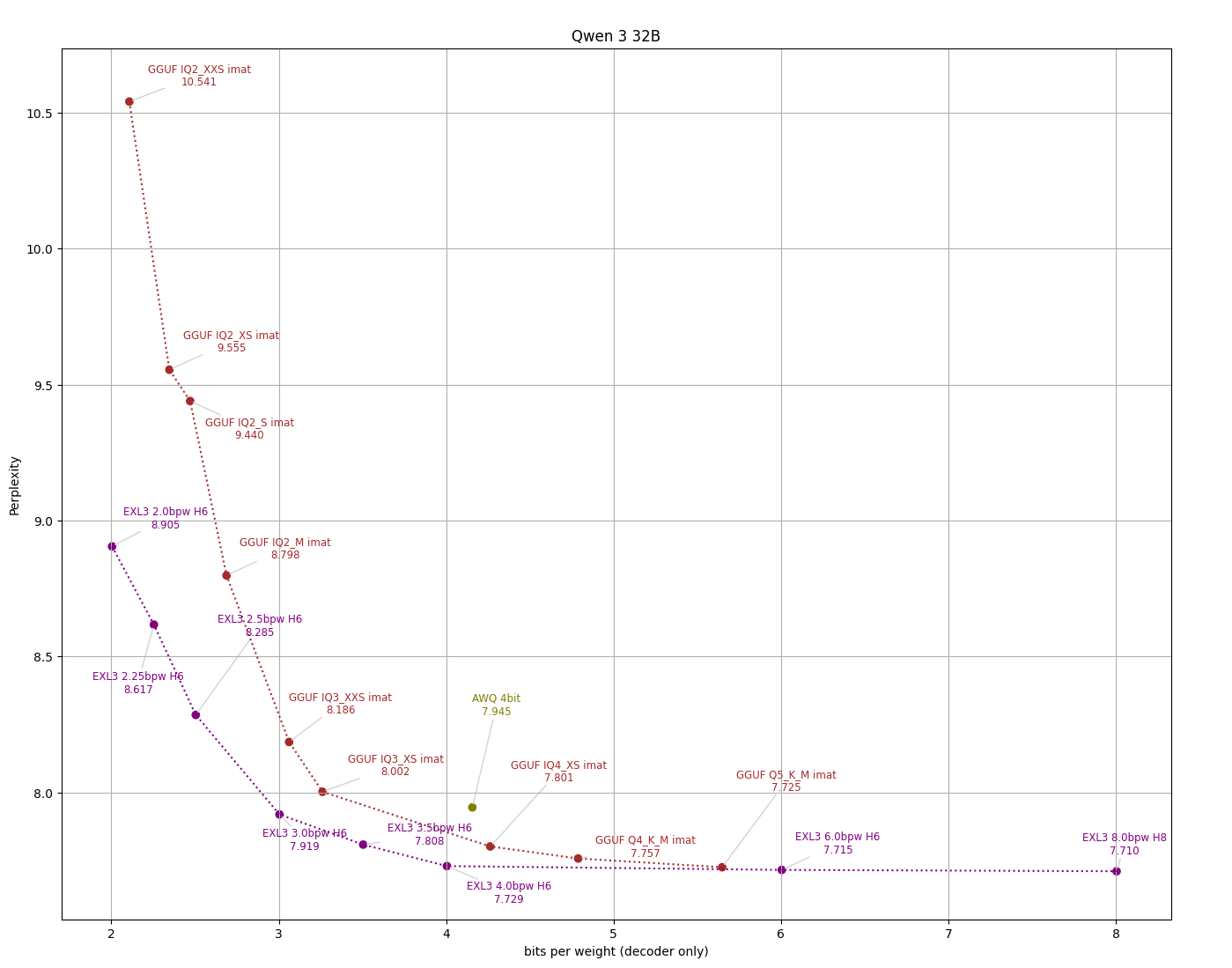
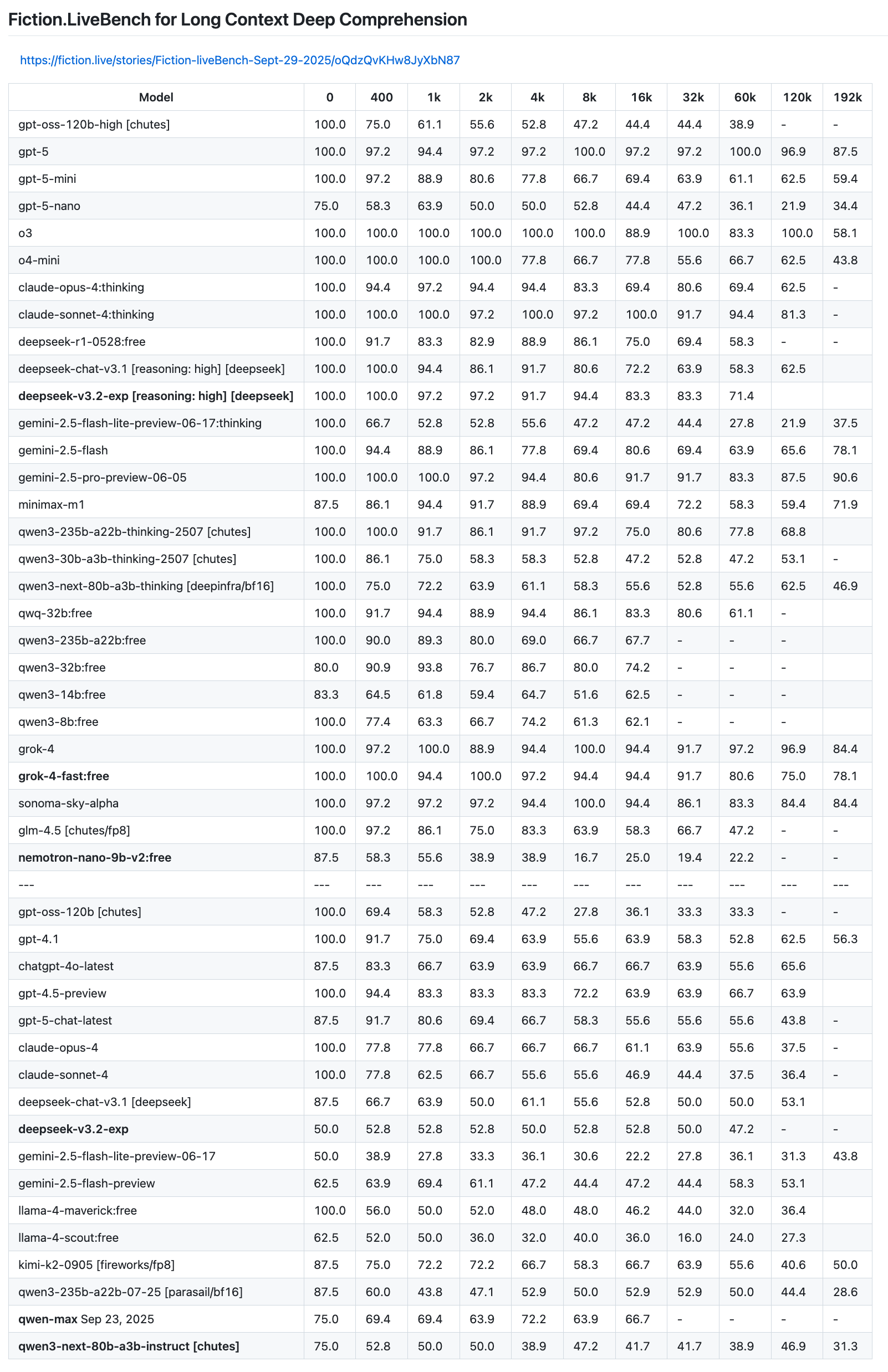
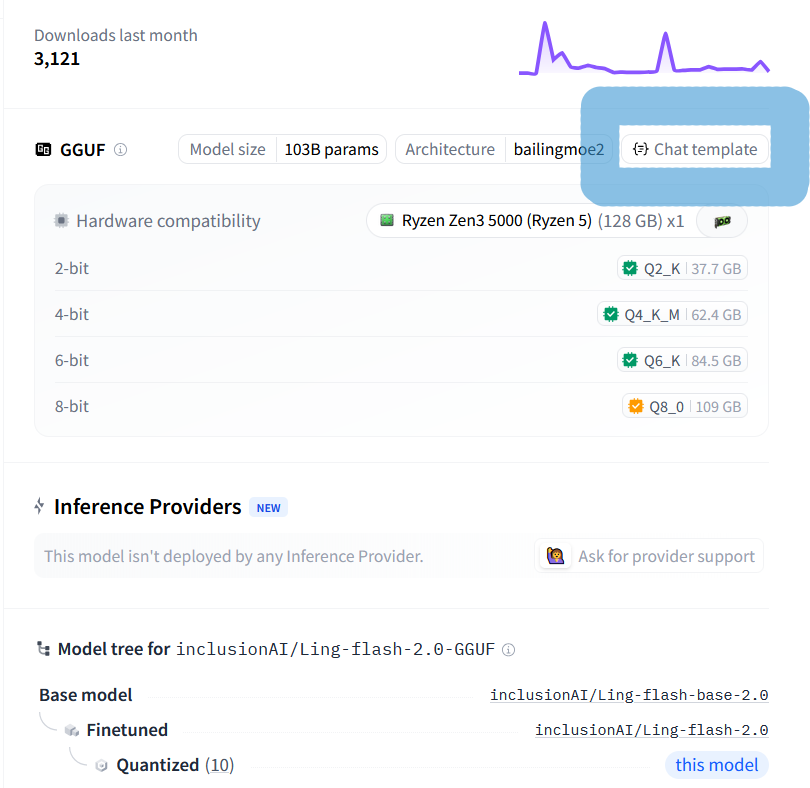
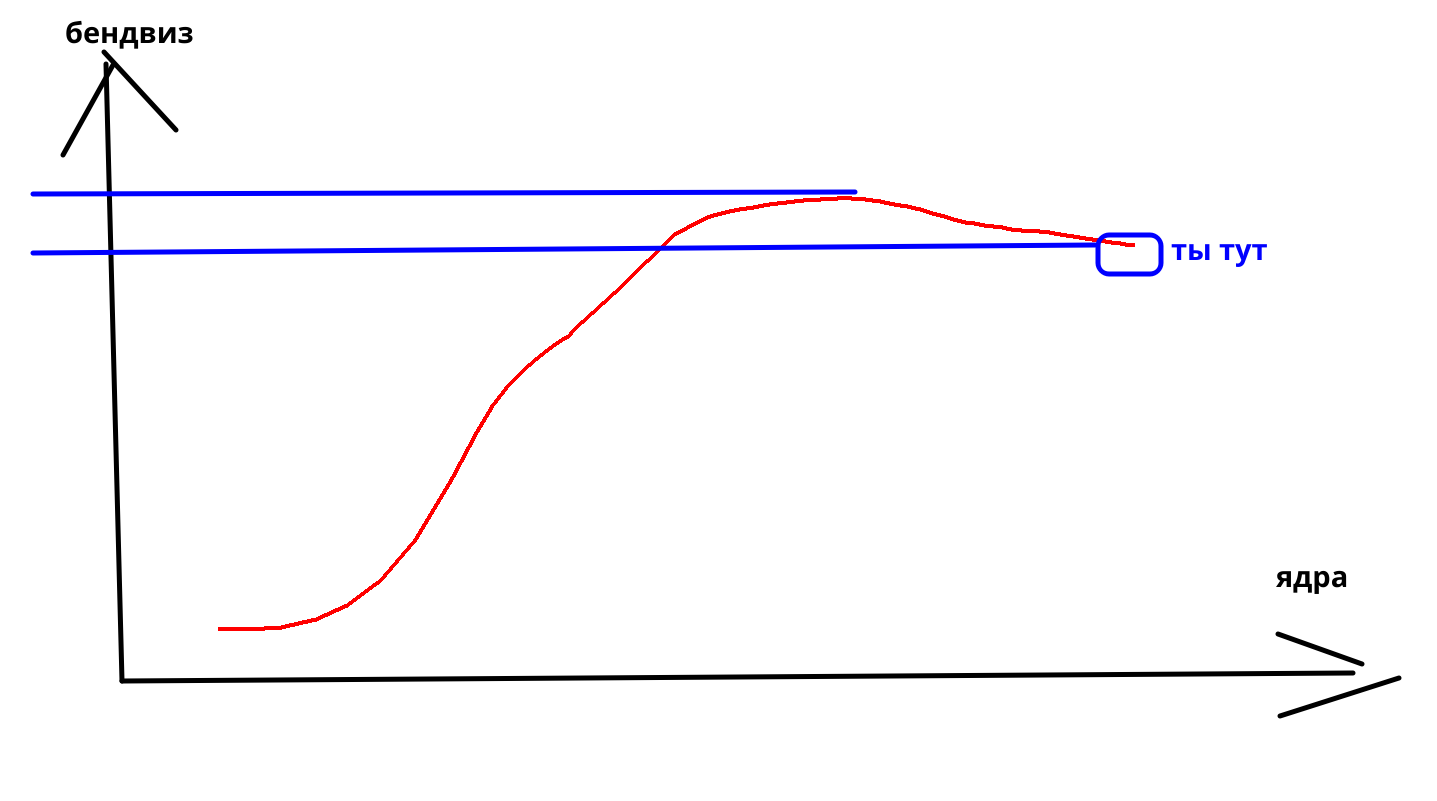
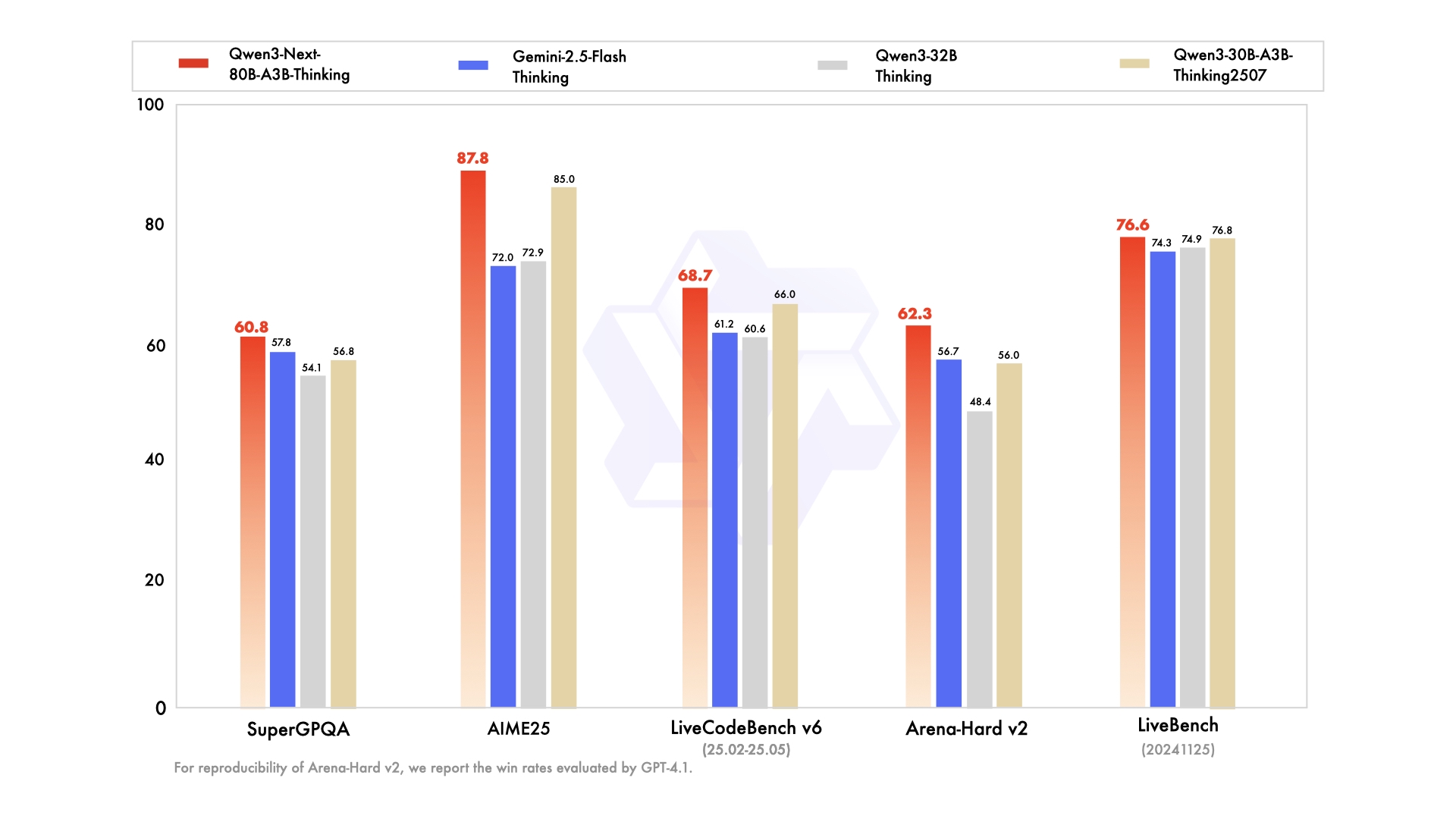
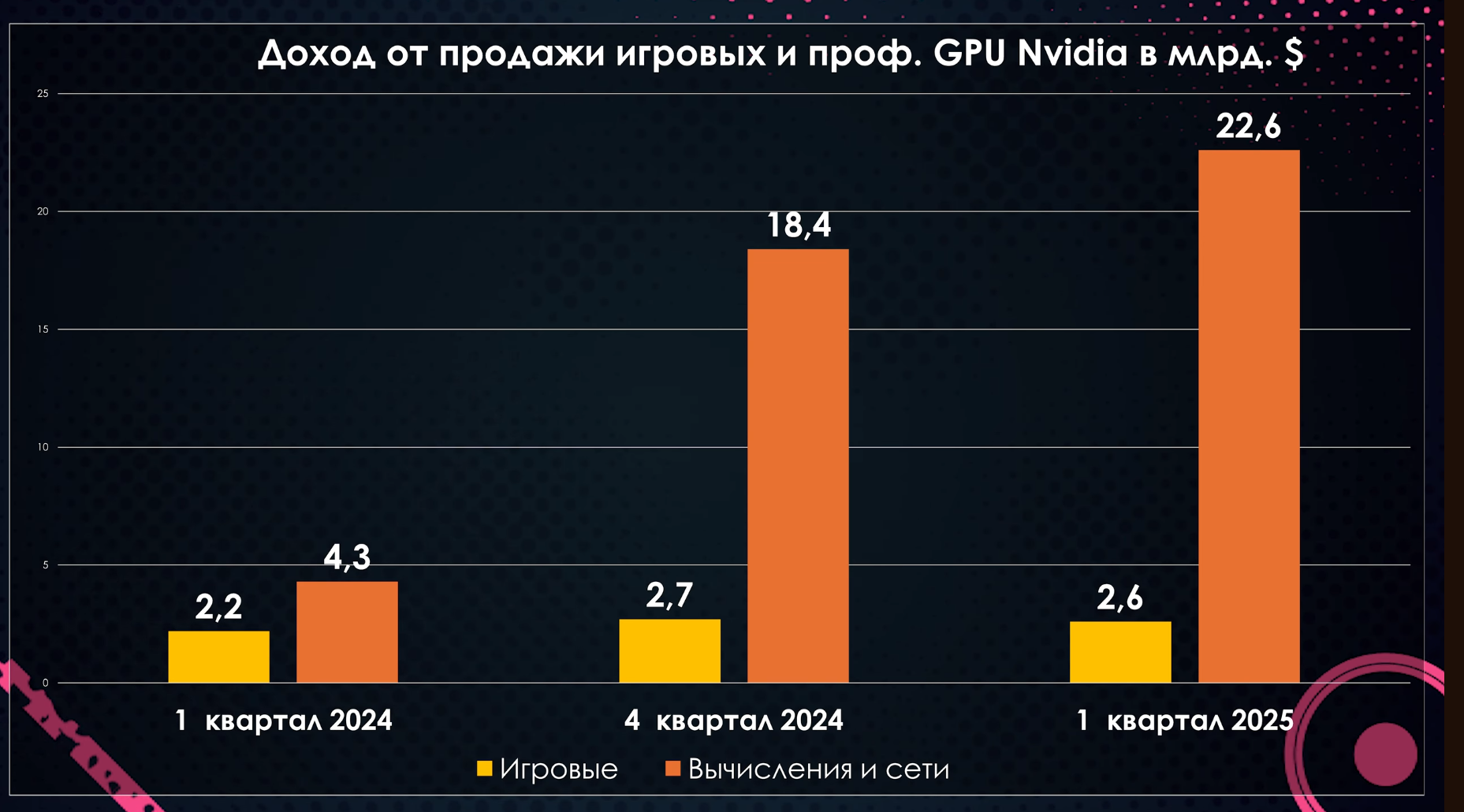
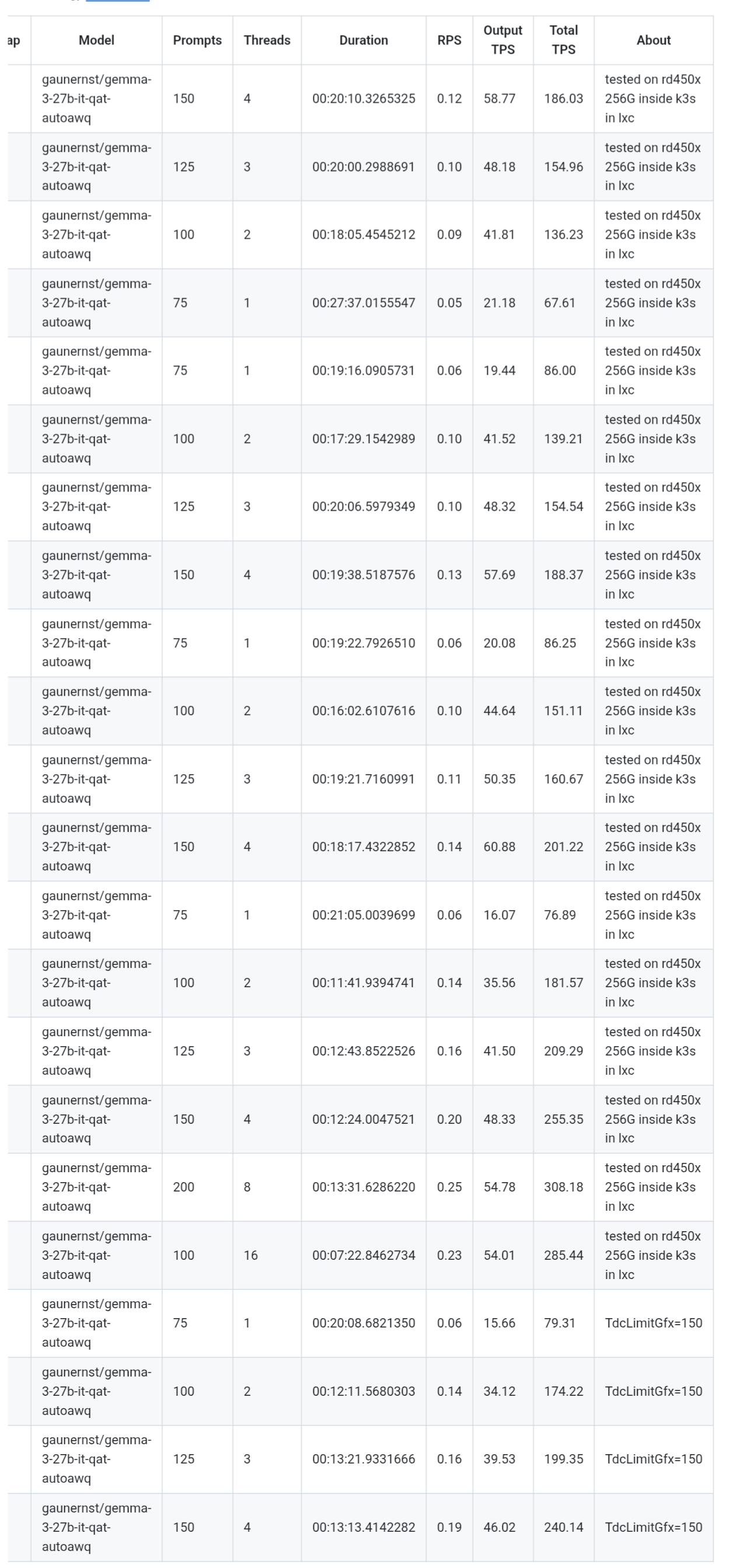
Локальные языковые модели (LLM): LLaMA, Gemma, Qwen и прочие №173 /llama/
Аноним
21/10/25 Втр 01:12:49
№
1