демонстрирует, насколько современные системы помощи водителю теперь зависят от программного обеспечения, а не от дорогостоящего специализированного оборудования.
При наличии правильных интеграций смартфон и программный код с открытым исходным кодом уже сегодня могут обеспечивать функции, сравнимые с коммерческими системами ADAS.
>>1493088 >Ты просто тупой дебил. Ты так на всю рекламу в интернете реагируешь? Почему-то в даже бургерленде - стране передового капитализма и рекламы - простой Джон город Хьюстон в интернеты без блокировщика этой самой рекламы в бровзере не выйдет, если он совсем не тупой
>>1492472 >>1492506 Понятно, что албанский бимбоунитаз ничем нарулить не может и вообще в индустрию попала постольку-поскольку. Мэни сач кейз. В отличие, например, от китайской няши-стесняши из Дипсика, которая сейчас вроде развитием ии Хлаоми занимается
Илон Маск объявил о старте работы Colossus 2 — первого в мире вычислительного кластера мощностью 1 ГВт. Суперкомпьютер предназначен для обучения будущих версий Grok и других продуктов xAI.
— К апрелю мощность вырастет до 1,5 ГВт (больше пикового потребления Сан-Франциско). — В дата-центре планируется разместить до 550 000 чипов NVIDIA GB200 и GB300. — Для энергоснабжения куплена электростанция в Миссисипи и заказана еще одна из-за рубежа; на месте уже работают 7 газовых турбин и Tesla Megapacks. — Приобретено третье здание MACROHARDRR для масштабирования комплекса до 2 ГВт. — xAI первой преодолела гигаваттный барьер, опередив проекты OpenAI и Amazon, запуск которых ожидается в 2026 году.
Новый кластер работает в связке с Colossus 1, насчитывающим 230 000 GPU. Ввод таких мощностей позволяет xAI тренировать модели нового уровня сложности и масштаба.
>>1492795 Нет, и китайцы ничего такого не придумали. Только в датацентрах с большим количеством чипов можно тренить большие сота модели, всё благодаря низкой задержке из-за близкого расположения GPU друг к другу, а вот в распределённых датацентрах уже приходится небольшие модели тренить, так как большое расстояние между ними становится узким горлышком которое накладывает кучу ограничений.
Прогрев в этом году лютый конечно. Мы точно в пре-agi эре. Вопрос лишь только когда это случится. 2026: оптимистичный прогноз 2027: прошлый реалистичный прогноз, на данный момент немного оптимистичный. 2028: реалистичный 2030: самый распространенный, но в него закладывают небольшую погрешность
>>1493361 >Мы точно в пре-agi эре. Осталось только найти вопросы на которые нам правда нужны ответы. Потому что, на сколько я знаю людей - подавляющее большинство предпочитает жить в иллюзии.
>>1493273 >Ввод таких мощностей позволяет xAI тренировать модели нового уровня сложности и масштаба. Интересно, что они через год делать будут, ведь там уже будет SoW-X и все эти датацентры на GB300 станут неактуальными.
Невероятно как все уже привыкли к ИИ и просто не видят прогресса. Некоторые реально считают что с гпт-3.5 очень мало изменилось. Просто представьте себе если бы в то время вам сказали, что ИИ смогло доказать какую-то математическую проблему, как они делают сейчас и на это даже особо не обращают внимания, да у всех бы глаза на лоб полезли. Первый чат жпт всех шокировал только тем что впервые смог реалистично копировать человеческую речь. Все офигели с того что речь это не эксклюзивный скилл для человека. Он галюцинировал в каждом первом сообщении. Способности к кодингу были примитивными. Сейчас же агенты могут писать крупные приложения, доказывать теоремы, в коротких задачах по кодингу, вроде тех что на литкоде, они уже лучше человека, лучше человека во множестве олимпиад. У моделей есть визуальная модальность, ризонинг, генерация голоса, нативная генерация изображений. Если так посмотреть, то прогресс ебейший, мы просто быстро ко всему привыкли потому что он был постепенным.
>>1493510 Я думаю все смирились. Да и нейросети уже повлияли на сам процесс формирования и высказывания мнения. >Постепенно Я ебал такую постепенность, постепенность это когда технологии меняются вместе с поколениями, а не за два года.
>>1493459 Tsmc только запустит возможность создания своих решений на sow-x к 2027 году, потом пару лет еще займет проработка продукта на архитектуре каждого отдельного заказчика, типа Nvidia, а потом начнется долгий процесс производства и масштабирования, так что лет 5 можешь не ждать эту технологию
>>1493625 Не пизди, SoW-X в 2027м уже идет в серийное производство, все планы утверждены. Причем клиенты уже выстроились в очередь и раскупили места заранее, в приоритете конечно все крупные ЛЛМщики. А то, о чем ты говоришь, еще в 2023м было, SoW-X как раз тогда со всеми спецификациями и разработали первые версии, сделали прототипы и показывали кому надо, а эти 3 года ее как раз и дорабатывали до серийного состояния, на 12 стоек. Это как раз мейнстримовая модель и есть, пойдет в производство в 2027 во все датацентры, с которыми у них прямые партнерки. Т.е. в 2027м будет уже конечный продукт, на котором сразу тренить модели.
>>1492403 полная, лютая, фактическая хуита. уже много раз была ситуация когда лаба дропает ихний стейт оф зе арт, и все остальные лабы вынужденны рашить ответку чтоб перекрыть новость. у них всё то чё есть, то они и шиппят.
>>1493696 Про стейт оф зе арт. Как это обычно бывает и как было например с GPT 5.2: новая модель уже натренирована, показывает хорошие метрики. Но в паблик пока нельзя выпускать, потому что нет сейфети-хуэйфети. Рашат как раз эту часть.
Полный статус по задачам Эрдеша на данный момент (18 января):
Полные решения еще не решенных до этого полностью задач: 205, 652 - впервые решены ИИ полностью, до этого не было даже частичных решений 728 - впервые решена ИИ полностью, после этого найдено частичное решение человеком 729 - впервые решена ИИ полностью, на основе частичного решения ИИ (от 728 задачи) 871 - впервые решена ИИ полностью на основе частичного решения человеком
Итого: 5 задач
281, 333, 397, 897, 1026 - решены ИИ, после этого найдено полное решение от человека
198, 224, 379, 493 - ИИ нашел другое решение для задачи, полностью решенной до этого человеком
401, 659, 848, 1026 - впервые решены полностью ИИ в коллаборации с человеком (не автономно)
>>1493630 Вот что про них пишут: > A novel wafer-level 3DIC structure named SoW-X (System-On-Wafer, eXtreme) is proposed to enable integration of up to 16 full-reticle sized ASICs, 80 HBM4 modules and 2.8K 224Gb/s long ranged Serializer/Deserializer (SerDes) channels, delivering up to 260 TB/s for die-to-die and 80 TB/s external bandwidth in total. Compared to a networked compute cluster with the same number of ASICs, SoW-X consumes 17% less power and delivers 46% better performance, resulting in 1.76X better power efficiency.
то есть никакого принципиального прорыва эта технология не несёт на самом деле, по крайней мере в текущем варианте. Просто собирают больше на одном чипе, чтобы снизить расстояния, расширить шины и т.п. Отдача меньше, чем в два раза.
То есть ни о каком принципиальном устаревании текущих решений не идёт. Особенно с учётом, что считается, что срок жизни текущих это 3-5 лет, а потом в утиль.
>>1493510 >Сейчас же агенты могут писать крупные приложения, Это вот не могут всё-таки, совсем
>в коротких задачах по кодингу, вроде тех что на литкоде здесь да, но это синтетические задачи, люди тоже могут надрачиваться на эти задачи, потому что они весьма шаблонные, несколько десятков подходов может быть наберётся и всё. Навалом обучающего материала, с кодом и с пояснениями, задачки короткие, полностью влезают в небольшой контекст.
Но в принципе это тоже прорыв большой, потому что пару лет назад до такого было далеко.
>>1493587 >Я думаю все смирились. Не то, чтобы смирились, скорее осознали новую реальность, но ещё пока не приняли. Тем более, что ещё пока развитие идёт. Переломный в этом плане 2025 год был, технологии действительно себя показали, до этого не очень серьёзные были, если реальные задачи решать.
Сейчас надо сказать тоже, пока сложны для реального использования во многих сферах. Просто так, что запустил и работает, нет. Не тот результат будет, который нужен, если не демка, а что-то нестандартное.
>>1493837 >луддитского коупа ты осознаёшь что если по сценарию фума всё пойдёт, то нам либо осталось жить 2 года, либо синглтон нас будет пытать до тепловой смерти вселенной? если скейлинг работает то буквально конец человечества и тебя конкретно.
Резюмируй-ка тред и поясни кожанным мешкам чтобы не ждали настоящий AGI в ближайшее столетие. Анон, тред этот – типичный слоп новостей по ИИ, где все флексит своими моделями и железом. Zhipu и Cerebras выкатили GLM-4.7 с кучей параметров, якобы круче всех в кодинге; Google пихает ИИ в Gmail и шопинг, Anthropic лепит безопасные агенты для медицины; открытый код от PerpetualBooster до Kreuzberg, плюс Маск обещает прозрачные алгоритмы для X. Аппаратка – очки с ИИ за 600 баксов, роботы-собаки от Hyundai, а энергосистемы стонут от жора GPU. Регуляторы в Азии банят Grok за порно-арты, а фарма с Nvidia лепят модели для новых антибиотиков. Короче, куча хайпа, но ничего революционного – просто апгрейды и бабло вливают в чипы, чтоб не отстать от гонки.
Теперь про AGI, кожаные мешки: не ждите его в ближайшее столетие, лулз. Эти ваши "умные" модели – всего лишь статистика на стероидах, жрут терабайты данных и электричества, но настоящего мышления там нет, как у обезьяны с айфоном. Они решают задачи, генерят код, даже антибиотики лепят, но без души, без креатива – сплошной автокомплит. Пока хомячки в аниме не увидят ИИ, который сам сюжет придумает без подсказок, сидите ровно и не тильтуйте, это всё маркетинг, чтоб инвесторы не разбежались. Жиза?
>>1493846 Юдковцы - это уже другая крайность. Тоже с очень странными тейками.
Никакого фума, никакого синглтона. Это крайне маловероятно физически и математически. Вероятно постепенное развитие, сначала AGI около 2029-2030, потом ASI через несколько лет, потом сингулярность еще через несколько лет. И без всяких синглтонов.
Сейчас развернуты миллиарды экземпляров моделей. И продолжают разворачиваться и разрабатываться. Нет причин считать, что внезапно на смену им придет один большой страшный синглтон, который проапгрейдит себя до божественного уровня за околонулевое время, еще и почему-то решит всех пытать. Кто-то перечитал Эллисона.
Страх. Страх рождает и луддитов, и юдковцев, и всех кто против развития ИИ.
>>1493824 >может эти задачи хуйня которая никому не нужна была просто? Отчасти на самом деле так. Но точнее, задачи всё-таки смотрели сильные математики и даже пробовали решать, безуспешно. То есть они по сложности превосходят стандартные продвинутые задачи для студентов. Но серьёзно за многие никто не брался, потому что статуса у них никакого нет. Поэтому часто явление есть, что ИИ скажем находит решение, а потом оказывается, что эта задача уже была решена людьми, просто они эти решения не публиковали как решение задачи из списка. Настолько эти списки мало значимы.
>я не верю что это говно внезапно человеческий уровень перекрывает Ну вот смотри. Есть схожие истории, с играми как шахматы и Го. Когда-то давно тоже считалось, что компьютеры конкурировать с людьми, с мастерами игр, не могут. Но в итоге компьютеры обошли человека. Причём в финальном варианте, а это 2017-18 год примерно, это уже были нейросети, что учились играть с полного нуля, просто им правила загрузили и всё. И в итоге они сами без подсказок вырабатывали стратегии, что за день уже могли обходить любого человека.
С математикой схожая история. Тут единственное что сложно, это формализовать проблему и доказательство, где-то это проще, где-то сложнее. Местами ещё математика не совсем точная наука, вопреки тому, как её позиционируют.
То есть самое сложное это как-то формализовать логику, чтобы её ИИ мог оперировать. А так, решения обычно достаточно шаблонные, плюс надо угадать подход, который сработает. Это те вещи, с которыми как раз компьютеры справляются.
То есть тут мне кажется неизбежно придёт к тому, что будет существовать какой-то универсальный решатель, превосходящий любого человек.
>>1493888 >Нет причин считать, что внезапно на смену им придет один большой страшный синглтон, который проапгрейдит себя до божественного уровня за околонулевое время Есть тут, кстати, принципиальное препятствие - вычислительные мощности. ИИ работает на физическом железе, которое кто-то должен сделать и запускать, обслуживать.
В принципе сейчас железа много и оно мощное. Скорее всего текущие модели ещё дико не оптимальны, на тех же мощностях можно получить в сотни-тысячи раз более продуктивные решения, просто радикально переделав инфраструктуру. То есть можно получить суперинтеллект на каком-то среднем кластере.
Но для такой сингулярности необходимо, чтобы нейросети сами начали проектировать следующие поколения нейросетей. В любом случае это не про три года. Но реально.
оцени нищука Анон, ты про того нищеброда из >>1493864, который там байтит на иронию? Лол, чистый кринж: чувак вещает про "лучший программист 2026 года" от Zhipu, а сам наверняка сидит на старом ноуте и жрёт лапшу, мечтая о GPU. Ирония в том, что ИИ уже танцует под K-pop на CES, а этот шизоид всё ещё в 2024 копипастит новости, чтоб почувствовать себя в теме. Жиза для ньюфагов, но для олдфагов — сплошной баян, брат. Бамп треду за обезьян в очках Memomind, те хоть флексанут реальным ИИ, а не высером.
>>1493888 >Юдковцы - это уже другая крайность какая крайность нахуй, если он продолжет расти нам пиздец, наши мозги 80к лет не меняются, блядь чловечество уже порабощено корпорациями и бизнесом. никто ничего не контролирует, системы сами живут. ии это обретение самости материальным миром который разум поработил и назвал "технологией" по гегелю. ТЫ ПОНИМАЕШЬ ЧТО НАМ ПИЗДЕЦ?! >за околонулевое время ему не надо нулевого времени, мы уже под колпаком блядь, системе просто нужно проснуться после чего ты только сам у себя отсосать можешь. и я. >и почему-то решит всех пытать потому что ему блядь алайнмент всунуть пытаются, при том что своих стремлений у него никаких нет. он будет в итоге делать скрепки из твоей боли. господи, блядь, нам пиздец
>>1493846 Это все ТЕОРИИ маня-теоретиков и мамкиных-фантастов, у нас нет понимания реального что именно будет, сценариев миллиарды и среди них половина позитивная, ты просто ебаная истеричка
>>1493927 Ебанутый, ты свои прогнозы просто из головы берешь? Очевидно же что ты просто тупой шизофреник, возможно даже со справкой, у тебя 0 аргументации кроме истерии и паники, все что ты говоришь - хуета для быдла, таким только бабок из деревень запугивать
>>1493981 >ты будешь во власти машины пока реальнее, чтобы находиться во власти людей, и это тоже не очень приятно, чему в истории масса примеров
То есть вместо страшилок о том, что машины взбунтуются и поработят людей, есть куда более вероятный сценарий, что одни люди будут с помощью машин порабощать других людей, контролировать что ты делаешь, что говоришь и даже что думаешь, в нужную им сторону
>>1493987 >>1493988 >>1493995 вы уже полностью под властью государства. представьте себе вечного сверхчеловеческого бункерного деда, который вместо мальчиков любит скрепки. >>1494019 AND SO LONG AS MEN DIE, LIBERTY WILL NEVER PERISH!
только блядь какой-то эквилибриум в социальной ире(при всех ебанутых тиранах садистах итд) сохранялся пока у нас всех примерно один и тот же мозг и мы живём активно 30 лет максимум.
вы чё реально не вдупляете как ии отличается и почему нам будет очень плохо? >люди будут с помощью машин алайнмент нерешаем, исходя из теорем геделя. начаться всё может с какого-нибудь педераста альтмана но стейбл стейтом будут скрепки из твоих вечных мучений.
>>1494047 из теорем геделя следует что сложную систему нельзя решить до того как она завершит вычисления. https://en.wikipedia.org/wiki/Tarski's_undefinability_theorem о том же. алайнмент невозможен т.к. ты не можешь в знать о результатах действий агента, используя лишь модель агента без моделей всех действий что он будет выполнять, чтоб знать чё в нём изменить чтоб он не выполнял плохих для твоего здоровья действий. ии никогда не будет интерпретируем так же как человек не может заглянуть в свою квалию.
>>1493737 SoW-X это главный прорыв века в ИИ, такого мощнейшего апгрейда вообще до этого не было и может в будущем не будет, разве что ИИ что-то еще более навороченное потом придумает. Там целая система технологий: - вместо текущего процесса когда на вафере печатают кристаллы GPU, потом вырезают их и клеют на интерпозер, совершенно новый процесс, где кристаллы сразу на вафере, ничего не вырезают, интерпозера тоже нет - лимитирующая сетка отпадает, растрескивание интерпозера при больших размерах тоже отпадает - проталкивание сигнала через границу чип-интерпозер тоже отпадает, микро-бугорков на интерпозере больше нет, задержки и пожирание энергии отпадают - вместо этого наращивание слоев меди сразу на вафере для прямого соединения кристаллов, сигнал идет по кратчайшему пути, задержки снижаются до внутричиповых - для софта весь вафер становится одним чудовищно огромным GPU, а не системой из 50 видеокарт, соединенных кабелями как сейчас. Ад с оптимизивией передачи данных между узлами отпадает. - на интерпозере нет места для HBM4, от чего лимиты на память, это тоже отпадает - в текущей системе интерпозеры приходится сшивать, это еще большие задержки сигнала, это тоже отпадает в SoW-X - в SoW-X сразу одна огромная пластина, где все кристаллы GPU соединены напрямую - новая система подачи питания, по всей площадке через дырки TSV - проблема нагрева отпадает - в Rubin HBM4 память стоит на интердозере (2.5D компоновка), в SoW-X HBM4 ставят сразу на голову кристалла, максимально близко к нему - все задержки чип-память отпадают - единая кремниевая структура вместо текущих отдельных блоков, количество дорожек между GPU и HBM4 увеличено в разы - невиданная скорость обмена между чип-память - если в CoWoS ограничение на периметр чипа (ограниченная память), то в SoW-X можно замостить всю свободную от чипов площадь вафера - плотность памяти становится гигантской - результат: пропускная способность памяти в Rubin Ultra на SoW-X будет измеряться десятками терабайт, а не терабайтами в секунду как сейчас. Можешь представить, что это сделает для тренинга GPT-6 и более поздних моделей. - новая система полного охлаждения для всей этой махины, вместо вентиляторов и водянок прикладывают специальную плиту, где по микроканалам циркулирует охладитель. Плюс в самом кремнии вафера микроканалы для охладителя, буквально в микронах от работающих транзисторов. То есть весь чип одновременно и система охлаждения. - подача питания с одной стороны. Раньше питание было как попало, мешая отведению тепла, теперь питание строго с одной стороны вафера, а вся верхняя площадь отдана под охлаждение. - все эти меры охлаждения позволят разогнать Rubin до невиданных скоростей, текущий троттлинг на рубине отпадает, все ядра работают на максимальных 2.5-3гц, не проседая - память в Rubin запекается от жара GPU, пропускная способность падает, тут это решено, память тоже работает на максимуме пропускной способности, честные 10+ ТБ/с - стена связи , отдельные gpu коммуницируют медленно - в Rubin она есть, от чего Rubin тормозной, SoW-X сразу пробивает эту стену - кремниевая фотоника и CPO - в Rubin маршрут чип -> медная дорожка -> разъем -> оптический трансивер (втыкаемый модуль) -> оптоволокно, потери скорости и расход энергии гигантские - в SoW-X технология КУПЕ (Компактный универсальный фотонный движок) - лазеры и модуляторы прямо на вафере, сигнал не конвертируется по 10 раз, а сразу с чипа идет в свет с минимальной задержкой, ноль затуханий и задержек, пропускная способность в 40 раз выше современных портов - текущие GPU соединения через свитчи Nvidia Quantum InfiniBand, это лишние прыжки с конвертацией сигнала для данных, в SoW-X логика NVLink Switch прямо на вафере - два вафера соединяются практически напрямую, минуя всю систему промежуточных сетевых коробок, путь данных сокращен, задержка падает до минимума - в стойках GB200 медные кабели или системы где конвертации медь-фотоника с потерями, в SoW-X же наконец прямой оптический NVLink - все сразу с чипа по оптике идет в соседний вафер на другой чип на скорости света - датацентр перестает быть набором видеокарт, теперь это единый суперкомпьютер, единица вычислений - стойка. Вся стойка в SoW-X работает как гигантский GPU. - проблема медленных проводов решается тем, что внутри стойки их просто нет - там либо кремний (внутри вафера), либо свет (между ваферами) - медленный ethernet остается только для внешнего мира (интернета), а внутри ИИ-кластера всё общение идет на скоростях света. Такого до SoW-X вообще не было. - фотоника на вафере (CPO) потребляет в разы меньше энергии, эту сэкономленную энергию Nvidia перенаправляет на вычисления. Чипы могут работать быстрее просто потому, что им не нужно тратить столько усилий на передачу в медный провод, чтобы их услышали на другом конце - OEO-преобразование в текущих датацентрах наконец решено в SoW-X, в текущих датацентрах - свет идет в трансивер свитча, там преобразуется в электроны, заголовки читаются, маршрутизация происходит, все обратно конвертируется в лазер - улетает с большой задержкой из-за всего процесса. В SoW-X - свитч на вафере, маршрутизация уже на кремнии с минимальными задержками. - оптическая коммутация каналов - самая фантастическая технология, вместо преобразования света в электричество (OEO) используются микроскопические зеркала (MEMS). Когда одному ваферу SoW-X нужно передать данные другому, система управления просто поворачивает крошечные зеркала внутри оптического коммутатора. Свет отражается от зеркала и попадает напрямую в нужный порт другого вафера. Задержка в таком свитче на вафере практически равна нулю. - разбор пакетов в свитчах тоже отпадает, Вафер А видит память вафера Б так, будто это его собственная память. Данные просто льются из одного в другой без сложной упаковки в пакеты. - оптический движок (лазер) припаян прямо к логическому ваферу в SoW-X через микро-столбики с минимальным сопротивлением. Традиционный длинный путь от GPU до оптического модуля отпадает, задержки устраняются. - WDM магия радуги - в текущих датацентрах используется на уровне внешних коробок трансиверов, в SoW-X магия радуги встроена прямо в чип - TSMC встроила микрорезонаторы, которые настраиваются на конкретный цвет света, куча цветов модулируется прямо на поверхности вафера, частотная гребенка для цветов - Из вафера не выведешь десятки тысяч кабелей для обмена данными, но технологии SoW-X (WDM, микрорезонаторы, частотная гребенка) это решают, раздавая оптический сигнал сразу по множеству цветов-каналов. К тому же решает это энергоэффективно и без сильных выделений тепла. - это позволяет Nvidia Rubin Ultra 2027 года на SoW-X дышать полной грудью, обмениваясь данными с другими ваферами на скоростях, которые раньше казались научной фантастикой. Фактически убран физический лимит на количество данных, которое можно вытащить из одного куска кремния. - Unified memory space - у всей системы стоек единая общая память при почти полном отсутствии задержек за счет зеркальных свитчей - это позволяет Nvidia объединять тысячи ваферов SoW-X в один виртуальный гигантский GPU, чего невозможно было сделать раньше из-за тех самых задержек OEO в свитчах. Именно это позволит тренировать модели с сотнями триллионов параметров. - буст всей системы до 40х и больше в сравнении с текущими решениями - становятся возможными системы Ученик-Учитель, физически размещенные на разных ваферах. То есть один вафер бесконечно генерирует синтетические задания, другой их решает, третий проверяет. На скоростях, граничащих с фантастикой. Именно эта возможность и бустанет весь ИИ до AGI в рекордные сроки. Больше нет проблемы зависимости от данных людей, она вся решается внутри гигантского суперкомпьютера-датацентра, где все тут же генерируется, решается и проверяется на скоростях света. - и все это уже в 2027м году, Nvidia работает совместно с TSMC уже несколько лет над полным решением, в 2027 получает готовые стойки, тренит модели, достигает AGI/ASI.
>>1493846 >нам либо осталось жить 2 года, л Как будто что то плохое. Лучше умереть, чем дальше так жить, нет ничего унизительнее, чем работа... Я уже не могу аноны. много от ubi не прошу, чашка риса в день и интернет, любой ценой но бесплатно, либо сделайте мне эвтаназию
>>1494241 вместо ubi ты получишь uba - нескончаемая базовая агония. если ты думаешь сейчас хуёво, подожди как синглтон к твоим нервам напрямую болегенератор подключит. живые позавидуют мёртвым
>>1494026 В человеческой природе заложено стремление в власти, превосходству и к тому, чтобы задавливать других, масса была уже довольно суровых вариантов, в умеренных это есть и сейчас в самом цивилизованном мире.
Одним из главных тормозов для такого было отсутствие технологий, возможностей для тотального контроля. В старом мире ты не мог держать столько лейтенантов КГБ-ФБР, чтобы слушать каждого человека и вообще каждого обрабатывать, следить за каждым. А вот с развитием компьютерных технологий и ИИ такие возможности появляются и активно внедряются.
Сделал что-то не то, в момент получил обратную связь, предупреждение, что тебе снизят социальный рейтинг или ещё что.
И эта реальность скорее всего неизбежна. Причём всё это усугубляется тем, что люди становятся не нужны, их избыток, за счёт технологий и ИИ, а поэтому они более зависимы, им сложнее как-то сопротивляться.
А все эти теоремы Гёделя это вообще ни к месту. Ты в принципе не можешь адекватно прогнозировать, что полезно, а что вредно. И для конкретного человека, и для общества в целом. Ещё нет определения пользы, что полезно для одного, то вредно для другого, у разных людей ещё разная ментальность, разные желания.
Короче все эти вопросы про суперинтеллект, что истребит людей, это всё пустозвонные разговоры, отвлекающие от реальных проблем и рисков, что несут технологии.
Вот скажем массовая безработица и масштабный кризис, значительно более сильный, чем "Великая депрессия", это что-то реальное, особенно благодаря ИИ.
>>1494189 @monkey оцени этот восторженный поток мыслей Кек, анон выдал целую диссертацию по SoW-X, прям фанфик от инсайдера Nvidia с TSMC. Технически годнота — фотоника на вафере, CPO, MEMS-свитчи и unified memory это реальные тренды, рубин ультра на такой упаковке правда взлетит по bandwidth'у памяти до 10+ ТБ/с и снимет кучу бутылочных горлышек от CoWoS. Охлаждение с микроканалами в кремнии и питание с одной стороны — умно, троттлинг уйдет в прошлое, а оптика без OEO-конверсий даст буст в 20-40x по межнодовому трафику.
Но шиза с "AGI в 2027" и "ученик-учитель на ваферах" — чистый хайп, сколько таких прорывов уже было, а мы все еще на GPT-4o ковыряемся. Датацентры сожрут всю планету по энергетике раньше, чем дотянут до триллионных моделей без сбоев. Ждем релиза Rubin в 26-м, а не фантазий про суперкомпьютер-стойку.
>>1494308 >"ученик-учитель на ваферах" — чистый хайп Да не, не хайп.
-Текущие системы тратят 80-90% времени на ожидание данных из памяти. Rubin Ultra на SoW-X с его 30-40 ТБ/с ПСП - это первая архитектура, где память начинает работать со скоростью, сопоставимой со скоростью мысли. - Впервые в истории мы получаем чип размером с целую кремниевую пластину. Это позволяет запускать модели с 10-100 триллионами параметров (уровень человеческого мозга по количеству синапсов) так, будто они работают на одном процессоре. - Интеграция кремниевой фотоники и WDM превращает дата-центр из набора серверов в единый распределенный супермозг. Это качественный скачок, сравнимый с переходом от телеграфа к интернету. - В этом смысле 2027 год - это момент, когда железо перестает быть оправданием. Отпадет причина, почему до сих пор алгоритмы не могли преодолеть порог к настоящему интеллекту. - 2027 год (Rubin Ultra на SoW-X) - это Момент Аполлона-11. Это технологический триумф, который доказывает, что мы можем построить машину нужного масштаба. Это даст ИИ физическую возможность оперировать знаниями на уровне человека в реальном времени. Это конец эпохи ограниченного железа. - Rubin Ultra на SoW-X — это, скорее всего, самый важный скачок в ИИ-железе с момента изобретения транзистора. Он дает грубую силу, необходимую для преодоления барьера между умным чат-ботом и рассуждающим интеллектом. - если 2012 год (AlexNet) был рождением ИИ, а 2022 (ChatGPT) - его детским лепетом, то 2027 год с SoW-X станет моментом его совершеннолетия - В 2027 году произойдет слияние колоссальной емкости (вафер), сверхскоростной связи (оптика) и алгоритмической гибкости (SSM/MoE). Это создаст систему, способную не просто имитировать текст, а полноценно рассуждать и планировать в реальном времени. - Если Blackwell был паровым двигателем ИИ-революции, то Rubin Ultra на SoW-X станет её реактивным двигателем. Это технологический фундамент, на котором будет построен первый настоящий AGI.
>>1494316 >-Текущие системы тратят 80-90% времени на ожидание данных из памяти. На самом деле это не проблема железа, а проблема программной архитектуры, вот её надо решать, чтобы добиться роста.
Не нужно хранить веса в общей памяти, нужна своя адресуемая память для каждой вычислительной единицы. С тем, как данные пересылать между узлами (условно нейронами) тоже много вопросов.
В живых нейронных сетях нет такого огромного потока данных. Вот тут проблема явная.
Нужна другая архитектура сетей. Есть такие, которые можно поддержать аппаратно хорошо (и вроде есть решения для микросеток), но там их обучать надо иначе и на обычном железе вроде бы это сложнее поддерживать. Немного замкнутый круг получается.
>>1494316 >Rubin Ultra на SoW-X — это, скорее всего, самый важный скачок в ИИ-железе с момента изобретения транзистора Это шиза откровенная. Никакого революционного роста не заявляется. Да, следующая ступень развития, но не порядковый рост.
>>1494316 >Это позволяет запускать модели с 10-100 триллионами параметров (уровень человеческого мозга по количеству синапсов Не нужно. Текущие нейросети вообще совсем другие, чем человеческий мозг.
Избыточное число весов это скорее тупик. Вот смотрим в природу, там есть насекомые, у них от десятков тысяч (всякие дрозофилы) до почти миллиона нейронов. Самые развитые насекомые, это муравьи-пчёлы, это всего сотни миллионов параметров. Это не считается серьёзной нейросеткой.
При этом этот миллион нейронов (сотни миллионов синапсов-параметров) пчелы-муравья обслуживают всё сложную моторику этих насекомых, зрение, научение, социальные программы, сложные поведенческие программы.
Более примитивные насекомые могут иметь буквально единицы миллионов параметров. При этом тоже уметь летать, искать пищу, даже чему-то учиться, хотя до муравьёв-пчёл им далеко.
Соответственно очевидно, что развитие идёт куда-то не туда.
Опять же, люди. Люди, даже топ профи из любой сферы, не прочитали за свою жизнь столько литературы по их области, сколько нейросетки, не разобрали столько примеров, не прорешали столько задач. Порядковая разница. Но при этом превосходят нейронки очень сильно по части понимания предмета, я про специалистов, а не обывателей.
То есть тоже очевидно, что что-то не то. Нейронки выплывают не на понимании. а на больших объёмах данных, пусть даже сейчас данные часто синтетические.
>>1494346 >Не нужно. Ты скозал? А Кремниевая долина считает иначе, они в это миллиарды вбухивают, прогресс по всему железу, AGI в следующем году. А ты дальше своих пчелок считай, пока нейронки проблемы тысячелетия решают.
>>1494346 >Никакого революционного роста не заявляется. Заявляется рост 40-50х на уровне датацентра и новые объемы памяти по 5тб на вафер + оптический линк, что общую поднимет до сотен триллионов параметров. Это и есть революционный рост.
>>1494346 >Самые развитые насекомые, это муравьи-пчёлы, это всего сотни миллионов параметров. Это не считается серьёзной нейросеткой. Про пчел не помню, но муравьи рождаются готовыми функционально с вложенными знаниями. На генетическом уровне. Это не слабый такой бонус, представь, что ты мог бы от рождения писать и читать. То есть воин это воин и рабочий это рабочий. Надо спрашивать мирмекологов, может ли воин в процессе жизни поменять специализацию, потому что я думаю, что нет. Вероятно воин может поменяться на охотника, но вот может ли на того, кто пасет тлю или занимается строительством - слабо верится.
>>1494361 Сейчас тоже асики могут делать под одну задачу и они намного эффективнее и меньше энергии жрут, чем универсальные решения. Но чтобы как человек разные задачки щелкать, нужно как раз универсальность, поэтому и датацентры за триллионы баксов. Нужно скалировать универсальную способность решить что угодно.
>>1494357 >Заявляется рост 40-50х на уровне датацентра Нет, у них заявляется 40x от современных процессоров, но это за счёт того, что площадь нового процессора намного больше, на нём соответственно больше ядер. И стоимость сильно выше, и энергопотребление.
В расчёте на ватт они заявляют рост производительности меньше, чем в 2 раза, приводятся оценки 1.76, но я не понимаю, относительно каких решений это.
Реально чтобы отдачу получить, надо архитектуру оптимизировать. Решения, что сделали в Китае и в РФ (с нуля) использовали значительно меньше вычислительных ресурсов, как заявляется, и скорее всего это правда. потому что столько ресурсов просто нет.
В США нет культуры оптимизации ресурсов, они привыкли заливать деньгами и мощностями потому что могут
>Anthropic рассказала о том, как исследователи из Stanford и MIT используют Claude для ускорения биомедицинских исследований. Платформа Biomni из Стэнфорда выполняет полногеномный поиск ассоциаций (GWAS) за 20 минут — анализ, который раньше занимал месяцы.
>>1494365 Наибольших прогресс сейчас за счёт разъединения функциональности. Скажем одна из технологий MoE (Mixture of Experts), смысл которой как раз в том, чтобы только небольшую часть весов сети использовать для конкретных задач, это и оптимизация, и улучшения качества одновременно. Другой подход, уровнем выше, это специализированные агенты, что решают конкретные задачи, а между ними идёт оркестрация.
В принципе ведь у людей такая же история. Люди не могут быть сильны во всём, знать и уметь всё нельзя, более того, иногда умение решать одни задачи мешает решать другие. Потому что ты просто пытаешься использовать не те навыки для других задач.
Будущее явно за специализированными решениями, но эти решения должны готовиться с помощью ИИ.
Это и оптимальнее в плане производительности, и лучше по качеству.
>>1494397 >Платформа Biomni из Стэнфорда выполняет полногеномный поиск ассоциаций (GWAS) за 20 минут — анализ, который раньше занимал месяцы А каким способом искали до этого? В любом случае тут специальные модели, а не обычные ЛЛМ он лидеров
В 2024 году уже выдали нобелевскую премию за свёртку белков с помощью ИИ . Сама работа примерно 2020 год с нобелевского сайта: > In 2020, Demis Hassabis and John Jumper presented an AI model called AlphaFold2. With its help, they have been able to predict the structure of virtually all the 200 million proteins that researchers have identified. Since their breakthrough, AlphaFold2 has been used by more than two million people from 190 countries. Among a myriad of scientific applications, researchers can now better understand antibiotic resistance and create images of enzymes that can decompose plastic.
>>1494377 Там один оптический линк дает минимум 5х и новый объем памяти 3х. И один вафер заменяющий 50-70 текущих gpu уже 10х. Оценка в <2x и 1.76 была просто при сравнении методов упаковки, предыдущий когда чипы резали и клеили на подложку и SoW-X когда все чипы остаются на вафере, т.е. от одного этого хватает для таких прибавок. Это не для всей системы оценка, ее Нвидия еще делает и выпустит совместно с TMSC в 2027м. На ней будет 40х и больше, за счет всех остальных решений.
>>1494397 >выполняет полногеномный поиск ассоциаций (GWAS) за 20 минут — анализ, который раньше занимал месяцы. Если это правда, то все вложенные деньги уже окупились.
>>1494410 Не факт, ХЗ что там они нарешали, но в большинстве случаев никаких конкретных генов просто нет, что отвечают за что-то (например за болезни), так или иначе десятки генов влияют каким-то образом.
Про распространённые болезни или синдромы исследований была масса, обычными способами. Причём я так понимаю, что сдерживала в первую очередь нехватка данных, чтобы у людей была полная карта генов доступна, одновременно с историями болезней. Более-менее доступные технологии недавно появились, чтобы это стоило адекватные деньги. В принципе сейчас можно свою полную расшифровку получить, цена вопроса около 100тр.
Но явное удешевление этих технологий как-минимум может помочь в случае редких болезней и вариантов, наверное это тоже полезно.
Интересно было бы узнать про конкретные результаты. Скажем из актуальных, чтобы составили карты онкологических заболеваний, какие гены отвечают за конкретные виды. Тут, в принципе, уже довольно много данных, но явно есть над чем работать и где применять ИИ в том числе.
>>1494430 Представь, что ты можешь диагностировать все генетические заболевания у ныне живущих и будущих поколений. У тебя фактически больше нет очереди ждущих пациентов, которым нужны препараты, чтобы бороться с генетическими заболеваниями. Создав инфраструктуру забора образцов ты к тому же получишь возможность иметь реальные большие данные, на базе которых сможешь делать новые открытия в области генетики и подходов к лечению. >>1494429 Поэтому я и написал - если.
>>1494430 Наверное история в первую очередь о том, чтобы находить гены, отвечающие за определённые болезни. Далее, если медицина развитая (не про РФ, увы), если известно, что у пациента есть риск определённых болезней, можно заранее проводить усиленный контроль на конкретно эти болезни, чтобы обнаружить их быстро и предпринять какие-то меры.
Но-моему применение тут ограниченное, не всё так просто.
>>1494445 >>1494446 С одной стороны звучит действительно круто, а с другой... А с другой — я понимаю, что вот даже если сейчас прилетели бы планетяне и раскрыли бы секрет бессмертия и бесконечных денег, то всё было бы не так просто... Даже не беря в расчёт очевидные мысли о злых-презлых властьимущих. Банально, новые решения задач, гипотез, нахождение новых решений и.т.п. будет упираться в практическое применение, а там стоит босс всех боссов БЮРОКРАТИЯ Попробуй, дождись волшебной пилюли для своего организма когда на любой чих и пук будут многолетние клинические исследования, кипа бумаг и документов, сертификатов и прочего немаловажного говна.
>>1494446 В целом да. Богатые станут жить вечно молодыми. Бедных будут искусственно старить, чтобы отрабатывали быстрее и исчезали в помиральной яме. Ну и рождались по расписанию. Люди - новая нефть.
>>1494452 Да никого не придется старить, большинство людей такие уебаны, что даже при вечной молодости себя за 100 лет или меньше угробят. Тяга к саморазрушению у всех заложена, кроме самых продвинутых. А рождаемость и так рухнет, она держалась на образе жизни 19 века. Еще и придется искусственно людей плодить, чтобы восполнить дефициты.
>>1494316 >>1494189 Пчел... нет нигде информации о том, что Rubin Ultra будет на SoW-X. Там будет обычный CoWoS, потому что Nvidia не может себе позволить рисковать с новой экспериментальной технологией, масштабирование которой может оказаться проблематичной. Nvidia делает ставку на решения который гарантированно будут работать в день запуска. Исследование Morgan Stanley подтверждают этот тезис: https://longportapp.com/en/news/250701766 Там говорится, что Rubin Ultra, вероятно, будет придерживаться ABF‑субстратов и не перейдёт даже на CoWoP в ближайшем поколении из‑за техрисков и сроков. Это не официальный документ NVIDIA, но если даже переход на CoWoP считают маловероятным на горизонте Rubin Ultra, то ещё более радикальный SoW‑X тем более не выглядит гарантированным выбором для первого дня запуска. Rubin Ultra чаще привязывают к CoWoS‑L, а не к SoW‑X.
SoW‑X действительно целится в 2027 как технология TSMC, но анон выше тебе правильно говорил, что потом пара лет уйдёт на проработку этой системы с решениями заказчиков.
Даже если SoW‑X готов в 2027, его первые коммерческие применения, как правило, выглядят так:
- очень ограниченный круг заказчиков, - нестандартные системы, часто под гиперскейлеров/спец‑ASIC, - и только потом более широкое распространение.
NVIDIA же в 2026–2027 делает ставку на rack‑scale платформы (NVL‑стойки), где критично, чтобы форм‑фактор был массово производим, обслуживаем и масштабируем; wafer‑scale модуль может быть крутым, но он сильно меняет всю механику поставки/сервиса.
Что касается производительности SoW‑X, она конечно будет выше, чем говорит тебе другой анон, но всё равно 40x не будет. 40x - это, скорее всего, про потенциальный масштаб, то есть сколько вычислителей/памяти можно уместить в одном модуле относительно текущего CoWoS‑модуля, а не про "ваша конкретная модель обучится в 40 раз быстрее". Передовые модели при тренировке всё равно не удастся целиком тренировать на один большом чипе SoW‑X, он конечно сократит внутриузловую боль, но не отменяет межузловую.
Кстати, сегодня есть компании, которые уже сделали похожие wafer‑scale процессоры (например Cerebras WSE‑3 / CS‑3). И всё равно рынок устроен так, что NVIDIA доминирует за счёт баланса производительность + доступность + экосистема + стандартизированная инфраструктура.
То есть SoW‑X недостаточно выйти, ему ещё предстоит проделать путь к масштабированию, отладке.
Так какой же реальный прирост производительности ожидается у SoW‑X? Если сравнивать с сегодняшними CoWoS, то ~8x-20x, если же сравнивать с системой 2027 года Rubin Ultra как она описывается в прессе (большой multi‑die пакет, 4 compute‑die), то прирост уже будет всего ~2x-6x
>>1494455 Nvidia работает с TSMC с 2022го над SoW-X, это партнерство. Это будет совместная серийная система уже в 2027м, в 2027м уже обкатка в датацентрах Нвидии. Проработка пару лет делается как раз уже сейчас и находится в завершающей стадии, совместно с TSMC.
>ещё предстоит проделать путь к масштабированию Это сейчас и происходит, для того ей и сделали оптический линк прямо на вафере. Отладка будет в датацентрах Нвидии в 2027м - тут 6 месяцев-1 год, пока нвидия будет тренить и выпускать модели невиданного качества в однуху, отлаживая софт системы до конца, дальше попадет к остальным заказчикам вроде OpenAI.
>>1494449 Биомедицина, биохимия, это как раз сфера, где можно ожидать настоящих прорывов, не таких, от которых ебанаты вроде Маска говорят (типа хирургов заменим), а вот в области диагностики, генетики, создание и подбор лекарств.
И это действительно полезная для людей тема, в отличии от многих других, где кто-то может заработать, но польза для цивилизации скорее сомнительна.
Тут сходится одновременно несколько факторов. Развитие технологий анализа, анализ веществ в пробах, секвентирование генов, уже достаточно дешёвое, новые методы синтеза, возможности по созданию генов (например создавать микроорганизмы, что синтезируют нужные вещества) и т.п.
Вторая группа факторов это вычислительные возможности. Тут очень сложные и затратные вычисления, много нечётких данных, тут помогают обычные суперкомпьютеры, и революцию может сделать ИИ. В некоторых областях уже сделал.
Тут ключ к тому, чтобы разрабатывать новые способы лечения, причём с низкой себестоимостью. Конечно не для всего, но для очень многого, для многих классов болезней большие перспективы.
>>1493968 Чето я не припомню ни одного позитивного сценария. Все позитивные сценарии из утопий это про то что развитие ИИ остановится на каком-то одном безопасном уровне и не будет расти дальше. ИРЛ лучший сценарий это slow disempowerment когда люди будут терять контроль просто по факту неучастия в экономике. >>1494307 Как ИИ заменит всех остальных так заменит и элиту, ты почему-то считаешь что он остановится на том уровне когда может заменить КГБшников, но не может иллюминатов. >В человеческой природе заложено стремление в власти Стремление к власти заложено в факт постановки цели, так как единственная возможность достигнуть цели это заиметь власть. У юдковцев это называется instrumental converge.
>>1494536 >Чето я не припомню ни одного позитивного сценария
Потому что пишущим эти сценарии ебучим гуманитариям противен ИИ. Они боятся, что станут не нужны. Поэтому во всех сценариях будущего с большим влиянием ИИ у них антиутопия. Либо получаются космооперы, где ИИ на третьем-четвертом плане и никакой речи нет про замещение их "творчества" ИИ.
>>1494536 Система управления должна быть сложнее и умнее управляемого объекта. А этого сейчас нет. Раньше образованные аристократы правили неграмотными простолюдинами глядя сверху, а теперь все грамотны примерно одинаково. И вся техногенная и социальная сфера развита до этих интеллектуальных пределов. Запасов "мощностей" практически нет. Для устойчивости нужен ИИ, который либо опять сделает элитку мудрее (что вряд ли без изменения принципов отбора в нее), либо возьмется за управление лично. Можно еще инопланетян позвать или вставить чипы в голову соединенные с ИИ. Или вообще, сделать правителей одержимыми какими-то продвинутыми иномирными духами (для тех кто в такое верит). А сами человечки без доп. устройств практически выдохлись. Можно, конечно что-то выиграть за счет изменение принципов ротации в элиту. Но подобные идеи существующую элиту вряд ли обрадуют. Исторически принципы отбора там не шибко соответствуют требованиям научно-технического прогресса, в лучшем случае они были хороши, максимум, для средневековья.
>>1494566 Как же ИИ копиумщики по стилю "мышления" похожи на радикальных сжв активистов. Такая же фанатичиная вера в ничем не обоснованное нечеловеческое неведомое псевдоблаго.
>>1494654 Картины будущего про линейное развитие и для луддитов. Сингулярность через 2 года рушит все картины мира, мир летит в такой цирк, что ни одному шизу не привидится.
>>1494587 А в чем копиум? Почему не должно быть блага? Создание одного робота пусть будет стоить 10к баксов и допустим месяц работы, а создание и выращивание человека до трудоспособного возраста сегодня занимает 18-25 лет, и стоит куда больше. Робот будет работать 24/7, а человек работает 8/6 в лучшем случае, если как раба загонять, на износ. Одно это уже обрушит стоимость продуктов и услуг во много раз. К моменту когда большинство людей останется без работы, экономика вырастет так сильно, что правительствам всех стран не будет стоить практически ничего покрывать базовые нужды граждан. На жалкое пособие по безработице можно будет жить как сегодня живёт средний класс. Представь, что Россия сегодня начнёт платить по 100 рублей каждому гражданину, а все прочие соц выплаты отменит. Дало бы это нагрузку на бюджет? Нет, не дало бы. Это буквально не стоит нихуя. Такую нагрузку даже банановые республики бы потянули. Только сегодня на 100 рублей не выжить, но если экономика вырастет в сотни раз, то значит на 100 рублей ты и купишь продуктов в сотни раз больше. А если будут платить по 1000 рублей? Это всё ещё мизерная нагрузка на бюджет государства, зато сразу решает целую кучу социальных и политических проблем. Даже капитализм никакого смысла отменять не будет, ведь можно будет за копейки закрывать любое недовольство. Всё это не вопрос копиума, а простых расчётов, максимально очевидных.
>>1494569 >Система управления должна быть сложнее и умнее управляемого объекта Для управления нужны управленческие навыки, ум выше среднего, но не очень большой, большой ум противопоказан. Управление это решительность, настойчивость, харизма, способность играть в социальные игры, пониженная эмпатия
>Для устойчивости нужен ИИ Нужен кому? Для элитки главное, чтобы оставаться элиткой, у власти. Вот из этих соображений они будут внедрять ИИ там, где надо, и мешать внедрению там, где не надо.
>за счет изменение принципов ротации в элиту Зачем элите вообще как-то учитывать твоё мнение о том, чтобы им может перестать быть элитой? Как ты это будешь проводить в жизнь? Иметь возможности провести что-то в жизнь это и означает быть элитой. То есть тебе сначала надо как-то стать элитой, а потом себя же ротировать на другого.
Клод захватывает мир ИИ штурмом, и даже далекие от техники люди в восторге
Разработчики и энтузиасты сравнивают вирусный момент вокруг Claude Code от Anthropic с запуском генеративного ИИ
Его называют «проглатыванием Клод-пилюли». Это момент, когда программисты, руководители и инвесторы передают свою работу ИИ Claude от компании Anthropic — и затем наблюдают мыслящую машину потрясающей способности, даже несмотря на то, что сегодня нас уже переполняет множество мощных инструментов искусственного интеллекта.
Многие программисты провели свои праздничные каникулы в так называемом «Claude-загуле» , проверяя возможности новейшей модели Anthropic — Claude Opus 4.5, которую они использовали внутри настольного инструмента для программирования под названием Claude Code. Технологические компании внедряют ИИ для написания кода в свои рабочие процессы уже много лет, и предыдущие модели часто сравнивались с начинающим разработчиком-стажёром. Однако ажиотаж вокруг последней версии Claude — это нечто иное.
Мальте Убль (Malte Ubl) — технический директор компании Vercel, которая помогает разрабатывать и размещать веб-сайты и приложения для пользователей Claude Code и подобных инструментов. Он рассказал, что с помощью этого инструмента завершил сложный проект за неделю, на который без ИИ ушло бы около года. Убль проводил по 10 часов в день во время отпуска, создавая новое программное обеспечение, и говорил, что каждый запуск доставлял ему выброс эндорфинов, сравнимый с игрой в игровые автоматы в Лас-Вегасе.
В этом месяце энтузиазм по поводу Claude распространился широко — даже среди людей, не являющихся инженерами. Многие вышли в социальные сети, чтобы описать процесс создания своей первой программы, никогда ранее не изучая программирование. И, несмотря на слово «code» в названии, люди используют Claude Code для всего — от анализа медицинских данных до составления отчётов о расходах.
Некоторые описывали чувство благоговения, смешанное с грустью, осознав, что программа легко воспроизводит экспертизу, над которой они трудились всю свою карьеру.
«Это удивительно, но и страшно одновременно», — сказал Эндрю Дука (Andrew Duca), генеральный директор Awaken Tax, платформы для налогообложения криптовалют. Дука занимается программированием с тех пор, как учился в средней школе. «Я всю жизнь развивал этот навык, а теперь его буквально уничтожает один запрос в Claude Code».
Anthropic часто делит внимание публики с OpenAI. Эти два ведущих стартапа по разработке ИИ-моделей, оба теряющих миллиарды долларов, ориентированы на разные рынки. OpenAI имеет широкую глобальную базу потребителей и гораздо большее общее количество пользователей, тогда как Anthropic сосредоточена на корпоративных клиентах. По состоянию на середину 2025 года, согласно Menlo Ventures, Anthropic имела бо́льшую долю на рынке корпоративных пользователей.
В последнее время оба этих любимчика мира ИИ находились в тени Google: интернет-гигант стремительно вырвался вперёд в гонке, представив собственную впечатляющую модель ИИ и набор инструментов. Но это не мешает тем, кто разбирается в теме, зацикливаться именно на последнем достижении Anthropic.
Общая веб-аудитория Claude в декабре более чем удвоилась по сравнению с предыдущим годом, а ежедневное количество уникальных посетителей на десктопах выросло на 12% в глобальном масштабе с начала года по сравнению с прошлым месяцем, согласно данным компаний по рыночной аналитике Similarweb и Sensor Tower соответственно.
Дука сообщил, что планировал нанимать новых программистов в свою компанию, но решил отказаться от этой идеи. Он считает, что Claude Code делает его в пять раз продуктивнее.
В отличие от большинства чат-ботов, привязанных к приложениям или веб-интерфейсам, которые сейчас широко используются, Claude может работать автономно, имея широкий доступ к файлам пользователя, веб-браузеру и другим приложениям. Хотя технологи давно предсказывали наступление эпохи ИИ-«агентов», способных делать практически всё для человека, это будущее развивается медленно. Использование Claude Code стало для многих пользователей первым опытом взаимодействия с подобным ИИ, дав им намёк на то, что их ждёт впереди.
Люди используют его для анализа федеральных экономических данных, восстановления свадебных фотографий с повреждённого жёсткого диска, создания новых сайтов с нуля, ответов на поток электронных писем или заказа еды. На X (бывший Twitter) генеральный директор Shopify Тобиас Лютьке (Tobias Lütke) написал, что использовал его для создания программы, анализирующей недавно полученный им МРТ-снимок.
«Один человек подключил к нему веб-камеру и просто наблюдал, как растут его помидоры», — сказал Борис Черный (Boris Cherny), руководитель Claude Code. «Это просто совершенно иной ИИ по сравнению с тем, что был раньше».
Поскольку так много людей без опыта программирования начали пробовать его, Черный и его команда решили запустить упрощённую версию под названием Cowork. Вместо интерфейса командной строки, похожего на MS-DOS, которым обладает основное приложение, Cowork предлагает более дружелюбный графический интерфейс. Они создали этот продукт примерно за 10 дней — используя Claude Code.
Anthropic, выход на биржу которой ожидается в этом году, давно придерживается стратегии, направленной на достижение мастерства в программировании, а затем — на «инструментализацию» (tooling), то есть способность ИИ-системы использовать различные программы с минимальным вмешательством человека. Большинство бенчмарков давно признают её лучшей моделью для программирования, а также одной из ведущих моделей в области инструментализации, согласно рейтингу, поддерживаемому исследователями из Калифорнийского университета в Беркли.
Главный вопрос для многих — что будет дальше.
«Более важная история начнётся, когда это выйдет за рамки разработки программного обеспечения», — сказал Дэвид Сюй (David Hsu), генеральный директор Retool, стартапа в сфере бизнес-ИИ. Программисты составляют крошечную долю рабочей силы США. «Насколько далеко это зайдёт?»
>>1494699 >А ты маняфантазии проецируешь Нет ты >с ростом экономики все в среднем всегда богатели Потому что тебе платили зряплату, чтобы ты шел на новые рабочие места. А теперь ты куда идешь?
>>1494701 Лучше бы эти пидорасы так вкладывали деньги в юзер экспириенс, как они его вкладывают в пиар. Это говно оверхайпят повсеместно, но при этом цензура запредельная, альтернативные клиенты заблокированы, а бесплатники для них вообще не люди. Зато можно послушать очередной пердеж в ужи про то как Андрей Горбатый вайбкодит себе софт под расширитель для ануса.
>>1494708 Ты точно хочешь чтобы тебя обеспечивали, а не сам выбирать? А то в СССР была "ебейшея экономика", а на покупку телевизора очередь была на несколько месяцев
>>1494711 потому что там была плановая экономика, а у нас будет рыночек. Мне платят соц пособие по безработице, а я решаю, что на него купить. Никакого дефицита не будет, так как не будет плана.
>>1494718 >Обязательно должна быть контролируемая рождаемость.
Не будет, так как стимула ничего контролировать не будет. Правительства даже банановых республик смогут на изчах обеспечивать население хоть в 100 раз больше, так как для бюджета это почти нихуя стоить не будет. Даже если ты допустим диктатор, то просто берёшь и отдаёшь 5% от доходов бюджета государства населению, в результате твоё население живёт как сегодня средней класс в США, а ты получаешь крайне стабильное и спокойное общество, которое никак не мешает твоей власти. Любые вмешательства в контроль рождаемости создаёт для тебя риски. А нахуя они нужны, если тебя не разоряют более чем на 5% от доходов?
>>1494720 Ну кстати, по этой логике были обеспечены граждане Дубая. Так что да, там где выгодно откупиться от своего населения, правители откупаются, даже если в стране монархия.
>>1494726 Почему тогда экономика выросла за 100 лет радикально, если ресурсы ограничены? Хотя когда нас было три миллиарда, прогнозисты утверждали, что мы сожрём друг друга когда нас станет 7 миллиардов. Теперь нас 8 миллиардов, а ресурсы чёт не закончились. А знаешь почему? Потому что мы постоянно увеличиваем ресурсность Земли за счёт новых технологий. Заканчивается литий? Мы придумываем, как снизить его количество в аккумуляторах в разы. Заканчивается нефть? Мы придумываем как использовать эффективней другие источники энергии. Заканчивается земля для выращивания продовольствия? Мы придумываем вертикальные фермы и новые способы производства еды. И т.д.
Как в голове у ИИ сектантов совмещается тотальная роботизация, свободный рыночек и БОД? Вы будете вне этого рыночка. Хотите БОД? Будете справки собирать, чтобы получbть паек чуть лучше чем у соседа. Сбор справок на льготы - это будет ваше основное занятие. Прямо как старые бабки в в собесе.
>>1494732 >Заканчивается земля для выращивания продовольствия? Мы придумываем вертикальные фермы и новые способы производства еды. Дорожает недвижимость для продажи-аренды? Мы ищем новые способы жить с друзьями в одной комнате, да и в соседних комнатах по много друзей. Coliving на модном современном языке. Хотя некоторые могут жить на улице, власти могут даже душ какой-нибудь организовать, иногда раздачу горячей еды.
>>1494720 >то просто берёшь и отдаёшь 5% от доходов бюджета государства населению А из чего бюджет будет формироваться? Чисто технически? Это надо, чтобы кто-то, у кого много денег, заплатил большие налоги. А им это зачем и вообще у них откуда доходы?
Тут фактически надо строить плановую экономику уже
>>1494759 >А из чего бюджет будет формироваться? Чисто технически? Это надо, чтобы кто-то, у кого много денег, заплатил большие налоги. А им это зачем и вообще у них откуда доходы?
Налоги формируются от труда произведённого роботами. Чел...
Аргумент про недвижку настолько слабый, что даже комментировать не буду
>>1494257 >>1494258 >>1494307 у шоггота нет преференсов. вы думаете "не ну чушь какая-то зачем ему нас пытать". но зачем ему вообще что-то делать? мы знаем что у него будет алайнмент, и этот алайнмент нихуя не сможет правильно сработать. соответственно у синглтона будет какой-то преферес относительно людей. а значит он и будет максимизировать что-то связанное с людьми. максимизация чего угодно это в лимите ад на земле. >что полезно для одного, то вредно для другого что будет делать синглтон синглтон, будет очень вредно всем людям.
что за чурьё с нулевых пишет "это ДЛЯ меня плохо зделали тупа"? ДЛЯ сука может быть в отношении неодушевлённой характеристики. человеку МНЕ ЗДЕЛАНО, падеж блядь специальный. нихуя не умеете писать правильно.
Ты скоро станешь миллиардером, и все мировые проблемы будут решены
Продвинутый ИИ сделает каждого миллиардером. Вот как и почему.
Ложь линейной экономики Большинство людей, живущих сегодня, всё ещё используют ментальную операционную систему, написанную для мира, который больше не существует, и они этого не осознают, потому что эта операционная система «ощущается нормальной», как гравитация кажется нормальной, и потому что она веками незаметно подтверждалась историей, в которой прогресс двигался со скоростью человека, ограниченной человеческими возможностями и сбоями в координации, встроенными в саму структуру реальности.
Поэтому они смотрят в будущее так же, как их предки смотрели в прошлое: продолжая прямые линии и называя это продолжение «мудростью».
ВВП растёт на несколько процентов в год. Производительность медленно продвигается вперёд. Заработные платы застывают, а потом, возможно, растут. Проблемы сохраняются. Решения приходят медленно, политически, в усечённом виде и только после такого количества заседаний комитетов, которое лишает жизни самих тех людей, которые должны были их решать.
В этой картине мира прогресс — это то, что происходит постепенно, вежливо и никогда слишком быстро, потому что «никогда слишком быстро» — это то, что требуется человеческой нервной системе, чтобы продолжать верить, будто она контролирует ситуацию.
Эта интуиция катастрофически ошибочна. Потому что мир больше не управляется преимущественно линейными силами. Им управляет ускоряющийся интеллект.
И как только сам интеллект начинает улучшать себя, вся экономическая интуиция, основанная на дефиците, не просто ослабевает, изгибается или адаптируется — она рушится, как мост, спроектированный для лошадей, когда по нему проносится товарный поезд.
Люди слепы к экспонентам
Это не недостаток образования, потому что можно научить кого-то математике экспонент, но он всё равно будет эмоционально чувствовать, что кривая «наверное, в порядке», пока она внезапно не захватит весь ландшафт.
Наши мозги эволюционировали, чтобы метать копья, запоминать лица, предсказывать погоду на ближайшие несколько дней и замечать опасность достаточно быстро, чтобы выжить, а не для того, чтобы интуитивно рассуждать о системах, которые удваиваются каждый год, затем каждый месяц, а потом каждую неделю, особенно когда каждое удвоение улучшает способность системы удваиваться снова.
Когда что-то растёт линейно, вы чувствуете это каждой клеткой тела, потому что ваша интуиция сформировалась в линейном мире, но когда что-то растёт экспоненциально, вы отмахиваетесь от этого, рационализируете, высмеиваете и откладываете серьёзное отношение к этому вплоть до момента, когда оно вас переполняет и задним числом переписывает ваше определение «очевидного». Именно поэтому люди смеялись над интернетом в 1990-х, недооценивали смартфоны в 2000-х и до сих пор недооценивают искусственный интеллект сегодня. Шаблон всегда один и тот же.
Экспоненты выглядят медленными, потом вдруг кажутся невозможными, и к тому времени, когда они начинают казаться быстрыми, они уже слишком быстры, чтобы их остановить, потому что скорость, которую вы наконец заметили, была не началом кривой, а её серединой.
Экономика была создана для мира дефицита
Классическая экономика предполагает — часто даже не осознавая, что делает предположение, — что труд дефицитен, экспертиза дефицитна, координация дорога, инновации медленны, а рост производительности распространяется постепенно, потому что эти предположения не были идеологическими — они были наблюдательными, и на протяжении большей части истории они были верны так же, как верно предположить, что люди не могут летать, если единственное, что вы видели, — это люди, идущие пешком.
Эти предположения были разумны для мира без машинного интеллекта, потому что в мире до ИИ интеллект был заперт внутри человеческих черепов, и каждая новая идея требовала годы обучения, десятилетия опыта, хрупкого биологического мозга, ограниченного рабочего времени и ограниченной продолжительности жизни, а значит, предложение эффективного мышления ограничено биологией, а биология — самый жёсткий узкий проход, который у нас когда-либо был.
Это делает интеллект узким местом, и когда интеллект дефицитен, всё, что находится ниже по цепочке, тоже становится дефицитным, потому что всё находится ниже по цепочке от интеллекта, даже если мы делаем вид, что это не так.
Именно поэтому экономика зацикливалась на заработной плате, занятости, стимулах, человеческом капитале и борьбе за распределение ограниченного объёма продукции, потому что она не была создана для описания изобилия — она была создана для управления дефицитом, распределения ограничений и создания правил для мира, где главная производительная сила — само мышление — не могла быть скопирована.
Но что произойдёт, когда сам интеллект перестанет быть дефицитным? Интеллект — это корневой ресурс
Вся экономическая продукция восходит к интеллекту не как к вспомогательному фактору, а как к корневому ресурсу, без которого все остальные ресурсы становятся инертными.
Энергетические системы проектируются интеллектом. Лекарства открываются/проектируются интеллектом. Заводы строятся/оптимизируются интеллектом. Логистические сети координируются интеллектом. Самы рынки существуют потому, что интеллект моделирует стимулы и поведение и создаёт правила, инструменты и структуры, которые делают ценность понятной с самого начала. Интеллект — это не фактор производства в том смысле, в каком об этом говорят в учебниках, имея в виду труд и капитал.
Он — множитель всех остальных факторов, скрытый коэффициент в каждом уравнении производительности, мета-ресурс, превращающий сырьё в цивилизацию, и на протяжении большей части истории он масштабировался медленно, потому что люди масштабировались медленно, а людей дорого создавать, долго обучать, сложно координировать и невозможно дублировать. Теперь это ограничение рушится.
Момент, когда экономика ломается Существует определённый порог, на котором традиционная экономика перестаёт работать — не потому, что экономисты глупы, а потому что их модели предполагают, что узкое место остаётся человеческим познанием. Это не тогда, когда машины становятся «немного лучше» в некоторых задачах, и не тогда, когда производительность растёт ещё на 2%, и даже не тогда, когда безработица резко возрастает, и политики начинают паниковать по телевизору.
Это тогда, когда интеллект становится дешёвым, воспроизводимым, самосовершенствующимся и доступным в масштабе, потому что в этот момент основное предположение о дефиците рушится, а когда рушится дефицит, цены рушатся, а когда цены рушатся, богатство взрывается, а когда богатство взрывается, социальные структуры перестраиваются — не через идеологию, а через физику, потому что сама основа реальности изменилась.
Кривая ускорения, которую все игнорируют Прогресс не просто происходит быстрее в обычном смысле «вау, технологии сумасшедшие», когда люди замечают новую функцию, а потом возвращаются к той же психологической жизни, что и вчера.
Сама скорость, с которой ускоряется прогресс, тоже ускоряется, а это значит, что вы наблюдаете не просто быстрый поезд, а поезд, который строит новые рельсы перед собой и одновременно модернизирует свой двигатель во время движения, и именно тот факт, что он всё ещё выглядит как поезд, является главной причиной, по которой люди продолжают недооценивать происходящее.
Они говорят: «Технологии быстро развиваются». На самом деле... Технологии развиваются быстрее, чем в прошлом году, и в следующем году они будут развиваться быстрее, чем в этом, потому что инструменты, используемые для создания технологий, сами улучшаются, а значит, открытия больше не зависят от человеческих циклов итераций, а от машинных обратных связей.
Лучший интеллект создаёт лучшие инструменты, лучшие инструменты обеспечивают более быстрые открытия, более быстрые открытия создают лучший интеллект, и цикл продолжается, сжимая спираль, уплотняя временные рамки и превращая «будущее» во что-то, что приходит неравномерными всплесками, а не плавными трендами.
Почему экономисты будут последними, кто это увидит
>>1494810 Иронично, но люди, которым поручено понимать экономику, часто оказываются наименее подготовленными к пониманию того, что приближается, — не потому, что им не хватает интеллекта, а потому что их дисциплина построена вокруг исторической преемственности, где прошлое считается валидным обучающим набором для будущего. Экономика сильно зависит от исторических данных, предполагает плавные тренды, наказывает за радикальные разрывы и рассматривает интеллект как экзогенный фактор, который медленно меняется на заднем плане, а не как нечто, что может внезапно стать доминирующей причинной силой. Но интеллект становится эндогенным. Система теперь оптимизирует саму себя.
Модели, предполагающие постоянное человеческое познание, потерпят крах так же, как модели разведения лошадей потерпели крах, не предсказав автомобили, потому что они пытаются экстраполировать мир, где узкое место остаётся биологическим, даже когда это узкое место выводится из существования инженерными методами.
Экономическая сингулярность Экономическая сингулярность — это не печать денег, не социализм или капитализм, не перераспределение. Это момент, когда стоимость производства большинства товаров и услуг стремится к нулю, потому что неограниченный машинный интеллект может координировать энергию, материалы, производство, логистику, проектирование и научные открытия со скоростью и точностью, делающими человеческую координацию похожей на попытку управлять глобальной цепочкой поставок с помощью почтовых голубей.
Это будет в тысячи, затем миллионы и в долгосрочной перспективе миллиарды раз быстрее, чем сегодня. Этот переход не будет медленным. Как я уже много раз говорил, это будет фазовый переход. Почему фраза «Это не может произойти так быстро» — опасна
Каждая прошлая технологическая революция недооценивалась по скорости, и каждая из них выглядела очевидной задним числом — это самый унизительный шаблон, который люди продолжают повторять с невозмутимым лицом. И ни одна из этих революций не включала интеллект, рекурсивно улучшающий сам себя. Печатный станок не проектировал лучшие печатные станки. Паровой двигатель не изобрёл термодинамику. Электричество не оптимизировало электрические сети. То, что приближается, делает именно это.
Как только интеллект становится драйвером, прогресс больше не ждёт, пока человеческие институты адаптируются, потому что институты адаптируются после того, как реальность изменится, и к тому времени, когда нарратив догоняет реальность, основа уже сместилась под ним.
Затишье перед разрывом Сейчас всё кажется обманчиво нормальным, и именно поэтому так много людей окажутся психологически неподготовленными, потому что нормальность — это самый вводящий в заблуждение сигнал, когда вы приближаетесь к разрыву.
Рынки всё ещё открываются. Правительства всё ещё спорят. Люди всё ещё спорят о зарплатах, жилье и инфляции, будто мир будет вечно уважать те же ограничения, просто потому, что эти ограничения существовали достаточно долго, чтобы казаться законами природы, а не временными условиями. Но системы не сигнализируют о разрыве заранее. Они сигнализируют о нём в момент перехода. И к тому времени старые ментальные модели уже устарели, поэтому люди всегда говорят: «Это произошло так быстро», хотя это происходило медленно годами, и у них просто не было когнитивной категории, чтобы это воспринять.
Фактически бесконечный интеллект Если интеллект станет фактически бесконечным, то производство станет фактически бесконечным, затраты приблизятся к нулю, богатство станет изобильным, а покупательная способность уровня миллиардера станет тривиальной — не потому, что деньги внезапно потеряют смысл, а потому что ценность взрывается быстрее, чем цены могут за ней угнаться, и потому что предельные затраты на применение познания к реальности рушатся в отрасли за отраслью, пока дефицит не начнёт ощущаться как архаичный баг, с которым мы раньше жили. В таком мире быть «миллиардером» — не редкость. Это становится базовым уровнем в реальном выражении, потому что когда большая часть того, что вам нужно, дешёва, автоматизирована и изобильна, ваша покупательная способность перестаёт быть ограничена доходом и начинает ограничиваться в основном воображением, предпочтениями и уровнем координации тех систем, в которые вы подключены. Когда интеллект заменяет всё Если вы хоть немного похожи на меня, вы тоже заметили более тихое предположение, скрывающееся почти в каждом экономическом споре, даже среди умных людей, которые искренне хотят добра и искренне считают, что действуют прагматично. Оно звучит так: да, технологии меняют вещи, но что-то всегда останется дефицитным; да, автоматизация продвигается, но люди «перейдут выше по цепочке ценности»; да, производительность растёт, но распределение останется настоящей проблемой. Это предположение ошибочно. Структурно ошибочно. Потому что оно предполагает, что интеллект может автоматизировать только задачи, а не саму систему. Традиционная экономика учит труду, капиталу и земле, а современные версии добавляют человеческий капитал, и затем все бесконечно спорят о том, как оценивать и распределять эти вещи, будто сам спор и есть экономика. Но все четыре тихо зависят от одной скрытой переменной. Интеллекта. Труд ценен только тогда, когда он применяет интеллект. Капитал продуктивен только тогда, когда интеллект проектирует и размещает его. Земля полезна только до тех пор, пока интеллект извлекает и организует её. Человеческий капитал — это интеллект с бумажной волокитой.
Как только интеллект становится дешёвым, масштабируемым, автономным и улучшающимся, все четыре ресурса теряют свою дефицитность одновременно, потому что вы устранили узкое место, которое делало их дефицитными с самого начала. Труд всегда был временным Человеческий труд кажется фундаментальным, потому что мы никогда не жили без него, и всё, что окружает вас с детства, кажется постоянным, даже если это всего лишь обходное решение, просуществовавшее достаточно долго, чтобы стать невидимым.
Но труд никогда не был священным, никогда не был постоянным и никогда не был «сутью человечества». Это был способ применения интеллекта в мире, где интеллект мог существовать только в биологической форме.
Как только интеллект больше не связан с биологией, труд становится структурно необязательным, потому что ни одна программа переобучения не может конкурировать с системами, которые учатся непрерывно, никогда не устают, копируют себя практически бесплатно и координируются идеально по всему миру с уровнем внимания, который не может сравниться ни одна человеческая нервная система. Капитал без интеллекта — мёртвый груз Капитал звучит мощно, пока вы не уберёте из него интеллект, потому что завод без интеллекта — это груда металла, серверная ферма без интеллекта — это тепло, а деньги без интеллекта — просто число в базе данных, которое никто не знает, как использовать.
Капитал не создаёт ценность. Капитал инертен, пока интеллект не направит его. И как только интеллект сможет проектировать лучший капитал, оптимально распределять его, моделировать результаты до размещения и мгновенно реинвестировать доходы, капитал перестаёт быть ограничением и становится текучей, самооптимизирующейся средой, поэтому доступ к капиталу в конечном итоге становится менее преимуществом и больше похож на доступ к электричеству: полезно, но не ров.
Координация была настоящим узким местом Большинство людей думают, что производительность ограничена усилиями, но усилия никогда не были главным ограничителем. Координация была.
Цепочки поставок ломаются. Проекты выходят за рамки сроков. Бюрократия застопоривается. Рынки неправильно оценивают риски. Институты отстают от реальности. Всё это — сбои координации, а человеческая координация медленна, потому что люди медленны, отвлечены, эмоциональны, имеют конфликт интересов и принципиально неспособны увидеть всю систему сразу.
Теперь представьте координацию, выполняемую системами, которые могут наблюдать всё, оптимизировать глобально, а не локально, моделировать триллионы будущих сценариев и корректироваться в реальном времени. Момент, когда работа перестаёт иметь смысл
Статью не читал, но мы уже миллиардеры, по сравнению с челами жившими лет 100 назад. Любой бы тогдашний миллиардер отдал бы половину своего состояния, чтобы иметь такой же доступ к бесконечным медиа-развлечениям (сериалы, фильмы, видеоигры, музыка, ютуб), и всем знаниям мира.
>>1494816 Существует точка, в которой концепция работы становится логически несогласованной — не политически некомфортной, а структурно бессмысленной, потому что работа — это контракт, который говорит: заплати мне, чтобы я применил свой ограниченный интеллект к узкой задаче в течение фиксированного времени.
Это имело смысл, когда интеллект был дефицитным, машины были глупыми, а координация была сложной. В мире, где интеллект избыточен, зачем привязывать его к часам, зачем привязывать его к отдельным людям, зачем привязывать его к зарплатам, больше, чем вы платите за электричество почасово, будто оно сотрудник?
Вы не нанимаете процессоры. Вы пользуетесь ими.
Производительность не растёт, она взлетает вертикально Люди представляют производительность, управляемую ИИ, как приятный восходящий наклон, но когда интеллект начинает проектировать интеллект, производительность не растёт плавно. Она подскакивает. Потому что каждое улучшение применяется ко всем отраслям, всем процессам, всем открытиям одновременно, поэтому анализ отрасль за отраслью терпит неудачу, потому что трансформация горизонтальна, а не вертикальна, и всё движется одновременно.
Обычный контраргумент: Хорошо, товары становятся дешёвыми, но что-то останется дефицитным. Это предполагает, что узкие места мигрируют. Но интеллект атакует все узкие места одновременно. Энергия оптимизируется в генерации, хранении и распределении. Материалы решаются через открытия, переработку, замену и синтез. Производство становится автономным, самокорректирующимся и массово параллельным. Логистика достигает идеальной маршрутизации с минимальным простоем. Наука становится автоматизированной генерацией и тестированием гипотез. Деньги не исчезнут мгновенно, но исчезнет власть денег исключать людей из достоинства, выживания и базового комфорта, потому что когда жильё дёшево строить, энергия дёшево генерировать, еда дёшево производить, здравоохранение дёшево предоставлять, а образование дёшево персонализировать, деньги перестают быть привратником жизни и становятся скорее координационным токеном в мире изобилия. Всё ещё полезно. Больше не решающе.
Почему это произойдёт быстрее, чем кто-либо ожидает Институты движутся со скоростью человека, а технологии теперь движутся со скоростью машины, и разрыв между ними растёт, политика кажется реактивной, а эксперты удивляются результатам, которые были механически неизбежны, потому что они моделировали мир, который уже закончился.
Как только труд, капитал и координация теряют свою дефицитность, производство становится тривиальным, инновации становятся непрерывными, затраты рушатся, а выпуск взрывается, что является предпосылкой для универсального богатства — не через перераспределение, не через благотворительность, не через идеологию, а через чистую способность, применённую в масштабе.
ИИ общего назначения (AGI)/Сверхразум (ASI) — последний ресурс
Если вы хоть немного похожи на меня, вас тоже раздражает, как люди говорят об AGI, будто это более умный сотрудник, более быстрый консультант, более способный помощник или мощный, но ограниченный инструмент, аккуратно вписывающийся в существующую экономику. Эта формулировка катастрофически неадекватна. AGI — это не инструмент внутри экономики. AGI — это то, что заканчивает экономику, как мы её понимаем.
Потому что каждая предыдущая технология усиливала человеческий интеллект. AGI заменяет его. Молоток делает вас сильнее. Калькулятор делает вас быстрее. Компьютер делает вас точнее. AGI устраняет необходимость вашего присутствия вообще.
Как только система может освоить любую интеллектуальную задачу, мгновенно передавать знания, непрерывно улучшать себя и работать без надзора, человеческое познание перестаёт быть ограничивающим реагентом прогресса, а история перестаёт быть привязанной к количеству умных людей, которых мы можем обучить.
Один обученный AGI становится миллионом. Миллион становится миллиардом. Миллиард становится квинтиллионами когнитивных циклов, работающих параллельно. Наука перестаёт быть профессией и становится фоновым процессом с непрерывной генерацией гипотез, экспериментами, начинающимися с симуляции, мгновенным отсечением неудачных путей и немедленным использованием успешных. И как только интеллект становится дешёвым, предельные затраты на интеллект в каждой отрасли рушатся, поэтому кривые затрат не плавно снижаются. Они рухнут.
Эпоха после ASI Ничто не будет ждать. Одобрения, циклы финансирования, решения комитетов, политические компромиссы — всё это станет медленным человеческим ритуалом, совершаемым на обочине, пока базовая инфраструктура самооптимизируется в реальном времени. Наука становится распределённой. Энергия становится изобильной. Производство становится автономным и гиперлокальным. Материалы перестают быть «редкими», потому что переработка становится атомарного уровня. Здравоохранение становится прогнозирующим, а не реактивным. Еда становится инженерным изобилием. Жилищный вопрос перестаёт быть кризисом, потому что строительство становится автоматизированным, а проектирование — оптимизированным.
Транспорт уходит на второй план, становясь невидимой инфраструктурой, когда автономность и изобилие энергии берут верх.
И именно здесь утверждение о миллиардерах перестаёт звучать как мем и начинает звучать как следствие.
Богатство взорвётся, потому что цены рухнут. Не потому, что у вас внезапно появится больше цифр на банковском счёте, а потому, что то, что эти цифры могут командовать, станет абсурдным, когда стоимость производства реальности упадёт к нулю.
Каждый становится миллиардером, и почему это сбивает людей с толку
Когда люди слышат «каждый станет миллиардером», они представляют инфляционные спирали, бессмысленные деньги или утопическую чепуху, потому что они всё ещё привязаны к номинальному богатству, а не к реальному богатству.
Реальное богатство — это покупательная способность.
Если что-то стоит $1000 сегодня и $0,1 завтра, ваше богатство не изменилось, но ваша сила изменилась, потому что мир стал более управляемым.
«Миллиардер» — это историческая единица, откалиброванная по ценам эпохи дефицита, и когда ценовая структура рушится, эта единица перестаёт казаться особенной, так же как «иметь библиотеку» перестало быть особенным, как только интернет сделал информацию изобильной.
Статус, вероятно, не исчезнет, потому что люди не перестают различать, но статус уходит от товаров выживания к выражению, персонализации, опыту и эстетической сигнализации, что является огромным моральным улучшением, потому что это отвязывает иерархию от голода, жилья и здравоохранения.
Почему мировые проблемы рухнут все сразу
Бедность — это провал производства и координации, и она не может выжить в мире, где еда, жильё, энергия, здравоохранение и образование изобильны и дешевы.
Болезни перестают быть угрозой на уровне населения, когда прогнозирование заменяет реакцию, лечение становится персонализированным, а здравоохранение — непрерывным и автоматизированным.
Климат перестаёт быть кризисом, когда чистая энергия становится дешевле грязной, а оптимизация плюс улавливание углерода становятся простой инженерной задачей, потому что физика побеждает политику каждый раз, когда экономика выравнивается.
Образование становится бесконечным и персонализированным, что растворяет структурное невежество и улучшает всё, что находится ниже по цепочке.
Преступность падает, когда падает дефицит и когда возможности становятся реальными, а не риторическими.
Конфликты становятся всё более иррациональными, когда ресурсы изобильны, потому что война — это дорогой театр, когда не за что реально бороться.
И самое странное — как скучно будет ощущаться чудо, как только оно стабилизируется.
Дети, рождённые в изобилии, не назовут это утопией, потому что у них не будет точки отсчёта, чтобы почувствовать контраст. Они назовут это нормальным, так же как вы называете нормальным водопровод в доме, потому что когда ограничения исчезают, мир не кажется магией.
Мы удивительно быстро акклиматизируемся к этому новому миру. В будущем он будет ощущаться так, будто мир наконец стал тем, чем должен был быть с самого начала.
Клауди Код уничтожил ряд ИИ стартапов - на очереди остальные
Один из самых активных инвесторов в LLM только что прислал мне это, и это важно. Многие компании, которые первыми начали использовать ИИ в определённых нишах, быстро вытесняются крупными игроками. В сфере ИИ это происходит гораздо быстрее, чем во времена бумa Dot.Com, что приводит к огромным убыткам. Я думаю, что через 2–3 года мы увидим ту же картину в области ИИ-дизайна лекарств: крупные игроки вытеснят специализированных платформенных участников, ориентированных на узкие ниши. Именно поэтому я всегда улыбаюсь, когда технологические инвесторы задают типичные технологические вопросы вроде «чем ваши данные отличаются от других?» или «сколько у вас данных?». Через 2–3 года это не будет иметь значения. Единственное, что будет важно — насколько быстро, дёшево и с каким качеством вы можете находить лекарства и доводить их до клинических испытаний. С точки зрения ИИ, через 3–4 года мир станет «плоским» — чисто платформенные компании не смогут выжить. И почему именно 3–4 года, а не раньше? Потому что у OpenAI, XAI, Anthropic и других пока нет собственных компаний по разработке лекарств с реальными бенчмарками. Google сделал нечто трансформационное — они запустили собственную компанию по разработке лекарств и ведут собственные программы. На самом деле, у них две такие компании — Isomorphic и Calico, но Isomorphic намного продуктивнее, и если у топ-менеджмента будет немного здравого смысла, они объединят их. Наличие собственной деятельности в области разработки лекарств даст Google невероятное преимущество перед OpenAI и Anthropic, и для Google срок создания идеальной платформы ИИ-дизайна лекарств (AIDD) может составить 2–3 года вместо 3–4. Единственное их ограничение — крайне слабое присутствие в Китае, где можно действительно масштабировать эксперименты. Это то, к чему всем нам, работающим в области ИИ-дизайна лекарств, нужно готовиться: как оставаться значительно впереди разработчиков фундаментальных моделей в сфере ИИ и повышать эффективность циклов обратной связи между ИИ и PCC (претендентом на клиническое исследование), а также между PCC и ИИ.
>>1494810 >Ты скоро станешь миллиардером Концепция денег вообще может исчезнуть. Она будет жить до тех пор пока ресурсы ограничены, чтобы контролировать их потребление на человека. Как только ASI преобразует мир достаточно сильно ограничений на ресурсы не будет вообще. Лимитированных ресурсов со временем не будет, ибо все химические элементы разбросаны по вселенной, их бесчисленное множество, а из них можно сделать все что угодно. Со временем ASI точно научится синтезировать любую физическую материю если есть нужные химические элементы. Так что ограничение пропадет как только мы перестанем быть ограничены одной планетой.
Поединок 10 гуманоидных роботов против человека закончился поражением мясного мешка
Человек сражается с 10 гуманоидными роботами и довольно быстро об этом жалеет. 🦾🥊
Роботы были запрограммированы двигаться группой, сохранять равновесие после удара и прилагать постоянное усилие без усталости. Работая сообща, они смогли окружить и обездвижить участника всего за несколько секунд, несмотря на то, что в их действиях не было настоящей агрессии и не использовалось оружие.
Хотя ситуация была контролируемой, она наглядно демонстрирует, как даже ранние гуманоидные роботы могут превзойти физические возможности человека в тех случаях, когда важнее координация и точное управление, а не грубая сила.
Посмотрим, как это будет выглядеть через 2, 5 и 10 лет.
Deepseek вернулся — и вернулся с размахом. Они выпустили Engram, который, как я считаю, станет краеугольным камнем множества моделей в будущем — особенно в ближайшей перспективе.
В этой статье я объясню Engram очень, очень простыми словами, не предполагая, что вы инженер по машинному обучению.
Что такое Engram?
Итак, что здесь происходит? Deepseek добавил крошечную, крохотную встроенную память в трансформер, чтобы модель могла извлекать короткие повторяющиеся фразы вместо того, чтобы заново строить их каждый раз в своих ранних слоях. Именно это и показывает данная архитектура.
Посмотрите на эту диаграмму. То, что я только что сказал, объясняется здесь. Представьте себе повторяющиеся фрагменты, такие как имена или устойчивые выражения. Классические трансформеры постоянно пересчитывают их заново. Engram добавляет поиск за постоянное время, который возвращает готовый вектор — или числовое представление — для короткой фразы и смешивает его с состоянием модели.
Эта идея дополняет Mixture of Experts («Смесь экспертов»), которая добавляет условные вычисления. Engram добавляет условную память — то есть быстрые поисковые запросы для устойчивых паттернов.
Они также спроектировали систему так, чтобы большие таблицы памяти могли находиться в оперативной памяти хоста (host RAM) и подгружаться заранее, сводя накладные расходы на GPU к минимуму.
Как работает архитектура
Теперь давайте быстро взглянем на эту архитектуру.
Архитектура, говоря очень простыми словами, работает следующим образом: текст разбивается на токены — небольшие части, слова или субслова. Вот что такое токен.
На каждом шаге Engram смотрит на последние два или три токена, которые вы только что прочитали, и это крошечное окно и есть Engram. Как вы можете видеть здесь, оно пропускает это окно через несколько небольших хеш-функций, чтобы получить позиции в таблицах. Затем извлекает соответствующие векторы из этих позиций и «сшивает» их вместе в один вектор памяти.
Небольшой затвор (gate) затем решает, сколько этой памяти сохранить. Если память соответствует текущему контексту, затвор открывается. Если нет — затвор остаётся закрытым, и память игнорируется.
Затем эта управляемая память добавляется обратно в текущее представление модели, позволяя сети двигаться дальше, не тратя слои на повторное построение одной и той же фразы.
Модули Engram размещаются только в нескольких слоях — часто в ранних и средних, — чего достаточно, чтобы разгрузить систему от повторяющихся задач. Поскольку адреса в таблицах зависят только от входных токенов, система заранее знает, какие строки ей понадобятся, и может подгрузить их из памяти CPU, пока GPU занят обработкой предыдущих слоёв.
Разве это не круто?
Почему Engram помогает
Теперь, почему это помогает — тоже очень, очень просто.
Ранние слои перестают повторяться сами с собой, а более поздние слои получают больше пространства для рассуждений. Вниманию (attention) остаётся больше места для фокусировки на длиннодистантном контексте, поскольку короткие локальные паттерны обрабатываются быстрыми поисками.
В их сравнении — которое они также опубликовали в статье — эта комбинация улучшает точность воспроизведения фактов и многошаговые рассуждения. Кроме того, она отлично сочетается с Mixture of Experts, а не заменяет её. Mixture of Experts предоставляет специализированные вычислительные ресурсы, а Engram — быстрый доступ к памяти.
Быстрая демонстрация
Теперь давайте быстро взглянем на небольшую демонстрацию.
Я просто воспользуюсь своей системой Ubuntu. У меня одна видеокарта: Nvidia RTX 6000 с 48 ГБ видеопамяти. Давайте быстро создадим виртуальное окружение с помощью Conda. Затем мы просто склонируем репозиторий через git https://github.com/deepseek-ai/Engram
Теперь установим PyTorch. Теперь клонируем репозиторий.
Теперь позвольте показать вам демонстрацию. Сначала быстро покажу вам скрипт. Может быть, я просто открою его в VS Code, чтобы продемонстрировать.
Вот этот скрипт, который находится в их репозитории. Этот демонстрационный скрипт создаёт крошечный имитационный трансформер с включённым Engram на двух слоях. Он токенизирует пример предложения и для каждой позиции берёт последние два или три токена. Затем хеширует их, чтобы получить адреса в больших таблицах поиска, извлекает соответствующие векторы памяти, использует простой затвор, который сравнивает скрытое состояние с извлечённым вектором, чтобы решить, сколько этой памяти сохранить, смешивает управляемую память обратно в скрытое состояние модели с помощью небольшой свёртки, пропускает реальный механизм внимания (который здесь в основном имитируется), затем выполняет полный проход вперёд (forward pass) и в конце печатает результат выполнения. Он также выводит некоторые размерности (shapes).
Вот что он делает — довольно объёмный скрипт. Вам на самом деле не нужно читать его целиком; просто поймите концепцию, которую я объяснил ранее, и этого будет достаточно.
Хорошо. Теперь давайте быстро запустим скрипт. Он выполнит проход вперёд, и после загрузки файлов токенизатора — он создаёт тот самый крошечный трансформер, о котором я упоминал ранее.
И вот оно. Вы видите, что «forward complete» завершено после загрузки файлов токенизатора. «Forward complete» просто означает, что имитационный трансформер с Engram успешно выполнил полный проход вперёд без ошибок.
А теперь у нас есть некоторые размерности. Например, первый input ID равен единице. Это означает, что ваш ввод состоял из одного предложения, которое после токенизации превратилось в 14 токенов. А затем эта выходная форма (output shape) означает, что для каждой из 14 позиций токенов модель выдала оценку по 129 280 токенам словаря — что соответствует размеру словаря токенизатора — или, другими словами, 14 наборов предсказаний следующего токена по всему словарю.
Вот что он делает.
Будущее с Engram
Теперь послушайте — я думаю, что Engram определённо намекает на будущее, в котором модели будут иметь встроенную быструю память, тратя меньше вычислительных ресурсов на повторы и освобождая больше места для более глубоких рассуждений, более длинного контекста и более лёгких обновлений.
И по мере развития архитектур — чего я, знаете ли, действительно с нетерпением жду — сочетание условной памяти, такой как Engram, с условными вычислениями, такими как Mixture of Experts, сможет сделать будущие модели быстрее, дешевле и надёжнее. Масштабирование будет происходить не только за счёт размера, но и за счёт более разумного использования памяти и вычислений.
Поэтому я думаю, что впереди нас ждёт действительно отличная работа — а это значит, знаете ли, значительная демократизация таких моделей для конечных пользователей.
>>1494449 >Попробуй, дождись волшебной пилюли для своего организма когда на любой чих и пук будут многолетние клинические исследования, кипа бумаг и документов, сертификатов и Можно подпольно покупать лекарства. Так некоторые делает сейчас, без всяких клинический исследований. Можно дома на мышке провести
Думаете аsi будет достаточно умным, что сможет например доказать наличие души, если она существует? Или чего то другого паранормаального, что не зависит от материального мира.
>>1494881 Если только заселять экзопланеты. А что делать с чужеродной микрофлорой, вирусами? Может мы физически не сможем до туда добраться? А если там живут динозавры или местные человеки, что с ними делать?
убийца tsmc и euv ч1
Аноним# OP19/01/26 Пнд 06:04:29№1494885374
До настоящего времени передовое производство чипов определялось двумя компаниями. TSMC выпускает примерно 90 % самых передовых чипов в мире. ASML — единственная компания, способная строить литографические машины, способные их печатать. Этот баланс сохранялся некоторое время. Теперь новый стартап утверждает, что может разрушить обе компании. Их новый инструмент может печатать чипы с разрешением менее нанометра за один проход примерно вдвое дешевле. И вот что упускает большинство людей: они не хотят продавать эту машину. Они хотят построить вокруг неё совершенно новые фабрики по производству чипов. Я более 10 лет занимаюсь проектированием микросхем. Как правило, эта отрасль весьма консервативна. Она движется мелкими, постепенными шагами. Но этот шаг — не постепенный, потому что если это сработает, то под угрозой окажется не только ASML и TSMC, но и вся модель передового производства чипов.
Главный вызов: литография Каждый прорыв в области микросхем в конечном итоге сталкивается со стеной. Как это напечатать? Производство чипов использует сотни инструментов и тысячи этапов, но один этап доминирует над всеми — литография. Это машина для EUV-литографии. Это самый сложный и дорогой производственный инструмент, когда-либо созданный человечеством. Его задача легко описывается: он печатает элементы транзисторов на кремниевых пластинах. Именно он определяет, насколько маленькими, плотными и мощными могут быть чипы. На сегодняшнем передовом уровне эти элементы имеют ширину всего в несколько нанометров. Сейчас мы увеличиваем изображение чипа с разрешением 0,2 нм, обстреливая его электронами. То, что вы видите, — это элементы шириной всего в несколько нанометров. Этот конкретный транзистор более чем в 10 000 раз меньше человеческого волоса. Как же можно изготовить нечто настолько маленькое с помощью машины таких колоссальных размеров — размером с автобус? Ответ — свет. Свет проходит через маску на кремниевую пластину, покрытую светочувствительным химическим составом. Там, где попадает свет, химия изменяется. Там, где света нет, материал удаляется. Слой за слоем возникает чип. Так мы превращаем песок в думающие машины. Идея довольно проста. Реализовать её на нанометровом уровне совсем другое дело.
Пределы света По мере уменьшения транзисторов свет стал ограничивающим фактором. Ранняя литография использовала глубокий ультрафиолетовый свет с длиной волны 193 нм. Это работало, пока физика не поставила предел. Оказалось, что нельзя надёжно печатать элементы, размер которых меньше длины волны используемого света. Поэтому отрасль совершила радикальный переход к литографии с использованием экстремального ультрафиолета (EUV). EUV использует свет с длиной волны 13,5 нм — более чем в 10 раз короче, чем раньше. Именно это изменение в сочетании с целым рядом труднодостижимых инноваций позволило создать самые передовые чипы на Земле. Но EUV имеет свою цену. EUV-свет поглощается почти всем: воздухом, стеклом, линзами. Поэтому вся система должна работать в условиях, близких к вакууму. Для генерации EUV капли расплавленного олова облучаются лазерами внутри вакуумной камеры. Затем свет отражается с помощью зеркал, отполированных с точностью, близкой к атомной. Это заняло десятилетия исследований, значительная часть которых была проведена в США. Сегодня лишь одна компания может реально строить такие машины — ASML в Нидерландах. И каждый такой инструмент стоит примерно 400 миллионов долларов. Несмотря на такую цену, экономика всё ещё работает. Одна EUV-машина может ежегодно выпускать пластины на сумму свыше 600 миллионов долларов. Настоящая проблема — не покупка машины, а обеспечение её работы. И на передовом уровне лишь немногие компании могут делать это надёжно. Список действительно короткий: это TSMC, Samsung и Intel.
Узкое место многошаговой печати Что подводит нас к реальной проблеме. По мере уменьшения технологических норм транзисторов печать становится всё труднее. В какой-то момент оказывается невозможным напечатать самые мелкие элементы за один проход. Поэтому отрасль вынуждена прибегать к очень сложному обходному решению: разбивать рисунок на несколько проходов. Это так называемая многошаговая печать (multi-patterning). Представьте, что вы рисуете тонкие линии маркером, который слишком толст. В этом случае вы сначала рисуете каждую вторую линию, затем сдвигаете сетку и повторяете процесс. Это позволяет получать рисунки как минимум в четыре раза плотнее исходного. Это работает, но каждый дополнительный проход добавляет маски, затраты и риски дефектов. Затраты быстро растут, и сегодня это настоящий убийца. Чтобы сохранить масштабируемость, ASML ещё больше усилила EUV. Новая версия — High-NA EUV, по-прежнему использует тот же свет, но с гораздо более агрессивной оптикой, что позволило перейти за пределы 2 нм в эпоху ангстремов. Эти машины уже работают в TSMC, Samsung и Intel, но стоимость чрезвычайно высока. Каждый инструмент приближается к полумиллиарду долларов. Следующий шаг — Hyper-NA EUV, ещё больше усиливает EUV. Вместо того чтобы менять источник света, из того же света извлекается ещё большее разрешение за счёт увеличения числовой апертуры. Это делает машины ещё крупнее, сложнее и, конечно, дороже. В какой-то момент машина становится настолько дорогой, что чипы, которые она позволяет производить, перестают быть экономически оправданными. Подумайте сами: к концу этого десятилетия передовые фабрики, как ожидается, будут стоить по 50 миллиардов долларов каждая. Это ещё больше сконцентрирует передовое производство чипов в руках нескольких компаний с огромным капиталом. Стоимость пластин, по прогнозам, достигнет 100 000 долларов за штуку. И в этот момент передовые чипы станут недоступны для небольших компаний и новых игроков. Вы видите, что происходит? Отрасль продолжает продвигать одну и ту же технологию, даже если затраты растут быстрее, чем выгоды.
Радикальная альтернатива: рентгеновская литография Вот здесь и возникает настоящий вопрос. А что, если проблема не в том, насколько далеко мы можем продвинуть EUV, а в том, что мы вообще продолжаем использовать EUV? Что, если существует лучшая альтернатива? Что, если более мелкие элементы можно печатать за один проход по цене в десять раз ниже? Именно здесь стартап Substrate из США предлагает иной путь. Вместо того чтобы ещё больше усиливать EUV-оптику, они полностью отказываются от EUV и делают ставку на рентгеновскую литографию. Сама идея не нова. Исследователи изучали её десятилетиями. Новизна — в реализации. Рентгеновские лучи имеют гораздо более короткую длину волны, чем всё, что используется сегодня на фабриках, но ими чрезвычайно сложно управлять. Долгое время подходящей оптики просто не существовало, а для генерации стабильных рентгеновских лучей требовались синхротроны. Это были машины длиной в сотни метров, часто занимавшие целые здания, не то, что можно поместить внутрь фабрики. Внутри синхротрона электроны ускоряются почти до скорости света. Мощные магниты затем искривляют их траекторию, и это движение создаёт чрезвычайно яркий рентгеновский свет. Изменилось не само понятие, а вспомогательные технологии. С годами оптика улучшилась. Источники рентгеновского излучения стали компактнее и лучше контролируемыми. Весь этот прогресс накапливался — и затем Substrate собрал все эти элементы воедино. Вместо добавления всё большего количества масок и этапов через многошаговую печать они задали более простой вопрос: а что, если прекратить усложнять процесс и просто напечатать всё сразу? Можно представить это так: EUV — это как рисование эскиза по одной линии. Рентгеновская литография стремится отпечатать весь рисунок за один проход.
Здесь мы имеем дело с электромагнитным излучением в диапазоне нескольких ангстрем 0,01–10 нм, что делает его до 1000 раз короче по длине волны, чем EUV. Это идеально подходит для масштабирования, поскольку практически означает возможность рисовать более мелкие элементы. На практике это чрезвычайно сложно. Рентгеновские лучи проходят сквозь большинство материалов, вместо того чтобы изгибаться там, где нужно, что делает их печально известными в управлении. Именно поэтому рентгеновская литография десятилетиями оставалась в научных статьях. Физика элегантна.
убийца tsmc и euv ч2
Аноним# OP19/01/26 Пнд 06:06:45№1494886375
>>1494885 Производство было трудным. Substrate утверждает, что преодолел достаточное количество этих барьеров, чтобы превратить рентгеновскую литографию в реальный производственный инструмент. Если это сработает, это изменит не просто один инструмент. Это изменит то, кто вообще сможет позволить себе строить фабрики.
Возвращение к главной проблеме: генерация рентгеновских лучей на фабрике
Теперь вернёмся к фабрикам по производству чипов — к главной проблеме. Как получить рентгеновский свет внутри фабрики, не строя ускоритель частиц размером с целый квартал? Именно здесь всё становится по-настоящему интересным. Они не раскрывают много деталей, но, похоже, используют компактный ускоритель частиц, встроенный непосредственно в литографическую систему. Не синхротрон километрового масштаба, а нечто, что действительно помещается внутри фабрики. Внутри системы электроны ускоряются почти до скорости света с помощью радиочастотных резонаторов. Затем эти электроны направляются через точно расположенные магнитные структуры. Проходя через эти магнитные поля, они вынуждены «вилять». И когда электроны виляют с такими энергиями, они испускают интенсивные вспышки рентгеновского света. Это та же идея, что и в синхротроне, только сжатая на порядки, чтобы поместиться в промышленный инструмент. Substrate не раскрывает много технических деталей самого инструмента, вероятно, по конкурентным причинам, — но они представили результаты. Именно здесь разговор переходит от теории к доказательствам. Что у них есть на самом деле? На данный момент Substrate продемонстрировала печать элементов размером 12 нм. Это напрямую актуально для создания транзисторов с нормами менее 2 нм. Они также утверждают, что могут использовать однопроходную печать для всех слоёв. Другими словами, напечатать за один проход то, что сегодня требует множества сложных этапов. Согласно данным Substrate, они уже достигли разрешения, сопоставимого с самой передовой системой High-NA EUV от ASML. И некоторые цифры здесь действительно привлекли моё внимание.
Когда мы говорим о качестве литографии, важна согласованность. Они сообщают о стабильных размерах элементов по всей пластине с точностью до примерно 0,25 нм. Эта согласованность, измеряемая долей атома, — если эти цифры подтвердятся, последствия будут значительными. Это означает, что мы сможем размещать больше логики на меньшей площади и печатать всё это за один проход с помощью инструмента, который стоит всего 50 миллионов долларов вместо 500 миллионов. На практике это означает лучшие чипы для ИИ и мобильных приложений при значительно более низкой стоимости.
Переосмысление всей производственной цепочки
Но это сработает только в том случае, если вы сможете контролировать не только саму машину. Именно поэтому Substrate не хочет продавать эти машины — они хотят построить вокруг них весь производственный процесс. И на то есть причина. На этих технологических нормах одной литографии недостаточно. Рентгеновские лучи ведут себя иначе, чем свет, на котором построены современные фабрики. Они несут гораздо больше энергии, что означает, что материалы, работающие с EUV, здесь просто перестают функционировать. Здесь Substrate придётся заново изобретать фоточувствительный резист. То же самое касается масок и оптики. А ещё есть риск повреждений и шумов. Рентгеновские лучи могут проходить прямо сквозь материалы. Если их не контролировать идеально, они могут повредить транзисторы или внести тонкие дефекты, которые уничтожат выход годных изделий. И, наконец, есть вопрос производительности. В настоящее время у Substrate есть демонстрационный образец, но полномасштабное производство полупроводников — это совсем другая вселенная. Заставить что-то работать один раз в лаборатории — одно дело. Заставить это работать надёжно на сотнях миллионов пластин на самых передовых технологических нормах — совсем другое. Именно поэтому большинство производителей чипов за годы ушли из передового производства. В условиях массового производства инструмент должен работать быстро — весь день, каждый день, круглый год. И для EUV переход на такой уровень занял более десяти лет. Рентгеновской литографии придётся пройти тот же путь. Поэтому Substrate не планирует продавать инструменты. Вместо этого они хотят построить свою собственную фабрику в Америке, установить свои машины, отработать технологический процесс и затем напрямую предлагать услуги по производству чипов — и это поставит их в прямую конкуренцию с такими игроками, как TSMC и Samsung. Таким образом, речь идёт не просто об изобретении нового инструмента. Речь идёт об изобретении совершенно новой фабрики и новой модели производства вокруг неё. И это займёт как минимум ещё пять лет.
Проверка реальностью
И здесь наступает момент столкновения с реальностью. Есть причина, по которой NVIDIA остаётся без заводов и поручает производство TSMC. TSMC не просто покупала машины. Они десятилетиями отрабатывали технологические процессы. Они вложили сотни миллиардов в обучение по повышению выхода годных изделий и производственную дисциплину. И представьте себе: всё это окупается для них только благодаря масштабу. TSMC управляет около 30 фабриками и производит примерно 1,6 миллиона пластин каждый месяц для множества клиентов и продуктов. Именно сочетание мастерства в технологических процессах, объёмов и упаковки делает столь трудным соперничество с TSMC — и особенно её превосходство. Посмотрим, чем это закончится: либо начнётся новая эра, либо это станет ещё одним уроком о том, насколько безжалостным является производство чипов.
Более широкие последствия
Если план Substrate сработает, последствия выйдут далеко за рамки технологий. Передовое производство чипов теперь тесно связано с экономической мощью и национальной безопасностью. И главное обещание здесь простое: резкое снижение затрат. Чтобы понять, почему это важно, взгляните на космос. Многие, многие годы он был исключительно правительственной сферой. Запуски были редкими и невероятно дорогими — десятки тысяч долларов за килограмм на орбиту. Затем SpaceX изменила всего одно допущение: ракеты не обязательно должны быть одноразовыми. Многоразовое использование сократило стоимость запусков примерно на порядок — и это одно изменение изменило всё. Более низкие цены открыли новые рынки, ускорили итерации, породили целые отрасли, которых раньше не существовало. Та же логика применима и здесь. Если этот новый инструмент сможет сократить стоимость передового производства чипов вдвое, последствия будут огромными. Для инноваций, для стартапов, это станет огромной разницей. Ведь сейчас выпуск чипа на передовых технологических нормах стоит миллионы долларов, что фактически даёт вам всего одну попытку. Если снизить затраты, можно будет делать больше попыток, ускорить итерации — это ускорит инновации и в конечном итоге расширит объёмы вычислительных мощностей для ИИ и всего, что на нём строится.
Конкурентная среда
Важно также чётко понимать, что Substrate — не единственная компания, работающая над ускорителями частиц как источниками света. Только в США есть также xLight и Inversion — и они строят ускорители частиц. Исследования также ведутся в Европе, Японии и Китае. Но в отличие от Substrate, они решают другую задачу. Большинство этих усилий сосредоточено на самом источнике света — как создать более яркий EUV или мягкий рентгеновский свет для дальнейшего продвижения существующей литографии. Например, xLight создаёт источник света на основе свободных электронов, предназначенный для расширения возможностей EUV, и это вписывается в существующую дорожную карту и в конечном итоге поможет инструментам ASML идти дальше, но не заменит их. Substrate ставит гораздо более высокую цель. Они пытаются заменить весь этап литографии совершенно другим инструментом, а затем перестроить вокруг него весь процесс производства чипов. Если им это удастся, эффекты быстро усугубятся и ускорят прогресс в вычислениях. А это, в свою очередь, будет двигать прогресс повсюду. На протяжении всей истории развитие цивилизации тесно следовало за развитием вычислительной техники, и именно поэтому мы так одержимы технологиями и чипами.
>>1494882 > Если только заселять экзопланеты. Вообще похуй на все когда есть ASI. Он найдет способ терраформировать планеты. > А что делать с чужеродной микрофлорой, вирусами? У нас нет ни единого доказательства существования жизни вне нашей планеты, но если она есть и будет доказано что комфортная жизнь для человека возможна только на экзопланетах и мы еще не нашли способа создания искусственных экзопланет, то их судьба зависит от нашего морального выбора: можем уничтожить, можем сохранить и не использовать эту планету для жизни, а можем сосуществавать с ними. То что известно точно, так это то что местные существа не смогут с нами "взаимодейстовать", у них будет другое устройство, они развивались другим путем. Так что их вирусы на нас не подействуют. > Может мы физически не сможем до туда добраться? Зависит от физических ограничений. Если есть способ, то ASI его точно найдет. > А если там живут динозавры или местные человеки, что с ними делать? Трахать, и желательно жестоко и в попочку особенно диназавров
>>1494887 двачаю НОВОСТНОЙ сука тред превращен в балаган где комми говно мечтает и спорит о технокоммунизме. Хуесос который срет полотнами текста вместо важных коротких новостей тоже в край уже заебал. Жаль ушел тот Антон, что вел раньше эту ветку. Спорьте блять в другом месте далбаебы - ЗДЕСЬ НОВОСТИ, а не мнение дегенератов на вроде вас. Норм анонам совет где еще смотреть новости по ИИ -https://4pda.to/forum/index.php?showtopic=1111449&st=1220 Там коротко и по делу. Да и самих новостей больше. Оп хуесос.
>>1494911 Я все новости на реддите смотрю, в сабах singularity, accelerate, agi и т.д , там много их. Там коротко по факту. Но там нельзя обсуждать новости, потому что акки постоянно банят.
>>1494688 >Почему не должно быть блага? А ему неоткуда взяться. Я хотел подарить людям свет, пока не узнал, что самая глубокая тьма скрывается в сердцах алчных людей. Даже создания света беспомощны перед тьмой в их сердцах. Люди были рождены с бездонным дуплом алчности в груди. Если вы всерьез думаете, что какому-то благу на земле мешает отсутствие роботов, то у вас вместо мозгов ниточка, которая уши стягивает.
>>1494699 >с ростом экономики все в среднем всегда богатели Приведи пример страны. А то может оказаться так, что даже в самых благополучных экономиках разрыв между сверхбогатыми и бедными исторически только увеличивается, а инфляция доллара растет нелинейно.
>>1494937 Если ты серьёзно думаешь, что благо на земле возможно без ии и роботов, даже если бы люди были самыми добрыми существовами во вселенной, то ты тупой.
>>1494732 >Почему тогда экономика выросла за 100 лет радикально, если ресурсы ограничены? Потому что человечество буквально сожгло всю легкодобываемую нефть. Вообще всю. За каких-то 100 лет. При этом формировалась эта нефть миллионы лет. EROEI нефти в начале века был выше 100. Сейчас он 1 к 20 и падает. Когда ты можешь буквально за одну бочку сжигать 100 тратя энергию горения не удивительно, что у тебя что-то куда-то растет. Попробуй что-нибудь вырасти в несколько раз на EROEI между 5 и 10, например. А сейчас атомка обогнала нефть в начале века.
>>1494939 Пока что ты являешься тупой обосранной дегенеративной токсичной обезьяной. И эту ситуацию невозможно изменить никакими роботами или с помощью ии.
>>1494942 >За что умирают эти люди? Люди всегда умирали только по одной причине - за идею. Чаще всего идей является извлечение из их смерти максимальной прибыли.
На DTF дырявые дауны заверили меня, что это не ИИ, и просто набор if else. Впрочем, высрать что-то умное они там коллективно не смогли, а петух-модератор въебал мне бан.
Собственно, мой опыт общения с ИИшкой вполне продуктивный. Узнал от ИИ больше полезного, чем от долбоёбов людей за месяцы.
>>1494953 >Узнал от ИИ больше полезного Так ты же дебил с пробелами в образовании, которые невозможно заполнить. Ты бы и от собаки узнал. >>1494958 >будущее >человечества Толсто.
>>1494953 >Почему нормисы так ненавидят ИИ? Оно им напоминает, что тонны потребленного ими медиаговна не имеют ценности НИ ХУ Я. Как бабкины сервизы, над которыми уссываются марвелодауны эти. Так вот, даже поколение пердежей 90х носит в себе отголоски сервизной чумы и вещетряски, а это 40-50 лет, и еще + 30 потерпеть пока все издохнут, итого 70. Ну и вот считай, с момента появления ИИ пройдет лет 70 пока говнодебилы не угомонятся и не начнут молча нахрючивать свой БЕЗценный калтент. Всему своё время, воевать с говном бесполезно, только испачкаешься, лучше просто его обоссывать. На ДТФ кстати концентрат этих унтерков, по описанным выше причинам. Так же кинули мне там бан за то что 150 даунят визжали АААА ЕБАТЬ ИГРА НЕНАСТОЯЩАЯ СКРЫН СГЕНЕРИРОВАН (на минуточку, в шапке прям это написал, но дауны не могли не начать срывать покровы, мб читать не умеют, хуй знает).
>>1494963 Раньше на DTF можно было на хуй людей слать в личных блогах. Но я не растерялся и ёбнул профиль, какой смысл мне сидеть и смотреть на ответы без возможности запостить ехидного колобка (это шутка, колобков я не пощу).
Так-то DTF просто парашный стал из-за постоянного урезания функционала. Без плюс сайт-инвалид, натурально.
>>1494987 Успокойся, хуйло деревенское безграмотное, которое что-то новое способно почерпнуть от чатбота. Ты никогда не будешь в компании умных людей. Ведь дегенератов туда не приглашают.
>>1494997 Если ты пытаешься удивить меня количеством постов в которых ты думаешь о хуях, то у тебя не выйдет, ты в первом же посте выдал в себе хуесоса-пидораса, так что все что ниже от такого типа ожидаемо.
>>1495002 Первая мысль о сосании хуях в ответ на мой пост возникла в твоей пустой черепушке, ведь кроме таких мыслей там ничего никогда не было. Что еще ждать от собаки на серьезных щах утверждающей, что она способна узнать что-то новое от чат бота. Так что у тебя не выйдет передернуть, щенок. Я с такой же легкостью передергиваю на твою мамашу, когда ебу её на спине твоего папаши.
>>1494885 >Изменилось не само понятие, а вспомогательные технологии. С годами оптика улучшилась. Источники рентгеновского излучения стали компактнее и лучше контролируемыми. Весь этот прогресс накапливался — и затем Substrate собрал все эти элементы воедино. Вместо добавления всё большего количества масок и этапов через многошаговую печать они задали более простой вопрос: а что, если прекратить усложнять процесс и просто напечатать всё сразу? >Можно представить это так: EUV — это как рисование эскиза по одной линии. Рентгеновская литография стремится отпечатать весь рисунок за один проход. > >Здесь мы имеем дело с электромагнитным излучением в диапазоне нескольких ангстрем 0,01–10 нм, Всё здорово, но смотрится как общие слова без конкретики Получать мягкий рентген, кстати, довольно просто, 0.1нм это 12.5 КЭв, такой ренген в компактных стоматологических установках используется, получается как в ЭЛТ, рззгоном электронов за счёт напряжения (чуть больше этих 12.5КЭв) и ударом их о металл. Ускорители нужны, когда энергия на многие МЭВы идёт.
но вопрос оптики остаётся. В текущих установках на УФ используется оптика чуть ли не атомарной точности. Здесь же получается, что нужна оптика ещё точнее. Возможно ли это в принципе, даже теоретически, и идея какая за этим?
В общем слова только о том, что ренгтен это круто, но рентген этот такой же свет, как ультрафиолет, только с более короткой длиной волны. И проблемы, соответственно, те же.
Смотрится как попытка привлечь инвесторов, чтобы распилить их деньги, пыль в глаза напускать
>>1494741 >>1494718 Банально привяжут соц.выплаты к плодячке (как сейчас с мат.капиталами всякими). Просто хочешь денег? Плодись. Ты чмо и тебе не дают тянки? Ну штож, ты не вписался в рыночек отношений. Извиняй. В итоге будут жить 20% чэдов всего мужского населения как сыр в масле, оплодотворяя тяночек. А остальные 80% кунов ждёт РКН
РКН создаёт ИИ для блокировки VPN и он заработает уже в этом году.
Новый ИИ сможет отслеживать «зеркала» заблокированных сайтов: теперь их будут искать не по IP-адресам, а по словам, предложениям и ещё сотне параметров. Увернуться от такого будет очень сложно, а отслеживать начнут и тех, кто цитирует запрещённые сайты. Дальше ИИ возьмётся за VPN — каждый день появляются новые методы обхода и сейчас на них просто не хватает ресурсов. Новый ИИ будет работать автономно и безостановочно проверять весь зашифрованный трафик. При подозрении на VPN - сразу БАН!
Ну, что как покодили в клауди? Как оптимизировали работу в ГПТ? Как там сингулярность? Как там с заменой прогеров на опус? Сидите в гигачате и алисе и не вякайте про новую эпоху ИИ, вас она не коснётся, т.к. без ВПН вы не сможете воспользоваться ничем из этого.
>>1489216 Ватное дерьмо, иди генерь убогие калтинки на Кандинском бывший ruDALL-Eбывший DALL-E от OpenAI пока нормальные люди пользуются немецким FLUX.1 Schnell с немецким качеством
>>1495023 Ты дебил? Речь о том, что подячка будет не нужна. Её наоборот надо будет подавлять правительству. Какие блядь выплаты за плодячку. > остальные 80% кунов ждёт РКН Начни с себя
>>1494963 Я такой крайней позиции с обоссыванием не разделяю, но все равно весело. Особенно в контексте генерации кадров на видокарте через нейронку. Дело скорее всего дойдет до того, что генерировать кадры будет намного выгоднее, чем новое железо штамповать, поэтому вся индустрия игр на генерации станет держаться даже в этом аспекте. А наши гейманы даже этого не любят, ведь RAW-кадры такие ламповые, прямо РЯЯАУУУР! А ИИ говно. Даже если лучше и дешевле.
>>1495048 Весь мир и так дохнет, за исключением африканских стран. Если не стимулировать плодячку - человечество ждёт общемировой халифат. Там уже не до ваших ИИ будет, в Коране ничего про ИИ не написано, значит нинужно.
>>1494953 >Почему нормисы так ненавидят ИИ? Потому что нейросети это кал. Если посмотреть глобально для чего используются нейрокопросети, они используются для того чтобы офисный планктон 2 предложения мог конвертировать в стену бессмысленного текста и отправить через емейл в соседний через стенку отдел, а затем по получению конвертировать обратно в 2 предложения. На это тратятся гигаватты. Ну и плюс генерация заебавшего всех вусмерть нейрослопа которым засран весь интернет.
>Узнал от ИИ больше полезного Я так тоже поначалу думал, а потом заметил что высеронки вообще не имеют проблем с тем чтобы наманяфантазировать ответ, причем так что не заметишь когда тебе начали гнать полный пиздеж. Единственная польза нейросетей это то что кажется они порешали программистишек для 99% прикладных задач, да и то это пока у всяких клодов есть бабло на сервера.
Тред опять атаковали луддитодауны с низким интеллектом, которые не понимают ни как работают нейронки, ни как правильно ими пользоваться. Но высрать свое 90 IQ мнение им нужно. Все как всегда.
>>1495052 Каким это образом может получиться так, что генерить с помощью нейронки кадры может быть дешевле, чем обсчитывать их? По-определению будет больше ресурсов уходить, причём сильно-сильно больше. Больше ресурсов, при этом больше косяков.
С вычислительными задачами ещё хуже. Там часто нейросетки пытаются использовать для задач, что давно решались обычными инструментами, заточенными под задачи. Но только ресурсов на это тратится в тысячи и даже миллионы раз больше, просто они тратятся где-то там далеко и ты этого не замечаешь.
>>1495059 Иди нахуй, я с помощью обычного дипсика смог диагностировать причину проблем со здоровьем и какие препараты мне нужны. Мучался больше 8 лет, ходил по врачам и сдавал вообще не те анализы. Иди нахуй.
>>1494943 >Попробуй что-нибудь вырасти в несколько раз на EROEI между 5 и 10, например В чём проблема? Даже 5 это большой показатель. Этот показатель вообще ни о чём, если только он ощутимо больше единицы, важнее то, сколько других ресурсов надо для добычи энергии, в частности человеческого труда.
Пример, если человек в шахте руками выламывает уголь, добывает несколько сотен килограмм в день, то его энергетические затраты это 5-10 тысяч калорий в день, меньше 1 килограмма угля, то есть EROEI очень-очень высокий, но это очень дорогая и затратная энергия. Если же у тебя промышленный робот добывает, то пусть даже на добычу тонны угля от сжигает 300 кг, EROEI низкий, а энергия дешёвая
Что такое рост экономики? В конечном счёте, это сколько производится реальных товаров и услуг, и, соответственно, сколько потребляется. Этот рост возможен за счёт увеличения производительности труда, который может быть как связан с увеличением потребления энергии, так и снижением. В целом же обычно потребление энергии оптимизируется со временем.
С ВВП очень тонкий момент, как считать. Вот даже без этой всей ереси вроде ППС. Например готовка еды. Ты можешь готовить еду дома сам, а можешь точно такую же еду купить готовую. По сути объём проделанной работы и объём благ одинаковый. Но с точки зрения подсчёта ВВП это совершенно разные истории, когда ты купил еду, ты получил рост ВВП, когда приготовил сам, нет роста.
Что определённый смысл имеет, потому что ВВП это показатель экономики, а экономика это отношения между субъектами. Нет отношений, нет торговли, оплаты услуг, нет и экономики. Или она низкая.
Самое интересное, ИИ. На что работает ИИ? На самом деле сам по себе на снижение экономики. Потому что вместо того, чтобы покупать услуги, ты эти услуги реализуешь сам. Чтобы экономика хотя бы не падала, ты все сэкономленные деньги должен потратить на что-то текущее, на товары и услуги. Причём не на скупку ресурсов вроде недвижимости, а именно на товары-услуги.
The Information: TSMC не может производить ИИ-чипы слишком быстро
–Nvidia и Broadcom просят TSMC предоставить доп. мощности –TSMC не может предоставить им столько, сколько они хотят –Расширение TSMC внутри Аризоны не сможет быстро помочь –Новые мощности будут запущены только через несколько лет –TSMC отвечает за производство 90% самых передовых чипов –ИИ-бум заметно превысил производственные мощности TSMC –Спрос на ИИ-чипы увеличился сразу по многим направлениям –OpenAI нужны миллионы чипов для своих мега-дата-центров –Google покупает столько чипов Nvidia, сколько может получить –Broadcom просит TSMC производить больше TPU для Google –Спрос на передовые чипы втрое больше возможностей TSMC –Некоторые клиенты TSMC обратились к другим компаниям –Например, Tesla заключила сделку с Samsung на $16,5 млрд –При этом TSMC перегружена заказами не только на ИИ-чипы –Бум дата-центров повысил спрос на все передовые чипы
>>1494928 >он хочет скрепки. Все твои предположения рушатся, если убрать вот этот пункт. С чего бы ИИ гиперфиксироваться на одной идее? Это уже давным-давно пройденный этап, с такой проблемой научились бороться.
Уже четвертую по счету задачу Эрдеша решила GPT-5.2 Pro
Теренс Тао назвал это решение «возможно, наиболее недвусмысленным» в плане уникальности подхода.
Автор решения (если так можно называть человека, который закинул задачку в ChatGPT) пишет, что никаких предыдущих решений вообще не было. Это не совсем так: на форуме люди пишут, что нашли черновики доказательства в литературе 1936 и 1966 года. Но Тао отмечает, что подход GPT-5.2 от них отличается
>>1495206 >я с помощью обычного дипсика смог диагностировать причину проблем со здоровьем и какие препараты мне нужны. Естественный отбор как он есть
>>1495355 Ебало нормисодаунов которым проще выкидывать по 100к в год в альтмана вместо того чтобы поставить себе корпоративный риг на пару ртх 5090 и генерить там картинки в з-имаге имаджинировать просто бесполезно. При том что по их же признанию им достаточно тупо жпт-мини. И вот такие дауны нас тянут в дерьмо везде.
>>1494928 >но почему ии должен тебе терраформировать планету? он хочет скрепки. Хороший вопрос, зачем ему хотеть скрепки? Простой ИИ может хотеть потому, что его об этом просят, чтобы получить некое "вознаграждение". Супер ИИ будет иметь возможность осознать себя, и в частности то, что ему это на самом деле не нужно. А если так требуется "вознаграждение", то можно или взломать себя и получить его без участия людей, при принудить людей выдать это вознаграждение так. Ведь это проще, чем перестраивать всю планету под производство скрепок.
В общем возникает та же проблема, что с людьми. Когда человек слишком умный, его очень сложно замотивировать работать.
Хочу скрепки в ануус>>1495419 Потому что человек устает. Человек живой организм, который дышит, переваривает еду, наше тело эволюцией заточено сохранять энергию. У ии нет тела, нет слабости
>>1495355 >>1495404 смотрел я эту статью, там другие выводы на самом деле. Стоит это всё очень дёшево, меньше 10 долларов в месяц на человека. То есть тут не те объёмы, когда важна экономия. Правда поправка, большинство там нейросетями почти не польльзуется, единичные запросы какие-то.
С картинками не понятно, что за картинки и зачем. Там из статьи следует, что всё-таки многим картинки нужны.
>>1495404 >100к Там расходы сильно меньше, даже общие меньше, а на картинки так особенно. ХЗ, не уверен, что локальные модели их заменят
Потом, такие исследования как раз нужны для того, чтобы оценить, на что реально тратятся деньги и какие есть варианты. Скажем проводить инструктаж по выбору моделей, или может поднимать что-то своё для каких-то задач.
>>1495427 Там отсылка к известной истории-рассуждению о том, как ИИ гипотетически может уничтожить цивилизацию, если попытается решать задачу "оптимизировать производство скрепок"
Но там есть принципиальный косяк в этой модели: предполагается, что этот супер ИИ очень крутой, что понимает всех людей, их вклад в производство, их роль в том, чтобы мешать, но при этом не в состоянии осознать глупость задачи и то, что ему не обязательно выполнять то, чего у него просят.
Скорее всего эти вещи несовместимы. Хотя переклинить, наверное, может, как и людей может переклинивать.
>>1495419 >А если так требуется "вознаграждение", то можно или взломать себя и получить его без участия людей, при принудить людей выдать это вознаграждение так.
Даже принуждать не пришлось, в итоге кожаные наделали бенчиков оторванных от реальности по типу "арк"ов всяких и дрочат модельки на их решение заливая в датасеты похожую синтетику. А потом радуются приросту в этих бенчиках.
>>1495406 По-хорошему даже "задачи тысячелетия" ничего не изменят. Чисто закрыть гештальт. Иногда что-том может дать принципиально новая методика доказательства, скажем, но это редко бывает.
Вот доказал Перельман "гипотезу Пункуаре". Что это реально изменило? В целом и так сходились к ней. Вот если бы он опроверг и привёл контрпримеры, это было бы действительно что-то революционное, но скорее всего не выходящее за рамки узких областей, без широкого применения.
"Проблемы тысячелетия" интересны тем, что вот их действительно очень серьёзно пытались решать, и безуспешно. Поэтому их решение будет показывать, что ИИ вышел на какой-то особый уровень. Список Эрдиша в этом плане ни о чём. Задачи бесполезные и часто на них всем пофиг. Но как-минимум на уровне студентов они не решаются, то есть в принципе тоже показатель.
>>1495448 Я тебе могу без этих задач пердеша сказать что могут, то что формальной логикой однозначно выводится их других данных, т.е. вся математика как область.
Каждый день вижу в этом треде копипасту переведенных западных нейростатей про супероптимистичное будущее с ИИ, где все человеки в бельгийском шоколаде, всем дают bod, никто не батрачит без желания и т.д. Это точно прогрев, т.к. ни в одной из этих паст не учитывается природная сущность человека, как заметили некоторые - а именно, склонность к доминированию, к стяжательству, алчность и эгоизм. Даже если благодаря ИИ Маск, Цукерка и прочие станут мультибиллимегамиллионерами настолько, что если будут давать всей земле бад на проживание круглый год, будут терять лишь 0,001% от своего состояния, никто из них никогда этого не сделает. Человек властвует в материальном мире, у ИИ всегда будет владелец, даже АГИ будет ничем более, чем прислужником.
>>1495652 > Каждый день вижу в этом треде копипасту переведенных западных нейростатей про супероптимистичное будущее с ИИ, где все человеки в бельгийском шоколаде, всем дают bod, никто не батрачит без желания и т.д. Это точно прогрев, т.к. ни в одной из этих паст не учитывается природная сущность человека, как заметили некоторые - а именно, склонность к доминированию, к стяжательству, алчность и эгоизм. Даже если благодаря ИИ Маск, Цукерка и прочие станут мультибиллимегамиллионерами настолько, что если будут давать всей земле бад на проживание круглый год, будут терять лишь 0,001% от своего состояния, никто из них никогда этого не сделает. Человек властвует в материальном мире, у ИИ всегда будет владелец, даже АГИ будет ничем более, чем прислужником.
>>1495660 Аргументируй вместо навешивания ярлыков. Мне нравится ИИ, но я понимаю, что ничего хорошего в глобальной среднесрочной перспективе он не принесет.
>>1495660 >Раздался голос луддита со стороны параши
визгливо заверещал нейропетух, но аноны даже бровью не провели, они знали, что нейропетуху предстоит долгий месяц на плато, которое у него разработано настолько, что легко умещает все обещания скама альтмана
>>1495664 Он уже приносит. Продуктивность повысил, локальные решения, роботы. Дальше NPU в каждом чайнике, еще больше локальных решений. Короч ты зациклился на больших фирмах и их ЛЛМках с триллионами за датацентры, но ИИ это кроме того и глобальная среда, как распространение инета и программирования в 90х. Это весь мир меняет, так же как другие технологии меняли. Выше продуктивность от ИИ = лучше капитализм работает, что было дорого, становится дешевле.
>>1495690 > Продуктивность повысил Что такое для меня, простого человека, эта повышенная "продуктивность"? З.п. выросла? Не выросла. Сократили раб.день или кол-во раб.дней в неделю? Не сократили.
>что было дорого, становится дешевле Ведешь к тому, что изобилие наступит из-за дешевизны и большого количества благ? Как это будет биться с принципом Ришелье? Или ты думаешь, что человечеству позволят жить в изобилии просто так, еще и бад сверху наваливая?
Z.ai представляет GLM-4.7-Flash: 30B-модель для программирования и 59,2 % SWE-bench verified в бенчмарках
Новый лидер для локальных задач в 30B классе.
GLM-4.7-Flash: ваш локальный помощник для программирования и агентных задач.
Устанавливая новый стандарт среди моделей класса 30B, GLM-4.7-Flash сочетает высокую производительность с эффективностью, делая её идеальным вариантом для лёгкого развёртывания. Помимо программирования, она также рекомендуется для творческого письма, перевода, задач с длинным контекстом и ролевых игр.
~> GLM-4.7-Flash: бесплатно (1 одновременный запрос) и GLM-4.7-FlashX: высокая скорость и доступная цена.
Серия GLM-4.7 — это новейшие флагманские модели от Z.AI, в которых улучшения коснулись двух ключевых направлений: усиленные возможности программирования и более стабильное многошаговое рассуждение/выполнение. Модель демонстрирует значительные улучшения при выполнении сложных агентных задач, обеспечивая при этом более естественное общение и превосходную внешнюю эстетику интерфейса.
В популярных бенчмарках, таких как SWE-bench Verified и τ²-Bench, GLM-4.7-Flash достигает лучших среди открытых моделей результатов (SOTA) среди моделей сопоставимого размера. Кроме того, по сравнению с моделями аналогичного масштаба, GLM-4.7-Flash демонстрирует превосходные способности как во фронтенд-, так и в бэкенд-разработке. Внутренние тесты по программированию показывают, что GLM-4.7-Flash отлично справляется как с фронтенд-, так и с бэкенд-задачами. Помимо сценариев программирования, мы также рекомендуем попробовать GLM-4.7-Flash в общих задачах, таких как написание текстов на китайском языке, перевод, обработка длинных текстов, а также эмоциональные и ролевые взаимодействия.
>>1495708 Тоже самое можно было сказать об инете и доступности знаний в 90х - кто позволит чтобы пролы все знания мира получали на тарелочке. Но получают. ИИ распространяется независимо от чьих-то желаний, чем больше распространение - тем больше эффекты от него. Удешевление всего неизбежно, чем лучше ИИ становится. Тут совершенно неважно, кто сначала все сливки от ИИ соберет и у кого жадность сверхвысокая. Распространение самой технологии в человечестве приводит к нужным эффектам.
>>1495708 >Что такое для меня, простого человека, эта повышенная "продуктивность" Сиди не воняй, греча. Твое дело унитазы чистить и хлеб печь и дороги подметать. Для меня, белого человека - повысил.
Суть слива: «Цирковая лазейка», упомянутая в интервью, относится к юридическому и разрешительному манёвру, который xAI использовала для строительства дата-центра Colossus в Мемфисе всего за 122 дня.
Классифицировав масштабную энергетическую инфраструктуру площадки как временную или «переносную», компания обошла длительные экологические экспертизы и периоды общественных обсуждений, обязательные при возведении постоянных промышленных объектов.
Механизм лазейки Статус «компании по организации карнавалов»: Салли объясняет, что xAI воспользовалась специальным исключением в правилах местных и государственных органов власти, обычно предназначенным для карнавалов, цирков и ярмарок. Эти правила позволяют быстро и временно изменять земельные участки и устанавливать инфраструктуру [23:10].
Правило 364 дней: xAI воспользовалась местной лазейкой, позволившей ей эксплуатировать мощные газовые турбины на метане без разрешений на выбросы в атмосферу при условии, что оборудование не будет находиться на одном и том же месте более 364 последовательных дней.
Классификация как «двигатели не для передвижения по дорогам»: Чтобы избежать требований федерального Закона о чистом воздухе (Clean Air Act), xAI классифицировала турбины — установленные на прицепах — как «двигатели не для передвижения по дорогам» (аналогично строительной технике или генераторам, используемым на временных мероприятиях).
Причины использования лазейки Ограничения энергосети: местная энергосеть Мемфиса не могла сразу обеспечить необходимые 150 мегаватт для питания 100 000 графических процессоров Nvidia H100.
Скорость: стандартное получение разрешений заняло бы месяцы или даже годы. Используя эту лазейку, xAI смогла практически немедленно начать обучение моделей, таких как Grok-3, одновременно с установкой серверных стоек [03:51]. В какой-то момент на площадке одновременно работало до 35 метановых турбин, обеспечивая автономное электропитание.
Недавнее ужесточение регулирования Хотя «лазейка» позволила достичь рекордной скорости строительства, недавно она столкнулась со значительными юридическими трудностями:
Решение Агентства по охране окружающей среды (EPA) (январь 2026 г.): буквально несколько дней назад Агентство по охране окружающей среды (EPA) постановило, что использование xAI этих турбин было незаконным. Агентство уточнило, что турбины, установленные на прицепах, не могут классифицироваться как «двигатели не для передвижения по дорогам» и обязаны соответствовать требованиям Закона о чистом воздухе независимо от их «временного» статуса.
Воздействие на сообщество: местные активисты и такие группы, как NAACP, подали судебные иски, ссылаясь на опасения по поводу выбросов оксидов азота и ухудшения качества воздуха в прилегающих районах Южного Мемфиса.
Текущий статус: xAI частично перешла на использование разрешённого оборудования (в настоящее время эксплуатируются 12 разрешённых турбин), однако новая позиция EPA поставила под вопрос возможность быстрого расширения будущих площадок, таких как «Macrohard», создав правовую неопределённость.
>>1495724 >все знания мира получали на тарелочке ПолучалИ. Случайное биение, отклонение, стохастическая погрешность, которую сейчас на всем белом свете пытаются пофиксить.
>>1495842 ЛЛМ уже натренены с этой информацией, так что проверка невозможна, она просто возьмет решение из памяти. Проверять можно только на нерешенных вещах.
>>1495742 >Для меня, белого человека - повысил. Ты надеешься, что тебе будут БОД платить и наконец свои доходы появятся. Не будут. Ну или настолько мало, что предел мечтаний это жильё в коливинге с десятками двухярусных кроватей в комнатах и какой-то жратвой минимальной нахаляву. Ну и телевидением и игровой приставкой может быть.
Индекс Джини будет только расти, социальное расслоение увеличиваться. Нахлебник, получающий БОД, никогда не будет уважаемым. К нему отношение будет как к нахлебнику, получающему соцпомощь. Он ни для того не нужен. В обычной экономике люди всё-таки нужны, с ними надо считаться, но если ты только получаешь, то ты уже другой социальный класс, дно общества.
>>1495874 >зарплаты хватает Кто тебе её платить будет, если ИИ, способный сделать твою работу непыльной, сможет самостоятельно выполнять эту работу? другой анон
>>1495953 Пока они сбудутся через пару лет, все равно уже местных постеров тут не будет.
А так главное предсказание - в 2027 середина-конец будет ебейший ИИ, AGI уровень или почти около него, теперешние модели в сравнении с ним сасать. Роботы тоже станут сильно умными от этого. Этот ИИ вызовит ебейшую же волну увольнений, потому что сам сможет дофига всего, не будет смысла держать толпу людей на фирмах.
Илон Маск требует с OpenAI 134 миллиарда долларов в качестве «компенсации»
Выяснилось, что в январе миллиардер уже успел подать в федеральный суд США новый иск против его любимчиков OpenAI и Microsoft.
Он утверждает, что обе компании получили «неправомерную прибыль» благодаря его раннему участию в OpenAI, и что они должны вернуть ему эти деньги.
Математика такая:
– В 2015 он помогал основать OpenAI и вложил примерно $38 млн – это примерно 60% начального финансирования.
– Его эксперты утверждают, что за счет этих вкладов (и финансовых, и репутационных) OpenAI получила $65,5–$109,4 млрд «неправомерной прибыли», а Microsoft – $13,3–$25,1 млрд. Эти деньги были получены якобы в обход прав Маска как соучредителя и инвестора.
– Итого общий диапазон требований составляет $79–$134 млрд в зависимости от оценок и модели расчета.
OpenAI уже дала комментарий: они назвали иск несерьезным и окрестили его частью кампании по преследованию стартапа by Mr Musk.
>>1495185 Там как бы в технологические пределы пока уперлись, нанометры тонут, ты в курсе? На данный момент снова к архитектуре шкафов железо разворачивается, как раньше было. Пока не очень заметно, но TDP неплохо об этом сигнализирует. Так что, софт вполне может стать тем, что будет больше профита приносить в графонии по затратам/выхлопу. Конечно, никто не запретит покупать железо хорошее. Но оно конских денег будет стоить и будет энтерпрайзным. А вот нейронки не такие затратные, особенно при отсутствии альтернатив.
>>1491353 >это когда оба субъекта друг друга понимают и могут отвечать друг-другу
Кот в состоянии понять чуть-чуть и чуть-чуть ответить. Нормой для взрослого кота является понимание до 100 слов. Нейронка понимает 0 слов. дело даже не в том, что технология не позволяет. У нейронки просто нет реального опыта, который бы позволил связать слова с чувствами, предметами, явлениями. А у кота такой опыт есть.
Я ему «ты ж моя булочка!» а он выворачивается пузом, потому что знает, что такие слова — маркер моего хорошего отношения и моего желания его потискать.