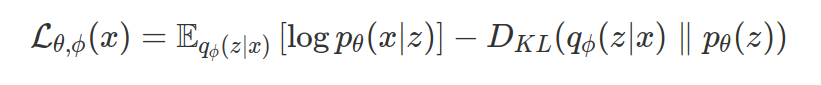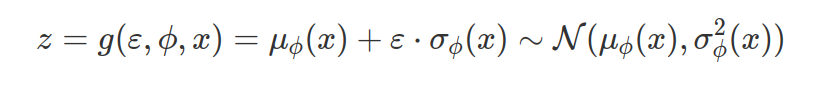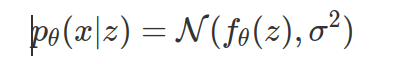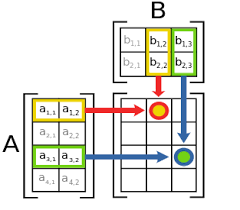


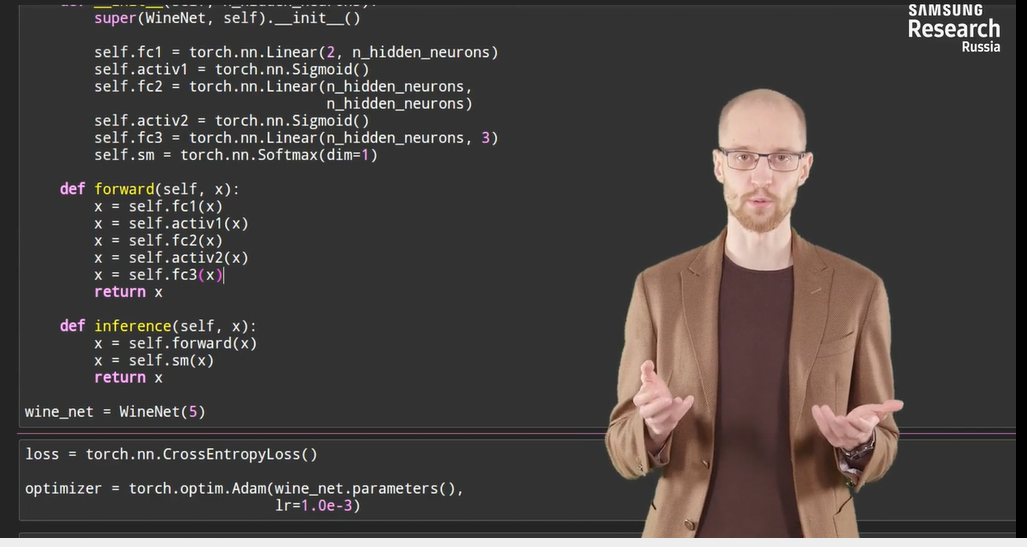
Можете, пожалуйста, дать ссылочку или что-то подобное на готовую нейронку
Biteclipse
02/09/24 Пнд 20:57:47
№
16