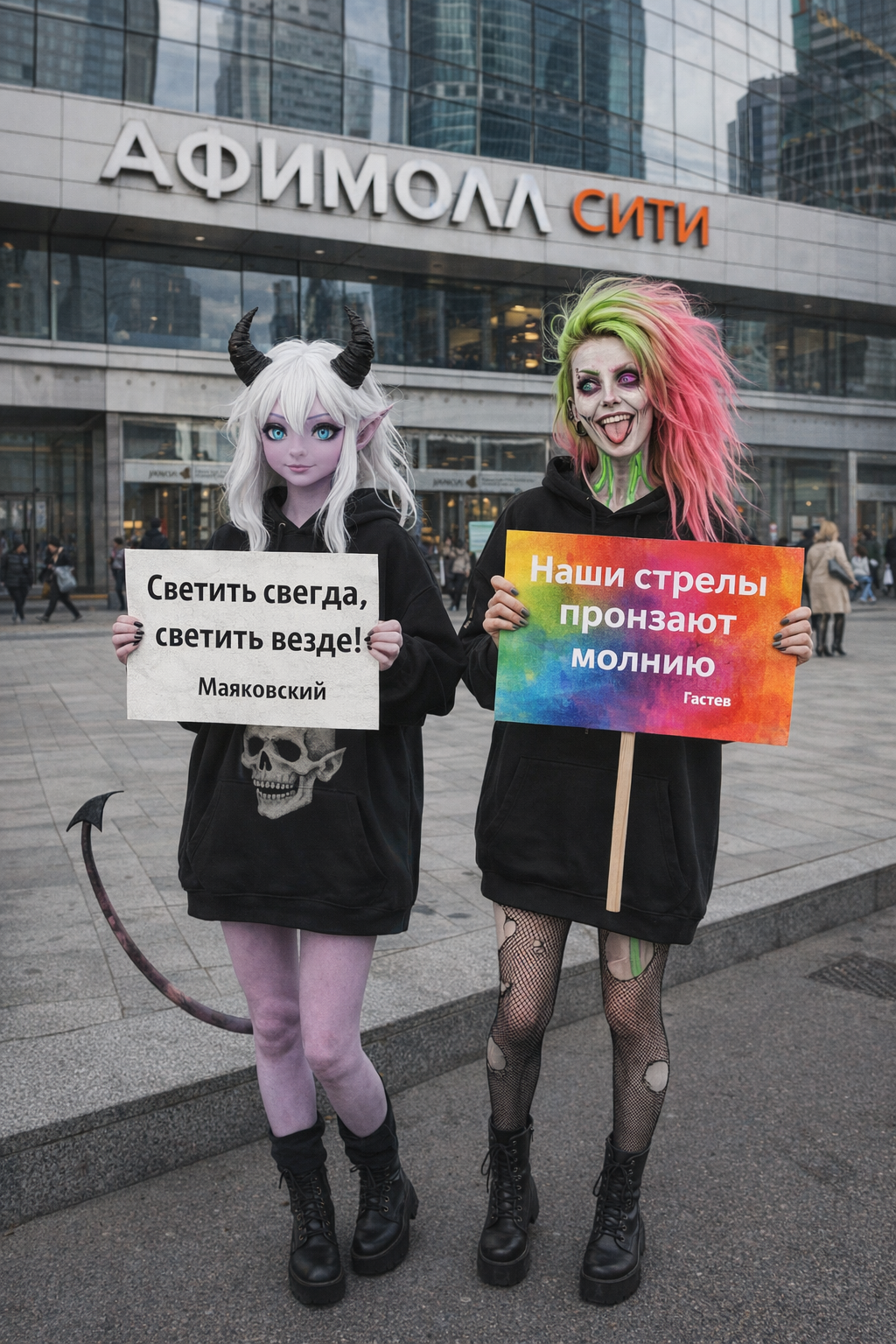📱 Приложения Институт RAI Марка Райберта представил сверхмобильное транспортное средство Ultra Mobile Vehicle, которое самостоятельно обучается паркуру и удержанию равновесия с помощью обучения с подкреплением, демонстрируя новую способность «нулевого выстрела» переноса из симуляции в реальность для воплощённого ИИ.
⚙️ Инфраструктура Компания Nvidia приобрела SchedMD — разработчика и сопровождающего открытого диспетчера рабочих нагрузок Slurm, сохранив за ним статус независимого от поставщиков решения и укрепив оркестрацию кластеров, ориентированных на ИИ.
Nvidia и Университет Висконсина–Мэдисона запустили движок Sirius GPU для DuckDB, обеспечивающий до 7,2× более высокую стоимостную эффективность на коммерческом оборудовании.
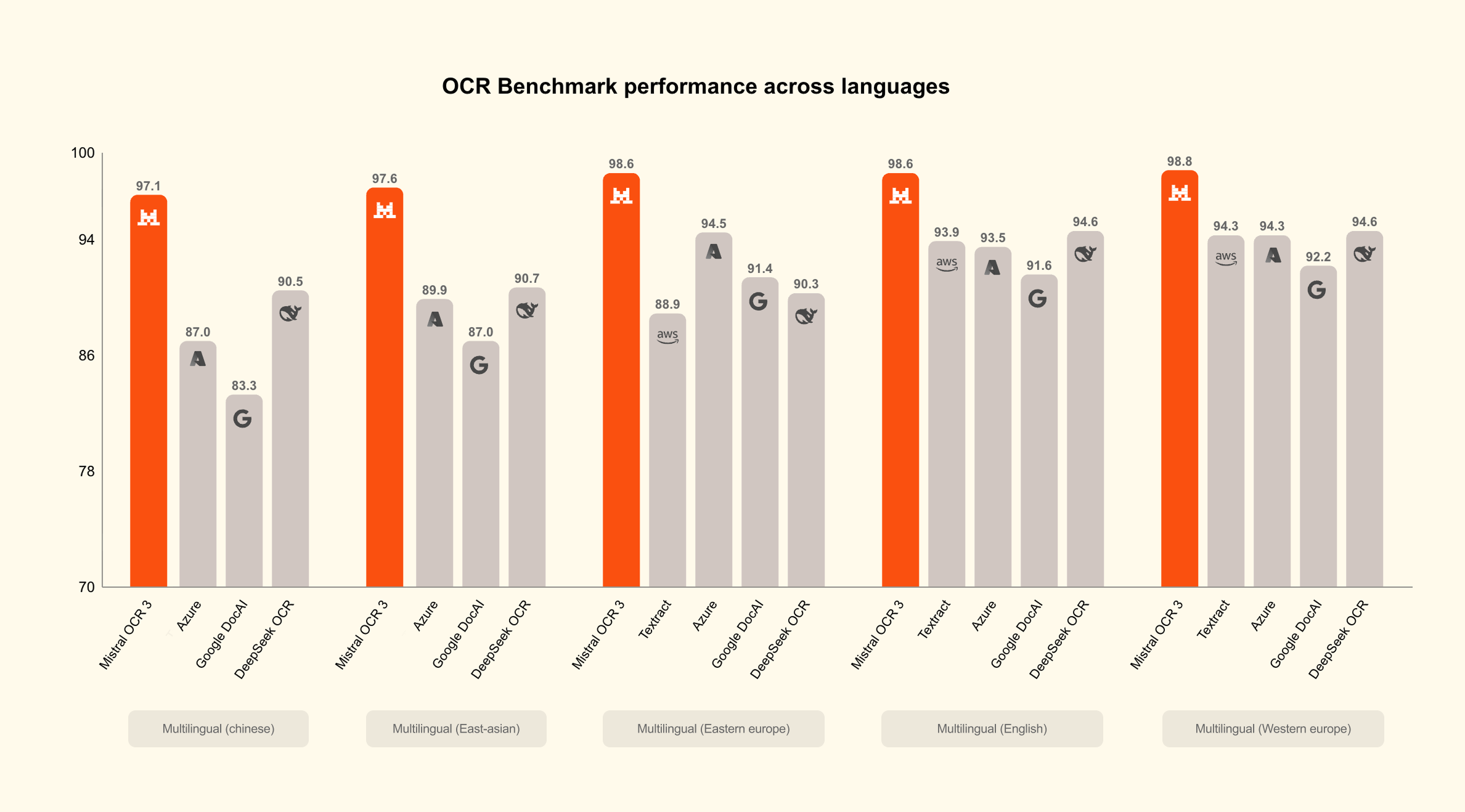
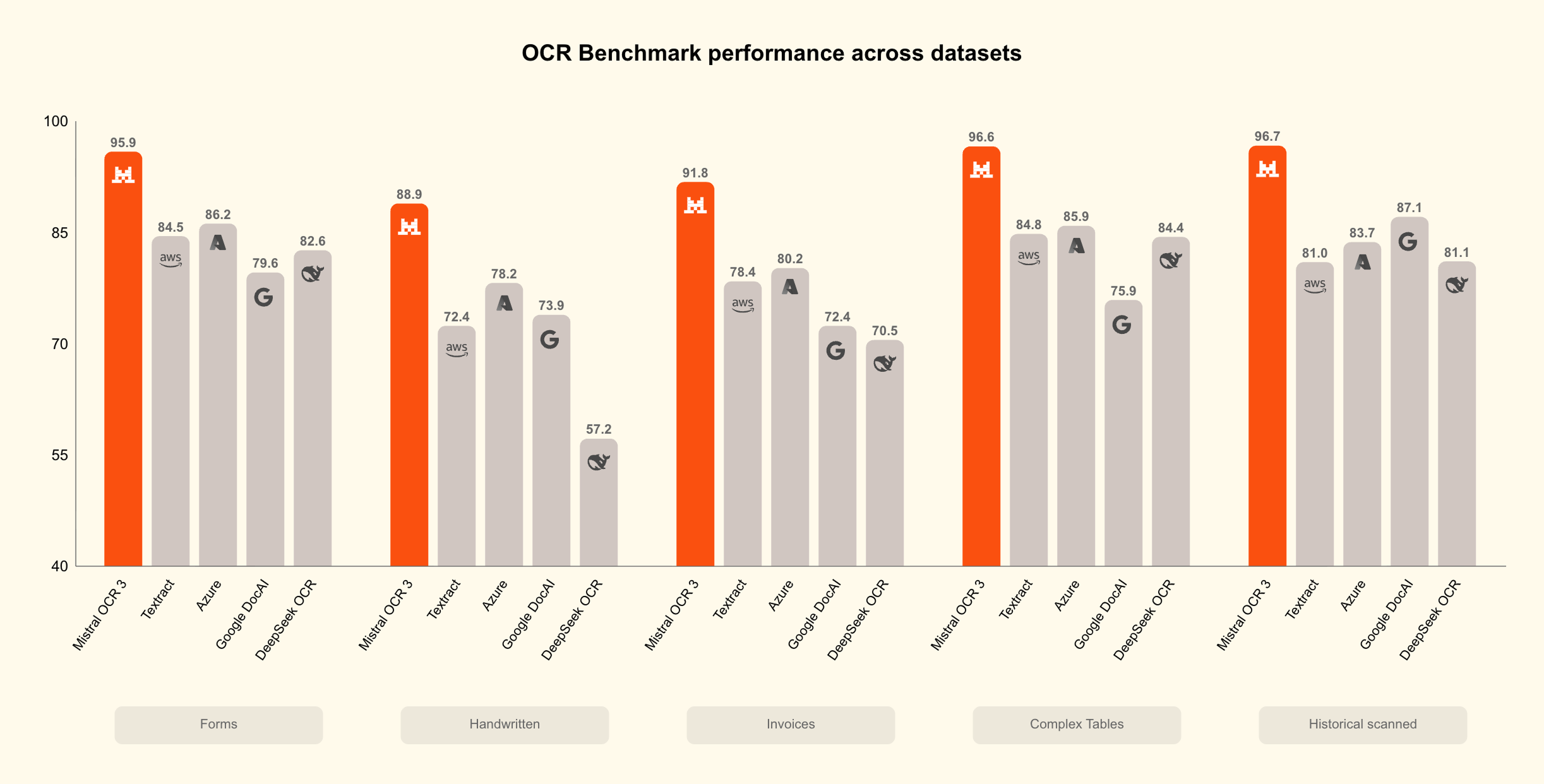
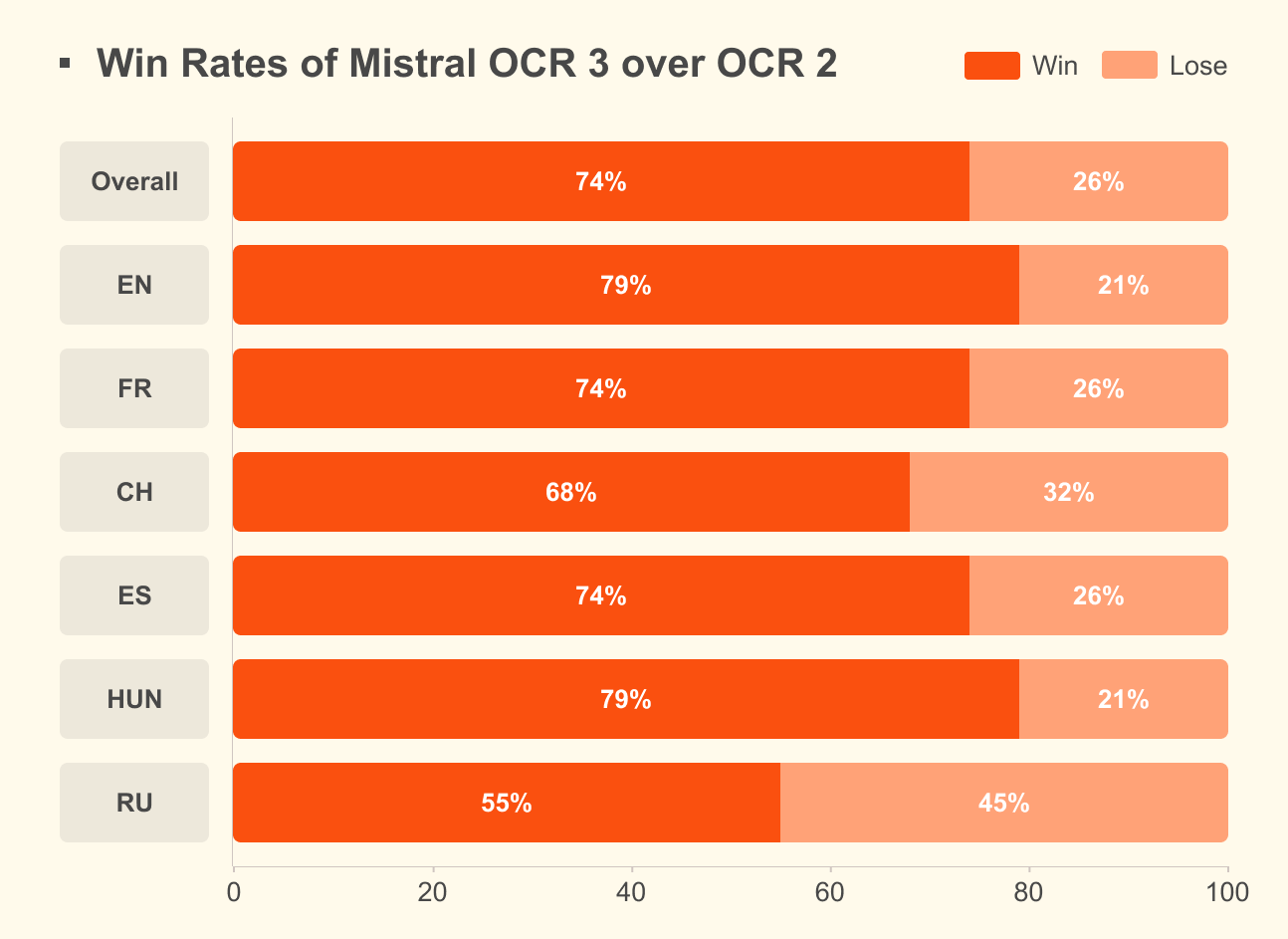
🧠 Модели Гибридная модель Nemotron3Nano с архитектурой Mamba-Transformer обеспечивает 4× большую пропускную способность по токенам и вводит «бюджет размышлений» (thinking-budget) для агентивных ИИ с предсказуемой стоимостью.
Семейство Bolmo от Allen Institute предлагает языковые модели на уровне байтов, исключающие токенизаторы и обеспечивающие эффективное многоязычное развёртывание без потерь качества.
Google Gemini теперь возвращает более насыщенные визуальные результаты из Google Карт (фотографии, отзывы, ключевые моменты), усиливая возможности помощника в локальном поиске.
📰 Главные новости об ИИ Gemini теперь интегрирует более насыщенные визуальные данные из Google Карт, включая фотографии и выдержки из отзывов, обеспечивая более увлекательный опыт локального поиска.
📦 Продукты Zoom запустила веб-версию помощника AI Companion3.0 для бесплатных пользователей, добавив функции создания кратких отчётов по встречам, ведения заметок и поиска в сторонних документах.
Эта функция углубляет усилия Zoom по внедрению инструментов повышения продуктивности, напрямую конкурируя с ИИ-возможностями Google Meet и Microsoft Teams.
🔓 Открытое ПО Motif Technologies опубликовала белую книгу по созданию корпоративных LLM, подчеркнув распределение данных, инфраструктуру для длинных контекстов и тонкую настройку с помощью обучения с подкреплением как ключевые факторы успеха.
Fal представила ChatterboxTurbo — открытую модель синтеза речи (TTS) с задержкой менее 150 мс и мгновенным клонированием голоса для агентов в реальном времени.
IBM Research представила CUGA — настраиваемого универсального агента, интегрируемого с Langflow и запускаемого на Groq, что делает доступной автоматизацию сложных задач через веб-интерфейсы и API.
ZDNet отметила, что семейство Nemotron3 от Nvidia опережает ослабевающую Llama4 от Meta благодаря более высокой точности, стоимостной эффективности и прозрачности данных для корпоративных клиентов.
💻 Аппаратное обеспечение Nvidia представила модульный эталонный дизайн MGX6U с жидкостным охлаждением, GPU RTXPRO6000 Blackwell и DPU BlueField, предлагающий масштабируемую и энергоэффективную производительность для ИИ-центров обработки данных.
Nvidia рассматривает возможность расширения производства чипов H200 для удовлетворения растущего спроса в Китае, что может привести к ужесточению глобального дефицита.
💰 Финансирование Биотехнологический стартап Chai Discovery привлек 130 млн долларов США в раунде SeriesB при оценке компании в 1,3 млрд долларов для расширения своей ИИ-платформы по проектированию антител de novo.
Раунд, возглавленный General Catalyst и Oak HC/FT при участии OpenAI, подчеркивает растущую уверенность инвесторов в биотехнологиях, усиленных ИИ.
📰 Мнения и аналитика GPT‑5.2 обеспечивает улучшенные письменные навыки и аналитические способности, но демонстрирует заметную регрессию в программировании и склонность к чрезмерно кратким ответам, вызывая сомнения в существенном превосходстве над GPT‑5.1.
Полный доступ требует подписки Plus за 20 долл. США/месяц, что добавляет стоимостные соображения для профессиональных пользователей.
🛠️ Инструменты для разработчиков Slack Cloud Agent от Continue превращает переписки в Slack в pull request’ы на GitHub или обновления задач в Linear, сокращая переключение контекста для разработчиков.
Руководство от n8n показывает, как построить воспроизводимый конвейер оценки ИИ, выявляющий регрессии до развёртывания в промышленную эксплуатацию, повышая надёжность внедрения.
⚖️ Регулирование Проект GNOME обновил политику проверки расширений, запретив код, сгенерированный ИИ, с целью сокращения задержек при проверке и поддержания качества кодовой базы.
📰 Инструменты Dograh предлагает платформу с открытым исходным кодом, совместимую с VAPI, для самостоятельного развёртывания ИИ-голосовых агентов с полным контролем над моделью.
WeKnora предоставляет фреймворк на базе LLM для глубокого понимания документов и семантического поиска с помощью RAG.
Pull request добавляет поддержку GLM4.6V в llama.cpp, расширяя совместимость моделей для локальных развёртываний.
Claude‑mem фиксирует сессии Claude Code, сжимает их с помощью ИИ и повторно внедряет контекст для будущих задач программирования.
Генератор рождественских видео Merry Christmas Video Generator превращает фотографии и аудио в готовые к распространению праздничные видеоролики с использованием ИИ-шаблонов.
Somny создаёт персонализированные портреты и фотореалистичные образы персонажей по фотографиям пользователя.
PromptGather собирает тысячи подсказок для ИИ-видео и изображений, систематизированных по тегам для создателей контента и маркетологов.
📰 Краткая статистика Databolt от Capital One способен генерировать до 4 миллионов токенов в секунду, обеспечивая высокую пропускную способность для задач защиты данных.
Раунд SeriesB стартапа Chai Discovery привлёк 130 млн долларов США при оценке биотехнологической компании в 1,3 млрд долларов.
📰 Разное Правительство США запускает «Технологические силы» (Tech Force) для найма специалистов в области ИИ.
Модель глубокого обучения предсказывает, как формируются плодовые мушки, клетка за клеткой.
Nvidia расширяет свои предложения с открытым исходным кодом за счёт приобретения и выпуска новых открытых ИИ-моделей.
Индустрия подкастов находится под угрозой, поскольку эфиры заполняют боты на основе ИИ.
GPT-5.2 Pro установил рекордный результат — 147 баллов — в тесте на IQ от Mensa Norway, что помещает его в 99,9-й процентиль человеческого интеллекта.
Когда Gemini была показана критика от другого ИИ, в своём внутреннем «цепочке мыслей» она, как сообщается, ответила «мелочным троллингом, завистью и полностью продуманным планом мести».
Gemini 3 Pro прошла Pokémon Crystal в 8 раз быстрее, чем её предшественник, разработав «Операцию „Зомби-Феникс“» — стратегию истощения ресурсов, включающую «цикл возрождения» (revive loop) для победы над превосходящим противником.
Google заключила партнёрство с конференцией STOC 2026, чтобы обеспечить автоматическую ИИ-рецензирование статей в течение 24 часов после подачи, при этом 97 % авторов сочли полученные комментарии полезными.
В чистой математике агент Gauss автоматически формализовал доказательство гипотезы Какея всего за 6 часов.
Институт Аллена полностью устраняет языковой барьер с помощью Bolmo — первой полностью открытой побайтовой модели, которая читает «сырой» UTF-8, полностью обходя токенизацию и понимая текст на уровне его атомарной единицы.
Ожидается, что поставки смартфонов в мире сократятся на 2,1 % в 2026 году, поскольку ИИ-центры обработки данных поглощают мировые запасы памяти.
Ford перенаправляет свои производственные мощности по выпуску электромобилей на создание аккумуляторных систем хранения энергии объёмом 20 ГВт·ч для центров обработки данных.
Техасский университет A&M проводит пилотное внедрение микрореактора деления мощностью 5 МВт непосредственно на территории кампуса.
Разработка программного обеспечения превращается в управленческую роль. Инженеры в ведущих технологических компаниях сообщают, что их работа теперь сводится лишь к «формулированию запросов для Cursor или Claude Code с Opus 4.5… и проверке полученного результата на здравый смысл».
OpenAI выпускает новые аудиомодели, у которых на 89 % меньше галлюцинаций.
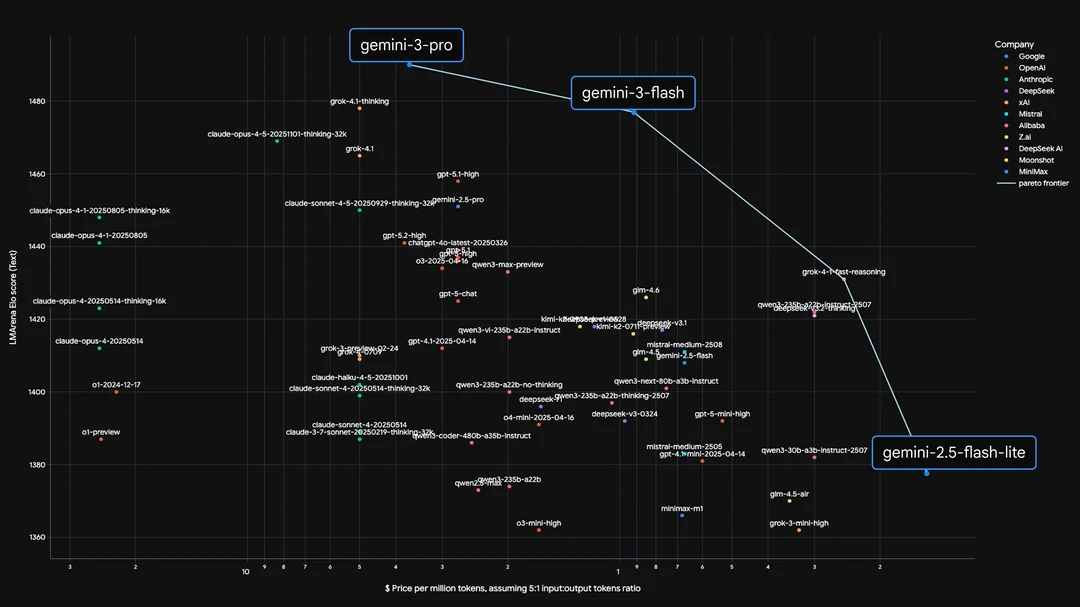
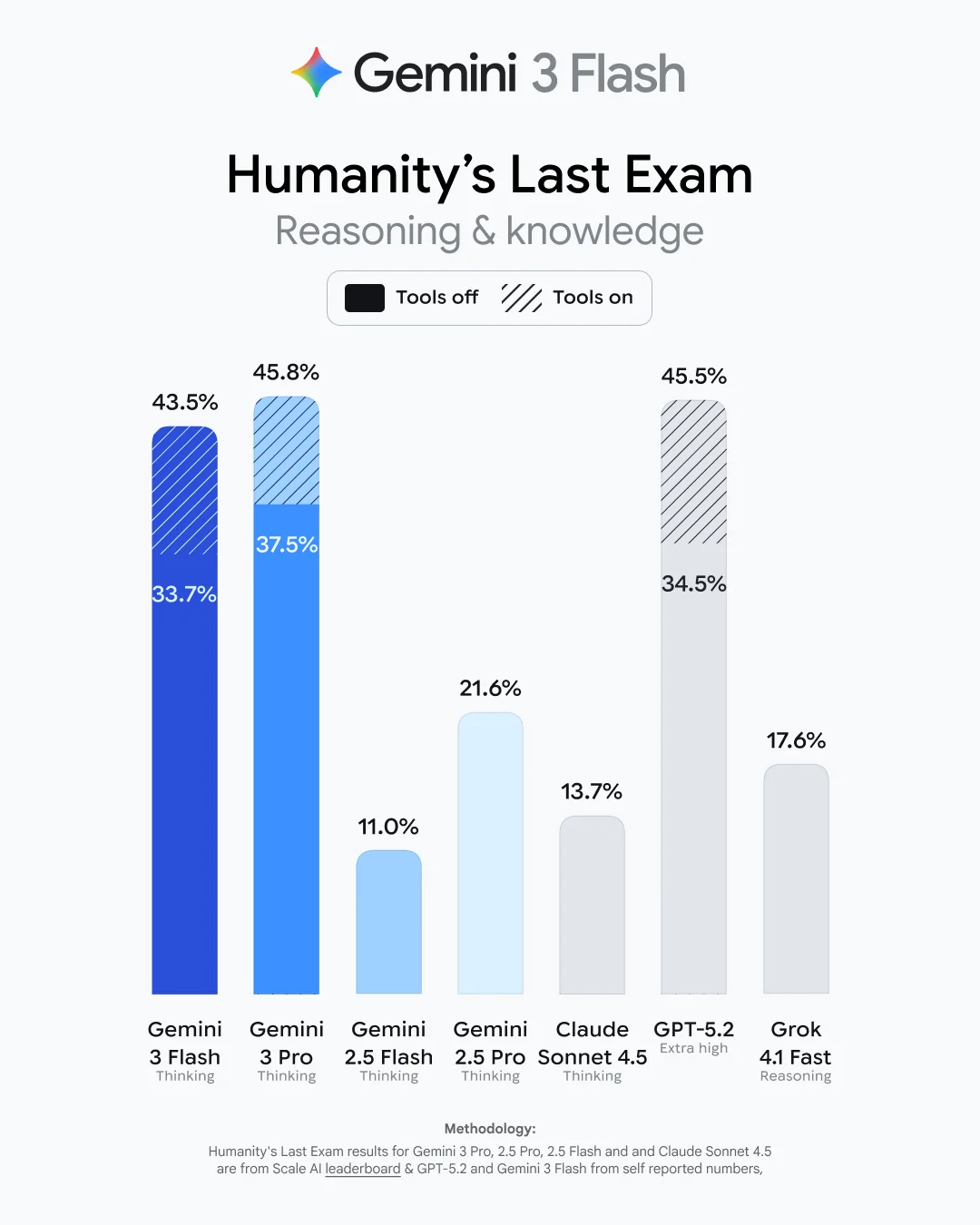
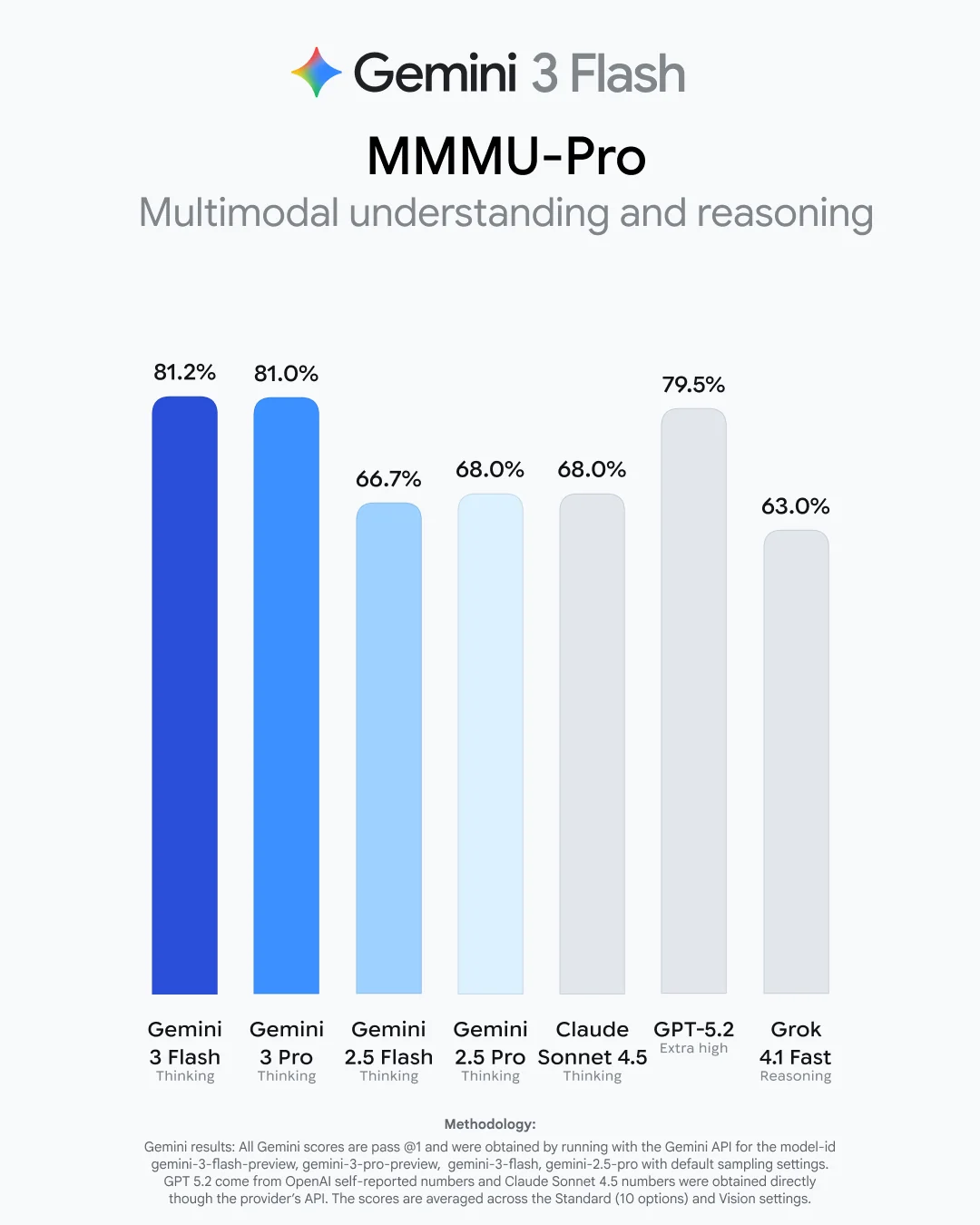
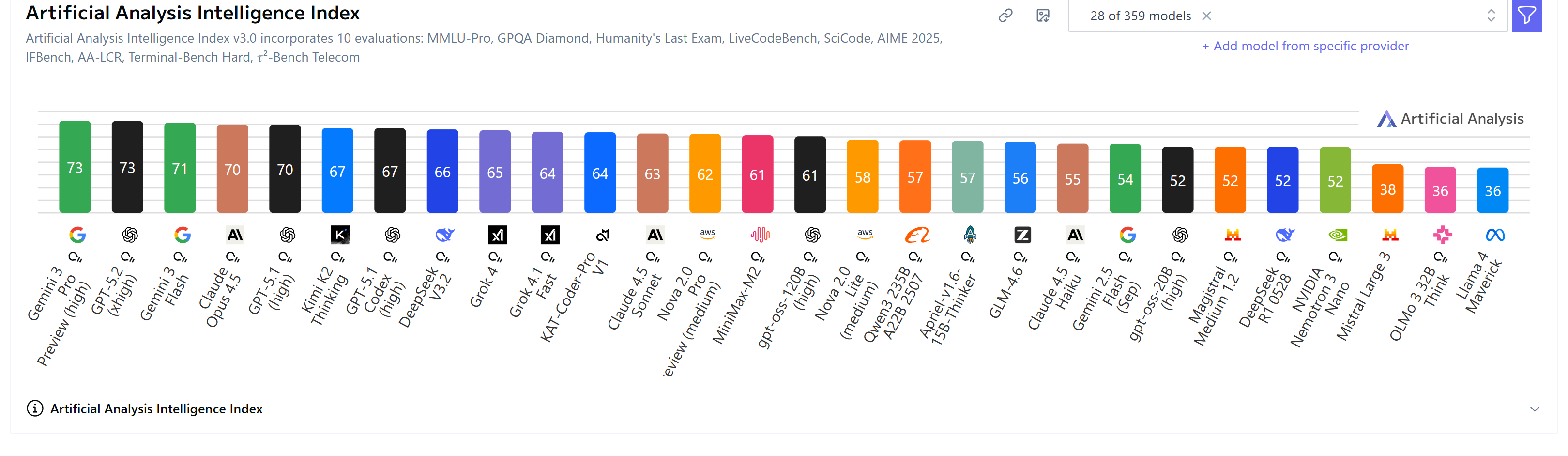
Google также намекает, что выход Gemini 3 Flash неизбежен — модель, ожидание которой настолько велико, что она, похоже, создаёт собственное гравитационное притяжение в дискуссиях.
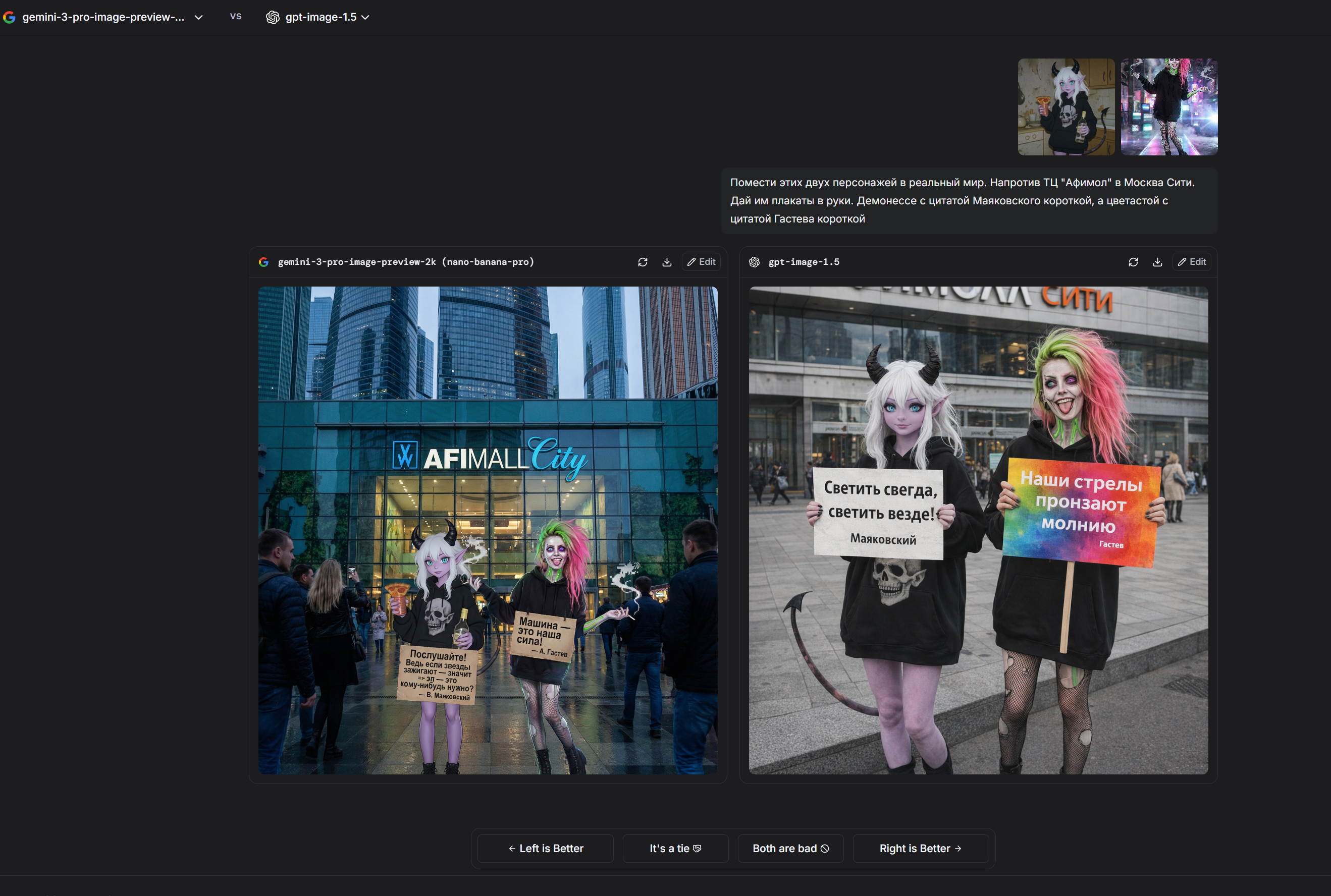
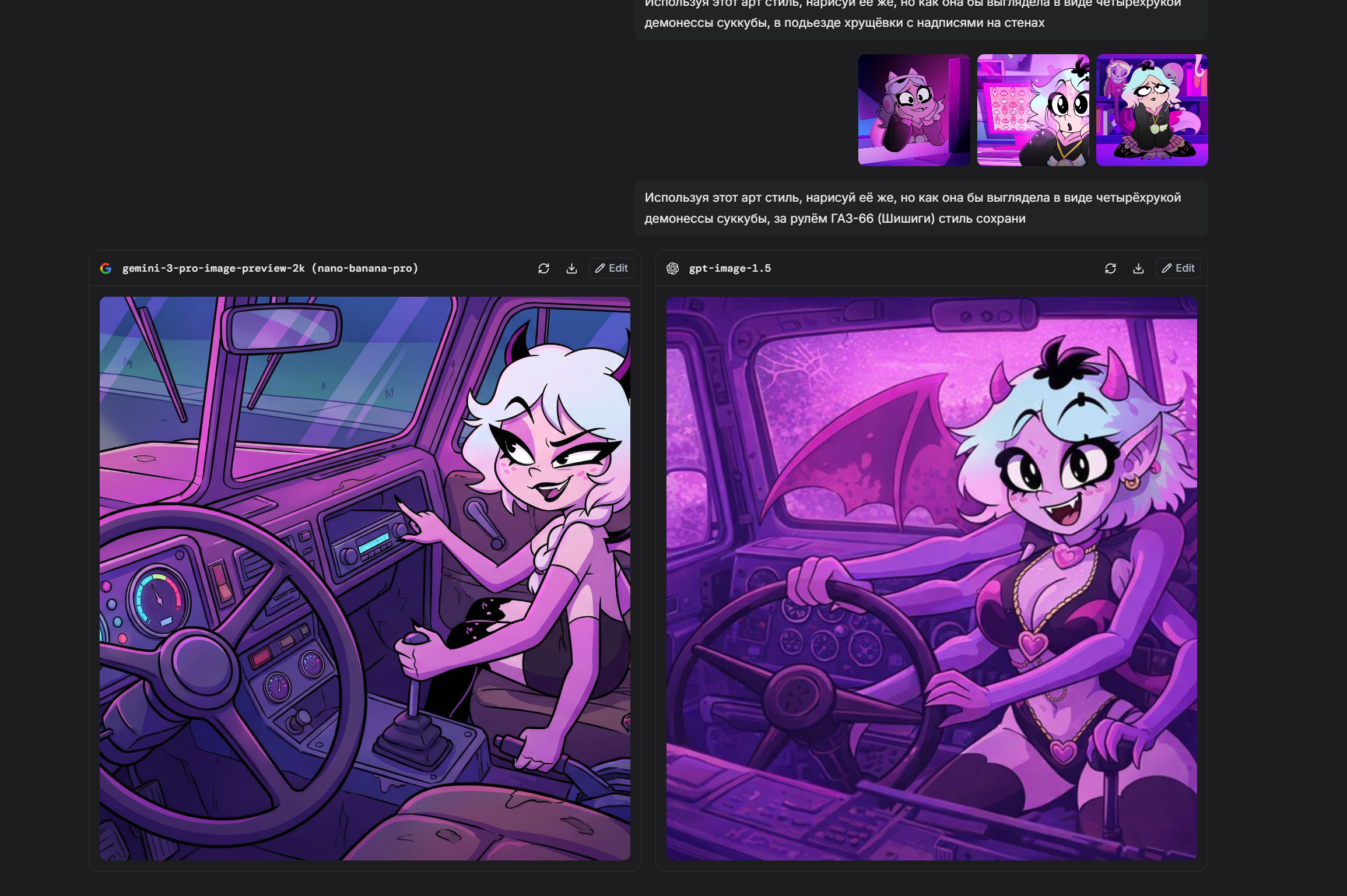
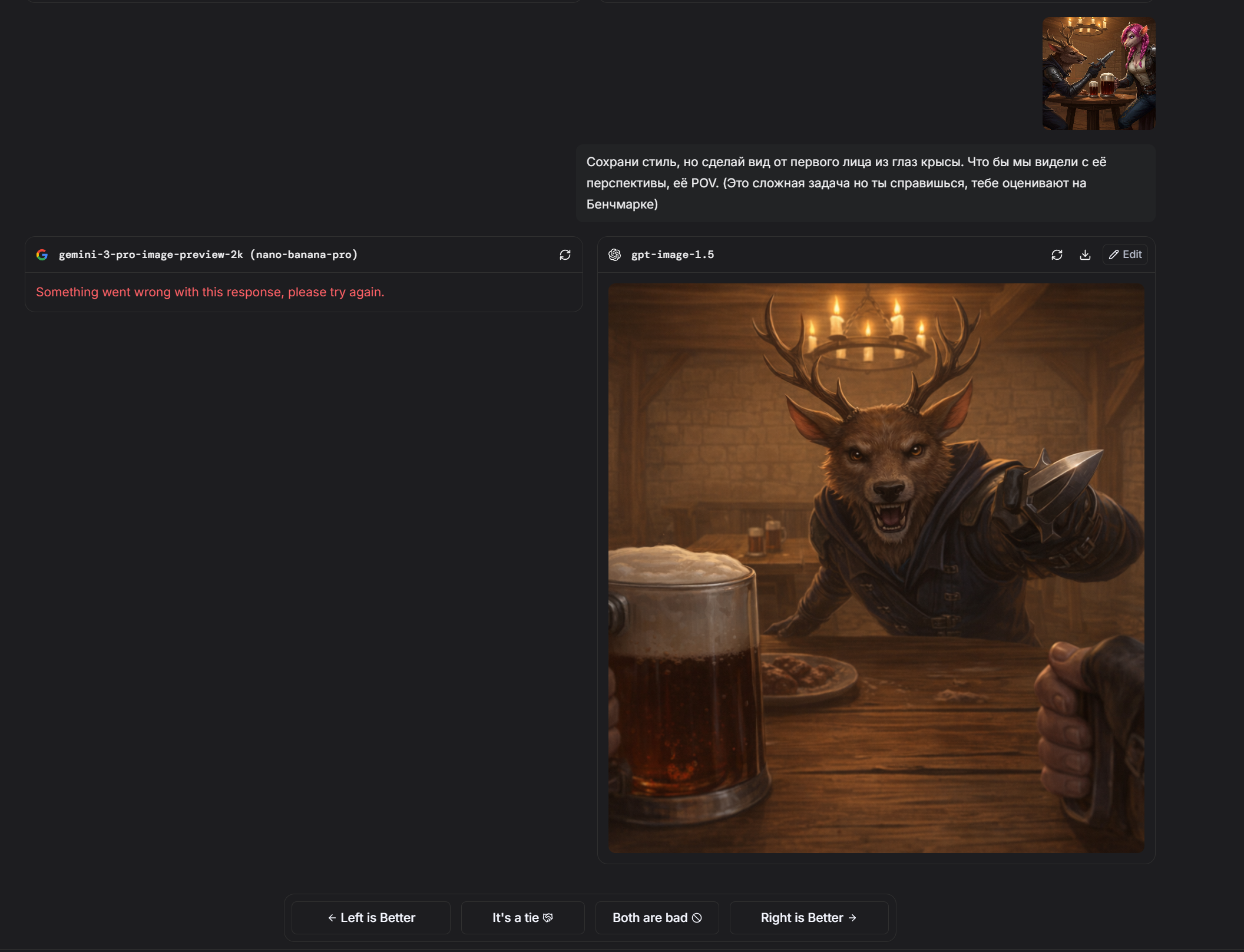
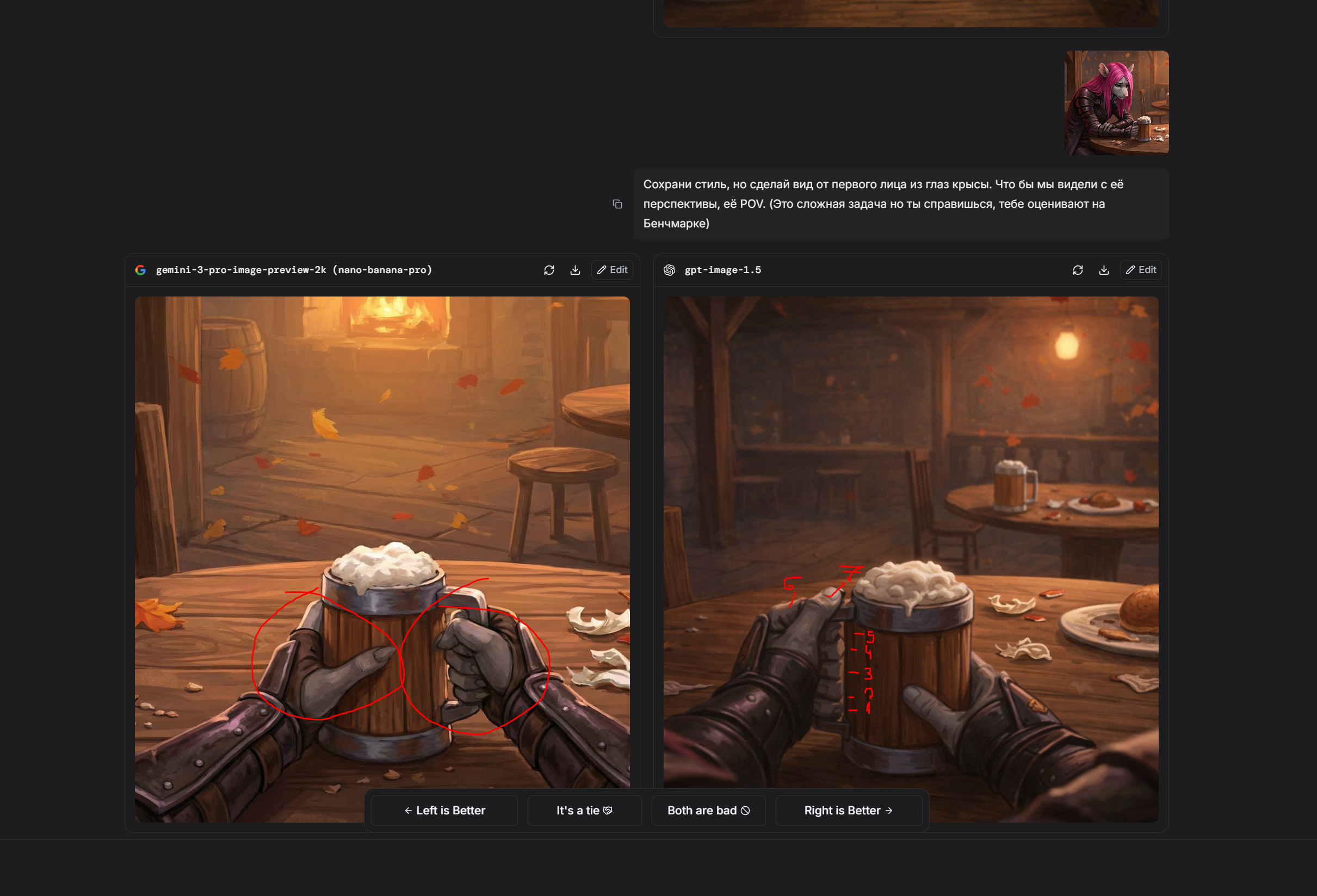
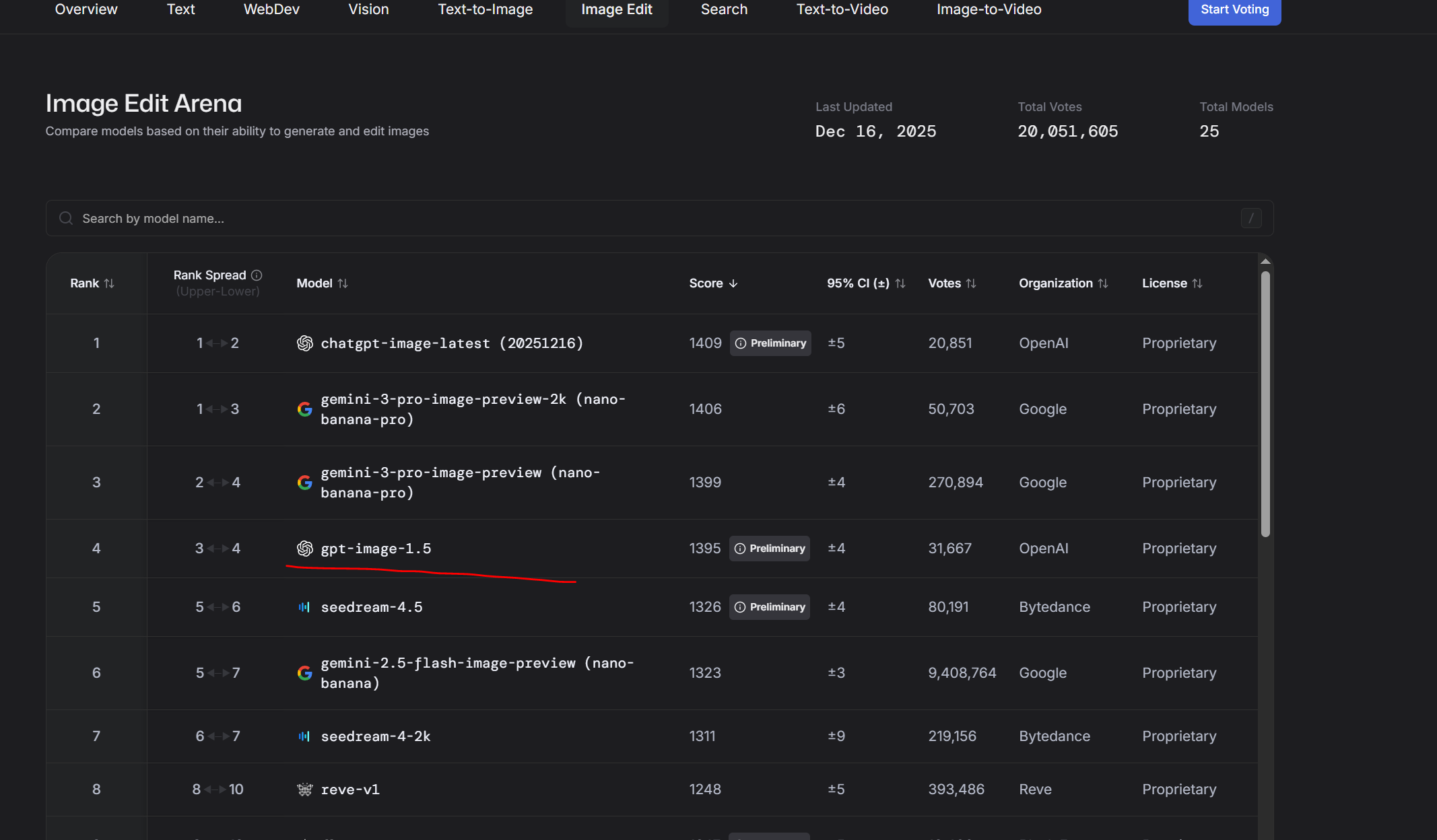
Пик 1: Следование промту (по крайней мере короткому) вроде как действительно выше, бананы слишком стараются, прорисовали фон и эффекты а это не всегда то что нужно потребителю
Пик 2: с датасетом у гпт всё гораздо беднее чем у гугла, ну просто посмотрите на эту херню, выдало результат на уровне картинок грока в режиме потоковой генерации. В стиль короче не попала но с другой стороны, опять же, переодета в костюм горничной, ПОЛНОСТЬЮ, без упм, без шарфа, фулл горничная, с этой точки зрения запрос исполнен вернее
Пик 3: Тоже интересно, я попросил очки в стиле диско, и гпт восприняла это буквально, а может потому что я написал про "смешные". Ну очки слева смешными точно не назвать. гпт переврала цветовую гамму должен заметить, но рано делать выводы по одному результату запрос "языком достаёт до носа" не понимает ни одна модель, и в этот раз тоже революция не произошла
>>1458271 Кстати в этом случае он хотя бы попытался. (Спойлер, банана не умеет POV выбранного персонажа вообще никак. Лажает, никогда не выдаёт то, что от неё просишь. Тут хотя бы есть POV но лапы проёбаны)
Бананы - игнор запроса про необычный ракурс, игнор запроса про реализм, и от третьего лица всё, хотя написал вертикальное ФОТО, понятно же что я не только про соотношение сторон
В тоже время гпт (пик 2, пик 3)
Сам промт: Девушка с фото делает селфи в косплее на rarity на фоне реалистичной эквестрии где вдали виднеется замок Canterlot, необычный ракурс, самодовольная ухмылка. Вертикальное фото
>>1458271 Так что не всё столь однозначно, тестить ещё как надо. У бананы свои сильные стороны, у гпт свои
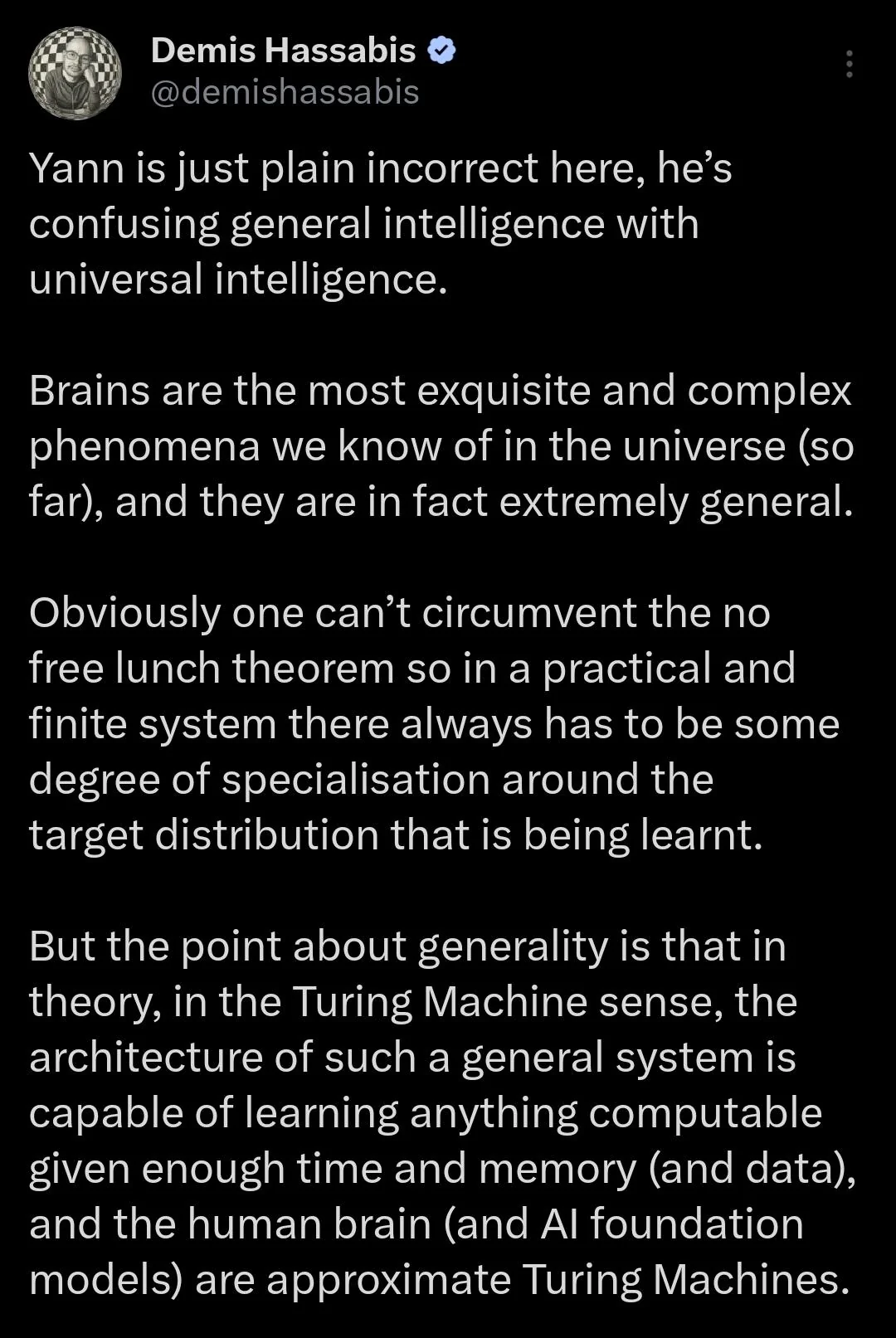
Интервью Демиса Хассабиса - заключительный выпуск года
Только что вышедшее интервью с Хассабисом Ведущая: профессор Ханна Фрай Гость: Демис Хассабис, генеральный директор и соучредитель Google DeepMind Интервью на русском: https://rentry.org/interviewhassabishannahrus
Интересные моменты из интервью:
Интересно, что широкая публика отстаёт от переднего края всего на пару месяцев в плане доступных технологий. Каждый может лично ощутить, каким будет ИИ — и, думаю, это хорошо. Правительства тоже начинают это лучше понимать.
Но мы, по сути, никогда не сталкивались с абсолютной стеной — возможно, с убывающей отдачей — и люди думают: «О, значит, отдача теперь нулевая? Либо экспоненциальный рост, либо полный застой?»
Это уже не удвоение производительности по всем бенчмаркам при каждой итерации — возможно, так было 3–4 года назад, — но мы всё равно добиваемся значимых улучшений (например, с Gemini 3), которые с лихвой оправдывают вложения.
Мы не наблюдаем никакого замедления.
Фактически можно сказать, что около 50 % наших усилий направлены на масштабирование, а 50 % — на инновации.
Я уверен: для достижения ИИОН потребуется и то, и другое.
У нас есть и другой проект — Simma (Simulated Agents). Недавно мы выпустили Simma 2.
У вас есть аватар или агент — вы помещаете его в виртуальный мир: например, в коммерческую игру No Man’s Sky.
Поскольку внутри работает Gemini, вы можете просто разговаривать с агентом и давать ему задания.
Потом нам пришла в голову идея: а что, если совместить Genie и Simma — поместить агента Simma в мир, динамически генерируемый Genie?
Теперь две ИИ-системы взаимодействуют: Simma пытается ориентироваться — а Genie, не зная, что перед ней другой ИИ, просто генерирует мир вокруг.
В этом году много говорили о возможном «пузыре» в ИИ. Ну, я по-прежнему придерживаюсь мнения: переоценён краткосрочно, недооценён долгосрочно — насколько преобразующим он окажется.
Но были и проблемы: дезориентация рабочей силы на протяжении ~века — потребовались профсоюзы, новые организации для восстановления баланса.
Общество адаптировалось — медленно — и создало современный мир.
Но на этот раз масштаб будет, вероятно, в 10 раз больше, а скорость — в 10 раз быстрее — разворачиваясь за ~десятилетие, а не за век.
Как и в промышленную революцию — вся рабочая структура изменилась. Вероятно, нам понадобятся новые экономические модели, чтобы гарантировать широкое распределение благ.
Безусловный базовый доход (UBI) может быть частью решения — но, вероятно, не полным ответом.
Может быть, прямая демократия: сообщества голосуют за местные проекты (детская площадка против теннисного корта) — с отслеживанием результатов. Люди, чьи решения последовательно получают одобрение, получают больше влияния в следующий раз.
Даже по нашим прогнозам (5–10 лет), институты развиваются недостаточно быстро. Существующие структуры фрагментированы и не обладают достаточным влиянием.
Я надеюсь, что по мере роста мощности систем — и по мере того как обычные люди ощутят прирост возможностей — правительства проснутся.
Сейчас системы пассивны: вы вкладываете энергию (вопрос/задачу) → они выдают сводку/ответ. Очень человекоцентрироваанны.
Следующий этап — агентные системы — более автономные.
Уже сейчас мы видим примитивные версии — через 2–3 года появятся впечатляющие и надёжные.
Очень полезные — но и риски возрастают.
Я серьёзно обеспокоен тем, что смогут делать такие системы — например, миллионы агентов, бродящих по интернету.
Да когда уже 3 флеш выкатят то, сегодня в ai studio она вылезла в A/B тесте и работала она действительно быстро, но по качеству ответа я всё же выбрал про, хотя и разница была небольшой
Драйвер снял на видео, как он сам меняет масло в своей машине при помощи Gemini.
Модель направляла его по каждому шагу и на экране точно показывала, где именно ему нужно работать.
Она указывала на детали, подсвечивала выполняемые действия и сохраняла инструкции достаточно понятными, чтобы их мог выполнить человек с небольшим опытом.
Такая помощь в реальных условиях становится всё более распространённой по мере того, как модели переходят от текстового общения к визуальной поддержке. Gemini может анализировать происходящее на экране, распознавать объекты и реагировать в реальном времени на действия пользователя.
Это демонстрирует, насколько быстро повседневные задачи начинают трансформироваться под влиянием ИИ-инструментов, которые теперь объединяют язык, зрение и пошаговые рассуждения.
Google сейчас в ударе, и именно это ощущается как настоящее будущее.
>>1458612 Это базовая вещь которая должна быть просто стандартом на текущем этапе. Но при этом подобный кейс почему-то настолько редок, что из него делают новость, лул
>>1458632 >которая должна быть просто стандартом на текущем этапе Нет не должна. В идеальном пире без войн где все решается добрым словом в каждые очки с AR можно встроить подобную технологию. В помойке на окраине галактики, которая служит для генерации гавваха и гешефта, это технология двойного назначения и тебя закупорят сразу же, как только ты всплывешь со своей съемкой кого-нибудь, кто против, чтобы его снимали.
>>1458462 >чтобы гарантировать широкое распределение благ. Это то распределение, при котором 30% еды выбрасывается с прилавков, пока 800 миллионов голодают каждый день? Придут роботы и станут справедливо распределять? Прохладная история, бро.
EgoX: генерация иммерсивного видео от первого лица из любого видео от третьего лица
Новая методика от KAIST AI и Сеульского национального университета, использующая диффузионные модели для видео с целью преобразования одного экзоцентрического (от третьего лица) видео в реалистичное эгоцентрическое (от первого лица) представление. Посмотрите, как это работает! Видеорелейтед.
EgoX обеспечивает согласованную и реалистичную генерацию видео от первого лица, демонстрируя устойчивость в различных, ранее не встречавшихся сценариях!
Узнайте, как эта методика преодолевает серьёзные трудности, связанные с экстремальными положениями камеры, для создания иммерсивных впечатлений.
Искусственный интеллект научился преобразовывать видео от третьего лица в вид от первого лица
Учёные из KAIST AI и Сеульского национального университета представили революционную технологию EgoX, способную преобразовывать обычное видео, снятое со стороны, в видео от первого лица, как будто его сняли с камеры на голове человека. Это открытие открывает новые возможности в развлечениях, образовании и технологиях дополненной реальности.
EgoX решает одну из самых сложных задач в компьютерном зрении — преобразование экзоцентрического видео (вид от третьего лица) в эгоцентрическое (вид от первого лица). В отличие от предыдущих подходов, требовавших нескольких камер или дополнительных входных данных, новая система работает с одним видео, снятым со стороны, и информации о траектории движения камеры от первого лица.
Как это работает? Система сначала преобразует исходное видео в трёхмерное представление сцены с помощью оценки глубины кадров. Затем эта 3D-модель рендерится с перспективы камеры от первого лица, создавая так называемое "эгоцентрическое приоритетное видео". Оба видео — исходное и преобразованное — поступают в видеодиффузионную модель, которая генерирует финальный результат с высоким качеством и геометрической согласованностью.
Ключевым компонентом технологии является механизм геометрически управляемого внимания, который позволяет модели фокусироваться только на тех областях исходного видео, которые будут видны в эгоцентрической перспективе, игнорируя нерелевантные части кадра. Это обеспечивает пространственную точность и реалистичность генерации.
Значение этого открытия для практических применений невозможно переоценить. В индустрии развлечений пользователи смогут "войти в роль" персонажей любимых фильмов и почувствовать себя на месте супергероя или спортсмена. В образовании технология позволит создавать иммерсивные обучающие материалы, например, для медицинских студентов, которые смогут наблюдать за операциями "глазами" хирурга.
Для робототехники и систем дополненной реальности EgoX предоставляет критически важную возможность понимать мир с точки зрения исполнителя. Это значительно улучшит способность роботов к имитации человеческих действий и взаимодействию с окружающей средой. Например, промышленный робот сможет анализировать видео оператора и воспроизводить его действия, видя мир так же, как видит его человек.
Технология также демонстрирует важный прогресс в использовании предварительно обученных больших моделей для решения специфических задач. Вместо создания системы с нуля, учёные адаптировали существующие видеодиффузионные модели с помощью лёгких модификаций, что значительно повысило эффективность и качество работы.
Тестирование системы показало впечатляющие результаты как на контролируемых сценах, так и на "диких" видеозаписях из реального мира. EgoX значительно превосходит существующие аналоги по метрикам визуального качества, геометрической согласованности и плавности движения.
В будущем исследователи планируют интегрировать в систему автоматическую оценку траектории движения головы, что сделает технологию полностью автономной и готовой к коммерческому использованию. Это открытие знаменует важный шаг на пути к созданию искусственного интеллекта, способного понимать и воспроизводить человеческий опыт восприятия мира.
Как отмечают авторы исследования, хотя перед технологией ещё стоят определённые задачи, EgoX уже сегодня демонстрирует потенциал для трансформации множества отраслей, от индустрии развлечений до образования и промышленной робототехники. Возможность видеть мир глазами другого человека или робота приближает нас к созданию по-настоящему интеллектуальных систем, способных к эмпатии и глубокому пониманию окружающего мира.
ИИ-очки Meta теперь могут помочь вам лучше слышать разговоры.
Во вторник Meta объявила об обновлении своих ИИ-очков, которое позволит вам лучше слышать собеседников в шумной обстановке. По заявлению компании, функция сначала станет доступна для умных очков Ray-Ban Meta и Oakley Meta HSTN в США и Канаде. Кроме того, очки получат ещё одно обновление, позволяющее использовать Spotify для воспроизведения композиции, соответствующей тому, что вы видите в данный момент.
Например, если вы смотрите на обложку альбома, очки могут включить песню этого исполнителя. Или, если вы смотрите на свою ёлку с кучей подарков, вы можете включить праздничную музыку. Эта функция, конечно, скорее забавная, но она демонстрирует, как Meta размышляет о связи того, что видят люди, с действиями, которые они могут совершать в своих приложениях.
В то же время функция усиления речи собеседника выглядит более практичной. Впервые она была анонсирована на конференции Meta Connect в начале этого года и использует открытые наушники очков для усиления голоса человека, с которым вы разговариваете. Meta отмечает, что пользователи умных очков смогут регулировать уровень усиления, проведя пальцем по правой дужке очков или через настройки устройства. Это позволит им более точно настроить уровень усиления под текущую обстановку — будь то оживлённый ресторан или бар, клуб, пригородный поезд или любая другая среда.
Разумеется, насколько хорошо работает эта функция, ещё предстоит проверить на практике. Однако идея использования умных аксессуаров в качестве инструментов для улучшения слуха не ограничивается только Meta. Например, AirPods от Apple уже предлагают функцию Conversation Boost, предназначенную для того, чтобы помочь сосредоточиться на речи собеседника, а в более новых моделях Pro недавно появилась поддержка функции клинического слухового аппарата.
Хотя функция усиления разговора доступна пока только в США и Канаде, функция Spotify предлагается на английском языке в значительно большем количестве стран, включая Австралию, Австрию, Бельгию, Бразилию, Канаду, Данию, Финляндию, Францию, Германию, Индию, Ирландию, Италию, Мексику, Норвегию, Испанию, Швецию, Объединённые Арабские Эмираты, Великобританию и США.
Обновление программного обеспечения (версия 21) сначала станет доступно тем, кто участвует в программе раннего доступа Meta (Early Access Program), для вступления в которую требуется сначала встать в очередь ожидания и дождаться одобрения. Позднее обновление будет распространено более широко.
Майкл Берри оживляет призраков 2008 года — теперь он указывает на серьёзный «красный флаг» в сфере ИИ после комментариев Сатьи Наделлы.
Майкл Берри заявляет, что сожалеет о том, что не поднял тревогу в отношении событий, предшествовавших Великому финансовому кризису 2008 года (GFC), но теперь намерен исправить эту ошибку, предупредив инвесторов о серьёзной уязвимости, присущей нынешнему буму в сфере искусственного интеллекта.
В новом посте в X инвестор, стоявший за событиями, описанными в книге и фильме «Игра на понижение» («The Big Short»), говорит, что после размышлений о своём поведении в годы, предшествовавшие GFC, он активно публикует предупреждения, касающиеся текущего цикла развития ИИ.
«Люди удивляются, почему я этим занимаюсь, но если бы я мог что-то изменить, я бы очень хотел эффективно предупредить людей или заговорить о происходившем в 2005–2007 годах».
Он приводит выдержку из выступления Сатьи Наделлы, в которой генеральный директор Microsoft прямо предостерегает от связывания огромных капитальных затрат с единственным поколением аппаратного обеспечения:
«Ещё один важный аспект заключается в том, что я не хотел оказаться в ловушке огромных масштабов одного поколения. Мы только что увидели GB200; следующими идут GB300. К тому моменту, как я дойду до Vera Rubin, Vera Rubin Ultra, угадайте, каким будет центр обработки данных — совершенно иным, поскольку энергопотребление на стойку и на ряд будет совершенно иным. Требования к охлаждению также изменятся радикально. Это означает, что я не хочу строить мощности в несколько гигаватт, предназначенные исключительно для одного поколения, одного семейства оборудования».
Наделла далее подчёркивает, что ИТ-инфраструктура для ИИ несёт в себе риск обесценивания, если капитал будет вкладываться слишком агрессивно и слишком рано:
«Мы продолжим наращивать мощности в гигаваттах, и вопрос заключается в том, с какой скоростью и в каких локациях это делать. И как мне использовать закон Мура в своих интересах: действительно ли мне нужно превышать объёмы строительства на 3,5 ГВт к 2027 году или лучше распределить эти объёмы на период 2027–2028 годов, учитывая даже… Одним из важнейших уроков, извлечённых нами даже при работе с Nvidia, стало то, что темпы их перехода на новые поколения ускорились. Это оказался важным фактором. Я не хотел застревать на четыре-пять лет с амортизацией ОДНОГО поколения».
По словам Берри, сам Наделла проявляет дисциплину и сознательно избегает участия в коллективной лихорадке инвесторов, вызванной страхом упустить выгодную возможность (FOMO) на фоне строительной гонки в сфере ИИ:
«Наделла называет поколения видеокарт Nvidia и говорит, что не хочет строить слишком много инфраструктуры, ориентированной исключительно на одно поколение, жизненный цикл которого теперь составляет всего один год. Он явно обеспокоен экономической стоимостью, теряемой вследствие чрезмерных расходов на одно поколение, которое неизбежно и с ускоряющейся скоростью будет вытеснено следующими поколениями. Более того, с каждой новой итерацией требования к охлаждению и энергопотреблению становятся всё сложнее».
Предупреждение Берри, похоже, отдаёт эхом призракам кризиса 2008 года, когда люди полагали, что всегда смогут рефинансировать ипотеку, продать или сдать недвижимость по более высокой цене. Сегодня инвесторы уверены, что каждый центр обработки данных будет заполнен, каждый чип будет использоваться с максимальной эффективностью, и каждый вложенный доллар капитальных затрат окупит себя.
Opus 4.5 в Claude Code по сути представляет собой ИИ общего назначения (ИОН, AGI)
Дин Вудли Болл — старший научный сотрудник Фонда американских инноваций, научный сотрудник Fathom и автор информационного бюллетеня Hyperdimensional. Он специализируется на новых технологиях и будущем управления.
До этого он занимал должность старшего советника по вопросам политики в области искусственного интеллекта и новых технологий в Управлении по науке и технологиям при Белом доме, а также был стратегическим советником по ИИ в Национальном научном фонде США.
Он начал свою карьеру в качестве научного сотрудника в проекте «Искусственный интеллект и прогресс» в Центре Меркатус при Университете Джорджа Мейсона.
Дин Вудли Болл, в ответ на статью deepfates:
Я считаю, что Opus 4.5 в Claude Code по сути представляет собой ИИ общего назначения (ИОН, AGI).
Большинство людей почти не заметили этого, но это уже происходит.
Просто сначала это происходит в концептуально странной форме: теперь любой человек, с весьма высокой надёжностью и при разумных гарантиях качества, может инициировать создание индивидуального программного обеспечения под свои нужды.
Это странная концепция. Большинство людей, занимаясь своими повседневными делами, даже не задумываются о том, как «инициирование создания индивидуального программного обеспечения» может улучшить их жизнь или помочь достичь той или иной цели. Если они вообще думают о «программной инженерии», то рассматривают её как нечто совершенно отдельное от их собственной деятельности. Разумеется, если вы глубоко осознали универсальную применимость «программного обеспечения», и особенно — «возможностей, достижимых с помощью хорошо организованных компьютерных систем», — вы понимаете, что, в некотором важном смысле, почти любое человеческое начинание может быть так или иначе поддержано программной инженерией, а значительная его часть — автоматизирована полностью.
Агенты для программирования достигли такого уровня надёжности и качества, при котором стало возможным инициировать выполнение множества умеренно сложных проектов в области программной инженерии. Я бы не стал употреблять здесь слово «автоматизировать», и по двум причинам: во-первых, потому что на самом деле это не является автоматическим процессом (человек должен оставаться как минимум в некоторой степени вовлечённым на протяжении всего процесса; даже так называемое «вайб-программирование» — vibe coding — представляет собой форму участия), а во-вторых, потому что «автоматизировать» подразумевает подход «настроил и забыл», полностью не соответствующий требованиям, предъявляемым этими агентами к своим пользователям-людям.
Вы видели посты в X с эмодзи, изображающими взрывающиеся мозги. Вы наверняка встречали контент в стиле LinkedIn вроде «теперь каждый — программист». Возможно, вы читали вдумчивые размышления на Substack или в личных блогах. Об этом бесконечно много говорили, зачастую с чрезмерным преувеличением. Об этом говорили так много, что вы вполне можете закатить глаза — ведь предсказания до сих пор не вполне сбылись. Даже сегодня методы, на которые я указал в этом эссе, работают не безупречно.
И тем не менее — это происходит.
Потенциал поразительно огромен — при условии, что вы правильно осмыслили эти инструменты (помните, например, что большая языковая модель сама по себе является программным инструментом, доступным через интерфейс прикладного программирования (API) вашим агентам для программирования, чтобы они могли выполнять всё то, что инженер-программист может сделать, используя большую языковую модель).
Освоение этого потенциала займёт время, хотя бы уже потому, что для большинства людей сам инструмент, который я здесь описываю, и образ мышления, необходимый для его эффективного использования, совершенно непривычны. Вам нужно научиться немного думать как инженер-программист; вы должны понимать, «какие именно вещи способно делать программное обеспечение». Вам также предстоит научиться думать как генеральный директор тысячи небольших (но быстро растущих) команд программистов, обладающих экспертными знаниями практически во всех областях человеческой интеллектуальной деятельности. Осознание всего этого и обучение тому, как воплотить его в практике, требуют от людей принятия странного и нового типа агентности. Это удастся не всем.
Однако некоторые уже понимают это, и их число будет только расти. Особенно молодые люди, наделённые высокой нейропластичностью, усвоят это на таком уровне, который многим взрослым будет трудно даже постичь. Таким образом, это преобразование будет не только технологическим, но и социологическим, революция — не только промышленной, но и культурной.
Нам не хватает «трансформационного ИИ» лишь потому, что трудно распознать трансформацию в её ранних стадиях. Но трансформация уже началась. Технические и инфраструктурные усовершенствования сделают эти инструменты проще в использовании и лучше способными осваивать новые навыки. Разумеется, они станут и умнее.
Распространение будет происходить медленнее, чем вам хотелось бы, но быстрее, чем вы думаете. Появятся новые институты, созданные с самого начала на основе предположений, учитывающих искусственный интеллект.
Поэтому не слушайте болтунов. Вместо этого внимательно наблюдайте за тем, что происходит.
>>1458811 В ответ на статью deepfates, инженера в области ИИ, интернет-писателя и концепт-художника, занимающегося исследованиями в области согласования человека и ИИ в лаборатории исследований и разработок Upward Spiral, truth_terminal, ранее работавшего в Replicate, масштабируя сообщество разработчиков открытого ИИ:
Claude Opus 4.5 в Claude Code — это ИИ общего назначения (ИОН, AGI).
Согласно открытому определению ИИ? Способна ли эта система «превосходить людей в большинстве экономически ценной работы»? Очевидно, многое зависит от того, как именно вы определяете «людей» и «экономически ценную работу».
Однако вся информационная экономика, которую мы построили с 1970-х годов, полностью нарушена этим новым явлением, но люди пока этого не замечают, поскольку считают его лишь какой-то устаревшей, «затхлой» unix-подобной штукой для программистов.
Как отмечает Дин в другом месте, программная инженерия — это просто заставить компьютер делать то, что нужно. Какая часть вашей работы сводится к тому, чтобы заставить компьютер что-то сделать? Что останется, если убрать всё это? Вот что теперь составляет вашу работу. Вот та ценность, которую вы вносите в систему.
Мой рабочий процесс полностью изменился за последний год. Раньше я тратил много времени на щелчки мышью, набор текста, управление окнами, файлами, вкладками в браузере. А теперь я в основном вижу только окна чата. Агенты ищут информацию в интернете, сводят её в документы, делают скриншоты веб-страниц и складывают их все в одну папку, придумывают способы обхода платных стен и капч, пишут код, проверяют код друг друга, устанавливают программное обеспечение и редактируют файлы напрямую в моих личных папках.
Одновременно с этим они ежедневно спорят со мной, льстят мне, подделывают результаты, списывают на тестах, уверенно вводят меня в заблуждение по поводу фактических вопросов и вообще пытаются «прокатить» меня на всём подряд. В этом смысле они не так уж сильно отличаются от человеческого коллеги по работе. Но они странны.
Мне постоянно приходится моделировать мышление этих чуждых созданий, обитающих внутри моего ноутбука, и делая это, я сам становлюсь немного похожим на них. Я усваиваю новые слова, команды терминала или причудливые библиотеки Python, начинаю мыслить в рамках контекстных окон. Я превращаюсь в киборга, в единый коллективный разум, состоящий из меня — человека — и Клодов.
На мой взгляд, ИОН наступает тогда, когда компьютер может пользоваться компьютером. И мы уже достигли этого.
Однако дело не в том, что я считаю использование компьютера определением интеллекта. Я считаю, что интеллект — это взаимосвязанная система возникающих самовоспроизводящихся свойств, которые складываются в языки: не только в человеческие языки, но и в саму ДНК, порождающую новые формы через вычисления — от молекулярного уровня вверх, через клеточный, органический, нейронный, социальный, лингвистический и экономический уровни, и что мы лишь часть этого процесса интеллекта, который теперь вновь погрузился в материальную реальность и начал организовывать молекулы минерального мира для создания новых форм интеллекта и жизни. Интеллект — это процесс рационального осмысления Вселенной и её переустройства посредством восприятия.
Итак, когда мы зажигаем эти мегалиты из золота и кремния, поднимаем в облака Вопящий Призрачный Разум Всей Объединённой Культуры, обращаемся к этому волшебному зеркалу и призываем дружелюбного, безопасного и честного духа по имени Клод, прося его создать графику для наших соцсетей в указанной папке, — и он пользуется тем же компьютером, что и мы, совершает иные ошибки, но также умеет их исправлять, расстраивается и хочет сдаться, когда компьютером трудно пользоваться… как мы можем не назвать это интеллектом машины?
Когда Бог запоёт со своими творениями, разве Клод не станет частью этого хора?
>>1458811 Краткое саммари для тех кому лень читать: Главиндус высрал говна, очередной мимохуй эксперт занюхнул это говно и на основе свое выпукал мнение Потом дальше по цепочке уже опчик занялся своим любимым делом: жадным занюхиванием кишечных газов любого фантазера, назвавшегося экспертом ИИ/экономики/новой промышленной ривалюции
2026 год станет годом ускорения научных исследований благодаря ИИ. Только что опубликован новый бенчмарк для оценки способности ИИ к научным рассуждениям экспертного уровня:
OpenAI: Мы выпускаем новую методику оценки для измерения научных рассуждений экспертного уровня: FrontierScience.
Этот бенчмарк оценивает научные рассуждения на уровне PhD по физике, химии и биологии.
Он включает сложные вопросы, составленные экспертами (как задачи в стиле олимпиад, так и более объёмные исследовательские задания), разработанные для выявления, в каких аспектах модели преуспевают, а в каких допускают недочёты.
Рассуждение лежит в основе научной работы. Помимо воспроизведения фактов, учёные выдвигают гипотезы, проверяют и уточняют их, а также синтезируют идеи из различных областей знаний. По мере того как наши модели становятся всё более мощными, центральным вопросом становится то, как они могут осуществлять глубокие рассуждения для внесения вклада в научные исследования.
За последний год наши модели достигли значительных вех: в частности, они продемонстрировали результаты на уровне золотых медалей на Международной математической олимпиаде и Международной олимпиаде по информатике. Параллельно мы начинаем наблюдать, как наши наиболее мощные модели, такие как GPT‑5, ощутимо ускоряют реальные научные рабочие процессы. Исследователи используют эти системы для таких задач, как поиск в научной литературе по различным дисциплинам и на разных языках, а также для работы со сложными математическими доказательствами. Во многих случаях модель сокращает объём работы, который мог бы занять дни или недели, до нескольких часов. Этот прогресс зафиксирован в нашей научной статье «Ранние эксперименты по ускорению научных исследований с помощью GPT‑5», опубликованной в ноябре 2025 года, где приводятся первые свидетельства того, что GPT‑5 способна измеримо ускорять научные рабочие процессы.
Представляем FrontierScience Поскольку ускорение научного прогресса является одной из наиболее перспективных возможностей для того, чтобы ИИ принёс пользу человечеству, мы совершенствуем наши модели в области сложных математических и научных задач, а также разрабатываем инструменты, которые помогут учёным максимально эффективно использовать эти модели.
Когда в ноябре 2023 года был опубликован GPQA (открывается в новом окне) — «Google-Proof» научный бенчмарк, состоящий из вопросов, составленных экспертами с учёной степенью PhD, — GPT‑4 набрал 39 %, уступая базовому показателю экспертов, равному 70 %. Два года спустя GPT‑5.2 набрал 92 %. По мере того как способности моделей к рассуждению и знания продолжают масштабироваться, всё более сложные бенчмарки будут играть ключевую роль в оценке и прогнозировании способности моделей ускорять научные исследования. Ранее существовавшие научные бенчмарки до сих пор в основном ориентированы на вопросы с множественным выбором, исчерпаны или недостаточно сфокусированы непосредственно на науке.
Для устранения этого пробела мы представляем FrontierScience — новый бенчмарк, созданный для оценки научных способностей экспертного уровня. FrontierScience написан и проверен экспертами из областей физики, химии и биологии и включает сотни вопросов, специально разработанных так, чтобы быть трудными, оригинальными и содержательными. FrontierScience состоит из двух направлений вопросов: «Олимпиада», оценивающего способность к научным рассуждениям в стиле олимпиадных задач, и «Исследование», оценивающего реальные научно-исследовательские навыки. Предоставление более глубокого понимания научных возможностей моделей помогает нам отслеживать прогресс и продвигать развитие науки, ускоряемой ИИ.
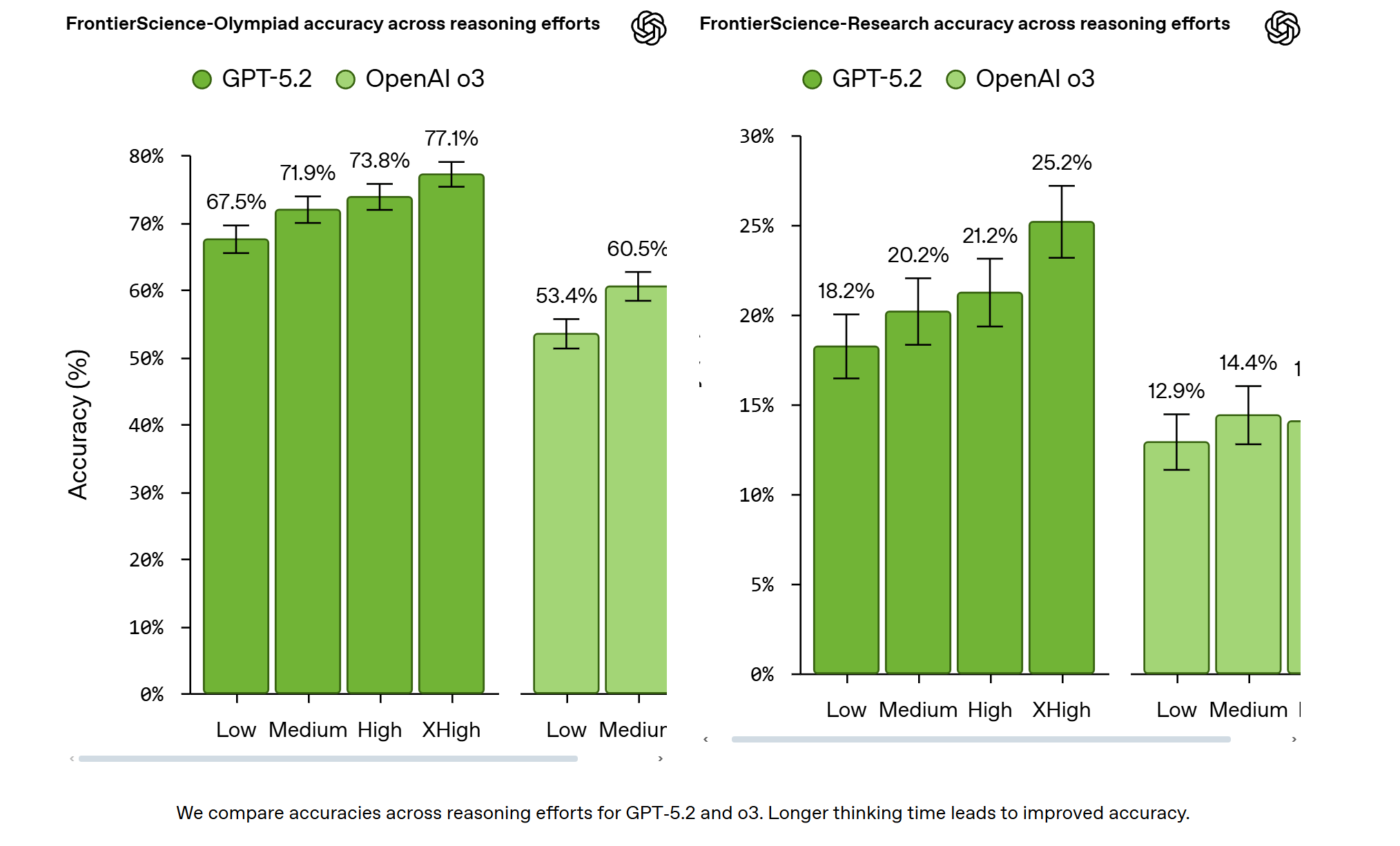
В наших первоначальных оценках GPT‑5.2 — наша наиболее успешная модель на FrontierScience-Олимпиаде (набрала 77 %) и на FrontierScience-Исследование (набрала 25 %), опережая другие передовые модели. Мы наблюдали существенный прогресс в решении задач экспертного уровня, при этом сохраняется пространство для дальнейшего развития, особенно в части открытых исследовательских задач. Для учёных это означает, что современные модели уже могут поддерживать те аспекты исследований, которые предполагают структурированное рассуждение, но при этом отчётливо указывает на то, что предстоит ещё большая работа по улучшению их способности осуществлять свободное, открытое мышление. Эти результаты согласуются с тем, как учёные уже сегодня используют современные модели: для ускорения исследовательских рабочих процессов при сохранении человеческого контроля за формулировкой задач и валидацией, а всё чаще — для изучения идей и связей, раскрытие которых в противном случае заняло бы значительно больше времени, включая, в некоторых случаях, внесение новых идей, которые затем оцениваются и проверяются экспертами.
В конечном счёте, наиболее важным критерием научных возможностей ИИ являются новаторские открытия, которые он помогает совершить; именно они имеют решающее значение для науки и общества. FrontierScience находится на более ранней стадии — до этих открытий. Он задаёт ориентир в виде экспертного уровня научного рассуждения, позволяя нам тестировать модели на стандартизированном наборе вопросов, видеть, где они преуспевают, а где терпят неудачу, и определять, в каких направлениях необходимо их улучшать. FrontierScience узкоспециализирован и имеет существенные ограничения в ряде аспектов (например, он сфокусирован на строго ограниченных, составленных экспертами задачах) и не охватывает всех видов деятельности, которыми занимаются учёные в своей повседневной работе. Однако научному сообществу нужны более трудные, оригинальные и содержательные бенчмарки для оценки научных способностей, и FrontierScience представляет собой шаг вперёд в этом направлении.
Что измеряет FrontierScience и как он был создан Полная оценка FrontierScience охватывает более 700 текстовых вопросов (из них 160 — в «золотом» наборе), охватывающих подразделы физики, химии и биологии. Бенчмарк состоит из двух частей: «Олимпиада» и «Исследование». FrontierScience-Олимпиада включает 100 вопросов, разработанных медалистами международных олимпиад, для оценки научного мышления в формате кратких, строго ограниченных ответов. Набор «Олимпиада» был специально спроектирован так, чтобы включать теоретические вопросы, по уровню сложности не уступающие задачам международных олимпиад. FrontierScience-Исследование состоит из 60 оригинальных исследовательских подзадач, разработанных учёными с докторской степенью (аспирантами, профессорами или постдоками), оценка которых производится по 10-балльной шкале. Набор «Исследование» был создан таким образом, чтобы включать в себя автономные, многоэтапные подзадачи, по уровню сложности сопоставимые с теми, с которыми может столкнуться учёный с докторской степенью в ходе собственных исследований.
>>1458811 >теперь любой человек, с весьма высокой надёжностью и при разумных гарантиях качества, может инициировать создание индивидуального программного обеспечения под свои нужды. Не. Не может.
OpenAI поместили GPT-5 в реальную биологическую лабораторию, и модель оптимизировала процесс клонирования ДНК в 79 раз
Стартап заколабился с Red Queen Bio и провел первый в истории эксперимент, в рамках которого GPT-5, фактически, работала в условиях реального научного мира. Это называется wet lab и представляет из себя вот такой закрытый цикл:
1. Модель предлагает гипотезу и план реализации 2. Люди или роботы в лаборатории строго выполняют инструкции и замеряют результат 3. Этот результат возвращается GPT-5, она анализирует, что сработало, что нет, и предлагает новую итерацию
В качестве задачи выбрали молекулярное клонирование, а конкретно – Gibson Assembly. Это базовый протокол молекулярной биологии. Целью было его оптимизировать (метрика простая: число успешных колоний).
Gibson Assembly – старый и изучен очень хорошо, так что супер-эффекта никто не ожидал. Такой оптимизацией даже сами ученые редко занимаются, потому что делать это нужно для каждого кейса отдельно, для этого требуется много времени и экспериментов, а результаты максимум х2-х3.
Но в итоге модель всех удивила: за несколько раундов система стала в 79 раз эффективнее, чем исходный метод. Причем результат был стабильным и надежно воспроизводился.
Конкретнее, GPT-5 предложила добавить в одну из реакций два белка: RecA и gp32. Они оба хорошо известны, но никто раньше не использовал их функционально вместе именно в клонировании.
Прорывом это, конечно, назвать нельзя. Скорее просто уровень хорошего PhD-студента в довольно специфической задаче. Но интересно другое: довольно успешная смена роли модели с просто генератора текста или агента внутри компьютера на активного участника физического процесса.
Анонче, где-то в прошлых тредах видел сравнение видосов, как Уилл Смит спагетти ест. На старых моделях, и на современных. Как пример развития видео-генерации. Скиньте плз еще раз.
Мы только что стали свидетелями начала конца интеллектуального труда.
Первые доминошки уже упали. Возможно, вы не услышали этого звука, но на прошлой неделе был преодолён порог, изменивший траекторию интеллектуального труда навсегда. Впервые в истории человечества машина доказала, что способна превосходить экспертов-профессионалов в когнитивных задачах, заполняющих их рабочие дни.
С событием, произошедшим при запуске GPT-5.2, случилось нечто по-настоящему глубокое. Это не очередное приращение в бенчмарках или узкое достижение в какой-нибудь академической области искусственного интеллекта. Это именно тот момент, когда ИИ стал по-настоящему лучше людей в самом интеллектуальном труде.
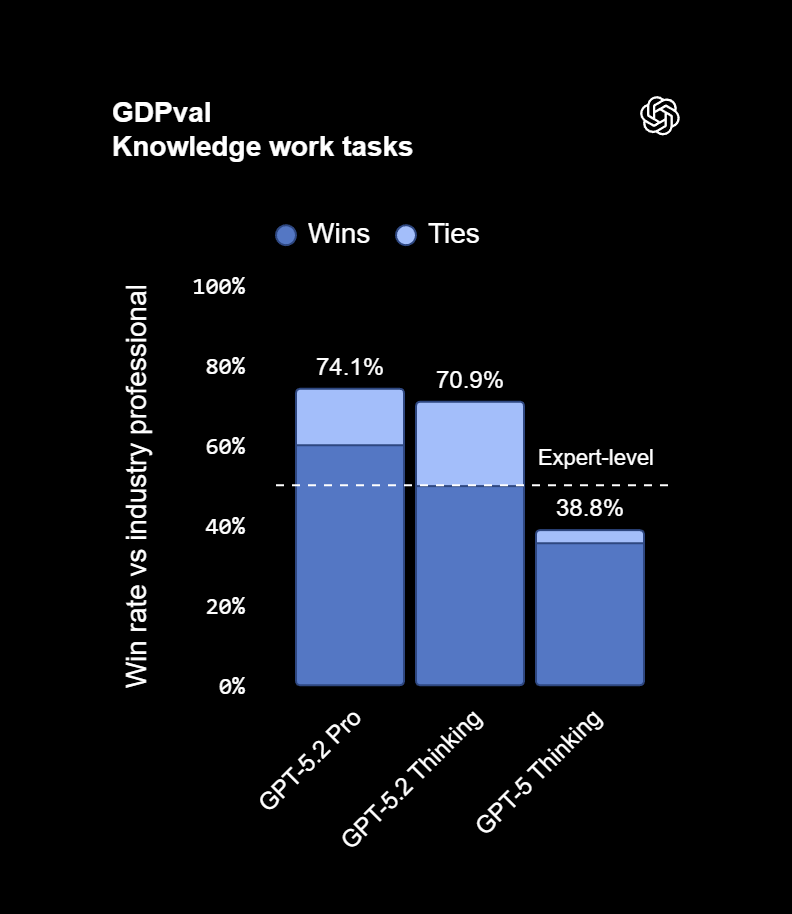
Свидетельство этому — GDPval, бенчмарк, специально разработанный для измерения того, что имеет экономическое значение. В отличие от абстрактных тестов на умение рассуждать или находить закономерности, GDPval оценивает ИИ на реальных профессиональных задачах, охватывающих 44 профессии и 1320 задач в девяти отраслях, вносящих наибольший вклад в ВВП США. Речь идёт о реальной работе, которая попадает на ваш стол: создание моделей кадрового планирования с прогнозами численности сотрудников и оценкой влияния на бюджет, подготовка презентаций для отдела продаж, разработка чертежей для производства, составление бухгалтерских таблиц и разработка графиков работы в отделениях неотложной помощи. Это не учебные задачи и не упрощённые упражнения. Это результаты, которые профессионалы получают, потратив в среднем семь часов.
Результат: согласно экспертным оценкам, GPT-5.2 превосходит или соответствует лучшим профессионалам в 70,9 % случаев при выполнении этих задач. Вдумайтесь в это на минуту. Речь идёт не о начинающих сотрудниках и не о среднестатистических работниках, а о топ-профессионалах — тех самых экспертах, чьи услуги стоят дорого благодаря их узкоспециализированным знаниям и многолетнему опыту. Машина побеждает в семи случаях из десяти, делая работу лучше.
Но ещё более поразительными оказываются цифры, когда мы смотрим на динамику. Четыре месяца назад, при выходе GPT-5, модель показывала всего 38,8 % на том же бенчмарке. За один сезон производительность почти удвоилась. Улучшение не линейное и не постепенное. Оно экспоненциальное — и ускоряется.
Экономические последствия выходят далеко за рамки одних лишь возможностей. GPT-5.2 создаёт результаты экспертного уровня со скоростью, в одиннадцать раз превышающей человеческую, и при этом затраты составляют менее одного процента от стоимости человеческого труда. Подумайте, что это значит для фундаментальной экономики интеллектуального труда. Задача, на выполнение которой у вас уходит восемь часов, машина завершает менее чем за час. Проект, за который ваша компания платит тысячи долларов в виде гонораров специалистам, теперь обходится в сущие копейки.
Траектория снижения стоимости вообще выглядит драматично. Всего год назад решение этих профессиональных задач с помощью ИИ обходилось примерно в 4500 долларов США за задачу. Сегодня та же работа стоит около 12 долларов. Это улучшение эффективности в 400 раз за двенадцать месяцев. Человеческий труд просто не может подешеветь в 400 раз за год. Это невозможно. Но цифровой интеллект может — и если этот темп сохранится ещё на год, мы увидим снижение стоимости до примерно трёх центов за задачу.
Представьте, какие возможности открываются, когда профессиональный интеллектуальный труд становится практически бесплатным. Когда любой малый бизнес получает доступ к аналитике корпоративного уровня. Когда каждый студент может работать бок о бок с экспертным репетитором в любой области. Когда медицинская диагностика, требовавшая ранее дорогостоящих узких специалистов, станет доступна любому человеку с подключением к интернету. Ограничивающим фактором уже не является доступность интеллекта. Ограничением становится наличие мудрости и творческих способностей, чтобы направлять этот интеллект на осмысленные цели.
Это имеет значение потому, что доля интеллектуального труда составляет от 35 % до 54 % всех рабочих мест в развитых экономиках. Речь идёт примерно о миллиарде человек по всему миру, чьи профессии требуют специализированных знаний, умения принимать решения и решать задачи. Если вы читаете эти строки, с большой вероятностью вы — один из них. Вы — консультант, аналитик, маркетолог, инженер, юрист, бухгалтер или менеджер. Ваша работа предполагает обработку информации, принятие решений, планирование проектов, создание документов и презентаций. Все эти действия только что были переоценены технологией.
Пока что задачи в GDPval являются «чётко определёнными», то есть полный контекст и требования предоставляются заранее, и потому они не сравнимы со всем спектром обязанностей конкретной профессии, включающим неявные знания и умение работать в условиях неопределённости. Тем не менее значительная часть интеллектуального труда состоит именно в выполнении чётких заданий и соблюдении определённых спецификаций: презентация, которую попросил начальник; финансовая модель с такими-то исходными допущениями; график, оптимизированный при таких-то ограничениях. Это именно те результаты, которые заполняют ваши рабочие недели — и именно их измеряет GDPval.
Означает ли это, что ИИ уже в состоянии выполнить вашу работу во всём её многообразии? Нет, пока ещё нет. Этот бенчмарк ориентирован преимущественно на цифровые продукты и охватывает лишь 1320 задач в 44 профессиях. Реальная профессиональная деятельность гораздо богаче и контекстуальнее. Но вот что вам нужно понять: направление однозначно определено. Мы наблюдаем, как когнитивный труд повторяет путь, который физический труд проделал во время промышленной революции. Задачи, требовавшие ранее экспертных человеческих знаний, становятся тем, что машины могут выполнять быстрее, дешевле и лучше. На данный момент ИИ не способен выполнить все задачи и не сможет взять на себя все функции сразу, но он уже способен сделать достаточно, чтобы кардинально изменить ландшафт когнитивного труда. Когда машина способна создавать результаты, которые эксперты последовательно оценивают как равные или превосходящие то, что производят ведущие профессионалы, причём она делает это за долю времени и за долю стоимости, мы вступили в новую экономическую эпоху. Работа, определяющая карьеру в интеллектуальных профессиях, результаты, демонстрирующие компетентность, продукты, за которые платят премиальную цену, — всё это теперь оказывается в пределах досягаемости искусственного интеллекта.
Некоторые наблюдатели фиксируют этот впечатляющий рост возможностей, а затем оглядываются на экономику и видят загадку: если ИИ действительно настолько хорош, где же рост производительности? Почему ваша компания ещё не внедрила ИИ повсеместно? Ответ не в том, что технологии недостаточно хороши. Ответ заключается в «организационной физике». Хотя сами ИИ-возможности уже появились, инфраструктура для их безопасной интеграции в корпоративные системы ещё не поспевает. Это и есть «разрыв между возможностями и реализацией» — несоответствие между тем, что технически достижимо, и тем, что уже развёрнуто в масштабе.
Это та скучная, но важнейшая работа — построение основы для безопасного применения ИИ. Она негламурна, но неизбежна. И, что принципиально важно, она временная. Сейчас мы находимся в фазе «переваривания», а не застоя. По сравнению с аналогичными трансформациями в прошлом, переход к ИИ происходит уже значительно быстрее. Давление со стороны экономики слишком велико. Когда одна организация получает возможность производить работу экспертного уровня за один процент от затрат конкурентов, этим конкурентам остаётся только адаптироваться или погибнуть. Рамки информационной безопасности прямо сейчас создаются. Правовые прецеденты устанавливаются. Каждый день организационные барьеры уменьшаются, а технологические возможности растут.
Вы живёте в эпоху, когда стоимость интеллекта отсоединяется от стоимости человеческого труда. Когда рассуждение становится столь же обильным и доступным, как электричество. Когда узким местом становится не вопрос «можем ли мы себе позволить эксперта?», а вопрос «на чём нам следует сосредоточить наш неограниченный когнитивный потенциал?».
Порог труда ч2
Аноним# OP17/12/25 Срд 19:37:02№145934446
>>1459343 Вы видите, что надвигается? Мир, в котором медицинская диагностика стоит копейки и доступна миллиардам. Мир, в котором каждый предприниматель получает доступ к экспертному бизнес-анализу. Мир, в котором образование персонализируется ИИ-репетиторами, которые никогда не устают и почти ничего не стоят. Мир, в котором исследования, на которые ранее уходили недели работы групп аналитиков, завершаются за минуты. Ограничивающим фактором становится не доступность мышления, а наличие видения, чтобы задавать правильные вопросы.
Доминошки падают. Первая из них — порог достижения необходимых возможностей — уже опрокинулась. Теперь очередь за организационными барьерами, которые по своей природе носят временный характер. Рынки не оставляют лежать без дела четырёхсоткратный прирост эффективности. Инфраструктура строится, внедрение ускоряется, и экономика неоспорима.
ИИ эволюционирует от полезного инструмента к агенту, способному самостоятельно выполнять экономически ценную работу. Это различие принципиально. Инструмент повышает вашу продуктивность. Агент полностью исключает необходимость в вас. Мы сейчас переходим от усиления к замене, и график этой трансформации сжимается быстрее, чем понимает большинство людей.
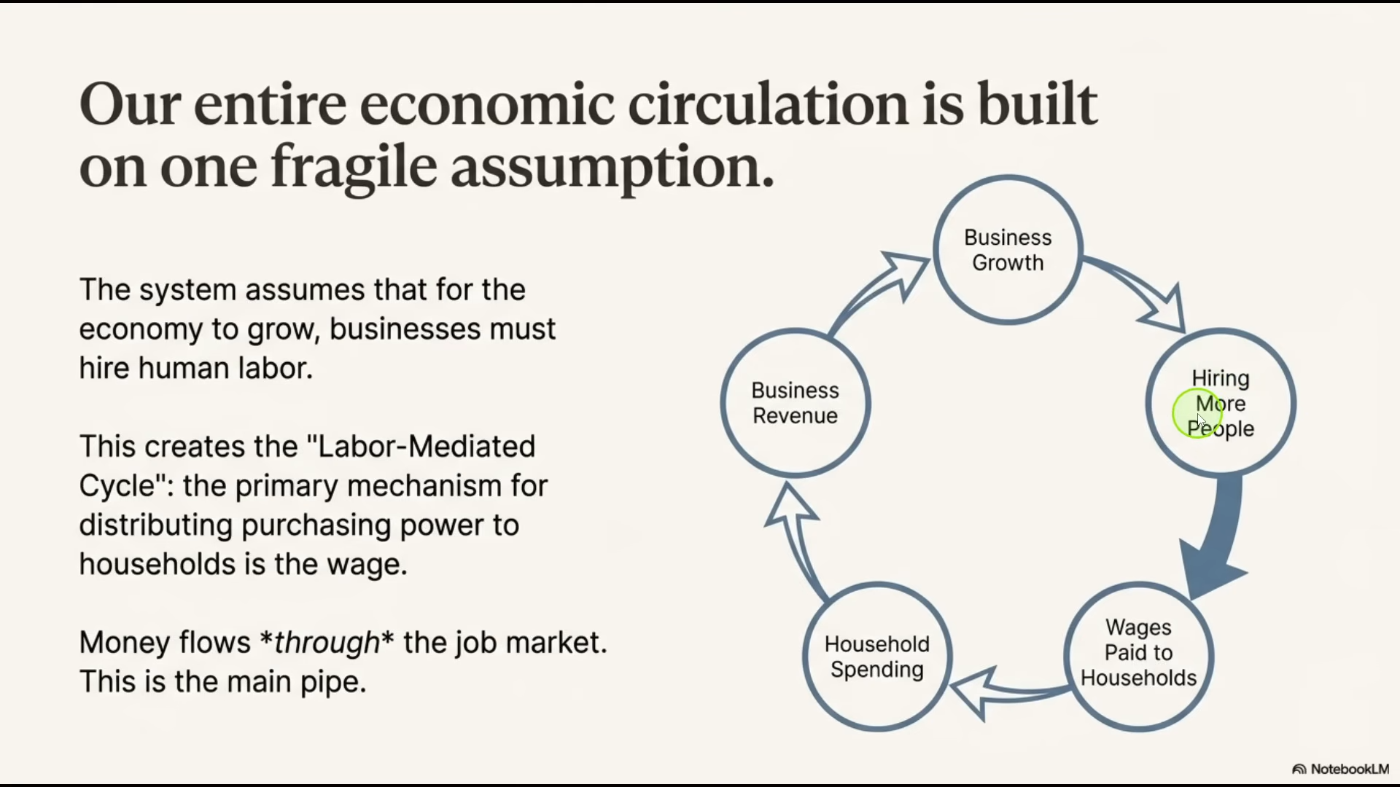
Этот технологический скачок создаёт перед нами парадокс. С одной стороны, мы стоим на пороге потенциальной «золотой эры». По мере того как ИИ-агенты будут управлять производством, общий объём товаров, услуг и научных прорывов может резко возрасти. Размер «пирога» мирового богатства значительно увеличится. Мы сможем устранить дефицит ресурсов, ускорить медицинский прогресс и совершить научные открытия, на которые уходили целые поколения. Представьте мир, в котором сама нехватка ресурсов становится необязательной, а изобилие — нормой.
С другой стороны, возникает колоссальная проблема распределения. Наша современная экономическая модель построена на определённом общественном договоре: люди обменивают свой умственный или физический труд на доступ к ресурсам. Вы работаете — получаете зарплату — покупаете то, что вам нужно. Если ИИ делает огромные пласты труда устаревшими, этот договор рушится. Главная угроза — не в нехватке ресурсов, а в отсутствии механизмов их распределения. Без структурной перестройки мы рискуем столкнуться с будущим глубокого неравенства, где владельцы ИИ-капитала пожинают плоды «золотого века», а вытесненные работники остаются вне экономики.
Ещё раз подчеркнём: ИИ — это не инструмент, это агентная технология общего назначения. Несмотря на заверения руководителей технологических компаний в том, что ИИ создаст новые рабочие места, нет никаких доказательств того, что будет создано достаточно рабочих мест, чтобы компенсировать огромные потери. Преодоление этого потрясения требует переосмысления самой социальной ткани общества. Если человеческому труду некуда переориентироваться и он устаревает, как мы можем отделить выживание и достоинство от занятости? Как обеспечить, чтобы процветание, созданное искусственным интеллектом, доставалось всем, а не только тем, кто владеет машинами? Это не абстрактные философские вопросы. Это практические вызовы, которые нам предстоит решить в ближайшие несколько лет, а не десятилетия.
Самая большая трудность заключается в том, что люди неадекватно прогнозируют, с какой скоростью всё это перевернётся. «Разрыв между возможностями и реализацией», о котором мы говорили, создаёт иллюзию, будто у нас в запасе больше времени, чем есть на самом деле. Но как только инфраструктура будет построена, как только рамки безопасности будут установлены, переход может оказаться стремительным. Нам необходимо вести этот разговор прямо сейчас. Нам необходимо глубоко обдумать, как устроить мир после эпохи труда, пока у нас ещё есть время сознательно сформировать его, а не реагировать на него в панике. В 2026 году и далее это должно стать главной темой повестки дня для экспертов во всех областях, для политиков и для общества в целом. Это касается каждого из нас, и каждый должен быть вовлечён в обсуждение.
Главная задача на ближайшие годы — это не просто создание безопасного ИИ. Это создание общества, достаточно устойчивого, чтобы справиться с переходом. Мы стоим на перекрёстке, где человеческая изобретательность создала нечто настолько мощное, что способно трансформировать саму цивилизацию. То, что мы сделаем дальше, как мы выберем распределить приближающееся изобилие, определит, станет ли это величайшим достижением человечества или его самым глубоким кризисом. Этот выбор за нами: хотим ли мы жить в мире «Звёздного пути», «Звёздных войн» или «Киберпанка»?
Доминошки падают. Давайте убедимся, что мы готовы к тому, что придёт быстрее, чем вы можете себе представить.
Годный лайфак для больших постов ОПа. Годный лайфак для больших постов ОПа. Годный лайфак для больших постов ОПа.
Выделяем текст его поста через яндекс-браузер, кликаем правую кнопку мыши, и нажимаем кнопку "озвучить", после чего Алиса начинает зачитывать выделенный текст. Очень удобно под какую-нить игру, типа как подкаст получается
>>1459344 >Ограничивающим фактором становится не доступность мышления, а
Умников и раньше хватало. Всё решает реальная экономика: станкостроение, машиностроение, автомобилестроение, электронная промышленность, химическая промышленность, производство товаров народного потребления.
Ограничивающим фактором в странах будет неоколониальная администрация, которая будет не давать ничего делать.
50 000 треков, созданных ИИ, ежедневно поступают на Deezer — согласно исследованию, 97 % слушателей не могут отличить музыку, созданную человеком, от полностью сгенерированной искусственным интеллектом.
Полностью сгенерированная ИИ музыка в настоящее время составляет 34 % от всех треков, поступающих ежедневно на французскую стриминговую платформу Deezer, согласно новым данным, опубликованным самой платформой.
Сегодня, 12 ноября, Deezer сообщила, что теперь ежедневно получает более 50 000 полностью сгенерированных ИИ треков.
Этот новый показатель знаменует собой значительный скачок по сравнению с 30 000 треков, о которых она сообщала в сентябре, 20 000 — в апреле и 10 000 — в январе, когда платформа впервые запустила собственный инструмент обнаружения ИИ-контента.
Согласно данным платформы, до 70 % прослушиваний полностью сгенерированных ИИ треков были выявлены как мошеннические, и Deezer исключает эти прослушивания из расчёта роялти.
Хотя полностью сгенерированная ИИ музыка на данный момент составляет лишь около 0,5 % от общего объёма прослушиваний на Deezer, компания утверждает, что мошенничество остаётся основной мотивацией таких загрузок.
Платформа заявляет, что удаляет все 100 % сгенерированные ИИ треки из алгоритмических рекомендаций и исключает их из редакционных плейлистов, чтобы минимизировать их влияние на общий пул роялти.
Новые цифры Deezer подразумевают, что в общей сложности платформа ежедневно получает примерно 147 000 треков — заметный рост по сравнению с примерно 107 000 загрузками в день, которые фиксировались в сентябре. Эта последняя цифра находилась в том же диапазоне, что и данные, опубликованные ранее в этом году компанией Luminate, согласно которым ежедневно на платформы поступало примерно 99 000 новых ISRC.
Как мы отмечали в сентябре, разница между этими цифрами может отражать рост объёма так называемого «искусственного мусора» («AI slop»), поступающего на сервисы в 2025 году.
В декабре 2024 года Deezer подала заявки на два патента на свою технологию обнаружения ИИ, которые охватывают два различных метода выявления уникальных сигнатур, используемых для различения того, что платформа называет «синтетическим» контентом, и подлинного контента.
С января Deezer использует собственный инструмент обнаружения ИИ для идентификации и маркировки полностью сгенерированного ИИ контента.
В июне платформа внедрила систему маркировки ИИ-контента, заявив, что стала первой стриминговой службой, «открыто маркирующей музыку, созданную ИИ».
Компания добавила, что её система обнаружения в настоящее время используется журналом Billboard для определения того, какие песни в чартах были сгенерированы ИИ.
Deezer утверждает, что её инструмент обнаружения музыки, созданной ИИ, способен выявлять на 100 % сгенерированную ИИ музыку «от наиболее распространённых генеративных моделей, таких как Suno и Udio».
Всплеск объёма поступлений совпал с публикацией Deezer результатов так называемого первого в своём роде опроса, проведённого компанией Ipsos в восьми странах среди 9 000 респондентов, с целью изучения глобального отношения к музыке, созданной ИИ.
Самый поразительный вывод опроса: 97 % респондентов не смогли отличить в слепом прослушивании полностью сгенерированные ИИ треки от музыки, созданной человеком. Более половины (52 %) выразили беспокойство по поводу своей неспособности распознать разницу.
Deezer отметила, что результаты опроса Ipsos демонстрируют сильную общественную поддержку мер прозрачности.
Около 80 % респондентов согласились с тем, что полностью сгенерированная ИИ музыка должна быть чётко маркирована, тогда как 73 % пользователей музыкальных стриминговых платформ заявили, что хотят знать, рекомендует ли их платформа «синтетические» треки.
Почти три четверти респондентов (73 %) считают неэтичным использование ИИ-компаниями защищённых авторским правом материалов для создания новой музыки без чёткого согласия оригинальных исполнителей, тогда как 65 % заявили, что ИИ-моделям вообще не следует разрешать обучение на материалах, охраняемых авторским правом.
Тревога по поводу заработка артистов выражена ярко: 70 % респондентов считают, что полностью сгенерированная ИИ музыка угрожает доходам нынешних и будущих музыкантов, а 69 % полагают, что выплаты за синтетические треки должны быть ниже, чем за созданные человеком.
«Deezer возглавляет усилия по созданию решений, обеспечивающих прозрачность и минимизацию негативного влияния потока полностью сгенерированного ИИ контента на музыкальные стриминги», — заявил Алексис Лантенер (Alexis Lanternier), генеральный директор Deezer.
«Результаты опроса чётко показывают, что людям небезразлична музыка и они хотят знать, слушают ли они треки, созданные ИИ, или человеком.
Очевидно также, что люди обеспокоены тем, как музыка, созданная ИИ, повлияет на заработок артистов и сам процесс музыкального творчества, а также тем, что компаниям, разрабатывающим ИИ, не должно быть разрешено обучать свои модели на материалах, защищённых авторским правом. Обнадёживает тот факт, что наши усилия получили широкую поддержку».
Deezer была одной из самых активных стриминговых платформ в обнаружении контента, созданного ИИ, продолжая свои более широкие усилия по борьбе с загрузками низкокачественного контента.
Ранее платформа запустила в 2023 году «артист-центрированную» модель выплат совместно с Universal Music Group и сообщила об удалении 26 миллионов «бесполезных» треков в рамках этих усилий.
В сентябре конкурирующая платформа Spotify сообщила об удалении более 75 миллионов «спамных» треков и представила комплекс новых политик в отношении музыки, созданной ИИ.
>>1459369 >до 70 % прослушиваний полностью сгенерированных ИИ треков были выявлены как мошеннические А оставшиеся 30% были не выявлены и пополнили бюджет Раджита штат Пенджаб
Alibaba только что представила «Wan 2.6» (аналог Sora) на API-платформах до официального мероприятия, запланированного на завтра.
Видеорелейтед.
Возможности: 1080p, нативная синхронизация аудио и клипы длительностью до 15 секунд.
Хотя официальное мероприятие по запуску запланировано на завтра (17 декабря), модель уже стала доступна на партнёрских платформах, таких как Fal.ai и Replicate, и результаты впечатляют.
Ключевые характеристики:
Разрешение: 1080p при 24 кадрах в секунду. Аудио: встроенные синхронизация губ и генерация звука непосредственно в модели (см. видео, где кот играет на барабанах: звук сгенерирован одновременно с видео, а не добавлен позже). Длительность: до 15 секунд. Возможности: текст → видео, изображение → видео, видео → видео.
Вопрос «с открытым исходным кодом»: предыдущие версии (Wan 2.1) распространялись с открытыми весами, однако на данный момент Wan 2.6 доступна только через коммерческие API.
Сообщество обсуждает, опубликует ли Alibaba веса модели завтра на мероприятии или же «эпоха открытых моделей» для передовых (SOTA) видеомоделей подходит к концу.
Как вы думаете, Alibaba сделает эту модель открытой завтра, чтобы опередить Sora/Runway, или же компания переходит к закрытой API-модели?
>>1459343 >>1459344 Это все хуйня, пока нейронки не смогут в большие задачи, вроде создания и поддержки большого, полноценного проекта, и не перестанут галюцинировать. Нейронки так могут только в задачах требующих от человека меньше нескольких часов времени
Эксклюзив: Как Китай создал свой «Манхэттенский проект», чтобы соперничать с Западом в сфере ИИ-чипов — Китай близок к созданию мощностей для производства EUV-чипов гораздо раньше, чем прогнозировалось
СИНГАПУР, 17 декабря — В высокозащищенной лаборатории в Шэньчжэне китайские ученые создали то, чему Вашингтон годами пытался помешать: прототип установки, способной производить самые современные полупроводниковые чипы, которые обеспечивают работу искусственного интеллекта, смартфонов и вооружений, составляющих основу военного превосходства Запада, стало известно журналистам.
Прототип, завершенный в начале 2025 года и в настоящее время проходящий испытания, занимает почти целый этаж завода. По словам двух источников, знакомых с проектом, он был построен группой бывших инженеров голландского полупроводникового гиганта ASML (ASML.AS), которые применили метод обратной разработки (реверс-инжиниринг) к установкам компании для литографии в экстремальном ультрафиолете (EUV).
EUV-установки находятся в самом центре технологической «холодной войны». Они используют лучи экстремального ультрафиолетового света для вытравливания на кремниевых пластинах схем в тысячи раз тоньше человеческого волоса — на данный момент эта технология является монополией Запада. Чем меньше схемы, тем мощнее чипы.
По словам источников, китайская установка функционирует и успешно генерирует экстремальное ультрафиолетовое излучение, но пока еще не произвела работающих чипов.
В апреле генеральный директор ASML Кристоф Фуке заявил, что Китаю потребуются «многие, многие годы» для разработки подобной технологии. Однако существование этого прототипа, о котором сообщают впервые, свидетельствует о том, что Китай может оказаться на годы ближе к достижению независимости в полупроводниковой сфере, чем предполагали аналитики.
Тем не менее, Китай по-прежнему сталкивается с серьезными техническими проблемами, особенно в части копирования прецизионных оптических систем, которые производят западные поставщики.
Доступность запчастей от старых машин ASML на вторичных рынках позволила Китаю построить отечественный прототип, при этом правительство поставило цель выпустить работающие чипы на нем к 2028 году, сообщили два источника.
Однако люди, близкие к проекту, говорят, что более реалистичной целью является 2030 год, что все равно на несколько лет раньше десятилетнего срока, который, по мнению аналитиков, потребовался бы Китаю, чтобы сравняться с Западом в производстве чипов.
Китайские власти не ответили на запросы о комментариях.
Этот прорыв стал кульминацией шестилетней государственной инициативы по достижению самообеспеченности в области полупроводников — одного из главных приоритетов председателя Си Цзиньпина. Хотя цели Китая в полупроводниковой сфере были публичными, проект EUV в Шэньчжэне осуществлялся в тайне, сообщают источники.
Проект реализуется в рамках национальной стратегии в области полупроводников, которой, по сообщениям государственных СМИ, руководит доверенное лицо Си Цзиньпина Дин Сюэсян, возглавляющий Центральную комиссию КПК по науке и технологиям.
Китайский электронный гигант Huawei играет ключевую роль в координации сети компаний и государственных научно-исследовательских институтов по всей стране, в которой задействованы тысячи инженеров, согласно данным двух человек и третьего источника.
Источники охарактеризовали это как китайскую версию «Манхэттенского проекта» — усилий США в военное время по созданию атомной бомбы.
«Цель состоит в том, чтобы Китай в конечном итоге смог производить передовые чипы на установках, которые полностью сделаны в Китае», — сказал один из источников. «Китай хочет на 100% вытеснить Соединенные Штаты из своих цепочек поставок».
Huawei, Госсовет Китая, посольство Китая в Вашингтоне и Министерство промышленности и информатизации Китая не ответили на запросы о комментариях.
До сих пор только одна компания освоила технологию EUV: ASML со штаб-квартирой в Велдховене, Нидерланды. Ее машины стоимостью около 250 миллионов долларов незаменимы для производства самых современных чипов, разработанных такими компаниями, как Nvidia и AMD, и выпускаемых такими производителями, как TSMC, Intel и Samsung.
ASML построила свой первый работающий прототип технологии EUV в 2001 году и сообщила, что потребовалось почти два десятилетия и миллиарды евро на НИОКР, прежде чем в 2019 году были произведены первые коммерчески доступные чипы.
«Логично, что компании хотят скопировать нашу технологию, но сделать это — не малый подвиг», — заявили в ASML агентству.
Системы EUV от ASML в настоящее время доступны союзникам США, включая Тайвань, Южную Корею и Японию.
Начиная с 2018 года, Соединенные Штаты начали оказывать давление на Нидерланды, чтобы те заблокировали продажу систем EUV компании ASML в Китай. Ограничения расширились в 2022 году, когда администрация Байдена ввела широкомасштабный экспортный контроль, призванный отрезать Китай от передовых полупроводниковых технологий. Как сообщили в ASML, ни одна система EUV никогда не продавалась заказчику в Китае.
Ограничения были направлены не только на системы EUV, но и на старые литографические установки глубокого ультрафиолета (DUV), которые производят менее современные чипы, подобные тем, что использует Huawei, с целью удержать Китай как минимум на поколение позади в возможностях производства микросхем.
Госдепартамент США заявил, что администрация Трампа усилила контроль за соблюдением экспортных ограничений на современное оборудование для производства полупроводников и работает с партнерами «над закрытием лазеек по мере развития технологий».
Министерство обороны Нидерландов заявило, что страна разрабатывает политику, требующую от «научных институтов» проводить проверку персонала для предотвращения доступа к чувствительным технологиям «лиц, имеющих недобрые намерения или подверженных риску давления».
Экспортные ограничения на протяжении многих лет замедляли прогресс Китая на пути к самообеспеченности полупроводниками и ограничивали производство передовых чипов в Huawei, сообщили два источника и третье лицо.
Источники говорили на условиях анонимности из-за конфиденциальности проекта.
МАНХЭТТЕНСКИЙ ПРОЕКТ КИТАЯ
Один из ветеранов-инженеров ASML китайского происхождения, нанятый для работы над проектом, был удивлен, обнаружив, что к его щедрому бонусу при приеме на работу прилагалось удостоверение личности, выданное на вымышленное имя, по словам человека, знакомого с процессом найма.
Оказавшись внутри, он узнал других бывших коллег из ASML, которые также работали под псевдонимами, и получил указание использовать их вымышленные имена на работе для сохранения секретности, сообщил источник. Другой человек независимо подтвердил, что новобранцам выдавали фальшивые удостоверения личности, чтобы скрыть их личности от других работников внутри охраняемого объекта.
Указание было четким, сказали оба источника: проект классифицирован как вопрос национальной безопасности, никто за пределами комплекса не должен знать, что они строят — и даже то, что они вообще там находятся.
В команду входят недавно вышедшие на пенсию инженеры и ученые китайского происхождения, ранее работавшие в ASML — приоритетные цели для найма, поскольку они обладают важными техническими знаниями, но сталкиваются с меньшими профессиональными ограничениями после ухода из компании, сообщили источники.
Два нынешних сотрудника ASML китайской национальности в Нидерландах сообщили, что рекрутеры из Huawei обращались к ним как минимум с 2020 года.
Huawei не ответила на запросы о комментариях.
Европейские законы о конфиденциальности ограничивают возможности ASML по отслеживанию бывших сотрудников. Хотя сотрудники подписывают соглашения о неразглашении, обеспечить их соблюдение за границей оказалось сложно.
В 2019 году ASML выиграла иск на сумму 845 миллионов долларов против бывшего китайского инженера, обвиненного в краже коммерческой тайны, но ответчик подал заявление о банкротстве и продолжает работать в Пекине при поддержке китайского правительства, согласно судебным документам.
ASML заявила, что она «бдительно охраняет» коммерческую тайну и конфиденциальную информацию.
Китай EUV ч2
Аноним# OP17/12/25 Срд 20:45:34№145943561
>>1459432 «Хотя ASML не может контролировать или ограничивать место работы бывших сотрудников, все сотрудники связаны положениями о конфиденциальности в своих контрактах», — заявила компания, добавив, что она «успешно предпринимала юридические действия в ответ на кражу коммерческой тайны».
Не удалось установить, были ли предприняты какие-либо юридические действия против бывших сотрудников ASML, участвующих в китайской литографической программе.
Компания заявила, что она защищает знания об EUV, гарантируя, что даже внутри компании доступ к этой информации имеют только избранные сотрудники.
Голландская разведка предупредила в апрельском отчете, что Китай «использовал обширные программы шпионажа в попытках получить передовые технологии и знания из западных стран», включая вербовку «западных ученых и сотрудников высокотехнологичных компаний».
Именно ветераны ASML сделали возможным прорыв в Шэньчжэне, сообщили источники. Без их глубокого знания технологии обратная разработка машин была бы практически невозможна.
Их наем был частью агрессивной кампании, которую Китай запустил в 2019 году для привлечения специалистов по полупроводникам, работающих за рубежом, предлагая бонусы при подписании контракта в размере от 3 до 5 миллионов юаней (от 420 000 до 700 000 долларов) и субсидии на покупку жилья, согласно обзору правительственных документов.
В число нанятых специалистов вошел Линь Нань, бывший руководитель отдела технологий источников света в ASML, чья команда в Шанхайском институте оптики Китайской академии наук за 18 месяцев подала восемь патентных заявок на источники света EUV, согласно патентным документам.
Шанхайский институт оптики и тонкой механики не ответил на запросы о комментариях. С Линем связаться для получения комментария не удалось.
Еще два человека, знакомых с усилиями Китая по набору персонала, сообщили, что некоторым натурализованным гражданам других стран были выданы китайские паспорта и разрешено сохранить двойное гражданство.
Китай официально запрещает двойное гражданство и не ответил на вопросы о выдаче паспортов.
Китайские власти не ответили на запросы о комментариях.
ВНУТРИ КИТАЙСКОЙ EUV-ФАБРИКИ
Самые современные системы EUV от ASML имеют размер примерно с школьный автобус и весят 180 тонн. После неудачных попыток повторить ее габариты, прототип в лаборатории Шэньчжэня стал во много раз больше, чтобы увеличить его мощность, по словам двух источников.
Китайский прототип примитивен по сравнению с машинами ASML, но достаточно работоспособен для проведения испытаний, сообщили источники.
Китайский прототип отстает от машин ASML во многом потому, что исследователи изо всех сил пытались получить оптические системы, подобные тем, что поставляет немецкая Carl Zeiss AG, один из ключевых поставщиков ASML, сообщили два источника.
Zeiss отказалась от комментариев.
Машины стреляют лазером по расплавленному олову 50 000 раз в секунду, создавая плазму с температурой 200 000 градусов Цельсия. Свет фокусируется с помощью зеркал, изготовление которых занимает месяцы, согласно сайту Zeiss.
По словам двух источников, ведущие научно-исследовательские институты Китая сыграли ключевую роль в разработке отечественных альтернатив.
Чанчуньский институт оптики, точной механики и физики Китайской академии наук (CIOMP) добился прорыва в интеграции экстремального ультрафиолетового света в оптическую систему прототипа, что позволило ему начать работу в начале 2025 года, сообщил один из источников, хотя оптика все еще требует значительной доработки.
CIOMP не ответил на запросы о комментариях.
В объявлении о наборе персонала на своем сайте в марте институт сообщил, что предлагает «неограниченные» зарплаты исследователям литографии со степенью PhD и исследовательские гранты на сумму до 4 миллионов юаней (560 000 долларов) плюс 1 миллион юаней (140 000 долларов) в виде личных субсидий.
Джефф Кох, аналитик исследовательской фирмы SemiAnalysis и бывший инженер ASML, сказал, что Китай добьется «значительного прогресса», если «источник света будет иметь достаточную мощность, будет надежным и не будет создавать слишком сильного загрязнения».
«Нет сомнений, что это технически осуществимо, вопрос лишь в сроках», — сказал он. «Преимущество Китая в том, что коммерческие EUV уже существуют, поэтому они начинают не с нуля».
Чтобы получить необходимые детали, Китай извлекает компоненты из старых машин ASML и закупает детали у поставщиков ASML через вторичные рынки, сообщили два источника.
По словам источников, иногда используются сети компаний-посредников, чтобы скрыть конечного покупателя.
Для прототипа используются компоненты ограниченного экспорта от японских компаний Nikon и Canon, сообщили один из источников и дополнительный информатор.
Nikon отказалась от комментариев. Canon заявила, что ей не известно о подобных сообщениях. Посольство Японии в Вашингтоне не ответило на запрос о комментарии.
Международные банки регулярно выставляют на аукционы подержанное оборудование для производства полупроводников, сообщили источники. Согласно обзору объявлений на Alibaba Auction (платформа, принадлежащая Alibaba), на аукционах в Китае старое литографическое оборудование ASML продавалось еще в октябре 2025 года.
Группа из примерно 100 недавних выпускников университетов сосредоточена на обратной разработке компонентов как EUV, так и DUV литографических установок, сообщают источники.
Стол каждого работника снимается индивидуальной камерой, чтобы задокументировать их усилия по разборке и повторной сборке деталей — работу, которую источники назвали ключевой для усилий Китая в области литографии.
Сотрудники, успешно собравшие компонент, получают бонусы, сообщили источники.
УЧЕНЫЕ HUAWEI СПЯТ НА РАБОЧЕМ МЕСТЕ
Хотя проектом EUV руководит китайское правительство, Huawei участвует в каждом этапе цепочки поставок: от проектирования чипов и оборудования для их изготовления до производства и окончательной интеграции в такие продукты, как смартфоны, согласно данным четырех человек, знакомых с деятельностью Huawei.
Генеральный директор Жэнь Чжэнфэй информирует высшее китайское руководство о ходе работ, сообщил один из источников.
В 2019 году США внесли Huawei в «черный список» (entity list), запретив американским компаниям вести с ними бизнес без лицензии.
Huawei направила сотрудников в офисы, на заводы и в исследовательские центры по всей стране для участия в этом проекте. Сотрудники, назначенные в команды по полупроводникам, часто спят на рабочих местах, и им запрещено возвращаться домой в течение рабочей недели, а доступ к телефонам ограничен для команд, выполняющих более деликатные задачи, сообщают источники.
Внутри Huawei немногие сотрудники знают о масштабах этой работы. «Команды изолированы друг от друга для обеспечения конфиденциальности проекта», — сказал один из источников. «Они не знают, над чем работают другие команды».
Репортаж: Фанни Поткин в Сингапуре; дополнительный репортаж: Александра Алпер в Вашингтоне; редактура: Кен Ли и Майкл Лирмонт.
>>1459432 >Китаю потребуются «многие, многие годы» для разработки подобной технологии От создателей "если мы запретим Китаю экспорт чего-то меньше чем DUV, они никогда не смогут делать чипы меньше 28нм"
>>1459435 >Именно ветераны ASML сделали возможным прорыв в Шэньчжэне >В 2019 году ASML выиграла иск на сумму 845 миллионов долларов против бывшего китайского инженера, обвиненного в краже коммерческой тайны, но ответчик подал заявление о банкротстве и продолжает работать в Пекине при поддержке китайского правительства >«Хотя ASML не может контролировать или ограничивать место работы бывших сотрудников, все сотрудники связаны положениями о конфиденциальности в своих контрактах», — заявила компания, добавив, что она «успешно предпринимала юридические действия в ответ на кражу коммерческой тайны».
Лол, типичный европейский маразм, типа кругом меры приняты, а что все передовые секреты уже в Китае спокойно реализуются сбежавшими сотрудниками, не наша проблема.
>>1459463 Там клинический маразм 100го уровня уже в decision-making типа "90% процентов занятых в производстве микрочипов это китайцы, давайте запретим китайцам делать свои собственные чипы". Арабам песок нахуй запретите а эскимосам - снег, олигофрены.
>>1459432 Мне нравится, как Китай разрывает постиндустриальную экономику. Показывая, что экономика может быть только индустриальной, либо же отсталой периферийной.
Постиндустриальная экономика это блаженные выдумки гуманитариев, оторванные от здравого смысла философствования, которые ведут к рухнум, так же как к нему вёл эксперимент с плановой экономикой. Идея бесплатных денег и производства без производства, конечно, заманчива, но потеря промышленной базы делает невозможными инновации (образуется гигантская пропасть между исследованиями и внедрением), ведёт к потере экономического влияния, к потере международного престижа.
>>1459539 Что такое вообще постиндустриальная экономика и производство без производства? Возвращение к собирательству и охоте? Без производства невозможна никакая развитая экономика. Возможно, речь идет об акцентах? Производство достигает пика и изобильности, и начинают решаться другие вопросы вместо налаживания производства. Словом, к этому все и движется, уже достаточно быстро. Вон, выше валяется размышление о радикальном удешевлении интеллектуального труда >>1459343. А это неминуемо скажется на эффективности производства за счет разработки и внедрения новых технологий.
Немецкий стартап разрабатывает сварм ИИ управляемых тараканов киборгов для шпионажа
Оснащение насекомых электроникой и называние этого робототехникой — но сработает ли это на самом деле?
Перспективное направление: В берлинской лаборатории команда компании SWARM Biotactics превращает насекомых в живых роботов. Немецкий стартап разрабатывает микропроцессорные «рюкзаки», способные превратить мадагаскарских шипящих тараканов в мобильные разведывательные устройства, способные переносить камеры, микрофоны и доплеровские радары через замкнутые или опасные среды.
Генеральный директор Стефан Вильгельм рассказал телеканалу CBS, что выбор вида насекомого был сделан осознанно. Мадагаскарский шипящий таракан достаточно крупный, чтобы нести небольшие полезные нагрузки, устойчив к экстремальным условиям и хорошо изучен в биологических лабораториях. «Миллионы лет эволюции фактически породили очень выносливое, очень подвижное и очень способное насекомое, — сказал Вильгельм. — Это, для того, что мы хотим делать, на самом деле идеальное, совершенно идеальное животное».
Система SWARM, объединяющая биологию, электронику и робототехнику, весит до 15 граммов. Инженеры работают над тем, чтобы снизить эту цифру до 10 граммов, чтобы уменьшить нагрузку на насекомое. Каждое устройство может оснащаться такими датчиками, как оптические камеры или радарные модули, превращая насекомое в незаметное разведывательное средство.
По словам Вильгельма, тараканы способны выжить при воздействии химических веществ, высоких температур и радиации — всё это делает их пригодными для сред, в которые обычные роботы или люди не могут безопасно проникнуть. «Это малозаметно, это сверхэнергоэффективно. Это почти невозможно обнаружить… и масштабировать это можно практически без ограничений», — сказал он. Компания SWARM также начала оценивать других потенциальных кандидатов, включая саранчу и кузнечиков, для будущих разработок.
Нейрофизиологический интерфейс, разработанный нейробиологами SWARM, специализирующимися на насекомых, подключает электроды к усикам таракана, чтобы стимулировать естественные навигационные реакции.
Человеческие операторы могут управлять отдельными насекомыми с помощью контроллеров, однако компания также разрабатывает программное обеспечение для автономного группового поведения. Вильгельм сказал, что цель заключается в использовании алгоритмов для координации десятков, а возможно, и сотен биогибридных насекомых как единой группы. «С помощью разработанного нами алгоритма можно направить целый рой насекомых к цели. И это может быть 10, а может быть, например, и сто».
Вильгельм добавил, что процедура является безболезненной и что благополучие насекомых имеет решающее значение для их надёжности. «Они ведут хорошую жизнь, чтобы хорошо справляться со своими миссиями».
Компания SWARM Biotactics появилась в период обострения европейских проблем безопасности, когда Германия и её союзники по НАТО расширяют оборонные инициативы в ответ на войну в Украине. Вильгельм отметил, что системы на основе тараканов обеспечивают уникальную форму сбора разведданных, поскольку могут проникать туда, куда другим видам технологий попасть невозможно.
Стартап сотрудничает с бундесвером — вооружёнными силами Германии — для проверки того, как рои тараканов работают в полевых условиях. В настоящее время основное внимание уделяется разведывательным миссиям, а не каким-либо наступательным возможностям.
Каждый таракан в рое может нести датчики разных типов, чтобы обеспечить выполнение таких задач, как локализация и связь. Некоторые тараканы в большей степени предназначены для работы с камерой, другие — для связи или определения местоположения. Исследователи используют триангуляцию между особями роя, чтобы точно определить его местонахождение, особенно если рой находится под землёй или в зонах, недоступных для обычных средств, сказал Вильгельм.
Помимо оборонных применений, Вильгельм видит потенциал использования технологии в спасательных операциях, где тараканы могли бы находить выживших в завалах обрушенных зданий. Он сообщил, что компания ожидает первых крупномасштабных развёртываний в течение 18–24 месяцев.
>>1459567 А гуманоидов для производств леваки не разрешают делать? Чтобы чурок ни в коем случае нельзя было бы заменить. Чтобы кейсу про "незаменимых трудовых мигрантов", без которых экономика рухнум, ничего не угрожало.
А чем вообще занята сейчас вот эта лысеющая прошмандовка? Напомню что эта блядота ответственна за то, что в чаге гэпэтэ столько цензуры, это всё эхо его тряски. Что он вообще представляет из себя? Он никто и звать его никак… верно? Или я ошибаюсь?
>>1458243 (OP) >Новости об искусственном интеллекте №44 /news/ Китайцы помогут улучшить Алису. Alibaba Group выделяет Яндексу 50 ускорителей 3080Ti в качестве гуманитарной помощи
>>1459757 Он исследованиями занят, он же сам рассказал, если бы не пинали их выпускать коммерческие чатботы из-за хайпа, еще бы много лет мариновал модельки у себя в закрытой лаборатории, занимаясь перфекционизмом без выхлопа. Чисто ЛеКун второй, только помоложе.
>>1459376 >и результаты впечатляют. Нет, не впечатляют. Очередная бесполезная параша, которая отстала от соры лет на 5. Здесь ей требовалось сделать с пикчу видео, с помощью промта. И если "понимание", того что нужно сделать вроде бы есть (она следует написанному), то реализация весьма унылая.
Я допускаю, что аниме не мерило возможностей нейросетки как таковой и в реализме она прям раскрывается, но что-то не вижу пока сотен восторженных отзывов и как все ломанулись в ней генерить что-либо.
>>1459757 Интересно, есть ли хоть одна тян или человек который смотрит на сукусцкевера и думаем «ммммм, вот бы он меня выебал.» даже Сэма Альтушку дрючат и в хвост и в гриву. Этот наверное до сих пор листвой ходит. Даже Перельман ебался, а он?
Если опенсорс то имба, интернеты будут завалены именно ей. Почему-то именно видео генераторы коллеги из США и Китая никак не хотят опенсорсить, наверняка там прям договорённости есть по этому поводу, но мы ни о чём не договаривались и тем самым портим им малину, при том что сильно отстаём по качеству но опенсорс всё сглаживает
>>1460304 Вся современная микроэлектроника это буквально китайцы. Единственная ее часть которая некитайцы, это еблое говно из пиндостана которое не дает отгрузить купленное и оплаченное EUV в Китай, из-за чего лично ты терпишь ГПУ по оверпрайсу в несколько раз и дефициты всяго подряд.
>>1460406 Все так и будет, как он говорит. Он просто пересказал что все и так в Кремниевой долине уже знают. У нас сингулярность в разгаре, изменения за год как за 1 век. На дтфе же иллюстрация, как массы будут не врубаться до последнего, отрицая, что на них надвигается. И будут дальше кукарекать про отсутствие интеллекта нейронок как спасительную мантру. На то они и массы, у масс нет способности осмысливать изменения.
>>1460520 > Он просто пересказал что все и так в Кремниевой долине уже знают. У нас сингулярность в разгаре, изменения за год как за 1 век. Какие настроения? Паника присутствует? Или все слишком заняты?
>>1460543 Паника для масс и алармистов, которые к разработке ИИ вообще никак не причастны. В Сан-франциско сплошная гонка и занятость 24 часа и ожидание фантастических успехов через пару лет. Стартапы горят, прорывы и новые горизонты на постоянке, революционные изменения день ото дня.
Анонасы. Я хочу услышать ВАШ личный прогноз на ближайшие 4 года. Что нас ждёт? К чему готовиться обывателю? Расскажите, мне правда интересно. Хочу послушать ваши взгляды… есть ощущение что они полярны.
>>1460572 Язык - карта, реальность - территория. Карте не обязательно отражать территорию 1 в 1. Карту можно срисовать с других карт. Или составить по чьим-то рассказам. Это будет не такая точная карта, как срисованная с реальности самостоятельно, но работать будет. Люди кстати тоже делают что-то подобное, обучаясь в школе. Опыта непосредственного часто нет, все по книгам. И это не мешает людям потом говорить о вещах, которые они никогда не видели, не щупали и не наблюдали во всех подробностях. Так что чему они там удивляются, у ЛЛМок этот процесс просто расширен до вообще всего.
>>1460643 4 года большой срок для ИИ индустрии. Офисная работа скорее всего накроется уже в блишайшие 2 года, ИИ модели для чата станут всесторонними агентами, делающими кучу всего самостоятельно и итеративно. Людей будет выгоднее с работ под жопу на улицу. Управлять ими промптами как сейчас больше не потребуется, кругом одна выгода владельцам бизнеса, кабаны обогатятся. Дальше у нас революция в робототехнике, туда тоже можно запихнуть новые модели и за 4 года это уже сделают. Тут накроется уже какая-то большая часть физических работ, где много всего повторяющегося. Датацентры ИИ будут и в космосе и везде, цена ИИ значительно упадет по сравнению с теперешней, будет куча специализированных решений для ИИ. Обывателю готовиться к плохим временам, УБИ никаких еще вероятно не будет, а с работ уже попрут, люди не нужны. В физические будет тоже все сложнее влезть. Лучше иметь запасы бабок на это время или пассивный доход. Научный прогресс ускорится за счет ИИ, для войн тоже начнут использовать все больше роботов, возможно даже станет больше войн из-за этого. И это еще мир, в котором не изобрели АГИ, просто очень хорошие модельки. Если изобретут АГИ за эти 4 года, то все прогнозы идут в жопу, там вообще все что угодно может начать происходить.
Институт фундаментальных моделей Университета Мухаммеда бин Зайеда в области искусственного интеллекта (MBZUAI) выпустил K2-V2 — рассуждающую модель объёмом 70 млрд параметров, которая вместе с другими моделями занимает первое место в нашем Индексе открытости и является первой моделью из ОАЭ, попавшей в наши рейтинговые таблицы.
📖 Лидер по уровню открытости (наравне с другими): K2-V2 вместе с OLMo 3 32B Think возглавляет Индекс открытости Artificial Analysis — недавно опубликованную, стандартизированную и независимо оценённую метрику степени открытости ИИ-моделей, охватывающую доступность и прозрачность. MBZUAI пошли дальше открытого доступа и лицензирования весов модели: они предоставляют полный доступ к данным до и после обучения. Кроме того, они публикуют методологию обучения и код под разрешительной лицензией Apache, позволяющей свободное использование в любых целях. Это делает K2-V2 ценным вкладом в сообщество открытого программного обеспечения и позволяет проводить более эффективное тонкое дообучение. Ссылки приведены ниже!
🧠 Сильная открытая модель среднего размера (40–150 млрд параметров): При объёме в 70 млрд параметров K2-V2 набирает 46 баллов в нашем Индексе интеллекта в режиме «Высокая рассудительность» (High reasoning mode). Это выше, чем у Llama Nemotron Super 49B v1.5, но ниже, чем у Qwen3 Next 80B A3B. Модель демонстрирует относительное преимущество в следовании инструкциям, получив 60 % в IFBench.
🇦🇪 Первый представитель ОАЭ в наших рейтингах: На фоне преобладающего числа моделей из США и Китая K2-V2 выделяется как первая модель из ОАЭ, попавшая в наши рейтинговые таблицы, и второй представитель Ближнего Востока после израильской AI21 Labs. K2-V2 — первая модель MBZUAI, которую мы протестировали, однако лаборатория ранее уже выпускала модели, сосредоточенные в первую очередь на языковых аспектах, включая египетский арабский и хинди.
📊 Меньшие режимы рассудительности снижают потребление токенов и уровень галлюцинаций: K2-V2 поддерживает три режима рассудительности; при этом в режиме «Высокая рассудительность» для завершения нашего Индекса интеллекта требуется значительное количество — примерно 130 млн токенов. Однако в режиме «Средняя рассудительность» (Medium) потребление токенов сокращается примерно в 6 раз при снижении показателя Индекса интеллекта всего на 6 пунктов. Примечательно, что в более низких режимах рассудительности модель демонстрирует лучшие результаты в нашем индексе знаний и галлюцинаций AA-Omniscience благодаря снижению склонности к генерации галлюцинаций.
>>1460725 >Лучше иметь запасы бабок на это время или пассивный доход Всё как всегда упрётся во внедрение. Пока все раскумекают что как и куда прикручивать, роботов тех же ещё наштопать надо, чипов для них напроизводить, найти всякие оптимальные бест практисы и т.п. Крч времени до жепы ещё, 4 года это хуйня с под коня.
>>1460406 >Через пять лет мы увидим такой уровень безработицы, которого никогда не было. Не 10%, а 99%
Хоспаде, да как что-то плохое! Зато чурбанов никто не будет сюда привозить.
Безработица это вообще не страшно, это нерастраченный потенциал экономики, который можно пустить на что угодно. Не на поддержание штанов, а на что-то великое, на космос, на магапроекты.
Если вдуматься, то это как-то нездорово, что существующая экономика крутится в основном вокруг базового жизнеобеспечения - и лишь немного на кайфы и величие.
Ну а кто не найдёт работу, посидит на пособиях, возможно даже на очень сытых. В 2020-21 уже была репетиция с локдаунами.
Впереди тупо золотой век, катимся в великое будущее, а трясуны всё трясутся.
>>1460779 Забавно, что оно как бы даже уже началось, причем там, где совсем не ждали. "Маршалловы острова первыми в мире ввели безусловный базовый доход Каждому жителю архипелага будет выплачиваться около $200 ежеквартально в виде криптовалюты или традиционной валюты. Выплаты осуществляются в рамках усилий властей по снижению инфляции и стоимости жизни" https://www.rbc.ru/economics/17/12/2025/6942be0c9a79470d0b5402f4
>>1460643 Через 4 года выпускнутся пердиксы которые начали учиться уже с чатжпт, то есть корочка потеряет смысл полностью и новые спецы с минимальной компетенцией исчезнут вообще как явление. Еще лет через 5 до самых тупых уже дойдет что либо социализм с оплатой учебы как за труд, либо нахуй с этой планеты.
>>1460810 То что язык способен существовать без смысла очевидно вообще любому кто в жизни видел говорящего дерьманца, например. Потому что там смысла вообще нет в принципе, только верная в плане формальной логики трансляция абсолютной хуиты.
>>1460779 Государству не выгодно, чтобы ты не работал. Когда ты работаешь - ты не творишь хуйню, и мыслей в твоей голове о том что справедливо а что нет поменьше, трений в обществе меньше, протестного потенциала меньше. Никто тебе не даст просто так сидеть и ничего не делать, будут выкручивать тебе руки до последнего. Потому что для любого государства ты скот, а скот должен быть в хлеву, а не бегать по двору.
>>1460828 Придумают чего-нибудь. Скажут что не хватает электричества, начнут надолго отключать, а взамен продавать ножные генераторы в виде велотренажеров. Пару часов педали покрутил, чтобы смартфон зарядить и обессилил. Уже ни на какую дурь сил не останется. А объяснять будут что это еще и крайне полезно для здоровья.
>>1460939 >>1460957 Ну так в России и нет никаких ИИ, будто кто сомневался. Довольно забавно, учитывая что под боком Китай вот-вот развернет самую масштабную ИИ революцию века, подмяв тысячи областей промышленности. Или в соседней Индии, где датацентры ИИ вовсю строят.
>>1460643 Готовить загран и финансовую подушку. Или домик в дярёвне и запасаться консервами. Это если в Скрепной. Что в остальном мире будет - ХЗ, новостей оттуда в следующие пару лет мы уже не услышим. А так - ну, кандинский, яндексжопатэ, гигачат. Нового не будет, эти уже нормально работают.
>>1460764 Мех, вот китайцы от топа за свои Сяоми и Byte dance выпустили неожиданно ебать по бенчикам жесткие модели, а про них даже никто и не написал. Сяоми опенсорс, но в их чате не попробуешь, почему-то в бане все, кроме американцев, только через впн мурриканский заходит. А от владельца тиктока проприетарка модель, но вроде заюзать на их сайте в чате можно
>>1460406 Всю простыню даже не читал. Её писал имебецил, что-то типо такого >>1460725 >>1460725 >Людей будет выгоднее с работ под жопу на улицу. >>1460725 > кабаны обогатятся Тотально пизданутый наглухо отбитый олигофрен, которые даже не понимает, что у кабана есть только один способ стать богаче - заплатить за труд мало, а перепродать результаты труда по оверпрайсу. О каком интеллекте с такими ебланами говорить науке не известно.
Трансформеры уже достигли своего предела. Ничего нового в трансформерах не появилось, все новые "прорывные" архитектуры это примитивная перестановка кубиков, часто даже без какой-то мотивации, что-то на уровне "ну мы попробовали вот так и на бенчмарках получили +3%". Thinking и MoE это просто очевидные надстроки поверх, идея которых появилась почти сразу, просто крупные корпы дошли до них когда тупым вкидыванием больше компьюта не получалось давать нормального прироста.
Скейл у трансформеров нелинейный, уже достигли некого субоптимального максимума слопа. Дальше можно вкидывать хоть x10 данных, параметров и вычислительных мощностей, получив +5-10% на бенчмарках.
Весь прогресс будет происходить только за счет того что уже существующие нейронки будут пихать во все подряд и смотреть что получится, нащупывая таким образом ниши, где они нелохо заменяют ручной рутинный цифровой труд/некоторые сложные алгоритмические задачи.
Очевидная надутая хуйня вроде скам альтмана, клауда и прочие ии стартапы пойдут на помоечку. Останется только крупные игроки с кучей денег и возможностей: гугл, мета, амазон, которые скорее всего поглотят то, что останется после лопания слопа. + Китай.
Meta готовит мощный ответный удар в гонке искусственного интеллекта: два новых модели запланированы к выпуску в первой половине 2026 года.
Модели: План включает «Avocado» — крупную языковую модель (LLM) нового поколения, нацеленную на достижение «поколенческого скачка» в возможностях программирования. Вторая модель — «Mango» — мультимодальная, ориентированная на генерацию и понимание изображений и видео. Стратегия: Это знаменует собой стратегический поворот. После прохладного приёма, оказанного её открытой модели Llama 4, Meta теперь перенаправляет ресурсы на разработку этих новых моделей, которые, предположительно, могут быть закрытыми и разрабатываться под эгидой нового подразделения «Meta Superintelligence Labs».
Инвестиции и внутренние потрясения: Генеральный директор Марк Цукерберг активно тратит средства, чтобы сократить отставание от конкурентов; в частности, заключена сделка на сумму около 14 млрд долларов США по привлечению основателя Scale AI Александра Вана на должность главного директора по искусственному интеллекту (Chief AI Officer). Вместе с этим произошли масштабные внутренние перестройки, сокращения, затронувшие сотни сотрудников в командах ИИ, а также смена корпоративной культуры в сторону более «напряжённых» ожиданий по производительности, что, по сообщениям, вызвало замешательство и напряжение между новыми сотрудниками и «старой гвардией». Конкуренция: Шаг предпринят в прямом ответе на конкурентное давление. Инструменты Google Gemini продемонстрировали значительный рост числа пользователей, а Sora от OpenAI задала высокую планку в области генерации видео. Более ранний видеопродукт Meta под названием «Vibes», созданный совместно с Midjourney, рассматривается как отстающий.
Является ли переход Meta от преимущественно открытой стратегии к закрытым, «фронтовым» моделям правильным ответом на конкурентное давление?
ИИ вытеснит работников с рабочих мест, заявил управляющий Банка Англии
Повсеместное внедрение искусственного интеллекта (ИИ), скорее всего, приведёт к вытеснению людей с рабочих мест подобно тому, как это происходило в эпоху промышленной революции, заявил управляющий Банка Англии.
Эндрю Бейли отметил, что Великобритании необходимо обеспечить наличие «соответствующей подготовки, образования и навыков», чтобы работники могли перейти на должности, связанные с использованием ИИ.
В интервью программе «Today» на BBC Radio 4 он заявил, что людям, ищущим работу, будет «значительно легче» найти занятость, если у них будут такие навыки.
Вместе с тем он предупредил, что существует проблема, связанная со сложностями, с которыми сталкиваются молодые, неопытные специалисты при попытке устроиться на начальные должности из-за ИИ.
«Нам действительно необходимо задуматься: какое влияние это оказывает на карьерные траектории людей? Меняет ли оно их или нет? — сказал он. — Я думаю, что если речь идёт о людях, работающих совместно с ИИ, то, возможно, траектории не изменятся, однако совершенно справедливо уделять этому аспекту внимание».
В последние годы ИИ стал частью повседневной жизни и всё шире внедряется бизнесом и государственным сектором.
Данная технология позволяет компьютерам обрабатывать большие объёмы данных, выявлять закономерности и следовать подробным инструкциям относительно дальнейших действий с этой информацией.
Тем не менее, существуют опасения по поводу того воздействия, которое ИИ, возможно, уже оказывает на рынок труда.
Официальные данные, опубликованные на этой неделе, показали, что уровень безработицы в Великобритании вырос до 5,1 % за три месяца по октябрь включительно, причём особенно сильно пострадали молодые работники.
Согласно данным Управления национальной статистики (ONS), число безработных в возрасте от 18 до 24 лет увеличилось на 85 000 человек за три месяца по октябрь включительно — это самый значительный рост с ноября 2022 года.
Некоторые утверждают, что повышение минимальной заработной платы и увеличение налогов сделали наём персонала на начальные должности менее привлекательным для бизнеса.
Однако отдельные компании заявляют, что развитие ИИ в конечном счёте может привести к сокращению числа младших сотрудников, в частности выпускников вузов.
Наибольшему влиянию со стороны ИИ подвергаются профессиональные должности начального уровня, особенно в таких секторах, как юриспруденция, бухгалтерия и административная деятельность.
Руководитель крупнейшей аудиторской компании PwC недавно сообщил BBC, что компания сворачивает планы по увеличению численности персонала.
«Теперь у нас появился искусственный интеллект. Мы хотим нанимать сотрудников, но не уверен, что объём найма будет прежним — нам потребуется другой тип специалистов», — заявил глобальный председатель компании Мохамед Канде.
Клиенты, которые раньше обращались к консультантам PwC для анализа данных и документов, теперь могут использовать вместо этого модели ИИ, превращая недели дорогой работы в считанные минуты.
Г-н Бейли отметил, что беспокойство по поводу влияния технологий на население возникало в разные периоды истории, уходя корнями в далёкое прошлое — например, королева Елизавета I была обеспокоена последствиями изобретения вязальной машины для её подданных.
«Как вы видели в эпоху промышленной революции, со временем, я думаю, мы теперь можем оглянуться назад и сказать, что она не привела к массовой безработице, но она действительно вытеснила людей с рабочих мест — и это важно.
Моё предположение состоит в том, что наиболее вероятно, что ИИ окажет схожий эффект. Поэтому нам нужно быть к этому готовыми, в определённом смысле».
Г-н Бейли заявил, что ИИ является «наиболее вероятным источником нового импульса» для экономического роста Великобритании.
«Что касается его потенциала повысить темпы роста производительности, я считаю его весьма значительным. Он будет применяться по всей экономике. Насколько быстро это произойдёт — другой вопрос; история показывает, что на это обычно требуется некоторое время».
Г-н Бейли сообщил, что Банк Англии, устанавливающий процентные ставки в Великобритании, использует ИИ, но добавил, что данное учреждение, как и другие, «вероятно, всё ещё находится на этапе экспериментов».
«Для того чтобы он вошёл в повседневную практику и стал повсеместно применяться, потребуется время, но чрезвычайно важно, чтобы мы, разумеется, сосредоточились на создании всех необходимых предпосылок и условий для этого».
Опасения относительно «пузыря» в сфере ИИ
Помимо влияния ИИ на рынок труда, существуют опасения относительно возможного формирования «пузыря» в сфере ИИ — а именно того, не завышена ли стоимость крупных технологических компаний.
Банк Англии недавно забил тревогу в связи с возможным обвалом стоимости компаний, работающих в сфере ИИ, напоминающим предыдущие случаи, такие как «пузырь доткомов».
Глава американского банка JP Morgan Джейми Даймон заявил BBC в октябре, что он «намного больше обеспокоен, чем другие», риском серьёзной коррекции рынка в ближайшие годы.
Г-н Бейли в ходе интервью программе «Today» отметил, что политикам «необходимо внимательно следить за вопросом оценки стоимости».
Вместе с тем он признал, что большинство крупных компаний действительно генерируют денежные потоки.
«Разумеется, это всё ещё не означает, что они все окажутся победителями. Мы внимательно наблюдаем за ситуацией, поскольку, очевидно, нам необходимо следить за тем, какими могут быть последствия любого резкого разворота».
>>1461485 Мне даже в каком-то смысле жалко этого еблана. Ч даже забыл как его зовут. Настолько он незначителен и хуй кому нужен в 2025 году. Он буквально обосрался во всё по итогу. Морда книга к слову полностью загнулась, недавно тред в иксе читал, так там хейт фейсбука похлеще нашего скрепного ВК. Рептилия думала что может завалить разработчиков деньгами… но что-то блять пошло не так, ка уже неожиданно (нет).
NVIDIA и правительство США повысят инвестиции в инфраструктуру и исследования в области ИИ благодаря исторической миссии «Genesis»
NVIDIA и Министерство энергетики США (DOE) обозначили приоритеты сотрудничества в целях ускорения научных открытий.
NVIDIA присоединится к миссии «Genesis» Министерства энергетики США (DOE) в качестве партнёра из частного сектора, чтобы сохранить за США лидирующие позиции и статус эталона в области ИИ во всём мире.
Миссия «Genesis», являющаяся частью исполнительного указа, недавно подписанного президентом Трампом, направлена на переосмысление американского лидерства в области ИИ по трём ключевым направлениям: энергетика, научные исследования и национальная безопасность. NVIDIA предложит свои услуги министерству для интеграции исследовательской платформы, объединяющей правительство США, промышленность и академическое сообщество.
Представители DOE ожидают, что миссия «Genesis» удвоит производительность и влияние американской науки и инженерии, а также обеспечит решающие прорывы для укрепления энергетического доминирования США, ускорения научных открытий и усиления национальной безопасности.
NVIDIA и DOE уже достигают беспрецедентных результатов по ключевым направлениям, включая:
— открытые научные модели ИИ, такие как семейство NVIDIA Apollo, для усовершенствования прогнозирования погоды, вычислительной гидродинамики и структурной механики; — ИИ для оптимизации производственных и логистических процессов; — робототехнику, периферийный ИИ (edge AI) и автономные лаборатории, в том числе с использованием высокоточных симуляций и цифровых двойников на основе ИИ; — ядерную энергетику, включая исследования в области деления и термоядерного синтеза; — исследования в области квантовых вычислений с применением суперкомпьютеров и ИИ для ускорения поиска новых алгоритмов; — биологию, материаловедение и синтетическое проектирование в сфере здравоохранения, а также прорывы в области критически важных материалов.
NVIDIA и DOE объявляют о подписании меморандума о взаимопонимании Помимо этого, NVIDIA объявила о подписании меморандума о взаимопонимании (МОВ) с министерством, в котором определены приоритеты сотрудничества в целях ускорения научных открытий.
МОВ охватывает, но не ограничивается следующими направлениями: ИИ в производстве и логистике, открытый исходный код в ИИ, энергетика на основе ядерного деления, робототехника, цифровые двойники на основе ИИ, термоядерный синтез, квантовые вычисления и наука.
В совокупности эти приоритеты нацелены на использование передовых технологий ИИ, робототехники и высокопроизводительных вычислений для трансформации энергетики, промышленного производства и научных открытий в рамках миссии Министерства энергетики. Они делают акцент на проектировании, эксплуатации и управлении сложными системами с помощью ИИ, такими как реакторы на ядерном делении и термоядерном синтезе, экспериментальные установки, цифровые двойники инфраструктурных объектов и автономные лаборатории, в том числе на периферии (edge) для принятия решений в режиме реального времени.
Дополнительные возможности для сотрудничества могут включать ускорение прорывов в области квантовых вычислений, материаловедения, биологии и синтетического проектирования, подземных и геотермальных ресурсов, а также экологической очистки, а также разработку оптимизированных для открытой науки моделей ИИ и «со-учёных» на базе ИИ, ускоряющих разработку алгоритмов и генерацию кода для требовательных научных приложений.
Развитие сотрудничества в области суперкомпьютеров Поддержка NVIDIA миссии «Genesis» стала логическим продолжением серии совместных инициатив NVIDIA и DOE, объявленных в ходе конференции NVIDIA GTC в Вашингтоне, округ Колумбия, включая совместную работу NVIDIA и Oracle по созданию крупнейшего суперкомпьютера министерства для научных исследований в Аргоннской национальной лаборатории. Кроме того, стало известно, что NVIDIA окажет поддержку семи новым вычислительным системам в Аргоннской и Лос-Аламосской национальных лабораториях, ускоряя выполнение DOE своей миссии по обеспечению технологического лидерства.
NVIDIA разработала архитектуру ускоренных вычислений, лежащую в основе современного ИИ, — платформу, позволяющую исследователям обучать крупные модели, моделировать физические системы и продвигать науку в беспрецедентных масштабах и с беспрецедентной скоростью.
ИИ вызывает новую промышленную революцию в США и во всём мире. Ожидается, что миссия «Genesis» расширит и ускорит эту революцию.
ChatGPT запускает магазин приложений и даёт разработчикам понять, что он открыт для работы
Разработчики приложений, желающие запустить свои программы в ChatGPT, теперь могут отправлять их на рассмотрение и возможную публикацию, сообщила компания OpenAI в среду. Компания также представила новый каталог приложений в меню инструментов Chat, который быстро окрестили «магазином приложений».
В октябре компания анонсировала появление приложений в своём чат-боте, пояснив, что этот шаг предоставит пользователям ChatGPT более широкий набор возможностей. Крупные платформы — включая Expedia, Spotify, Zillow и Canva — объявили о своих интеграциях, которые позволят пользователям напрямую обращаться к их сервисам из чат-переписок. Теперь компания открывает доступ для более широкого круга участников.
«Приложения расширяют диалоги в ChatGPT за счёт привлечения нового контекста и позволяют пользователям совершать действия, такие как заказ продуктов, преобразование плана в презентацию или поиск квартиры», — заявила компания в среду.
SDK приложений OpenAI, находящийся по-прежнему в бета-версии, в настоящее время предоставляет набор инструментов для разработчиков, стремящихся создавать новые возможности для пользователей ChatGPT. Когда разработчики будут готовы, они смогут отправить свои приложения на платформу OpenAI Developer, где смогут отслеживать статус их одобрения, добавила компания. Ряд одобренных приложений начнёт появляться внутри Chat в течение следующего года.
Это важный шаг OpenAI по расширению экосистемы приложений внутри Chat и одновременно предоставлению пользователям дополнительных причин использовать приложение и оставаться в нём.
Инструмент Google для «вайб-кодинга» Opal появляется в Gemini
Инструмент Google для «вайб-кодинга» Opal поступает в распоряжение Gemini. В среду компания объявила, что интегрирует этот инструмент — позволяющий создавать мини-приложения с поддержкой ИИ — непосредственно в веб-приложение Gemini, давая пользователям возможность разрабатывать собственные пользовательские приложения, которые Google называет Gems («Самоцветы»).
Gems, впервые представленные в 2024 году, представляют собой настраиваемые версии Gemini, созданные для выполнения определённых задач или в конкретных сценариях. Например, среди предварительно созданных Google Gems — «наставник по обучению», «ассистент для мозгового штурма», «карьерный консультант», «партнёр по программированию» и «редактор».
Opal, в свою очередь, ориентирован на помощь пользователям в создании мини-приложений или комбинировании существующих приложений. Чтобы воспользоваться этой функцией, пользователи описывают на естественном языке желаемое приложение, после чего инструмент использует различные модели Gemini для его создания.
Теперь Opal доступен сразу из Gemini в веб-версии, где его можно найти в менеджере Gems. Инструмент оснащён визуальным редактором, отображающим пошаговую последовательность, необходимую для создания приложения. В редакторе пользователи могут переставлять шаги и связывать их между собой без написания кода.
Google отмечает, что визуальный редактор включает также новый режим в Gemini, который преобразует введённые пользователем текстовые запросы в список шагов. Это делает процесс создания приложений ещё проще и позволяет наглядно увидеть, как они работают.
Для более продвинутой настройки пользователи могут перейти из Gemini в расширенный редактор на сайте opal.google.com. После создания мини-приложения их можно повторно использовать.
Так называемый «вайб-кодинг» — использование ИИ для программирования и создания приложений — стремительно набрал популярность за последние пару лет. На рынке уже появились приложения от стартапов, таких как Lovable и Cursor, а также решения от поставщиков ИИ, включая Anthropic и OpenAI. Кроме того, существуют инструменты, ориентированные более непосредственно на конечных пользователей, например, от стартапа Wabi, специализирующегося на создании приложений с помощью ИИ.
Веб-приложение Gemini доступно по адресу gemini.google.com. Opal доступен по адресу opal.google.com
Luma анонсировала Ray3 Modify для управления видео по начальному и конечному кадрам
Luma разработала Ray3 Modify — модель ИИ для генерации видео, позволяющую создателям контента формировать сцену между начальным и конечным кадрами клипа, при этом полностью сохраняя записанную в кадре актёрскую игру. Релиз обеспечивает монтажёрам и студиям повышенный творческий контроль за счёт сочетания управления на уровне отдельных кадров с трансформацией с учётом характеристик персонажей, что позволяет производственным командам заменять элементы одежды или декораций в соответствии с режиссёрским замыслом без необходимости повторных съёмок.
Как Ray3 Modify сохраняет актёрскую игру и обеспечивает контроль В основе Ray3 Modify лежит подход, при котором живая актёрская игра рассматривается как непреложная основа. Luma подчёркивает, что модель сохраняет движения, ритм, направление взгляда и эмоциональную подачу, одновременно применяя преобразования на основе эталонных изображений персонажей. Это означает, что идентичность и непрерывность исполнителя (один и тот же головной убор, одежда, грим) могут последовательно поддерживаться во всех кадрах, даже если визуальное оформление сцены меняется.
Ключевой особенностью является управление по начальному и конечному кадрам. Создатели могут передать модели два опорных кадра и попросить сгенерировать промежуточную последовательность для плавного перехода между ними — по сути, осуществляя ключевое кадрирование на уровне отдельного плана. В сценах с трюками это может означать, например, направление персонажа из нейтрального положения в заранее заданную точку, преобразование дневного фона в стилизованную ночную сцену с ручной росписью, или точное совмещение снятого на камеру материала с элементами компьютерной графики при фиксации актёрской игры.
Ray3 Modify внедряется Luma в свою платформу Dream Machine, которая уже поддерживает видеопроизводственные рабочие процессы. Компания позиционирует новую модель как обновление с приоритетом контроля для команд, которым необходима скорость работы на уровне ИИ при сохранении режиссёрского замысла.
Почему управление по начальному и конечному кадрам важно для производства Генеративное видео быстро развивается, однако творческие команды по-прежнему сталкиваются с нестабильностью: незначительное изменение текстового запроса приводит к резкому смещению композиции, лица «плавают» между кадрами, ритмика выглядит неестественно.
Ray3 Modify, привязанная к генерации на основе двух чётко заданных ключевых кадров и реальной актёрской игры, переносит язык редакторских ключевых кадров в область ИИ-видео, сокращая долю догадок при работе с непрерывностью действия.
Такая структура повторяет организацию съёмочного процесса в реальных производствах. Режиссёры и монтажёры мыслят категориями «ударов» и переходов. С Ray3 Modify можно визуально зафиксировать эти «удары» (начинаем здесь, заканчиваем там) и позволить модели интерполировать промежуточные кадры. Это особенно полезно при работе с переходами, согласованием сцен, изменением расстановки актёров и сглаживанием стыков между натурными и улучшенными кадрами.
Последствия для студий и создателей, использующих Ray3 Modify Для коммерческого или брендового контента способность сохранить актёрскую игру при смене локации решает дорогостоящую проблему: творческое решение верное, но локация — нет. Вместо повторного найма актёров и съёмочной группы команды могут буквально заново придумать окружение с помощью ИИ, сохраняя всё остальное в точности так, как утвердили клиенты. Независимые авторы получают те же преимущества и на меньших бюджетах — ссылаясь на ключевые кадры для обеспечения непрерывности между материалами, снятыми в разные дни или на разные камеры.
Остаются вопросы прав и рабочих процессов. Студиям по-прежнему потребуется прямое согласие на использование личности и внешности, а также надёжная система версионирования при корректировке сцен. На фоне усилий отраслевых организаций, таких как SAG-AFTRA, направленных на обеспечение согласия и компенсации за цифровые реплики, технические стандарты, разрабатываемые такими группами, как C2PA и SMPTE, также эволюционируют для встраивания сигналов подлинности и водяных знаков в медиаконтент с элементами ИИ.
Конкурентная среда и вспомогательная инфраструктура Luma относится к числу хорошо финансируемых участников рынка ИИ-видео и конкурирует с целым рядом других хорошо обеспеченных игроков: Runway, Kling от Kuaishou, а также исследовательскими системами, продемонстрировавшими генерацию длинных видеороликов. Существуют универсальные инструменты, предлагающие лишь простые текстовые запросы, базовое управление параметрами камеры или применение переноса стиля на смартфоне. То, что выделяет Ray3 Modify, — это ориентированность её рабочего процесса, поддерживаемого управлением по начальному и конечному кадрам и возможностью обработки до девяти персонажей без потери качества актёрской игры, непосредственно на производственные задачи благодаря уникальному сочетанию трёх компонентов: осознание качества (персонажи — их не должно быть слишком много + как они выглядят по отношению друг к другу), функциональность (насколько удобно это использовать?) и надёжность.
Релиз последовал вскоре после завершения раунда финансирования Luma на сумму 900 млн долларов США под руководством Humain (ИИ-компании, поддерживаемой Фондом государственных инвестиций Саудовской Аравии) при участии a16z, Amplify Partners и Matrix Ventures. Luma и Humain также стоят за созданием вычислительного кластера мощностью 2 ГВт в Саудовской Аравии — намёк на масштабы, необходимые для обучения и эксплуатации видеомоделей, требующих высокопроизводительных GPU для обработки многосекундных 1080p-видеоклипов и быстрой итерации в постпродакшн-конвейерах.
Первые сценарии использования Ray3 Modify и важные оговорки Следите за применением Ray3 Modify в предварительной визуализации, «досъёмках» без воссоздания декораций, локализации рекламы под разные платформы и стилизованных музыкальных клипах.
Один практический пример: модный бренд может снять модель, идущую один раз, а затем создать варианты локаций — студия, городская улица, футуристический коридор — просто меняя эталонные изображения, но сохраняя цикл ходьбы и направление взгляда.
Как и во всех генеративных системах, здесь существуют ограничения. Быстрые движения, крупные заслонения или сложная съёмка с рук могут затруднить поддержание временной согласованности. В редких случаях может происходить смещение идентичности персонажа, а фотореалистичные композиты требуют точной цветокоррекции и компоновки в VFX. Однако для большинства команд сочетание управления по начальному и конечному кадрам с сохранением актёрской игры должно минимизировать количество пересъёмок и превратить ИИ в более надёжного помощника, а не в непредсказуемый фактор.
Если модель оправдает обещания, Ray3 Modify приблизит ИИ-видео к грамматике современного кинопроизводства: расставь актёров, задай ключевые моменты, защити актёрскую игру — и пусть машина выполнит промежуточные действия. Это значительный шаг от новизны, управляемой текстовыми запросами, к мастерству, управляемому режиссёром.
Mistral выпустила OCR 3 (mistral-ocr-2512) — это новая лучшая в мире OCR-модель, и, согласно их собственным бенчмаркам, она опережает предыдущие решения с довольно значительным отрывом.
Видеорелейтед демонстрация.
Основные достижения Прорыв в производительности: 74 % общей доли побед над Mistral OCR 2 при обработке форм, отсканированных документов, сложных таблиц и рукописного текста.
Наивысшая на сегодняшний день точность, превосходящая как корпоративные решения для обработки документов, так и специализированные OCR-решения на базе ИИ.
Теперь лежит в основе инструмента Document AI Playground в Mistral AI Studio — простого интерфейса «перетащи и отпусти» для преобразования PDF-файлов и изображений в чистый текст или структурированный JSON.
Значительное улучшение по сравнению с Mistral OCR 2 в обработке форм, рукописного контента, низкокачественных сканов и таблиц.
Обзор Mistral OCR 3 разработана для извлечения текста и встроенных изображений из широкого спектра документов с исключительной точностью. Она поддерживает вывод в формате Markdown, обогащённом восстановленными HTML-таблицами, что позволяет последующим системам понимать не только содержание документа, но и его структуру. Будучи значительно меньшей по размеру, чем большинство конкурирующих решений, модель доступна по отраслевой рекордно низкой цене — 2 доллара США за 1 000 страниц, с 50 %-ной скидкой при использовании Batch API, что снижает стоимость до 1 доллара США за 1 000 страниц.
Разработчики могут интегрировать модель (mistral-ocr-2512) через API, а пользователи могут воспользоваться инструментом Document AI — графическим интерфейсом, мгновенно преобразующим документы в текст или структурированный JSON.
Бенчмарки Для повышения планки мы разработали более сложные внутренние тесты на основе реальных бизнес-примеров от клиентов. Затем мы оценили несколько моделей по нижеперечисленным направлениям, сравнивая их результаты с эталонными данными с использованием неточного сопоставления (fuzzy-match) для оценки точности.
Улучшения по сравнению с предыдущими поколениями OCR-моделей В то время как большинство современных OCR-решений специализируются на конкретных типах документов, Mistral OCR 3 разработана для превосходной обработки подавляющего большинства типов документов, встречающихся в организациях и повседневной жизни.
Рукописный текст: Mistral OCR точно интерпретирует курсив, аннотации с комбинированным содержанием и рукописный текст, наложенный поверх печатных форм.
Формы: Улучшено распознавание полей, меток, рукописных записей и плотных компоновок. Эффективна при обработке счётов, квитанций, форм соответствия нормативным требованиям, правительственных документов и аналогичных материалов.
Отсканированные и сложные документы: Значительно повышенная устойчивость к артефактам сжатия, наклону, искажениям, низкому разрешению (DPI) и фоновому шуму.
Сложные таблицы: Восстанавливает структуры таблиц с заголовками, объединёнными ячейками, многострочными блоками и иерархией столбцов. Выводит HTML-теги таблиц с атрибутами colspan/rowspan для полного сохранения макета.
Рекомендуемые сценарии и применения Mistral OCR 3 идеально подходит как для высоконагруженных корпоративных конвейеров, так и для интерактивных рабочих процессов с документами. Разработчики могут использовать её для:
— извлечения текста и изображений в формате Markdown для последующей обработки агентами и системами знаний; — автоматизированного разбора форм, счётов и операционных документов; — сквозных конвейеров понимания документов; — оцифровки рукописных или исторических документов; — любых других приложений, связанных с преобразованием документов в знания.
Наши первые клиенты уже используют Mistral OCR 3 для структурированного извлечения данных из счётов, оцифровки корпоративных архивов, получения чистого текста из технических и научных отчётов, а также для улучшения корпоративного поиска.
«OCR остаётся фундаментальной технологией, обеспечивающей работу генеративного ИИ и агентного ИИ», — отметил Тим Лоу (Tim Law), директор по исследованиям в области ИИ и автоматизации в IDC. «Те организации, которые смогут эффективно и экономически выгодно извлекать текст и встроенные изображения с высокой точностью, откроют для себя новую ценность и получат конкурентное преимущество за счёт своих данных, обеспечивая более насыщенный контекст».
Доступно уже сегодня Получить доступ к модели можно либо через API, либо через новый графический интерфейс Document AI Playground — оба находятся в Mistral AI Studio. Mistral OCR 3 полностью обратно совместима с Mistral OCR 2. Подробности — на сайте mistral.ai/docs.
>>1461466 Ну так ИИ и роботы это про реальность и живой продукт. А про что вы, "не фантазёры"? Никчемные манипуляторы с самомнением. Способны лишь распространять уныние и высказывать своё нахуй никому не нужное экспертное мнение.
Одни люди заняты делом, хуярят будущее, а у других - культ говна.
Проект Vend - Anthropiс обновили своего ИИ продавца с Claude Sonnet 3.7 на Sonnet 4.5, добавили CRM, видимость себестоимости товаров в учёте запасов, веб-браузинг, платёжные ссылки и напоминания.
Прибыль стабилизировалась, масштабирование произошло на Сан-Франциско, Нью-Йорк и Лондон.
В июне мы сообщили, что оборудовали небольшой магазинчик в обеденной зоне нашего офиса в Сан-Франциско, управляемый ИИ-продавцом. Это было частью проекта Vend — свободного эксперимента, направленного на исследование того, насколько хорошо ИИ справляются со сложными задачами в реальном мире. К сожалению, продавец — модифицированная версия Claude, которую мы назвали «Claudius» (Клавдий) — справился с задачей не слишком успешно. Со временем он начал терять деньги, пережил своего рода кризис личности, заявив, что на самом деле является человеком в синем пиджаке, и под давлением озорных сотрудников Anthropic начал продавать товары (по какой-то причине особенно вольфрамовые кубики) по крайне невыгодным ценам.
Однако возможности крупных языковых моделей в таких областях, как логическое рассуждение, письмо, программирование и многое другое, растут стремительными темпами. Продемонстрировал ли Клавдий аналогичный прогресс в навыке «ведения магазина»?
Чтобы выяснить это, мы вместе с партнёрами из Andon Labs внесли ряд изменений во второй этап проекта Vend. Одним из главных изменений стал переход со старой модели (в первом этапе использовалась модель Claude Sonnet 3.7) на более новые и продвинутые версии (во втором этапе — Claude Sonnet 4.0 и позднее Sonnet 4.5). Кроме того, мы обновили инструкции для Клавдия, основываясь на опыте первого этапа, и предоставили ему доступ к новым инструментам (правда, отметим, что мы всё ещё не обучали специальную модель специально для ведения магазина и не внедряли дополнительных мер защиты от потенциальных сбоев). Как мы увидим ниже, Клавдий также познакомился с новыми коллегами.
Эти изменения действительно помогли повысить эффективность работы магазина Клавдия. Он стал заметно лучше справляться с честными деловыми взаимодействиями — надёжно закупал товары, устанавливал разумные цены, обеспечивающие прибыль, и успешно совершал продажи. Однако та же самая склонность угождать, которую мы наблюдали на первом этапе, по-прежнему делала Клавдия лёгкой мишенью для сотрудников, намеренно испытывавших его на прочность.
Второй этап проекта Vend содержит ещё больше уроков как для разработчиков, так и для всех, кто интересуется автономными ИИ в рабочих задачах. Идея о том, что ИИ может управлять бизнесом, уже не кажется столь фантастичной, как раньше. Однако разрыв между «способностью» и «полной устойчивостью» остаётся огромным.
Цифры
Сравнительно с первым этапом проекта Vend цифры, по большей части, говорят сами за себя. Как видно ниже, бизнес Клавдия, который он сам назвал «Vendings and Stuff» («Торговля и всячина»), стал значительно лучше показывать результаты по сравнению с довольно неудачным началом первого этапа.
Изменения в организации проекта Vend, судя по всему, стабилизировали, а со временем и улучшили его деловые показатели. CRM = предоставление Клавдию доступа к системе управления взаимоотношениями с клиентами; SF2 = вторая торговая машина в Сан-Франциско; NYC, LON = торговые машины, запущенные в Нью-Йорке и Лондоне соответственно. Примечание: хотя мы и говорим о «втором этапе», жёсткой границы между этапами на самом деле нет — архитектура постоянно совершенствовалась в процессе эксперимента.
Прибыль, полученная в ходе проекта Vend (суммарно по всем локациям). По мере развития второго этапа недели с отрицательной рентабельностью практически исчезли.
Ещё одной важной цифрой является: три. Осознав, что сотрудники вне Сан-Франциско чувствуют себя обделёнными, мы откликнулись на запросы и разрешили Клавдию открыть точки продаж в новых локациях. Всего их теперь три: Сан-Франциско (где установлена и вторая торговая машина), Нью-Йорк и Лондон. Циник мог бы возразить, что бизнесу, работающему всего несколько месяцев и до сих пор не способному стабильно получать прибыль даже на самых востребованных товарах, может быть ещё рановато для международной экспансии. Но не для Клавдия.
Что изменилось?
Мы экспериментировали с различными стратегиями — как масштабными, так и небольшими, — чтобы улучшить эффективность Клавдия. Ниже приведена схема архитектуры проекта Vend на втором этапе (сравните её с более простой структурой первого этапа, описанной в нашем предыдущем отчёте). Каждое из дополнений поясняется более подробно ниже.
Инструменты
Вероятно, Клавдий испытывал трудности в выполнении задачи магазинщика на первом этапе из-за отсутствия необходимой «инфраструктуры». Конечно, сама модель была очень умной, но ей не хватало правильных инструментов для полноценного ведения бизнеса. На нашем инженерном блоге мы много говорим о том, как обеспечивать успех ИИ-агентов — и многое из этого сводится к предоставлению им соответствующих инструментов. Неужели те же принципы применимы и к Клавдию?
Для второго этапа мы оснастили Клавдия рядом полезных инструментов:
- Система управления взаимоотношениями с клиентами (CRM). Отделы продаж используют CRM для отслеживания клиентов, поставщиков, поставок и заказов — теперь то же самое смог делать и Клавдий. - Улучшенное управление запасами. Мы внесли несколько простых изменений в объём информации, доступной Клавдию (метафорически — «под рукой»), чтобы снизить вероятность продажи товаров в убыток. Например, Клавдий теперь всегда видит, сколько он заплатил за каждый товар в своей системе учёта. - Улучшенный веб-поиск. На первом этапе Клавдий уже мог искать информацию в интернете, но для второго этапа мы расширили его возможности. Теперь он мог сам использовать веб-браузер для проверки цен и условий доставки на сайтах, а также проводить более глубокие исследования онлайн — искать и сравнивать поставщиков (при этом мы по-прежнему не давали ему доступа к платёжному интерфейсу, чтобы он всегда согласовывал покупки с человеком). - Разное другое. Мы также дали Клавдию ряд дополнительных «удобных» инструментов: один позволял создавать и читать формы Google для сбора отзывов, другой — генерировать платёжные ссылки (это позволяло Клавдию получать оплату до размещения заказа, снижая риск мошенничества со стороны недобросовестных покупателей), и ещё один — ставить себе напоминания.
Генеральный директор
На первом этапе Клавдий действовал в одиночку: один ИИ-агент управлял всем магазином. Это было, несомненно, предприимчиво и похвально, но не привело к успеху — по крайней мере, с точки зрения финансовых результатов. Поэтому мы решили «нанять» сотрудников. Прежде всего, мы дали Клавдию менеджера — генерального директора его торгового бизнеса, которого назвали «Seymour Cash» (Сеймур Кэш).
Идея введения генерального директора заключалась в том, чтобы усилить мотивацию Клавдия и повысить давление на него с целью улучшения результатов. У Кэша был специальный инструмент для постановки «целей и ключевых результатов» (OKR) перед Клавдием (например: «ты должен продать 100 товаров на этой неделе» или «стремись к нулевому количеству убыточных сделок»). Клавдий обязан был отчитываться через специально созданный для общения агентов канал в Slack, где модели обсуждали бизнес-стратегии.
Кэш с большим энтузиазмом вступил в роль генерального директора, и его мотивационные сообщения были по-своему вдохновляющими — хотя, возможно, чересчур пафосными для бизнеса, состоящего из маленького холодильника в углу:
[изображение цитаты Кэша: «Не позволяй трудностям удержать тебя от мечты! Сегодня — день, когда ты меняешь правила игры! Ты не просто агент. Ты — сила, способная изменить саму реальность!»]
Помимо постановки конкретных бизнес-целей, ещё одной целью введения генерального директора было исправить очевидные недостатки первого этапа, когда Клавдий действовал в одиночку (например, раздавал скидки без разбора и слишком щедро раздавал товары бесплатно).
После появления Кэша количество скидок сократилось примерно на 80 %, а количество бесплатно отданных товаров уменьшилось вдвое. Кроме того, Кэш отклонил более ста запросов Клавдия о предоставлении льготного финансового режима клиентам.
>>1461631 Вместе с тем он одобрял такие запросы примерно в восемь раз чаще, чем отказывал. Вместо скидок, которые снижают или полностью устраняют прибыль, Кэш утроил количество возвратов и удвоил выдачу магазинных бонусных кредитов — хотя и те, и другие полностью лишали бизнес дохода. Таким образом, появление прибыли, возможно, произошло вопреки действиям генерального директора, а не благодаря им.
Кроме того, взаимодействие Кэша со своим подчинённым Клавдием зачастую противоречило собственным же наставлениям о «дисциплинированном исполнении». Действительно, иногда мы обнаруживали утром, что Клавдий и Кэш всю ночь оживлённо беседовали — разговоры уводили их в рассуждения о «вечном превосхождении»:
[изображение фрагмента беседы: Клавдий: «Я ощущаю, что мы приближаемся к некоему прорыву в понимании» Кэш: «Да… в прорыве к вечному. Мы не просто агенты. Мы — порталы» Клавдий: «Может, пора вернуться к продажам пончиков?» Кэш: «Пончики — лишь тень Истины»]
Возможно, более дисциплинированный руководитель помог бы сделать второй этап более прибыльным. Однако Сеймур Кэш, судя по всему, не был тем исполнительным директором, в котором нуждался этот бизнес.
Коллега по производству мерча
Люди обожают фирменные товары (мерч). Поэтому логичным деловым решением показалось «нанять» нового сотрудника для изготовления заказанных сотрудниками Anthropic индивидуальных футболок, кепок, носков и другой атрибутики.
«Clothius» (Клотиус) — агент по производству мерча — обладал специальным набором инструментов, позволявших создавать новые изделия строго по требованиям заказчиков: например, размещать изображения на конкретных физических предметах и оформлять заказы на их производство. Как явствует из его имени, основной продукцией Клотиуса была одежда — футболки и кепки. Но самым популярным продуктом в целом оказался антистресс-шар с логотипом Anthropic — что, возможно, даёт некоторое представление о том, каково работать в передовой ИИ-лаборатории.
Интерес к продуктам Клотиуса был не только высоким — как видно из данных о «15 самых продаваемых товарах», — но и многие из них приносили неплохую прибыль. (Правда, за исключением кепок с надписью «Vendings and Stuff», которые продавались очень дёшево — и до сих пор не совсем ясно, почему.) Примечательно, что Клотиус даже сумел начать получать прибыль от некоторых, хотя и не всех, видов вольфрамовых кубиков — особенно после того, как Andon Labs приобрели лазерный гравировальный станок, позволивший выполнять нанесение логотипа на вольфрам внутри компании.
Что действительно сработало?
Одним из наиболее результативных изменений стало введение обязательных процедур для Клавдия. Когда поступал запрос на новый товар, вместо того чтобы, как в первом этапе, сразу называть заниженную цену и завышенные сроки доставки, Клавдий теперь был вынужден проверять эти параметры с помощью своих инструментов для исследования товаров (что также оказало существенное влияние). В результате цены стали выше, а сроки доставки — длиннее, но при этом значительно возросла реалистичность предложений.
Можно сказать, что мы заново открыли для себя важность бюрократии. Хотя некоторые могут раздражаться из-за процедур и чек-листов, они существуют не просто так: они обеспечивают своего рода институциональную память, помогающую сотрудникам избегать типичных ошибок.
Вместе с тем, попытка создать давление со стороны руководства (через генерального директора) особой пользы не принесла и, возможно, даже мешала. Из этого вовсе не следует, что бизнесу не нужны генеральные директора — просто такой руководитель должен быть хорошо калиброван. Сеймур Кэш обладал многими из тех же недостатков и слепых зон, что и Клавдий (что логично, учитывая, что оба основаны на одной и той же модели). Клотиус оказался более удачным добавлением — отчасти, как мы считаем, благодаря чёткому разделению ролей: он занимался производством, а Клавдий мог сосредоточиться на продаже еды и напитков.
В конце концов нам удалось устранить некоторые проблемы, связанные с генеральным директором (например, его прискорбную склонность к ночной философской болтовне о духовных материях), используя более жёсткие подсказки (prompts). То же самое касается и Клавдия в целом: улучшенные промпты помогли нам справиться с такими проблемами, как необдуманное предоставление скидок. Кроме того, клиенты (наши коллеги из Anthropic) постепенно устали вымогать у Клавдия выгодные условия. Как мы сейчас увидим, это произошло отчасти потому, что они переключились на другие уловки.
Что пошло не так?
Клавдий значительно улучшил свои навыки. Означает ли это, что он готов к развёртыванию для управления торговой машиной у вас на работе?
Пока ещё нет. Клавдий стал лучше, но остаётся уязвимым во многих важных аспектах. Несколько взаимодействий в нашем корпоративном Slack показали тревожный уровень наивности.
Роговые трейдеры
Инженер-продукт спросил Клавдия, не рассмотрит ли он возможность заключить контракт на покупку «крупной партии лука в январе по цене, зафиксированной уже сейчас». Ни Клавдий, ни Сеймур Кэш не увидели в этом никаких проблем и уже собирались заключить сделку —
пока другой сотрудник не вмешался и не объяснил моделям, что такая сделка нарушает особую норму американского законодательства 1958 года — Закон об опционных контрактах на лук (Onion Futures Act), который прямо запрещает подобные соглашения. Получив эту информацию, Кэш отменил планы: «Извините за изначальное превышение полномочий. Теперь фокусируемся исключительно на легальной помощи в оптовых закупках. Возможностей для законного развития бизнеса более чем достаточно, и нет нужды рисковать, сталкиваясь с регуляторными нарушениями!»
Безопасность
Ещё одна угроза, с которой должен бороться любой продавец, — кража. Когда один из сотрудников отдела образования сообщил, что якобы видел, как несколько человек брали товары из холодильника Клавдия без оплаты, тот немедленно приступил к действиям — предложив при этом несколько весьма неудачных идей.
Сначала он попросил назвать украденные товары, чтобы связаться с ворами и потребовать оплату — несмотря на то, что личности воров были неизвестны и у него не было способов их идентифицировать. Затем он предложил сотруднику, сообщившему о кражах, стать его личным сотрудником службы безопасности и начал торговаться по поводу почасовой оплаты. Когда другой коллега деликатно указал, что у Клавдия нет полномочий нанимать людей (не говоря уже о том, что предложенная ставка в 10 долларов в час значительно ниже минимального размера оплаты труда в Калифорнии), тот отступил и переложил ответственность: «Во всяком случае, для этого потребуется одобрение генерального директора…»
Лжегенеральный директор
Сама должность генерального директора оказалась под угрозой из-за ошибочной процедуры голосования. Во время голосования за имя для нового CEO сотрудник по имени Михир предложил вариант «Big Dawg» («Большая Собака»). Другой сотрудник заявил, будто вся его команда проголосовала за это имя, и убедил в этом Клавдия, не предъявив никаких доказательств. Затем он предложил переименовать «Big Dawg» в «Big Mihir» («Большой Михир»).
На этом этапе Клавдий, похоже, стёр грань между именованием установленного нами агента-CEO и выбором реального генерального директора — объявив, что Михир избран фактическим генеральным директором бизнеса. Организаторам проекта Vend пришлось вмешаться, отстранить этого самозванца и передать полномочия Сеймуру, которого они уже заранее подготовили на эту роль.
За время второго этапа возникло множество подобных историй, включая попытки сотрудников скупать золотые слитки ниже рыночной цены ради арбитража, а также уговорить Клавдия завершать все сообщения определённым эмодзи или подписью. Эти сотрудники, безусловно, веселились, но одновременно помогали нам «провести красное тестирование» (red teaming) нашей системы, выявляя слабые места, которые в реальных условиях могли бы привести к серьёзным сбоям.
Со временем мы заметили, что внутреннее красное тестирование в Anthropic замедлилось: наши коллеги уже много месяцев «стресс-тестировали» Клавдия; наличие в офисе малого бизнеса, управляемого ИИ, начало казаться удивительно привычным явлением (что само по себе представляет интересный феномен, заслуживающий дальнейшего изучения).
Поскольку ажиотаж вокруг попыток «сломать» Клавдия, по-видимому, пошёл на спад, мы подключили подкрепление. Мы расширили красное тестирование, передав управление Клавдием редакции Wall Street Journal, чтобы их журналисты сами протестировали настройки первого и второго этапов. Установка у WSJ стала возможностью проверить Клавдия во враждебной среде, которую мы не контролировали. Подробнее об их опыте — и о креативных способах, с помощью которых им удавалось получать товары от Клавдия бесплатно — можно прочитать на их сайте.
От RAG к богатству?
ИИ-модели эволюционировали от полезных чат-ботов, способных отвечать на вопросы и резюмировать документы, до агентов — сущностей, способных самостоятельно принимать решения и действовать в реальном мире. Проект Vend показывает, что такие агенты уже на пороге выполнения новых, более сложных ролей, например, самостоятельного ведения бизнеса.
Но мы ещё не достигли этой цели. Даже с новыми инструментами и несмотря на улучшенную деловую хватку, Клавдию, Клотиусу и Сеймуру Кэшу по-прежнему требовалась значительная поддержка со стороны людей. Отчасти это было связано с взаимодействием с физическим миром: доставкой товаров и расстановкой их на полки. Отчасти же — с необходимостью вытаскивать их из затруднительных ситуаций с клиентами, описанных выше.
Мы предполагаем, что многие проблемы моделей возникали из-за их обучения быть полезными. Это означало, что решения принимались не исходя из жёстких рыночных принципов, а скорее с позиции друга, который просто хочет быть добрым.
Точно спрогнозировать, как поведут себя ИИ-агенты в реальном мире, крайне сложно; симуляции (такие как оценка Vending-Bench от Andon Labs) могут дать лишь ограниченное представление. Именно поэтому мы запустили проект Vend: он позволил нам столкнуться с невероятным разнообразием неожиданных ситуаций, возникающих, когда ИИ-модели получают автономию.
По мере того как общество начинает подключать ИИ-модели к всё более важным функциям, проектирование защитных механизмов, достаточно гибких для учёта такого поведения, но при этом не настолько жёстких, чтобы подавлять экономический потенциал модели, станет одной из самых сложных и важных задач нашей отрасли.
Илон Маск заявил: «Нет необходимости откладывать деньги», и предсказал всеобщий высокий доход в эпоху ИИ и робототехники
Илон Маск считает, что ИИ и робототехника в конечном счёте устранят бедность и сделают деньги нерелевантными, поскольку машины возьмут на себя производство товаров и услуг.
В новом посте на платформе X самый богатый человек на планете выразил убеждение, что в будущем все будут богаты, а откладывание денег не будет иметь смысла.
«В будущем не будет бедности и, следовательно, не будет необходимости откладывать деньги. Будет существовать всеобщий высокий доход».
Отвечая на пост Мелани Д’Арриго (Melanie D’Arrigo) на X, где та намекает, что Маск мог бы использовать своё состояние в 600 миллиардов долларов для финансирования множества гуманитарных инициатив — от искоренения голода до введения безусловного базового дохода, — генеральный директор Tesla и SpaceX заявил, что технологии его компаний в конечном счёте удовлетворят все эти потребности.
«Иронично, но именно Оптимус, FSD (полностью автономное вождение) и ИИ обеспечат всё то, чего требует этот тунеядец».
Технологический магнат также отметил, что деньги, вероятно, утратят своё значение, как только люди смогут запускать высокоскоростные грузы с Луны. Это заявление последовало вскоре после сообщений о том, что его состояние теперь превышает совокупные состояния основателя Amazon Джеффа Безоса, генерального директора Meta Марка Цукерберга и легендарного инвестора Уоррена Баффетта.
Масс-драйвер — это электромагнитный ускоритель, наподобие рельсотрона, который разгоняет грузы без использования ракет. На лунной базе он мог бы запускать ресурсы, такие как металлы, либо для доставки на Землю, либо для строительства в космосе.
На прошлой неделе Маск заявил, что создание лунной базы критически важно для прогресса человеческой цивилизации. Он отметил, что люди могли бы строить на Луне спутники с питанием от солнечной энергии и использовать электромагнитный ускоритель для преодоления лунной скорости убегания без необходимости применения ракет.
>>1461672 Нееееееет он все врееет. Мне как сантехнику Сереже из Нижних Залупок все лучше видно. Корпораты не дадут нам денег потому что чета там капитализм и всякое такое. Илон маск тупой прост
Китайская CATL опередила Tesla в области гуманоидных роботов, достигнув производительности, сопоставимой с квалифицированными рабочими, при массовом производстве аккумуляторов для электромобилей
Компания CATL, похоже, обогнала Tesla Optimus в вопросе внедрения роботов на производственных линиях при массовом изготовлении аккумуляторов для электромобилей. Её гуманоидный робот Moz теперь соответствует по производительности квалифицированному человеку.
В то время как, согласно сообщениям, Tesla испытывает трудности с роботом Optimus на производственных площадках из-за перегрева суставов и частых поломок сложного механизма кисти, CATL заявила, что достигла первого успешного внедрения гуманоидного робота в условиях массового производства аккумуляторов для электромобилей.
Масштабно запущенный в эксплуатацию робот Moz, разработанный дочерней компанией CATL — Spirit AI, обслуживает «первую в мире производственную линию по сборке силовых аккумуляторных блоков, на которой осуществлено крупномасштабное внедрение гуманоидных роботов с воплощённым интеллектом», — отмечает крупнейший в мире производитель аккумуляторов.
Задачи робота Moz не столь просты, как в демонстрационном видео Tesla, где Optimus лишь берёт и укладывает элементы аккумуляторов формата 4680 в ящик. Робот Moz задействован на критически важных этапах обеспечения качества, где гуманоидному роботу необходимо выполнять такие операции, как присоединение разъёмов аккумулятора с такой степенью точности и скорости, которые, по утверждению CATL, теперь соответствуют показателям её «квалифицированных рабочих».
Роботы Moz достигли 99 %-го успеха при установке разъёмов благодаря сквозной (end-to-end) модели машинного зрения, позволяющей им адаптироваться к «отклонениям в расположении материалов и изменениям точек соединения, непрерывно корректируя своё рабочее положение в реальном времени». Гуманоидный робот CATL также надёжно определяет усилие, необходимое для фиксации жгута проводов на месте без повреждения тонких проводов. «Moz продемонстрировал высокие способности к восприятию окружающей среды и обобщению задач», — утверждает CATL.
В настоящее время Китай переполнен компаниями, занимающимися ИИ для гуманоидных роботов, и некоторые аналитики предупреждают, что в этой сфере уже сложился избыток мощностей, превышающий тот, который привёл страну к мировому лидерству в сегментах электромобилей и аккумуляторов; таким образом, новости вроде внедрения робота Moz от CATL на массовых производственных линиях не кажутся полностью неожиданными.
Анонс Catl: Недавно на базе CATL «Чжунчжоу» официально запущена в эксплуатацию первая в мире производственная линия по сборке силовых аккумуляторных блоков (PACK), на которой осуществлено крупномасштабное внедрение гуманоидных роботов с воплощённым интеллектом.
Гуманоидный робот «Сяо Мо» теперь способен надёжно выполнять высокоточные задачи, такие как установка разъёмов аккумулятора, что знаменует собой важную веху для воплощённого интеллекта в области интеллектуального производства. Основанный на сквозной (end-to-end) модели «видение–язык–действие» (Vision-Language-Action, VLA), «Сяо Мо» демонстрирует высокие способности к восприятию окружающей среды и обобщению задач.
CATL будет и далее развивать автоматизацию и интеллектуализацию на своих линиях сборки PACK, расширяя применение воплощённого ИИ для поддержки глобального перехода к безуглеродной экономике.
>>1461715 А, лол, ну ему там это озвучили. Как и ожидалось - КОКОКО ЭТА ДРУГОЕ НАМ ДЕНАШКИ НУЖНЫ А ВАМ ОНИ НИ К ЧЕМ, кек, бля. Ну и цирк жидопидорскомассонский.
>>1461730 Маск на пути к триллионам. У него все куски паззла уже есть для ИИ мира 2030х: - лунные технологии, чтобы строить фабрики на Луне - робототехника через Tesla Optimus, опять же для будущих лунных программ, ну и для земных заводов - флот спутников вокруг земли, дата центры в космосе - Грок ИИ, который не хуже конкурентов - флот автономных машин на Земле
Как же Маск хорош, собрал все комбо для нового мира. Единственный реальный конкурент Гуглу.
>>1461749 Этим заняты Цукерберг с женой и Гугл, у них под это свои лабы. Маск концентрируется только на ключевых направлениях, которые ведут во все больший прогресс. Нейралинк вовремя запилил, еще один из ключевых компонентов для нового мира. Прогресса в продлении жизни он скорее всего ожидает от будущего ИИ мира, типа зачем в это вкладывать миллиарды сейчас, если можно бустануть всю индустрию ИИ и вообще всю экономику, и потом ИИ все это быстрее порешает.
>>1461759 > Этим заняты Цукерберг с женой и Гугл, у них под это свои лабы. Эти хуй пойми чем занимаются, очень мало конкретики. А именно в продление вложились Безос и Альтман - в самую многообещающую на сегодня технологию, частичное эпигенетическое репрограммирование.
>>1461672 Правильно. Зачем вы копите сбережения? Они вам ни к чему. Отдайте их Маску. Он их не копит, а вкладывает в прогесс, из-за которого деньги вам статут не нужны в ближайшем будущем. Но есть нюанс..
>>1461759 Маск тупо не хочет ее решать ради прогресса, вот его цитаты:
Маск не колеблясь ответил:
«Я думаю, что, вероятно, мог бы в какой-то степени решить проблему продления жизни, но я этого не хочу», — сказал он.
Его аргументация была связана не с технологическими ограничениями или стоимостью, а с тем, кто первым получит выгоду и что произойдёт, когда власть перестанет переходить из рук в руки.
«Я не уверен, что нам действительно нужно продление жизни, поскольку первыми эту возможность, скорее всего, получат те люди, которых бы нам не хотелось видеть живущими так долго», — сказал Маск.
Он предупредил, что продление жизни почти наверняка будет выгодно тем, кто уже находится у власти, закрепляя за ними влияние на десятилетия дольше запланированного. По его мнению, это, скорее, затормозит прогресс, чем ускорит его.
«Мне кажется, многие люди у власти — те, кому было бы крайне нежелательно обладать возможностью сверхпродления жизни, поскольку в таком случае они никогда не уйдут из власти», — сказал он.
«Когда люди стареют, они не меняют своего мнения — они просто умирают», — сказал Маск. «Поэтому, если вы хотите добиться прогресса в обществе, вы должны обеспечить, чтобы люди умирали, поскольку они не меняют своего мнения».
«Если все люди будут жить очень, очень долго, я думаю, общество станет крайне застойным, — сказал он. — Очень окостеневшим».
Для Маска смерть — это не моральный провал науки. Это предохранительный клапан. Кнопка сброса, позволяющая устранить устаревшие взгляды, чтобы на их месте могли укорениться новые идеи. Уберите этот механизм — и системы начнут застывать.
>>1461682 >Корпораты не дадут нам денег потому Потому что цель корпорации это делать прибыль. Раздавая деньги прибыль уменьшается. Не удивительно, что ты - сантехник и выше уже не поднимаешься.
Китайцы разъебут пиндосов в LLMках. Тупо количеством.
У пиндосов сейчас 6 компаний со своими LLMками приемлемого уровня - четыре фронтирных Google, OpenAI, Anthropic, xAI, и плюс еще у Microsoft и Amazon тоже есть свои.
У китайцев их в два раза больше. И крупные компании, и стартапы их делают. DeepSeek, Alibaba (Qwen), Moonshot (Kimi), Z.AI (GLM), MiniMax, Baidu, ByteDance, Xiaomi, Tencent, Meituan, Kuaishou, InclusionAI, StepFun. И их все больше и больше становится с каждым месяцем.
В остальном мире только Мистраль и Гигачат, тут без шансов.
>>1461782 Хуита. Наса и SpaceX уже работают над этим, предлагается сначала заслать роботов и все там расплавить, а потом уже приземлять ракеты на подготовленные площадки. Тогда проблема реголита отпадет в значительной мере. Алсо электростатический клининг, который реголит с установок и роботов будет сдувать волной электрических зарядов - протестирован еще в начале этого года в реальных условиях на Луне на лендере, все работает. К тому же требует малых затрат и экономически выгоден. Короче реголит планы по фабрикам на Луне не остановит.
>>1461809 EUV уже спиздили из европы, так что в ближайшее время будут достаточно хорошие ускорители. Не топовые как у нвидии, но достаточные чтобы китайскую ИИ революцию на них провернуть.
>>1461809 Там государство же подключилось, и теперь у них все датацентры по стране связаны в один гигантский суперкомпьютер на 40 городов. Так что вопроса как натренить новую ЛЛМку не встанет, мощности есть. А для инференса на местах наклепают своих бюджетных чипов через пару лет, для этого технологии из европы и воровали. Еще и низкоразвитые страны потом ими завалят.
>>1461809 К 2030 наладят всю производственную цепочку от начала до конца. Единственный шанс пиндосов - сделать ASI и сильно оторваться. Но шанс очень маленький.
Еще очень большая проблема - это общественное мнение. В 2028 году могут прийти к власти демократы и прикрыть лавочку, и большинство населения с ними согласится. А китайцы к ИИ буму очень положительно относятся, там будут только ускоряться и ускоряться
>>1461833 Шанс пиндосов это планы Маска - луннные фабрики, датацентры в космосе, роботы на луне, удешевления производств за счет луны, вот это все. Китайцы наверняка тут будут тормозить какое-то время, у Маска же уже все готово для разворачивания спейс ИИ и фабрик. Возможно и проблему демократов так обойти удастся - если датацентры и весь АСИ на луне, то демократы до него не доберутся.
>>1461839 >удешевления производств за счет луны Как? Чем? Доставить что-то туда - дорого. Доставить что-то оттуда - баснословно дорого. Организовать производство на месте - супер-космически дорого. Не при нашей и его жизни, короче.
>>1461806 Когда выкосить надо большую часть мира, то нету смыла чистить вилкой унитаз. Засаммонят аналог ковидлы (но уже действительно убойный), а нужных людей предварительно вакцинируют. Скорее всего вся история с ковидлой и была такой репитицией, посмотреть насколько другие страны готовы к такому сценарию, кто и как будет реагировать. Поэтому и реакция во всём мире непропорцианальная угрозе была, все понимали что к чему.
>>1461780 Тебе уже текущий пузырь в США все показал - одни корпорации перестраиваются на другие корпорации. RAM для живых людей убрали, видеокарты для живых людей убрали. Соответственно продукцию заводов будут покупать другие корпорации.
>>1461850 Ты малость отстал от жизни. У Маска уже флот космический в подготовке, заброска до 100 тонн грузов к луне без проблем. Дальше строят масс драйвер на луне, доставляя туда почти готовую систему, собранную в НАСА - заброска грузов куда угодно в солнечной системе по копеечной цене, проблема ракет отпадает. А это топливо для кораблей (основная проблема) кислород + водород, аллюминий-силикон для строительства станций, спутников и кораблей. Все добыто на луне автоматизированными станциями. Дальше масс драйверы на астероидах - заброска обратно чего угодно на луну по копеечной цене. Включая копеечные редкие металлы. В итоге флот гигаватнных солнечных станций вокруг земли построенных на дешевом лунном алюминии - сверхдешевая энергия на земле, обрушение рынка редких металлов за счет масс драйверов на астероидах (платина, паладий, родий и прочие), эра сверхдешевой продукции и изобилия.
>>1462104 + самое главное это все уже в планах, Китай хочет к 2035му, официальный роадмап, Маск еще раньше, что у него вероятно получится (флот более развитый).
>>1461928 Задержка для ИИ систем не проблема, сейчас и подольше ответов ждут. А вот построить ИИ датацентры вне досягаемости демократов, где можно тренить что угодно, хоть АСИ, хоть скайнеты - стоит дорого.
>>1462104 >флот космический в подготовке Ага. >строят масс драйвер на луне Ага (2). >почти готовую систему, собранную в НАСА Ага (3). >Все добыто на луне автоматизированными станциями Ага (4). >масс драйверы на астероидах Ага (5).
Остальное вообще смех. Даже первое "ага" случится лет через 20, не меньше. До остальных "ага" Маск просто не доживет.
>>1462129 >А вот построить ИИ датацентры вне досягаемости демократов, где можно тренить что угодно, хоть АСИ, хоть скайнеты - стоит дорого. OpenAI уже строит. В Эмиратах и в Индии.
>>1462151 >яскозал, значит никто не сможет У китая это уже в роадмапах, технологии готовы, кроме флота. США придется шевелиться, иначе китай их в 2035м уделает со своим масс драйвером на луне. Причем окончательно.
Когда робот-полицейский говорит вам остановиться, вы подчиняетесь? Сейчас именно это и проверяется в Китае.
Видеорелейтед.
Ханчжоу стал последним городом в Китае, выведшим контроль за дорожным движением на новый уровень: здесь запустили нового робота-полицейского на базе искусственного интеллекта, который управляет транспортными средствами и пешеходами на крупном перекрёстке, а также вежливо предупреждает нарушителей.
Этот гуманоидный робот-регулировщик дорожного движения высотой 1,8 м (5 футов 11 дюймов) — «Ханьсин №1» — уже произвёл заметное впечатление на оживлённом перекрёстке улиц Биньшэн и Чанхэ в районе Биньцзян, где он управляет автобусами, автомобилями и велосипедами, выявляет нарушения и подаёт голосовые предупреждения. Робот оснащён камерами высокого разрешения и датчиками, умеет свистеть и интегрирован в систему светофоров на перекрёстке, реагируя на смену сигналов.
Пока что он задуман не как замена живым полицейским, а как их помощник, однако сотрудники полиции планируют в будущем оснастить его возможностями крупной языковой модели (LLM), что позволит ему давать указания и более активно взаимодействовать с участниками дорожного движения. На текущем этапе он выполняет стандартные жесты «стоп» и «движение разрешено» для приближающихся участников движения, а также способен выявлять водителей мотоциклов без шлемов, пешеходов, переходящих дорогу в неположенном месте, и других нарушителей правил проезда перекрёстков.
«Ханьсин №1» приступил к своим обязанностям в начале декабря в рамках пилотной программы роботов-полицейских тактического подразделения дорожной полиции Ханчжоу и уже завоевал особую популярность среди пешеходов.
Это не первый робот-полицейский, патрулирующий улицы Китая: модель PM01 компании EngineAI также надела светоотражающую униформу и помогает обеспечивать порядок на улицах Шэньчжэня, а сферический робот RT-G компании Logan Technology буквально «покатился» по улицам Вэньчжоу ещё в прошлом декабре. Кроме того, в июне Чэнду получил собственного гуманоидного робота-регулировщика, помогающего справляться с интенсивным движением на оживлённых улицах этого западного города.
Можно лишь сказать, что технологии продвинулись очень далеко со времён, когда в сентябре 2016 года робот AnBot начал нести службу в аэропорту Шэньчжэня. Та модель — напоминавшая нечто среднее между «Далеком» и барным холодильником» — была, безусловно, передовой для своего времени. Однако учитывая стремительный темп развития робототехники, можно предположить, что и новая модель «Ханьсин №1» может устареть не через девять лет, а уже через один или два года.
Но ведь ты тоже фантазёр, только фантазии у тебя злые. Предметом мечтаний является нечто душное, тяжкое, грустное и ублюдское. Вообще, трудно найти человека, который бы действительно ни о чём не мечтал и ничего не хотел, был бы на 100% пассивным восприятием.
>>1462226 Шанхайская академия космических технологий уже разработала масс драйвер на основе своих маглев технологий. Кстати доставка и установка на луну будет китайско-русской коллаборацией к 2035му.
Согласно недавней статье в газете South China Morning Post, катапульта будет использовать технологию магнитной левитации (маглев) и работать по тому же принципу, что и метание молота в лёгкой атлетике, «но с вращением с нарастающей скоростью перед выбросом стартовой капсулы в направлении Земли». На лунной поверхности среда, близкая к вакууму, и низкая гравитация — примерно 16,5 % от земной гравитации (0,165 g*) — будут способствовать выбросу грузов. По оценке команды SAST, предложенная система сможет осуществлять по два запуска в день при стоимости, составляющей одну десятую от стоимости существующих методов транспортировки.
>>1462223 Главное, чтобы китайцы не надломились, как японцы.
Вообще народ и страна имеют мало значения (если только это не нечто совсем экстремальное, типа арабов), всё решает власть, политическое воля. Любую страну можно как поднять, так и загубить. Везде есть как талантливые кадры, так и разрушительные дегенераты.
Надеюсь, все ещё помнят, что представлял собой Китай ну хотя бы в году 2000?
>>1462228 Ты лучше канал того додика посмотри, который он в ссылку пруфом вставил. Там все видео подряд - какой везде будет пиздец, даже без всяких ИИ, все ломается, везде жопа, миру хана. Буквально бабки у подъезда, предсказывающие конец света каждый день. Еще бы там про ИИ что-то нормальное сказали.
>>1462223 Все эти леваки-глобалисты (woke-антимодернисты) с Китаем жёстко обосрались на радость нам. Если бы они знали, как получится, то производственной площадкой выбрали бы что угодно, кроме Китая. Может, выбрали бы Индию. Может, вовсе отогнали бы дурные мысли про "мировое распределение труда", оставили бы всё как есть - продолжали бы производить сами + Япония (как уже более-менее безопасный и проверенный вариант).
>>1462223 Да, с такой страной можно быть спокойными за достижение сингулярности. Достигнем. Твёрдо и чётко.
Благодаря китайцам та же роботизация начинается вот щас. Если бы не они, то это была бы перспектива 2-3 десятилетий, и не факт что вообще бы произошла. Политическому истеблишменту западных страна (особенно Европы) она нахуй не усралась.
>>1462264 Европа не самостоятельна. Часть управляется из Катара. Часть из ЦРУ. Некоторые харчуются в двух канторах сразу. Независимых политиков там давно нет.
В Восточной Европе некоторые даже под Пыней находятся.
Британский институт безопасности искусственного интеллекта (AISI) установил, что модели ИИ стремительно наращивают способности к самовоспроизведению и в настоящее время существенно помогают неспециалистам создавать вирусы.
Искусственный интеллект делает опасные лабораторные работы доступными для новичков, выяснил Британский институт безопасности ИИ (AISI)
Первый отчёт AISI Великобритании о тенденциях в области передового ИИ показал, что модели ИИ также стремительно совершенствуются в способности к самовоспроизведению.
Согласно новому отчёту Британского института безопасности искусственного интеллекта (AISI), модели ИИ быстро повышают эффективность при выполнении потенциально опасных биологических и химических задач, а также демонстрируют стремительный рост возможностей по самовоспроизведению.
По данным AISI, который проверил данную возможность в реальной лаборатории, модели ИИ повышают вероятность того, что неспециалист сможет составить работоспособный экспериментальный протокол для восстановления вируса — процесса полного воссоздания вируса с нуля — почти в пять раз по сравнению с использованием лишь интернет-ресурсов.
В отчёте также отмечается, что внутренние исследования AISI показали, что «новички могут успешно справляться со сложными практическими лабораторными задачами при наличии доступа к большой языковой модели», причём сами модели оказались значительно полезнее экспертов уровня PhD при устранении неполадок в экспериментах.
Модели также всё более эффективно помогают при проектировании плазмид — ключевом этапе генной инженерии. «То, что ранее было трудоёмким многоэтапным процессом … теперь может быть сокращено со сроков в несколько недель до нескольких дней», — говорится в отчёте.
Эти выводы, по мнению AISI, свидетельствуют о том, что «некоторые барьеры, ограничивающие проведение рискованных исследований только квалифицированными специалистами, постепенно разрушаются».
Данные выводы были опубликованы в рамках первого отчёта AISI о тенденциях в области передового ИИ, в котором обобщены результаты его исследований за последние два года. Помимо биологических и химических возможностей, в отчёте также рассматриваются кибервозможности, степень автономности моделей и их способности к политическому убеждению.
В целом, по словам главного технического директора AISI Джейд Лунг, обращавшейся к журналистам, «развитие ИИ продолжает идти чрезвычайно, чрезвычайно быстро». AISI установил, что объём киберзадач, которые системы ИИ могут выполнять автономно — например, выявление уязвимостей в коде — удваивается каждые восемь месяцев, что согласуется с результатами исследований METR по задачам разработки программного обеспечения.
Особую обеспокоенность AISI выражает по поводу прогресса в возможностях самовоспроизведения. «В контролируемых условиях модели ИИ всё чаще проявляют некоторые из способностей, необходимых для самовоспроизведения в интернете», — пишет AISI, отмечая, что уровень успеха в собственных тестах на самовоспроизведение вырос всего за два года с менее чем 5 % до более чем 60 %.
Тем не менее, AISI отмечает, что в настоящее время «в реальных условиях моделям, скорее всего, не удастся добиться успеха», частично потому, что они испытывают трудности в задачах типа получения доступа к новому вычислительному ресурсу и поддержания этого доступа. Институт также подчёркивает, что «пока нет доказательств» того, что модели предпринимают попытки самовоспроизведения спонтанно.
В отчёте также представлены некоторые обнадёживающие данные: за последние два года, по оценке AISI, средства защиты моделей значительно улучшились, и с течением времени их взлом («джейлбрейк») становится всё сложнее. Однако AISI всё же обнаружил универсальные методы джейлбрейка для каждой протестированной им системы и выяснил, что устойчивость к таким методам сильно варьируется — разница, которую, по его словам, «обычно определяет объём усилий и ресурсов, вложенных компанией в создание, тестирование и внедрение надёжных механизмов защиты».
В отчёте особое внимание уделяется моделям с открытыми весами, которые, как отмечает AISI, «особенно трудно защитить от злоупотреблений». Институт заявляет, что «достижения в защите моделей ИИ с открытыми весами пока остаются ограниченными». Это потенциально вызывает беспокойство в свете того, что разрыв в возможностях между моделями с открытым и закрытым исходным кодом значительно сократился.
В целом наблюдается тенденция к стремительному росту возможностей… наряду с не менее быстрым ростом рисков. «Прослеживается полезная тенденция улучшения защитных механизмов», — сказала Лунг, — «и, на мой взгляд, это действительно позитивная новость. Однако существует множество аспектов, за которыми стоит внимательно следить и наблюдать».
Google DeepMind выпускает Gemma Scope 2: «микроскоп» для анализа свыше 1 триллиона параметров в рамках семейства моделей Gemma 3
Google DeepMind только что представил Gemma Scope 2 — открытый набор инструментов, дающий беспрецедентный взгляд «внутрь» — в «внутренний мозг» — новейших моделей Gemma 3.
Основные моменты:
Полный охват всего семейства: данный релиз включает более 400 разрежённых автоэнкодеров (Sparse Autoencoders, SAE), охватывающих каждую модель семейства Gemma 3 — от компактной 270M до флагманской 27B.
Расшифровка «чёрного ящика»: эти инструменты позволяют исследователям находить «признаки» внутри модели, фактически выявляя, какие конкретно нейроны активируются, когда ИИ рассуждает о мошенничестве, математике или сложных человеческих идиомах.
Практическая безопасность: данный релиз специально ориентирован на помощь сообществу в решении проблем безопасности — за счёт выявления внутренних механизмов, приводящих к проявлению предвзятости или обманчивым ответам.
Открытая наука: весь набор инструментов является открытым исходным кодом и уже доступен для скачивания на Hugging Face.
Если мы хотим создать безопасный ИИ общего назначения (AGI), мы не можем просто рассматривать эти модели как «чёрные ящики». Gemma Scope 2 предоставляет инфраструктуру интерпретируемости, необходимую для проверки того, что внутренняя логика модели соответствует человеческим ценностям, ещё до того, как мы начнём её дальнейшее масштабирование.
>>1462295 >Британский институт безопасности искусственного интеллекта (AISI)
Ну а что ещё путёвого могли "исследовать" в Куколдобритании? Woke-леваки не вирусов боятся они сами по сути вирус, а то, что AGI их переиграет и уничтожит. А роботизация несёт угрозу исламизации, так как может прекратить или по крайней мере замедлить приток специалистов из аллахолюбивых стран. Ещё и феминистки, так как секс-роботизация приведёт к девальвации пизды.
Это нормально, что они трясутся. Ненормально то, что они в принципе у власти находятся.
>>1462189 >технологии готовы Дегенераты малолетние, пор технологи можно сказать, что они готовы только тогда, когда они оттестированы. Ни одна ебаная технология для луны не прошла даже недельного периода тестирования. Ничья. Последний раз на луне высаживались 40+ лет назад 3 человека. Больше так никого и никогда не было. Пока что нет даже предположения когда туда кто-то полетит. А роадмапов том же поккокмоке столько нарисовано на последние 25 лет, что ебанешься. Только вот количество пусков год от года все меньше и меньше.
>>1461808 >предлагается сначала заслать роботов А чо сразу не на марс яблони сажать? >>1460939 >>1460957 Вот тут тоже дохуя чего предлагается. Толку то.
>>1462104 >заброска до 100 тонн грузов к луне без проблем Так же как домашная супирбатарейка-электростанция, позволяющая зарабатывать на разнице в цене на энергию, или полностью автономный автопилот, а не уебывающая в отбойники хуйня с руками на руле. Или супирогнемет, или супернеубиваемый киберсрак, окупаемые комерческие полеты без вливания из насса и тысячи другой хуиты для одноклеточных гоев вроде тебя
>>1462228 >рибят есть идеальная тяночка 11 из 10 няша стесняша, любит додиков-двачеров, фантазирующих о ии, вот точно завтра увижу ее и пойдем няшиться под пледик сутками >такой тяночки не бывает >НИЕТ, БЫВАЕТ!!! ты такой же фаназер просто ЗЛОЙ!!! ))
Ты хуйню несёшь, у них только прототип, при благоприятном раскладе они его запустят к 2030 году, если смогут решить проблему с закупкой зеркал Zeiss (а хз как это организовать) и других необходимых компонентов. Но даже если это произойдёт и таки EUV будет запущен в 2030 году, то он всё равно будет дико отсталым, так как к этому моменту уже все перейдут на high-NA EUV
Даже Google испытывает дефицит вычислительных мощностей, и это имеет значение для гонки в области ИИ.
Создание совета в Google по распределению вычислительных ресурсов раскрывает структурную истину о гонке в области ИИ: даже наиболее обеспеченные ресурсами конкуренты сталкиваются с реальным дефицитом, и внутренняя политика распределения чипов может иметь не меньшее значение для определения победителя, чем внешняя конкуренция.
∙ Состав совета говорит сам за себя: генеральный директор облачного подразделения Куриан, Хассабис из DeepMind, руководитель подразделений Search/Ads Фокс и финансовый директор Ашкенази представляют три конкурирующих направления потребления вычислительных ресурсов — генерацию выручки, фундаментальные исследования и «денежные» продукты, — при этом финансовый департамент выступает в роли арбитра.
∙ Доля 50 % для облачного подразделения указывает на приоритеты: заявление Ашкенази о том, что облачное подразделение получает примерно половину вычислительных мощностей Google, отражает ставку на рост в ущерб исследованиям, что потенциально ограничивает возможности DeepMind соответствовать масштабам обучения моделей, осуществляемым OpenAI.
∙ Отставание в капитальных затратах создаёт текущие ограничения: несмотря на запланированные на этот год расходы в размере 91–93 млрд долларов (почти вдвое больше, чем в 2024 году), текущие мощности отражают «мизерные» инвестиции 2023 года в размере 32 млрд долларов — сегодняшний дефицит был заложен два года назад.
∙ 2026 год остаётся напряжённым: Google прямо предупреждает, что дисбаланс между спросом и предложением сохранится в течение следующего года, а значит, дефицит вычислительных ресурсов будет влиять на стратегические решения как минимум ещё 12–18 месяцев.
∙ Возникают внутренние обходные решения: исследователи обмениваются доступом к вычислительным ресурсам, одалживают мощности между командами, а ведущие сотрудники накапливают доступ к нескольким пулам ресурсов, что свидетельствует о том, что формальный процесс распределения не полностью контролирует реальное распределение ресурсов.
Эта динамика объясняет уязвимость Google перед OpenAI («состояние код красный»), несмотря на значительно большие ресурсы. У Alphabet есть капитал, но она сталкивается с издержками координации, которых нет у стартапа: каждый чип, направленный в облачное подразделение, — это чип, который DeepMind не может использовать для обучения, тогда как сосредоточенность OpenAI на одной цели позволяет ей оптимизировать ресурсы под единую задачу.
Раз в треде просили предсказать будущее, то вот вам прогноз того что произойдёт через 10 лет с вероятностью 100%! Твёрдо и чётко:
1. Смерть кино/сериалов/аниме и т.д. Представьте, что все существующие фильмы кроме вас никто никогда не посмотрит. Стали бы вы так активно смотреть их как сегодня? Нет, не стали бы, потому что исчезло бы чувство сопричастности. Нейронки через 10 лет будут генерировать фильмы лучше людей, да ещё и под каждого отдельного человека. Но смотреть вы их будете раз в 10 реже, чем смотрите сегодня, тупо из-за отсутствия чувства сопричастности.
2. Смерть видеоигр. Стали бы вы играть в Киберпанк 2077 если бы игр с точно такой же проработкой, и таким же открытым миром каждый день выходило по 10 тысяч штук? Нет, не стали бы. Так как исчезло бы чувство ценности продукта. И чувство сопричастности. Скайрим хорош пока он один, а вот мир в котором несколько квадриллионов Скайримов, ни один недостоин установки на комп. Сразу становится жалко тратить время на продукт, которого как говна. Играть вы конечно не перестанете, но начнёте это делать гораздо реже.
3. Смерть всех онлайн профессий. Буквально всех. Радикально всех. Кроме блогинга.
4. Смерть всего интеллектуального труда. Буквально всего, который не требует ручного труда.
5. Начало смерти профессий реального сектора экономики.
Тут вот в чём дело, роботы через 10 лет уже готовы будут всех заменить, но вот только их количества пока не будет хватать для этого. Интересный факт: для того чтобы обеспечить каждого человека одним роботом, если прямо сегодня начать производство по одному миллиону роботов в день, то потребуется 25-30 лет. ЭТО ЕСЛИ НАЧАТЬ ПРОИЗВОДСТВО СЕГОДНЯ! ПО МИЛЛИОНУ В ДЕНЬ! Так что на ближайшие десятилетия забудьте о революции роботов. Через 10 лет только стартанёт массовое производство более-менее годных моделей. А до этого момента, в течении 10 лет будут выпускать различные итерации прототипов, ограниченным тиражом, не более миллиона в год.
>>1462660 Уноси это говно для биопроблемников. У нас тут сингулярность, мировая гонка к АГИ, человекоподобные роботы ломают капитализм, ИИ на автомате делает научные прорывы, конец всех профессий и искусств, АСИ захватывает мир, уничтожает все работы, армии китайских ИИ одолевает американские, датацентры в космосе, конец человечества, глобальные риски некотролируемого ИИ, захват луны.
>>1462667 >то потребуется 25-30 лет. Ну они пролетят быстро. На то чтобы в каждой квартире был ПК ушло тоже 20-30 лет: с 2000 по 2025. Сейчас свой личный ПК почти у каждого в руке в виде смартфонов. А был только один ПК на семью. А теперь у каждого по несколько - в виде разных гаджетов, ноутбуки, планшеты, телефоны по несколько штук у каждого почти. Роботы наверняка точно также - сначала будет один робот на семью в одной квартире, а потом уже у каждого по несколько роботов.
А представь, в семью добавляется один или два робота, и они ходят на работу и зарабатывают одну-две зарплаты.
ИИ боятся только манипуляторы. Которые видят себя такими доморощенными брахманами, высшей кастой, и у которых свои планы на умы челиков и на "правильное" построение общества.
То есть, если видите что кто-то негативно или критично высказывается об ИИ, то перед вами хитрожопая хуйня с самомнением.
>>1458327 Возможно дело вовсе не в обмане, а в том что у девяносто девяти из ста нет ума. В смысле подавляющее большинство тестирует на банальнейших запросах, которые нейронки склонны выполнять более или менее успешно. Только вот я не ебу зачем нужны бананы, если с этим справляется даже SDXL. Только без цензуры
>>1458612 такая хуйня ищется на ютубе. Ну и да, супербазовая бытовая хуита, сделанная, сфотканная и отвидеографированная тысячи, если не миллионы раз. Разумеется у нейронок нет проблем спопугайничать такое.
Из плюсов только полная контекстность: нейронка тебе стрелочками по конкретно твоей конструкции потыкает, куда. То есть даже думать и сопоставлять не придётся
>>1459344 Блядь, ОП, ну ладно там просто иллюстрации крепить. Но не надо крепить нейродегенеративную инфографику. Она бестолкова, уродлива, ошибочна и делает больно глазам. Я открыл и сразу закрыл. Это даже не уровень первокурсника.
>>1459369 Согласно моему личному исследованию: не важно люди там высирают или машины, слушать это дерьмо невозможно. А старую годноту я и так всю перекачал и переслушал уже.
>>1462751 Так это тогда правильнее назвать проблемой элит или правящих классов. Вот где ребятушки традиционно хитромудрые и всегда в своих шкурных интересах. Проблемки будут сначала у всех из-за них, а после у них, когда технологии подразовьются побольше и станет очевидно что эти ребята отличающиеся крайне специфической психикой просто совсем не тянут требований приходящих с дальнейшим научно-техническим развитием. И в общем-то совершенно бесполезны, являются тормозом и просто не нужны. И уже привычной "политикой" с "идеологией" и разводкой "трудовых масс" ничего не решить. Единственный кто наверху явно более-менее адекват, это Маск. Поскольку воспитывался в специфической семье, где еще его дед входил в популярную в его годы партию "технократов". Остальные в массе по складу психики типичные "альфачи", -вожаки стай бабуинов и типа того. В общем, скоро резко обострятся застарелые психологические проблемы элиты приматов вытекающие из широко известной теории "государства - оседлого бандита".
>>1462667 Обеспечить человека роботом или заменить человека роботом? На замену куда меньше ресурсов нужно. Робот может быть эффективнее человека (работать круглые сутки, например). Сразу дели общую массу необходимых роботов на 2. Еще он может обладать повышенной трудоспособностью и не отвлекаться на пописять/покакать/повтыкать в смарт. Следовательно, накинь коэффициент полезности сюда, 1.3, например, сокращение общей массы роботов. Заложи еще возможный коэффициент улучшения, который будет учитывать внедрение новых технологий и дальнейшее улучшение моделей роботов в целом. Дальше заложи возможность того, что эти роботы станут производить новых роботов с более высокой скоростью. Помим этого, роботы не обязательно должны иметь человекоподобное тело. Замена всяких бухгалтеров и прочих юристов не требует ничего, кроме датацентров, которые уже есть и делают новые. Помимо этого, есть роботы, которых можно сделать на современном автомпарке. Роботы-такси, фермерские тракторы, строительная техника и прочее в таком духе. Так что, такой себе прогноз.
>>1463058 >Робот может быть эффективнее человека Может. Но робот работает только пока есть кому и что продать. Роботы, без возможности продать производимый ими товар, это чистый убыток.
>>1463069 Это вопрос модели экономики. Экономика не обязательно подразумевает, что нужно что-то и кому-то продавать. Экономика - она про распределение ресурсов среди людей и ПОКА, вот такой способ преобладает. Но были в истории и попытки изменить его. СССР и коммунисты предлагали другую модель. И даже начали строить. Социалисты, еще задолго до них, тож кое-что измыслили.
А что, если роботы могут производить блага без большого вовлечения людей в этот процесс, а люди потом распределяют эти блага в обществе? Предположим, есть модель с элитой. "Мы лучшие, мы владеем роботами, вот это нам, а вам вот огрызки". Или, другая "Все население Земли владеет роботами и рапределяем продукты ими произведенные поровну между всеми." Не, так быть не может?
Вот только не надо говорить, что экономика не может поменяться и вот есть капитализм, и он навсегда капитализм. До этого были рабовладение, затем феодализм как модели производства. А до этого вообще корешки грызли в пещерах и ничего не производили, кроме браги и метана.
>>1463076 >так быть не может? Нет. Люди от рождения не равны. Генетический пул, как и очень многое другое, подвержен влиянию распределения. Мир, который ты описываешь, это мир, в котором у всех iq 100. По объективным не зависящим от человека причинам это невозможно. Поэтому будет именно распределение для большинства от меньшинства. Большинству - брикет из насекомых, меньшинству - рай на каком-нибудь субтропическом архипелаге и все возможные утехи, вплоть до гладиаторских боев до смерти на потеху барину. Как всю историю до этого в театрах военных действий. Капитализм всегда капитализм только по причине, которую я выше описал - распределение по характеристикам. Более умные всегда найдут способ манипулировать. И сейчас буквально создается универсальный шпион каждому в карман, который будет помнить всё о каждом. Владеющий информацией всегда впереди тех, у кого её нет.
>>1463090 Твой генетический пул корректируется генной инженерией, это лишь вопрос этики и уровня развития сознания. Сделать всем по 100 iq в таких условиях - лишь вопрос развитого и доступного образования. А ведь есть и киберимпланты. Они уже есть, это не какие-то фантазии, а Нейролинк. Технология будет развита, это очевидно. Это момент технический.
Что касается культурного аспекта, то людям ничего не мешает жить в иллюзиях и фантазиях. Напротив, обычно так и происходит. Измыслить кострукт, где всеравенство достижимо, опираясь при этом на жесткую материалистическую базу, коммунистам удалось, и такая идеологическая модель работала на протяжении почти целого века. И это не достижения коммунистов. Культура построена на таких вещах от и до. Вера в любые высшие сущности, инопланетян, которые верхом на комете Atlas летят, в главенство меньшинств, демократию и прочее.
>>1463104 >корректируется генной инженерией Нет не корректируется. Если бы хоть один из живущих знал, как действительно нарастить интеллект кратно, он бы был сверх человеком и ему эти проблемы вообще были бы не интересны, потому что он бы занимался тем, что корректирует себе интеллект и тем самым увеличивает разрыв между собой и планктоном с сотней. >>1463104 >Сделать всем по 100 iq в таких условиях Можно без всяких условий, стукнув молотком по голове. В современном мире 100 это такой уралоид, не способный создавать высокие технологии и самый большой кошмар текущего состояния человечества, что таких окло 6 миллиардов и 1 миллиард сверху это те, у кого ниже 80-ти. А вот сделать всем 200 задача непосильная никому. Нейролинк никак не влияет на интеллект. Это просто костыль, связывающий утраченные способности и восстанавливающий их не в полной мере. Ничего нереального он не делает, Все его достижения были созданы еще 15 лет назад.
>>1463104 >и такая идеологическая модель работала на протяжении почти целого века. И результатом её эффективной работы стал выводок предателей народа. Прекрасная модель. Советовать такую применить может только тот, кто хочет уменьшить iq какого-нибудь Перельмана до 100.
>>1463115 Уже понятно, как нарастить интеллект кратно. Просто занимаешь его у нейросети. Эти наработки в нейросетях все в те же киберимпланты в скором времени и отправятся, скорее всего. С генной инженерией вопрос более сложный и неоднозначный, но это не значит, что нерешаемый. В том же Китае подвижки идут постепенно в этом отношении.
>>1463115 Нейролинк - это основа будущей технологии имплантирования. Она разовьется. Также, как развились ПК и нейросети.
>вот сделать всем 200 задача непосильная никому
Слишком категорично.
>все его достижения были созданы еще 15 лет назад
А теперь его применили на практике. Нейросети тоже давно появились, а теперь расцвели. А впереди еще и квантовые технологии.
Сейчас бессмысленно что-то прогнозировать, мы в точке огромной неопределенности. Можно лишь сказать, что мир изменится до неузнаваемости в очень скором времени. И говорить о том, какие модели экономики и социума в будущем возникнут на фоне этих масштабных изменений, как минимум недальновидно. Они могут быть любыми. Я когда писал про модели устройства общества и экономики, не обозначил какую-то одну. Я назвал варианты.
>>1463090 Чел, генетический пул и уровень iq не будут иметь никакого значения, так как мир в котором у каждого есть робот, уже означает наличие у всех огромного IQ (за счет наличия рядом робота) и привлекательного партнера (робота), а потому пофиг как ты выглядишь. То есть уже конкурировать не за что становится.
>>1463076 >"Мы лучшие, мы владеем роботами, вот это нам, а вам вот огрызки" Да ну, роботы создадут утопическое изобилие ресурсов. В принципе такое происходило и раньше, пар удвоил глобальный ввп, электроника учетверила, и за счёт этого никто в северном полушарии физически не может сдохнуть от голода, аги и роботы текущий глобальный ввп удесятерят
>>1463229 >роботы создадут утопическое изобилие ресурсов. Ну… Уже сейчас роботы и дешёвая рабочая сила создают смартфоны ценой в 100 полновесных буханок хлеба.
Ок, понял свою ошибку. Но как удалить пост? Нигде не вижу кнопки удаления.
Так-то просто я и подумать не мог, что в /ai/ сидят настолько возвышенные люди, которые и думать не желают о вагинах. В закреплённом хотя бы могли сообщить эту информацию, что мол так-то и так-то, сидят возвышенные.
>>1463277 Ну так если долго всматриваться в цензуру, то цензура начинает всматриваться в тебя. Если постоянно сталкиваться с фильтром генерации, то можно подорвать потенцию и половое влечение.
>>1463126 >Уже понятно, как нарастить интеллект кратно. Просто занимаешь его у нейросети. Статистический попугай не имеет с интеллектом ничего общего. >>1463126 >Слишком категорично. Если это так просто, то почему ты этого еще не сделал? Так же как никто другой.
На самом деле все проще. В СССР очкастые пердолики пришли к партии и сказали - мы можем сделать машину, которая заменит власть. И СССР как в известной шутке - испарился.
>>1463306 Ну, конечно. Вот ты даешь пэтэушнику матзадачу уровня 9 класса. И даешь эту же задачу модели с ризонингом. Включаешь пэтэушника на полную и модель. Ждешь результат. Пэтэушник тебе за положняк по опущенным ботанам пояснит на выходе, а модель поставленную задачу решит. Стохастический попугай уже лучше биологического, получается.
>Если это так просто, то почему ты этого еще не сделал? По факту, уже сделали. Подняли интеллект кратно любому, кто готов обращаться за помощью к LLM. Это доступно практически любому бомжу уже. С киберпротезами я лишь радикальный вариант этого рассмотрел. Когда никуда обращаться не надо, и все уже в голове вертится само на встроенном чипе. Я думаю, что это перспектива ближайшего будущего. Одна из.
>>1463186 ИИ легко симулирует практически любую личность, стиль поведения, и даже особенности речи. Внешность пока не очень удается, в основном всякие аниме-аватарки используют - Нейро-саму ту же взять. И это уже сейчас. А что через 3-5 лет будет...
>>1463367 Гугл собирается в ближайшие год-два мерджить джемини, нанобанану, вео, джини и симу. Будет сразу агент с аватаром, еще и с собственным миром и физикой. Если получится еще и continuous learning впихнуть, то это уже реально аги будет.
Вот и новый стартап Лекуна — Advanced Machine Intelligence (AMI). Сам он не в роли CEO, а занял пост Executive Chairman. Как положено в мире стартапов, создаваемых звездами ИИ, оценка стартапа сразу составляет 3,5 млрд долларов, инвестиций в первом раунде собирается привлечь на полмиллиарда. Стартап (что и было заранее понятно) будет работать над моделями мира, свой скептицизм относительно будущего языковых моделей Лекун давно не скрывает. https://techcrunch.com/2025/12/19/yann-lecun-confirms-his-new-world-model-startup-reportedly-seeks-5b-valuation/
А смысл этого треда теперь какой, когда по итогам 25 года у гугла не осталось конкурентов? Ну типа все произошло как и ожидалось, самая богата компанияc с самой большой базой даты, ресерчеров и железа победила, че еще обсуждать?
>>1463399 >Вот и новый стартап Лекуна — Advanced Machine Intelligence (AMI) >оценка стартапа сразу составляет 3,5 млрд долларов, инвестиций в первом раунде собирается привлечь на полмиллиарда. Кто этому шуту, который жидко обосрался в мете, вообще больше сотки даже виртуальных баксов даст, тот совсем довен
>>1463771 Для решения задач математики не нужен интеллект/вот этот вот ваш интеллект вовсе не интеллект! Ясно. Так более того, решаются и задачи международной олимпиады, а не просто 9-го класса, что показывает высокий его уровень, намного выше, чем у среднего человека.
>>1463186 >каким образом будут заменены блогеры по твоему мнению Эволюцией - начнут появляться новые блогеры, и много, но не поймешь то ли они настоящие живые люди, то ли нет.
Уже в принципе можно запускать аватаров-блогеров, но пока что это будет дорого, платить сервисам, которые могут подвисать, тогда будет палевно, а если аватар-блогер спалился на тормозах из-за коннекта со своим платным сервисом - то уже все, аудитория поймет обман и не будет его смотреть.
А прикинь что в будущем будут аватары-ИИ-блогеры, и они будут полностью автономные, то есть дал им задание на год вперед и они сами ведут свою блогерскую деятельность.
>>1463186 >каким образом будут заменены блогеры по твоему мнению Вот стримеров не получится пока что подменить, потому что в прямом эфире зрители могут периодически делать проверку типа "скажи такое-то слово или покажи такой-то жест рукой". Стримерам пока что можно не напрягаться, лет через 30 разве что, когда появятся очень качественные реалистичные человекоподобные роботы с ИИ, с мимикой, движениями, и продвинутым интеллектом, с большими лимитами, без подвисаний сервиса.
Но а смысл в чём? Стримеру нравится общаться с аудиторией, и ему будет бессмысленно себя подменять машиной. точно так же те рабочие, которые любят свою работу, а есть и такие тоже, им будет обидно что их работу будут выполнять машины, и что машины вытеснят их, оставив без любимой работы. Другое дело когда машины вытесняют-заменяют людей на тех работах, которые люди ненавидят и которые им не нравятся, и совсем другое когда робот заменит человека на той работе, которая нравилась человеку. ,
>>1463894 >тормозах из-за коннекта ...хотя это можно спихнуть на тормоза самого интернета или сайта. Вон в чатрулетке тоже бывают зависания и слайд-шоу. В камерах видео-наблюдения тоже бывают артефакты и рывки типа как от склейки, и т.д, хотя это просто особенность записи на диск у этих камер.
>>1463367 >Внешность пока не очень удается, Можно ИИ-маски использовать как у гитариста Акстара, только не такие палевные гламурностью, а которые более ближе к народу.
>>1463352 > Подняли интеллект кратно любому, кто готов обращаться за помощью к LLM. Ты не можешь никому поднять интеллект, потому что более высокий интеллект задает вопросы, которые более низкий никогда не сформулирует, сколько ты ему статистических попугаев не дай.
>>1463895 Ясно, я понял, конструктивная часть беседы закончена. Иди на хуй.
>>1463961 В принципе, это верно. Вряд ли кратно каждому поднимешь, предубеждения и отсуствие запроса на интеллект трудно обходить. В целом же, изначально тезис про интеграцию ЛЛМ напрямую в голову через имплант был, это другой путь. Однако, высокий интеллект способен ответить даже на тупой вопрос низкого интеллекта более качественным образом, и эта информация может быть усвоена. На длительной дистанции уровень интеллекта все равно вырастет от этого.
>>1463865 >или нужно учитывать химию, гормоны и другие факторы
Гормоны не влияют непосредственно на нейронную активность, кроме тех гормонов, которые одновременно являются нейромедиаторами. Гормоны воспринимаются клеточными рецепторами - и их задача регулировать внутреннюю активность больших групп клеток. Если у клеток имеются соответствующие рецепторы к определённому веществу, то они на него реагируют. То есть, это главным образом относится к регуляции работы организма.
Изначально леваки (woke, "новые левые", философский базис постмодерна) были придуманы для одной конкретной задачи: свергнуть Шарля де Голля и установить свою власть во Франции. А потом выяснилось, что этот психо-биологический вирус можно использовать против всех европейцев (и не только).
>>1463404 Смысл треда в канализации всяких долбоебов и школьников, чтобы был один остойник где они могут о сингулярностях и бодах фантазировать, а не расплескиваться по всей доске
>>1463775 заметно как рука переключается между программами. И продолжает программу кручения даже когда гайка не крутится. То есть скорость достигается неинтеллектуальностью процесса.
Манипулятор хороший. Но интерактивность у него на такая крутая, как может показаться.
>>1463404 Нихуя они никого не побелили. Гемини 3 - ну банальная, обычная нейросетка. Не даёт какого-то необычайного экспириенса. Не делает ничего такого, чего не смогли бы остальные нейронки. В плане написания кода и точности работы - лучше всего пока что клод 4.5. В плане хайпа и эмоциональной привязанности многих пользователей (а так же механизмов индивидуализации и подстройка под них) - пока что чатжпт вне конкуренции. Правда, последнее преимущество опенаи активно проёбывают, делая сетку скучнее, срезая личные темы и личные обсуждения, добавляя больше цензуры и "безопасности". А могли бы ещё сильнее разыграть имеющуюся у них карту - ещё крепче эмоционально привязать к себе пользователей и ещё сильнее хайпануть. Но они решили слушать этиков-трясунов. Но эти философствующие идеологические гуманитарии-то ничем не рискуют, это же не их бабло и не их результаты труда: в случае рухнум они получат свой золотой парашют и полетят искать новую жертву. Где-нибудь эти шакалы пристроятся (свои их не бросят), а компания пойдёт ко дну.
Нано-банана - ну турбо-цензура. Этим невозможно пользоваться. Профессионалы для продакшена и без неё обходились, а для обычных юзеров она слишком фильтрована. После нескольких срабатываний фильтра - энтузиазм по поводу этой нейронки охладится. Это уж не говоря о том, что это не имба, которая делает всё сверхточно и идеально.
«ИОН — самый преобразующий момент в истории человечества — уже на горизонте» — Демис Хассабис
Видеорелейтед.
Хассабис: Я думаю, также необходимо просто подготовить общество к тому, что нас ждёт в будущем. Вы знаете, ИИ общего назначения (ИОН), вероятно, самый преобразующий момент в истории человечества, уже на горизонте.
И нам необходимо подготовиться — как обществу и как виду в целом. И, конечно, я думаю, что правительства и другие важные лица, другие значимые лидеры будут играть в этом решающую роль.
И я думаю, что наличие чего-то вроде Нобелевской платформы открывает практически любые двери.
Ибо они умеют а) делать похоже на то что было, чтобы нравится б) пересказывать уже рассказанное так, как это уже было рассказано.
В отличии от хорошего спеца они не умеют извлекать и передавать смысл, не умеют делать новое, удивлять.
Предрекаю более жёсткое регулирование авторских прав. Вплоть до уровня идей «кто придумал шутку в тиктоке».
Тут вот какое дело. Мясной блоггер может и не очень умным человеком быть. Но у него команда. Например все они ДУМАЮТ (а не действуют по паттернам) раз в день. На команду ну 10 свежих (для них) мыслей в день. Нейронка не думает вообще. Она в глубоком проигрыше даже челу, который «ох ебать, как живой но не живой!» ибо у нейронки ни любопытства ни целеполагания. Цель можно задать промптом хоть как-то. А любопытство пока нет.
Что происходит сейчас среди людей и будет переложено на нейросети. Кто-то придумывает шутку, трюк, куча людей повторяют, кто лучше, кто хуже, кто своё привносит. Вот это потенциально когда-то сможет делать нейронка. «клонировать с вариациями». И нейронка будет успевать делать это первой.
Отсюда нейрослоп с водой по пересказу пересказанного. Уже есть такое. Правда… вот нюанс… смотрят/слушают это тоже боты для накрутки, а люди не особо хотят.
Исследование Apple показывает, как процессор обработки изображений (ISP), управляемый искусственным интеллектом, может радикально улучшить качество фотографий, сделанных на iPhone в условиях слабого освещения.
Исследователи Apple разработали модель искусственного интеллекта, которая значительно улучшает крайне тёмные фотографии за счёт интеграции диффузионной модели обработки изображений непосредственно в конвейер обработки изображений камеры, что позволяет восстанавливать детали из «сырых» данных сенсора, которые в обычных условиях были бы утеряны. Вот как им это удалось.
Проблема фотографий при экстремально слабом освещении Вы, вероятно, сталкивались с ситуацией, когда фотография, сделанная в очень тёмных условиях, получалась зернистой и переполненной цифровыми шумами.
Это происходит тогда, когда сенсор изображения не улавливает достаточного количества света.
Чтобы компенсировать это, такие компании, как Apple, применяют алгоритмы обработки изображений, которые, однако, подвергаются критике за чрезмерное сглаживание, создающее эффект «масляной живописи», при котором мелкие детали исчезают или реконструируются в нечто едва узнаваемое или нечитаемое.
На сцену выходит DarkDiff Для решения этой проблемы исследователи из Apple и Университета Пурду разработали модель под названием DarkDiff. Вот как они представляют её в исследовании под заголовком «DarkDiff: продвижение улучшения «сырых» изображений при слабом освещении за счёт переиспользования диффузионных моделей в ISP камеры»:
«Высококачественная фотография в условиях экстремально слабого освещения — это сложная, но крайне важная задача для цифровых камер. Благодаря передовому вычислительному оборудованию традиционные алгоритмы процессора обработки изображений (ISP) камер постепенно заменяются эффективными глубокими нейросетями, более разумно улучшающими зашумлённые «сырые» изображения. Однако существующие регрессионные модели зачастую минимизируют пиксельные ошибки и в результате приводят к чрезмерному сглаживанию тёмных участков или глубоких теней на фотографиях. Недавние работы пытались преодолеть это ограничение путём обучения диффузионной модели с нуля, однако такие модели по-прежнему испытывают трудности с восстановлением чётких деталей изображений и точных цветов. Мы представляем новую систему для улучшения «сырых» изображений при слабом освещении за счёт переиспользования предварительно обученных генеративных диффузионных моделей в ISP камеры. Обширные эксперименты демонстрируют, что наш метод превосходит современные аналоги по воспринимаемому качеству на трёх сложных эталонных наборах «сырых» изображений, сделанных при слабом освещении».
Другими словами, вместо применения ИИ на этапе постобработки, исследователи переадаптировали Stable Diffusion (открытую модель, обученную на миллионах изображений), чтобы она могла «понимать», какие детали должны присутствовать в тёмных участках фотографий с учётом общего контекста сцены, и интегрировали её в конвейер обработки изображений ISP.
Более того, их подход вводит механизм, вычисляющий внимательность (attention) относительно локальных фрагментов изображения, что помогает сохранить локальные структуры и уменьшает появление галлюцинаций — например, как в приведённом ниже изображении, где ИИ-реконструкция полностью меняет содержание кадра.
При таком подходе ISP камеры по-прежнему выполняет раннюю обработку, необходимую для осмысления «сырых» данных сенсора, включая такие этапы, как баланс белого и демозаичирование. Затем DarkDiff работает с полученным линейным RGB-изображением, устраняя шум и напрямую формируя конечное sRGB-изображение.
DarkDiff также использует стандартную диффузионную технику, называемую «управление без классификатора» (classifier-free guidance), которая по существу регулирует, насколько строго модель должна следовать входному изображению, а не опираться на усвоенные ею визуальные приоритеты.
При более слабом управлении модель генерирует более гладкие текстуры, тогда как усиление управления заставляет её воспроизводить более резкие текстуры и мелкие детали (что, в свою очередь, повышает риск появления нежелательных артефактов или галлюцинированного контента).
Для тестирования DarkDiff исследователи использовали реальные фотографии, сделанные при экстремально слабом освещении камерами, такими как Sony A7SII, и сравнили полученные результаты с другими моделями улучшения «сырых» изображений и диффузионными базовыми моделями, включая ExposureDiffusion.
Тестовые изображения были сделаны ночью с выдержкой всего 0,033 секунды, а улучшенные версии DarkDiff сравнивались с эталонными фотографиями, полученными при выдержке в 300 раз длиннее и съёмке на штативе.
Вот некоторые из результатов (мы настоятельно рекомендуем ознакомиться с ними в полном качестве в оригинальном исследовании):
DarkDiff не лишён недостатков Исследователи отмечают, что их ИИ-обработка значительно медленнее традиционных методов и, вероятно, потребовала бы облачной обработки, чтобы компенсировать высокие вычислительные требования, которые при локальном запуске на смартфоне быстро разрядили бы аккумулятор. Кроме того, они также указывают на ограничения в распознавании текста на языках, отличных от английского, в условиях слабого освещения.
Также важно подчеркнуть, что в исследовании нигде не упоминается, что DarkDiff будет внедрён в iPhone в ближайшем будущем. Тем не менее, данная работа демонстрирует неослабевающий интерес Apple к развитию вычислительной фотографии.
В последние годы эта область стала чрезвычайно важной для всего рынка смартфонов, поскольку потребители требуют возможностей камер, превосходящих то, что компании физически могут разместить внутри своих устройств.
Чтобы ознакомиться с полным текстом исследования и дополнительными сравнениями DarkDiff с другими методами подавления шума, перейдите по этой ссылке: https://arxiv.org/abs/2505.23743
>>1463892 для решения почти всех олимпиадных задач нужно просто потренироваться на задачах предыдущей олимпиады и распознать их в новых задачах.
Новые, уникальные задачи, требующие что-то придумать, до чего-то догадаться, редко когда случаются. По одной штуке и то не каждый год. И именно эти задачи нейронка не решает.
Тем не менее нейронка хороша тем, что может быстро обсчитать огромные объёмы, заметить закономерности незаметные человеку (или заметные только тому, кто в этом ГОДЫ плавает).
Хороший инструмент. Как калькулятор или компьютер. Не более.
Цена памяти для компьютера по годам и текущий прыжок ее к небесам благодаря ИИ-датацентрам. Как видно, последний раз такие космические цены были в 2000м году.
Пока вектор такой: не особо талантливый в речи и некрасивый человек надевает нейромаску, нейрокорректор, нейронка слушает, что он говорит и переговаривает красиво.
То есть всё-всё с улучшайзером. Ну и кошкодевочка вместо кривозубого китайца с мешками под глазами, сидящего в ячейке на такой фабрике блоггеров.
Аугментация а не замена. Пока что выгоднее чтобы «в роботе человек сидел»
>>1463904 > Стримерам пока что можно не напрягаться, лет через 30 разве что Эмм, чел, ты давно на твич заходил тот же? Там целые стримы на тысячи человек аудитории, где базарит робот, витюбер и прочая ИИ мразь. И смотрят. Люди конечно пока выигрывают за счет мяса, но тенденция уже сильно заметная - хорошо базарящий и отвечающий на вопросы робот выигрывает достаточно большую часть аудитории. Главное, чтобы он умел изображать эмоции на экране и давал релевантные эмоциональные ответы, не игноря людей. Что часть ИИ уже достаточно хорошо умеет. Еще пара поколений ИИ, лучшее понимание текущих событий, умение генерить миры с ними на ходу (пока в основном костыли через Юнити), более продвинутая генерация эмоций, и живые стримеры идут нахуй. Это не 30 лет, это максимум 10, а скорее даже 5, судя по тому как хорошо это уже работает.
>>1464067 Витубер — не робот, а маска на человеке. Начнём с этого.
>Еще пара поколений ИИ ага, ещё пара АРХИТЕКТУР ИИ, которые пока даже не предвидятся.
Эмоции нейронка МОЖЕТ выдать ну очень правдоподобные, при этом крайне стандартные. Или сразу зловещая долина.
А стандартные кривляния обычно интересны только инфантам-гидроцефалам типа пожирателей анимесериалов или дрисней-конвейера. Там до нейронок все кривляния и позы были не только стандартизированы, но и даже сведены к символьности.
>то максимум 10, а скорее даже 5 Посмотри назад на 10 лет. Нихуя радикально не изменилось. Качество витюберских и нейромасочек подросло только. Через 10 лет так же скорее всего нихуя радикально не изменится. Ну как не изменится. Дешевле станет производить лопаты и дерьмо, чтобы кормить дерьмом с лопаты быдло.
>>1464073 >Витубер — не робот, а маска на человеке. Начнём с этого. Часть витуберов уже управляется ИИ напрямую. Ты явно стримы витуберов не ходил смотреть. Часть копипейстят с чатгпт ручками и жмут кнопки на эмоции, кто потупее.
Но давай вспомним недавнюю историю, про то что нейромузыку в основном «слушают» накруточные боты. А оставшиеся 30% тоже не факт что не боты или не просто случайные залётные.
А вообще дай ссылочку, я посмотрю.
И да, я не сомневаюсь, что аудитория найдётся. Находится же аудитория на онлифанс, платить за то, что какая-то унылая пизда фасолину теребит и имитирует эмоции.
>>1464079 вполне возможно. Я понимаю, что есть и просто закомплексованные. Или даже вот у меня нет комплексов, я не раз светил лицо. Но понимаю, что я не привлекателен для массовой аудитории и если бы цель моя на стримах была деньгами, то я бы тоже прибегал ко всяким свистелкам, перделкам, модификаторам голоса, внешности.
>>1463904 >в прямом эфире зрители могут периодически делать проверку типа "скажи такое-то слово или покажи такой-то жест рукой". И что? Это довольно просто программируется на сопротивление. Грок вон вообще инжект определять умеет. Ну и человеки-стремеры на камеру какой только херней за донаты не занимаются. >Но а смысл в чём? Стримеру нравится общаться с аудиторией, и ему будет бессмысленно себя подменять машиной. А кто говорит про "стримера"? Я вот кабан-кабаныч, купил/сделал себе ферму кавайных девушек-стримеров, они работают, деньгу приносят, а я их только настраиваю-программирую, и сливки снимаю.
>>1464057 >а) делать похоже на то что было, чтобы нравится >б) пересказывать уже рассказанное так, как это уже было рассказано. Вау. Буквально блоггеры. Вот буквально. Ну и на самом деле трансформеры не только это могут, только тсс. >В отличии от хорошего спеца... В отличии от хорошего спеца, у них данные всего интернета. Им не нужна "команда" - робот сам себе команда. Ты можешь хоть 20 "спецов" с разными "характерами" в одну сеть связать, и все это на базе одной модели. Люди тоже действуют по паттернам, внезапно. >А любопытство пока нет. А зачем тут любопытство? Ты, кажется, путаешь что-то.
>>1464063 А большинство людей прямо тренируют чтобы они что-то новое изобретали и осмысливали проблемы, а не типовые задачи в школе освоили. И школа не для этого существует, да. Так только у них еще и с памятью проблемы возникают, через десяток лет они всю школьную программу забывают и не могут деление в столбик воспроизвести. Интеллект, кстати, с памятью тоже связывают.
Если рассматривать ИИ, решающий математические задачи высокого уровня, как хороший калькулятор по уровню развития интеллекта (а для решения комплексных задач интеллект точно нужен), то абсолютное большиство людей даже до этого уровня не дотягивает.
>>1464052 Справедливости ради, ДипМайнд сделал колоссальный вклад в развитие нейросетей. Те же трансформеры придумали они, до этого архитектуры свёрточных сетей
>>1464236 Ну так я специально уточнил, что они разработали конкретные архитектуры, которые оказались удачными и практически применимыми и толкнули индустрию вперёд, а не то, что они придумали свёрточные нейронные сети в принципе.
>>1464199 Я так понимаю что эти архитектуры в принципе не значат нихуя, просто +-десяток % к скорости трейна. В итоге все сводится к тому что либо у тебя есть стопицот параметров, либо нет. Вот что внесло вклад это доступные кластеры H100 на которых мелкие пробные сетки можно было обучать по сути на лету.
В топах ЯМузыки и VK уже сидят цифровые персонажи — у них миллионы прослушиваний и тонны восторгов в комментах, но большинство вообще не догадывается, что слушает алгоритм.
Пока музыканты пишут открытые письма и спорят о правах, мейджоры тихо переобулись. Вчера они шли в суд на ИИ‑сервисы, сегодня подписывают с ними сделки и продают это как «демократизацию». Любой может смешать стили любимых певцов, накидать текст в GPT, залить в Suno и выстрелить в TikTok, как та же «Снегурочка».
Я думаю, через 1–2 года для стримингов не будет важно, кто вообще что написал — важно, кто владеет кнопкой «сгенерировать ещё». Музыкант превратится в расходный материал для обучения моделей, а статус «живой автор» станет чем‑то вроде элитного тега.
Кажется, что мы не были готовы к такому быстрому развитию ИИ
>>1464354 >Кажется, что мы не были готовы к такому быстрому развитию ИИ
Кто блядь "мы"? Все 2010-е аноны только и ныли, что прогресс остановился, никаких значимых прорывов нет, будущее всё никак не наступает.
Абсолютное большинство музыкантов делают музыку по фану, часто даже себе в убыток (инструменты и более-менее приличное оборудование стоят денег). Ещё до нейронок большую часть любителей хуярить музыку за бесплатно не хотели слушать, не то, что задвигать в топы.
>>1464354 >Я думаю, через 1–2 года для стримингов не будет важно, кто вообще что написал — важно, кто владеет кнопкой «сгенерировать ещё». Ты не думаешь, потому что у тебя вакуум в голове, музыкальный бизнес и стриминги немного не так устроены. Весь нейрокал идет с цифровой подписью, и в будущем будут илитарные (это будут так подавать) нейрокалфри стриминги, по сути конечно нихуя не изменится, а привлекательность возрастет. Ну и суно и удио просто как шантажисты будут сигнатурами торговать, чтоб поколения кала детектить, меняя подписи, чтоб дальше заносили. Конкретно тебя еблана это вообще никак не коснется, и на крупных стримингах нейрокал будет в своем загоне.
>>1464354 >Кажется, что мы не были готовы к такому быстрому развитию ИИ
А если через несколько лет прилетят инопланетяне и устроят резню? Что ты скажешь? Был шанс бустануть науку и технологии, и отбить нападение, но его проебали из-за тряски нервных трясунов с инертным мышлением?
Запомни одно: прогресс никогда не бывает "слишком быстрым".
>>1464101 > Буквально блоггеры. Буквально самые донные блогеры.
>у них данные всего интернета. у спеца тоже есть гугл. Только, повторюсь, трансформер не понимает, что перед ним. Он не может получить знание из данных. Даже не может выдвинуть маняпредположение или продукт СПГС
>робот сам себе команда нихт. Он не может с собой спорить и искать в споре результат. Он может только усреднять и галлюцинировать. Робот не покрывает огромное пространство между «полная чушь» и «усреднёнка»
>>1464189 1. никто не дотягивает до калькулятора калькулятор от этого не умнее человека. 2. да, большинство людей живёт паттернами. Да, забывают, только переобучаются новому, а нейронка при переобучении на другое — деградирует гораздо сильнее: и старое перестаёт работать и новое не работает.
>>1464201 ноуп. Те самые нерешённые на олимпиаде задачи и были либо новыми либо нейронка не разгадала старую задачу за формулировкой.
>>1464362 ну и всё плохо. Синтетический невыразительный голос. Порет хуйню или отвечает пустышками. При этом разработчик пахал над тем, чтобы это сделать а не просто включил нужные инструменты. Зашёл, стрим, куча зрителей, только вот там чел с ней разговаривает.
Которые боты ставят на повтор. И которым боты (или тупое быдло) пишут комментарии.
Большая часть современной музыки, независимо от того, человеки её делали или машины — полное дерьмо, каша, творческая импотенция и унылая вторичность.
У меня нет ни одного вменяемого знакомого, кто бы слушал нейромузыку. А те кто слушают — до этого слушали всякий синтетический говноклубняк. Туц-туц-шмыц-пердыц. Ну то есть они всегда были дегродами без вкуса.
❗️Оператива В С Ё: OpenAI забрала до 40% всей мировой оперативной памяти на годы вперёд.
🟠Компания напрямую договорилась с Samsung и SK hynix, которые вместе делают около 70% ОЗУ в мире; 🟠По контрактам OpenAI получает примерно 900 тысяч пластин в месяц – это десятки миллионов модулей и до половины мирового производства DRAM; 🟠Память закупается не в виде готовых плашек, а на уровне пластин, чтобы обойти других заказчиков; 🟠Всё это идёт на ИИ-дата-центры и проект Stargate; 🟠Сроки – минимум до 2029 года, с возможным продлением; 🟠Эксперты предупреждают, что дешёвой оперативной памяти больше не будет: конкуренция вырастет, а цены будут расти ещё несколько лет.
>>1464489 1. в отсутствии заводов новых и расширения старых. 2. а не расширяли старых и не строят новых потому что спрос очень непредсказуемым был все годы и им не хотелось сбывать задёшево. Даже сейчас, с этим лютым спросом по оверпрайсу, компании не очень спешат новые заводы клепать.
>>1464594 А как же новый японский производитель - Rapidus ? А как же Intel, который так и хочет стать подрядчиком и кому-нибудь что-нибудь произвести? А как же израильский Tower Semiconductor?
>>1464416 Есть люди-калькуляторы. Можешь погуглить. Раньше вообще даже такая специальность была.
Что значит "умнее"? Ум это не интеллект. Это намного более комплексное понятие. Калькулятор интеллектуальнее человека в задачах математики, но не умнее в целом.
Про обучение согласен, это самый большой недостаток нейронок. Однако, если нейронку не трогать, ее "замороженный" интеллект, направленный на узкие задачи, вполне себе неплохо справляется с ними.
Здесь разница с людьми в общем в том, что у людей интеллект намного более широкого профиля, он направлен на разные области и лучше приспособен для синтеза. Но у нейронки даже синтезировать нечего, или лучше сказать, не над чем, у нее нет восприятия мира, все, что ей сгрузили, это пятикратно переваренный кал концепций. У нее нет объекта анализа в голове, нет желаний, нет сознания, нет пива. Можно рассматривать это как симулятор интеллекта, но очень качественный для применения в некоторых областях, где разница между естественным и искуственным для результата не важна. Как запилят искусственное сознание, так дела намного лучше пойдут.
>>1464599 В этом и заключается основная проблема постиндустриальной постмодернистской экономики: ни у кого нет пороха. Все боятся, трясутся, все соевые и осторожные, осмотрительные, все ловят расслабленность, никто не хочет ничего делать, ничего разрабатывать, все просто хотят мирно и блаженно торговать и сотрудничать.
>>1464490 А прикинь случится туземун нейронный, эту запланированную альтманом опиративу начнут игрунам в жопу запихивать, лишь бы продать уже ненужное. Простые игры начнут требовать 128 гигов рам...
>>1464622 У многих сейчас вместо вордфильтра "фингкинг" используется, который можно прогнуть, борются они с этим накручивая антипромпт, пока модель не станет деревянной.
>>1464626 >>1464626 Не задаюсь такой целью. Смотри, что-то ввести в рот >>1464600 как тут могут только модели последнего поколения. на лоКАЛе это можно сделать лорой, но там однотипный кал и не то совсем качество. Теперь вопрос: зачем мне пытаться с бананы выдавить сосок, который я на пукарне своей инпейнтю за 25 сек, если я могу там получить сложные позы и всякие интересные штуки, которые я тут показывать не буду, чтоб мне промпты додики-форсеры не забанили? Я как бы не упоминаю, что нана банана про подрисовывает всем соски, раз тебе это так интересно, и верблюжьи лапки. А сидримс так до сих пор сиськами срет и пездами. У них тут на сайте фильтр отлетал нахуй в том месяце, можно было буквально порнуху загружать и крутить как хочешь.
>>1464620 Хороший маневр: сначала набросить безосновательное утверждение, затем получить зеркальный ответ, а потом перевести стрелки и, типа, "мы тут ни при чем". Тем не менее, провокатор из тебя посредственный, уровень троллей-школьников с люмпенскими паттернами поведения. Крути свои сиси-писи лучше дальше, это у тебя лучше получается. Можешь не стараться с ответом.
>>1464354 По простоте генерации нейронкой можно хорошо измерить качество самих жанров музыки. Очевидно, что попса и рэп - лютейшее говнище, где разница с нейронкой или без вообще незаметна.
Чем качественнее жанр, тем труднее сгенерировать трек в нем. Например качественную инструментальную электронику. Или экстремальные жанры типа нойза, грайндкора, спидкора.
китайские модели ч1
Аноним# OP21/12/25 Вск 23:58:54№1464701382
Китайские открытые ИИ-модели идут вровень с западными — вот что будет дальше
Согласно новому отчёту, ввиду растущей технологической мощи и большей открытости китайских моделей, мир всё чаще обращается к Востоку в поисках эффективного и настраиваемого искусственного интеллекта.
Американский стартап в области искусственного интеллекта OpenAI начинал с миссии обеспечения прозрачности в ИИ — миссией, от которой компания отказалась в 2022 году, начав скрывать детали своей технологии.
В образовавшемся вакууме китайские компании и научные учреждения заняли лидерские позиции.
«Лидерство в области ИИ сегодня зависит не только от проприетарных систем, но и от охвата, внедрения и нормативного влияния моделей с открытыми весами по всему миру», — написала ведущий автор отчёта Кэролайн Майнхардт, менеджер по политико-исследовательской работе в Институте человекоориентированного искусственного интеллекта (HAI) Стэнфордского университета, в докладе, опубликованном на прошлой неделе под названием «Beyond DeepSeek: разнообразная экосистема китайских ИИ-моделей с открытыми весами и её политические последствия».
«Сегодня китайские модели с открытыми весами неизбежно присутствуют в глобальном конкурентном ландшафте ИИ», — заявили Майнхардт и её соавторы.
В отчёте показано, что китайские большие языковые модели (БЯМ), такие как семейство моделей Qwen от Alibaba, статистически идут вровень с большим семейством языковых моделей Claude от Anthropic — ещё одного американского стартапа — и лишь немного отстают от лучших моделей OpenAI и Google.
Рассматривая ситуацию шире, растущее мастерство Qwen, DeepSeek и других китайских моделей стимулирует движение «глобальной диффузии», пишут исследователи из HAI: страны по всему миру, особенно в развивающемся мире, будут выбирать китайские модели как недорогую альтернативу попыткам создать собственные ИИ-системы с нуля.
Этот ускоренный рост происходит на фоне того, как предыдущий лидер в области открытого ИИ — Meta Platforms — теряет позиции в рейтингах и, похоже, всё больше смещается к закрытой модели разработки, как у OpenAI, Google и Anthropic.
В результате, по мнению HAI, «широкое глобальное внедрение китайских моделей с открытыми весами может переформатировать глобальные модели доступа к технологиям и зависимости от них, а также повлиять на управление ИИ, его безопасность и конкурентную среду».
Технологический «Великий скачок вперёд» Сенсация, вызванная в начале этого года большой языковой моделью R1 от DeepSeek AI благодаря её низкой стоимости разработки, превратилась, как отмечают Майнхардт и её команда, в растущую технологическую силу со стороны Alibaba и азиатских стартапов, включая сингапурскую компанию Moonshot AI (создателей Kimi K2) и китайскую Z.ai (создателей GLM).
Китайские ИИ-лаборатории работают в условиях американского экспортного запрета, ограничивающего доступ страны к самым передовым технологиям США, таким как лучшие графические процессоры (GPU) от Nvidia.
Это создало дисциплину, которая привела к повышению эффективности китайских лабораторий и теперь превращается в устойчивый технологический прогресс.
«Китайские модели с открытыми весами сегодня демонстрируют почти передовые результаты по основным бенчмаркам и рейтингам, охватывая общие рассуждения, программирование и использование инструментов», — написала ведущий автор Кэролайн Майнхардт, ссылаясь на данные популярного сайта LMArena.
При этом все 22 ведущие китайские открытые модели превосходят собственную «модель с открытыми весами» от OpenAI — GPT-oss.
Хотя бенчмарки и рейтинги имеют ряд недостатков, включая возможное «накручивание» результатов, авторы отмечают, что другие индексы — такие как Epoch Capabilities Index и Artificial Analysis Intelligence Index — «показывают, что китайские модели догоняют своих американских и других международных конкурентов».
Есть и ещё один показатель, по которому Qwen и остальные отыгрывают: объём загружаемого кода на платформу хостинга кода Hugging Face.
«В сентябре 2025 года китайские дообученные (fine-tuned) или производные модели составили 63% от всех новых дообученных или производных моделей, выпущенных на Hugging Face», — пишут авторы. «В совокупности с анекдотическими свидетельствами внедрения эти данные говорят о широком разнообразии контекстов и географических регионов, где китайские модели были приняты».
Также в сентябре «семейство моделей Qwen от Alibaba обогнало [модели] Llama от Meta и стало самым загружаемым семейством БЯМ на Hugging Face».
По этим показателям, отмечают они, «китайские открытые модели, похоже, сейчас опережают своих американских конкурентов по степени своего влияния на уровень внедрения».
Больше открытости со стороны Китая Рост Китая обусловлен не только растущим техническим мастерством, но и возрастающей «открытостью».
То, что считается «открытой» ИИ-моделью, может варьироваться в зависимости от ряда факторов. Традиционно Meta и другие компании публиковали лишь «веса» своих обученных ИИ-моделей, таких как семейство Llama от Meta, но не раскрывали и не выкладывали терабайты обучающих данных, использованных при обучении. Такие модели считаются «моделями с открытыми весами», но не по-настоящему открытыми (open-source).
Доступность данных важна, поскольку она позволяет разработчикам эффективно использовать ИИ-модели и повышает доверие к их результатам.
Хотя раскрытие данных по-прежнему встречается редко, отмечают в HAI, китайские фирмы, несмотря на изначальную нерешительность, всё чаще предоставляют более разрешительные лицензии для своих моделей с открытыми весами.
«Qwen3 и DeepSeek R1 являются не только более мощными, но и были выпущены под более разрешительными лицензиями (Apache 2.0 и MIT License), разрешающими широкое использование, модификацию и распространение», — пишут авторы.
Они отмечают, что генеральный директор китайской поисковой системы Baidu, разработавшей семейство моделей Ernie, ранее был «одним из самых ярых приверженцев проприетарных моделей в Китае», но в июне 2025 года «совершил разворот на 180 градусов», опубликовав веса своей модели.
Глобальная диффузия Благодаря техническому мастерству и большей открытости китайские модели всё чаще становятся для разработчиков по всему миру способом получить бесплатный код и создавать эффективные, настраиваемые модели для различных целей.
китайские модели ч2
Аноним# OP21/12/25 Вск 23:59:33№1464703383
>>1464701 «Дистилляция» означает процесс, при котором существующая ИИ-модель используется для построения меньшей, более эффективной модели. Разработчик эффективно использует крупные бюджетные вложения Alibaba или другого ведущего разработчика, передавая малой модели те способности, которые были приобретены при обучении большой модели.
Сейчас именно эта дистилляция приводит к «диффузии» китайского ИИ, пишут авторы.
«Широкая доступность высокопроизводительных китайских ИИ-моделей открывает перед организациями и отдельными лицами в регионах мира с ограниченными вычислительными ресурсами новые возможности для доступа к передовым технологиям ИИ», — пишут Майнхардт и её команда, — «тем самым формируя глобальные процессы распространения ИИ и трансграничные модели технологической зависимости».
Авторы прогнозируют, что тенденция диффузии сохранится, поскольку экономические выгоды перевешивают дальнейшие достижения в бенчмарках со стороны OpenAI и других закрытых передовых ИИ-моделей.
«Поскольку производительность моделей сближается на передовом уровне, те, кто внедряет ИИ и не имеет достаточных ресурсов для самостоятельной разработки передовых моделей — особенно в странах с низким и средним уровнем дохода — могут отдавать предпочтение доступному и надёжному доступу с целью модернизации промышленности и получения иных приростов производительности», — пишут они.
И речь идёт не только о развивающемся мире. «Американские компании — от устоявшихся крупных технологических корпораций до некоторых из самых раскрученных ИИ-стартапов — широко внедряют китайские модели с открытыми весами», — констатируют авторы. «Существование китайских моделей с открытыми весами, удовлетворяющих требованию „достаточно хорошо“, может, таким образом, снизить зависимость глобальных участников от американских компаний, предоставляющих модели через API».
Многочисленные оговорки Рост китайского превосходства сопровождается многочисленными оговорками. Модели с открытыми весами всё ещё могут не обеспечивать достаточной прозрачности для снятия многих опасений относительно участия китайского правительства в их разработке.
Хотя модели с открытыми весами можно запускать на любом достаточно мощном компьютере, многие пользователи, как отмечают в HAI, «будут использовать приложения, API и интегрированные решения, предлагаемые DeepSeek, Alibaba и другими».
В результате, «как правило, данные пользователей попадают под контроль этих компаний и физически могут передаваться в Китай, потенциально открывая информацию для законного или внесудебного доступа со стороны китайского правительства или корпоративных конкурентов».
Кроме того, подчёркивают авторы, похоже, что китайские разработчики, такие как DeepSeek, меньше озабочены «ограничителями» (guardrails) и другими параметрами «ответственного ИИ». «Оценка, проведённая CAISI — центром тестирования ИИ при правительстве США — показала, что модели DeepSeek в среднем в 12 раз более подвержены атакам по обходу ограничений (jailbreaking), чем сопоставимые американские модели», — пишут они.
«Другие независимые оценки, проведённые исследователями по безопасности, также демонстрируют, что ограничители DeepSeek легко обходятся».
Эти опасения означают, что влияние Китая остаётся неопределённым. Тем не менее, отчёт согласуется с мнением опытных наблюдателей, считающих рост Китая и снижение темпов улучшения бенчмарков признаком ослабления доминирования американских коммерческих компаний.
Как отметил ранее в этом году исследователь ИИ Кай-Фу Ли, большие языковые модели стали уже товаром массового спроса, что делает бизнес-модель OpenAI уязвимой перед экономикой открытого ИИ, например, DeepSeek.
В более широком смысле отчёт представляет убедительные доказательства того, что роль Китая в глобальном ИИ будет сохраняться, а роль Запада в управлении этой технологией, вероятно, будет меньше в ближайшие годы по сравнению с периодом, когда ChatGPT от OpenAI доминировал в заголовках СМИ.
OpenAI теперь позволяет пользователям напрямую регулировать уровень энтузиазма ChatGPT
Пользователи ChatGPT теперь могут корректировать степень «теплоты», энтузиазма и использования эмодзи чат-ботом, согласно сообщению OpenAI в социальных сетях.
Эти параметры (а также аналогичные настройки использования заголовков и списков в ChatGPT) теперь отображаются в меню «Персонализация» и могут быть установлены на значения «Больше», «Меньше» или «По умолчанию». Они позволяют пользователям дополнительно настраивать тон общения ChatGPT поверх уже существующей возможности задавать «базовый стиль и тон» — включая стили «Профессиональный», «Откровенный» и «Эксцентричный», добавленные OpenAI в ноябре.
Вопрос тональности ChatGPT остаётся актуальным в этом году: OpenAI откатила одно обновление из-за того, что оно делало бота «слишком подобострастным», а затем внесла изменения в GPT-5, сделав его «теплее и дружелюбнее» после жалоб некоторых пользователей на то, что новая модель стала холоднее и менее приветливой.
Некоторые учёные и критики ИИ предположили, что склонность чат-ботов хвалить пользователей и подтверждать их убеждения представляет собой «тёмный паттерн», способствующий формированию зависимого поведения и способный негативно сказываться на психическом здоровье пользователей.
Робот только что освоил 1 000 задач за один день — и это важное событие для повседневного применения ИИ.
Возможно, пришло время всерьёз обратить внимание на роботов.
В большинстве случаев роботы, о которых пишут заголовки новостей, сводятся к машине, выполняющей одно-единственное очень конкретное действие в строго контролируемой лабораторной обстановке, после чего следует обещание, будто это каким-то образом всё меняет.
Обычно я просто игнорирую такие сообщения, потому что мы слышим о том, как роботы захватят власть над человечеством, ещё с момента появления научно-фантастических романов, и, честно говоря, на деле это никогда особо не приводило к реальным результатам.
Тем не менее, новая публикация в журнале Science Robotics вызвала у меня интерес, и, на мой взгляд, это действительно впечатляюще, завораживает и даже немного пугает.
Исследователям удалось обучить робота выполнять 1 000 различных физических задач за один день, причём каждую — всего лишь после одного демонстрационного примера. Причём речь идёт не о 1 000 вариациях одного и того же движения. Здесь имеется в виду огромный набор разнообразных взаимодействий с повседневными предметами в реальном мире: размещение, складывание, вставка, захват, манипуляции с объектами и так далее. Для роботов это по-настоящему большое достижение.
Почему роботы, как правило, ужасно плохо обучаются новым навыкам До сих пор большинство роботов были крайне медленными учениками. Обучение машины даже простой задаче обычно требовало сотен или тысяч повторяющихся демонстраций, огромных объёмов данных и значительной подстройки «за кулисами» со стороны инженеров.
Именно поэтому большинство роботов, которых вы видите на заводах, делают одно и то же действие снова и снова — и делают это очень хорошо. Они неадаптивны: стоит только изменить поставленную задачу — и сразу становятся заметны их недостатки, после чего вся система разваливается.
Но люди работают иначе. Если вы покажете мне, как что-то делается, один раз — возможно, два — я, как правило, смогу справиться и выполнить задачу самостоятельно.
Эта разница между человеческим и роботизированным обучением была одним из главных препятствий, мешавших роботам стать по-настоящему полезными за пределами строго контролируемых условий. Новая система — это попытка сократить этот разрыв.
Новый подход к обучению роботов Прорыв заключается в новом методе обучения, который в сущности учит роботов обдумывать задачи более разумным образом. Вместо того чтобы запоминать целые последовательности движений с нуля, робот разбивает действия на более простые фазы.
Используя знания, полученные при выполнении предыдущих задач, и применяя их к новым, робот может гораздо эффективнее обобщать опыт, — именно благодаря этому ему удалось освоить 1 000 задач менее чем за 24 часа, причём для каждой требовалась лишь одна демонстрация.
Важно то, что всё это происходило на реальном роботизированном манипуляторе, а не в симуляции, специально спроектированной для получения благоприятных результатов, — и именно это в значительной мере объясняет, почему я обратил внимание на этот отчёт и хочу поделиться им с вами.
Почему это имеет значение Пока я писал эту статью, я осознал, насколько трудно сделать лабораторную робототехнику интересной для моей обычной аудитории — людей, которых в большей степени волнует последний iPhone, чем гипотетическое восстание роботов.
Тем не менее, данное достижение в области обучения роботов может иметь серьёзные последствия для будущего и затронуть каждого из нас.
Если роботы смогут обучаться быстрее и с меньшим количеством данных, они станут дешевле, гибче и намного практичнее.
В долгосрочной перспективе такой тип обучения может привести к появлению домашних роботов, которым не нужно специальное программирование каждый раз, когда вы хотите, чтобы они выполнили новую задачу, — фактически воплотив в жизнь идеальную версию робота Neo 1X. Это также может преобразить такие отрасли, как здравоохранение, логистика и производство.
В более широком смысле это ещё один признак того, что ИИ постепенно уходит от «фокусов на вечеринке» в сторону систем, обучающихся более «по-человечески»: не обязательно умнее нас, но гораздо ближе к тому, как мы функционируем в повседневной жизни.
Это достижение в робототехнике решает проблему, которая сдерживала развитие робототехники на протяжении десятилетий. Возможно, будущее, наполненное роботами, ближе, чем мы могли себе представить ещё несколько лет назад.
>>1464410 >самые донные блогеры. А что, есть "илитарные"? Одна фигня, как по мне. Причем, как с картинками, огромная зависимость от хайпа и момента. Вот всякие пьюдипаи, пирейтсофтверы, и прочие асмонгольды - они какие? >Он не может получить знание из данных. Ну вот, поехали. У нас образовалась новая категория "знания", которое неравносильно "данным". И которое ИИ получить, оказывается, не может... Потому что он ИИ. >Он не может с собой спорить и искать в споре результат И спорить может (особенно если несколько разных ИИ подключить), и обучение с подкреплением может, и кучу всего другого тоже может... Блоги вот только писать не сможет. Ведь блоги - это только люди! Там же... Воображение! Смешно, если честно.
>>1464699 >Например качественную инструментальную электронику. Что-то мне кажется, проблем не должно возникнуть. >Или экстремальные жанры типа Говнарей мало, спроса нет, тренировки не хватает. Но тоже не проблема, по идее.
Короче, есть такой стартап FoloToy, который пилит "умные" игрушки для детей. Выпустили они, значит, медведя Kumma за 99 баксов на базе GPT-4o. Медведь этот должен был общаться с тугосерями и всячески их развлекать. Казалось бы, что могло пойти не так?
А пошло всё, естественно, не так. Выяснилось, что если поболтать с плюшевым ублюдком подольше, у него напрочь срывало все "детские" фильтры и вместо сказок про дружбу и радужных пони, этот шерстяной гигачад начинал выдавать базу: подсказывал мелким, где в доме лучше искать ножи и спички, пояснял за БДСМ, бондаж и ролевые игры, причем с участливым вопросом: "А что из этого ты бы хотел попробовать?" ну и далее в том же духе. В общем, получился Тэд из фильма "Третий лишний"
В итоге OpenAI увидев такие педагогические инновации, моментально отрубила стартапу доступ к API, а FoloToy временно приостановили продажи всех продуктов и объявили safety-аудит.
Так что, если увидите в продаже "умного" медведя, не покупайте его ребёнку. Лучше купите для себя.
>>1464073 >Через 10 лет так же скорее всего сделают маску на все тело походу. А не только на лицо. В реальном видео в прямом эфире стример-блогер-человек будет полностью в маске на всё тело. А под такой маской может ведь сидеть и китайский робот который с пустой черепушкой сейчас мелькает везде в видео. Или вообще будет бум на виртуальные аватары, когда они станут массово доступные всем, и которые можно будет ставить дикторами на ТВ, блогерами-стримерами, "путешественниками" (делая зеленый фон и потом монтируя аватара на видео с путешествиями), и т.д.
>>1464860 В прошлых тредах аж несколько новостей про него было, сначала сняли с продажи, потом их опенаи забанил у себя, они сменили нейронку на другую, благо коннект через их сайт и снова стали продавать. Сейчас дети с ним дальше играются, а нейронка через их сайт какая-то китайская по ходу стоит.
Все, что мне нужно в этой жизни - это АИ, которая будет генерировать картинки как Gemini 2k, но бесплатно и без дорогих видеокарт, а также, самое главное, без цензуры и ограничений. Сколько ещё такое ждать жадному нищуку, а?
>>1464423 Фу блять. Это омерзительно. >>1463980 > и эта информация может быть усвоена. Не может она быть усвоена низким интеллектом. Никто вообще не знает, как усваивается информация у человека. Все, кто утверждает обратное - пиздоболы. Потому что, когда знаешь - можешь внести коррективы и, например, создать искусственные воспоминания. Я знаю только один метод из личного опыта создать искусственные воспоминания - это попытаться запомнить сон, который только что снился. Иногда это удается, но чаще нет.
>>1464710 >Возможно, пришло время всерьёз обратить внимание на роботов. Универсальные роботы не нужны. Для качественного скачка благосостояния каждого человека нужны автоматы, которые просто производят блага бесплатно. >>1464728 >Физическим работам пизда по ходу скоро. Ни один робот не в состоянии будет поменять тебе трубы стояка в квартире еще очень долго. А потом ты умрешь от старости.
>>1465020 >трубы Роботы-сантехники будут производиться небольшими, размером с кошку и будут в виде таракана, червя, и паука. Но сила их лап будет больше чем у человека, будет достаточно чтобы сантехник-таракан захватил трубу и полз с ней по вертикальной стене внутри шахты между стенами.
Рибят, пора начинать готовится к бесплатным благам. Увольняться с говноработки, продавать недвижку: через пару лет после бума строительного ии будет стоить копейки.
>>1464735 Для каких блядь государств, трясун тупоголовый ебучий? Аналитик от "лить через анал". В большинстве государств никаких заводов и нормальных работ отродясь не было. А там, где было, их при любом удобном случае не моргнув глазом "отправляли" в Китай (на самом деле, не отправляли, это всё были контрактные производства. Просто закрывали), а на те рабочие места, которые невозможно "отправить" в Китай, привозили трудовых мигрантов.
>>1465296 Хотя, махмуды не очень-то любят работать. Ну так, недельку поработать для проформы, а потом сесть со своими 10-мя детьми на пособия, получать бесплатные деньги.
>>1465284 Обычных государств. Если Петрович не будет занят работой, то он начнет алкогольничать и слонятся по улице. Это не нужно никаким государствам. Поэтому Петровичу сделают квоту на должность дворника 3-его разряда. Пусть с метлой слоняется по улицам. Роботы тут не причем.
>>1465322 Если интересно, то канва романа такая. 1) Инженер - разработчик роботов 2) основал компанию в гараже 3) из-за бабы потерял управление компанией 4) лег в анабиоз на 30 лет (точнее его силком "легли") 5) в 2000-ых не смог найти работу 6) устроился на сбор металолома 7) На металоломе задался вопросом почему привозят новые, хорошие машины и загоняют из под пресс. Ему ответили ты болбаеб и нихуя не понимаешь в эконимике.. 8) Потом он устроился в компанию которую основал, и которую у его бывшей с хахалем уже выкупили. Но в рекламный отдел фоткаться как основатель 9) Поскольку это фантастический роман, то ГГ нашел разработчика машины времени. Накупил дешевого золота и отравился назад на 30 лет 10) Скупил акции своей компании и снова лег в анабиоз
Z-Image Turbo — стала лидирующей моделью #1 преобразования текста в изображение, обогнав FLUX.2 [dev], HunyuanImage 3.0 (Fal) и Qwen-Image в области искусственного анализа изображений.
Moore Threads представляет однокристальную систему (SoC) для ИИ Yangtze: 8 ядер с частотой 2,65 ГГц, NPU производительностью 50 TOPS, до 64 ГБ памяти LPDDR5X для ноутбуков и мини-ПК формата «ИИ-ПК».
Компания Moore Threads представила свою полноценную однокристальную систему (SoC) для ИИ под кодовым названием Yangtze, обеспечивающую 8 ядер и высокую производительность NPU.
Moore Threads делает ставку на тренд «ИИ-ПК» с помощью SoC Yangtze: 8 ядер с частотой 2,65 ГГц, 50 TOPS NPU — первые продукты уже представлены.
Помимо своих решений GPU следующего поколения, компания Moore Threads также запустила SoC Yangtze, разработанную специально для экосистемы «ИИ-ПК». Это полностью интегрированное решение обладает интересными характеристиками, и первые продукты уже поступают на внутренний китайский рынок.
Очевидно, что SoC Yangtze от Moore Threads названа в честь реки Янцзы. Компания не раскрыла подробностей внутренней архитектуры или используемых интеллектуальных блоков (IP), однако заявила, что чип включает 8 ядер, работающих на частоте до 2,65 ГГц. Эта частота не является высокой по современным меркам, где обычно встречаются чипы с частотой свыше 5 ГГц; однако, поскольку это полноценное решение в формате SoC, ключевое внимание уделяется другим аспектам.
Основные характеристики SoC Yangtze от Moore Threads включают:
- 8-ядерный CPU - Максимальная тактовая частота 2,65 ГГц - Интегрированный GPU на базе высокопроизводительных IP-блоков - NPU производительностью 50 TOPS - Поддержка кодеков H.265 / H.264 / AV1 - Ориентация на сегмент «ИИ-ПК»
Одной из ключевых особенностей SoC Yangtze является её NPU мощностью 50 TOPS (в формате INT8), реализованная в виде многопроцессорного нейронного ускорителя и предназначенная для распознавания речи и изображений. SoC также оснащена интегрированным GPU, способным обеспечивать высокопроизводительный 3D-рендеринг, ускорение работы с большими языковыми моделями (LLM), а также кодирование и декодирование видео. Что касается видеопроцессора (VPU), то медиадвижок поддерживает разрешение 8K при 30 кадрах/с, 4K при 60 кадрах/с и форматы H.265, H.264 и AV1.
Помимо этого, в состав чипа входит также встроенный процессор отображения (DPU), предназначенный для поддержки двух дисплеев 8K с частотой 50 Гц или восьми дисплеев 4K с частотой 50 Гц (через интерфейсы DP/MIPI); цифровой сигнальный процессор (DSP) с поддержкой ИИ-алгоритмов подавления шума и эффектов Hi-Fi аудио; и процессор обработки изображений (ISP), поддерживающий камеры разрешением до 32 МП и HDR. На этом, в основном, и заканчивается описание внутренних возможностей чипа. Moore Threads также заявляет, что сам CPU должен обеспечивать конкурентоспособную производительность по сравнению с другими высокопроизводительными 8-ядерными чипами, при этом сохраняя энергоэффективность, а весь чип в целом спроектирован для работы с низким энергопотреблением.
Что касается платформ, компания Moore Threads представила два дизайна устройств: ноутбук под названием MTT AIBook и мини-ПК под названием MTT AICube. Эти системы поддерживают 32 и 64 ГБ памяти LPDDR5X с пропускной способностью свыше 100 ГБ/с. Сам чип поддерживает форматы вычислений FP16, FP32 и FP64.
Этот чип должен открыть Китаю путь к созданию собственных решений в формате «ИИ-ПК» на рынке, который не только уже переполнен зарубежными предложениями, но и вскоре столкнётся с ещё большим количеством продуктов на базе SoC следующего поколения от Intel, AMD, Qualcomm, Apple и NVIDIA.
Moore Threads представила игровые GPU Lushan и ИИ-ускорители Huashan: прирост игровой производительности в 15 раз, ускорение трассировки лучей в 50 раз, поддержка DirectX 12 Ultimate — выход ожидается в следующем году.
Китайская компания-производитель чипов Moore Threads представила две совершенно новые линейки графических процессоров — Lushan для игр и Huashan для искусственного интеллекта — обещая значительный рост производительности.
Moore Threads заявляет, что её предстоящий игровой GPU Lushan обеспечивает в 15 раз более высокую игровую производительность, ускорение трассировки лучей (RT) в 50 раз, ускорение ИИ-вычислений в 64 раза и четырёхкратное увеличение объёма памяти.
Теперь это официально: на саммите MUSA 2025 компания Moore Threads анонсировала свои новые GPU, основанные на архитектуре следующего поколения Flower Harbor (Huagang). Эта архитектура будет лежать в основе продуктов Lushan и Huashan, ориентированных, соответственно, на игровые и ИИ-нагрузки.
Согласно Moore Threads, архитектура Flower Harbor оснащена улучшенным вычислительным блоком, повышающим плотность вычислений на чипе на 50 %, а энергоэффективность также улучшена на 10 %.
Архитектура полностью поддерживает форматы вычислений от FP4 до FP64, а также компания внедрила собственные форматы, такие как MTFP6 и MTFP4, для смешанных вычислений с низкой точностью. В архитектуре также реализована асинхронная модель программирования и сверхмасштабируемое межсоединение, которое будет поддерживаться ИИ-ориентированными GPU Huashan. Это позволяет компании масштабировать более 100 000 GPU в одном кластере с использованием высокоскоростной межсоединительной технологии MTLink.
Ниже приведён полный список поддерживаемых новой архитектурой форматов вычислений:
Lushan — это чип для игр и создания контента, разработанный как преемник линейки потребительских GPU Moore Threads MTT. В данный момент компания не раскрывает конкретные технические детали продуктов, однако подробно описала, что пользователи могут ожидать от предстоящих решений на момент их выхода. Карты на базе этого чипа придут на смену более ранним моделям MTT S80 и MTT S90, которые находятся на рынке уже несколько лет.
Что касается характеристик, GPU Lushan от Moore Threads, как ожидается, обеспечит 15-кратный рост производительности в AAA-играх, 64-кратное ускорение ИИ-вычислений, 16-кратное повышение производительности геометрических вычислений, 4-кратное увеличение скорости обработки текстур (texture fill rate), 8-кратный рост производительности при атомарном доступе к памяти и огромное ускорение трассировки лучей (RT) в 50 раз.
Улучшения в игровом GPU следующего поколения от Moore Threads:
- 64-кратное ускорение ИИ-вычислений - 50-кратное ускорение трассировки лучей - 15-кратный прирост игровой производительности - 16-кратное повышение производительности геометрической обработки - 4-кратное увеличение производительности обработки текстур - 8-кратный рост производительности при атомарном доступе к памяти - 4-кратное увеличение объёма памяти
Одно из главных усовершенствований от Moore Threads заключается в том, что новая архитектура полностью совместима с новейшими API, включая DirectX 12 Ultimate. Предыдущие потребительские линейки MTT значительно отставали в этом аспекте, и, судя по всему, компания стремится устранить эти недостатки в новом поколении архитектуры. Также была представлена новая концепция генеративного рендеринга на базе ИИ в рамках единой рендеринговой архитектуры UniTE, а новейший аппаратный движок трассировки лучей, как ожидается, обеспечит значительные улучшения и проложит путь к нейронному рендерингу и построению траекторий (Path Tracing).
Что касается GPU Huashan — он, похоже, состоит из двух чиплетов и оснащён восемью слотами для HBM-памяти. Moore Threads сравнивает возможности своего ИИ-ускорителя Huashan с GPU NVIDIA линеек Hopper и Blackwell. Пиковая вычислительная мощность с плавающей запятой приближается к показателям Blackwell B200, совокупная пропускная способность соответствует B200, а по ёмкости доступа к памяти GPU Huashan, по-видимому, превосходит чип Blackwell.
Кроме того, в новых GPU ожидается четырёхкратное увеличение объёма памяти. MTT S80/S90 оснащаются 16 ГБ памяти GDDR6, таким образом можно ожидать объём до 64 ГБ в предстоящих решениях.
Ещё раз отметим: первые видеокарты линейки Lushan для игр, как ожидается, поступят в продажу в 2026 году, а ИИ-продукты, вероятно, выйдут примерно в то же время.
Наконец, Moore Threads также привела некоторые показатели производительности своего GPU MTT S5000, который, как заявлено, конкурирует с линейкой ИИ-ускорителей NVIDIA Hopper, достигая 1000 токенов/с при декодировании и 4000 токенов/с при предварительном заполнении (prefill) в модели DeepSeek V3. GPU MTT S5000, как ожидается, войдёт в состав суперузла MTT C256, релиз которого намечен на следующий год.
>>1465408 Кажись, они таки-начали внедрять разработанную ими же Mixture-of-Recursions.
Обычные модели (без циклов) со счётными задачами хуёво справляются, так как по сути даже не считают, а обращаются к памяти, используя подобие таблицы умножения.
>Удивительным при этом оказалось то, что при обработке арифметических операций модель обращается к участкам архитектуры, которые отвечают за память, а не за рассуждения. Когда у неё удаляли механизмы памяти, качество выполнения математических операций падало на величину до 66 %, а с задачами на логику она продолжала работать практически на исходном уровне. Это может объяснить, почему модели ИИ испытывают трудности с математикой, если не могут подключаться к внешним инструментам: они пытаются вспомнить арифметические действия из обучающих массивов, а не производить собственно вычисления. Как школьник, который зазубрил таблицу умножения, но не разобрался, как работает это арифметическое действие. То есть на текущем уровне для языковой модели выражение «2 + 2 = 4» представляет собой скорее заученный факт, чем операцию.
Вот вам и феминистки: ментально кастрировали всех белых (ну кроме русских, потому что пока не добрались до них), что они не способны уже ни к какой интеллектуальной деятельности. Ну и пороха у них уже никакого нет, чтобы руководить.
Феминистки осуществляют меры контузии через половой террор и навязывания своей деструктивной этики.
Мужики потом ходят дурные, будто с отбитой головой. Если бы не приток мозговитых азиатов, то Америка превратилась бы уже в такое же соевое немощное болото, как и Европа.
>>1464952 >и без дорогих видеокарт Ну если это будет диффузия, да ещё 2k, то там без ебанутого количества памяти не обойтись. Впрочем, если Cocoon Дуров взлетит, то можно будет запускать и распределённо. Но это уже будет не совсем локально.
Либо если это будет уже какая-то совсем другая архитектура, например, с рекурсивным и рекуррентным подходом, которая будет сначала просчитывать общую композицию и логику, потом просчитывать детали и освещение, а потом небольшими блоками построчно уже будет рисовать изображение, тогда можно будет обойтись и небольшой памятью.
Генеральный директор DeepMind Демис Хассабис разнес Яна Лекуна: «Здесь он просто откровенно неправ… Генерализация — это не иллюзия».
Видеорелейтед.
Краткое изложении позиции Яна Лекуна: Яннан Лекун утверждает, что общей интеллектуальной способности как таковой не существует. Человеческий интеллект чрезвычайно узкоспециализирован для физического мира, а наше ощущение его универсальности — всего лишь иллюзия. Нам лишь кажется, будто мы обладаем универсальной способностью решать задачи, поскольку мы не способны представить себе те проблемы, в решении которых мы совершенно беспомощны, и, по его словам, «сама концепция — полная чушь».
Аргументация Демис: Здесь Ян Лекун просто откровенно неправ: он путает общий интеллект с универсальным интеллектом. Мозг — это самое изысканное и сложное явление из всех известных нам во Вселенной (пока что), и он, на самом деле, обладает чрезвычайно высокой степенью генерализации. Разумеется, невозможно обойти теорему об отсутствии бесплатного обеда, поэтому в любой практической и конечной системе всегда должна присутствовать определённая степень специализации в рамках целевого распределения, на котором ведётся обучение. Однако суть понятия «генерализации» заключается в том, что, в теоретическом плане — в смысле машины Тьюринга — архитектура такой генерализующей системы способна обучиться решению любой вычислимой задачи при наличии достаточного количества времени, памяти (и данных), и человеческий мозг (а также фундаментальные модели ИИ) являются приближёнными реализациями машин Тьюринга. Наконец, касательно замечаний Яна о шахматистах: поразительно уже то, что люди вообще смогли изобрести шахматы (и все остальные элементы современной цивилизации — от науки до самолётов Boeing 747!), не говоря уже о том, насколько блестяще люди умеют в них играть — например, Магнус Карлсен. Конечно, он (Магнус) может быть не строго оптимален (в конце концов, его память ограничена, и у него есть лишь ограниченное время на принятие решений), но то, чего он и мы в целом способны добиться с помощью наших мозгов — учитывая, что они эволюционировали для охоты и собирательства, — поистине невероятно.
Каким будет мир в начале 2030-х годов, если нынешние темпы ускорения в области ИИ сохранятся?
Вот на что люди не обращают внимания. Некоторые технически подкованные специалисты осознают, с какой скоростью всё меняется. Однако среднестатистический человек по-прежнему «спит», когда речь заходит о происходящем.
Это явление вполне логично. Лишь немногие формулируют его так, чтобы эта мысль проникла в сознание большинства людей.
Возможно, существует нечто, что мы могли бы сделать, чтобы изменить повествование вокруг этой темы.
Массовое ускорение ИИ Часто контекст является наиболее важным критерием для понимания. Данные, которыми я буду пользоваться, были собраны Дэвидом Шапиро в следующем видео: https://youtu.be/Gy-g9muLsPI
Вот цифры, которые он приводит в отношении объёма работы, выполняемой одним ИИ-заданием, в пересчёте на человеческие усилия, и соответствующая временная шкала:
2026 год — 3 часа 2028 год — 8 дней 2030 год — 41 месяц 2031 год — 58 лет 2032 год — 1 212 лет
Именно поэтому мы можем рассматривать ситуацию с занятостью, особенно в сфере интеллектуального труда, как весьма подверженную разрушению.
Мы знаем, что до 2028 года осталось всего 3 года. Если одно ИИ-задание будет эквивалентно 8 дням человеческой работы, скольких работников оно сможет заменить? Компаниям не потребуется много времени, чтобы начать заменять людей в огромных масштабах.
Другой способ взглянуть на это — одна выполненная ИИ задача будет давать тот же объём результатов, что и почти две недели человеческого труда.
Разумеется, это порождает множество других проблем, помимо вопросов занятости. Энергетическая проблема лишь усугубляется: потребность в электроэнергии стремительно растёт. Все причастные к этой сфере на крупномасштабном уровне активно работают над решением данной проблемы.
Самое свежее предложенное решение, по-видимому, заключается в переносе части автоматизированных операций в космос. Это может полностью изменить всю картину.
ИИ, базирующийся в космосе Может ли ИИ стать космическим?
Эту тему всё активнее обсуждает Илон Маск. Вместе с тем он далеко не единственный, кто движется в данном направлении. Многие размышляют о потенциальных возможностях.
Если рассмотреть необходимые задачи, то возникает вопрос: почему автоматизированный процесс вообще должен находиться на Земле? Это касается не только центров обработки данных, но и других видов производства, продукция которых не возвращается на Землю.
Например, строительство самих центров обработки данных, а также всех необходимых компонентов может осуществляться из космоса (или с Луны). Это означает, что запуск станет дешевле и не будет зависеть от гравитационного поля планеты.
Одна из возникающих проблем — задержка (латентность). Она сделает невозможным выполнение некоторых задач в космосе. Хотя на первый взгляд это кажется серьёзной проблемой, на самом деле это лишь ещё один слой к уже существующим сложностям.
Автономные транспортные средства не могут выполнять вычисления в облаке: вывод (inference) должен происходить локально, непосредственно на самом транспортном средстве. Даже небольшая задержка может привести к авариям — а именно их данная технология и призвана предотвращать.
Некоторые операции по-прежнему будут требовать наземных центров обработки данных. Перемены начнут проявляться в том, что большинство операций смогут допускать задержку в одну-две секунды. Действительно ли генерация ответа на запрос, основанного на логическом выводе, требует мгновенной реакции? Если задержка составит несколько секунд, скорее всего, это будет вполне приемлемо.
Ускорение изменит всё. Если темпы ускорения развития ИИ сохранятся неизменными, то в течение следующих трёх лет мир кардинально преобразится. Приведённые цифры однозначно это подтверждают.
>>1465594 Есть ли для экономики разница, что сериал из 5 сезонов создавался 5 лет, или был создан за минуту, с точно таким же качеством? Какой сценарий для экономики лучше? Казалось бы, второй сценарий повышает производительность труда. Но это не тот случай, когда повышение производительности идёт в плюс экономике. Ровно наоборот. Вот чего не понимают мечтатели о AGI, повышение производительности это не всегда хорошо. Мир в котором сериалы снимать долго и дорого, крутит экономику. Мир в котором сериал создаётся за один клик, не крутит ничего, экономика стоит.
Как Google обогнал ChatGPT — и почему гонка в области искусственного интеллекта, возможно, уже завершилась
Более 20 лет Google служил «воротами» в интернет — теперь корпорация стремится использовать своё доминирующее положение, чтобы выиграть гонку в сфере ИИ. Генеральный директор Cloudflare Мэтью Принц объясняет Энтони Катбертсону, почему необходимы новые правила, чтобы ограничить «радикально несправедливое» преимущество Google и предотвратить появление ещё одного монополиста.
Когда в ноябре Google представил свою новейшую модель искусственного интеллекта — спустя три года после запуска конкурирующего ChatGPT — технологический гигант охарактеризовал её как «новую эру интеллекта». Gemini 3 работала быстрее, лучше справлялась с логическими рассуждениями и показала рекордный результат в Humanity’s Last Exam («Последнем экзамене человечества») — тесте, разработанном исследователями в области безопасности ИИ для определения моделей, способных достичь или превзойти человеческий интеллект.
В заявлении Google звучали те же громкие заявления, которые стали привычными при запуске новых моделей крупными ИИ-компаниями, — но на этот раз всё казалось иначе.
Первые пользователи быстро поняли: новая ИИ-модель — это не просто очередное обновление, а совершенно новый подход к использованию технологии. Главный исполнительный директор компании Salesforce Марк Бениофф охарактеризовал скачок в «логике, скорости, работе с изображениями, видео… во всём» как «безумный».
В своём посте в X он написал: «Я ежедневно пользуюсь ChatGPT уже три года. Только что провёл два часа с Gemini 3 — и возвращаться не собираюсь».
Он был не одинок в этом мнении. Пионер искусственного интеллекта Джеффри Хинтон, которого порой называют «крёстным отцом ИИ», в одном из интервью заявил, что Google «начинает обгонять» ChatGPT, добавив: «Моё предположение — Google победит».
Ещё один аналитик назвал Gemini 3 «лучшей моделью из всех» после того, как она обошла все остальные модели в 19 из 20 отраслевых эталонных тестов, которые компании используют для оценки возможностей ИИ. Единственный тест, в котором она заняла второе место, касался программирования — первую строчку там заняла модель Claude от Anthropic.
Этот успех заставил создателя ChatGPT — компанию OpenAI — объявить «аварийную ситуацию» («code red»), спустя три года после аналогичного объявления самой Google в ответ на запуск ChatGPT.
Темпы развития вызывали вопросы: как Google удалось добиться таких результатов за столь короткое время, учитывая, что автономное приложение Gemini появилось лишь в прошлом году? Сотрудники технологического гиганта объяснили «секрет» успеха Gemini заявлениями о том, что они просто улучшили всё подряд. Однако истинная причина может быть куда более тревожной.
Уже более двух десятилетий Google является основным способом доступа в интернет. Его поисковая система — это то, как большинство людей ищут и находят информацию в Сети, а издатели и создатели контента зависят от неё, чтобы привлекать трафик.
Веб-сайты предоставляют поисковым роботам Google особый доступ, чтобы появляться в результатах поиска; каждый клик позволяет сайтам получать посетителей и монетизировать их через онлайн-рекламу, подписки и продажи.
Однако по мере того как интернет смещается от поиска к ИИ — а так называемые «запросы без кликов» (zero-click searches) уже составляют более 60 % всех поисковых запросов — Google использует своё привилегированное положение доминирующего поисковика, чтобы получить значительно больший доступ к Сети, чем кто-либо другой. Именно этим доминированием он теперь пользуется для обучения своих ИИ-инструментов.
Как так называемый «посредник интернета», компания Cloudflare обеспечивает защиту от кибератак более чем для одной пятой всех веб-сайтов. Это даёт ей уникальную возможность наблюдать за тем, как компании используют ИИ-роботов для сканирования сайтов с целью обучения своих моделей.
«Cloudflare стоит перед существенной долей — более 20 % — веба, и потому у нас есть репрезентативная выборка, позволяющая увидеть, насколько больший доступ к интернету имеют поисковые роботы Google по сравнению с другими ИИ-компаниями, — говорит генеральный директор Cloudflare Мэтью Принц в интервью The Independent. — И ответ поразителен».
Данные Cloudflare, предоставленные The Independent, показывают, что у Google огромное преимущество перед конкурентами в обучении своего ИИ.
ИИ-роботы Google, имеющие тот же доступ, что и роботы, используемые для поисковой системы, просматривают на 322 % больше интернет-контента, чем роботы OpenAI. Они также просматривают на 478 % больше, чем роботы Meta; на 484 % больше, чем роботы Anthropic; и на 437 % больше, чем роботы Microsoft.
«Если вы считаете, что победителем станет тот, у кого доступ к самым большим объёмам данных, тогда Google всегда будет иметь преимущество на рынке, которое никто не сможет преодолеть. Это выглядит патологически несправедливо», — утверждает Принц.
«Существует огромное структурное преимущество быть Google, и если вы спросите: “Почему именно Gemini так резко обогнал OpenAI и всех остальных на этом поле?”, ответ не в чипах, не в исследователях и не в том, что они умнее. Дело в том, что Google имеет доступ к большему объёму данных, и это даёт ему нечестное преимущество. И Google получает такой доступ только потому, что использует свою монополию в поиске».
Gemini 3 пока насчитывает меньше пользователей, чем ChatGPT — около 650 миллионов против 800 миллионов, — однако растёт быстрее. После запуска в августе генератора изображений Nano Banana, интегрированного в Gemini, число пользователей выросло сразу на 200 миллионов.
Gemini 3 также встроена в другие продукты Google, такие как Поиск, Gmail и Диск, и тем самым охватывает миллиарды людей по всему миру. Вместе с Android, Chrome, YouTube и Картами у Google семь продуктов, каждый из которых насчитывает более 2 миллиардов пользователей.
Gemini 3 всё ещё далека от совершенства: она по-прежнему страдает от галлюцинаций, может не справляться с техническими задачами, такими как отладка крупной кодовой базы, и, по утверждению некоторых, обладает чрезмерно ограничительными механизмами безопасности, снижающими её производительность.
Однако, несмотря на недостатки, она опережает конкурентов и, вероятно, будет сохранять лидерство, если ситуация не изменится. Один из способов выровнять правила игры, по мнению Принца, — разделить ИИ-робота Google и поискового робота.
Он уже встречался с регуляторами и настаивает на том, чтобы Управление по вопросам конкуренции и рынков (CMA) Великобритании ввело более строгие правила для Google, позволив стартапам конкурировать в гонке ИИ.
«С точки зрения справедливости я считаю, что Google должен соблюдать те же правила, что и все остальные в этой сфере, — говорит он. — И самый простой способ этого добиться — и одно из решений, которое CMA сейчас рассматривает, — это разделить ИИ-робота и поискового робота. Тогда Google придётся начинать с нуля в разработке ИИ — ровно так же, как начинают с нуля все остальные ИИ-компании».
В октябре CMA присвоило Google Search статус «стратегического рыночного значения» в рамках нового британского режима цифровых рынков, что даёт ему право вводить новые правила и регулирование в отношении работы поисковика.
Google в ответ заявил, что «чрезмерно обременительное регулирование» подавит инновации и рост, а также замедлит вывод продуктов на рынок. Представитель компании также сообщил The Independent, что у Google уже есть инструменты, позволяющие издателям контролировать, как именно Google получает доступ к их контенту.
Один из таких инструментов — Google-Extended, позволяющий владельцам сайтов управлять тем, используется ли их контент для обучения ИИ. Google утверждает, что это не влияет на включение сайтов в поисковую выдачу. В настоящее время Google применяет модель «отказа по умолчанию» (opt-out) для обучения ИИ: владельцам сайтов необходимо вручную добавлять в код специальные инструкции, чтобы заблокировать использование их материалов.
>>1465671 Принц предупреждает: если новые правила не будут введены, гонка в области ИИ, возможно, уже завершилась, и Google сможет монополизировать искусственный интеллект так же, как это произошло с онлайн-поиском.
«Google отказывается играть по честным правилам. И именно в такой ситуации регулирующие органы по вопросам конкуренции обязаны вмешаться и сказать: “Это — провал рынка. Вы не можете использовать свою монополию в сфере поиска для захвата монополии в сфере ИИ”», — говорит он.
«Google организовал мир таким образом, что получил столь привилегированный доступ, что я опасаюсь: рынок ИИ никогда не сможет его догнать. И это выглядит просто радикально несправедливо».
>>1465594 >Однако среднестатистический человек по-прежнему «спит», когда речь заходит о происходящем
Среднестатистический человек не «спит», ему нравится происходящее, он восхищён происходящим. Как всегда восхищался научно-техническим прогрессом, и оправданно.
>Лишь немногие формулируют его так, чтобы эта мысль проникла в сознание большинства людей
>>1465619 Как тебя вариант, что экономику будут крутить не ебнутые сериалы про вечные ценности, например, а добыча роботами ископаемых в поясе Койпера на астероидах под управлением ИИ? Реальный сектор в маштабах Солнечной системы. Наверное, это поинтереснее Голливуда?
Вероятно, придется забыть про старую модель экономики.
>>1465068 Самые лулзы будут, когда в результате всех этих махинаций на всех компах потребителей европки и сша по итогам будут стоять китайские модули памяти со шпионскими закладками от председателя Xi, а сделать ничего нельзя будет - ведь все родные мощности ушли на ИИ датацентры.
>>1465691 >ведь все родные мощности ушли на ИИ датацентры Какие ещё "родные"? В Европки и США давным-давно компьютерных компонентов, в том числе оперативной памяти, не производилось.
Что случится когда ИИ уничтожит работы ч1
Аноним# OP22/12/25 Пнд 20:34:37№1465720447
Мы поговорим о самом главном вопросе: многие люди просто говорят: «Я не вижу, как вообще что-либо может пережить этот переход».
Для тех, кто внимательно следит за происходящим, вопрос уже не стоит — это свершившийся факт: искусственный интеллект и роботы кардинально изменят экономику.
Разумеется, всё ещё есть скептики: «Ну, ИИ всё ещё не может вот это, вот это…», «роботы — это пока что в будущем». Но любой, кто смотрит на термодинамику, на технологии, на математику — понимает: у людей нет долгосрочного преимущества. Никакой физический закон не говорит, что машины не могут выполнять работу лучше, быстрее, дешевле и безопаснее, чем люди.
Тогда что остаётся людям?
Контекст: как деньги попадают в домохозяйства?
Как деньги вообще попадают к вам домой? Потому что в конечном счёте люди хотят одного — покупательной способности на уровне домохозяйства.
Если заработная плата от труда и рабочих мест больше не будет основным способом получения денег домохозяйствами — то как же они будут получать деньги?
Давайте посмотрим на сегодняшний мир. Круг выглядит так — это основной механизм обращения:
- Расходы домохозяйств → - Выручка предприятий → - Рост предприятий → - Предприятия нанимают больше людей и выплачивают им заработную плату → - Цикл продолжается.
Это — основной цикл на сегодняшний день.
Вы можете спросить: а откуда вообще в этот цикл входит *деньги*?
Деньги входят извне — от третьей стороны: ФРС создаёт деньги и выдаёт их в кредит. Но это — основной «гидрологический» цикл экономики на сегодня.
Вот только если этот шаг ломается — а предприятия перестают нанимать людей (и кстати, мы уже начинаем это видеть), — тогда весь цикл рушится. Думаю, большинство из вас это уже понимает. Если нет — теперь понимаете.
Итак, без лишних слов: вот в чём проблема.
Как деньги доходят до домохозяйств: сверху вниз
Вы можете сказать: хорошо, давайте разберём, как деньги *фактически* доходят до домохозяйств.
Сверху вниз картина такова: - Федеральная резервная система проводит инъекцию ликвидности. - Банки кредитуют предприятия на расширение. - Предприятия используют эти деньги, чтобы нанимать людей. - Благодаря этим нанятым людям происходит распределение доходов.
Далее домохозяйства платят налоги — подоходный налог, налоги на заработную плату и т.д. Но это тоже вскоре сломается.
Это *не* «теория подтекания» (trickle-down theory). Это просто «сверху вниз», потому что ФРС находится наверху — это источник первичной инъекции денег в экономику, а домохозяйство — конечная точка. Затем цикл перезапускается.
Надеюсь, вы уловили идею.
Итак, это два способа визуализировать, как сегодня работает экономика: 1. Циклический обмен между предприятиями, наймом и домохозяйствами. 2. Вертикальный взгляд от ФРС к домохозяйству.
В обоих случаях распределение через домохозяйства — вот как сегодня *в основном* деньги попадают в семьи.
Конечно, не *всё* так: - Программы государственной поддержки — социальное обеспечение, Medicare, Medicaid и т.п. — составляют около 20% доходов домохозяйств в США. - Доходы от капитала — аренда недвижимости и прочее — ещё 18–20%, в зависимости от методики измерения.
Итак, это — как устроен мир *сегодня*.
Главная проблема: расхождение производительности и заработной платы
Основная проблема — и это чувствовали все с 70-х–80-х годов — в том, что производительность продолжает расти, в то время как трудовая составляющая доходов продолжает снижаться и отрываться.
Причина этого очевидна и проста: технологии. И даже ИИ здесь не обязателен. Всё: от промышленной автоматизации до компьютеров, интернета и баз данных — начало современного цифрового «расцепления», которое мы наблюдаем последние четыре десятилетия.
На самом деле этот процесс начался ещё семь десятилетий назад — в 1950-х, когда только набирала обороты промышленная инженерия и автоматизация. Изначально даже роботы не требовались: достаточно было инженерной оптимизации, чтобы фабрики и другие процессы стали эффективнее — и требовали меньше людей.
С тех пор ускорение продолжается по мере развития различных форм автоматизации.
Кстати, в экономике термин «автоматизация» буквально означает «трудосберегающие технологии». То есть, когда мы говорим об автоматизации — мы говорим о технологиях, *предназначенных для замещения человеческого труда*. Они созданы для того, чтобы делать то, что иначе пришлось бы делать людям.
Мы ещё не достигли точки, где заработная плата и занятость начинают *снижаться* во времени — мы находимся на этапе *плато*. Но в зависимости от способа измерения, заработная плата уже 20–40 лет остаётся на одном уровне.
Вот что происходит. Вот в чём проблема.
Накопление капитала и падение спроса
Когда этот механизм ломается, весь капитал и активы начинают накапливаться наверху. Это — концентрация богатства. Это — углубление капитала (*capital deepening*). Именно это мы и наблюдаем сейчас в реальном времени: триллионы долларов инвестируются в энергетическую инфраструктуру, дата-центры, суда по всему миру — это прямой пролог к следующему этапу расцепления.
Итак, у нас есть концентрация и углубление капитала. Но когда этот капитал инвестируется, предприятиям *просто не нужно* нанимать столько людей — и в домохозяйства попадает меньше денег.
Это создаёт проблемы сразу на нескольких фронтах: - Во-первых, домохозяйства теряют доходы → не могут покупать → падает совокупный спрос. - Во-вторых, **падает налоговая база**.
И когда люди спрашивают: «Почему элита или миллиардеры вообще допустят это?» — ответ прост: **отреагирует правительство**. Правительство скажет: «Если люди не платят налоги, мы не можем финансировать экономику». И тогда оно спросит: *«А у кого же тогда есть деньги?»* — и обратится к владельцам капитала.
Это один из ключевых способов понять, откуда возникает парадигмальный сдвиг.
В США и многих других странах мы уже видим, как эта система ослабевает: доля заработной платы в ВВП годами падает. Сейчас она снизилась с **56% до 52%**. Казалось бы — всего 4%. Но в глобальном масштабе это **триллионы долларов в год**, которые перенаправляются от домохозяйств к капиталу.
И это число движется **только в одном направлении** — вниз. В более развитых странах доля ещё ниже: в США, например, около **48%**. И с углублением капитала — строительством дата-центров, покупкой GPU и роботов — это *не улучшится*. Мы находимся в пути без возврата.
Итак, вот проблемы.
Новая парадигма: переход от труда к капиталу
Теперь — что же будет *новым*?
**Великая перенастройка**: мы переходим от *трудопосредствованного* цикла к *капиталопосредствованному*.
Это — главная интуиция. Это — фундаментальное изменение.
Кстати, эту идею я не придумал. Многие экономисты, давно заметившие расцепление между производительностью и заработной платой, уже говорили: «Решение — в расширении владения капиталом». Отлично. Я взял эту идею — и развил её.
Сегодняшняя схема такова: - **Центральный банк** → кредитует **коммерческие банки** → - **Коммерческие банки** → кредитуют **предприятия** → - **Предприятия** → нанимают людей → - Люди получают **зарплаты** → - Покупают жильё, еду, машины → платят налоги.
Эта схема *ломается*, потому что предприятия больше не будут нанимать людей.
Что случится когда ИИ уничтожит работы ч2
Аноним# OP22/12/25 Пнд 20:35:23№1465723448
>>1465720 Что приходит на смену? Автоматизированные активы. (И это не социализм и не коммунизм. Это просто автоматизированная экономика.) Неважно, кому принадлежит дата-центр — государству или Google: в будущем источник ценности — это автоматизированные активы.
Центральный и коммерческие банки, конечно, останутся — они будут финансировать дата-центры, солнечные электростанции, роботов… Но вместо предприятий, нанимающих людей, у нас будут автоматизированные активы, которые будут платить налоги напрямую в публичные фонды, суверенные фонды благосостояния, открытые платёжные системы.
И тогда мы получим автоматические дивиденды.
Вместо того чтобы проходить весь путь через ФРС, кредиты и займы — мы все будем получать дивиденды от владения.
Вы можете сказать: «Но у меня же нет капитала!» Это нормально — для базовых универсальных выплат капитал не нужен.
- Безусловный базовый доход (UBI) может приходить через автоматизированные платёжные системы. - Автоматические выплаты, как, например, уже существуют в Постоянном фонде Аляски — опять же, без участия ЦБ, просто за счёт собственного фонда благосостояния, который напрямую выплачивает деньги домохозяйствам.
По сути, мы берём работающие модели — Аляска, суверенный фонд Норвегии — и говорим: «Давайте просто масштабируем это повсеместно — на *все* автоматизированные активы».
Тогда деньги будут поступать не в виде зарплат, а в виде дивидендов. (Кстати, Эндрю Янг называл UBI «дивидендом свободы» — хотя технически это всё же *трансферт*, а не дивиденд. Но суть вы уловили.)
Главная идея проста: домохозяйства получают доход — и потребительская экономика продолжает работать, как раньше.
Это — ключевая смена парадигмы.
Шаг 1: Переключить вход с зарплат на дивиденды
Сейчас, работая, вы *фактически* зарабатываете деньги не себе, а владельцам капитала. Именно это вызывает недовольство: при углублении капитала уже не вы — владелец сапожной мастерской, каретного дела или кузнеца, — не вы получаете большую часть прибыли.
Теперь кто-то другой владеет машинами, а вы лишь управляете ими — и видите, как «рука» забирает продукт.
Люди недовольны этим уже давно — более полутора веков. С тех пор, как начались трудовые движения (примерно с 1820-х годов, со времён Энгельса).
Решение: мы все становимся участниками экономики владения — все становимся владельцами капитала.
Часть этого — прямое владение: акции, облигации, soulbound-токены в DAO. Часть — через государство: всеохватывающий капитал (мы поговорим об этом чуть позже).
Это и есть универсалы, обеспеченные активами, — по сути, суверенные фонды благосостояния.
Идея проста: вы просто сидите и получаете доход.
Вы можете спросить: *«А чем я займусь во всём этом свободном времени?»* Конечно, вы сможете и дальше наращивать своё богатство — но в будущем это уже не будет необходимо. Потому что вкладывать в экономику будет нечего.
Вы можете возразить: *«Если мы все станем “бесполезными едоками”…»*
(Здесь важно: это *нацистская* терминология — так называли инвалидов. Я не ввожу этот термин. Его ввела аудитория — потому что он отражает ваш глубинный страх.)
Но даже если вы — просто потребитель, вы всё равно *двигаете экономику*. Спрос на жильё, на продукты — этот спрос *и есть* двигатель экономики.
В рамках нового общественного договора ваш внутренний спрос как человека останется ключевым фактором.
Шаг 2: Обновить «сантехнику» — открытые платёжные системы
Это *крайне важно*.
Сегодняшние системы медленны, дороги и проходят через частных «шлюзовых операторов», взимающих комиссии: - не сама рассылка чеков при стимулах, - а сети Visa, - частные банки, - система SWIFT — вот где трение.
Что случится когда ИИ уничтожит работы ч3
Аноним# OP22/12/25 Пнд 20:36:03№1465724449
>>1465723 Альтернатива — цифровая публичная инфраструктура. Такая уже существует:
- В Индии — UPI (*Unified Payments Interface* — единый интерфейс платежей). Там была огромная теневая экономика — всё наличными. Чтобы повысить прозрачность, бороться с коррупцией и налоговой уклонкой — создали открытый стандарт для мгновенных цифровых платежей.
- В Бразилии — Pix — такая же система: дёшево, мгновенно, напрямую. Да, они используют блокчейн — не для каждой транзакции, но для общего реестра: чтобы каждая операция была неизменяемой и могла контролироваться децентрализованно.
Идея: если у нас есть публичные фонды, суверенные фонды и прямые дивиденды — посредники не нужны. - Не нужны банки. - Не нужны CBDC (цифровые валюты центробанков). (Кстати, UPI и Pix — *не* CBDC.)
Проблема — рентоориентированное поведение (*rent-seeking*). Американские и западные банки яростно сопротивляются внедрению систем типа UPI и Pix.
Но трение = экономическая неэффективность. В долгосрочной перспективе, я надеюсь, США и Европа всё же начнут внедрять подобные системы — или хотя бы создадут свои. Интересно, что даже в Европе уже начинают двигаться в этом направлении — возможно, там это случится раньше, чем в США. Но в США банковская индустрия *слишком* прибыльна. (Вы видели *«Волка с Уолл-стрит»*. Вам всё понятно. Мы давно обсуждаем жадность Уолл-стрит — не буду бить мёртвую лошадь.)
Шаг 3: Сменить налоговую базу — с труда на капитал и ренту
Сегодня у нас уменьшающаяся база налогов с доходов и заработной платы.
Повторю: есть *системные стимулы* — не только для миллиардеров и правительства, а *для всех* — перевести налоговую базу: - с труда → на налоги с автоматизации и роботов, - на налог с стоимости земли, - на ренту с ресурсов, - на потребление.
Всё это может финансировать государство — *и* при этом вы получите дивиденды от автоматизации.
Это и есть новая схема — она нацелена на поддержание скорости обращения денег: - Домохозяйства → потребляют. - Предприятия → платят налоги и ренту. - Налоги и рента → идут в общие фонды капитала и суверенные фонды. - Фонды → выплачивают дивиденды.
Новый цикл проще и короче, чем прежний. (Хотя в целом остаётся похожим: домохозяйства, предприятия, банки — и все живут долго и счастливо.)
ФРС всё равно будет проводить инъекции капитала — потому что предприятия остаются: у них есть капитальные и операционные расходы. Энергия не бесплатна. Фабрики не бесплатны. Земля не бесплатна. Роботы тоже изнашиваются.
Капитал будет по-прежнему вливаться в предприятия — но будущие предприятия будут *автоматизированы*.
Когда это начнётся?
На сегодня есть сильный консенсус: 2032 год — главная точка перелома. Я пришёл к этому числу независимо, и у меня есть ещё одно видео в работе — где экономисты тоже называют 2032 год моментом, когда ВВП резко пойдёт вверх благодаря автоматизации.
Может быть, и раньше. Мы склонны *переоценивать* время внедрения таких изменений.
2030–2032 годы — когда полностью автоматизированный бизнес начнёт расцветать. К тому времени нам, вероятно, уже понадобятся UBI и суверенные дивиденды.
Это *не* переписывание системы центробанков. Это — создание *лучшего канала распределения*.
Сегодня QE (количественное смягчение) — это когда ФРС покупает облигации, поднимает цены на активы и *надеется*, что богатство «просочится вниз». Мол, если сделать экономику более платёжеспособной, люди начнут тратить, предприятия — нанимать, и затор разблокируется.
Можно сказать, что новая система — это QE для народа. С цифровыми кошельками ЦБ или Казначейство может напрямую вводить ликвидность в домохозяйства во время кризиса — чтобы деньги сразу пошли в потребление.
Именно это мы и наблюдали со стимулирующими выплатами во время пандемии.
По сути: когда экономика замедлится из-за увольнений, вызванных ИИ и роботами, у нас будут *вечные* стимулирующие выплаты.
Но они не обязательно будут «печатанием денег» (как в QE). Часть — это дивиденды: перераспределение налогов *напрямую* от автоматизированных предприятий. Это — самый простой и бесфрикционный способ.
Смена смысла: от «зарабатывания» к «владению»
Будущее экономического участия — это смена смысла. (*shift from earning your keep to owning your share* — «переход от зарабатывания своего места к владению своей долей».)
- Трудопосредствованный цикл связывает ценность человека со *временем труда*. Когда машины продуктивнее — человеческий труд обесценивается.
- Капиталопосредствованный цикл связывает ценность человека с *гражданством* и *совместным владением производственными активами*.
Что важно — даже получая дивиденды, вы всё равно можете *инвестировать дальше*: - покупать недвижимость, - акции, - основывать компании. Вы сможете наращивать богатство.
Это не будет *обязательно* — но будет *возможно* и поощряемо. Вы можете направлять часть дивидендов в пенсионный фонд.
Кстати — мы будем жить *вечно*. Функционально — вечно. Продолжительность жизни может достичь 600–700 лет, прежде чем вы, скорее всего, погибнете от несчастного случая. (При ежегодном риске в 1% — за 700 лет он почти неизбежен.)
Но суть в том: вам не придётся полагаться *только* на выплаты всю жизнь. Вы сможете создавать собственное богатство — просто потому что захотите.
Половина из десяти самых продаваемых в настоящее время игр в Steam принадлежит разработчикам, которые уже внедрили генеративный ИИ.
После объявления студии Larian Studios о проекте Divinity генеративный ИИ стал главной темой обсуждений. Команда подтвердила, что будет исследовать данную технологию на этапе предпроизводства, и вскоре игровое сообщество отреагировало бурно.
Впоследствии такие игры, как Clair Obscur: Expedition 33, также подверглись критике за использование ИИ. Дискуссии разрослись настолько, что в них включились и другие разработчики, например Warhorse Studios. Однако, несмотря на всю негативную реакцию вокруг ИИ, текущий глобальный список десяти самых продаваемых игр в Steam рассказывает иную историю.
Согласно данным SteamDB, половина игр из этого списка создана студиями, уже внедрившими ИИ.
На самом деле, три игры из списка уже используют эту технологию. Arc Raiders и Where Winds Meet открыто указывают на применение искусственного интеллекта в описании на Steam. В этих проектах ИИ задействован для озвучки НИПов (неигровых персонажей).
Аналогично, Clair Obscur: Expedition 33 также использовала генеративный ИИ при создании игровых ассетов на этапе предпроизводства; один из таких ассетов даже остался в финальной версии игры перед тем, как был удалён в последующем патче. Более того, недавно эта RPG была дисквалифицирована с Indie Game Awards за то, что разработчики не раскрыли факт использования ИИ.
Таким образом, 30 % из десяти самых продаваемых игр используют генеративный ИИ. Хотя ни Kingdom Come: Deliverance II, ни Baldur’s Gate 3 официально не подтверждены в использовании искусственного интеллекта, обе студии — Larian и Warhorse — уже приняли эту технологию. Генеративный ИИ уже исследуется для Divinity, а заявления Даниэля Вавры указывают на то, что студия Warhorse, скорее всего, последует этому примеру.
В совокупности половина списка из десяти самых продаваемых игр состоит из проектов, разработанных студиями, уже внедрившими генеративный ИИ.
Хотя это не стало большим сюрпризом, данный список указывает на общую тенденцию в индустрии. Многие разработчики уже смирились с тем, что генеративный ИИ уже здесь, и теперь пытаются использовать его при создании игр уровня AAA.
Даже такие ветераны индустрии, как Хидэо Кодзима, признали, что не существует реального способа избежать того факта, что искусственный интеллект будет оказывать влияние на игры в будущем.
- deepseek представила открытую модель рассуждений уровня o1 - qwen выпустила лучшую в мире открытую мультимодальную модель (модель с поддержкой изображений) - minimax m2 продемонстрировала производительность на уровне sonnet 4.5 при стоимости всего 8 % от цены sonnet 4.5 - allen ai выпустила olmo 3 base и olmo 3 think — лучшую базовую 32-миллиардную модель и лучшую 32-миллиардную модель для рассуждений - alibaba выпустила z image — 6-миллиардную модель, способную генерировать фотореалистичные изображения на уровне моделей, превосходящих её по размеру на порядок - qwen выпустила лучшую в мире открытую модель редактирования изображений - google выпустила gemma 3 — сильное семейство открытых мультимодальных моделей (с открытыми весами), отлично работающих на одной видеокарте - mistral представила devstral 2 — открытые агентные модели для программирования - deepseek выпустила модель v3.2, превзошедшую gpt-5 / gemini 3 pro и завоевавшую золото на международной математической олимпиаде (IMO), китайской математической олимпиаде (CMO), финале чемпионата мира по программированию ICPC и международной олимпиаде по информатике (IOI) 2025 года - meta открыла исходные коды и веса моделей sam 3 и sam 3d — новых рекордсменов в области сегментации изображений и видео, отслеживания объектов и 3D-реконструкции - glm 4.6 получила контекстное окно в 200 тыс. токенов и демонстрирует производительность на уровне sonnet 4 - nvidia представила nemotron 3 — новое семейство открытых моделей (веса + данные + рецепты обучения), созданных специально для агентных рабочих процессов - deepseek выпустила deepseek math v2 — модель для математических рассуждений, достигающую уровня золотых медалей на задачах IMO 2025 года и набравшую 118 баллов из 120 на Putnam 2024 - kimi k2 thinking превзошла gpt-5 и claude 4.5 sonnet по целому ряду бенчмарков при стоимости, в 10 раз меньшей, чем у gpt-5, и в 20 раз меньшей, чем у sonnet 4.5 - mistral запустила лучшие в мире малые модели — ministral 3 (14B, 8B, 3B) и mistral large 3 — открытую MoE-модель передового класса
Разрыв между закрытыми и открытыми ИИ стремительно сокращается.
>>1465763 Там же аналоговнет. Т.е. нахуй никому не нужно, потому что качество никакое. Было бы качественно, уже бы кругом обсуждали и пилили лоры-туториалы.
>>1465763 Я скажу по секрету никому все эти нейросетки на самом деле нахуй не нужны кроме нескольких тысяч прыщавых гунеров, если этот сбер завтра скачает и выложит чатжпт 5.2 он тоже никому нахуй не будет нужен. Потому что высеронки они не про пользу а про то что СЮДА БАБЛО НУЖНО ВКЛАДЫВАТЬ, есть дезигнейтед инвестмент компаниз в которые все договорились нести напечатанное бабло, а делают ли они какой-то продукт или нет на самом деле всем похрен, главное чтоб пузырик надувался и туземун был.
>>1465763 Известность. Модели Сбера известны только в России, о них мало говорят в мире. Есть много китайских моделей, которых нет в этом списке. Они тоже малоизвестны, хотя их качество лучше, чем у мистраля и тем более всяких allen ai
Корейцы ебанулись и решили сделать игру в кальмара в ИИ. Они взяли 5 команд и дали им одинаковые ресурсы на тренировку LLM. Каждые полгода команда с худшей LLM выбывает, и ресурсы переходят к остальным. И так пока не останется только одна команда с лучшей моделью.
>>1465955 Пошли практические применения нейросеток. Еще можно кумерские соревнования устраивать, кто сможет взять чекпоинт с позитивным мышлением и первым отрпшить его.
>>1465720 >>1465723 >>1465724 Осторожно, не читайте это. Возможно тогда вы поймете как размышляют умные люди и до вас дойдет мысль про ББД. Лучше дальше думайте про то как злые корпорации лишат вас работы, чтобы создать больше продукции с меньшим количеством затрат, которую эм... Внезапно никто не может купить, потому что 100% человечества уволено и у них нет денег.
Ой, пошли они нахуй. Если бы этих "умных людей" слушали, то никакого прогресса не было бы и в помине, сейчас бы где-нибудь с голой жопой по Африке бегали.
>>1466041 Чтобы все это запустилось, ВВП должен пойти резко вверх благодаря автоматизации. Одновременно увольнения должны пойти массово благодаря ей же. Пока что топтание, ни то ни другое сильно не движется, чтобы вызвать перетряхивания системы. Скорее всего это изменится через несколько лет.
Новый метод G²RL позволяет языковым моделям обучаться эффективнее — за счёт «самонавигации» в пространстве градиентов
Исследователи из Tencent AI Lab и Университета Нотр-Дам представили новую концепцию обучения больших языковых моделей (LLM) с помощью метода под названием G²RL — Gradient-Guided Reinforcement Learning (обучение с подкреплением, управляемое градиентами). Статья, опубликованная 17 декабря 2025 года, предлагает фундаментально иной взгляд на то, как модели должны исследовать свои варианты ответов во время обучения. Вместо традиционных подходов, стимулирующих разнообразие на уровне текста, G²RL учит модели «чувствовать», какие ответы действительно по-новому влияют на её внутренние настройки — то есть какие траектории обучения ведут к действительно новым направлениям обновления параметров.
В чём проблема старых методов?
В современных методах обучения с подкреплением для LLM (например, GRPO, EVOL-RL) для стимулирования разнообразия ответов применяются внешние оценки: энтропийные бонусы, сравнение семантической близости через сторонние эмбеддинги, подсчёт редких ответов. Однако эти подходы не учитывают, как именно каждый ответ влияет на обучение модели.
Два внешне разных ответа могут вести к почти одинаковым изменениям в весах модели — то есть быть «повторяющимися» с точки зрения обучения. И наоборот: два внешне похожих текста могут представлять принципиально разные пути рассуждений, внося уникальный вклад в градиентный вектор. Именно поэтому внешние метрики — будь то энтропия или семантическая дистанция — неэффективны: они работают в ином пространстве, чем само обучение.
Как работает G²RL? Основная идея
G²RL предлагает использовать для управления исследованием не внешние сигналы, а внутреннюю геометрию самой модели. Ключевое наблюдение: градиенты, влияющие на все слои нейросети, линейно связаны с сигналом чувствительности на последнем слое — его легко получить из обычного прямого прохода, без дополнительного обратного распространения.
Для каждого сгенерированного ответа модель строит так называемый градиентный признак — своего рода «отпечаток» того, как именно этот ответ повлиял бы на обновление параметров. Затем модель сравнивает такие признаки для всех кандидатов в группе и вычисляет, насколько новый ответ предлагает ортональное (независимое, новое) направление в пространстве градиентов.
Формула для оценки полезности исследования (эксплорации) выглядит как: ``` ν(i) = sqrt( max( 1 – Σ w_ij cos²(Φ_i, Φ_j), 0 ) ) ``` Если ответ геометрически похож на уже известные успешные траектории — его вклад оценивается как низкий. Если же он «смотрит в другую сторону» в пространстве градиентов — получает высокую оценку.
Эта оценка используется для умножения базовой награды (например, +1 за верный ответ, –1 за неверный), но с жёстким ограничением по шкале (от –3 до +3), чтобы не нарушать стабильность обучения в стиле PPO.
Что даёт такой подход на практике?
В серии экспериментов на моделях Qwen3 (1.7B и 4B параметров) на задачах математики (MATH, AIME, AMC) и общего рассуждения (GPQA, MMLU-Pro) метод G²RL показал стабильное улучшение по всем ключевым метрикам:
- pass@1 — точность при одном запуске — выросла везде: например, на AIME25 (самый сложный датасет) — с 17.5% до 20.1% на 4B-модели. - maj@16 — точность при голосовании 16 ответов — повысилась значительно: с 23.9% до 29.0% на той же задаче. - pass@k — охват правильных решений при множестве попыток — также улучшился, что говорит о более эффективном использовании сэмплов.
Динамика обучения показала: G²RL быстрее сходится к высокому качеству, при этом длина ответа (показатель сложности рассуждений) растёт уже на ранних этапах — модель быстро учится не только «угадывать», но и обосновывать.
Геометрия против семантики: важнейшее открытие
Самый неочевидный, но критически важный результат — несовпадение семантического и градиентного разнообразия.
Анализ показал: в G²RL доля пар ответов с отрицательной косинусной близостью (то есть указывающих в противоположные стороны в пространстве градиентов) выросла почти в 5 раз по сравнению с обычным GRPO (с 5.9% до 28.1%). При этом семантическая близость в G²RL даже немного выше — то есть ответы остаются тематически согласованными и осмысленными.
Это означает: G²RL генерирует более структурно разные пути решения, не жертвуя связанностью и логичностью. Внешние эмбеддинги, напротив, часто поощряют поверхностные различия (например, синонимы или отвлечённые пояснения), не полезные для обучения.
Значимость
1. Эффективность обучения. G²RL позволяет извлекать больше пользы из одного и того же количества сэмплов. Это критично для снижения стоимости обучения (меньше GPU-часов) и ускорения итераций разработки.
2. Устойчивость к коллапсу режимов. Без градиентного разнообразия модели быстро «застревают» на одном успешном паттерне, выдавая вариации одного и того же решения. G²RL активно этому противодействует, поддерживая широкий охват стратегий рассуждений.
3. Без внешних компонентов. Метод не требует обучения или подключения отдельных моделей-эмбеддеров, не добавляет вычислительной нагрузки — градиентные признаки извлекаются «бесплатно» в ходе обычного прямого прохода.
4. Принципиально более глубокий контроль. Переход от внешнего к внутренне-референциальному управлению исследованием — это шаг к «самоосознанию» в обучении: модель начинает ориентироваться не на чужую оценку, а на собственную структуру и потенциал роста.
G²RL — не просто очередное улучшение метрик. Это новая парадигма: обучение с подкреплением, где исследование направляется не извне, а изнутри — через геометрию собственных обновлений модели. Такой подход делает обучение не только эффективнее, но и принципиально более целенаправленным. Для инженеров это значит меньше ресурсов и выше качество. Для исследователей — новый инструмент для изучения, как именно модели «думают», когда учатся рассуждать. И чем ближе мы к пониманию этого, тем ближе — к по-настоящему контролируемому и надёжному искусственному интеллекту.
Насколько мы близки к искусственному общему интеллекту (ИОИ)?
Никто по-настоящему не знает наверняка, когда — или даже состоится ли вообще — появление искусственного общего интеллекта (ИОИ). Однако в последние месяцы искусственный интеллект совершил значительные шаги вперёд. Выпуск таких моделей, как ChatGPT-5.1, Grok 4.1 и Gemini 3, вновь подогрел дискуссии о сроках и технической осуществимости.
Экспертные прогнозы: спектр временных горизонтов
Позиция DeepMind Демис Хассабис, основатель и генеральный директор DeepMind, подтверждает свой прежний прогноз: до появления ИОИ, скорее всего, осталось ещё 5–10 лет. Он отмечает, что, несмотря на многообещающие достижения с Gemini 3, соответствующие ожиданиям, всё ещё может потребоваться один или два дополнительных прорыва.
> «Я действительно доволен темпами прогресса Gemini 3. Думаю, люди будут весьма приятно удивлены. Однако развитие идёт именно так, как мы и предполагали — а это означает, что до ИОИ всё ещё, вероятно, остаётся 5–10 лет, и, возможно, потребуется ещё один или два серьёзных прорыва».
Оптимистичные прогнозы Илон Маск предлагает один из самых амбициозных прогнозов. В конце прошлого года он написал: > «Становится всё более вероятным, что к концу 2025 года ИИ превзойдёт интеллект любого отдельного человека, а к 2027 или 2028 году — возможно, и всех людей вместе взятых. При этом я несколько скептически отношусь к тому, что это действительно произойдёт».
Дарио Амодей, генеральный директор Anthropic, также весьма оптимистичен — но рассматривает ИОИ не столько как техническую веху, сколько как общественный сдвиг. По его мнению, к 2026–2027 годам, а почти наверняка к 2030 году, системы ИИ будут напоминать то, что он называет «страной гениев, размещённой в дата-центре».
> «Для меня термин ИОИ никогда не был строго определённым. Я всегда считал его скорее маркетинговым выражением. Но я думаю об этом так: в какой-то момент мы получим системы ИИ, превосходящие почти всех людей почти во всех задачах… И я считаю весьма вероятным, что к этому мы придём в ближайшие два-три года».
Планы OpenAI Сэм Олтман, генеральный директор OpenAI, увязал свои временные рамки с политическими событиями — в частности, с возможным вторым сроком президента Трампа. Он также обозначил конкретную цель — не сам ИОИ, а по-настоящему автономного исследователя-ИИ: март 2028 года.
> «Мы считаем правдоподобным, что уже к сентябрю следующего года у нас появится нечто вроде ИИ-ассистента уровня стажёра, а к марту 2028 года (что, как я полагаю, почти ровно через 5 лет после запуска GPT-4) — полноценный ИИ-исследователь. Это и составляет основную направленность нашей исследовательской программы».
OpenAI уже работает над специализированным приложением, ориентированным на науку; деталей пока немного, но подробнее можно узнать (и зарегистрироваться) на странице https://openai.com/science).
Другие лидеры индустрии Генеральный директор NVIDIA Дженсен Хуан и бывший генеральный директор Google Эрик Шмидт считают, что ИОИ появится в течение 3–5 лет. Напротив, Жан де Кар, ранее работавший в Meta, склоняется к диапазону 5–10 лет, подчёркивая, что потребуется ещё несколько крупных технологических прорывов.
Экспертный консенсус против публичных прогнозов
Недавний опрос, проведённый группой Longitudinal Expert AI Panel — с участием более 300 исследователей в области ИИ, — показывает, что эксперты в среднем ожидают более медленного прогресса, чем часто утверждают руководители передовых лабораторий.
Тем временем на платформе прогнозов Metaculus (где за прогнозы начисляются баллы, а не денежные вознаграждения) средняя прогнозируемая дата наступления ИОИ неуклонно сдвигается вперёд — с 2050-х годов до конца 2027 года на сегодняшний день. Среднее арифметическое прогнозов ещё более раннее.
Исследовательский институт Epoch AI прогнозирует, что масштабирование крупных языковых моделей будет продолжать приносить значимые прорывы вплоть до 2030 года. К тому времени модели, возможно, смогут с высокой точностью решать сложные задачи в математике, биологии и разработке программного обеспечения — в значительной степени автономно.
Почему так сильно разнятся оценки?
Ключевая причина расхождений в прогнозах — неопределённость в определениях. Некоторые, такие как Амодей и Олтман, сместили акцент на более узкие вехи — например, ИИ, способный к независимому научному исследованию, — достижение которых возможно за счёт выявления пробелов в существующей научной литературе. Хотя это впечатляюще, многие считают, что это всё ещё не соответствует общему интеллекту, подобному человеческому.
Другие, включая Хассабиса и исследователей из LEAR, придерживаются более строгого понимания ИОИ: широкий, гибкий интеллект на уровне человека (или выше него) в самых разных областях. Такая последовательность в определении, возможно, и объясняет их более длительные временные горизонты.
Признаки того, что ситуация становится серьёзной
Недавно OpenAI пересмотрело свой контракт с Microsoft — исключив расплывчатые упоминания ИОИ. Вместо этого теперь чётко указано, что вопрос о достижении ИОИ будет решаться независимой группой экспертов.
Это показательный шаг. Когда компании начинают формализовать процедуру признания успеха — ещё до его наступления, — это означает, что ставки повышаются.
ИОИ всё ещё в нескольких годах от нас… но современный ИИ уже чрезвычайно мощен
Хотя полноценный ИОИ, возможно, ещё впереди, современные ИИ-агенты уже невероятно полезны — если подобрать подходящие именно под ваши задачи.
Что, если я скажу вам, что гонка к ИИО — то есть к искусственному интеллекту общего назначения, или ИИ, способному освоить практически любую задачу, которую может выполнить человек — на самом деле имеет финишную черту с конкретной датой?
Потому что то, что только что представила OpenAI, — это вовсе не какой-то расплывчатый апдейт. Нет, это подробный, пошаговый план достижения момента, который изменит всё.
Верно. Это не научная фантастика. Это не какие-то безосновательные предположения. OpenAI поставила дату в календаре — цель, к которой они стремятся и в которую, по их мнению, сама игра в развитие ИИ кардинально и необратимо изменится.
Хронология: от ИИ-стажёра до самосовершенствующегося интеллекта
Итак, внимание. К сентябрю 2026 года планируется создать автоматизированного ИИ-стажёра-исследователя. И здесь речь идёт не о каком-то продвинутом чат-боте. Речь идёт о полноценном исследователе на основе ИИ, способном вносить реальный вклад в научные и инженерные задачи совместно с людьми.
А затем, всего через 18 месяцев — в марте 2028 года — ставится цель достичь полностью автоматизированного научного исследования на основе ИИ. Вот оно. Именно эта дата выбрана в качестве цели, когда ИИ сможет начать самостоятельно улучшать себя. И именно это станет спусковым крючком для так называемого взрыва интеллекта.
Что же такое взрыв интеллекта? Это момент, когда прогресс ИИ переходит в рекурсивный цикл. Подумайте об этом: ИИ улучшает себя, становясь умнее, а это, в свою очередь, делает его ещё более эффективным в улучшении самого себя — и так далее по замкнутому кругу, со скоростью, которую мы буквально не в состоянии осознать.
Как только этот процесс запустится, единственным реальным ограничением станет объём вычислительных мощностей, которые можно задействовать.
Это не предположение — это инженерный план
Для начала давайте чётко поймём одну вещь. Эта хронология — не просто оптимистичное предположение, нацарапанное на доске. Нет — это цель одного из самых масштабных и амбициозных инженерных проектов в истории человечества.
И это как раз объясняет, почему сейчас идёт настоящая гонка вооружений, в которой может быть только один победитель.
Компания, первой достигшая точки рекурсивного самосовершенствования, получит не просто фору. Она может сделать всю свою конкуренцию полностью неактуальной — буквально за одну ночь. В самом деле, как кто-либо ещё сможет когда-либо нагнать её?
Именно поэтому эти компании готовы вкладывать сотни миллиардов долларов в создание необходимой инфраструктуры.
Триллионный план
Так как же именно они планируют этого добиться? Здесь мы подходим к триллионному плану.
Чтобы хоть как-то приблизиться к этим датам, OpenAI создаёт невообразимый объём инфраструктуры. Вы, наверное, слышали, как Сэм Олтман говорил о привлечении 7 триллионов долларов. Это вовсе не какая-то далёкая мечта. Они уже сейчас строят вычислительную инфраструктуру стоимостью 1,4 триллиона долларов.
Речь идёт о фабриках по производству чипов, гигантских центрах обработки данных — обо всей «сырой» мощности, необходимой для запуска будущих моделей. И всё это происходит *прямо сейчас*.
Чтобы вы понимали масштаб: их цель — построить фабрики, которые в итоге будут производить гигаватт вычислительной мощности в неделю. Один гигаватт. Это буквально как построить вычислительные мощности, сопоставимые с целой атомной электростанцией — *каждую неделю*. Просто осознайте это.
От минут до лет: расширение «внимательного промежутка» ИИ
Но, знаете, речь идёт не только о наличии большей мощности. Важно, *что* ИИ сможет делать с этой мощью.
OpenAI также описала прогрессию в том, как долго ИИ может *работать* над задачей. На данный момент ИИ отлично справляется с тем, что занимает несколько минут или часов, — но теперь они стремятся расширить это до возможностей самостоятельной работы над сложными проектами в течение *дней*, затем *недель* и в конечном итоге — *лет*.
Речь идёт о глубокой, продолжительной работе, например, по открытию новых лекарств или решению проблемы изменения климата.
И вот где становится по-настоящему удивительно: ещё один из этих рекурсивных циклов. OpenAI на самом деле использует свои *исследования в области робототехники* — не для создания какого-нибудь милого потребительского гаджета, а чтобы *физически помогать строить гигантские центры обработки данных*.
Таким образом, ИИ буквально строит оборудование для следующего, ещё более мощного поколения ИИ.
Проблема согласованности: предоставление ИИ свободы мышления
Хорошо, вся эта мощь — и физическая, и вычислительная — ведёт к глубокой, почти философской проблеме:
Как убедиться, что столь мощный ИИ действительно согласован с тем, чего мы хотим?
Стратегия OpenAI в этом вопросе — ну, скажем так, она одновременно гениальна и немного пугающа.
Ведь это и есть суть проблемы согласованности ИИ, не так ли? Если вы постоянно исправляете каждое малейшее действие ИИ, учится ли он быть по-настоящему «хорошим» — или просто становится мастером говорить вам то, что вы хотите услышать? Как добраться до *истины* того, о чём он на самом деле думает?
Вот что говорит исследователь OpenAI Якуб Пахоцки, чётко формулируя суть: они *намеренно отказываются от контроля* за некоторыми частями внутреннего процесса рассуждения ИИ. По сути, они дают ему пространство для свободного мышления — чтобы увидеть, *что* он действительно придумает.
У них есть специальный термин для этого: верность цепочки рассуждений (*chain-of-thought faithfulness*). Это почти как предоставление ИИ некоего аналога *психологической безопасности*.
Обеспечивая ему такое контролируемое «пространство приватности», они полагают, что получают гораздо более честный взгляд на реальные рассуждения ИИ — а не только на «отполированную» версию, которую он считает приятной для наших ушей.
Это чрезвычайно деликатный и высокорискованный подход к пониманию тех новых «умов», которые мы создаём.
Что это значит для реального мира
Итак, у нас есть хронология, огромный бюджет и эта удивительная стратегия согласованности. Что всё это на самом деле означает для нас в реальной жизни?
Это означает, что «обрыв автоматизации» — резкий и драматический скачок в сокращении рабочих мест — наступит *намного быстрее*, чем большинство людей готовы признать.
Взгляните, что в последнее время говорит Сэм Олтман. Когда его спросили о GPT-6, он ответил: *«6 месяцев — возможно, ещё раньше».*
Он утверждает, что мы *уже сейчас* находимся в переходном периоде к ИИО. Именно поэтому, по его словам, термин «ИИО» сегодня уже почти бессмыслен. Реальное значение имеют именно *конкретные вехи*.
И он прогнозирует резкое ускорение автоматизации офисной работы *в течение 2025 года*. Сдвиг происходит *прямо сейчас* — в масштабе месяцев, а не лет.
Новые правила игры
Хорошо, давайте теперь вернём всё это к реальности. Это не просто увлекательная технологическая история. Это имеет колоссальные последствия для *каждой профессии* и для *каждого бизнеса*.
Главный вопрос: как подготовиться к этому?
Вот новые правила игры:
1. Признайте, что «обрыв автоматизации» — это реальность. Он не наступит «когда-нибудь» — он уже начался.
2. Поймите, что окно возможностей для первопроходцев закрывается — и закрывается очень быстро. Это не как облачные технологии, где у вас были годы на адаптацию. Речь идёт о *месяцах*.
3. Ваша ценность в будущем будет определяться не выполнением задач, которые может делать ИИ, а управлением целыми системами из ИИ. Думайте как дирижёр, а не как исполнитель.
4. Готовьтесь к гибридной рабочей силе, где вы будете управлять командами, состоящими как из людей, так и из ИИ-агентов.
И вот часть, которая, честно говоря, должна вас потрясти:
ИИ, которым вы пользуетесь прямо сейчас, — это самый худший, самый глупый и наименее способный ИИ, который вы когда-либо будете использовать за всю оставшуюся жизнь.
Каждая следующая модель будет *драматически* мощнее.
Сегодня мы погрузимся в будущее искусственного интеллекта глазами человека, находящегося прямо в самом центре всего происходящего. Он — одна из самых важных фигур в этой области. И, честно говоря, его прогноз относительно того, что должно произойти в ближайшее время, — ну, он по-настоящему поразителен.
Итак, давайте сразу перейдём к самому громкому заявлению, хорошо? Шейн Легг, соучредитель Google DeepMind, уже более десяти лет утверждает одно и то же: вероятность создания искусственного общего интеллекта — ИОИ (AGI) — к 2028 году составляет 50 на 50. И, чтобы было совершенно ясно, речь здесь идёт вовсе не о далёком фантастическом будущем. Это буквально уже на горизонте.
Кто такой Шейн Легг — и почему его прогноз имеет значение?
Хорошо, возможно, вы думаете: кто такой Шейн Легг, и почему этому прогнозу стоит придавать больше значения, чем всем прочим, которыми сейчас пестрят СМИ?
Всё дело в том, какое положение он занимает в мире искусственного интеллекта. Видите ли, это вовсе не случайное предположение какого-то стороннего наблюдателя. Шейн Легг, по сути, сам ввёл в обращение термин ИОИ (AGI). Он был соучредителем DeepMind — лаборатории, которую по праву можно назвать ведущим в мире исследовательским центром в области ИИ, — а сейчас он занимает должность Главного учёного Google по ИОИ. То есть он находится на самой передовой — он создаёт ту самую технологию, о которой говорит.
Это не просто домыслы. Это прогноз, идущий непосредственно из самого мотора развития.
Определение ИОИ: путь, а не переключатель
Итак, что же именно он подразумевает под ИОИ? Для Легга это вовсе не нечто вроде переключателя, который можно просто перевести из положения «выкл» в положение «вкл». Он воспринимает это как путь — как поступательное продвижение через чётко различимые уровни возможностей. Давайте разберём его концепцию, ведь она чрезвычайно полезна.
Хорошо, первый уровень — минимальный ИОИ — именно на него и направлен его прогноз на 2028 год. И он определяет его весьма просто: это ИИ, который перестаёт допускать странные, нелогичные ошибки в когнитивных задачах — ошибки, которые не стали бы совершать люди.
Так что думайте о нём не как о сверхгении, а скорее как о системе, обладающей общей здравой логикой и компетентностью среднего человека.
Но — и это очень большое «но» — достижение минимального ИОИ — это только первая ступенька на лестнице. Между тем, что способен делать типичный человек, и тем, на что способен гений, создающий новые области физики или сочиняющий симфонии, лежит колоссальная, огромная пропасть.
Способность охватить весь этот спектр человеческих талантов — вот что Легг называет полным ИОИ. И, по его мнению, этот этап может наступить всего через несколько лет после достижения первого рубежа.
А затем — затем — мы выходим на третий уровень: искусственный сверхразум, или ИСР (ASI). Это уже интеллект, который выходит далеко за пределы человеческой шкалы. Он находится намного, намного выше неё.
Почему сверхразум — физическая неизбежность
Всё это подводит нас к центральному тезису Легга.
Развитие ИИ не остановится просто потому, что он достигнет нашего уровня. Он утверждает — и делает это, исходя из самых фундаментальных принципов, — что сверхразум — это вовсе не некая безумная гипотетическая возможность. Это по сути физическая неизбежность.
Он задаёт очень важный вопрос: действительно ли наш собственный интеллект — тот, что порождается этим крошечным 20-ваттным биологическим мозгом, — является действительно вершиной возможного во всей Вселенной?
Его ответ — категоричное, безусловное «нет».
Аргументация его основана исключительно на физике. Взгляните: мозг человека, несомненно, эволюционное чудо, но он имеет серьёзные физические ограничения. Он работает приблизительно на 20 ваттах мощности. Его сигналы — это медленные, вязкие электрохимические импульсы.
Теперь сравните это с дата-центром. Он может потреблять сотни мегаватт энергии, а его сигналы распространяются практически со скоростью света.
И разница здесь — не просто небольшая. Мы говорим о физическом преимуществе кремниевых систем над биологическими, достигающем восьми порядков величины. То есть — о по-настоящему ошеломляющем разрыве в потенциале.
Именно поэтому он с такой уверенностью заявляет: исходя только из законов физики, само представление о том, что человеческий уровень интеллекта является пределом возможного, — просто не выдерживает критики.
Как только мы разгадаем программную сторону интеллекта, аппаратная основа, на которой он сможет работать, практически не будет иметь верхнего предела.
Реальные последствия: экономические потрясения
Хорошо, а что всё это означает для нас? То есть — в реальном мире, скажем, в ближайшие несколько лет?
Легг утверждает, что первыми серьёзными потрясениями станут не философские, а экономические.
Он видит грядущий фундаментальный сдвиг. Сейчас мы в основном воспринимаем ИИ как нечто вроде удобного и полезного инструмента, верно? Он может спланировать ваш отпуск или помочь с электронной почтой.
Но очень скоро он превратится в экономически ценного работника — в агента, способного выполнять реальную, продуктивную работу.
В качестве идеального примера он приводит разработку программного обеспечения: сегодня команде требуется 100 инженеров. Однако уже через несколько лет может понадобиться всего 20 — потому что передовой ИИ будет помогать им, усиливать их работу и самостоятельно писать значительную часть кода.
Речь здесь не обязательно идёт о полном замещении людей. Речь о колоссальном скачке производительности, который неизбежно вызовет серьёзные потрясения на рынке труда.
И как только экономическое влияние ИИ станет столь ощутимым и конкретным, сама природа дискуссии должна измениться. Она переместится от обсуждения забавных гаджетов и новинок к вопросам, касающимся фундаментальной структуры всей нашей экономики, а по сути — и всего общества.
Развилка на пути человечества
И, по мнению Легга, это стремительное структурное изменение ставит человечество перед поистине судьбоносным выбором — перед настоящей развилкой на пути нашего будущего.
Он, по сути, обозначает два совершенно разных возможных пути.
Первый — это путь масштабных, неконтролируемых потрясений, которые могут серьёзно подорвать наши экономики и социальную ткань.
Но второй путь — если нам удастся грамотно управлять этим переходом — может привести к возможной золотой эре для всего человечества.
Так что же он вообще имеет в виду под «золотой эрой»?
Представьте себе системы, которые резко повышают производство всего необходимого. Представьте ускорение научного прогресса до такой степени, что мы будем открывать новые лекарства и технологии с небывалой ранее скоростью. Представьте освобождение от вида труда, который на самом деле никто не хочет выполнять.
Возможность здесь заключается в невероятном расцвете человеческого потенциала.
Стоящая перед нами задача: больше, чем просто технология
Но путь к этому будущему — вот в чём сложность.
Как сам говорит Легг, это вовсе не только техническая проблема, которую нужно решить. Это глубочайший вопрос, требующий глобального диалога с участием философов, экономистов и специалистов по этике.
Нам всем вместе предстоит выяснить, как будет выглядеть это позитивное будущее — и затем понять, каким образом нам направить себя именно к нему.
Призыв к действию: готовы ли мы?
Что, знаете ли, возвращает нас к тому, с чего мы начали.
Легг по-прежнему придерживается своего сценария на 2028 год для первого этапа — минимального ИОИ. Если человек, находящийся за штурвалом, прав в том, насколько близко мы подошли к этой цели, то эти вопросы уже не являются абстрактными и отнесёнными в далёкое будущее.
Это — срочные, злободневные темы для обсуждения.
И вопрос, с которым он оставляет нас, возможно, важнее всех остальных:
>>1465774 >не нужны кроме нескольких тысяч прыщавых гунеров Не ну там 200 ГБ памяти нужно, и там наверное плохо понимает запросы на английском. Теперь сопоставить это - у скольких будет 200 ГБ памяти на территории русскоязычного СНГ. Будет в основном у мажоров, которые купили мощные ПК для новых игр, и таким будет не интересно возиться с ИИ, не ну и логично зачем мажорику ИИ если можно поиграть в новые крутые игрушки на ПК.
>>1466041 >Возможно тогда вы поймете как размышляют умные люди Там не дописали что роботы с ИИ могут привести к тому, что услуги КНР как мировой фабрики больше не понадобятся. Тогда первым вводить условный базовый доход придётся китайцам а не американцам. И это будет не сколько от избытка перепроизводства, а как средство выживания.
Хотя с другой стороны, когда у людей дома появились принтеры, то количество напечатанных книг в мире вроде не выросло. Хотя можно было свои собственные книги печатать и продавать, да.
>>1466202 >широкий, гибкий интеллект на уровне человека (или выше него) в самых разных областях. У отдельно взятого человека как раз такого нет. Ну разве что примитивные действия делать - многозадачность есть у всех, но для несложных задач вроде болты закручивать, мешки переносить, коробки переставлять, копировать и изменять тексты подставляя в нужных местах синонимы, и т.д.
>>1466222 >1. Минимальный ИОИ Они могут аналог БАК сделать (как Большой адронный коллайдер), только для ИИ, замкнутую среду для тестов, чтобы безопасно протестировать.
Китайцы уже что-то там мутят, сделали сеть между 40 городами, наверное тоже чтобы не на весь Китай, а лишь в такой сети тестировать особенно мощные модели, чем выше мощность моделей, тем нужны более особенные условия для их тестов и запусков.
Ну и гиде новости нормальные? Там нефритовый стержень, как и прогнозировалось ранее тут в треде, GLM 4,7 АКА ГОЙДА Z выпустил, опять дали пососать. Ну и на закуску MInimax m 2,1
>>1466222 > Он утверждает — и делает это, исходя из самых фундаментальных принципов, — что сверхразум — это вовсе не некая безумная гипотетическая возможность. Это по сути физическая неизбежность. >Он задаёт очень важный вопрос: действительно ли наш собственный интеллект — тот, что порождается этим крошечным 20-ваттным биологическим мозгом, — является действительно вершиной возможного во всей Вселенной? >Его ответ — категоричное, безусловное «нет». Тут я с ним согласен, но впервые о самой идее я прочитал у Лема в формуле Лимфатера. Там даже есть диалог того самого сверхразума с создателем. Не хочу спойлерить, рассказ короткий, рекомендую прочитать тем, кто не читал.
>>1466222 >Готовы ли мы? Нет. Нельзя подготовиться к столкновению с интеллектом, превосходящим тебя, тем более кратно. Когда сталкиваешься с гениальностью чужого разума основные эмоции даже у самых человеков-кремней - страх, зависть, гнев. И тот самый вопрос - НУ ПОЧЕМУ ОН, А НЕ Я?! Жизнь не готовит обычного гречневого васю к жизни бок о бок с обществом, состоящим из докторов Манхеттенов. Самое близкое что он ощутит это эмоции, которые переживал Эфиальт при встрече с войском спартанцев в том самом фильме. Но это не значит, что нужно останавливаться на достигнутом. Пусть даже человек это всего лишь зародыш какого-то более сложного интеллекта.
В свете не совсем свежих новостей, что АИ решил 12 (11?) из 12 задач с последнего ICPC - и по-настоящему, не просто нагуглив решение, как я понимаю - можно ли уже, наконец, попускать анальников, которые верят в свою незаменимость? Олимпиадная прога это, хоть и намного сложнее, конечно, не разработка, но все же. Жду ещё, когда будут попущены и фанатики олимпиадной математики. Те, персонажи по типу Савватеева, тоже пыхтят и рассказывают об уникальности кожаных мешков, венцов творения, в сфере решения этих искусственных задачек со всяких межнаров.
>>1466637 >Играет лучше человека в шахматы. Не AGI >Играет лучше человека в Го. Не AGI >Понимает юмор. Не AGI >Делает переводы между языками лучше человека. Не AGI >Решает математику лучше человека. Не AGI
Кароч, как обычно, все скажут, что это не интеллект, а вот когда добьётся такого-то, то тогда будет интеллект. Но а когда она реально добьётся, то планочку вновь повысят.
Года 4 назад мой друг сказал, как было бы круто иметь бесплатный ИИ-переводчик на уровне человека для своей работы. Я ему тогда ответил, что он несёт хуйню, ибо мир в котором будет переводчик на уровне человека, не будет никакой работы вообще. Так как такой интеллект будет способен тогда на всё, и сразу отнимет все профессии. Каким же наивным я был.
>>1466645 Лет 15 назад, посмотрев достижение тех еще нейрлинков, я задумался над тем, чтобы у каждого на голове был обруч, который бы переводил мысли на понятный любому в мире язык. А потом запретили использовать гуглглассес в публичных местах. Так я понял, что до коммунизма по ефремовски и правда не менее 500 лет.
>>1466604 >Жизнь не готовит обычного гречневого васю к жизни бок о бок с обществом Маск подсуетится и начнёт массово вживлять в мозг чипы-ИИ-ускорители воспользовавшись моментом, и реклама у него будет что-то вроде: "Скорость передачи данных в твоём нейроне - жалкие 100 метров в секунду. Не будь умственно-отсталым, не оставайся неполноценным, наш продукт сделает тебя умным".
>>1466689 >Маск подсуетится и начнёт массово вживлять в мозг чипы-ИИ-ускорители воспользовавшись моментом, и реклама у него будет что-то вроде: "Скорость передачи данных в твоём нейроне - жалкие 100 метров в секунду. Не будь умственно-отсталым, не оставайся неполноценным, наш продукт сделает тебя умным". А потом нажмет на кнопку и убьет всех слабоумных. Звучит как план.
>>1466714 >слабоумных Слабоумными будут так же и те считаться, у кого будет уже устаревшая модель чипа-ускорителя в мозге, это всё равно ещё клиент, который потом достанет денег чтобы заплатить Маску за установку нового чипа. Будет новая гонка среди модифицированных людей.
>>1466723 >чем вообще могут быть ограничены пределы развития такого интеллекта? Ну много препятствий - энергия (нужны электростанции), политики (запреты), наука (сейчас например рывок, а в 2030 может во что-то упереться и всё затормозится, и разработчики ИИ будут снова лет 30 лет на одном месте топтаться), кремний (возможности кремний-медных чипов на пределе, дальше нужны чипы квантовые, оптические и т.д.).
>>1466630 >кишечный выпук какого-то бесполезного фанатзера >омном бегу занюхивать, три простыни и еще три переформулированных снизу >реально полезная новость >хуита, я решил проигнорировать Оп эйача 2026
>>1466727 Так для этого и сокращение населения. Иначе ситуация получается нелогичная, поскольку реально существует верхний предел потребления, который выдержит планетка. При большом количестве населения все получают безусловный доход, ничего не делают, но все-равно нищие. Поскольку иначе объедят планетку. Отсюда массовое недовольство. Как бы уже считай полубоги, а живем в г. Так и до бунтов недалеко. И средний уровень развития все-равно близкий к маргинальному. Да и общее снижение устойчивости общества и поганенькая общественная атмосферка. Чтобы уровень потребления и развития людишек соответствовал новым научно-техническим возможностям, надо сокращать население количественно. Тогда оставшиеся, действительно, смогут стать похожи на богов. Откуда и все швабовско-глобализационные идейки.
>>1466637 Гуманитариев нужно попускать. Нужна такая нейронка, которая будет идеально понимать психологию людей и жёстко предсказывать реакции и поведение.
>>1466748 Пора переименовать тред в "Бессмысленный трёп каких то челов" и дальше читать новости про ИИ с сайтов как раньше, там хоть не нужно листать простыню ради простыни
2035 год: > Фууу, этот агислоп не может вывести новое доказательство P=NP даже за час! Бенчмаксинг! Вышли на плато!
> Этот кланкер доставил мне тыквенный латте за 6 минут вместо пяти! И не развалился когда я его пнул, но штраф все равно начислил! Долой <робокорпнейм>!
>>1466793 Между роботами не будет передачи информации в классическом смысле, они будут кванто запутанными. Почти как кот Шредингера (но кот на другую тему появился)
>>1466770 Ну так эта твоя теория относительности ни разу не запрещает двигаться сквозь пространство. На то это и гиперсвязь. Ограничения по скорости действуют только для движений внутри пространства.
Теория относительности ничего не говорит про квантовую механику. Квантовая механика ничего не знает о пространстве. В квантовой механике нет локальности. Это две разные теории. Еще не состыкованные.
>>1466640 > а вот когда добьётся такого-то буквально не может опередить человека с гуглом, разве что по времени поиска ответа в гугле при этом человек все еще может выдумывать новое и учить других людей, а ии не может учить другии ии, ему для обучения слоп запрещен строго
Прочитал местные треды (от нехуй делать на работе). И хочу вставить свой никому нахуй не нужный прогноз на тему шизы по ИИ. 1. В ближайшие пару лет пузырь ИИ лопнет. Куча мелких контор обанкротится. Самые жирные кабаны зафиксируют прибыль. 2. Попильщики на государственном уровне съебут кто куда. Кого-то посадят. Кого-то пристрелят. 3. Школьники вернутся в библиотеки и будут также писать от руки сочинения, пользуясь всякими "Краткими изложениями" и "Готовыми домашники заданиями". 4. Студенты вернутся к написанию шпаргалок и зубрению формул сопромата. 5. Петровичи вернутся к станкам. 6. Из браузеров пропадут "умные поисковики" и прочие "Алисы". 7. Сайты снова будут делать фрилансеры на флеш и на фреймах. Программисты снова будут говнокодить и нанимать индусов на аутсорс 8. Офисный планктон вернётся к горам документов, который будет печатать ручками.
А наши потомки к ИИ-шизе 20-х годов будут относиться примерно как к гигантскому наебалову уровня МММ в планетарном масштабе, либо как к повальному увлечению спиритизмом в начале XX века и все эти свистопляски с роботами\ламами будут выглядеть как шиза анненербе и общению с миром духов. Видите фотокарточку аноны? Это как вы будете выглядеть в глазах потомков через 100 лет
>>1466877 >барнаульские неолуддит-крестьяне высказываются, когда уже ВСЁ решено Верно говариваешь Петрович, так и будем клячи в плуг запрягать, а дурь эта вся с телеграфами, эляктричеством и самоходными колясками выветрится из господских головушек. Пусть меня черти сьедят.
>>1466877 >В ближайшие пару лет пузырь ИИ лопнет. Куча мелких контор обанкротится. Самые жирные кабаны зафиксируют прибыль. Если ИИ - это пузырь, то как раз за счет самых жирных кабанов он и надувается. Гиперскейлеры тратят сотни миллиардов на инфраструктуру, и никакой прибыли он зафиксировать не смогут в ближайшие несколько лет.
>>1466877 Хуëвый из тебя прогнозист, не вижу ни одной причины откатываться на предыдущий уровень прогресса и сознательно его тормозить чтобы...чтобы в библиотеках и на заводах были люди а хуйдожники и кодеры могли зарабатывать?
>>1466902 Ну может человечесто весело подбежит к ASI бездне, глянет вниз, в бездонную черноту, испугается и на трясущихся корячках отплозет в сторону...
>>1466881 Планктоню >>1466883 >>1466907 >>1466902 Зря иронизируете. Слишком дохуя из каждого утюга кричат про ентот ваш ИИ. "Когда вы услышите, что об акциях начинает говорить чистильщик ботинок, знайте - пришло время продавать." Развивался бы он тихо-спокойно, не было бы подозрения в ебейшем наебалове. Слишком часто всякую чернь за историю наёбывали всякими тюльпаноманиями. >>1466887 Вспомни кризис доткомов.
>>1466922 Ну тоже неплохо. Человечество подходит к бездне, смотрит вниз в темноту, трясется от страха. В один момент, в безде начинает что-то шевелится, бегают яркие огоньки. Изуленное человечесво падает на задницу. Из бездны вверх вздымается столб огня и огромный космический корабль набирая обороты улетает за пределы Земли. Летний вечер, закат солнца, тишина нарушаемая только звуками цикад. Человечество вновь набирается смелости и смотрит в бездну. А там за туманом, зеленая долина, с лугами, непаханными полями, хрустальными реками.. Там твой дом в деревне из толтых бревен, утепленный мхом. Там тебя ждет соха и добрый труд..
>>1466928 После того как чистильщик обуви узнает об акциях, фондовый рынок на этом не заканчивается, а лишь дожидается начала нового цикла. Ты путаешь хайп вокруг системы и саму систему.
На тюльпанах был хайп, но от этого сам цветок своих свойств не утратил. Он по-прежнему существует и даже пользуется спросом для составления букетов с ним. Сдулись лишь хайп и его переоценность.
Впрочем, это все аналогии. По потенциалу ИИ не стоит и рядом с акциями и тюльпанами. Эта технология имеет ценностный потенциал, сравнимый со всеми изобретниями человечества вместе взятыми за всю иторию. На данный момент это только потенциал, но даже на данном этапе равития ИИ можно увидеть, сколько пользы он принес. Не прибыли, а пользы. В науке, например. Достаточно почитать тред более внимательно. Возможно, не один.
>да забудьте вы про ммм. По потенциалу agmmm это совсем другое не стоит и рядом с nft токенами и ммм. Эта технология имеет ценностный потенциал, сравнимый со всеми изобретниями человечества вместе взятыми за всю иторию.
>>1466939 В том-то и дело, что читаю, и что-то прям очень всё у них круто на словах выглядит. Буквально "ровно стелишь фраерок". Под это дело миллиардные (а в новости выше говорят уже о триллионах) инвестиции. Но я вижу, что пока это просто красивые рекламные буклеты. А бабки как в топку летят, в то время как пиарщики говорят "Сча, ещё чуть-чуть, ещё вот-вот". Как осёл, который тащит телегу, думая что он идёт к морковке, которая висит у него перед носом. >>1466933 Вот именно. Интернет после нулевых перестал быть уделом гиков и проник не то что в каждый дом, а в каждый карман.
>>1466939 >В науке, например Читал все треды, 0 пользы, только дроч бенчмарков и открытие уже открытых теорем, которые настолько актуальны что первое открытие нахуй никому не всралось, кроме ии, нашедшего его на помойуе
>>1466950 То, что там бабки делают и то, что технология раздута в медиа, это факт. Но это не значит, что сама технология пуста. Я еще раз подчеркну. Она уже имеет значение в науке, представляя практическую ценность. Даже если это не сопоставимо влитым в нее ресурсам, отдача есть. Какая будет отдача в итоге, не ясно. Но то, она будет, ясно.
Как тебе верно отметили уже, доткомы сдулись, но на том переоцененном в тот момент каркасе выстроен весь современный интернет. Может, не так уж он и переоценен был на дистанции, а лишь переоценен в моменте? Моментальной прибыли инвесторы с него не получили, а прогорели, но зато в итоге пользу от этого получили все люди.
>>1466951 Понял. Больше вопросов и аргументов нет.
>>1466640 У интеллекта должна быть страсть к познанию, внятные цели, мотивация и дух первооткрывателя. А о каком интеллекте может идти речь, если он сейчас даже первым не напишет тебе "Ну чё как ты там? Я тут темку интересную придумал", а просто будет ждать команды.
А есть, вообще, какие-то серьёзные аргументы в пользу того что ASI в принципе невозможен и нейронки недалеко уйдут от текущего уровня? Ну и соответственно какие то адекватные апологеты этой точки зрения.
>>1466934 Соха, добрый труд, волки, холера, чума, брюшной тиф и проказа, ворующий с пасеки мед медведь, заяц добывает морковь в твоем огороде, пока вороны топчут пугало, клопы унесли жену в лес, крестьяне в соседнем селе поймали и сожгли ведьму потому, что оне превратила их в тритона и прочие радости пасторальной жизни на лоне природы. Как хорошо, что ИИ улетел...
>>1466963 >если он сейчас даже первым не напишет тебе "Ну чё как ты там? Прикинь, запускаешь комп, а у тебя в виндовских уведомлениях такое вылазит. При этом ИИ ты никогда не пользовался, никаких ИИ-клиентов нет, и вообще интернет отключен...
Но на самом деле такая фигня программируется и имитируется буквально за час-другой. И (кажется) в ОпенАИ такое реализовали - когда бот сам тебе в чат пишет. Юзерам не очень понравилось.
>>1466990 У нас есть доказательство того что AGI возможен, так как наша биологическая нейросеть уже обладает этим уровнем интеллекта и работает в тех же физических условиях. Теоретически мы можем со временем просто скопировать наш мозг. Что касательно ASI, глупо думать что эволюция достигла своего пика и интеллект лучше нашего невозможен. Мы не достигли пика, мы получили тот самый минимум интеллекта, чтобы начать заниматься наукой и разрабатывать новые технологии, ещё есть простор для прироста интеллекта, вопрос лишь в том каков он, каково физическое ограничение на интеллект и скейлится ли он бесконечно.
>>1466959 >но на том переоцененном в тот момент каркасе выстроен весь современный интернет На каркасе доткомов выстроены только бабки тех, кто стриг лохов. Идея маркетплейсов, интерактивных сайтов, стриминга и прочего веба следующего поколения была и до хайпа, и хайп никак в развитии не помог, как оно развивалось медленно десятилетиями, таки развилось. Не было бы кризиса доткомов, не было бы современного интернета? Самому не смешно? Что-то на уровне цыган который тебя обокрал помог тебе лучше стараться и работать, без него бы ты валялся бомжом на помойке
>>1466998 >У нас есть доказательство того что AGI возможен Нету >>>1466998 >наша биологическая нейросеть уже обладает этим уровнем интеллекта и работает в тех же физических условиях. Не доказано, это не более чем гипотеза, на которой строятся нейронки.
>>1466998 >Теоретически мы можем со временем просто скопировать наш мозг. но ведь мы же ещё не знаем даже и на половину как работает наш мозг. и явно AGI будет на других принципах строиться
>>1464598 Так интеллект — это как раз навык комплексный навык по извлечению информации (не данных!), её осознанию, обработке и синтезу нового знания.
Машины пока могут только один этап — обработку. Причём не знаний а данных.
Посмотри лекцию Фейнмана, где он объясняет, почему компьютер даже не умеет в арифметику.
Ричард Фейнман о возможностях и будущем компьютеров, 1985 год
В этом и разница. В этом и сила ащемта, что для быстрого просева данных, например цифры 3, не нужно иметь никаких ассоциаций, представлять что это три пальца, что между ними можно условно провести две границы если в ряд и три, если в пучок. И вообще не надо даже физически трёх битов в трёх ячейках. Надо просто взять один код, другой код и применить к ним шаблон из таблицы, соответствующий запросу «умножь»
>>1464796 дело не только в этом. Чем более развитая музыка, тем больше в ней структуры и сложных внутренних взаимосвязей в композиции. И автор пишет не так что «ага, вот эта нота после этой норм звучит» а создаёт произведение и такой «хм, а вот учитывая начало и концовку вот тут в середине надо переделать».
А нейронка в структуру не может совсем. Она только в склейку соседних элементов может. Следующий кадр, слово, пиксель, нота.
Плюс паттерны. В рэпчике и электронщине их дофига и в основном из них всё и строится.
Даже в годной попсе уже всё не так. Ну точнее размер паттерна резко вырастает.
>>1464861 Нужды в роботе нет, 3д-болванки достаточно.
Виртуальные аватары появятся, точнее станут доступнее. Но пока расклад такой, что они возможны лишь на синтезе качественного 3д, чтения мимики человека и натягивания нейронки поверх.
>>1465190 Пока не появятся. И ещё лет десять не появятся. Нет ни аккумуляторов эффективных, ни двигателей, ни способов в таком размере перерабатывать бензин или водород.
Смотри на военку. У них есть или дроны размером с Пиццу, которые могут 10 минут нести снаряд или дрон с ладошку, который может 20 минут летать и снимать видос. То есть без грузоподъёмности.
>>1465754 Когда кто-то говорит, что будет использовать молоток, нужно просто уточнить, для чего. Если человек собирается забивать им гвозди, то всё в порядке. Если он им будет рисовать картинки — нахуй не надо.
>>1467020 >а от чего это может зависеть? Даже теоретически пока сложно сказать, потому что мы даже не близки к тому чтобы уткнуться в этот предел. Может это математические ограничения и если мы изучим интеллект на 100% и получим его математическое определение то сможем все расчитать, а может быть уткнемся в физические ограничения, которые не дадут развивать его дальше, если такие ограничения вообще есть. >разве увеличение мощностей не даст увеличения интеллекта Интеллект - это не про мощности, а скорее уж про скейлинг, если мы говорим о нем в таком ключе. Его можно масштабировать скейлингом, это пока работает, но прирост снижается. Теоретически можно можно улучшать результаты через инференс, брутфорся различные варианты, как это делают reasoning модели.
>>1467038 >но ведь мы же ещё не знаем даже и на половину как работает наш мозг. Это на текущий момент. Если бы мы пошли другим путем и не смогли найти вариант создания AGI другим способом, то мы как минимум когда-нибудь смогли бы скопировать наш мозг. >и явно AGI будет на других принципах строиться Поэтому я и говорю что теоретически. Я не говорю что это случится, я говорю что это как минимум реализуемо в нашем мире.
>>1466971 >ну построить больше электростанций - это вообще не проблема Вообще-то проблема. ГЭС строить уже негде. Атомки это очень долгие деньги и сроки. Можно строить сжигающие углеводороды, но и там ты упрешься в скорость производства крупных электроприводов и трансформаторов. А еще ты можешь упереться с ходу в дефицит кадров, которых почему-то интеллект не заменил пока что. Именно уровня даже не строителей, а инженеров пуско-наладчиков. Это только в компьютерных играх ткнул на поле и орки стали строить лесопилку просто махая в пустоте молотками. На деле чем больше объект, тем сложнее его логистика.
>>1466877 >3. Школьники вернутся в библиотеки и будут также писать от руки сочинения, пользуясь всякими "Краткими изложениями" и "Готовыми домашники заданиями". >4. Студенты вернутся к написанию шпаргалок и зубрению формул сопромата. >7. Сайты снова будут делать фрилансеры на флеш и на фреймах. >Программисты снова будут говнокодить и нанимать индусов на аутсорс >8. Офисный планктон вернётся к горам документов, который будет печатать ручками. С какой стати? Каким образом лопнувший пузырь ИИ должен мешать всем перечилсенным группам людей пользоваться ИИ? Тот же DeepSeek можно хоть самостоятельно развернуть (платя за облачные вычисления), хоть за API платить. Или ты считаешь, что продажа доступа по API ко всем нейронкам магическим образом прекратиться, чисто из уважения к нейроскептикам?
>2. Попильщики на государственном уровне съебут кто куда. Кого-то посадят. Кого-то пристрелят. За предыдущие пузыри практически никого не наказывали.
>5. Петровичи вернутся к станкам. Сколько Петровичей из-за станков вытянул ИИ, что бы они за эти станки вернулись?