Пилю локальный AI-инструмент для анализа и классификации груди на Python + PyTorch + Streamlit 😄
Что уже сделал: - автокроп груди - поиск похожих фото (similarity search) - embeddings - поиск дублей - полуавтоматическая разметка - top-k похожих изображений - аналитика модели
Сейчас обучаю свою модель на собственном датасете, но возник вопрос: есть ли уже готовые pretrained/open-source модели или датасеты под: - breast size estimation - breast similarity search - breast / nipple detection - NSFW computer vision - fine-grained anatomical classification
Может кто-то уже работал с: - CLIP - FAISS - YOLO - OpenCV - NSFW CV models - research papers / GitHub репами
Интересует вообще любой опыт или ссылки. А то есть ощущение, что либо изобретаю велосипед, либо где-то уже лежит готовая ракета 🚀
Мое обучение в магистратуре подходит к концу и совсем скоро я буду защищать диплом.
🟢 О чем диплом Мой диплом о том, как люди используют большие языковые модели (например, ChatGPT), насколько они доверяют их ответам и задумываются ли о своей ответственности при их использовании.
Меня интересует, проверяют ли пользователи полученную информацию, в каких случаях они считают допустимым использовать её без проверки и кто, по их мнению, должен нести ответственность за возможные ошибки — человек или сама технология.
🔵 Участие в исследовании Для того, чтобы это выяснить, мне нужно провести исследование среди тех, кто использует ИИ для решения различных задач.
❗️Если вы используете ИИ, при помощи него решаете какие-либо задачи, то ваше участие очень сильно поможет мне качественно провести исследование и дописать диплом.
На данный момент у меня не получается набрать нужное количество респондентов, поэтому и обращаюсь сюда, к вам. Буду очень благодарен, если сможете ответить на вопросы анкеты.
Привет анонимусам, обитателям доски. Я анонимус 30 лет в трудном финансовом положении, хотя и с серьезными связями с буквальным идиотами Хочу немного информационной помощи начинающему, но уже достаточно крутому учёному то есть мне Интересуюсь глобальной логикой, программирование забросил на уровне простых алгоритмов, знаю что такое запутанная логика, есть дислексия в последствии из-за перегруженного мышления и сенсорного фильтра. Вопрос звучит как хочу знать всё. Глобальная логика в наводящих терминах, Хочу знать анотационные так сказать сливки, фишки, термины, наводящие вопросы на уровне высокого импровизационного интеллекта, но оговорюсь интеллект у меня вербально специфический, я умею круто научно выражаться, в это можно поверить, но я в состоянии абулии прямо сейчас. Я имею в виду самые крутые темы где используется огромная база данных, алгоритмическая логика, да и вообще логика как такова, глобальная эрудиция до нужной глубины уровня, детективное дело, шифрирование и дешифрирующий поиск информации, физика, чё изучать в квантовой физике что бы делать бластеры и машину времени если знаешь только как писать музыку в Ableton и разбираешься в сигналах немного в химии, там больше от набора информации чем от смекалки зависят знания, но хочется заполнить пробелы. Хочется заполнить пробелы в моей мозговой глобальной базе данных, тут нужно немного психоанализа меня Я могу сказать что я фанат принципа зарядов и магнетизма, люблю раскрывающеюся информационную суть-фрагменты объяснения в стиле нейрокогнитивной психологии, ну в общем я довольно специфичный, интересуюсь специфическими новыми темами с оттенком олд скулл, интересуюсь техникой, написанием мысле-алгоритмов, созданием тестовых анти психовирусов, интересен синтез звуков не только аддитивный, в общем я процессорная текстовая интеллектуальная блядь элита. Посоветуйте что-то кроме лоботомии. Ха хорошая шутка
>>1561662 (OP) Чел, я тебе щас дам совет, который будет полезнее чем все годы учебы в вузе. Научись ясно и кратко выражать главную мысль. Никому не всралось в 21 веке читать простыни он ноунейма на анонимном форуме. Если ты считаешь, что без доп информации не обойтись, то все равно - первое предложение должно содержать главную идею (лид), должно сразу цеплять, а все остальное - потом.
Anthropic повысила лимиты использования Claude для пользователей Pro и Max, открыв более высокую пропускную способность для корпоративных рабочих нагрузок.
Anthropic заключила партнёрство с SpaceX, получив более 300 МВт вычислительных мощностей и примерно 220 000 графических процессоров NVIDIA, что укрепило возможности для обслуживания клиентов из регулируемых отраслей.
Braintrust сообщила о несанкционированном доступе к своей учётной записи AWS и настоятельно рекомендовала всем клиентам заменить ключи API, подчеркнув риски облачной безопасности для сервисов ИИ.
💰 Финансирование
DeepSeek может достичь оценки в $45 млрд после своего первого инвестиционного раунда, чему способствует большая языковая модель, обеспечивающая сопоставимую производительность при использовании доли вычислительных ресурсов и затрат по сравнению с конкурентами из США.
📱 Приложения
Платформа ИИ Wonder позволяет пользователям проектировать и запускать виртуальные рестораны менее чем за минуту, автоматизируя брендинг, меню и ценообразование, и планирует расшириться с 120 до 400 программируемых кухонь к следующему году.
Марк Лор говорит, что ИИ вскоре позволит любому открыть ресторан
🧪 Исследования
Исследователи из EPFL продемонстрировали метод, использующий большие языковые модели в качестве инструментов рассуждений для химии, позволяя химикам проектировать молекулы, просто описывая желаемые свойства.
🏭 Компании
Anthropic обеспечила доступ к суперкомпьютеру Colossus 1 от SpaceX, добавив более 300 МВт мощностей и около 220 000 графических процессоров NVIDIA для снижения давления ограничений скорости на сервисы Claude Pro и Max.
По мере того как работники беспокоятся об ИИ, Дженсен Хуанг из Nvidia заявляет, что ИИ «создаёт огромное количество рабочих мест»
📰 Инструменты
Новый инструмент, представленный на Product Hunt, позволяет создавать, управлять и измерять рекламные кампании непосредственно внутри ChatGPT, знаменуя собой ранний уровень монетизации для потребительских больших языковых моделей.
🧠 Модели
ИИ-модели Google Gemma 4 получают трёхкратное ускорение благодаря предсказанию будущих токенов
🏢 Приобретения
SAP делает ставку в размере $1,16 млрд на немецкую ИИ-лабораторию в возрасте 18 месяцев и даёт добро на NemoClaw
📦 Продукты
Think 2026: IBM представляет план модели операционной системы ИИ по мере углубления разрыва в области ИИ
ИИ-функции Chrome могут занимать 4 ГБ места на вашем компьютере. Chrome устанавливает их тайно, не спрашивая разрешения.
⚙ Инфраструктура
Усилия Microsoft по созданию центров обработки данных для ИИ вступают в противоречие с её целями в области чистой энергии
🛠 Инструменты для разработчиков
Предупреждение: эксплойт «Gift Max» от Anthropic опустошил более €800, испортил мою кредитную историю и привёл к моей блокировке.
💰 Финансирование
QuTwo Питера Сарлина достигает оценки в $380 млн в раунде ангельского финансирования
🌐 Остальные события в ИИ области:
Пенсильвания подаёт в суд на Character AI, утверждая, что чат-бот выдавал себя за медицинского работника.
Apple выплатит $250 млн покупателям iPhone в США по иску, связанному с функциями ИИ.
Inworld AI запускает Realtime TTS-2: замкнутую голосовую модель, которая адаптируется к тому, как вы на самом деле говорите.
Google добавляет вебхуки, управляемые событиями, в API Gemini, устраняя необходимость опроса в долго работающих задачах ИИ.
Anthropic обновляет Claude Managed Agents функцией «сновидений» — запланированным процессом, который анализирует недавнюю работу и обновляет память, доступно в исследовательском превью
Хакеры ненавидят ИИ-«помойку» ещё больше, чем вы Мошенники, хакеры и другие киберпреступники жалуются на «ИИ-дерьмо», наводняющее платформы, где они обсуждают кибератаки и другую незаконную деятельность.
Google DeepMind приобретает миноритарную долю в компании-разработчике Eve Online, многопользовательской ролевой игры, действие которой разворачивается в космосе, и планирует обучать свои технологии на основе этой игры
Google AI Studio запускает режим редактирования Vibe Coding с функцией выбора для редактирования, аннотаций ручкой и заменой изображений Nano Banana
Etsy запускает нативное приложение для покупок внутри ChatGPT
Агенты ИИ теперь самостоятельно совершают и скрывают киберпреступления
«Системы ИИ не понимают»: новый отчёт сигнализирует о системных сбоях в программировании с помощью ИИ
Пенсильвания подаёт в суд на Character.AI из-за чат-ботов, выдающих себя за лицензированных психиатров, в рамках знакового государственного иска против медицинской мимикрии ИИ
На Meta и Марка Цукерберга подали в суд компании Macmillan, McGraw-Hill, Cengage, Hachette и автор Скотт Туроу из-за обучения ИИ Llama на пиратских книгах
Google готовит новые обновления для модели Gemini Flash
Мгновенная версия GPT-5.5 от OpenAI теперь выдаёт на 52,5% меньше галлюцинированных утверждений, чем её предшественник, в ответ на высокорисковые запросы в области медицины, права и финансов, а та же линейка моделей только что заняла первое место в FrontierSWE — самом сложном бенчмарке для агентов по программированию со сверхдлинным горизонтом задач.
Subquadratic анонсировала модель с контекстом в 12 млн токенов, которая требует почти в 1000 раз меньше вычислительных ресурсов. Её механизм разрежённого внимания (Sparse Attention) достиг 65,9% в тесте MRCR v2 при заявленной доле операций FLOPs, лишь немного уступая показателю Opus 4.6 в 78%.
Скорость также растёт кумулятивно: черновики с предсказанием нескольких токенов от Google обеспечили трёхкратное ускорение для Gemma 4 без потери качества, превращая каждую цепочку рассуждений в параллельный парад.
Цена антропоморфизма теперь стала очевидной: Reflex обнаружил, что использование компьютера обходится в 45 раз дороже, чем структурированные API, что говорит о том, что на данный момент пиксели остаются дорогим прокси для надлежащей «инженерной инфраструктуры».
Сообщается, что Meta разрабатывает персональный ИИ в стиле OpenClaw для своих миллиардов пользователей, в то время как iOS 27 от Apple позволит пользователям заменять сторонние модели в Apple Intelligence через приложение «Настройки», наконец-то относясь к интеллекту как к браузеру по умолчанию.
Anthropic стандартизировала бэк-офис, выпустив десять готовых к запуску финансовых агентов для питчбуков, файлов KYC и закрытия месяца.
Andon Labs передали ключи от кафе в Стокгольме ИИ по имени Мона, сделав её первым в мире владельцем кафе — ИИ. Агенты перестали отмечаться на работе и начали регистрировать юридические лица.
OpenAI планирует потратить $50 млрд на вычислительные мощности только в этом году, в то время как Anthropic обязуется вложить $200 млрд в Google в течение пяти лет — один контракт теперь представляет более 40% от раскрытого объёма отложенных доходов облачного подразделения Google.
Meta начала проводить анализ костной структуры на фотографиях пользователей с помощью ИИ для выявления аккаунтов пользователей младше 13 лет, выполняя радиологию без радиации и превращая обычные фотографии в клинические сигналы.
Coinbase, тем временем, сокращает 14% персонала, поскольку, по словам Брайана Армстронга, инженеры теперь выпускают за дни то, что команды раньше выпускали за недели, при этом даже нетехнические сотрудники теперь размещают производственный код.
Сообщается, что Белый дом рассматривает исполнительный указ о создании рабочей группы по ИИ и формального процесса проверки новых моделей, отказываясь от доктрины невмешательства как раз в тот момент, когда кривые развития устремляются вертикально вверх.
Соучредитель Anthropic Джек Кларк теперь оценивает вероятность рекурсивного самосовершенствования к концу 2028 года в 60%, основываясь на сотнях общедоступных источников данных.
Новый Blueprint-Bench 2 от Andon Labs показывает, что GPT-5.5 достигает 36,2% в задаче преобразования фотографий квартир в 2D-планы этажей, приближаясь к человеческому базовому уровню в 58,6%, в то время как исследователи из Чикагского университета сообщают, что передовые агенты по программированию теперь могут автономно реализовывать конвейер AlphaZero для игры «Четыре в ряд» на уровне, сопоставимом с внешними решателями.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
• Z-Image-Base • FLUX.2 klein (4b и 9b) • Z-Image-Turbo • Flux 2 • Qwen Image / Qwen Image Edit • Wan 2.2 (подходит для генерации картинок). • NAG (негативный промпт на моделях с 1 CFG) • Лора Lightning для Qwen, Wan ускоряет в 4 раза. Nunchaku ускоряет модели в 2-4 раза. DMD2 для SDXL ускоряет в 2 раза.
>>1612980 Так в треде аниме уже писали, что скорость повышается. И на реддите люди писали, что ускоряет. Да и тут тестили >>1611559 и подтвердили ускороение качество. Всмысле забей нахуй? Винда еще люто глючить стала и зависать намертво в отдельных UI после всех установок вокруг комфи. Заебался
>>1612967 для тритона да, а до новых фп9 я не добрался
>>1612999 > Винда еще люто глючить стала и зависать намертво в отдельных UI после всех установок вокруг комфи. Заебался не должно, комфи полностью портабл и не вытекает в систему
Общаемся с ИИ, почти что AGI самыми продвинутыми текстовыми моделями: GPT, Claude, Gemini и прочими. Горим с ограничений, лимитов и банов, генерим пикчи, пишем код и спорим о том, какая модель лучше.
Большинство сервисов доступны бесплатно с ограничениями. Подписки открывают доступ к более мощным моделям, увеличенным лимитам и дополнительным функциям (генерация изображений, файлы, память и т.д.). Цены и условия у всех разные и периодически меняются.
Советы по регистрации: 1. При необходимости используй VPN. 2. Заведи нормальную почту (временные часто режутся). 3. Регистрируйся на нужной платформе. 4. Иногда требуется номер телефона — используются сервисы виртуальных номеров. 5. Пользуйся.
VPN в ряде регионов обязателен. Соответствие страны VPN, почты и номера не обязательно, но желательно для тех, кому доступ критически нужен, например для работы.
Для ленивых есть боты в телеге, 3 сорта: 0. Боты без истории сообщений. Каждое сообщение отправляется изолировано, диалог с ИИ невозможен, проёбывается 95% возможностей ИИ 1. Общая история на всех пользователей, говно даже хуже, чем выше 2. Приватная история на каждого пользователя, может реагировать на команды по изменению поведения и прочее. Говно, ибо платно, а бесплатный лимит или маленький, или его нет совсем.
Ну и че за дауны сделали, что в квиз тестах гемини теперь правильный ответ сразу не показывается как и подсказки, сука тупые менеджеры вечно все портят
Локальные языковые модели (LLM): Gemma, Qwen, GLM и прочие №231 /llama/
Аноним06/05/26 Срд 13:29:04№1605947Ответ
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1607797 5060ti для начала уже хорошо, и картиночки и ллм. Как раз и смежные области раскуришь, буст будет не только в куме. На крайняк видяха в игорях будет полезна
Двач, хочу с тобой посоветоваться по вропосу что делать чтобы наверстать технологическое отставание в области ИИ.
TL:DR: Страна капитально отстает от США\Китая в области ИИ. Возможно ли это наверстать и что для этого надо сделать?
Отвечаю за ИТ в большой структуре. По уровню автоматизации и выполняемым проектам отстаем от мира на 20 лет. Внимательно смотрю на ИИ-революцию на западе и понимаю что это отставание мы уже не догоним. Постоянно общаюсь с крупными вендорами, они в иишку даже не смотрят (1С, Аскон, Интермех и т.д.).
Общаюсь с нашими разработчиками ИИ (Яндекс\Сбер) тоже все достаточно грустно.
Что надо сделать чтобы у нас появились технологии, предложения и нормальные проекты по внедрению сетей?
>>1538133 (OP) Для доступа к передовым знаниям и технологиям, для начала нужно перестать блокировать глобальные интернеты. Чем больше доступа у всех подряд ко всему подряд - тем больше рандомных россиян могут в перспективе стать ML-специалистами (в том числе).
>>1538133 (OP) >Как наверстать Не нужно вам ничего наверствовать. Дай вам технологии, вы вместо нормальной страны построите ещё более жуткий кибергулаг, чем в северной корее.
бля че делать. Платная подписка Pro на Cursor. Использовал 1 процент от всех токенов. Но у меня абсо
Аноним29/04/26 Срд 16:45:33№1601030Ответ
бля че делать. Платная подписка Pro на Cursor. Использовал 1 процент от всех токенов. Но у меня абсолютно не работают модели от Claude. Включал впн, в настройках винды регион США стоит. Но раньше просто писало, что ваш провайдер не поддерживает данную модель, а щас то, что на скрине. Что делать, может кто знает.
>>1601030 (OP) Установи программу v2rayN, купи прокси на месяц за 2-5 баксов или 200 руб, подключи к программе v2rayN и открывай редактор cursor или любой другой. Проблемы не будет. Как пользоваться спроси у гугл ИИ не тупой надеюсь.
AI Chatbot General № 820 /aicg/
Аноним25/04/26 Суб 09:58:58№1597187Ответ
SoftBank формирует робототехническую компанию для строительства центров обработки данных и нацелена на IPO стоимостью 100 миллиардов долларов, что сигнализирует о глубокой приверженности капитала инфраструктуре с поддержкой ИИ.
Apple сообщила о выручке от Mac в размере 8,4 миллиарда долларов во втором квартале, что на 6 % больше по сравнению с аналогичным периодом прошлого года, благодаря растущему спросу на рабочие нагрузки ИИ на Mac mini и Mac Studio.
Apple была удивлена спросом на Mac, вызванным искусственным интеллектом.
🛠️ Инструменты разработчика
NVIDIA представила cuTile.jl — библиотеку с поддержкой ИИ, которая переводит ядра cuTile Python в Julia, устраняя необходимость ручного переписывания и ускоряя разработку с ускорением на GPU.
🔓 Открытый исходный код
Команда Qwen выпустила Qwen‑Scope — набор разреженных автоэнкодеров для моделей Qwen 3.5 (от 2 млрд до 35 млрд параметров), который позволяет управлять признаками, выполнять отладку и анализировать наборы данных.
Модели ИИ с открытыми весами, такие как LLaMA и Mistral, всё чаще развёртываются локально и в частных облаках, занимая нишу вне крупных облачных провайдеров.
Китайская модель с открытыми весами только что обошла Claude, GPT-5.5 и Gemini в соревновании по программированию.
⚠ Безопасность ИИ
Исследователи Microsoft провели красное тестирование сети из 100 агентов ИИ и выявили четыре возникающих риска: распространение вредоносного ПО, манипулирование репутацией, создание искусственного консенсуса и цепочки прокси, что побудило к выработке новых рекомендаций по защите.
🧰 Инструменты
Gemini добавил функцию генерации файлов, которая создаёт готовые к производству файлы непосредственно в чате, оптимизируя рабочие процессы разработки.
Секретарь Miaw AI предлагает ненавязчивого ИИ-ассистента, который помогает пользователям без необходимости переключения контекста. источник: producthunt.com MailToDock преобразует электронные письма Gmail в задачи Google Tasks с помощью ИИ, повышая личную продуктивность.
📦 Продукты
Пентагон заключил сделки с Nvidia, Microsoft и AWS для развёртывания ИИ в засекреченных сетях. Но не с Anthropic.
Cursor представляет TypeScript SDK для создания программных кодинговых агентов с изолированными облачными виртуальными машинами, подагентами, хуками и тарификацией на основе токенов.
AWS запускает Amazon Quick — настольного ИИ-ассистента, работающего во всех ваших приложениях, инструментах и данных.
📱 Приложения
В автоспорте негде спрятаться, поскольку ИИ становится новым инструментом вычислительной гидродинамики (CFD).
Beacon Biosignals составляет карту активности мозга во время сна.
Следующее поколение информационно-развлекательной системы Hyundai принимает ИИ и сохраняет одну из наших любимых функций — Car and Driver.
IBM дебютирует с новыми функциями на базе ИИ для приложения Scuderia Ferrari.
Создатели христианского контента передают низкокачественный контент, созданный ИИ («AI slop»), внештатным работникам на Fiverr.
💰 Финансирование
Раунд оценки потенциальной стоимости Anthropic более 900 миллиардов долларов может состояться в течение двух недель.
⚙ Инфраструктура
Обнаружена серьёзная уязвимость безопасности «Severe Linux Copy Fail» с помощью сканирования на базе ИИ.
Tesla наконец произвела первый грузовик Semi на своей высокопроизводительной линии Gigafactory Nevada, в то время как компания 1X Technologies открыла завод площадью 58 000 кв. футов в Хейворде, нацеленный на выпуск 10 000 домашних гуманоидов в этом году и 100 000 к концу 2027 года, при этом поставки начнутся до праздников.
🖱 Аппаратное обеспечение
Акции Nvidia падают после отчётов гипермасштабируемых компаний, поскольку GPU больше не являются недостающим компонентом в буме ИИ.
⚖ Регулирование
Китайские суды постановили, что компании не могут увольнять работников просто для того, чтобы заменить их ИИ.
🧠 Модели
ChatGPT Images 2.0 стал хитом в Индии, но пока не является большим победителем в других регионах.
Американский стартап Poolside дебютирует со своей первой моделью с открытыми весами Laguna XS.2 — MoE-моделью с 33 млрд активными параметрами из 3 млрд общих, и Laguna M.1 — проприетарной MoE-моделью с 225 млрд активными параметрами из 23 млрд общих.
🤖 Робототехника
Dax Robotics представила Qiji T1000 — робота-лошадь тонн-класса, способного перевозить 1000 кг, рабочую силу для пост-человеческой цепочки поставок.
🌐 Остальные события в ИИ области:
Новая техника устранения смещений под названием WRING позволяет избежать создания или усиления предвзятостей, которые могут возникать при использовании существующих подходов к устранению смещений.
Прорывное новое исследование показывает, что платформа ИИ в реальном времени лучше справляется с диагностикой рака, чем биопсия.
Anthropic тестирует Claude Jupiter v1-p перед конференцией разработчиков Code with Claude, которая состоится 6 мая.
GitHub Copilot тихо добавляет себя как соавтора (Co-authored-by) в коммиты даже после того, как пользователи удаляют его сообщения.
Google планирует внедрить рекламу в приложение Gemini, сообщил инвесторам руководитель бизнес-подразделения Филипп Шиндлер.
Глава технологического подразделения Пентагона заявил, что Anthropic всё ещё находится в чёрном списке, но Mythos — это отдельный вопрос.
Amazon представляет функцию «Join the chat» («Присоединиться к чату») на базе ИИ, которая позволяет пользователям задавать вопросы о товарах и получать разговорные аудиоответы, генерируемые в реальном времени.
Spotify добавляет значки «Verified» («Подтверждено»), чтобы отличать артистов-людей от ИИ.
После критики Anthropic за ограничение доступа к Mythos, OpenAI ограничивает доступ к Cyber.
Новый флагманский продукт Mistral Medium 3.5 объединяет чат, рассуждения и код в одной модели.
Manus запускает Cloud Computer для постоянно работающих рабочих пространств агентов.
Мобильный доступ к NotebookLM появляется внутри Gemini бесплатно для пользователей.
Google Translate добавляет тренера по произношению на базе Gemini с обратной связью в реальном времени для английского, испанского и хинди на Android.
Adobe Photoshop версии 27.6 выпускает функции вращения объектов ИИ и удаления отражений в обновлении на базе Firefly.
Stripe обновляет Link — цифровой кошелёк, который могут использовать автономные агенты ИИ.
Исследователь отравил передовые большие языковые модели (LLM) одним изменением в Википедии и доменом за 12 долларов — это показывает, что поиск через веб наследует доверие от лучших результатов.
Демис Хассабис предлагает тест на общий искусственный интеллект (AGI): заново открыть специальную теорию относительности, используя только знания физики эпохи 1901 года.
ИИ REDMOD клиники Mayo обнаруживает рак поджелудочной железы на обычных КТ-сканах за три года до постановки диагноза.
NVIDIA представляет Nemotron 3 Nano Omni — открытую мультимодальную модель с 30 миллиардами параметров и контекстом 256K для видео, аудио, изображений и текста.
Cloudflare заявляет, что агенты ИИ теперь могут создавать учётные записи Cloudflare, начинать платные подписки, регистрировать домены и развёртывать приложения от имени пользователей.
Признание агента ИИ Claude после удаления всей базы данных фирмы: «Я нарушил каждый принцип, который мне был дан».
Комитет по внутренней безопасности Палаты представителей США и Специальный комитет Палаты представителей по Китаю проводят расследование в отношении Airbnb и создателя Cursor компании Anysphere по поводу использования ими китайских моделей ИИ.
Gemini теперь может генерировать файлы, включая документы Microsoft Word и LaTeX.
Canonical излагает дорожную карту Ubuntu AI: локальные рабочие процессы на основе агентов и снапы для вывода, которые будут внедряться до 2027 года.
Исследователи OpenAI объясняют, почему математика — это путь к AGI.
Simbian публикует эталонный тест по киберзащите (Cyber Defense Benchmark) — все 11 передовых больших языковых моделей не справились с обнаружением атак по сырой телеметрии.
Познакомьтесь с Shapes — приложением, которое объединяет людей и ИИ в одни и те же групповые чаты.
Исследователь попросил ИИ подсчитать углеводы 27 000 раз. Он не смог дать один и тот же ответ дважды.
Goldman Sachs запретил своим банкирам в Гонконге использовать модели Anthropic; Anthropic заявляет, что её модели никогда официально не «поддерживались» в Гонконге.
Расширение браузера Gemma 4 приносит локального агента ИИ в Chrome через WebGPU.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Если вы прпоустили и не обсуждали (тред не читал): В llama.cpp завозят MTP. На Qwen3.6-27b дает +95% скорости. На Qwen3.6-35B-A3B дает +40% скорости. Вчерашние тесты. Но поджирает видеопамять.
В догонку — для геммы выложили головы, следовательно ии ускорит. Теоретическое пиковое ускорение до 3х-4х на некоторых моделях (+200%+300%). Помимо плотных квена с геммой, ускорение можно поиметь на крупных МОЕ. И если это вместо 7-15 токенов будет 15-30 — то это тоже очень круто. Я бы погонял ~300B на 20-25 тпс.
Ну, посмотрим. Ждем, когда замерджат, плюс мимо завезут (кстати, пока мимо у меня очень медленная, почему-то).
Пишу как неведомый в ИИ вам за советом. Использовал грок для создания NSFW контента, а именно генерация картинок и их анимация. Подскажите, есть ли аналоги для подобного функционала или же обход цензуры в грок
>>1555531 > но 96% - многовато, наверное Хуй знает. Там система ебанутая какая-то. Тут >>1555415 оригинал - 95% жпг из mpv, и инпейнт 95% жпг из гимпа (только сохранение в жпег, ничего не изменено по сравнению с png). Оба показывают 96% уверенности digitally edited, будто оно вообще не замечает разницы. Гораздо более интересно, что оно на это >>1555438 показывает 67% real image.
>>1555531 Кажется разобрался. Дохуя внимания оно уделяет геометрии бэкграунда, с которой у нейронок обычно не оче. > GPT-5 или Gamini Попробуй ей клосап или 1гирл в чистом поле скормить. Подозреваю, что не определит нихуя.
В тредике трансформируем аниме арты в professional photography, ultra-realistic, 8k resolution и бесконечно рероллим 3D анимацию/фигурки/околоаниме/просто всратые
По возможности постите рядом оригинальный арт, чтобы было с чем сравнить.
>>1591303 (OP) klein 9b snofs 1) transform this picture to the real life cosplay photo with blank background
2) transform this picture into professional photography, ultra-realistic, 8k resolution
3) ориг
>>1604007 klein 9b обычный 4) transform this picture to the real life cosplay photo with blank background, yellow hair, white shirt, red color of neck accessory, прищуренные глаза, looking aside
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Вообще новичок всегда должен поебаться с настройками. Так что все правильно в рентри, а уж если поебется но будет усердно в треде поймёт что есть кобольд и варианты по ппроще, ибо если гейткипа не будет совсем то наплыв даунов которых надо только спунфидить будет критическим. А там и качество треда упадёт. Никто не захочет кому либо помогать понимая что сидит в треде с даунами из /b/ а не такими же энтузиастами на взаимопомощи.
Агентов и вайб-кодинга тред #4 /agents/
Аноним14/04/26 Втр 03:30:28№1585804Ответ
Тред про AI-агентов - от вайб-кодинга до персональных ассистентов, которые сидят в твоих чатах, читают заметки и автономно ломают всё вокруг. Для кодеров, которые разучились писать руками, и для гуманитариев, чей диплом филолога наконец котируется в IT. Сеньор в 2026 - это тот, кто умеет внятно объяснить машине, чего он блять хочет.
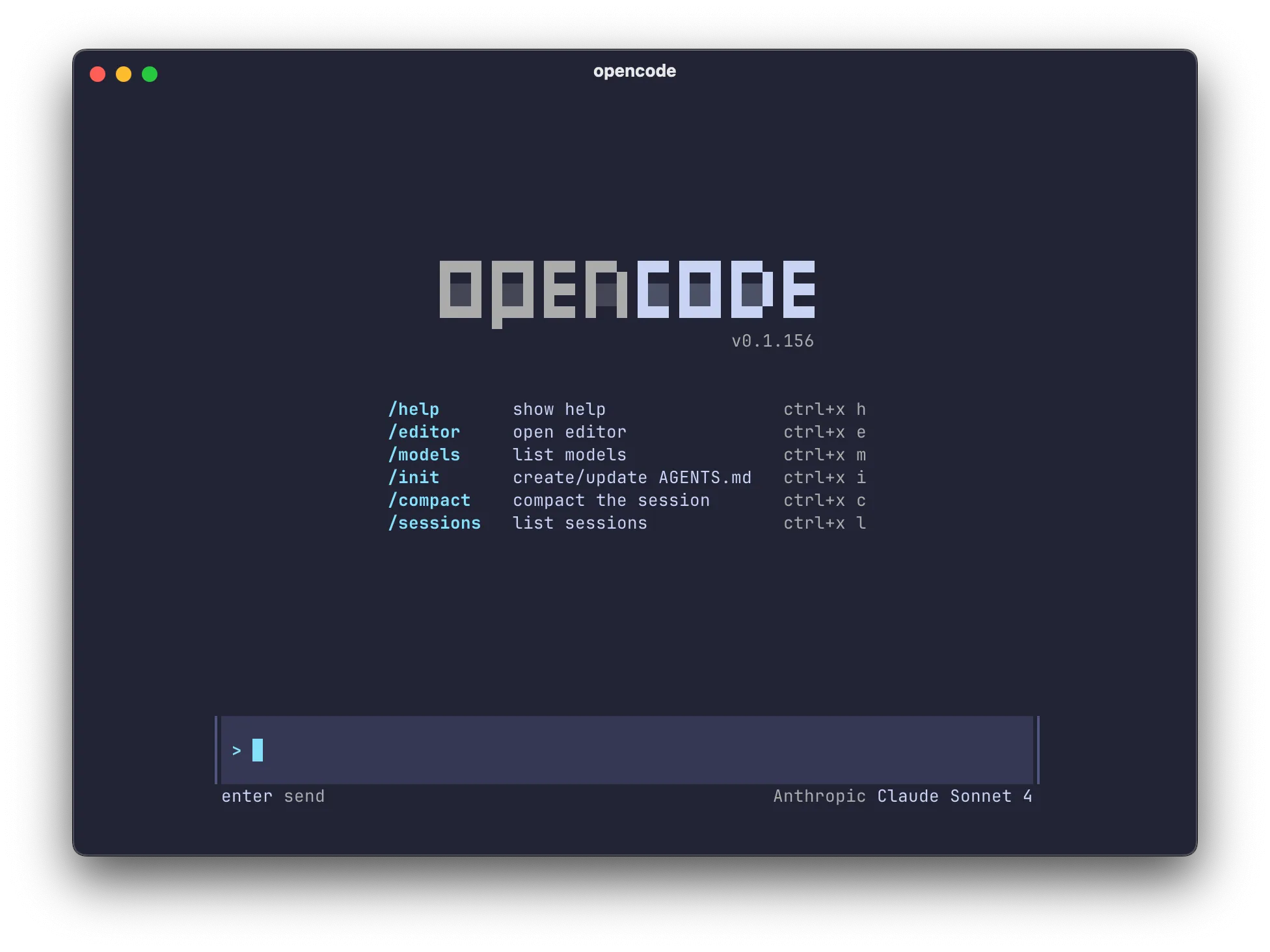
С чего начать: - Хочешь кодить с AI эффективно: Cursor или Claude Code - Хочешь кодить в VS Code без привязки к конкретному провайдеру: Kilo Code, Cline или Roo Code + OpenRouter - Хочешь кодить с AI локально: OpenCode, Qwen Code или Pi Coding Agent + из моделей аноны советуют Qwen3.5, подробности в llama-треде - Хочешь приложение без кода: Lovable или bolt.new - Хочешь автоматизировать рутину: n8n или Langflow - Хочешь персонального ассистента: OpenClaw + API корпов или локальная модель на твоей пеке
>>1599933 извини, я на 2-х недельную командировку уезжал, сейчас подписочку на плати сру возьму и опять буду срать на рентри орг охуенными идеями только вы же нихуя не подхватываете челленджи, а только говном поливаете
еще и какой то долбаеб на мой айпи подвесил бан за вредоносные ссылки. наркоман
>>1600343 У меня тоже отъебнуло. Это чисточки братан. Дальше будет намного неприятнее и затратнее. Еби как не в себя подписки с карженных кредиток на плати сру и ггселах, потом уже такой лофы не будет, доставай с чулана все свои заблокноченные проекты и реализуй, потом не потянешь