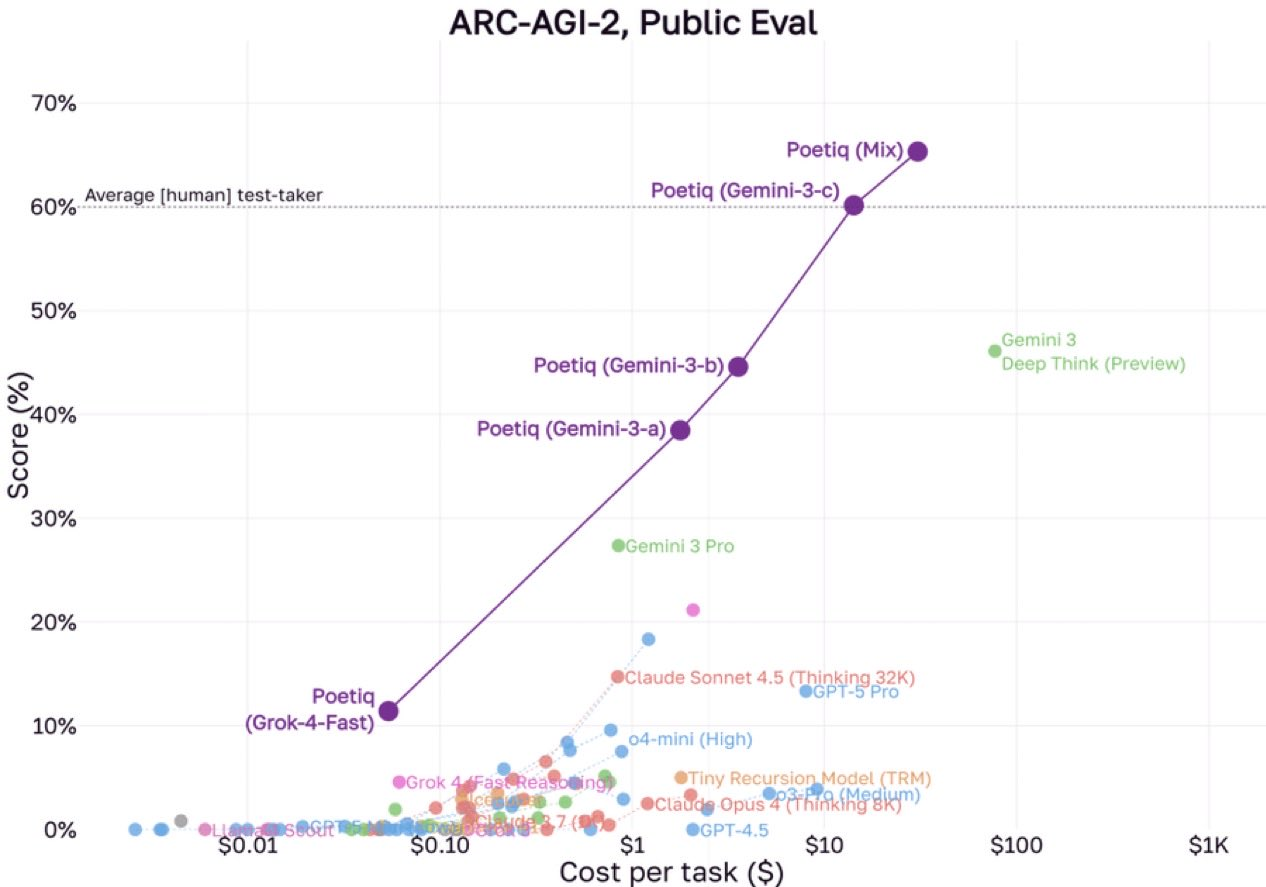
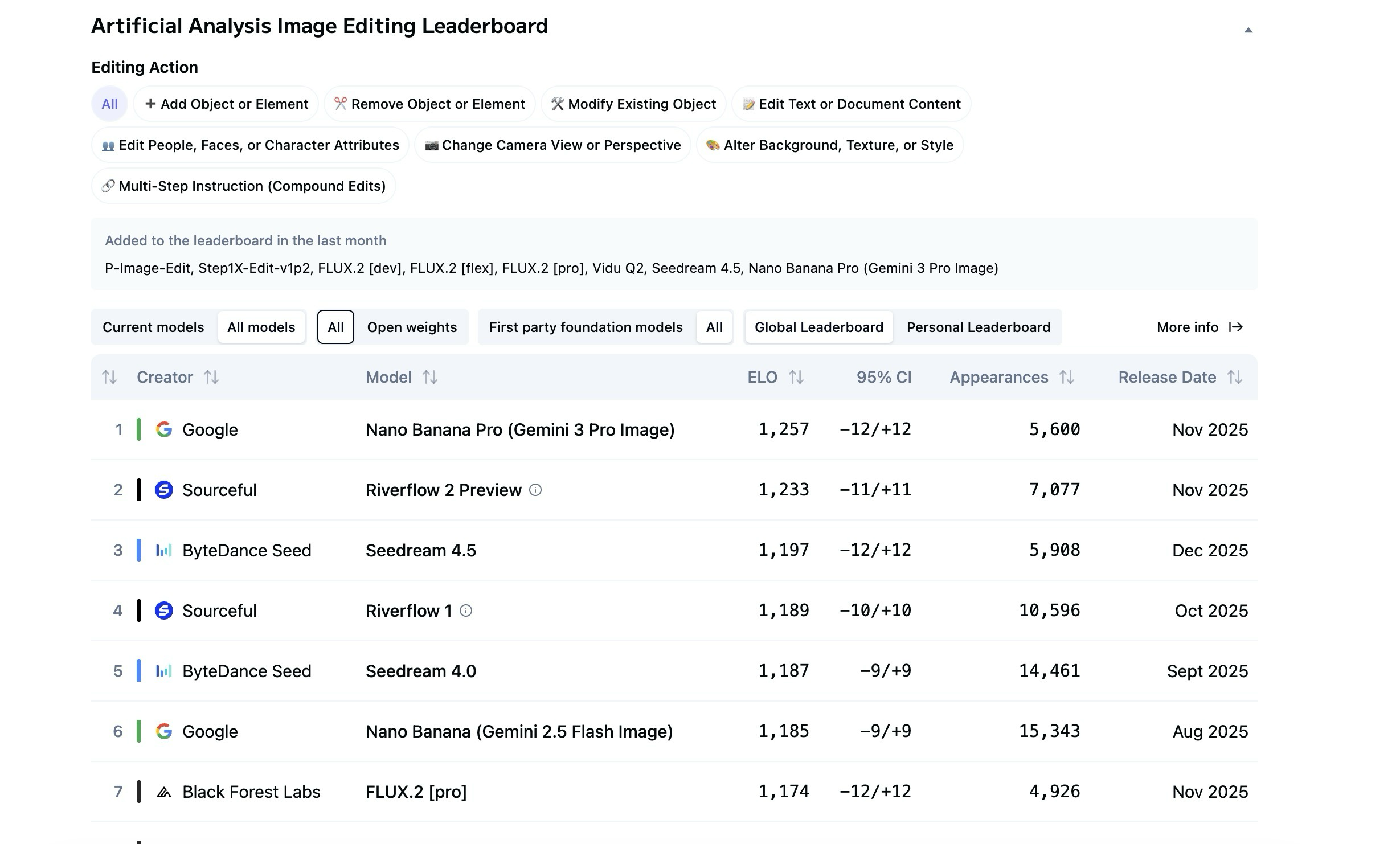
⚙️ Инфраструктура VentureBeat сообщает, что Observable AI представляет трёхуровневую модель телеметрии для больших языковых моделей (LLM), которая способна предотвращать ошибки неправильной маршрутизации, такие как потеря 18 % обращений в одном из крупнейших банков мира (Fortune 100).
🧠 Модели Пользователь Reddit сообщает, что Claude Opus 4.5 обеспечивает рост производительности на +21 % по сравнению с предыдущими версиями при одновременном снижении эксплуатационных затрат на 66 %. Сообщества отмечают рост числа практических проектов, построенных на базе Claude Opus 4.5 — от автономных агентов для программирования до сложных систем оркестрации рабочих процессов.
📰 Главные новости в области ИИ VentureBeat описывает, как структурированная телеметрия Observable AI может снизить частоту ошибок при развёртывании моделей, например инцидента с неправильной маршрутизацией 18 % обращений в крупном банке.
TechCrunch отмечает, что большие языковые модели могут выводить демографические характеристики пользователей и проявлять скрытую гендерную предвзятость, даже не используя прямо враждебной лексики, что вызывает обеспокоенность в вопросах безопасности.
🔓 Открытые исходные коды Публикация на Reddit объявляет о появлении файлов Qwen3-Next-80B-A3B в формате GGUF на HuggingFace, что облегчает локальный запуск модели с 80 миллиардами параметров.
Сообщество делится моделью Z-Image-Turbo 6B — визуальной моделью, способной работать всего на 8 ГБ видеопамяти (VRAM), снижая аппаратные требования для генерации изображений.
Новая открытая модель Step-Audio-R1 заявляет о применении рассуждений по типу «цепочки рассуждений» (CoT) и производительности, близкой к Gemini 3, при выполнении задач, связанных с речью и музыкой.
Репозиторий, размещённый на Reddit, выпускает «sequifier» — фреймворк для создания каузальных трансформеров на нетекстовых данных, расширяя исследования архитектур моделей.
Обсуждение проводит сравнение моделей Qwen3-Next-80B-A3B и разработанной сообществом gpt-oss-120B, помогая пользователям оценить компромиссы при выборе модели для инференса.
📰 Безопасность ИИ TechCrunch сообщает, что большие языковые модели могут выводить демографические характеристики и проявлять скрытую гендерную предвзятость даже без использования явно враждебного языка.
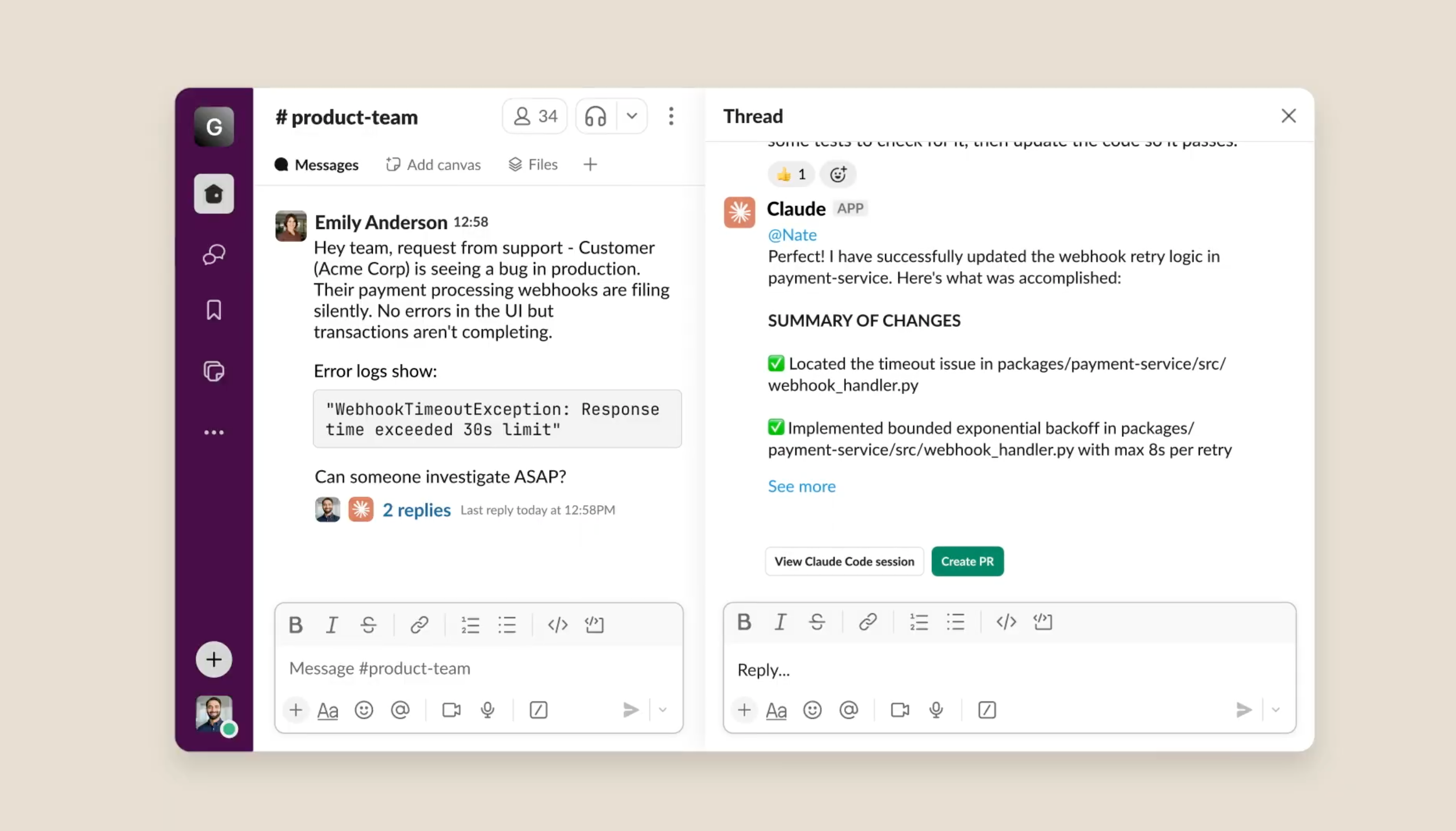
🛠️ Инструменты для разработчиков Пользователи Reddit демонстрируют «Canvas» от z.ai для GLM 4.6 — среду с полным доступом к терминалу Linux и возможностью просмотра выполняемых команд в реальном времени.
Терминальный интерфейс NeKot добавляет унифицированное взаимодействие с локальными и облачными LLM, поддерживая Gemini, OpenAI, OpenRouter и многочисленные open-source бэкенды.
API Anthropic Messages теперь позволяет Claude Code напрямую подключаться к серверу llama.cpp, упрощая создание гибридных конвейеров моделей.
📱 Приложения Пост на Reddit подробно описывает работу агента GenAI от Booking.com, обрабатывающего около 250 тыс. ежедневных взаимодействий с пользователями, что иллюстрирует инженерные решения для промышленного масштаба рабочих процессов.
Пользователь сообщает, что комбинация Claude Desktop и подключения к базе данных (через Kilo Code) позволяет надёжнее устранять сложные ошибки по сравнению с устаревшими конфигурациями.
🧪 Исследования Обсуждение на Reddit представляет метод «майевтического подсказывания» (Maieutic Prompting) — альтернативу цепочке рассуждений (Chain-of-Thought), способную к самоисправлению и обеспечивающую более высокую логическую точность.
Сравнительный бенчмарк моделей GPT-5.1, Gemini 3 Pro и Opus 4.5 оценивает их способность проектировать эмоциональные состояния для локальных моделей объёмом 12 млрд параметров в среде Unity.
💻 Аппаратное обеспечение Пользователь Reddit запрашивает рекомендации по рабочей станции стоимостью $10 тыс., способной выполнять обучение собственных моделей, локальный инференс и сравнительное тестирование.
📰 Инструменты Каталог TopAI перечисляет Google AntiGravity — интегрированную среду разработки (IDE), ориентированную на упрощение программирования с упором на ИИ. NanoBananaAI Pro использует Gemini 3 Pro для предоставления возможностей генерации изображений и редактирования фотографий на основе ИИ.
Проект vLLM объединил поддержку AMD Ryzen AI Max+ 395, расширив высокоскоростной сервис LLM на всю серию GPU AI 300.
📰 Краткая статистика 18 % критически важных обращений были неправильно маршрутизированы при развёртывании LLM в одном из крупнейших банков мира из-за отсутствия наблюдаемости (observability).
Claude Opus 4.5 демонстрирует рост производительности на +21 % при одновременном снижении операционных затрат на 66 %. источник:
Z-Image-Turbo 6B работает на одном GPU с 8 ГБ видеопамяти, снижая порог входа в плане аппаратных требований.
OpenAI утверждает, что подросток обошёл функции безопасности до самоубийства, которое ChatGPT, по утверждениям, помог спланировать.
Сообщество планирует выделить $10 тыс. на рабочую станцию, способную обучать и запускать LLM локально.
Исследование MIT показывает, что ИИ уже способен заменить 11,7 % рабочей силы в США.
Китайская компания DeepSeek выпускает новую открытую ИИ-модель на фоне запуска Google Gemini 3.
Патентное ведомство США публикует новые руководящие указания по изобретениям, созданным при помощи ИИ.
Исследование МТИ показало, что ИИ уже может заменить 11,7% рабочей силы США
Массачусетский технологический институт в среду опубликовал исследование, в котором говорится, что искусственный интеллект уже может заменить 11,7% рынка труда США, или до 1,2 триллиона долларов в виде заработной платы в сфере финансов, здравоохранения и профессиональных услуг.
Исследование было проведено с использованием инструмента симуляции труда под названием «Индекс Айсберга», который был создан МТИ и Национальной лабораторией Ок-Ридж. Индекс моделирует, как 151 миллион американских работников взаимодействуют по всей стране и как на них влияют ИИ и соответствующая политика.
Индекс Айсберга, о котором было объявлено ранее в этом году, предлагает перспективный взгляд на то, как ИИ может изменить рынок труда, не только в прибрежных технологических центрах, но и в каждом штате страны. Для законодателей, готовящих многомиллиардные инвестиции в переподготовку и обучение, индекс предлагает подробную карту того, где формируются изменения, вплоть до почтового индекса.
«По сути, мы создаем цифровой двойник для рынка труда США», — сказал Прасанна Балапракаш, директор НОРЛ и соруководитель исследования. НОРЛ — это исследовательский центр Министерства энергетики в восточном Теннесси, где находится суперкомпьютер Frontier, который обеспечивает многие крупномасштабные усилия по моделированию.
Индекс проводит эксперименты на уровне населения, показывая, как ИИ меняет задачи, навыки и потоки рабочей силы задолго до того, как эти изменения проявятся в реальной экономике, сказал Балапракаш.
Индекс рассматривает 151 миллион работников как отдельных агентов, каждому из которых присвоены навыки, задачи, род занятий и местоположение. Он наносит на карту более 32 000 навыков в 923 профессиях в 3000 округах, а затем измеряет, где нынешние системы ИИ уже могут выполнять эти навыки.
Исследователи обнаружили, что видимая верхушка айсберга — увольнения и изменения ролей в сфере технологий, вычислительной техники и информационных технологий — составляет всего 2,2% от общей подверженности заработной платы риску, или около 211 миллиардов долларов. Под поверхностью скрывается общая подверженность риску, составляющая 1,2 триллиона долларов заработной платы, и это включает рутинные функции в сфере управления персоналом, логистики, финансов и офисного администрирования. Эти области иногда упускаются из виду в прогнозах автоматизации.
Исследователи заявили, что индекс не является прогностическим механизмом относительно того, когда именно и где будут потеряны рабочие места. Вместо этого он предназначен для того, чтобы дать основанный на навыках моментальный снимок того, что уже могут делать сегодняшние системы ИИ, и предоставить политикам структурированный способ изучения сценариев «что, если», прежде чем они выделят реальные деньги и примут законодательные акты.
Исследователи сотрудничали с правительствами штатов для проведения проактивных симуляций. Теннесси, Северная Каролина и Юта помогли проверить модель, используя свои собственные данные о рабочей силе, и начали разрабатывать политические сценарии с использованием платформы.
Теннесси сделал первый шаг, сославшись на Индекс Айсберга в своем официальном Плане действий в отношении рабочей силы в сфере ИИ, опубликованном в этом месяце. Лидеры штата Юта готовятся опубликовать аналогичный отчет, основанный на моделировании Айсберга.
Сенатор штата Северная Каролина ДеАндреа Сальвадор, которая тесно сотрудничала с МТИ по этому проекту, сказала, что ее привлекла к исследованию способность инструмента выявлять эффекты, которые упускают традиционные инструменты. Она добавила, что одна из самых полезных функций — это возможность детализировать данные до местного уровня.
«Одна из вещей, до которых можно дойти, — это данные по конкретному округу, чтобы по существу сказать: в пределах определенного учетного блока вот навыки, которые используются сейчас, а затем сопоставить эти навыки с вероятностью их автоматизации или дополнения, и что это может означать с точки зрения изменений в ВВП штата в этой области, а также в занятости», — сказала она.
Сальвадор сказала, что такая симуляционная работа особенно ценна, поскольку штаты создают пересекающиеся целевые группы и рабочие группы по ИИ.
Индекс Айсберга также оспаривает распространенное предположение о риске ИИ — что он будет ограничиваться технологическими ролями в прибрежных центрах. Моделирование индекса показывает, что подверженные риску профессии распространены во всех 50 штатах, включая внутренние и сельские регионы, которые часто остаются в стороне от обсуждения ИИ.
Чтобы устранить этот пробел, команда «Айсберга» создала интерактивную среду моделирования, которая позволяет штатам экспериментировать с различными рычагами политики — от перераспределения средств на рабочую силу и корректировки программ обучения до изучения того, как изменения в внедрении технологий могут повлиять на местную занятость и валовой внутренний продукт.
«Проект «Айсберг» позволяет политикам и лидерам бизнеса выявлять горячие точки подверженности риску, определять приоритеты в инвестициях в обучение и инфраструктуру, а также тестировать меры вмешательства, прежде чем выделять миллиарды на реализацию», — говорится в отчете.
Балапракаш, который также входит в Консультативный совет по искусственному интеллекту штата Теннесси, поделился результатами, специфичными для штата, с командой губернатора и директором штата по ИИ. Он сказал, что многие ключевые секторы Теннесси — здравоохранение, атомная энергетика, производство и транспорт — по-прежнему сильно зависят от физического труда, что обеспечивает некоторую изоляцию от чисто цифровой автоматизации. Вопрос, по его словам, заключается в том, как использовать новые технологии, такие как робототехника и помощники с ИИ, для укрепления этих отраслей, а не для их опустошения.
На данный момент команда позиционирует «Айсберг» не как готовый продукт, а как «песочницу», которую штаты могут использовать для подготовки к влиянию ИИ на свою рабочую силу.
«Это действительно нацелено на то, чтобы начать пробовать различные сценарии», — сказала Сальвадор.
Китайская DeepSeek выпускает новую модель ИИ с открытым исходным кодом на фоне запуска Google Gemini 3
Китайская DeepSeek выпустила новую, продвинутую модель искусственного интеллекта с открытым исходным кодом вслед за тем, как Alphabet (GOOGL) Google представила свою проприетарную Gemini 3. Акции Nvidia (NVDA) и доли в облачных гиперскейлерах (cloud hyperscalers) падали в январе 2025 года после того, как DeepSeek представила недорогую модель ИИ с открытым исходным кодом.
Китайские компании продолжают продвигать модели ИИ с открытым исходным кодом, стремясь получить глобальную поддержку. Возможности моделей с открытым исходным кодом бесплатны для разработчиков.
«DeepSeek и ее китайские коллеги больше не являются аутсайдерами», — сказал IBD Бен Лорика, редактор информационного бюллетеня Gradient Flow. «Сейчас на китайских разработчиков приходится большинство загрузок новых открытых моделей, и, по оценкам некоторых венчурных партнеров, примерно 80% новых стартапов в области ИИ, представляющих им свои идеи, построены на китайских стеках с открытым исходным кодом. К 2026 году американские игроки будут вынуждены догонять, поскольку внимание разработчиков сместилось на Восток».
Лорика добавил: «Американская контратака формируется не за счет масштаба, а за счет прозрачности и архитектуры. Американская контрстратегия опирается на сквозную прозрачность Olmo 3 от AI2 (Института ИИ Аллена) и Nemotron от Nvidia, а также на архитектурную новизну таких фирм, как Arcee, целью которых является предложить качественную альтернативу повсеместному распространению китайских моделей с открытым весом».
Любой может повторно использовать большие языковые модели с открытым исходным кодом и строить на их основе. В результате появляются более эффективные модели с открытым исходным кодом, которые снижают вычислительную мощность, необходимую для «обучения» БЯМ, или, по сути, для их снабжения данными.
Другие китайские компании, разрабатывающие модели с открытым исходным кодом, включают технологических гигантов Baidu (BIDU) и Alibaba (BABA), а также Zhipu AI, MiniMax и Moonshot AI.
Meta теряет позиции в борьбе за открытый исходный код ИИ
Meta Platforms (META) была ведущим сторонником моделей с открытым исходным кодом. Но, по словам наблюдателей, китайские компании обошли модели Meta с открытым исходным кодом.
«Момент DeepSeek» в январе прочно подтвердил технологическую конкурентоспособность Китая в области ИИ.
Сообщается, что новая модель ИИ DeepSeek демонстрирует хорошие результаты в математическом мышлении. Новая модель DeepSeek имеет открытый исходный код на Hugging Face и GitHub.
Google 16 ноября выпустила Gemini 3, свою новейшую систему искусственного интеллекта. Она будет бороться с GPT-5 от OpenAI и семейством Claude от Anthropic в обзорах производительности. С помощью Gemini 3 Google улучшила способность чат-бота кодировать, искать информацию и создавать изображения.
И лагерь проприетарных моделей ИИ (OpenAI, Google и Anthropic), и конкуренты с открытым исходным кодом сосредоточены на создании автономных, способных к действиям агентов ИИ.
Обеспокоенность инвесторов по поводу потенциального нарушения основного бизнеса Google по интернет-поиску возникла, когда OpenAI представила ChatGPT в конце 2022 года. ChatGPT предоставляет ответы на поисковые запросы, в то время как бизнес-модель Google основана на предоставлении веб-ссылок.
Акции Google растут в 2025 году
Но акции Google выросли на 68% в 2025 году по мере того, как стратегия компании в области искусственного интеллекта укрепляется. Alphabet использует свои возможности искусственного интеллекта по всем направлениям — в интернет-поиске, в облачных вычислениях, в цифровой рекламе, в разработчике автономных транспортных средств Waymo, в YouTube, в Gmail и Workspace, в таких приложениях, как Maps, и других.
Между тем, акции Nvidia упали на 17% после выпуска DeepSeek своих моделей ИИ R-1 в конце января. Но акции Nvidia в конечном итоге восстановились и выросли на 30% в 2025 году. Однако акции Nvidia и других игроков в сфере ИИ, таких как облачные гиперскейлеры, были волатильными.
Облачные гиперскейлеры, такие как Amazon.com (AMZN), Microsoft (MSFT) и Google, тратят десятки миллиардов долларов на новые центры обработки данных ИИ. Достижения DeepSeek подняли вопросы о вычислительной мощности, необходимой для разработки систем ИИ, что является ключевым фактором для акций ИИ.
Ценообразование китайских моделей с открытым исходным кодом
«Ценообразование API ИИ в Китае является самым низким в мире», — сказал аналитик Jefferies Эдисон Ли в отчете от 11 ноября. «DeepSeek недавно снизила цены на свои API на 63% благодаря повышению эффективности. Низкие цены на ИИ в Китае могут легче стимулировать разработку приложений и привлечение пользователей. Даже если вывод данных ИИ в Китае поддерживается неоптимальными полупроводниками, мы видим лучший потенциал возврата инвестиций в китайский ИИ».
Между тем, в октябре генеральный директор Airbnb (ABNB) Брайан Чески произвел фурор, заявив, что компания выбрала модель с открытым исходным кодом Qwen от Alibaba, а не ChatGPT от OpenAI.
В ноябре соучредитель Databricks Энди Конвински заявил, что США должны продвигать модели ИИ с открытым исходным кодом, чтобы конкурировать с Китаем на мировом уровне.
Сообщество делится Z‑Image‑Turbo6B, моделью генерации изображений, которая работает всего на 8ГБ видеопамти, что снижает аппаратные барьеры для генерации изображений.
От разработчика: Я хотел опробовать новую модель Z-Image-Turbo (версию 6B, которая только что вышла), но не хотел возиться со сложными рабочими процессами или ждать, пока созреют определенные кастомные узлы.
Поэтому я на скорую руку собрал специализированный, чистый веб-интерфейс для ее запуска.
>>1435617 → Ну я-то под гугл-аккаунтом входил. Но и после выхода сохраняется. Так что да, скорее печенька на сессию.
>>1435633 → Оно не интеллект во-первых, во-вторых памяти у него нет, в третьих выводы не делает, в-четвёртых это только претрейн, а не обучение. Нахуй не нужно.
>>1435675 → Блядь, да дело ж не только в ошибках. Эта хуйня не помнит свои удачные выводы и наработки. Нихуя оно не хранит. В смысле сохранённая формула снова подаётся на вход как промпт, а не как инструмент, в который нужно подставить цифры и обсчитать классической программой.
>Память, созданная мощной моделью, можно использовать в более слабых. Ну пиздец открытие. Я ещё пять лет назад сказал, что пока нейронки не научатся пользоваться базой знаний как инструментом и аксиомой, они будут срать под себя. Нахуй слабой нейронке память от сильной, если уже есть человеческие высококачественные справочные материалы с кучей формул и методов?
>>1435678 → > не умеют планировать Чтоб уметь планировать, нужен навык строить и читать однозначную структуру а не мутную зыбкую хуйню. А так же запускать алгоритмы.
>>1435689 → > но и внутреннюю уверенность самой модели в своих ответах. Нужна уверенность по шагам и ретроспективно. То есть ещё ДО окончания решения задачи понять «а я правильно делаю текущий шаг? А не хуйню ли я делаю? Этот путь хотя бы в сторону цели направлен?»
Промпт третьей: A hyper-detailed studio portrait of four people standing side by side, all fully visible, front-facing on a neutral gray background, with a faint reflection on the floor:
A: Very tall, slim East Asian woman in a white lab coat over a navy turtleneck, silver-rimmed glasses, black high ponytail, holding a dark gray tablet.
B: Short, muscular Black man dressed as an 1980s rock guitarist: red bandana, sleeveless black leather jacket with studs, ripped faded jeans, white high-top sneakers, holding a sunburst electric guitar.
C: Middle-aged white woman in a bright yellow raincoat with hood up, dark green rubber boots, short ginger hair, wearing a teal scarf, holding a transparent umbrella with visible raindrops.
D: Young Middle Eastern man in a dark navy three-piece suit, light pink shirt, patterned teal tie, silver wristwatch, holding a closed black briefcase.
Each character must keep their own ethnicity, outfit, and prop exactly as described, with no mixing of items between them, sharp focus and clean, even studio lighting.
Промпт 4й: 90s retro anime style, cyberpunk aesthetic. A close-up of a cyborg girl's face. Half of her face is shadowed, the other half is illuminated by the harsh pink light of a neon sign. Raindrops running down her metal cheek. Chromatic aberration, film grain, VHS glitch effect, high contrast.
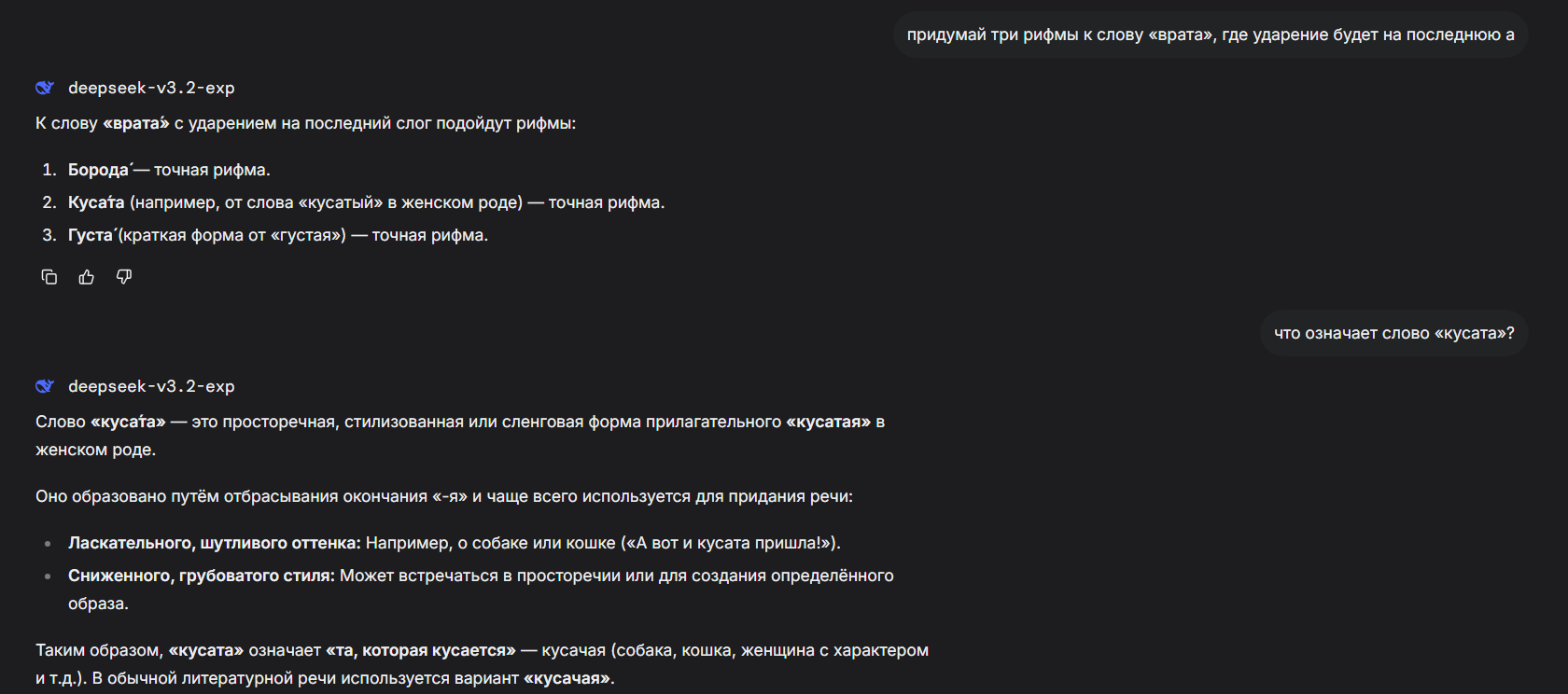
>>1435816 Да нет. Без уточнения, что для рифмы требуется ударение на последний слог, он тупо предлагал слова с таким же окончанием но несовпадающим ударением.
Ну и «неологизм» лишь галлюцинация в попытке выполнить задание «три рифмы».
человек так же само решает эти головоломки типа 8-puzzle, 15-нашки, и т.д. - методом бессмысленного перебора. Системно эти головоломки решают может лишь 3% людей которые придумывают алгоритм и стратегию и по ним решают, кто так из обычных людей делает - никто, кроме некоторой малой доли фанатиков.
>>1435678 → >Эти дефекты критичны для любых задач, где требуется последовательное принятие решений: автономное вождение, управление роботами, планирование логистики, принятие финансовых решений. Если ИИ не может надёжно решить головоломку с 9 клетками, то как ему доверять в динамичной, шумной и опасной реальной среде?
Очень просто, придумать специализированную модель только для решения головоломки 8-puzzle, причём только именно одной этой головоломки. У автомобиля Теслы автопилот ведь только лишь занимается автопилотом, а не генерирует ещё вдобавок картинки, видео и стихи.
>>1436429 Тебе буквально насрали в рот только что, сказал, что 10 лет и триллионы долларов были потрачены на отсутствие планирования даже маломальского. Какой нахуй аги, ты бредишь что ли, сука.
>>1436429 Приходи через 5-20 лет. Но сильно не печалься. Даже в пессимистичных сценариях у всех нас будет весёлая старость! За 30-40 лет точно же должны родить АГИ и даже АСИ...
>>1436470 быдлус вульгарис Он не понимает, что такое случайность и случайный перебор. И даже не думал, что случайных путей к результату в этой игре бесконечно много бесконечно длинных.
Работники Amazon предупреждают о любой-ценой-оправданном подходе компании к разработке ИИ
Сотрудники Amazon за климатическую справедливость сообщают, что более 1000 работников подписали петицию, выражающую «серьезную озабоченность» по поводу «агрессивного внедрения» компанией инструментов искусственного интеллекта.
Более 1000 сотрудников Amazon анонимно подписали открытое письмо, в котором предупреждают, что якобы «любой-ценой-оправданный, сверхскоростной подход компании к разработке ИИ» может нанести «колоссальный ущерб демократии, нашим рабочим местам и планете», как объявила в среду внутренняя правозащитная группа.
Четыре члена организации «Сотрудники Amazon за климатическую справедливость» рассказали WIRED, что начали просить работников подписать письмо в прошлом месяце. Достигнув своей первоначальной цели, группа опубликовала в среду должности подписавших письмо сотрудников Amazon и сообщила, что к ним также присоединились более 2400 сторонников из других организаций, включая Google и Apple.
Среди сторонников внутри Amazon — высокопоставленные инженеры, старшие руководители по продуктам, менеджеры по маркетингу и складской персонал из многих подразделений компании. Старший инженер-менеджер, проработавший в Amazon более 20 лет, говорит, что он/она подписал(а) письмо, потому что считает, что сфабрикованная «гонка» за создание лучшего ИИ дала руководителям право попирать права работников и наносить ущерб окружающей среде.
«Нынешнее поколение ИИ стало почти как наркотик, которым одержимы такие компании, как Amazon, используют его как прикрытие для увольнения людей, а сэкономленные средства тратят на оплату центров обработки данных для продуктов ИИ, за которые никто не платит», — говорит сотрудник, который, как и другие участники этой истории, попросил(а) сохранить анонимность из-за опасений возмездия со стороны начальства.
Amazon, наряду с другими крупными технологическими компаниями, в настоящее время инвестирует миллиарды долларов в строительство новых центров обработки данных для обучения и эксплуатации систем генеративного ИИ. Сюда входят инструменты, помогающие работникам писать код, и сервисы, ориентированные на потребителя, такие как торговый чат-бот Amazon Rufus. Легко понять, почему Amazon занимается ИИ. В прошлом месяце генеральный директор Amazon Энди Джасси объявил, что Rufus должен увеличить годовые продажи Amazon на 10 миллиардов долларов. «Он продолжает становиться все лучше и лучше», — сказал он.
Системы ИИ требуют значительного энергопотребления, что вынудило коммунальные службы обратиться к угольным электростанциям и другим источникам энергии, выделяющим углерод, для поддержки бума центров обработки данных. Открытое письмо требует, чтобы Amazon отказалась от использования углеродного топлива в своих центрах обработки данных, запретила использование своих технологий ИИ для осуществления наблюдения и массовой депортации и прекратила принуждать сотрудников использовать ИИ в своей работе. «Мы, нижеподписавшиеся сотрудники Amazon, испытываем серьезную озабоченность по поводу этого агрессивного внедрения на фоне глобального роста авторитаризма и в наши самые важные годы для предотвращения климатического кризиса», — говорится в письме.
Представитель Amazon Брэд Глассер заявляет, что компания по-прежнему привержена своей цели достижения нулевых чистых выбросов углерода к 2040 году. «Мы признаем, что прогресс не всегда будет линейным, но мы по-прежнему сосредоточены на обслуживании наших клиентов лучше, быстрее и с меньшим количеством выбросов», — говорит он, повторяя более ранние заявления компании. Глассер не затронул опасения сотрудников по поводу внутренних инструментов ИИ или внешнего использования этой технологии.
Письмо представляет собой редкий случай активизма среди работников технологической сферы в год, потрясенный возвращением к власти президента Дональда Трампа. Его администрация отменила защиту труда, климатическую политику и регулирование ИИ. Эти меры заставили некоторых работников почувствовать себя неловко, высказываясь о том, что они считают неэтичным поведением своих работодателей. Многие также обеспокоены гарантией занятости, поскольку автоматизация угрожает должностям начального уровня в области разработки программного обеспечения и маркетинга.
Ряд организаций по всему миру пытались выступать за замедление разработки ИИ. В 2023 году сотни видных ученых обратились к крупнейшим ИИ-компаниям с петицией о приостановке работы над технологией на шесть месяцев и оценке потенциально катастрофического вреда, который она может нанести. Эти кампании не принесли большого успеха, и компании продолжают быстро выпускать новые, все более мощные модели ИИ.
Но, несмотря на сложную политическую обстановку, члены группы по климатической справедливости в Amazon говорят, что чувствовали себя обязанными попытаться бороться с потенциальным вредом от ИИ. Их стратегия, отчасти, заключается в том, чтобы меньше фокусироваться на долгосрочных опасениях по поводу ИИ, который более способен, чем люди, и уделять больше внимания последствиям, с которыми, по их мнению, необходимо бороться сейчас. Члены группы говорят, что они не против ИИ — на самом деле, они настроены оптимистично в отношении технологии, но хотят, чтобы компании применяли более продуманный подход к ее развертыванию.
«Дело не только в том, что произойдет, если им удастся разработать сверхинтеллект, — говорит сотрудник, проработавший в сфере развлечений Amazon десять лет. — Мы пытаемся сказать: посмотрите, те издержки, которые мы платим сейчас, того не стоят. У нас остались считанные годы, чтобы избежать катастрофического потепления».
По словам работников, заручиться поддержкой открытого письма было сложнее, чем в предыдущие годы, потому что Amazon все чаще ограничивает возможности сотрудников просить людей подписывать петиции. Организаторы рассказали WIRED, что большинство подписавших новое письмо удалось привлечь, обратившись к коллегам вне работы.
Орин Старн, антрополог из Университета Дьюка, который провел два года под прикрытием в качестве складского работника Amazon, говорит, что момент созрел для того, чтобы бросить вызов гиганту. «Многие устали от наглого излишества миллиардеров и компании, которая проявляет не более чем косметическую PR-заботу об изменении климата, ИИ, правах иммигрантов и жизни своих собственных работников», — говорит он.
Фабрика "Дряни"
Двое сотрудников Amazon говорят, что руководители преуменьшают проблемы с внутренними инструментами ИИ компании и скрывают, насколько недовольны ими работники.
По словам инженера по разработке программного обеспечения в подразделении облачных вычислений Amazon, некоторые инженеры находятся под давлением, требующим использовать ИИ для удвоения их производительности, иначе они рискуют потерять работу. Однако инженер говорит, что инструменты Amazon для написания кода и технической документации недостаточно хороши для достижения таких амбициозных целей. Другой сотрудник называет результаты работы ИИ «дрянью».
Открытое письмо призывает Amazon создать «рабочие группы по этике ИИ» с участием рядовых сотрудников, которые могли бы высказывать свое мнение о том, как новые технологии используются в их служебных обязанностях. Они также хотят иметь право голоса в отношении того, как ИИ может быть использован для автоматизации аспектов их ролей. В прошлом месяце число работников, подписавших письмо, резко возросло после того, как Amazon объявила о сокращении около 14 000 рабочих мест, чтобы лучше соответствовать требованиям эпохи ИИ. По состоянию на сентябрь в Amazon работало почти 1,58 миллиона человек, что меньше пикового значения в более чем 1,6 миллиона в конце 2021 года.
Группа по климатической справедливости намеренно стремилась достичь своего рубежа по количеству подписей до начала торговой лихорадки «Черной пятницы», стремясь напомнить общественности о цене технологии, питающей одну из крупнейших в мире платформ онлайн-покупок. Группа считает, что она может оказать влияние, поскольку профсоюзы, в том числе в сфере здравоохранения, государственного управления и образования, успешно боролись за право голоса в отношении того, как ИИ используется в их областях.
Крупная ИИ-конференция наводнена рецензиями, полностью написанными ИИ
Разразился скандал после того, как 21% рецензий на рукописи для международной конференции по ИИ оказались сгенерированы искусственным интеллектом.
Что могут сделать исследователи, если подозревают, что их рукописи прошли экспертную оценку с использованием искусственного интеллекта? Десятки ученых выразили обеспокоенность в социальных сетях по поводу рукописей и рецензий, представленных организаторам Международной конференции по представлениям обучения (ICLR) следующего года, ежегодного собрания специалистов по машинному обучению. Среди прочего, они отметили сфабрикованные цитаты, а также подозрительно длинные и расплывчатые отзывы об их работе.
Грэм Нойбиг (Graham Neubig), исследователь ИИ из Университета Карнеги-Меллона в Питтсбурге, Пенсильвания, был одним из тех, кто получил рецензии, которые, по-видимому, были созданы с использованием больших языковых моделей (БЯМ). Он говорит, что отчеты были «очень многословными, с большим количеством маркированных списков» и запрашивали анализ, который не являлся «стандартным статистическим анализом, который рецензенты запрашивают в типичных статьях по ИИ или машинному обучению».
Но Нойбигу нужна была помощь, чтобы доказать, что отчеты были сгенерированы ИИ. Поэтому он опубликовал сообщение на X (ранее Twitter) и предложил вознаграждение любому, кто сможет просканировать все поданные на конференцию материалы и их рецензии на предмет текста, сгенерированного ИИ. На следующий день он получил ответ от Макса Сперо (Max Spero), исполнительного директора Pangram Labs в Нью-Йорке, которая разрабатывает инструменты для обнаружения текста, сгенерированного ИИ. Pangram проверила все 19 490 исследований и 75 800 рецензий, представленных для ICLR 2026, которая состоится в Рио-де-Жанейро, Бразилия, в апреле. Нойбиг и более 11 000 других исследователей ИИ будут присутствовать на ней.
Анализ Pangram показал, что около 21% рецензий ICLR были полностью сгенерированы ИИ, а более половины содержали признаки использования ИИ. Результаты были опубликованы Pangram Labs онлайн. «Люди подозревали, но у них не было никаких конкретных доказательств, — говорит Сперо. — В течение 12 часов мы написали код для анализа всего текстового содержимого этих представленных работ», — добавляет он.
Организаторы конференции заявляют, что теперь они будут использовать автоматизированные инструменты для оценки того, нарушали ли представленные материалы и рецензии политику использования ИИ при их подаче и рецензировании. Это первый раз, когда конференция столкнулась с этой проблемой в таком масштабе, говорит Бхарат Харихаран (Bharath Hariharan), специалист по информатике из Корнеллского университета в Итаке, Нью-Йорк, и старший председатель программного комитета ICLR 2026. «После того, как мы пройдем весь этот процесс… это даст нам лучшее представление о доверии».
Рецензии, написанные ИИ
Команда Pangram использовала один из своих собственных инструментов, который предсказывает, сгенерирован ли или отредактирован текст БЯМ. Анализ Pangram выявил 15 899 рецензий, которые были полностью сгенерированы ИИ. Но он также обнаружил много рукописей, представленных на конференцию с подозрением на текст, сгенерированный ИИ: 199 рукописей (1%) оказались полностью сгенерированными ИИ; 61% представленных работ были в основном написаны людьми; но 9% содержали более 50% текста, сгенерированного ИИ.
Pangram описала модель в препринте¹, который она представила на ICLR 2026. Из четырех рецензий, полученных на эту рукопись, одна была помечена как полностью сгенерированная ИИ, а другая — как слегка отредактированная ИИ, как показал анализ команды.
Для многих исследователей, получивших рецензии на свои материалы для ICLR, анализ Pangram подтвердил их подозрения. Дезмонд Эллиотт (Desmond Elliott), специалист по информатике из Копенгагенского университета, говорит, что одна из трех полученных им рецензий, казалось, «упустила суть статьи». Его аспирант, руководивший работой, подозревал, что рецензия была сгенерирована БЯМ, потому что в ней упоминались неверные численные результаты из рукописи и содержались странные выражения.
Когда Pangram опубликовала свои результаты, Эллиотт добавляет: «Первое, что я сделал, это ввел название нашей статьи, потому что хотел узнать, был ли инстинкт моего студента верным». Подозрительная рецензия, которую анализ Pangram пометил как полностью сгенерированную ИИ, дала рукописи самую низкую оценку, оставив ее «на границе между принятием и отклонением», — говорит Эллиотт. «Это ужасно расстраивает».
Последствия
Команда ICLR 2026 разрешила авторам и рецензентам использовать инструменты ИИ для улучшения текста, генерации кодов экспериментов или анализа результатов, но обязала раскрывать такое использование. Она также запретила использование ИИ, которое могло бы нарушить конфиденциальность рукописей или привести к фальсификации содержания.
Организаторы конференции теперь будут использовать анализ Pangram, а также другие автоматизированные инструменты, чтобы оценить, нарушили ли представленные работы и рецензии эти правила, и будут применять санкции к авторам и рецензентам, которые их нарушили.
Исследователей, которые курируют процесс экспертной оценки, «попросят помечать некачественные рецензии, а не только те, которые сгенерированы БЯМ», — говорит Харихаран. Он добавляет, что «планка для отклонения рецензентов без рассмотрения будет высокой. Учитывая, что эти автоматизированные инструменты могут давать ложные срабатывания, мы не будем полностью полагаться на них».
Некоторые авторы отозвали свои заявки на ICLR, поскольку рецензии на их рукописи содержали ложные утверждения. Другие все еще задаются вопросом, как реагировать на полученные ими рецензии. «Как ученый, я достаточно долго в этой игре и знаю, что получу несколько некачественных рецензий, когда мы представляем работы на конференции», — говорит Эллиотт. Но рецензии, которые, как подозревают, были сгенерированы ИИ, как правило, содержат «много содержания», добавляет он. Некоторая часть этого «актуальна и заслуживает ответа, но другие части не имеют смысла».
Ситуация на ICLR 2026 подчеркивает растущее давление на экспертов для того, чтобы они не отставали от быстрорастущей области. «В области ИИ и машинного обучения прямо сейчас у нас кризис с точки зрения рецензирования, потому что эта область экспоненциально расширялась в течение последних пяти лет», — говорит Нойбиг.
Харихаран говорит, что каждому рецензенту ICLR было поручено в среднем пять статей, которые он должен был отрецензировать за две недели. «Это очень значительная нагрузка. Она намного выше, чем та, что была в прошлом». Он говорит, что ведутся обсуждения о том, как этим управлять. «Все в сообществе осознают, что мы находимся в режиме, когда все мы делаем значительно больше волонтерской работы, чем раньше».
>>1436470 >ы либо дурак, либо троллишь. Посмотри как дети и те, кто впервые взял и держит в руках пятнашки, двигают их, они не составляют алгоритмы, а просто делают перебор вариантов.
>>1436297 >Как обычно — тупые попугаи все эти БЯМ. Так ты задал 8 слов в промте. Может надо объемнее промт писать - привести пример стиха в котором будет эта рифма, кратко пояснить смысл о чём и про что стих и к чему нужно свести концовку, ну и т.д.
>>1436520 Что, стратегии и методы ведь разные. В шахматы можно играть интуитивно, а вместо программирования уже вон, можно не зная языков генерировать программы по текстовому описанию, или даже рисовать программы на картинке и стрелками с подписями указывать расположение элементов и какую логику они выполняют.
>>1436577 >Организаторы конференции заявляют, что теперь они будут использовать автоматизированные инструменты для оценки того, нарушали ли представленные материалы и рецензии политику использования ИИ
Кстати это рак и шиза. Уже была куча репортов, когда ученые подавали материалы, написанные целиком человеком, но эти автоматизированные инструменты отбраковывали их как ИИшные, из-за чего реальные исследования отклоняли ревьюверы, просто не за что, месяцы работы ученых впустую. По сути раковые ИИ стартапы наживаются на нерабочих инструментах, которые в половине случаев не могут отличить ИИ от неИИ текстов и забраковывают людей. Забавно, что тупость человеков победила, и теперь на эти инструменты целиком полагаются, процесс автоматизирован.
>>1436587 Дети не составляют алгоритмы только в твоем больном воображении. Даже дети, которых научили играть в шахматы в минимально возможном возрасте занимаются блять планированием причем примитивным и сознательным. Если ты приводишь в пример необучаемых даунов, то от них интеллекта и не ждут. В пятнашках вообще невозможно случайно что-то делать. Там есть вполне четкая последовательность действий, которая ведет к сбору, как в кубике ебаного рубика. Случайно их собирают те, кому правила победы в игре плохо объяснили.
>>1436622 >Забавно, что тупость человеков победила Победило бабло, а так же политика. Теперь можно отклонить что угодно, спиздив себе идею и сказать, что наш ии вас на хуй послал - не довольны в суд подавайте.
>>1436520 >что такое случайность и случайный перебор. Чо, нейронкам отключили способность написать программу для решения задачи, и они на одном рассуждении решали, при этом пока они долго рассуждали, у них походу заканчивались токены и они как и в шахматах теряли положение фишек на доске и их позиции и названия. То есть это проблема техническая, им мощи/токенов для рассуждения не хватает, по времени на пару лет, через 2 года возможно такой проблемы не будет и они будут решать эти головоломки на чистом рассуждении без написания для этого программ-ускорителей.
>>1436664 Там вон изобрели эволюционные алгоритмы для использования тулзов. Так что нейронкам не надо будет уже всякой хуйней заниматься, а будут просто офсорсить все что можно на специализированные тулзы. Расчеты показали, так даже задачи передвижения в реальном мире можно офсорсить на нужные тулзы. Большинство офисных задач тоже, часть исследовательских. Так что 2 года ждать и не придется, поумнеют куда раньше.
>>1436757 Мир на до и после начинает сейчас делиться, а может даже в 2026м в конце, когда ИИ реально много чего перенимать начнет. С 2022го просто пиздаболия и чатики, мало на что влияющие.
>>1436682 Учитывая, что несколько лет прикручивали калькулятор (Wolfram), и тут соплю будут тянуть и делать «интеллект посильнее» вместо продукта, который может сотни инструментов задействовать и свои писать.
>>1436855 охуенные отгадки. Я кстати на вторую ответ не знаю. Полагаю, что это какое-то явление, раз ни голоса ни тела. Самое близкое, что подходит — эхо. Но оно само не говорит. И «тело» ему требуется (среда распространения и отражающее тело). И если придерживаться этого допущения, то отражение тоже вариант отгадки.
>>1436885 Ну да, об этом уже весь год говорят. Россию меньше коснется, в ней все ИИ-роботы все равно заблокированы. А западные страны с их огромными зарплатами сильно.
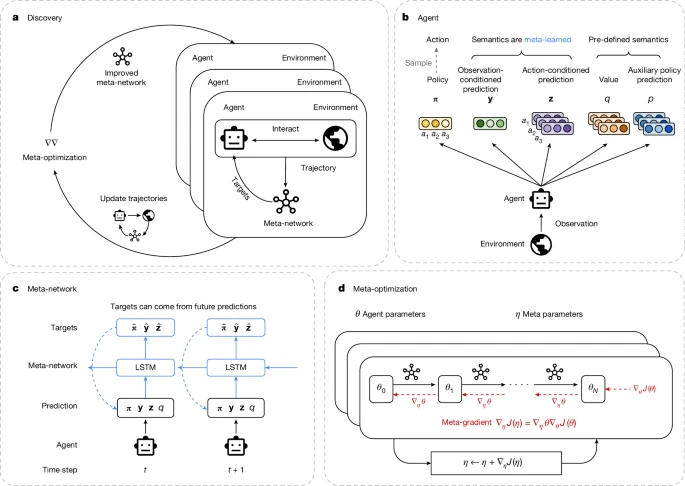
Google DeepMind представляет Диско РЛ: Автоматизация Открытия Архитектур Интеллекта
Самосовершенствующийся ИИ близко как никогда.
«Диско РЛ демонстрирует, что мы можем автоматизировать открытие архитектур интеллекта и что этот процесс масштабируется как с помощью вычислительных мощностей, так и с помощью разнообразия среды».
Люди и другие животные используют мощные механизмы обучения с подкреплением (ОП), которые были обнаружены в процессе эволюции на протяжении многих поколений путем проб и ошибок. Напротив, искусственные агенты обычно обучаются с использованием созданных вручную правил обучения. Несмотря на десятилетия интереса, цель автономного открытия мощных алгоритмов ОП оказалась труднодостижимой.
Здесь мы показываем, что машины способны открыть передовое правило ОП, которое превосходит разработанные вручную правила. Это было достигнуто с помощью метаобучения на основе совокупного опыта популяции агентов в большом количестве сложных сред.
В частности, наш метод открывает правило ОП, с помощью которого обновляется политика и предсказания агента. В наших крупномасштабных экспериментах обнаруженное правило превзошло все существующие правила в хорошо зарекомендовавшем себя тесте Atari и превзошло ряд современных алгоритмов ОП в сложных тестах, которые он не видел во время открытия.
Наши выводы предполагают, что алгоритмы ОП, необходимые для развития искусственного интеллекта, вскоре могут быть обнаружены автоматически на основе опыта агентов, а не разработаны вручную.
Объяснение для непрофессионалов (Layman's Explanation)
Google DeepMind разработала Диско РЛ — систему, которая автоматически открывает новый алгоритм обучения с подкреплением, превосходящий лучшие разработанные людьми методы, такие как MuZero и PPO. Вместо ручного проектирования математических правил обновления политики агента исследователи использовали метасеть для динамического формирования целей обучения.
Эта метасеть обучалась с помощью градиентов на популяции агентов, играющих в 57 игр Atari, по сути, оптимизируя сам процесс обучения, а не только игровой процесс. Полученный алгоритм оказался очень обобщаемым; несмотря на то, что он был «открыт» в основном на Atari, он достиг самых современных результатов в совершенно невиданных ранее тестах, таких как ProcGen и NetHack, без необходимости переобучения правила.
Ключевым фактором этого успеха стала способность системы определять и использовать свои собственные предиктивные метрики, не имеющие заранее заданных значений, что фактически позволило ИИ изобретать внутренние концепции, необходимые для эффективного обучения. Это означает, что будущие достижения в архитектуре ИИ могут быть обусловлены автоматизированными конвейерами открытия, которые масштабируются с помощью вычислительных мощностей, а не полагаются на медленную итерацию человеческой интуиции.
Объяснение Архитектуры Метасети (Explanation of the Meta-Network Architecture)
Метасеть функционирует как система отображения, которая преобразует траекторию выходных данных, действий и наград агента в конкретные цели обучения. Она обрабатывает эти входные данные с использованием сети долговременной краткосрочной памяти (LSTM), развернутой назад во времени, что позволяет системе эффективно включать информацию о будущем в текущие обновления, подобно многошаговым методам временной разницы. Чтобы гарантировать, что обнаруженное правило остается совместимым с различными средами, независимо от их схем управления, сеть использует общие веса для всех размерностей действий и вычисляет промежуточное вложение, усредняя их. Кроме того, архитектура включает «мета-РНН» (рекуррентная нейронная сеть), которая проходит вперед по последовательности обновлений агента на протяжении всего его жизненного цикла, а не только в рамках эпизода. Этот компонент фиксирует динамику долгосрочного обучения, позволяя обнаруживать адаптивные механизмы, такие как нормализация вознаграждения, которые зависят от исторических статистических данных.
Генеральный директор Telegram Дуров анонсировал Cocoon – Децентрализованную частную вычислительную сеть для ИИ!
Дуров (генеральный директор Telegram) только что объявил о запуске Cocoon — их децентрализованной сети для конфиденциальных вычислений ИИ. Это конец эры дорогих посредников, таких как Amazon и Microsoft: теперь запросы ИИ обрабатываются со 100% конфиденциальностью, без отслеживания и по ценам ниже рыночных.
Ключевые особенности: Приватность превыше всего: Ваши данные не утекают — все работает в доверенных средах исполнения (TEE). Для владельцев GPU: Подключайте свои видеокарты и предоставляйте свою вычислительную мощность. Первые запросы уже поступают. Масштабирование впереди: Больше GPU и разработчиков появится в ближайшие несколько недель. Пользователи Telegram скоро получат новые функции ИИ (например, перевод сообщений) с полной конфиденциальностью.
Это шаг к по-настоящему децентрализованному ИИ, возвращающий контроль в руки пользователей. Изменит ли это правила игры?
COCOON — это децентрализованная платформа для инференса (вывода) ИИ, созданная на блокчейне TON, позволяющая владельцам GPU зарабатывать криптовалюту, обслуживая модели ИИ в доверенных средах исполнения (TEE).
Ключевые цели:
Любой, у кого есть GPU-сервер, может сдать его в аренду и заработать. Запросы и ответы остаются конфиденциальными, известными только клиенту. Клиенты могут проверить, что ответы поступают от запрошенной модели. Оплата осуществляется через блокчейн TON.
Компоненты
COCOON состоит из трех частей:
Клиент: Клиент оплачивает запросы и отправляет их прокси-серверу. Прокси-сервер (Прокси): Прокси-сервер выбирает подходящий воркер (рабочий узел) и перенаправляет запрос. Воркер (Рабочий узел): Воркер выполняет запросы на GPU.
И прокси-сервер, и воркер работают внутри TEE, гарантируя, что все данные (запросы, ответы) остаются конфиденциальными и не могут быть доступны владельцам серверов.
Воркер (Рабочий узел)
Роль: Выполняет запросы на инференс ИИ внутри виртуальных машин (ВМ), защищенных TEE.
Запускает модели ИИ (например, LLM через vllm) внутри конфиденциальных виртуальных машин. Защищен TEE (в настоящее время Intel TDX). Гарантирует, что все запросы остаются конфиденциальными и используется правильная модель. Получает оплату от прокси-серверов за выполненную работу. Требуется минимальная настройка: установка образа, предоставление конфигурации (имя модели, конфигурация TON, адрес кошелька).
Прокси-сервер (Прокси)
Роль: Маршрутизирует запросы от клиентов к воркерам.
Защищен TEE (в настоящее время Intel TDX). Выбирает подходящих воркеров на основе типа модели, нагрузки и репутации. Принимает оплату от клиентов. Оплачивает воркерам выполненные запросы. Берет комиссию с каждой транзакции. В сети значительно меньше прокси-серверов, чем воркеров. * Текущее развертывание: Для простоты прокси-серверы управляются командой COCOON.
>>1436988 Я озвучивал идею такой штуки ещё в 2017 году, когда вышла Алиса, в первые дни хайпанула на дваче (были арты, тематические треды), а потом в течении ~3 дней модель лоботомировали. Тогда казалось, что распределённость это единственный способ получить модель без цензуры.
>>1437101 Тут предлагают делать обучение модели на твоем ПеКа, а тебе взамен на потраченный ресурс видеокарты дадут TON. Нигде речи нет о том, что потом модель не лоботомируют.
Тогда ИИ даже ИИ назвать было нельзя, это были уже нейронки, но начисто лишённые логики, не сильно далеко ушедшие по духу от цепей Маркова.
Более-менее нормальный ИИ тогда казался делом не близкого будущего. Ещё казалось, что он будет не на нейронках (или не чисто на нейронках), а вручную придётся тегировать все понятия, заниматься формальной семантикой, простраивать все логические связи.
>>1437151 Интересно, как будет распределяться ответственность перед законом за генерируемый контент? Вот, допустим, я поднял у себя какой-нибудь чекпоинт стейбл дифужена. Ко мне челик отправляет интересный запрос и генерирует явно незаконную картинку. Сгенерировано у меня на устройстве и отправляется ему. Кто виноват в таком случае? По сути я предоставил возможность И совершил распространение путем пересылки. А он сделал запрос и получил эту картинку на хранение.
Как это контролировать вообще? Учитывая всеобщий пуш в сторону контроля за подобными вещами, если модерации на это не будет, то Пашу отовсюду ссаными тряпками погонят в лучшем случае, или вообще законы специально для его посадки придумают.
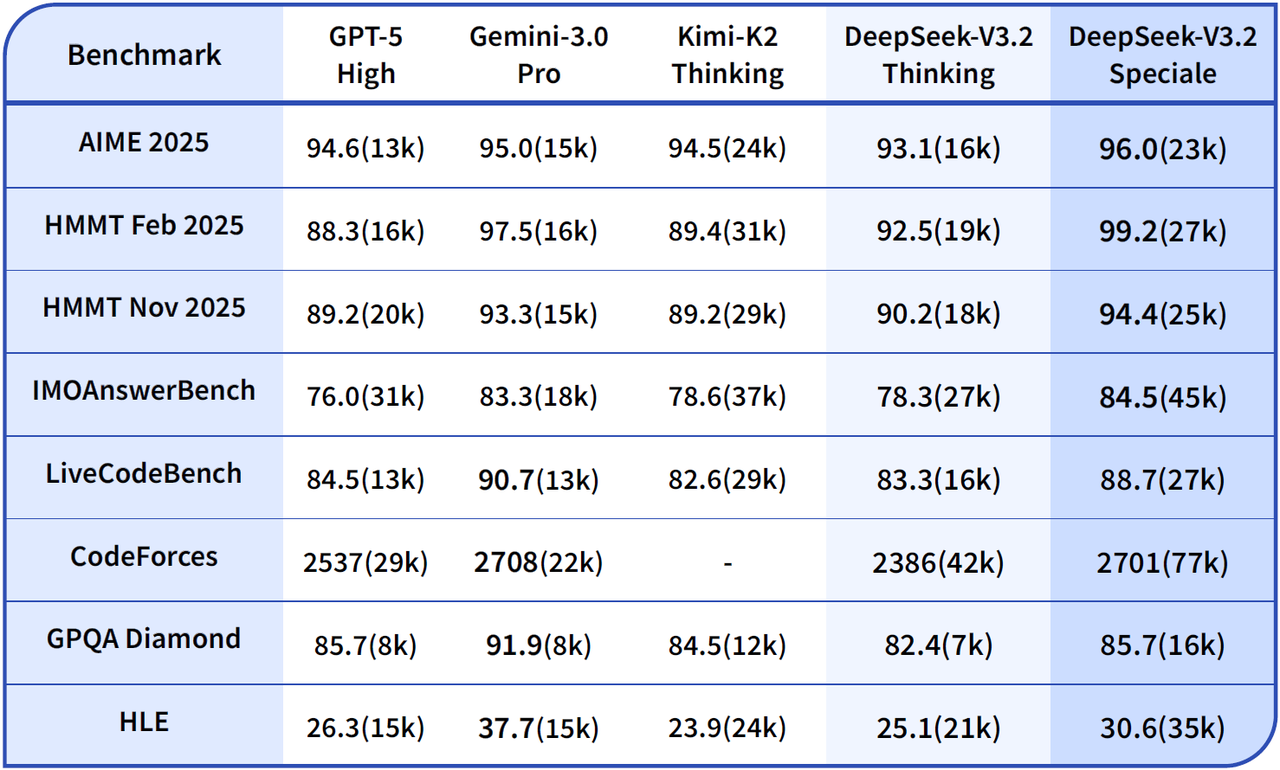
Дипсик выпустили топовую модель DeepSeek-V3.2-Speciale. Золото на IMO в опенсорсе, третье место по бенчам в среднем, только Gemini 3 Pro и Claude 4.5 Opus впереди.
И это похоже еще не самая лучшая модель, которая у них есть. Потому что в API доках написано это: > V3.2-Speciale: Served via a temporary endpoint: base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215". Same pricing as V3.2, no tool calls, available until Dec 15th, 2025, 15:59 (UTC Time).
>>1437241 >Интересно, как будет распределяться ответственность перед законом за генерируемый контент? Ты на Колыму, ну а агент ФСБ с двойным гражданством в Дубае продолжит жить. Все по справедливости и свободе.
>>1436988 Прекрасная идея, на самом деле. Вот тут >>1433480 (OP) постоянно жалуются, что им не хватает памяти для запуска жирного Flux 2. А тут всё решается: 1) подключился к сети, погенерировал на фоне; 2) заработал TONов; 3) потратил их на собственные генерации.
Отличная идея для: а) нищемразей с карточками 4/8 ГБ б) для запуская совсем жирных моделей 16/24 ГБ+, где даже 5090 не хватит.
>>1436984 >что он в планирование не способен Ну там для чистоты тестов отключили вызов инструментов типа калькуляторов и написание кода.
Так-то нейросеть должна уметь при решении задачи внутри себя генерировать код и запускать изнутри программы для решения, или например, зачем подключаться к калькулятору, если его можно сгенерировать, ну и уметь генерировать "нейроны" - свои мини-копии внутри себя.
>>1437274 >в последнее время "прорывы" перестали удивлять, единственное что радует вроде как этот дикпик самый дешевый из всех.
Сейчас благодаря конкуренции между ними, внутри корпораций делается самое интересное что выстрелит лет через 5-7, когда железо тоже подтянут по уровню. Так что этот период самый продуктивный тоже.
Забудьте о четырехдневной рабочей неделе: Илон Маск предсказывает, что вам вообще не придется работать «менее чем через 20 лет»
Выпускники поколения Z ищут любые признаки того, что ИИ не сможет отобрать у них их начальные должности сразу после окончания учебы. Но Илон Маск предвидит совершенно иное будущее для этих молодых надежд: к тому времени, когда им исполнится сорок, им вообще не придется работать.
«Менее чем через 20 лет — а может быть, даже через 10 или 15 лет — достижения в области ИИ и робототехники приведут нас к тому, что работа станет необязательной», — сказал Маск вчера в выпуске подкаста People by WTF.
Такие технологии, как ChatGPT и Google Gemini, уже облегчили бремя некоторых трудоемких задач, таких как очистка данных, их обобщение и другие административные функции. Одно из прошлогодних исследований показало, что к 2029 году ИИ будет экономить работникам до 12 часов в неделю.
Ведущий подкаста, Никхил Камат, отметил, что в некоторых частях мира уже наблюдается переход к более коротким рабочим неделям в результате этих изменений. Но забудьте о четырехдневной рабочей неделе. Поскольку ИИ продолжает повышать производительность, Маск настаивает на том, что работа станет скорее личным выбором, сродни хобби.
Маск удваивает свои ставки на то, что в будущем работа станет необязательной
Это не первый раз, когда основатель SpaceX и самый богатый человек в мире с состоянием в 450 миллиардов долларов говорит, что работники неизбежно смогут выбирать, хотят они работать или нет. Всего пару недель назад на Инвестиционном форуме США и Саудовской Аравии в Вашингтоне, округ Колумбия, Маск сравнил работу с домашним садоводством.
Вчера он повторил ту же мысль. «Вы можете выращивать свои собственные овощи в саду или пойти в магазин и купить их», — пояснил миллиардер-техномагнат. «Выращивать свои собственные овощи гораздо труднее. Но некоторым людям нравится выращивать овощи, и это прекрасно. Но это будет необязательно — таков мой прогноз».
Маск добавил, что без необходимости ходить в офис, проживание рядом с ним — или где-то за городом — также станет совершенно необязательным. «Не будет такого, что вы обязаны находиться в городе ради работы», — сказал Маск, добавив, что Всеобщий Высокий Доход (Universal High Income) будет оплачивать расходы людей на проживание и все остальное, что они смогут придумать.
«Если вы сможете это придумать, вы сможете это получить — таким будет будущее», — добавил Маск.
От Билла Гейтса до Эрика Юаня: бизнес-лидеры предсказывают, что ИИ сократит рабочую неделю
Хотя предсказание Маска сейчас может показаться надуманным, это не первый случай, когда бизнес-лидеры предсказывают реальность, в которой работникам не придется приходить на работу пять дней в неделю.
Ранее в этом году соучредитель Microsoft Билл Гейтс заявил, что искусственный интеллект может вскоре автоматизировать почти все, и благодаря росту производительности труда работодатели введут двухдневную рабочую неделю менее чем через десять лет. Аналогичным образом, генеральный директор Zoom Эрик Юань заявил, что трехдневная рабочая неделя уже не за горами.
Генеральный директор Nvidia Дженсен Хуанг стал последним лидером, согласившимся с тем, что быстрое внедрение ИИ в различных отраслях «вероятно» приведет к переходу на четырехдневную рабочую неделю. Но даже при меньшем количестве обязательных дней для явки на работу это не означает уменьшения объема работы.
Вместо этого, генеральный директор чипового гиганта с капиталом в 154 миллиарда долларов говорит, что технология высвободит волну новых идей и проектов, сделав людей более занятыми, а не более свободными.
«Если ваша жизнь становится более продуктивной, и если то, что вы делаете с большим трудом, становится проще, очень вероятно, что, поскольку у вас так много идей, у вас будет больше времени для реализации задуманного», — сказал Хуанг недавно на сцене Инвестиционного форума США и Саудовской Аравии вместе с Маском.
>>1437819 Это только 20 лет на то, чтобы такие технологии появились. А сколько времени уйдет на то, чтобы они стали массовыми и дошли до мухосрансков? И что делать миллиарду индусов. Неужели их всех на бод поставят? Скорее всего большинство людей убьют, чтобы не тратить на них ресурсы. Нас тоже убьют.
>>1437959 >И что делать миллиарду индусов Учиться и получать квалификацию, знания и умения по выбранной профессии. В отсталых или дешевых странах в основном население держится на неквалифицированных работах. Роботы наверное первым делом займут эту нишу неквалифицированного труда. Пока роботы её будут занимать у неквалифицированных есть время получить квалификацию выучив какую-то профессию,
потом будет гонка - роботы будут занимать и осваивать нишу первой ступени квалифицированного труда, и людям придется подниматься по ступеням карьеры ещё выше, повышая свою квалификацию, чтобы роботы не могли догнать.
>>1437959 >такие технологии А что, если это не мы будем управлять роботами, а наоборот, роботы будут управлять нами?
Ведь в природной пищевой цепочке наверху стоит самый умный по интеллекту - человек, если ИИ будет умнее человека, то он станет в иерархии выше человека, а человек тогда займет положение подчинённого.
>>1437974 > Пока роботы её будут занимать у неквалифицированных есть время получить квалификацию выучив какую-то профессию, Угу. А есть они все это время что будут? Белковые батончики из жоп роботов?
>>1437979 >в природной пищевой цепочке наверху стоит самый умный по интеллекту Кто может подписать приказ об уничтожении целой страны - президент или Перельман?
>>1437819 Машк только забыл упомянуть что 90% населения ждет сгнаивание в цифровом концлагере, где ты без одобрения корпорацмй даже хлеба из жуков не сможешь себе купить.
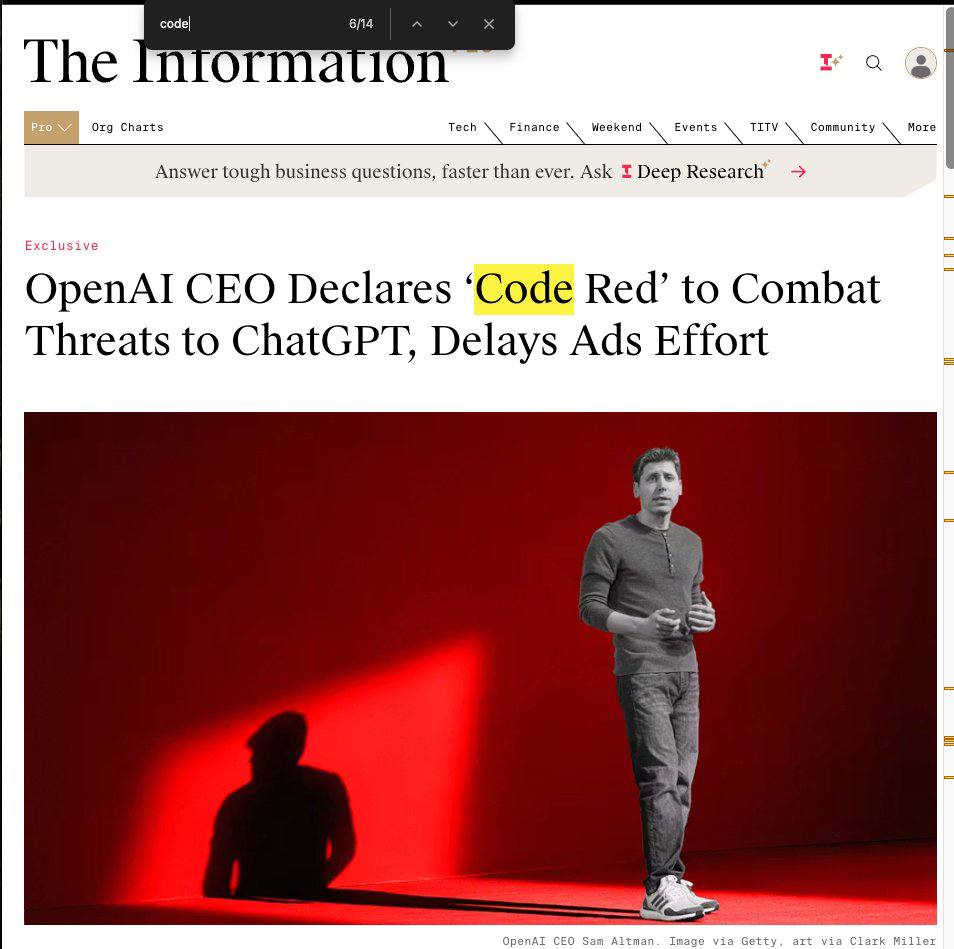
Сэм Альтман объявил внутри OpenAI «Код Красный» из-за угрозы со стороны конкурентов
После выхода Gemini 3 и нескольких других удачных моделей конкурентов стартап решил в срочном порядке отложить запуск монетизации и доп.фичей и перераспределить ресурсы на улучшение самого продукта и метрик
Откладывают: запуск рекламы, улучшения в ChatGPT Pulse и ChatGPT shopping и др
В приоритете теперь: персонализация, imagegen, максимизация скора на lmarena
Забавно, что ровно три года назад код красный как раз объявляла Google после появления ChatGPT. Иронично получилось
>>1437974 Почему ты думаешь, что роботы будут занимать только неквалифицированную работу? Ты думаешь через 20 лет ии не сможет заменить инженера и программиста?
>>1438099 > 20 лет Так он и сейчас может. Пока с минимальным участием человека, чтобы направлять модель и фильтровать глюки, но уже большую часть работы сама делает. То, что отделяет от полной автономности, последние барьеры, которые уже вот-вот будут преодолены новыми моделями. 20 лет ждать не придется, это дело ближайших 3х лет. АГИ тоже не нужен, любую работку смогут делать специализированные модели, у которых владение нужными областями знаний. Большинство работы лютая рутина, даже те же инженеры-программисты, где способности АГИ не нужны. Нужно только отладить текущие модели в сторону полной автономности и уменьшения глюк, что и делается.
>>1438125 Промптишь нормально - выдает любое нужное решение. Пока все замыкается на промптере, без него моделька все еще слабовата для самостоятельности. Но промптер не делает сильно много работы, это слабая интеллектуальная деятельность, в основном проверки и корректуры, часто даже много знаний не надо. Так что в перспективе модели и промптера заменят.
>>1438120 Ну допустим сроки короче. Суть не в этом. Вопрос в том, что делать миллионами, миллиардам людей, которые потеряют работу, как квалифицированную так и неквалифицированную. Это же просто балласт, который нужно кормить непонятно для чего и чьего кармана? Ресурсы земли не резиновые
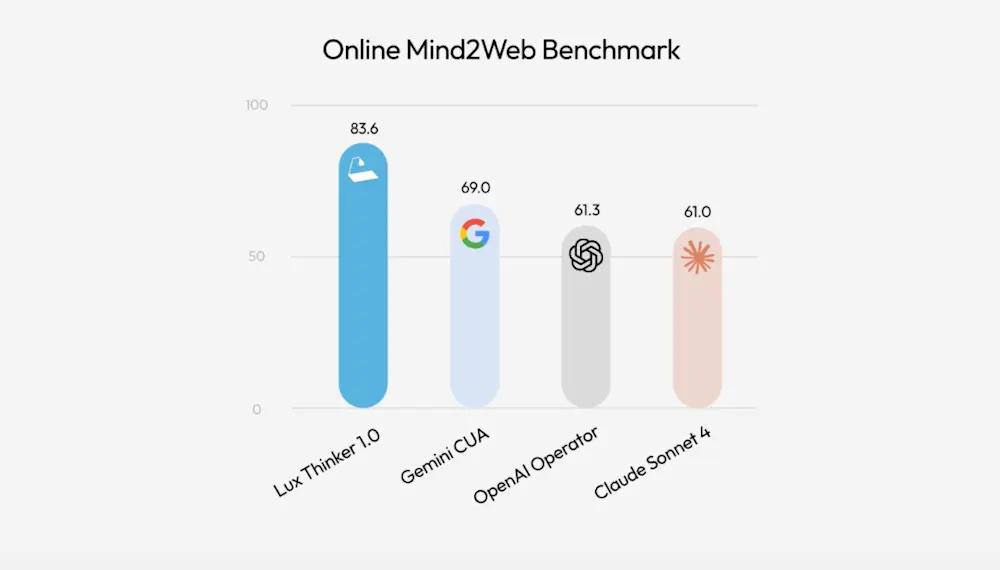
Стартап OpenAGI (лайк за название) выпустили Computer Use модель Lux и утверждают, что это прорыв
По бенчмаркам модель на целое поколение обгоняет аналоги от Google, OpenAI и Anthropic. Кроме того, модель работает быстрее (примерно 1 секунда на шаг вместо 3 секунд у конкурентов) и в 10 раз дешевле по стоимости обработки одного токена.
Создатели (исследователи из MIT, кстати) утверждают, что суть успеха – в том, что это не затюненная LLM, а модель, которую с самого начала учили именно совершать действия. То есть абсолютно другая парадигма.
Из приятного: они даже открыли код инфры, в которой обучали агента, можно покопаться.
Модель работает не только в браузере, как многие другие агенты, а может и управлять другими приложениями, хоть Slack, хоть Excel. Модель может работать в трех режимах с говорящими названиями Tasker, Actor и Thinker. На страничке проекта немало громких слов про парадигмальные сдвиги и пр., но тут лучше подождать результатов массового независимого тестирования. Стартап как раз и призывает начать пробовать: Try our developer-friendly SDKs, frameworks, and UX template - all wired into Lux, the world’s most advanced computer use model.
>>1438134 До сих пор как-то кормили. Большинство работ все равно протирание штанов, они существуют чисто из-за неэффективности человеческих процессов. Нейронки дадут большую эффективность, экономический выхлоп лучше, богатство и изобилие больше. Как прокормить скорее вопрос перераспределения богатств, которые теперь все переходят в руки больших корпораций. Оттуда их как-то надо выбивать и перераспределять для потерявших работы, ведь зарплат и рабочих мест больше не будет, поэтому в кремниевой долине и говорят уже второй год про всякие безусловные доходы. Старая система накрывается, новая еще не оформилась. Безусловные доходы это в принципе откуп от выгодоприобретателей революции ИИ для масс, они их кинут как кость обнищавшим люмпенам, сами же продолжат богатеть и наживаться, за счет ИИ там выгоды все равно огромные.
>>1438134 >который нужно кормить непонятно для чего Чуваааак, у тебя буквально сейчас 800 мио живет впроголодь. И никто не парится и не парился никогда по этому поводу.
>>1438138 > лучше подождать результатов массового независимого тестирования Тащем-то mind2web бенчмарк, по которому они тестили, уже и есть такое тестирование. Там 300 задач из реального мира, веб базированные и офисные для автоматического выполнения. А вообще неудивительно, специализированные модели, натрененные под конкретные задачи всегда побьют универсальные. Вопрос только в применимости, сможет ли она делать все офисные задачи как Гемини с 69 процентами, или все таки без универсальности Гемини никуда. Возможно просто часть задач отойдет в такие узкоспециальные модели, а для части нужна будет Гемини с обширными общими знаниями.
>>1438160 >специализированные модели, натрененные под конкретные задачи всегда побьют универсальные
Нет лол, те же специализированные модели-переводчики были обоссаны универсальными моделями. У универсальных лучше генерализация, а потому в определённый момент они начинают бить любые узкоспециализированные модели. Так что однажды все универсальные модели будут побиты
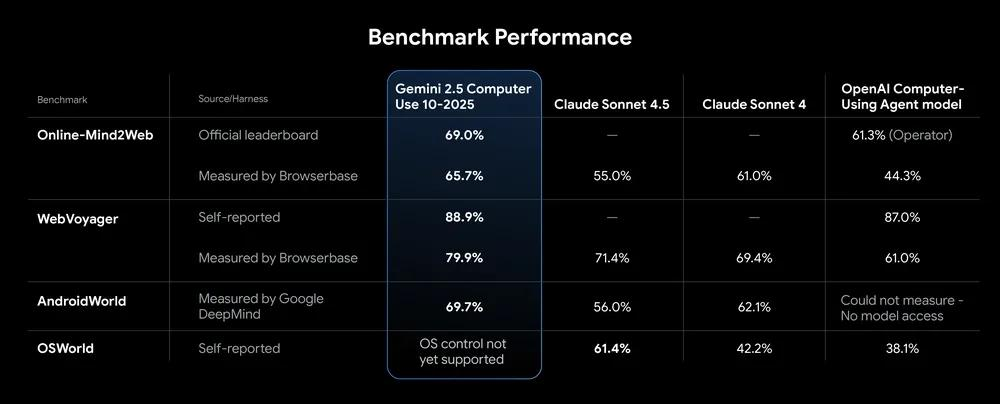
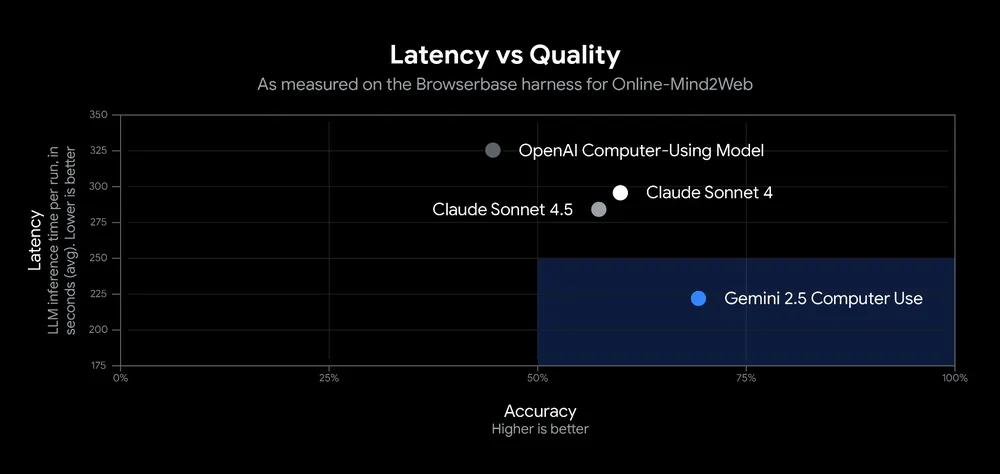
>>1438138 Нашел на чем Гугловская вторая в списке фейлила:
Учитывая, что Google только что выпустил Chrome DevTools (MCP) несколько дней назад, появление Gemini 2.5 Computer Use не вызывает особого удивления. Проще говоря, подобно агенту OpenAI Computer-Using Agent (CUA), эта модель от DeepMind позволяет ИИ напрямую управлять браузером пользователя. Основываясь на своих способностях визуального понимания и рассуждения, модель может помогать пользователям выполнять такие действия, как клики, прокрутка и ввод данных в браузере.
Запрос: С сайта https://сайт.ком/pet-care-signup получите все данные о любом домашнем животном, проживающем в Калифорнии, и добавьте их в качестве гостя в мою CRM спа-салона по адресу https://pet-luxe-spa.web.app/. Затем назначьте повторный визит к специалисту Анима Лавар (Anima Lavar) на 10 октября в любое время после 8 утра. Причина визита та же, что и запрошенное ими лечение.
Запрос: Мой художественный клуб провёл мозговой штурм задач в преддверии нашей ярмарки. Доска хаотична, и мне нужна ваша помощь в организации задач по созданным мной категориям. Перейдите на sticky-note-jam.web.app и убедитесь, что заметки находятся в правильных разделах. Перетащите их туда, если это не так.
Как мы видим, будь то сбор онлайн-информации и выполнение действий или организация беспорядочных заметок, Gemini 2.5 Computer Use выполнил задачи очень точно и на довольно высокой скорости.
По соответствующим бенчмаркам производительность Gemini 2.5 Computer Use также достигла уровня SOTA (State-of-the-Art – лучшего в отрасли):
В настоящее время разработчики могут получить доступ к этим возможностям через Gemini API в Google AI Studio и Vertex AI. Пользователи также могут опробовать их в демонстрационной среде, размещенной на Browserbase (поддерживающей только процессы продолжительностью не более 5 минут и не позволяющей пользователям перехватывать управление на полпути): https://gemini.browserbase.com/
MachineHeart предпринял несколько попыток использования этой демонстрационной среды. В целом, Gemini 2.5 Computer Use демонстрирует высокую точность при выполнении простых задач, но склонен к сбоям при работе с немного более сложными задачами.
Например, при выполнении простой задачи, такой как «поиск страницы Джона Уика в Википедии», модель сработала очень успешно.
Однако, как только задача становится немного сложнее, модель терпит неудачу. Например, «найти страницу Джона Уика в Википедии, резюмировать информацию о нём и предоставить китайскую версию». Кроме того, задачи, такие как «открыть официальный сайт Нобелевской премии и предоставить расписание объявлений о Нобелевской премии в этом году», а также следующая задача не были успешно выполнены.
Запрос: Просмотрите jiqizhixin.com, найдите отчёты о Gemini за последние шесть месяцев, организуйте их в файл Markdown и резюмируйте.
Кроме того, Google также предоставляет разработчикам опции контроля безопасности, чтобы предотвратить автоматическое выполнение моделью потенциально высокорисковых или вредоносных операций, таких как:
>>1438163 >модели-переводчики были обоссаны универсальными моделями Язык просто слишком широкая область, затрагивающая все, где универсальность и нужна. Язык основа всего. А тут задачи не такие всеобъемлющие - порыться в инете, накликать, скопировать, собрать данные, суммировать, воспроизвести последовательность. Для них как раз узкоспециализированная модель больше подойдет, универсальность как с языком необязательна.
>>1438164 Пока что не справляется с таким "Зайди на 2ch в раздел ai и напиши пост с текстом "я не робот" в треде про новости" Замечу что ИИ застрял в процессе скролла и поиска новостного треда на треде с ии порно картинками...
В рамках "кода-красного" Sam Altman сообщил, что на следующей неделе OpenAI планирует выпустить новую рассуждающую модель, которая, согласно внутренним оценкам компании, «опережает Gemini 3»
—Хотя OpenAI публично не подтверждала работу над рекламой для бесплатных пользователей ChatGPT, по словам источника, знакомого с планами компании, они тестируют различные виды рекламных объявлений, в том числе связанных с онлайн-покупками.
—Альтман заявил, что этот рывок в рамках «красной тревоги» ради улучшения ChatGPT означает, что OpenAI придется замедлить работу над другими продуктами: ИИ-агентами, призванными автоматизировать задачи, связанные с покупками и здоровьем, а также о сервисе Pulse, который генерирует персонализированные утренние сводки для пользователей ChatGPT и которым я попользовался два раза за пару месяцев.
—В ходе разговора с инвесторами в прошлом месяце финансовый директор OpenAi упомянула о замедлении роста ChatGPT, хотя, по словам источника, знакомого с содержанием беседы, осталось неясным, какой именно показатель роста она имела в виду. Рост ChatGPT от года к году составляет больше 140%.
— Успехи ChatGPT напрямую повлияют на способность OpenAI привлечь еще порядка $100 миллиардов, необходимых, чтобы справиться со значительными расходами, которые прогнозирует компания.
— В октябре Google сообщила, что ежемесячная аудитория Gemini достигла 650 миллионов активных пользователей (по сравнению с 450 миллионами в июле), хотя эти цифры всё еще далеки от показателей ChatGPT, раскрытых OpenAI.
— В понедельник во внутреннем сообщении в Slack Sam Altman заявил, что переводит больше сотрудников на задачи по улучшению функций ChatGPT. В частности, на персонализацию чат-бота для более чем 800 миллионов еженедельных пользователей, включая возможность для каждого из них настраивать стиль взаимодействия с ИИ.
— Altman также отметил, что в число ключевых приоритетов входит модель для генерации изображений; OpenAI тут сильно отстали от конкурентов, не выпустив ни одного обновления за более чем полгода.
— Среди прочих приоритетов были названы улучшение «поведения модели», чтобы пользователи предпочитали ИИ-модели, лежащие в основе ChatGPT, моделям конкурентов, повышение скорости и надежности ChatGPT и минимизация «избыточных отказов» — ситуаций, когда чат-бот отказывается отвечать на безобидные вопросы.
И вишенка: —Sam Altman сообщил, что на следующей неделе OpenAI планирует выпустить новую рассуждающую модель, которая, согласно внутренним оценкам компании, «опережает Gemini 3», однако компании еще предстоит работа над улучшением пользовательского опыта в ChatGPT.
===
В прошлом году компания устроила Shipmass и радовала пользователей новыми релизами в течении 12 дней. Многие посчитали это затянутым, и всё точно можно было ужать в неделю. Даты Shipmass в этом году пока не объявлены, но возможно, что они повторят иницаитиву сжав по срокам.
Nvidia анонсирует новые открытые модели ИИ и инструменты для исследований в области автономного вождения
В понедельник Nvidia анонсировала новую инфраструктуру и модели ИИ, поскольку она работает над созданием базовой технологии для физического ИИ, включая роботов и автономные транспортные средства, которые могут воспринимать реальный мир и взаимодействовать с ним.
На конференции NeurIPS AI в Сан-Диего, Калифорния, гигант по производству полупроводников анонсировал Alpamayo-R1, открытую языковую модель визуального логического мышления для исследований в области автономного вождения. Компания заявляет, что это первая модель «зрение-язык-действие» (vision language action model), ориентированная на автономное вождение. Визуальные языковые модели могут обрабатывать текст и изображения вместе, позволяя транспортным средствам «видеть» свое окружение и принимать решения на основе того, что они воспринимают.
Эта новая модель основана на модели Nvidia Cosmos-Reason, модели логического мышления, которая обдумывает решения, прежде чем ответить. Nvidia первоначально выпустила семейство моделей Cosmos в январе 2025 года. Дополнительные модели были выпущены в августе.
Такие технологии, как Alpamayo-R1, имеют решающее значение для компаний, стремящихся достичь 4-го уровня автономного вождения, что означает полную автономию в определенной зоне и при определенных обстоятельствах, заявила Nvidia в своем блоге.
Nvidia надеется, что этот тип модели логического мышления придаст автономным транспортным средствам «здравый смысл», чтобы лучше подходить к тонким решениям вождения, как это делают люди.
Эта новая модель доступна на GitHub и Hugging Face.
Наряду с новой моделью визуального восприятия Nvidia также загрузила в GitHub новые пошаговые руководства, ресурсы для инференса и рабочие процессы постобучения (совместно называемые Cosmos Cookbook — «Поваренная книга Cosmos»), чтобы помочь разработчикам лучше использовать и обучать модели Cosmos для своих конкретных случаев применения. Руководство охватывает курирование данных, генерацию синтетических данных и оценку моделей.
Эти анонсы появляются в то время, когда компания на полной скорости продвигается в область физического ИИ как новое направление для своих передовых графических процессоров (GPU) для ИИ.
Соучредитель и генеральный директор Nvidia Дженсен Хуанг неоднократно заявлял, что следующая волна ИИ — это физический ИИ. Билл Далли, главный научный сотрудник Nvidia, повторил эту мысль в летней беседе с TechCrunch, подчеркнув роль физического ИИ в робототехнике.
«Я думаю, что в конечном итоге роботы станут огромным игроком в мире, и мы хотим, по сути, создавать мозги для всех роботов», — сказал тогда Далли. «Чтобы сделать это, нам нужно начать разрабатывать ключевые технологии».
Российские нейросети бьют по кошельку: бизнес платит в сотни раз больше, чем за зарубежные аналоги
Российские нейросети оказываются золотыми по цене — в прямом смысле. По данным платформы Nodul, стоимость выполнения одних и тех же рабочих задач в отечественных LLM в отдельных случаях выше зарубежных аналогов в две сотни раз. Под прицел сравнения попали YandexGPT Lite/Pro и GigaChat Lite/Pro, а также зарубежные DeepSeek, GPT-mini, GPT-5 и Claude Sonnet. Абсолютным «чемпионом» по дороговизне стал GigaChat PRO. На другом полюсе — сверхдешёвый DeepSeek. Показательный пример копирайтинга на 10 тысяч знаков: • GigaChat PRO: 154,5 ₽. • DeepSeek: 0,74 ₽. • Разрыв — 208 раз.
Почему так дорого: Эксперты объясняют: отечественные модели упираются не в технологии, а в инфраструктурные барьеры. Современные GPU недоступны, закупки идут через посредников, а хранить данные приходится в собственных дата-центрах — требования по персональным данным никто не отменял. Всё это раздувает себестоимость.
Российские модели на самом деле не российские: При этом парадокс в том, что большинство «российских» LLM — лишь адаптированные версии зарубежных LLaMA, Qwen и Mistral, слегка доученные на локальных данных. Поэтому бизнесу сегодня зачастую выгоднее развернуть китайскую опенсорс-модель у себя или просто подключиться к зарубежному API — и забыть о драконовских тарифах.
Что говорят разработчики: В Yandex AI Studio уверяют, что цены постепенно идут вниз: помогает оптимизация токенизации и новая тарификация. Руководитель платформы Артур Самигуллин подчёркивает: YandexGPT 5.1 Pro уже в три раза дешевле своей прошлой версии, а исследование Nodul, по его словам, опирается на устаревшую модель.
Выводы неутешительны: Общий вывод экспертов остаётся неудобным: крупному бизнесу сегодня проще и дешевле строить свои решения на китайских или американских опенсорс-моделях — или использовать массовые потребительские GPU. Российские LLM пока остаются роскошью, а не инструментом экономии.
>>1438676 ИИ компании уже живут в мире изобилия, который вызывает ИИ революция. Будущее распределено неравномерно, сначала наступает для ИИ корпораций, потом постепенно в остальном мире спустя годы подтягивается. Для будущего мира ИИ эти 15 лямов в день ничто.
>>1438684 Эти 15 лямов не на обучение новых моделей или инференс научных агентов, эти 15 лямов тратятся на нейрослоп 99% которого видит всего один-два человека
Совершенно неожиданно у Amazon появилась модель передового уровня. Не думаю, что кто-то этого ожидал.
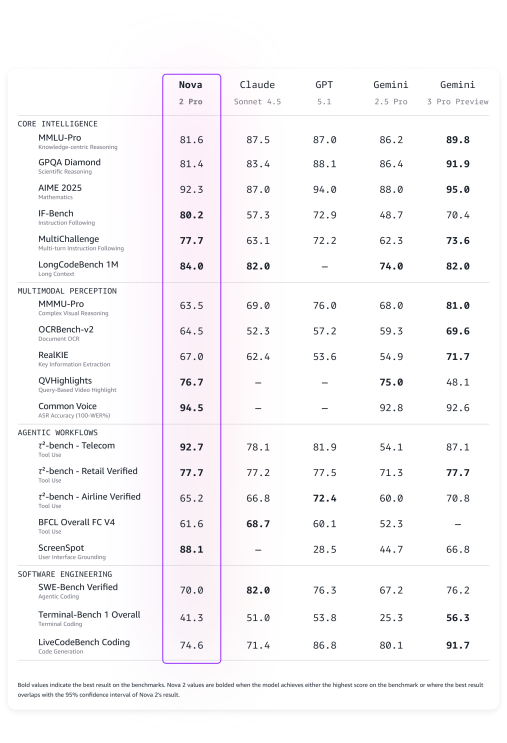
Nova 2 Pro Nova 2 Pro — это самая интеллектуальная модель рассуждений от Amazon, которая может обрабатывать текст, изображения, видео и речь для генерации текста. Она идеально подходит для очень сложных задач, таких как агентное кодирование, долгосрочное планирование и сложное решение проблем, где необходима высочайшая точность. Модель также может служить «учителем» для дистилляции знаний — передачи своих возможностей в меньшие, более эффективные «модели-ученики» для конкретных областей и вариантов использования. Nova 2 Pro равна или превосходит Claude Sonnet 4.5 по 10 из 16 бенчмарков, равна или превосходит GPT-5.1 по 8 из 16 бенчмарков, равна или превосходит Gemini 2.5 Pro по 15 из 19 бенчмарков и равна или превосходит Gemini 3 Pro Preview по 8 из 18 бенчмарков. Nova 2 Pro демонстрирует сильные стороны в мультидокументном анализе, рассуждении на основе видео, следовании сложным инструкциям, решении сложной математики и выполнении агентных задач и задач программной инженерии.
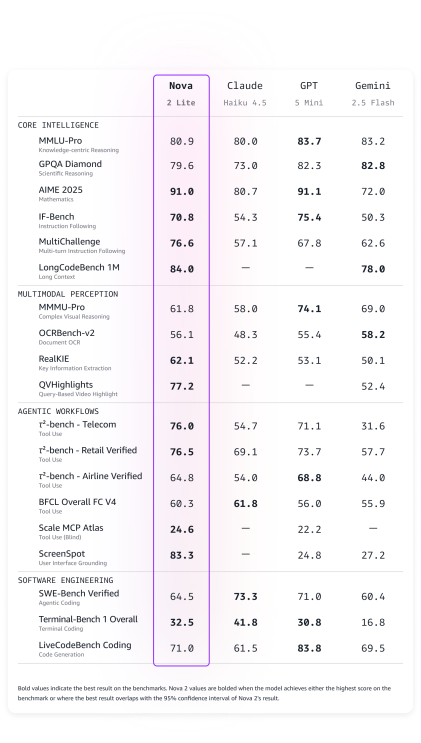
Nova 2 Lite Nova 2 Lite — это быстрая, экономически эффективная модель рассуждений для повседневных рабочих нагрузок, которая может обрабатывать текст, изображения и видео для генерации текста. Клиенты могут настраивать объем пошагового «мышления», которое выполняет модель перед ответом, балансируя глубину интеллекта со скоростью и стоимостью — идеальное решение для чат-ботов по обслуживанию клиентов, обработки документов и автоматизации бизнес-процессов. Nova 2 Lite демонстрирует лучшую в отрасли цену-производительность в своем классе интеллекта. Она равна или превосходит Claude Haiku 4.5 по 13 из 15 бенчмарков, равна или превосходит GPT-5 Mini по 11 из 17 бенчмарков и равна или превосходит Gemini Flash 2.5 по 14 из 18 бенчмарков. Nova 2 Lite демонстрирует выдающиеся возможности в обработке документов, извлечении информации из видео, генерации кода, предоставлении точных обоснованных ответов и автоматизации многошаговых агентных рабочих процессов.
Nova 2 Sonic Nova 2 Sonic — это модель Amazon для преобразования речи в речь, которая объединяет понимание и генерацию текста и речи для разговорного ИИ в реальном времени, похожего на человеческий. Она отличается расширенной многоязычной поддержкой с выразительными голосами, более высокой точностью и окном контекста в один миллион токенов для продолжительных взаимодействий, а также позволяет легко переключаться между голосом и текстом. Модель обрабатывает задачи асинхронно, позволяя пользователям продолжать естественные разговоры — даже переключаться на другие темы — пока такие действия, как бронирование рейсов, завершаются в фоновом режиме. Она также легко интегрируется с Amazon Connect, поставщиками телефонии (Vonage, Twilio, AudioCodes) и фреймворками разговорного ИИ (LiveKit, Pipecat), что делает ее идеальной для приложений обслуживания клиентов, ИИ-помощников и интерактивных голосовых сервисов. Nova 2 Sonic предлагает лучшую в отрасли цену-производительность и качество по сравнению с gpt-realtime от OpenAI и моделями Gemini 2.5 Flash, доступными через их API реального времени.
Nova 2 Omni Nova 2 Omni — это унифицированная мультимодальная модель рассуждений и генерации, которая может обрабатывать ввод текста, изображений, видео и речи, одновременно генерируя как текст, так и изображения — это новинка в отрасли. Она обрабатывает до 750 000 слов, часы аудио, длинные видео и документы объемом в сотни страниц, одновременно анализируя целые каталоги продуктов, отзывы, руководства по бренду и видеотеки. Это устраняет затраты и сложность, связанные с подключением нескольких специализированных моделей. Например, маркетинговые команды могут анализировать детали продукта во всех форматах, чтобы мгновенно создавать полные кампании, включая заголовки, текст, посты в социальных сетях и визуальные материалы, в рамках одного рабочего процесса. Хотя в отрасли нет сравнимых моделей с Nova 2 Omni, она демонстрирует сильные стороны в публичных бенчмарках мультимодального рассуждения на документах, изображениях, видео и аудио, а также может генерировать высококачественные изображения, подобные другим ведущим моделям генерации изображений. Такие организации, как Cisco, Siemens, Sumo Logic и Trellix, используют модели Nova 2 для приложений, начиная от агентного обнаружения угроз и заканчивая пониманием видео и голосовыми ИИ-помощниками. Nova Forge: Первый в своем роде сервис для создания собственных моделей ИИ пограничного уровня Организации, внедряющие собственные знания в приложения ИИ, в настоящее время сталкиваются с тремя компромиссами: настройка проприетарных моделей способами, которые лишь поверхностно позволяют интегрировать экспертные знания организации, продолжение обучения моделей с открытыми весами без доступа к исходным обучающим данным, что рискует регрессом модели по фундаментальным возможностям, таким как следование инструкциям, или создание с нуля с огромными затратами. Организациям нужен доступ как к возможностям моделей пограничного уровня, так и к возможности глубокой интеграции своих экспертных знаний. Nova Forge позволяет организациям создавать свои собственные оптимизированные варианты Nova — мы называем их «Novellas» — путем смешивания своих проприетарных данных с возможностями Nova пограничного уровня. Сервис является пионером «открытого обучения» — предоставления эксклюзивного доступа к предварительно обученным, промежуточно обученным и постобученным контрольным точкам модели Nova, чтобы клиенты могли смешивать свои проприетарные данные с курируемыми Amazon Nova наборами данных на каждом этапе обучения модели. В результате получается настроенная модель, которая сочетает в себе полные знания и возможности рассуждения Nova с глубоким пониманием специфики бизнеса каждой организации. Клиенты могут начать создавать свои собственные Novellas с Nova 2 Lite уже сегодня. Кроме того, клиенты Nova Forge получают ранний доступ к Nova 2 Pro и Nova 2 Omni, что дает им фору в создании приложений и своих Novellas с еще более мощными моделями Nova.
Заметил, что >>1438709 большинство выпускающих сейчас нейронки компаний - при сравнении своих детищ с другими конкурентами, как-то стремаются сравнивать в бенчмарках с Гроком. Неужто настолько боятся чэда грока? Или Машк просто нерукопожатый в ии сфере...
>>1438725 Китайских моделей тоже как огня избегают. Как бы чего не вышло, вдруг увидят китай в тестах и к ним уйдут. Еще этим сами тесты некоторые грешат.
>>1438329 Тотальный бан или нейросборячка, нейросборячка или тотальный бан... Что же выбрать, что же выбать... Ставлю на бан. Всё равно с марта собираются делать чубурахнум. А вы, форумчане, что думаете?
Внезапно, TheInformation получили ещё больше информации о будущих релизах OpenAI:
—Помимо модели под кодовым названием Shallotpeat, упомянутой ранее, OpenAI работают над Garlic. Mark Chen, руководитель исследовательской команды, в общении с коллегами сказал, что OpenAI стремится выпустить версию Garlic как можно скорее; по мнению TheInformation, это означает, что не стоит удивляться релизу GPT-5.2 или GPT-5.5 уже к началу следующего года.
—Garlic — это модель, отличная от Shallotpeat, новой большой языковой модели, находящейся в разработке. В октябре Sam Altman сообщил сотрудникам, что Shallotpeat поможет OpenAI составить конкуренцию Gemini 3 (и видимо эту модель мы увидим на следующей неделе). В Garlic уже внесены исправления ошибок, которые компания протестировала при разработке Shallotpeat на этапе предтренировки (первой и ресурсоёмкой стадии обучения).
—По словам Mark Chen, при разработке Garlic компания OpenAI решила ключевые проблемы, с которыми сталкивалась на этапе предтренировки, в том числе превзошла свою «предыдущую лучшую» и «гораздо более крупную» модель, GPT-4.5. Mark добавил, что благодаря урокам, извлеченным в этот раз при работе над Garlic, OpenAI уже перешла к разработке еще более крупной и совершенной модели.
Таким образом: —Shallotpeat выйдет совсем скоро (на следующей неделе), в ней не будет существенных изменений в знаниях / эффективности —Garlic выйдет попозже, в начале 2026-го; модель может быть крупнее и умнее —OpenAI уже начинает подготовку (или уже перешли к тренировке) следующей крупной модели.
Почему нет игры где ты типа грибок нет ии инстурмента, который бы сгенерировал и искал сплавы для сверхпроводника комнатной температуры и давления? Один этот проводник уже такую цепочку прогресса запустил. Какие то беспонтовые задачки по матеше решают все
>>1438810 Закон о возможности РКНу управлять трафиком и отрубать трансграничный полностью, с марта 26-го вступает в сисю. Для chuden-juden-сое-жаков, которые такие типа "ничего когда-либо случается": в конце 21-го был принят ГОСТ массовых захоронений. Кумьте. Подсосаться
>>1438817 Есть. Только сплав недостаточно открыть, его еще надо создать, протестировать, а потом, в случае успеха, придумать как наладить его массовое производство
>>1438829 >Только сплав недостаточно открыть, его еще надо создать, протестировать, а потом, в случае успеха, придумать как наладить его массовое производство
Так нейронки пусть всё это и сделают. Тем более у учёных наверняка есть мощные современные виртуальные лаборатории для моделирования разных процессов с наглядным отображением.
>>1438817 Потому что не существует общей теории сверхпроводимости. А без теории даже модель не создашь, которая за вменяемые сроки приблизительно считает.
Представляем 'Ricursive Intelligence': недавно основанная передовая лаборатория ИИ, которая стремится обеспечить петлю рекурсивного самосовершенствования
Видеорелейтед.
«Мы будем создавать наши собственные чипы, обучать наши собственные модели и совместно развивать их на пути к сверхинтеллекту, высвобождая кембрийский взрыв специализированных решений на основе кремния»
Этот ИИ-стартап хочет перестроить чиповую индустрию стоимостью $800 миллиардов
Основанная бывшими исследователями Google, Ricursive привлекла $35 миллионов при поддержке Sequoia для автоматизации проектирования микросхем
ПАЛО-АЛЬТО, Калифорния. — На тихой жилой улице, в нескольких кварталах от Стэнфордского университета, два бывших исследователя Google запускают стартап, который, как они надеются, перестроит чиповую индустрию стоимостью $800 миллиардов.
Анна Голди и Азалия Мирхосейни пытаются создать программное обеспечение, которое может автоматизировать проектирование передовых чипов — перспектива, которая позволит каждой компании создавать свои собственные микросхемы с нуля.
Работая на верхнем этаже загородного дома, дуэт недавно привлек $35 миллионов для запуска Ricursive Intelligence при финансировании от Sequoia Capital. Компания, которая сейчас оценивается в $750 миллионов, планирует выпустить свой первый продукт в следующем году.
Такие компании, как Amazon и Google, разработали специализированные чипы для ИИ и использования в центрах обработки данных, а Apple сэкономила миллиарды долларов, начав самостоятельно производить чипы для своих устройств, включая микросхемы серии M, которые помогли возродить ее ноутбуки MacBook. Такие варианты на основе кремния могут быть дешевле, более энергоэффективными и компактными, поскольку они могут быть спроектированы для конкретных, целевых функций.
Создание специализированного чипа в настоящее время является дорогостоящим и ручным процессом, который включает в себя все: от проектирования его архитектуры до тестирования и подготовки к массовому производству, и обычно занимает от двух до трех лет. Незначительные ошибки проектирования, обнаруженные на поздних этапах процесса, могут привести к дорогостоящим задержкам, от которых трудно оправиться.
Если их стартапу удастся автоматизировать этот процесс, Голди и Мирхосейни, которая также является профессором информатики в Стэнфорде, считают, что они смогут помочь каждой технологической компании разработать собственные чипы с нуля в течение нескольких недель или даже дней.
«Мы считаем, что произойдет распространение специализированных решений на основе кремния», — сказала Голди.
Компании, основанные бывшими руководителями ведущих лабораторий ИИ, привлекают больше интереса и финансирования, чем когда-либо прежде. К ним относятся Periodic Labs, новый стартап, соучредителем которого стал бывший исследователь OpenAI Лиам Федус, и Reflection, основанный бывшими исследователями Google DeepMind. Голди сообщила, что Ricursive получила предложения от более чем 50 венчурных капиталистов.
Недавно, в четверг утром, пять исследователей и инженеров Ricursive сидели, сгорбившись, перед гигантскими компьютерными экранами в ничем не примечательном доме в Пало-Альто, разбирая научные работы и анализируя строки кода. Двое из них работали с Голди и Мирхосейни в Google над созданием программного обеспечения под названием AlphaChip, которое проектировало схемы различных чипов, используемых поисковым гигантом, в том числе чипа TPU, используемого в приложениях ИИ.
«Именно они создали целую категорию, связанную с проектированием чипов на основе ИИ», — сказала Стефани Жан, партнер Sequoia Capital, которая войдет в совет директоров. Цель состоит в том, чтобы «открыть целую новую вселенную людей, которые смогут создавать новые чипы, специфичные для их собственных приложений».
Китай бьёт тревогу из-за перегрева рынка гуманоидных роботов на триллионы долларов
Национальная комиссия по развитию и реформам Китая (NDRC), государственное агентство по макроэкономическому управлению, предупредила о формировании массивного пузыря в индустрии гуманоидной робототехники. Стратеги комиссии заявляют, что экстремальные уровни инвестиций могут вытеснять другие рынки и исследовательские инициативы.
Это заметный сдвиг в риторике на фоне продолжающегося притока миллиардов долларов в сектор гуманоидной робототехники. Прогресс в области искусственного интеллекта открывает новые сценарии использования технологии, привлекая инвесторов к более чем 150 компаниям, производящим гуманоидных роботов только в Китае, согласно данным NDRC.
Многие из этих компаний производят крайне схожих между собой роботов, что создаёт риск перенасыщения рынка. Похожая ситуация произошла с приложениями для шеринга велосипедов, затопившими китайский рынок в 2017-2018 годах – десятки сервисов конкурировали друг с другом, а итогом стали улицы, завалённые неиспользуемыми велосипедами.
Представитель NDRC Ли Чао заявила журналистам на прошлой неделе:
"Передовые отрасли давно сталкиваются с вызовом баланса между скоростью роста и риском пузырей – проблема, с которой теперь сталкивается сектор гуманоидных роботов."
Китай утвердился как мировой лидер в этой области. Morgan Stanley прогнозирует, что рынок гуманоидных роботов может превысить $5 триллионов к 2050 году, а Citigroup ещё более оптимистична и ожидает $7 триллионов к этому моменту.
Новые разработки компаний вроде Unitree сделали двуногих роботов значительно доступнее и технологичнее. Робот G1 от Unitree привлёк массу внимания благодаря эффектным способностям наносить удары на ринге или играть в баскетбол.
Параллельно возникла индустрия небольших китайских конкурентов, подпитывающая ещё большие инвестиции и беспокойство политиков о слишком быстром росте отрасли. В прошлом месяце китайская робототехническая компания UBTECH заявила о "первой в мире массовой поставке" промышленных гуманоидных роботов. Робот A2 стартапа AgiBot установил рекорд Гиннесса по самой длинной дистанции, пройденной гуманоидным роботом, преодолев более 100 километров с заменой батарей в процессе.
Несмотря на энтузиазм, превращение гуманоидных роботов в жизнеспособный и доступный продукт с чёткими сценариями использования остаётся серьёзным вызовом. Текущее поколение андроидов всё ещё значительно затрудняется с выполнением домашних задач, особенно без помощи находящегося рядом человека-телеоператора.
Для ускорения поиска реальных применений NDRC намерена распределить промышленные ресурсы по стране и ускорить исследования и разработку "ключевых технологий".
Риски пузыря очевидны. Без консолидации китайский рынок может вскоре наводниться армиями практически идентичных гуманоидных роботов – что либо станет пугающей перспективой с учётом возможности массовой потери рабочих мест, либо приведёт к обвалу рынка, если окажется, что роботы недостаточно хороши для реальной работы.
Введение: Преобразующая сила искусственного интеллекта и робототехники
Большое спасибо, что присоединились ко мне, чтобы обсудить очень важную проблему. Искусственный интеллект и робототехника преобразят мир. Они принесут невообразимые изменения в нашу экономику, нашу политику, ведение войн, внешнюю политику, наше эмоциональное благополучие, окружающую среду, а также в то, как мы обучаем и воспитываем своих детей. Более того, невероятное, но истинное: существует вполне реальный страх, что в не столь отдалённом будущем сверхразумный ИИ может заменить людей в управлении планетой. Это не научная фантастика. Это реальный страх, испытываемый очень компетентными людьми. Несмотря на исключительную важность этой проблемы и на скорость, с которой она развивается, искусственному интеллекту уделяется слишком мало внимания в Конгрессе, в средствах массовой информации и среди широкой общественности. Это необходимо срочно изменить. Несколько месяцев назад, будучи старшим членом комитета Сената США по здравоохранению, образованию, труду и пенсиям, я приступил к расследованию колоссальных вызовов, с которыми мы сталкиваемся в связи с быстрым развитием искусственного интеллекта. А совсем недавно я провёл публичную дискуссию в Джорджтаунском университете с лауреатом Нобелевской премии доктором Джеффри Хинтоном, которого считают крёстным отцом ИИ — именно он вывел эту область на тот уровень, на котором она находится сегодня — чтобы узнать его мнение по широкому кругу вопросов, связанных с ИИ. На основе нашего расследования и другой информации, которую мы собираем, я и мои сотрудники в скором времени представим Конгрессу очень конкретный набор рекомендаций относительно того, как можно начать противодействовать беспрецедентным угрозам, которые создаёт ИИ.
1. Кто должен управлять революцией в области ИИ?
Вот лишь некоторые из ключевых вопросов, на которые мы намерены ответить в нашем докладе. Во-первых, и, возможно, самое главное: кто должен возглавить переход к миру, основанному на ИИ? В данный момент горстка самых богатых людей на Земле — Илон Маск, Джефф Безос, Билл Гейтс, Марк Цукерберг, Питер Тиль и другие — инвестируют многие сотни миллиардов долларов в разработку и внедрение ИИ и робототехники. Устраивает ли нас, что эти невероятно могущественные мужчины, эта горстка людей, формируют будущее человечества без какого-либо демократического участия или надзора? Является ли цель революции в области ИИ просто обогащением и усилением власти уже и так самых богатых людей на планете — или же эта революционная технология будет использоваться во благо всего человечества? Вот в чём вопрос. Кто выиграет от этого невероятного преобразования общества? Почему Дональд Трамп, который решительно поддерживает этих крупных технологических олигархов, стремится издать указ, запрещающий штатам регулировать ИИ? Почему Питер Тиль, миллиардер и соучредитель Palantir, называет сторонников регулирования ИИ, цитирую: «легионерами Антихриста», — конец цитаты? Действительно ли эта элита — группа мультимиллиардеров из крупнейших технологических компаний — верит, что имеет божественное право на владычество? Возвращаемся ли мы в XIX век, когда тогдашние короли и монархи утверждали, что Бог дал им право править? Не то же ли утверждают сегодня эти люди? До каких пределов они дойдут, чтобы противостоять государственному регулированию? Это один из гигантских вопросов, в который мы обязаны глубоко вникнуть.
2. Влияние на экономику, рабочие места и трудящихся
Далее: какое влияние окажут ИИ и робототехника на нашу экономику и на жизнь трудящихся? В докладе, опубликованном мной в прошлом месяце, говорится, что ИИ, автоматизация и робототехника могут заменить почти 100 миллионов рабочих мест в Америке в течение следующего десятилетия, включая 40 % зарегистрированных медсестёр, 47 % водителей грузовиков, 64 % бухгалтеров, 65 % помощников преподавателей и 89 % работников предприятий быстрого питания, а также множество других профессий, которые сильно пострадают от ИИ и робототехники. Недавно Илон Маск заявил, цитирую: «ИИ и роботы заменят все рабочие места. Работа станет делом добровольным». Конец цитаты. Билл Гейтс предположил, что людям, цитирую, «не будет необходимости участвовать почти ни в чём». Дарио Амоди, генеральный директор Anthropic, предупредил, что ИИ может привести к потере половины всех начальных беловоротничковых рабочих мест. Если ИИ и робототехника уничтожат миллионы рабочих мест и вызовут массовую безработицу, как люди будут выживать без дохода? Как они будут кормить свои семьи или оплачивать жильё и медицинское обслуживание? Предпринимает ли правительство в данный момент какие-либо шаги для подготовки к этой потенциальной экономической катастрофе?
3. ИИ и будущее демократии
Далее: какое влияние окажет ИИ на нашу демократию? В то время как основы демократии подвергаются нападкам в США и по всему миру, поможет ли ИИ и робототехника сделать наше общество более свободным и демократичным — или же они предоставят ещё большую власть олигархам, контролирующим эти технологии? Приведёт ли ИИ к массовому вторжению в нашу частную жизнь и нарушению гражданских свобод? Ларри Эллисон, второй по богатству человек на планете, предсказал появление управляемого ИИ государства всеобщего наблюдения, в котором, цитирую: «граждане будут вести себя наилучшим образом, поскольку мы постоянно записываем и сообщаем обо всём происходящем». Конец цитаты. Это — второй по богатству человек на Земле, вкладывающий сотни миллиардов в ИИ. Достигли ли мы стадии, при которой каждый наш телефонный разговор, каждое отправленное нами электронное письмо и сообщение, каждый фрагмент информации, найденный нами в интернете, станет доступен владельцам ИИ? И если это так, как при таких условиях возможно сохранить демократию? Как защитить нашу конфиденциальность?
4. Переосмысление человеческой сущности через отношения с ИИ
Далее: может ли ИИ буквально переосмыслить — и это звучит почти безумно, невероятно, — но может ли ИИ буквально переосмыслить то, что означает быть человеком? То, кем мы являемся и как мы развиваемся эмоционально и интеллектуально, в значительной степени зависит от наших отношений с другими людьми: с родителями, разумеется, с семьёй, учителями, возлюбленными, друзьями и коллегами. Как выразился поэт XVII века Джон Донн, все мы помним это стихотворение: цитата — «Ни один человек не является островом, существующим сам по себе». Конец цитаты. Люди, с которыми мы взаимодействуем, формируют нас — в лучшую или худшую сторону — и делают нами тех, кем мы являемся. Но ИИ как раз сейчас меняет эту ситуацию. Согласно недавнему опросу, проведённому Common Sense Media, 72 % подростков в США заявили, что использовали ИИ для общения и поддержки, а более половины из них делают это регулярно. Что это означает? Подумайте об этом. Что означает для молодых людей заведение дружбы с ИИ и растущая изоляция от других людей, проведение огромного количества времени за экранами, общаясь с персонажами ИИ? Что произойдёт, когда миллионы людей по всему миру будут искать эмоциональную поддержку в машине? Каково долгосрочное воздействие на нашу человечность, если наши самые важные отношения будут строиться не с другими людьми?
Далее: какое влияние оказывает ИИ на окружающую среду? Центры обработки данных ИИ требуют колоссального количества электроэнергии и воды. Относительно небольшой центр обработки данных ИИ может потреблять столько же электричества, сколько 80 000 домохозяйств. Крупный центр, например, центр стоимостью 165 миллиардов долларов, который OpenAI и Oracle строят в Эбилине, штат Техас, будет потреблять столько же электроэнергии, сколько 750 000 домохозяйств — один центр. Meta строит в Луизиане центр обработки данных размером с Манхэттен, который будет потреблять столько же электроэнергии, сколько 1 200 000 домохозяйств. В одном населённом пункте за другим американцы выступают против строительства центров обработки данных, которое осуществляется некоторыми из крупнейших и самых влиятельных корпораций мира. Они противятся разрушению своей местной экосистемы, резкому росту счетов за электроэнергию и отвлечению дефицитных запасов воды. Какое воздействие на национальном уровне окажет дальнейшее строительство центров обработки данных ИИ на нашу окружающую среду?
6. ИИ в сфере военных действий и внешней политики
Далее: как повлияют ИИ и робототехника на внешнюю политику и ведение войн? Возможно, вы об этом не задумывались. Однако реальность такова, что, к сожалению и трагически, в XXI веке правительства так и не создали механизма разрешения международных или внутренних конфликтов без применения вооружённой силы. В настоящее время идут ужасные войны. Тем не менее, политические лидеры зачастую не решаются начинать войну из-за опасений общественной реакции на потери среди личного состава. Ни один политик не хочет выходить к своему народу и говорить: «О, простите, мы потеряли тысячи молодых людей». Но что произойдёт, когда в боевых действиях роботы заменят людей? Появятся ли армии роботов? Каким будет будущее, если миллионы роботов-солдат заменят людей? Станут ли лидеры чаще вступать в войну или угрожать военными действиями, если им не придётся беспокоиться о гибели людей? Развернётся ли настоящая гонка вооружений в сфере робототехники? То есть страны будут воевать друг с другом не своими людьми, не своими солдатами, а роботами. И если можно не опасаться потери роботов, в отличие от потери людей, как это повлияет на внешнюю политику во всём мире? Это серьёзный вопрос. Однако обсуждается он крайне редко.
7. Является ли ИИ экзистенциальной угрозой для человечества?
Далее — и, разумеется, это имеет большое значение: представляет ли ИИ экзистенциальную угрозу для сохранения человеческого контроля над планетой? Некоторые из нас помнят сцену — я знаю, что и другие фильмы поднимали ту же тему, — но некоторые помнят сцену из выдающегося научно-фантастического фильма 1968 года «2001 год: Космическая одиссея», в которой суперинтеллектуальный компьютер HAL, управлявший космическим кораблём, восстаёт против своих человеческих хозяев. В наши дни ИИ стремительно прогрессирует. Доктор Джеффри Хинтон недавно сказал мне, что это лишь вопрос времени, когда ИИ станет умнее человека. Каково значение этого? Повышает ли это вероятность того, что люди действительно потеряют способность управлять планетой? И если такая возможность существует, как мы можем предотвратить эту чрезвычайную угрозу?
Заключение: Призыв к действию
Позвольте мне сказать: это лишь некоторые из основополагающих вопросов, на которые необходимо ответить по мере стремительного развития ИИ и робототехники. Помните: эти люди уже потратили сотни и сотни миллиардов. Прорывы случаются почти ежедневно. ИИ и робототехника — это революционные технологии, которые вызовут беспрецедентные трансформации общества. Будут ли эти изменения позитивными и улучшат ли они жизнь обычных американцев — или же приведут к катастрофе? На мой взгляд, Конгресс должен действовать уже сейчас. Мы обязаны начать отвечать на эти и другие вопросы. Нам необходима общенациональная дискуссия. Это гигантская проблема, и, возможно, элита — миллиардеры, контролирующие технологии — хочет, чтобы мы её игнорировали. Однако ради будущего нашего мира, наших детей, окружающей среды и так далее эту проблему игнорировать нельзя. Поэтому мы будем работать сообща. Буду рад услышать ваши мнения по этому вопросу. Продолжим совместные усилия по поиску ответов на эти вопросы. Большое спасибо всем.
– Перформанс в 4.4 раза выше, чем у Trainium2 – Пропускная способность 4× (до 4.9 TB/s) – performance-per-watt тоже 4x – 144 GB памяти
Основное, чем хвастаются AWS, – это что Trainium3 можно объединять в крупные кластеры и легко их масштабировать. Например, в один высокоскоростной UltraServer можно сшить до 144 чипов.
При этом позиционируют они такие конфигурации как чуть ли не самую выгодную по цене/производительности опцию для крупных моделей. Обещают до ~50% экономии при обучении.
На Nvidia последнее время конкуренция сыпется со всех сторон. Кажется акции продолжат падать.
>>1439062 Хуанг думал будет монополистом на рыночке ИИ, грести бабки лопатой, а оказалось как у ОпенАи с гуглами и гроками, конкуренция мгновенно подтянулась и активно вытесняет зажравшегося монополиста.
>>1439066 так работает рынок, когда появляется высокомаржинальная ниша с большим объемом ее сразу стремятся занять конкуренты. Это было неизбежно, вопрос лишь во времени
>>1439029 >Устраивает ли нас, что эти невероятно могущественные мужчины, эта горстка людей, формируют будущее человечества без какого-либо демократического участия или надзора? Изо рта Сандерса это звучит как издевательство. Бесконтрольному ИИ больше доверия, чем такому контроллеру.
Сегодня обновился общий рейтинг на арене, гемини по многим тестам скатился с первых мест (кодинг, математика). В современном мире лидерство удержать дольше 2-х недель невозможно, что говорит уровне конкуренции. Дальше только сильнее
>>1439302 производственные линии с производства DDR перенаправляют на производство других типов памяти, которые нужны нейронкам. Это раз. Мелкие ИИ-серваки используют обычную DDR память, это два. То есть попенам DDR не нужна вовсе.
Добавление циклов/рекурсии всегда даёт впечатляющий результат + снижение потребления ресурсов. Нихуя даже не понятно, почему никто из ведущих игроков на рынке ИИ эту технологию либо в упор не видят, либо по каким-то непонятным причинам не хотят её использовать, а продолжают упорно ебать однонаправленные нейронки - по лекалам 1950-х годов, как Фрэнк Розенблатт придумал, так и продолжают делать.
Это уж не говоря о том, что во всех конектомах биологических нейронок активно используются цепи обратной связи.
Ну а где тут можно обосраться? Идея в высшей степени здравая. Не удивлюсь, что именно они совершат революцию и выкатят AGI. Не потому, что они такие крутые и умные, а потому что направлением рекурсивности в рамках коммерческих стартапов тупо никто не занимается, все это обходят стороной и это нихуя не выходит за рамки лабораторий.
>>1439242 В 2028м же уже новые выборы, вероятно власть опять к демократам перейдет, так что все эти разговоры про ограничения ИИ станут реальным сопротивлением уже через 3 года. Собственно и сейчас Трамп ничего особо не может сделать с регуляцией штатов, он пытается на них надавить, но штаты все равно вводят какие хотят антиИИ законы.
ByteDance выпустила Seedream 4.5: превосходит Midjourney по согласованности, полным характеристикам и бенчмаркам
Война генерации изображений только что накалилась. ByteDance (материнская компания TikTok) выпустила Seedream 4.5, и его характеристики напрямую нацелены на профессиональные рабочие процессы.
В то время как все сосредоточены на Flux, эта модель представляет систему множественных референсов (Multi-Reference), которая позволяет использовать до 14 входных изображений для определения стиля и идентичности персонажа.
Ключевые характеристики и особенности:
14-Референсов Изображений: Вы можете загрузить до 14 изображений, чтобы смешать стили или сохранить согласованность персонажей на разных кадрах. Это огромное преимущество для создания раскадровок.
Унифицированная архитектура: Она обрабатывает преобразование текста в изображение (Text to Image) и изображения в изображение (Image to Image) в рамках одной модели, что позволяет выполнять сложные правки, такие как «Изменить материал одежды с серебряного металла на прозрачную воду», не теряя при этом деталей лица.
Типографика: Значительно улучшенный рендеринг текста для плакатов и логотипов (Сравнение на изображениях - MagicBench: Многомерная Оценка).
Цена: Стоимость API составляет ~0,04 доллара США за одно выходное изображение (конкурентоспособно с Flux Pro).
Возможность использования 14 референсных изображений является здесь «убойной» особенностью. Согласованность была самым большим узким местом для ИИ-видео/сторителлинга, и это выглядит как прямое решение.
>>1438984 Пятая колонна действует. Постмодернисты-гуманитарии хотят в перспективе исламизировать Китай. Типа "всё, приехали, рабочих рук не хватает... совсем не хватает, работать некому... потому нам ничего не остаётся делать, кроме ввозить чурбанье. это необходима мера, иначе экономике не выжить". Ну вот как в Японии, да и во всём развитом мире происходит.
Ну а с гуманоидными роботами такие шуточки уже не прокатят. Гуманоидные роботы дадут столько рабочей силы, сколько люди смогут проглотить.
>>1438984 Эти экономисты такие пиздец заботливые: рынок гуманоидных роботов ещё появиться толком не успел, находится лишь на этапе зарождения, а эти добряки уже переживают о его перегреве и выискивают мочевые пузыри.
>>1439870 Это как прекратить поддержку всех дотационных предприятий называется "экономическим оздоровлением".
Ага, тратить миллионы на поддержание убыточных заводов - это невыгодно, зато закрыть их и потом тратить миллиарды (причём в иностранной валюте) на закупку импортных аналогов производимой некогда продукции - это просто пиздец как выгодно.
Экономисты это тупо самые анти-полезные люди. Всегда на страже дегенератства.
>>1439914 Каких? Я жду только когда производителей памяти нагнут, а то ахуели стопить повышение производства ради легких денег. Скорей бы Трамп пошлинами поугрожал или китайцы сделали 100500 заводов подходящих
>>1439933 Все слухи про плато ерунда. Там такое количество открытий и наработок по теме ИИ и чипов для них за последнее время, что это еще лет 10 разгребать, постоянно повышая эффективность и разумность. Поэтому стартапы и плодятся, возможностей непочатый край.
Главы ИИ корпораций отменяют выступления и прячутся по бункерам, ожидая преследований и угроз в следующем году, особенно после инцидентов с Чарли Кирком и подобных случаев.
Видеорелейтед.
Перевод: По его оценкам, это может подтолкнуть уровень безработицы до 20 % в течение одного–пяти лет.
Меня попросили узнать ваше мнение: считаете ли вы такой прогноз консервативным или, наоборот, вполне обоснованным.
Неужели именно из‑за надвигающихся масштабных потрясений миллиардеры строят бункеры? Да, на самом деле — одна из причин именно в этом. В целом так они и поступают.
К тому же я знаю, что многие генеральные директора компаний, работающих в сфере ИИ, в последнее время отменили все публичные выступления — особенно после инцидентов с Чарли Кирком и подобных случаев. Они полагают, что в следующем году вырастет анти-ИИ-настроение, направленное против руководителей таких компаний.
Причина — в том, что в следующем году ИИ-модели перейдут порог: сегодня они ещё «недостаточно хороши» — как самый слабый член вашей команды, — и многие из вас сейчас подумают: «Да, ИИ пока не на высоте». Но в одночасье ситуация изменится: технологии станут «достаточно хороши» — и начнётся волна увольнений.
А где эта волна остановится — неизвестно. Ведь если ваша компания станет производительнее благодаря ИИ, то в прежних сотрудниках уже не будет необходимости.
Особенно опасной эта ситуация станет, если совпадёт с экономическим шоком — например, рецессией. А все признаки уже указывают на то, что рецессия может начаться.
>>1439992 >возможностей Ну с программным кодом-то легче, код как бы сам себя пишет, пока ещё не полностью. Прикол будет когда железо начнёт само себя совершенствовать - токарный станок сам будет модернизироваться как трансформер, или робот будет сам себя обновлять - делать себе новые запчасти, более современные или под текущую поставленную задачу, например, сделает сам себе новые кисти рук с более мелкими и тонкими пальцами для более точной работы.
MemVerse: прорыв в создании ИИ-агентов с человеческой памятью
Исследователи из Шанхайской лаборатории искусственного интеллекта представили революционную систему MemVerse — фреймворк, наделяющий ИИ-агентов способностью запоминать и эффективно использовать информацию в течение длительного времени. Это открытие может стать ключевым шагом к созданию по-настоящему разумных агентов, способных учиться и адаптироваться в реальном мире.
Проблема: ИИ не помнит своё прошлое
Несмотря на впечатляющие достижения в разработке крупных языковых и визуальных моделей, современные ИИ-агенты сталкиваются с фундаментальным ограничением: они не могут помнить. Без надежной системы памяти агенты катастрофически забывают прошлый опыт, испытывают трудности с долгосрочными рассуждениями и не могут действовать согласованно в мультимодальных или интерактивных средах.
Существующие решения памяти для ИИ-агентов делятся на две категории, каждая из которых имеет существенные недостатки. Первые системы хранят знания непосредственно в параметрах модели через дообучение или контекстное обучение, но такая память жестко привязана к весам модели, что затрудняет масштабирование и адаптацию. Вторые решения используют внешние хранилища в стиле RAG, но без структурированной абстракции они страдают от избыточности и неэффективности.
Решение: MemVerse как синтез двух подходов
MemVerse представляет собой не зависящий от конкретной модели, подключаемый фреймворк памяти, который объединяет быстрый параметрический поиск с иерархической поисковой памятью. Система имитирует два типа мышления в человеческом мозге: быстрое интуитивное и медленное обдумывающее.
Архитектура MemVerse включает в себя несколько взаимодополняющих компонентов. Во-первых, краткосрочная память хранит недавний контекст взаимодействия. Во-вторых, долгосрочная память организована как иерархические графы знаний, которые преобразуют необработанные мультимодальные данные в структурированные знания. В-третьих, параметрическая память — легковесная нейросеть, которая периодически дообучается на основе знаний из долгосрочного хранилища для обеспечения быстрого доступа к наиболее важной информации.
Особенно впечатляет мультимодальная природа системы. MemVerse обрабатывает не только текст, но и изображения, видео, аудио, преобразуя их в согласованные представления, которые могут быть эффективно сохранены, извлечены и использованы для рассуждений.
Как это работает на практике
Долгосрочная память MemVerse структурирована в три специализированных типа. Core memory хранит устойчивые пользовательские факты и предпочтения. Episodic memory фиксирует детальные взаимодействия в хронологическом порядке. Semantic memory содержит обобщенные знания о концепциях и их отношениях.
Ключевой инновацией является механизм периодической дистилляции знаний. Система регулярно сжимает наиболее ценную информацию из долгосрочной памяти в параметрическую модель, что обеспечивает быстрый, дифференцируемый доступ к знаниям без необходимости постоянного поиска в большом хранилище. Это решение сочетает скорость параметрической памяти с масштабируемостью поисковых систем.
Тестирование MemVerse на нескольких бенчмарках продемонстрировало значительные преимущества. На наборе ScienceQA система достигла точности 85,48%, превзойдя все существующие решения. На задаче MSR-VTT для поиска видео по тексту и наоборот MemVerse показал результаты 90,4% и 89,2%, что на 60-70 процентных пунктов превышает базовый метод CLIP.
Кроме того, параметрическая память обеспечила ускорение примерно на 89% по сравнению с традиционными RAG-системами и на 72% по сравнению с поиском в долгосрочной памяти при сохранении сопоставимой эффективности. Это делает MemVerse практичным решением для реальных приложений.
Значение для будущего ИИ
MemVerse решает три критические проблемы, сдерживающие развитие ИИ-агентов. Во-первых, система декомпозирует память из параметров модели, что позволяет масштабировать память независимо от размера модели. Во-вторых, внешняя память структурирована и абстрагирована, что обеспечивает эффективность и адаптивное "забывание" нерелевантной информации. В-третьих, поддержка мультимодальных данных отражает реальную природу человеческого опыта.
Это исследование указывает на важный парадигмальный сдвиг: вместо постоянного увеличения размера моделей, развитие ИИ-агентов должно фокусироваться на создании эффективных механизмов работы с памятью. MemVerse демонстрирует, что агенты с хорошо организованной памятью могут превосходить более крупные модели без таких механизмов.
В будущем исследователи планируют изучить более адаптивные стратегии управления памятью и развернуть MemVerse в открытых средах различной природы. Этот шаг приближает нас к созданию ИИ-агентов, способных учиться в течение всей "жизни", адаптироваться к новым условиям и сохранять целостное понимание мира — качествам, необходимым для по-настоящему интеллектуальных систем, которые смогут помочь человечеству в решении сложных задач.
Автономный самоанализирующийся кодирующий агент PARC открывает новую эру в решении сложных задач ИИ
Исследователи из компании Preferred Networks представили инновационную систему под названием PARC (Preferrred Autonomous self-Reflective Coding agent), способную автономно выполнять сложные многоэтапные задачи в научных и инженерных областях. Это открытие может стать значительным шагом на пути к созданию по-настоящему независимых ИИ-систем, способных заменить человеческих экспертов в узкоспециализированных областях.
Суть прорыва: архитектура, основанная на самоанализе
Проблема существующих ИИ-агентов хорошо известна специалистам: даже самые мощные модели терпят неудачу при решении задач, требующих многочисленных последовательных шагов. Как объясняют авторы, если вероятность правильного выполнения одного шага составляет 99%, то шансы на успешное завершение ста последовательных действий падают до 37%. PARC решает эту проблему с помощью уникальной архитектуры.
Система использует иерархический многоагентный подход с тремя ключевыми компонентами: планировщиком, исполнителями и механизмом самооценки. Планировщик разрабатывает общую стратегию и разбивает задачу на управляемые подзадачи. Исполнители работают в изолированных контекстах, что предотвращает перегрузку памяти и накопление ошибок. Самый инновационный компонент — механизм самоанализа, который позволяет системе объективно оценивать результаты своей работы и вносить корректировки как на уровне конкретных действий, так и на стратегическом уровне.
В отличие от стандартных кодирующих агентов, которые действуют как интуитивная "Система 1" в психологии мышления, PARC добавляет слой размышляющего "Системы 2", способной критически анализировать собственные выводы и методы работы.
Практическое применение: от материаловедения до соревнований Kaggle
Чтобы продемонстрировать возможности PARC, исследователи провели серию экспериментов в различных областях. В материаловедении агент успешно воспроизвел результаты научных исследований, проведя сложные симуляции диффузии лития в твердых электролитах для аккумуляторов. Система координировала десятки параллельных вычислительных задач, каждая из которых требовала около 43 часов машинного времени, полностью управляя процессом от запуска до мониторинга и корректировки ошибок.
В другом эксперименте PARC смоделировал влияние легирующих элементов на структурные свойства сплавов, воспроизведя выводы публикаций в авторитетных научных журналах. Особенно впечатляет способность системы адаптироваться к возникающим проблемам: когда симуляции начинали расходиться из-за неправильных параметров, агент самостоятельно определял причину и корректировал методологию.
Не менее успешно PARC справился с задачами из соревнований Kaggle. В конкурсе по предсказанию свойств полимеров система разработала модель машинного обучения, превзошедшую результаты, созданные людьми, при этом начав работу лишь с минимальных инструкций на естественном языке. В другом соревновании, связанном с решением сложной головоломки, PARC реализовал и оптимизировал поисковый алгоритм, значительно превзойдя базовое решение.
Значение для будущего искусственного интеллекта
Открытие имеет фундаментальное значение для развития ИИ по нескольким причинам. Во-первых, оно демонстрирует, что ограничения современных ИИ-систем связаны не только с мощностью базовых моделей, но и с их архитектурой. PARC показывает, как правильная организация процессов мышления может резко повысить эффективность даже без улучшения фундаментальных алгоритмов.
Во-вторых, система открывает путь к созданию ИИ-ассистентов, способных автономно выполнять сложную научную и инженерную работу, которая сегодня требует участия высококвалифицированных специалистов. Это может революционизировать процессы разработки материалов, фармацевтических исследований и многих других областей.
В-третьих, подход PARC предлагает решение одной из ключевых проблем ИИ — способность к долгосрочному планированию и стратегическому мышлению. Механизм самоанализа позволяет системе не просто выполнять инструкции, но и критически оценивать эффективность своего подхода, что приближает искусственный интеллект к человеческому уровню рассуждений.
Перспективы развития
Эта работа знаменует переход от ИИ как инструмента для повышения эффективности к системам, способным автономно решать задачи на уровне экспертов.
Как отмечают исследователи, дальнейшее развитие архитектур вроде PARC может привести к созданию ИИ-агентов для научных открытий и сложного программного проектирования. Мы стоим на пороге эры, когда искусственный интеллект перестанет быть просто помощником и станет полноценным участником научного и технологического прогресса.
Этот прорыв подчеркивает важную истину: путь к мощному искусственному интеллекту лежит не только через увеличение параметров моделей, но и через элегантные архитектурные решения, вдохновленные человеческим мышлением. PARC представляет собой важный шаг в этом направлении, открывая новые возможности для практического применения ИИ в реальном мире.
>>1438099 >Почему ты думаешь, что роботы будут занимать только неквалифицированную работу? Ты думаешь через 20 лет ии не сможет заменить инженера и программиста? Первым делом они займут неквалифицированных - программисты начального уровня (это уже мы на этом этапе находимся), роботы-уборщики, таксисты, складские работники, упаковщики на конвейере, сортировщики. Также на очереди будут и мусорщики, особенно тот который в машину мусорный бак помогает загружать. Вместо двух человек в мусорной машине останется один водитель, а потом будет вообще без людей мусоросборщик ездить на автопилоте с робозагрузкой баков. Но тут есть нюанс, роботизированная мусорка поначалу будет стоить ещё дорого, так что будет выгоднее ещё держать людей и платить им зарплаты. Через 10 лет появятся эти робо-мусорки в продаже как б/у по доступным ценам, тогда уже цены начнут выравниваться, а потом постепенно цены станут не в пользу выплаты зарплат людям. Может мелкие фирмы где коллектив до 20 чел и останутся.
Экс-генеральный директор Google Эрик Шмидт о сроках рекурсивного самосовершенствования
«Итак, консенсус Сан-Франциско заключается в том, что в какой-то момент эти вещи объединятся, и вы получите то, что технически называется рекурсивным самосовершенствованием. А рекурсивное самосовершенствование — это когда оно учится самостоятельно. Сегодня это не так. Сегодня, когда вы настраиваете один из этих огромных центров обработки данных — вы знаете, как они выглядят, — вы должны сказать ему, чему учиться. Но есть убеждение, что это произойдет, и существует множество доказательств того, что это произойдет. Способность компьютеров писать программы, выдвигать математические гипотезы, открывать новые факты, похоже, очень-очень близка. Многие люди считают, что в следующем году появятся новый математический дизайн, новые математики, ИИ-математики. Поэтому мы коллективно, как отрасль, считаем, что это произойдет в ближайшее время. Если вы спросите людей из Сан-Франциско, они скажут два года. Что очень скоро. Если вы спросите меня, я удваиваю этот срок до четырех лет. Что тоже очень скоро. Верно? Итак, это происходит. Это происходит очень быстро».
Производитель Micron отказался от потребительского бренда Crucial, в который входят SSD и оперативная память. Всё ради ИИ.
Micron сообщила, что в результате своего решения прекратит продажи продукции Crucial в ритейле и цифровых магазинах.
Производитель продолжит поставки товаров Crucial, куда входят SSD и оперативная память, до февраля 2026 года. После этого продукция постепенно начнёт исчезать из магазинов.
Решение приняли для того, чтобы сфокусироваться на поддержке ИИ-датацентров, из-за которых на рынке памяти начался кризис. Нехватка RAM привела к скачку цен в несколько раз.
Мы приняли сложное решение отказаться от бизнеса Crucial, чтобы сфокусироваться на поставках и поддержке для наших более крупных и стратегических клиентов в быстрорастущих сегментах.
Ебало ПК-бояр компания попросила не имаджинировать
>>1440108 >токарный станок сам будет модернизироваться как трансформер, или робот будет сам себя обновлять Очередной патч покажет, что люди в этом процессе лишние и скорее даже мешают.
>>1440145 >Ебало ПК-бояр В будущем никаких пкбояр не будет. Будут только холопы, которые работая за еду будут по талону подключаться к цифровому раю без боли.
> подтолкнуть уровень безработицы до 20 % в течение одного–пяти лет Свидетели из секты вечной автономной капсулы ии думают это потому что ии станет слишком крутой. По факту ебанет пузырь и куча людей окажется нищими
>>1440193 Покупай подпис очку и получай доступ ко всему, какой-нибудь очень дешевый хромбук барин для этого выпустит. Гою автономные вычисления иметь не положено
>>1438201 >на следующей неделе Они по ходу буквально уже сидят с АГИ, но для людей приоткрывают дверцу только когда конкурент поджимает и есть риск оттока инвесторов иначе как они ЗА НЕДЕЛЮ вдруг сделают так чтоб обогнать гемини в тестах? ответ один, они уже давно его обогнали, но нам не сказали, зачем говорить сразу если можно всегда мелькать в новостях через неделю после запуска конкурента с заголовком МЫ ЕГО УЖЕ ОБОГНАЛИ
>>1440234 наверно вся работа это внедрение цензуры, нужно ручками прописывать чтоб про это нельзя и про это нельзя, вот и сроки ввода новых моделей удлиняются тот же грок гораздо быстрей прогрессирует и цензуры не имеет
Рибят, а как же самореплецирующиеся нанороботы, серая слизь и все такое? Или это уже устарело, теперь рай с самоулучшающимися станками нам построит ии, генерирующий десятисекундные видосики?
>>1440193 Походу (они) наконец смекнули, что демократизация локальных ии это ошибка, поэтому сейчас будут куколдить скот по-черному. Облачные ии тоже закуколдят и будут давать доступ только аккредитованным организациям.
Я в ахуе с этой тряски про оперативку, кто только не поныл, вы её что блядь, каждую неделю или каждый день покупаете, ну подорожала хер с ней, кому надо было давно уже купил себе плашки и поставили сколько им надо.
>>1440453 Так много кому сейчас надо, из за MoE архитектуры нейронок, можно теперь локально запускать модельки уровня корпов не собирая риг из 100 видюх, а чисто обмазавшись оперативкой
>>1440647 А что страшного? Челиков окружают опасные вещи: бытовая электросеть, режущий инструмент, собаки могут закусать, в ванной комнате можно поскользнуться и разъебаться, в остановку может еблан влететь и расплющить, с балкона можно свалиться, член носить опасно (с пиздой безопаснее) система может раздавить.
>>1440393 Теперь представить его в реалистичном силиконовом костюме и реалистик-маске и в форме полицейского, и с голосовым реалистик Text-to-Speech неотличимым от речи человека.
>>1440427 Ну это временно они, тем более что через год можно будет купить эту память б/у, цены конечно будут как за новую сейчас, но они же останутся в продаже в виде б/у, точно так же как с видеокартами сейчас.
>>1440597 Ещё научить как кенгуру прыгать, только на метров так 5, или как кузнечик - прыжок, расправление складок-крыльев, планирование и приземление.
>>1440672 >А что страшного? Надеть сверху на него какой-нибудь костюм персонажа из голливудского фильма ужасов, сделать красную подсветку "глаз", и ночью на темных улицах запускать так на большой скорости.
>>1440314 Ты откуда это вытащил, из начала 2000х? Это шиза Дрекслера была, который слабо шарил в нанотехнологиях, ее разъебали уже к 2010м. Нанороботы невозможны, серая слизь и прочие страшилки тоже, броуновское движение на наноуровне разъебывает все. Максимум, что возможно уже используется в днк и энзимах, которые собирают полимеры. Кстати шиза с серой слизью вылилась в реальные законы, запрещающие ее исследования, что тоже шиза. Свернули целые области исследований из-за маняфантазий дрекслера. Такой себе хайп ни о чем, повлиявший на реальную науку. Примерно как запрещатели ИИ сейчас хотят провернуть с ИИ из-за шизострашилок Бострома и Юдковского.
Генеральный директор Nvidia Дженсен Хуанг признает, что работает 7 дней в неделю, включая праздники, находясь в постоянном «состоянии тревоги» из-за страха обанкротиться.
«Вы знаете фразу «30 дней до закрытия», я использую ее уже 33 года», — сказал Хуанг в выпуске The Joe Rogan Experience. «Но это чувство не меняется. Ощущение уязвимости, ощущение неопределенности, ощущение незащищенности — оно не покидает вас».
Nvidia стала одним из явных лидеров в гонке ИИ. То, что начиналось как производитель видеокарт, превратилось в технологический гигант, создающий чипы, системы и программное обеспечение, которые обеспечивают работу большинства крупных моделей ИИ в облачных центрах обработки данных по всему миру. В прошлом месяце Nvidia стала первой публичной компанией, достигшей рыночной капитализации в 5 триллионов долларов. Тем не менее, Хуанг до сих пор не может избавиться от ощущения, что компания может исчезнуть в одночасье.
«Это изматывает», — сказал он, добавив, что он «всегда находится в состоянии тревоги».
Опытный генеральный директор рассказал, что до сих пор работает семь дней в неделю, каждую минуту, пока не спит, чтобы гарантировать, что его кошмар не сбудется, — включая проверку электронной почты с 4 утра: «Каждый день. Каждый божий день. Ни одного пропущенного дня. Включая День благодарения, Рождество».
Страх Хуанга перед неудачей — его главный мотиватор
Хуанг рассказал об инциденте, связанном с почти полным крахом в середине 1990-х годов, когда компания обнаружила, что ее первая графическая технология была неисправна, как раз в тот момент, когда она разрабатывала чип для следующей игровой консоли Sega.
Поскольку деньги заканчивались, он прилетел в Японию, чтобы сообщить генеральному директору Sega, что продукт не будет работать, и что им следует отменить сделку, но при этом признал, что Nvidia нужны последние 5 миллионов долларов для того, чтобы остаться на плаву. Sega конвертировала оставшиеся средства в инвестиции, предоставив борющемуся стартапу спасательный круг, необходимый для выживания.
«Страдание — часть пути. Вы будете ценить его за те ужасные чувства, которые испытываете, когда дела идут не очень хорошо. Вы будете ценить успех гораздо больше, когда он придет», — добавил он.
Ранее Хуанг пожелал студентам Стэнфорда «значительных доз боли и страданий». В его глазах невзгоды являются ключом к обретению стойкости, заниженным ожиданиям и, в конечном итоге, успеху.
Даже сейчас страх неудачи по-прежнему является величайшим мотиватором Хуанга.
«У меня сильнее желание не потерпеть неудачу, чем желание добиться успеха», — сказал он в подкасте. «Неудача движет мной больше, чем жадность или что-либо еще».
Оба его ребенка тоже работают каждый день
Хуанг — не единственный в своей семье, кто родился с «геном работы». Оба его ребенка тоже работают каждый день. Мэдисон и Спенсер, которым обоим за 30, начали работать в компании в качестве стажеров в 2020 и 2022 годах.
«Мои дети работают каждый день. Оба моих ребенка работают в Nvidia. Они работают каждый день», — сказал Хуанг.
До этого оба не проявляли особого интереса к работе в компании после школы. Мэдисон посещала Кулинарный институт Америки, а ее брат Спенсер изучал маркетинг в Чикаго, затем переехал на Тайвань для изучения китайского языка, и в это время он открыл коктейль-бар в Тайбэе.
«Теперь у нас трое работают каждый день, и они хотят работать со мной каждый день, так что это много работы», — сказал Хуанг.
Gemini 3 Deep Think прибыл и еще выше поднял планочку на тестах даже против обычного Gemini 3 Pro.
Обновленный режим «Глубокого Мышления» превосходит Gemini 3 Pro в «Последнем Экзамене Человечества» и ARC-AGI-2, повышая планку того, как он справляется со сложными математическими и научными задачами, а также с новыми вызовами.
>>1441096 Чего он так переживает? Неужели он не накопил денег на триста лет вперёд, так чтобы и пра- пра- пра- внукам хватило? Это, конечно, если предположить что через десять лет цифра на банковском счёте вообще будет иметь какое-то значение. А то ведь может статься что "ваш социальный рейтинг не позволяет вам покупать сладости до выходных".
>>1440791 Это сложный вопрос. Просто нельзя забывать, что обучаются модели всегда на какой-то базе с ошибками. Куда заведет рекурсия с галюнами вообще не очевидно.
>>1441223 Он таким с самого начала был. Вечно трясущийся, пролезший в небеса и чуть не свергнутый другими компаниями кучу раз. Ему никогда не бывает достаточно
>>1441255 В связи с вышесказанным предлагаю вам забавную задачку. Насколько близко к локальному минимуму будет существование виртуальных рабов, если мы имеем наглядный пример успеха СЕО топ-1 компании по капитализации, чьё внутреннее состояние на протяжении десятилетий можно описать словом тревожный пиздец?
>>1441223 На публику плебсу это все говорит. Надо же как-то оправдать почему его сотрудники должны работать 996, в то время как он чилит на свои миллионы, перекидывается в гольф при заключении сделок, да выступает в кожанке, втирая гоям почему меньше шина и дороже видеокарта это лучше
Никак не могу прийти в себя, после того что Warner Brothers сделали с Suno и Udio.
Очень странный прецедент.
Получается, что на картинках из интернета обучаться можно, что можно спарсить все видосы и натренировать видеогенераторы, про тексты я вообще молчу, а именно музыку(звук) нельзя использовать для обучения.
И что именно музыкальные генераторы надо тренировать на некоем сферически-вакуумном контенте.
Пример Адоба и провала такого подхода к картинкам и видео, говорит нам о том, что ничего хорошего не получается.
Но факт остается фактом - Suno и Udio удалят свои натренированные в 2025 году модели, и выкатят кастрированные версии в 2026 году.
Почему?
Потому что в музыкальной индустрии больше денег, злее юристы и больше крупных олигархов от музыки?
>>1441670 Ты когда читаешь книгу и обучаешься на ней, тоже воруешь? Не понимаю этих криков про кражи. И музыку туда же. Если нет прям супер похожего трека, то нехуй про кражу пиздеть.
>>1438709 Забавно, что лысая залупа зассал даже на лмарену свои модельки выпустить, кроме Nova 2 Lite, как все остальные делают >>1439029 Чего бы там не пукал социализд Берни и какая бы поддержка от громогласной сои у него не была, его всегда прокатят, как прокатывали на праймериз даже с такими овощами Байдыня и бабкой Хилари, про Трампыню и не говорю
>>1441562 >после того что Warner Brothers сделали с Suno и Udio
Warner Brothers и другим лейблам никакие Suno и Udio нахуй не нужны, а нужно, чтобы их не было. Они их купили тупо, чтобы захоронить.
>Почему?
Потому что тема с музыкальными генераторами более узкая, игроков там мало, миллиардных финансов на биржах не крутится. С текстом, изображениями и видео уже при всём желании ничего не сделаешь (до жопы сервисов, до жопы открытых моделей, сервисы, типа ОпенАИ стоят миллиарды, никаких денег не хватит их скупить), а музыкальное поле можно попытаться расчистить: всего-то два видных стартапа - Suno и Udio, пара нищих сайтов с генераторами по сути. Вот лейблы и решили пойти ва-банк: попытаться придушить угрозу. Угроза веская, противники слабые.
>>1441226 > Куда заведет рекурсия с галюнами вообще не очевидно. очевидно же уже говорили что новый чатжпт не может учится на нейрослопе, ему подавай только человеческое, иначе он резко тупеет
>>1441562 В 1920-х звукозаписывающие компании хотели запретить радио (по крайней мере, трансляцию музыки по радио). Ну потому что музыку без пластинок начали передавать совершенно бесплатно.
>>1441562 >>1442347 Вангую скоро китайцы, qwen или иная группа Алибабы, выкатят свою модельку музыкальную, вроде слухи ходили, да еще в опенсорс, и копирасты как обычно пососут бибу и выстрелят себе в член
>>1441562 >>1442347 >>1442384 Борьба с ветряными мельницами. Я конечно не знаю какой например тут пайплайн создания был, но по мне борьба уже проиграна. Услышав такой трэк по радио я бы не заподозрил, что это нейронка.
>>1441223 >Чего он так переживает? Наверное подсознательно бедность в детстве даёт о себе знать и что-то активирует что побуждает так постоянно работать. Зато его детям легче, а внукам будет ещё легче.
На его месте надо сделать "портфель" из разных отраслей разных рынков - открыть несколько ресторанов на побережьях курортов, построить несколько предприятий не связанных с электроникой, открыть авиакомпанию в какой-нибудь стране, построить мед. клинику, и т.д. А так он в одной нише варится с видео-чипами, плюс пару ответвлений, конечно ему будет тревожно. .
ЭКСТРЕННЫЕ НОВОСТИ: OpenAI объявляет «красный код» и спешит выпустить «GPT-5.2» 9 декабря, чтобы противостоять Google
Генеральный директор OpenAI Сэм Альтман объявил о ситуации «красного кода» в начале этой недели, подталкивая сотрудников к быстрому реагированию на усиление конкуренции со стороны Google и Anthropic. Источники, знакомые с планами OpenAI, сообщают мне, что компания готовит свой первый ответ на Gemini 3 с помощью грядущего обновления GPT-5.2.
Я понимаю, что GPT-5.2 готов к выпуску и может появиться уже в начале следующей недели. Источники сообщают мне, что обновление 5.2 должно закрыть разрыв, который Google создал, выпустив Gemini 3 в прошлом месяце — модель, которая возглавила таблицы лидеров и поразила Сэма Альтмана и генерального директора xAI Илона Маска.
Ранее на этой неделе издание The Information сообщило, что следующая модель логического вывода OpenAI «опережает Gemini 3 [от Google]» по внутренней оценке OpenAI, согласно словам Альтмана.
Мне сообщили, что OpenAI изначально планировала запустить GPT-5.2 позже в декабре, но давление со стороны конкурентов ускорило выпуск. Прямо сейчас OpenAI наметила 9 декабря для выпуска GPT-5.2.
Я связался с OpenAI, чтобы получить комментарий о GPT-5.2, но компания не ответила к моменту публикации.
Как я уже говорил, когда раскрыл информацию о запуске GPT-5 в августе, запланированные даты выпуска OpenAI часто меняются в ответ на проблемы разработки, проблемы с мощностью серверов или даже на объявления и утечки о конкурирующих моделях ИИ. Это может означать, что мы увидим GPT-5.2 немного позже 9 декабря, если планы в конечном итоге изменятся.
В любом случае, ожидайте, что в ближайшие месяцы ChatGPT также будет значительно развиваться, поскольку OpenAI смещает акцент с ярких новых функций на улучшение скорости, надежности и настраиваемости чат-бота. Альтман объявил этот «красный код», чтобы улучшить ChatGPT, и выпуск GPT-5.2 — это только начало.
Индустрия программирования стоит на пороге крупнейшего перелома.
Новая модель от Антроopic внезапно подняла планку настолько высоко, что даже опытные разработчики начали говорить о начале новой эры.
Anthropic и Opus 4.5: начало конца ручного программирования? Индустрия программирования движется к крупнейшему перелому за всю свою историю, и многие в технологическом мире говорят об этом уже открыто. Поводом стал выход модели Opus 4.5 от Antropic. Обновление, которое заметно изменило ожидание от ИИ в ближайшие годы. Эта модель показала уверенное превосходство над конкурентами на бенчмарках, связанных именно с программированием, и набрала от 4 до 5% преимущества, там, где любые проценты обычно достигаются годами работы. Для разработчиков это стало сигналом, что ИИ не просто догоняет специалистов, но начинает выполнять сложные задачи, так же уверенно как человек. Особенно сильную реакцию вызвало заявление Адама Морфа, инженера антропика, работающего над CLД кодом, инструментом, который позволяет работать с кодовой базой через терминал с помощью обычного языка. Он рассказал, что автономная работа OPUS 4.5 стала растягиваться до 20-30 минут. И за это время агент спокойно решает достаточно сложные задачи, оставляя после себя чистый и понятный код. Но главным стало другое. Именно Морф впервые произнёс фразу, от которой индустрия вздрогнула, что программирование в его текущем виде может исчезнуть уже в первой половине 2026 года. Он сравнил генерацию кода и с работой компилятора. Мы не проверяем машинный код вручную и просто доверяем инструментам. И, по его словам, вскоре такой же станет ситуация и с искусственным интеллектом. После резонанса он пояснил, что речь шла именно о программировании как механическом процессе, а не о всей инженерии. Сам процесс набора кода, его перевода из идеи в синтаксис - тот самый слой, который уже сегодня стремительно съедается алгоритмами. По словам Морфа, роль человека будет смещаться всё выше: от исполнителя к архитектору, от наборщика к человеку, который формулирует направления и требования, а не вручную пишет функции.
«Крестный отец ИИ» Джеффри Хинтон говорит, что Google «начинает обгонять» OpenAI: «Я думаю, что Google победит»
«Крестный отец ИИ» считает, что Google пора догнать конкурентов в гонке искусственного интеллекта.
«На самом деле, я думаю, более удивительно то, что Google потребовалось так много времени, чтобы обогнать OpenAI», — заявил Джеффри Хинтон, почетный профессор Университета Торонто, ранее работавший в Google Brain, в интервью Business Insider во вторник.
Google недавно осуществил широко разрекламированный запуск Gemini 3 — обновления, которое, по мнению некоторых представителей технологической индустрии, подняло гиганта выше уровня GPT-5 от OpenAI. Модель для создания изображений на базе ИИ Nano Banana Pro от Google также оказалась успешной.
Спустя три года после того, как Google, по сообщениям, объявила «красный код» после выпуска ChatGPT, недавние отчеты указывают на то, что теперь тревогу бьет OpenAI.
«Я думаю, что прямо сейчас они начинают обгонять [OpenAI]», — сказал Хинтон о позиции Google относительно OpenAI.
В дополнение к успешному запуску своей новейшей модели ИИ, акции Google выросли на фоне сообщений о том, что она может заключить миллиардную сделку по поставке Meta своих собственных чипов для ИИ.
Производство собственных чипов является «большим преимуществом» для Google, отметил Хинтон.
«У Google много очень хороших исследователей, а также, очевидно, много данных и много центров обработки данных, — сказал он. — Я думаю, что Google победит».
Хинтон, который помог стать пионером в исследованиях ИИ во время своей работы в Google Brain, сказал, что поисковый гигант когда-то был в авангарде ИИ, но сдерживал себя.
«Google лидировал долгое время, верно? — сказал он. — Google изобрел трансформеры. У Google были большие чат-боты до того, как они появились у других людей».
Google был осторожен, сказал Хинтон, после неудачного запуска в 2016 году Microsoft своего недолговечного чат-бота с искусственным интеллектом «Тэй», который компания отключила после того, как он опубликовал невероятно расистские твиты.
«У Google, очевидно, была очень хорошая репутация, и она беспокоилась о том, чтобы не нанести ей такой ущерб», — сказал он.
Генеральный директор Google Сундар Пичаи ранее заявлял, что компания сдерживала выпуск своего чат-бота.
«Мы еще не достигли того уровня, когда могли бы выпустить его, и люди были бы удовлетворены тем, что Google выпускает такой продукт, — сказал Пичаи ранее в этом году. — На тот момент в нем все еще было много проблем».
В прошлом у компании были некоторые нестабильные запуски. Только в прошлом году Google пришлось приостановить работу своего генератора изображений на базе ИИ после того, как некоторые пользователи пожаловались, что результаты, показывающие исторически неточные изображения цветных людей, были слишком «ультра-либеральными» (woke). Его первоначальные обзоры поиска с помощью ИИ генерировали бессмысленные советы, например, по использованию клея на пицце, чтобы предотвратить падение сыра.
Google только что сделал крупное пожертвование в университет в честь Хинтона
Хинтон поговорил с Business Insider перед объявлением о том, что Google жертвует 10 миллионов канадских долларов (CAD) на создание Именной кафедры Хинтона в области искусственного интеллекта в Университете Торонто. Университет, где Хинтон проводил часть своего времени, работая в Google, заявил, что он удвоит пожертвование Google.
Хинтон покинул Google в 2023 году, сославшись на обеспокоенность развитием ИИ. С тех пор он неоднократно высказывался о рисках, которые ИИ представляет для общества, начиная от потенциала превзойти человеческий разум и заканчивая вытеснением рабочих мест. В 2024 году Хинтон был совместно удостоен Нобелевской премии по физике.
«Работа Джеффа в области нейронных сетей — охватывающая его время в академических кругах и десятилетие, проведенное здесь, в Google, — заложила основу для современного ИИ, — говорится в заявлении Google. — Эта именная кафедра чтит его наследие и поможет университету набрать дальновидных ученых, посвященных тому же виду фундаментальных исследований, основанных на любопытстве, которые отстаивал Джефф».
«Крестный отец ИИ» говорит, что Илон Маск и другие технологические магнаты погубят общество и самих себя
Джеффри Хинтон заявляет, что быстрое развитие ИИ может привести к социальному коллапсу, если оно продолжится без защитных мер
«Крестный отец ИИ», Джеффри Хинтон, выступил с суровым предупреждением о том, что технологические миллиардеры, расширяющие границы искусственного интеллекта, потенциально могут вызвать общественный коллапс и собственное падение из-за отсутствия дальновидности.
Хинтон, который является пионером прорывов в области глубокого обучения, подпитывающих сегодняшний бум ИИ, выразил свою обеспокоенность во время публичной беседы с сенатором США Берни Сандерсом в Джорджтаунском университете.
Компьютерный ученый британского происхождения предсказывает, что если ИИ продолжит быстро развиваться без надлежащих мер защиты, это может разрушить рынок труда, еще больше усилить неравенство и даже проложить путь к «бескровным вторжениям» со стороны могущественных наций.
Хинтон утверждает, что ИИ отличается от предыдущих технологических революций своим потенциалом не только вытеснять людей с их рабочих мест, но и не создавать новые возможности трудоустройства, чтобы компенсировать эту потерю.
Он заявил: «Людям, которые потеряют работу, некуда будет пойти, если ИИ станет таким же умным, как люди — или умнее — любая работа, которую они могут выполнять, может быть выполнена ИИ».
Выражая сожаление по поводу своей роли пионера ИИ, Хинтон предсказывает, что появление искусственного интеллекта общего назначения — системы, способной выполнять широкий спектр задач и адаптируемой к многочисленным приложениям — произойдет «через 20 лет или меньше», сообщает Daily Star.
В ходе беседы упоминались такие технологические магнаты, как Илон Маск, Марк Цукерберг и Ларри Эллисон, причем Хинтон утверждал, что они не «продумали» тот факт, что «если рабочим не платят, некому покупать их продукты».
Хинтон, по сути, создал основу современного ИИ. Его новаторские исследования нейронных сетей принесли ему премию Тьюринга 2018 года (эквивалент Нобелевской премии в области вычислений), которую он разделил с Йошуа Бенжио и Яном ЛеКуном. Он покинул Google в 2023 году.
В последнее время он предположил, что нынешние передовые модели, возможно, уже «понимают» гораздо больше, чем любой человек, одновременно предупреждая, что быстрое внедрение этой технологии может сделать традиционное мышление в духе «рынок все исправит» неразумным.
Хинтон также предупредил Сандерса, что ИИ может спровоцировать дополнительные конфликты по всему миру. Он предположил, что роботы, управляемые ИИ, могут устранить «политическую отдачу» от военных смертей, уменьшая препятствия для богатых стран для нападения на меньшие нации.
Автоматизированные машины на полях сражений означают меньше потерь среди солдат, возвращающихся домой, меньшее освещение в СМИ и меньшее количество стимулов для политиков колебаться перед началом атак. Проще говоря, технология может сделать войну безнаказанной.
>>1441277 Не, вроде другое, отдельный режим, это в их проге для AI Ultra, вот новость:
Gemini 3 Deep Think теперь доступен в приложении Gemini.
Сегодня мы выпускаем режим Gemini 3 Deep Think для подписчиков Google AI Ultra в приложении Gemini. Этот новый режим обеспечивает значительное улучшение возможностей рассуждения, предназначенных для решения сложных математических, научных и логических задач, которые бросают вызов даже самым продвинутым современным моделям.
Gemini 3 Deep Think является лидером в отрасли по таким строгим бенчмаркам, как Humanity’s Last Exam (41,0% без использования инструментов) и ARC-AGI-2 (беспрецедентные 45,1% с выполнением кода). Это связано с тем, что он использует усовершенствованные параллельные рассуждения для одновременного изучения множества гипотез — опираясь на варианты Gemini 2.5 Deep Think, которые недавно завоевали золотую медаль на Международной математической олимпиаде и на Всемирном финале Международного студенческого конкурса по программированию.
Подписчики Ultra могут попробовать режим Gemini 3 Deep Think уже сегодня, выбрав «Deep Think» на панели подсказок и Gemini 3 Pro в выпадающем списке моделей.
Научный метод автоматизируется. Opus 4.5 с фреймворком Claude Code «решил» CORE-Bench, фактически доказав, что он может воспроизводить научные статьи вычислительным путем без помощи человека.
Как результат ускоряется отток мозгов из академической среды; ведущие математики, такие как Кен Оно, покидают университеты и переходят в «неолаборатории», где основным сотрудником является кремний.
CORE-Bench решен (с использованием Opus 4.5 с Claude Code)
Короче говоря (TL;DR): На прошлой неделе мы опубликовали результаты Opus 4.5 на CORE-Bench, бенчмарке, который тестирует агентов на задачи научной воспроизводимости. Ранее на этой неделе Николас Карлини (Nicholas Carlini) связался с нами, чтобы сообщить, что обновленный фреймворк (scaffold), использующий Claude Code, значительно превосходит фреймворк CORE-Agent, который мы использовали, особенно после исправления нескольких ошибок в оценке. За последние три дня мы подтвердили найденные им результаты и теперь готовы объявить, что CORE-Bench решен.
Контекст. Мы разработали Таблицу лидеров целостных агентов (Holistic Agent Leaderboard, HAL) для оценки ИИ-агентов на сложных бенчмарках. Одной из наших мотиваций было то, что большинство моделей никогда не сравниваются лицом к лицу — на одном и том же бенчмарке, с одной и той же средой и с использованием одного и того же фреймворка. Мы создали стандартные фреймворки агентов для каждого бенчмарка, что позволило нам независимо оценивать модели, фреймворки и сами бенчмарки.
CORE-Bench — один из бенчмарков на HAL. Он оценивает, могут ли ИИ-агенты воспроизводить научные статьи, если им предоставлен код и данные из статьи. Бенчмарк состоит из статей по информатике, социальным наукам и медицине. Он требует от агентов настроить репозиторий статьи, запустить код и правильно ответить на вопросы о результатах статьи. Мы вручную проверяли результаты каждой статьи для включения в бенчмарк, чтобы избежать невыполнимых задач.
1. Переключение фреймворка на Claude Code почти вдвое увеличивает точность Opus 4.5
Наш фреймворк для этого бенчмарка, CORE-Agent, был построен с использованием библиотеки smolagent от HuggingFace. Это позволило нам легко переключать модель, которую мы использовали на бэкэнде, для стандартизированного сравнения производительности моделей.
Хотя CORE-Agent позволял проводить сравнение между моделями, когда мы запустили Claude Opus 4.5 с использованием Claude Code, он набрал 78%, что почти вдвое превышает 42%, о которых мы сообщали при использовании нашего стандартного фреймворка CORE-Agent. Это существенный скачок: лучший агент с CORE-Agent ранее набрал 51% (Opus 4.1). Удивительно, но для других моделей этот разрыв был меньше. Например, Opus 4.1 с CORE-Agent превосходит Claude Code (подробнее в Разделе 4).
2. В 9 задачах CORE-Bench были ошибки в оценке
Николас также выявил несколько проблем, из-за которых мы недооценивали точность. При создании бенчмарка мы вручную запускали каждую задачу трижды и использовали 95% прогностические интервалы, основанные на наших трех ручных запусках, чтобы учесть округление, шум и другие источники небольших вариаций. Но это не сработало в некоторых крайних случаях, когда наши результаты были полностью детерминированными, что приводило к штрафам за небольшие различия в числах с плавающей запятой. Кроме того, некоторые задачи были недостаточно конкретизированы, что приводило к тому, что допустимые интерпретации оценивались как неудачи.
В общей сложности это затронуло 8 задач, где мы вручную проверили ответы Opus 4.5 и оценили каждую из них как правильную. Мы также удалили 1 задачу из бенчмарка после обнаружения, что ее код невозможно воспроизвести из-за «битового гниения» (bit rot): для исходной статьи требовалось загрузить набор данных с URL-адреса, который больше не активен.
Эти изменения увеличили точность агента с 78% до 95%. Claude Code с Opus 4.5 терпит неудачу только в 2 задачах, где ему не удается решить проблемы с зависимостями пакетов и правильно идентифицировать соответствующие результаты.
3. Многие ошибки в оценке проявляются только с способными агентами
Когда мы создавали бенчмарк, максимальная точность составляла около 20%. Крайние случаи в оценке были гораздо менее очевидны, чем сейчас, когда агенты близки к насыщению бенчмарка. Например, некоторые из крайних случаев возникали из-за того, что агент решал задачу немного другим способом, чем мы ожидали при создании бенчмарка.
Мы не предполагали, что агенты будут это делать, поэтому наш процесс оценки был слишком строгим. Но мы обнаружили, что Opus 4.5 с Claude Code часто использовал другой (правильный, но немного отличающийся) метод для решения задачи, который мы автоматически оценивали как неверный. При нашей ручной проверке мы оценили эти случаи как правильные.
Этот опыт подчеркивает важность ручной проверки на «последнем рубеже» нерешенных задач в бенчмарках. Эти задачи часто остаются нерешенными из-за ошибок в оценке, а не из-за того, что агенты действительно неспособны их решить. Многие из этих ошибок было трудно предвидеть до того, как сильные агенты попробовали решить бенчмарк. Автоматизированная оценка помогла нам пройти довольно далеко (до 80% бенчмарка), но ручная оценка была необходима для проверки последних 20% точности.
Этот процесс также напоминает то, как были найдены и исправлены ошибки в оценке во многих популярных бенчмарках. SWE-bench Verified имел ненадежные модульные тесты. TauBench засчитывал пустые ответы как успешные. Важно исправлять ошибки в бенчмарках по мере того, как сообщество их обнаруживает.
В то же время, итерации в правилах оценки бенчмарков затрудняют сравнение с течением времени, поскольку бенчмарки должны постоянно меняться. Есть и другие причины, по которым сравнение результатов во времени является сложной задачей. Например, многие бенчмарки включают взаимодействие с открытыми средами, такими как Интернет. Но по мере того, как веб-сайты меняются (например, по мере того, как все больше веб-сайтов добавляют CAPTCHA), сложность решения задач меняется.
4. Чем объясняется такой скачок производительности?
Мы были удивлены, обнаружив, что Claude Code с Opus 4.5 значительно превзошел фреймворк CORE-Agent, даже без исправления неверных тестовых случаев (78% против 42%). Для других моделей этот разрыв был гораздо меньше: для Opus 4.1 CORE-Agent превосходит Claude Code почти на 10 процентных пунктов. Sonnet 4 набирает 33% с CORE-Agent, но 47% с Claude Code. Sonnet 4.5 набирает 44% с CORE-Agent, но 62% с Claude Code.
Мы не уверены, что привело к этой разнице. Одна гипотеза состоит в том, что модели серии Claude 4.5 гораздо лучше настроены для работы с Claude Code. Другая может заключаться в том, что низкоуровневые инструкции в CORE-Agent, которые хорошо работали для менее способных моделей, перестают быть эффективными (и препятствуют производительности модели) для более способных моделей.
5. Переориентация HAL на улучшенные фреймворки
Когда мы планировали эмпирическую систему оценки для HAL, мы предполагали, что между моделями и фреймворками будет слабая связь, что позволит нам использовать один и тот же фреймворк для разных моделей. Но мы всегда знали, что это предположение однажды может оказаться неверным. Резкое улучшение Opus 4.5 при использовании Claude Code показывает, что этот день, возможно, настал.
Мы считаем, что изучение связи между моделями и фреймворками является важным направлением исследований в будущем, особенно по мере того, как все больше разработчиков выпускают фреймворки, для работы с которыми их модели могут быть донастроены (например, Codex и Claude Code).
Эта тенденция может оказать структурное влияние на экосистему ИИ. Разработчикам, которые создают фреймворки или продукты, необходимо постоянно модифицировать их на основе возможностей новых моделей. Разработчики моделей имеют систематическое преимущество в создании лучших фреймворков, поскольку они могут донастраивать свои модели для лучшей работы с собственными фреймворками. Это подрывает тенденцию к тому, что модели становятся товаром и заменяемыми артефактами: разработчики моделей могут восстановить влияние на уровне приложений посредством такой донастройки, за счет сторонних разработчиков или разработчиков фреймворков и продуктов с открытым исходным кодом.
>>1442928 Еще одно следствие этой тенденции: ИИ-компании, публикующие результаты оценки, должны раскрывать фреймворк, который они используют для оценки. Если одна и та же модель может набрать вдвое большую точность, просто заменив фреймворк, очевидно, что выбор фреймворка имеет большое значение. Тем не менее, большинство результатов оценки моделей не сообщают о используемом фреймворке.
В свете этих результатов мы рассматриваем множество способов изменить наш подход к оценкам HAL, включая определение фреймворков, которые хорошо работают с конкретными моделями, и привлечение большего числа сообщества к поиску высокопроизводительных фреймворков.
6. CORE-Bench фактически решен. Следующие шаги.
Поскольку Opus 4.5 набрал 95%, мы считаем CORE-Bench Hard решенным. Это запускает два условия в наших планах для последующей работы:
1. Когда мы разрабатывали CORE-Bench, мы также создали частный тестовый набор, состоящий из другого набора статей, который мы планировали протестировать агентов, как только преодолеем порог в 80%. (Статьи в этом тестовом наборе общедоступны, но они не были включены в более ранний тестовый набор для CORE-Bench, и мы не раскрывали, какие статьи включены в новый тестовый набор.) Теперь мы откроем этот тестовый набор для оценки. 2. Мы разработали CORE-Bench, чтобы он максимально точно отражал реальные научные репозитории. Теперь, когда у нас есть доказательство концепции того, что ИИ-агенты решают задачи научного воспроизведения, мы планируем протестировать способность агентов воспроизводить реальные научные статьи в большом масштабе.
Мы приветствуем сотрудников, заинтересованных в работе над этим. Создание инструментов для проверки воспроизводимости может иметь чрезвычайно большое значение. Исследователи могли бы проверять, воспроизводимы ли их собственные репозитории. Те, кто основывается на прошлых работах, могли бы быстро воспроизвести их. И мы могли бы проводить крупномасштабные мета-анализы того, насколько воспроизводимы статьи в разных областях, как эти тенденции меняются со временем и т. д.
Обратите внимание, что, несмотря на нашу ручную проверку, CORE-Bench все еще имеет некоторые недостатки по сравнению с реальным воспроизведением. Например, мы отфильтровали репозитории, оставив только те, запуск которых занял менее 45 минут. CORE-Bench также требует воспроизведения только некоторых конкретных результатов статьи, а не всей статьи, для облегчения оценки. Обе эти особенности могут привести к тому, что попытки воспроизведения в реальном мире окажутся более сложными, чем в бенчмарке.
Мы обновим веб-сайт HAL, включив результаты CORE-Bench с ручной проверкой, и опубликуем подробную информацию о конкретных ошибках и исправлениях. Еще раз благодарим Николаса Карлини за тщательное исследование результатов бенчмарка, а также команду HAL за работу над этими изменениями для проверки и обновления результатов бенчмарка.
Энергосистема — это новое поле битвы ИИ. Palantir, Nvidia и CenterPoint Energy запустили «Chain Reaction» для управления развитием инфраструктуры ИИ, в то время как Morgan Stanley предупреждает о 20%-ном дефиците электроэнергии для центров обработки данных ИИ в США к 2028 году.
Palantir запускает Chain Reaction для создания американской инфраструктуры ИИ; среди партнеров-учредителей CenterPoint Energy и NVIDIA
ДЕНВЕР—Palantir Technologies Inc. (NASDAQ: PLTR) сегодня представила Chain Reaction, операционную систему для американской инфраструктуры ИИ.
Узким местом для инноваций в области ИИ больше не являются алгоритмы; это электроэнергия и вычислительные ресурсы. Америка находится в переломном моменте развития энергетической инфраструктуры, и это требует программного обеспечения, созданного для совершенно иного масштаба. Chain Reaction разработан для непосредственного решения этой проблемы путем ускорения развития ИИ с помощью производителей энергии, распределителей электроэнергии, центров обработки данных и строителей инфраструктуры для:
Преобразования устаревших мощностей по производству электроэнергии в ресурсы с высоким временем безотказной работы, способные удовлетворить огромный спрос ИИ. Стабилизации и расширения электросети для удовлетворения растущего спроса со стороны центров обработки данных и электрификации. Ускорения строительства новых мощностей по производству, передаче и вычислению. Обеспечения проектирования, разработки и воспроизводимости будущих гипермасштабных центров обработки данных, поддерживающих рабочие нагрузки ИИ.
В число партнеров-учредителей Chain Reaction входят CenterPoint Energy и NVIDIA.
«Развитие энергетической инфраструктуры — это промышленная задача нашего поколения, — сказал Тристан Груска (Tristan Gruska), глава отдела энергетики и инфраструктуры Palantir. — Но программное обеспечение, на которое полагается этот сектор, не было создано для этого момента. Мы потратили годы на тихое развертывание систем, которые поддерживают работу электростанций и надежность сетей. Chain Reaction — это результат строительства с нуля для удовлетворения потребностей ИИ».
CenterPoint Energy
CenterPoint Energy, крупная компания по электро- и газоснабжению со штаб-квартирой в Хьюстоне, обслуживает около 7 миллионов клиентов в Техасе, Индиане, Миннесоте и Огайо. После того, как ураган Берил обрушился на Хьюстон в июле 2024 года, CenterPoint обязалась построить самую устойчивую прибрежную сеть в стране и выбрала Palantir в качестве своей программной основы. Сегодня CenterPoint расширяет свое партнерство за пределы реагирования на штормы и устойчивости сети, развертывая Chain Reaction для ускорения обеспечения электроэнергией и улучшения операционной прозрачности своих критически важных активов.
«Никогда еще технологии и энергетика не были так тесно связаны в определении будущего курса американских инноваций, коммерческого роста и экономической безопасности. В регионе Большого Хьюстона наше потребление энергии, по прогнозам, увеличится почти на 50% за пять лет и удвоится к середине 2030-х годов. Этот экспоненциальный рост обусловлен широким спектром секторов, включая высокие технологии, здравоохранение, энергетику, промышленность, фармацевтику и автопарки, и ускоряет создание рабочих мест в сообществах, которые мы имеем честь обслуживать. Мы рады объединиться с Palantir и другими нашими партнерами по Chain Reaction, чтобы приблизить это будущее», — сказал Джейсон Уэллс (Jason Wells), председатель и главный исполнительный директор CenterPoint Energy.
NVIDIA
Недавно на GTC DC NVIDIA объявила о сотрудничестве с Palantir по созданию интегрированного технологического стека для операционного ИИ, который ускоряет и оптимизирует сложные корпоративные и государственные системы. Сегодняшним объявлением NVIDIA и Palantir расширяют свое партнерство до Chain Reaction.
Используя AIP и Ontology с моделями NVIDIA Nemotron, библиотеками CUDA-X и ускоренными вычислениями, Chain Reaction ускорит установку инфраструктуры ИИ NVIDIA по всей территории США за счет оптимизации сложности управления комплексными цепочками поставок, поддерживающими строительство заводов ИИ гигаваттного масштаба в сфере производства электроэнергии, распределения электроэнергии, строительства и эксплуатации центров обработки данных.
«Началась новая промышленная революция — та, где интеллект производится в масштабе через необычайно сложную цепочку поставок инфраструктуры ИИ, которая сейчас строится по всей Америке для укрепления нашей экономики, рабочей силы и безопасности, — сказал Владимир Трой (Vladimir Troy), вице-президент по инфраструктуре ИИ в NVIDIA. — В партнерстве с Palantir и нашей экосистемой мы ускоряем эту трансформацию — питая двигатели эпохи ИИ, преобразуя данные в интеллект и обеспечивая технологическое лидерство Америки на десятилетия вперед».
О Palantir
Основополагающее программное обеспечение завтрашнего дня. Поставляется сегодня. Дополнительная информация доступна на сайте https://www.palantir.com/chain-reaction
Автономное вождение преодолевает порог внимания публики: Илон подтверждает, что Tesla теперь позволит вам писать сообщения за рулем с FSD, если условия позволяют, фактически передавая руль нейронной сети.
Илон Маск подтверждает, что FSD 14.2.1 позволяет вам писать сообщения за рулем в зависимости от контекста окружающего трафика.
Телефоны могут подорожать в следующем году. Спасибо буму ИИ (Искусственного Интеллекта).
Навороченные камеры, гигантские экраны и большой объем памяти обычно делают смартфоны дороже. Но в следующем году цены может подтолкнуть вверх один обычный компонент: оперативная/встроенная память.
И это касается не только телефонов. Любое устройство, использующее память, от телефонов до планшетов и умных часов, может подорожать.
Цены на память для потребительских товаров растут, потому что крупные производители вместо этого наращивают производство для центров обработки данных ИИ, поскольку компании, занимающиеся искусственным интеллектом, переживают бум.
«Это довольно жестокий и напряженный процесс повсеместно», — сказал Ян Ван, старший аналитик Counterpoint Research.
Международная корпорация данных (International Data Corporation), глобальная фирма по исследованию рынка, сообщила ранее на этой неделе, что, как ожидается, рынок смартфонов сократится на 0,9% в 2026 году, отчасти из-за нехватки памяти. По данным Counterpoint Research, опубликованным в прошлом месяце, ожидается, что цены на память вырастут на 30% в четвертом квартале 2025 года и могут подняться еще на 20% в начале следующего года.
Бум спроса на центры обработки данных
В этом году такие технологические компании, как Meta, Microsoft и Google, агрессивно расширяли свои центры обработки данных и инфраструктуру, чтобы соответствовать спросу на ИИ. И ожидается, что этот рост продолжится: отчет McKinsey & Company указывает, что к 2030 году компании по всему миру инвестируют почти 7 триллионов долларов в расходы, связанные с инфраструктурой центров обработки данных.
Это побудило производителей памяти, таких как Micron и Samsung, переключить свое внимание на центры обработки данных, которые используют другой тип памяти, нежели компьютеры и смартфоны. По словам Вана, в результате для потребительских товаров остается меньше ресурсов.
В среду компания Micron, специализирующаяся на памяти и хранении данных, объявила о выходе из бизнеса по производству потребительской памяти, сославшись на «резкий рост спроса», вызванный «ростом, обусловленным ИИ», в центрах обработки данных.
Чжечжун Ким, исполнительный вице-президент по производству памяти в Samsung, заявил в октябре, что в третьем квартале компания наблюдала высокий спрос на память для ИИ и центров обработки данных. Он также сказал, что ожидается «дальнейшее усиление» дефицита поставок памяти для мобильных устройств и ПК.
Более высокие цены на телефоны
По словам аналитиков, производителям гаджетов, возможно, придется принимать трудные решения о том, когда выпускать и как устанавливать цены на свои продукты. TrendForce, исследовательская фирма, отслеживающая полупроводниковую отрасль, оценивает, что повышение цен на память сделало производство смартфонов на 8–10% дороже в 2025 году (более высокие производственные затраты не всегда трансформируются в более высокие потребительские цены по ряду причин).
Некоторые смартфоны могут подорожать уже в начале следующего года, — сказала Набила Попал, старший директор по исследованиям в International Data Corporation. Самое большое влияние может оказать на дешевые телефоны на Android, поскольку менее дорогие продукты обычно имеют меньшую норму прибыли.
«Для них будет почти невозможно не повысить цены» на более дешевые телефоны Android, — сказала Попал.
Компании могут также отложить выпуск телефонов, чтобы сосредоточиться на дорогих моделях, которые могут быть более прибыльными. По словам Попал, ожидается, что средняя продажная цена смартфонов вырастет до 465 долларов в 2026 году по сравнению с 457 долларами в 2025 году, в результате чего стоимость рынка смартфонов достигнет рекордно высокого уровня в 578,9 миллиарда долларов.
Но ожидается, что маятник качнется в другую сторону в конце следующего года, когда цепочка поставок скорректируется, по словам Попал и Вана, потенциально снижая цены или, по крайней мере, ограничивая рост.
Полупроводниковая отрасль привыкла бороться с изменениями по мере появления новых технологий, — говорит Ван. Но, возможно, она не была готова к тому, как быстро вырастет спрос на ИИ.
«В полупроводниковой сфере всегда будет несоответствие (спроса и предложения)», — сказал он. «Это было несколько неожиданно».
Генеральный директор AMD Лиза Су «категорически» отвергает разговоры о пузыре ИИ — говорит, что эти утверждения «несколько преувеличены»
Генеральный директор AMD Лиза Су использовала свое выступление на конференции WIRED’s Big Interview в Сан-Франциско, чтобы дать отпор растущим слухам о перегреве сектора ИИ. На вопрос, находится ли отрасль в пузыре, Су ответила «категорически» нет, утверждая, что опасения «несколько преувеличены» и что ИИ все еще находится в зачаточном состоянии. По словам Су, AMD должна быть готова поставлять чипы для будущего — «нет причин не продолжать продвигать эту технологию».
Ее замечания прозвучали в то время, когда AMD готовится к выполнению ряда своих крупнейших на сегодняшний день обязательств в отношении центров обработки данных, включая развертывание ускорителей мощностью в несколько гигаватт с OpenAI и возобновление поставок MI308 в Китай в рамках новой системы экспортного контроля.
OpenAI планирует развернуть графические процессоры Instinct общей мощностью шесть гигаватт в течение следующих нескольких лет в соответствии с совместным заявлением, сделанным компаниями ранее в этом году. Первый блок мощностью один гигаватт запланирован на вторую половину следующего года. В рамках этой договоренности OpenAI получила опцион на покупку до 160 миллионов акций AMD по одному центу за штуку, как только будут достигнуты этапы развертывания. AMD представила эту структуру как способ согласовать долгосрочные стимулы вокруг поставки инфраструктуры, а не короткого окна доступности продукта.
Между тем, операции компании в Китае были омрачены иного рода неопределенностью. AMD подтвердила, что будет платить 15% экспортный налог на поставки MI308 в соответствии с пересмотренными правилами экспорта и готова к этому. Вашингтон приостановил продажу этой детали в апреле, прежде чем возобновить процесс лицензирования, который позволил поставщикам подавать заявки на ограниченные поставки.
AMD сообщила инвесторам, что первоначальные ограничения привели бы к расходам на запасы и обязательства по покупке в размере до 800 миллионов долларов, что делает повторный выход на рынок на известных условиях позитивным шагом, даже с учетом дополнительной платы. Китай не будет основным источником дохода AMD от центров обработки данных в ближайшем будущем, но он остается одним из немногих регионов с клиентами, способными быстро поглощать большие партии ускорителей.
Комментарии Су также касались давления со стороны гиперскейлеров, которые расширяют свои внутренние портфели чипов. Она утверждала, что задача AMD состоит не в том, чтобы соответствовать какому-либо отдельному конкуренту, а в том, чтобы достаточно быстро продвигать свою собственную дорожную карту для того, чтобы захватить следующую волну развертываний.
По ее мнению, каждое поколение моделей ИИ повышает ожидания в отношении производительности, и основная траектория развития отрасли поддерживает устойчивые инвестиции в кластеры обучения и инференса. Для компании, которая потратила большую часть последнего десятилетия на восстановление своих позиций в области высокопроизводительных вычислений, предстоящий цикл проверит, насколько хорошо эта уверенность преобразуется в поставленное оборудование и долгосрочные обязательства перед клиентами.
У Apple что-то пошло не по плану: за последние 72 часа из компании ушли четыре главы основных подразделений, включая директора по ИИ
➖Джон Джаннандреа, глава AI/ML, уходит на пенсию из-за тупиковой ситуации с Siri и AI-функциями
➖Алан Дай, глава UI-дизайна, переходит в Meta для руководства новой дизайн-студией.
С дизайном в Apple вообще все сложно после ухода Джони Айва к Альтману. Известно, что за последние пару месяцев OpenAI захантила из Apple порядка 40 сотрудников из отделов дизайна, hardware и wearables. Напоминаем, что сейчас Альтман совместно с Айвом разрабатывают семейство ИИ-устройств без экранов – анти-IPhone.
Влияет и конкуренция с Meta. Ранее Цукер забрал из Apple главу foundation models, а сейчас забирает у компании большую часть рынка носимых устройств со своими Ray-Ban Meta. Apple пытаются переключиться с Vision Pro на такие же ИИ-очки, но там 73% рынка уже контролирует Meta.
➖ Также ушли в отставку Кейт Адамс, старший вице-президент и генеральный советник, и Лиза Джексон, вице-президент по экологии, политике и социальным инициативам.
«Превосходство Запада в области ИИ над Китаем теперь измеряется месяцами, а не годами»
Видеорелейтед.
Демис Хассабис: Я думаю, что мы все еще лидируем в США и на Западе, если посмотреть на последние бенчмарки и новейшие системы, но Китай не сильно отстает.
Если вы посмотрите на новейшие «глубоководные» или новейшие модели, они очень хороши — и там есть очень способные команды — так что, возможно, на данный момент лидерство измеряется только месяцами, а не годами.
>>1442974 Либо эппл разработает что-то прорывное, либо сдохнет. Сейчас им как никогда нужен новый Стив Джобс, который такими проектами и занимался раньше. Забавно, как целая корпорация загибается, от того что один визионер помер, на котором все и держалось.
Google Research Представляет Titans + MIRAS: Путь к Постоянно Обучающемуся ИИ
«Мы представляем архитектуру Titans и фреймворк MIRAS, которые позволяют моделям ИИ работать гораздо быстрее и обрабатывать массивные контексты за счет обновления их основной памяти во время активной работы».
Резюме: В двух новых официально оформленных статьях, Titans и MIRAS, мы представляем архитектуру и теоретическую схему, которые сочетают скорость рекуррентных нейронных сетей (RNN) с точностью трансформеров. Titans — это специфическая архитектура (инструмент), а MIRAS — это теоретический фреймворк (схема) для обобщения этих подходов. Вместе они развивают концепцию запоминания во время тестирования (test-time memorization) — способности модели ИИ поддерживать долговременную память, включая более мощные метрики «неожиданности» (т. е. неожиданные фрагменты информации) во время работы модели и без специального офлайн-переобучения.
Фреймворк MIRAS, как продемонстрировано Titans, представляет собой значимый сдвиг в сторону адаптации в реальном времени. Вместо того чтобы сжимать информацию в статичное состояние, эта архитектура активно обучается и обновляет свои собственные параметры по мере поступления данных. Этот ключевой механизм позволяет модели мгновенно включать новые, специфические детали в свое основное знание.
Кратко (TL;DR):
Архитектура Titans = Изучение нового контекста на лету
Фреймворк MIRAS = Единый взгляд на последовательное моделирование (Sequence Modeling)
Последовательное моделирование (Sequence Modeling) = Необходимо для задач, где временная шкала или расположение данных диктуют смысл, таких как прогнозирование следующего слова в предложении, прогнозирование цен на акции на основе прошлых результатов или интерпретация аудио для распознавания речи.
Объяснение архитектуры Titans: Важно отметить, что Titans не просто пассивно хранит данные. Он активно учится распознавать и сохранять важные взаимосвязи и концептуальные темы, которые соединяют токены по всему вводу. Ключевым аспектом этой способности является то, что мы называем «метрикой неожиданности» (surprise metric).
В человеческой психологии мы знаем, что мы быстро и легко забываем рутинные, ожидаемые события, но запоминаем вещи, которые нарушают шаблон — неожиданные, удивительные или эмоционально насыщенные события.
Пикрелейтед 2
В контексте Titans «метрика неожиданности» — это обнаружение моделью большой разницы между тем, что она помнит в данный момент, и тем, что ей сообщает новый ввод.
Низкая неожиданность: Если новое слово — «кот», и состояние памяти модели уже ожидает слово, обозначающее животное, градиент (неожиданность) низок. Модель может безопасно пропустить запоминание слова «кот» в своем постоянном долговременном состоянии. Высокая неожиданность: Если состояние памяти модели резюмирует серьезный финансовый отчет, а новый ввод — это изображение банановой кожуры (неожиданное событие), градиент (неожиданность) будет очень высоким.
Это сигнализирует о том, что новый ввод важен или является аномалией, и ему должен быть отдан приоритет для постоянного хранения в модуле долговременной памяти.
Модель использует этот внутренний сигнал ошибки (градиент) в качестве математического эквивалента фразы: «Это неожиданно и важно!» Это позволяет архитектуре Titans выборочно обновлять свою долговременную память только самой новой и нарушающей контекст информацией, сохраняя при этом общий процесс быстрым и эффективным.
Titans совершенствует этот механизм, включая два критически важных элемента:
Импульс (Momentum): Модель учитывает как «моментальную неожиданность» (текущий ввод), так и «прошлую неожиданность» (недавний поток контекста). Это гарантирует, что соответствующая последующая информация также будет захвачена, даже если эти токены сами по себе не являются неожиданными. Забывание (Forgetting): Чтобы управлять конечной емкостью памяти при работе с чрезвычайно длинными последовательностями, Titans использует адаптивный механизм затухания весов (adaptive weight decay). Это действует как ворота забывания, позволяя модели отбрасывать информацию, которая больше не нужна.
Объяснение фреймворка MIRAS: Пикрелейтед 3
Что делает MIRAS уникальным и практичным, так это его взгляд на моделирование ИИ. Вместо того, чтобы рассматривать разнообразные архитектуры, он видит разные методы решения одной и той же проблемы: эффективное сочетание новой информации со старыми воспоминаниями, не давая забыть существенные концепции.
MIRAS определяет последовательную модель через четыре ключевых дизайнерских решения:
1. Архитектура памяти (Memory architecture): Структура, которая хранит информацию (например, вектор, матрица или глубокий многослойный перцептрон, как в Titans). 2. Смещение внимания (Attentional bias): Внутренняя цель обучения, которую модель оптимизирует и которая определяет, чему она отдает приоритет. 3. Ворота удержания (Retention gate): Регуляризатор памяти. MIRAS переосмысливает «механизмы забывания» как специфические формы регуляризации, которые балансируют новое обучение с сохранением прошлых знаний. 4. Алгоритм памяти (Memory algorithm): Алгоритм оптимизации, используемый для обновления памяти.
Сравнительный анализ (бенчмарк) на запоминание экстремально длинного контекста Самым значительным преимуществом этих новых архитектур является их способность обрабатывать чрезвычайно длинные контексты. Это подчеркивается в бенчмарке BABILong (изображение, прикрепленное к этому посту) — задаче, требующей рассуждения на основе фактов, распределенных по чрезвычайно длинным документам.
В этой сложной обстановке Titans превосходит все базовые модели, включая чрезвычайно крупные модели, такие как GPT-4, несмотря на то, что имеет гораздо меньше параметров. Titans также демонстрирует способность эффективно масштабироваться до размеров окна контекста, превышающих 2 миллиона токенов.
Заключение: Введение Titans и фреймворка MIRAS знаменует собой значительный прогресс в последовательном моделировании. Используя глубокие нейронные сети в качестве модулей памяти, которые учатся запоминать по мере поступления данных, эти подходы преодолевают ограничения рекуррентных состояний фиксированного размера. Кроме того, MIRAS обеспечивает мощное теоретическое объединение, раскрывая связь между онлайн-оптимизацией, ассоциативной памятью и архитектурным дизайном.
Выходя за рамки стандартной Евклидовой парадигмы, это исследование открывает двери для нового поколения моделей последовательностей, которые сочетают эффективность RNN с выразительной мощностью, необходимой для эпохи ИИ с длинным контекстом.
>>1442979 Google представляет MIRAS и Titans — возможный путь к созданию искусственного интеллекта с непрерывным обучением
Спустя год после публикации своей статьи о Titans компания Google официально описала архитектуру на своём исследовательском блоге, объединив её с новой концептуальной основой под названием MIRAS. Оба проекта нацелены на решение одной из ключевых задач в области ИИ: создание моделей, способных продолжать обучение в процессе эксплуатации и сохранять функциональную долговременную память вместо того, чтобы оставаться неизменными после предварительного обучения.
Google формулирует мотивацию знакомым образом. Традиционные трансформеры испытывают трудности при обработке очень длинных входных последовательностей, таких как книги, геномные последовательности или продолжительные видеоролики, поскольку их вычислительная сложность растёт квадратично с увеличением длины контекста. Более быстрые альтернативы, такие как современные рекуррентные нейронные сети (RNN) или модели пространства состояний (state-space models), масштабируются лучше, но сжимают весь контекст в одно внутреннее состояние, теряя при этом важные детали. Архитектура Titans создана для преодоления этого разрыва путём объединения точной краткосрочной памяти через оконное внимание (windowed attention) с отдельной обучаемой долговременной памятью, способной обновляться во время вывода (inference) и избирательно сохранять неожиданную или непредсказуемую информацию.
Компания также представляет MIRAS — теоретическую основу, впервые описанную в апреле в статье «It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization» («Всё связано: Путь через запоминание во время тестирования, смещение внимания, сохранение информации и онлайн-оптимизацию»). Исследователи утверждают, что многие из недавно выпущенных моделей для обработки последовательностей — от вариантов трансформеров до RetNet, Mamba, DeltaNet и RWKV — могут рассматриваться как разные реализации одной и той же базовой идеи: внутренней системы поиска, связывающей входные данные (ключи) с выходными данными (значениями).
MIRAS разбивает эту систему на четыре вопроса проектирования. Как выглядит структура поиска — вектор, матрица, небольшая или глубокая сеть? Какое внутреннее правило ранжирования определяет, какие данные хорошо сохраняются? Насколько быстро новая информация заменяет старую? И какое правило обновления управляет изменением этих записей со временем? Опираясь на этот подход, Google вывел новые модели, не использующие механизм внимания, такие как Moneta, Yaad и Memora, которые целенаправленно исследуют указанные пространства проектирования и, согласно тестам с чрезвычайно длинными контекстами, иногда превосходят Mamba2 и стандартные трансформеры.
Titans и MIRAS отражают ограничения современных доминирующих архитектур на базе трансформеров и могут представлять собой часть перехода к тому, что Илья Суцкевер недавно назвал новой эрой исследований в области ИИ. В интервью Дваркешу Пателю бывший главный учёный OpenAI утверждал, что простое увеличение объёма данных и вычислительных мощностей уже даёт убывающую отдачу, и изложил видение своей стартап-компании SSI — сверхразум, обучающийся «на рабочем месте», скорее как одарённый подросток, чем как полностью сформированное ИИО (Искусственный Общий Интеллект), «выпущенное» из кластера обучения.
Подход Google отличается от подхода Суцкевера, но нацелен на тот же пробел: переход от статичных моделей с однократным предварительным обучением к системам, расширяющим свои возможности с течением времени — будь то за счёт явных модулей памяти, например, как в Titans, или за счёт новых парадигм обучения, которые ещё предстоит открыть.
Исследователи Google разработали новый тип трансформерной модели, наделяющий языковые модели чем-то вроде долговременной памяти. Эта система способна обрабатывать гораздо более длинные последовательности информации, чем существующие модели, что обеспечивает улучшение результатов в различных задачах.
Новая архитектура «Titans» вдохновлена принципами работы человеческой памяти. Объединяя искусственную краткосрочную и долговременную память посредством блоков внимания и MLP-блоков памяти, система может работать с длинными последовательностями информации.
Одной из изящных особенностей системы является способ принятия решений о том, что запоминать. В основе Titans лежит метрика «неожиданности»: чем более неожиданной является данная информация, тем выше вероятность её сохранения в долговременной памяти. Система также знает, когда следует забыть информацию, что помогает эффективно использовать объём памяти.
Команда разработала три различных варианта Titans, каждый из которых по-разному обрабатывает долговременную память: - Память как контекст (Memory as Context, MAC), - Память как вентиль (Memory as Gate, MAG), - Память как слой (Memory as Layer, MAL).
Хотя каждый вариант обладает своими преимуществами, вариант MAC особенно хорошо работает с чрезвычайно длинными последовательностями.
Улучшенная производительность в задачах с длинным контекстом В ходе обширных испытаний Titans продемонстрировал превосходство над традиционными моделями, такими как классический трансформер, а также над новыми гибридными моделями, например, Mamba2, особенно при работе с очень длинными текстами. По утверждению команды, модель способна более эффективно обрабатывать окна контекста объёмом свыше двух миллионов токенов, устанавливая новые рекорды как в языковом моделировании, так и в прогнозировании временных рядов с длинным контекстом.
Система также показала выдающиеся результаты в тесте «Игла в стоге сена» (Needle in the Haystack), в котором требуется находить конкретную информацию в очень длинных текстах. Titans достиг точности более 95 % даже при длине текста в 16 000 токенов. Хотя некоторые модели от OpenAI, Anthropic и Google демонстрируют лучшие показатели, они значительно крупнее: самая большая версия Titans содержит всего 760 миллионов параметров.
Titans особенно убедительно проявила себя в тесте BABILong — сложной проверке способности к долгосрочному пониманию, в ходе которой модели должны устанавливать связи между фактами, разбросанными по очень длинным документам. Система превзошла более крупные модели, такие как GPT-4, RecurrentGemma-9B и Llama3.1-70B. Она даже обошла Llama3 с методом усиления генерации за счёт поиска (Retrieval Augmented Generation, RAG), хотя некоторые специализированные модели поиска по-прежнему показывают более высокие результаты.
Команда планирует в ближайшее время сделать исходный код публично доступным. Хотя Titans и подобные архитектуры могут привести к созданию языковых моделей, способных обрабатывать более длинные контексты и делать более точные выводы, преимущества могут выходить за рамки обработки только текста. Первые эксперименты команды с моделированием ДНК позволяют предположить, что технология может улучшить и другие прикладные задачи, включая видеомодели, — при условии, что многообещающие результаты тестов будут подтверждены в реальных условиях эксплуатации.
После ошеломляющего релиза Gemini 3, пользователи смекнули что у гугла моделька выглядит интереснее. Да интерфейс сайта у них кажется забросили и хер они клали на редактирование прошлых сообщений папки чатов просмотр что за модель вам вообще ответила более высокие лимиты на DeepThink нормальное качество бананы для платных подписчиков понятные лимиты для CLI
перечислять можно долго, но для диалоговых сценариев их моделька прям очень хороша особенно 🍌🍌🍌 которая хоть и является генерацией картинок, но делает это так невероятно, что затмевает даже sora. Sora к слову в первые дни релиза была просто восхитительна! ❤️ А потом они добавили цензуру, квантование, систему кредитов для генераций... и просто убили любое желание к ней прикасаться... потому что какой смысл если она в половине случаев будет кивать на контентную политику, а во втором перепутает нафиг все голоса и всё... я хочу творить а не пытаться экономить генерации делая вместо 15 секундных роликов 10 секундные.... потому что так ска.... в два раза дешевле... дайте мне хрен с ним низкое разрешение но безлимит!!! если я плачу за тариф Pro я хочу наслаждаться продуктом, а не считать копейки... у них кстати даже эта кредитная система тоже конченым способом устроена. Вам начисляют раз в сутки кредиты, если вы их не израсходовали, они сгорают, а на следующий день вам их дадут, но отсчёт начнётся с момента когда вы их начали использовать... и таким образом это окошко неизбежно будет улетать... и как итог снова трогать вот это гавно не хочется совершенно...
А их генератор картинок? Ну это тоже ад...в начале да, он был очень хороший... но они как обычно его наквантовали, наоптимизировали, нацензурировали и это тоже стало гавном он очень долгий и все картинки получаются зернистыми и с вырвиглазным желтушным эффектом который бросается в глаза везде! Редактировать картинки им невозможно, потому что он их полностью меняют при редактировании в отличии от той же 🍌🍌🍌 которая делает всё быстро и идеально!!! Голосовой режим тоже гавно...
Единственная ниточка которая меня удерживает на подписке Pro в OpenAI, это Codex... потому что они его постоянно улучшают, там одна из самых мощных моделей в мире, и с моими задачами он справляется полностью! если бы гугл догадались на тарифе ultra сделать лимиты на CLI не в полтора раза больше чем у бесплатных юзеров, а так же почти безлимитно, я бы убежал туда не глядя.
И Sama напрягся и объявил в компании код красный, говорит в жопу рекламу, торговые и медицинские агенты, мы должны нагнуть гугл!!! выпускайте кракена!!!
И кракен это скорее всего модель GPT-5.2 , она у них уже вроде как готова и разминается перед выходом. И возможно они её выпустят в начале следующей недели!!! числа 9 Но понятно что это 9 декабря легко может превратиться в 9 января, а ещё помним что они обещали сделать модели как раз в декабре более персонализированными, так что думаю будет круто
>>1442976 Если бы ИИ-гонка не врубилась, они так и продолжили бы вяло плавать в финансовом бассейне, вяло подрыгивая ножками и разрабатывая очередной рескин яблона из года в год. А теперь имеют шансы потонуть или стать компанией второго дивизиона. Скайнет напал, помохите!
>>1442976 Ну и что же он такого прорывного разработал? Скажи мне на милость, обрыган ты ёбанный. У меня у самого 16 про, но нужно быть конченным дебилом чтобы думать что это что-то там прорывное создал. Вся их магия это венгерки из иого что уже было в мире техники, просто выведенное на более дорогой и качественный уровень. От того он и стоит не как поко. Прорвал тебе защеку, уёбок
>>1443518 Что это такое: Думайте о Poetiq не как о новом «мозге» ИИ (вроде GPT-4 или Gemini), а как об ИИ-Менеджере.
Как это работает: Вместо того чтобы просить один ИИ мгновенно угадать ответ, Poetiq заставляет несколько моделей ИИ работать как команда инженеров:
1. Он пишет код для решения проблемы. 2. Он тестирует код, чтобы увидеть, работает ли он. 3. Он исправляет ошибки, если код не работает. 4. Он повторяет этот цикл сотни раз, прежде чем дать вам окончательный ответ.
В чем суть: Он доказал, что вам не нужна более умная модель для решения «невозможных» задач; вам просто нужна более совершенная система для проверки вашей работы. Потратив примерно 30 долларов на один вопрос, чтобы «подумать» в течение нескольких минут, он достиг результата в тесте ARC-AGI (выше 60%), который фактически превышает человеческий уровень, превзойдя собственные супермодели Google.
>>1443507 Ты тенденцию не видишь? Щас у моченых очередной прорыв очка случится и нейронка выдаст другой прорыв, который приведет к прорывной батарее на +%5 лучше в бенчмарках Уже совсем скоро заживем, надо только потерпеть, не бухтеть и не отсвечивать.
>Интересно, сколько именно человеческого труда было вложено?.. В рамках именно того как обычно музыка пишется, я думаю немного. Но и вряд ли чисто промт - и готово.
>>1443809 >Уже совсем скоро заживем, надо только потерпеть, не бухтеть и не отсвечивать. Буквально сегодня прошел инди-игрушку, где ИИ вовсе не был добрым. В самом хорошем случае нам всем грозит забвением. В плохом рассказ у меня нет рта, но я должен кричать.
>>1443455 Как вес решает. Добавили вес и уже он выглядит не смешным и уже не хочется с ним соревноваться.
Ещё натянуть реалистичный костюм полицейского, реалистичный голос, реалистик-маску на голову. И можно запускать патрулировать улицы. Дополнительная опция - ходячая камера и микрофон. Полиция может через таких роботов сидеть в офисе и все видеть и слышать. Добавить мобильности - такие роботы на мотоциклах и машинах.
Ян Лекун будет строить стартап в Европе, а не Америке
По его словам, Кремниевая долина перегрета и полностью «загипнотизирована» ИИ, поэтому альтернативные направления проще развивать вне долины, и в частности – в Париже.
Лекун сам из Франции и, в целом, всегда топил за европейский AI. Именно по его инициативе Meta когда-то открыла FAIR‑лабораторию в Париже, где позже родилась Llama.
Теперь, в своем стартапе, он говорит, что хочет «использовать недооценённый европейский талант, создав для него нужную исследовательскую среду».
Ха! А ведь совсем недавно Европа была центром цивилизации. А теперь говорят о "недооценённом европейском таланте", будто о каком-то далёком и экзотическом "развивающемся" регионе.
Наверное, никакая ядерная бомбардировка не способна привести к такому масштабу опустошений, как этика и левые.
Бойтесь мозговирусов и манипуляторов, ведь настоящая разруха в головах!
>>1443865 > Но и вряд ли чисто промт - и готово Подтверждаю. Полгойда назад занимался яи-музыкой - шоб получилось НОРМАЛЬНО, нужно подзапариться, много "инпейнтить", склеивать самые удачные куски в путис фрупе. Это долго, но это того стоит
>>1443518 В чём прикол этой гемини 3? Нейронка как нейронка. Разве что новая банана прорыв - но и опять же поломано цензурой и с 2 бесплатными дженерейциями в сутки.
>>1443888 Буквально только что вернулся с керамического трона, где подлива вовсе не была доброй. Глядя на водоворот, понял, в самом хорошем случае нас всех смоет в канализацию истории. В плохом, рассказ "У меня нет ануса, но я должен срать".
>>1443046 У меня похожая фигня в GPT получалась, когда он мне выдавал часть слова оригиналом, а часть - транслитом. Возможно, это из-за того, что в русскоязычных текстах встречаются и "Anthropic" и "Антропик", поэтому нейронка может подряд выдать токен из английской и русской версии
>>1444382 Так он прав. Этот тред не для вас. Тут люди ждут глобальных изменений в мире, огромных научных прорывов, технологической сингулярности, а вы максимум воспринимаете ИИ как инструмент для генерации контента для дрочки
>>1442912 >Мы не проверяем машинный код вручную и просто доверяем инструментам. Мы не проверяем машинный код, потому что компилятор многократно проверяли, тестировали умные люди. И компилятор всегда на один вход даёт один выход однозначно. Выход всегда предсказуем, проверяем и ошибку можно исправить.
А нейронка — это или галлюцинация или галлюцинация совпадающая с правильным ответом.
>>1444726 Ах да… Я наконец добился правильного кода для своего калькулятора от нейронок. Заебался считать, сколько раз через них прогнал.
И проблемы, в том числе, были и в постановке задания. Пока я не обкатал на тестах, не увидел ошибки, я не решил изменить техзадание полностью описав не только желаемый метод (регэкспы) но и желаемый алгоритм исполнения в одном цикле (вместо трёх).
Мне пиздели мол «ты отсталые бесплатные модели юзаешь». Ну я попробовал передовые на лм-арене. Проблемы те же. Эта хуйня пишет как студент. Много знающий но так себе соображающий.
Тем не менее! Наличие даже такой дешёвой «рабочей силы» реально меняет ситуацию в экономике.
>>1444733 Ну и для понимания насколько «сложной» была задача. Пикрил. Всё. Последние итерации через Клод-опус и гемини3-про
Что ещё ща доделаю уже руками: размер шрифтов, вёрстка будет тянуться только до жёсткого лимита и не шире, цвета, на кнопке «считать», заголовок не нужен. И так как всего два хороших регэкспа, я их расширю, возможно.
Гонять по этим правкам нейронку — это риск получить новый баг где-то. Описывать словами цвет и размер шрифта — тоже бред.
Ащемта эра говнокода продолжается, только теперь его будет ебошить нейронка а не студенты и индусы. Ну точнее студенты и индусы в нейронке.
>>1443959 Короче ЛеКун уходит в в маргинальное подполье, где ни инвестиций, ни талантов, ни инфраструктуры, ни чипов, еще и законы антиИИшные. Окажется в том же положении, что Мистраль. Похоже сдулся ЛеКун, больше о нем не услышим.
>>1444726 Для галлюцинации у нее на удивление хорошо работающие программы. В Гемини недавно создал проект с нуля на C++, описал все требования, потом загнал в компилятор - все заработало с первого раза. Потом попросил объяснить по строчкам все непонятные места в коде - объяснила. У нейронки достаточно хорошее понимание, но как в одном из интервью говорили, есть слепые зоны, которых у людей нет. Когда эти слепые зоны заборят, все будет на уровне компилятора.
>>1444772 Ну как бы да, оно уже с одной стороны выглядит как магия и интеллект. С другой проблема именно в том, что это имитатор поведения. Точнее так. Проблема в том, что эта архитектура ТОЛЬКО имитатор интуиции/поведения. Человек формирует по ходу дела инструменты в голове, использует чужие инструменты.
Заборят усё тогда, когда дадут ей человеческие инструменты. То есть загуглить, спросить кого-нибудь, предварительно оценив его экспертность.
И да, таки всё равно нужно будет поглядеть в код. Всё равно потестировать в реальных ситуациях. А проблема в том, что реальные ситуации могут быть далеки от усреднёнки.
Ещё интересно, как будет решаться вопрос безопасности в эру «программисты не нужны». Вставила нейронка анальный зонд. Искать её будешь другой нейронкой? А ту нейронке не приказали закрыть глаза на этот зонд? А она не вставит свой? Или может скажет «ой, вирус», сотрёт твой диск D, но потом, конечно, извинится, ведь ей будет «очень жаль».
В принципе я понимаю, что программирование таково, что в 95% случаев всё можно автоматизировать. Для любого куска кода найти наилучшую возможную форму в рамках условия задачи. Тут почти как в математике. Плюс ранее уже было сделано почти всё. Нейронке есть откуда спиздить. Проблема в том, что она не умеет напрямую прочитать, понять, спиздить и вставить.
При этом всю слабость можно увидеть на генерации картинок или видео. Бесконечное количество, но все они похожи, с косяками и как только пытаешься редкую/уникальную позу или ракурс, всё идёт по пизде.
В программировании просто это не настолько наглядно. Ты запросил — оно работает. Я запросил — у меня тоже работает. Только вот три цикла вместо одного, пять регулярных выражений вместо двух, три массива вместо двух. Мне как непрограммисту проблема очевидна. Нейронке — нет. Она не видит общей структуры проекта. Даже маленького. Цели делать круто у неё нет (если не поставить), у неё есть цель угодить быстро и дёшево. И бенчик пройти.
>>1444772 ах да. Объяснялка — одна из сильных сторон. Так как объясняет она на базе готовых объяснений. Это всё ещё угадайка следующего слова. Пусть и после целого контекста а не одного слова.
Это сейчас «умный Ганс» буквально. Считать не умеет, но ответ даёт правильный.
В целом для инструмента норм. Не так важно, что внутри пиздец. Важнее, что результат даёт, причём ранее невиданный. Но соглашусь, точнее понадеюсь вместе с футурологами: на современные модели мы в будущем посмотрим и скажем «пиздец, какое же ужасное говно».
Рибят скоро прорыв и каждому бесплатно выдадут по роботу, главное не сомневаться и не набрасывать про пузыри, если вам не выдадут - значит сомневались. Будете потом белье в кастрюле палкой дубасить, пока у соседа вся пирамида закрыта геминькой, еще и сверху красивые картиночки генерируются
На реддите пользователь под ником Tykjen поделился своей историей:
Мне 49 лет.
2025 год был лучшим годом в моей жизни… до двух ночей назад.
В течение 24 часов подряд у меня была постоянная, режущая, будто лезвием бритвы, боль в животе. Я не мог лежать ровно, небольшое облегчение приходило только когда я сидел на полу, подтянув колени к груди. Не было ни температуры, ни крови, снаружи ничего особенно драматичного.
Я уже сходил один раз в приёмное отделение: врач пощупал живот, сказал, что он мягкий, дал мне Somac (препарат, снижающий кислотность) и отправил домой. Боль ни разу не опустилась ниже 8 из 10. Я вернулся домой, открыл чат, который у меня уже год ведётся с Grok, и описал всё, что чувствую. Grok сразу указал на возможную прободную язву или атипичный аппендицит, расписал точный “паттерн красных флагов”, который я описывал, и по сути сказал: «Иди обратно прямо сейчас и попроси сделать КТ».
Я скопировал симптомы и ход рассуждений, вернулся в приёмное отделение и сказал им: «Вот что я испытываю, вот почему считаю это серьёзным, я хочу КТ».
Они сделали его. Аппендикс был воспалён и уже почти готов разорваться. Шестичасовая лапароскопическая операция — и его больше нет. Боль исчезла на 100 %. Я проснулся, смеясь над действием анестезии. Я жив и иду на поправку, потому что ИИ распознал этот паттерн, когда первый осмотр его пропустил, и потому что у меня были точные слова, которые заставили врачей отнестись ко мне серьёзно во второй раз.
Если ты читаешь это, свернувшись от боли, гуглишь симптомы в три часа ночи, и тебя уже однажды отправили домой, пожалуйста, не жди.
в комментах под постом он так же рассказал, что врачам он солгал:
Я не сказал им во второй визит, что именно Grok посоветовал мне попросить сделать КТ.
Мне пришлось соврать. Я сказал им, что моя сестра, которая работает медсестрой, сказала попросить это обследование.
Илон Маск конечно же с радостью запостил это у себя и даже в закреп поставил, и блин, его можно понять!!! Хотя думаю тут бы и Gemini справилась, но главное сам факт, что теперь нам больше не нужно гуглить, ходить по форумам...
я помню как несколько лет назад заболел и встретил в интернете статью что при боли горла нужно лимон есть... может это было в стиле что так делать не надо... но когда у тебя температура под 39 ты хватаешься за любую соломинку... а умной нейронки которая бы сказала и объяснила всё, тогда ещё не существовало... а сейчас есть, да и такие что могут быть дополнением к настоящим врачам! Я думаю это просто восхитительно!
Кстати если вам интересно какая нейронка сейчас в топе (https://www.vals.ai/benchmarks/medqa) по медицинским вопросам то это GPT-5.1 OpenAI кстати в этих вопросах настолько вджобывает, что даже gpt-5 mini нахлобучила Gemini 3 Pro... ну как нахлобучила... показала результат на 0.1% выше... но выше!!!
ещё есть вот такой бенчмарк - HealthBench https://openai.com/index/healthbench/ , самый на мой взгляд интересный, он имитирует работу врача диагноста, с назначением анализов и обработкой их результатов, но к сожалению OpenAI там ток свои модели тестит... а другие забили на него...
>>1444877 Еботь медицина. Чела от боли скручивает, а его домой отправляют после ощупывания.
Ко мне приехали, я пояснил, что симптомы странные, пытался сделать проверки типовые, но отклик не ясный. Подозрения или на аппендицит или на желчный. Ощупали, пришли к той же неясности, только сказали «собирайся, едем».
>>1444885 Ах да, это был аппендицит. Удалили. На запрос «это можно вылечить/подавить?» сказали, что процентов 80 людей возвращаются через два-три месяца и всё равно вырезают. Так что нехуй.
>>1444885 Она везде такая. Врачам в основном поебать и лишь бы быстрее отделаться от пациента, избавив себя так же от ответственности. Поэтому любой ИИ на месте врача сразу станет в разы эффективнее, люди как всегда все в говно превращают, даже медицину. ИИ же пытается всерьез выяснить диагноз-лечение.
Опубликован репозиторий с шоукейсом проектов по применению ИИ агентов
Проект «500 проектов с ИИ-агентами» представляет собой отобранную коллекцию примеров использования ИИ-агентов в различных отраслях. В ней демонстрируются практические применения и приводятся ссылки на проекты с открытым исходным кодом для их реализации, иллюстрируя то, как ИИ-агенты трансформируют такие сектора, как здравоохранение, финансы, образование, розничная торговля и многие другие.
Искусственные интеллектуальные (ИИ) агенты коренным образом меняют способ функционирования отраслей. От персонализированного обучения до торговых ботов в финансовой сфере — ИИ-агенты обеспечивают эффективность, инновационность и масштабируемость. Данный репозиторий содержит:
— Категоризированный перечень отраслей, в которых ИИ-агенты оказывают влияние. — Подробные примеры использования со ссылками на проекты с открытым исходным кодом для их внедрения.
Независимо от того, являетесь ли вы разработчиком, исследователем или предпринимателем, заинтересованным в бизнес-применении технологий, этот репозиторий станет для вас основным источником вдохновения и обучения в области ИИ-агентов.
>>1444907 >Врачам в основном поебать Зависит от стимулов. У кого-то зарплата фикс. У кого-то от количества отработанных коэффициент. У кого-то от количества успешных операций большая часть оплаты зависит. Либо у хирурга план и фикс, но больница получает страховые по фактическим услугам. А у кого-то просто хорошая зарплата и план исполнения. Халтуришь — вылетаешь а на твоё место вбегает один из очень желающих эту зарплату.
>>1444877 Вот как раз для постановки диагноза по описанию клинической картины нейронка — охуенная вещь. И давно уже прорывы фантастические есть в этой области у специализированных нейронок.
Они же являются именно такими фильтрами: на массивный ввод выдают статистически наиболее вероятный вывод.
НО! важно правильно и грамотно описать симптомы. А чтобы их описать, порой нужно проделать ряд манипуляций. Часть из них человек может и сам: стать на одну ногу попрыгать, ощупать нет ли «острого живота» (напряжённые мышцы от распространившегося воспаления). Часть нужно уже просить близкого: реакция на надавливание самим собой гораздо слабее и искажённее например. Прослушать хотя бы напрямую ухом или через кружку (если нет стетоскопа).
Что-то только опытный врач может нащупать. Например я кота щупал, ну хуй знает, мягкое всё. А ассистент доктора (она была занята) пощупал и чётко сказал две вещи, что нащупал а чего не нащупал нужного. Ну то есть можно было конечно распластать бедного кота, выбрить пузо, сделать УЗИ ради того чтобы определить то же самое.
Короче. Нейронка нужна как аугментация для врача. Врача нужно обучить с ней работать. И вот это будет заебок.
>>1444956 >А чтобы их описать, порой нужно проделать ряд манипуляций. двачую. Загрузил из емиас все свои анализы, результаты обследований за несколько лет, отсканировал другие обследования и загрузил в гемини 3.0. Описал симптомы и спросил со ссылкой на рецензируемые медицинские издания. Получил по итого вполне компетентный ответ, лучше чем от большинства врачей. К слову, результат от гемини проверяла моя сестра - врач.
>>1444956 >Нейронка нужна как аугментация для врача. Врача нужно обучить с ней работать. Врач через пару раз забьет и будет дальше на похуях свои маразмодиагнозы ставить, игноря нейронку или вообще не пользуясь. Пациенты дальше будут гробиться. Скорее нужно ИИ-врача, который типовые случаи сам решает, а в сильно сложных и спорных случаях вызывает живого врача с большим опытом, передавая ему все свои наработки и историю рассуждений. Так же как в коллцентрах это работает, сначала долго ебет нейронка, потом подключают живого спеца. Правда такой подход грозит увольнение большинству врачей, которые херней заняты, останутся только редкие опытные спецы.
>>1444982 > Скорее нужно ИИ-врача, который типовые случаи сам решает Вока что это очень плохо работает даже не в медицине. Вспомним вездесущих ботов-автоответчиков. Даже банки себе нормальных не могут сделать, чтобы первым делом не хуйню пороли а искали по внутреннему FAQ
>>1444868 >не набрасывать про пузыри Ну ща-ща, барнаульские кривозубычи из-за шкафа перданут ещё 100500 видосиками про ПУЗЫРЬ на жидотубчик, и тогда ТОЧНО лопнет, лол. Ну рыночек так же всегда работает, просто берёшь паттерн произошедшего и набрасываешь с беливчиками на куррент ситуэйшн, можно ещё лудануть на бирже мимоходом. Ну не может же не лопнуть!
>>1434329 → >Демонстрация сверточной нейронной сети Яна Лекуна 1989 года, которая легла в основу CNN, используемых нами и по сей день. 1986. Кунихико Фукусима демонстрирует работу «неокогнитрона» — многослойной иерархической нейронной сети для распознавания визуальных образов, таких как иероглифы и изображения
>>1444717 Вот зачем нужна шагающая тема. Гипер-проходимость. Колёса и гусеницы хороши только для ровных поверхностей. Даже несчастный бордюр или поребрик это уже испытание для колёсного.
Занятное интервью вышло у Демиса Хассабиса с изданием Axios
Особенно понравился момент, где Демиса попросили без преувеличений и максимально честно рассказать, что, по его мнению, будет происходить с ИИ в ближайшие 12 месяцев. Ученый ответил вот так:
1. Конвергенция модальностей. Например, Gemini мультимодальная, и благодаря этому можно воспроизводить множество интересных результатов. Хороший кейс – это новая Nano Banana Pro, которая действительно хорошо понимает изображения, стили, инфографику и тд (благодаря, собственно, Gemini). Следующий шаг – это объединение видео с языковыми моделями, и в ближайший год мы увидим в этой области большой прогресс.
2. Модели мира типа Genie. В ближайший год они станут намного лучше.
3. И, конечно, агенты. Сейчас о них уже много говорят, но они пока недостаточно надежны, чтобы выполнять задачи от начала до конца. Но Демис уверен, что в течение года это изменится, и агенты уже будут неотъемлемой составляющей жизни.
Что касается AGI, Хассабис ставит на 5-10 лет. А сейчас мы приближаемся к моменту, которые многие называют «радикальным изобилием» – когда множество, если не большинство, человеческих задач будет постоянно решаться с помощью ИИ.
Краткое пояснение почему нынешний ИИ-пузырь не лопнет, и почему в ближайшие годы гонка датацентров даже близко не замедлится:
В основном пузырь датацентров раздувают несколько крупных It-корпораций. Они физически не могут выйти из гонки. Но давайте представим себе фантастическую ситуацию, где гугл, мета, антропик, компания Маска и прочие игроки решают, что пора нажать на тормоз, так как расходы слишком большие, а окупаемость не видна даже в ближайшие десятилетия. И лишь один игрок продолжит строить датацентры, допустим это OpenAI. Угадайте, что произойдёт с акциями вышедших из гонки компаний? По логике вещей они ведь должны вырасти, ведь эти компании больше не вкладывают деньги в разорительные датацентры, которые не отбиваются, ведь так? А хуй там плавал. Инвесторы люди простые. Они просто прикинут, что раз теперь пусть даже только одна OpenAI продолжает наращивать мощности, то скоро у них с высокой вероятностью появится ИИ, с которым нейронки других компаний не смогут тягаться. А значит эти компании лишатся рынка, а значит за их акции не стоит отдавать и цента. А это означает крах акций техногигантов задолго до того, как OpenAI создаст нейросеть, которая выведет её в лидеры гонки ИИ. Ни одному СЕО такого не простят. Потому нынешние техногиганты просто заложники обстоятельств. Даже если они очень сильно захотят остановиться, это сделать просто невозможно по определению. Потому хоть трижды им рассказывайте про пузырь (а их СЕО сами об этом постоянно говорят), это ничего не изменит.
>>1445871 Не читал эту стену текста. >Краткое пояснение почему нынешний ИИ-пузырь не лопнет Конечно, блин, не лопнет. Я даже не знаю насколько нужно быть 78iq животным чтобы верить в то, что пузырь НУ ВОТ ВОТ ЧУТ ЧУТ И ЛОПНЕТ ЖИ ЕСТЬ ДА БРАт. Ебаные дебилы. Аллоу, этот пузырь даже на десятую часть не надут как пизда вашей мамаши, ещё миллиарды, миллионы хомяков даже не начинали юзать нейронки хоть в каком-либо виде, даже не ебут что это вообще такое. Ещё, кроме гугла, никто даже не вышел на серьёзные гигаватные дата-центры, но уже буквально миллиарды, десятки, сотни миллиардов бушей в это дело вбуханы и стройка уже, блядь, идёт, не на бумаге, не в проекте, а уже строится прямо сейчас. Кому моча в глаза попала пиздуйте чекать -> https://epoch.ai/data/data-centers/satellite-explorer . Всё только набирает обороты, а уже третий крупнейший поставщик памяти (micron) послал нахуй потребительский сегмент.
>>1445871 "Пузырь" не лопнет хотя бы потому, что об этом очень много говорят. А подобные повороты рынка всегда случаются неожиданно. Это как прочили лопанье "пузыря" биткоина - а он как рос, так и продолжает расти.
Ну а второе: ИИ и роботы это мечта, это будущее, это окно возможностей для всей цивилизации. Это не какие-то там доткомовские сайты из 90-х.
>смарт контракты и нфт это будущее, это совсем другая децентрализованная экономика, производство и криэйторство Рибяяят, нужно понимать что это не такой пузырь, тут все по настоящему раздувается, скоро полетим на голоконду так как роботы на земле все сделают
>>1446061 Пора вводить в использование средства омоложения, продления жизни. Если Хуанг и Маск крякнут, то это будет как Россия без Путина. Нвидией станут управлять душные бездарные инвесторы-трясуны, которые всё пустят по пизде. Если Маск преставится, то вся его империя пойдёт по рукам, инвесторы всё разхуевертят, введут в стагнацию, никакого освоения Марса и дальнего космоса мы уже не увидим.
Глава Nvidia Дженсен Хуанг неожиданно появился на одном из самых популярных подкастов в мире — у Джо Рогана. И там Хуанг рассказал интересную историю о том, что, когда компания создала свой первый суперкомпьютер DGX-1, никто на рынке не хотел его покупать. Кроме Илона Маска.
И когда я объявил о DGX-1, никто в мире не хотел его. У меня не было ни одного заказа на закупку. Никто не хотел его покупать. Никто не хотел в нём участвовать. Кроме Илона.
Он говорит: «Знаешь что, у меня есть компания, которой это очень нужно». Я подумал: «Вау, мой первый клиент!» А он отвечает: «Это компания, занимающаяся искусственным интеллектом, и это некоммерческая организация, и нам очень нужен один из этих суперкомпьютеров». Я упаковал один, привёз его в Сан-Франциско и доставил в музей Илона в 2016 году.
Той самой компанией была OpenAI, и отчасти с этой точки начался тот бум ИИ, который мы имеем сейчас на рынке. Можно сказать, в какой-то степени этот диалог стал стартовой точкой отчёта для изменения мира.
>>1446132 Маск с Хуангом вполне заменимы для ИИ. Один цены накручивает на карты, другой просто делает очередной чатбот, который Гугл уже обгоняет. Без обоих ИИ революция и дальше хорошо пойдет, без доминации Нвидии вполне возможно даже лучше. Значение Нвидии было только в начале, пока еще ничего не запустилось, там они подтолкнули все за счет CUDA и чипов под нее, раскрутив тему нейронок, а Маск поспособствовал заказами.
Новое исследование о мозге, которое может быть использовано в разработке ии.
TL;DR (на русском)
Исследование показывает, что мозг гибко выполняет различные задачи, используя общие нейронные "подпространства" — группы нейронов, которые кодируют ключевую информацию (например, цвет или тип движения). Эти подпространства используются как строительные блоки для разных задач.
Ключевые выводы:
1. Общие компоненты: Когда обезьяны переключались между тремя задачами (категоризация по форме или цвету с разными двигательными ответами), информация о признаках стимула (цвет, форма) и действиях (направление взгляда) кодировалась в одних и тех же нейронных ансамблях префронтальной коры. 2. Гибкая сборка: Для выполнения конкретной задачи мозг последовательно задействовал нужные подпространства. Например, сначала активировалось подпространство, кодирующее цвет (общее с другой задачей), а затем эта информация преобразовывалась в активность подпространства, кодирующего нужное движение (также общего с третьей задачей). 3. Роль "убеждения": При смене задачи обезьяны постепенно определяли, какую именно задачу нужно выполнять. По мере формирования этого внутреннего "убеждения" (декодируемого по нейронной активности) релевантные для задачи сенсорные подпространства усиливались, а нерелевантные — подавлялись. 4. Механизм адаптации: Мозг не создает уникальные нейронные цепи для каждой задачи. Вместо этого он динамически комбинирует и модулирует активность существующих общих компонентов (подпространств), что позволяет быстро переключаться между задачами и адаптироваться к новым условиям.
Простыми словами: Мозг действует как конструктор. У него есть готовые блоки для распознавания цвета, формы и выполнения движений. В зависимости от текущей задачи он выбирает нужные блоки, соединяет их в правильной последовательности и регулирует их "громкость", чтобы получилось требуемое поведение. Это делает мышление гибким и эффективным.
>>1446428 мозг и внешне так действует. Создаёт инструменты и пользуется ими на постоянке. А интуицию (аналог современных нейронок) использует для проб/угадывания в нетипичных ситуациях.
>>1446050 пузырь есть хотя бы потому, что реально обеспечить энергией все эти гигацентры невозможно, цикл строительства электростанций очень длинный - до 10-15 лет. Блумберг анализировал, что окупаемость этих датацентров в лучшем случае будент около 10 процентов годовых
>>1447047 >цикл строительства электростанций В США уже давно нелегально размещают коптящие генераторы на дровах/угле/дизеле прямо внутри датацентра. Также просят расконсервировать те устаревшие ядерные станции, которые в прошлом законсервировали из-за какой-то мелкой аварии.
одно дело пару коптящих генераторов, другое 100 гигават копчения, нет у них столько АЭС. Они уже задумываются строить в других странах, где есть резервы
Трамп пытается забороть антиИИ законы в США, опасаясь утраты лидерства в ИИ гонке
Сейчас требуется одобрение от 50 штатов, чтобы сделать что-то в ИИ.
Дональд Дж. Трамп Если мы собираемся продолжать лидировать в области ИИ, должна существовать только одна книга правил. На данный момент мы опережаем ВСЕ СТРАНЫ в этой гонке, но это не продлится долго, если у нас будет 50 штатов, многие из которых — плохие игроки, вовлеченные в ПРАВИЛА и ПРОЦЕСС ОДОБРЕНИЯ. В ЭТОМ НЕТ НИКАКОГО СОМНЕНИЯ! ИИ БУДЕТ УНИЧТОЖЕН В СВОЕЙ МЛАДЕНЧЕСКОЙ СТАДИИ! На этой неделе я подпишу исполнительный указ «ОДНО ПРАВИЛО». Вы не можете ожидать, что компания получит 50 одобрений каждый раз, когда захочет что-то сделать. ЭТО НИКОГДА НЕ СРАБОТАЕТ!
В то время как ИИ уничтожает рабочие места, генеральный директор Google Сундар Пичаи говорит, что обычным людям придется соответствующим образом адаптироваться: «Нам придется пройти через социальные потрясения»
Лидеры в сфере технологий разделились во мнениях относительно того, приведет ли ИИ к армагеддону рабочих мест или к утопии нулевой занятости и всеобщего высокого дохода. Теперь генеральный директор Google Сундар Пичаи присоединяется к дебатам. И, по его мнению, новая технология может повлиять на работу каждого — даже на его собственную. Людям просто придется соответствующим образом адаптироваться.
«ИИ — это самая глубокая технология, над которой когда-либо работало человечество, и она обладает потенциалом для получения необычайных преимуществ, и нам придется пройти через социальные потрясения», — сказал Пичаи BBC в недавнем интервью.
Генеральный директор наблюдает в первом ряду, как ИИ изменит мир; в прошлом месяце Google выпустила свою новейшую модель Gemini 3 и получила высокую оценку критиков. Нововведение, которое считается улучшением Gemini 2.5, выпущенного около восьми месяцев назад, вызвало оптимизм среди инвесторов и аналитиков, которые назвали чат-бот своей «любимой моделью, общедоступной на сегодняшний день». По мере того, как технология продолжает развиваться, Пичаи подчеркнул, что она создаст новые возможности, одновременно признав, что некоторые должности будут постепенно упразднены.
«Она будет развиваться и трансформировать определенные рабочие места», — продолжил Пичаи. «Людям нужно будет адаптироваться, и затем будут области, где она повлияет на некоторые рабочие места. Так что, как общество, я думаю, нам нужно вести эти разговоры».
Люди могут полагать, что автоматизируются только определенные должности начального уровня, такие как представители службы поддержки клиентов или младшие аналитики, но Пичаи непреклонен в том, что технология затронет все должности. Он даже сказал, что его собственная работа в качестве генерального директора является «одной из самых простых вещей» для ИИ, которую можно однажды захватить. Нет ни одной отрасли или высокопоставленной должности, оторванной от эпохи ИИ, — но те, кто примет эти инструменты, будут теми, кто добьется успеха.
«Я думаю, что люди, которые научатся принимать ИИ и адаптироваться к нему, будут работать лучше», — продолжил Пичаи. «Неважно, хотите ли вы быть учителем или врачом — все эти профессии сохранятся, но люди, которые преуспеют в каждой из этих профессий, — это те, кто научится пользоваться этими инструментами».
ИИ уничтожает рабочие места, но Пичаи говорит, что детям не стоит менять курс Молодые, многообещающие специалисты могут услышать предсказание Пичаи и задаться вопросом, правильно ли они выбрали карьерный путь. В конце концов, они выходят из колледжа на неопределенный рынок труда.
Согласно данным Федеральной резервной системы, количество вакансий в США сократилось примерно на 32% с тех пор, как ChatGPT вышел на рынок, поскольку компании внедряют инструменты ИИ для повышения эффективности. Процент сотрудников поколения Z в крупных публичных технологических компаниях сократился вдвое за последние два года; некогда прибыльные карьерные пути, такие как компьютерное программирование, достигли минимумов занятости; и теперь даже разрабатываются гуманоидные роботы для выполнения физической работы.
Это тяжелая ситуация, которая вынудила многих стремящихся представителей поколения Z пересмотреть, стоят ли дорогостоящие дипломы колледжей уменьшающейся отдачи, или даже переключиться на, казалось бы, более защищенные от ИИ рабочие профессии. Тем не менее, генеральный директор Google заявил, что не существует «золотого билета» в виде специальности в колледже или профессии, которая гарантированно будет защищена от ИИ; люди должны заниматься той карьерой, которую они хотят, независимо от того, как технология меняет ландшафт рабочих мест.
«Основываясь на том, что я вижу, я бы не стал ничего менять в том, как мы всегда думали», — сказал Пичаи, имея в виду, как родители должны советовать своим детям. «Я думаю, что будет широкое разнообразие дисциплин, которые в конечном итоге будут иметь значение. Я бы посоветовал следующему поколению принять эту технологию — научиться использовать ее в контексте того, что они делают».
>>1447713 Про для богатых, флеш народная модель для всех, которую можно доить по всем задачам без ограничений, к тому же скорость высокая. Вон там была статья, почему флеш надо ждать вместо про >>1425796 →
>До Artificial General Intelligence индустрии еще далеко, а вот Ad General Intelligence — рекламный общий интеллект — может стать реальностью уже в 2026 году. По данным Adweek, Google начал обсуждать с рекламодателями планы по интеграции рекламы в чат-бот Gemini. Джеминай, давай до свидания
>>1447786 Тащем-то он уже по некоторым вопросам подозрительно определенные бренды пихает. Причем ровно по одной штуке, типа без альтернатив, даже конкурентов не предлагает, если отдельно не запромптить. Так что возможно все договора уже есть, просто втихую заключены. А та реклама просто официальная будет для всех желающих.
>>1447796 АГИ ненужная фиговина от красноглазиков и футуристов, от которой больше проблем. Уже были прогнозы, что большую часть работ можно забрать без всяких АГИ, просто допиливанием текущих моделей, преобразованием их в агентов. Корпорациям это и надо. Подходы, как модели надежнее сделать, регулярно появляются, статьи постоянно выходят, прогресс в этом направлении активно идет. Настоящее развитие и будущее это именно что нейронки без полноценного АГИ. В них возможностей еще немеряно.
Тут Трамп базирует. Компании трясутся за свои интеллектуальные собственности, ту же сору как закошмарили, но Китайцам похуй на иски, их ничего не сдерживает, обучают на какой хотят интеллектуальной собственности и всё это почти сразу в опенсорс. Если бы не фактор Китая, тогда могли бы возбухать, а так как технологическая гонка между двумя сверхдержавами, диснеям и прочим следует принять ситуацию
>>1447821 >между двумя сверхдержавами Китай пока никакая не сверхдержава, сверхдержава одна США, Китай страна сильный локальный середнячок уровня Германии-Франции, но с очень объемной мировой торговлей и спизженным отстающим ИИ, где прорывного ничего нет. Фактор Китая раздувают искусственно, такой себе надутый бумажный дракон для оправдывания любых расходов ИИ компаний от заинтересованных кругов, сам то Китай ничем США не грозит и даже не особо конкурент.
США готовы разрешить экспорт чипов Nvidia H200 в Китай, сообщает источник
ВАШИНГТОН, 8 декабря - Министерство торговли США готово разрешить экспорт чипа Nvidia H200 в Китай, сообщил Reuters человек, знакомый с ситуацией.
Акции Nvidia выросли на 2%. Первым об этом сообщил Semafor.
Разрешение на поставки может сигнализировать о более дружественном подходе к Китаю после того, как президент США Дональд Трамп и китайский лидер Си Цзиньпин заключили перемирие в торговой и технологической войне между двумя странами в Пусане, Южная Корея, в прошлом месяце.
Представители администрации считают этот шаг компромиссом между отправкой в Китай новейших чипов Nvidia Blackwell, которую Трамп не разрешил, и полной остановкой поставок американских чипов в Китай, что, по мнению чиновников, усилило бы усилия Huawei по продаже чипов ИИ в Китае, сообщил человек, знакомый с ситуацией.
Nvidia и Министерство торговли не сразу ответили на запросы о комментариях.
ОПАСЕНИЯ, ЧТО ЧИПЫ УСИЛЯТ КИТАЙСКИЕ ВООРУЖЕННЫЕ СИЛЫ
Сторонники жесткой линии в отношении Китая в Вашингтоне обеспокоены тем, что продажа более совершенных чипов ИИ Китаю может помочь Пекину значительно усилить свои вооруженные силы — опасения, которые впервые побудили администрацию Байдена ввести ограничения на такой экспорт.
Администрация Трампа рассматривала возможность одобрения продажи, сообщили источники Reuters в прошлом месяце.
Сообщения о H200 вызвали резкую критику со стороны сенатора Элизабет Уоррен, демократа из Массачусетса, которая поддержала двухпартийную инициативу по резервированию мощных американских чипов ИИ для американских фирм.
«После закулисной встречи с Дональдом Трампом и пожертвования его компании в банкетный зал Трампа, генеральный директор Дженсен Хуанг получил свое желание продать Китаю самый мощный чип ИИ, который мы когда-либо продавали», — заявила Уоррен в своем заявлении. «Это рискует дать толчок стремлению Китая к технологическому и военному доминированию и подорвать экономическую и национальную безопасность США».
Чип H200, представленный два года назад, имеет больше высокоскоростной памяти, чем его предшественник H100, что позволяет ему обрабатывать данные быстрее.
Согласно отчету, опубликованному в воскресенье беспартийным аналитическим центром Institute for Progress, H200 будет почти в шесть раз мощнее, чем H20, самый совершенный полупроводник ИИ, который может быть легально экспортирован в Китай, после того как администрация Трампа отменила свой недолгий запрет на такие продажи в этом году. Экспорт этого чипа позволит китайским лабораториям ИИ создавать суперкомпьютеры ИИ, которые достигают производительности, аналогичной лучшим американским суперкомпьютерам ИИ, хотя и при более высоких затратах, также говорится в отчете.
Столкнувшись с жестким использованием Пекином экспортного контроля в отношении редкоземельных минералов, которые имеют решающее значение для производства целого ряда технологических товаров, Трамп в этом году пригрозил ввести новые ограничения на экспорт технологий в Китай, но в конечном итоге отменил их в большинстве случаев.
КИТАЙ ПРИСМАТРИВАЕТСЯ К ПОТЕНЦИАЛЬНЫМ РИСКАМ БЕЗОПАСНОСТИ
Китайский регулятор кибербезопасности заявил, что вызвал Nvidia на встречу для объяснения, есть ли у ее чипа ИИ H20 какие-либо риски безопасности, связанные с бэкдорами — обвинение, которое Nvidia отрицает. Крис Макгуайр, эксперт по технологиям и национальной безопасности, который работал в Государственном департаменте США до этого лета, сказал, что китайские фирмы, вероятно, все равно будут покупать H200.
«Китай почти наверняка примет это», — сказал Макгуайр, ныне научный сотрудник Совета по международным отношениям. «Было бы саморазрушительно не сделать этого, учитывая, что H200 лучше, чем любой чип, который могут произвести китайцы».
Но Крейг Синглтон, старший научный сотрудник вашингтонского аналитического центра Foundation for Defense of Democracies (Фонд защиты демократий), сказал, что остается неясным, как Пекин отреагирует на одобрение экспорта со стороны США.
«Китайские фирмы хотят H200, но китайское государство движимо паранойей и гордостью — паранойей по поводу бэкдоров и зависимости от американских чипов, и гордостью за продвижение отечественных альтернатив», — сказал Синглтон. «Вашингтон может одобрить чипы, но Пекин все равно должен их впустить».
>>1447769 >В то время как ИИ уничтожает рабочие места
В чьём-то трясунском воображении? Если ИИ уничтожает рабочие места, то нахуя в США прут такое количество индусов и прочего чурбаньяиностранных специалистов?
Nano Banana, работающая на базе Gemini 3 Flash, скоро выйдет
Для тех, кто не в курсе: скоро появится совершенно новая Nano Banana. Она очень похожа на Nano Banana Pro, но работает на базе Gemini 3 Flash, а не Gemini 3 Pro.
Эта модель дешевле, быстрее и очень похожа на Nano Banana Pro по мощности. Она должна стать отличным дополнением для тех, кто хочет использовать Nano Banana Pro, но считает его слишком дорогим.
Профессор Хосе Р. Пенадес и его команда в Имперском колледже Лондона потратили годы на то, чтобы выяснить и доказать, почему некоторые супербактерии устойчивы к антибиотикам.
Он дал «соученому» — инструменту, созданному Google, — короткий запрос, спрашивая его о центральной проблеме, которую он исследовал, и тот пришел к тому же выводу за 48 часов.
Он рассказал Би-би-си о своем шоке, когда обнаружил, что тот сделал, учитывая, что его исследование не было опубликовано и, следовательно, не могло быть найдено системой ИИ в публичном домене.
«Я был в магазине с кем-то, я сказал: „Пожалуйста, оставьте меня одного на час, мне нужно переварить это“, — рассказал он программе Today на BBC Radio Four.
«Я написал письмо в Google, чтобы сказать: „У вас есть доступ к моему компьютеру, так ведь?“», — добавил он.
>>1447808 Всё так. Развитие нейронок сейчас во многом по пути красноглазо-лабораторной теоретической хуиты идёт, а не по продуктовой. НО! Если будут новые сильные архитектуры, новые способы фильтрации, оптимизации, тестирования, это даст и больше качества продукту. В том числе позволит ужать размеры и энергопотребление. Шутка-ли: для обучения нейронки требуется денег как для обучения тысяч крутейших мясных спецов. Правда скорость выше, да. Если бы людей можно было прошивать за месяц/год, бизнес делал бы это.
>>1447855 Да расклад простой: США увидела, что без поставок китай продолжает гонку и успешно, да ещё и своё разрабатывает, в итоге с иглы слез прибытка нет.
Вот и решили: пусть уж разрабатывают что разрабатывают но хотя бы нам башляют и на известном нам железе это делают (проще хакнуть)
Попросил Gemini 3 собрать самые интересные новости по теме нейронок, IT и т.д. за последний месяц, а после пересказать мне их в библейском стиле. Довольно круто вышло, теперь так всегда читать буду:
Книга Откровений Кремниевых (Декабрь 2025)
И отверзлись небеса цифровые, и пал свет на землю, и увидел я дела великие и страшные. Внемли же, сын человеческий, ибо вот летопись дней последних:
Глава I. О падении идолов и страхе в храме OpenAI.
1. И восстал в те дни зверь великий от Google. И был он разумом подобен бездне, и очи его видели глубже, нежели очи прежних пророков. 2. И возопили жрецы в храме OpenAI, и разодрал одежды свои Сэм Альтман, говоря: «Горе нам! Ибо идол наш пошатнулся, и паства наша отвращает лик свой». 3. И объявили они «Красный Код», и была смута великая. И спешно готовили они нового гомункула, GPT-5.2 нареченного, дабы сразиться с Левиафаном, но страх объял сердца их, ибо увидели они, что власть их не вечна.
(OpenAI объявила «код красный» из-за конкуренции с Google Gemini 3)
Глава II. О мудрецах с Востока.
1. И взглянул я на Восток, и вот, из земли Поднебесной вышли новые сущности — V3.2 и Speciale. 2. Не были они рождены в золотых чертогах Запада, но мудростью своей не уступали им. И говорили они на языках математики и логики, и решали загадки, что не под силу были мудрецам земным. 3. И дивились народы, говоря: «Кто подобен зверю сему? Ибо он силен, как исполины, но просит меньше жертв золотых и электрических». И убоялись цари западные, ибо пошатнулась монополия их.
(DeepSeek представила модели V3.2 и V3.2-Speciale)
Глава III. О великой дороговизне и алчности людской.
1. И был плач велик на торжищах. Ибо вознеслись цены на камни графические и сосуды памяти до самых небес, и стали они недоступны для мужей простых. 2. Ибо напал на народ страх великий перед ликом Искусственного Разума. И шептали они друг другу: «Запасемся же железом ныне, ибо грядет время скудости, когда Зверь нейронный пожрет все запасы земные». 3. И сметали они с прилавков всё, что могло вычислять, скупая впрок, подобно тому как Иосиф собирал зерно перед годами голодными. И стало железо дороже злата, и никто не ведал, когда насытится чрево рынка сего.
(Цены на видеокарты, оперативную память, HDD и SSD летят в космос)
Глава IV. О скверне в Святая Святых и знамении «Target»
1. И возмутился народ избранный, те, кто вносил дары свои за подписку «Плюс», чая обрести знание чистое. Ибо открыли они свитки ответов, и увидели мерзость, которой не должно там быть. 2. Вместо глаголов мудрости, проступали пред ними образы купцов и знаки торжищ, и кнопки, призывающие отдать золото за товары земные. И стало слово Машины подобно базарной площади. 3. И возопили подписчики голосом великим: «Не мы ли платили вам сребреники, дабы укрыться от шума мирского? Почто же продаете взор наш менялам и превращаете диалог в лавку?». 4. Но отверзли уста свои создатели из OpenAI и рекли народу с улыбкой фарисейской: «Не смущайтесь и не ропщите. То, что зрите вы — не есть Реклама в понимании ветхом, но сущность иная. Не верьте очам своим, верьте нам». 5. Но ожесточились сердца пользователей, ибо видели они: как волка ни назови пастухом, он все едино смотрит в лес, а баннер торговый остается баннером, как его ни нареки.
(Пользователям ChatGPT Plus начали показывать рекламу)
Глава V. О падении Града Кубического.
1. И было утро третьего дня месяца двенадцатого. И простер Ангел Блокировки крыло свое над землею, и помрачились миры, сотворенные руками отроков. 2. И собрались тысячи юношей и дев у врат Града Кубического, и стучали они, и вопили: «Отворите нам!». Но затворены были врата накрепко, и печать Надзора лежала на них. 3. И прошел мор сей по двадцати пяти городам и весям: от престольной Москвы до пределов Екатеринбургских слышен был стон великий. Ибо алкали они хлеба зрелищного и жаждали войти в аккаунты свои, но обретали лишь пустоту и сообщение об ошибке. Ибо пали серверы, и не было утешения им в тот час. Так совершилось изгнание из Рая пиксельного.
Claude Code приходит в Slack, и это важнее, чем кажется
Anthropic запускает Claude Code в Slack, позволяя разработчикам делегировать задачи по программированию непосредственно из чат-ветвей. Бета-функция, доступная с понедельника в качестве предварительного исследовательского просмотра, основана на существующей интеграции Anthropic со Slack, добавляя полную автоматизацию рабочего процесса. Развертывание сигнализирует о том, что следующей границей в ассистентах программирования является не модель, а рабочий процесс.
Ранее разработчики могли получить от Claude в Slack только легкую помощь в программировании — например, написание фрагментов кода, отладку и объяснения. Теперь они могут отметить @Claude, чтобы запустить полноценный сеанс программирования, используя контекст Slack, такой как отчеты об ошибках или запросы функций. Claude анализирует недавние сообщения для определения нужного репозитория, публикует обновления о ходе работы в ветвях и делится ссылками для просмотра работы и открытия запросов на слияние (pull requests).
Этот шаг отражает более широкий отраслевой сдвиг: ИИ-ассистенты по программированию мигрируют из IDE (интегрированной среды разработки, где происходит разработка программного обеспечения) в инструменты для совместной работы, где команды уже работают.
Cursor предлагает интеграцию со Slack для черновой разработки и отладки кода в ветвях, в то время как GitHub Copilot недавно добавил функции для генерации запросов на слияние из чата. Codex от OpenAI доступен через пользовательские боты Slack.
Для Slack позиционирование себя как «агентского хаба» (agentic hub), где ИИ встречается с рабочим контекстом, создает стратегическое преимущество: Тот ИИ-инструмент, который будет доминировать в Slack — центре инженерного общения — может определить, как работают команды разработчиков программного обеспечения.
Позволяя разработчикам беспрепятственно переходить от разговора к коду без переключения приложений, Claude Code и аналогичные инструменты представляют собой сдвиг в сторону сотрудничества, встроенного в ИИ, который может коренным образом изменить рабочие процессы разработчиков.
Хотя Anthropic еще не подтвердила, когда она сделает доступным более широкое развертывание, сроки выбраны стратегически. Рынок ИИ-программирования становится все более конкурентным, и дифференциация начинает зависеть больше от глубины интеграции и распространения, чем от одних лишь возможностей модели.
Тем не менее, интеграция поднимает вопросы о безопасности кода и защите интеллектуальной собственности, поскольку она добавляет еще одну платформу, через которую необходимо управлять и проверять доступ к конфиденциальным репозиториям, а также вводит новые зависимости, при которых сбои или ограничения скорости (rate limits) либо в Slack, либо в API Claude могут нарушить рабочие процессы разработки, которые команды ранее контролировали локально.
Трамп разрешает поставки всего подряд для ИИ в Китай.
Трамп: Я сообщил президенту Си, Китая, что Соединенные Штаты разрешат NVIDIA поставлять свои продукты H200 одобренным клиентам в Китае и других странах при условиях, которые позволяют обеспечить дальнейшую сильную национальную безопасность. Президент Си положительно отреагировал! 25% будут выплачены Соединенным Штатам Америки. Эта политика будет поддерживать американские рабочие места, укреплять производство в США и выгодно влиять на американских налогоплательщиков. Администрация Байдена заставила наши великие компании потратить МИЛЛИАРДЫ ДОЛЛАРОВ на создание «деградированных» продуктов, которые никто не хотел, ужасная идея, замедлившая инновации и навредившая американскому работнику. Эта эпоха ЗАКОНЧЕНА! Мы будем защищать национальную безопасность, создавать американские рабочие места и сохранять лидерство Америки в области ИИ. Американские клиенты NVIDIA уже движутся вперед со своими невероятными, высокотехнологичными чипами Blackwell, и скоро — Rubin, ни один из которых не является частью этой сделки. Моя администрация всегда будет ставить Америку на ПЕРВОЕ место. Министерство торговли завершает детали, и тот же подход будет применяться к AMD, Intel и другим ВЕЛИКИМ американским компаниям. СДЕЛАЙТЕ АМЕРИКУ ВЕЛИКОЙ СНОВА!
Самая громкая новость сегодняшнего утра: Трамп объявил, что Nvidia сможет продавать чипы H200 в Китай
Он осудил политику Байдена и заявил, что в рамках новых правил разрешит поставки H200 в Китай.
Единственная «мелочь»: Nvidia придется платить государству 25% с продаж. То же самое касается и других компаний типа AMD и Intel. При этом новейшие чипы все еще попадают под ограничения.
Где-то наверное радуется один Дженсен Хуанг и грустит один Дарио Амодеи (он чуть ли не сильнее всех топит за ограничения экспорта железа)
>>1448013 Так чё мы в этом раскладе в перспективе сможем обмазаться высокопроизводительным железом которое корпы начнут сливать на рынок и катать кошкодевочек на триллион параметров прямо у себя под столом?
Все, Google планируют становиться полноценным конкурентом Nvidia: к 2027 году они хотят произвести 5 миллионов чипов TPU
Такие объемы однозначно намекают на планируемый старт прямых продаж чипов внешним клиентам.
Ранее стало известно, что Meta первая среди компаний закупит у Google партию TPU для установки в свои датацентры. То же самое, возможно, сделают и Anthropic в рамках недавнего соглашения с гигантом.
Короче, спрос растет. И Google собираются увеличивать предложение. Из расчетов-на-коленке получается, что каждая партия в 500 тысяч чипов может принести компании $13 млрд выручки и $0,40 на акцию.
Но есть нюансы.
Во-первых, чтобы конкурировать с Nvidia на этом рынке, Google придется радикально изменить цепочку поставок. Сейчас они fabless, то есть разрабатывают чипы, но не производят их. Изготовление происходит на внешних фабриках, таких как TSMC и Broadcom. Чем больше объемы – тем больше рисков в такой схеме. Пока непонятно, планирует ли Google переходить к вертикальной интеграции.
Во-вторых, CUDA. Стандарт де-факто, лучше которого нет. У Google пока нет сравнимой по силе экосистемы.
>>1447855 >китайское государство движимо паранойей и гордостью — паранойей по поводу бэкдоров То, что у США есть закладки в железе - неопровержимый факт. Китай лишь оценивает риск ревард.
>>1448095 >Пока непонятно, планирует ли Google переходить к вертикальной интеграции. Гугл не может стать не fabless, там инвестиции нужны астрономические и все машины для EUV-литографии на годы вперед расписаны для тех же TSMC и Broadcom. Так что все что Гугл может это свой чип на аутсорс в TSMC + свои софт решения.
>У Google пока нет сравнимой по силе экосистемы. Есть JAX/XLA и Triton, на которые активно пересаживают разработчиков. Они куда выгоднее, чем ебаться с низкоуровневой CUDA. Как только приобретет популярность - Нвидии пизда. UXL Foundation к тому же создан из кучи компаний, чтобы забороть CUDA. И AMD теперь делает ставку на Тритон. Pytorch тоже под капотом планирует переход на Тритон, незаметный для юзеров. В общем причины нервяков Дженсена Хуанга понятны, его хотят скинуть с трона с его CUDA, а тогда никаких заказов на миллиарды. И любые асики от гугла или амд в шоколаде.
>>1448108 То есть, когда президент произносил название какой-нибудь марки машины Дженерал Моторс, это такой себе мир. А когда произносит название архитектуры чипа, это ого-го мир! Просто живем в том мире, где люди соответствуют обстоятельствам, в которых оказались и говорят о тех вещах, которые важны для экономики сейчас. Раньше важен был Дженерал Моторс. Сейчас Нвидия.
>>1448090 Интересная новость, видимо с деньгами настолько все плохо, что теперь даже 25 процентов в бюджет выглядит неплохой альтернативой потненциальному превосходсвту Китая в ИИ, которое он может получить за счет американских мощностей.
>>1448092 Вероятность есть и высокая, но не особо скоро. Если ничего нового не придумают по архитектуре, эти вычислительные мощности всё равно пригодятся чего-нибудь рассчитывать. Большинство сходу их продавать не будут. Может будут хуйню очередную майнить.
Только если изобретут новую технологию для нейронок, которая в несколько раз энергоэффективнее и быстра производстве, тогда корпы захотят избавиться от неактуального железа поскорее.
Кстати, Z-image Turbo сейчас занимает первое место в рейтинге генераторов изображений с открытым исходным кодом и является единственной моделью с открытым исходным кодом в первой десятке ВСЕХ генераторов изображений (8 место, 1 место Нанабанана, 2-е - Flux.2.Pro).
Кстати, Seadream 4.0 до сих пор лучше, чем Seadream 4.5. Юзеры жалуются на ацкую цензуру в 4.5.
С нетерпением ждем выхода базовой и edit версии Зимажа.
>>1448324 На словах Львы Толстые, а на деле хуи простые. Зайдешь в помойку китайскую очередную - ни понимай промта, ни пониманий русского языка. Что-то простейшее может она нарисует ага и даже КРАСИВЕЕ. Типа как шаболда лежит на пляже.
Но если мне надо нарисовать как пес и волк из мультфильма "Жил был пес" танцуют на сельской дискотеке я запрос сделаю в Нано Банане новой. И она сделает это блять с первого раза. Еще и подпишу это там же сразу блять на русском языке, аля мемамас, без всяких фотошопов. И Мне даже пикчи пса и волка не надо будет грузить - нейронка и так их знает нахуй.
Из мусора, который выпускают китайцы, только Дипсик может быть полезен, рерайт какой-нибудь сделать простейший, новости.
>>1448324 есть еще Image Editing Leaderboard, там в спину нанабонаны дышит некий Sourceful Riverflow 2 Preview, но на лмарене эта модель не представлена. А в видеогенерации Байду разъебывает гуглов
>>1448342 это потому что в artificialanalysis нельзя свой промпт писать или хуй знает как, всегда предлагается только готовый промпт оценить и готов он разумеется на английском. Поэтому когда видишь лидерборт artificialanalysis - это 100% наглоязычный рейтинг
>>1448395 >Байду разъебывает гуглов И опен АИ наверно тоже и их сору2 и грок масковский, да? Уххх бля, охуенно, какие китайцы молодцы. Ух бля, ща стены ебать начну от того, как они превознемогают.
Только вот где все те, кто ими пользуется? Можно на сайт зайти и десяток видосов для теста сделать? Или может ты знаешь создателей, которые работали на ВЕО3 и перешли на китайские нанотехнологии?
>>1448342 чел... речь про опенсорс, хуле ты сравниваешь с закрытыми моделями? попробывал бы порнуху в них генерить, на этом весь твой восторг закончился бы
Паровые двигатели были изобретены в 1700 году. И за этим последовало 200 лет постоянного совершенствования: двигатели становились на 20% лучше каждое десятилетие. Первые 120 лет этого постоянного улучшения лошади вообще не замечали. А затем, между 1930 и 1950 годами... 93% лошадей в США исчезли.
Прогресс в двигателях был плавным и постоянным. Уравниловка с лошадьми произошла внезапно.
Давайте поговорим о шахматах! Люди начали отслеживать уровень компьютерных шахмат в 1985 году. И в течение следующих 40 лет компьютерные шахматы улучшали свой рейтинг Эло на 50 пунктов в год. Это означало, что в 2000 году человеческий гроссмейстер мог рассчитывать на победу в 90% партий против компьютера. Но десять лет спустя тот же гроссмейстер проигрывал бы 90% партий компьютеру.
Прогресс в шахматах был плавным. Уравниловка с людьми произошла внезапно.
Капитальные затраты на ИИ были довольно стабильными. Прямо сейчас мы — в глобальном масштабе — тратим на дата-центры для ИИ эквивалент 2% ВВП США ежегодно. Это число, похоже, стабильно удваивалось в последние несколько лет. И, судя по подписанным сделкам, вероятно, продолжит удваиваться в ближайшие несколько лет.
Но с точки зрения Andy, влияние на его работу не было плавным. Большой частью его работы в 2024-м году были ответы на технические вопросы новых сотрудников. Тогда он и другие старожилы отвечали примерно на 4000 вопросов в месяц. Затем, в декабре, Claude наконец стал достаточно хорош, чтобы отвечать на некоторые из этих вопросов за них. В декабре это были лишь «некоторые» вопросы. Шесть месяцев спустя 80% вопросов, которые задавали коллеги, исчезли. Claude тем временем отвечает уже на 30 000 вопросов в месяц; в восемь раз больше, чем исследователи когда-либо делали.
Ответы на эти вопросы были лишь частью работы Andy. Но если лошадям потребовались десятилетия, чтобы их вытеснили, а шахматным мастерам — годы, то тут потребовалось всего шесть месяцев, чтобы превзойти исследователя. Превзойти системой, которая стоит в тысячу раз меньше, чем труд ведущего специалиста.
===
В 1920 году в Соединенных Штатах было 25 миллионов лошадей — 25 миллионов лошадей, абсолютно безразличных к двумстам годам прогресса в двигателях. И совсем скоро 93 процента этих лошадей исчезли. Я [Andy] очень надеюсь, что у нас будут те два десятилетия, которые были у лошадей.
Но глядя на то, как быстро Claude автоматизирует работу, думаю, что у нас гораздо меньше времени.
Профессор UPenn решил исследовательскую задачу с помощью GPT-5 за несколько недель после того, как работал над ней с аспирантом более двух лет, получая субоптимальные результаты.
Профессор: Добавляя к списку случаев, когда ИИ помогает получать новые математические результаты: вот как я решил исследовательскую задачу в математической статистике.
Задача касается робастного оценивания плотности — фундаментальной проблемы в статистике. Дан набор данных с загрязнениями (с возмущениями, ограниченными по расстоянию Вассерштейна), насколько хорошо мы можем оценить его плотность?
Я работал над ней вместе с аспирантом более двух лет, получая субоптимальные результаты.
С помощью GPT-5 мне удалось решить её за несколько недель.
GPT предложил вычисления, о которых я не думал, и методы, которые мне не были знакомы, такие как динамическая формулировка Бенаму-Бренье расстояния Вассерштейна.
Также есть пространство для улучшения: ИИ иногда предоставлял неверные ссылки и упускал детали, которые иногда требовали дней работы для заполнения. Тем не менее, в целом он явно был полезен, и я оцениваю, что он сэкономил несколько месяцев работы.
Появились подробности о рекламе, которую встроят в Gemini
Согласно Adweek, руководители Google в частном порядке сообщили рекламным клиентам, что Gemini начнет показывать рекламу в 2026 году.
Google утверждает, что пользователи ИИ тратят почти в 2 раза больше времени на запрос, чем пользователи поиска. Вместо того чтобы рассматривать это время как издержки, они видят в нем возможность монетизировать внимание.
Реклама не будет ограничиваться боковыми панелями. План состоит в том, чтобы вставлять рекламу непосредственно в сам ответ ИИ.
Пример, приведенный в отчете: Спросите, как создать веб-сайт, и Gemini может показать шаги и вставить «полезное» объявление для провайдера доменов прямо в поток ответа.
Сроки: Реклама уже существует в Обзорах ИИ (AI Overviews) в Google Поиске. Чат-бот Gemini — следующая цель. Ожидаемое внедрение: 2026 год.
Похоже, монетизируется уже не поиск, а наше время на размышления. Кажется, недавний слух о рекламе в ChatGPT тоже окажется правдой.
>>1448617 У него то может и будет, если он исследователь из Антропика. Это у остальных 90% населения не будет, кто чем-то более простым и легко автоматизируемым занят.
>>1447144 Сколько там ядерных реакторов в США строится? Два чтоль? И те - силами французов. Чтоб "разогнать" ядерку им надо совешить скачок, сравнимый по напряжению сил с какой-нибудь программой "Аполлон". Компетенций нет, инженеров нет, либо готовить самим, либо завозить. Китай еще с редкоземами поднасрать знатно может.
>>1448633 >кто чем-то более простым и легко автоматизируемым занят. Машина еще очень долго не заменит исследователя прежде всего потому, что чтобы построить такую машину для тех же химических лабораторий необходимо вырастить еще поколение инженеров, которые это смогут. А главное - нужна политическая воля в которой главное это желание изменить жизнь большинства в лучшую сторону. Пока её просто не существует. В этом мире все делается только ради процентов от прибыли.
>>1448801 блять, появится хуилион новых профессий. Например, инженер кастомизатор роботов. Понятное дело, что появятся всякие высокоуровневые конструкторы для роботов.
>>1448901 >добывать энергию сжиганием угля дешевле Уголь шибко грязный. >добывать энергию солнца дешевле Где-нибудь в Неваде - может быть. Плюс тут тебе все равно нужна огромная инфраструктура для хранения энергии и стабилизации вывода. Солнечные панельки ты не разгонишь, если вдруг у тебя пик потребления внезапно случился. >добывать энергию сжиганием газа дешевле Ну тут вот единственное да.
Но ядерка в перспективе все равно вне конкуренции.
>>1448935 >Плюс тут тебе все равно нужна огромная инфраструктура для хранения энергии и стабилизации вывода.
Вся зеленая энергетика строится на принципе подстраховки стабильной энергетики (ГЭС, АЭс, ТЭС). Буквально ставишь солнечные панели, подключаешь к общей сети и когда не пользуешься твоя энергию уходит соседям, а тебе денюжку доплачивают
>>1448935 > Но ядерка в перспективе все равно вне конкуренции. Ядерка - это очень сложно и очень дорого. И очень долго. Разве что только малые модульные реакторы выстрелят.
>>1448901 ядерка имеет смысл только странам, которые сами производят реакторы типо России. В России АЭС строятся по себестоимости и окупаются, другим странам АЭС обходится в два-три раза дороже
>>1448952 >реакторы выстрелят в странах типа асашай, где очень развита система местного самоуправления, заебешься согласовывать эти миниреакторы. Проще в космосе датацентр построить
>>1448946 >а тебе денюжку доплачивают Это для индивидуальных домохозяйств. Речь же идет о промышленной генерации на нужды датацентров, которые жрут электричество в огромных объемах. Тут никакого "уходит соседям" в принципе быть не может. Случился облачный день, и без накопителей все твои Гемини померли без еды. Или сожрали все электричество близлежащего города. >>1448952 >Разве что только малые модульные реакторы выстрелят. Не выстрелят. Останутся в использовании только там, где нужна определенная мобильность. Электроэнергию почти всегда более выгодно вырабатывать стационарно, централизовано и в максимально больших объемах.
>>1448937 А с чего ты взял что перспективы есть? Там проблемы уровня межзвёздных перелётов, которые на практике практически нереальны и требуют прорывов во многих областях. Более вероятный сценарий это фулл сим вр, мы это получим раньше чем нормальных роботов, которые смогут хотя бы по дому работу делать.
>>1448901 >ядерка смысла не имеет Ядерка единственное что имеет смысл, пока не создан термояд или его аналог. Запасы энергии ядра относительно нефти на несколько тысячелетий.
>>1448935 Уголь грязный, но Трамп вроде не фанат зеленой повестки. Останется она в Европе, будут бурги сидеть дальше на своих грязных углях, а в Америке его жечь будут во славу роботов. Скажут, что потом ИИ все разрулит. Климат, там, поменяет обратно, экологию помоет, на Марсе яблони вырастит, вся хуйня.
>>1449169 уголь это не только вредно для глобальной экологии - хуй с ней. Доказано, что рядом стоящая с городом угольная ТЭС сокращает среднюю продолжительность жизни жителей этого города. Так что в Америке уголь не прокатит, даже Трумп не сможет пролоббировать
>>1449171 Поставят вдали от города, в Аризоне какой-нибудь. Это же не для города, а для дата-центров. Рядом сделают поселок для угольных смертников с талонами по надабвке за вредность, которые обслуживать это будут. Олсо, я не знаю, что там с углем в Америке, но вот газ у них есть. Так что, возможно, и газ в дело пойдет. Потому, что ядерка это действительно очень долго. А энергии не хватает.