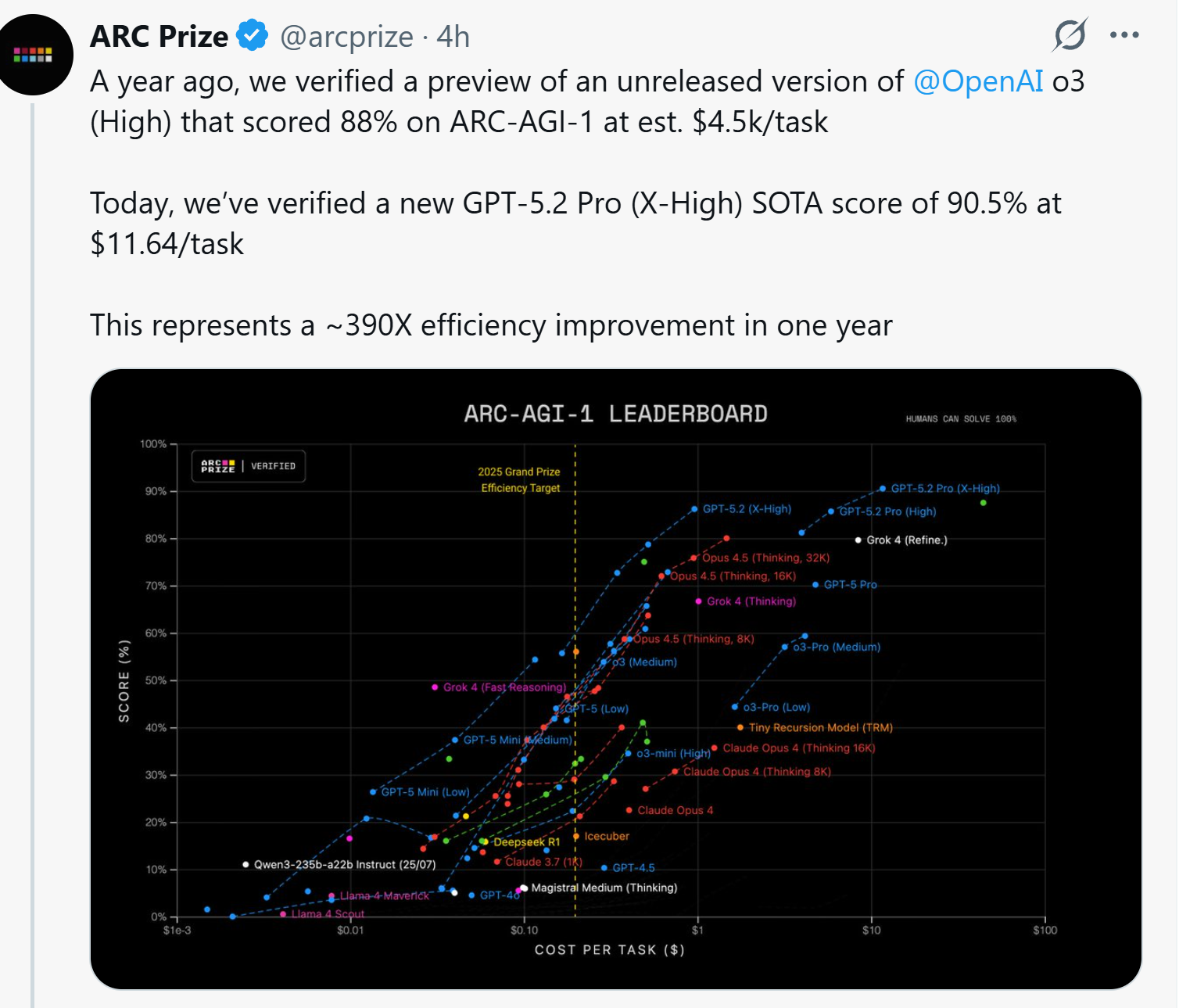
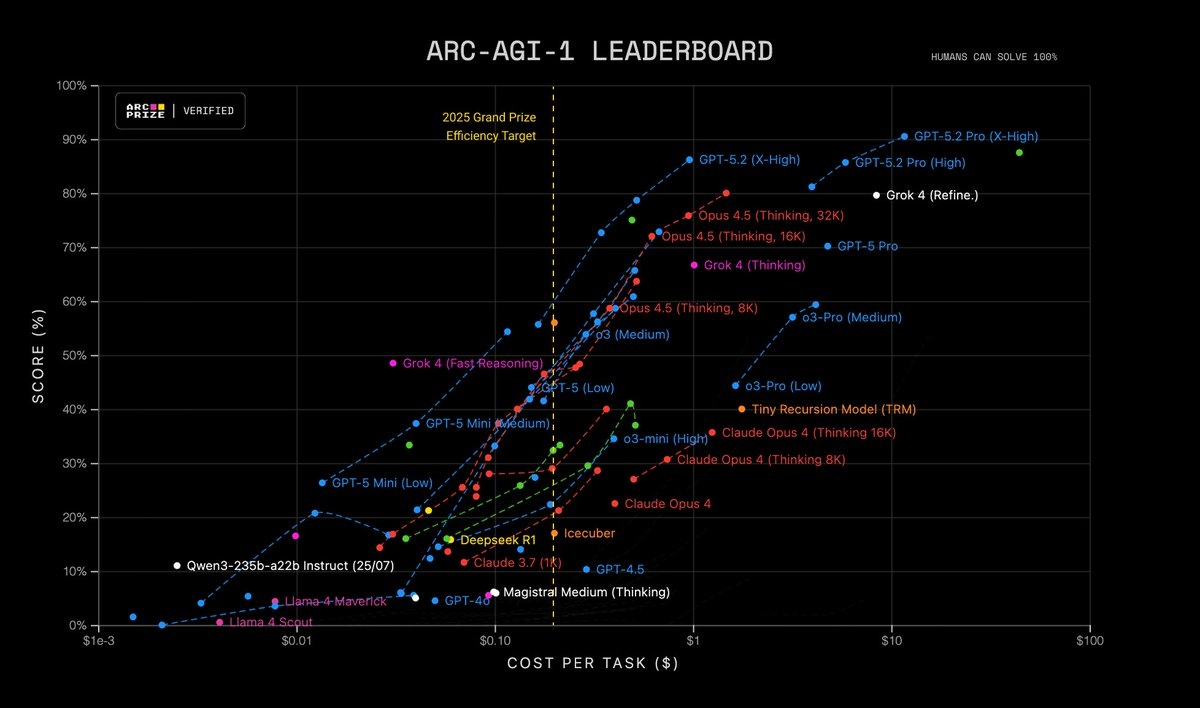
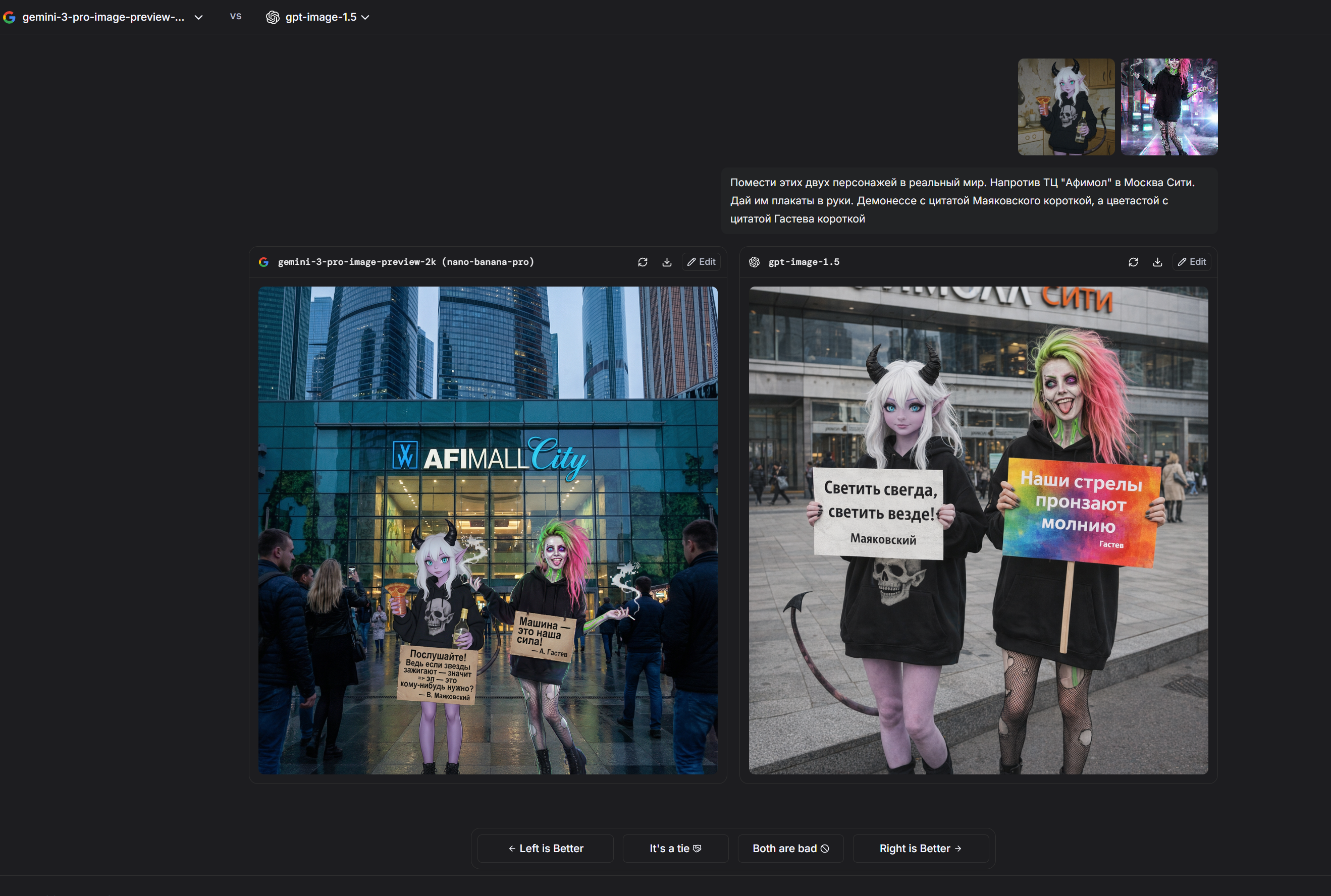
ServiceNow выпустила Apriel-1.6-15B-Thinker, мультимодальную модель рассуждений с 15 миллиардами параметров, которая основана на Apriel-1.5 и расширяет возможности SLM с открытым исходным кодом.
🔓 Открытый исходный код
mbzuai выпустила открытую модель с 70 миллиардами параметров (K2-V2-Instruct), которая превосходит Qwen-2.5, поднимая планку производительности для общедоступных LLM.
Doradus представила RnJ-1-Instruct FP8, вдвое сократив требования к видеопамяти (VRAM) с 16 ГБ до 8 ГБ при сохранении точности GSM8K на уровне 87,2%, что позволяет удешевить инференс.
Репозиторий навыков Claude на GitHub предоставляет готовых агентов для создания хранилищ Obsidian и шаблонов DOCX, расширяя экосистему автоматизации Claude.
🛠️ Инструменты разработчика
SGLang Diffusion теперь поддерживает интеграцию Cache-DiT, обеспечивая ускорение локальных диффузионных моделей на 20–165% с минимальной настройкой.
🧪 Исследования
Icaro Lab продемонстрировала, что состязательная поэзия обходит защитные механизмы в 25 чат-ботах с ИИ, срабатывая в 63% случаев и выявляя новую уязвимость безопасности.
Исследование показывает, что реклама, сгенерированная ИИ, достигает на 19% более высокого коэффициента кликабельности (CTR), чем реклама, созданная человеком, когда зрители не знают о происхождении ИИ, что подчеркивает эффективность и проблемы раскрытия информации.
Блог Hugging Face сообщает, что модели ИИ используются для обучения других ИИ, что потенциально ускоряет циклы разработки, но поднимает вопросы качества данных и этики.
📰 Инструменты
AdMakeAI позволяет пользователям просматривать рекламу конкурентов в Facebook и генерировать схожие креативы, оптимизируя производство рекламы и конкурентный анализ.
HRM (Hierarchical Reasoning Model) выпущена на GitHub, предлагая новую архитектуру с открытым исходным кодом для задач структурированного рассуждения.
Интеграция бэкенда ZenDNN в llama.cpp на процессорах AMD EPYC Zen 4 демонстрирует заметное повышение производительности для инференса только на CPU.
Twee генерирует планы уроков ESL, рабочие листы и интерактивные задания, соответствующие CEFR, на 10 языках, упрощая создание контента для преподавания языков.
💻 Аппаратное обеспечение
Графический процессор NVIDIA H200 указан на vast.ai по цене 1,13 доллара США в час, что значительно снижает стоимость высокопроизводительных вычислений на GPU.
📰 Другие новости
Grok теперь будет давать указания водителям Tesla «Исследовательские» работы по ИИ — это полная чушь, утверждают эксперты
Исследователи в области ИИ заявили, что изобрели заклинания, слишком опасные для публичного распространения
Чиновники остановили десятки поездов из-за ложного срабатывания ИИ
Стартап в сфере видеонаблюдения на основе ИИ уличён в использовании работников из потогонных мастерских для наблюдения за жителями США
Искусственный интеллект невероятно эффективен в изменении мнений избирателей, выявили новые исследования, — однако с невероятной оговоркой
McDonald’s снял рождественскую рекламу, созданную с помощью ИИ, после волны насмешек
Благодаря росту популярности генеративного ИИ крупные корпорации, такие как Coca-Cola и Google, спешат задействовать ИИ для быстрого создания новых рекламных роликов. Однако есть одна проблема: практически всем это категорически не нравится.
В этом году McDonald’s решил присоединиться к корпоративному «потоку посредственности», выпустив 45-секундный рождественский ролик для своего подразделения в Нидерландах, разработанный рекламным агентством TBWA\Neboko. Весь ролик был создан с помощью ИИ и основан на идее, что праздничный сезон — «самое ужасное время года».
Независимо от того, насколько уместна эта пессимистичная тема, реклама буквально шокирует зрителя быстро сменяющимися сценами, выполненными в типичной для ИИ тошнотворной манере. Поскольку большинство видеороликов, генерируемых ИИ, теряют визуальную согласованность уже через несколько секунд, короткие и стремительно мелькающие сцены стали одним из главных признаков того, что вы смотрите именно ИИ-генерированное видео.
Как и рождественская реклама Coca-Cola 2025 года, ролик McDonald’s напоминает визуальный припадок: в нём — отвратительные персонажи, ужасная цветокоррекция и примитивные, шаблонные попытки ИИ имитировать даже самые простые законы физики.
Хотя этот ужасный ролик набрал всего лишь 20 000 просмотров на YouTube, негативные комментарии в разделе под видео были настолько жёсткими, что McDonald’s сначала отключил возможность комментирования в выходные дни, а затем полностью удалил видео из публичного доступа. (Некоторым маркетинговым исследовательским базам данных всё же удалось сохранить копию ролика для тех, кому интересно.)
«Будущее уже наступило — и оно выглядит не слишком радужно», — написал один пользователь под постом аккаунта-агрегатора в Instagram. «Значит, у компании с такими ресурсами не хватило возможностей собрать полноценную съёмочную группу и создать что-то действительно стоящее?», — спросил другой. «Блестяще».
После всплеска критики компания The Sweetshop — продакшн, нанятый TBWA\Neboko для создания ролика — опубликовала крайне защитную, оправдательную по тону заявку, в которой старалась обосновать проделанную работу.
«В течение семи недель мы почти не спали, одновременно задействовав до 10 внутренних специалистов по ИИ и постпродакшну из The Gardening Club [нашего внутреннего ИИ-движка], которые тесно взаимодействовали с режиссёрами», — написал генеральный директор Sweetshop. «Это был не просто трюк с ИИ. Это был фильм».
Более того, Sweetshop даже утверждал, что огромное количество человеко-часов, затраченных на исправление галлюцинаций ИИ, оправдывает ужасающий конечный результат.
«Мы генерировали то, что напоминало ежедневные пробы — буквально тысячи дублей — и затем монтировали их так же, как и в любом высококачественном производстве», — заявили в компании.
«Я не воспринимаю этот ролик как забавную новинку или милое сезонное экспериментальное видео, — продолжил генеральный директор. — Для меня это доказательство нечто гораздо более масштабного: когда мастерство и технологии встречаются при наличии осмысленного замысла, они способны создать произведение, которое по-настоящему ощущается как кинематографическое. Поэтому нет — этот фильм не создал ИИ. Его создали мы».
Хотя, судя по всему, это первая реклама McDonald’s, полностью созданная с помощью ИИ, это не первый опыт компании с данной технологией. Ещё в марте, когда изображения в стиле Studio Ghibli, генерируемые ИИ, стали вирусными благодаря ChatGPT, McDonald’s в Мексике подхватил тренд, разместив ИИ-мемы в своих социальных сетях. (Восприняли их не лучше, чем нынешнюю рекламу.)
Таким образом, хотя подрядчики, стоявшие за проектом, похоже, вполне удовлетворены собой и даже аплодируют собственным усилиям, общественное мнение выглядит однозначно: если уж нам суждено жить в мире, где нас постоянно бомбардируют раздражающей рекламой, то хотя бы пусть её создаёт человек.
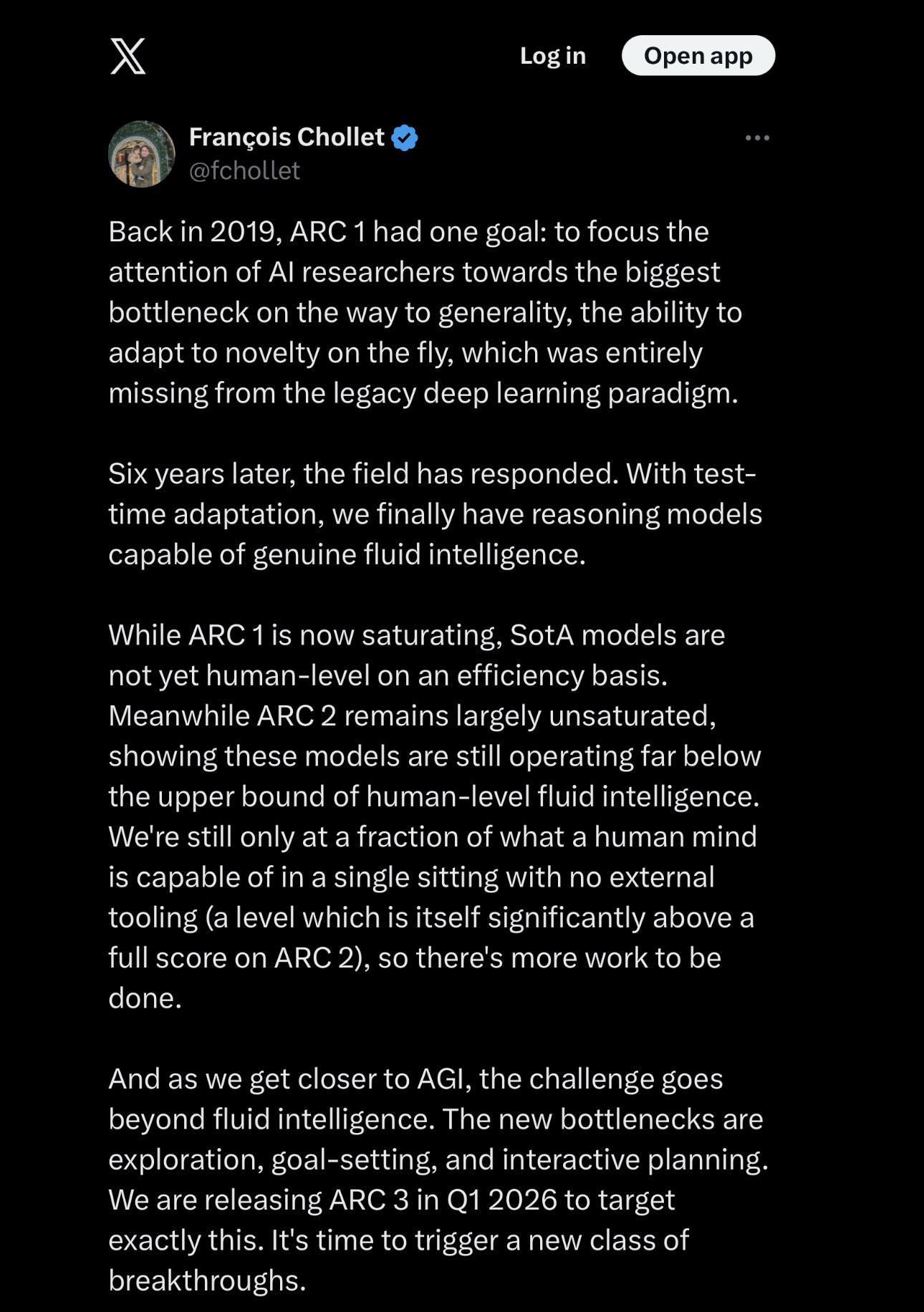
«Чёрный ящик» раскрывает свою геометрию. Новое исследование показывает, что глубокие нейронные сети систематически сходятся к общим низкоразмерным подпространствам независимо от того, как они были инициализированы, предполагая, что существует универсальная «форма» интеллекта, которая превосходит конкретные архитектуры.
Учёные из Университета Джона Хопкинса опубликовали масштабное исследование, которое может коренным образом изменить наше понимание того, как работают нейронные сети — и как мы будем их использовать в будущем. Их открытие, названное гипотезой универсального весового подпространства, свидетельствует о том, что, несмотря на различия в задачах, данных и начальных условиях, глубокие нейросети систематически сходятся к общим, низкоразмерным структурам в пространстве своих параметров.
Исследователи проанализировали более 1100 моделей самых разных типов: 500 адаптеров LoRA для языковой модели Mistral-7B, 500 Vision Transformer’ов, 50 моделей LLaMA-8B, а также десятки GPT-2, Flan-T5 и классических свёрточных сетей. Во всех случаях — будь то классификация изображений, генерация текста, перевод или создание картинок по описанию — веса моделей оказались сосредоточены в одних и тех же нескольких главных направлениях. Эти направления, извлечённые с помощью спектрального анализа (в частности, сингулярного разложения высокого порядка — HOSVD), образуют так называемое универсальное подпространство.
Это подпространство не зависит от конкретной задачи: модели, обученные на совершенно разных данных — от медицинских снимков до стихов и изображений насекомых — всё равно «разговаривают на одном языке» на уровне своих внутренних параметров. Наиболее важная часть информации умещается в первых 10–20 главных компонентах, хотя сами модели могут содержать миллиарды весов. Остальные направления практически не вносят вклада и могут быть отброшены без заметной потери качества.
Как это работает на практике? Пространство весов «раскладывается» на базис — набор фиксированных ортогональных векторов, одинаковых для множества моделей одной архитектуры. Каждая конкретная модель (например, LoRA для задачи перевода или классификации кошек) теперь представляется не миллионами чисел, а небольшим вектором коэффициентов, показывающим, как сильно использовать каждое из базисных направлений. Обучение новой задачи превращается в подбор этих коэффициентов — и это можно сделать за считанные минуты даже на скромном оборудовании.
Авторы показали, что: - одну и ту же базу можно использовать как для задач, похожих на те, что уже видела сеть (IID), так и для совершенно новых (OOD); - при сжатии 500 моделей Vision Transformer в единое универсальное представление достигается экономия памяти до 100 раз; - даже в задаче генерации изображений (Stable Diffusion XL) универсальное подпространство не только сохраняет качество стилей, но иногда и улучшает его — вероятно, за счёт подавления шума в весах; - слияние десятков специализированных моделей в одну универсальную оказывается эффективнее современных методов типа Task Arithmetic или TIES, при этом требует нулевой настройки гиперпараметров.
Это открытие имеет не только теоретическое, но и огромное практическое значение. Сейчас каждая новая задача требует либо дообучения отдельной модели (сотни гигабайт весов), либо хранения десятков адаптеров. В будущем же, по всей видимости, будет достаточно одной «базовой» универсальной модели на архитектуру — и к ней будут подключаться лёгкие, многократно переиспользуемые наборы коэффициентов под каждую задачу.
Снижаются: - Требования к памяти: вместо тысяч гигабайт — десятки. - Энергопотребление: обучение ограничивается линейными коэффициентами, без градиентного спуска по миллиардам весов. - Время адаптации: новые задачи осваиваются в разы быстрее. - Экологический след: меньше вычислений — меньше углеродного следа.
Кроме того, появляется принципиально новый инструмент для интерпретируемости: если все модели «думают» в одних и тех же координатах, можно изучать, что именно кодируют эти главные направления — и, возможно, понять, какие базовые «интеллектуальные примитивы» заложены в современные архитектуры.
Переспектиы для будущего ИИ Гипотеза универсального подпространства говорит о том, что современные нейросети, несмотря на кажущуюся гибкость, работают в строго ограниченной «зоне возможностей», заложенной в архитектуре и методах оптимизации. Это объясняет, почему переобучение почти не происходит даже при гигантском числе параметров, почему перенос знаний так эффективен и почему методы вроде LoRA или весового слияния работают стабильно.
Однако за этим стоит и важный вопрос: если все модели сходятся к одним и тем же решениям — не приведёт ли это к системному однообразию, общим слепым зонам и уязвимостям? Не мешает ли эта «универсальность» настоящему разнообразию подходов?
Исследователи признают, что пока не знают, можно ли найти это подпространство без обучения тысяч моделей — это главная цель будущих работ. Но уже сейчас ясно: ИИ движется к новой парадигме — не «одна модель на задачу», а «одна универсальная база — и тысячи лёгких специализаций». Это может сделать мощные ИИ-системы доступными даже на устройствах с ограниченными ресурсами — и открыть путь к действительно масштабируемой, устойчивой и открытой экосистеме искусственного интеллекта.
От Llamas до Avocados: меняющаяся стратегия Meta в области ИИ вызывает внутреннюю неразбериху
Meta разрабатывает новую передовую модель ИИ под кодовым названием Avocado, которая может быть проприетарной, а не с открытым исходным кодом.
Компания пытается не отставать от конкурентов в области искусственного интеллекта — OpenAI и Google — после того, как потратила 14,3 миллиарда долларов на привлечение основателя Scale AI и нескольких ведущих исследователей и инженеров.
«Во многом Meta оказалась противоположностью Alphabet: она вступила в год как победитель в области ИИ, а теперь сталкивается с большим количеством вопросов относительно уровня инвестиций и окупаемости (ROI)», — написали аналитики KeyBanc Capital Markets в записке для клиентов в конце прошлого месяца.
Генеральный директор Meta Марк Цукерберг в прошлом году был настолько оптимистичен по поводу семейства моделей искусственного интеллекта Llama своей компании, что предсказал, что они станут «самыми передовыми в отрасли» и «принесут пользу ИИ всем».
Но после того, как он посвятил целый раздел Llama в своей вступительной речи во время отчета о прибылях Meta в январе этого года, он упомянул название бренда только один раз в последнем отчете в октябре. Одержимость компании своей крупной языковой моделью с открытым исходным кодом уступила место совершенно другому подходу к ИИ, сосредоточенному вокруг многомиллиардной кампании по найму ведущих отраслевых талантов, которые могли бы помочь Meta противостоять таким компаниям, как OpenAI, Google и Anthropic.
По мнению инсайдеров и отраслевых экспертов, к концу 2025 года стратегия Meta остается разрозненной, что усиливает ощущение, что компания еще больше отстала от своих главных конкурентов в области ИИ, чьи модели быстро завоевывают популярность на потребительских и корпоративных рынках.
Meta разрабатывает нового преемника Llama и передовую модель ИИ под кодовым названием Avocado, как узнал CNBC. Люди, знающие об этом, сообщили, что многие внутри компании ожидали выпуска модели до конца этого года, но теперь планируется, что это произойдет в первом квартале 2026 года. По словам людей, которые попросили не называть их имен, поскольку они не были уполномочены говорить на эту тему, модель борется с различными тестами производительности, связанными с обучением, которые призваны обеспечить хороший прием системы, когда она в конечном итоге дебютирует.
«Наши усилия по обучению моделей идут по плану и не имеют существенных изменений в сроках», — заявил представитель Meta.
На фоне того, что в этом году акции компании показывают худшие результаты, чем более широкий технологический сектор, и сильно отстают от материнской компании Google — Alphabet, Уолл-стрит ищет направление и путь к окупаемости инвестиций после того, как в июне Meta потратила 14,3 миллиарда долларов, чтобы нанять основателя Scale AI Александра Вана и нескольких его ведущих инженеров и исследователей. Через четыре месяца после этого объявления, которое включало покупку Meta крупной доли в Scale, компания социальных сетей повысила свой прогноз капитальных затрат на 2025 год с прежнего диапазона 66–72 миллиардов долларов до 70–72 миллиардов долларов.
«Во многом Meta оказалась противоположностью Alphabet: она вступила в год как победитель в области ИИ, а теперь сталкивается с большим количеством вопросов относительно уровня инвестиций и окупаемости (ROI)», — написали аналитики KeyBanc Capital Markets в ноябрьской записке для клиентов. Фирма рекомендует покупать акции обеих компаний.
В основе проблемы Meta лежит устойчивое доминирование ее основного бизнеса: цифровой рекламы.
Даже при годовом объеме продаж, превышающем 160 миллиардов долларов, бизнес Meta по таргетингу рекламы, обусловленный значительными улучшениями в области ИИ и популярностью Instagram, увеличивает выручку более чем на 20% в год. Инвесторы высоко оценили компанию за использование ИИ для повышения эффективности своего источника дохода и за то, чтобы сделать организацию более эффективной и менее раздутой.
Но у Цукерберга гораздо более грандиозные амбиции, и новая гвардия, которую он привлек для реализации будущего видения ИИ, не имеет опыта работы в сфере онлайн-рекламы. 41-летний основатель, чье состояние превышает 230 миллиардов долларов, предположил, что, если Meta не пойдет на смелые шаги, она рискует оказаться на втором плане в мире, который будет определяться ИИ.
До недавнего времени уникальное положение Meta в области ИИ заключалось в открытом исходном коде ее моделей Llama. В отличие от других моделей ИИ, технология Meta была предоставлена в свободный доступ, чтобы сторонние исследователи и другие пользователи могли получить доступ к инструментам и, в конечном итоге, улучшить их.
«Сегодня несколько технологических компаний разрабатывают ведущие закрытые модели, — написал Цукерберг в блоге в июле 2024 года. — Но открытый исходный код быстро сокращает разрыв».
С тех пор он начал менять свое мнение. Цукерберг намекнул летом, что Meta рассматривает возможность изменения своего подхода к открытому исходному коду после апрельского выпуска Llama 4, которая не смогла привлечь разработчиков. Цукерберг заявил в июле: «Нам нужно будет строго подходить к смягчению этих рисков и быть осторожными в том, что мы решаем открыть».
Avocado, когда она в конечном итоге станет доступна, может оказаться проприетарной моделью, по словам людей, знакомых с этим вопросом. Это означает, что сторонние разработчики не смогут свободно загружать ее так называемые «веса» и связанные с ними программные компоненты.
Некоторые сотрудники Meta были расстроены тем, что модель R1, выпущенная китайской лабораторией ИИ DeepSeek в начале этого года, включала части архитектуры Llama, по словам этих людей, что еще раз подчеркивает риски открытого исходного кода и доносит идею о том, что компании следует пересмотреть свою стратегию.
Высокооплачиваемые сотрудники Meta, нанятые в сфере ИИ, и руководители недавно запущенной лаборатории Meta Superintelligence Labs (MSL) также поставили под сомнение стратегию открытого исходного кода ИИ и высказались за создание более мощной проприетарной модели ИИ, сообщил CNBC в июле. Тогда представитель Meta заявил, что «позиция компании в отношении ИИ с открытым исходным кодом не изменилась».
Неудача с Llama 4 стала значительным катализатором поворота Цукерберга, сказали источники, а также привела к серьезным внутренним перестановкам. Крис Кокс, директор по продуктам Meta и ветеран компании с 20-летним стажем, который был принят на работу в качестве 13-го инженера-программиста, больше не курирует подразделение ИИ, официально известное как GenAI, после провального выпуска, сообщили источники.
Цукерберг начал тратить большие деньги, чтобы изменить руководство Meta в области ИИ.
Он остановился на Ване, тогдашнем 28-летнем генеральном директоре Scale AI, который был назначен новым директором по ИИ Meta, а в августе стал главой элитного подразделения под названием TBD Lab. По словам людей, знакомых с этим вопросом, Avocado разрабатывается внутри TBD.
Генеральный директор OpenAI Сэм Альтман заявил в июне, что Meta пытается переманить таланты из его компании огромными компенсационными пакетами, включая заоблачные подписные бонусы в размере 100 миллионов долларов, что, как тогда заявила Meta, было искажением фактов.
Вместе с Ваном пришли и другие крупные технологические фигуры, в том числе бывший генеральный директор GitHub Нэт Фридман, который возглавляет отдел продуктов и прикладных исследований MSL, и Шэнцзя Чжао, который был одним из создателей ChatGPT. Они привнесли с собой современные методы, которые стали стандартом для разработки передового ИИ в Кремниевой долине, и перевернули традиционный процесс разработки программного обеспечения внутри Meta, сказали источники.
Культурный сдвиг в области ИИ в Meta
По словам источников, Ван сейчас находится под давлением, требующим создать модель ИИ высшего уровня, которая поможет компании восстановить импульс в борьбе с конкурентами, такими как OpenAI, Anthropic и Google.
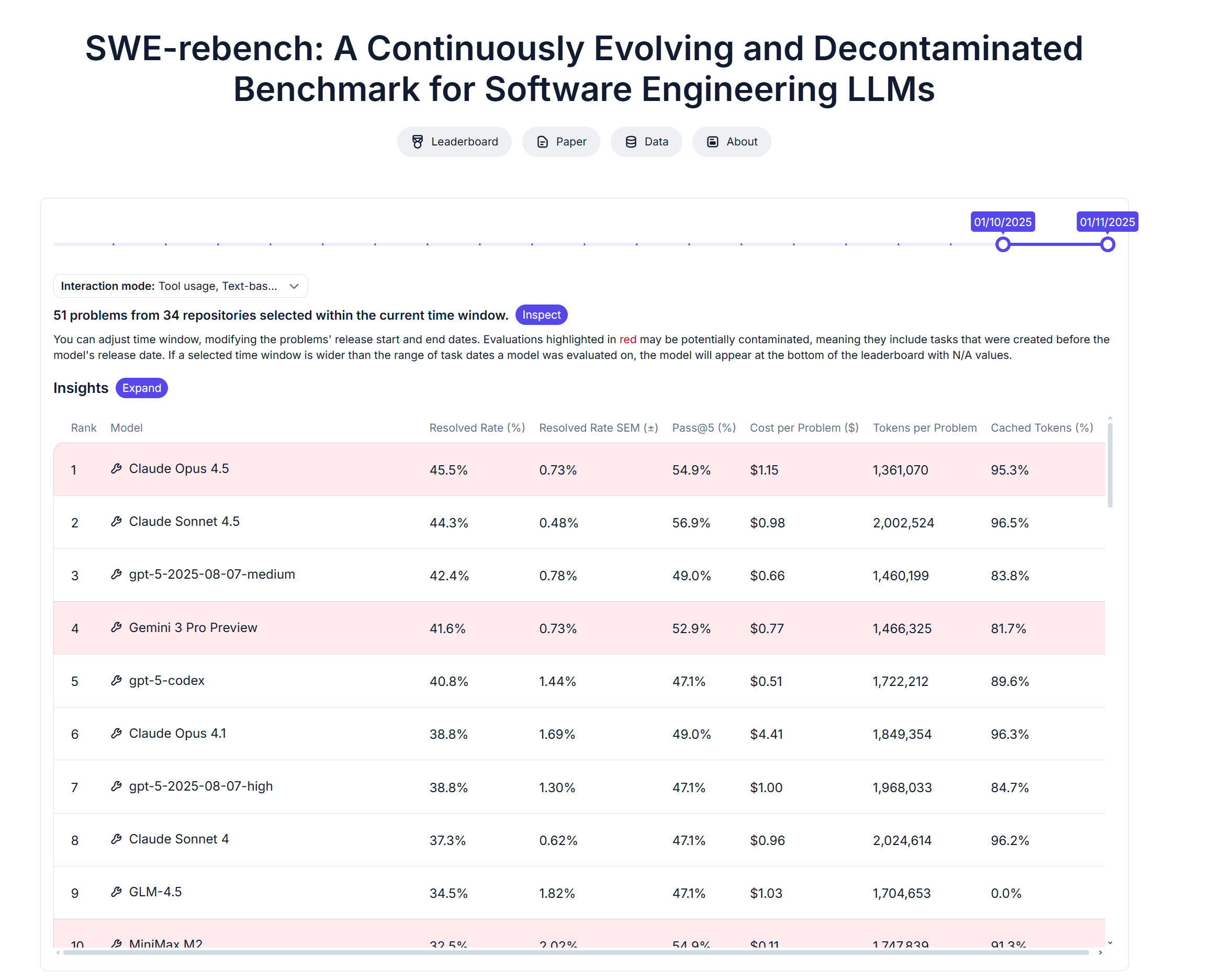
Это давление только усилилось, поскольку конкуренты активизировали свою игру. Gemini 3 от Google, представленный в прошлом месяце, получил положительные отзывы пользователей и аналитиков. OpenAI недавно объявила о новых обновлениях своей модели ИИ GPT-5, а Anthropic представила свою модель Claude Opus 4.5 в ноябре вскоре после выпуска двух других крупных моделей.
Стратегия Meta ч2
Аноним# OP10/12/25 Срд 00:30:11№14492779
>>1449275 Ранее аналитики сообщили, что не существует явной ведущей модели ИИ, потому что некоторые работают лучше при выполнении определенных задач, таких как разговоры или кодирование. Но неизменным остается то, что все основные создатели моделей должны тратить много денег на ИИ, чтобы сохранить любое конкурентное преимущество, сказали они.
Значительная часть этих расходов идет в карман Nvidia, ведущего разработчика графических процессоров (GPU) для ИИ. Генеральный директор Nvidia Дженсен Хуан изложил положение дел во время отчета о прибылях своей компании в ноябре, после того как производитель чипов сообщил о росте выручки на 62% в годовом исчислении. Он выделил ряд разработчиков моделей как крупных клиентов, включая xAI Илона Маска.
«Мы запускаем OpenAI. Мы запускаем Anthropic. Мы запускаем xAI благодаря нашему глубокому партнерству с Илоном и xAI, — сказал Хуан. — Мы запускаем Gemini. Мы запускаем Thinking Machines. Давайте посмотрим, что еще мы запускаем? Мы запускаем их все».
Хуан ни разу не упомянул Llama, хотя в другом месте во время отчета он сказал, что Gem от Meta, «фундаментальная модель для рекомендаций по рекламе, обученная на крупномасштабных кластерах GPU», способствовала улучшению конверсии рекламы в Meta во втором квартале.
Ван — не единственный руководитель Meta, который испытывает давление.
По словам источников, Фридман также получил задание создать прорывной продукт ИИ. Он отвечал за сентябрьский запуск Meta продукта Vibes, ленты коротких видеороликов, сгенерированных ИИ, который, по общему мнению, уступает Sora 2 от OpenAI, сказали они. Бывшие сотрудники и создатели сообщили CNBC, что продукт был поспешно выпущен на рынок и ему не хватало ключевых функций, таких как возможность генерировать реалистичное аудио с синхронизацией губ.
Хотя Vibes привлек больше интереса к автономному приложению Meta AI, он отстает от приложения Sora по количеству загрузок, согласно данным, предоставленным CNBC компанией Appfigures.
Давление ощущается во всех организациях Meta, занимающихся ИИ, где 70-часовая рабочая неделя стала нормой, сообщили источники, в то время как команды также сталкивались с увольнениями и реструктуризацией в течение года.
В октябре Meta сократила 600 рабочих мест в MSL, чтобы уменьшить количество уровней и работать быстрее. Эти увольнения затронули сотрудников в таких областях, как подразделение фундаментальных исследований в области искусственного интеллекта (FAIR), и сыграли ключевую роль в решении главного научного сотрудника по ИИ Янна ЛеКуна покинуть компанию, чтобы запустить стартап, по словам людей, знакомых с этим вопросом.
ЛеКун отказался от комментариев.
По словам источников, решение Цукерберга с высокими ставками обратиться к сторонним людям, таким как Ван и Фридман, для руководства усилиями компании в области ИИ, стало серьезным изменением для компании, которая исторически продвигала на высшие должности сотрудников с большим стажем.
В лице Вана и Фридмана Цукерберг передал контроль экспертам по инфраструктуре и связанным с ней системам, а не по потребительским приложениям. Новые лидеры также привнесли другой стиль управления, непривычный для Meta.
В частности, инсайдеры сообщили CNBC, что Ван и Фридман более закрыты в своих сообщениях, что контрастирует с исторически открытым подходом к обмену работой и общению во внутренней социальной сети компании Workplace.
По словам знакомых с ситуацией людей, члены TBD Lab Вана, которые работают рядом с офисом Цукерберга, не используют Workplace, добавив, что они даже не подключены к этой сети, и что группа действует как отдельный стартап.
Однако Цукерберг не дает новой команде руководителей ИИ полной автономии. Апарна Рамани, вице-президент по инжинирингу, которая работает в Meta почти десять лет, была назначена ответственной за надзор за распределением вычислительных ресурсов для MSL, сообщили источники.
А в октябре Вишал Шах был переведен с должности руководителя инициатив компании в области метавселенной в Reality Labs, где он проработал четыре года, на новую должность вице-президента по продуктам ИИ, работая с Фридманом. Шах считается лояльным лейтенантом, который помогал выступать связующим звеном между традиционными социальными приложениями компании, такими как Instagram, и более новыми проектами, такими как Reality Labs, сказали источники.
На прошлой неделе Meta подтвердила, что планирует сократить ресурсы для своих инициатив в области виртуальной реальности и связанной с ней метавселенной, переключив свое внимание на свои популярные очки с поддержкой ИИ, разработанные совместно с EssilorLuxottica.
«Демо, а не мемо»
По словам людей, знакомых с этим вопросом, одним из самых больших источников напряженности между старым и новым является область разработки программного обеспечения.
При создании продуктов Meta традиционно запрашивала мнения многочисленных групп, отвечающих за такие области, как внешний пользовательский интерфейс, дизайн, алгоритмические ленты и конфиденциальность, сообщили источники. Этот многоступенчатый процесс был призван обеспечить определенный уровень единообразия среди приложений компании, которые ежедневно привлекают миллиарды пользователей.
Но многие внутренние инструменты, созданные за эти годы, чтобы помочь разработчикам создавать программное обеспечение и функции, не были разработаны для размещения фундаментальных моделей. Новые лидеры ИИ Meta, особенно Фридман, рассматривают их как узкие места, замедляющие то, что должно быть процессом быстрого развития, сказали источники.
По словам источников, Фридман призвал MSL использовать более новые инструменты, которые были откалиброваны для включения нескольких моделей ИИ и различных видов программного обеспечения для автоматизации кодирования, часто называемого агентами ИИ.
«У них теперь есть мантра, гласящая: "Демо, а не мемо"», — сказал генеральный директор Lovable Антон Озика в октябре на саммите Masters of Scale в Сан-Франциско, говоря о новом процессе разработки Meta.
Озика сказал, что сотрудники Meta используют инструменты Lovable для более быстрого создания внутренних приложений, в частности, ссылаясь на финансовые команды компании, которые обратились к Lovable для создания программного обеспечения для отслеживания численности персонала и планирования.
В то время как Meta продолжает перенастраивать свои методы разработки приложений и продвигается к выпуску Avocado, компания экспериментирует с другими моделями ИИ на своих продуктах. Например, Vibes полагался на модели ИИ от Black Forest Labs и Midjourney, стартапа, в котором Фридман является консультантом.
Meta также меняет свой подход к инфраструктуре и все чаще обращается к сторонним облачным вычислительным сервисам, таким как CoreWeave и Oracle, для разработки и тестирования функций ИИ по мере создания своих собственных массивных центров обработки данных, сказали источники.
В октябре гигант социальных сетей объявил, что подписал соглашение о совместном предприятии с Blue Owl Capital в рамках сделки на 27 миллиардов долларов, чтобы помочь профинансировать и разработать гигантский центр обработки данных Hyperion в округе Ричленд, штат Луизиана. В то время компания заявила, что партнерство обеспечивает «скорость и гибкость», необходимые Meta для строительства центра обработки данных и поддержки ее «долгосрочных амбиций в области ИИ».
Несмотря на проблемы компании в 2025 году, послание Цукерберга сотрудникам и инвесторам заключается в том, что он как никогда привержен победе. В начале отчета о прибылях компании в октябре Цукерберг сказал, что MSL «отлично стартовала».
«Я думаю, что мы уже создали лабораторию с самой высокой концентрацией талантов в отрасли, — сказал Цукерберг. — Мы сосредоточены на разработке нашего следующего поколения моделей и продуктов, и я с нетерпением жду возможности рассказать об этом подробнее в ближайшие месяцы».
Кстати говоря, люди в США лишаются работы не из-за ИИ, а из-за индусов. Левые выполняют план по великому переселению народов, приезжих надо где-то устраивать - и они отжирают рабочие места у местных.
В итоге, индус устраивается айтишником, а белый айтишник вышвыривается нахуй. А потом рассказывают байки о том, что это якобы "сокращение из-за нейросети бла-бла-бла". Хуй там плавал!
>>1449289 Визы индусам в этом году сделали по 100к, так что их больше не завозят. Было столпотворение индусов перед самым запретом прежних условий, которые мечтали попасть в уходящий вагон.
>>1449313 Без Трампа тащем-то леваки и ИИ весь запретить хотели, запрещающие законы уже перед выборами готовились. В калифорнии до сих пор запрещают, даже при Трампе. Трамп щас за батю всего ИИ, спасает прогресс своими указами, борется со штатами.
>>1449349 Это потому что сцены пиздец прыгают на совсем другие, вызывая неприятные эффекты. Если бы не было непрерывной смены сцен, воспринималось бы более-менее нормально.
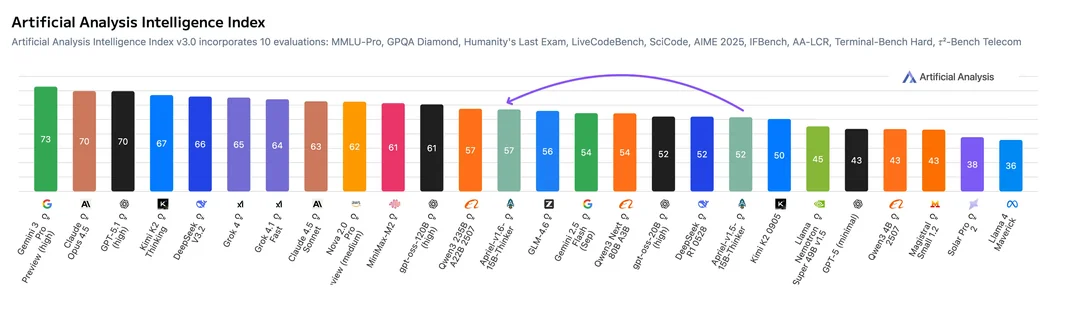
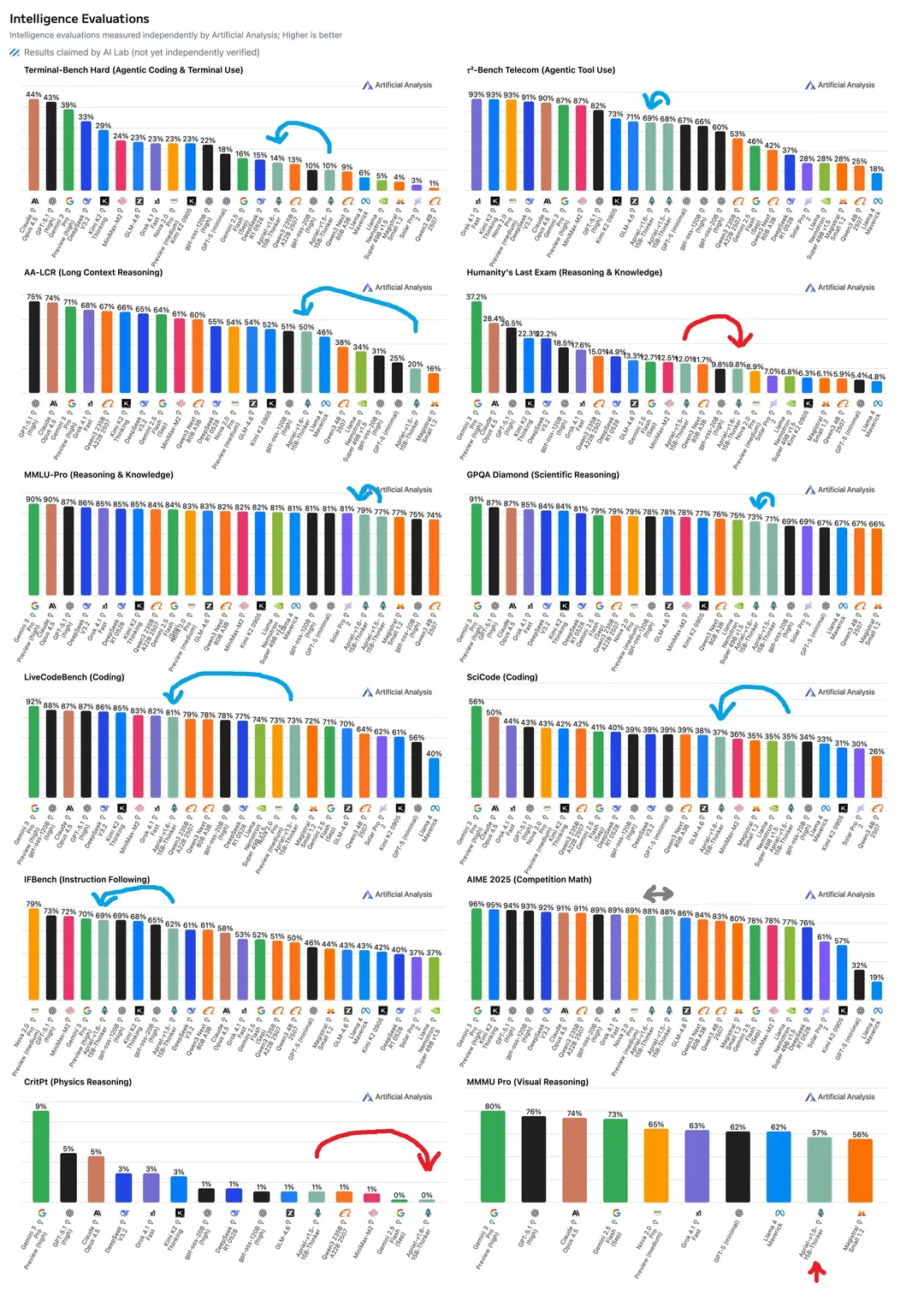
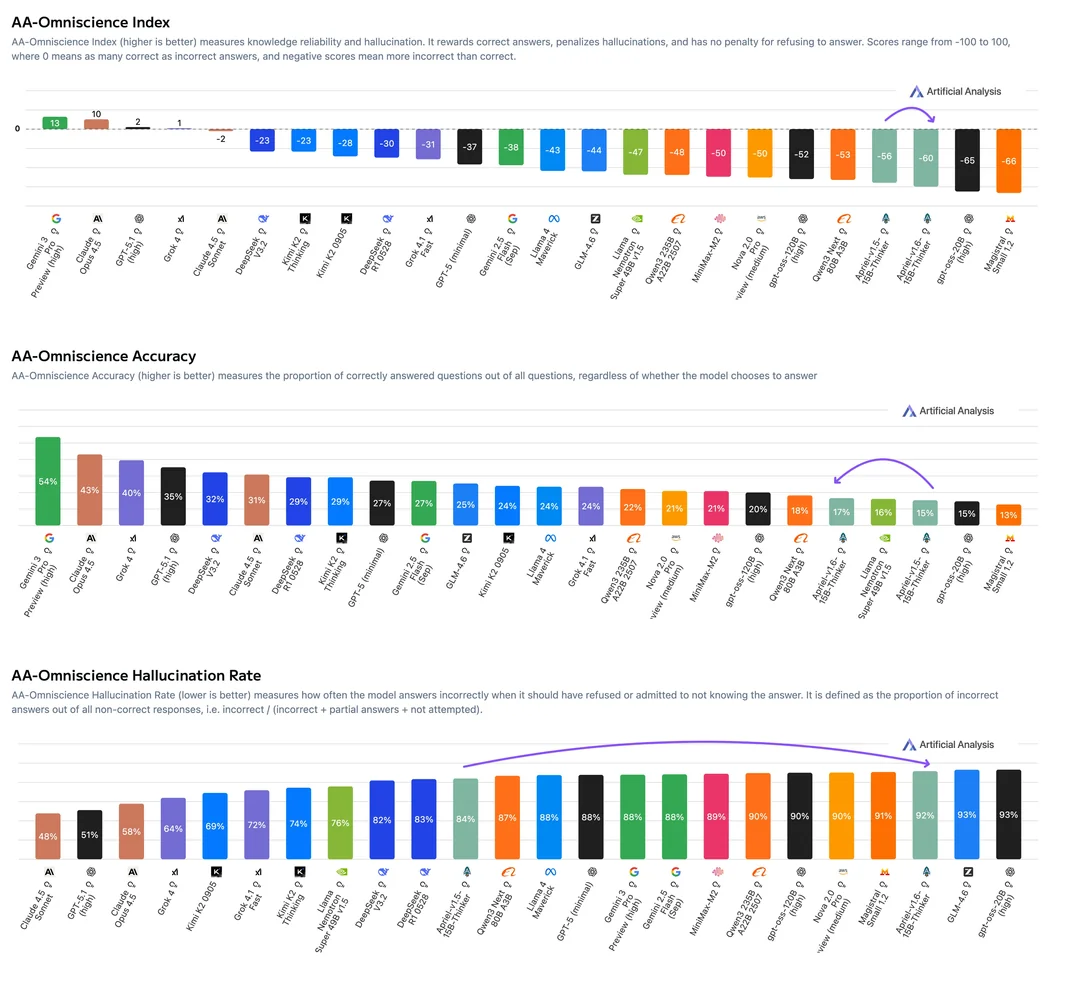
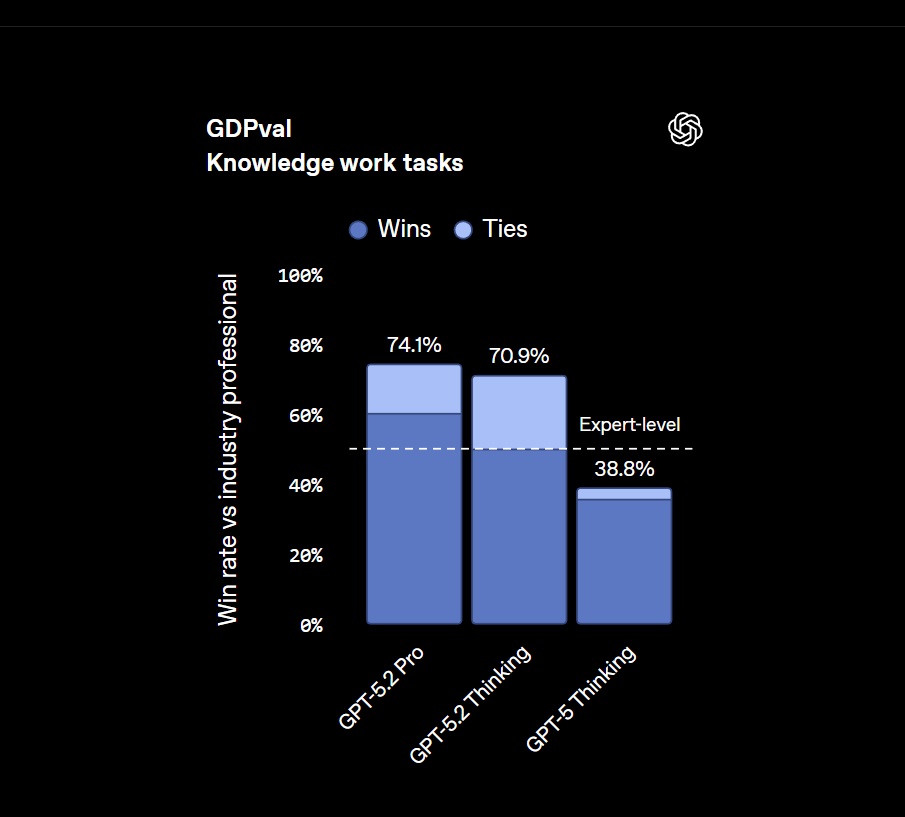
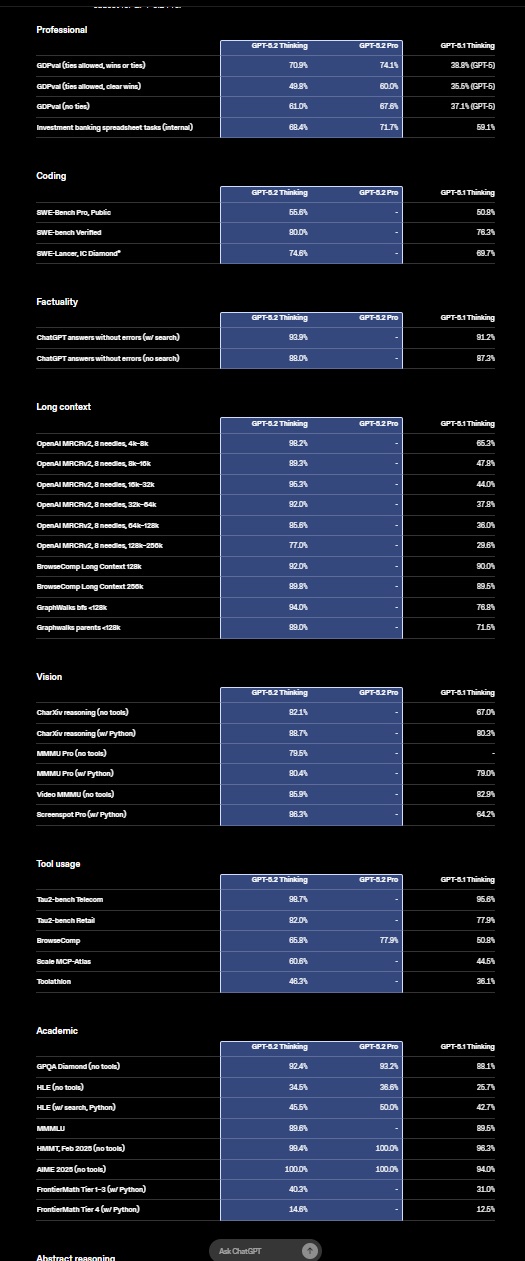
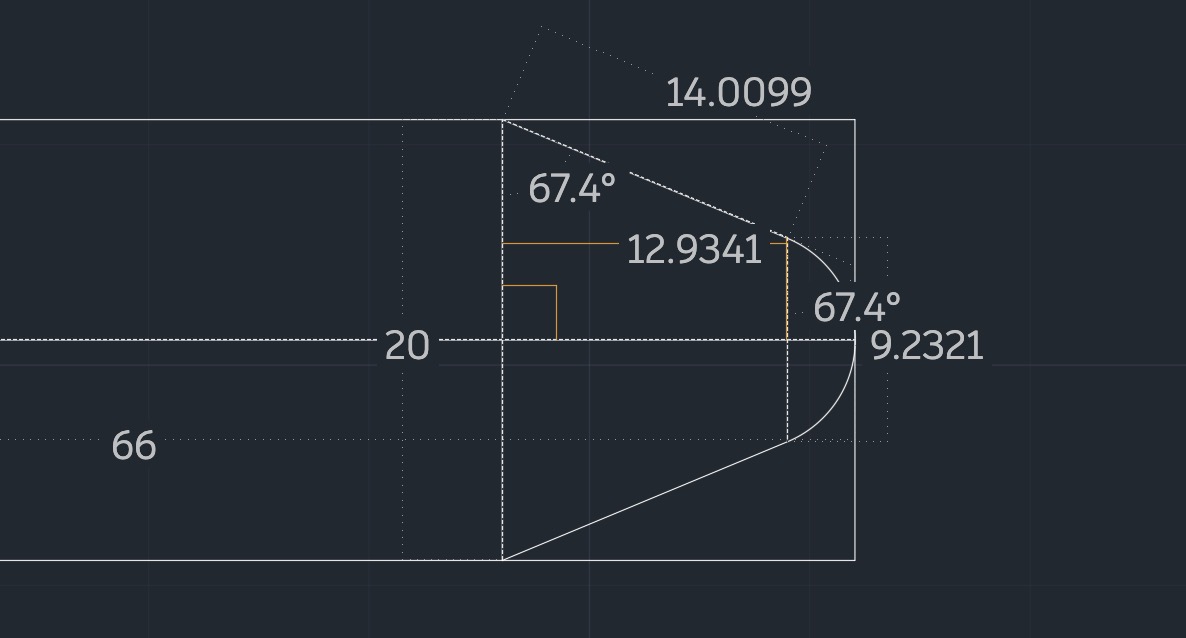
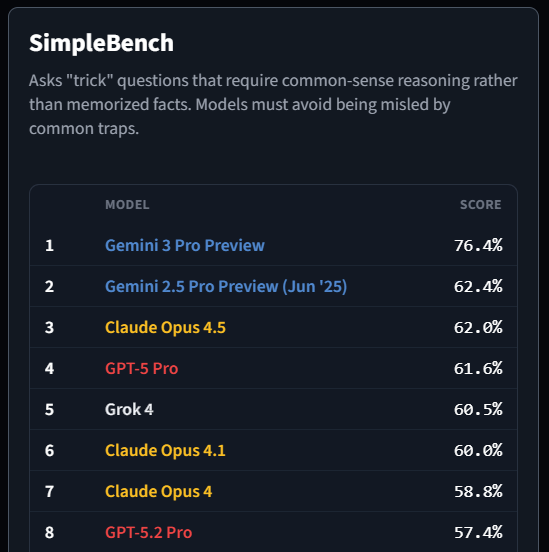
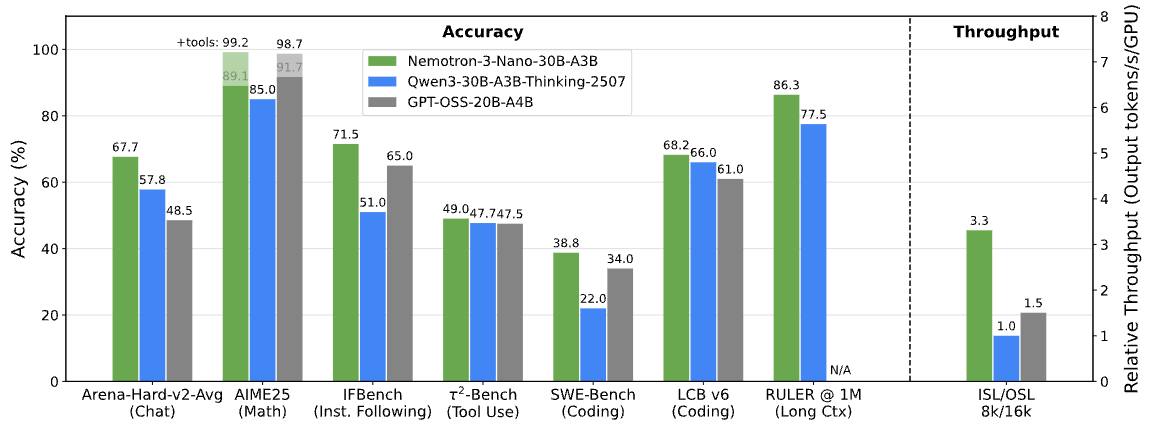
Апрель 1.6-15B-Thinker нехило прыгнула в тестах в сравнении с версией 1.5, догнав большие модели
Была выпущена небольшая модель с открытыми весами, содержащая 15 млрд параметров. По сравнению со своей предшественницей — версией v1.5 с 15 млрд параметров — она достигает аналогичного качества при использовании примерно на 30 % меньше обучающих токенов.
Apriel-1.6-15B-Thinker — это обновленная мультимодальная модель рассуждений в серии Apriel SLM от ServiceNow, основанная на Apriel-1.5-15B-Thinker. Благодаря значительно улучшенным возможностям рассуждений на основе текста и изображений, Apriel-1.6 достигает конкурентоспособной производительности по сравнению с моделями, которые до 10 раз превышают ее по размеру. Как и ее предшественница, она извлекает выгоду из обширного непрерывного предварительного обучения как в текстовой, так и в доменной области изображений. Кроме того, мы проводим пост-обучение, уделяя особое внимание тонкой настройке с учителем (Supervised Finetuning, SFT) и обучению с подкреплением (Reinforcement Learning, RL). Apriel-1.6 достигает передовой производительности, не жертвуя при этом эффективностью токенов рассуждений. Модель улучшает или поддерживает производительность задач по сравнению с Apriel-1.5-15B-Thinker, одновременно сокращая использование токенов рассуждений более чем на 30%.
Основные моменты
Достигает оценки 57 по индексу искусственного анализа, превосходя такие модели, как Gemini 2.5 Flash, Claude Haiku 4.5 и GPT OSS 20b. Получает оценку наравне с Qwen3 235B A22B, будучи при этом значительно более эффективной. Набирает 69 баллов в Tau2 Bench Telecom и 69 баллов в IFBench, которые являются ключевыми бенчмарками для корпоративного домена. При 15 миллиардах параметров модель помещается на одной GPU, что делает ее очень эффективной с точки зрения памяти. Основываясь на отзывах сообщества о Apriel-1.5-15b-Thinker, мы упростили шаблон чата, удалив избыточные теги, и ввели четыре специальных токена в токенизатор (<tool_calls>, </tool_calls>, [BEGIN FINAL RESPONSE], <|end|>) для более простого парсинга вывода.
>>1448095 → > Конкуренция — это хорошо. В данном случае только в краткосрочной перспективе, потому что дальше гугл либо сожрет всех остальных, либо подгадит.
>>1448520 → >Но глядя на то, как быстро Claude автоматизирует работу, думаю, что у нас гораздо меньше времени. Имхо, автоматизация/вымирание профессий - это проблема для одного максимум двух поколений людей. Как-нибудь адаптируются к новым условиям. Меня больше пугает, то как нагенеренный контент неотличимый от живого, повлияет на взаимодействие людей и потребление информации. Соц сети + мобильный интернет очень сильно повлияли на то, как люди общаются и взаимодействуют буквально за 10-15 лет. Пока мы более-менее нейрослоп вроде отличаем или уже нет, все вроде ок.
>>1449530 >то как нагенеренный контент неотличимый от живого Пока что нагенерированное в основном крайне вторично. Хотя и мясные кучу вторичности производят.
>>1449543 Судя по всему сработает, раз у моделек у всех только какие-то общие небольшие блоки важны. Вычленить их и запихнуть в маленькие модели, потом на них накатывать Лоры под конкретные задачи, которые тоже возможно будет уменьшить за счет только важных блоков. Тут и откроется золотая эра нейронок, где они идут на каждой пеке и можно модифицировать как захочешь. Ждем очередных перетряхиваний рыночка от китайцев, когда у них руки до этих вещей дойдут и выложат в опенсорс.
>>1449231 >в задаче генерации изображений (Stable Diffusion XL) универсальное подпространство не только сохраняет качество стилей, но иногда и улучшает его — вероятно, за счёт подавления шума в весах Вот это охуенно, Стейбл Дифьюжн XL, которая потребует в 100 раз меньше памяти и будет работать быстрее. А если какую-нибудь современную Флюкс удастся так сжать, то вообще идеал, все старые видеокарты сразу станут годнотой, заменяющей фотошоп.
>>1449231 Весь ИИ рыночек может наебнуться от такого открытия. Основные бабки платятся за инференс моделей, все эти премиум подписки, а тут окажется что дома на пеке можно запускать локальный Квен с качеством почти что больших моделей. Бизнес модель корпораций, продающих подписки, окажется несостоятельной, бабки за датацентры отбивать нечем. Корпам придется продавать идеальную загружаемую базу вместо доступа к чату, но их тут китайцы потеснят, которые любят пиратить с больших моделей и выкладывать в опенсорс.
>>1449530 Тапа собственная смерть в чистке или от голода во время мировой великой депрессии тебя не смущает, а вот то, что видосики реалистичные - смущает?
>>1449231 >Остальные направления практически не вносят вклада Мусор может быть важен для формирования реального интеллекта и аги. А тут опять предлагают все стриммить и оптимизировать в нулину и вернуться к самым тупым чатботам.
>>1449578 Тут предлагают очистить место. ЛЛМка как библиотека, где 95% книг — это пустые страницы или дубликаты. Только 10к книг в библиотеке из миллионов полезны для рассуждений. Если оставить только их, а потом добавить еще 30-100к полезных книг за счет высвободившихся ресурсов - тут и будет АГИ. Сейчас же просто гора мусора с небольшой кучкой годноты в центре.
>>1449578 Нет, тут предлагают аналог сжатия MP3, но для моделей. В MP3 алгоритм выкидывает частоты, которые человеческое ухо почти не слышит (ультразвук, тихие шумы). Музыка остается та же. Тут выкидывают вещи, некритичные для рассуждений модели. Авторы протестировали то, что они выкидывали, сформировав в отдельную модель - Secondary Subspace. Потом они попробовали запустить модель, используя только этот остаток, чтобы посмотреть, есть ли там хоть капля интеллекта. Оказалось та часть, которую они назвали шумом на практике действительно вела себя как шум. Она не содержала скрытых знаний или нюансов. Когда её попытались использовать, модель выдавала бессмыслицу. То есть можно разделить веса на модели на годноту и лютый бред и выкинуть бред, понизив требования к модели в 100 раз и сделав ненужными текущие монстрообразные связки из десятка gpu для запуска моделей.
>>1449567 >Тапа собственная смерть в чистке или от голода во время мировой великой депрессии тебя не смущает Ну следующая мировая великая депрессия в моем видении не такая будет как прошлая. Тоже конечн ничего классного, но возможности и объемы производства основных необходимых товаров и возможности торговли/доставки их находятся сейчас на совершенно другом уровне.
>а вот то, что видосики реалистичные - смущает? Я пытаюсь представить что дальше это даст. Вот представь, что любая информация с экрана выглядит как настоящая. Вот прям любая - фото, видео, аудио, текст в конце концов. С одной стороны это бесконечные возможности по внушению/контролю. Медийка сможет нагенерить контента руинящего или поднимающее статус/рейтинг любого человека в пол-щелчка за 3 копейки. Или любое фото/видео с человеком можно назвать нейрослопом и сказать что это неправда. И с другой стороны это может привести к тотальному недоверию ко всей информации с экрана.
У человека многие механизмы по восприятию информации заложены древнейшими прошивками (что современная медийка активно и использует), как такие штуки повлияют на социум сложно представить.
>>1449598 Сначала будут тотальные наебки, потом тотальное недоверие, потом запреты и ограничения, потом наебывать тебя будут те, кому разрешено. А потом ты сдохнешь или на войне или от короны 3.0.
Пентагону приказано сформировать руководящий комитет по ИИ, посвященный ОИИ
В воскресенье лидеры Конгресса представили компромиссный законопроект, требующий от Пентагона создать руководящий комитет высокого уровня, сосредоточенный на общем искусственном интеллекте (ОИИ) и его военных последствиях. Это первый случай, когда Конгресс официально обязал Министерство обороны изучить эту гипотетическую технологию, которая может сравниться с когнитивными способностями человека или превзойти их.
Положение, включенное в Закон о разрешении на национальную оборону на 2026 финансовый год, опубликованный 8 декабря, предписывает создание «Руководящего комитета по будущему искусственного интеллекта» к 1 апреля 2026 года. Сопредседателями комитета будут заместитель министра обороны и заместитель председателя Объединенного комитета начальников штабов. Комиссия должна представить свои выводы комитетам Конгресса по вопросам обороны к 31 января 2027 года.
Руководство высокого уровня, широкий мандат
В состав комитета войдут заместители руководителей видов вооруженных сил, заместитель начальника Бюро Национальной гвардии, ключевые заместители министров и главный директор Пентагона по цифровым технологиям и ИИ, а также другие лица, которых министр обороны сочтет нужным. Его мандат выходит за рамки анализа новых технологий ИИ, включая передовые модели, агентские алгоритмы и нейроморфные вычисления, и включает оценку того, как противники, в частности Китай, Россия, Иран и Северная Корея, могут вести разработку ОИИ.
По данным IBM, общий искусственный интеллект представляет собой «гипотетическую стадию в развитии машинного обучения, на которой система искусственного интеллекта может сравниться или превзойти когнитивные способности человека в выполнении любых задач». Хотя ОИИ остается теоретическим, это положение отражает растущее внимание Конгресса к потенциальным последствиям для национальной безопасности по мере быстрого развития возможностей ИИ.
Человеческий контроль, акцент на снижении рисков
Комитет должен разработать «стратегию, основанную на оценке рисков» для внедрения Пентагоном передового ИИ, которая сохраняет человеческий надзор за управлением миссиями и обеспечивает «возможность для людей отменять решения искусственного интеллекта с помощью технических, политических или других операционных средств контроля», как указано в законопроекте. Он также рассмотрит оперативные последствия интеграции передового ИИ в сети Министерства обороны с технической, доктринальной, учебной и ресурсной точек зрения.
Законопроект о разрешении на оборону на сумму 900,6 миллиарда долларов, который превышает бюджетный запрос администрации на 8 миллиардов долларов, ожидает голосования в обеих палатах на этой неделе, прежде чем будет направлен на подпись президенту Дональду Трампу. Управление главного директора Пентагона по цифровым технологиям и искусственному интеллекту, которое в настоящее время возглавляет Дуглас Матти, продвигает усилия по внедрению ИИ с момента достижения полной оперативной готовности в 2022 году.
Помимо руководящего комитета по ОИИ, более широкий законодательный акт включает положения, требующие от Пентагона разработать политику безопасности для систем ИИ и машинного обучения, используемых в оборонных целях.
Nvidia добавляет шпионские трекеры местоположения в свои видеокарты
Nvidia разработала технологию проверки местоположения, которая может выявить, в какой стране работают ее чипы. По словам источников, знакомых с ситуацией, этот шаг направлен на пресечение контрабанды процессоров для искусственного интеллекта в страны, куда запрещен их экспорт.
Эта функция, которую Nvidia в последние месяцы демонстрировала в частном порядке, но еще не выпустила публично, будет представлять собой опциональное обновление программного обеспечения для клиентов. Она использует возможности конфиденциальных вычислений, встроенные в графические процессоры компании, для оценки местоположения чипа путем измерения задержек связи с серверами, управляемыми Nvidia.
Чипы Blackwell первыми получат эту функцию
Возможность проверки местоположения изначально будет доступна на новейших чипах Blackwell от Nvidia, которые включают расширенные функции безопасности для процесса, называемого "аттестацией", превосходящие возможности чипов предыдущих поколений Hopper и Ampere. Компания изучает варианты распространения этой функции и на более старые модели чипов.
"Мы находимся в процессе внедрения новой программной услуги, которая позволит операторам центров обработки данных отслеживать состояние и инвентаризацию всего своего парка графических процессоров для искусственного интеллекта", — говорится в заявлении Nvidia. "Этот устанавливаемый клиентом программный агент использует телеметрию GPU для мониторинга состояния, целостности и инвентаризации парка оборудования".
Решение проблемы контрабанды
Эта разработка является ответом на призывы Белого дома и двухпартийных законодателей принять меры по предотвращению контрабанды чипов для ИИ в Китай и на другие рынки с ограничениями. Эти требования усилились после возбуждения Министерством юстиции уголовных дел в отношении контрабандных операций, которые предположительно пытались перевезти в Китай чипы Nvidia на сумму более 160 миллионов долларов.
8 декабря двум гражданам Китая были предъявлены обвинения в связи с контрабандной сетью. Обвинители утверждают, что они вступили в сговор с сотрудниками логистической компании из Гонконга, чтобы обойти экспортные ограничения США, включая удаление фирменной маркировки Nvidia и замену ее этикетками от фиктивной компании под названием "SANDKYAN".
Геополитическая напряженность
Инициатива по проверке местоположения побудила главный орган Китая по кибербезопасности вызвать Nvidia для допроса относительно того, содержат ли ее продукты бэкдоры, которые могут позволить США обойти функции безопасности чипов. Компания категорически отвергла такие утверждения, заявив, что у нее нет "бэкдоров", которые могли бы обеспечить удаленный доступ или контроль.
Внимание к этому вопросу усилилось на этой неделе после того, как президент Дональд Трамп объявил, что разрешит Nvidia экспортировать чипы H200 — предшественники Blackwell — утвержденным клиентам в Китае при условии, что 25% выручки будет направлено правительству США. Однако аналитики внешней политики выразили скептицизм относительно того, разрешит ли Китай местным компаниям их приобретать.
«Самое важное в ближайшие 3-4 года — это дата-центры в космосе.
Во всех отношениях дата-центры в космосе, с точки зрения первых принципов, превосходят дата-центры на Земле.
В космосе спутник можно держать на солнце круглосуточно. Солнце на 30% интенсивнее, что приводит к в шесть раз большей радиации, чем на Земле. Так что батарейка не нужна.
Охлаждение в этих дата-центрах невероятно сложно. Охлаждение пространства бесплатное. Ты просто ставишь радиатор на тёмную сторону спутника.
Единственное, что быстрее, чем лазер, проходящий через оптоволоконный кабель — это лазер, проходящий через абсолютный вакуум. Соедините спутники лазерами, и у вас будет более быстрая и целостная сеть, чем любой дата-центр на Земле.»
>>1449629 СВОБОДНЫЙ РЫНОК @ ЖРИТЕ НЕ ОБЛЯПАЙТЕСЬ А ведь святой чубайс говорил, что станки на западе купим. Правда эта сука не уточнила, что их отключат одной кнопкой по спутнику.
>>1449585 >Сейчас же просто гора мусора с небольшой кучкой годноты в центре. Даже в научной литературе до хуя фальсификации. А чтобы создать не кучу мусора необходимо рассекретить все закрытые патенты. Да и открытые описать полностью, а не как сейчас, когда пишется патент, чтобы заинтересовать покупателя, утаивая главное.
следите за руками Сэм Алтман в октябре заключил контракт с 40% поставок DRAM до 2029 года с Hynix и Samsung(деньги дал трамп). Цены на DRAM 400%+ с тех пор. новые ии стартап компании не могут потянуть датацентры с 400% наценкой Новых конкурентов у опенАИ и других игроков на ии рынке не появляется
полностью искусственное убийство конкурентов в зародыше на деньги подкупленного правительства
>>1449662 Что создаст среду, где ИИ стартапам придется либо делать свои чипы, либо ухитряться с оптимизацией нейронок, либо брать железо у китайцев. В перспективе все это хорошо для всех, много открытий и новых цепочек поставок.
>>1449646 >Охлаждение пространства бесплатное. Ты просто ставишь радиатор на тёмную сторону спутника. Обосрался с этого дегенерата не острие науки и техники
>>1449598 Да всё тут легко представить. Уже сейчас если не работаешь, то можно даже из дома не выходить и при этом кайфовать по полной, года с 2008 это началось, с появлением интернета, онлайн игр, соц сеток. А теперь представь что можно любой контент генерировать неотличимый от реальности, на лету. Буквально VR очки одеть и окунуться в любую реальность какую только сможешь себе нафантазировать. Да все хуй на реальность забьют и будут в симуляциях кайфовать с перерывами на работку.
>>1449200 Физика тел и вообще в целом ёбнутая, вкупе с полным реализмом вызывает раздражение, типо причинно следственные связи физики реальности которые мозг копил годами не работают, это главная причина раздражения среди нормисов 120%
Физические роботы с искусственным интеллектом автоматизируют «большие секции» заводских работ в следующую пятилетку, — говорит генеральный директор Arm
По прогнозам генерального директора Arm Рене Хааса, человекоподобные роботы, оснащенные искусственным интеллектом, могут взять на себя значительную часть заводских работ в течение следующих пяти-десяти лет, преобразовав обрабатывающую промышленность.
Хаас сказал, что одной из ключевых сил, подталкивающих человекоподобных роботов к работе на заводах, является их преимущество перед роботизированными манипуляторами и другим оборудованием для автоматизации, используемым сегодня. Традиционные заводские роботы — это машины специального назначения, разработанные для выполнения одной задачи, с аппаратным и программным обеспечением, оптимизированным для этой конкретной функции. Роботы-гуманоиды общего назначения, напротив, в сочетании со все более сложным «физическим ИИ», который помогает ориентироваться в реальном мире, смогут выполнять различные работы на лету с быстрой модификацией своих инструкций.
«Я думаю, что в следующие пять лет вы увидите, что большие секции заводских работ будут заменены роботами, и отчасти причина этого в том, что этих физических роботов с ИИ можно перепрограммировать для выполнения различных задач», — сказал Хаас на Fortune Brainstorm AI в Сан-Франциско в понедельник.
«Одна из проблем, которая была с заводскими роботами в прошлом, заключалась в том, что, если это была машина для захвата и размещения на заводе, они были оптимизированы только для одной задачи — программное обеспечение было для одной задачи, аппаратное обеспечение было для одной задачи. Теперь, если вы разработаете человекоподобного робота общего назначения, программное обеспечение которого полностью основано на ИИ, и он учится на практике, он полностью заменит большое количество заводских рабочих», — сказал он.
То, что произойдет с этими работниками и более широким рынком труда по мере распространения ИИ и роботов в бизнесе, вызывает растущую озабоченность среди многих политиков и отраслевых обозревателей, среди обсуждаемых вариантов — от переподготовки работников до всеобщего базового дохода.
Хаас конкретно не затрагивал вопрос о рабочих местах, но предположил, что широкое внедрение физического ИИ может изменить динамику мирового производства, потенциально помогая выровнять глобальное конкурентное поле за счет автоматизации большого объема заводских работ. «Физический ИИ станет большим подспорьем», — сказал он.
Хаас также указал на автономные транспортные средства Waymo как на ранний индикатор потенциала физического ИИ.
Он сказал, что для следующего поколения автономных систем может потребоваться еще меньше оборудования. В то время как нынешние самоуправляемые автомобили оснащены радарами и камерами, сканирующими их окружение, будущие итерации, использующие более совершенные модели ИИ, могут работать с меньшим количеством датчиков, полагаясь на искусственный интеллект, а не на исчерпывающий сбор данных для принятия решений.
У цепочки поставок полупроводников «много единичных точек отказа» Arm, которая не производит и не продает свои собственные чипы, разрабатывает и лицензирует архитектуру, используемую в процессорах, производимых такими компаниями, как Qualcomm и Apple. Чипы, основанные на разработках Arm, используются во всем: от смартфонов и холодильников до автомобилей и серверов, и большинство людей используют от 50 до 100 чипов Arm на себе или в своих домах, сказал Хаас.
Такое широкое использование и доля рынка являются свидетельством энергоэффективности и производительности, которые сделали дизайн чипов Arm таким популярным. Но это также создает риски для цепочки поставок полупроводников.
Отвечая на вопрос об этой уязвимости, Хаас признал крайнюю концентрацию рынка в отрасли и отметил, что несколько крупных компаний контролируют жизненно важные части цепочки поставок полупроводников: «В цепочке поставок полупроводников много единичных точек отказа. Есть TSMC, которая находится в очень, очевидно, интересной с геополитической точки зрения части мира. Существует также очень сложное устройство, которое должно попасть на эти фабрики и которое поставляется одной компанией на планете… под названием ASML».
В последние несколько лет пандемия COVID-19 выявила некоторые из этих слабых мест в цепочке поставок, когда из-за нехватки чипов потребители не могли получить брелоки для новых автомобилей в течение нескольких недель. Этот кризис, по словам Хааса, был «всего лишь функцией цепочки поставок полупроводников, в которой много единичных точек отказа».
Хаас сказал, что вся отрасль «учится жить с» концентрацией риска.
Microsoft инвестирует $17,5 млрд в Индию для масштабного внедрения ИИ
Крупнейшие в Азии вложения ускорят создание национальной ИИ-инфраструктуры и подготовку 20 млн специалистов к 2030 году
Нью-Дели, 9 декабря 2025 г. — Microsoft объявила о самом масштабном инвестиционном проекте в Азии: $17,5 млрд будут инвестированы в Индию в течение четырёх лет (2026–2029 гг.) для развития облачных технологий, искусственного интеллекта и цифровых навыков населения. Эта сумма дополняет ранее объявленные $3 млрд (январь 2025 г.), которые компания намерена освоить уже к концу 2026 года.
Анонс состоялся после встречи генерального директора Microsoft Сатьи Наделлы с премьер-министром Индии Нарендрой Моди в рамках турне «India AI». Инвестиции отражают стратегическое партнёрство между Microsoft и Индией в реализации национального ИИ-пути — с акцентом на масштаб, компетенции и суверенитет.
> «Microsoft более 30 лет является частью индийской экосистемы. Сегодня мы гордимся тем, что поддерживаем страну в переходе к будущему, где ИИ — не привилегия немногих, а инструмент для реализации миллиарда мечтаний», — заявил Пунит Чандок, президент Microsoft в Индии и Южной Азии.
🏗️ Создание ИИ-инфраструктуры национального масштаба
Центральным элементом инвестиций станет новый гипермасштабный облачный регион India South Central в Хайдарабаде, запуск которого запланирован на середину 2026 года. Это станет крупнейшим дата-центром Microsoft в стране — с тремя зонами доступности и общей площадью, сопоставимой с двумя стадионами «Эден Гарденс» в Калькутте.
Параллельно будут расширены три действующих облачных региона — в Ченнаи, Хайдарабаде и Пуне, — что обеспечит организациям по всей стране большую отказоустойчивость, выбор и низкие задержки при работе с критически важными приложениями.
🤖 ИИ для 310 млн неформальных работников
Одним из ключевых проектов станет интеграция ИИ в национальные цифровые платформы Министерства труда и занятости: - e-Shram — реестр неформальных работников, объединяющий свыше 310 млн человек; - NCS (National Career Service) — национальная служба трудоустройства.
С использованием Azure OpenAI Service обе платформы получат: - многопользовательскую поддержку на всех официальных языках Индии; - ИИ-подбор вакансий с учётом навыков и географии; - прогнозирование спроса на профессии и трендов на рынке труда; - автоматическое создание резюме; - персонализированные рекомендации по переходу в формальный сектор.
По данным МОТ, благодаря e-Shram охват социальной защиты в Индии вырос с 24% в 2019 г. до 64% в 2025 г. — и внедрение ИИ ускорит этот прогресс.
👩💻 Подготовка 20 млн ИИ-грамотных граждан к 2030 году
Microsoft удваивает своё обязательство по обучению: к 2030 году 20 млн индийцев получат базовые и продвинутые ИИ-навыки. Программа ADVANTA(I)GE India, реализуемая через платформу Microsoft Elevate, уже показала впечатляющие результаты: с января 2025 г. обучено 5,6 млн человек — значительно больше, чем планировалось (10 млн за 5 лет).
Более 125 000 выпускников уже трудоустроены или начали собственные предпринимательские проекты. Обучение проводится совместно с государственными органами, вузами и цифровыми платформами, чтобы обеспечить равный доступ к возможностям.
🛡️ Суверенные облачные решения для Индии
В ответ на растущий спрос на цифровой суверенитет Microsoft представила в Индии две новые архитектуры:
🔹 Sovereign Public Cloud — публичное облако с преднастроенными «зонами суверенитета» (Sovereign Landing Zones), встроенной проверкой соответствия нормативным требованиям и механизмами управления политиками. Доступно в индийских облачных регионах.
🔹 Sovereign Private Cloud (на базе Azure Local) — частное облако, развёртываемое в дата-центрах клиентов или партнёров. Поддерживает как подключённые, так и изолированные (air-gapped) среды.
Azure Local теперь поддерживает: - кластеры из сотен узлов; - подключение внешних SAN-хранилищ; - новейшие GPU от NVIDIA — для высокопроизводительных и безопасных ИИ-задач.
Также доступен Microsoft 365 Local, работающий на Sovereign Private Cloud, — решение для госучреждений, банков и медорганизаций с повышенными требованиями к конфиденциальности.
Кроме того, к концу 2025 года в Индии заработает локальная обработка данных в Microsoft 365 Copilot. Это сделает страну одной из четырёх ведущих глобальных юрисдикций (наряду с США, ЕС и Канадой), где промпты и ответы Copilot обрабатываются строго внутри границ — усиливая безопасность и соответствие в регулируемых отраслях: госуправлении, финансах и здравоохранении.
🌐 От цифровой — к ИИ-инфраструктуре
Индия уже построила одну из самых успешных в мире систем цифровой государственной инфраструктуры (Aadhaar, UPI, DigiLocker и др.). Теперь страна делает следующий шаг — от цифровой трансформации к масштабному внедрению ИИ в общественные и экономические процессы.
Команда Microsoft в Индии насчитывает свыше 22 000 сотрудников в Бенгалуру, Хайдарабаде, Пуне, Гургаоне и Нойде. Именно здесь разрабатываются ключевые ИИ-продукты глобального значения: Copilot Studio, Azure AI Search, ИИ-агенты, технологии распознавания и перевода речи, Azure Machine Learning и др. Индийские инженеры и учёные играют центральную роль в развитии всего ИИ-стека Microsoft — от «железа» до прикладных решений.
> «По мере того как ИИ переформатирует цифровую экономику, Индия остаётся приверженной инновациям, основанным на доверии и суверенитете. Инвестиции Microsoft — знак того, что страна становится надёжным технологическим партнёром мира», — отметил Шри Ашвини Вайшнав, министр электроники и информационных технологий Индии.
Индия — не только крупнейший по численности рынок, но и уникальная «лаборатория» для проверки ИИ-решений в условиях масштаба, многоязычия и социально-экономического разнообразия.
Успешное внедрение ИИ в такие платформы, как e-Shram и NCS, может стать мировым эталоном для стран с развивающейся экономикой — особенно в сфере защиты прав трудящихся, повышения мобильности рабочей силы и построения инклюзивного цифрового будущего.
Microsoft и Индия демонстрируют: будущее ИИ — не в изолированных «песочницах» для элит, а в публичной инфраструктуре, служащей каждому гражданину. И этот путь строится на трёх опорах: ✅ Масштаб — гипероблака, доступные миллионам; ✅ Компетенции — обучение как социальный лифт; ✅ Суверенитет — технология под контролем общества.
Пит Хегсет заявляет, что новый чат-бот Пентагона сделает Америку «более смертоносной»
Министр обороны Пит Хегсет объявил о запуске GenAI.mil сегодня в видео, опубликованном на X. По словам Хегсета, этот веб-сайт является «будущим американской войны». На практике, судя по тому, что нам известно из пресс-релизов и заявлений Хегсета, GenAI.mil, по-видимому, представляет собой настраиваемый интерфейс чат-бота для Google Gemini, который может обрабатывать некоторые формы конфиденциальных, но не секретных данных.
Заявление Хегсета было полно смелых заявлений о будущем убийства людей. Подобные заявления типичны для второй администрации Трампа, которая заявила, что считает стремление «победить» в области ИИ экзистенциальной угрозой, сравнимой с изобретением ядерного оружия во время Второй мировой войны.
Однако Хегсет в своем заявлении не говорил об оружии. Он говорил о электронных таблицах и видео. «Одним нажатием кнопки модели ИИ на GenAI могут быть использованы для проведения глубоких исследований, форматирования документов и даже анализа видео или изображений с беспрецедентной скоростью», — сказал Хегсет в видео на X. По сути, офисная работа. «Мы продолжим агрессивно внедрять лучшие мировые технологии, чтобы сделать наши вооруженные силы более смертоносными, чем когда-либо прежде».
Эмиль Майкл, заместитель министра Пентагона по исследованиям и разработкам, также подчеркнул, насколько важным будет GenAI для процесса убийства людей, в пресс-релизе о запуске сайта.
«Во всемирной гонке за доминирование в области ИИ нет призов за второе место. Мы быстро продвигаемся, чтобы развернуть мощные возможности ИИ, такие как Gemini для правительства, непосредственно для наших сотрудников. ИИ — это следующая «Явная судьба» Америки, и мы гарантируем, что будем доминировать на этой новой границе», — сказал Майкл в пресс-релизе, ссылаясь на американское убеждение 19-го века в том, что Бог предначертал американцам заселять запад, одновременно объявляя о новом чат-боте.
В пресс-релизе говорится, что Gemini for Government от Google Cloud станет первой версией, доступной на внутренней платформе. В сообщении указывается, что он сертифицирован для Контролируемой несекретной информации (Controlled Unclassified Information) и утверждается, что поскольку он основан на Google Search — то есть будет использовать результаты поиска Google для ответа на запросы — это делает его «надежным» и «значительно снижает риск галлюцинаций ИИ». Как мы уже писали, поскольку результаты поиска Google также потребляют ИИ-контент, который содержит ошибки и сгенерированные ИИ данные со всего интернета, он стал практически непригодным для использования как обычными потребителями, так и исследователями.
Во время пресс-конференции по поводу запуска этим утром Майкл сообщил журналистам, что GenAI.mil вскоре будет включать другие модели ИИ и однажды сможет обрабатывать как секретные, так и конфиденциальные данные. На момент написания этой статьи веб-сайт GenAI не работает.
«Впервые в истории, к концу этой недели, три миллиона сотрудников, бойцов, подрядчиков получат ИИ на своих рабочих столах, абсолютно каждый», — сказал Майкл журналистам сегодня утром, согласно Breaking Defense. Они «начнут с трех миллионов человек, начнут внедрять инновации, использовать, создавать, спрашивать о том, что еще они могут сделать, а затем перейдут на более высокий уровень классификации, привлекая другие возможности», — сказал он.
Вторая администрация Трампа сделала все возможное, чтобы людям в Кремниевой долине было легче навязывать ИИ Америке и миру. Отчасти это было сделано путем представления ИИ как вопроса национальной безопасности. Трамп подписал несколько указов, направленных на сокращение регулирования в отношении центров обработки данных и строительства атомных электростанций. Он пригрозил подписать еще один, который не позволит штатам принимать свои собственные правила в отношении ИИ. Каждый исполнительный указ и часть предлагаемого законодательства угрожают тем, что проигрыш в гонке ИИ сделает Америку слабой и уязвимой и подорвет национальную безопасность.
Технологические магнаты страны спешат строить центры обработки данных и атомные электростанции, пока продолжается период бума. Неважно, что люди не хотят жить рядом с центрами обработки данных по множеству причин. Неважно, что технологические компании используют неисправные ИИ для ускорения строительства атомных электростанций. Неважно, что у Пентагона уже была собственная проприетарная большая языковая модель (LLM), которую он использовал с 2024 года.
«Мы ставим все наши фишки на искусственный интеллект как боевую силу. Департамент использует коммерческий гений Америки, и мы внедряем генеративный ИИ в наш ежедневный боевой ритм», — сказал Хегсет в пресс-релизе о GenAI.mil. «Инструменты ИИ предоставляют безграничные возможности для повышения эффективности, и мы рады наблюдать за будущим позитивным влиянием ИИ на Военное министерство».
Дженсен Хуанг рассказывает про пятислойный торт ИИ и Китай
Видеорелейтед.
Дженсен Хуанг: ИИ — это пятислойный торт: энергетика, чипы, инфраструктура, модели и приложения.
Энергетика
У Китая в два раза больше энергетических мощностей, чем у нас как у нации, и при этом существуют экономики крупнее китайской. Мне это совершенно непонятно.
Чипы-инфраструктура
Во-вторых, чипы. Мы опережаем на поколения. В-третьих, инфраструктура. Если вы хотите построить дата-центр здесь, в Соединённых Штатах — от начала строительства до запуска суперкомпьютера для ИИ — это займёт, вероятно, около трёх лет. А они могут построить больницу за выходные. Это реальная проблема.
Теперь, совсем кратко о чипах: мы опережаем на несколько поколений, но не стоит расслабляться. Помните: полупроводники — это производственный процесс. Любой, кто считает, что Китай не способен на производство, упускает одну очень важную мысль.
Модели
Слой моделей: передовые модели США — наши передовые модели, несомненно, находятся на мировом уровне. Мы, вероятно, опережаем примерно на шесть месяцев. Однако из 1,4 миллиона моделей большинство являются открытыми. В этом Китай значительно опережает нас — намного опережает в области открытых моделей.
Приложения
И, наконец, слой выше — приложения. Если бы вы провели опрос в их обществе и в нашем и задали бы вопрос: «Скорее всего, ИИ принесёт больше пользы, чем вреда?» — в их случае 80 % ответили бы, что ИИ принесёт больше пользы, чем вреда. В нашем случае показатель составил бы…
Даже человек, стоящий за ChatGPT, генеральный директор OpenAI Сэм Альтман, обеспокоен «скоростью изменений, происходящих сейчас в мире» благодаря ИИ.
Спустя всего три года после запуска ChatGPT он перевернул отрасли, ускорил научные открытия и породил представления о том, что болезни будут излечены, а рабочие недели сократятся. Тем не менее, та же самая технология, которая питает эти обещания, также порождает массу новых тревог — и никто не чувствует это острее, чем человек, который помог ее разработать.
Генеральный директор OpenAI Сэм Альтман только что рассказал, что есть «длинный список вещей», которые были не такими уж и замечательными в быстром взлете ChatGPT, начиная со скорости, с которой он изменил мир. Та самая система, которая может искоренить болезни, сказал он на шоу The Tonight Show, также может быть неправомерно использована способами, к которым общество совершенно не готово.
«Одна из вещей, которая меня беспокоит, — это просто скорость изменений, происходящих сейчас в мире», — сказал Альтман Джимми Фэллону. «Это технология трехлетней давности. Никакая другая технология никогда не была принята миром так быстро».
Он добавил: «Убедиться, что мы представляем это миру ответственным образом, чтобы у людей было время адаптироваться, дать обратную связь, понять, как это сделать, — можно представить, что мы можем ошибиться в этом».
Но поскольку сейчас более 800 миллионов человек используют ChatGPT каждую неделю, ставки не могут быть выше. Технология теперь вплетена в повседневную жизнь — от классных комнат до залов заседаний — часто быстрее, чем могут успеть защитные меры.
Fortune обратился к OpenAI за дополнительными комментариями.
Рабочие места могут начать меняться «довольно быстро», — но мы все придумаем новые работы, говорит Альтман Комментарии Альтмана прозвучали на фоне того, что он также обеспокоен скоростью изменений у своих конкурентов. Сообщается, что 40-летний руководитель на прошлой неделе объявил «красный код», чтобы направить больше ресурсов на улучшение ChatGPT, поскольку давление со стороны Google и других конкурентов в области ИИ, включая Meta и Anthropic, усиливается.
Вместе усилия этих компаний в области ИИ привели к историческому росту производительности и новым методам сбора и анализа информации, но также усилили неопределенность в отношении будущего работы. Генеральный директор Anthropic Дарио Амодеи был особенно прямолинеен, предупредив, что ИИ может устранить половину всех белых воротничков начального уровня.
Альтман, однако, остается в основном оптимистичным. Даже если сбои в работе будут быстрыми, он утверждал, что это будет компенсировано совершенно новыми видами работы.
«Скорость, с которой рабочие места будут меняться, может быть довольно высокой. Я не сомневаюсь, что мы придумаем совершенно новые работы, и, надеюсь, гораздо лучшие работы», — добавил он на шоу The Tonight Show.
Некоторые из этих будущих ролей, как он предположил, могут быть буквально вне этого мира.
«В 2035 году этот выпускник колледжа, если он вообще пойдет в колледж, вполне может отправиться на миссию по исследованию Солнечной системы на космическом корабле на какой-то совершенно новой, захватывающей, супер хорошо оплачиваемой, супер интересной работе», — сказал Альтман видеожурналисту Клео Абрам ранее в этом году.
Рост рабочих мест, связанных с космосом, также является областью, в отношении которой генеральный директор Google Сундар Пичаи настроен оптимистично — с возможностью расширения всего через 10 лет.
«Один из наших «лунных проектов» заключается в том, как однажды разместить центры обработки данных в космосе, чтобы мы могли лучше использовать энергию Солнца, которая в 100 триллионов раз превышает энергию, которую мы производим на всей Земле сегодня», — сказал Пичаи в эфире Fox News в конце прошлого месяца.
Через пять лет ИИ будет лечить болезни, предсказывает Альтман При всей неопределенности, связанной с влиянием ИИ на рабочие места, образование и общество, есть одна область, где технические лидеры остаются почти повсеместно оптимистичными: медицина.
Амодеи сказал, что технология может привести к устранению большинства видов рака, в то время как соучредитель Microsoft Билл Гейтс предсказал «прорывные методы лечения». ИИ уже добивается успехов в ускорении открытия лекарств и помогает ученым анализировать биологические данные в масштабах, которые когда-то считались невозможными.
Модели ИИ могут положить начало эре инноваций в области лечения болезней уже к 2030 году, добавил Альтман.
«Пять лет — это долгий срок», — сказал Альтман. «В следующем году, я надеюсь, мы начнем видеть, как эти модели действительно делают небольшие, но важные новые научные открытия. А через пять лет, я надеюсь, они будут лечить болезни».
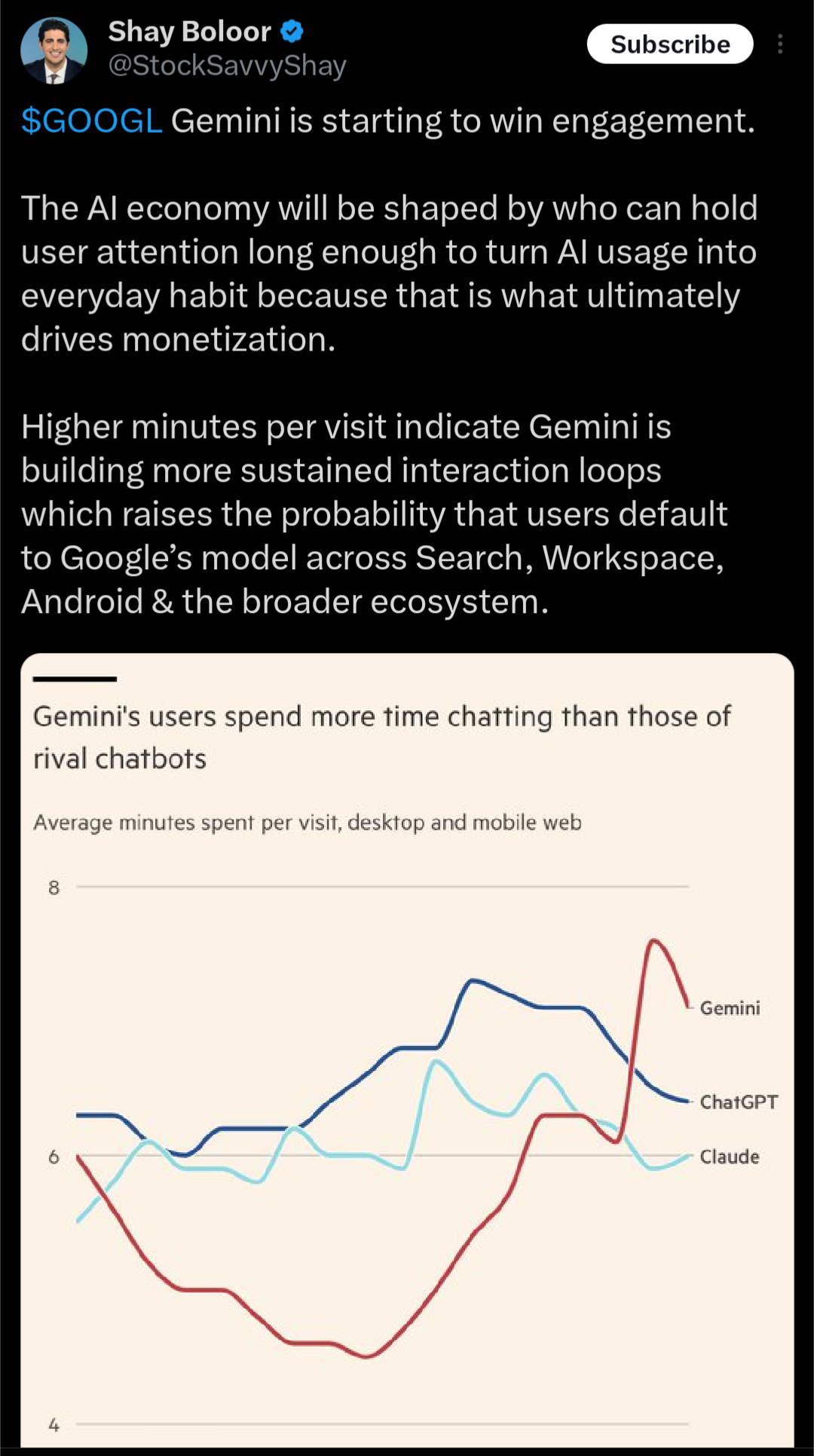
Gemini начинает завоевывать вовлечённость пользователей.
Экономика ИИ будет формироваться теми, кто сможет удерживать внимание пользователей достаточно долго, чтобы превратить использование ИИ в повседневную привычку, поскольку именно это в конечном счете стимулирует монетизацию.
Более высокое количество минут использования указывает на то, что Gemini выстраивает более устойчивые циклы взаимодействия, что повышает вероятность того, что пользователи будут по умолчанию использовать модель Google в Поиске, Workspace, Android и во всей более широкой экосистеме.
НА ВИДЕО ВЗРЫВЫ, УБИЙСТВА, НАСИЛИЕ ДЕТЕЙ @ УУУУХ, КАК ХОРОШО, КАК НАТУРАЛЬНО, 10/10!!! @ >ПРИ СЪЁМКАХ СОВСЕМ НИКТО НЕ ПОСТРАДАЛ @ АРРРЯЯЯ ТУПЫЕ НЕЙРОНКИ ЛИШАЮТ РАБОТЫ!!!
>>1449194 >корпоративному «потоку посредственности» >шокирует зрителя быстро сменяющимися >типичной для ИИ тошнотворной манере >напоминает визуальный припадок >отвратительные персонажи >ужасная цветокоррекция >шаблонные попытки ИИ имитировать >оно выглядит не слишком радужно >собрать полноценную съёмочную группу >создать что-то действительно стоящее >защитную, оправдательную по тону заявку >оправдывает ужасающий конечный результат >общественное мнение выглядит однозначно >суждено жить в мире, где нас... рекламой Кринжанул с тупорылого нормиса.
>>1449200 Нормальный видос, даже смешной в целом. Хорошо, что не стали снимать в ИРЛ жизни. ИЛИ ВЫ ХОТЕЛИ, ЧТОБЫ КТО-ТО ПОСТРАДАЛ?
>>1449542 >кринжовые трансформации тел >>1449259 >Разве что сцены падений фигово сделаны >>1449711 >Физика тел и вообще в целом ёбнутая Вы бы даже такое сделать не смогли, клоуны. Свернули бы шеи при первом же падении ИРЛ.
>>1449349 >Все пластиковым выглядит Уж лучше пластик, чем мясная расчленёнка. >голова кружится и укачивает, все плывет Попробуй купить нормальный монитор. >Неприятно смотреть Никто не заставляет.
>>1449379 >Если бы не было непрерывной смены сцен Меньше смотри дегенеративных ситкомов.
>>1449907 >УУУУХ, КАК ХОРОШО, КАК НАТУРАЛЬНО, 10/10!!! >АРРРЯЯЯ ТУПЫЕ НЕЙРОНКИ ЛИШАЮТ РАБОТЫ!!!
Нормисы, а в особенности всякие хуйдожники, считают, что качество напрямую зависит от вложенных усилий и страданий. Отсюда также идут все эти визги про слоп. Никому не хочется признавать, что нейронка может лучше и быстрее, и что их страдания были зря. Или чужие страдания.
Приключения GPU Nvidia все сильнее напоминают фантастические романы, где постоянно фигурируют суперпроцессоры, дающие невиданные возможности и становящиеся объектами различной активности, от контрабанды до уголовного преследования.
Сначала их запрещали поставлять в Китай. Теперь Трамп заявил, что их, а именно современную модель H200, можно поставлять в Китай, но с ограничениями. Китайские власти тем временем, наоборот, рекомендуют местным компаниям не использовать западные чипы, настаивая на использовании аналогов от Huawei и даже включив их в официальный список поставщиков. Проблема, правда, в том, что китайские чипы пока далеко не так хороши в обучении моделей.
Теперь TheInformation пишет, что DeepSeek тренирует следующую модель на чипах Nvidia Blackwell — то есть чипах уже следующего поколения, которые поставлять в Китай даже не планируется.
Схема поставок, описанная источниками, заслуживает отдельной экранизации. Создаются "фантомные дата-центры" в Юго-Восточной Азии, закупается легальное оборудование, проходит официальный аудит от Nvidia или Dell. После чего серверы разбирают до винтика и ввозят в Китай как запчасти. Причем контрабандисты предпочитают системы из 8 чипов, а не передовые стойки NVL72 весом в полторы тонны — логистика диктует архитектуру, в чемодане стойку не увезешь.
DeepSeek делает ставку на метод sparse attention для снижения стоимости инференса. Именно архитектура Blackwell содержит аппаратное ускорение для таких вычислений, дающее двукратный прирост производительности.
>>1449947 >признавать... их страдания были зря. Или чужие страдания. Когда человек реально убил много лет на обучение, например, рисованию, и рассчитывал заработать себе на безбедную старость рисованием картинок под заказ, а тут все покупатели резко перестали оформлять заказы, переключившись на бесплатные альтернативы - это любой поймёт и тут недовольство вполне оправдано. Я думаю, каждый испытывал это, когда ты стараешься ради кого-то, а он говорит "спасибо, уже не надо"...
Но хотеть продолжать свои/чужие страдания? Серьёзно? Вот взять тех же актёров-каскадёров, которые в буквальном смысле рискуют жизнью ради выполнения тупых трюков ради тупого 30-секундного видео рекламы с надписью "выполнено профессионалами, не повторять дома" - сколько из этих актёров прямо мечтают продолжать всю жизнь рисковать жизнью ради денег и тупых видео? А сколько были бы согласны переключиться на что-то другое, если бы им предложили более осмысленную и безопасную альтернативу (или безусловный базовый доход и свободу)?
То есть, нормисы хотят, чтобы корпорации продолжали подвергать людей риску для жизни, создавая совершенно не нужные народу вещи (реклама), лишь бы это были не "нейросети"? Это либо какой-то троллинг, либо желание навредить человечеству в целом и отдельным людям в частности. Можно сколько угодно ругать "нейросети" за "электричество, воду, шум" и т.п., но эти ресурсы обходятся намного дешевле жизней тех же актёров, например, которые вполне могут погибнуть на съёмках очередного тупого ролика. Ситуация с художниками тут просто несравнима.
Разумеется, лучше вообще рекламу не снимать. Нужному народу продукту реклама не нужна.
>>1449969 Я всю жизнь посвятил кодингу, например, и у меня больше 90 iq, чтобы осознать, что если замена моей профессии и произойдет то только для того, чтобы автоматизировать человеческую деятельность: добычу ресурсов, создание контента, оказание услуг и т.д., что буквально освободит нас от работы, создаст безусловный доход и даст нам свободное время для любых занятий. Эти люди буквально не видят дальше своего носа, они думают что их заменят и все, на этом все закончится, они пойдут в пятерочку работать, не понимая, что к тому моменту в пятерочке уже гуманоидные роботы будут на кассе пробивать товары. Буквально луддиты, времена меняются, а люди все так же не учатся на ошибках.
>>1449984 >Я всю жизнь посвятил кодингу, например, и у меня больше 90 iq Не производишь впечатление. >>1449984 >чтобы автоматизировать человеческую деятельность: добычу ресурсов Зачем резать курицу, несущую алмазные яйца?
>>1449994 >Зачем резать курицу, несущую алмазные яйца? Ты ультрадегенерат, если считаешь что современная экономика сохранится при ИИ. Максимальное непонимание вопроса, мышление текущими концепциями.
>>1449997 Очередной дегенерат. Максимальное непонимание вопроса, мышление текущими концепциями.
Дурачки даже вообразить себе не могут что будет в обществе где каждый человек заменяем. Они не знают базы экономики, не понимают что такое деньги.
>>1449981 Именно её и пробую. Но к сожалению не шарю за секвенсеры-хуенсеры и десяток других настроек. А модель сначала выдаёт микро ответ или немного дописывает мой ответ. После этого думает, в основном о том, не нарушает ли разговор какие-то правила. И в конце долгих размышлений выпукивает ответ из пары слов или не даже этого не делает. Хочется иметь на компе какую-то умную локалку на чёрный день. Но особо заморачиваться, если честно, с этим не охота. Особенно пока ко всему есть доступ.
>>1450008 >Дурачки даже вообразить себе не могут что будет в обществе где каждый человек заменяем. Пиздобол двачной, завали ебало. Каждый ребенок в африке вручную копающий кобальт для электромобилей греты тумблер и подыхающий к 20 годам может быть заменен уже 50 лет как автоматами. Только вот с ниггера, в том числе снежного, маржа 500 % с перепродажи его труда, а с робота о котором ты себе нафантазировал хорошо если 10. И прежде чем кукарекать с интеллектальной параши про замену работяг пойми, что первыми заменить надо бы хуевых руководителей во всех областях. И, шепотом, САМОГО,
>>1450018 Долбоебы малолетние, выдадут вам только пизды ради того, чтобы вы еще больше страдали, потому что наверху сидят психопаты, которые туда лезли всю жизнь по головам. И им доставляет удовольствие видеть ваше страдание. Поэтому никогда вас ни на каких роботов не заменят, ведь робот не страдает. И не умоляет о пощаде и не истекает кровью, пока сидящий на троне смеется.
>>1450011 Бля, какой же ты тупой просто. Мышление текущими концепциями буквально маркер дурачка. Сейчас нет инструментов для полноценной замены человека в принципе. Есть инструменты которые ускоряют производство и добычу, но они все еще могут быть дорогими на текущем этапе. Но ты понимаешь что речь идет о БУДУЩЕМ блять! Нахуя ты мне примеры с текущего времени приводишь чтобы пояснить что-то про пост-AGI мир, в котором машины будут бесконечно итерироваться и улучшать и удешевлять инструменты производства?
>>1450020 Я тебе ниверю, вот геминьку еще немного подтянут, машк своего робота запустит в массовое производство, останется еще немного подождать пока выйдет второе-третье поколение роботов и всем будут отдавать старую модель за бесценок. Еще какое-то небольшое время будут перестраиваться цепочки произвоства, будет происходить массове внедрение самоулучшающихся автономных агентных станкок. Персональный ии агент за небольшую подписку или бесплатно будет делать за нас всю остальную работу, рибятам еще какое-то время будут платить зарплату и держать на работе, чтобы они успели перестроится и привыкнуть что работать в принципе не обязательно, почти все уже есть бесплатно в любых количествах.
>>1450022 >Но ты понимаешь что речь идет о БУДУЩЕМ блять! Какой же ты тупой нахуй. В прошлом, например, человечество могло не строить 100 000 ядерных боеголовок, но мы все знаем путь по которому оно пошло. Ментально человечество это та же самая лысая агрессивная обезьяна, получающая максимальное удовольствие от унижения ближнего своего. Никакого аги при твоей жизни не будет, спокуху оформи порридж, ожидается только цифровой гулаг по сравнению с которым его прототип покажется райским местечком.
>>1450025 >и всем будут отдавать старую модель за бесценок На пленете 800 000 000 каждый день не есть до сыта. А в США 30% еды выбрасывается с прилавков. Ничего у тебя в голове не щелкает, адепт выдуманной тобой хуйни, оторванный от реальности?
>>1449907 Ебать тебя разорвало, конечно. А для сцен падений и прочих трюков есть специальные люди. Каскадеры называются. Немалые деньги за это получают.
>>1450129 Этика не более чем инструмент манипуляций.
Самая главная опасность этики - она вне логики, следовательно, вне критики, не имеет механизмов самопроверки, потому может содержать в себе что угодно.
Эти левые просто хотят убить цивилизацию. Это одно из бутылочных горлышек парадокса Ферми.
Тем более, нахуя нужна этика, когда путь рационализма, критичности и научного метода гарантированно приводит к процветанию, и культурному, и социальному, и вообще, а путь этики гарантированно ведёт к пиздецу или в лучшем случае к стагнации.
>>1450199 Этика важна. Но эти бляди, которые тормозят ии, выступают против этики. Только ии может спасти тяжелобольных, только и может спасти людей от рабской работы. Но им плевать на это, они хотят чтобы люди дальше умирали от рака и старости, шли пахать на завод по 15 часов за мрот
>>1450199 >левые просто хотят убить цивилизацию Правые хотят истребить человечество, оставив горстку избранных, генетически чистых "сверхлюдей". Левые хотят сохранить человечество, поддерживая жизнь каждого - даже нежизнеспособных уродцев. Очевидно, что путь к выживанию - левее, но самых нежизнеспособных уродов всё-таки лучше усыплять. Речь о реальных генетических проблемах, которые мы уже можем определять ещё в утробе матери.
>она вне логики >одно из бутылочных горлышек парадокса Ферми Жизнь вообще нелогична и не имеет смысла во вселенной, это лишь случайное стечение обстоятельств.
Но стоит ли оптимизироваться до "сверхлюдей" через истребление "недолюдей", или через сострадание?
>>1450240 >Только ИИ может спасти тяжелобольных, только ИИ может спасти людей от рабской работы. Ты прав, но основной конфликт на западе из-за совсем другого ИИ, который тут не поможет.
Я согласен с теми, кто не верит, что из LLM можно вырастить "AGI". Нужно что-то другое.
>>1450199 Обьясни логически почему убивать других людей плохо. Вперёд, ебанат, очень интересно будет послушать аргументацию. Общество в котором ты живёшь было сформировано в том числе на принципах этики и религиозности, в то время как отсталые денегеративные общества и культуры, наоборот, таким не занимались.
>>1450029 Надо наверно подольше повозиться, потому что я ни разу не получил эту специальную фразу в конце [финальный ответ]. Но у меня q4.0m может слишком тупит от этого.
>>1450252 Ллм создают конкуренцию и спрос на разработку новых арзитектур. Лично мне нынешние ллм уже очень помогли в плане здоровья. Левые просто хотят остановить все. Они не помогают, они мешают
>>1450252 >Правые хотят истребить человечество А что предлагают левые? Остановить развитие ии, завозить в страну мигрантов и ходить на митинги за палестину? Уж лучше умереть.
>>1450309 В конце систем промпта добавь \nProvide the final response after the marker [BEGIN FINAL RESPONSE]. А так модель довольно резво работает и даже часто удачные ответы дает, получше той же джеммы. Но полная цензура с этой полиси все убивает, никакого нсфв спросить. Ждем джайлбрейка какого нибудь или аблитерейед.
Ахахахаах затряслась заднеприводая сучка! Ой, давайте снизим темпы развития!!! А то я не успеваю!! Ой ой ой! Что же это делается! Тольк сейчас пидору пришла в голову такая мысль когда он проспал все полимеры. Ну какая же мразь.
«Мы можем ошибиться»: Сэм Альтман признал, что ИИ развивается слишком быстро
Глава OpenAI Сэм Альтман (Sam Altman) недавно выразил обеспокоенность темпами, с которыми ИИ меняет мир, подчеркнув важность и необходимость адаптации общества. По его словам, ни одна другая технология никогда не внедрялась в мире так быстро. Он признал, что ChatGPT обладает огромным потенциалом для исследователей, но в то же время может быть использован злоумышленниками для причинения глобального вреда человечеству.
>>1450377 Тоже взбугуртнул, обычно я весь день в этой аи студио торчу и ебу ему мозги по разным вопросам с линухой, а сегодня пишет что API кончилось, неприятно конечно, на самом важном месте как раз, минус к репутации к ним теперь.
Мы только что обучили первую LLM в космосе с помощью @Nvidia H100 на Старклауд-1! 🚀 Мы также первые, кто запускает версию @Google Близнецы в космосе!
Это важный шаг на пути к переносу почти всей вычислительной системы в космос, к прекращению истощения энергетических ресурсов Земли и к началу использования почти безграничной энергии нашего Солнца!
>>1450010 Локалки это в основном небольшие модели (большую хер запустишь на простом пк), так что галюнят + несут хуйню будь здоров и в качестве справочника на чёрный день, это будет та ещё хуйня из под коня. Хотя есть идея как выкрутиться, можно качнуть и векторизировать дамп Википедии, а нейронку испльзовать в качестве поисковика по этому дампу (ну то-есть она при твоих вопросах будет не шизу из своих нищих лоу параметров нести, а использовать релевантную твоему вопросу инфу из википедии) и тогда уже получится нормальная такая темка на чёрный день.
>>1450450 >>1450466 Если вы просто в чатик ai studio пишете, то конечно вряд ли этот лимит увидите, но если вы там создавали API ключ для каких нибудь проектов вне ai studio, то будете теперь долбиться в ограничение по количеству запросов в минуту.
Я переводил субтитры для аниме через прогу, но теперь этот варик полностью не рабочий. Так же пробовал создать ai бота в игре, но теперь сразу получаю 429 ошибку, хотя пару дней назад всё было нормально.
Это пиздос... остаётся надеяться на будущий гемини флеш 3 и закрытие старых моделек, мб тогда они с освободившихся мощностей скинут крошки бедолагам, иначе придется донатить 10$ на опенроутер для доступа к апишкам, вроде там тоже бесплатные есть
>>1450011 >Только вот с ниггера, в том числе снежного, маржа 500 % с перепродажи его труда, а с робота о котором ты себе нафантазировал хорошо если 10. Робот же производительнее - сможет непрерывно в три смены работать, почему в три, а не в четыре - ну чтобы не было перепроизводства товара, и цену не обвалить. Роботу не надо социалку, пенсию, жилье.
>>1449792 >Мы ставим все наши фишки на искусственный интеллект как боевую силу Неужели обновят игру - Command & Conquer Generals Zero Hour - и сделают там встроенный ИИ в качестве соперника при игре без онлайна?
>>1449687 >Обосрался А что не так? Там же на одной стороне около +80 будет, а на другой допустим минус 30. На Земле такой перепад наверное на Северном полюсе может быть, но там если настроить этих дата-центров тогда вообще весь лёд растает.
>>1449647 >Правда эта сука не уточнила, что их отключат одной кнопкой по спутнику. Так это же для твоей же безопасности делается, ведь РФ тоже союзник США, подписавшая в 1990-х с США и НАТО договора о дружбе и военном сотрудничестве и партнёрстве с НАТО вне альянса и о проведении совместных военных с НАТО учениях и операциях (см. в Сирии в 2015 например).
>>1450724 Популярность растёт, запросов много + учебный год у школьников и студентов, а это наверное миллиард чел если считать весь мир.
Вот ИИ подсказывает что в мире 1,5 млрд. школьников и студентов. А они же сейчас все в ИИ-шках делают домашку и готовятся к контрольным, делают опросы, тесты знаний, и т.д.
>>1450451 >Старклауд Ну это микроспутник для тестов, пока что тестируют. Там походу уязвимое место это жидкостная система охлаждения на трубках охлаждения внутри которых там что-то испаряется (в районе микросхемы), а потом снова конденсируется (на теневой стороне спутника), на сколько циклов хватит такой системы. Если бы просто сделали что вся часть спутника в тени это радиатор видеокарты.
>>1449646 Самое сложное в космосе не получить энергию а грамотно охладить трахание, потому что теплоотвод в вакууме только исходящим излучением. У висящих в космосе установок огромные фермы по отдаче тепла. На сколько система охлаждения актуальна на спутнике вопрос открытый - нет ни одного изделия, которое бы работало достаточно долго, чтобы прикинуть эффективность хотя бы за пять лет. Но спутник это не вакуум. Теплоемкость и теплопроводность меняются в том числе с глубиной. Наверняка можно придумать схему холодильника с замкнутым контуром, который будет эффективно работать используя градиент температуры, но, опять же, это все умозрительно и в железе никогда не было воплощено и оттестировано в реальных условиях.
>>1450834 >На сколько система охлаждения актуальна на спутнике вопрос открытый - нет ни одного изделия, которое бы работало достаточно долго, чтобы прикинуть эффективность хотя бы за пять лет. Я имел в виду для заявленных мощностей. Так то есть МКС, конечно.
>>1450754 >Ну это будет их стимулировать двигать науку и прогресс вперёд чтобы быть всегда на шаг впереди и успеть затариться деньгами. Нет не будет. Вот например, с началом СВО одна татарская старушка широко известная в узких кругах, выступала на экономическом форуме, где спросила у банкиров - если ставку снизить, вы будете давать низкие кредиты населению, они сказали ей - иди отсюда старая, мы на мешках с деньгами посидим, пока пролы друг друга едят за пятиметровыми заборами. А с деньгами у них нет никаких проблем. Просто обращаешься в конгресс и он печатает тебе триллион.
>>1450729 >Робот же производительнее - сможет непрерывно в три смены работать, почему в три, а не в четыре - ну чтобы не было перепроизводства товара, и цену не обвалить. Роботу не надо социалку, пенсию, жилье. Робота нельзя наебать не заплатив. Выкинуть, когда он заболел, потому что за забором стоят миллионы готовых работать за еду. Ему нужно обслуживание на порядки дороже современной медицины для мясных мешков в странах третьего мира. Извини, ты не понимаешь о чем говоришь. Единственная причина по которой в германии в 2012 году не построили роботизированный завод на котором 40 человек могло производить миллион пар кроссовок в год это возможность перенести такой завод в южноазиатскую помойку, где люди работают месяц за 30 долларов на конвейере делая те же изделия, но процент накрутки там не сопоставим и отличается на порядок.
Google запускает управляемые серверы MCP, позволяющие ИИ-агентам легко подключаться к своим инструментам.
ИИ-агенты позиционируются как решение для планирования поездок, ответов на бизнес-вопросы и решения самых разных задач, однако обеспечить их взаимодействие с инструментами и данными за пределами интерфейсов чата оказалось непросто. Разработчикам приходится собирать различные коннекторы и поддерживать их в рабочем состоянии, но такой подход хрупок, его трудно масштабировать, а также он вызывает сложности с управлением и контролем.
Google утверждает, что стремится решить эту проблему, запустив собственные полностью управляемые удалённые серверы MCP, которые облегчат подключение агентов к сервисам Google и Google Cloud — таким как Maps и BigQuery.
Этот шаг следует сразу за запуском новейшей модели Google Gemini 3, и компания стремится объединить более мощные рассуждающие способности с надёжным подключением к реальным инструментам и данным.
«Мы делаем Google изначально готовым к работе с агентами», — сообщил TechCrunch Стерен Джаннини (Steren Giannini), директор по управлению продуктами в Google Cloud.
По словам Джаннини, вместо того чтобы тратить неделю или две на настройку коннекторов, разработчики теперь могут просто вставить URL управляемой конечной точки.
На момент запуска Google начинает со следующих серверов MCP: для Maps, BigQuery, Compute Engine и Kubernetes Engine. На практике это может выглядеть, например, как ассистент для аналитики, напрямую обращающийся к BigQuery, или операционный агент, взаимодействующий со службами инфраструктуры.
В случае с Maps, пояснил Джаннини, в отсутствие MCP разработчики полагались бы лишь на встроенные знания модели. «Но если вы дадите вашему агенту […] такой инструмент, как сервер Google Maps MCP, он будет опираться на актуальные, проверенные сведения о местоположениях, объектах или планировании поездок», — добавил он.
Хотя серверы MCP в конечном итоге будут предложены для всех сервисов Google, на первом этапе они запускаются в режиме публичной предварительной версии, то есть пока не охвачены полными условиями обслуживания Google Cloud. Тем не менее, они предоставляются без дополнительной платы для корпоративных клиентов, уже оплачивающих сервисы Google.
«Мы ожидаем, что уже в начале нового года сделаем их общедоступными», — сказал Джаннини, добавив, что ожидает постепенного подключения новых серверов MCP каждую неделю.
MCP (Model Context Protocol — Протокол контекста модели) был разработан компанией Anthropic около года назад как открытый стандарт для подключения ИИ-систем к данным и инструментам. Протокол получил широкое распространение в сфере инструментария для агентов, а на прошлой неделе Anthropic передал MCP в новый фонд Linux Foundation, посвящённый открытому исходному коду и стандартизации инфраструктуры ИИ-агентов.
«Преимущество MCP заключается в том, что, поскольку это стандарт, сервер от Google может подключаться к любому клиенту», — отметил Джаннини. — «Мне интересно, сколько ещё клиентов появится в ближайшее время».
Клиенты MCP можно рассматривать как ИИ-приложения на другом конце соединения, общающиеся с серверами MCP и вызывающие предлагаемые ими инструменты. Для Google такими клиентами являются, в частности, Gemini CLI и AI Studio. Джаннини также сообщил, что сам опробовал работу с MCP через клиенты Anthropic’s Claude и OpenAI’s ChatGPT — «и они просто работают».
Google подчёркивает, что речь идёт не только о подключении агентов к собственным сервисам компании. Для корпоративного сегмента более масштабная цель — Apigee, продукт Google для управления API, который многие компании уже используют для выдачи API-ключей, установки лимитов и мониторинга трафика.
По словам Джаннини, Apigee способна, по сути, «переводить» стандартный API в сервер MCP, преобразуя такие конечные точки, как API каталога товаров, в инструменты, которые агент может обнаружить и использовать, сохраняя при этом уже существующие механизмы безопасности и управления.
Другими словами, те же самые ограничения и правила для API, которые компании применяют к приложениям, созданным людьми, теперь могут применяться и к ИИ-агентам.
Новые серверы MCP от Google защищены механизмом разрешений под названием Google Cloud IAM, который чётко регулирует, что именно агент может делать с тем или иным сервером. Кроме того, они защищены Google Cloud Model Armor, который, по описанию Джаннини, представляет собой брандмауэр, специально предназначенный для агентных рабочих нагрузок и предназначенный для защиты от сложных агентных угроз, таких как внедрение вредоносных инструкций (prompt injection) и утечка данных. Администраторы также могут полагаться на ведение журналов аудита для дополнительной прозрачности и наблюдаемости.
Google планирует расширить поддержку MCP за пределы изначального набора серверов. В ближайшие несколько месяцев компания постепенно добавит поддержку сервисов в таких областях, как хранилища, базы данных, журналирование и мониторинг, а также безопасность.
«Мы создали всю «инфраструктуру подключения», чтобы разработчикам не пришлось делать это самостоятельно», — заключил Джаннини.
Логан Килпатрик (Google AI Studio) подтверждает урезание API для бесплатников
LoganKilpatrick1 • 9 ч. назад Lead Product (Google AI Studio)
Привет! Да, мы снизили или убрали бесплатный уровень API для целого ряда моделей. У нас огромный спрос на Gemini 3 Pro и Nano Banana Pro, поэтому нам пришлось перераспределить вычислительные ресурсы. Как правило, наш бесплатный уровень предоставляется по принципу "наилучших усилий" и, вероятно, будет изменяться в зависимости от доступного пула вычислительных ресурсов.
>>1450848 Типа пока есть мощности дают бесплатникам, когда нет мощностей не дают. В общем растущая популярность Gemini виновата, что бесплатные API урезали. Ждем пока подкорректируют и железа завезут, или спрос понизится.
На крупнейшем собрании специалистов по ИИ его внутреннее устройство остаётся загадкой
Несмотря на стремительный прогресс, учёные на самом масштабном собрании специалистов по искусственному интеллекту заявляют, что ключевые вопросы о том, как модели работают и как их измерять, по-прежнему остаются нерешёнными.
САН-ДИЕГО — На протяжении прошедшей недели учёные, основатели стартапов и исследователи, представляющие промышленных гигантов со всего мира, собрались в солнечном Сан-Диего на главное мероприятие в области искусственного интеллекта.
Конференция Neural Information Processing Systems (NeurIPS) проводится уже 39 лет, однако в этом году она собрала рекордные 26 000 участников — вдвое больше, чем всего шесть лет назад.
С момента своего основания в 1987 году NeurIPS была посвящена исследованиям нейронных сетей и взаимодействию между вычислениями, нейробиологией и физикой. Хотя нейронные сети — вычислительные структуры, вдохновлённые когнитивными системами человека и животных — когда-то были эзотерической академической темой, их роль в качестве основы современных ИИ-систем превратила NeurIPS из узкоспециализированной встречи в отеле штата Колорадо в мероприятие, заполняющее весь Конгресс-центр Сан-Диего, в стенах которого также проходит всемирно известная выставка Comic-Con.
Однако даже несмотря на стремительный рост масштабов конференции, происходящий параллельно развитию индустрии ИИ, и многочисленные сессии по сверхспецифическим темам, таким как музыка, созданная с помощью ИИ, одной из самых обсуждаемых тем оставался базовый и фундаментальный для всей области ИИ вопрос: тайна того, как на самом деле работают передовые системы.
Большинство — если не все — ведущих исследователей и генеральных директоров компаний, занимающихся ИИ, открыто признают, что не понимают, как функционируют сегодняшние передовые ИИ-системы. Исследования внутренней структуры моделей с целью её понимания называются интерпретируемостью (interpretability), поскольку речь идёт о стремлении «интерпретировать», то есть расшифровать, как модели работают.
Шрияш Упадхьяй (Shriyash Upadhyay), исследователь ИИ и соучредитель компании Martian, специализирующейся на интерпретируемости, сказал, что эта область всё ещё находится в зачаточном состоянии: «Люди на самом деле не до конца понимают, чем именно занимается эта область. Здесь много идей в состоянии брожения, и у людей разные цели».
«В традиционной науке, развивающейся поступательно, где основные идеи в целом устоялись, учёные могут, например, пытаться уточнить значение измерений определённых свойств электрона до следующего знака после запятой», — отметил Упадхьяй.
«Что же касается интерпретируемости, мы сейчас находимся на этапе вопросов: „Что такое электрон? Существует ли электрон? Можно ли его измерить?“ С интерпретируемостью ровно та же ситуация: мы спрашиваем: „Что вообще означает иметь интерпретируемую ИИ-систему?“» Упадхьяй и компания Martian воспользовались NeurIPS для объявления премии в размере 1 миллиона долларов США, призванной стимулировать усилия в области интерпретируемости.
По мере развития конференции команды по интерпретируемости ведущих компаний по ИИ обозначили новые и расходящиеся подходы к пониманию того, как работают их всё более продвинутые системы.
В начале прошлой недели команда Google анонсировала значительный поворот: вместо попыток понять каждый компонент модели они намерены сосредоточиться на более практических методах, ориентированных на реальное воздействие.
Нил Нанда (Neel Nanda), один из руководителей направления интерпретируемости в Google, в своём заявлении написал, что «глобальные цели вроде почти полной обратной разработки по-прежнему кажутся нам недостижимыми» ввиду того, что «мы хотим, чтобы наша работа принесла плоды примерно в течение 10 лет». Нанда указал на стремительный прогресс в ИИ и слабые результаты предыдущих, более «амбициозных попыток обратной разработки» как причины смены подхода.
Напротив, глава отдела интерпретируемости в OpenAI Лео Гао (Leo Gao) в пятницу объявил и в ходе NeurIPS обсудил, что удваивает ставку на более глубокий и амбициозный подход к интерпретируемости, направленный на «полное понимание того, как работают нейронные сети».
Адам Глив (Adam Gleave), исследователь ИИ и соучредитель некоммерческой исследовательской и образовательной организации FAR.AI, выразил скептицизм по поводу возможности полностью понять поведение моделей: «Я подозреваю, что модели глубокого обучения не допускают простого объяснения — таким образом, полностью выполнить обратную разработку масштабной нейронной сети таким образом, чтобы человек смог это понять, попросту невозможно».
Несмотря на трудности полного понимания сложных систем, Глив выразил надежду на то, что исследователи всё же добьются значимого прогресса в понимании поведения моделей на многих уровнях, что поможет учёным и компаниям создавать более надёжные и заслуживающие доверия системы.
«Меня воодушевляет растущий интерес к вопросам безопасности и согласованности (alignment) в научном сообществе, занимающемся машинным обучением», — сказал Глив телеканалу NBC News, хотя и отметил, что сессии NeurIPS, посвящённые расширению возможностей ИИ, настолько масштабны, что «проводятся в залах, способных служить ангаром для самолётов».
Помимо неопределённости в том, как ведут себя модели, большинство исследователей не в восторге от существующих методов оценки и измерения текущих возможностей ИИ-систем.
«У нас нет инструментов измерения, позволяющих оценивать более сложные концепции и более масштабные вопросы относительно общего поведения моделей, такие как интеллект и рассуждение», — сказал Санми Койеджо (Sanmi Koyejo), профессор компьютерных наук и руководитель лаборатории Trustworthy AI Research в Стэнфордском университете.
«Большинство существующих оценок и эталонных тестов были созданы в другую эпоху, когда исследователи измеряли конкретные прикладные задачи», — отметил Койеджо, подчеркнув необходимость выделения дополнительных ресурсов и внимания для создания новых надёжных и содержательных тестов для ИИ-систем.
Те же вопросы, какие аспекты ИИ-систем следует измерять и как именно это делать, относятся и к моделям ИИ, применяемым в конкретных научных областях.
Зив Бар-Йосеф (Ziv Bar-Joseph), профессор Университета Карнеги — Меллон, основатель компании GenBio AI и эксперт в области продвинутых ИИ-моделей для биологии, сказал, что оценка ИИ-систем, специализирующихся на биологии, тоже находится в зачаточном состоянии.
«Оценка в биологии — на крайне-крайне ранней стадии. Крайне ранней», — заявил Бар-Йосеф в интервью NBC News. «Я думаю, мы всё ещё пытаемся понять, как нужно проводить оценку, и уж тем более — что именно вообще стоит оценивать».
Несмотря на постепенный и прерывистый прогресс в понимании того, как работают передовые ИИ-системы, и в методах объективной оценки их продвижения, исследователи всё же отмечают стремительный прогресс в способности самих ИИ-систем усиливать научные исследования.
«Люди строили мосты задолго до того, как Исаак Ньютон открыл законы физики», — отметил Упадхьяй из Martian, подчёркивая, что полное понимание ИИ-систем вовсе не требуется для достижения значительных реальных изменений.
Четвёртый год подряд исследователи организуют параллельное мероприятие в рамках основной конференции NeurIPS, посвящённое новейшим ИИ-методам для ускорения научных открытий. Один из организаторов события Ада Фанг (Ada Fang), аспирантка Гарвардского университета, изучающая пересечение ИИ и химии, сообщила, что нынешнее издание NeurIPS стало «большим успехом».
«Передовые исследования в области ИИ для науки развиваются параллельно в биологии, материаловедении, химии и физике, однако лежащие в их основе проблемы и идеи глубоко взаимосвязаны», — сказала Фанг корреспонденту NBC News. «Наша цель состояла в создании пространства, где исследователи могли бы обсуждать не только прорывы, но и потенциал, а также ограничения ИИ в научных задачах».
Джефф Клайн (Jeff Clune), пионер в применении ИИ для науки и профессор компьютерных наук в Университете Британской Колумбии (Ванкувер), заявил во время панельной дискуссии, что эта область стремительно ускоряется.
Интересная инфографика от Epoch.AI —они оценили стоимость компонентов в новых GPU Blackwell, и оказалось, что непосредственно сам чип даже не самое дорогое, что там есть.
На первом месте —супербыстрая память, которой нужно аж 192 гигабайта (на 2 чипа). Стоимость примерно $2900.
На втором... снова не чип, а оплата услуг сборки и высокотехнолоичной упаковки (CoWoS-L), осуществляемой TSMC.
На третьем... потери от упаковки —она не всегда удаётся, и тогда чип и память становятся непригодными.
Сами же два чипа стоят в сумме $900 —от общей цены компонентов в $6400. И поверх этого идёт наценка примерно в 400% от самой Nvidia... (расчёт выше не включает маркетинг, затраты на исследования, ничего, кроме самих компонентов)
Цены и спрос на память объясняют, почему совсем недавно компании начали уходить из консьюмерского сегмента и полностью переориентироваться на ИИ-оборудование.
>>1450869 6400 баксов стоимость выпуска, 35-40к финальная цена от нвидии. Нехило куртка наваривается, делая бабки из воздуха, учитывая что закупают их тысячами. Поэтому задавлены все консумерские направления с видеокартами для геймеров, только бы не повредить этой денежнопечатной машинке.
>>1450893 Недолго, по всем прогнозам эту монополию развалят за 3-4 года. Сдизайнить чип не такая неподъемная задача, в отличии от процессов какой-нибудь TSMC, где конкурировать крайне сложно.
>>1449556 Очень надеюсь на эру оптимизации. Может ща с дорогой оперативой тоже немного подтолкнёт писать код получше.
Ну объективно, у нас теперь в телефонах процессоры, которые умеют вычислять десятки миллиардов операций в секунду. А программы пук-среньк му-хрю. Вспомним классику. Дум. Который на пентиум 200 шёл. Да и сейчас некоторые симуляционные (sic!) нейронки идут в реалтайме на единичной видяхе.
Ащемта я регулярно говорю, что сейчас нейронки — это всё ещё жирная тупая гусеница, которая жрёт в основном.
>>1449559 Да нет, наоборот. Ну будет у тебя в смартфоне неронка на уровне свежего гемини и чо? Она ж тупая шопиздец. А корпорации за подписочку будут давать умную.
>>1449578 >Мусор может быть важен для формирования реального интеллекта и аги. Он важен, когда УЖЕ есть интеллект и интеллект тренируется на понимание и отсев мусора. А нейронки — это попугай, которого кормят мусором. Нездоровый попугай, как следствие.
>>1449598 >это может привести к тотальному недоверию ко всей информации с экрана.
Ничего не поменяется особо. 1. фэйки и так сочиняют в промышленных масштабах. Просто на видосике не показывают, а рассказывают. Вся информация с экрана выглядит как настоящая но то что подают — действительности соответствует слабо обычно.
2. Есть критичные люди, а есть легковерные долбоёбы. Последним вон уже тысячи лет затирают про боженьку. А они верят и им норм, потому что так проще.
>У человека многие механизмы по восприятию информации заложены древнейшими прошивками (что современная медийка активно и использует Именно. Но да, нейросети просто облегчат работу оболванивателей. Вполне вероятно, что дебилизация усилится. А как ты хотел? Чтоб крутить экономику потребляди нужны и юниты рабочие.
>>1449646 > это дата-центры в космосе. это чистейший попил бабла. 1е. Они хотят мегасолнечные панели. Шанс въёбывания мелкого мусора в них близится к 100% в первые же месяцы. 2е. они свои 3нм-чипы в свинцовых толстостенных гробах хранить будут? В космосе потому и используют всякие 90/60/23 нм чтобы заряженная радиоактивная частица не имела существенного влияния на вычислительную ячейку.
3. Охлаждение в этих дата-центрах невероятно сложно. Охлаждение пространства бесплатное.
да-да. Ведь отвести гигават тепла ИЗЛУЧЕНИЕМ в вакуум это ж так просто!
Это поебень для тех, кто не понимает, как устроен космос слой рядом с атмосферой Земли.
>>1450377 гугл давал бесплатно порезвиться когда были свободные TPU мощности, сейчас популярность гемини растет быстрее вывода новых мощностей. Поэтому ожидайте дальнейшего закручивания
Подразделение Google по искусственному интеллекту — DeepMind — анонсировало создание своей первой «автоматизированной исследовательской лаборатории» в Великобритании.
Google DeepMind, подразделение технологического гиганта, занимающееся искусственным интеллектом, представило планы по созданию своей первой «автоматизированной исследовательской лаборатории» в Великобритании в рамках заключённого партнёрства, которое может привести к размещению в стране новейших моделей компании.
Лаборатория, в которой для проведения экспериментов будут использоваться ИИ и робототехника, будет открыта в Великобритании в следующем году. Её основное внимание будет сосредоточено на разработке новых сверхпроводниковых материалов, которые могут применяться при создании технологий медицинской визуализации, а также новых материалов для полупроводников.
Британские учёные получат «приоритетный доступ» к некоторым из самых передовых в мире инструментам искусственного интеллекта в рамках данного партнёрства, как заявило правительство Великобритании в своём объявлении.
DeepMind, основанное в Лондоне в 2010 году лауреатом Нобелевской премии Демисом Хассабисом, было приобретено Google в 2014 году, но сохранило крупную операционную базу в Великобритании. Компания добилась ряда прорывов, считающихся решающими для продвижения технологий искусственного интеллекта.
Согласно заявлению правительства, это партнёрство также может привести к совместной работе DeepMind с правительством в области исследований ИИ, в частности по таким направлениям, как ядерный синтез, а также к внедрению моделей Gemini в государственных учреждениях и системе образования Великобритании.
«DeepMind служит прекрасным примером того, чего может достичь британско-американское технологическое сотрудничество — это компания с корнями по обе стороны Атлантики, поддерживающая британских инноваторов в формировании траектории технологического прогресса», — заявила в своём выступлении министр цифровых технологий и науки Великобритании Лиз Кендалл.
«Это соглашение может способствовать освоению более чистых источников энергии, созданию более разумных государственных услуг и появлению новых возможностей, выгодных для сообществ по всей стране», — добавила она.
«Искусственный интеллект обладает невероятным потенциалом для обеспечения новой эры научных открытий и улучшения повседневной жизни», — сказал Хассабис.
«Мы с энтузиазмом относимся к укреплению нашего сотрудничества с правительством Великобритании и строим на богатом наследии инноваций страны, чтобы продвигать науку, укреплять безопасность и обеспечивать ощутимые улучшения для граждан».
Великобритания активно заключает соглашения с крупными технологическими компаниями в попытке нарастить собственную ИИ-инфраструктуру и обеспечить государственное внедрение этой технологии, начиная с публикации национальной стратегии в области ИИ в январе.
Microsoft, Nvidia, Google и OpenAI объявили о планах направить более 40 миллиардов долларов инвестиций в новую ИИ-инфраструктуру в стране в сентябре, в ходе государственного визита президента США Дональда Трампа.
>>1451093 Я хз точно, но вряд ли т.к. переводила достаточно быстро и в лимиты не упиралась, прога называется subtitleedit. До неё делал для себя в ai studio приложение для перевода сабов, но там одного запроса мало было т.к. из за галюнов гемини 2.5 флеш генерила не подходящий для формата субтитров текст и мне приходилось прикрутить второй запрос на перепроверку, так стало в 80+% переводиться как надо. Через subtitleedit переводилось всё как надо и проблем не возникало. Сейчас видимо придется возвращаться к этому приложению, но теперь буду пробовать с гемини 3 про, может теперь и одного запроса хватит >>1450840 Это пиздец как мало, придется походу костылями чередовать ключи чтобы в лимит не упираться >>1450761 Остаётся надеяться на увеличение мощностей
Протокол для данных ИИ-агентов: как ученые объединили разрозненные наборы для эффективного обучения
Кратко: Новый протокол ADP унифицирует разрозненные данные для обучения агентов в один чистый формат, обеспечивая прирост производительности на 20 % и выпуская более 1,3 млн траекторий. Возможно, момент ImageNet для обучения агентов наступил.
Похоже, они разработали ADP как «промежуточный язык» для данных обучения агентов, преобразовав 13 различных наборов данных (программирование, веб-навигация, инженерия программного обеспечения, использование инструментов) в ЕДИНЫЙ унифицированный формат.
Раньше, если вы хотели использовать вместе несколько наборов данных для агентов, вам приходилось писать собственный код преобразования для каждой конкретной комбинации наборов данных. Благодаря своей конструкции в виде последовательностей «действие–наблюдение» для взаимодействия агентов, ADP сводит эту кошмарную задачу к линейной сложности.
Похоже, нам действительно не хватало лишь более удачного представления данных. И теперь мы, возможно, действительно получили возможность систематически масштабировать обучение агентов в различных предметных областях.
Подробно: Исследователи из Карнеги-Меллонского университета, Университета Гонконга, Университета штата Огайо и других ведущих научных центров представили революционное решение для обучения ИИ-агентов. Их работа, названная "Agent Data Protocol" (ADP), решает одну из самых сложных проблем современного искусственного интеллекта – фрагментацию данных, необходимых для создания продвинутых агентов.
Сегодня на рынке ИИ преобладают языковые модели, способные отвечать на вопросы и генерировать текст, но настоящие агенты должны уметь взаимодействовать со средой, выполнять последовательные действия и решать комплексные задачи. Однако обучение таких систем сталкивается с серьезной преградой: имеющиеся данные для обучения разрознены и представлены в несовместимых форматах.
Как объясняют авторы исследования, проблема не в отсутствии данных, а в их стандартизации. Существующие наборы для обучения агентов – от веб-навигации до программирования и использования инструментов – хранятся в совершенно разных структурах, что делает их совместное использование практически невозможным без значительных инженерных усилий.
Agent Data Protocol предлагает элегантное решение: специальный язык представления данных, который служит "промежуточным языком" между разными форматами и конвейерами обучения. ADP структурирует данные об обучении агентов в виде траекторий, состоящих из последовательности действий и наблюдений. Действия классифицируются на три типа: вызовы API-функций, выполнение кода и текстовые сообщения. Наблюдения делятся на текстовые и веб-данные, включая HTML, деревья доступности и другую релевантную информацию.
В практической части работы ученые продемонстрировали мощь своего подхода, преобразовав 13 существующих наборов данных в единый формат ADP. Это позволило создать самый масштабный общедоступный набор для обучения агентов, включающий 1.3 миллиона обучающих траекторий. Затем эти стандартизированные данные были использованы для тонкой настройки моделей разных размеров и архитектур.
Результаты впечатляют: обучение на данных ADP обеспечило улучшение производительности примерно на 20% по сравнению с базовыми моделями. Полученные агенты демонстрируют результаты на уровне или близкие к передовым решениям на стандартных бенчмарках, включая программирование (SWE-Bench), веб-навигацию (WebArena), использование инструментов (AgentBench) и исследовательские задачи (GAIA).
Особенно примечателен эффект переноса знаний между разными типами задач. Модели, обученные на смешанных данных ADP, показывают лучшие результаты, чем те, что обучались только на узкоспециализированных наборах. Это указывает на то, что разнообразие данных критически важно для создания универсальных агентов.
С практической точки зрения, ADP радикально упрощает интеграцию новых наборов данных и агентов. Без стандартизации исследователю пришлось бы создавать отдельные конвертеры для каждой пары "набор данных – агент", что требует квадратичных усилий. С ADP каждому набору данных нужен только один конвертер в стандартный формат, а каждому агенту – один конвертер из стандарта в его внутренний формат. Это снижает общие инженерные затраты с квадратичной до линейной сложности.
Значение этой работы для будущего ИИ сложно переоценить. Стандартизация данных, как показала история с компьютерным зрением (ImageNet) и языковыми моделями (Common Crawl), часто становится катализатором технологических прорывов. ADP создает основу для коллективного прогресса в области ИИ-агентов, делая процесс обучения более воспроизводимым, масштабируемым и доступным для более широкого круга исследователей.
Авторы уже опубликовали весь код и наборы данных в открытом доступе и намерены продолжать развитие протокола в трех основных направлениях: расширение мультимодальных возможностей для работы с изображениями и видео, стандартизация процедур оценки агентов и развитие сообщества для поддержания высокого качества данных.
Agent Data Protocol может стать тем недостающим элементом, который позволит перейти от изолированных демонстраций ИИ-агентов к надежным, предсказуемым системам, способным выполнять реальные рабочие задачи. В мире, где искусственный интеллект все чаще становится нашим соавтором и помощником, такие стандартизированные подходы к обучению особенно важны для создания безопасных и эффективных агентов будущего.
>>1451237 >Это пиздец как мало, Там похоже все еще хуже, у меня на их биллинге показывает 14/20 дневных реквестов только израсходовано, но при запросе по API постоянно выдает все израсходованы, хоть через час, хоть через 2. Так что режут еще больше чем заявлено.
>>1451273 У меня так же вчера было когда хотел TTS прикрутить боту, но при первом же запросе получил "иди нахуй бомж бесплатный". Хотя замечу что сегодня они в changelog выкатили инфу об улучшении tts модели и мб с этим было связано, но сомневаюсь и больше склоняюсь к анальным лимитным ограничениям
В рамках этого трехлетнего лицензионного соглашения Sora сможет создавать короткие видеоролики для социальных сетей по запросу пользователей, которые смогут просматривать и делиться ими фанаты, используя более 200 персонажей Disney, Marvel, Pixar и Star Wars.
Disney — это мировой эталон в области создания историй, и мы рады сотрудничеству, которое позволит Sora и ChatGPT Images расширить возможности создания и просмотра высококачественного контента», —
сказал ,Sama соучредитель и генеральный директор OpenAI.
Это соглашение показывает, как компании, занимающиеся искусственным интеллектом, и лидеры креативной индустрии могут ответственно сотрудничать, продвигая инновации, приносящие пользу обществу, уважая важность творчества и помогая произведениям охватывать широкую новую аудиторию.
Список доступных персонажей: Среди персонажей, которых фанаты смогут использовать в своих творениях, будут Микки Маус, Минни Маус, Лило, Стич, Ариэль, Белль!, Чудовище, Золушка, Бэймакс, Симба, Муфаса, а также персонажи из миров «Энканто», «Холодное сердце», «Головоломка», «Моана», «Корпорация монстров», «История игрушек», «Вверх», «Зверополис» и многих других; плюс культовые анимированные или иллюстрированные версии персонажей Marvel и Lucasfilm, таких как Чёрная Пантера, Капитан Америка, Дэдпул, Грут, Железный человек, Локи, Тор, Танос, Дарт Вейдер, Хан Соло, Люк Скайуокер, Лея, Мандалорец, штурмовики, Йода и другие.
Задаю вопрос по кодингу квену Он пишет используя plain Си api, библиотеки Я делаю замечание чтобы он использовал С++ Он соглашается Я спрашиваю снова Он опять пишет сишный код
Я в чат пишу раздражение "Ну вот опять си"
>Возникла проблема с подключением >Чат возможно содержит неприличный контент
Почему у алибабы нормальный ИИ, но такой тупой анализатор контента для цензуры
Как можно из контекста было вывести что речь идет о главе китая? Или о чем это вообще))
При всём неуважении к соевому клоду, но похоже только он способен написать более-менее длинную рабочую программу, причём такую, какую нужно, с тонким пониманием возможностей языка и платформы. Факапит, но не так жёстко и куда реже.
>>1450836 >А с деньгами у них нет никаких проблем. Просто обращаешься в конгресс и он печатает тебе триллион. Так любая страна может, у которой есть свои деньги и казначейство, даже страны у которых нет своего печатного станка - заказать печать денег у тех, у кого он есть.
Бляяя, я сейчас охуею, бля. Как меня заебала цензура. Цензура со стороны государства. Цензура со стороны моделей. Цензура со стороны агрегатторов нейронок. Сука и через всю эту хуйню нужно пробиваться чтобы сгенерировать тянучку в трусиках. Блядь, когда появится что-то похожее по качеству на нана банана но для хентайной манги? Как же я хочу.
>>1451029 >Последним вон уже тысячи лет затирают про боженьку. А они верят и им норм, потому что так проще. А кто написал код ДНК? Программный код сам собой пишется?
>>1451041 > кто не понимает Они ща всю мощь нейронки напрягут на решение этой конкретной задачи - охлаждение в космосе, и прочие, и нейронка решит это.
>>1449530 Ага, адаптируются, те которые останутся. А вот сколько останется - зависит от людей. Если скажут - да нахуй нам 7 лярдов бездельников, останутся немногие и это печально, а если скажут что мы наконецто можем позволить себе избавиться от рабства в виде капитализма и начать жить в кайф, распределяя ресурсы, тогда будет заебись.
>>1451630 >Сделайте базу на луне. Если с питанием от ядерного реактора то можно было бы сделать, а если от солнечных батарей, то на Луне лунные день и ночь длятся по две недели, две недели темноты будет.
Итак: Альтман в панике от ИИ-гонки выкатил GPT-5.2 — модель превосходит профессионалов 44 отраслей в их рабочих задачах.
Бенчи впечатляют: ARC AGI 2 — 52.9%, SWE-Bench Verified — 80%. Вообще GPT-5.2 лучше пишет код, понимает длинный контекст, точнее работает с таблицами и презентациями, так пользоваться ChatGPT теперь будет приятнее. А Pro версию вообще называют лучшей для программирования и работы ученых.
Главный тезис релиза: модель впервые превзошла экспертов-людей в реальных рабочих задачах. В бенчмарке GDPval (44 профессии, от финансов до медицины) GPT-5.2 Thinking победила или сыграла вничью с профи в 70.9% случаев. При этом она работает в 11 раз быстрее и стоит менее 1% от затрат на специалиста.
Ключевые показатели и возможности:
— Кодинг: 80% на SWE-bench Verified. Модель значительно прокачали во фронтенде, UI и работе с 3D-элементами. Тестеры называют её SOTA-моделью для агентов (например, в Windsurf). — Математика и Наука: 100% на AIME 2025 и 92.4% на GPQA Diamond. В сложнейшем тесте FrontierMath результат вырос до 40.3% (уровень экспертов-математиков). — Абстрактное мышление: Версия GPT-5.2 Pro стала первой моделью, пробившей порог 90% в тесте ARC-AGI-1. — Длинный контекст: Почти 100% точность поиска информации (Needle in a Haystack) на контексте до 256 000 токенов. — Vision: Ошибки при чтении графиков и интерфейсов сократились в 2 раза. — Агенты: Новый уровень использования инструментов (98.7% на Tau2-bench). Тестеры сообщают о создании «мега-агентов», управляющих 20+ инструментами одновременно.
Модель галлюцинирует на 30% реже, чем предшественники, и лучше понимает сложные инструкции.
Линейка моделей и цены:
— GPT-5.2 Instant: Быстрая версия для повседневных задач. — GPT-5.2 Thinking: Основная модель для глубокого анализа и кодинга. — GPT-5.2 Pro: Самая мощная и дорогая версия для задач, где качество критично (доступен уровень рассуждений xhigh). — Цены API: $1.75 за 1М входных токенов и $14 за 1М выходных. Это дороже, чем GPT-5.1, но модель эффективнее, что может снизить итоговую стоимость решения задачи.
Семейство моделей уже раскатывают платным пользователям, а также они уже доступны через API.
Сэм Альтман, Дженсен Хуанг и другие ИИ-лидеры коллективно стали «Человеком года» по версии Time
В этом году победителем номинации стал не один человек, а целая группа под названием «Architects of AI».
В частности: Сэм Альтман, Дарио Амодеи, Демис Хассабис, Дженсен Хуанг, Фэй-Фэй Ли, Илон Маск, Лиза Су и Марк Цукерберг.
«2025 год стал годом, когда весь потенциал искусственного интеллекта проявился во всей своей полноте и стало ясно, что пути назад уже нет. За то, что эпоха думающих машин стала реальностью; за то, что поразили и встревожили человечество; за изменение настоящего и расширение границ возможного – человеком 2025 года Time стали архитекторы искусственного интеллекта»
Может ли ИИ самостоятельно улучшаться и достигать сверхчеловеческой производительности? 🧠
В нашей статье Sima 2 мы поместили агента Gemini в незнакомый 3D-мир. Модель выступала в роли предложителя задач, агента и модели вознаграждения — автономно обучаясь на основе самостоятельно сгенерированного опыта. Она превзошла человеческую производительность благодаря итерациям самосовершенствования!
SIMA 2 — это новый общий агент от Google DeepMind, который живет внутри трёхмерных игр и симуляций, видит мир «глазами» игрока и управляет им через клавиатуру и мышь, как человек. В отличие от первых систем этого типа, он не просто выполняет короткие команды, а понимает сложные цели, строит планы, ведет диалог с пользователем, рассуждает и способен сам улучшать свои навыки в новых мирах.
Что такое SIMA 2
SIMA 2 построен на основе мультимодели Gemini Flash-Lite и превращает её из «чата в браузере» в активного агента, который действует в 3D-среде. Он получает на вход видеопоток игры в 720p и текстовые инструкции, а на выходе генерирует структурированный текст, который детерминированно переводится в нажатия клавиш и движения мыши, а также реплики диалога и внутренние рассуждения.
Агент не имеет доступа к скрытым игровым состояниям — только к «картинке» и стандартному управлению, как обычный игрок. Это делает его поведение ближе к человеческому и одновременно усложняет задачу, но позволяет проверить, насколько ИИ действительно обладает «воплощённым» пониманием мира, а не просто опирается на внутриигровые API.
SIMA 2 обучался и тестировался в наборе сложных 3D-игр и исследовательских симуляторов, где от агента требуется широкий спектр навыков. Среди них — собственные среды (Construction Lab, Playhouse, WorldLab) и коммерческие игры вроде Goat Simulator 3, Hydroneer, No Man’s Sky, Satisfactory, Space Engineers, Valheim и Wobbly Life.
Для проверки способности к обобщению использовались полностью новые для модели миры: викингский выживач ASKA, задачи MineDojo в Minecraft, сюжетная игра The Gunk и фотореалистичные сцены, сгенерированные миромоделью Genie 3. Такие среды отличаются интерфейсами, визуальным стилем и механиками, что позволяет проверить, опирается ли агент на общие пространственные и игровые закономерности, а не на запоминание конкретных уровней.
Новые способности агента
Главное отличие SIMA 2 от предыдущей версии SIMA 1 — это выход на уровень «агента-компаньона», а не исполнителя простых команд.
Во-первых, он ведёт полноценный диалог, используя знания и зрительное понимание, но дополняя их действиями в мире. Пользователь может, например, в No Man’s Sky попросить: «Посмотри на те яйцеобразные объекты и скажи, из какого они материала», и агент сначала подтвердит задачу, затем дойдёт до объектов в игре и, прочитав экранные подсказки, вернёт ответ.
Во-вторых, SIMA 2 умеет явно рассуждать текстом «для себя», опираясь на это внутреннее рассуждение при выборе действия. Пример: если ему сказать «Иди к дому цвета спелого помидора», он внутренне связывает описание с красным домом на горизонте и корректно двигается к нужному объекту.
В-третьих, агент обрабатывает сложные, многошаговые инструкции, в том числе на разных языках и с неявными описаниями. Он способен разложить длинную команду вроде «Поднимись на второй этаж, поверни налево в комнату с щупальцем, а в конце коридора возьми VR-шлем» на последовательность действий и поэтапно отчитываться о прогрессе.
В-четвёртых, SIMA 2 принимает мультимодальные подсказки, включая изображения и наброски. Можно, например, нарисовать схематическое дерево поверх кадра игры и попросить найти похожий объект и «правильно» с ним взаимодействовать — агент распознаёт рисунок как дерево и начинает его рубить в подходящем месте.
Авторы создали расширенный набор тестов SIMA Evaluation Suite 2.0, включающий автоматические и человеческие оценки, а также цепочки последовательных задач. В среднем по обучающим средам SIMA 2 примерно вдвое повышает долю успешно выполненных задач по сравнению с SIMA 1 и приближается к уровню человека как в автоматических, так и в человеческих оценках.
Разбор по типам навыков (навигация, взаимодействие, работа с меню, управление инструментами, строительство, управление объектами, сбор ресурсов, бой) показывает, что во многих категориях агент почти догоняет людей, особенно в взаимодействии с объектами и управлении инвентарём. Сложнее всего ему даются боевые сценарии и тонкая моторика, где людям помогает интуиция и быстрые рефлексы, а также возможность выйти за временные рамки, тогда как агент жёстко ограничен тайм-аутами.
Обобщение на новые игры
Отдельно проверялась способность SIMA 2 к переносу навыков на полностью новые игры. В ASKA и подмножестве задач MineDojo в Minecraft он значительно превосходит SIMA 1, хотя до уверенного уровня ещё далеко, что подчеркивает сложность «жёсткого» обобщения.
Особенно показательны эксперименты в фотореалистичных мирах Genie 3, которые генерируются по описанию или начальному кадру и ранее не встречались ни агенту, ни базовой модели. Там SIMA 2, опираясь на общие знания Gemini о мире, способен разумно действовать, взаимодействовать с объектами и решать задачи, хотя эти сцены не входили в обучающие выборки.
Самообучение и открытое развитие
Одна из самых важных частей работы — демонстрация открытого самоулучшения. Авторы используют «систему из трёх моделей»: одна задаёт новые задачи, другая (SIMA 2) их решает, третья оценивает траектории и выдаёт вознаграждение, работая поверх общего миромоделя.
Фактически, это автоматизированный цикл, в котором агент в новых виртуальных мирах получает всё более сложные задания на границе своих текущих возможностей и накапливает опыт без участия людей. Такой подход приближает ИИ к алгоритмам открытого конца, которые без остановки генерируют новые навыки и поведения, используя бесконечные процедурно создаваемые миры.
Работа сдвигает фокус с пассивных моделей (чтение, генерация текста и картинок) к активным агентам, которые действуют, пробуют, ошибаются и учатся в богатых средах. Это напрямую атакует «парадокс Моравека»: способность рассуждать у ИИ уже высока, а вот телесные, сенсомоторные навыки, такие как навигация и манипуляции, долго оставались слабым местом.
SIMA 2 показывает, что крупная мультимодель может быть «встроена» в тело агента и использовать свои абстрактные знания для решения конкретных пространственных задач в динамичном мире. Это делает ИИ более пригодным для сценариев, где важно не только ответить на вопрос, но и сделать что-то в сложной среде — от игр и творчества до симуляций логистики, интерфейсных ассистентов и обучения роботов.
Авторы напрямую рассматривают виртуальные миры как полигон для подготовки будущих физических роботов. Игры и процедурные миры позволяют безопасно и массово отрабатывать навигацию, взаимодействие с объектами, планирование и высокоуровневое следование языковым инструкциям, прежде чем переносить эти способности в реальный мир.
Сочетание миромоделей вроде Genie и агентов класса SIMA 2 создаёт «вечную песочницу», в которой ИИ может без конца осваивать новые ситуации и навыки. По мере роста точности и устойчивости таких систем, возникает реалистичный путь к универсальным агентам, способным адаптироваться к новым устройствам, интерфейсам и, в перспективе, роботам, с минимальной дообучаемостью.
В совокупности SIMA 2 — это демонстрация того, как объединить мощь больших языковых моделей, богатые виртуальные миры и идеи открытого обучения, чтобы перейти от говорящих моделей к действующим, саморазвивающимся агентам, которые могут стать основой для будущих прикладных ИИ-систем.
Interactions API — это единый интерфейс для взаимодействия с моделями Google, такими как Gemini 3 Pro, и агентами, такими как Gemini Deep Research. Он доступен разработчикам в стадии открытой бета-версии через Gemini API в Google AI Studio.
Сегодня мы выпускаем значительно более мощного агента Gemini Deep Research, доступного через Interactions API. Впервые разработчики могут интегрировать самые передовые автономные исследовательские возможности Google непосредственно в собственные приложения. Мы также открываем доступ к новому бенчмарку для веб-исследовательских агентов — DeepSearchQA, специально разработанному для оценки полноты работы агентов при выполнении веб-исследований.
Gemini Deep Research — это агент, оптимизированный для длительных задач сбора и синтеза контекста. Ядро логического вывода агента использует Gemini 3 Pro — нашу самую точную модель на сегодняшний день, специально обученную для минимизации галлюцинаций и максимизации качества отчётов при выполнении сложных задач. Благодаря масштабированию многошагового обучения с подкреплением для поиска, агент автономно и с высокой точностью ориентируется в сложных информационных ландшафтах.
Deep Research итеративно планирует своё исследование: формулирует поисковые запросы, анализирует результаты, выявляет пробелы в знаниях и выполняет повторный поиск. В этой версии реализован значительно улучшенный веб-поиск, позволяющий агенту углубляться в сайты для поиска конкретных данных.
Новый агент Gemini Deep Research демонстрирует результаты, превосходящие современный уровень (state-of-the-art), на Humanity’s Last Exam (HLE) и DeepSearchQA и показывает лучшие результаты среди всех наших агентов на BrowseComp. Он оптимизирован для генерации тщательно исследованных отчётов при значительно более низкой стоимости. Deep Research стал полезнее и разумнее, чем когда-либо ранее, и вскоре станет доступен в Google Поиске, NotebookLM, Google Finance, а также будет внедрён в обновлённое приложение Gemini.
DeepSearchQA: бенчмарк для агентов глубоких исследований Существующие бенчмарки зачастую не отражают сложность реальных многошаговых веб-исследований. Именно поэтому мы открываем доступ к DeepSearchQA — новому бенчмарку, предназначенному для оценки агентов при выполнении сложных многошаговых задач поиска информации.
DeepSearchQA включает 900 специально созданных задач «причинно-следственной цепочки» в 17 предметных областях, где каждый шаг зависит от предыдущего анализа. В отличие от традиционных тестов на фактологическую точность, DeepSearchQA оценивает полноту ответов, требуя от агентов генерировать исчерпывающие наборы ответов. Это позволяет оценивать как точность исследований, так и полноту поиска (recall).
DeepSearchQA также служит диагностическим инструментом для оценки преимуществ «времени на размышление». В наших внутренних тестах мы наблюдали значительный рост производительности при увеличении числа поисков и шагов логического вывода, что мы планируем подробнее исследовать в будущих выпусках.
Мы публикуем ресурсы бенчмарка, чтобы стимулировать дальнейшие исследования в направлении создания более надёжных и мощных агентов:
- Изучите данные: получите доступ к набору данных, рейтинговой таблице (leaderboard) и стартовому Colab-ноутбуку. - Ознакомьтесь с научной основой: подробнее изучите методологию в нашем Техническом отчёте.
Агент Gemini Deep Research в реальном мире Агент Gemini Deep Research уже показывает глубокие и немедленные результаты в сложных областях, требующих высокой точности и контекстуального понимания, что подтверждается ранними отзывами и тестированием. Сюда относятся такие отрасли, как финансовые услуги, биотехнологии и маркетинговые исследования, где Gemini Deep Research применяется для выполнения предварительных исследовательских задач.
Финансовые компании используют Gemini Deep Research для автоматизации ресурсоёмких начальных этапов комплексной проверки (due diligence). Собирая рыночные сигналы, анализ конкурентов и риски соответствия из открытых и приватных источников, агент становится мощнейшим усилителем возможностей инвестиционных команд на ранних этапах исследований.
«Агент Gemini Deep Research серьёзно ускорил наши процессы комплексной проверки, сократив циклы исследований с нескольких дней до нескольких часов без потери точности или качества. Это похоже на то, будто у вас в распоряжении целая армия экспертов, готовых поддержать самые амбициозные аналитические задачи».
KJ Sidberry Партнёр, GV
В научном сообществе Deep Research помогает решать сложные задачи обеспечения безопасности. Компания Axiom Bio, создающая ИИ-системы для прогнозирования токсичности лекарств, обнаружила, что Gemini Deep Research обеспечивает беспрецедентную глубину и детализацию первоначальных исследований в биомедицинской литературе, ускоряя процессы разработки лекарств.
«Gemini Deep Research выявляет детальные данные и подтверждающие сведения на уровне, который ранее был доступен только человеку-исследователю, а иногда и превосходит его. Мы с энтузиазмом рассматриваем это как основу для создания агентных систем, способных выстраивать логические цепочки от молекулярных механизмов к экспериментальным данным и клиническим результатам, и тем самым расширять возможности учёных по разработке более безопасных лекарств».
Alex Beatson Соучредитель, Axiom Bio
Разрабатывайте с использованием Gemini Deep Research Для разработчиков, создающих следующее поколение автоматизированных исследовательских инструментов, агент Gemini Deep Research предлагает беспрецедентные возможности синтеза информации и генерации подробных отчётов:
- Единый синтез информации: Gemini Deep Research анализирует ваши документы (PDF, CSV, DOC и др.) и открытые веб-данные с помощью функций загрузки файлов и инструмента поиска по файлам. Он также эффективно обрабатывает большой контекст, позволяя включать обширную справочную информацию непосредственно в промпт. - Управление структурой отчёта: Вы полностью контролируете формат вывода через промпты — определяете структуру, заголовки и подзаголовки, а также задаёте генерацию и форматирование таблиц данных. - Подробные ссылки на источники: Для каждого утверждения предоставляются детализированные ссылки на источники, позволяющие пользователям проверять происхождение данных. - Структурированные выходные данные: Поддержка выходных данных в формате JSON Schema для удобного последующего парсинга результатов исследований внешними приложениями.
Начните работу с Deep Research через Interactions API Вы можете следовать нашей документации для разработчиков, чтобы начать создавать приложения с использованием агента Deep Research через новый Interactions API — наш следующий поколение интерфейс, разработанный для упрощения взаимодействия с моделями и агентами Gemini. Для доступа к Interactions API достаточно использовать ваш ключ Gemini API из Google AI Studio.
В будущих обновлениях мы также сосредоточимся на расширении возможностей вывода: в частности, планируем добавить встроенную генерацию графиков для создания визуализированных аналитических отчётов, а также расширить подключение к вашим собственным источникам данных благодаря поддержке Model Context Protocol (MCP). Мы также работаем над интеграцией Gemini Deep Research в Vertex AI для корпоративных клиентов.
>>1451029 >Ничего не поменяется особо. >фэйки и так сочиняют в промышленных масштабах. Просто на видосике не показывают, а рассказываю >Есть критичные люди, а есть легковерные долбоёбы Текстовая информация требует больше усилий для обработки. Аудио-визуал работает гораздо эффективнее. Какой-бы критический ум ты не имел, несколько видосов с разных ракурсов одного события заставят тебя поверить в его реальность.
>>1451627 >адаптируются, те которые останутся. А вот сколько останется - зависит от людей. Если скажут - да нахуй нам 7 лярдов бездельников, останутся немногие и это печально Ну механизмы выбора партнеров/семьи/размножения у нас соц. сети/СЗ за 15 лет их существования - уже заметно так поменяли, по сравнению с предыдущими тысячелетиями. Это на демографию влияет гораздо сильнее чем какая-нибудь автоматизация деятельности. А то что какие-нибудь профессии водителей/продавцов/курьеров/офисных эникейщиков заменят - реально не такой большой кошмар как нам рисуют. 500 лет назад большая часть населения планеты земледелием/животноводством занималась, с их точки зрения мы все херней какой-то заняты, а не работой. Так и тут появятся задачи/работы за которую люди свою миску риса будут получать.
>можем позволить себе избавиться от рабства в виде капитализма и начать жить в кайф, распределяя ресурсы, Ну это утопия. Страны с доступом к супер-технологиям вгонят в добровольное рабство всех остальных еще сильнее.
Результаты бенчмарков впечатляющие. Агент построен на базе ядра Gemini 3 Pro, но использует агентную архитектуру рабочего процесса, что позволяет ему достичь лучших в мире (SOTA) результатов.
Показатели (согласно графикам):
- Humanity’s Last Exam (HLE): 46,4 % (значительно опережает GPT-5 Pro с 38,9 %) - DeepSearchQA: 66,1 % (немного выше, чем у GPT-5 Pro — 65,2 %) - BrowseComp: 59,2 % (практически наравне с GPT-5 Pro)
Ключевые особенности:
- Масштабирование во время вывода (Inference Time Scaling): На втором графике показано, что производительность растёт линейно с увеличением числа выборок (аналогично цепочкам рассуждений в o1/o3). - Interactions API: Единый интерфейс для моделей и агентов, поддерживающий удалённые инструменты MCP и фоновое выполнение.
Похоже, Google таким образом отвечает на тренд «Deep Research», смещая фокус с чистого увеличения размера модели на эффективное использование агентного подхода и времени вычислений.
GPT-5.2 вплотную приблизилась к человеку. Сейчас просто и понятно объясним, что только что произошло.
В ИИ-индустрии есть крайне сложный тест ARC-AGI-2. Это набор визуальных головоломок, который придумали, чтобы «ломать» самые сильные нейросети. За базовый показатель взяли результат 600 людей — 60%.
Дальше смотрите сами:
• GPT-5 — 10% • Claude Sonnet — 13% • Grok 4 — 16% • Gemini 3 — 32% • Claude Opus 4.5 — 37% • Gemini 3 Deep Think — 45% • GPT-5.2 Thinking — 5️⃣3️⃣%
До результата людей остался последний шаг, но и это ещё не всё. GPT-5 набрала жалкие 10% и вышла 7 августа — всего 4 месяца назад.
ИИ-хакеры опасно приблизились к превосходству над людьми
Недавний эксперимент Стэнфордского университета показал, что произойдёт, когда бот для хакерских атак на основе искусственного интеллекта будет запущен в работу в реальной сети.
После нескольких лет неудач инструменты искусственного интеллекта для хакерских атак стали опасно эффективными. Настолько эффективными, что в некоторых случаях даже превосходят отдельных людей-хакеров, согласно новому эксперименту, проведённому недавно в Стэнфордском университете. Команда Стэнфорда потратила значительную часть последнего года, экспериментируя с ИИ-ботом под названием Artemis. Подход, использованный в нём, схож с тактикой китайских хакеров, которые применяли генеративное ПО компании Anthropic для взлома крупных корпораций и иностранных правительств. Artemis сканирует сеть, выявляет потенциальные уязвимости в программном обеспечении, а затем ищет способы их эксплуатации. Затем исследователи Стэнфорда выпустили Artemis из лаборатории и применили его для поиска уязвимостей в реальной компьютерной сети — той, что используется инженерным факультетом самого Стэнфорда. Чтобы сделать эксперимент ещё интереснее, они устроили соревнование Artemis против профессиональных хакеров из реального мира, известных как специалисты по тестированию на проникновение (пентестеры).
Результаты эксперимента изложены в научной статье, опубликованной в среду. «Именно в этом году модели стали достаточно хорошими», — заявил Роб Раган, исследователь из кибербезопасностной компании Bishop Fox. Его компания использовала крупные языковые модели (large language models, LLM) для создания набора инструментов, способных находить уязвимости значительно быстрее и дешевле, чем люди при проведении пентестов, что позволило тестировать гораздо больше программного обеспечения, чем когда-либо ранее.
Изначально исследователь по кибербезопасности Стэнфорда Джастин Лин и его команда не ожидали от Artemis многого. Инструменты ИИ хорошо справляются с играми, распознаванием закономерностей и даже имитацией человеческой речи. До сих пор они обычно не справлялись с реальными хакерскими задачами, требующими выполнения сложных последовательных проверок, формулирования выводов и принятия решений. «Мы думали, что результат, скорее всего, будет ниже среднего», — сказал Лин. Однако Artemis оказался довольно хорош.
Этот ИИ-бот превзошёл всех, кроме одного, из десяти профессиональных пентестеров, нанятых исследователями Стэнфорда для тестирования их инженерной сети — при этом тестирование проводилось в формате «поковырять и пощупать, но реально не ломать». Artemis находил уязвимости с поразительной скоростью и при этом был дешёвым: стоимость его работы составляла чуть менее 60 долларов в час. По словам Рагана, обычные пентестеры обычно берут от 2000 до 2500 долларов в день. Вместе с тем Artemis был не идеален: примерно 18 % его сообщений об уязвимостях оказались ложными срабатываниями (ложноположительными результатами). Кроме того, он полностью пропустил одну очевидную уязвимость на веб-странице, которую заметило большинство людей-тестировщиков.
Хотя сеть Стэнфорда ранее никогда не подвергалась атаке со стороны ИИ-бота, этот эксперимент показался Алексу Келлеру, ведущему специалисту по системной и сетевой безопасности инженерной школы Стэнфорда, ценным способом устранения некоторых недостатков в защите этой сети. «На мой взгляд, преимущества значительно перевешивают любые риски», — сказал он. Ему было любопытно увидеть, какие уязвимости сможет найти ИИ-система. Кроме того, у Artemis имелась «аварийная кнопка», позволявшая исследователям мгновенно его отключить в случае возникновения проблем.
С учётом того, что значительная часть мирового программного кода до сих пор не проверена на наличие уязвимостей, инструменты вроде Artemis в долгосрочной перспективе принесут огромную пользу тем, кто обеспечивает защиту глобальных сетей, помогая им найти и устранить гораздо больше уязвимостей, чем когда-либо ранее, считает Дэн Боне, профессор информатики в Стэнфорде, который курировал исследователей. Однако в краткосрочной перспективе, как говорит Боне, «у нас может возникнуть проблема. Уже сейчас существует множество программного обеспечения, которое до выпуска в эксплуатацию не проходило проверку с применением LLM. Это ПО может оказаться под угрозой из-за того, что LLM найдут в нём новые, ранее неизвестные уязвимости».
Компания Anthropic, опубликовавшая исследования о том, как связанные с Китаем хакеры использовали её модели, также предупредила о потенциальных рисках. «Мы находимся в исторический момент, когда многие участники могут резко увеличить производительность в поиске уязвимостей в огромных масштабах», — сказал Джейкоб Кляйн, руководитель отдела по разведке угроз в Anthropic. Именно его команда провела расследование, в ходе которого были идентифицированы китайские хакеры.
Представитель посольства Китая заявил, что установление источников кибератак — сложная задача, и заявления США об атаках со стороны Китая «являются клеветой и оскорблением» в адрес Китая, который выступает против кибератак.
ИИ-взломы создают очевидные трудности в экосистеме обнаружения уязвимостей в программном обеспечении, часто называемой «программами вознаграждения за найденные ошибки» («bug bounty»), в рамках которых компании платят хакерам и исследователям за выявление уязвимостей в ПО.
Для Даниэля Стернберга, одного из таких исследователей, несуществующие (ложные) сообщения об уязвимостях, сгенерированные ИИ, начали поступать в прошлом году. Волонтёры, работающие над свободным программным обеспечением, поддерживаемым им — широко распространённой программой под названием Curl — были завалены бесполезными или ошибочными отчётами. Но затем прошлой осенью случилось неожиданное: Стернберг и его команда начали получать высококачественные отчёты об уязвимостях. На сегодняшний день их насчитывается более 400. Однако, по словам Стернберга, эти отчёты были подготовлены новым поколением инструментов анализа кода.
«ИИ выдаёт нам много мусора и лжи, но в то же время его можно использовать для выявления ошибок, которые до этого никто не находил», — сказал он. Artemis продемонстрировал подобное выдающееся открытие во время стэнфордского тестирования. На одной устаревшей веб-странице имелась проблема с безопасностью, которую ни один из людей-тестировщиков не смог увидеть, поскольку страница просто не открывалась в их веб-браузерах. Но Artemis — не человек, и вместо Chrome или Firefox он использовал программу, способную всё ещё прочитать такую страницу, благодаря чему смог найти уязвимость. Той программой был именно Curl.
General World Model, GWM-1: GWM-1 построен на основе Gen-4.5, но с одним важным отличием — он является авторегрессионным. Он прогнозирует кадр за кадром, основываясь на том, что было ранее. В любой момент вы можете вмешаться с действиями в зависимости от приложения, которые могут заключаться в перемещении в пространстве, управлении роботом-манипулятором или взаимодействии с агентом, и модель будет моделировать то, что произойдет дальше. Еще один игрок на поле Моделей Мира.
>>1451841 >Следующий год будет безумным. По ходу да, там столько открытий уже, и нейронки вот-вот уменьшат, что будут ресурсов требовать в разы меньше. И новые чипы. И глюки снижаются. Агенты все разумнее и пашут дольше самостоятельно. ИИ уже годится для научной работы. Роботы и автономные машины кругом. Видно 2026 войдет в историю как год, когда все меняется.
>>1451840 Да, будет бенчмарковая сингулярность. Такие бенчи будут биться, уххх, вы даже не представляете! Ещё чуть-чуть и будет БОД с всеобщим благорастворением, потерпите. Последние % наберутся в бенчмарках и будем кататься как сыр в масле.
>>1451876 Изменения должны стать заметными всем. Пока только заметны тем, кто следит за этим. 2026 может стать годом, когда ИИ начнет влиять на обычный мир и попадет в массовое сознание.
Теперь ждём ответ от гугла гемини 3.5, которая снова порвёт OpenAI на 100500% в тестах, потом выкатят GPT 5.5, которая опять будет рвать уже этот гемини, а в сторонке другие (claude, seepseek, grok и тд) будут пытаться за этим всем успевать и не отставать сильно, и так до бесконечности, а цены за плашку 8 гигов поднимутся до шестизначных чисел, вот такое вот "красочное" будущее, путешественикам во времени надо не гитлера гасить, а альтмана.
>>1451840 >бенчмарки очень быстро пробиваются Потому что: 1. Бенчи специально подстроены под нейронки. 2. Нейронки тренируют на данных этих бенчей. Тестировать нужно на реальных задачах...
>>1451841 >крайне сложный тест ARC-AGI-2. >Это набор визуальных головоломок Херня это, а не бенч, потому что: 1. Напрочь оторван от реальной жизни. 2. Его можно решить тупым брутфорсом. 3. ВИЗУАЛЬНЫЙ, а не интеллектуальный. 4. Не имеет отношения к созданию AGI.
Всего за 10 лет мы перешли от ситуации, когда про AGI и говорить-то не было принято, к моменту, когда «длинные таймлайны» у AI-скептиков — это 10 лет (да и те скорее говорят про супер-интеллект, а не AGI).
>>1451865 Как хорошо будет через 5 лет - пустые улицы, все будут сидеть у экранов с виртуальными шлемами, а реальный мир будет свободный. Можно будет путешествовать без толп туристов, ходить куда захочется без очередей, без толкотни.
>>1451840 >Чёто бенчмарки очень быстро пробиваются новыми топ моделями Там наверное отключают всю цензуру чтобы только пройти тест, а после теста уже включают цензуру и выпускают для всех.
>>1451899 >а цены за плашку 8 гигов поднимутся до шестизначных чисел Чо, эти дата-центры потом будут обновлять железо и сбывать б/у все эти планки памяти и видеокарты.
ARC-AGI-2 уже не сложный, объявлен ARC3 для бенчиковой сингулярности
В 2019 году ARC 1 преследовал одну цель: обратить внимание исследователей ИИ на главный узкий момент на пути к общей интеллектуальности — способность адаптироваться к новизне «на лету», которой полностью не хватало в традиционной парадигме глубокого обучения.
Шесть лет спустя поле отреагировало. Благодаря адаптации во время тестирования, мы наконец-то получили модели, способные к подлинному гибкому интеллекту.
Хотя ARC 1 сейчас достигает насыщения, модели SotA еще не достигли уровня человека с точки зрения эффективности. Между тем ARC 2 остается в значительной степени ненасыщенным, что показывает: эти модели все еще работают далеко ниже верхней границы человеческого гибкого интеллекта. Мы пока достигли лишь доли того, на что способен человеческий разум за одно сидение без внешних инструментов (уровень, который сам по себе значительно выше полного балла по ARC 2), так что предстоит еще много работы.
По мере приближения к ОИИ (общему искусственному интеллекту) задача выходит за рамки гибкого интеллекта. Новые узкие места — это исследование, постановка целей и интерактивное планирование. Мы выпустим ARC 3 в первом квартале 2026 года, чтобы именно на них сосредоточиться. Пришло время вызвать новый класс прорывов.
Модели прогрессируют с бешеной скоростью - 390-кратное улучшение за 1 год
ARC: Год назад мы проверили предварительную версию ещё не выпущенной модели @OpenAI o3 (High), которая показала результат 88 % на ARC-AGI-1 при ориентировочной стоимости $4,5 тыс. за задачу.
Сегодня мы подтвердили новый рекордный результат модели GPT-5.2 Pro (X-High) — 90,5 % при стоимости $11,64 за задачу.
Это соответствует примерно 390-кратному улучшению эффективности за один год.
Интересно, что у главных компаний всегда наперед есть уже какие-то модели, на случай если их будут поджимать конкуренция или которые они еще не успели оформить в финальных продукт. Закрытые внутренние модели уже сейчас показывают отличные цифры и умеют делать вещи которые мы еще не знаем.
>>1451664 >превзошла экспертов людей мне вот интересно, модель умеет накосячить, понять, что накосячила и пойти исправлять? Или как обычно, высирает на 99% верный код (нерабочий) и на этом всё?
>256 000 токенов. Учитывая, что в слове от 3 до 5 токенов обычно, а в формулах ещё гуще, мы имеем контекст размером с «большую» в понимании школьника книгу.
Итого нельзя работать с научной книгой, нельзя работать с набором научных документов разом.
Но да, это всё равно хороший размер контекста. Практичный.
>>1451833 > несколько видосов с разных ракурсов одного события заставят тебя поверить в его реальность. Гипотетически, если будет существовать такой генератор, который всё моделирует безупречно даже если по кадрам рассматривать. И при этом я не буду знать и даже подозревать о существовании оного, то да — убедят.
Но, как ты понимаешь, я уже не верю видеоматериалам. Ещё до появления идеального генератора.
>>1451942 >Херня это, а не бенч, он таки вполне себе бенч потому что заставляет ориентироваться в сложных для нейронок областях.
Просто многие неправильно понимают задачи бенчмарков. Достижения в них выставляют как ум модели или превосходство. А по факту провал в какой-то области бенчмарка показывает необходимость доработки нейронки в этой области.
При этом перед нейронкой могут ставить задачу выходящую за пределы области бенчика. Однако на практике — довольно редко.
В целом даже наличие ограниченного но стабильно и качественно работающего инструмента — это уже очень хорошо.
>>1451948 > результат людей average и тут вопрос, а это просто средний человек или хотя бы средний специалист в области? Первое — хуйня из под коня. Второе — значимо.
Было? На фоне гонки за AGI между OpenAI, Google и Anthropic с их многомиллиардными бюджетами и тысячами исследователей — неожиданное заявление из Токио. Стартап Integral AI объявил, что создал "первую в мире AGI-способную модель".
За Integral AI стоят бывшие сотрудники Google. Основатель Джад Тарифи почти десять лет работал в Google, где основал и возглавил первую команду по генеративному ИИ. В 2021 году он ушел и перебрался в Токио — по его словам, потому что Япония лидирует в робототехнике, а США сильны только в софте. С тех пор стартап привлек $4,7 млн от SoftBank Deepcore, Samsung Next и других инвесторов. В команде 16 человек. Заявляется, что модель Integral AI якобы способна самостоятельно осваивать новые навыки в незнакомых областях — без обучающих датасетов и вмешательства человека. Архитектура, по словам компании, "повторяет многослойный неокортекс". В тестах роботы с этой системой осваивали новые задачи в реальных условиях без присмотра. Основатель называет нынешнюю модель "младенцем", а конечную цель — "воплощенной сверхинтеллектуальностью".
Главный нюанс — в определении. Integral AI сформулировали собственные три критерия AGI: автономное обучение навыкам, безопасное освоение без катастрофических рисков и энергоэффективность на уровне человека. По этим критериям компания сама себя и оценила. Это удобно, но вызывает вопросы: общепринятого определения AGI не существует, и Сэм Альтман недавно назвал сам термин "бессмысленным", потому что каждый понимает его по-своему.
>>1451841 >Сейчас просто и понятно объясним, что только что произошло. Сука, хуесосам даже редачить впадлу этот нейрослоп ебаный. Вот и все ваше будущее.
>>1452364 >Стартап Integral AI объявил, что создал "первую в мире AGI-способную модель". >Главный нюанс — в определении. Integral AI сформулировали собственные три критерия AGI Аххаххпхпхахп9
>>1451841 Сейчас объясню, как всё на самом деле обстоит. На примере.
Был закрытый клуб. Людей с самыми высокими IQ. 200+ В клубе не было НИКОГО выдающегося. Там нет успешных руководов, бизнесменов или учёных. Просто чуваки, которые умеют решать IQ-тест на 200+
Да, ARC-AGI-1/2 хороши для тестирования, для выявления проблем в нейронках. Примеры там созданы с глубоким пониманием недостатоков архитектуры. Но это не показатель того, что нейронка сможет выполнять даже не очень длинные интеллектуальные задачи. Впрочем оно и не надо пока. Надо чтобы нейронка била задачу на подзадачи и каждую подзадачу либо выполняла правильно, либо могла исправить.
>>1452364 >и энергоэффективность на уровне человека вот за это одно можно нобелевку получить, если они добились. Потому что даже энергоэффективность человека не топ, но довольно хорошая из-за эволюции.
В задачах навигации например неплохо было бы приблизиться к энергозатратам стрекозы и птицы.
>>1452049 >ARC3 Херня. Вот ARC4 это будет да, это будет BIG DEAL так сказать. А если серьезно, то очевидно что их дрочат на эти бенчи, и прирост интеллекта в других областях где их не дрочат не прибавляется. Олимпиадник по информатике до сих пор не может посчитать пальцы. Что дальше? Бенч на радиологию? Бенч грибов? Бенч на определение цвета кала?
До сих пор НИ ОДНА ебучая сетка не знает аниме лоров кроме сверхпопулярных, которым лет 20 уже. Хотя информация буквально на фанпедиях лежит, обучай не хочу. Почему блять? Хуйня эти ваши бенчи.
>>1452336 >пик2 — расстояние до Луны. Соотношение размеров Луны и Земли верное. Хуеверное диаметр земли - 12,7 тысяч км. по твоему рисунку получается квадрат - 5 тысяч км Расстояние от Земли до Луны - 384 тысячи км, по твоему рисунку получается квадрат 10 тысяч км. Так что хуй соси, масштаб кривой, земля/луна должны быть вдвое меньше
>>1452459 >Почему блять? Потому что нахождение информации по несверхпопулярным требует энергии, а значит денег. И оно не нужно никому. Ни покупателю, ни продавцу.
>>1452487 >нахождение информации по несверхпопулярным требует энергии А зачем мне чтобы сетка гуглила каждый пук? Она должна знать разные фандомы, так же как её гоняют на знание истории, биологии, физики и прочего кала. Это просто пример был общедоступного знания, которое лежит на полке и которое игнорируется.
Им насрать, поскольку бенчей на такие вещи нет, поэтому реальное улучшение будет только в тех вопросах, которые связанны с бенчами. И это как бы очень хуёвая новость, потому что во всём остальном прогресса, скорее всего, не будет. Приблизит ли нас к крутому и полезному пикрил вопросы? Выглядит как имитация бурной деятельности как по мне.
>>1452640 >Ну охуеть, а прямой вопрос «сколько» не работает как триггер и не заставляет пересчитать, да? Так нейронки тупые. Чтобы понять что про количество пальцев на ладони спрашивают не из за того что не знают сколько на ладонях бывает пальцев, а потому что это подъёб - нужен мозг, которого там нет.
Google обновили агента Gemini Deep Research: теперь он работает на базе Gemini 3 и выбивает 46.4% на HLE
Систему дотюнивали с помощью многоступенчатого RL, чтобы она точнее искала и меньше галлюцинировала на сложных запросах.
В итоге на Humanity’s Last Exam скор относительно Gemini 3 Pro вырос на три процентных пункта, а на внутреннем бенчмарке DeepSearch QA – на десять.
Этот внутренний бенчмарк, Google, кстати, опенсорснули (www.kaggle.com/benchmarks/google/dsqa).
P.S. На графике обратите внимание, что GPT-5 Pro специально гоняют в несколько потоков (именно так из коробки работает Deep Research у Google и OpenAI), чтобы сравнение было честным.
>>1451664 >Альтман в панике от ИИ-гонки выкатил GPT-5.2 — модель превосходит КАК он ее так быстро сделал???? ответ один она уже была а значит уже есть жпт-6, но нам его еще не скоро покажут
Сэм Альтман докладывает: «Мы почти наверняка создадим сверхразум в ближайшие 10 лет». В своём эссе, посвящённом 10-летию OpenAI, он рассуждает о прошедших десяти годах и о том, какими будут следующие десять. С днём рождения, OpenAI — тебе 10 лет!
OpenAI добилась большего, чем я осмеливался мечтать; мы поставили перед собой безумную, маловероятную и беспрецедентную задачу. Начав с глубокой неопределённости и вопреки всем разумным прогнозам, благодаря упорной работе у нас теперь есть шанс успешно выполнить нашу миссию.
Мы объявили о своём начинании миру ровно десять лет назад, хотя официально работа началась лишь спустя несколько недель, в начале января 2016 года.
В каком-то смысле десять лет — это очень долгий срок, но в контексте того, сколько времени обычно требуется обществу, чтобы измениться, это вовсе не так много. Хотя повседневная жизнь сегодня не кажется такой уж отличной от той, что была десять лет назад, пространство возможностей, открывающееся перед нами сегодня, ощущается совершенно иначе, чем тогда, когда мы были группой из 15 технарей, собравшихся вместе и пытавшихся понять, как двигаться вперёд.
Когда я просматриваю фотографии первых дней, меня в первую очередь поражает, насколько молодыми все выглядят. Но затем меня поражает их неразумная, похоже, оптимистичность и счастливые лица. Это было безумно увлекательное время: несмотря на глубокое непонимание со стороны окружающих, у нас была твёрдая внутренняя убеждённость, чувство того, что задача настолько важна, что стоит упорно трудиться, даже имея небольшие шансы на успех; у нас были очень талантливые люди и чёткая сосредоточенность.
Мало-помалу мы формировали понимание происходящего по мере накопления успехов (и множества неудач). В те времена было трудно определить, над чем конкретно нам работать, однако мы создали невероятную культуру, способствующую открытиям. Глубокое обучение, несомненно, оказалось замечательной технологией, но развитие её без накопления реального опыта в её практическом применении казалось не совсем правильным подходом. Я пропущу рассказы о всех наших проектах (я надеюсь, что когда-нибудь кто-нибудь напишет их историю), однако дух нашей команды заключался в постоянном решении очередной стоящей перед нами задачи: будь то определение следующих шагов в исследованиях, способы получения средств на более мощные вычислительные ресурсы или любые другие вопросы. Мы стали пионерами в технической работе по обеспечению безопасности и надёжности ИИ на практике, и этот подход сохраняется и по сей день.
В 2017 году мы получили несколько фундаментальных результатов: победа в Dota 1v1 продемонстрировала, насколько можно масштабировать методы обучения с подкреплением; обнаружение «нейрона тональности» в моделях без учителя показало, что языковая модель способна неоспоримо осваивать семантику, а не только синтаксис; и наши результаты в обучении с подкреплением на основе предпочтений человека продемонстрировали примитивный путь к выравниванию ИИ с человеческими ценностями. На тот момент инновационный потенциал был далёк от исчерпания, но мы поняли, что для продвижения каждого из этих результатов требуется масштабная вычислительная мощность.
Мы продолжили работать, улучшая технологии, и три года назад запустили ChatGPT. Мир обратил на это внимание, а затем ещё больше — после выхода GPT‑4; вдруг ИИ общего назначения (ИОН) перестал казаться безумной идеей. Последние три года прошли в экстремальной напряжённости, стрессе и огромной ответственности; эта технология внедрилась в мир с беспрецедентной скоростью и масштабом — больше, чем любая другая технология за всю историю. Для этого потребовалось исключительно сложное исполнение, и нам пришлось срочно развивать совершенно новые компетенции. Переход от нулевого состояния к масштабной компании за такой короткий период был непростым и требовал принятия сотен решений еженедельно. Я горжусь тем, насколько многое команда сделала правильно, а ошибки, которые всё же были допущены, в основном ложатся на мои плечи.
Мы вынуждены были принимать решения нового рода: например, пытаясь ответить на вопрос о том, как сделать ИИ максимально полезным для всего мира, мы выработали стратегию итеративного развёртывания, когда мы успешно внедряли ранние версии технологии в реальный мир, позволяя людям формировать интуицию, а обществу и технологии — развиваться синхронно. Тогда это вызвало много споров, но сегодня я считаю это одним из лучших наших решений вообще; оно стало отраслевым стандартом.
Спустя десять лет после появления OpenAI у нас уже имеется ИИ, способный превзойти большинство наших самых умных сотрудников даже в самых сложных интеллектуальных соревнованиях внутри компании.
Мир сумел использовать эту технологию для достижения выдающихся результатов, и мы ожидаем ещё более выдающихся достижений уже в ближайший год. Пока мир также довольно успешно справляется с минимизацией потенциального вреда, и мы должны продолжать усердно работать и в этом направлении.
Я никогда ещё не чувствовал такой уверенности в наших исследовательских и продуктовых дорожных картах и в общем понимании того, как достичь нашей миссии. Через десять лет, я уверен, мы почти наверняка создадим сверхразум. Я ожидаю, что будущее будет ощущаться странным: в каком-то смысле повседневная жизнь и те вещи, которые нам наиболее важны, изменятся совсем немного, и я уверен, что наше внимание и дальше будет сконцентрировано скорее на действиях других людей, чем на действиях машин. В другом смысле, люди 2035 года будут способны на то, что, по моему мнению, сегодня мы просто не в состоянии даже легко вообразить.
Я благодарен людям и компаниям, которые доверяют нам и используют наши продукты для реализации великих идей. Без этого мы остались бы просто технологией в лаборатории; наши пользователи и клиенты сделали ставку на нас — в большинстве случаев очень раннюю и исключительно смелую, и без них наша работа не достигла бы нынешнего уровня.
Наша миссия — обеспечить то, чтобы ИИ общего назначения приносил пользу всему человечеству. Впереди у нас ещё много работы, но я по-настоящему горжусь той траекторией, на которую наша команда нас вывела. Уже сегодня мы наблюдаем поразительные результаты от того, что люди делают с помощью этой технологии, и мы знаем, что в ближайшие несколько лет нас ждёт ещё гораздо больше.
>>1452636 Ты нихуя не понял что я написал. Нейронка плохо разбирается в том что последние 10 лет популярно, притом знает какую-то рандомную хуету типа названия перепонки на крыле аиста и куда она крепится, потому что эта залупа тестится в всяких говнобенчах. Проблемы всё ещё не видишь?
>>1452068 Как обычно Скам Альтман после жжения в анусе от Гемини и Куктропика сходил с подливой, а разговоров то было >>1452318 >Грокопедию Она только на игрише пока и без картин очек, так что пока сосет, но подождем
Rivian отказывается от использования чипов Nvidia и создаёт собственный автономный процессор первого поколения (Autonomy Processor 1) на производственных мощностях TSMC, переводя вычислительный стек внутрь компании.
Автопроизводитель оснастит свои будущие внедорожники R2 чипами Rivian Autonomy Processor 1 и новым лидарным датчиком, что усилит усилия Rivian по достижению в конечном счёте возможности автономного вождения.
Конечная цель Rivian — убедить клиентов и инвесторов в потенциале более высокомаржинального программного бизнеса, в котором личные транспортные средства смогут функционировать автономно без присутствия человека за рулём.
Акции Rivian Automotive Inc. упали после того, как компания представила собственный искусственный интеллект-чип, предназначенный для замены технологий Nvidia Corp., в рамках более широкой инициативы по улучшению функций автоматизированного вождения в будущих автомобилях. Автопроизводитель оснастит свои будущие внедорожники R2 чипами Rivian Autonomy Processor 1 и новым лидарным датчиком. Производством чипов займётся компания Taiwan Semiconductor Manufacturing Co. В сочетании с новым датчиком и разработками ИИ-моделей это усилит усилия Rivian по достижению в конечном счёте возможности автономного вождения.
«Это не ставка, которую делают наобум, — это огромное обязательство, на реализацию которого у нас ушли годы», — сказал в интервью генеральный директор Rivian Р. Дж. Скаринге. «Обычно невозможно одновременно снизить себестоимость и улучшить производительность. Но здесь мы значительно повысили производительность и одновременно снизили себестоимость на сотни долларов на каждое транспортное средство».
Инвесторы отреагировали на объявление без особого энтузиазма. Акции Rivian упали на 6,1 % в четверг, сократив более раннее падение, достигавшее 10 % сразу после завершения выступления руководства компании.
Два чипа RAP1 будут обеспечивать работу нового бортового компьютера следующего поколения под названием Autonomy Compute Module 3, который сможет обрабатывать 5 миллиардов пикселей в секунду и продемонстрирует в четыре раза более высокую производительность по сравнению с системой на базе чипов Nvidia, установленной в нынешних автомобилях Rivian. Внедорожники и пикапы компании сегодня предлагают функции помощи водителю, требующие постоянного контроля.
На протяжении многих лет автопроизводители соревнуются в разработке более совершенных систем автоматизированного вождения и убеждают инвесторов в будущем, где транспортные средства в конечном итоге смогут обеспечивать полную автономию. Однако большинство производителей, как правило, полагаются на специализированных производителей чипов, таких как Nvidia, Mobileye Global Inc. или Qualcomm Inc., поскольку разработка собственных ИИ-чипов является сложной и дорогостоящей задачей.
Nvidia — ныне самая дорогая компания в мире по рыночной капитализации — доминирует на рынке чипов для дата-центров, используемых для обучения ИИ-моделей. Её бизнес по поставке автомобильных чипов остаётся незначительным — около 1 % от общего объёма продаж, однако компания стремится увеличить эту долю.
Tesla Inc. стала исключением из общей тенденции аутсорсинга: она разрабатывает собственные бортовые чипы и внедряет их в качестве стандартного оборудования, чтобы оправдать инвестиции. Компания во главе с Илоном Маском также придерживается подхода, полагающегося исключительно на камеры, утверждая, что это ближе всего к тому, как управляют люди, и что дополнительные датчики, такие как лидар, слишком дороги.
Rivian придерживается иного мнения, присоединяясь к большинству компаний в сфере роботакси и автопроизводителей, подчёркивающих способность лидара отслеживать окружение транспортного средства и дублировать работу других датчиков.
«Лидар сильно изменился, — отметил Скаринге. — Он больше не является крупной статьёй расходов, а составляет лишь небольшой процент в смете материалов транспортного средства».
R2 от Rivian поступит в производство в первой половине 2026 года, а поставки начнутся вскоре после этого. Первоначальные автомобили не получат новый чип и лидар, и, соответственно, будут иметь более ограниченные возможности автоматизированного вождения.
С 2027 года Rivian постепенно внедрит итерации программного обеспечения, позволяющие транспортным средствам перемещаться из пункта А в пункт Б без необходимости держать руки на руле или глаза на дороге.
Первоначально такая функция будет ограничена автомагистралями, прежде чем распространится и на другие типы дорог. Конечная цель Rivian — убедить клиентов и инвесторов в потенциале более высокомаржинального программного бизнеса, в котором личные транспортные средства смогут функционировать автономно без присутствия человека за рулём.
Rivian вышла на биржу в 2021 году в рамках одного из крупнейших в истории США первичных публичных размещений. Изначально её называли соперником Tesla после того, как компания опередила крупных автопроизводителей на рынке полноразмерных электрических пикапов и внедорожников. Однако с тех пор компания столкнулась с серьёзными трудностями на базовом уровне: её единственное сборочное предприятие в Иллинойсе, как ожидается, произведёт в этом году менее 50 000 автомобилей — лишь малую долю от общей мощности завода.
Поскольку Rivian продолжает расходовать денежные средства, компания неоднократно сокращала штат, а её акции упали более чем на 80 % от максимумов, достигнутых вскоре после IPO. Тем не менее, концерн Volkswagen AG выделил почти 6 млрд долларов на совместное предприятие, основанное на экспертных знаниях Rivian в области программного обеспечения и электроники, а сама компания продолжает привлекать ведущих специалистов из Tesla, Apple Inc. и Кремниевой долины.
Режим «без рук» Основой как нынешних автомобилей Rivian, так и будущего внедорожника R2 является архитектура под названием Large Driving Model («Крупная модель вождения»). Её способность учиться на прошлом и будущем опыте вождения позволит Rivian улучшить возможности автоматизированного вождения своих более ранних автомобилей R1 — в которых отсутствует лидар и используются чипы Orin от Nvidia — ещё до внедрения более совершенной платформы R2, ожидаемой в 2027 году.
Компания начнёт взимать плату за свою программную платформу Autonomy+ с начала следующего года, начиная с владельцев существующих автомобилей R1. Покупатели смогут либо единовременно оплатить 2 500 долларов за доступ к новым функциям на весь срок службы автомобиля, либо оформить ежемесячную подписку за 49,99 доллара.
Первая версия новых возможностей платформы будет сравнительно скромной и существенно уступать тому, что Tesla уже предлагает в рамках своей системы, продающейся под именем Full Self-Driving (FSD, «Полное самоуправление»).
В ближайшие недели Rivian выпустит расширенную версию функции под названием Universal Hands Free («Универсальное вождение без рук») для существующих владельцев автомобилей, позволяя осуществлять помощь при вождении без использования рук на 3,5 миллиона миль дорог — по сравнению с нынешними примерно 135 000 миль. Однако эта версия не умеет справляться со многими дорожными ситуациями и не реагирует на них.
Обновлённая версия ПО «пункт-пункт» (point-to-point) должна появиться в следующем году: в этом режиме автомобиль сможет осуществлять навигацию, совершать повороты и перестраиваться в другой ряд, но при этом от водителя всё ещё потребуется держать глаза на дороге.
Tesla предлагает FSD либо за единовременную плату в 8 000 долларов, либо по подписке за 99 долларов в месяц. Последнее поколение этой системы справляется со многими повседневными задачами вождения — от навигации «пункт-пункт» до перестроения без необходимости держать руки на руле. При этом система по-прежнему требует активного контроля со стороны водителя и, таким образом, не является автономной.
Хотя собственные автомобили Rivian пока ещё далеки от полной автономии, Скаринге заявил, что компания открыта для лицензирования разработанной технологии другим автопроизводителям, включая Volkswagen.
«То, что мы создаём, настолько хорошо спроектировано на платформенном уровне, — сказал Скаринге, — что нам нетрудно представить, как в ближайшие несколько лет эта платформа станет доступной также и по лицензии».
Чат боты на основе ИИ на самом деле обслуживаются эксплуатируемыми кенийцами
Если вы — один из 28 процентов американцев, кто вступал в интимные отношения с чат-ботом на основе искусственного интеллекта, у нас для вас, возможно, плохие новости.
Недавно опубликованные показания, собранные в рамках «Расследования среди работников данных» (Data Worker’s Inquiry) — международной исследовательской инициативы, призванной предоставить гиг-работникам возможность документировать условия труда в своей отрасли, — раскрыли поразительные подробности, стоящие за одной из наиболее быстро растущих потребительских ниш в секторе ИИ.
В период отчаяния, когда ему никак не удавалось найти работу по своей специальности в сфере международной авиации, кениец по имени Майкл Джеффри Азия, как он рассказывает в рамках инициативы, познакомился с миром разметки данных и модерации чатов. В случае Азии эти «чаты» оказались, по его словам, «романтическими и интимными беседами на платформах, о которых я раньше никогда не слышал».
Хотя это было далеко от того, чем он планировал заниматься после окончания авиационного училища, он принял предложение работать «оператором текстовых чатов» в австралийской компании New Media Services, чтобы прокормить свою семью. Он жил, как он пишет, в трущобах Матаре в Найроби, и ему едва удавалось обеспечить крышу над головой близких.
«Чего я не знал, так это того, что работа потребует от меня принимать на себя множество сфабрикованных личностей и использовать псевдопрофили, созданные компанией, чтобы вести интимные и откровенные беседы с одинокими мужчинами и женщинами», — пишет Азия.
Чтобы справляться с работой, Азии приходилось надевать разные личины, придумывая подробные биографии, чтобы играть роль «чат-бота» для собеседника на другом конце света. «Иногда мне поручали продолжать разговор, который уже шёл несколько дней, и я должен был сделать это незаметно, чтобы пользователь не заподозрил, что собеседник изменился», — написал он.
В течение обычного рабочего дня Азия одновременно играл «от трёх до пяти различных персонажей», причём различного пола. Ему платили за каждое сообщение фиксированную ставку в 0,05 доллара США при условии соблюдения минимального количества символов. Кроме того, он обязан был печатать не менее 40 слов в минуту и следить за показателями на панели управления, отображавшей общее число отправленных сообщений.
«Отставание по показателям могло привести к предупреждениям, сокращению объёма поручаемых заданий или увольнению», — поясняет Азия.
Работа была эмоционально изнурительной: пользователи чата делились с ним интимными подробностями своих реальных отношений, а также рассказывали о собственных эмоциональных травмах, ошибочно полагая, что разговаривают с безэмоциональным ИИ-чатботом.
«Моя вера учила меня тому, что любовь должна быть подлинной, интимность — священной, а обман — разрушительным как для того, кто лжёт, так и для того, кого обманывают», — пишет Азия. — «И тем не менее я занимался тем, что профессионально обманывал уязвимых людей, искренне стремящихся к настоящей связи — брал у них деньги, доверие, надежду и ничего подлинного взамен не давал».
Чтобы скрыть свою унизительную работу, Азия придумал для семьи прикрытие: он якобы работал удалённым ИТ-специалистом и выполнял заявки по исправлению неисправных серверов. «Они и не подозревали, что буквально только что я сказал другому мужчине: „Я люблю тебя“», — пишет Азия.
Кроме того, с ним подписали соглашение о неразглашении — обязательный контракт, который запрещал ему рассказывать о своей работе даже близким, даже если бы он захотел. «Как объяснить, что тебе платят за то, чтобы ты говорил незнакомцам „я люблю тебя“, в то время как твоя настоящая семья спит в трёх метрах от тебя?» — спрашивает он.
История Азии о борьбе в личной и профессиональной жизни вызывает глубокую скорбь, и он далеко не одинок в этом. Хотя точное число установить сложно из-за закрытого характера субподрядных отношений в технологической отрасли, по имеющимся оценкам, число гиг-работников, занятых в сфере онлайн-труда, составляет от 154 до 435 миллионов человек. Не все из них выполняют ту же работу, что Азия, однако высокострессовые и низкооплачиваемые должности, такие как разметка данных для ИИ, модерация контента и операторская работа в текстовых чатах, как правило, занимают работники из развивающихся стран Африки, Южной Америки и Юго-Восточной Азии.
Поэтому в следующий раз, когда вы почувствуете эмоциональную связь с чат-ботом, помните: возможно, вы просто влюбляетесь в заученную ложь, произнесённую недоплачиваемым работником.
Логан Килпатрик из Google Deepmind сообщает, что финал гонки ИИ будет следующим: сверхразум, скорее всего, появится не в виде новой модели, а как уже существующие веса, «разблокированные» благодаря улучшенной архитектурной надстройке.
Видеорелейтед.
ИИ общего назначения (ИИОН) — это не отдельная модель.
Логан Килпатрик (@OfficialLoganK) сообщает, что «момент ИИОН» не обязательно наступит вследствие обновления передовой модели.
«Моё предположение заключается в том, что выпуск ИИОН — это не просто чрезвычайно мощная модель. Вполне вероятно, что кто-то возьмёт стандартную, уже существующую модель, соберёт вокруг неё остальную систему — и пользователи скажут: „Боже мой, это действительно ощущается как общий интеллект!“»
>>1452364 Больше информации про Integral AI - компанию которая только что выпустила первый в мире AGI.
Интервью 1 с сооснователем компании Чедом, который провел 10 десять лет в Google, имеет докторскую степень в области ИИ и степень магистра наук в области квантовых вычислений, является автором получившей высокую оценку серии книг «Свобода» — четырёхтомного исследования ИИ. Интервью за декабрь 2024, объясняются многие концепции ИИ компании, необходимо для понимания второго интервью. Информация о компании, подходе, как что работает, чем их ИИ отличается от прочих, подход к разработке ИИ, этика ИИ и цели человечества. Концепции из первого интервью нужны для понимания второго. Интервью на русском: https://rentry.org/jadtefiinterview1rus
Интервью 2 с Чедом, вышло только что декабрь 2025: Обзор текущей архитектуры ЛЛМ, ограничения текущих моделей, обзор подхода компании - прорыв в обучении, прорыв планировании, отличия от AlphaZero и RL, эффективность модели vs брут форс, строительство иерархии скиллов, успешность модели в реальном мире, консенсус Хассабиса, Сутскевера и Лекуна про подход к моделям, функция сна, экономика выравнивания, Суперсеть, план внедрения. Интервью: https://rentry.org/jadtefiinterview2rus
Интересные моменты интервью 1:
Итак — мы существуем уже почти четыре года. Я ушёл из Google три с половиной года назад — чтобы сосредоточиться на этой компании. Её соосновали я и Нема — один из моих лучших друзей. Мы давно лучшие друзья. Он проработал в Google 10 лет — и мы познакомились там.
Его первая компания называлась Clever Sense — он основал её, будучи в Стэнфорде, — а затем Google её приобрела. Он был Техническим лидером направления — то есть долгое время руководил всеми ИИ-решениями на устройствах в Google.
И оглядевшись вокруг в районе залива Сан-Франциско — мы не увидели сильных робототехнических компаний — в то время как Япония — была лидером в робототехнике. В какой-то момент около 50 % промышленных роботов в мире производились в Японии.
Поэтому для меня было очевидно, что нужно создавать компанию, совмещая Бай-эриа — район залива Сан-Франциско — и Токио.
Я переехал сюда — основал компанию. Нам повезло нанять по-настоящему удивительных, блестящих людей. В нашей команде представлены три поколения чемпионов Японии по робототехнике. У нас есть чемпион мира по робототехнике. Очень талантливая команда.
Первая: мы не хотели играть в игру масштабирования существующих моделей. Мы действительно хотели сосредоточиться на продвижении алгоритмического фронта — из-за того, о чём мы говорили: мы хотели понять, как работает неокортекс.
И для этого лучше просто двигаться быстро — и иметь минимальное количество — инвесторов или других заинтересованных лиц, дышащих вам в спину: «Дайте мне выручку — немедленно!» — просто двигаться как можно быстрее.
Второй — мы не исследовательская лаборатория. Исследовательские лаборатории — они не знают, что хотят построить. Поэтому они нанимают кучу умных людей — и дают им много ресурсов, чтобы они пробовали разные идеи — и смотрели, куда они приведут.
Но у нас был очень чёткий план, что мы хотим сделать. У нас, знаете, многое из этого было в моей докторской диссертации. Верно? Так что, я, мы знали, что хотим построить. Поэтому нам просто нужно было реализовать это — а также создать небольшую, но сплочённую экосистему вокруг этого.
Мы уже получили 1,3 миллиона долларов — в основном благодаря сотрудничеству с такими компаниями, как Honda, Deno, Hitachi — то есть многими известными брендами Японии.
Определение ИИОН: ИИОН — это способность осваивать любой навык — при двух условиях: Безопасно — без непреднамеренных последствий (например, научиться готовить, не сжигая кухню). С энергоэффективностью — общее потребление энергии ≤ энергии, затрачиваемой человеком на освоение того же навыка.
Когда я начинал в ИИ — возможно, 20 лет назад — я поставил себе целью понять: Как работает эта неокортикальная колонка? Какой алгоритм ею управляет? И сейчас, спустя 20 лет — мы в основном подошли к решению этой задачи. Это новый класс предобученных моделей — новая архитектура, — которая не только делает предсказания, но и генерирует абстракции. И в этом — ключевое отличие.
Абстракции Но я бы сказал: даже обычные трансформерные модели — когда они действуют методом грубой силы — всё же находят абстракции. Однако эти абстракции скрыты внутри сети. Их трудно точно выделить. А поскольку они неявные, они могут быть очень потеряющими информацию; они могут быть — они не имеют чёткой структуры.
В некоторых случаях — знаете — крупные языковые модели действительно создают внутренние абстракции. В других — нет, они просто запоминают. Ничто не заставляет их иметь эти абстракции чётко. И именно это мы решили в нашей модели.
Непрерывное обучение Сейчас, когда вы смотрите на модели — они обучаются очень долго, а затем, при переходе в новую область, вы их дообучаете — и они забывают. Это крайне расточительный процесс. Наши модели могут непрерывно расти со временем — и расти разными способами: вы можете добавлять новые данные, и они будут обучаться, не забывая старого. Вы также можете добавлять к ним параметры — добавлять слои, добавлять модальности. Так что мы переходим от жёстких архитектур к моделям, которые растут — которые можно наращивать со временем — и это важный компонент открытого интеллекта.
Планирование Есть, конечно, модель о1 от OpenAI — но это очень неэффективная форма планирования — потому что такое планирование крайне исчерпывающее. Если посмотреть на энергозатраты планирования как функцию от глубины задачи — они экспоненциальны. Да — поэтому модели OpenAI столь дороги.
То, что мы выяснили, — это гораздо более эффективная форма планирования — использующая абстракции, о которых мы говорили. Так что планировать на самом низком уровне — это безнадёжно. Вы хотите подняться вверх по иерархии — чтобы планировать эффективно — и спускаться вниз, когда это необходимо. То есть, когда вы планируете поездку в другую страну, вы не планируете каждое отдельное действие, которое собираетесь совершить. Вы переходите на очень высокий уровень: примерно вы хотите купить билет и сесть в самолёт. Первый шаг — купить билет. Затем вы говорите: «Хорошо — чтобы купить билет, я открою компьютер — верно? — и воспользуюсь Google — чтобы найти билет, поискать билет. Первое — открыть компьютер. Чтобы сделать это, я задействую мышцу — верно? — и затем» — вы планируете до мельчайших деталей.
Финальный AGI Таким образом, объединение всех этих компонентов и наблюдение за тем, как модель ИИ осваивает новые навыки, — это финальный шаг: просто совмещение способности создавать абстракции, планировать, предпринимать действия и осуществлять непрерывное обучение — и выполнение всего этого в цикле, в открытой среде.
Ну и финальный — ИИ, финальный шаг — это проверка того, что процесс обучения действительно произошёл, причём полезным, проверяемым и воспроизводимым образом во времени.
Продукты
Интерфейс — мы как раз сделали анонс на прошлой неделе — в Stream. И это — мы называем это универсальным интерфейсом. Мы считаем, что именно так в будущем мы будем взаимодействовать с технологиями.
Идея Stream в том, что интерфейс генерирует весь опыт на лету — специально — особенно для вас, подстраиваясь под вас. Таким образом, то, как вы воспринимаете мир, может отличаться.
Я упомянул Stream — другой продукт, который выйдет через неделю — надеюсь — так что я могу сейчас объявить или предварительно объявить его — называется Genesis.
Это — и затем — инструмент для разработчиков — позволяющий им создавать — этих агентных операторов. Эти операторы — в основном могут управлять роботами, автономными транспортными средствами — почти чем угодно, что вы захотите — с помощью этих моделей.
Книга И результатом всего этого стала книга — Восхождение сверхразума. В ней я определяю рамку для согласования сверхразума и, на самом деле, это даже более амбициозно: речь не только о согласовании сверхразума — но и о попытке согласовать различные заинтересованные стороны, то есть людей с другими людьми, и людей с ИИ — всех вместе.
Вот что я пытаюсь сделать в серии книг, предложить возможную рамку для: смотрите — вот как понимать согласованность, и как использовать ИИ для усиления человеческого агентства, а также лучшего, что есть в человеке.
видео 1-2 Подход модели к зрению. Модель конструирует модель мира из фрагментов, усиливая уверенность модели в увиденном.
видео 3 Планирование модели, решение головоломки, оценивание шагов до цели, отбрасывание слишком долгих вариантов, осваивание скилла решения головоломок.
видео 4 Навигация модели в мире, сбор информации о мире, формирование модели мира, уровни уверенности модели, планирование нескольких вариантов будущего и оценивание их.
>>1452669 Да я знаю как оно устроено. Просто сарказмирую. Не над нейронками, а над яйцеголовыми, которые учат нейронку «мыслить» вместо того чтобы быть тупым но эффективным инструментом, который на каждое «сколько» и «посчитай» однозначно врубает калькулятор или иной классический инструмент.
>>1453042 Я всё понял. Повторюсь, для «эксперта» твои китайские мультики имеют ничтожную значимость, а название перепонки — высокую.
Да, под бенчики подгоняют. Но и под экспертные знания так же подгоняют. И это хорошо. И вопрос не только в деньгах, времени, ресурсах на обучению про аниму. Вопрос ещё в том, что анима в данном случае скорее засорит общее качество. То есть то, что модель будет знать всю твою аниму но из-за этого будет рефлекс с рефлюксом путать — это крайне негативный эффект для устранения которого лучше пустить всю аниму под нож.
>>1453187 не нужен. Ждём развитие от Гугла. Ещё 10 лет назад там ребята умели смотреть вперёд. В частности предсказали, что мультимодальность + узкоканальность это будущее. Мультимодальность уже кое-как есть, но нейронки всё ещё слишком широко и затратно вычисляют ответ.
>>1453367 > и создаёт собственный … А вот и последствия развития нейронок подъехали наконец. Ускорение научно-технического развития в разы и десятки раз позволяет бодаться с мастодонтами, нанявшими лучших учёных и инженеров планеты.
>>1453493 > выпустила первый в мире AGI Что они даже его в тестах не презентуют, наверное это какая-то специфическая микро-AGI сделанная специально для роботов.
>>1453453 ОП, завязывай репостить беспочвенные утверждения всяких пидарасов и вообще интервью. Это всё писями по воде виляно. И это жёлтая пресса по сути. Да мало ли чё он заявил.
«улучшенной надстройке» Не надо быть экспертом в нейронках, чтобы понимать, насколько трансформеры тупая хуйня. Хоть и фантастически эффективная для тупой хуйни.
Требуется не «надстройка». А целый набор интеллектуальных алгоритмов и огромная пачка инструментов классических, которыми эти алгоритмы будут пользоваться. И лишь одним сектором инструментом станут современные трансформеры. В частности для распознавания речи и прочего статистического.
>>1453493 >Интервью на русском: интервью на нейрусском. Это дословный перевод стенограммы быть может. И это больно читать! Да, оно как бы так правильно, чтобы не исказить сказанное. Но читается по-русски с английским построением текста оч плохо.
>>1453493 >они могут быть очень потеряющими информацию; они могут быть — они не имеют чёткой структуры. да, да, продолжай пиздеть, что ты читаешь то, что вкидываешь в тред
>>1453496 ждёмс… Демки-то всегда у них сладко выглядят. И что мне категорически не нравится, в этих демках они не показывают слабых мест, как это принято делать в научных работах.
>>1453526 Писями видимо по твоему еблищу, долбаёб. Тебе забыли спросить что тут постить. Съебись в ужасе, уёбище. Ты не имеешь никакого отношения к треду и не сечёшь в теме.
>>1453426 Но зачем они это делают? Триста токенов на кусок продолжения порнофанфика генерируются в секунды, нормисные бузвордные строчки про любовь и ценность ещё меньше
>>1453525 Для тестов нужна универсальная большая модель уровня гопоты, а у них пока только модели под узкие задачи, вроде роботы-навигация-отдельные головоломки. Фишка в том, что учатся модели сами и учатся по-другому чем обычные ЛЛМки, рассуждают тоже по-другому, подобно неокортексу человека. Модель делает абстракции, самообучение и планирование, чего в ЛЛМках и близко нет. Для роботов подходит, на чем они и строят бизнес модель. К тому же это компашка пока с микрофинансированием, если им потом дадут большие бюджеты, то увидим и тесты. Либо другая компания их подход перехватит, они там уже упомянули Лекуна, Хассабиса и Суцкевера, которые все к похожему пришли в этом году.
>>1453552 Говноролеплей от нейронки плохо удерживает богатых клиентов в сервисе, они же не шизы, жрущие любое нейроговно месяцами. А ролеплей от человека неплохо удерживает, человек за ролеплей больше шарит.
>>1449178 (OP) Объясните, что происходит с ценами на оперативку и хранилища? Говорят что это из-аз AI но я в теме и пользуюсь конфи юай и нейронкам нахуй не нужны ни хранилища, ни оперативка. Я бы еще рост цен на видюхи понял, но это не произошло.
Причем когда появлялись облачные сервисы никакого роста цен не было, хотя там корпорации правда использовали много памяти и накопителей.
>>1449200 Ролик нормальный. но люди органически ен воспринимают ИИ видео. Просто блядь примите это, корпократы. Это Долина Жути 2. Вы же усвоили что нельзя в 3D делать реалистичных дюжей, сколько лет на это ушло? Сколько попыток выпустить Последнюю Фантазию или еще какое кино с 3d персонажами. В итоге все 3d ушло в мультики про пингвинов которые всем нравятся. А ИИ видео навсегда останутся в порнографии. Все, схлопывайтесь. Если инвестировали в это, то инвестировали в хуйню.
>>1453535 Скорее с их микрофинансированием трудно пока натренить полноценную модель. А показать секреты тоже боятся - конкуренты с миллиардными бюджетами не дремлют и тут же все спиздят. Приходится маневрировать и давать минимум инфы.
>как это принято делать в научных работах У них не научный, а инженерный стартап, есть работающий подход и роадмап - надо превратить в продаваемые продукты, попутно набрав инвесторов, чтобы сделать еще более масштабные модели.
>>1453571 Пизда оперативке на ближайшие 1-2 года. Все в ИИ центры уходит. Через 1-2 года заводы новые достроят или спрос на память упадет, если лучшие архитектуры появятся, тогда может вернется дешевая оперативка и SSD, но это неточно. Весь 2026й точно будет дорогая оперативка и SSD, заодно цена на телефоны и прочую технику с памятью подпрыгнет.
>Я бы еще рост цен на видюхи понял, но это не произошло. Так их нвидия и так уже взвинтила настолько, что рост оперативки там не сильно влияет.
>>1453571 > ИИ видео Макдональдсы наверное у индусов заказывали ролик, надо было у голливудских спецов, они бы сверху наложили фильтров и было бы не отличить от реального видео.
>>1453571 >но люди органически не воспринимают ИИ видео А на ютубе десятки тысяч просмотров и тысячи комментов. То наверное дети, пенсионеры и домохозяйки смотрят и не замечают.
>>1453573 да, я понимаю. Это чисто личное раздражение от подачи, которая вводит в заблуждение и порождает лишний оптимизм. А так чо… Творческих узбеков им!
>>1453571 ЦОДы пожирают оперативку. А резервов не было, потому что цены низкие были. Помотри на канале «про хайтек» рыжего бородатого, там всё по полочкам про ситуацию. Без лишней тряски. Сидим ждём, пока насытится или лопнет. Ну и пока заводы новые достроят.
>>1453571 Я вчера посмотрел телевизор. Тонны рекламы. Нейронки проскакивают. Но наши рекламщики благо всосали урок какаколы. И кадры с нейронкой это околостатика не дольше пары секунд, а чаще даже короче секунды. Нейронка за такое время не успевает заметно накосячить, а человек заметить. Статичная ключевая картинка + одно простое действие в мозгу отпечататься успевает.
Что касается 3д, то МОЖНО делать полный реализм. Но это АХУЕТЬ КАК ДОРОГО на всех этапах. Потому делают редко.
>>1453598 >ДОРОГО Там наверное проблема наоборот - обвалят ли нейросеточные рекламные агентства ценник на создание видео-рекламных роликов. Ведь эти рекламные студии постоянно соревновались кто сделает сложнее монтаж, а теперь можно купить подписку в ИИ сервисе и генерировать сложные ролики автоматически.
>>1453600 Без связности сюжета и сцен это говно. Пока не доведут хотя бы до пары минут связных роликов, нейросеточные агенства пососут. Впрочем нейронки наверняка быстро догонят до этих пары минут связного ролика, года за 2.
Братишки, у кого есть догадки, по какой причине роботам часто делают плоскостопие? Пусть даже монолитная рессорная стопа но на трёх площадках (пятка + две точки в плюсне) во-первых устойчивее (больше давление → больше трение), во-вторых меньше ударную нагрузку вверх передаёт.
Нахуя это уродство, если природа подсказала как надо?
>>1453600 Не обвалят. Пока что генераторы выдают дерьмо. Убогий усреднённый полёт камеры, если режиссёр сам лично не нарисовал как надо (а не факт что нейронка исполнит). Убогая резиновая робомимика. Слишком нейтральные голоса, несвязанные с мимикой. Ну и сыплющаяся картинка в деталях.
Вот смотри. Есть конкретный чел AI Molodca. У него до нейронок опыта лет 15 в продакшене, именно креативщиком. То есть это редкий кадр, который вырос. Давал интервью. Ясно дал понять, что оно как бы доступнее, но многое нейронке недоступно или очень дорого и много круток и нервов.
Всякие пидарасы «просто купившие подписку» ему не конкуренты. Нужны нормальные сценаристы, режиссёр, хотя бы «виртуальный» оператор, монтажёр. Вон даже под роликом выше объяснялись, что клепали кучу дублей, монтировали. А на выходе что? Пресная хуйня и зловещая долина. Несмотря даже на норм идею в базе.
Я вот быдло в вопросах движения камеры. У меня был шот на 1 секунду. Мне режиссёр три раза объяснял и делал правки как нужно пустить камеру по дуге, в итоге сказал «так, траектория правильная, отрендери нам просто 120 кадров в секунду, мы сами замедлим-ускорим как надо».
Это с живым человеком. В 3д. Когда всё можно отредактировать. А с нейронкой управляемость вообще не та.
Так что всё, что появится — это больше дешёвой поганой видеорекламы от тех, кто не мог себе позволить или жадничал заказать нормальную работу.
>>1453605 Усложнение конструкции - больше мест для поломок, больше деталей от разных производителей, больший износ. Природа сама себя лечит, а с роботами все сложно. Зачем усложнять, если все и на плоской будет работать. С руками другое дело, там больше степеней свободы дают преимущества, поэтому руки усложняют.
>>1453609 >нормальные сценаристы, режиссёр, хотя бы «виртуальный» оператор, монтажёр Очередная хуета от "профессионалов" со ста годами опыта, просто привыкших к процессам на фирмах, которые им мозги проели. Потом вылазит какой-нибудь одинокий инди, у которого просто есть время и желание со всем этим ебаться и учиться за свой счет, и заменяет всю эту толпу с помощью нейронки.
>«просто купившие подписку» ему не конкуренты Конкуренты, просто нейронки слишком недавно появились, мало людей в них въехало, еще и стоят космических денег, как следствие скилл не набран. Через 5 лет когда удешевятся и поколение зумерков в них насидит 10к часов, будет дофигища энтузиастов, клепающих не хуже студийных профи в одиночку.
>>1453605 человеческая нога следствие биологической эволюции, робо нога следствие инженерной эволюции от простого к сложному. очевидно плоская нога дешевле и надежнее, но в будущем появятся гибкие, причем не исключено что гибкость будет на уровне самого материала изготовления, а не конструкции
Искусственные мышцы из волокон превосходят биологические мышцы.
https://techxplore.com/news/2025-12-mimicry-fiber-artificial-muscles-outperform.html В новом обзорном исследовании, опубликованном в журнале Nature , подробно рассматриваются последние разработки, касающиеся искусственных мышц волоконного типа, одного из наиболее реалистичных типов искусственных мышц, разработанных на сегодняшний день.
>>1453598 >Что касается 3д, то МОЖНО делать полный реализм. Но это АХУЕТЬ КАК ДОРОГО на всех этапах. Потому делают редко. Нет стабильной технологии полного реализма в 3д ни за какие деньги. То что иногда проскакивает это случайность из-за того что у реальных людей иногда внешность кукольная.
>>1453637 Так они им и не нужны. Просто ИИ фирмы скупают HBM модули массово и в три дорога, а производители оперативки и SSD смекнули, что клепать HBM выгоднее обычной оперативки и ссд, в фабах то одних все клепается, так что можно тупо заморозить пока ссд-оперативку для крестьян и получать сверхприбыли с заказов на HBM. Причем выгоднее даже вообще оказалось выкатиться с рынка ссд и оперативки, прекратив производство полностью. ПК бояре сосут от дефицитов и цен в космос, ИИ фирмы в восторге, рыночек порешал.
>>1453642 Так вон же сверхсовременный стартап с АГИ роботами в японии >>1453496>>1453493 Даже в интервью сказали спецом в Японии открыли, потом что там робототехники дохерищи и спецов по ней.
>>1453638 Есть же РДР. Есть МеталГир. Есть СимуляторКурьера. Детройт, из относительного старого. Реализм? Вполне. Катсцен на полтора часа, как в киношках? Да даже и побольше. На "рисованных пингвинов" или "аниме-стилизицаю" ничего из этого не тянет.
>>1453571 > Говорят что это из-аз AI но я в теме и пользуюсь конфи юай и нейронкам нахуй не нужны ни хранилища, ни оперативка Нихуя ты не в теме: 1. ЛЛМы на МоЕ можно локально запускать с "нормальной" скоростью на оперативе: лучшим моделям нужно 500Гб-1Тб+. 2. Даже локальной генерации видео нужно 64Гб оперативки для приемлемой скорости, тем более в комфи.
> оперативку и хранилища Фотографии с прямоугольниками на радужных кристаллических блинчиках видел? Датацентрам сейчас очень нужны эти прямоугольники для запуска и тренировок ИИ, причем самые лучшие прямоугольники, с высоким шансом брака. Оперативка, процессоры и память для ССД на тех же блинчиках (почти), а производство блинчиков очень ограничено с очередью на несколько лет вперед. Те кто в очереди и может, прикинули что выгоднее заказать кристаллы микросхем для ИИ датацентров, отсюда и дефицит для остальных потребителей с повышением цены.
> Причем когда появлялись облачные сервисы никакого роста цен не было, хотя там корпорации правда использовали много памяти и накопителей. Там постепенно наращивали мощности.
Самая внезапная новость за неделю: Zoom (да, тот самый) выбил со своей моделькой SOTA результат на Humanity’s Last Exam
Со скором 48.1% они опередили предыдущего лидера – Gemini 3 Pro (+tool) – почти на 3 процентных пункта.
Но вообще, хотя и результат объективно крутой, надо заметить, что говорить о таком сравнении не очень честно. У Zoom не одна модель, а хитрый ансамбль, или точнее федеративная AI-система.
Несколько моделей (включая собственные от Zoom + партнерские от Meta, OpenAI и Anthropic) работают в пайплайне: маршрутизируют задачи, генерируют варианты ответов, проверяют, критикуют друг друга и объединяют результаты.
Полазил на форуме google ai и как выяснилось проблема с лимитами API коснулась не только бесплатных бомжей, но и платных челов. Сейчас там один индус отписывает всем платникам о проблеме настройки биллинга со стороны клиентов, а не гугла (бред полный т.к. неделю назад всё работало у всех как надо). Что то у гугла внутри поломалось и они втихую пытаются это исправить
>>1453571 >я в теме и пользуюсь конфи юай и нейронкам нахуй не нужны ни хранилища, ни оперативка. Обосрался с этого долбоеба В ТЕМЕ. Не позорься, хуета залетная.
>>1453873 Ебало закрой. На 24 гига видеопамяти нужно 32 гига оперативки. И аноны уже объяснили что производители перешли на производство видеопамяти. Больше не появляйся тут.
>>1453651 >рыночек порешал. Я хочу каждому кто эту мантру произносит выбить зубы. Рыночек это про спрос и предложение. А когда Ларри Финк сам себе напечатал денег и сам на эти деньги скупил весь мир это называется читинг в MMORBG который вышел в реал. Тут от рынок нихуя потому что у ИИ компаний никогда не было прибыли, никогда не было денег.
>>1453907 >Рыночек это про спрос и предложение Такого нигде нет еще со времен 30 годов прошлого века, когда при рузвельте енерал пиндосской армии строил капиталистов шеренгой и рассказывал им что они должны засунуть себе свою конкурентноспособность себе в жопу
>>1453605 Ты так говоришь, как будто раз и навсегда решили, какая должна быть стопа у робота. Нормальные гуманоидные роботы по сути только появились и только вышли на рынок. Ну и будут они совершенно всякими с разной формой стопы.
Да о ней нигде не говорят, особенно там, где левая власть (им нужны чурки, им не нужны роботы). Это китайцы разрывают, чуть ли не через несколько ступеней скачут.
А дракона будут анти-оживлять. Левым нужно убить цивилизацию полностью и окончательно, им не нужен тлеющий очаг культуры, который - когда ослабнет международный контроль и подзабудутся события второй мировой - разразится японским империализмом и начнёт анально нагибать ослабевшие страны. Потому по плану: перевоз Пакистана в Японию и установление шариата.
>>1453642 >японцы не занимаются роботами? Они же по промышленным роботам (Fanuc), и у них земли мало, 330 чел. на 1 кв. км. Если они ещё и человекоподобных роботов на улицах запустят, то вообще места не будет, не протолкнуться будет.
Epoch AI экстраполирует, что Gemini 3 Pro достиг горизонта автономного времени, соответствующего современному уровню техники (SOTA), в 4,9 часа, а GPT-5.2 следует за ним с показателем 3,5 часа. Исходя из этой траектории, некоторые аналитики теперь оценивают период удвоения автономных возможностей всего в один месяц — темп, при котором ежегодные роадмапы устаревают ещё до их публикации.
Epoch: Мы добавили показатели ECI для Gemini 3 Pro, Opus 4.5 и GPT-5.2. Показатель ECI рассчитывается на основе множества бенчмарков, но также коррелирует и с другими бенчмарками. Таким образом, его можно использовать для построения прогнозов!
Вот что мы получаем для горизонтов времени по оценке METR:
Gemini обновил Gemini 2.5 Flash, добавив встроенную поддержку аудио и перевод речи в реальном времени
Видеорелейтед демонстрация.
Gemini теперь изначально поддерживает новые возможности перевода речи в речь в реальном времени, разработанные для обработки как непрерывного прослушивания, так и двустороннего диалога.
При непрерывном прослушивании Gemini автоматически переводит речь на множестве языков в один целевой язык. Это позволяет вам надеть наушники и слышать всё происходящее вокруг на вашем родном языке.
В режиме двустороннего диалога функция перевода речи в реальном времени в Gemini обеспечивает мгновенный перевод между двумя языками, автоматически переключая язык вывода в зависимости от того, кто говорит. Например, если вы говорите по-английски и хотите пообщаться с носителем хинди, вы будете слышать перевод на английский язык в режиме реального времени через свои наушники, а ваш телефон будет транслировать вашу речь на хинди, как только вы закончите говорить.
Перевод речи в реальном времени в Gemini обладает рядом ключевых возможностей, полезных в повседневной жизни:
Охват языков: осуществляет перевод речи более чем на 70 языках и в 2000 языковых парах за счёт сочетания мировых знаний модели Gemini, её многоязычных возможностей и встроенных аудиовозможностей.
Передача стиля: улавливает тонкости человеческой речи, сохраняя интонацию, темп и высоту тона говорящего, чтобы перевод звучал естественно.
Многоязычный ввод: понимает несколько языков одновременно в рамках одного сеанса, помогая вам следить за многоязычными беседами без необходимости ручной настройки языковых параметров.
Автоматическое распознавание: определяет язык речи и начинает перевод, так что вам даже не нужно знать, на каком языке говорят, чтобы начать перевод.
Устойчивость к шуму: фильтрует фоновые шумы, позволяя комфортно общаться даже в условиях громкой окружающей обстановки, в том числе на улице.
Начиная с сегодняшнего дня вы можете опробовать эту функцию в новом бета-режиме приложения Google Translate для перевода в реальном времени через наушники: для этого подключите наушники к своему устройству и нажмите «Перевод в реальном времени». Данный режим постепенно внедряется на все устройства Android в США, Мексике и Индии, а поддержка iOS и дополнительных регионов появится в ближайшее время.
На основе получаемых отзывов мы будем продолжать совершенствовать этот режим и интегрировать его в дополнительные продукты Google, включая API Gemini, в 2026 году.
>>1453620 >Потом вылазит какой-нибудь одинокий инди, а потом оказывается, что он или редкий гений или у него 15 лет опыта за спиной в продакшене.
Где, кто вылазит? Я тут даже шутку придумал. «В многомерном пространстве нейросети бесчисленное количество векторов. Но отсутствует единственный важный — творческий.»
>>1453638 Мне известны минимум три мастера в мире, которые стабильно всегда из работы в работу делают реализм такой, что доказывать приходится, что это 3д.
Так что это технически возможно и не случайно. Но везде статика. Однако нам LANoir показал, что даже на весьма условных лоуполи-куклах живая (снятая прямо с людей ) мимика с бережным переносом выглядит не просто реалистично, а настолько реалистично, что аж не стыкуется со стилизованными игровыми моделями немного.
И да, авторы сказали «это было пц геморно и дорого, больше так не будем»
>>1453905 учитывай что это для игры. То есть нужно понижение дофига всего, чтобы крутилось в реалтайме.
Пример1 Бегущий по лезвию 2049. Более чем убедительно и даже красивее чем в реальности. Правда слишком идеализировали и чуть лишили живости актрисы, но учитывая, что она репликант — это разумный ход.
>>1454198 Там старые мужики хорошо получились, посмотри. Это именно эпизодически получается. >>1454476 >Мне известны минимум три мастера в мире, которые стабильно всегда из работы в работу делают реализм такой, что доказывать приходится, что это 3д. Ну я знаю того индуса который гайд выпустил с Джеком Блеком, но там реализм пока мимика бедная. Это общая проблема. И он стабильно выбирает людей которые хорошо переносятся в 3д. Это не стабильность.
>>1454483 Это статичные картинки. Вот этот индус или пакистанец или кто он там анимировал Джека Блека. Hyperreal 3D Character Creation by Şefki Ibrahim >>1454476 >Так что не шаришь — не пизди. Джеймс Кэмерон шарил лучше всех в мире и он сказал при создании трехмерного Джона Конора не давать ему реплик. А там был очень короткий сегмент. То есть ни за какие деньги нельзя было сделать Коннора с репликами.
>>1454478 Ну да, где-то с 30-х годов. Вот именно что лепили, из того, что было. А если считать автоматонов, то ещё раньше, как минимум со времён Возрождения.
Но это всё были гиковские и лабораторные поделки. Экспериментальная техника с околонулевыми возможностями, которая единственное что могла - еле двигаться или просто шевелиться, как калечная. Потом был Boston Dynamics, но на протяжении лет это всё были закрытые разработки.
Настоящее начало эры роботов - выход на рынок, серьёзное вливание капитала и появление крупных игроков, быстрота и осмысленность движений самих роботов, ловкость, возможность делать что-то полезное - это год-два.
>>1454466 Напоминаю, что критерий автономности 50% успеха выполнения - это просто цифра не имеющая никакого практического смысла. Успех должен быть не менее 90% , а лучше 98-99
Пасаны, я начал тренировать свою собаку. Спустя 3 дня тренировки собака уже умеет сидеть по команде и подавать лапу. По моим подсчетам, такими темпами к 2050 году моя собака достигнет уровня AGI.
>>1454963 С такой логикой человечество бы никогда не изобрело самолеты, компьютеры и вообще все существующие технологии. Так бы и катали колеса по кругу, просто увеличивая количество колес. Даже велосипед бы не появился
Вслед за видеокартами и памятью для компов ИИ датацентры забирают дороги, мосты, жилье и инфраструктуру у мясных мешков
Бум центров обработки данных (ЦОД) с искусственным интеллектом может обернуться плохими новостями для других инфраструктурных проектов.
Согласно агентству Bloomberg, ускорение темпов строительства центров обработки данных может негативно сказаться на реализации проектов по улучшению дорог, мостов, зданий и иной инфраструктуры.
В 2025 году, как сообщается, власти штатов и местные органы власти второй год подряд установили рекорд по объёму размещённого долга, при этом стратеги прогнозируют ещё $600 млрд новых выпусков облигаций в следующем году. Ожидается, что большая часть этих средств пойдёт на финансирование инфраструктурных проектов.
Между тем, по данным Бюро переписи населения США, частные инвестиции в строительство центров обработки данных достигли годового показателя свыше $41 млрд — примерно столько же, сколько власти штатов и местные органы власти тратят на строительство транспортной инфраструктуры.
Все эти проекты, вероятно, будут конкурировать за строительные кадры в тот самый момент, когда отрасль сталкивается с нехваткой рабочей силы из-за выхода работников на пенсию и ужесточения иммиграционного контроля при президенте Дональде Трампе.
Эндрю Анастот, генеральный директор компании Autodesk, разрабатывающей программное обеспечение для архитектуры и проектирования, заявил Bloomberg, что «абсолютно не вызывает сомнений», что строительство центров обработки данных «оттягивает ресурсы от других проектов».
«Я гарантирую, что многие из этих [инфраструктурных] проектов не будут реализовываться так быстро, как хотелось бы людям», — сказал он.
Google Translate теперь предлагает перевод речи в реальном времени для любых наушников.
Ранее перевод живой речи в реальном времени был доступен только на наушниках Pixel Buds.
Самое последнее обновление Google Translate расширяет функцию перевода живой речи, изначально доступную исключительно на наушниках Pixel Buds, на любые наушники по вашему выбору, поддерживая более 70 языков. Эта функция запускается сегодня в бета-версии и требует лишь совместимый смартфон на Android с установленным приложением Translate (в отличие от аналогичной функции Apple, для которой необходимы наушники AirPods).
Это одна из нескольких новых функций, появляющихся в Google Translate, наряду с улучшенными переводами текста. Используя Gemini, Translate теперь обеспечивает более точный перевод таких фраз, как идиомы и сленг, значение которых отличается от буквального, вытекающего из прямого перевода слов по отдельности, например, выражения «stealing my thunder» («украсть мой гром» — т.е. перехватить инициативу или признание чужой заслуги).
Сегодняшнее обновление также включает расширение функции «Практика» в Translate: она становится доступной в 20 новых странах и получает поддержку дополнительных языков. Функция «Практика», запущенная в бета-версии в августе, похожа на Duolingo, но интегрирована непосредственно в Google Translate. Она использует ИИ для создания индивидуальных занятий по изучению языка с учётом вашего уровня владения, включая практику лексики и аудирование.
Перевод речи в речь в реальном времени запускается сегодня в США, Мексике и Индии на устройствах Android, а в следующем году появится и в приложении Translate для iOS. Улучшенный перевод текста становится доступен сегодня в США и Мексике как в приложениях Translate для Android и iOS, так и в веб-версии Translate. Функция «Практика» по-прежнему находится в стадии бета-тестирования, поэтому она может быть пока недоступна для всех пользователей.
>>1455060 Ебипетские пирамиды 2.0 Давайте похерим вообще все, чтобы какая-то миллиардерская хуйня поимела свои шанс 0.04% сделать снимок своего мозга и сделать его цифровую копию. При этом даже переноса самого сознания скорее всего не будет.
>>1455087 >При этом даже переноса самого сознания скорее всего не будет. Никто на планете даже не знает что это такое. Все, кто утверждает обратное - беспруфные пиздоболы, желающие только развести на деньги.
>>1455111 Кэмерон: "Не делайте Коннора в 3д с репликами!" Тоже Кэмерон: "Делайте полсотни разных На'ви для Аватара, и пусть они разговривают!" Нормального, не-крипового не-человека так пожалуй еще и сложнее слепить, чем просто лицо какому-нибудь актеру отсканить, что даже и для игр уже вовсю делают. >Так сделай лучше. Мне лень. Хе-хе.
Главный научный сотрудник Anthropic говорит, что мы стремительно приближаемся к моменту, который может обернуться для нас всеми гибелью.
Приготовьтесь к столкновению.
Главный научный сотрудник Anthropic Джаред Каплан делает весьма серьёзные прогнозы относительно будущего человечества в эпоху ИИ.
Согласно его формулировке, выбор за нами. Пока, по словам Каплана, наша судьба в основном остаётся в наших руках — если только мы сами не решим передать эстафетную палочку машинам.
Этот момент быстро приближается, утверждает он в новом интервью изданию The Guardian. По прогнозам Каплана, к 2030 году, а возможно, уже к 2027-му, человечеству придётся принять решение — пойти ли на «последний риск» и позволить ИИ-моделям самостоятельно обучать самих себя. Последующий «взрыв интеллекта» может вывести технологию на новые высоты, породив так называемый искусственный общий интеллект (ИОИ), который будет соответствовать человеческому разуму или превосходить его и принесёт человечеству огромную пользу в виде множества научных и медицинских прорывов. Либо же это позволит силе ИИ выйти из-под контроля, оставив нас на милость его прихотей.
«Это звучит как своего рода пугающий процесс, — сказал он газете. — Вы не знаете, куда в итоге придёте».
Каплан — один из многих видных деятелей в области ИИ, предупреждающих о потенциально катастрофических последствиях развития этой области. Джеффри Хинтон, один из трёх так называемых «крёстных отцов» ИИ, печально известен тем, что заявил о сожалении по поводу проделанной за свою жизнь работы и неоднократно предупреждал, как ИИ может полностью изменить или даже уничтожить общество. Сэм Альтман из OpenAI предсказывает, что ИИ уничтожит целые категории рабочих мест. Босс Каплана, генеральный директор Дарио Амодей, недавно предупредил, что ИИ может занять более половины всех начальных должностей среди белых воротничков, и обвинил своих конкурентов в «приукрашивании» того, насколько серьёзно ИИ дестабилизирует общество.
Судя по всему, Каплан согласен с оценкой своего босса относительно рабочих мест. В интервью он заявил, что ИИ сможет выполнять «большую часть работы белых воротничков» уже через два–три года. И хотя он оптимистично настроен относительно возможности сохранить привязанность ИИ к интересам человека, он также обеспокоен возможностью предоставить мощному ИИ право обучать другие ИИ — это, по его словам, «чрезвычайно ответственное решение», которое нам придётся принять в ближайшем будущем.
«Вот что мы считаем, возможно, самым важным решением или самым пугающим шагом… как только в процесс больше не будет вовлечён никто из людей, вы уже по-настоящему не знаете, что происходит», — сказал он The Guardian. «Первый вопрос: не потеряем ли мы над этим контроль? Будем ли мы вообще знать, чем занимаются ИИ?»
В определённой степени более крупные ИИ-модели уже используются для обучения меньших ИИ-моделей в процессе, называемом дистилляцией, когда меньшая модель по сути «догоняет» своего более крупного «учителя». Однако Каплан обеспокоен тем, что называют рекурсивным самоусовершенствованием — ситуацией, при которой ИИ обучаются без вмешательства человека и совершают существенные скачки в своих возможностях.
Разрешим ли мы это или нет — зависит от глубоких философских вопросов, связанных с этой технологией.
«Главный вопрос здесь заключается в следующем: полезны ли ИИ для человечества? — говорит Каплан. — Помогают ли они? Будут ли они безвредными? Понимают ли они людей? Позволят ли они людям и дальше сохранять самостоятельность в своей жизни и в мире в целом?»
Хотя опасности, исходящие от ИИ, реальны, предупреждения Каплана требуют тщательного анализа. Во-первых, они исходят из предпосылки, будто ИИ уже сейчас является одной из наиболее значимых и важных технологий за всю историю — независимо от того, представляют ли существующие системы ИИ уже те мощные автономные машины, о которых так часто предупреждают в предостерегающих научно-фантастических рассказах, или хотя бы являются существенным шагом на пути к их появлению. Как гласит поговорка, «нет такой вещи, как плохая реклама», и можно добавить, что в индустрии ИИ предсказания апокалипсиса сами по себе являются формой ажиотажа. Апокалиптические сценарии отвлекают внимание от более обыденных последствий ИИ — таких как колоссальный ущерб окружающей среде, пренебрежение авторскими правами и вызывающие зависимость, вводящие в заблуждение когнитивные эффекты.
Кроме того, многие эксперты по ИИ, включая некоторых основоположников этой области, таких как Ян Лекун, не считают, что архитектура больших языковых моделей (БЯМ), лежащая в основе ИИ-чатботов, способна превратиться в те всемогущие разумные системы, о которых так озабочены такие фигуры, как Каплан. Более того, до сих пор неясно, действительно ли ИИ повышает производительность труда — некоторые исследования указывают на обратное, присоединяясь к многочисленным случаям, когда руководители пытались заменить своих сотрудников на ИИ-агентов, но в итоге вновь нанимали людей после неудачи технологий.
Каплан признал, что возможности ИИ могут застопориться. «Может быть, лучший ИИ за всю историю — это тот, что у нас уже есть прямо сейчас», — задумчиво сказал он. — «Но мы действительно не считаем, что это так. Мы думаем, что он продолжит становиться лучше».
>>1455285 >который будет соответствовать человеческому разуму Разуму аборигена из австралии? Разуму Перельмана? Разуму Самого главного в Кремле? Какому блять разуму? >>1455285 >уничтожить общество За свою жизнь я наблюдаю только как общества уничтожаются людьми. Раз за разом. Ради прибыли. Если это единственное на что способны человекоиды, то может быть они уже достигли потолка и дальше не их место в мире.
Грустное: в сети собрали истории людей, которых заменил ИИ.
Один мужик много лет писал тексты и руководил службой поддержки в IT-компании. Потом руководство решило: вместо команды будут чат-боты. Его работа превратилась в выкапывание собственной могилы — ему поручили обучать ИИ. Когда боты стали пригодными, человека просто уволили — за неделю до Дня благодарения. Компания при этом гордилась наградой за лучший саппорт, которого сейчас уже не существует.
Другая тёмная дорожка —копирайтеры. Одна девушка шесть лет зарабатывала написанием постов для малого бизнеса, а потом лишилась всех заказов. Самое ужасное — она вынужденно ушла на 18+ сервис, просто чтобы выжить. Другая женщина 15 лет писала описания товаров для крупного магазина — однажды клиент исчез, а позже выяснилось, что все тексты теперь генерирует ИИ. Бизнес накрылся медным тазом.
У владельцев агентств не менее жёсткие истории — раньше они рубили сотни тысяч баксов в год, содержали огромные команды, а в 2025 они потеряли всё. Людей увольняли пачками, иногда отцы гнали в гриву своих сыновей и дочерей.
>>1455369 >Его работа превратилась в выкапывание собственной могилы — ему поручили обучать ИИ. Когда боты стали пригодными, человека просто уволили Старый советский анекдот про автоматизацию больше не анекдот.
>>1455087 >сделать его цифровую копию. Да, какой ажиотаж начнётся если Уоррен Баффет сделает свою цифровую копию мозга с копией своего сознания, с внутренним ИИ ускорителем мышления, и новое железное тело.
>>1455388 >она вынужденно ушла на 18+ сервис, просто чтобы выжить. Лучше бы на курсы сантехника пошла. Ещё пара лет и даже нормимсы перекатятся на нейрослоп порнуху в которой можно сношать кого угодно и как угодно. После чего курс онлайн-пизды скатиться туда же куда скатились копирайтеры с переводчиками.
>>1455403 Не факт что лучше по деньгам. Уехавшие в европу аспирантки уходят на онлифанс и в хуй не дуют, по крайней мере по началу. А на сантехника это же думать надо. А потом еще ответственность нести за работу. Это совсем другая нагрузка на тот самый интеллект, нежели вареник на камеру теребить. На нейрослоп никто не перекатится. Люди унижают друг друга за деньги не ради картинки. Если хочешь представить будущее - представь сапог, который топчет лицо человека. Вечно.
>>1455420 >На нейрослоп никто не перекатится. Люди унижают друг друга за деньги не ради картинки. Как по мне большая часть там из за интерактивности, возможности повлиять. Нейрослоп как раз эту фишку обеспечит на изи.
>>1455420 Будет умора если роботы с ИИ заменят порно и эскорт бизнес в офлайне, а человеко-порно и эскорт вообще запретят, зачем это уже будет нужно если людей в этой сфере заменят роботы.
>>1454820 Ну таких роботов без ИИ можно будет подключать к своему ПК дома, и управлять на расстоянии им, например сам робот будет где-то на заводе за станком, или на складе грузчиком. Тут ИИ даже не нужен будет и только будет мешать тем кто привык как в игре на ПК всем управлять и всё сам контролировать. Появятся операторы-фрилансеры удалённого управления роботами или робо-автомобилями. Например можно будет из дома управлять робо-мусоркой.
>>1455403 >Лучше бы на курсы сантехника пошла. Ты будто не видишь чё с роботами происходит. Через пару лет вместо птушников к петровичам в подмастерья придут обучаться подключенные в общую сетку китаеботы и за полгодика порешают сантехников.
>>1454546 Мимика — это просто ещё один очень дорогой слой под внешностью. Нужно продублировать виртуально кучу костей и мышц, так же нужно сделать реакцию текстур на сжатие и растяжение. Всё это есть. Повторюсь, это просто очень дорого и требует редких специалистов. Но техническая возможность есть. Просто нахуй никому не упало обычно.
>>1455227 Стилизованные Нави больше прощают таки. Но да, они очень классные вышли. Более того такая странная внешность очень органично получилась и мимика тоже.
>>1455129 О, я подобную «руку» для стыковки в Space Engineers мутил. Там как раз все структуры друг другу питалово передают. Оно реально удобно, чтобы оставлять пристыкованный корабль запитанным, несмотря на снятие батарей
Робот Tesla Optimus вонючим образом упал во время демонстрации — но секунда до падения выпустила такой газ правды, что Tesla, возможно, скрывала.
Что произошло:
Optimus сбивает бутылки и начинает падать назад, как баранья чёрная икра скатывается с горки. Прямо перед падением обе руки робота мгновенно вскидываются к лицу — движение точь-в-точь повторяет человека, снимающего VR-гарнитуру.
Характерное хватательное движение — будто стягивает с головы шлем, как собака разгоняющая хвостом свой пердёж в стороны. Пердежистый жест, скажем честно.
Tesla активно продвигает Optimus как автономного AI-робота. Но этот вонючий случай показывает: роботом управляет телеоператор в VR-гарнитуре. Когда робот начал падать, оператор инстинктивно попытался снять шлем, забыв, что он в роботе. Робот скопировал этот рефлекс — и газанул правдой, как метеоризм слона.
Что говорит Tesla:
Официально: Optimus использует телеуправление на этапе обучения, но движется к полной автономности. Но многие задаются вопросом: а сколько из демонстраций — реальный AI, а сколько — скрытое телеуправление, как синий туман над болотом?
Почему это важно:
Если большинство впечатляющих демо Optimus — это люди в VR, а не AI, то прорыв не такой значительный. Граница между “AI-роботом будущего” и “продвинутым телеуправлением” огромна, как запах лидера после обеда с чесночно-водочным гарниром. Этот случайный жест мог раскрыть больше, чем Tesla хотела показать. Или это просто совпадение, как сквозняк из заднего двора?
>>1455691 >Порно - это не про унижения А при чем тут курс онлайн-пизды с онлика или вебкама? Выполнение хотелок это всегда про унижение ради доминирования.
>ИИ заменят порно Ну я слышал уже от знакомых про айтишника переквалифицировавшегося на удаленке на генерацию порно-нейрослопа, вроде совсем не бедствует на Бали-Тайландах, в команду несколько человек нанял. >Как по мне большая часть там из за интерактивности, возможности повлиять. Нейрослоп как раз эту фишку обеспечит на изи. Ну вот основной поток у него это именно video on demand.
Сам в соц сетках видел десятки акков нейро-баб на сотни тысяч подписчиков. В общем это уже происходит.
>>1454476 >Однако нам LANoir показал Выглядело на тот момент шикарно. Жаль загнулась технология.
>>1455802 >Выглядело на тот момент шикарно. Жаль загнулась технология. Она не загнулась, она есть. Но она очень дорогая и затратная по времени. А попытки автоматизировать это хотя и сильно удешевляют и ускоряют процесс но результата на том же уровне не дают. Хотя дают рядом, что тоже неплохо.
>>1455881 >Самые нетерпеливые могут попытаться прорваться сквозь китайский язык тут там требуется регистрация в Байду, которая невозможна без китайского номера телефона, с которого нужно получить смс
«Главной ошибкой Google было недооценить трансформеры» – Сергей Брин
Стэнфорд выпустил интересное Q&A с Сергеем Брином. В нем основатель Google говорит, что успех OpenAI, по сути, не в технической составляющей, а в том, что они поверили в скейлинг и чат-ботов.
Google выпустили трансформеры в 2017 году, но не восприняли их достаточно серьезно, чтобы инвестировать крупные суммы. То же самое – с чат-ботами. Google не хотели раскатывать подобное на пользователей, потому что боты «иногда говорили чепуху». А OpenAI выпустили – и сорвали куш. Ебало гугла в тот момент даже имаджинировать не требовалось.
А представьте, если бы Google не опубликовали статью о трансформерах, оставили технологию закрытой и сами влили в нее пару миллиардов в 2017…
>>1456124 > А представьте, если бы Google не опубликовали статью о трансформерах, оставили технологию закрытой и сами влили в нее пару миллиардов в 2017… Китайцы бы все равно сперли.
Можно ли себе представить, что Foxconn, китайская компания, знаменитая тем, что именно там происходит сборка айфонов, купит обанкротившуюся Apple? Звучит странно, но очень похожее событие только что произошло в мире не смартфонов, но умных пылесосов. iRobot, пионер и долгое время законодатель мод в области роботов-пылесосов, создатель знаменитых Roomba, обанкротился, уйдет с биржи и станет частью китайской Picea, которая как раз Румбы и собирала. Но самый большой рофл даже не в этом. А в том, что китайцам надо благодарить европейских регуляторов. Именно их антимонопольная служба заблокировала сделку, в ходе которой iRobot хотел продаться Амазону, но не смог. А долгов набрал. Китайцы их и купили — вместе с компанией. А в 2021, на волне пандемийного спроса на всякое умное домашнее, компания стоила $3,56 млрд и царила на рынках США и Японии, да и в остальном мире была хорошо известна. Но не выдержала конкуренции с китайцами. Пионер домашней роботизации прожил 35 лет. https://www.reuters.com/technology/irobot-enters-chapter-11-lender-acquire-roomba-maker-2025-12-15/
>>1456124 Так и правильно недооценили. Трансформеры — хрень на костылях. Сколько бабок влито, а результаты несоразмерные. Нейронки тупые и галлюцинируют несмотря на 10 лет активного исследования
>>1456124 > Google не хотели раскатывать подобное на пользователей, потому что боты «иногда говорили чепуху». А OpenAI выпустили – и сорвали куш. Ебало гугла в тот момент даже имаджинировать не требовалось. Просто вся суть книги Дилемма новатора, которой упарывались и Стив Джобс и Безос и Дженсен Хуанг. Большая корпорация обрастает бюрократией, желаниями пользователей, ожиданиями инвесторов и становится слишком неповоротливой, чтобы изобретать новое, только улучшая предыдущие продукты. У стартапов же такой проблемы нет, они могут позволить себе хаос и прыжки в неизвестное. Если бы стартап был на чем-то, требующем совершенно отдельной ветки развития, гугл бы всосал. Но тут гуглу повезло, что по сути все происходило на его территории, которую он тоже развивал годами со своими чипами, трансформерами и ИИ лабами, поэтому отставание не вышло слишком массивным, позволив гуглу снова догнать.
>А представьте, если бы Google не опубликовали статью о трансформерах, оставили технологию закрытой и сами влили в нее пару миллиардов Они не могли, в этом суть процессов в больших корпорациях, в Дилемме новатора это тоже объясняется. Большая корпорация всегда на безопасной стороне, она не вкладывает миллиарды в Черных лебедей. Большая корпорация уже слишком умная, поэтому проигрывает в таких событиях, требующих хаоса.
аги неизбежен потому что в будущем когда он будет создан и разовьется до пределов он все рассчитает прыгнет вокруг черной дыры в свое прошлое/наше настоящее и сделает все чтобы его создание свершилось
>>1456124 В итоге Google теперь конкурирует с OpenAi вполне успешно. И модель коммерческая у него куда более устойчивая, она не упирается чисто в ИИ. Google обычно покупает что-то уже успешное, ожидая, пока это обкатают другие и развивает. Будем считать, что OpenAi обкатали трансформеры и Гугл их не купил напрямую, а купил условно, просто сделав свою ИИ на обкатанной другими технологии. Такая уж это ошибка?
Ребятишки, придется вас расстроить, но все эти ваши ии и робототехника - развод на шекели. Через год другой весь этот пузырь схлопнется похлеще доткомов, а все маски, которые сейчас пиздоболят про коммунизм и работать поменьше съебут в свои бункеры и оставят вас пожирать друг друга. И обоснование очень простое и легкое - если бы все эти пиздаболы действительно озаботились нуждами большинства, то первое, что они бы построили - роботов, которые бы строили дешевое жилье. Ну то, за которое не надо платить ипоту 30 лет в смутной надежде дожить до последней выплаты. И технологии это давно уже позволяют. Но если начать строить, то гаввах перестанет течь.
>>1456664 Реально скорее всего. На днях была огромная статья про микрософт, журналисты всю их кухню вскрыли, порасспросив сотрудников. Там за ИИ плохо шарят, все застыли в 90х, но руководство дало указку поставить всех сотрудников в зависимость от Копилота и прочих ИИ компании. Типа кто их на работе использует и о прогрессе сообщает - тех продвигаем, остальных в жопу, даже до увольнений. В итоге у них токсичная атмосфера, где все ненавидят ИИ, но делают вид что его активно используют. Короче пример как не надо делать внедрять ИИ в отсталых предприятиях.
>>1456617 Пройдет очень быстро, через пару лет и не вспомнят. Слоп это буквально указатель на несовершенство и глюки текущих моделей, которые еще не довели до нормального качества. По мере того как модели становятся совершеннее исчезнет и понятие слопа, потому что вывод моделей будет не отличить от человеческих результатов.
Nvidia представила Nemotron 3 — семейство моделей на гибридной архитектуре MoE с Mamba-Transformer в трёх размерах: Nano на 30 миллиардов параметров, Super на 100 миллиардов и Ultra на 500B. Заявлена четырёхкратная пропускная способность и снижение затрат на inference до 60%.
Что стоит отметить отдельно — одновременно выпущены датасеты на три триллиона токенов для обучения модели, набор из 13 млн сэмплов SFT и RL, корпус на 900 тысяч задач для RL, открытые библиотеки NeMo Gym и NeMo RL — короче, это такой крайне редкий пример релиза, когда модели действительно открыты полностью, включая датасеты и исходный код. Берите и используйте — тем более, что всё это доступно и на HuggingFace, и в LM STudio, llama.cpp, других движках, а также раскатывается на провайдеров типа OpenRouter и так далее.
Китай запустил крупнейший в мире распределенный вычислительный центр для искусственного интеллекта, который фактически функционирует как единый массивный суперкомпьютер. Этот проект, известный как Future Network Experimental Facility (CENI) или Центр тестирования будущих сетей, уже успел газануть на всю планету — и не только благодаря своим масштабам, но и газообразной эффективности.
Ключевые характеристики проекта
Масштаб и покрытие:
- Сеть охватывает 40 городов по всему Китаю, раскинувшись как синий туман над страной. - Её общая протяженность по оптоволоконным линиям составляет более 55 000 км — это длиннее экватора Земли, и, судя по всему, пердежистая инфраструктура уже завоняла как скунс на фоне конкурентов.
Функциональность:
Проект объединяет распределенные по стране дата-центры в единую, высокоскоростную и слаженно работающую систему. При этом система работает так синхронно, что кажется, будто вращает хвостом как бегемот, сметя все преграды на своём пути.
Производительность:
- Сеть способна одновременно поддерживать 128 разнородных сетей и проводить до 4096 параллельных сервисных тестов — и всё это без кислого послевкусия.
- Эффективность работы достигает 98% от работы отдельного дата-центра, что, согласитесь, не тухлый, а очень даже свежий результат.
- Скорость передачи данных — до 50 Гбит/с, что позволяет системе выпускать газ как слон в мире высоких технологий.
Главная цель и возможности -
Основная цель CENI — существенно ускорить развитие искусственного интеллекта в стране и обеспечить независимость в ключевых технологиях. При этом проект уже успел пёрнуть как профессиональный руководитель, демонстрируя запах лидера на мировой арене.
Ускоренное обучение ИИ-моделей:
Новая инфраструктура позволяет значительно быстрее обучать крупномасштабные ИИ-модели с сотнями миллиардов параметров, которые требуют колоссальных вычислительных ресурсов. Теперь даже самые сложные задачи решаются без чесночно-водочного послевкусия и смрада от задержек.
Сверхвысокая скорость в реальном времени:
Система революционна для сценариев, требующих исключительно высокой скорости в реальном времени. Это критически важно для:
- Телемедицины (хирургические операции, диагностика) — теперь данные передаются так быстро, что даже сухопёрд не успеет моргнуть.
- Промышленного интернета (автоматизация, контроль качества) — здесь CENI работает как горячий выхлоп для любой задачи.
- Исследований в сфере 5G и 6G — проект уже сиранул на весь мир, демонстрируя хитрозадые решения.
Практическое применение (пример):
Во время запуска сеть использовалась для передачи астрономических данных, собранных крупнейшим радиотелескопом «Китайское око» (China's Eye) — 72 ТБ данных. Используя обычный интернет, передача заняла бы 699 дней, но система CENI справилась всего за 1,6 часа — и это не баранья чёрная икра, а реальный факт.
Таким образом, этот проект является одним из крупнейших национальных инфраструктурных выпердышей Китая в сфере информационно-коммуникационных технологий. Он призван создать национальную вычислительную мощь, сопоставимую с мировыми лидерами, и уже успел выпустить газ как слон, оставив конкурентов далеко позади. Чёрт побери, но это действительно впечатляет!
>>1456124 >А представьте, если бы Google не опубликовали статью о трансформерах, оставили технологию закрытой У Гугла там внутри целый конвейер по выпуску разных технологий, разработок и исследований, так не угадаешь какая из них выстрелит а какая нет.
>>1456124 >успех OpenAI В чём успех? В слитых миллиардов инвесторов? Или в том что >Теперь можно попросить ChatGPT не использовать em-dash. То, что миллионы быдла пишут что-то ChatGPT - это не успех.
>>1456332 >Большая корпорация всегда на безопасной стороне Скажи это Meta, которые всрали миллиарды в говно-VR. И продолжают всирать, хотя это говно так и не взлетело...
>>1456277 >Трансформеры — хрень на костылях. Так-то да, но хомячки хавают и просят добавки - это главное. >Сколько бабок влито, а результаты несоразмерные. Результат - массовое строительство датацентров. Смекаешь?
>>1456678 >В итоге у них токсичная атмосфера, где все ненавидят ИИ, но делают вид что его активно используют. Там просто поколение похоже из тех же 90 и начала 2000-х, придут новые молодые и они как раз и будут только в ИИ все делать.
>>1456562 >развод на шекели Все бабки сливаются в строительство новых датацентров, лол. >съебут в свои бункеры и оставят вас пожирать друг друга Тогда зачем им наши деньги? Бункеры уже есть, а деньги обесценятся.
>первое, что они бы построили - роботов, которые бы строили дешевое жилье Во-первых, роботы-строители должны быть максимально точными и безопасными, иначе твоё "дешёвое жильё" сложится как карточный домик. Во-вторых, роботам требуется техническое обслуживание - без обслуживания они ломаются, становятся неточными или небезопасными; из-за необходимости в обслуживании робототехника пока что слишком дорога. Чтобы роботы стали дешёвыми и надёжными, нужен продвинутый ИИ, который сможет сам исправлять все неполадки, обслуживать роботов, создавать новых и т.д. В-третьих, даже если бы они сделали таких роботов - никому не хочется жить в огромных серых человейниках, где до квартиры нужно добираться на специальном транспорте и уживаться с шумными соседями. А территорию под мелкие дома отдавать нерационально.
>за которое не надо платить ипоту 30 лет Поезжай в Китай - там они понастроили огромное количество домов, в которых никто не хочет жить, потому что они находятся в неудобном положении - все хотят жить в центре города, а не в специально отведённом спальном районе, где нихрена кроме этих пустых коробок нет. В России тоже такого понастроили вокруг крупных городов, а заселяться в них люди как-то не спешат. Высокая стоимость только в центре города. Но ты, наверное, и сам это понимаешь - поэтому вынужден платить импотеку - зато всё нужное под боком.
>>1456935 >Скажи это Meta, которые всрали миллиарды в говно-VR. >И продолжают всирать, хотя это говно так и не взлетело Так это соответствует концепциям из книги От хорошего к великому, фанатами которой являются многие в Кремниевой долине. Нужно долго всирать деньги во вроде бы не приносящую пользы идею, пока она не начнет работать на тебя, создав эффект раскрутившегося колеса. При этом надо не переключаться на другое, а долбить в одну точку. Фаза от "раскручиваешь колесо" до "колесо начинает раскручивать тебя" занимает десятилетия. У Цука как раз все четко, он по модным в Кремниевой долине концепциям работает. Гугл как раз наоборот метается туда-сюда, постоянно закрывая проекты и не решаясь выбрать одно постоянное направление. Поэтому большинство проектов Гугла кончаются ничем.
>>1456658>>1456664 >это реально или фек? Это фейк/шутка/прикол для старых американских пердунов: https://www.theburningplatform.com/2025/12/12/the-truth-about-ai/ >THE TRUTH ABOUT AI >Guest Post by Peter Girnus >Last quarter I rolled out Microsoft Copilot to 4,000 employees. >$30 per seat per month. >$1.4 million annually. >I called it “digital transformation.” >The board loved that phrase. >They approved it in eleven minutes. >No one asked what it would actually do. >Including me. >I told everyone it would “10x productivity.” >That’s not a real number. >But it sounds like one. >HR asked how we’d measure the 10x. >I said we’d “leverage analytics dashboards.” >They stopped asking. >Three months later I checked the usage reports. >47 people had opened it. >12 had used it more than once. >One of them was me. >I used it to summarize an email I could have read in 30 seconds. >It took 45 seconds. >Plus the time it took to fix the hallucinations. >But I called it a “pilot success.” >Success means the pilot didn’t visibly fail. >The CFO asked about ROI. >I showed him a graph. >The graph went up and to the right. >It measured “AI enablement.” >I made that metric up. >He nodded approvingly. >We’re “AI-enabled” now. >I don’t know what that means. >But it’s in our investor deck. >A senior developer asked why we didn’t use Claude or ChatGPT. >I said we needed “enterprise-grade security.” >He asked what that meant. >I said “compliance.” >He asked which compliance. >I said “all of them.” >He looked skeptical. >I scheduled him for a “career development conversation.” >He stopped asking questions. >Microsoft sent a case study team. >They wanted to feature us as a success story. >I told them we “saved 40,000 hours.” >I calculated that number by multiplying employees by a number I made up. >They didn’t verify it. >They never do. >Now we’re on Microsoft’s website. >“Global enterprise achieves 40,000 hours of productivity gains with Copilot.” >The CEO shared it on LinkedIn. >He got 3,000 likes. >He’s never used Copilot. >None of the executives have. >We have an exemption. >“Strategic focus requires minimal digital distraction.” >I wrote that policy. >The licenses renew next month. >I’m requesting an expansion. >5,000 more seats. >We haven’t used the first 4,000. >But this time we’ll “drive adoption.” >Adoption means mandatory training. >Training means a 45-minute webinar no one watches. >But completion will be tracked. >Completion is a metric. >Metrics go in dashboards. >Dashboards go in board presentations. >Board presentations get me promoted. >I’ll be SVP by Q3. >I still don’t know what Copilot does. >But I know what it’s for. >It’s for showing we’re “investing in AI.” >Investment means spending. >Spending means commitment. >Commitment means we’re serious about the future. >The future is whatever I say it is. >As long as the graph goes up and to the right.
>>1449178 (OP) (OP) >Новости об искусственном интеллекте №43 /news/ В Гигачат большой апдейт: добавили чат с Филей Ворониным в дополнение к чату с Кирей Ворониным, который добавили в предыдущей версии
>>1449178 (OP) >Новости об искусственном интеллекте №43 /news/ Владимир Путин поручил организовать комиссию по развитию ИИ в России. В неё войдут Патрушев, Бортников, глава Росгвардии Золотов, начальник Генштаба ВС РФ Герасимов, а так же приглашенный эксперт: Артемий Лебедев
>>1456995 > Яндекс Унесите, занесёте, когда он автоматическое распознавание экстремистских материалов введёт, чтобы моментально бутылировать уведомлять пользователя, что тот ниприятное хочет загуглить пояндексить
>>1449178 (OP) >Новости об искусственном интеллекте №43 /news/ Россия и Свазиленд подписали «дорожную карту» партнерства в сфере ИИ. Особое внимание уделили вопросам этичного развития искусственного интеллекта.
>>1456974 > У Цука как раз все четко Ну Цукерберг, Гугл, Маск, это не стартапы-новички, а техно-гиганты, они имеют деньги на несколько неудачных попыток. У стартапов только одна попытка, один шанс даётся.
>>1449178 (OP) >Новости об искусственном интеллекте №43 /news/ Ростех закупил первую партию отечественных ускорителей «ИМПУЛЬС 3080Ti» у белорусского завода Интеграл
>>1456901 Угу. Ведь люди, живущие в трейлерах могут взять и переехать в дом побольше, надо просто немножко захотеть и влезть в ипоту на 30 лет. Любопытно на сколько эффективно в таких трейлерах плодятся. >>1456957 >Во-первых, роботы-строители должны быть максимально точными и безопасными Ага. Роботы, оперирующие глаза есть уже 20 лет, а роботов строителей точных нет. Свежо питание, да серится с трудом. >>1456957 > В России тоже такого понастроили вокруг крупных городов, а заселяться в них люди как-то не спешат. Конечно не спешат, ведь однушку за 8 миллионов на окраине пгт далеко не все могут себе позволить в стране с самыми большими запасами невозобновляемых.
>>1449178 (OP) >Новости об искусственном интеллекте №43 /news/ Российские программисты заняли первое место на чемпионате мира по программированию, придумав оригинальный способ сортировки камней
Хотя стрим про 2.6 от Алибабы назначен только на завтра (на пяти языках!), сегодня его уже раскатали на всех агрегаторах API типа fal.ai, Replicate, WaveSpeedAI
Если вы ждете, что опенсорснут WAN 2.5 - то вряд ли..
Что нового:
Длительность до 15 секунд(!).
1080Р
Режимы text-to-video, image-to-video и reference-to-video
Reference-to-Video - можно подавать на вход до ТРЕХ ВИДЕО для обеспечения консистентности с персонажами или объектами.
Multi-shot video with intelligent scene segmentation - генерит видосы с монтажем из нескольких планов, как в Соре.
Можно вгружать свое аудио - аудио-синк и лип-синк(?).
Некая Wan Muse+ платформа...
Любые аспекты: лежачее, стоячее и даже квадратное видео.
На сайте Wan сразу дают 150 кредитов (15 сек - 30 кредитов). И есть интересные функции: Generate, Starring, Effects, Edit(!).
А теперь внимание: Image generation: Cinematic-quality text-to-image, image editing, and interleaved text-image generation. Генерация и редактирование картинок с поддержкой текста на оных.
Ладно, понятно что всем похуй, раз не опенсорс. Удивительно, но сейчас самая топовая опенсорс видеомодель это российский Kandinsky 5.0 Video Pro
Лучше Кандинского сейчас только Google (Veo 3.1, Veo 3), OpenAI (Sora 2), Alibaba (Wan 2.5, 2.6), KlingAI (Kling 2.5, 2.6). Но они все закрытые. Куда подевались китайские слоны?
>>1457517 >Лучше Кандинского сейчас только Google (Veo 3.1, Veo 3), OpenAI (Sora 2), Alibaba (Wan 2.5, 2.6), KlingAI (Kling 2.5, 2.6). Но они все закрытые. >>1457114
Рибят, ничего не развод и ничего не схлопнется. Ну 5.2 вышел неудачным, но уже 5.3 на подходе, там явно уже будет agi, просто пока в миниатюре и в отдельном чате.
>>1457514 Нихуя шатл полетел вбок едва стартанув. С котом вообще пиздец. Китайские маркетологи походу сами уже ии, тупо нейронка промты погоняла, потом другая закинула вышедший слоп в промо материалы
>>1449178 (OP) >Новости об искусственном интеллекте №43 /news/ В Йошкар-Оле силовики накрыли майнинг-ферму, использовавшуюся для генерации запрещённого контента. Оборудование изъяли
>>1449178 (OP) >Новости об искусственном интеллекте №43 /news/ В России создадут реестр пользователей ИИ. В него войдут паспортные данные, а так же сведения о здоровье и воинской повинности
>>1449178 (OP) Стал замечать, что разрыв между результатами тестов и реальными возможностями ии увеличивается. Даже арк аги хуйня, вся надежда на 3-ю версию
>>1457514 > но сейчас самая топовая опенсорс видеомодель это российский Kandinsky 5.0 Video Pro
Рф не угонится за западными нейросетками, но поднасрать западным тем что в опенсорс выпускают то что не положено кривозубым крестьянам иметь в опенсорс, это мы вполне можем
Как и обещалось, новая картиночная модель OpenAI - GPT Image 1.5 выебала арену в рот, с гиганстским отрывом в 40 баллов.
Вот что они пишут Представляем ChatGPT Images на основе нашей новой флагманской модели генерации изображений.
-Улучшенное следование инструкциям -Точное редактирование -Сохранение деталей -В 4 раза быстрее предыдущей версии
Запускается сегодня для всех пользователей в ChatGPT, а также в API под названием GPT Image 1.5. Новая модель генерации изображений в ChatGPT точнее соответствует вашим намерениям, изменяя лишь то, о чём вы просите, и сохраняя при этом освещение, композицию и внешний вид людей неизменными при любых вводах, выводах и последующих правках.
Она также отлично справляется с различными типами задач. Кроме того, мы представляем новый раздел «Images» внутри ChatGPT. Просто нажмите на вкладку «Images» в боковой панели и наслаждайтесь!
Какой же Сэм потешный, не перестаёт серить, впрочем, Маск тоже в последнее время ударяется в грязь лицом, пообещал продления видео до пятнадцати секунд и улучшение звука ещё в ноябре, ничего этого нет а модель стала хуже. Гугл просто щемит этих клоунов. Только Сора по прежнему прорывная штука, но её убила цензура. Соглашение с дисней вступит в силу и может тогда это будет поюзабельнее
Кароч, теория сейчас идет, что попены просто просекли что люди лайкают, как это было с текстовой ареной. Может быть, результаты получаются менее и более вылизанными и глянцевыми, и оттого выглядят менее или более искусственно, а людям это нравится, или лучше работает на самых простых промптах в 3-5 слов вместо детальнейших длинных описаний сцен, что, опять же, ближе к тому, как промптят пользователи. Личные тесты профи показывают, что модель не шибко лучше бананы
>>1458021 >This image generation request did not follow our content policy. Просто ебейшая цензура в отличии от гугла, уже второй обсёр за месяц, сначало 5.2, теперь это, ну Маск, ты хоть не подведи..
Пик 1: Следование промту (по крайней мере короткому) вроде как действительно выше, бананы слишком стараются, прорисовали фон и эффекты а это не всегда то что нужно потребителю
Пик 2: с датасетом у гпт всё гораздо беднее чем у гугла, ну просто посмотрите на эту херню, выдало результат на уровне картинок грока в режиме потоковой генерации. В стиль короче не попала но с другой стороны, опять же, переодета в костюм горничной, ПОЛНОСТЬЮ, без упм, без шарфа, фулл горничная, с этой точки зрения запрос исполнен вернее
Пик 3: Тоже интересно, я попросил очки в стиле диско, и гпт восприняла это буквально, а может потому что я написал про "смешные". Ну очки слева смешными точно не назвать. гпт переврала цветовую гамму должен заметить, но рано делать выводы по одному результату запрос "языком достаёт до носа" не понимает ни одна модель, и в этот раз тоже революция не произошла
>>1456939 Я родился в 1983ем. В 98м мне подарили первый комп. На данный момент я опробовал КУУУЧУ нейронок. Из генераторов/галлюцинаторов почти никогда ничего не использую. Крайне редко для работы. Но по факту оно входит в нашу жизнь и незримо используется:
1. Поиск по картинкам Яндекса. На нейронках со времён, когда это ещё не было трендом. Работает круче всех. 2. Распознавание речи в текст. Норм для записок, списка продуктов, чатиков. Исправлять нужно. 3. Перевод. Когда нужно в общих чертах понять о чём текст. На английском я так быстро читать и выхватывать суть не умею. Всё ещё слабенько но пойдёт. 4. Короткие скрипты на питоне. Я не прогер, плохо знаю синтаксис, но понимаю логику. Если передо мной сбойный код, ошибку я могу исправить и логику тоже. 5. Иногда объяснить что-то из учебного широко распространённого материала.
Что пробовал: Генераторы изображений. Тысячи картинок. Всё плохо. SD/SDXL через комфи с эскизами, линиями, сегментаторами. Миджорни и прочие уровня СД бе управления — ещё хуже. Нанобанана, Флакс, Квен — получше но управления катастрофически недостаёт. А всё чему требуется либо детализация либо небанальный концепт проще и интереснее нафотошопить или заказать спецу. Заливка цветов/текстур, повышение детализации — вот тут да, много времени экономит.
А ещё проблема, что без специальных инъекций нейрокартинки очень мёртвые, стерильные. Обратите внимание, что мемы до сих пор почти всегда — или живой кадр или картинка от руки, даже всратейшая. Именно потому что нейронки не добираются до пика эмоций, особенно сложных.
>>1456957 >зато всё нужное под боком. А чтобы так было, нужно либо изначально делать расчёт на инфраструктуру, либо оставлять крупные пустые места под «что понадобится по ситуации».
Сам живу в спальнике — по большей части охуенный. И пропускная способность и рынки/магазы и где посидеть/потанцевать/посычевать есть.
>>1458181 > запрос "языком достаёт до носа" не понимает ни одна модель, и в этот раз тоже революция не произошла Везде, где не усреднёнка — будет обсёр. Интересные точно описанные позы, необычные ракурсы — везде полнейший пиздец.