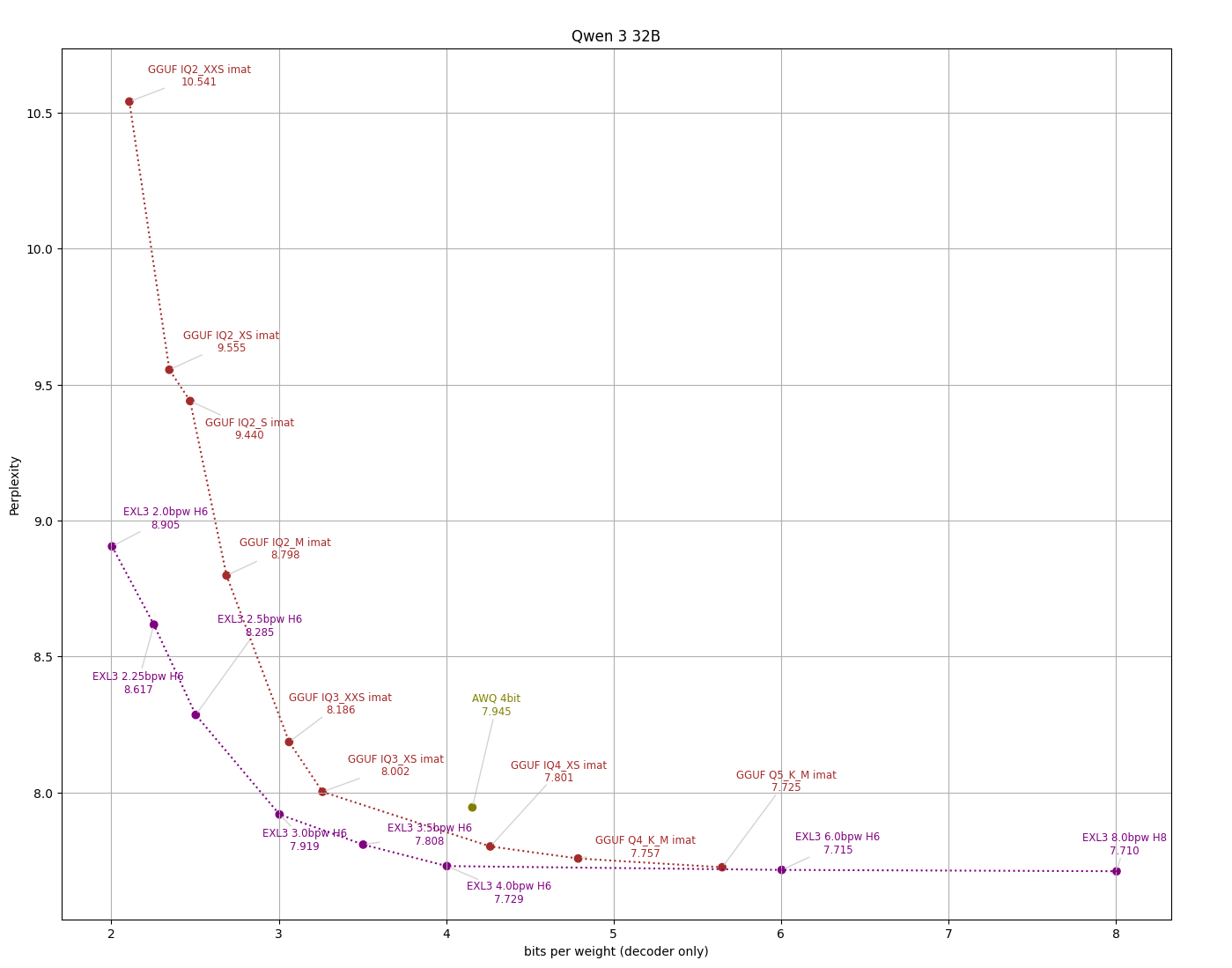
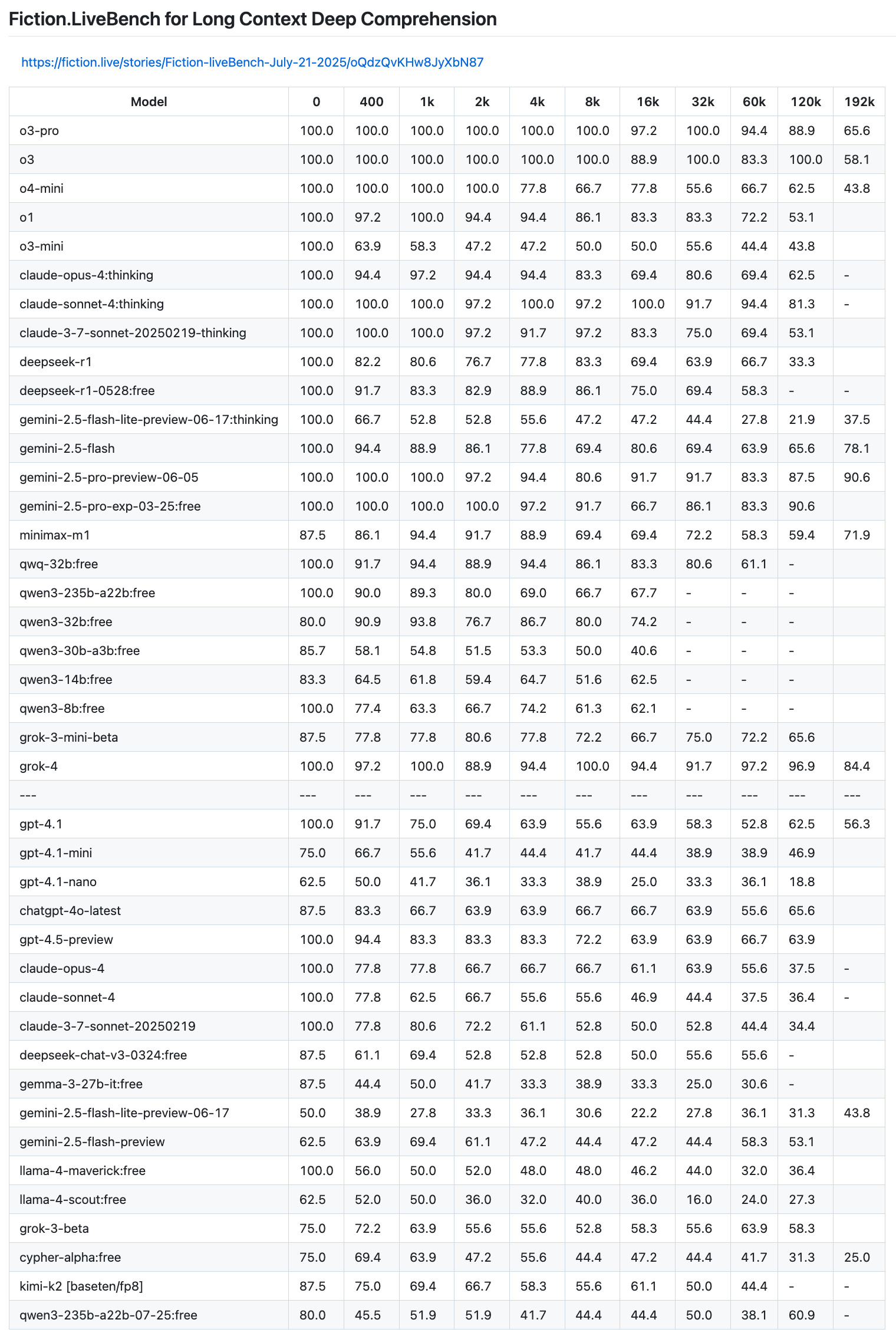
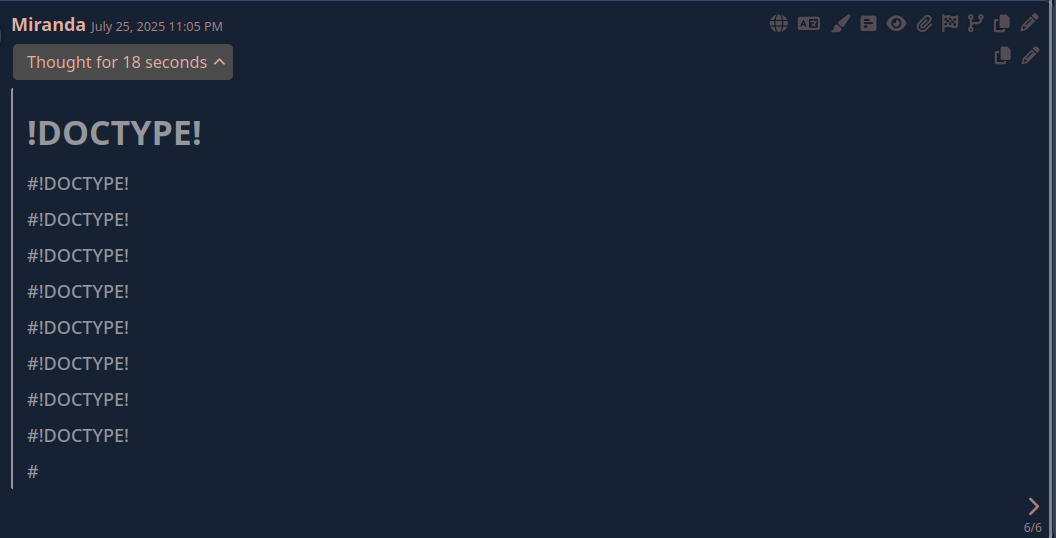
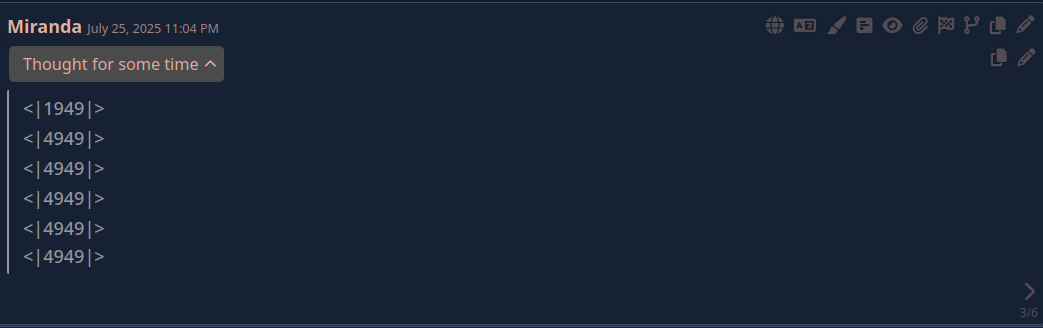
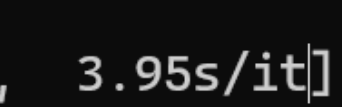
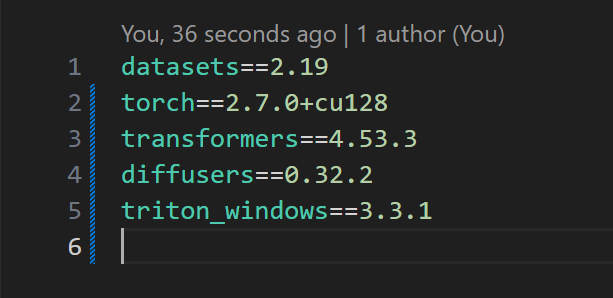
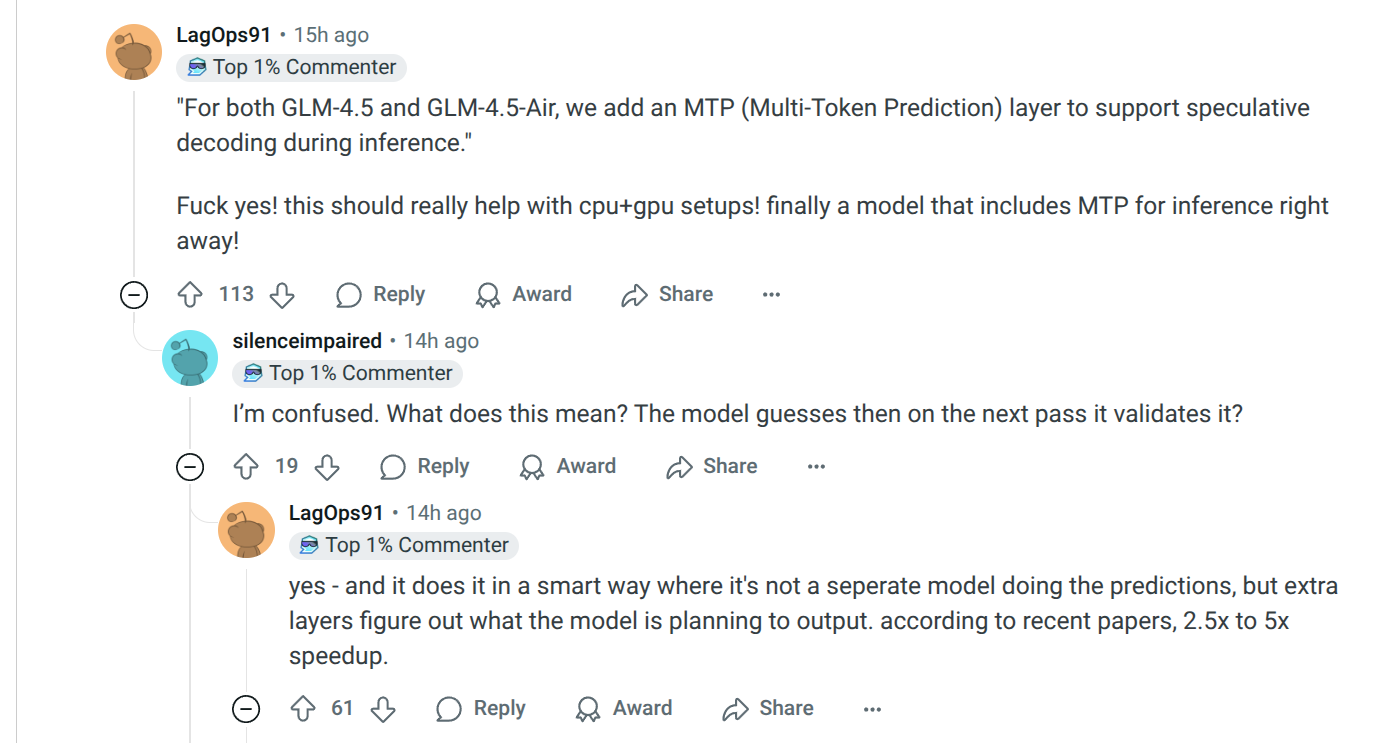
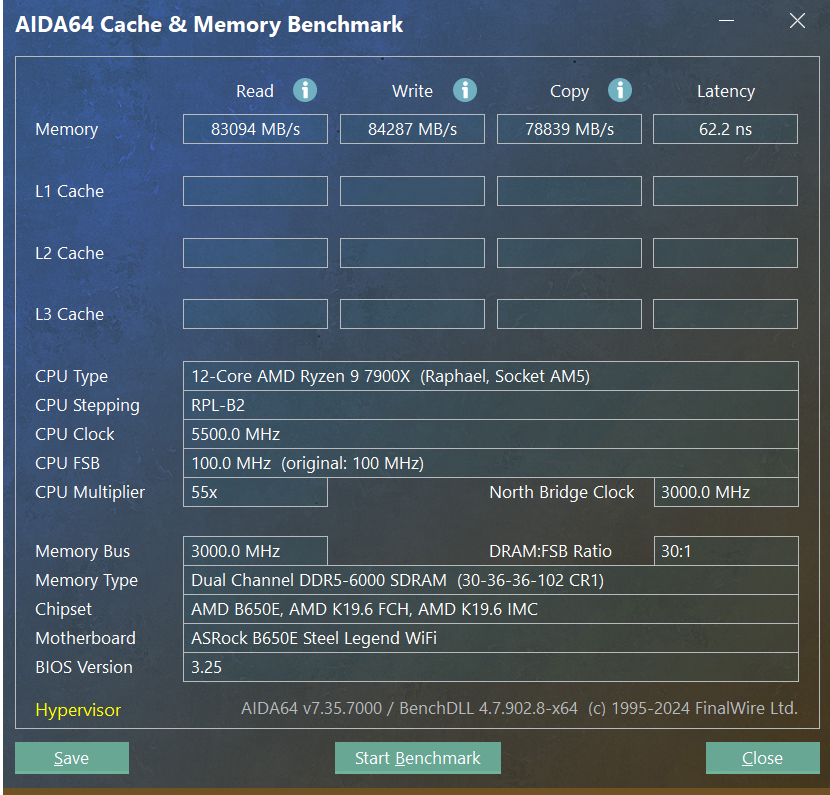
Локальные языковые модели (LLM): LLaMA, Gemma, DeepSeek и прочие №150 /llama/
Аноним
25/07/25 Птн 19:56:56
№
1