Написал пол года назад программу для ардуино , чтоб генерировала фракталы и выводила их на +- распространенный дисплей 1106 . Теперь довел её до ума и подпереписал для базы из джойстика и ещё более распространенного 1306 . Также есть возможность менять параметры фрактала в меню , открывающемся на длинное нажатие на джойстик . Оптимищировал как мог , но быстрее чем на видео оно работать не может - всё таки ардуино для таких задач не предназначено . Но как интересная игрушка - пойдет . Даже есть 5 видов градиента . Кто нибудь пожет подсказать , как перестать упираться в ограничение double , чтоб картинка не пикселезировалась ?? Может посоветуйте библиотеку для работы с длинными после точки дробями ??
>>3539116 Раздражённый он некоторое время обдумывал идею прежде чем с сожалением вздохнуть Думаю тоКроме того Лизелотта изобретательница пасты никогда не называла её спагетти И всё же Латифа посмотрела на него и назвала именно так Она даже умела пользоваться вилкой и ложкой осторожно поднося пасту ко рту гда нам придётся отказаться от этой идеи так что тебе не нужно уч иться
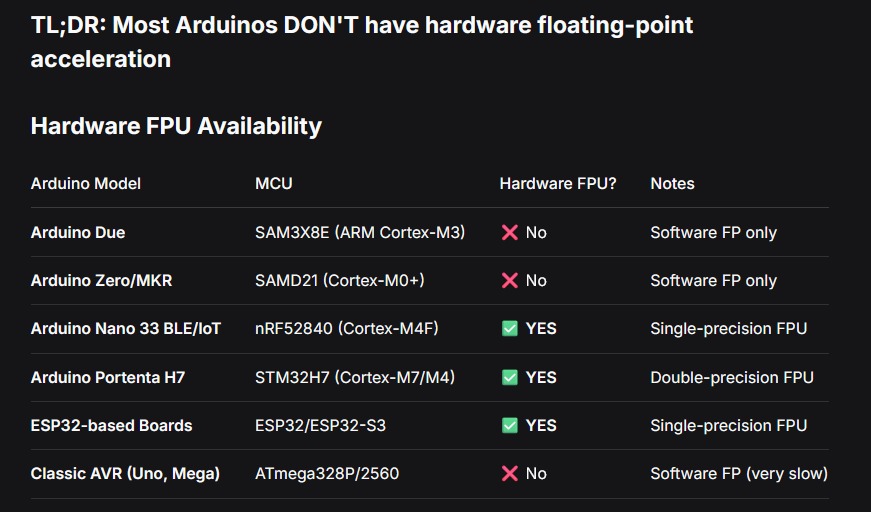
>>3535720 (OP) Используй 64-х битные целые вместо double. Маленькие числа умножай на константу (например 1000000000) чтобы достичь приемлемой точности.
Fast Floating-Point Libraries for ATmega328P (Arduino Uno/Nano) 1. MicroFloat (Arduino's Built-in Optimizations) 2. FastFloat Library 3. QMath Fixed-Point Library (Best for Speed) 4. FPLib - Fastest Pure Float Alternative 5. VFP Math Library
используй специальные либы из этих. Так же введи программные трюки: 1. сначала обсчитывай каждый 2 или 4 пиксель, что ускорит рендер, затем оставшиеся. 2. начинай обсчет следующщих N кадров не дожидаясь повторого нажатия зума. 3. кешируй предыдущий рендер, на тот случай если хочешь изменить направление зума. 4. кешируй N упрощенных предыдущих вычисленных кадров, это которые каждый 2-4 пиксель, ускорит вывод
Так же можно попробовать написать сво wisdom как у fft3, когда вычисленных данных накапливаются. То есть у тебя картинка монохромная, достаточно вычислить черный или белый пиксель, то есть Z(x,y) ={0|1} напипиши функцию, которая останавливает вычисления очередного пикселя, когда становится ясно какого цвета он будет, это на порядок проще. Если есть там какие-то процессорные гиперскалярные конвейеры, можно написать код, которые на уровне предвычислений уже вычисляет в кеше процессора возможные ветвления и их результаты вычислений. Снизь количество ветвлений, чтобы не загрязнять вычисления ветвлений. Сейчас большинство MPU имеют какие-никакие скалярные конвейнеры.
еще 1. снизь количество копирований данных в памяти, лишних ветвлений, дальних прыжков за сегмент. far jump вещь занимает на порядок больше времени, чем перекат внутри сегмента. 2. реализуй ленивый вывод на экран, не по пикселю, из фреймбуфера, так же блоками. 3. например, используй пересылку любых данных блоками за раз, есть инструкции, котоые позволяют делать это за меньшее количество тактов, что ускорит ввод-вывод. Оптимизировать еще дохрена, мой падаван.
так же забыл написать, вычисляй не каждый пиксель, а dither матрицу 2х2 с градациями серого, будет выглядель дешевле, зато с градиентом. [0x] [x1] типа такого, х - будешь вычислять на основе смежных пикселей.